

Behavior-Based Video Summarization System for Dog Health and Welfare Monitoring


Abstract
1. Introduction
- Handling video data containing dogs and people, matching real-life situations, and automatically detecting and selecting the data where the dog is alone.
- Tracking the dog’s location and performing behavior recognition in real time to provide live visualization and urgent alerts to owners.
- Summarizing the dog’s video using its tracked location data and recognized behaviors and providing an effective visualization that helps draw insightful information to understand and assess its health and welfare.
2. Related Work
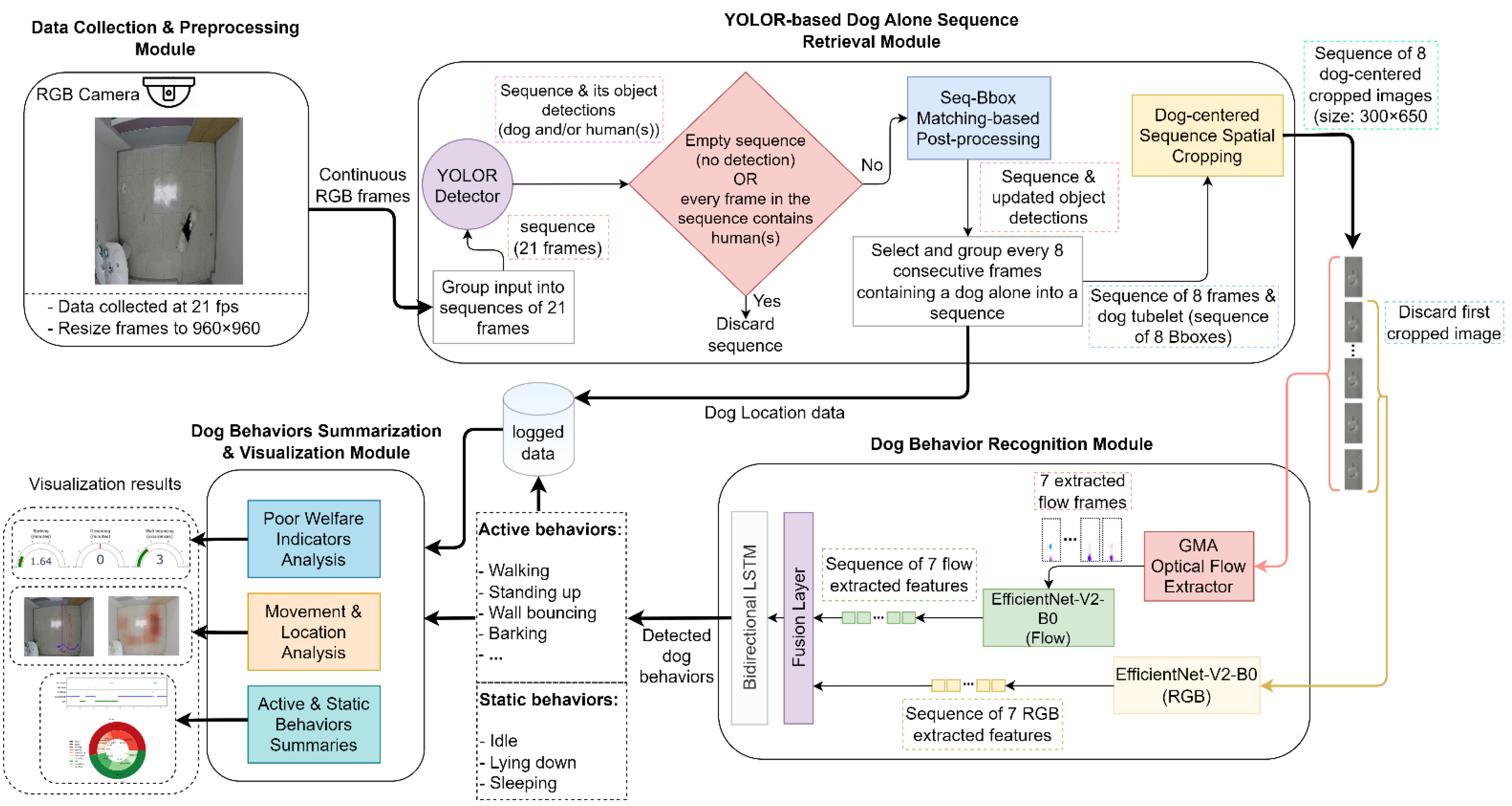
3. Behavior-Based Dog Video Summarization System
3.1. Data Collection and Preprocessing Module
3.2. YOLOR-Based Dog-Alone Sequence Retrieval Module
3.2.1. Dog and Human Object Detection
3.2.2. Seq-Bbox Matching-Based Postprocessing
3.2.3. Dog-Centered Sequence Spatial Cropping
3.3. Dog Behavior Recognition Module
3.4. Dog Behavior Summarization and Visualization Module
3.4.1. Poor-Welfare Indicator Monitoring
3.4.2. Dog Movement Visual Summary
3.4.3. Summarization of Dog’s Displayed Behaviors
4. Experimental Results
4.1. Data Collection and Datasets
4.2. Experimental Environment and Setup
4.3. Performance Evaluation
4.3.1. Evaluation Metrics
4.3.2. YOLOR-P6 Dog-Alone Sequence Retrieval Results
4.3.3. Dog Behavior Recognition Results
4.3.4. Dog Behavior Summarization and Visualization Results
4.3.5. System Graphical User Interface
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Min, D.; Lee, S.J. Factors associated with the presenteeism of single-person household employees in Korea: The 5th Korean working conditions survey (KWCS). J. Occup. Environ. Med. 2021, 63, 808–812. [Google Scholar] [CrossRef]
- Friedmann, E.; Gee, N.R.; Simonsick, E.M.; Studenski, S.; Resnick, B.; Barr, E.; Kitner-Triolo, M.; Hackney, A. Pet ownership patterns and successful aging outcomes in community dwelling older adults. Front. Vet. Sci. 2020, 7, 293. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Chun, B.C. Association between companion animal ownership and overall life satisfaction in Seoul, Korea. PLoS ONE 2021, 16, e0258034. [Google Scholar] [CrossRef] [PubMed]
