1. Introduction
Effective communication is essential for full participation in society, yet deaf individuals often face challenges in accessing information and communicating with hearing unimpaired individuals [
1]. Sign language is a visual language that provides the primary means of communication for deaf individuals. It uses a combination of hand movements, facial expressions, mouth movements, and upper body movements to convey information. However, sign language is often not well understood by those unfamiliar with it, making it difficult for deaf individuals to communicate with the general population. In order to address this issue, research on sign language translation (SLT) using computers has been conducted for some time to facilitate communication between deaf and non-deaf people via translating sign language videos into spoken language [
2,
3].
Most existing deep-learning-based SLT methods rely on gloss annotations, a minimum vocabulary set of expressions that follow the sign language sequence and grammar, to translate the sign language into spoken language. However, collecting gloss annotations can be costly and time-consuming, and there is a need for SLT methods that do not require them. The state-of-the-art study [
4] attempted to perform translation without glosses, but came across two major limitations. Firstly, the translation was based on the features of the image, which resulted in it being influenced by the background rather than focusing solely on the signer. Secondly, dimensionality reduction was applied to the features through embedding to fix the input size of the model. However, this may result in the loss of important information in sign language videos.
To address the first issue, we propose a sign language translation method based on the body movement of the signer. Sign language represents a visual language essential for communication among the deaf population, and it uses various complementary channels to convey information [
5]. These channels include hand movements and nonverbal elements such as the signer’s facial expressions, mouth, and upper body movements, which are crucial for effective communication [
6]. Therefore, the meaning of sign language can vary depending on the position and space of the signer’s hand. Taking these factors into consideration, we focus on the signer’s movement by accurately capturing their body’s movement using keypoints, namely, specific points on the body that are used to define the movement of the signer. These keypoints are defined as the joint points of these signers.
