
New Cognitive Deep-Learning CAPTCHA

Abstract
1. Introduction
- First, we show that the combination between deep learning and cognition can significantly improve the security of image-based and text-based CAPTCHAs.
- Second, we suggest a promising direction for designing CAPTCHAs. The proposed CAPTCHA can be varied for different cognitive CAPTCHA schemes by changing their attributes. Specifically, the attribute of text group order can be natural order, inverse order, or special order, such that any text group with special characteristics can be requested to be picked up with higher priority. Furthermore, the background images and text can be localized to make them more familiar to users in their local surroundings. As a result, we can see that the use of this CAPTCHA is widespread and simple to adapt to any system that requires CAPTCHA protection against automated bots.
2. Related Works
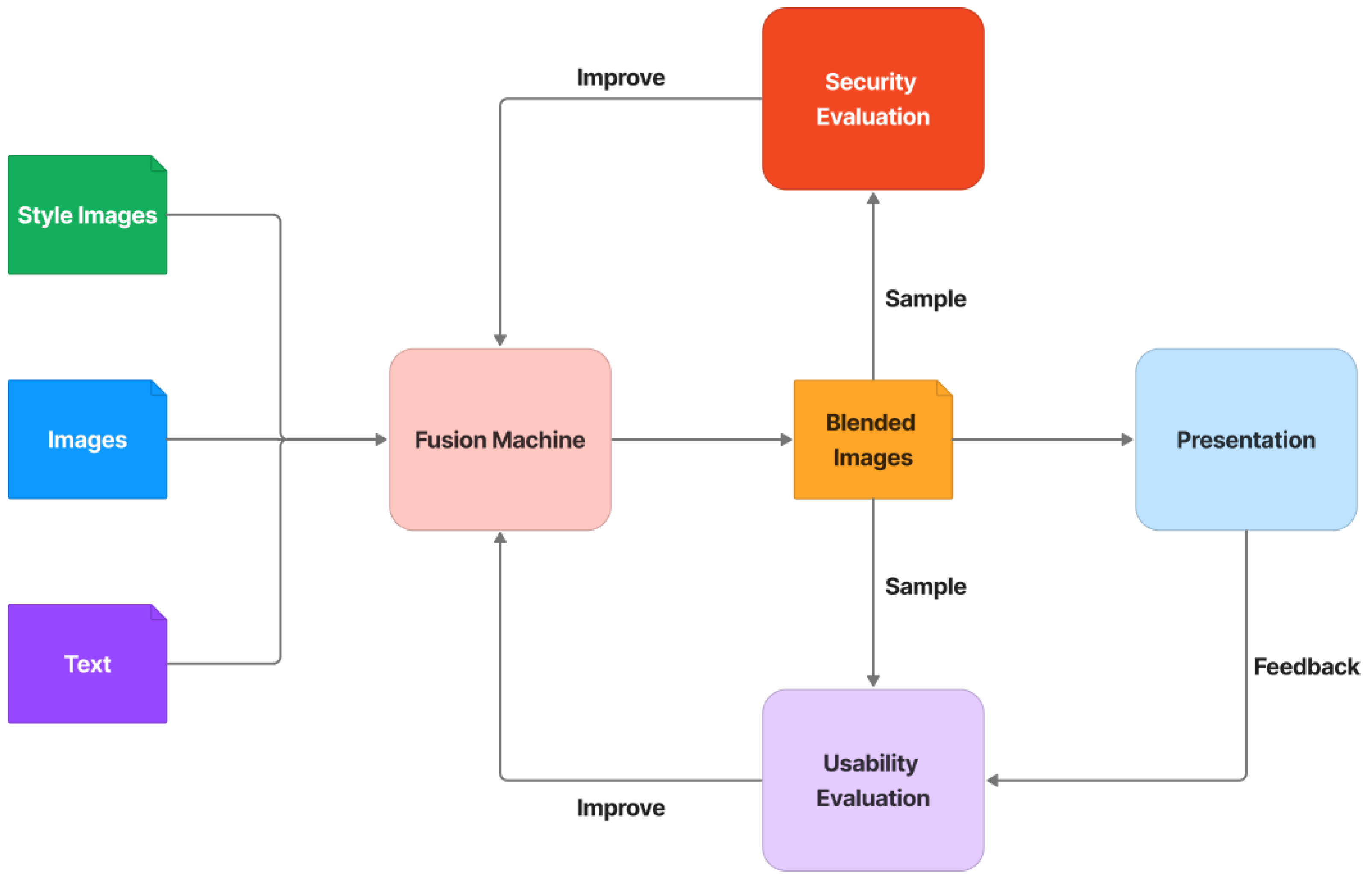
3. Proposed CAPTCHA System
3.1. Design Concept
3.2. CAPTCHA Architecture
4. Applied Techniques
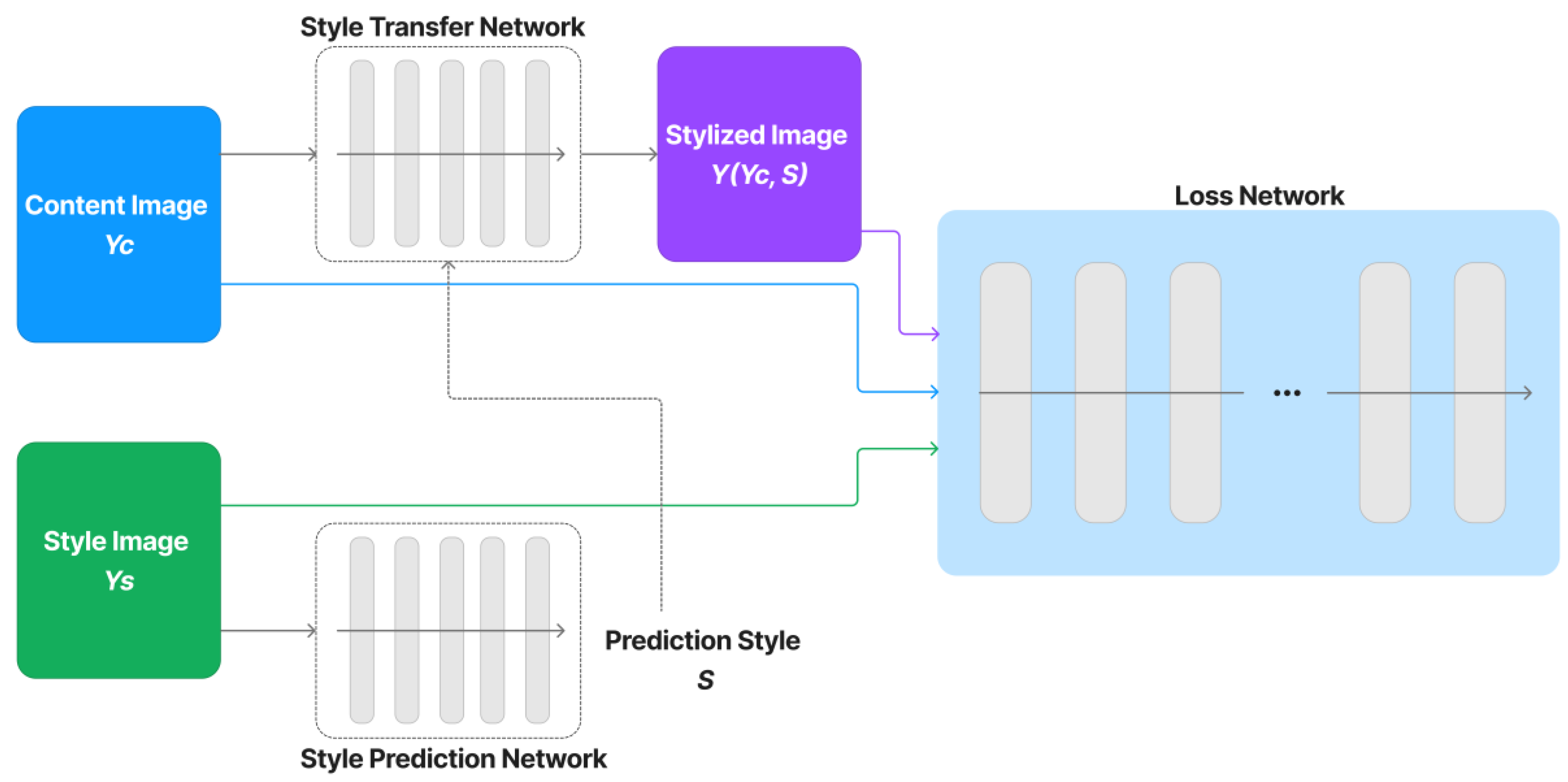
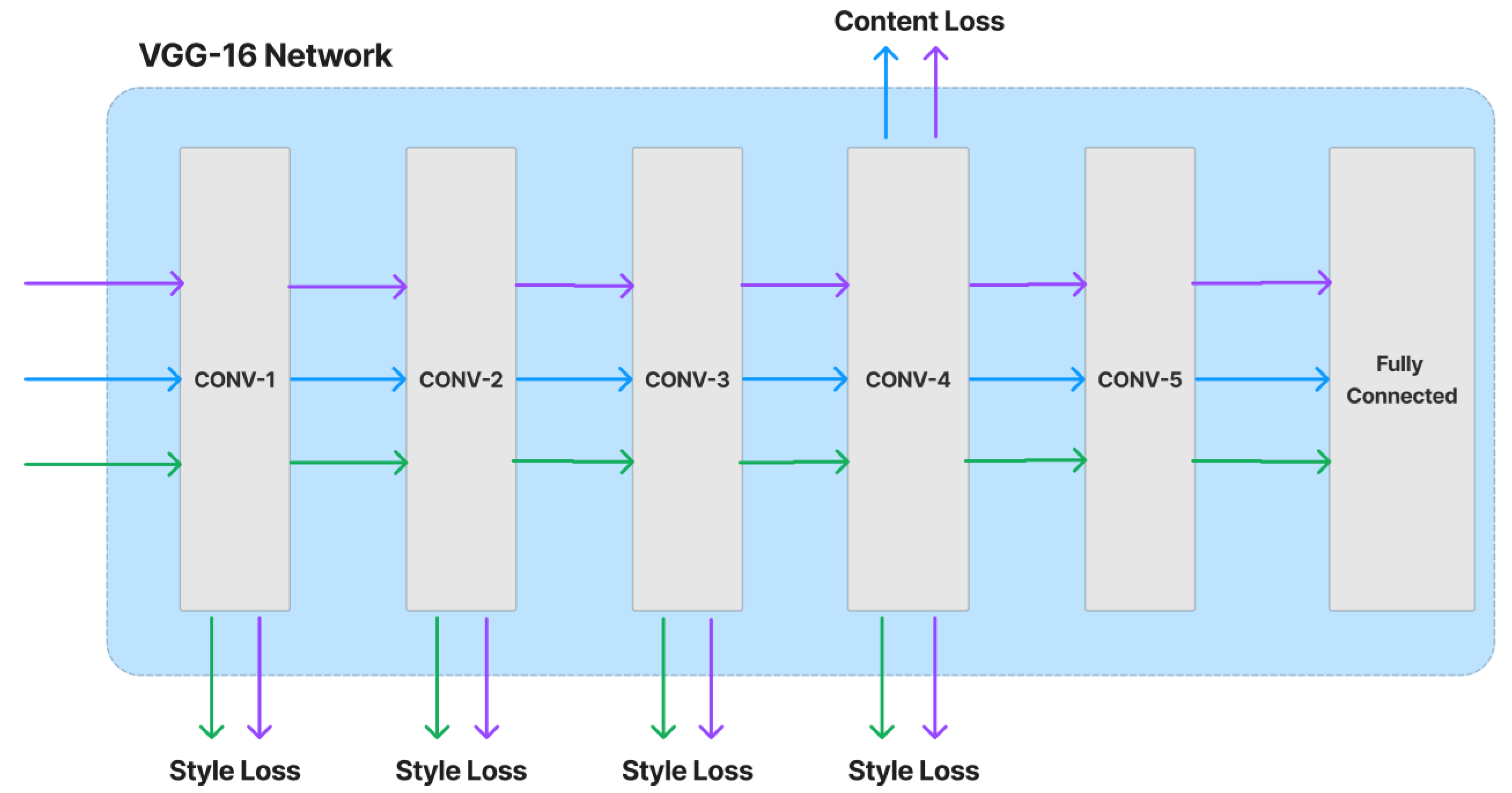
4.1. Neural Style Transfer
- If the difference between the features’ Gram matrices has a small Frobenius norm, then the two images are stylistically similar.
