
End-to-End Detection of a Landing Platform for Offshore UAVs Based on a Multimodal Early Fusion Approach


Abstract
1. Introduction
- Real-time multimodal marker detection that is deployable onboard a UAV;
- Resilient and high-accuracy detection based on early-fusion approaches against sensor failure integrated in the YOLOv7 framework;
- Robustness against demanding weather and operating conditions for extensive experiments using real UAVs landing on a floating platform;
- A new multimodal dataset collected in real offshore and onshore environments during a UAV landing operation, comprised of diverse joint representations of visual, infrared and point-cloud images.
2. Related Work
3. Multimodal Early Fusion Approach for Fiducial Marker Detection
3.1. Early Fuser
3.1.1. Calibration
3.1.2. Pre-Processing
3.1.3. Concatenation
3.2. Detector
4. Experimental Setup
- Visual Camera—The Imaging Source DFM 37UX273-ML—Frame Rate: 15 Hz, Resolution: 1440 × 1080 pixels, Field of View: 45° horizontal;
- Thermal Camera—FLIR Boson 640 Radiometry—Frame Rate: 15 Hz, Resolution: 640 × 512 pixels, Field of View: 50° horizontal, Temperature Measurement Accuracy: ±5 °C;
- 3D LiDAR—Ouster OS1-64—Frame Rate: 10 Hz, Resolution: 64 × 1024 channels, Range: 120 m, Accuracy: ±0.05 m, Field of View: 360° horizontal and 45° vertical.
4.1. Datasets
4.1.1. Visual Dataset
4.1.2. Thermal Dataset
4.1.3. LiDAR Dataset
4.1.4. Fusion Dataset
4.1.5. Annotation
5. Results
5.1. Training
5.1.1. Training Settings
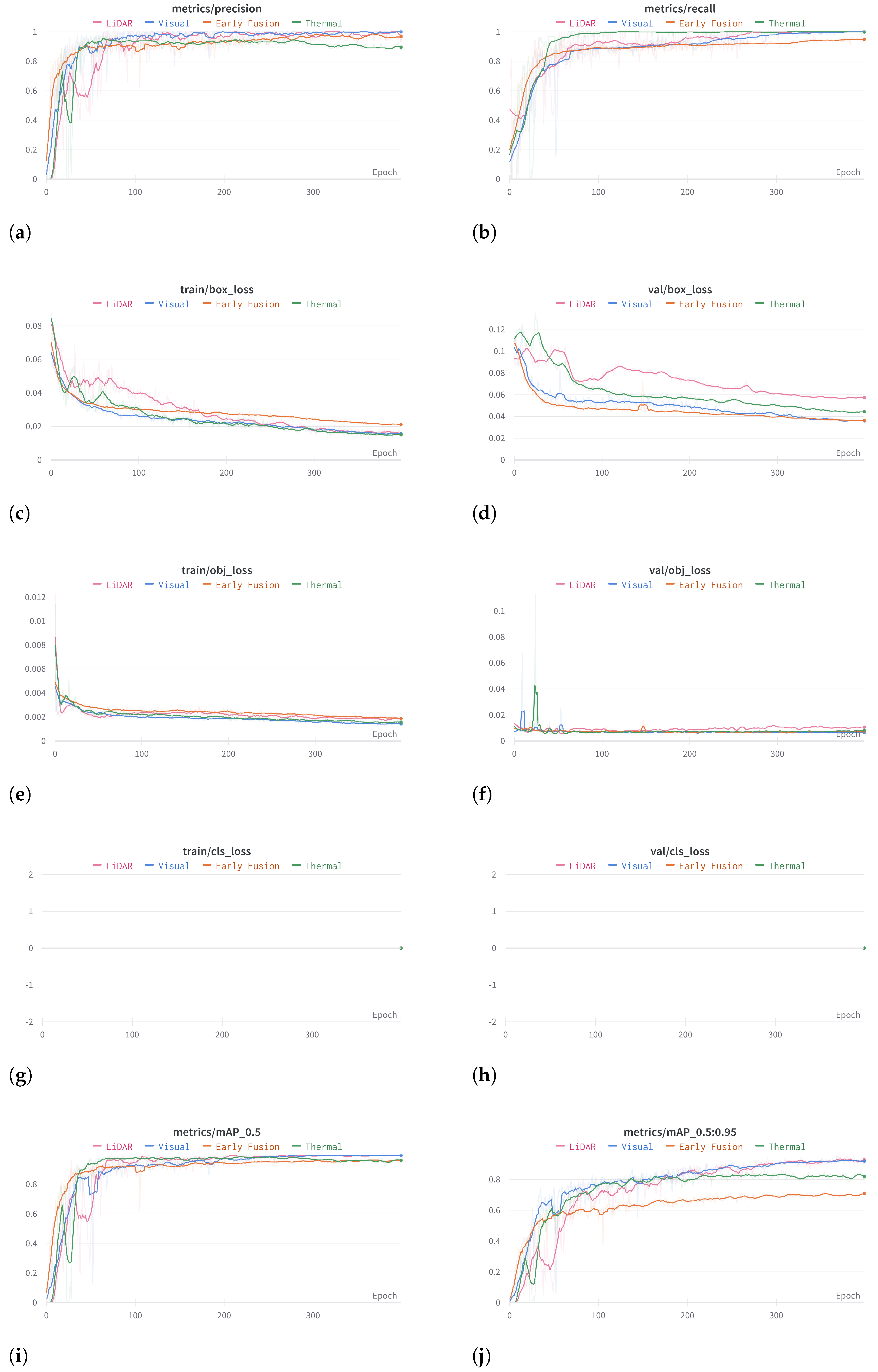
5.1.2. Training Results
5.2. Testing
5.2.1. Ablation Test
5.2.2. Weather test
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pendleton, S.D.; Andersen, H.; Du, X.; Shen, X.; Meghjani, M.; Eng, Y.H.; Rus, D.; Ang, M.H. Perception, planning, control, and coordination for autonomous vehicles. Machines 2017, 5, 6. [Google Scholar] [CrossRef]
- Lim, T.Y.; Ansari, A.; Major, B.; Fontijne, D.; Hamilton, M.; Gowaikar, R.; Subramanian, S. Radar and camera early fusion for vehicle detection in advanced driver assistance systems. In Proceedings of the Machine Learning for Autonomous Driving Workshop at the 33rd Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 14 December 2019; Volume 2. [Google Scholar]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and Sensor Fusion Technology in Autonomous Vehicles: A Review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef] [PubMed]
