
Big Data Analytics Using Cloud Computing Based Frameworks for Power Management Systems: Status, Constraints, and Future Recommendations

 ,
,  ,
,  ,
,
Abstract
1. Introduction
1.1. Research Background
Power System Condition Monitoring
1.2. Challenges
- Meet the multiple real-time requirements of power system condition monitoring;
- The weakness of traditional data mining based on single-node serial mining;
- The insufficient algorithm that combines data mining and computing technology to deal with massive data.
1.3. Novelty
1.4. Organizing of Paper

2. Parallel Computing
2.1. Concept of Parallel Computing
2.2. Classification of Parallel Computing Technology
Flynn Classification
- (1)
- SISD is a traditional serial computing method. Early computers fell into this category in a certain clock cycle, only one instruction is executed and only one data stream is processed;
- (2)
- SIMD is uses one instruction to process multiple data streams simultaneously in a certain clock cycle. Current single-core computers also fall into this category and are widely used in the fields of digital signal processing, image processing, and multimedia information processing;
- (3)
- MISD is uses multiple instruction streams to process a single data stream. Currently, it is only a theoretical model and has no application examples;
- (4)
- MIMD are currently the most popular. Multicore processors fall into this category which can execute multiple instruction streams on multiple different data streams at the same time.
2.3. Classification by Computational Characteristics of Applications
3. Shortcomings of Traditional Parallel Computing
3.1. Computational Complexity Issues
3.2. Multi-Source Heterogeneous Problem
3.3. Data-Intensive Challenges
3.4. Scalability
3.5. Usability
4. Cloud Computing
4.1. Concept of Cloud Computing
- (1)
- Virtualization: Virtualization is the core technology of cloud computing, and many other features that depend on it. The application of virtualization technology can integrate heterogeneous computing resources to form a resource pool for users to access [142].
- (2)
- Service-oriented: Cloud computing provides three levels of services, namely Infrastructure as a Service (IaaS), Platform as a Service (PaaS), and Software as a Service (SaaS). IaaS is the lowest-level service that directly provides compute, memory, and networking equipment. Users have the greatest degree of freedom and can build their own platforms and software. PaaS is one level higher than IaaS, providing a ready-made cloud platform, saving the work of developing the platform. SaaS provides more convenient services; users can directly use the provided software without any development [143];
- (3)
- Elasticity and scalability: The cloud scale can be easily expanded without affecting the cloud services currently provided externally. Resources in the cloud are infinitely desirable to users and can be automatically provisioned and reclaimed quickly on demand [144];
- (4)
- Reliable and universal: Cloud computing technology provides a variety of fault-tolerant mechanisms to ensure high reliability of services [145]. Data is placed with multiple copies to prevent data loss due to hardware failure [146]. Compute services that were stopped due to hardware failures can still continue elsewhere through virtual machine migration. Virtualization makes cloud computing resources transparent to users and supports applications in different industries at the same time [147];
- (5)
- Economies of scale: The cloud computing platform does not have high requirements for hardware facilities, and a large number of idle ordinary computers can be integrated into the resource pool through virtualization [33]. For users, it saves hardware costs and daily management costs of self-built platforms [57]. For cloud service providers, the versatility of cloud computing has greatly improved the utilization of resources, and the scale has significantly increased economic benefits [148].
4.2. Cloud Computing Environment
4.2.1. Hadoop Technology
4.2.2. Spark Technology
4.2.3. Storm Technology
5. Comparison of Parallel Computing with Cloud Computing
Distributed Cloud Computing and Parallel Computing
6. The Application Basis of Cloud Computing in a Power System
- (1)
- Public cloudAs the name suggests, it is a cloud service that is open to the public. It is large-scale, low-cost, and the most popular cloud service for the public. The most typical application is Amazon Web Services (“AWS”). The app provides a complete set of infrastructure and cloud solutions to customers around the world. AWS provides users with a complete set of cloud computing services, which can help enterprises reduce IT investment costs and maintenance costs and easily migrate to the cloud [193].
- (2)
- Private cloudIt is a cloud that does not provide services publicly and is used within a group or organization. Provide private cloud services to internal users. Because they cannot be used publicly, most firewalls are set up [194]. The typical representative of private cloud is the Blue Cloud plan launched by IBM. Blue Cloud is based on open standards and open source software powered by IBM software, systems technologies and services [195]. The Blue Cloud developed by more than 200 IBM researchers around the world, will help clients quickly and easily explore cloud computing infrastructure for extreme-scale computing [196].
- (3)
- Hybrid cloudThat is, the combination of public cloud and private cloud is between private and public, such as Amazon’s virtual private cloud (VPC) [54]. A VPC is a dynamically provisioned pool of public cloud computing resources that requires the use of encryption protocols, tunneling protocols, and other security procedures to transfer data between private enterprises and cloud service providers [197,198,199,200]. The services provided by each layer are as follows:
- (1)
- Application layerThe application layer provides users with various application software and services required by a friendly user interface [201]. The application layer directly faces customer needs and provides enterprise customers with enterprise applications such as enterprise resource planning (ERP) and customer relationship management (CRM) [202], and office automation (OA) [203].
- (2)
- Platform layerThe platform layer provides services for users who can use the platform to realize the value they want to achieve [204].
- (3)
- Infrastructure layerThis layer provides infrastructure-level services, that is, the establishment of the cloud computing platform infrastructure is directly open to users, so that they can use the powerful storage and computing capabilities of cloud computing. Users can directly store files and run calculations in the cloud, and also the infrastructure can be allocated independently, which is equivalent to the user having a scalable computer with large storage space and supercomputing performance through the terminal [205].
7. Future Trend
- First, it will help grid companies to carry out grid operation and maintenance monitoring and improve response sensitivity [215]. Use the data collected from the power system to monitor, control, or adjust the power generation, load, and fault status in the network, and respond accordingly when there is an error or an upgrade in the power grid [209,216].
- Secondly, it will help grid companies conduct special analysis on equipment maintenance, operation and maintenance, improve system reliability, power supply qualification rate, reduce costs, and reduce power outages [217]. In the field of power grid maintenance, operation and maintenance, through the selection of key indicators of power equipment from the three aspects of safety, benefit, and cost, analysis of the mutual influence of “safety”, “benefit” and “cost” in maintenance management, coordination of the three these factors are comprehensively optimized, and at the same time, real-time online monitoring of the maintenance indicators of power grid enterprises is realized, providing guidance and services for the company’s maintenance strategy formulation [218,219,220].
- ➢
- ➢
- The coverage of parallel algorithm design is relatively narrow, and the application range in power system data processing is not wide enough. However, with the increasing informatization of the power system and the continuous quantification of power data, the application scope of data mining technology continues to expand. Parallel algorithms can be designed in more aspects to enhance the data processing effect and carry out all around power system production and dispatching [223,224];
- ➢
- ➢
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lin, W.; Wu, G.; Wang, X.; Li, K. An artificial neural network approach to power consumption model construction for servers in cloud data centers. IEEE Trans. Sustain. Comput. 2019, 5, 329–340. [Google Scholar] [CrossRef]