- KB Financial Group Management Institute. 2021 Korea Pet Animals Report (In Korean). Available online: https://www.kbfg.com/kbresearch/report/reportView.do?reportId=2000160 (accessed on 20 November 2022).
- Animal, Plant and Fisheries Quarantine and Inspection Agency. Results of a Survey on Public Awareness about Animal Protection in 2012 (Summary). (In Korean). Available online: https://www.korea.kr/common/download.do?tblKey=EDN&fileId=206324 (accessed on 23 November 2022).
- Lee, H.S. A study on perception and needs of urban park users on off-leash recreation area. KIEAE J. 2010, 10, 49–55. [Google Scholar]
- Christian, H.; Bauman, A.; Epping, J.N.; Levine, G.N.; McCormack, G.; Rhodes, R.E.; Richards, E.; Rock, M.; Westgarth, C. Encouraging dog walking for health promotion and disease prevention. Am. J. Lifestyle Med. 2018, 12, 233–243. [Google Scholar] [CrossRef]
- Boisvert, J.A.; Harrell, W.A. Dog walking: A leisurely solution to pediatric and adult obesity? World Leis. J. 2014, 56, 168–171. [Google Scholar] [CrossRef]
- Enmarker, I.; Hellzén, O.; Ekker, K.; Berg, A.G.T. Depression in older cat and dog owners: The Nord-Trøndelag health study (HUNT)-3. Aging Ment. Health 2015, 19, 347–352. [Google Scholar] [CrossRef]
- Lee, H.S.; Song, J.G.; Lee, J.Y. Influences of dog attachment and dog walking on reducing loneliness during the covid-19 pandemic in Korea. Animals 2022, 12, 483. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.Y.; Youn, G.H. The Relationship between pet dog ownership and perception of loneliness: Mediation effects of physical health and social support. J. Inst. Soc. Sci. 2014, 25, 215–233. [Google Scholar] [CrossRef]
- Jobst, N. Number of Pet Dogs in South Korea 2010–2020. Available online: https://www.statista.com/statistics/661495/south-korea-dog-population/ (accessed on 19 November 2022).