To process the frames for SLT based on the signer’s skeleton, we must address the issue of keypoint vectors that vary significantly depending on the angle and position of the signer in the frame. To address this issue, we propose a simple but effective method. First, we propose a normalization method that uses the distance between keypoints and applies different normalization methods according to the part of the body, which we call “Customized Normalization”. This normalization method is robust to variations in the signer’s body and helps improve the performance of the translation system.
To solve the second issue of previous studies [
4], we propose selecting and augmenting frames based on probabilities. Our method can reduce the loss of image information due to embedding by prioritizing frames in sign language images. Previous keypoint-based studies [
7,
8,
9,
10] have also employed various methods to fix the length of the input keypoint vector. However, these studies either use frame sampling to lose information or use only augmentation, leading to increased memory usage and slower processing time. Therefore, we propose the“Stochastic Augmentation and Skip Sampling (SASS)” method that adjusts to the length of a dynamic video frame by simultaneously using both augmentation and sampling techniques based on the length of the video.
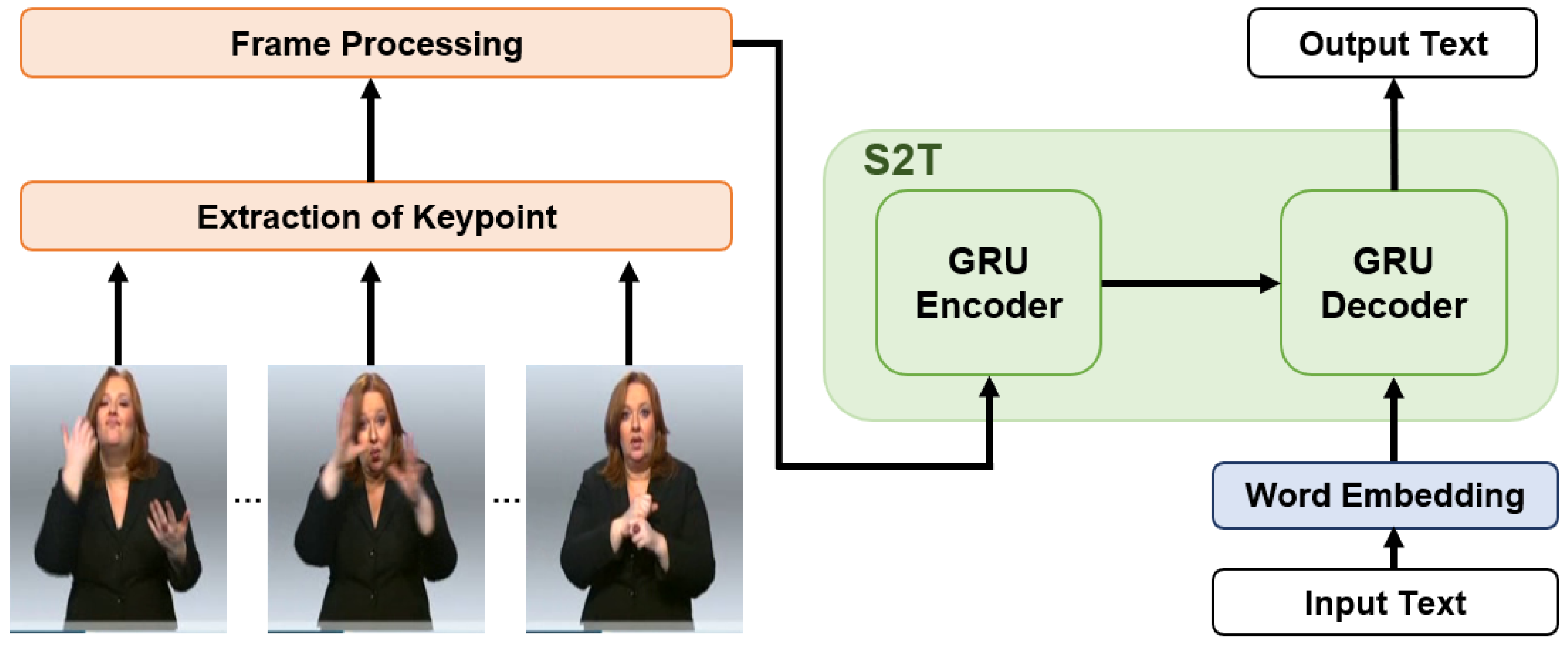
In this paper, we apply the Sign2Text method to the dataset without gloss and propose a frame-processing method that can perform well even in cases where the video resolution differs. For sign language translation, we use the Gated Recurrent Unit (GRU) [
11]-based Sequence-to-Sequence (Seq2Seq) model [
12] with the Attention of Bahdanau et al. [
13]. An overview of our framework is illustrated in
Figure 1, and the contributions of this paper are as follows.
- •
We propose a new normalization method most suitable for sign language translation in keypoint processing.
- •
We propose a stochastic frame selection method that prioritizes frames for videos of different lengths to consider the characteristics of a sign language video.
- •
Our method is versatile because it can be applied to datasets without gloss.
The remainder of this paper is structured as follows:
Section 2 reviews existing research on SLT and video processing methods.
Section 3 presents our proposed video processing method and SLT approach.