- Liu, Y.; Liang, S.; He, C.; Zhou, Z.; Fang, W.; Li, Y.; Wang, Y. A Cloud-computing and big data based wide area monitoring of power grids strategy. IOP Conf. Ser. Mater. Sci. Eng. 2019, 677, 042055. [Google Scholar] [CrossRef]
- Raza, M.Q.; Khosravi, A. A review on artificial intelligence based load demand forecasting techniques for smart grid and buildings. Renew. Sustain. Energy Rev. 2015, 50, 1352–1372. [Google Scholar] [CrossRef]
- Santos, M.A.G.; Munoz, R.; Olivares, R.; Filho, P.P.R.; Del Ser, J.; de Albuquerque, V.H.C. Online heart monitoring systems on the internet of health things environments: A survey, a reference model and an outlook. Inf. Fusion 2020, 53, 222–239. [Google Scholar] [CrossRef]
- Sharma, S.; Kotturu, P.K.; Narooka, P.C. Implication of IoT components and energy management monitoring. In Swarm Intelligence Optimization: Algorithms and Applications; John Wiley & Sons, Inc.: New York, NY, USA, 2020; pp. 49–65. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, C.C.; Schneider, K.P.; Tuffner, F.K.; Ton, D.T. Microgrids for service restoration to critical load in a resilient distribution system. IEEE Trans. Smart Grid 2018, 9, 426–437. [Google Scholar] [CrossRef]
- AL-Jumaili, A.H.A.; Al Mashhadany, Y.I.; Sulaiman, R.; Alyasseri, Z.A.A. A Conceptual and Systematics for Intelligent Power Management System-Based Cloud Computing: Prospects, and Challenges. Appl. Sci. 2021, 11, 9820. [Google Scholar] [CrossRef]
- Miu, W.; Zhang, Z.; Wang, X.; Hou, J.; Sun, Y. A Real-time Detection Framework for Abnormal Devices in the Power Internet of Things. J. Phys. 2022, 2166, 012057. [Google Scholar] [CrossRef]
- Jain, S.; Chandrasekaran, K. Industrial automation using internet of things. In Research Anthology on Cross-Disciplinary Designs and Applications of Automation; IGI Global: New York, NY, USA, 2022; pp. 355–383. [Google Scholar]
- Zaheeruddin; Singh, K.; Amir, M. Intelligent Fuzzy TIDF-II Controller for Load Frequency Control in Hybrid Energy System. IETE Tech. Rev. 2021, 39, 1355–1371. [Google Scholar] [CrossRef]
- Manimegalai, C.T.; Kalimuthu, K.; Gauni, S. Toward integrating bidirectional multiband data and power transmission using double clad optical fibers for the next generation disaster resilient managing communication systems. Microw. Opt. Technol. Lett. 2022, 64, 816–820. [Google Scholar] [CrossRef]
- Jia, X. Research on network abnormal data flow mining based on improved cluster analysis. Distrib. Parallel. Databases 2021, 40, 797–813. [Google Scholar] [CrossRef]
- Ahamed, R.; Habeeb, A.; Nasaruddin, F.; Gani, A.; Abaker, I.; Hashem, T.; Ahmed, E.; Imran, M. International Journal of Information Management Real-time big data processing for anomaly detection: A Survey. Int. J. Inf. Manag. 2018, 45, 289–307. [Google Scholar]
- Lin, Z.; Xiangping, L.; Wenzhong, C.; Haoyue, P. Computer aided analysis and control of power system based on data mining technology. In Proceedings of the 2021 IEEE Asia-Pacific Conference on Image Processing, Electronics and Computers, Dalian, China, 14–16 April 2021; pp. 1258–1261. [Google Scholar] [CrossRef]
- Malik, M.I. Cloud Computing-Technologies. Int. J. Adv. Res. Comput. Sci. 2018, 9, 379–384. [Google Scholar] [CrossRef]
- Li, X.; Liu, H.; Wang, W.; Zheng, Y.; Lv, H.; Lv, Z. Big data analysis of the internet of things in the digital twins of smart city based on deep learning. Futur. Gener. Comput. Syst. 2022, 128, 167–177. [Google Scholar] [CrossRef]
- Gharehpasha, S.; Masdari, M.; Jafarian, A. Power efficient virtual machine placement in cloud data centers with a discrete and chaotic hybrid optimization algorithm. Cluster Comput. 2021, 24, 1293–1315. [Google Scholar] [CrossRef]
- Li, Y.; Shi, F.; Zhang, H. Panoramic synchronous measurement system for wide-area power system based on the cloud computing. In Proceedings of the 2018 13th IEEE Conference on Industrial Electronics and Applications (ICIEA), Wuhan, China, 31 May–2 June 2018; pp. 764–768. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, S. An approach to smart grid online data mining based on cloud computing. Int. J. Simul. Syst. Sci. Technol. 2016, 17, 17.1–17.5. [Google Scholar] [CrossRef]
- Sun, C.; Wang, X.; Zheng, Y.; Zhang, F. A framework for dynamic prediction of reliability weaknesses in power transmission systems based on imbalanced data. Int. J. Electr. Power Energy Syst. 2020, 117, 105718. [Google Scholar] [CrossRef]
- Sliwa, J. Assessing complex evolving cyber-physical systems (case study: Smart medical devices). Int. J. High Perform. Comput. Netw. 2019, 13, 294. [Google Scholar] [CrossRef]
- Urooj, S.; Singh, T.; Amir, M.; Tariq, M. Optimal Design of Power Transformer with Advance Core Material using ANSYS Technique. Eur. J. Electr. Eng. Comput. Sci. 2020, 4, 1–17. [Google Scholar] [CrossRef]
- Bekemeier, B.; Park, S.; Whitman, G. Challenges and lessons learned in promoting adoption of standardized local public health service delivery data through the application of the Public Health Activities and Services Tracking model. J. Am. Med. Inform. Assoc. 2019, 26, 1660–1663. [Google Scholar] [CrossRef]
- Sagheer, N.S.; Yousif, S. Canopy with &-means Clustering Algorithm for Big Data Analytics. AIP Conf. Proc. 2021, 2334, 070006. [Google Scholar] [CrossRef]
- Tao, D.; Lin, Z.; Wang, B. Load feedback-based resource scheduling and dynamic migration-based data locality for virtual hadoop clusters in openstack-based clouds. Tsinghua Sci. Technol. 2017, 22, 149–159. [Google Scholar] [CrossRef]
- Dong, F.; Guo, X.; Zhou, P.; Shen, D. Task-aware flow scheduling with heterogeneous utility characteristics for data center networks. Tsinghua Sci. Technol. 2019, 24, 400–411. [Google Scholar] [CrossRef]
- Javed, A.; Larijani, H.; Ahmadinia, A.; Gibson, D. Smart Random Neural Network Controller for HVAC Using Cloud Computing Technology. IEEE Trans. Ind. Inform. 2017, 13, 351–360. [Google Scholar] [CrossRef]
- Eddoujaji, M.; Samadi, H.; Bohorma, M. Data Processing on Distributed Systems Storage Challenges. In Smart Innovation, Systems and Technologies; Springer: Berlin, Germany, 2022; Volume 237, pp. 795–811. [Google Scholar]
- Yang, C.; Huang, Q.; Li, Z.; Liu, K.; Hu, F. Big Data and cloud computing: Innovation opportunities and challenges. Int. J. Digit. Earth 2017, 10, 13–53. [Google Scholar] [CrossRef]
- Zhang, Y.; Lang, Y.; Yang, S.; Zhao, K.; Liu, P.; Han, F. Big Data Storage Technology suitable for the Operation and Maintenance of New Generation Power Grid Dispatching Control System Operation. IOP Conf. Ser. Earth Environ. Sci. 2019, 300, 042084. [Google Scholar] [CrossRef]
- Kulkarni, N.; Lalitha, S.V.N.L.; Deokar, S.A. Real time control and monitoring of grid power systems using cloud computing. Int. J. Electr. Comput. Eng. 2019, 9, 941. [Google Scholar] [CrossRef]
- Ahmed, M.H.; Tiun, S.; Omar, N.; Sani, N.S. Short Text Clustering Algorithms, Application and Challenges: A Survey. Appl. Sci. 2022, 13, 342. [Google Scholar] [CrossRef]
- Alarifi, A.; Dubey, K.; Amoon, M.; Altameem, T.; El-Samie, F.E.A.F.E.A.; Altameem, A.; Sharma, S.C.C.; Nasr, A.A.A. Energy-Efficient Hybrid Framework for Green Cloud Computing. IEEE Access 2020, 8, 115356–115369. [Google Scholar] [CrossRef]
- Ali, A.H.; Mohammad, O.K.J. Impacting of the E-Platforms on the 4.0th Industrial Educational Revolution. In Proceedings of the Pervasive Health: Pervasive Computing Technologies for Healthcare, Cairo, Egypt, 24–26 March 2019. [Google Scholar]
- Al-Nuaymy, A.I.; Hamed, W.A.; Ali, A.H. The Role of Social Media in Enhancing the Learning Process of Iraq Students. ARPN J. Eng. Appl. Sci. 2019, 14, 7142–7153. [Google Scholar] [CrossRef]
- Li, X.; Zhuang, W.; Zhang, H. Short-term Power Load Forecasting Based on Gate Recurrent Unit Network and Cloud Computing Platform. Pervasive Health Pervasive Comput. Technol. Healthc. 2020, 29, 1–6. [Google Scholar] [CrossRef]
- Yuan, J. An Anomaly Data Mining Method for Mass Sensor Networks Using Improved PSO Algorithm Based on Spark Parallel Framework. J. Grid Comput. 2020, 18, 251–261. [Google Scholar] [CrossRef]
- Deng, C.; Liu, J.; Liu, Y.; Yu, Z. Cloud computing based high-performance platform in enabling scalable services in power system. In Proceedings of the 2016 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Changsha, China, 13–15 August 2016; pp. 2200–2203. [Google Scholar] [CrossRef]
- Hu, L.; Yang, C.; Meng, X.; Pang, P. Short-Term Power Load Forecasting Method Based on Cloud Computing and Intelligent Algorithms. In Lecture Notes on Data Engineering and Communications Technologies; Springer: Berlin, Germany, 2022; Volume 98, pp. 518–525. [Google Scholar]
- Litchfield, A.T.; Althouse, J. A systematic review of cloud computing, big data and databases on the cloud. In Proceedings of the Americas Conference on Information Systems, Savannah, GA, USA, 7–9 August 2014. [Google Scholar]
- Wan, L.; Zhang, G.; Li, H.; Li, C. A Novel Bearing Fault Diagnosis Method Using Spark-Based Parallel ACO-K-Means Clustering Algorithm. IEEE Access 2021, 9, 28753–28768. [Google Scholar] [CrossRef]