- Ministry of Agriculture, Food and Rural Affairs. 8.6 Million Companion Animals Are Raised in 6.38 Million Households Nationwide. (In Korean). Available online: https://www.mafra.go.kr/bbs/mafra/68/248599/download.do (accessed on 19 November 2022).
- Kang, D. Companion Animal Market Is Booming... Visits to “Veterinary Hospital” Double in 3 Years. (In Korean). Available online: https://kdx.kr/news/view/148 (accessed on 15 November 2022).
- Consumers Union of Korea. The Average Medical Cost per Veterinary Hospital Is 84,000 Won, 8 out of 10 Consumers Bear Medical Expenses. Only 23% of Consumers Receive Information before Treatment. There Is a Need to Strengthen the Provision of Advance Information on Medical Expenses. (In Korean). Available online: https://kiri.or.kr/PDF/weeklytrend/20211206/trend20211206_10.pdf (accessed on 19 November 2022).
- Epstein, M.; Rodan, I.; Griffenhagen, G.; Kadrlik, J.; Petty, M.; Robertson, S.; Simpson, W. AAHA/AAFP pain management guidelines for dogs and cats. J. Am. Anim. Hosp. Assoc. 2015, 51, 67–84. [Google Scholar] [CrossRef]
- Azkona, G.; García-Belenguer, S.; Chacón, G.; Rosado, B.; León, M.; Palacio, J. Prevalence and risk factors of behavioural changes associated with age-related cognitive impairment in geriatric dogs. J. Small Anim. Pract. 2009, 50, 87–91. [Google Scholar] [CrossRef]
- Beaver, B.v.; Haug, L.I. Canine behaviors associated with hypothyroidism. J. Am. Anim. Hosp. Assoc. 2003, 39, 431–434. [Google Scholar] [CrossRef]
- Shihab, N.; Bowen, J.; Volk, H.A. Behavioral changes in dogs associated with the development of idiopathic epilepsy. Epilepsy Behav. 2011, 21, 160–167. [Google Scholar] [CrossRef] [PubMed]
- Storengen, L.M.; Boge, S.C.K.; Strøm, S.J.; Løberg, G.; Lingaas, F. A descriptive study of 215 dogs diagnosed with separation anxiety. Appl. Anim. Behav. Sci. 2014, 159, 82–89. [Google Scholar] [CrossRef]
- Ogata, N. Separation Anxiety in Dogs: What progress has been made in our understanding of the most common behavioral problems in dogs? J. Vet. Behav. Clin. Appl. Res. 2016, 16, 28–35. [Google Scholar] [CrossRef]
- Camps, T.; Amat, M.; Manteca, X. A review of medical conditions and behavioral problems in dogs and cats. Animals 2019, 9, 1133. [Google Scholar] [CrossRef] [PubMed]
- Rehn, T.; Keeling, L.J. The effect of time left alone at home on dog welfare. Appl. Anim. Behav. Sci. 2011, 129, 129–135. [Google Scholar] [CrossRef]
- De Assis, L.S.; Matos, R.; Pike, T.W.; Burman, O.H.P.; Mills, D.S. Developing diagnostic frameworks in veterinary behavioral medicine: Disambiguating separation related problems in dogs. Front. Vet. Sci. 2020, 6, 499. [Google Scholar] [CrossRef]
- Salonen, M.; Sulkama, S.; Mikkola, S.; Puurunen, J.; Hakanen, E.; Tiira, K.; Araujo, C.; Lohi, H. Prevalence, comorbidity, and breed differences in canine anxiety in 13,700 Finnish pet dogs. Sci. Rep. 2020, 10, 2962. [Google Scholar] [CrossRef] [PubMed]
- Scaglia, E.; Cannas, S.; Minero, M.; Frank, D.; Bassi, A.; Palestrini, C. Video analysis of adult dogs when left home alone. J. Vet. Behav. Clin. Appl. Res. 2013, 8, 412–417. [Google Scholar] [CrossRef]
- Duranton, C.; Bedossa, T.; Gaunet, F. Interspecific behavioural synchronization: Dogs present locomotor synchrony with humans. Sci. Rep. 2017, 7, 12384. [Google Scholar] [CrossRef] [PubMed]