Section 4 presents the results of experiments evaluating the effectiveness of our method.
Section 5 presents the results of the ablation study. Finally,
Section 6 provides concluding remarks and suggestions for future work.
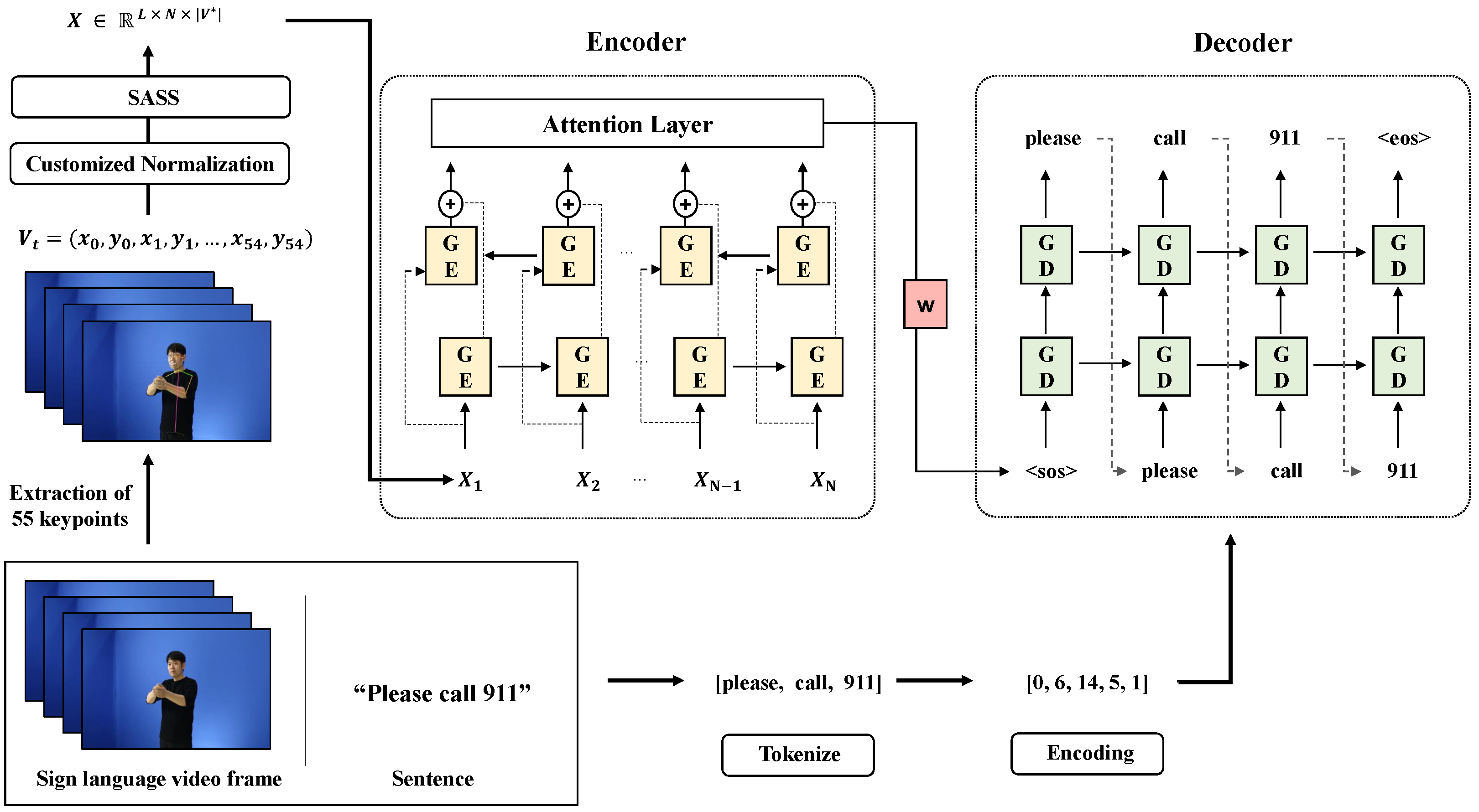
3. Proposed Method
In this section, we introduce the overall architecture of the proposed method. Our architecture is decomposed into four parts: Extraction of keypoint, keypoint normalization, Stochastic Augmentation and Skip Sampling (SASS) and sign language translation model. The overall flow of our proposed architecture is described in
Figure 2.
Camgoz et al. [
4] underwent the embedding process after extracting the feature of the sign language video frame through CNN. It aims to reduce the dimension by embedding the feature point of the large amount extracted from the learning image. However, all the features extracted can include backgrounds, which can affect learning by becoming noise. Therefore, in this paper, instead of extracting features through CNN, we propose a method of extracting the keypoint of the signer and using it as a feature value. Using keypoint, we can construct a robust model against the background by only looking at the movement. Initially, the location of keypoints is taken into consideration, followed by the proposal of Customized Normalization that emphasizes hand movement, an essential aspect of sign language. In many languages, verbs and nouns, the core of a sentence, are placed in the middle. Furthermore, there are cases in which hands do not appear at the beginning and end of the video. Therefore, we define the ’key frame’ as the frame in the middle part of the video. We propose a stochastic augmentation method that enables the model to better learn essential parts of sign language videos by assigning stochastic weights to ’key frames’ of videos. Additionally, we propose Stochastic Augmentation and Skip Sampling (SASS), which combines sampling and augmentation to apply to dynamic video frame length. Finally, we perform sign language translation by applying the method of Bahdanau et al. [
13] of the NMT task.
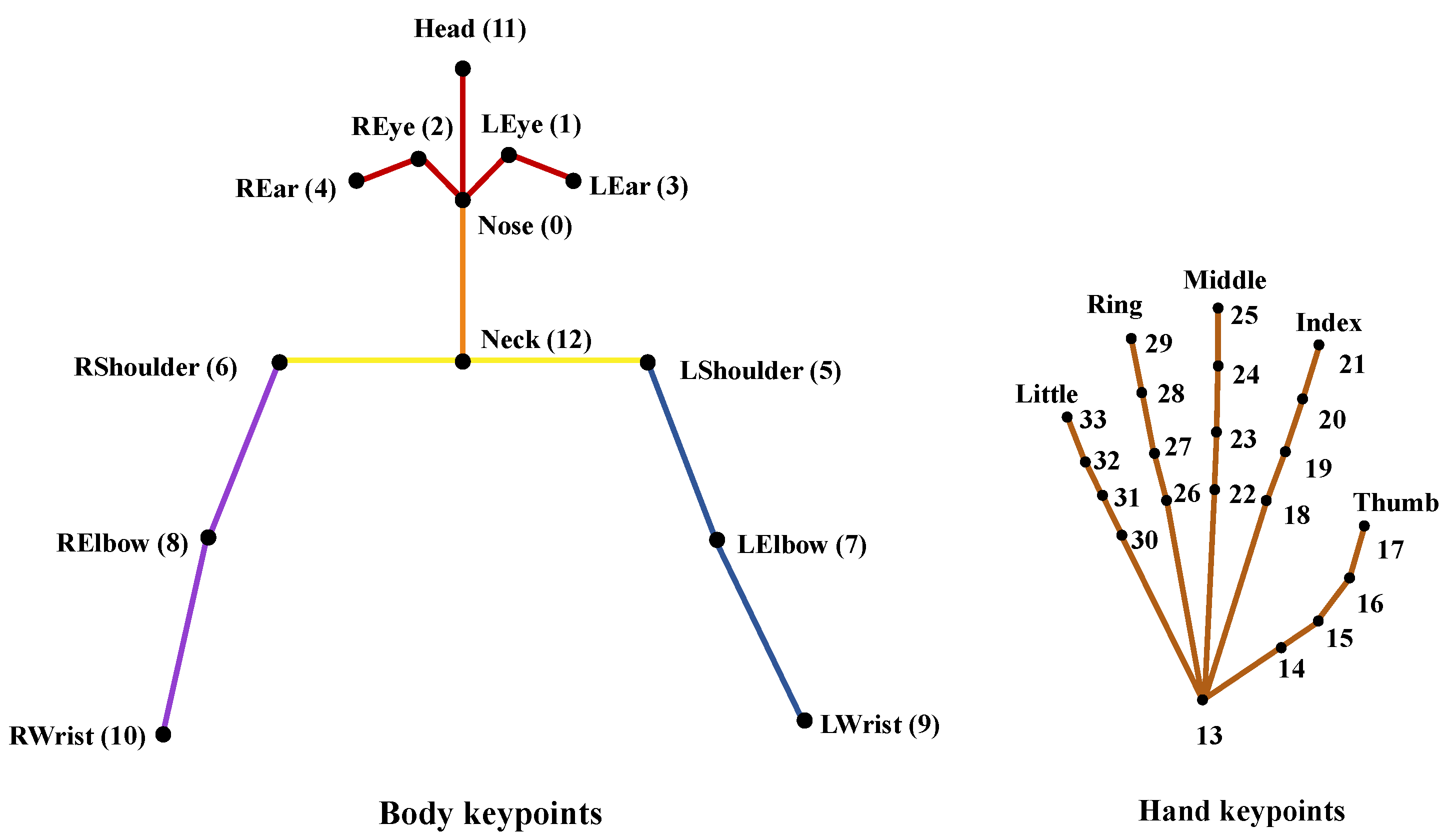
3.1. Extraction of Keypoint
To minimize the impact of the surrounding background on the video and focus solely on the signer, we extracted the signer’s keypoint using a skeleton point extraction method. Our approach involved using Alphapose, a framework developed by Fang et al. [