- Aziz, K.; Zaidouni, D.; Bellafkih, M. Real-time data analysis using Spark and Hadoop. In Proceedings of the 2018 International Conference on Optimization and Applications, ICOA 2018, Mohammedia, Morocco, 26–27 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Zhu, T.; Xiao, S.; Zhang, Q.; Gu, Y.; Yi, P.; Li, Y. Emergent Technologies in Big Data Sensing: A Survey. Int. J. Distrib. Sens. Networks 2015, 2015. [Google Scholar] [CrossRef]
- Jiang, H.; Wang, K.; Wang, Y.; Gao, M.; Zhang, Y. Energy big data: A survey. IEEE Access 2016, 4, 3844–3861. [Google Scholar] [CrossRef]
- Sami, S.; Sael, N. Extract Five Categories CPIVW from the 9V’s Characteristics of the Big Data. Int. J. Adv. Comput. Sci. Appl. 2016, 7, 254–258. [Google Scholar] [CrossRef]
- Jayaprakash, J.S.; Balasubramanian, K.; Sulaiman, R.; Hasan, M.K.; Parameshachari, B.D.; Iwendi, C. Cloud data encryption and authentication based on enhanced Merkle hash tree method. Comput. Mater. Contin. 2022, 72, 519–534. [Google Scholar] [CrossRef]
- Lin, C.-H.; Amir, M.; Tariq, M.; Shahvez, M.; Alamri, B.; Alahmadi, A.; Siddiqui, M.; Beig, A.R. Comprehensive Analysis of IPT v/s CPT for Wireless EV Charging and Effect of Capacitor Plate Shape and Foreign Particle on CPT. Processes 2021, 9, 1619. [Google Scholar] [CrossRef]
- Jimeno, J.; Anduaga, J.; Oyarzabal, J.; De Muro, A.G. Architecture of a microgrid energy management system. Eur. Trans. Electr. Power 2011, 21, 1142–1158. [Google Scholar] [CrossRef]
- Nizeyimana, E. Remote Sensing and GIS Integration; McGraw-Hill Professional Publishing: New York, NY, USA, 2020. [Google Scholar]
- Sharma, B.S.S.P.M.; Kamath, H.R.; Brahmaiah Rama, V.S. Modelling of cloud based online access system for solar charge controller. Int. J. Eng. Technol. 2018, 7, 58–61. [Google Scholar] [CrossRef]
- Kong, X.; Zheng, Y.; Ouyang, M.; Li, X.; Lu, L.; Li, J.; Zhang, Z. Signal synchronization for massive data storage in modular battery management system with controller area network. Appl. Energy 2017, 197, 52–62. [Google Scholar] [CrossRef]
- Kabalcı, E.; Kabalcı, Y.; Siano, P. Design and implementation of a smart metering infrastructure for low voltage microgrids. Int. J. Electr. Power Energy Syst. 2022, 134, 107375. [Google Scholar] [CrossRef]
- Amir, M.; Zaheeruddin. ANN Based Approach for the Estimation and Enhancement of Power Transfer Capability. In Proceedings of the 2019 International Conference on Power Electronics, Control and Automation (ICPECA), New Delhi, India, 16–17 November 2019; pp. 1–6. [Google Scholar]
- Yuan, H.; Bi, J.; Zhou, M. Spatiotemporal Task Scheduling for Heterogeneous Delay-Tolerant Applications in Distributed Green Data Centers. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1686–1697. [Google Scholar] [CrossRef]
- Bitzer, B.; Gebretsadik, E.S. Ensuring future clean electrical energy supply through cloud computing. In Proceedings of the 2015 International Conference on Clean Electrical Power (ICCEP), Taormina, Italy, 16–18 June 2015; 155–159. [Google Scholar] [CrossRef]
- Ma, F.; Luo, X.; Litvinov, E. Cloud Computing for Power System Simulations at ISO New England-Experiences and Challenges. IEEE Trans. Smart Grid 2016, 7, 2596–2603. [Google Scholar] [CrossRef]
- Hassen, H.B.; Ayari, N.; Hamdi, B. A home hospitalization system based on the Internet of things, Fog computing and cloud computing. Inform. Med. Unlocked 2020, 20, 100368. [Google Scholar] [CrossRef] [PubMed]
- Rao, S.N.V.B.; Yellapragada, V.P.K.; Padma, K.; Pradeep, D.J.; Reddy, C.P.; Amir, M.; Refaat, S.S. Day-Ahead Load Demand Forecasting in Urban Community Cluster Microgrids Using Machine Learning Methods. Energies 2022, 15, 6124. [Google Scholar] [CrossRef]
- Xia, D.; Ning, F.; He, W. Research on Parallel Adaptive Canopy-K-Means Clustering Algorithm for Big Data Mining Based on Cloud Platform. J. Grid Comput. 2020, 18, 263–273. [Google Scholar] [CrossRef]
- Wang, T.; Zhang, W.; Ye, C.; Wei, J.; Zhong, H.; Huang, T. FD4C: Automatic Fault Diagnosis Framework for Web Applications in Cloud Computing. IEEE Trans. Syst. Man, Cybern. Syst. 2016, 46, 61–75. [Google Scholar] [CrossRef]
- Wang, H.; Sun, J. Quantitative analysis of data mining application and sports industry financing mechanism based on cloud computing. Int. J. Grid Distrib. Comput. 2016, 9, 233–244. [Google Scholar] [CrossRef]
- De Assis, M.V.O.; Novaes, M.P.; Zerbini, C.B.; Carvalho, L.F.; Abrao, T.; Proenca, M.L. Fast Defense System Against Attacks in Software Defined Networks. IEEE Access 2018, 6, 69620–69639. [Google Scholar] [CrossRef]
- Henao, N.; Agbossou, K.; Kelouwani, S.; Dube, Y.; Fournier, M. Approach in Nonintrusive Type i Load Monitoring Using Subtractive Clustering. IEEE Trans. Smart Grid 2017, 8, 812–821. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, H.; Shen, Y.; Ma, S.; Lu, H. Optimization of virtual resource management for cloud applications to cope with traffic burst. Futur. Gener. Comput. Syst. 2016, 58, 42–55. [Google Scholar] [CrossRef]
- Ngah Nasaruddin, A.; Tee, B.T.; Mohd Tahir, M.; Md Jasman, M.E.S. Data Assessment on the relationship between typical weather data and electricity consumption of academic building in Melaka. Data Br. 2021, 35, 106797. [Google Scholar] [CrossRef] [PubMed]
- Gharehpasha, S.; Masdari, M.; Jafarian, A. Virtual machine placement in cloud data centers using a hybrid multi-verse optimization algorithm. Artif. Intell. Rev. 2021, 54, 2221–2257. [Google Scholar] [CrossRef]
- Amir, M.; Zaheeruddin; Haque, A. Integration of EVs Aggregator with Microgrid and Impact of V2G Power on Peak Regulation. In Proceedings of the 2021 IEEE 4th International Conference on Computing, Power and Communication Technologies (GUCON), Kuala Lumpur, Malaysia, 24–26 September 2021; pp. 1–6. [Google Scholar]
- Zhou, Y.; Zhou, Y.; Luo, Q.; Abdel-Basset, M. A simplex method-based social spider optimization algorithm for clustering analysis. Eng. Appl. Artif. Intell. 2017, 64, 67–82. [Google Scholar] [CrossRef]
- Sui, X.; Liu, D.; Li, L.; Wang, H.; Yang, H. Virtual machine scheduling strategy based on machine learning algorithms for load balancing. Eurasip J. Wirel. Commun. Netw. 2019, 2019, 160. [Google Scholar] [CrossRef]
- Hasan, M.K.; Hosain, M.S.; Saha, T.; Islam, S.; Paul, L.C.; Khatak, S.; Alkhassawneh, H.M.; Kariri, E.; Ahmed, E.; Hassan, R. Energy efficient data detection with low complexity for an uplink multi-user massive MIMO system. Comput. Electr. Eng. 2022, 101, 108045. [Google Scholar] [CrossRef]
- Naeem, M.; Jamal, T.; Diaz-Martinez, J.; Butt, S.A.; Montesano, N.; Tariq, M.I.; De-la-Hoz-Franco, E.; De-La-Hoz-Valdiris, E. Trends and future perspective challenges in big data. In Proceedings of the Advances in Intelligent Data Analysis and Applications, Arad, Romania, 15–18 October 2019; pp. 309–325. [Google Scholar]
- Cen, B.; Hu, C.; Cai, Z.; Wu, Z.; Zhang, Y.; Liu, J.; Su, Z. A configuration method of computing resources for microservice-based edge computing apparatus in smart distribution transformer area. Int. J. Electr. Power Energy Syst. 2022, 138, 107935. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, J.; Sun, S. Real-time big data processing framework: Challenges and solutions. Appl. Math. Inf. Sci. 2015, 9, 3169–3190. [Google Scholar] [CrossRef]
- Yang, F.; Hua, Y.; Li, X.; Yang, Z.; Yu, X.; Fei, T. A survey on multisource heterogeneous urban sensor access and data management technologies. Meas. Sensors 2022, 19, 100061. [Google Scholar] [CrossRef]
- Chen, Y. Integrated and Intelligent Manufacturing: Perspectives and Enablers. Engineering 2017, 3, 588–595. [Google Scholar] [CrossRef]
- Niden, H.; Spriggs, T. How smart, connected products are transforming companies: Interaction. Harv. Bus. Rev. 2016, 94, 4. [Google Scholar]
- Nosratabadi, S.M.; Hooshmand, R.A.; Gholipour, E. A comprehensive review on microgrid and virtual power plant concepts employed for distributed energy resources scheduling in power systems. Renew. Sustain. Energy Rev. 2017, 67, 341–363. [Google Scholar] [CrossRef]
- Edpuganti, A.; Khadkikar, V.; Zeineldin, H.; El Moursi, M.S.E.M.S.; Al Hosani, M.; Al Hosani, M. Comparison of Peak Power Tracking Based Electric Power System Architectures for CubeSats. IEEE Trans. Ind. Appl. 2021, 57, 2758–2768. [Google Scholar] [CrossRef]
- Wu, B.; Widanage, W.D.D.; Yang, S.; Liu, X. Battery digital twins: Perspectives on the fusion of models, data and artificial intelligence for smart battery management systems. Energy AI 2020, 1, 100016. [Google Scholar] [CrossRef]
- Anusha, P.; Shabanabegum, S.K.K.; Pavaiyarkarasi, R.; Seethalakshmi, E.; Vadivukkarasi, K.; Vijayakumar, P. Smart internet of vehicle maintenance system. Mater. Today Proc. 2021. [Google Scholar] [CrossRef]
- Iqbal, A.; Amir, M.; Kumar, V.; Alam, A.; Umair, M. Integration of Next Generation IIoT with Blockchain for the Development of Smart Industries. Emerg. Sci. J. 2020, 4, 1–17. [Google Scholar] [CrossRef]