- If the high-level features of two images, as determined by a trained classifier, are near in Euclidean distance, then the two images have similar content.
4.2. Adversarial Examples
4.2.1. FGSM Generation Method
- Forward propagation is used to obtain the expected labels.
- The gradient direction is set to reduce the likelihood that the label is true.
- The backward propagation modifies the weight parameters.
- The adversarial examples are recomputed using forward propagation with the modified weights.
4.2.2. BPDA Generation Method
- Use any of the defense techniques to denoise x and obtain .
- Forward propagate through the net and compute its loss.
- Calculate the gradient of the loss from the denoised image.
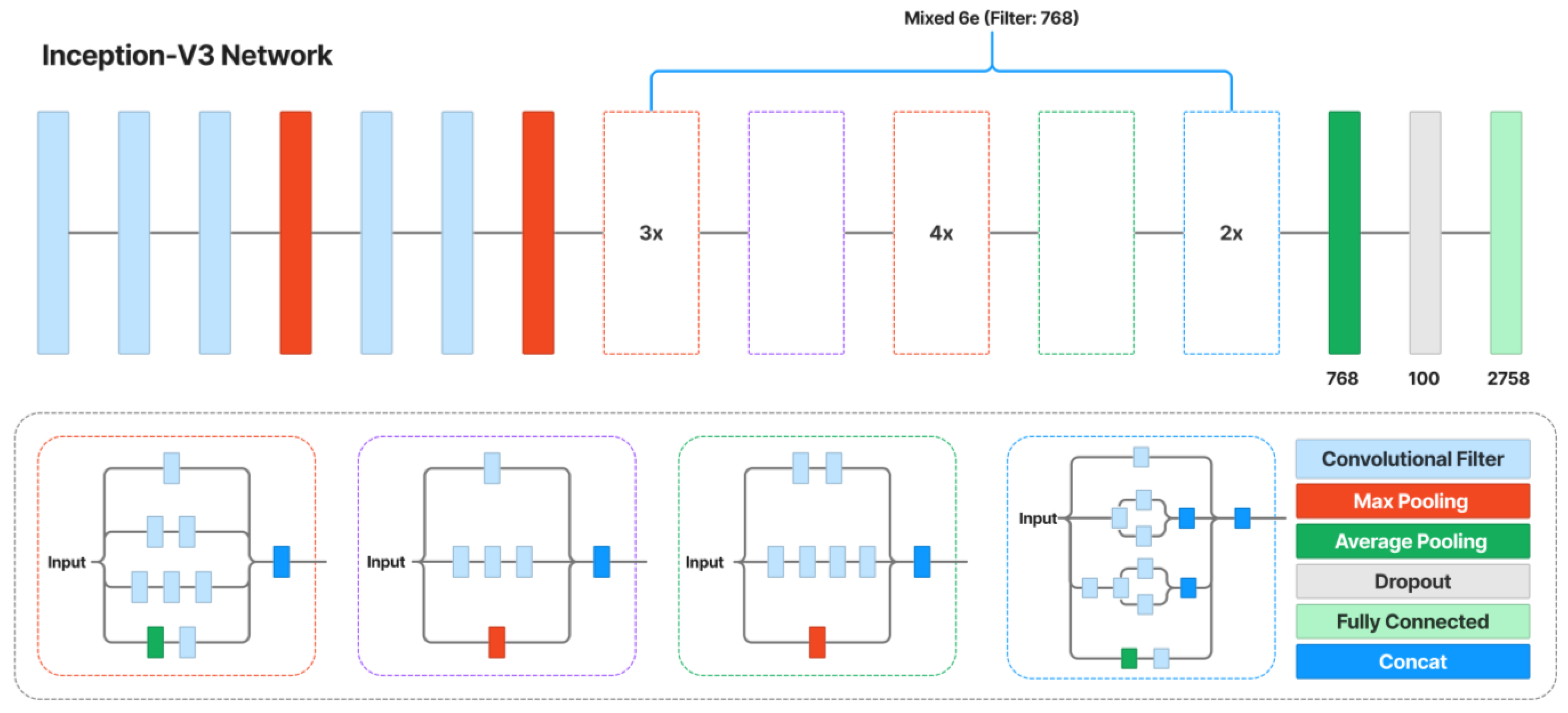
4.2.3. Generation Networks
4.3. Text Distortion Optimization
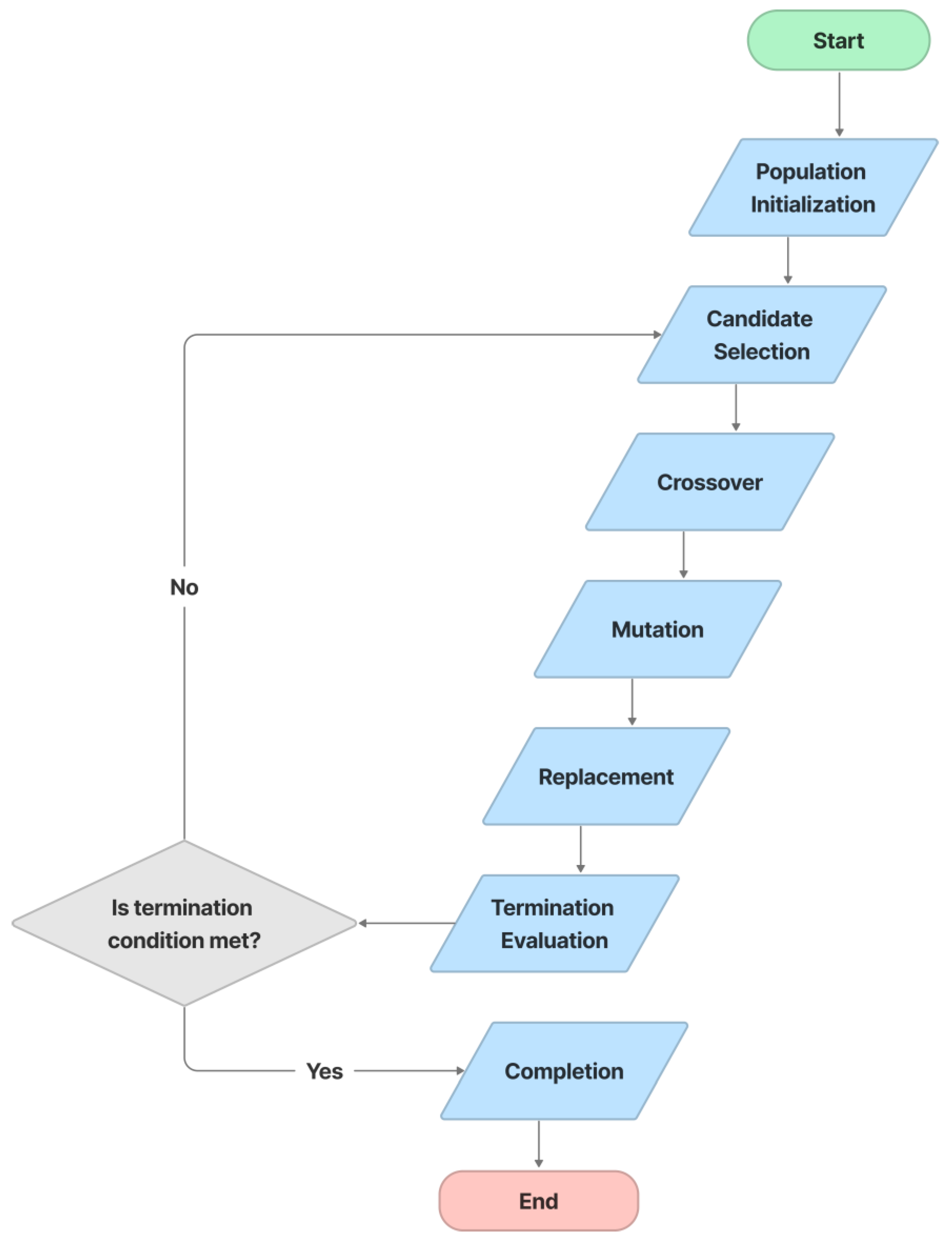
4.3.1. Chromosome Initialization
4.3.2. Candidate Selection
- Determine S, which is the sum of fitness.
