
Pose ResNet: 3D Human Pose Estimation Based on Self-Supervision

Abstract
1. Introduction
- (1)
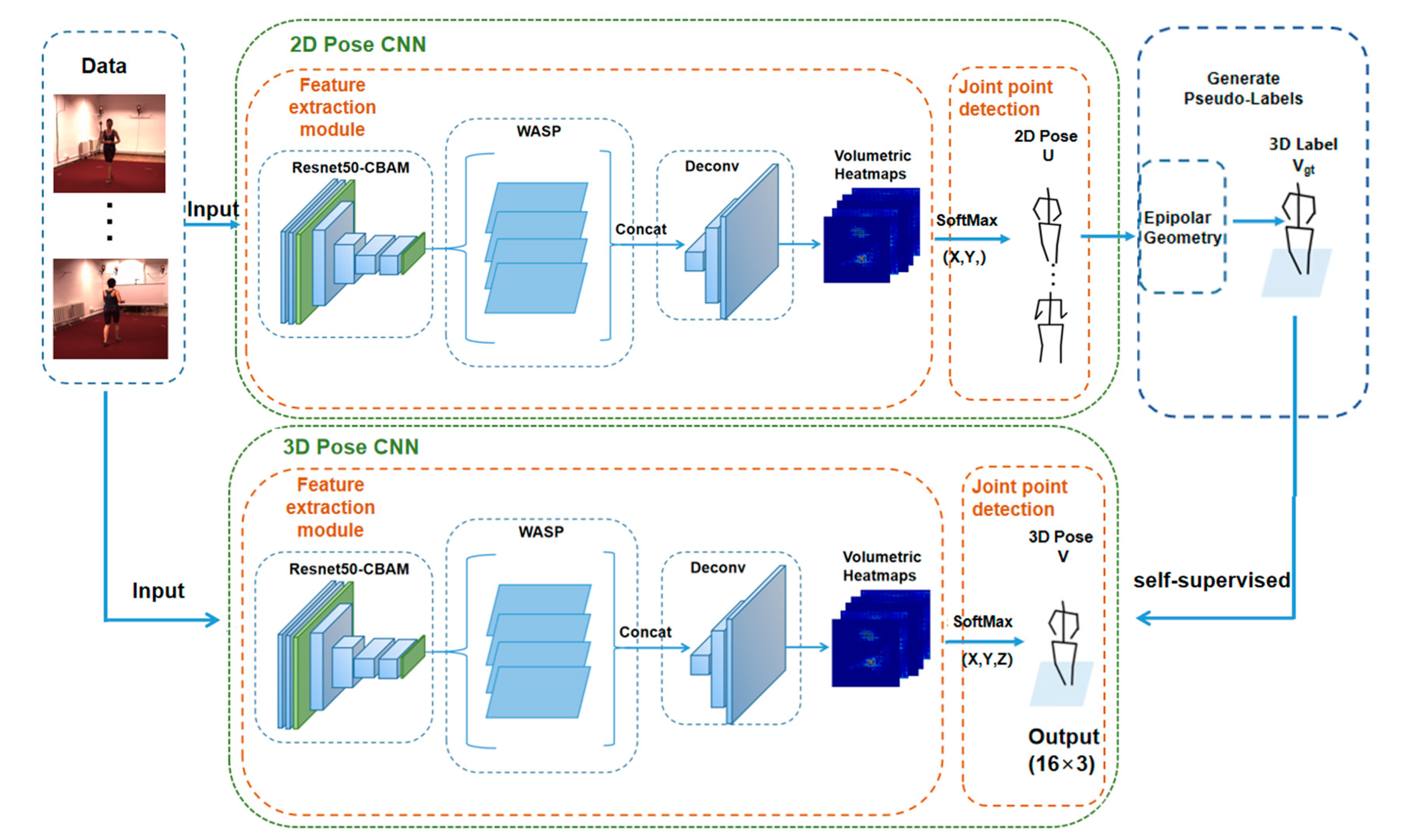
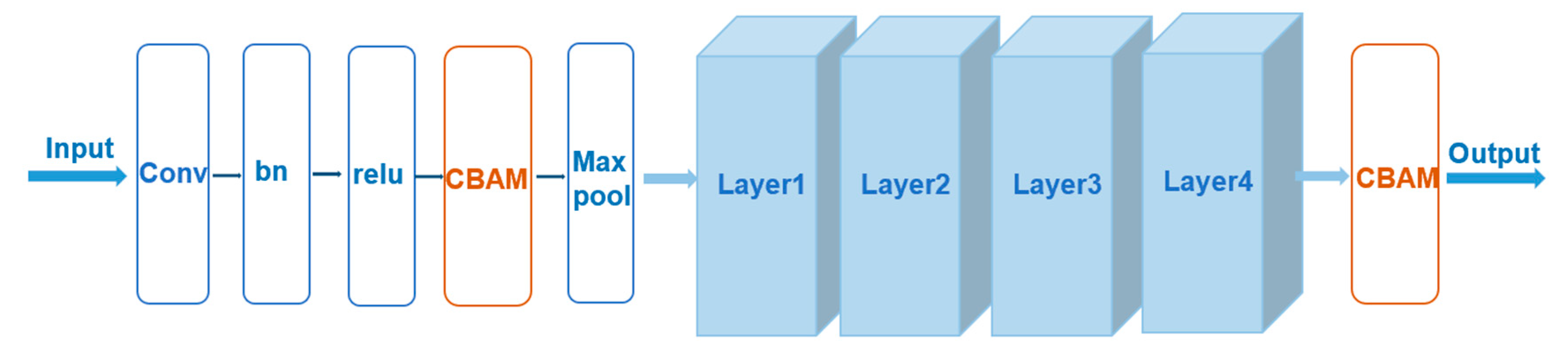
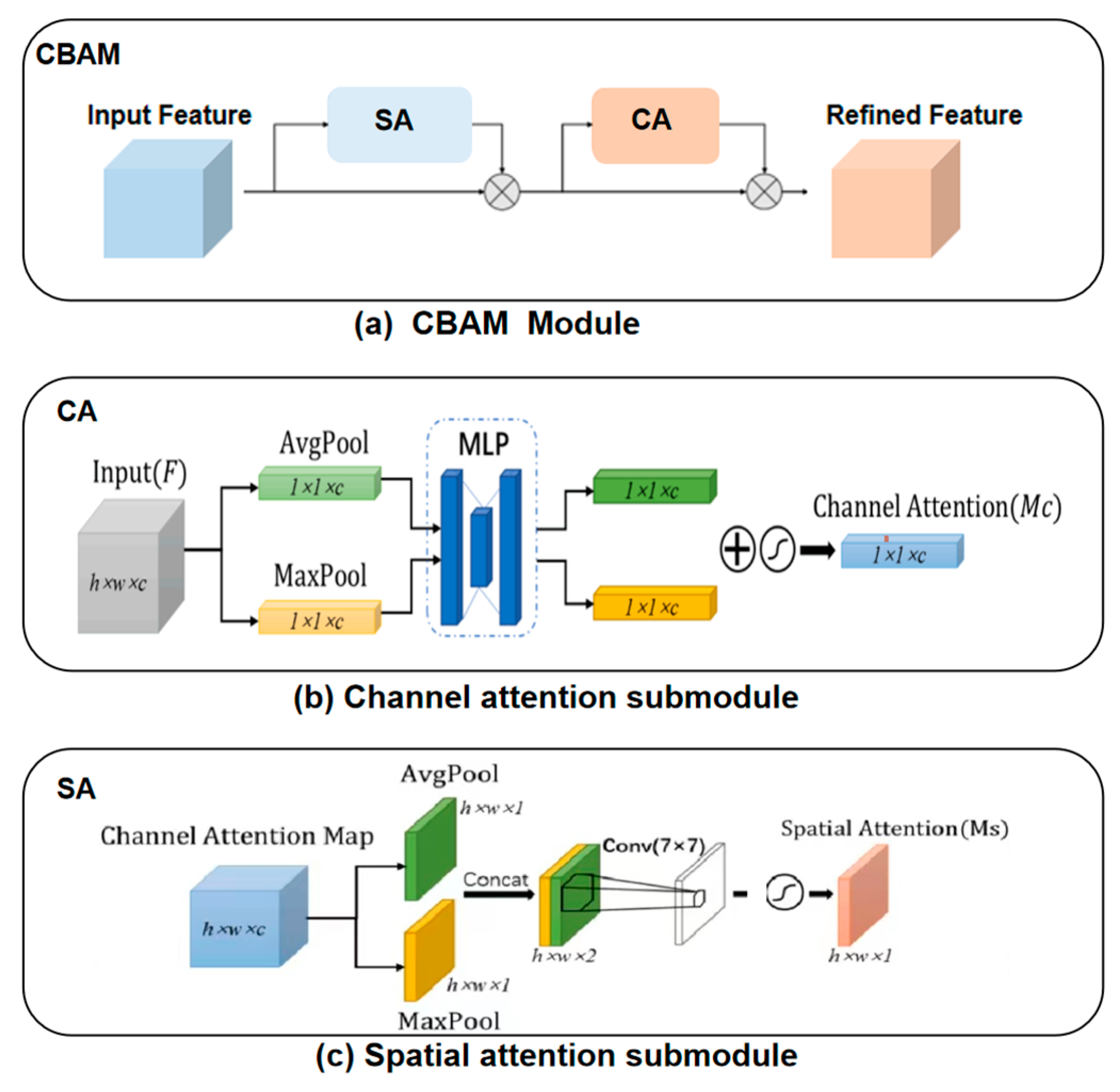
- A network model called Pose ResNet is designed for 3D human pose estimation. This model is based on ResNet50 and WASP, and a CBAM attention mechanism is introduced to increase the receptive field and select the important pixels in a fine-grained way.
- (2)