20] that employs a top-down detection technique for signers and then extracts keypoints from cropped images. We used a pretrained model from the Halpe dataset [
20], which has 136 keypoints. By removing the keypoints of the lower body and face keypoints to construct the keypoint vector
. The location of these keypoints are shown in
Figure 3.
3.2. Customized Normalization
We propose customized normalization according to body parts considering skeleton positions. Since the body length varies depending on the person, a normalization method considering this is needed. Although Kim et al. [
8] mentioned the robust keypoint normalization method, it cannot be said to be a normalization method considering all positions because the reference point was set in some parts, not all parts. Therefore, we propose a normalization method that can further emphasize the location of each skeleton and also the movement of the hand.
We aim to normalize the keypoint vector,
V. The
V is divided into
x and
y coordinates,
and
, and normalized, respectively. First, we designated reference points for each body part according to the face, upper body, left arm, and right arm. The reference point is defined as
. The corresponding keypoint numbers according to each body part are shown in
Table 1, and the names corresponding to each number can be referred to in
Figure 3. Furthermore, the representative value for the entire body of the signer is defined as center point,
, and follows:
After obtaining the Euclidean distance,
, between the center coordinate,
c, and the reference point,
r, of each part, it is normalized based on it. It follows:
Therefore, the keypoint for the body excluding both hands follows, .
Next, we apply min-max scaling to the keypoints of both hands in order to make them equal in scale and compare their movements equally. Min-max scaling adjusts the range to [0,1] by dividing the difference between the maximum and minimum values of the coordinates by subtracting the minimum values from the corresponding coordinates. Here, to avoid encountering the vanishing gradient problem caused by a minimum value of 0, the range was adjusted to
by subtracting
. Therefore, we define the normalized hand keypoint vectors,
and
, by min-max scaling the keypoint and subtracting 0.5 from it, which follows:
where,
and
are the maximum and minimum values of the hand keypoint, respectively. Consequently, each and point subjected to our normalization method follows vectors,
and
, and the final keypoint vector is a concatenation of them,
.