- Zhang, Q.; Lin, M.; Yang, L.T.; Chen, Z.; Khan, S.U.; Li, P. A Double Deep Q-Learning Model for Energy-Efficient Edge Scheduling. IEEE Trans. Serv. Comput. 2019, 12, 739–749. [Google Scholar] [CrossRef]
- Hasan, M.K.; Alkhalifah, A.; Islam, S.; Babiker, N.B.M.; Habib, A.K.M.A.; Aman, A.H.M.; Hossain, M.A. Blockchain Technology on Smart Grid, Energy Trading, and Big Data: Security Issues, Challenges, and Recommendations. Wirel. Commun. Mob. Comput. 2022, 2022. [Google Scholar] [CrossRef]
- Amir, M.; Haque, A.; Kurukuru, V.S.B.; Bakhsh, F.; Ahmad, A. Agent based online learning approach for power flow control of electric vehicle fast charging station integrated with smart microgrid. IET Renew. Power Gener. 2022. [Google Scholar] [CrossRef]
- Shariff, S.M.; Alam, M.S.; Faraz, S.; Khan, M.A.; Abbas, A.; Amir, M. Economic approach to design of a level 2 residential electric vehicle supply equipment. In Advances in Power and Control Engineering: Proceedings of GUCON; Springer: Singapore, 2020; pp. 25–40. [Google Scholar]
- Hasan, M.K.; Habib, A.K.M.A.; Islam, S.; Balfaqih, M.; Alfawaz, K.M.; Singh, D. Smart Grid Communication Networks for Electric Vehicles Empowering Distributed Energy Generation: Constraints, Challenges, and Recommendations. Energies 2023, 16, 1140. [Google Scholar] [CrossRef]
- Bera, S.; Misra, S.; Rodrigues, J.J.P.C. Cloud Computing Applications for Smart Grid: A Survey. IEEE Trans. Parallel Distrib. Syst. 2014, 26, 1477–1494. [Google Scholar] [CrossRef]
- Cui, B.; He, S. Anomaly detection model based on hadoop platform and weka interface. In Proceedings of the 2016 10th International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, IMIS, Fukuoka, Japan, 6–8 July 2016; pp. 84–89. [Google Scholar] [CrossRef]
- Feng, C.; Wang, Y.; Chen, Q.; Ding, Y.; Strbac, G.; Kang, C. Smart grid encounters edge computing: Opportunities and applications. Adv. Appl. Energy 2021, 1, 100006. [Google Scholar] [CrossRef]
- Narayan, A.; Krüger, C.; Göring, A.; Babazadeh, D.; Harre, M.C.; Wortelen, B.; Luedtke, A.; Lehnhoff, S. Towards future SCADA systems for ICT-reliant energy systems. In ETG-Kongress 2019-Das Gesamtsystem im Fokusder Energiewende; VDE: Esslingen am Neckar, Germany, 2019; pp. 364–370. [Google Scholar]
- Meng, L.; Sanseverino, E.R.; Luna, A.; Dragicevic, T.; Vasquez, J.C.; Guerrero, J.M. Microgrid supervisory controllers and energy management systems: A literature review. Renew. Sustain. Energy Rev. 2016, 60, 1263–1273. [Google Scholar] [CrossRef]
- Suganya, R.; Pavithra, M.; Nandhini, P. Algorithms and Challenges in Big Data Clustering. Int. J. Eng. Tech. 2018, 4, 40–47. [Google Scholar]
- Narayanan, V.; Kavitha, R.; Srikanth, R. Performance Evaluation of Brahmagupta-Bhaskara Equation Based Algorithm Using OpenMP BT. Proc. Data Anal. Manag. 2022, 90, 21–28. [Google Scholar]
- Dafir, Z.; Lamari, Y.; Slaoui, S.C. A Survey on Parallel Clustering Algorithms for Big Data; Springer: Amsterdam, The Netherlands, 2021; Volume 54. [Google Scholar]
- Carro, M.; Zhao, J. Serial computing vs. parallel computing: A comparative study using MATLAB. Int. J. Comput. Sci. Mob. Comput. 2014, 3, 815–820. [Google Scholar]
- Thakur, V. Perspective Study and Analysis of Parallel Architecture. Int. J. Comput. Appl. 2016, 148, 21–25. [Google Scholar] [CrossRef]
- Navarro, A.; Hitschfeld-kahler, N.; Mateu, L. A Survey on Parallel Computing and its Applications in Data-Parallel Problems Using GPU Architectures. Commun. Comput. Phys. 2014, 15, 285–329. [Google Scholar] [CrossRef]
- Yazici, A.; Mishra, A.; Karakaya, Z. Teaching Parallel Computing Concepts Using Real-Life Applications*. Int. J. Eng. Educ. 2016, 32, 772–781. [Google Scholar]
- Meng, F. Performance Modeling on the Basis of Application Type in Virtualized Environments. J. Softw. 2013, 8, 2847–2854. [Google Scholar] [CrossRef]
- Chen, C.L.P.; Zhang, C. Data-intensive applications, challenges, techniques and technologies: A survey on Big Data. Inf. Sci. 2014, 275, 314–347. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, N.; Zhang, Y.; Chen, X. Dynamic computation offloading in edge computing for internet of things. IEEE Internet Things J. 2019, 6, 4242–4251. [Google Scholar] [CrossRef]
- Ferry, D.; Li, J.; Mahadevan, M.; Agrawal, K.; Gill, C.; Lu, C. A Real-Time Scheduling Service for Parallel Tasks; IEEE: Piscataway, NJ, USA, 2013; pp. 261–272. [Google Scholar]
- Guo, Y.; Rao, J.; Cheng, D.; Member, S. iShuffle: Improving Hadoop Performance with Shuffle-on-Write. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 1649–1662. [Google Scholar] [CrossRef]
- Juan, A.A.; Faulin, J.; Grasman, S.E.; Rabe, M.; Figueira, G. A review of simheuristics: Extending metaheuristics to deal with stochastic combinatorial optimization problems. Oper. Res. Perspect. 2015, 2, 62–72. [Google Scholar] [CrossRef]
- Schryen, G. Parallel computational optimization in operations research: A new integrative framework, literature review and research directions. Eur. J. Oper. Res. 2020, 287, 1–18. [Google Scholar] [CrossRef]
- Diaz, J.; Muñoz-Caro, C.; Niño, A. A survey of parallel programming models and tools in the multi and many-core era. IEEE Trans. Parallel Distrib. Syst. 2012, 23, 1369–1386. [Google Scholar] [CrossRef]
- Schulz, C.; Hasle, G. GPU computing in discrete optimization. Part I: Introduction to the GPU. EURO J. Transp. Logist. 2013, 2, 129–157. [Google Scholar] [CrossRef]
- Zohrabad, Z.M. Application of Hybrid HS and Tabu Search Algorithm for Optimal Location of FACTS Devices to Reduce Power Losses in Power Systems. Eng. Technol. Appl. Sci. Res. 2016, 6, 1217–1220. [Google Scholar] [CrossRef]
- Wang, B.; Xu, J.; Cao, B.; Ning, B. Adaptive mode switch strategy based on simulated annealing optimization of a multi-mode hybrid energy storage system for electric vehicles. Appl. Energy 2017, 194, 596–608. [Google Scholar] [CrossRef]
- Bouchekara, H.R.E.H.; Shahriar, M.S.; Javaid, M.S.; Sha, Y.A.; Zellagui, M.; Bentouati, B. A variable neighborhood search algorithm for optimal protection coordination of power systems. Soft Comput. 2021, 4, 10863–10883. [Google Scholar] [CrossRef]
- Demesure, G.; Charpentier, P.; Siadat, A.; Mouayni, E.; El, I.; Mouayni, E. Jobs scheduling within Industry 4.0 with consideration of worker’s fatigue and reliability using Greedy Randomized Adaptive Search Procedure. Isc. FAC Pap. 2019, 52, 85–90. [Google Scholar] [CrossRef]
- Tan, Y.; Member, S.; Ding, K. A Survey on GPU-Based Implementation of Swarm Intelligence Algorithms. IEEE Trans. Cybern. 2016, 46, 2028–2041. [Google Scholar] [CrossRef] [PubMed]
- Hasan, M.K.; Ismail, A.F.; Islam, S.; Hashim, W.; Pandey, B. Dynamic spectrum allocation scheme for heterogeneous network. Wirel. Pers. Commun. 2017, 95, 299–315. [Google Scholar] [CrossRef]
- Hadji, S.; Gaubert, J.; Krim, F. Real-Time Genetic Algorithms-Based MPPT: Study and Comparison (Theoretical an Experimental) with Conventional Methods. Energies 2018, 11, 459. [Google Scholar] [CrossRef]
- Asgher, U.; Rasheed, M.B.; Al-Sumaiti, A.S.; Rahman, A.U.; Ali, I.; Alzaidi, A.; Alamri, A. Smart energy optimization using heuristic algorithm in smart grid with integration of solar energy sources. Energies 2018, 11, 3494. [Google Scholar] [CrossRef]
- Search, S. Scatter Search; Springer: Berlin, Germany, 2018. [Google Scholar]
- Crainic, T.G. Parallel metaheuristics and cooperative search. In Handbook of Metaheuristics; Springer: Berlin, Germany, 2019. [Google Scholar]
- Saber, T.; Marques-Silva, J.; Thorburn, J.; Ventresque, A. Exact and Hybrid Solutions for the Multi-Objective VM Reassignment Problem. Int. J. Artif. Intell. Tools 2017, 26, 1760004. [Google Scholar] [CrossRef]
- Boyer, V.; El Baz, D. Recent advances on GPU computing in operations research. In Proceedings of the 2013 IEEE 27th International Symposium on Parallel & Distributed Processing Workshops and PhD Forum, Cambridge, MA, USA, 20–24 May 2013. [Google Scholar] [CrossRef]
- Brodtkorb, R.; Schulz, C.; Hasle, G.; Hagen, T.R. GPU computing in discrete optimization. Part II: Survey focused on routing problems. EURO J. Transp. Logist. 2013, 2, 159–186. [Google Scholar] [CrossRef]
- Cong, J.; Fang, Z.; Huang, M.; Wei, P.; Wu, D.; Yu, C.H. Customizable Computing—From Single Chip to Datacenters. Proc. IEEE 2019, 107, 185–203. [Google Scholar] [CrossRef]
- Wang, K.; Mi, J.; Xu, C.; Zhu, Q.; Shu, L.; Deng, D.-J. Real-Time load reduction in multimedia big data for mobile internet. ACM Trans. Multimed. Comput. Commun. Appl. 2016, 12, 1–20. [Google Scholar] [CrossRef]
- Chien, S.F.; Zarakovitis, C.C.; Ni, Q.; Xiao, P. Stochastic Asymmetric Blotto Game Approach for Wireless Resource Allocation Strategies. IEEE Trans. Wirel. Commun. 2019, 18, 5511–5528. [Google Scholar] [CrossRef]
- Cheng, D.; Rao, J.; Guo, Y.; Jiang, C.; Zhou, X. Improving Performance of Heterogeneous MapReduce Clusters with Adaptive Task Tuning. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 774–786. [Google Scholar] [CrossRef]