- Kim, J.; Koh, J.; Kim, Y.; Choi, J.; Hwang, Y.; Choi, J.W. Robust deep multi-modal learning based on gated information fusion network. In Proceedings of the Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; pp. 90–106. [Google Scholar]
- Boulahia, S.Y.; Amamra, A.; Madi, M.R.; Daikh, S. Early, intermediate and late fusion strategies for robust deep learning-based multimodal action recognition. Mach. Vis. Appl. 2021, 32, 1–18. [Google Scholar] [CrossRef]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the ICML, Bellevue, WA, USA, 28 June–2 July 2011. [Google Scholar]
- Yi, S.; Jiang, G.; Liu, X.; Li, J.; Chen, L. TCPMFNet: An infrared and visible image fusion network with composite auto encoder and transformer–convolutional parallel mixed fusion strategy. Infrared Phys. Technol. 2022, 127, 104405. [Google Scholar] [CrossRef]
- Panigrahy, C.; Seal, A.; Mahato, N.K. Parameter adaptive unit-linking dual-channel PCNN based infrared and visible image fusion. Neurocomputing 2022, 514, 21–38. [Google Scholar] [CrossRef]
- Shopovska, I.; Jovanov, L.; Philips, W. Deep visible and thermal image fusion for enhanced pedestrian visibility. Sensors 2019, 19, 3727. [Google Scholar] [CrossRef]
- Farahnakian, F.; Heikkonen, J. Deep Learning Based Multi-Modal Fusion Architectures for Maritime Vessel Detection. Remote Sens. 2020, 12, 2509. [Google Scholar] [CrossRef]
- Choi, J.D.; Kim, M.Y. A Sensor Fusion System with Thermal Infrared Camera and LiDAR for Autonomous Vehicles and Deep Learning Based Object Detection; ICT Express: Jeju, Republic of Korea, 2022. [Google Scholar]
- Liu, L.; He, J.; Ren, K.; Xiao, Z.; Hou, Y. A LiDAR and Camera Fusion 3D Object Detection Algorithm. Information 2022, 13, 169. [Google Scholar] [CrossRef]
- Claro, R.; Silva, D.; Pinto, A. ArTuga: A Novel Multimodal Fiducial Marker for Aerial Robotics. Robot. Auton. Syst. 2022, in press.