- This model uses the strategies of transfer learning and data enhancement for training, which not only improve the accuracy of joint detection but also enhance the generalization performance of the model. Transfer learning involves a transfer from 2D to 3D data, while data enhancement refers to the synthetic occlusion of images in the 3D dataset.
- (3)
- A set of 3D labels constructed through an epipolar geometric transformation between multiple views are used to train this model. Without the need for 3D ground truth labels, this model realizes true self-supervised training.
2. Related Work
2.1. Single- and Two-Stage Models
2.2. Weakly Supervised and Self-Supervised Methods
3. Models and Methods
3.1. Pose ResNet
3.2. CBAM
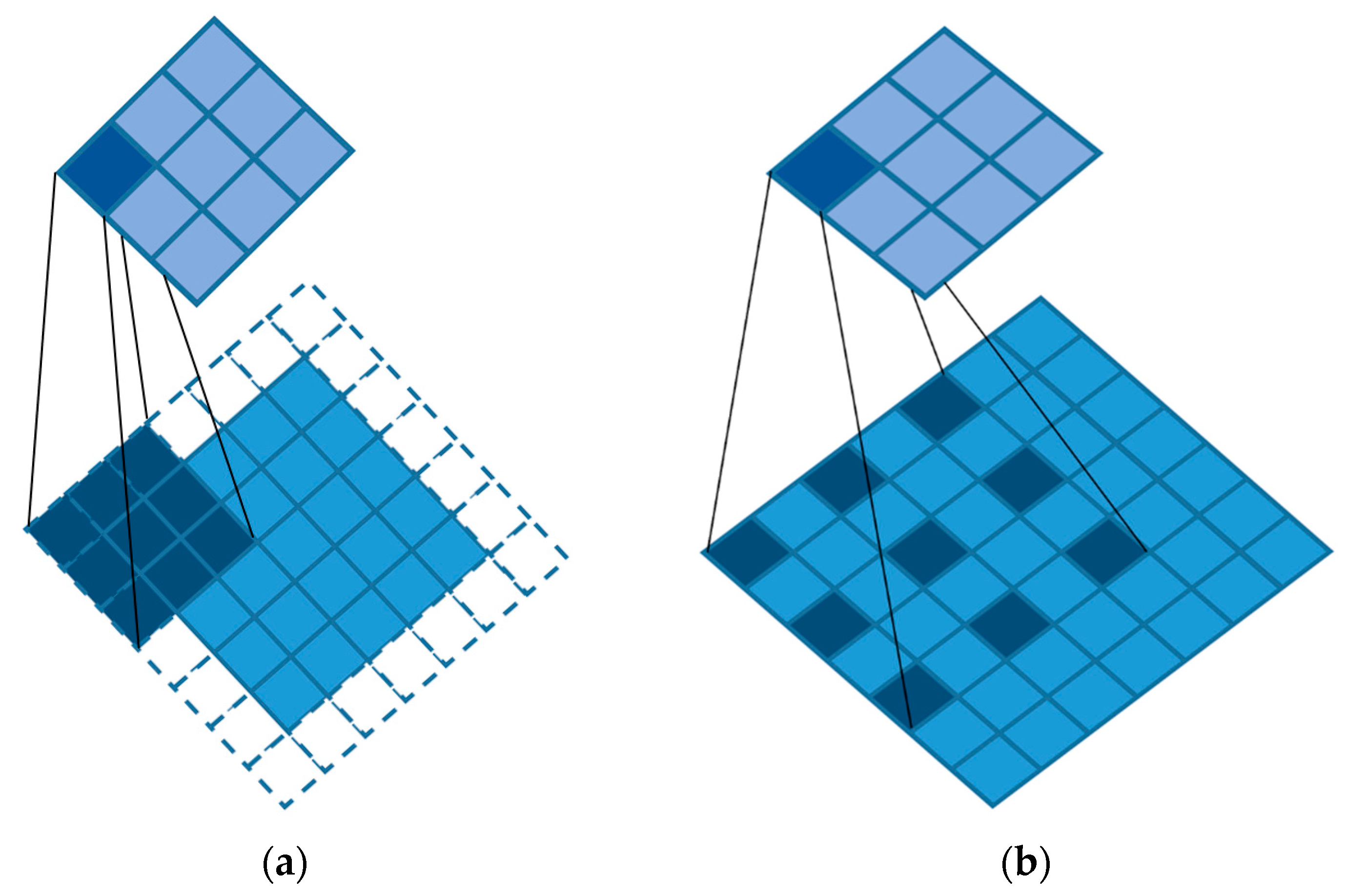
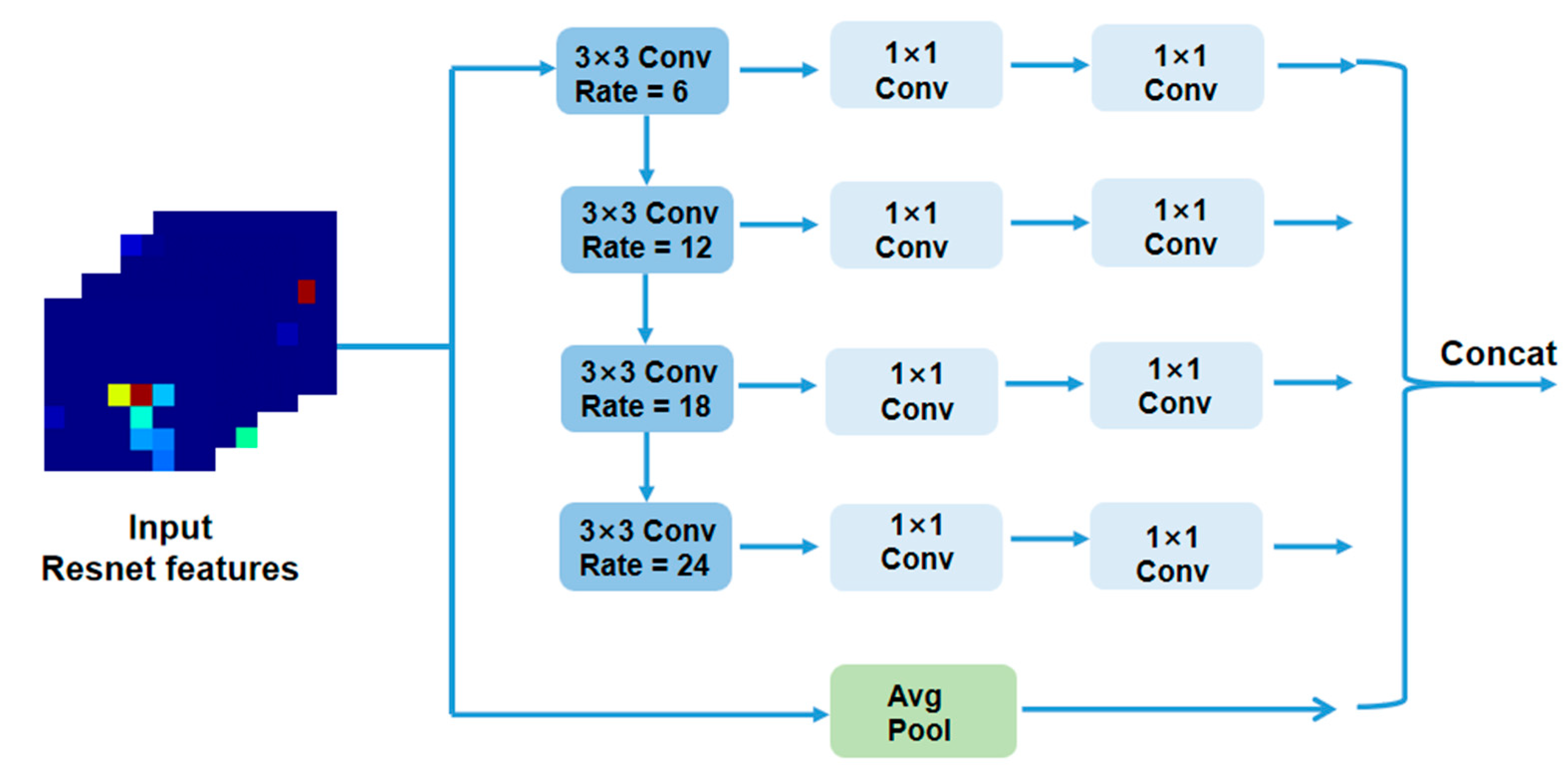
3.3. WASP Module
4. Model Training
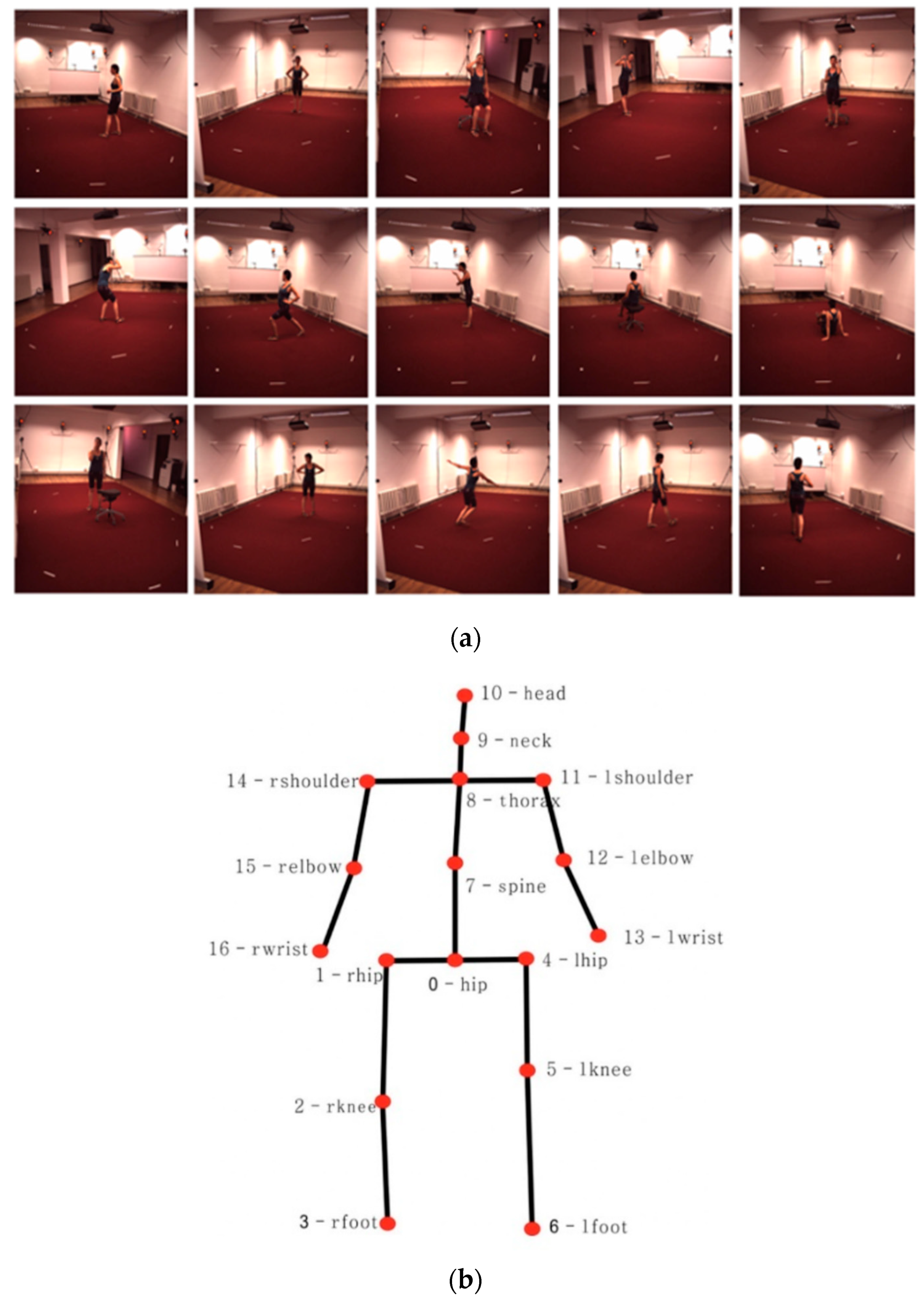
4.1. Dataset
4.2. Data Augmentation
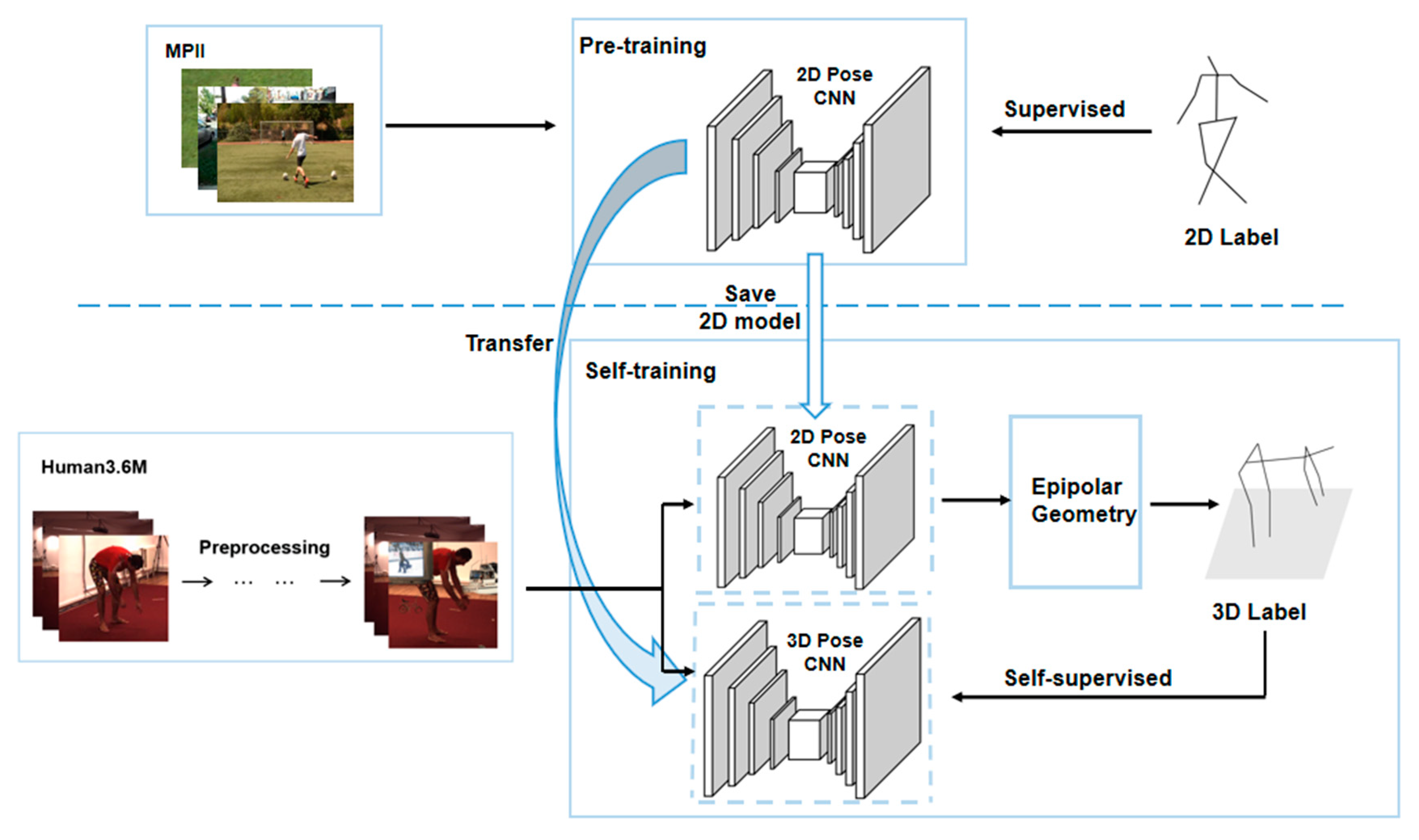
4.3. Pre-Training of 2D Pose CNN
4.4. Self-Supervised Training of 3D Pose CNN
- (a)
- Let the 2D coordinate of the joint in the image be and its 3D coordinate be . We can then describe the relation between them by assuming a pinhole image projection model. The following formulas are obtained from the pinhole image projection model:where is the depth of the joint in the camera’s image with respect to the reference frame of the camera, encodes the intrinsic parameters of the camera ( and are the focal length, and are the principal points), and R and T are the extrinsic parameters of rotation and translation of the camera.