- Generate a random number between 0 and S.
- Sort the population in descending order of chromosome fitness.
- Starting at the top of the population, add the fitness to the partial sum P until P < S.
- The chosen individual is the one for which P exceeds S.
4.3.3. Crossover
4.3.4. Mutation
4.3.5. Replacement
4.3.6. Termination Evaluation
4.3.7. Completion
5. Implementation
5.1. Datasets
- ByClass
- ByMerge
- Balanced
- Letters
- Digits
- MNIST
5.2. Text-Based Adversarial CAPTCHA
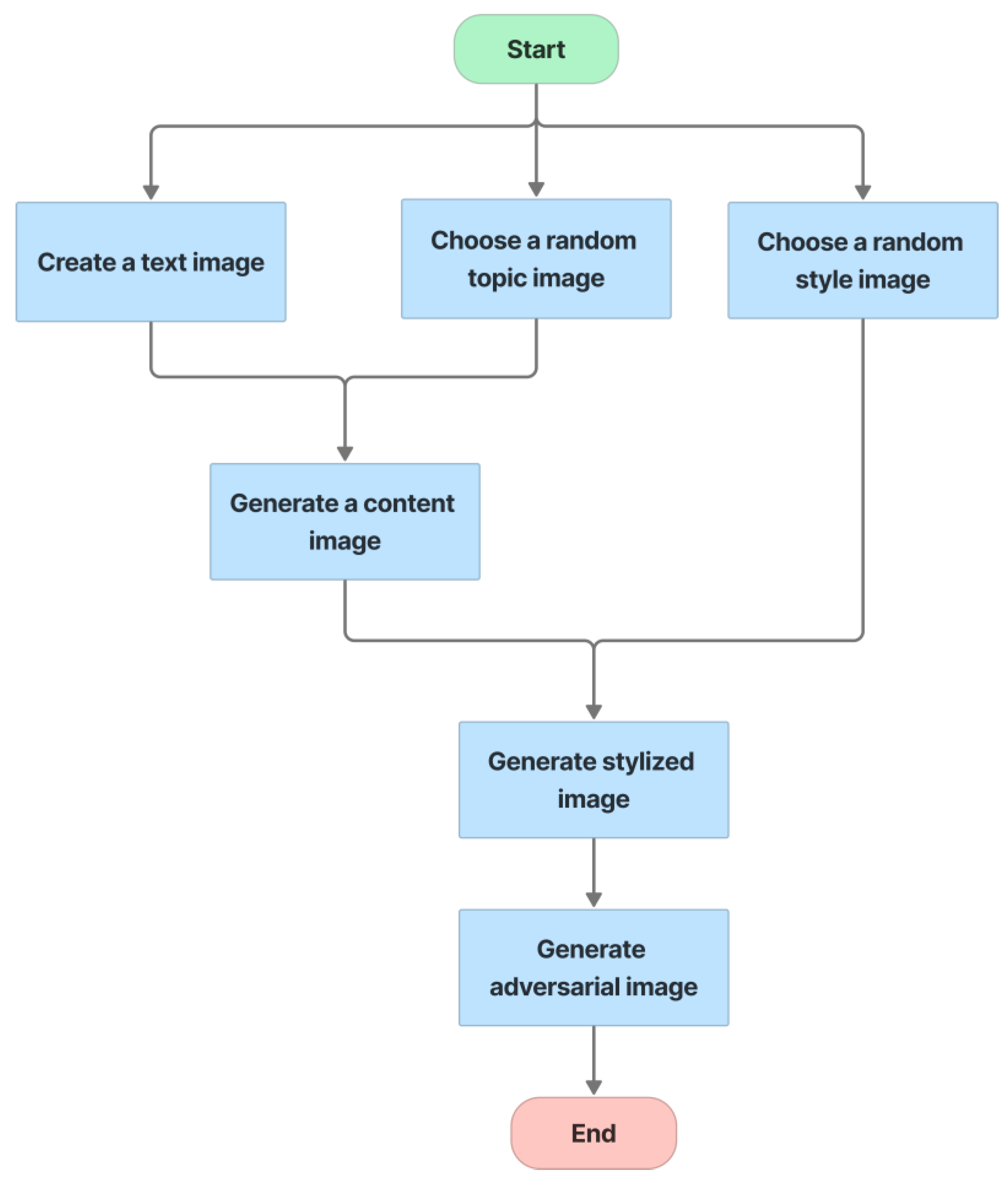
- Step 1, text image creation: for each group, select three to five letters at random from EMNIST. The characters of each group are distorted [4.3], and parameter O is used to control the overlap between two characters, with the default value for O being 0. The text from three groups are then concatenated to form a whole CAPTCHA with a white background. The size of a whole text-based CAPTCHA is 256 × 768.
- Step 2, topic image selection: from the ImageNet dataset, choose a random image of the global topic, called the topic image.
- Step 3, style image selection: from the ImageNet dataset, choose a random image for the style image.
- Step 4, fusion: by using seamless cloning [48], the fusion machine merges the text image with the topic image to create the content image. This content image is then style transferred from the style image by the neural-style-transfer method. Finally, the stylized image is transformed into an adversarial example to cause misclassification of the CNN/DNN networks.
5.3. Grid-Based Adversarial CAPTCHA
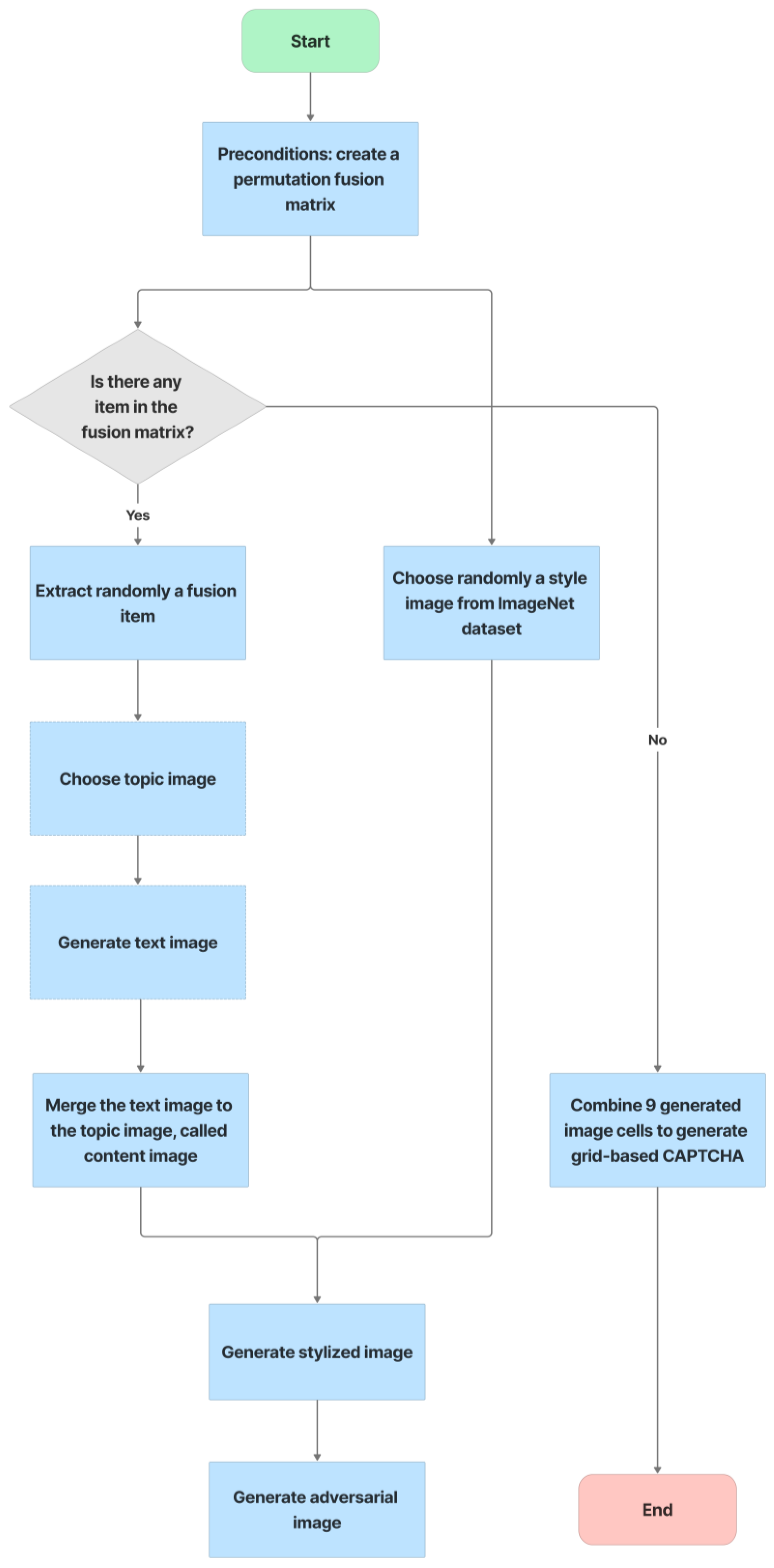
- Preconditions: set the grid-based CAPTCHA size to nine and create a Boolean permutation fusion matrix. The fusion matrix contains nine status pairs reflecting the correct or incorrect topic background and the correct or incorrect group text, with three correct fusion items (correct topic background and correct group text).