- Gai, K.; Qiu, M.; Zhao, H. Cost-Aware Multimedia Data Allocation for Heterogeneous Memory Using Genetic Algorithm in Cloud Computing. IEEE Trans. Cloud Comput. 2016, 1, 1212–1222. [Google Scholar] [CrossRef]
- Agron, J.; Andrews, D. Hardware microkernels for heterogeneous manycore systems. In Proceedings of the International Conference on Parallel Processing Workshops Hardware, Vienna, Austria, 22–25 September 2009. [Google Scholar] [CrossRef]
- Wang, W.; Jiang, K.; Tan, Y.; Wu, Q. Dominant fairness fairness: Hierarchical scheduling for multiple resources in heterogeneous datacenters. IEICE Trans. Inf. Syst. 2016, E99D, 1678–1681. [Google Scholar] [CrossRef]
- Hwang, E.; Kim, S.; Kim, J.-S.; Hwang, S.; Choi, Y.-R. On the role of application and resource characterizations in heterogeneous distributed computing systems. Cluster Comput. 2016, 19, 2225–2240. [Google Scholar] [CrossRef]
- Gomatheeshwari, B.; Selvakumar, J. Appropriate allocation of workloads on performance asymmetric multicore architectures via deep learning algorithms. Microprocess. Microsyst. 2020, 73, 102996. [Google Scholar] [CrossRef]
- Akhtaruzzaman, M.; Hasan, M.K.; Kabir, S.R.; Abdullah, S.N.H.S.; Sadeq, M.J.; Hossain, E. HSIC Bottleneck Based Distributed Deep Learning Model for Load Forecasting in Smart Grid with a Comprehensive Survey. IEEE Access 2020, 8, 222977–223008. [Google Scholar] [CrossRef]
- Gou, C.; Benoit, A.; Marchal, L. Memory-aware tree partitioning on homogeneous platforms. In Proceedings of the 2018 26th Euromicro International Conference on Parallel, Distributed and Network-based Processing (PDP), Cambridge, UK, 21–23 March 2018; pp. 321–324. [Google Scholar] [CrossRef]
- Beaumont, O.; Becker, B.A.; Deflumere, A.; Eyraud-Dubois, L.; Lambert, T.; Lastovetsky, A. Recent Advances in Matrix Partitioning for Parallel Computing on Heterogeneous Platforms. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 218–229. [Google Scholar] [CrossRef]
- Yin, F.; Shi, F. A Comparative Survey of Big Data Computing and HPC: From a Parallel Programming Model to a Cluster Architecture; Springer: Berlin, Germany, 2022; Volume 50. [Google Scholar]
- Nguyen, G.; Šipková, V.; Dlugolinsky, S.; Nguyen, B.M.; Tran, V.; Hluchý, L. A comparative study of operational engineering for environmental and compute-intensive applications. Array 2021, 12, 100096. [Google Scholar] [CrossRef]
- Mutlu, O.; Ghose, S.; Gómez-Luna, J.; Ausavarungnirun, R. Processing data where it makes sense: Enabling in-memory computation. Microprocess. Microsyst. 2019, 67, 28–41. [Google Scholar] [CrossRef]
- Zheng, X.; Mukkamala, R.R.; Vatrapu, R.; Ordieres-Mere, J. Blockchain-based personal health data sharing system using cloud storage. In Proceedings of the 2018 IEEE 20th international conference on e-health networking, applications and services (Healthcom), Ostrava, Czech Republic, 17–20 September 2018. [Google Scholar] [CrossRef]
- Zhou, Y.; He, F.; Hou, N.; Qiu, Y. Parallel ant colony optimization on multi-core SIMD CPUs. Futur. Gener. Comput. Syst. 2018, 79, 473–487. [Google Scholar] [CrossRef]
- Schmidt, B.; Hildebrandt, A. Next-generation sequencing: Big data meets high performance computing. Drug Discov. Today 2017, 22, 712–717. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Christie, R.; Manjula, R. Scalability in Internet of Things: Features, Techniques and Research Challenges. Int. J. Comput. Intell. Res. 2017, 13, 1617–1627. [Google Scholar]
- Xiong, Z.; Xu, K. Lightweight job submission and file sharing schemes for a teaching ecosystem for parallel computing courses. J. Ambient Intell. Humaniz. Comput. 2020. [Google Scholar] [CrossRef]
- Badger, L.; Patt-corner, R.; Voas, J. Cloud Computing Synopsis and Recommendations Recommendations of the National Institute of Standards and Technology. Nist Spec. Publ. 2012, 800, 81. [Google Scholar]
- Hogan, M.; Liu, F.; Sokol, A.; Tong, J. NIST Cloud Computing Standards Roadmap. Commun. Comput. Inf. Sci. 2015, 3, 1–6. [Google Scholar]
- Javadpour, A. Improving Resources Management in Network Virtualization by Utilizing a Software-Based Network. Wirel. Pers. Commun. 2019, 106, 505–519. [Google Scholar] [CrossRef]
- Al-Janabi, S.; Al-Shourbaji, I.; Shojafar, M.; Abdelhag, M. Mobile Cloud Computing: Challenges and Future Research Directions. In Proceedings of the 2017 10th International Conference on Developments in eSystems Engineering (DeSE), Paris, France, 14–16 June 2017; pp. 62–67. [Google Scholar] [CrossRef]
- Lehrig, S.; Sanders, R.; Brataas, G.; Cecowski, M.; Ivanšek, S.; Polutnik, J. CloudStore—towards scalability, elasticity, and efficiency benchmarking and analysis in Cloud computing. Futur. Gener. Comput. Syst. 2018, 78, 115–126. [Google Scholar] [CrossRef]
- Kurte, K.; Sanyal, J.; Berres, A.; Lunga, D.; Coletti, M.; Yang, H.L.; Graves, D.; Liebersohn, B.; Rose, A. Performance analysis and optimization for scalable deployment of deep learning models for country-scale settlement mapping on Titan supercomputer. Concurr. Comput. 2019, 31, e5305. [Google Scholar] [CrossRef]
- Kaseb, M.R.; Khafagy, M.H.; Ali, I.A.; Saad, E.M. An improved technique for increasing availability in Big Data replication. Futur. Gener. Comput. Syst. 2019, 91, 493–505. [Google Scholar] [CrossRef]
- Neaime, J.; Dhaini, A.R. Resource management in cloud and tactile-capable next-generation optical access networks. IEEE/OSA J. Opt. Commun. Netw. 2018, 10, 902–914. [Google Scholar] [CrossRef]
- Pedreno-Manresa, J.; Khodashenas, P.S.; Siddiqui, M.S.; Pavon-Marino, P. On the Need of Joint Bandwidth and NFV Resource Orchestration: A Realistic 5G Access Network Use Case. IEEE Commun. Lett. 2018, 22, 145–148. [Google Scholar] [CrossRef]
- Daki, H.; El Hannani, A.; Aqqal, A.; Haidine, A.; Dahbi, A. Big Data management in smart grid: Concepts, requirements and implementation. J. Big Data 2017, 4, 13. [Google Scholar] [CrossRef]
- Lin, S.; Maalla, A.; Wu, G. Research on Real-Time Database Recovery Method of Smart Grid System Based on IEC61970 Standard. IOP Conf. Ser. Earth Environ. Sci. 2019, 242, 022046. [Google Scholar] [CrossRef]
- Santodomingo, R.; Uslar, M.; Specht, M.; Rohjans, S.; Taylor, G.; Pantea, S.; Bradley, M.; McMorran, A. IEC 61970 for Energy Management System Integration. Smart Grid Handb. 2016, 1–29. [Google Scholar] [CrossRef]
- Lordan, F.; Badia, R.M. COMPSs-Mobile: Parallel Programming for Mobile Cloud Computing. J. Grid Comput. 2017, 15, 357–378. [Google Scholar] [CrossRef]
- Sweetline Priya, E.; Suseendran, G. Cloud computing and big data: A comprehensive analysis. J. Crit. Rev. 2020, 7, 185–189. [Google Scholar] [CrossRef]
- Berlian, M.H.; Sahputra, T.E.R.; Ardi, B.J.W.; Dzatmika, L.W.; Besari, A.R.A.; Sudibyo, R.W.; Sukaridhoto, S. Design and implementation of smart environment monitoring and analytics in real-time system framework based on internet of underwater things and big data. In Proceedings of the 2016 International Electronics Symposium (IES) IES 2016, Denpasar, Indonesia, 29–30 September 2016; pp. 403–408. [Google Scholar] [CrossRef]
- Xu, X.; Cao, L.; Wang, X. Adaptive Task Scheduling Strategy Based on Dynamic Workload Adjustment for Heterogeneous Hadoop Clusters. IEEE Syst. J. 2016, 10, 471–482. [Google Scholar] [CrossRef]
- Guo, Y.; Rao, J.; Jiang, C.; Zhou, X. Moving Hadoop into the Cloud with Flexible Slot Management and Speculative Execution. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 798–812. [Google Scholar] [CrossRef]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauley, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing. In Proceedings of the 9th {USENIX} Symposium on Networked Systems Design and Implementation ({NSDI} 12), USENIX, San Jose, CA, USA, 25–27 April 2012; pp. 15–28. [Google Scholar]
- Gopalani, S.; Arora, R. Comparing Apache Spark and Map Reduce with Performance Analysis using K-Means. Int. J. Comput. Appl. 2015, 113, 8–11. [Google Scholar] [CrossRef]
- Hosseini, B.; Kiani, K. A big data driven distributed density based hesitant fuzzy clustering using Apache spark with application to gene expression microarray. Eng. Appl. Artif. Intell. 2019, 79, 100–113. [Google Scholar] [CrossRef]
- Liu, X.; Nielsen, P.S. Regression-based Online Anomaly Detection for Smart Grid Data. arXiv 2016, arXiv:1606.05781v1. [Google Scholar]
- Nguyen, V.-Q.; Nguyen, S.N.; Kim, K. Design of a Platform for Collecting and Analyzing Agricultural Big Data. J. Digit. Contents Soc. 2017, 18, 149–158. [Google Scholar] [CrossRef]
- Na, C.; Xin, C. The research of large scale data processing platform based on the spark. In Proceedings of the 2016 International Conference on Intelligent Transportation, Big Data & Smart City (ICITBS), Changsha, China, 17–18 December 2016. [Google Scholar] [CrossRef]
- Tan, J.; Meng, S.; Meng, X.; Zhang, L. Improving ReduceTask data locality for sequential MapReduce jobs. In Proceedings of the IEEE INFOCOM, Turin, Italy, 14–19 April 2013; pp. 1627–1635. [Google Scholar]