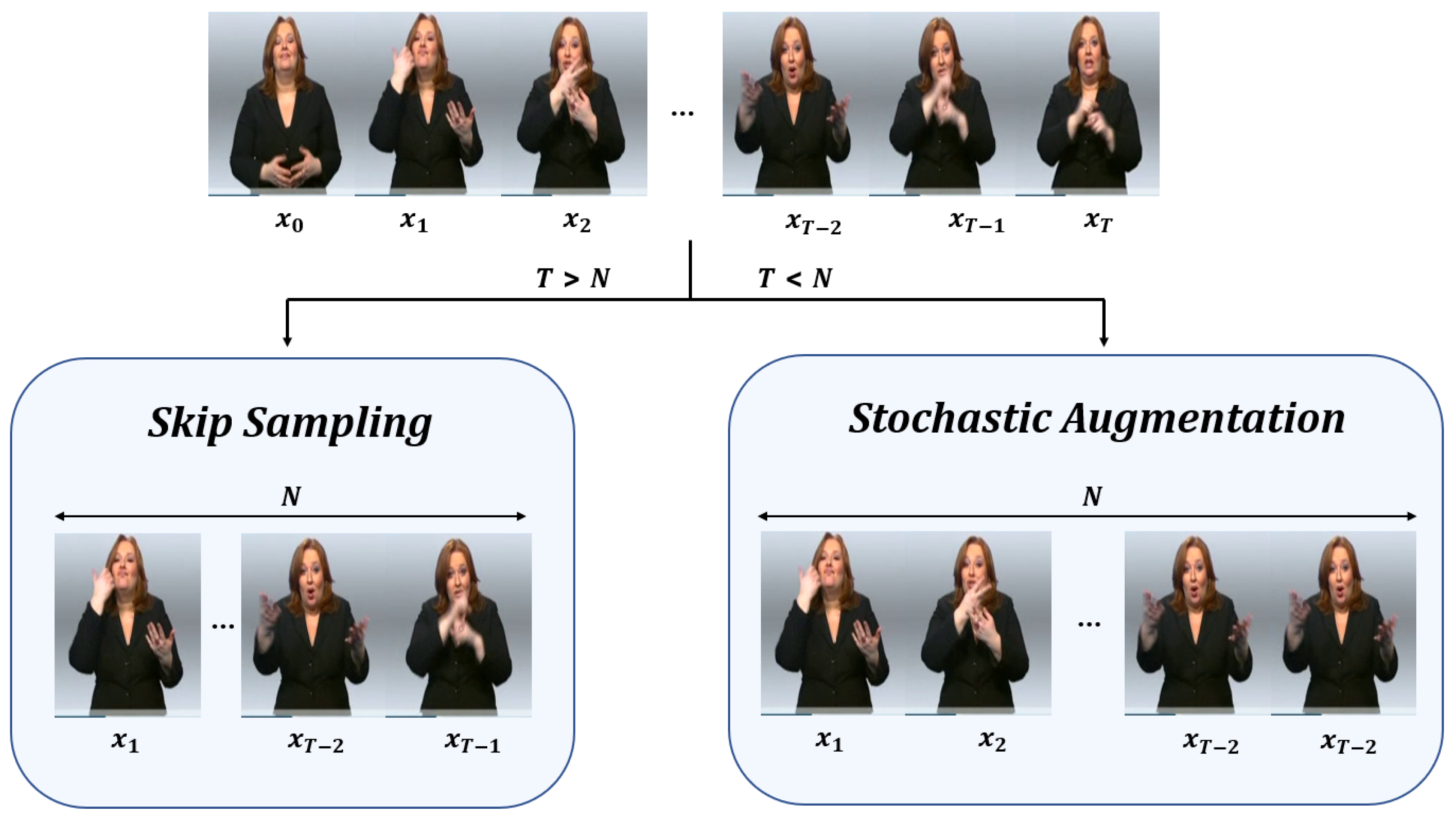
3.3. Stochastic Augmentation and Skip Sampling (SASS)
To train a deep learning model, it is necessary to fix the input size. Previous studies have used embedding to reduce the dimension and fix the size of the input. However, this can result in the loss of important information from the video. Therefore, we propose a method that preserves the information in the sign language video without using embedding. We achieve this by adjusting the input value length through augmentation or sampling the frames. We propose the SASS (Stochastic Augmentation and Skip Sampling) method, which is a general technique that can be applied to various datasets and emphasizes the key frames of sign language videos without losing them. This is achieved through a combination of an augmentation method that considers frame priority and a sampling method that reduces frame loss. We define the
j-th training video as
and
L as the number of training videos, where
. We select
N frames from between the frames of training video
, which follows:
If the number of video frames
is bigger than
N, the sampling is used, and if the number of the video frame is less than
N, the number of frames in each video is adjusted to
N using augmentation. Therefore, input value,
X, follows
. Our method can prevent the loss of video information, which is a disadvantage of frame sampling, and the disadvantage of frame augmentation, which can prevent a lot of memory consumption. The overall flow of our SASS method follows
Figure 4.
3.3.1. Stochastic Augmentation
Our proposed method does not follow uniform distribution when selecting the frame but rather reconstructs the key frame into a probability distribution that can be preferentially extracted with a high probability of being selected.