- (b)
- Without using the external parameters of the camera, we can assume that the first camera is located at the center of the coordinate system, meaning that R for this camera is constant. The corresponding joints in and satisfy Equation (4). By substituting and into Equation (4), the fundamental matrix F can be obtained.
- (c)
- By substituting K and F into Equation (5), we obtain the essential matrix E. By using SVD to decompose E, we get four possible solutions to R.
- (d)
- By substituting the 2D coordinates into the epipolar geometry triangulation in Equation (6), we obtain the 3D coordinates of the corresponding joints by polynomial triangulation, and cache them as 3D labels, .
5. Experiments
5.1. Evaluation Indicators
5.2. Experimental Environment and Parameter Selection
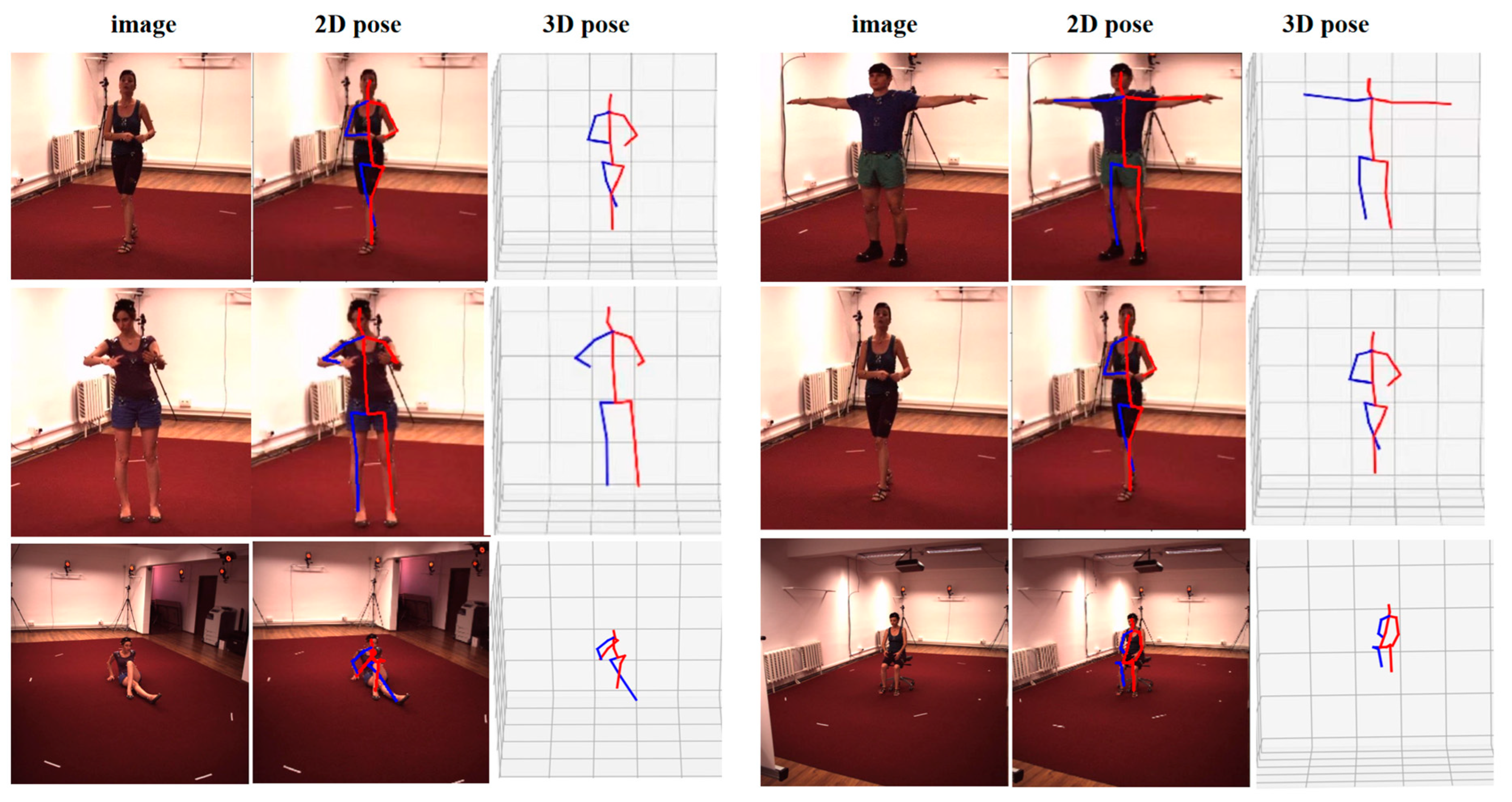
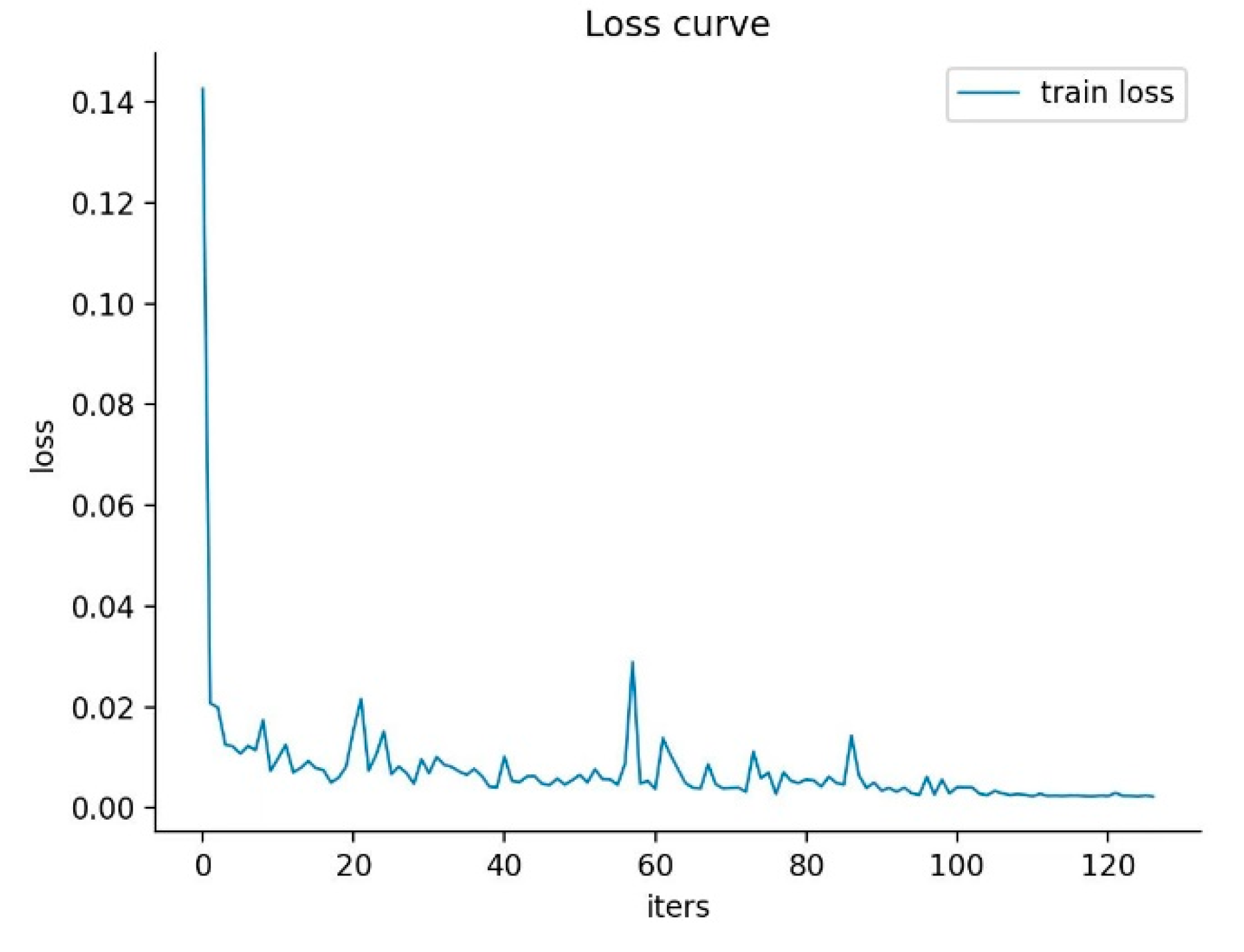
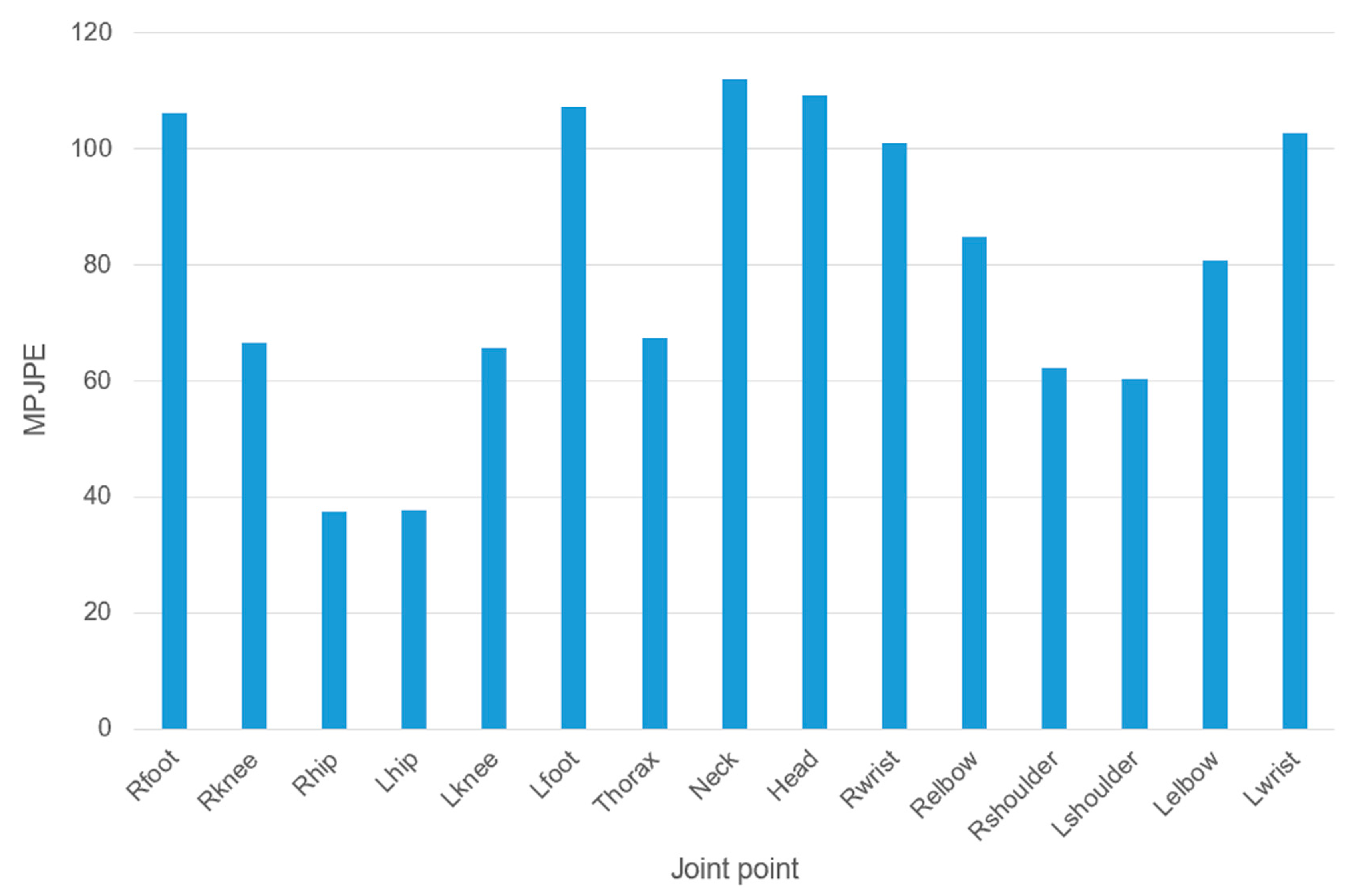
5.3. Analysis of Experimental Results
5.3.1. Comparison with Fully Supervised Methods
5.3.2. Comparison with Weakly Supervised and Self-Supervised Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MPJPE (↓) | P_MPJPE (↓) | N_MPJPE (↓) |
|---|---|---|---|
| Nie et al. [27] (2017) | 97.5 | 79.5 | |
| Rhodin et al. [24] (2018) | 66.8 | 51.6 | 63.3 |
| Martinez et al. [16] (2017) | 62.9 | 47.7 | ― |
| Pavlakos et al. [14] (2017) | 71.9 | ― | ― |
| Sun et al. [11] (2018) | 49.6 | 40.6 | ― |
| Kocabas et al. [43] (2020) | 65.6 | 41.4 | ― |
| Kevin Li et al. [44] (2021) | 54.0 | 36.7 | ― |
| Zheng et al. [37] (2021) | 44.3 | 34.6 | ― |
| Zhang et al. [38] (2022) | 40.9 | 32.6 | ― |
| Ours (fully supervised) | 51.8 | 41.9 | 49.4 |
| Ours (self-supervised) | 74.6 | 63.8 | 73.2 |
5.3.3. Comparison of Different Depth Networks
5.3.4. Ablation Experiment
5.4. Discussion
6. Conclusions and Prospects
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhao, L.; Zhu, J.; Bu, J.; Chen, C. A survey of human pose estimation: The body parts parsing based method. J. Vis. Commun. Image Represent. 2015, 32, 10–19. [Google Scholar]
- Zhang, F.; Zhu, X.; Wang, C. Single Person Pose Estimation: A Survey. arXiv 2021, arXiv:2109.10056. [Google Scholar]
- Zheng, C.; Wu, W.; Chen, C.; Yang, T.; Zhu, S.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep Learning-Based Human Pose Estimation: A Survey. arXiv 2020, arXiv:2012.13392. [Google Scholar]
- Mcilroy, P.; Izadi, S.; Fitzgibbon, A. Kinectrack: 3D Pose Estimation Using a Projected Dense Dot Pattern. IEEE Trans. Vis. Comput. Graph. 2014, 20, 839–851. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Chan, A.B. 3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014. [Google Scholar]