- Rooney, N.J.; Bradshaw, J.W.S.; Robinson, I.H. A Comparison of dog-dog and dog-human play behaviour. Appl. Anim. Behav. Sci. 2000, 66, 235–248. [Google Scholar] [CrossRef]
- Sherman, B.L. Separation anxiety in dogs. Compend. Contin. Educ. Pract. Vet. 2008, 30, 27–42. [Google Scholar] [CrossRef]
- Ladha, C.; Hammerla, N.; Hughes, E.; Olivier, P.; Plötz, T. Dog’s life: Wearable activity recognition for dogs. In Proceedings of the 2013 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Zurich, Switzerland, 8–12 September 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 415–418. [Google Scholar] [CrossRef]
- Kiyohara, T.; Orihara, R.; Sei, Y.; Tahara, Y.; Ohsuga, A. Activity recognition for dogs based on time-series data analysis. In Agents and Artificial Intelligence; Duval, B., van den Herik, J., Loiseau, S., Filipe, J., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 163–184. [Google Scholar] [CrossRef]
- Kumpulainen, P.; Valldeoriola, A.; Somppi, S.; Törnqvist, H.; Väätäjä, H.; Majaranta, P.; Surakka, V.; Vainio, O.; Kujala, M.v.; Gizatdinova, Y.; et al. Dog activity classification with movement sensor placed on the collar. In Proceedings of the Fifth International Conference on Animal-Computer Interaction, Atlanta, GA, USA, 4–6 December 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Aich, S.; Chakraborty, S.; Sim, J.S.; Jang, D.J.; Kim, H.C. The design of an automated system for the analysis of the activity and emotional patterns of dogs with wearable sensors using machine learning. Appl. Sci. 2019, 9, 4938. [Google Scholar] [CrossRef]
- Chambers, R.D.; Yoder, N.C.; Carson, A.B.; Junge, C.; Allen, D.E.; Prescott, L.M.; Bradley, S.; Wymore, G.; Lloyd, K.; Lyle, S. Deep learning classification of canine behavior using a single collar-mounted accelerometer: Real-world validation. Animals 2021, 11, 1549. [Google Scholar] [CrossRef] [PubMed]
- Fux, A.; Zamansky, A.; Bleuer-Elsner, S.; van der Linden, D.; Sinitca, A.; Romanov, S.; Kaplun, D. Objective Video-Based Assessment of Adhd-like Canine Behavior Using Machine Learning. Animals 2021, 11, 2806. [Google Scholar] [CrossRef]
- Wang, H.; Atif, O.; Tian, J.; Lee, J.; Park, D.; Chung, Y. Multi-level hierarchical complex behavior monitoring system for dog psychological separation anxiety symptoms. Sensors 2022, 22, 1556. [Google Scholar] [CrossRef]
- Kim, J.; Moon, N. Dog behavior recognition based on multimodal data from a camera and wearable device. Appl. Sci. 2022, 12, 3199. [Google Scholar] [CrossRef]
- Choi, Y.; Atif, O.; Lee, J.; Park, D.; Chung, Y. Noise-robust sound-event classification system with texture analysis. Symmetry 2018, 10, 402. [Google Scholar] [CrossRef]
- Hong, M.; Ahn, H.; Atif, O.; Lee, J.; Park, D.; Chung, Y. Field-applicable pig anomaly detection system using vocalization for embedded board implementations. Appl. Sci. 2020, 10, 6991. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 568–576. [Google Scholar]
- Palestrini, C.; Minero, M.; Cannas, S.; Rossi, E.; Frank, D. Video analysis of dogs with separation-related behaviors. Appl. Anim. Behav. Sci. 2010, 124, 61–67. [Google Scholar] [CrossRef]
- Landsberg, G.; Hunthausen, W.; Ackerman, L. Behavior Problems of the Dog and Cat, 3rd ed.; Saunders; Elsevier: New York, NY, USA, 2013; pp. 181–210. [Google Scholar]