The probability distribution that increases the priority for the key frame is constructed from a combination of binomial distributions. The frame selection probability set,
, has a size equal to the length of the video,
T, and follows:
where,
We prioritize frames with this set of probabilities. Furthermore, we construct a set,
, for probability with a binomial distribution,
p, rather than fixing the probability to a single value. The set
follows:
In other words, the probability,
p, follows the probability set,
, and
is reconstructed accordingly. The reconstructed final frame selection probability set,
is as follows.
where,
is length of
. However,
cannot augment the middle part of the video, which is the keyframe we defined. Therefore, we rearrange
around the median to increase the selection probability for the middle part of the video. That is, if the frame order,
k, is smaller than
, it is sorted in ascending order, and if it is larger, it is sorted in descending order. Therefore, a final set of frame selection probabilities is produced, and based on this, priority probabilities for frame augmentation order are obtained.
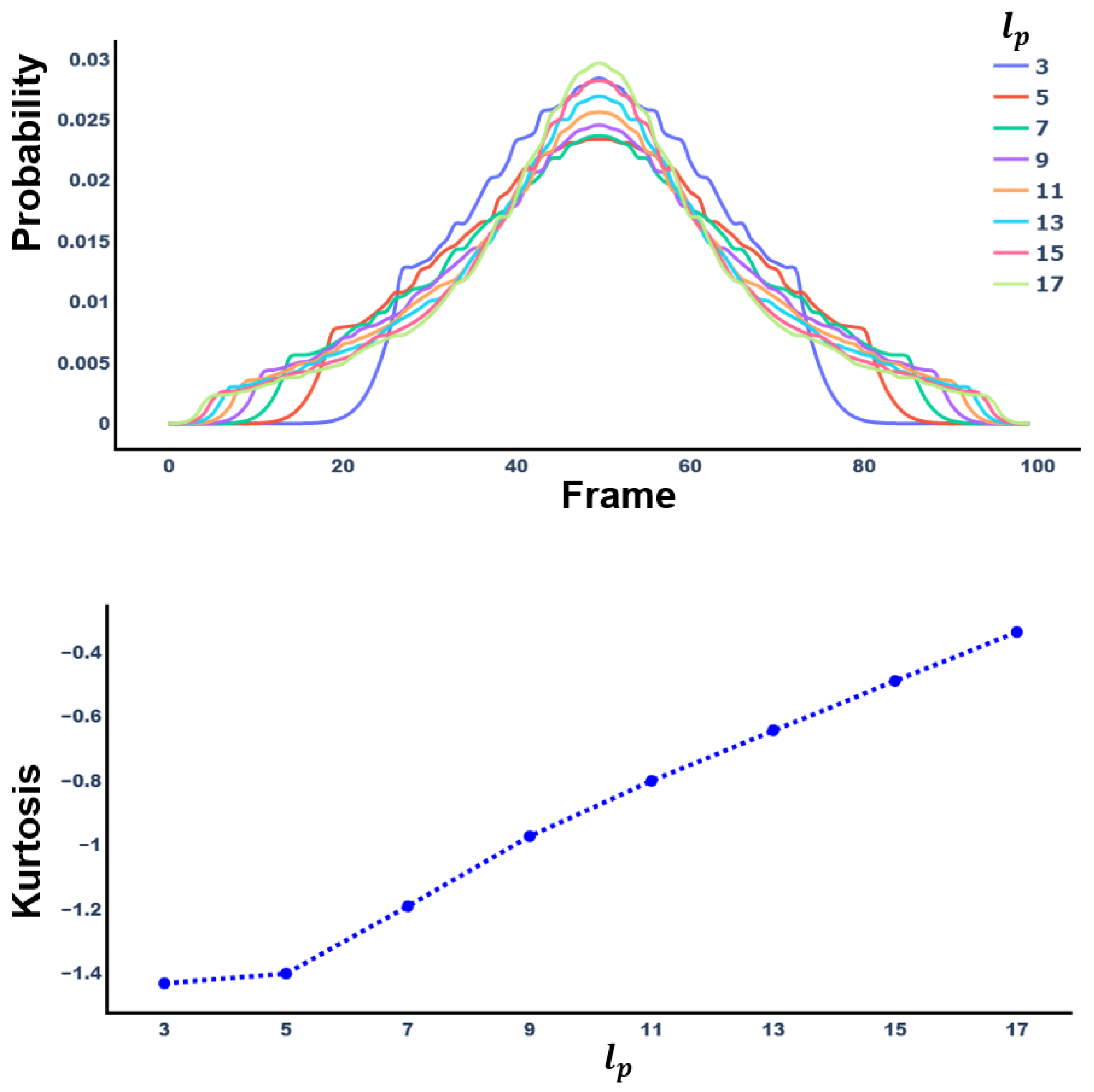
Figure 5 shows the probability distribution and kurtosis of
according to
. As
increases, kurtosis increases.