- Each fusion item is extracted from the matrix. To obtain the cell topic image, a random image of a correct or incorrect topic is chosen at random from the ImageNet dataset based on the status of the topic background in the fusion item. In addition, to obtain the cell text, if the status of the text group in the fusion item is correct, a group text is extracted randomly from the text-based CAPTCHA’s text groups. In contrast, three to five characters are chosen at random from MINST for this cell text. The cell text is then distorted and generated into the text image. To obtain the stylized image, the fusion machine merges the text image with the cell topic image to produce the content image, which is then style transferred from the style image. To deceive CNN/DNN networks, the stylized image is transformed into an adversarial example, known as a blended image.
- Finally, the grid-based CAPTCHA is created by combining nine blended image cells.
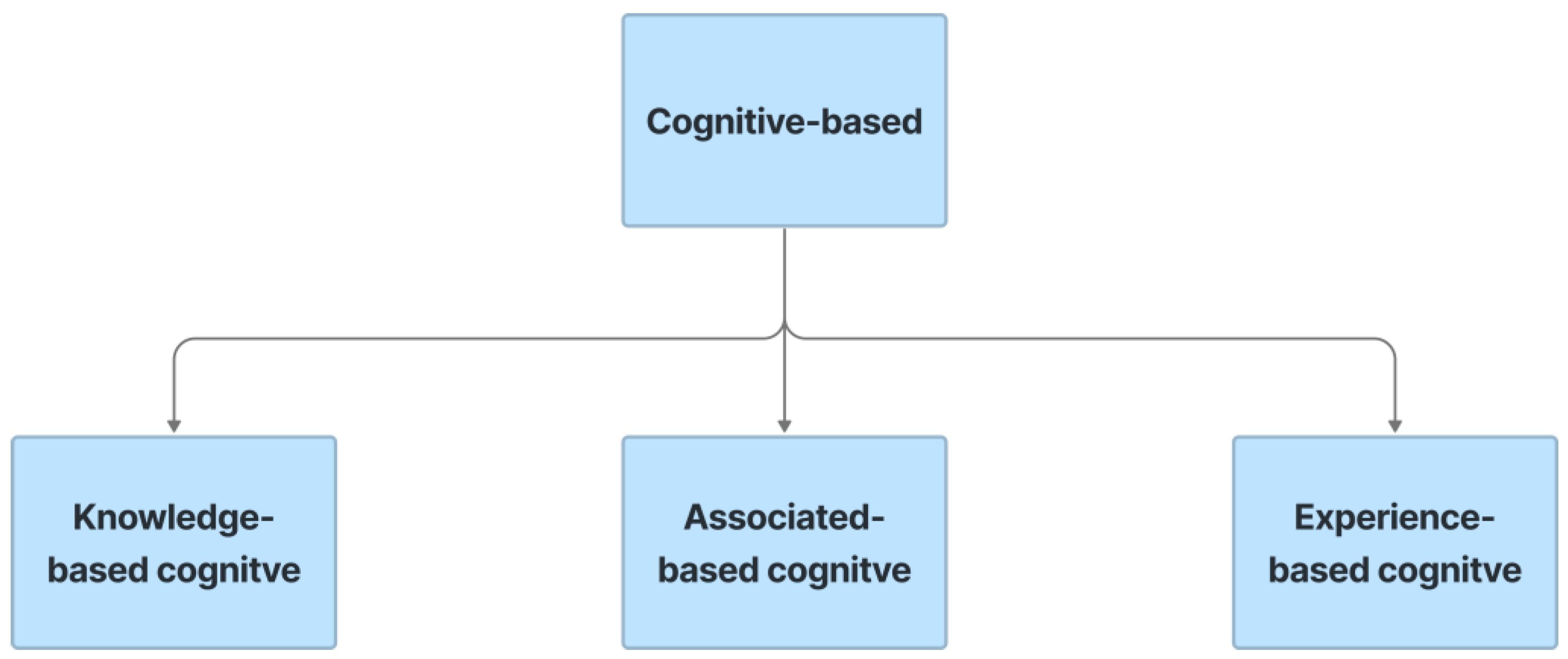
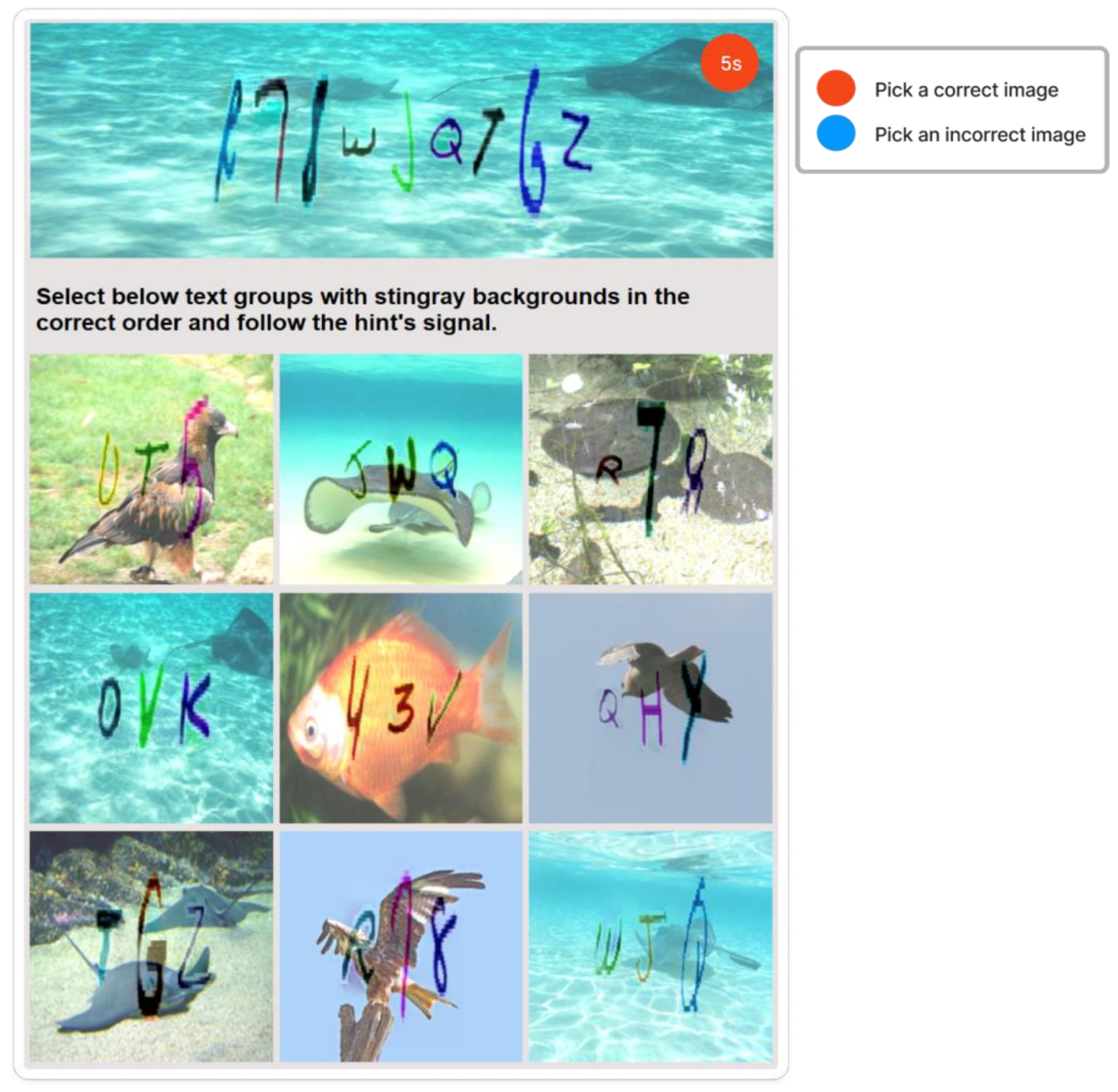
5.4. Cognitive-Based CAPTCHA
5.4.1. Knowledge-Based
5.4.2. Associated-Based
5.4.3. Experience-Based
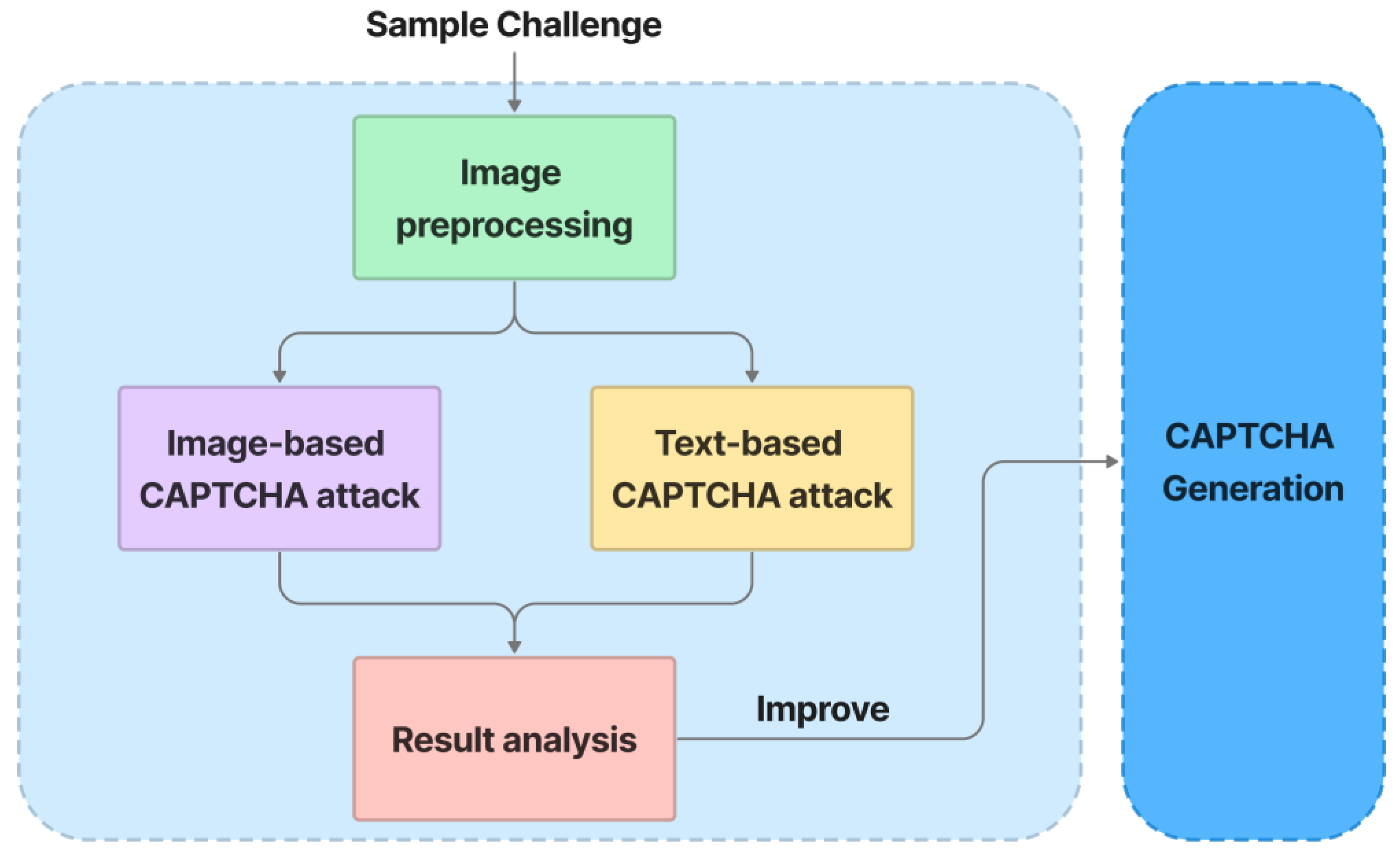
5.5. Security Evaluation
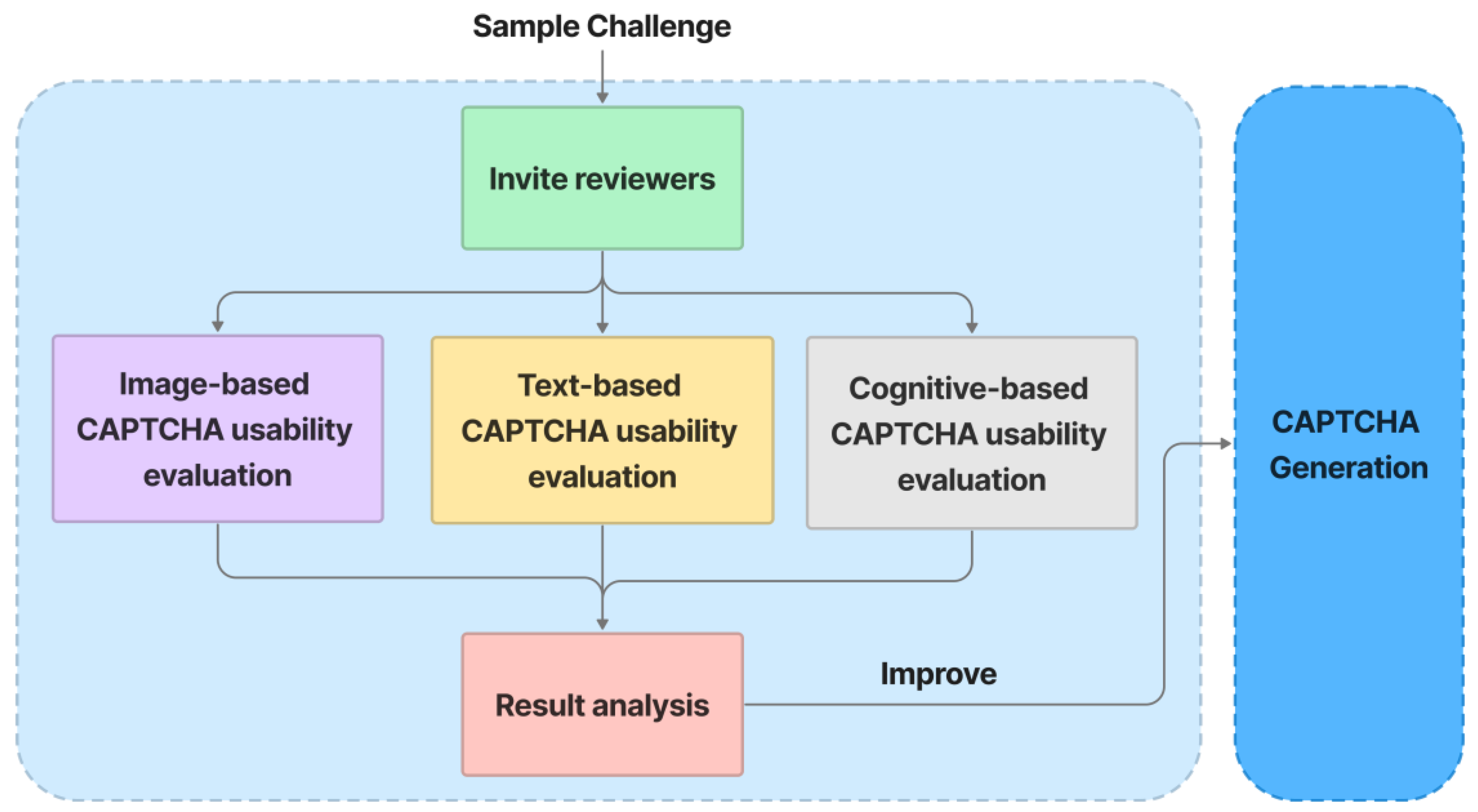
5.6. Usability Evaluation
- Invite involved testers to evaluate a sample challenge.
- Testers evaluate image-based CAPTCHA sections based on how easily the background images can be classified in terms of the overall topic.
- Text-based CAPTCHA sections are evaluated by testers based on how easily they can recognize text.
- The cognitive-based CAPTCHA sections are then evaluated by testers based on how easily a user can interact with CAPTCHA during the resolving time.
6. Experiments
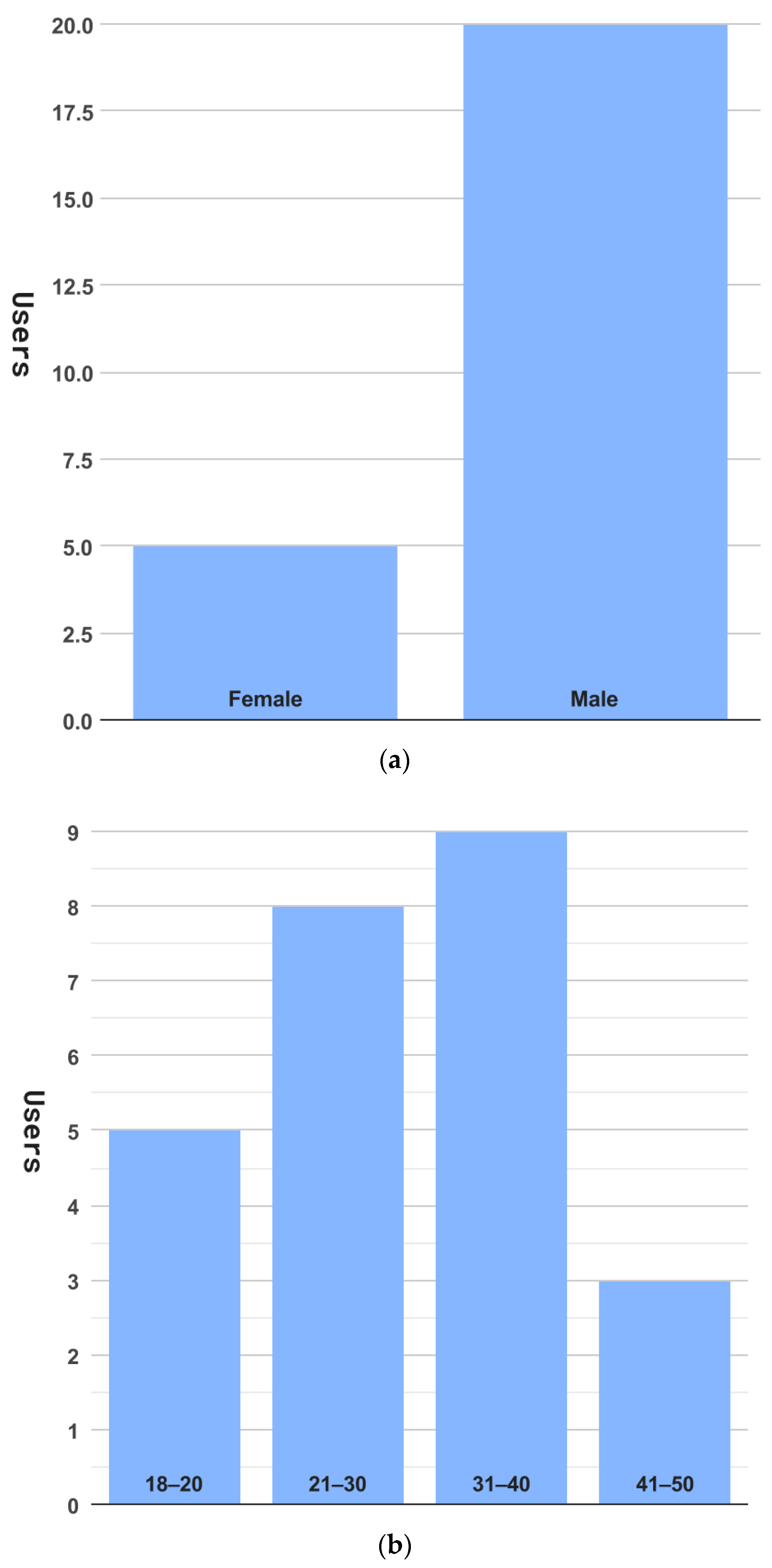
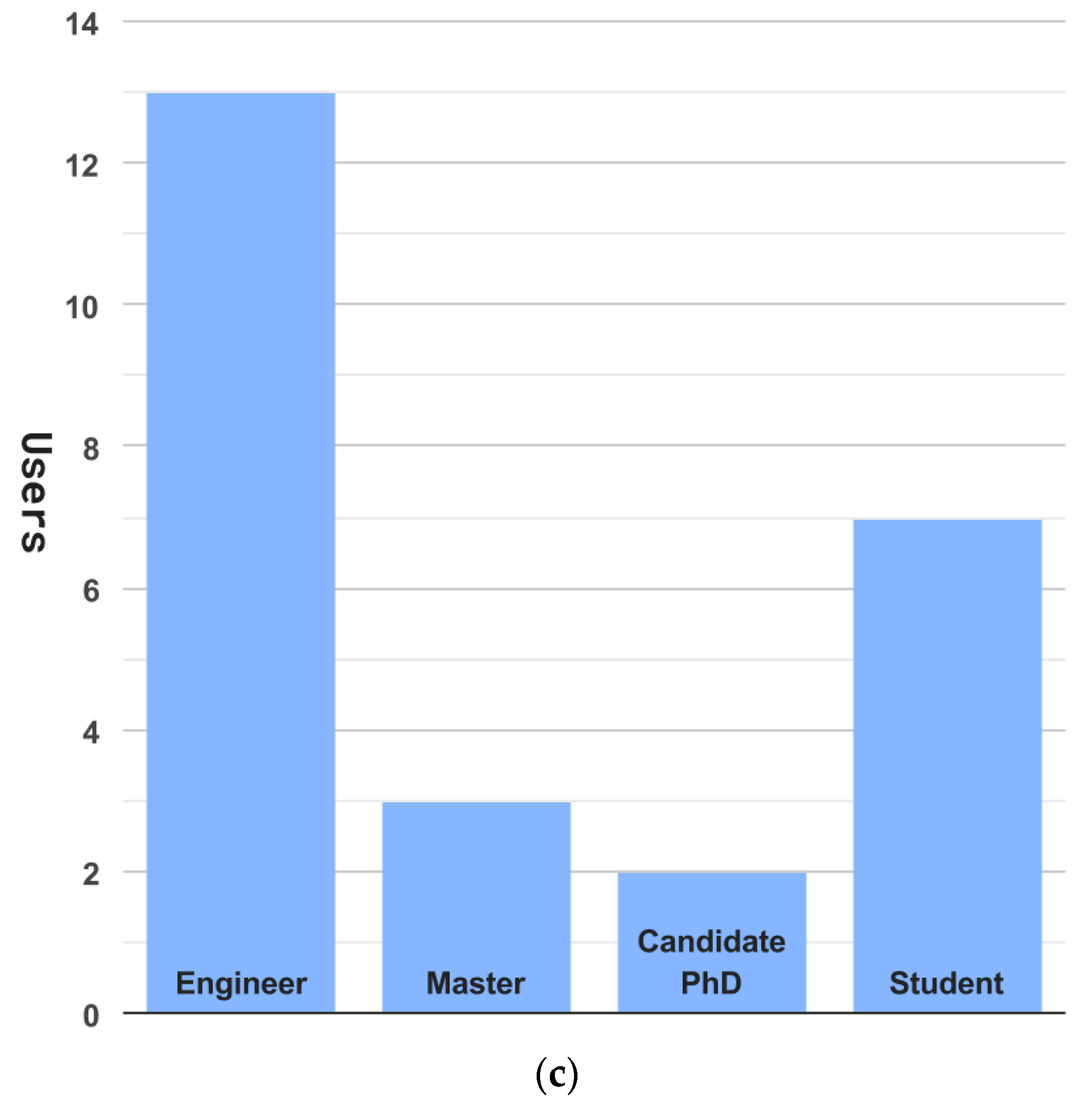
6.1. Experiment Setup