- Goldman, D.B.; Curless, B.; Salesin, D.; Seitz, S.M. Schematic storyboarding for video visualization and editing. In Proceedings of the 2006 ACM Special Interest Group on Computer Graphics and Interactive Techniques Conference, Boston, MA, USA, 30 July–3 August 2006; Association for Computing Machinery: New York, NY, USA, 2006; pp. 862–871. [Google Scholar] [CrossRef]
- Li, Y.; Merialdo, B.; Rouvier, M.; Linares, G. Static and dynamic video summaries. In Proceedings of the 19th ACM International Conference on Multimedia, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 1573–1576. [Google Scholar] [CrossRef]
- Lee, Y.J.; Ghosh, J.; Grauman, K. Discovering important people and objects for egocentric video summarization. In Proceedings of the 2012 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1346–1353. [Google Scholar] [CrossRef]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Bouridane, A.; Beghdadi, A. A combined multiple action recognition and summarization for surveillance video sequences. Appl. Intell. 2021, 51, 690–712. [Google Scholar] [CrossRef]
- Tejero-De-Pablos, A.; Nakashima, Y.; Sato, T.; Yokoya, N.; Linna, M.; Rahtu, E. Summarization of user-generated sports video by using deep action recognition features. IEEE Trans. Multimed. 2018, 20, 2000–2011. [Google Scholar] [CrossRef]
- Almaadeed, N.; Elharrouss, O.; Al-Maadeed, S.; Bouridane, A.; Beghdadi, A. A Novel approach for robust multi human action recognition and summarization based on 3D convolutional neural networks. arXiv 2019. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Steibel, J.; Siegford, J.; Wurtz, K.; Han, J.; Norton, T. Recognition of aggressive episodes of pigs based on convolutional neural network and long short-term memory. Comput. Electron. Agric. 2020, 169, 105166. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Steibel, J.; Siegford, J.; Han, J.; Norton, T. Classification of drinking and drinker-playing in pigs by a video-based deep learning method. Biosyst. Eng. 2020, 196, 1–14. [Google Scholar] [CrossRef]
- Yin, X.; Wu, D.; Shang, Y.; Jiang, B.; Song, H. Using an EfficientNet-LSTM for the recognition of single cow’s motion behaviours in a complicated environment. Comput. Electron. Agric. 2020, 177, 105707. [Google Scholar] [CrossRef]
- Singh, B.; Marks, T.K.; Jones, M.; Tuzel, O.; Shao, M. A multi-stream bi-directional recurrent neural network for fine-grained action detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1961–1970. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. You only learn one representation: Unified network for multiple tasks. arXiv 2021, arXiv:2105.04206. [Google Scholar]
- Belhassen, H.; Zhang, H.; Fresse, V.; Bourennane, E.B. Improving video object detection by Seq-Bbox matching. In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Prague, Czech Republic, 25–27 February 2019; Volume 5, pp. 226–233. [Google Scholar]
- Jiang, S.; Campbell, D.; Lu, Y.; Li, H.; Hartley, R. Learning to estimate hidden motions with global motion aggregation. arXiv 2021, arXiv:2104.02409. [Google Scholar]
- Bo, Z.; Atif, O.; Lee, J.; Park, D.; Chung, Y. GAN-based video denoising with attention mechanism for field-applicable pig detection system. Sensors 2022, 22, 3917. [Google Scholar] [CrossRef]