3.3.2. Skip Sampling
We chose a sampling method to avoid missing key frames when selecting a frame. Ko et al. proposed a random sampling method that does not lose the keyframe. Therefore, this paper also conducts sampling according to this method. When a fixed size is
N and the number of frames in the current video is
T, the average difference
z of frames follows:
Through
z, the baseline sequence
of the video frame follows:
A random sequence R in the [1, z] range is added to the baseline sequence. At this time, the baseline sequence does not exceed the T. With this skip sampling method, we do not lose key frames, and the order of frames is maintained.
3.4. Sign Language Translation
We used a GRU-based model with a sequence-to-sequence (Seq2Seq) structure with an encoder and decoder in the translation step and improved translation performance by adding attention. This model is widely used in NMT and is suitable for translation tasks with variable-length inputs and outputs. We used Bahdanau attention [
32].
Unlike encoding the source sentence in the NMT task, we encode a video’s keypoint vector,
, and predict the target sentence,
. First, the encoder calculates the hidden state and generates a context vector, which follows:
where,
is the hidden state calculated in time step
t and
c is the context vector generated through the encoder a nonlinear function. In the decoder, the joint probability is calculated in the process of predicting words, and this follows.
The conditional probability at each time point used in the above equation is as follows.
where,
is the hidden state calculated from the time
i of the decoder and follows:
The context vector
is calculated using the weight for
and follows:
where,
where, the score is an alignment function that calculates the match score between the hidden state of the encoder and the decoder.
4. Experiments
To prove the effectiveness of our proposed method, we conduct several experiments on two datasets: KETI [
7], RWTH-PHOENIX-Weather 2014 T [
21]. KETI dataset is a korean sign language video consisting of 105 sentences and 419 words and has a full high-definition (HD) video. There were 10 signers, and they filmed the video from two angles. However, the KETI dataset is not provided with a test set, so we randomly split the dataset at a ratio of 8:1:1. The split of training, dev, and test videos are 6043, 800, and 801, respectively. We divided these videos into frames at 30 fps. The KETI dataset did not provide glosses.
The RWTH-PHOENIX-Weather-2014-T dataset is a data set extended from the existing RWTH-PHOENIX-Weather 2014 [
23] with the public german sign language. The split of training, dev, and test videos are 7096, 519, and 642, respectively. It has no overlap with the RWTH-PHOENIX-Weather 2014.
The average number of frames of training videos in these two datasets is 153 and 116 frames, respectively. Therefore, the input dataset, X, follows and ,respectively.
Our experiment was conducted in NVIDIA RTX A6000 and AMD EPYC 7302 16-Core environment for CPU. Our model was constructed using Pytorch [
42], Adam Optimizer [
43], and Cross-Entropy loss. The learning rate was set to 0.001 and epochs 100, and the dropout was set to 0.5 for preventing overfitting. Finally, the dimension of hidden states was 512.
We tokenize differently according to the characteristics of Korean and German. In Korean, the KoNLPy [
44] library’s Mecab part-of-speech (POS) tagger was used, and in German, the tokenization was performed through the nltk library [
45]. Finally, our evaluation metric evaluates our model in three ways: BLUE-4 [
46], ROUGE-L [
47], and METEOR [
48] according to the metric of NMT.
Our experiments focused on four aspects. The first aspect involved conducting comparative experiments to evaluate the performance of different normalization methods. The second aspect entailed testing the effectiveness of SASS by experimenting with video sampling and augmentation. The third aspect explored the impact of changes to the length of set (i.e., ), the representative value N, and the sequence of input values. Lastly, we compared our model’s performance to previous studies to confirm its effectiveness.
4.1. Effect of Normalization
This experiment proves that our method is robust compared to various normalization methods. The results of this are shown in
Table 2. We fixed and experimented with all factors except the normalization method. We compared our method with “Standard Normalization”, “Min-Max Normalization” and “Robust Normalization”. First, standard normalization uses standard deviation,
, and mean values,
, of points,
x, and follows (17). Second, min-max normalization uses the minimum value,
, and maximum value,
, of points and follows (18). Finally, robust normalization uses median,
, and interquartile range (IQR),
, and follows (19).
In this case, standard normalization is the method proposed by Ko et al. Moreover, we experimented by adding two normalization methods that did not exist before. First, “all reference” is the normalization method in which (3) is applied to the hand. Second, “center reference” uses only each keypoint vector,
v, and center vector,
c, without a separate reference point. This divides the difference between
v and
c by distance. Finally, the reference point was compared with the Kim et al. [
8] normalization method by fixing it with the right shoulder.
Customized normalization proved to be the most powerful in the experiment. The performance has improved significantly compared to the methods of Kim et al. and Ko et al., which are previous studies. Furthermore, it has proven that it is a new powerful method that can improve performance by performing better in the dataset, KETI, with a relatively large scale frame and in relatively small images, PHOENIX.