- Niu, S. Research on the application of machine learning big data mining algorithms in digital signal processing. In Proceedings of the 2021 IEEE Asia-Pacific Conference on Image Processing, Electronics and Computers (IPEC), Dalian, China, 14–16 April 2021; pp. 776–779. [Google Scholar] [CrossRef]
- Peng, B.; Hosseini, M.; Hong, Z.; Farivar, R.; Campbell, R. R-storm: Resource-aware scheduling in storm. In Proceedings of the 16th annual middleware conference, Vancouver, BC, Canada, 7–11 December 2015; pp. 149–161. [Google Scholar] [CrossRef]
- Soualhia, M.; Khomh, F.; Tahar, S. Task Scheduling in Big Data Platforms: A Systematic Literature Review. J. Syst. Softw. 2017, 134, 170–189. [Google Scholar] [CrossRef]
- Simão, J.; Esteves, S.; Pires, A.; Veiga, L. GC-Wise: A Self-adaptive approach for memory-performance efficiency in Java VMs. Futur. Gener. Comput. Syst. 2019, 100, 674–688. [Google Scholar] [CrossRef]
- Bobroff, N.; Westerink, P.; Fong, L. Active control of memory for java virtual machines and applications. In Proceedings of the 11th International Conference on Autonomic Computing ({ICAC} 14), Philadelphia, PA, USA, 18–20 June 2014; pp. 97–103. [Google Scholar]
- Cugola, G.; Margara, A. Processing flows of information: From data stream to complex event processing. ACM Comput. Surv. 2012, 44, 1–62. [Google Scholar] [CrossRef]
- Li, C.; Zhang, J.; Luo, Y. Real-time scheduling based on optimized topology and communication traffic in distributed real-time computation platform of storm. J. Netw. Comput. Appl. 2017, 87, 100–115. [Google Scholar] [CrossRef]
- Cheng, J.Y.; Hung, M.H.; Lin, S.S.; Cheng, F.T. New remote monitoring and control system architectures based on cloud computing. Adv. Mater. Res. 2012, 579, 312–329. [Google Scholar] [CrossRef]
- Shetty, S.D.; Vadivel, S.; Gandhi, N. A cloud enabled online quiz application deployed on Google cloud. In Proceedings of the 2012 International Conference on Cloud Computing Technologies, Applications and Management, ICCCTAM, Dubai, United Arab Emirates, 8–10 December 2012; pp. 108–113. [Google Scholar] [CrossRef]
- Rashid, Z.N.; Zebari, S.R.M.; Sharif, K.H.; Jacksi, K. Distributed Cloud Computing and Distributed Parallel Computing: A Review. In Proceedings of the ICOASE 2018-International Conference on Advanced Science and Engineering, Duhok, Iraq, 9–11 October 2018; pp. 167–172. [Google Scholar] [CrossRef]
- Yue, S.; Ma, Y.; Chen, L.; Wang, Y.; Song, W. Dynamic DAG scheduling for many-task computing of distributed eco-hydrological model. J. Supercomput. 2019, 75, 510–532. [Google Scholar] [CrossRef]
- Jafarnejad Ghomi, E.; Rahmani, A.M.; Qader, N.N. Applying queue theory for modeling of cloud computing: A systematic review. Concurr. Comput. Pract. Exp. 2019, 31, e5186. [Google Scholar] [CrossRef]
- Cao, Y.; Li, P.; Zhang, Y. Parallel processing algorithm for railway signal fault diagnosis data based on cloud computing. Futur. Gener. Comput. Syst. 2018, 88, 279–283. [Google Scholar] [CrossRef]
- Alzakholi, O.; Haji, L.; Shukur, H.; Zebari, R.; Abas, S.; Sadeeq, M. Comparison Among Cloud Technologies and Cloud Performance. J. Appl. Sci. Technol. Trends 2020, 1, 40–47. [Google Scholar] [CrossRef]
- Tripathy, L.; Ranjan Patra, R. Scheduling in Cloud Computing. Int. J. Cloud Comput. Serv. Archit. 2014, 4, 21–27. [Google Scholar] [CrossRef]
- Sobie, R. Distributed cloud computing in high energy physics. In Proceedings of the 2014 ACM SIGCOMM workshop on Distributed cloud computing, Chicago, IL, USA, 18 August 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Pawade, P.A.; Gaikwad, P.V.T. Semi-Distributed Cloud Computing System with Load Balancing Algorithm. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 2942–2947. [Google Scholar]
- Lv, X.; Cheng, X.; Lv, Y.X. Distributed cloud storage and parallel topology processing of power network. In Proceedings of the 2016 Third International Conference on Trustworthy Systems and their Applications (TSA), Wuhan, China, 18–22 September 2016; pp. 142–146. [Google Scholar] [CrossRef]
- Varghese, B.; Buyya, R. Next generation cloud computing: New trends and research directions. Futur. Gener. Comput. Syst. 2018, 79, 849–861. [Google Scholar] [CrossRef]
- Peng, Z.; Gong, Q.; Duan, Y.; Wang, Y. The Research of the Parallel Computing Development from the Angle of Cloud Computing. J. Phys. Conf. Ser. 2017, 910, 012002. [Google Scholar] [CrossRef]
- Ali, M.F.; Khan, R.Z. Distributed Computing: An Overview. Int. J. Adv. Netw. Appl. 2015, 7, 2630–2635. [Google Scholar]
- Kapur, R. A workload balanced approach for resource scheduling in cloud computing. In Proceedings of the 2015 8th International Conference on Contemporary Computing (IC3), Noida, India, 20–22 August 2015; pp. 36–41. [Google Scholar] [CrossRef]
- Li, X.; Jia, S.; Wang, K.; Yin, X. Distributed parallel processing of mobile robot PF-slam. IET Conf. Publ. 2012, 2012, 927–930. [Google Scholar] [CrossRef]
- Khiyaita, A.; El Bakkali, H.; Zbakh, M.; Kettani, D. El Load balancing cloud computing: State of art. In Proceedings of the 2012 National Days of Network Security and Systems, Marrakech, Morocco, 20–21 April 2012; pp. 106–109. [Google Scholar] [CrossRef]
- Sun, Y.; Zhu, Z.; Fan, Z. Distributed Caching in Wireless Cellular Networks Incorporating Parallel Processing. IEEE Internet Comput. 2018, 22, 52–61. [Google Scholar] [CrossRef]
- Rao, P.S.; Rao, V.P.C.; Govardhan, A. Dynamic Load Balancing with Central Monitoring of Distributed Job Processing System. Int. J. Comput. Appl. 2013, 65, 43–47. [Google Scholar]
- Sharma, A.; Peddoju, S.K. Response time based load balancing in cloud computing. In Proceedings of the 2014 International Conference on Control, Instrumentation, Communication and Computational Technologies (ICCICCT), Kanyakumari, India, 10–11 July 2014; pp. 1287–1293. [Google Scholar] [CrossRef]
- Chen, H.; Wang, F.; Helian, N.; Akanmu, G. User-priority guided min-min scheduling algorithm for load balancing in cloud computing. In Proceedings of the 2013 National Conference on Parallel Computing Technologies (PARCOMPTECH), Bangalore, India, 21–23 February 2013. [Google Scholar] [CrossRef]
- Mondal, B.; Choudhury, A. Simulated Annealing (SA) based Load Balancing Strategy for Cloud Computing. Int. J. Comput. Sci. Inf. Technol. 2015, 6, 3307–3312. [Google Scholar]
- Chen, H.; Liu, G.; Yin, S.; Liu, X.; Qiu, D. ERECT: Energy-efficient reactive scheduling for real-time tasks in heterogeneous virtualized clouds. J. Comput. Sci. 2018, 28, 416–425. [Google Scholar] [CrossRef]
- Chunlin, L.; LaYuan, L. Optimal scheduling across public and private clouds in complex hybrid cloud environment. Inf. Syst. Front. 2017, 19, 1–12. [Google Scholar] [CrossRef]
- Kim, J.; Lee, K. FunctionBench: A suite of workloads for serverless cloud function service. In Proceedings of the 2019 IEEE 12th International Conference on Cloud Computing (CLOUD), Milan, Italy, 8–13 July 2019; pp. 502–504. [Google Scholar] [CrossRef]
- Wendy; Wang, G. Measuring information security and cybersecurity on private cloud computing. J. Theor. Appl. Inf. Technol. 2019, 97, 156–168. [Google Scholar]
- Yu, J.; Zhao, Y.; Zhu, S.; Xu, B.; Li, S.; Zhang, M. Research on development of cloud computing based on patent analysis. In 2018 3rd Joint International Information Technology, Mechanical and Electronic Engineering Conference (JIMEC 2018); Atlantis Press: Berlin, Germany, 2018. [Google Scholar] [CrossRef]
- Yu, J.; Yang, Z.; Zhu, S.; Xu, B.; Li, S.; Zhang, M. A bibliometric analysis of cloud computing technology research. In Proceedings of the 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 October 2018; pp. 2353–2358. [Google Scholar] [CrossRef]
- Mane, A.S.; Ainapure, B.S. Private Cloud Configuration Using Amazon Web Services BT-Information and Communication Technology for Competitive Strategies (ICTCS 2020); Springer: Singapore, 2021; pp. 839–847. [Google Scholar]
- Duan, J.; Yang, Y. A Load Balancing and Multi-Tenancy Oriented Data Center Virtualization Framework. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 2131–2144. [Google Scholar] [CrossRef]
- AL-Jumaili, A.H.A.; Muniyandi, R.C.; Hasan, M.K.; Singh, M.J.; Paw, J.K.S. Analytical survey on the security framework of cyber-physical systems for smart power system networks. In Proceedings of the 2022 International Conference on Cyber Resilience (ICCR), Dubai, United Arab Emirates, 6–7 October 2022; pp. 1–8. [Google Scholar]
- Hasan, M.K.; Habib, A.K.M.A.; Shukur, Z.; Ibrahim, F.; Islam, S.; Razzaque, M.A. Review on cyber-physical and cyber-security system in smart grid: Standards, protocols, constraints, and recommendations. J. Netw. Comput. Appl. 2022, 209, 103540. [Google Scholar] [CrossRef]
- Satoh, F.; Yanagisawa, H.; Takahashi, H.; Kushida, T. Total energy management system for Cloud Computing. In Proceedings of the 2013 IEEE International Conference on Cloud Engineering (IC2E), San Francisco, CA, USA, 25–27 March 2013; pp. 233–240. [Google Scholar] [CrossRef]