- Soviany, P.; Ionescu, R.T. Optimizing the trade-off between single-stage and two-stage deep object detectors using image difficulty prediction. In Proceedings of the 2018 20th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC), Timisoara, Romania, 20–23 September 2018; pp. 209–214. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. arXiv 2015, arXiv:1506.02640. [Google Scholar]
- Liu, W.; Dragomir Anguelov, D.E.; Szegedy, C.; Reed, S.E.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. arXiv 2015, arXiv:1512.02325. [Google Scholar]
- Akkus, C.; Chu, L.; Djakovic, V.; Jauch-Walser, S.; Koch, P.; Loss, G.; Marquardt, C.; Moldovan, M.; Sauter, N.; Schneider, M.; et al. Multimodal Deep Learning. arXiv 2023, arXiv:2301.04856. [Google Scholar]
- Katsaggelos, A.K.; Bahaadini, S.; Molina, R. Audiovisual Fusion: Challenges and New Approaches. Proc. IEEE 2015, 103, 1635–1653. [Google Scholar] [CrossRef]
- Gadzicki, K.; Khamsehashari, R.; Zetzsche, C. Early vs. Late Fusion in Multimodal Convolutional Neural Networks. In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Azam, S.; Munir, F.; Sheri, A.M.; Ko, Y.; Hussain, I.; Jeon, M. Data fusion of lidar and thermal camera for autonomous driving. In Proceedings of the Applied Industrial Optics: Spectroscopy, Imaging and Metrology, Optical Society of America, Washington, DC, USA, 8–10 July 2019; pp. 2–5. [Google Scholar]
- Bhanushali, D.; Relyea, R.; Manghi, K.; Vashist, A.; Hochgraf, C.; Ganguly, A.; Kwasinski, A.; Kuhl, M.; Ptucha, R. LiDAR-Camera Fusion for 3D Object Detection. Electron. Imaging 2020, 2020, 257. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Benjumea, A.; Teeti, I.; Cuzzolin, F.; Bradley, A. YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles. arXiv 2021, arXiv:2112.11798. [Google Scholar]
- Murthy, J.S.; Siddesh, G.; Lai, W.C.; Parameshachari, B.; Patil, S.N.; Hemalatha, K. ObjectDetect: A Real-Time Object Detection Framework for Advanced Driver Assistant Systems Using YOLOv5. Wirel. Commun. Mob. Comput. 2022, 2022, 9444360. [Google Scholar] [CrossRef]
- Al-Qubaydhi, N.; Alenezi, A.; Alanazi, T.; Senyor, A.; Alanezi, N.; Alotaibi, B.; Alotaibi, M.; Razaque, A.; Abdelhamid, A.A.; Alotaibi, A. Detection of Unauthorized Unmanned Aerial Vehicles Using YOLOv5 and Transfer Learning. Electronics 2022, 11, 2669. [Google Scholar] [CrossRef]
- Kasper-Eulaers, M.; Hahn, N.; Berger, S.; Sebulonsen, T.; Myrland, Ø.; Kummervold, P.E. Detecting heavy goods vehicles in rest areas in winter conditions using YOLOv5. Algorithms 2021, 14, 114. [Google Scholar] [CrossRef]
- Jung, H.K.; Choi, G.S. Improved YOLOv5: Efficient Object Detection Using Drone Images under Various Conditions. Appl. Sci. 2022, 12, 7255. [Google Scholar] [CrossRef]
- Mseddi, W.S.; Sedrine, M.A.; Attia, R. YOLOv5 Based Visual Localization for Autonomous Vehicles. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; pp. 746–750. [Google Scholar]
- Liu, W.; Wang, Z.; Zhou, B.; Yang, S.; Gong, Z. Real-time signal light detection based on yolov5 for railway. IOP Conf. Ser. Earth Environ. Sci. 2021, 769, 042069. [Google Scholar]
- Ultralytics. YoloV5. Available online: https://ultralytics.com/yolov5 (accessed on 19 February 2023).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Neves, F.; Pinto, A.M.; Claro, R.M. Early Fusion Datasets for UAV Landing Operations Using Multimodal Fiducial Marker. Figshare 2023. [Google Scholar] [CrossRef]
- Roboflow. 2022. Available online: https://roboflow.com/ (accessed on 21 January 2023).