All of the methods compared, except our proposed method, have the issue of not properly accounting for the length of human body parts. First, commonly used methods such as Standard, Robust, and Minmax do not account for the fact that people have different body lengths, resulting in poor performance. Secondly, the method used by Kim et al. and the “Center Reference” method, which both use a single reference point, also fail to properly consider the length of each body part. Finally, the “All Reference” method fails to achieve good performance by changing the distribution of hand gestures, which are the most important in sign language. In contrast, customized normalization places a reference point for each body part, allowing the model to understand the length of the human body, and uses min-max normalization for the hand gestures to maintain their distribution, resulting in good performance.
4.2. Effect of SASS
This section shows a difference in performance according to frame selection method experiments. Keypoints were normalized with our experimental normalization method, and everything else was fixed except the frame selection method. We demonstrate that our proposed method is excellent with three comparative experiments. We conduct comparison experiments using only sampling, only augmentation, and both sampling and augmentation methods.
To evaluate the impact of frame sampling, we conduct experiments with different numbers of input frames, N, for each dataset. The KETI dataset is set to , which aligns with the results of prior research by Ko et al. For the PHOENIX dataset, N is set to , the smallest number of frames among the videos in the training dataset, as no similar methods have been reported in previous studies. In this experiment, our goal is to compare the results of frame sampling only, so we set the number of frames to the minimum among the training videos to eliminate any effects of frame augmentation. The skip sampling method showed the best results for the two datasets in the video sampling comparison experiment. Moreover, the stochastic sampling method differs in performance significantly from random sampling following the uniform distribution. While stochastic sampling is more effective than random sampling because it does not miss key frames, skip sampling was more effective because it extracts key frames by taking into account the gap between the frame and the key frame.
Second, we experimented with the performance change when only frames were augmented. We set the maximum frame value of the training video in the dataset to N and the N of KETI and PHOENIX to 426 and 475, respectively. For the same reason as the experiment that proves the effect of sampling, we set the maximum number of frames of training videos so that frames are not lost (i.e., without the sampling process).
We compared and experimented with a randomly augmented method following an even distribution and a stochastic augmented method following our method. This is shown in
Table 3. At KETI, the random augmentation was high performance in every way. However, in PHEONIX, the main evaluation index, BLEU-4, was the best in stochastic augmentation. The overall performance was improved when the frame augmentation was performed compared to when only sampling was performed.
Finally, we experimented with a combination of sampling and augmentation. We experiment with a total of 4 cases. In the previous experiment, since the random sampling method among sampling methods had poor results, we experimented by combining the number of cases except random sampling. This is shown in
Table 4. Our method, which combines skip sampling and stochastic augmentation, showed excellent performance in KETI, and BLEU-4 showed the highest performance in PHOENIX.
4.3. Additional Experiments
In this section, we experiment with several factors affecting the model. We compare the performance according to the change in the probability set,
, and compare it according to
N. Moreover, we experiment with how to invert the order of input values, a method of enhancing the translation performance proposed in the previous study of Sutskever et al. [
30]. For the first time, we experiment with the performance change according to
, the length of probability set
. We experiment only with
and evaluate only with BLEU-4. This is shown in
Table 5. Our methods outperform other methodologies, including the average BLEU value in the PHOENIX dataset, achieving the best performance on both datasets in the test set with
of 17.
Second, we experiment with comparison according to
N. We set and compare
N according to the training video’s mean and median frame length. The median number of frames of training videos in these two datasets is 148 and 112 frames, respectively. The comparison accordingly is shown in
Table 6.
Finally, we experiment with the effect of encoding by inverting the order of input
X. To this end, we reverse the order of frames and encode each video by changing the order of frames to
. This is shown in
Table 7. These results show that setting
N as the average has the best effect and that entering the frame’s original order has the best effect. It is analyzed that the change in the order of the input sentences is meaningless because our input value is the keypoint value of the frame, not the sentence.
4.4. Comparison of Previous Works
In this section, we compared our keypoint and sign language video processing method with a previous study that used the same deep learning model as ours to demonstrate their superiority. In other words, we compared our approach with a study that used an RNN-based Encoder-Decoder model with Attention [
13,
49]. The KETI dataset was implemented directly and conducted a comparative experiment because we randomly divided it into the training, validation, and test sets. In Ko et al.’s study, additional data were used, and we reproduced and compared the proposed model without adding data, as shown in
Table 8.
Moreover, since we present a robust method of experimenting without glosses dataset, the PHOENIX dataset only compares video-to-text translation without glosses. Most recent studies use glosses, so we compare them with Camgoz et al. [
4]. This is shown in
Table 9.
Our model also demonstrates high performance compared to previous studies in the dataset. Notably, the KETI dataset exhibits the best performance among keypoint based SLT models. Furthermore, the BLEU score was the highest in the PHOENIX dataset. BLEU-4 increased significantly (about 4%p) compared to Sign2Text (Bahdanau Attention), indicating that the ideal performance was improved through our video-processing method even though the same Bahdanau Attention was used.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}