- Ruivo, P.; Oliveira, T.; Mestre, A. Enterprise resource planning and customer relationship management value. Ind. Manag. Data Syst. 2017, 117, 1612–1631. [Google Scholar] [CrossRef]
- Li, B.; Li, Z. Office Automation Sub-Summary of the Work and the Project Management System. Adv. Eng. Res. (AER) 2017, 61, 346–348. [Google Scholar]
- Chamoso, P.; González-Briones, A.; Rodríguez, S.; Corchado, J.M. Tendencies of Technologies and Platforms in Smart Cities: A State-of-the-Art Review. Wirel. Commun. Mob. Comput. 2018, 2018, 3086854. [Google Scholar] [CrossRef]
- Alghofaili, Y.; Albattah, A.; Alrajeh, N.; Rassam, M.A.; Al-Rimy, B.A.S. Secure cloud infrastructure: A survey on issues, current solutions, and open challenges. Appl. Sci. 2021, 11, 9005. [Google Scholar] [CrossRef]
- Byun, J.; Hong, I.; Park, S. Intelligent cloud home energy management system using household appliance priority based scheduling based on prediction of renewable energy capability. IEEE Trans. Consum. Electron. 2012, 58, 1194–1201. [Google Scholar] [CrossRef]
- Fang, B.; Yin, X.; Tan, Y.; Li, C.; Gao, Y.; Cao, Y.; Li, J. The contributions of cloud technologies to smart grid. Renew. Sustain. Energy Rev. 2016, 59, 1326–1331. [Google Scholar] [CrossRef]
- Singh, K.; Amir, M.; Ahmad, F.; Refaat, S.S. Enhancement of Frequency Control for Stand-Alone Multi-Microgrids. IEEE Access 2021, 9, 79128–79142. [Google Scholar] [CrossRef]
- Cao, Z.; Lin, J.; Wan, C.; Song, Y.; Zhang, Y.; Wang, X. Optimal Cloud Computing Resource Allocation for Demand Side Management in Smart Grid. IEEE Trans. Smart Grid 2017, 8, 1943–1955. [Google Scholar] [CrossRef]
- Amir, M.; Prajapati, A.K.; Refaat, S.S. Dynamic Performance Evaluation of Grid-Connected Hybrid Renewable Energy-Based Power Generation for Stability and Power Quality Enhancement in Smart Grid. Front. Energy Res. 2022, 10, 1–16. [Google Scholar] [CrossRef]
- Colak, I.; Sagiroglu, S.; Fulli, G.; Yesilbudak, M.; Covrig, C.-F.F. A survey on the critical issues in smart grid technologies. Renew. Sustain. Energy Rev. 2016, 54, 396–405. [Google Scholar] [CrossRef]
- Singh, H.; Bawa, S. A MapReduce-based scalable discovery and indexing of structured big data. Futur. Gener. Comput. Syst. 2017, 73, 32–43. [Google Scholar] [CrossRef]
- Qureshi, N.M.F.; Shin, D.R.; Siddiqui, I.F.; Chowdhry, B.S. Storage-Tag-Aware Scheduler for Hadoop Cluster. IEEE Access 2017, 5, 13742–13755. [Google Scholar] [CrossRef]
- Zhu, Z.; Zeng, F.; Qi, G.; Li, Y.; Jie, H.; Mazur, N. Power system structure optimization based on reinforcement learning and sparse constraints under DoS attacks in cloud environments. Simul. Model. Pract. Theory 2021, 110, 102272. [Google Scholar] [CrossRef]
- Zhang, S.; Luo, X.; Litvinov, E. Serverless computing for cloud-based power grid emergency generation dispatch. Int. J. Electr. Power Energy Syst. 2021, 124, 106366. [Google Scholar] [CrossRef]
- Latif, S.N.A.; Chiong, M.S.; Rajoo, S.; Takada, A.; Chun, Y.Y.; Tahara, K.; Ikegami, Y. The trend and status of energy resources and greenhouse gas emissions in the Malaysia power generation mix. Energies 2021, 14, 2200. [Google Scholar] [CrossRef]
- Aceto, G.; Persico, V.; Pescapé, A. Industry 4.0 and Health: Internet of Things, Big Data, and Cloud Computing for Healthcare 4.0. J. Ind. Inf. Integr. 2020, 18, 100129. [Google Scholar] [CrossRef]
- Attaran, M.; Woods, J. Cloud computing technology: Improving small business performance using the Internet. J. Small Bus. Entrep. 2019, 31, 495–519. [Google Scholar] [CrossRef]
- Zhang, G.; Zhang, H.; Zheng, Y.; Liu, Y.; Li, T.; Wang, M.; Wang, X. Research on power grid operation and maintenance cost based on analysis of internal and external influence factors. E3S Web Conf. 2021, 329, 01068. [Google Scholar] [CrossRef]
- Real-Time Monitoring of a Solar Charge Controller for Stand-Alone Photovoltaic Systems. Int. J. Recent Technol. Eng. 2019, 8, 6295–6300. [CrossRef]
- Schmidt, L.; Talwar, K.; Santurkar, S.; Tsipras, D.; Madry, A. Adversarially robust generalization requires more data. Adv. Neural Inf. Process. Syst. 2018, 31, 5014–5026. [Google Scholar]
- Vabalas, A.; Gowen, E.; Poliakoff, E.; Casson, A.J. Machine learning algorithm validation with a limited sample size. PLoS ONE 2019, 14, e0224365. [Google Scholar] [CrossRef]
- Wang, Z.Q.; Bai, W.J.; Dong, A.Q.; Zhang, F.H.; Li, B. A Global Data Model for Electric Power Data Centers. J. Signal Process. Syst. 2021, 93, 201–208. [Google Scholar] [CrossRef]
- Huang, L.; Zhuang, W.; Sun, M.; Zhang, H. Research and application of microservice in power grid dispatching control system. In Proceedings of the 2020 IEEE 4th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chongqing, China, 12–14 June 2020; pp. 1895–1899. [Google Scholar] [CrossRef]
- Lv, Z.; Li, X.; Wang, W.; Zhang, B.; Hu, J.; Feng, S. Government affairs service platform for smart city. Futur. Gener. Comput. Syst. 2018, 81, 443–451. [Google Scholar] [CrossRef]
- Rahman, A.; Srikumar, V.; Smith, A.D. Predicting electricity consumption for commercial and residential buildings using deep recurrent neural networks. Appl. Energy 2018, 212, 372–385. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Existing Challenging | Proposed Solution | Challenging Proposed Solutions and Future Work |
|---|---|---|---|
| [20] | The problem with concurrent power transmission networks is the uneven temporal distribution and the growing number of fault occurrences that cause power outages or interruptions. | The suggested model incorporates and explicitly assesses seldom occurring environmental components, faults, and periods with fewer fault events, which improves the forecast performance of power transmission fault events. | challenging to deal with the massive amount of monitoring data |
| [24] | The problem of conventional clustering algorithms for Big Data Analytics. | Parallel algorithms of k-means and canopy are implemented using the Hadoop environment and Mahout to solve the problem of conventional clustering algorithms. | Process locally after storage data. |
| [14] | Problems with traditional data mining that is generated in single-node chain mining. | This work uses single-node serial mining to tackle the classic data mining problem in power systems. It has vast storage and processing capacities, and accuracy 87%. | Did not use cloud computing so it was hard to meet real-time and large scale |
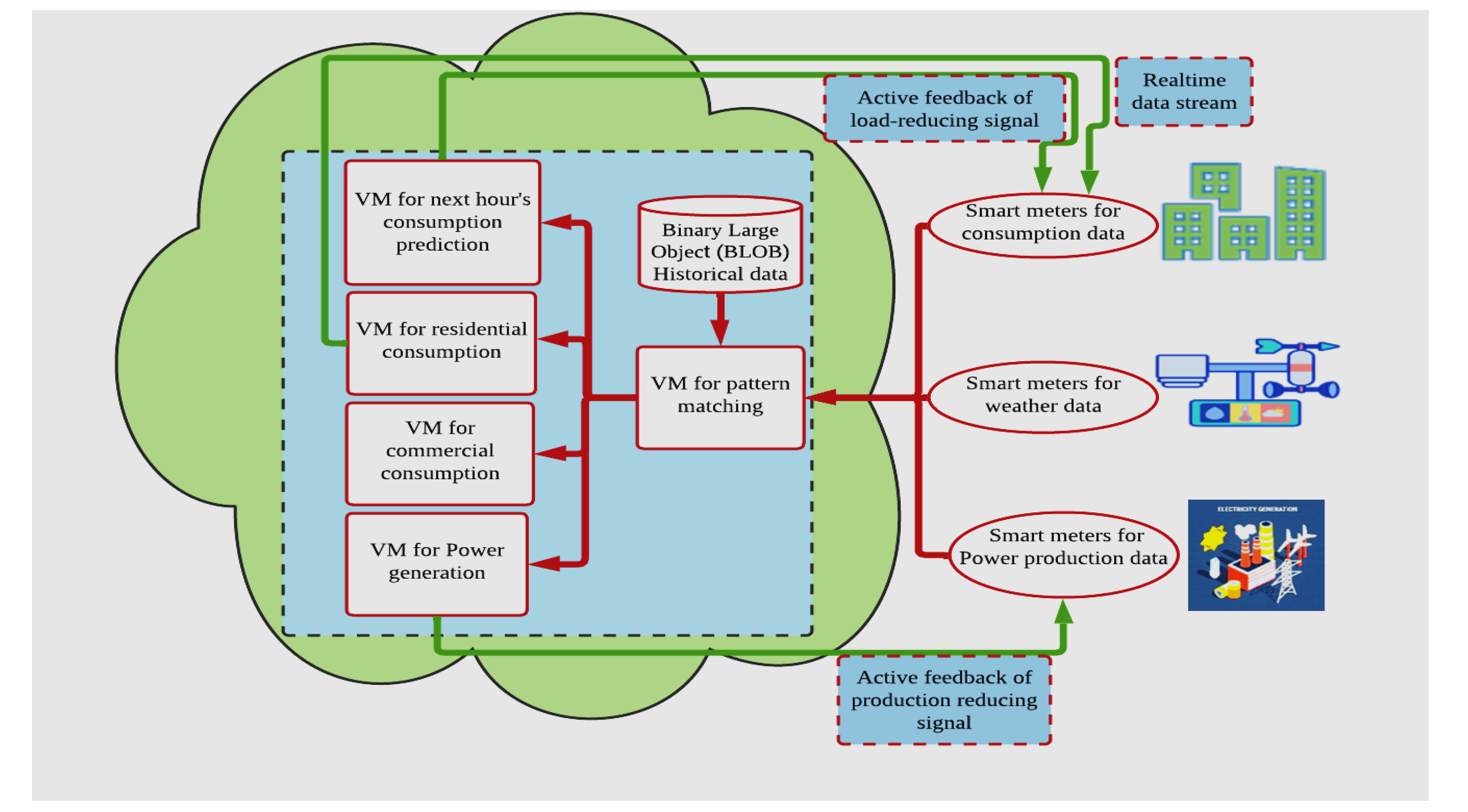
| [2] | The limitations of centralised administration based on LAN design prevent broad-area monitoring and the resolution it’s issues. | This study describes cloud-based power grid-wide-area monitoring architecture for parallel computing and big data mining to give intelligent grid decisions. | This paper’s flaw is a lack of data exchange during processing. |
| [31] | Considering real-time application, the smart grid still needs to advance in terms of efficiency, power management, dependability, and value. | Using cloud computing architecture from any location and at any time, design remote real-time monitoring of substation power data in a safe, efficient, and effective manner. | The weakness of this work the power flow in the grid is continuously monitored using PLC and Energy Meter, it doesn’t use cloud computing applications. |
| [19] | Large-scale data processing and analysis methods in a real-time panoramic grid are a challenge for smart grids. | This paper use data mining and integrated information technology platform to present a smart grid building a large multi-level data storage system to extract valuable knowledge to support grid scheduling decisions. | Dealing with redundant data and noise in data mining results remains a barrier for technology. It is also uncertain if the current cloud platform will get real-time smart grid monitoring data. |
| [70] | As smart grids spread, terminal devices like cutting-edge sensors and smart metres tend wide access to distribution networks, providing major challenges to the information perception, analysis, and processing capacities of the distribution automation system. | This paper aims at guiding to preserve CPU and memory resources and increase resource utilisation. through presents a configuration technique for computing resources for the microservice-based edge computing apparatus in the smart distribution transformer region. | The lack is the trade-off methods between robustness and economy in computing resource configuration problems and apply the achievement of this work to investigate the computing resource scheduling problem of the cloud-edge collaborative system in the smart grids. |
| [71] | It has become very difficult to process big amounts of real-time data in research and applications, and it hasn’t been researched how to employ cloud computing technology for large-scale real-time data processing. | This research focuses on the big data processing architecture of the cloud computing platform. It creates a large data processing calculation mode and establishes the overall real-time big data processing architecture that acts as the foundation for the RTDP (Real-Time Data Processing) | The RTDP is a tough project, and many issues still need to be researched further: Choosing the most effective technique for calculating future design performance; Real-time data processing hardware must be implemented equally. |