- Zhao, Y.; Cheng, J.; Zhou, W.; Zhang, C.; Pan, X. Infrared pedestrian detection with converted temperature map. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 2025–2031. [Google Scholar]
- Liu, K.Q.; Wang, J.Q. Fast dynamic vehicle detection in road scenarios based on pose estimation with Convex-Hull model. Sensors 2019, 19, 3136. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wu, H.; He, S.; Deng, Z.; Kou, L.; Huang, K.; Suo, F.; Cao, Z. Fishery monitoring system with AUV based on YOLO and SGBM. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 4726–4731. [Google Scholar] [CrossRef]
- Sha, Z.; Feng, H.; Rui, X.; Zeng, Z. PIG Tracking utilizing fiber optic distributed vibration sensor and YOLO. J. Lightwave Technol. 2021, 39, 4535–4541. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, Y.; Dai, J.; Yuan, L.; Wei, Y. Flow-guided feature aggregation for video object detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 408–417. [Google Scholar]
- Mishra, B.K.; Thakker, D.; Mazumdar, S.; Neagu, D.; Gheorghe, M.; Simpson, S. A novel application of deep learning with image cropping: A smart city use case for flood monitoring. J. Reliab. Intell. Environ. 2020, 6, 51–61. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller models and faster training. arXiv 2021. [Google Scholar] [CrossRef]
- Zhang, M.; Hu, H.; Li, Z.; Chen, J. Action Detection with Two-Stream Enhanced Detector. Vis. Comput. 2022, 39, 1193–1204. [Google Scholar] [CrossRef]
- Butler, D.J.; Wulff, J.; Stanley, G.B.; Black, M.J. A naturalistic open source movie for optical flow evaluation. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; pp. 611–625. [Google Scholar] [CrossRef]
- Stephen, J.M.; Ledger, R.A. An audit of behavioral indicators of poor welfare in kenneled dogs in the United Kingdom. J. Appl. Anim. Welf. Sci. 2005, 8, 79–96. [Google Scholar] [CrossRef] [PubMed]
- Della Rocca, G.; Gamba, D. Chronic pain in dogs and cats: Is there place for dietary intervention with micro-palmitoylethanolamide? Animals 2021, 11, 952. [Google Scholar] [CrossRef]
- Kaplun, D.; Sinitca, A.; Zamansky, A.; Bleuer-Elsner, S.; Plazner, M.; Fux, A.; van der Linden, D. Animal health informatics: Towards a generic framework for automatic behavior analysis. In Proceedings of the 12th International Conference on Health Informatics, Prague, Czech Republic, 22–24 February 2019. [Google Scholar]
- Bleuer-Elsner, S.; Zamansky, A.; Fux, A.; Kaplun, D.; Romanov, S.; Sinitca, A.; Masson, S.; van der Linden, D. Computational analysis of movement patterns of dogs with ADHD-like behavior. Animals 2019, 9, 1140. [Google Scholar] [CrossRef]
- Konok, V.; Kosztolányi, A.; Rainer, W.; Mutschler, B.; Halsband, U.; Miklósi, Á. Influence of owners’ attachment style and personality on their dogs’ (Canis familiaris) separation-related disorder. PLoS ONE 2015, 10, e0118375. [Google Scholar] [CrossRef] [PubMed]
- Raudies, C.; Waiblinger, S.; Arhant, C. Characteristics and welfare of long-term shelter dogs. Animals 2021, 11, 194. [Google Scholar] [CrossRef]
- Polgár, Z.; Blackwell, E.J.; Rooney, N.J. Assessing the welfare of kennelled dogs—A review of animal-based measures. Appl. Anim. Behav. Sci. 2019, 213, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Owczarczak-Garstecka, S.C.; Burman, O.H.P. Can sleep and resting behaviours be used as indicators of welfare in shelter dogs (Canis lupus familiaris)? PLoS ONE 2016, 11, e0163620. [Google Scholar] [CrossRef] [PubMed]