- Chen, C.H.; Ramanan, D. 3D Human Pose Estimation = 2D Pose Estimation + Matching. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, X.; Lin, K.Y.; Liu, W.; Qian, C.; Lin, L. Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Tekin, B.; Katircioglu, I.; Salzmann, M.; Lepet, V.; Fua, P. Structured Prediction of 3D Human Pose with Deep Neural Networks. In Proceedings of the British Machine Vision Conference (BMVC), York, UK, 19–22 September 2016. [Google Scholar]
- Tekin, B.; Márquez-Neila, P.; Salzmann, M.; Fua, P. Learning to Fuse 2D and 3D Image Cues for Monocular Body Pose Estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tome, D.; Russell, C. lifting from the deep: Convolutional 3d pose estimation from a single image supplementary material. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sun, X.; Xiao, B.; Wei, F.; Liang, S.; Wei, Y. Integral Human Pose Regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Mehta, D.; Sridhar, S.; Sotnychenko, O.; Rhodin, H.; Shafiei, M.; Seidel, H.P.; Xu, W.; Casas, D.; Theobalt, C. VNect: Real-time 3D Human Pose Estimation with a Single RGB Camera. ACM Trans. Graph. 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, X.; Zhang, W.; Liang, S. Deep Kinematic Pose Regression. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–10 October 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Towards 3D Human Pose Estimation in the Wild: A Weakly-supervised Approach. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Martinez, J.; Hossain, R.; Romero, J.; Little, J.J. A Simple Yet Effective Baseline for 3d Human Pose Estimation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Fang, H.; Xu, Y.; Wang, W.; Liu, X.; Zhu, S. Learning Pose Grammar to Encode Human Body Configuration for 3D Pose Estimation. arXiv 2017, arXiv:1710.06513. [Google Scholar]
- Pavllo, D.; Feichtenhof, C.; Grangi, D.; Auli, M. 3D Human Pose Estimation in Video With Temporal Convolutions and Semi-Supervised Training. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. arXiv 2016, arXiv:1611.08050. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Kocabas, M.; Karagoz, S.; Akbas, E. MultiPoseNet: Fast Multi-Person Pose Estimation using Pose Residual Network. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Kanazawa, A.; Black, M.J.; Jacobs, D.W.; Malik, J. End-to-end Recovery of Human Shape and Pose. arXiv 2017, arXiv:1712.06584. [Google Scholar]