| [72] | The huge challenge of integrating and exchanging vast sensor information resources that differ widely in hardware design, connection protocols, formatting, conversational skills, sampling rate, and data accuracy. | This paper provides a deeper understanding of the needs, platforms, most current technical developments, and open research problems of urban sensor applications for academics and leaders in the IoT and smart cities sectors. | Relational databases usually struggle with scalability, availability, and concurrent reading and writing, especially for big data handling in wireless sensor networks. As IoT and sensor technology continues to progress, cloud computing will be used. |
| [86] | The ability to detect and analyse anomalies for huge data in real-time is a tough problem due use conventional detection methods of data processing. | An anomaly detection model based on Hadoop distributed processing method, cloud computing and MapReduce monitoring framework is presented using machine learning. | The challenge to Meeting the real-time and large scale |
| [16] | Data from networks and smart cities is increasing and it is becoming huge so it need to big data analysis (BDA) | BDA generated in the smart city (IoT) to turn the smart city toward safety, efficient data processing, and good governance. | The flaw is the system created for the study only offers offline batch analysis and prediction functions. |
| [87] | Smart grids (SGs) are utilizing massive data for operations and services. | Information and communication technologies (ICTs) play an important role, particularly in the computing model, which governs how data analytics in SG may be carried out. | The design of EC systems, EC-appropriate algorithms, resource management in the EC environment, and even hardware accelerations might all be improved. |
| [88] | Increasing renewable energy sources making the power system more complex. | This study focuses on using ICT data in smart grid decision-making to ensure systems are secure and reliably operate. | The SCADA issues caused by ICT integration continue to exist like interdependency analysis, and decision-making. |
| [89] | There are challenges to controlling MGs in a logical and coordinated way | In this study, control objectives are categorized in line to the hierarchical control layers in MGs, and the development approaches given by MGSC/EMS are summarized. | the challenging issue is the uncertainty about power production related to weather, load calculation times and response time brings more challenges to MGSC/EMS. |
| [21] | The challenge of extracting data value through the statistical analysis of an immense amount of data generated by cyber-physical systems. | The goal of this paper was not to give the solutions, but rather to name the problems. A major challenge is the changing nature of the technical systems | software-based devices change frequently due to bug fixing and software updates. Therefore, the data we collected is after time only partially valid. |
| [90] | The challenge of clustering techniques in Big Data context. | Provide a thorough analysis of the Big Data clustering problems and highlight the benefits of the key methods. | Data are too big, dynamic, and complex. Traditional data handling struggle to collect, store, and analyse data. |
| [28] | The execution of the Hadoop cluster when processing a high number of tiny files is the true problem businesses face. The solutions are restricted to NameNode memory | Some novel strategies have been put forth, such as combining tiny heterogeneous files in various formats in a quasirandom manner, which resolves the memory issue by drastically reducing the amount of metadata. | Hadoop cannot satisfy real-time demands because it stores data before processing. |
| [29] | Big Data poses difficulties for Digital Earth in terms of data mining, processing, and storage. Transforming big data’s volume, velocity, and diversity into values is the main challenge. | Cloud computing provides fundamental support to address the challenges with shared computing resources including computing, storage, networking and analysis, that fostered Big Data advancements. | It is extremely difficult to achieve in real-time processing. |
| [30] | Large data environments lack capabilities like support for massive data, high performance, high reliability, scalability, and high resource. | This paper studied features of popular NoSQL and NewSQL databases for unified storage management and quick data access. | It is extremely difficult to achieve in real-time processing. |
| [69] | Big data is currently the most difficult organisational problem due to the rapid generation of new data every second. Systems cannot be compatible with typical DBMS solutions. | In order to address diversity in greater detail, this article discusses current problems, possibilities, trends, and difficulties associated with big data. We’ll talk about an effective fix for the huge data variety issue. | It is extremely difficult to achieve in real-time processing. |
| Algorithm | Reference |
|---|---|
| Tabu search (TS) | [107] |
| Simulated annealing (SA) | [108] |
| Variable neighbourhood search (VNS) | [109] |
| Greedy Randomized Adaptive Search Procedures | [110] |
| Swarm intelligence algorithms | [111] |
| Particle swarm optimization algorithms | [112] |
| Genetic algorithms (GAs) | [113] |
| Ant colony optimization algorithms | [114] |
| Scatter search | [115] |
| Several reviews have covered sets of Metaheuristics | [116] |
| Hybrid Metaheuristics | [117] |
| General-purpose computation on graphics processing units (GPC-GPU), in particular, are noteworthy parallelization approaches | [118,119] |
| Feature | [178] | [179] | [180] | [181] | [182] | [183] | [184] |
|---|---|---|---|---|---|---|---|
| Reduction in CPU use | ✓ | ||||||
| Reduce multiple-process tasks | ✓ | ✓ | ✓ | ✓ | ✓ | ||
| Reduce waiting times. | ✓ | ||||||
| enhanced use of resources | ✓ | ||||||
| Enhance server efficiency | ✓ | ✓ | |||||
| Increasing server performance | ✓ | ||||||
| Balance of loads | ✓ | ||||||
| performance in terms of costs | ✓ | ||||||
| lessen the demand on the memory | ✓ | ✓ | |||||
| Create a cloud architecture program | ✓ | ✓ | ✓ | ||||
| enhance inter-humans communication | ✓ | ||||||
| Increasing safety | ✓ | ||||||
| Increasing effectiveness and creating a system expand | ✓ | ||||||
| Increase the scope of cloud computing | ✓ | ||||||
| Comparison of the benefits and drawbacks of MPI, oprnMPI, and MapReduce | ✓ |
| Features | [181] | [182] | [186] | [187] | [188] | [189] | [185] | [190] |
| Utilize load balancing to increase performance | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Requesting each node’s status | ✓ | |||||||
| developed a reduce reaction time-based algorithm | ✓ | ✓ | ✓ | |||||
| Decrease requests on resources that are available | ✓ | |||||||
| Minimize server-to-server interaction and processing | ✓ | |||||||
| Take every resource’s load into account | ✓ | |||||||
| Optimize CPU throughput | ✓ | |||||||
| Reduce productivity | ✓ | |||||||
| Reduce reaction time. | ✓ | |||||||
| Reduce long waits | ✓ | |||||||
| lessen the cost of resources | ✓ | ✓ | ||||||
| Ensure error tolerance and QoS | ✓ | |||||||
| Effective implementation of parallelism | ✓ | |||||||
| Improving the way jobs are arranged | ✓ | |||||||
| Improve allocation of resources | ✓ | |||||||
| Faster performance with better outcomes | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
AL-Jumaili, A.H.A.; Muniyandi, R.C.; Hasan, M.K.; Paw, J.K.S.; Singh, M.J. Big Data Analytics Using Cloud Computing Based Frameworks for Power Management Systems: Status, Constraints, and Future Recommendations. Sensors 2023, 23, 2952. https://doi.org/10.3390/s23062952
AL-Jumaili AHA, Muniyandi RC, Hasan MK, Paw JKS, Singh MJ. Big Data Analytics Using Cloud Computing Based Frameworks for Power Management Systems: Status, Constraints, and Future Recommendations. Sensors. 2023; 23(6):2952. https://doi.org/10.3390/s23062952
Chicago/Turabian StyleAL-Jumaili, Ahmed Hadi Ali, Ravie Chandren Muniyandi, Mohammad Kamrul Hasan, Johnny Koh Siaw Paw, and Mandeep Jit Singh. 2023. "Big Data Analytics Using Cloud Computing Based Frameworks for Power Management Systems: Status, Constraints, and Future Recommendations" Sensors 23, no. 6: 2952. https://doi.org/10.3390/s23062952
APA StyleAL-Jumaili, A. H. A., Muniyandi, R. C., Hasan, M. K., Paw, J. K. S., & Singh, M. J. (2023). Big Data Analytics Using Cloud Computing Based Frameworks for Power Management Systems: Status, Constraints, and Future Recommendations. Sensors, 23(6), 2952. https://doi.org/10.3390/s23062952