6.2. Usability Analysis
6.2.1. Methodology
6.2.2. Analysis
6.3. Security Analysis
6.3.1. Methodology
- We assessed the effects of random guess and relay attacks on the CAPTCHA.
- We assessed the ability of some state-of-the-art CNN/DNN networks in Section 5.5 to recognize generated adversarial stylized images and text from the ImageNet and EMNIST datasets.
6.3.2. Analysis
- Random Guess Attack
- 2.
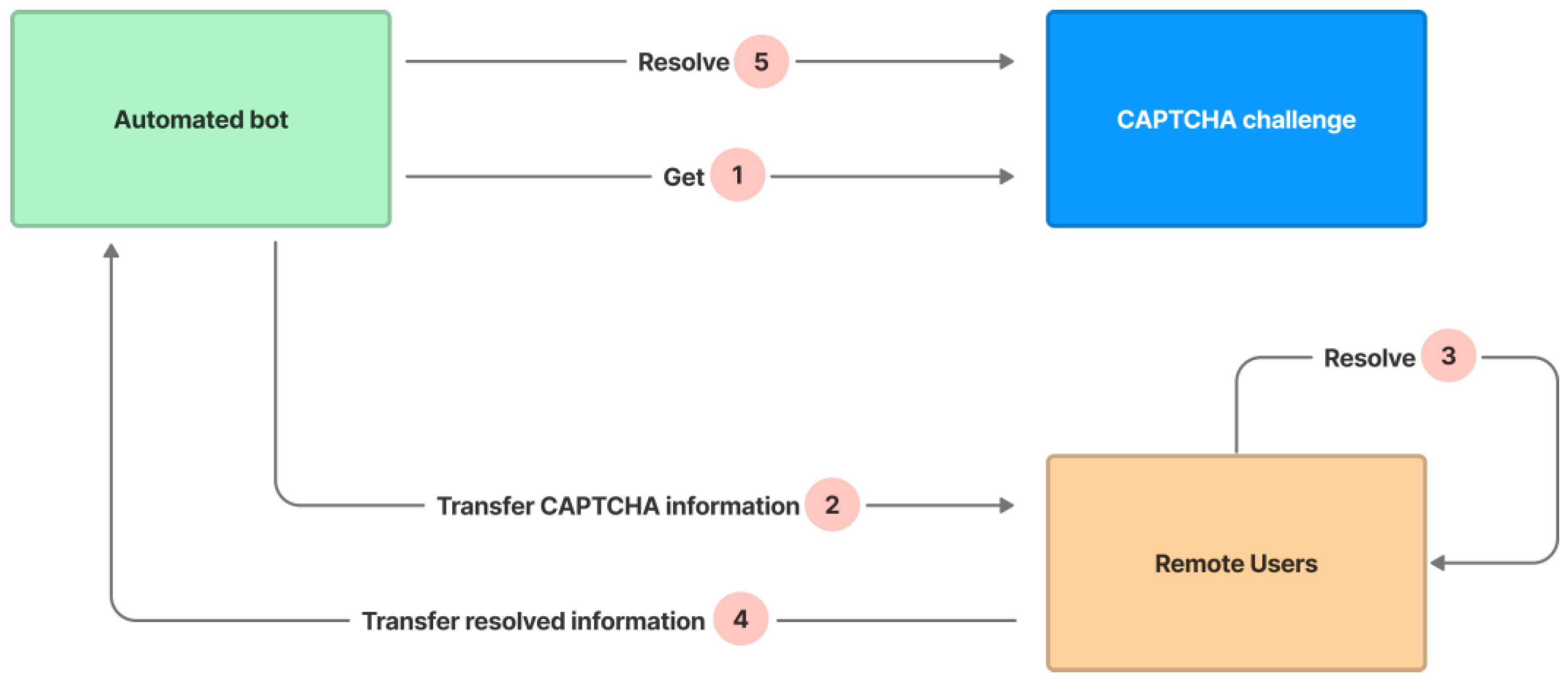
- Relay Attack
- An automated bot gets a challenge from the CAPTCHA in step 1.
- The bot transfers the CAPTCHA’s information to a remote user in step 2.
- The remote user resolves the CAPTCHA by recognizing the text and indicating correct or incorrect image cells in step 3.
- The remote user transfers the resolved information to the bot through API in step 4.
- The bot resolves the CAPTCHA’s challenge based on the remote user’s resolved information in step 5.
- 3.