- Biresaw, T.A.; Nawaz, T.; Ferryman, J.; Dell, A.I. ViTBAT: Video tracking and behavior annotation tool. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 295–301. [Google Scholar] [CrossRef]
- Cartucho, J.; Ventura, R.; Veloso, M. Robust object recognition through symbiotic deep learning in mobile robots. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2336–2341. [Google Scholar] [CrossRef]
- Lund, J.D.; Jørgensen, M.C. Behaviour patterns and time course of activity in dogs with separation problems. Appl. Anim. Behav. Sci. 1999, 63, 219–236. [Google Scholar] [CrossRef]
- Parthasarathy, V.; Crowell-Davis, S.L. Relationship between attachment to owners and separation anxiety in pet dogs (Canis lupus familiaris). J. Vet. Behav. Clin. Appl. Res. 2006, 1, 109–120. [Google Scholar] [CrossRef]
- Sherman, B.L.; Mills, D.S. Canine anxieties and phobias: An update on separation anxiety and noise aversions. Vet. Clin. N. Am. Small Anim. Pract. 2008, 38, 1081–1106. [Google Scholar] [CrossRef] [PubMed]
- Kaur, J.; Seshadri, S.; Golla, K.H.; Sampara, P. Efficacy and safety of standardized ashwagandha (Withania somnifera) root extract on reducing stress and anxiety in domestic dogs: A randomized controlled trial. J. Vet. Behav. 2022, 51, 8–15. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensor Type | Method | Real-Life Scenarios Data Containing Dog and Humans * | Real-Time Processing | Detect and Track Dog Location | Video Summarization * | Ref. |
|---|---|---|---|---|---|---|
| Accelerometer | Statistical classification | Not applicable | Not specified | No | Not applicable | [30] |
| Accelerometer | Dynamic time warping distance | Not applicable | Not specified | No | Not applicable | [31] |
| Accelerometer | Discriminant analysis classifier | Not applicable | Not specified | No | Not applicable | [32] |
| Accelerometer and gyroscope | ANN model | Not applicable | Yes | No | Not applicable | [33] |
| Accelerometer | FilterNet | Not applicable | Not specified | No | Not applicable | [34] |
| RGB camera | Faster RCNN and random forest | No | Not specified | Yes | No | [35] |
| Accelerometer and gyroscope | LSTM-CEP | Not applicable | Not specified | No | Not applicable | [36] |
| RGB camera, accelerometer and gyroscope | Multimodal CNN-LSTM | No | Not specified | No | No | [37] |
| Behavior | Description and Threshold |
|---|---|
| Barking | Excessive vocalization when dog is alone (>1 min) |
| Wall bouncing | Jumping and bouncing against a wall (>3 times) |
| Grooming | repeatedly licking own body (>5 min) |
| Category | Behavior | Description | Data Count (Sequences of 8 Images) |
|---|---|---|---|
| Active behaviors | Barking | Vocalization usually accompanied with a slight movement of the head. | 1000 |
| Door biting | Biting and pulling of door. | 1000 | |
| Door scratching | Scratching surface of door. | 363 | |
| Engaging toy | Making contact with and pushing around a toy with nose and mouth. | 663 | |
| Grooming | Self-licking of body parts. | 1000 | |
| Wall Bouncing | Jumping against a wall and bouncing back to the ground. | 1000 | |
| Shaking off | Twisting movement from left to right. | 166 | |