- Drover, D.; Mv, R.; Chen, C.H.; Agrawal, A.; Tyagi, A.; Huynh, C.P. Can 3D Pose be Learned from 2D Projections Alone? In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Rhodin, H.; Meyer, F.; Sporri, J.; Muller, E.; Constantin, V.; Fua, P.; Katircioglu, I.; Salzmann, M. Learning Monocular 3D Human Pose Estimation from Multi-view Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Tung, H.; Harley, A.W.; Seto, W.; Fragkiadaki, K. Adversarial Inverse Graphics Networks: Learning 2D-to-3D Lifting and Image-to-Image Translation from Unpaired Supervision. arXiv 2017, arXiv:1705.11166. [Google Scholar]
- Pavlakos, G.; Zhou, X.; Derpanis, K.G.; Daniilidis, K. harvesting multiple views for marker-less 3d human pose annotations supplementary material. arXiv 2019, arXiv:1704.04793. [Google Scholar]
- Nie, B.X.; Zhu, S.C.; Ping, W. Monocular 3D Human Pose Estimation by Predicting Depth on Joints. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wandt, B.; Rosenhahn, B. RepNet: Weakly Supervised Training of an Adversarial Reprojection Network for 3D Human Pose Estimation. arXiv 2019, arXiv:1902.09868. [Google Scholar]
- Kocabas, M.; Karagoz, S.; Akbas, E. Self-Supervised Learning of 3D Human Pose using Multi-view Geometry. arXiv 2019, arXiv:1903.02330. [Google Scholar]
- Hua, G.; Liu, H.; Li, W.; Zhang, Q.; Ding, R.; Xu, X. Weakly-supervised 3D human pose estimation with cross-view U-shaped graph convolutional network. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Gong, K.; Li, B.; Zhang, J.; Wang, T.; Huang, J.; Mi, M.B.; Feng, J.; Wang, X. PoseTriplet: Co-evolving 3D human pose estimation, imitation, and hallucination under self-supervision. arXiv 2022, arXiv:2203.15625. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Artacho, B.; Savakis, A. UniPose: Unified Human Pose Estimation in Single Images and Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6M: Large Scale Datasets and Predictive Methods for 3D Human Sensing in Natural Environments. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Sárándi, I.; Linder, T.; Arras, K.O.; Leibe, B. Synthetic Occlusion Augmentation with Volumetric Heatmaps for the 2018 ECCV PoseTrack Challenge on 3D Human Pose Estimation. arXiv 2018, arXiv:1809.04987. [Google Scholar]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3d human pose estimation with spatial and temporal transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11656–11665. [Google Scholar]
- Zhang, J.; Tu, Z.; Yang, J.; Chen, Y.; Yuan, J. MixSTE: Seq2seq Mixed Spatio-Temporal Encoder for 3D Human Pose Estimation in Video. arXiv 2022, arXiv:2203.00859. [Google Scholar]
- Wang, C.; Kong, C.; Lucey, S. Distill Knowledge from NRSfM for Weakly Supervised 3D Pose Learning. arXiv 2019, arXiv:1908.06377. [Google Scholar]