- Adversarial and Style Transfer
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CAPTCHA | Completely Automated Public Turing test to tell Computers and Humans Apart |
| HIP | Human Interactive Proof |
| EMNIST | Extended Modified National Institute of Standard and Technology |
| CNN | Convolutional Neural Network |
| DNN | Deep Neural Network |
| ML | Machine Learning |
| CI/CD | Continuous Integration and Continuous Delivery |
| FGSM | Fast Gradient Sign Method |
| BPDA | Backward Pass Differentiable Approximation |
| VGG | Visual Geometry Group |
| ResNet | Residual Neural Network |
| CV | Computer Vision |
| OCR | Optical Character Recognition |
| IAN | Immutable Adversarial Noise |
| GAN | Generative Adversarial Network |
| SVM | Support Vector Machine |
References
- Inayat, U.; Zia, M.F.; Mahmood, S.; Khalid, H.M.; Benbouzid, M. Learning-Based Methods for Cyber Attacks Detection in IoT Systems: A Survey on Methods, Analysis, and Future Prospects. Electronics 2022, 11, 1502. [Google Scholar] [CrossRef]
- von Ahn, L.; Blum, M.; Hopper, N.J.; Langford, J. CAPTCHA: Using Hard AI Problems for Security. In Eurocrypt; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Gatys, L.; Ecker, A.; Bethge, M. A Neural Algorithm of Artistic Style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Gao, H.; Tang, M.; Liu, Y.; Zhang, P.; Liu, X. Research on the Security of Microsoft’s Two-Layer Captcha. IEEE Trans. Inf. Secur. 2017, 12, 1671–1685. [Google Scholar] [CrossRef]
- Gao, H.; Yan, J.; Cao, F.; Zhang, Z.; Lei, L.; Tang, M.; Zhang, P.; Zhou, X.; Wang, X.; Li, J. A Simple Generic Attack on Text Captchas. In The Network and Distributed System Security Sym-Posium; NDSS: SanDiego, CA, USA, 2016; pp. 1–14. [Google Scholar]
- Gao, H.; Wang, X.; Cao, F.; Zhang, Z.; Lei, L.; Qi, J.; Liu, X. Robustness of text-based completely automated public turing test to tell computers and humans apart. IET Inf. Secur. 2016, 10, 45–52. [Google Scholar] [CrossRef]
- Gao, H.; Wang, W.; Qi, J.; Wang, X.; Liu, X.; Yan, J. The robustness of hollow CAPTCHAs. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4 November 2013; pp. 1075–1086. [Google Scholar]
- Bursztein, E.; Aigrain, J.; Moscicki, A.; Mitchell, J.C. The end is nigh: Generic solving of text-based CAPTCHAs. In Proceedings of the 8th {USENIX} Workshop on Offensive Technologies ({WOOT} 14), San Diego, CA, USA, 19 August 2014. [Google Scholar]
- Goodfellow, I.J.; Bulatov, Y.; Ibarz, J.; Arnoud, S.; Shet, V. Multi-digit number recognition from street view imagery using deep convolutional neural networks. arXiv 2013, arXiv:1312.6082. [Google Scholar]
- Chew, M.; Tygar, J.D. Image recognition captchas. In the International Conference on Information Security; Springer: Berlin/Heidelberg, Germany, 2004; pp. 268–279. [Google Scholar]
- Datta, R.; Li, J.; Wang, J.Z. Imagination: A robust image-based CAPTCHA generation system. In Proceedings of the 13th annual ACM International Conference on Multimedia, Singapore, 6–11 November 2005; pp. 331–334. [Google Scholar]
- Goswami, G.; Powell, B.M.; Vatsa, M.; Singh, R.; Noore, A. FR-CAPTCHA: CAPTCHA Based on Recognizing Human Faces. PLoS ONE 2014, 9, e91708. [Google Scholar] [CrossRef] [PubMed]
- Rui, Y.; Liu, Z. ARTiFACIAL: Automated Reverse Turing test using FACIAL features. Multimed. Syst. 2004, 9, 493–502. [Google Scholar] [CrossRef]
- Cheung, B. Convolutional Neural Networks Applied to Human Face Classification. In Proceedings of the 2012 11th International Conference Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 12–15 December 2012; Volume 2, pp. 580–583. [Google Scholar]
- Sivakorn, S.; Polakis, I.; Keromytis, A.D. I am Robot: (Deep) Learning to Break Semantic Image CAPTCHAs. In 2016 IEEE European Symposium on Security and Privacy (EuroS&P); IEEE: Saarbrucken, Germany, 2016; pp. 388–403. [Google Scholar] [CrossRef]
- Zhu, B.B.; Yan, J.; Li, Q.; Yang, C.; Liu, J.; Xu, N.; YI, M.; Cai, K. Attacks and design of image recognitionCAPTCHAs. In Proceedings of the 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010; pp. 187–200. [Google Scholar]
- Gao, H.; Lei, L.; Zhou, X.; Li, J.; Liu, X. The robustness of face-based CAPTCHAs. In Proceedings of the 2015 IEEE International Conference on Computer and Information Technology; Ubiquitous Computing and Communications; Dependable, Autonomic and Secure Computing; Pervasive Intel-ligence and Computing (CIT/IUCC/DASC/PICOM), Liverpool, UK, 26–28 October 2015; pp. 2248–2255. [Google Scholar]
- Li, Q. A computer vision attack on the Artifacial Captcha. Multimed. Tools Appl. 2013, 74, 4583–4597. [Google Scholar] [CrossRef]
- Srivastava, M.; Sakshi, S.; Dutta, S.; Ningthoujam, C. Survey on Captcha Recognition Using Deep Learning. In Soft Computing Techniques and Applications, Proceeding of the International Conference on Computing and Communication (IC3 2020), SMIT, Sikkim, India, 13–14 July 2020; Borah, S., Pradhan, R., Dey, N., Gupta, P., Eds.; Springer: Singapore, 2021; Volume 1248. [Google Scholar]
- Alqahtani, F.H.; Alsulaiman, F.A. Is image-based CAPTCHA secure against attacks based on machine learning? An experimental study. Comput. Secur. 2020, 88, 101635. [Google Scholar] [CrossRef]
- Gossweiler, R.; Kamvar, M.; Baluja, S. What’s up Captcha? Acaptcha based on image orientation. In Proceedings of the 18th International Conference on World Wide Web, Madrid, Spain, 20–24 April 2009; pp. 841–850. [Google Scholar]
- Capy Puzzle Captcha. Available online: https://www.capy.me (accessed on 21 May 2022).
- Geetest Captcha. Available online: http://www.geetest.com (accessed on 23 May 2022).
- Hernandez-Castro, C.J.; R-Moreno, M.D.; Barrero, D.F. Side-Channel Attack against the Capy HIP. In Proceedings of the 2014 Fifth International Conference on Emerging Security Technologies, Alcala de Henares, Spain, 10–12 September 2014; pp. 99–104. [Google Scholar] [CrossRef]
- Zhang, Y.; Gao, H.; Pei, G.; Kang, S.; Zhou, X. Effect of Adversarial Examples on the Robustness of CAPTCHA. In Proceedings of the 2018 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Zhengzhou, China, 18–20 October 2018; pp. 1–109. [Google Scholar]
- Osadchy, M.; Hernandez-Castro, J.; Gibson, S.; Dunkelman, O.; Pérez-Cabo, D. No bot expects the DeepCAPTCHA! In-troducing immutable adversarial examples, with applications to CAPTCHA generation. IEEE Trans. Inf. Secur. 2017, 12, 2640–2653. [Google Scholar] [CrossRef]
- Ye, G.; Tang, Z.; Fang, D.; Zhu, Z.; Feng, Y.; Xu, P.; Chen, X.; Wang, Z. Yet another text captcha solver: A generative adversarial network-based approach. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 332–348. [Google Scholar]
- Acien, A.; Morales, A.; Fierrez, J.; Vera-Rodriguez, R. BeCAPTCHA-Mouse: Synthetic Mouse Tra-jectories and Improved Bot Detection. Pattern Recognit. 2022, 127, 108643. [Google Scholar] [CrossRef]
- Mohamed, M.; Saxena, N. Gametrics: Towards attack-resilient behavioral authentication with simple cognitive games. In Proceedings of the 32nd Annual Conference on Computer Security Applications, Los Angeles, CA, USA, 5–9 December 2016. [Google Scholar]
- Guerar, M.; Migliardi, M.; Merlo, A.; Benmohammed, M.; Messabih, B. A Completely Automatic Public Physical test to tell Computers and Humans Apart: A way to enhance authentication schemes in mobile devices. In Proceedings of the 2015 International Conference on High Performance Computing & Simulation (HPCS), Amsterdam, The Netherlands, 20–24 July 2015; pp. 203–210. [Google Scholar]
- Hupperich, T.; Krombholz, K.; Holz, T. Sensor Captchas: On the Usability of Instrumenting Hardware Sensors to Prove Liveliness. In Trust and Trustworthy Computing; Franz, M., Papadimitratos, P., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 40–59. [Google Scholar]
- Kulkarni, S.; Fadewar, H.S. Pedometric CAPTCHA for mobile Internet users. In Proceedings of the 2nd IEEE International Conference on Recent Trends in Electronics, Information Communication Technology (RTEICT), Bangalore, India, 19–20 May 2017; pp. 600–604. [Google Scholar]
- Mantri, V.C.; Mehrotra, P. User Authentication Based on Physical Movement Information. U.S. Patent 9,864,854, 9 January 2018. [Google Scholar]
- Frank, B.Z.; Latone, J.A. Verifying a User Utilizing Gyroscopic Movement. U.S. Patent 9,942,768, 10 April 2018. [Google Scholar]
- Guerar, M.; Merlo, A.; Migliardi, M.; Palmieri, F. Invisible CAPPCHA: A usable mechanism to dis-tinguish between malware and humans on the mobile IoT. Comput. Secur. 2018, 78, 255–266. [Google Scholar] [CrossRef]
- Liao, C.-J.; Yang, C.-J.; Yang, J.-T.; Hsu, H.-Y.; Liu, J.-W. A Game and Accelerometer-based CAPTCHA Scheme for Mobile Learning System. In EdMedia & Innovate Learning; Herrington, J., Couros, A., Irvine, V., Eds.; Association for the Advancement of Computing in Education (AACE): Victoria, BC, Canada, 2013; pp. 1385–1390. [Google Scholar]
- Yang, T.-I.; Koong, C.-S.; Tseng, C.-C. Game-based image semantic CAPTCHA on handset devices. Multimed. Tools Appl. 2013, 74, 5141–5156. [Google Scholar] [CrossRef]
- Ababtain, E.; Engels, D. Gestures Based CAPTCHAs the Use of Sensor Readings to Solve CAPTCHA Challenge on Smartphones. In Proceedings of the 2019 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 5–7 December 2019; pp. 113–119. [Google Scholar] [CrossRef]
- Feng, Y.; Cao, Q.; Qi, H.; Ruoti, S. SenCAPTCHA: A Mobile-First CAPTCHA Using Orientation Sensors. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, New York, NY, USA, 12–17 September 2020; Volume 4, pp. 1–26. [Google Scholar]
