

ArtiLock: Smartphone User Identification Based on Physiological and Behavioral Features of Monosyllable Articulation


Abstract
1. Introduction
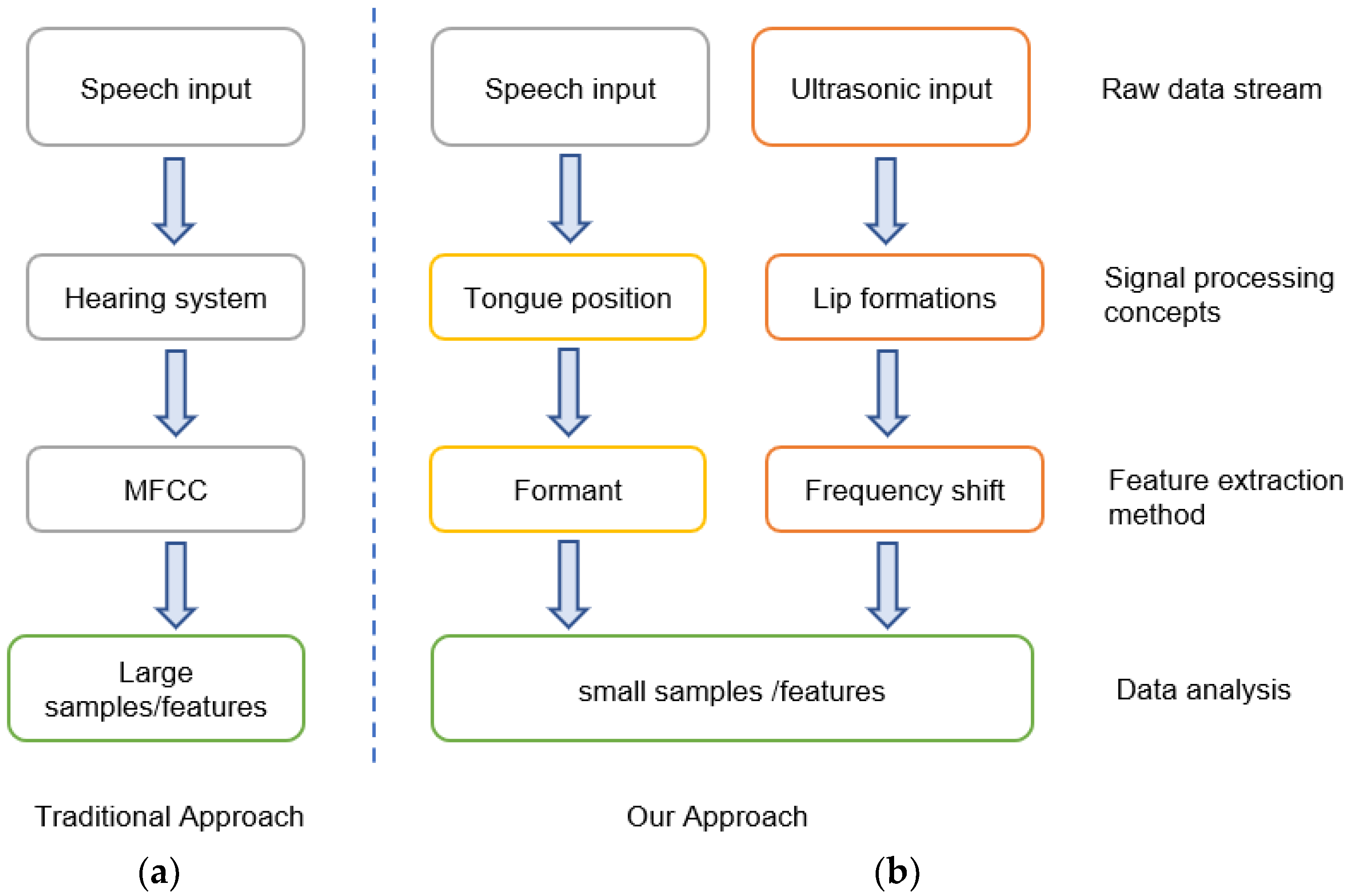
- We propose a system that requires single utterances with respect to physiological and behavioral speech characteristics for smartphone user authentication, resulting in less calculations and resistance to attacks and environmental noise.
- We extract articulation features by simultaneously detecting audible (speech) and inaudible (ultrasonic) signals to build a user identification model based on individual articulation characteristics.
- We implement a prototype and verify the performance of the proposed system under real scenarios. The system is robust in resisting mimicry attacks in three environmental interferences with 99% accuracy, requiring few training samples.