| Standing up | Standing up on back feet. | 1000 | |
| Walking | Constant movement around the room. | 1000 | |
| Static behaviors | Sleeping | Lying on the side with head on the floor. | 204 |
| Lying down | Chest, belly, and forearms in contact with the floor. | 1000 | |
| Idle | Sitting or standing on four paws with little to no motion | 1000 |
| YOLOR-P6 | YOLOR-P6 with seq-Bbox Matching | |
|---|---|---|
| APdog | 0.903 | 0.962 |
| APperson | 0.863 | 0.864 |
| mAP | 0.883 | 0.913 |
| inference time (ms) | 54.39 | 54.58 |
| YOLOR-Based Dog-Alone Sequence Retrieval | ||||
|---|---|---|---|---|
| Sequence | Data Count | Precision | Recall | F1 Score |
| Empty room | 1220 | 0.996 | 0.994 | 0.995 |
| Person alone | 216 | 0.906 | 0.981 | 0.942 |
| Dog alone | 1628 | 0.995 | 0.990 | 0.992 |
| Dog and Person | 309 | 0.973 | 0.948 | 0.960 |
| Average | 0.988 | 0.987 | 0.987 | |
| Two-Stream EfficientNetV2-LSTM (Cropped Images) | ||||
|---|---|---|---|---|
| Behavior | Data Count | Precision | Recall | F1 Score |
| Barking | 101 | 0.970 | 0.970 | 0.970 |
| Door biting | 100 | 0.960 | 0.960 | 0.960 |
| Door scratching | 37 | 0.925 | 1.00 | 0.961 |
| Engaging toy | 67 | 0.985 | 1.00 | 0.993 |
| Grooming | 100 | 1.00 | 0.990 | 0.995 |
| Idle | 100 | 0.947 | 0.890 | 0.918 |
| Wall bouncing | 100 | 0.898 | 0.970 | 0.933 |
| Lying down | 101 | 0.952 | 0.990 | 0.971 |
| Shaking off | 18 | 1.00 | 0.944 | 0.971 |
| Sleeping | 21 | 0.955 | 1.00 | 0.977 |
| Standing up | 97 | 0.967 | 0.880 | 0.921 |
| Walking | 100 | 0.940 | 0.940 | 0.940 |
| Average | 0.956 | 0.956 | 0.955 | |
| Behavior | F1 Score | ||||
|---|---|---|---|---|---|
| TDMap-CNN | VGG16-LSTM | ResNet50-LSTM | Proposed Method (Original Images) | Proposed Method (Cropped Images) | |
| Barking | 0.782 | 0.881 | 0.926 | 0.929 | 0.970 |
| Door biting | 0.814 | 0.910 | 0.923 | 0.910 | 0.960 |
| Door scratching | 0.657 | 0.954 | 0.985 | 0.935 | 0.961 |
| Engaging toy | 0.735 | 0.942 | 0.983 | 0.992 | 0.993 |
| Grooming | 0.840 | 0.976 | 0.994 | 0.976 | 0.995 |
| Idle | 0.415 | 0.491 | 0.618 | 0.834 | 0.918 |
| Wall bouncing | 0.723 | 0.854 | 0.897 | 0.898 | 0.933 |
| Lying down | 0.592 | 0.886 | 0.930 | 0.961 | 0.971 |
| Shaking off | 0.303 | 0.710 | 0.929 | 0.923 | 0.971 |
| Sleeping | 0.739 | 0.973 | 0.973 | 0.977 | 0.977 |
| Standing up | 0.577 | 0.757 | 0.864 | 0.828 | 0.921 |
| Walking | 0.610 | 0.582 | 0.718 | 0.887 | 0.940 |
| Average | 0.668 | 0.812 | 0.876 | 0.913 | 0.955 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atif, O.; Lee, J.; Park, D.; Chung, Y. Behavior-Based Video Summarization System for Dog Health and Welfare Monitoring. Sensors 2023, 23, 2892. https://doi.org/10.3390/s23062892
Atif O, Lee J, Park D, Chung Y. Behavior-Based Video Summarization System for Dog Health and Welfare Monitoring. Sensors. 2023; 23(6):2892. https://doi.org/10.3390/s23062892
Chicago/Turabian StyleAtif, Othmane, Jonguk Lee, Daihee Park, and Yongwha Chung. 2023. "Behavior-Based Video Summarization System for Dog Health and Welfare Monitoring" Sensors 23, no. 6: 2892. https://doi.org/10.3390/s23062892
APA StyleAtif, O., Lee, J., Park, D., & Chung, Y. (2023). Behavior-Based Video Summarization System for Dog Health and Welfare Monitoring. Sensors, 23(6), 2892. https://doi.org/10.3390/s23062892