- Guerar, M.; Migliardi, M.; Merlo, A.; Benmohammed, M.; Palmieri, F.; Castiglione, A. Using Screen Brightness to Improve Security in Mobile Social Network Access. IEEE Trans. Dependable Secur. Comput. 2016, 15, 621–632. [Google Scholar] [CrossRef]
- Guerar, M.; Migliardi, M.; Palmieri, F.; Verderame, L.; Merlo, A. Securing PIN-based authentication in smartwatches with just two gestures. Concurr. Comput. Pr. Exp. 2019, 32, e5549. [Google Scholar] [CrossRef]
- Guerar, M.; Verderame, L.; Migliardi, M.; Merlo, A. 2 Gesture PIN: Securing PIN-Based Authentication on Smartwatches. In Proceedings of the IEEE 28th International Conference on Enabling Technologies: Infrastructure for Collaborative Enterprises (WETICE), Napoli, Italy, 12–14 June 2019; pp. 327–333. [Google Scholar]
- Tariq, N.; Khan, F.A. Match-the-Sound CAPTCHA. In Information Technology—New Generations. Advances in Intelligent Systems and Computing; Latifi, S., Ed.; Springer: Cham, Switzerland, 2018; Volume 558. [Google Scholar]
- Krzyworzeka, N.; Ogiela, L.; Ogiela, M.R. Cognitive Based Authentication Protocol for Distributed Data and Web Technologies. Sensors 2021, 21, 7265. [Google Scholar] [CrossRef]
- Ogiela, M.R.; Krzyworzeka, N.; Ogiela, L. Application of knowledge-based cognitive CAPTCHA in Cloud of Things security. Concurr. Comput. Pract. Exp. 2018, 30, e4769. [Google Scholar] [CrossRef]
- Dinh, N.; Ogiela, L. Human-artificial intelligence approaches for secure analysis in CAPTCHA codes. EURASIP J. Info. Security 2022, 8. [Google Scholar] [CrossRef]
- Pérez, P.; Gangnet, M.; Blake, A. Poisson image editing. ACM Trans. Graph. (TOG) 2003, 22, 313–318. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherland, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Goodfellow, I.J. Jonathon Shlens and Christian Szegedy. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ulyanov, D.; Lebedev, V.; Vedaldi, A.; Lempitsky, V. Texture networks: Feed-forward synthesis of textures and stylized images. ICML 2016, 1, 1349–1357. [Google Scholar]
- Ghiasi, G.; Lee, H.; Kudlur, M.; Dumoulin, V.; Shlens, J. Exploring the structure of a real-time, arbitrary neural artistic stylization network. In Proceedings of the British Machine Vision Conference (BMVC), London, UK, 4–7 September 2017. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A learned representation for artistic style. In Proceedings of the International Conference of Learned Rep-Resentations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Gross, S.; Wilber, M. Training and Investigating Residual Nets. 2016. Available online: http://torch.ch/blog/2016/02/04/resnets.html (accessed on 21 July 2022).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Moosavi Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (No. EPFL-CONF-218057), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial Examples in the Physical World. In Proceedings of the International Conference on Learning Representations (ICLR) Workshop, Toulon, France, 24–26 April 2017. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sarkar, S.; Bansal, A.; Mahbub, U.; Chellappa, R. UPSET and ANGRI: Breaking High Performance Image Classifiers. arXiv 2017, arXiv:1707.01159. [Google Scholar]
- Eykholt, K.; Evtimov, I.; Fernandes, E.; Li, B.; Rahmati, A.; Xiao, C.; Prakash, A.; Kohno, T.; Song, D. Robust physical-world attacks on deep learning models. arXiv 2017, arXiv:1707.08945. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The Limitations of Deep Learning in Adversarial Settings. In 2016 IEEE European Symposium on Security and Privacy (EuroS&P); IEEE: Saarbruecken, Germany, 2016; pp. 372–387. [Google Scholar]
- Baluja, S.; Fischer, I. Adversarial transformation networks: Learning to generate adversarial examples. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Brown, T.B.; Mané, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial patch. arXiv 2017, arXiv:1712.09665. [Google Scholar]
- Gu, S.; Rigazio, L. Towards deep neural network architectures robust to adversarial examples. arXiv 2014, arXiv:1412.5068. [Google Scholar]
- He, W.; Wei, J.; Chen, X.; Carlini, N.; Song, D. Adversarial example defenses: Ensembles of weak defenses are not strong. In Proceedings of the 11th USENIX Workshop on Offensive Technologies (WOOT 17), Vancouver, BC, Canada, 14–15 August 2017. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A. Adversarial Examples for Semantic Segmentation and Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Lu, J.; Sibai, H.; Fabry, E.; Forsyth, D. No need to worry about adversarial examples in object detection in autonomous vehicles. arXiv 2017, arXiv:1707.03501. [Google Scholar]
- Athalye, A. Robust Adversarial Examples. Available online: https://blog.openai.com/robust-adversarial-inputs/ (accessed on 23 May 2022).
- Athalye, A. Nicholas Carlini, and David Wagner. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. arXiv 2018, arXiv:1802.00420. [Google Scholar]
- Mitchell, M. An Introduction to Genetic Algorithms; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Cohen, G.; Afshar, S.; Tapson, J.; van Schaik, A. EMNIST: An extension of MNIST to handwritten letters. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- ImageNet. Available online: http://www.image-net.org/ (accessed on 1 June 2022).
- Shaham, U.; Garritano, J.; Yamada, Y.; Weinberger, E.; Cloninger, A.; Cheng, X.; Stanton, K.; Kluger, Y. Defending against Adversarial Images using Basis Functions Transformations. arXiv 2018, arXiv:1803.10840. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. In Proceedings of the IEEE; IEEE: Piscataway, NJ, USA, 1998. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large Scale Machine Learning. In Proceedings of the 12th USENIX conference on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; Volume 16, pp. 265–283. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distortion Type | Category | Level | Intensity Range |
|---|---|---|---|
| Rotation | Geometric | 1 | 45–135 |
| Width scaling | 1 | 1.5–3 | |
| Height scaling | 1 | 1.5–3 | |
| Piecewise scaling | 2 | 1.5–3 | |
| Shadow | 2 | 2–5 | |
| Outline | 1 | 1–10 | |
| Striped | 1 | 45–135 | |
| Tilting | 1 | 1–10 | |
| Erosion | Degradation | 2 | 3–3.5 |
| Grains | 2 | 1–10 | |
| Random outline degradation | 2 | 1–10 | |
| Periodic noise | Noise | 1 | 5–7 |
| Salt and pepper noise | 1 | 10–20 | |
| Speckle noise | 1 | 2–5 |
| Factor | Normal | Normal Cognitive | Stylized | Stylized Cognitive | Adversarial | Adversarial Cognitive | Stylized Adversarial | Stylized Adversarial Cognitive |
|---|---|---|---|---|---|---|---|---|
| Success rate | 88% | 80% | 84% | 72% | 88% | 76% | 84% | 76% |
| Average time | 12.7 s | 15.2 s | 12.3 s | 14.9 s | 11.8 s | 15.7 s | 12.5 s | 15.6 s |
| Median time | 9.5 s | 13.1 s | 10.5 s | 12.5 s | 9.3 s | 13.5 s | 10.7 s | 12.3 s |
| Style | Normal | Stylized | Adversarial | Stylized Adversarial |
|---|---|---|---|---|
 |  |  |  |  |
| Recognition Network | Normal | Stylized | Adversarial | Stylized Adversarial | ||
|---|---|---|---|---|---|---|
| Generated by VGG-16 | Generated by ResNet-101 | Generated by VGG-16 | Generated by ResNet-101 | |||
| LeNet-5 | 95.7 | 37.6 | 17.3 | 19.7 | 7.8 | 9.3 |
| ResNet-50 | 97.5 | 43.6 | 25.5 | 28.1 | 15.8 | 17.3 |
| Recognition Network | Normal | Stylized | Adversarial | Stylized Adversarial | ||
|---|---|---|---|---|---|---|
| Generated by VGG-16 | Generated by ResNet-101 | Generated by VGG-16 | Generated by ResNet-101 | |||
| LeNet-5 | 95.7 | 37.6 | 23.3 | 25.6 | 11.3 | 13.6 |
| ResNet-50 | 97.5 | 43.6 | 31.1 | 32.5 | 20.3 | 23.5 |
| Style | Normal | Stylized | Adversarial | Stylized Adversarial |
|---|---|---|---|---|
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
 |  |  |  |  |
| Recognition Network | Normal | Stylized | Adversarial | Stylized Adversarial | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Generated by VGG-16 | Generated by ResNet-101 | Generated by VGG-16 | Generated by ResNet-101 | |||||||||||||||
| l = 3 | l = 4 | l = 5 | l = 3 | l = 4 | l = 5 | l = 3 | l = 4 | l = 5 | l = 3 | l = 4 | l = 5 | l = 3 | l = 4 | l = 5 | l = 3 | l = 4 | l = 5 | |
| VGG-16 | 78.5 | 77.3 | 76.7 | 61.6 | 61.3 | 60.1 | 48.7 | 46.3 | 45.7 | 54.2 | 53.1 | 52.3 | 35.1 | 34.7 | 34.5 | 40.3 | 39.2 | 37.4 |
| ResNet-101 | 87.1 | 85.3 | 85.1 | 70.5 | 68.3 | 67.7 | 58.3 | 56.1 | 54.6 | 60.4 | 58.7 | 56.2 | 43.2 | 41.5 | 42.1 | 44.7 | 43.5 | 42.3 |
| Recognition Network | Normal | Stylized | Adversarial | Stylized Adversarial | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Generated by VGG-16 | Generated by ResNet-101 | Generated by VGG-16 | Generated by ResNet-101 | |||||||||||||||
| l = 3 | l = 4 | l = 5 | l = 3 | l = 4 | l = 5 | l = 3 | l = 4 | l = 5 | l = 3 | l = 4 | l = 5 | l = 3 | l = 4 | l = 5 | l = 3 | l = 4 | l = 5 | |
| VGG-16 | 78.5 | 77.3 | 76.7 | 61.6 | 61.3 | 60.1 | 35.6 | 33.3 | 31.5 | 41.3 | 40.3 | 39.7 | 27.3 | 25.6 | 23.7 | 33.4 | 31.8 | 31.5 |
| ResNet-101 | 87.1 | 85.3 | 85.1 | 70.5 | 68.3 | 67.7 | 45.3 | 43.6 | 42.7 | 47.1 | 46.3 | 45.7 | 35.3 | 33.5 | 31.8 | 37.1 | 36.5 | 35.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trong, N.D.; Huong, T.H.; Hoang, V.T. New Cognitive Deep-Learning CAPTCHA. Sensors 2023, 23, 2338. https://doi.org/10.3390/s23042338
Trong ND, Huong TH, Hoang VT. New Cognitive Deep-Learning CAPTCHA. Sensors. 2023; 23(4):2338. https://doi.org/10.3390/s23042338
Chicago/Turabian StyleTrong, Nghia Dinh, Thien Ho Huong, and Vinh Truong Hoang. 2023. "New Cognitive Deep-Learning CAPTCHA" Sensors 23, no. 4: 2338. https://doi.org/10.3390/s23042338
APA StyleTrong, N. D., Huong, T. H., & Hoang, V. T. (2023). New Cognitive Deep-Learning CAPTCHA. Sensors, 23(4), 2338. https://doi.org/10.3390/s23042338