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar]
- Toet, A. TNO Image Fusion Dataset; Springer Data in Brief: Soesterberg, The Netherlands, 2022. [Google Scholar]
- Heinzler, R.; Piewak, F.; Schindler, P.; Stork, W. Cnn-based lidar point cloud de-noising in adverse weather. IEEE Robot. Autom. Lett. 2020, 5, 2514–2521. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Quantity |
|---|---|
| Epochs | 400 |
| Batch size | 32 |
| IoU threshold | 0.2 |
| Momentum | 0.937 |
| Learning rate | |
| Weight decay |
| Detector | Modality | mAP@.5 | mAP@.5:.95 | Precision | Recall |
|---|---|---|---|---|---|
| Visual | Unimodal | 0.999 | 0.999 | 1 | 1 |
| Thermal | Unimodal | 1 | 1 | 1 | 1 |
| LiDAR | Unimodal | 0.999 | 0.999 | 1 | 1 |
| Early Fusion | Multimodal | 0.989 | 0.989 | 1 | 0.985 |
| Confidence Threshold (%) | False Positives |
|---|---|
| 60 | 19 |
| 70 | 9 |
| 75 | 4 |
| 80 | 1 |
| 90 | 0 |
| Unable Signals | True Positives (Conf > 0.8) | Recall | Inference Time (ms) |
|---|---|---|---|
| None | 1 | 5.6 | |
| Visual and Thermal | 1 | 5.5 | |
| Visual and LiDAR | 1 | 4.2 | |
| Thermal and LiDAR | 1 | 4.7 | |
| LiDAR | 1 | 4.2 | |
| Visual | 1 | 4.1 | |
| Thermal | 1 | 4.8 |
| Weather Condition | True Positives (Conf > 0.6) | False Negatives | Recall | Inference Time (ms) |
|---|---|---|---|---|
| Bright () | 99 | 1 | 0.99 | 2.2 |
| Bright () | 98 | 2 | 0.98 | 2.1 |
| Bright () | 87 | 13 | 0.87 | 2.0 |
| Dark () | 99 | 1 | 0.99 | 2.6 |
| Dark () | 100 | 0 | 1 | 2.1 |
| Dark () | 96 | 4 | 0.96 | 2.0 |
| Fog (stochastic) | 96 | 4 | 0.96 | 2.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Neves, F.S.; Claro, R.M.; Pinto, A.M. End-to-End Detection of a Landing Platform for Offshore UAVs Based on a Multimodal Early Fusion Approach. Sensors 2023, 23, 2434. https://doi.org/10.3390/s23052434
Neves FS, Claro RM, Pinto AM. End-to-End Detection of a Landing Platform for Offshore UAVs Based on a Multimodal Early Fusion Approach. Sensors. 2023; 23(5):2434. https://doi.org/10.3390/s23052434
Chicago/Turabian StyleNeves, Francisco Soares, Rafael Marques Claro, and Andry Maykol Pinto. 2023. "End-to-End Detection of a Landing Platform for Offshore UAVs Based on a Multimodal Early Fusion Approach" Sensors 23, no. 5: 2434. https://doi.org/10.3390/s23052434
APA StyleNeves, F. S., Claro, R. M., & Pinto, A. M. (2023). End-to-End Detection of a Landing Platform for Offshore UAVs Based on a Multimodal Early Fusion Approach. Sensors, 23(5), 2434. https://doi.org/10.3390/s23052434