- Iqbal, U.; Molchanov, P.; Kautz, J. Weakly-Supervised 3D Human Pose Learning via Multi-view Images in the Wild. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wandt, B.; Rudolph, M.; Zell, P.; Rhodin, H.; Rosenhahn, B. CanonPose: Self-Supervised Monocular 3D Human Pose Estimation in the Wild. arXiv 2020, arXiv:2011.14679. [Google Scholar]
- Jenni, S.; Favaro, P. Self-supervised multi-view synchronization learning for 3d pose estimation. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Kocabas, M.; Athanasioun, B.J. Vibe: Video inference for human body pose and shape estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5253–5263. [Google Scholar]
- Lin, K.; Wang, L.; Liu, Z. End-to-End Human Pose and Mesh Reconstruction with Transformers. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]













| Model | MPJPE (↓) | P_MPJPE (↓) | N_MPJPE (↓) |
|---|---|---|---|
| Pavlakos et al. [14] (2017) | 118.4 | ― | ― |
| Kanzawa et al. [22] (2018) | 106.8 | 67.5 | ― |
| Jenni et al. [42] (2020) | 104.9 | 78.4 | 91.7 |
| Wang et al. [39] (2019) | 83.0 | 57.5 | ― |
| Rhodin et al. [24] (2018) | 80.1 | 65.1 | ― |
| Wandt et al. [28] (2019) | 89.9 | 65.1 | ― |
| Wandt et al. [41] (2021) | 81.9 | 53.0 | ― |
| Kocabas et al. [29] (2019) | 76.6 | 67.5 | 75.2 |
| Lqbal et al. [40] (2020) | 69.1 | 55.9 | 66.3 |
| Ours (fully supervised) | 51.8 | 41.9 | 49.4 |
| Ours (self-supervised) | 74.6 | 63.8 | 73.2 |
| Backbone | PCK (%) |
|---|---|
| ResNet18 | 84.7 |
| ResNet34 | 86.3 |
| ResNet50 | 88.3 |
| ResNet101 | 88.9 |
| Transfer Learning | Synthesis Occlusion | WASP | CBAM | MPJPE (↓) | P_MPJPE (↓) | N_MPJPE (↓) |
|---|---|---|---|---|---|---|
| ― | ― | ― | ― | 102.7 | 89.5 | 98.0 |
| √ | ― | ― | ― | 83.7 | 71.7 | 82.8 |
| √ | √ | ― | ― | 76.1 | 65.8 | 74.5 |
| √ | ― | √ | ― | 83.3 | 71.2 | 82.3 |
| √ | ― | ― | √ | 82.8 | 73.2 | 81.8 |
| √ | √ | √ | ― | 76.0 | 65.0 | 74.4 |
| √ | √ | ― | √ | 74.8 | 64.1 | 72.9 |
| √ | √ | √ | √ | 74.6 | 63.8 | 73.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bao, W.; Ma, Z.; Liang, D.; Yang, X.; Niu, T. Pose ResNet: 3D Human Pose Estimation Based on Self-Supervision. Sensors 2023, 23, 3057. https://doi.org/10.3390/s23063057
Bao W, Ma Z, Liang D, Yang X, Niu T. Pose ResNet: 3D Human Pose Estimation Based on Self-Supervision. Sensors. 2023; 23(6):3057. https://doi.org/10.3390/s23063057
Chicago/Turabian StyleBao, Wenxia, Zhongyu Ma, Dong Liang, Xianjun Yang, and Tao Niu. 2023. "Pose ResNet: 3D Human Pose Estimation Based on Self-Supervision" Sensors 23, no. 6: 3057. https://doi.org/10.3390/s23063057
APA StyleBao, W., Ma, Z., Liang, D., Yang, X., & Niu, T. (2023). Pose ResNet: 3D Human Pose Estimation Based on Self-Supervision. Sensors, 23(6), 3057. https://doi.org/10.3390/s23063057