2. Literature Reviews
2.1. Current Authentication Approaches of Mobile Devices
2.2. Articulation-Based Authentication and Current Limitations
3. Materials and Methods
3.1. Data Collection
3.2. System Overview
3.2.1. Register Stage
3.2.2. Login Stage
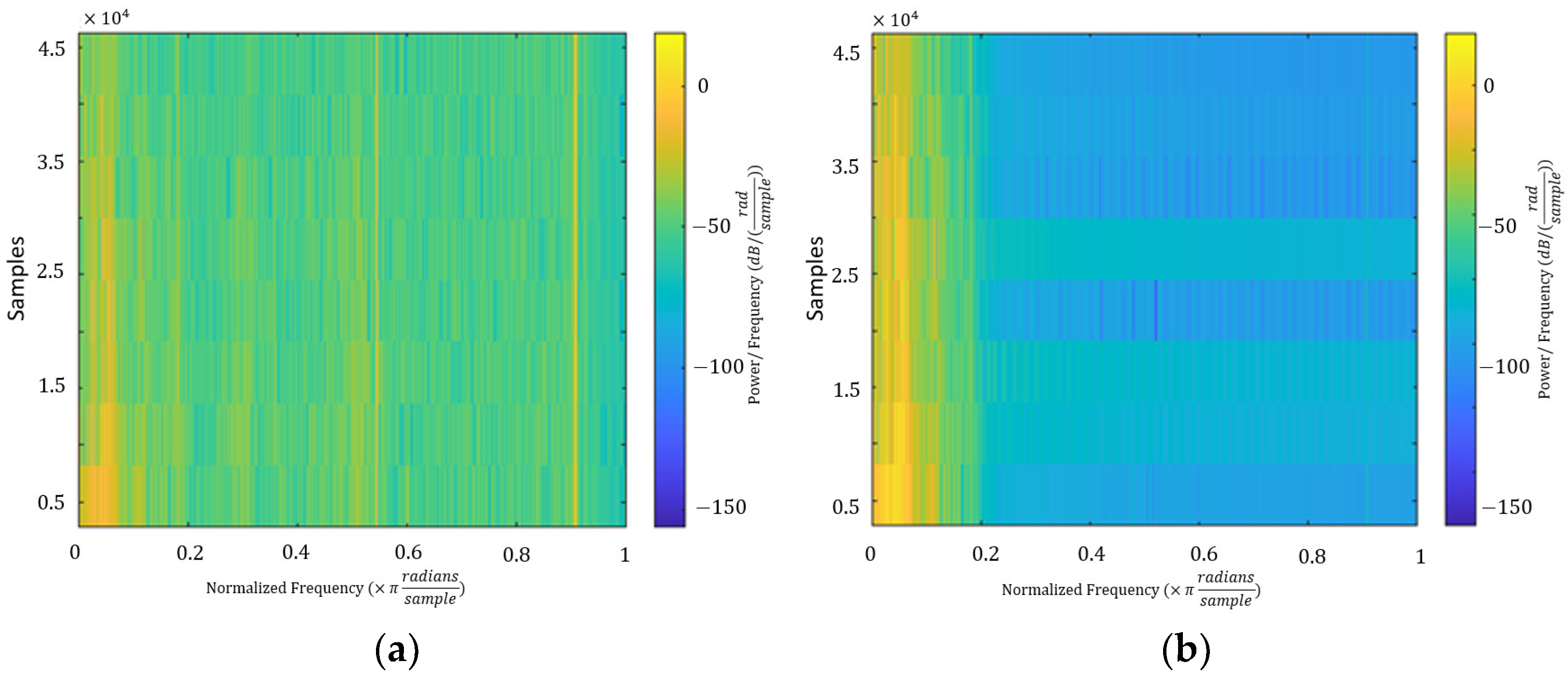
3.3. Interference Elimination
3.4. Extract Feature Articulator from Ultrasonic Signals
| Algorithm 1 Ultrasonic Signals Articulation Feature Extraction Algorithm |
| Input:in_sig: the input signals; Output:env_mean: the mean of two characteristics; env_meanfreq: the mean normalized frequency of the two characteristics; env_bw: the power bandwidth of the two characteristics; env_obw: the occupied bandwidth of the two characteristics; env_medf req: the median normalized frequency of the two characteristics; 1: bw_sig[i] ← filterButterworth(in_sig i]) 2: lms_sig[i] ← filterLMS(bw_sig [i]) 3: for i ← 0 to 1 do 4: h ← hibertFun(in_sig [i]) 5: p ← pwelchFun(in_sig [i], h) 6: e ← envelopeFun(p) 7: env[i] ← e 8: end for 9: env ← dwtFun(env [0], env [1]) 10: env_meanfreq ← meanFreq(env) 11: env_bw ← powerbw(env) 12: env_obw ← obw(env) 13: env_medfreq ← medFreq(env) |
3.5. Extract Feature Articulator from Speech Signals
| Algorithm 2 Speech Signals Articulation Feature Extraction Algorithm |
| Input: data: audio data; order: order; fs: sampling frequencies; Output: fre: formant frequencies; pre_pitch: pitch estimation of data; vol_tlenh: volcal track length of data; 1: r: autocorrelation coefficient; a: prediction coefficient; 2: e: mean square error; N: length of data; 3: fori ← 0 to order do 4: for i ← 0 to N − i do 5: r[i] ← r[i] + data[n] ∗ data[n + i] 6: end for 7: end for 8: Initialize a[0],a[1],e[0] and e[1]. 9: for k ← 1 to order do 10: for j ← 0 to k + 1 do 11: λ ← λ − a[j] ∗ r[k + 1 − j] 12: end for 13: λ ← λ ÷ e[k] 14: for i ← 1 to k + 1 do 15: U [i] ← a[i] 16: V [k + 1 − i] ←a[i] 17: end for 18: for i ← 0 to k + 2 do 19: a[i] ← U [i] + λ ∗ V [i] 20: end for 21: e[k + 1] ← e[k] ∗ (1 − λ2) 22: end for 23: rts ← findRoots(a) 24: for i ← 0 to rts.length do 25: arg ← atan2(rts[i].imaginary, rts[i].real) 26: argList.add(arg) 27: end for 28: argSort(argList) 29: for i ← 0 to rts.length do 30: freqs[i] ← argList[i] ∗ (fs/2π) 31: end for 32: pre_pitch ← esPitch(data) 33: vol_tlen ← volcalTrack(data) 34: return pre_pitch, vol_tlen, freqs; |
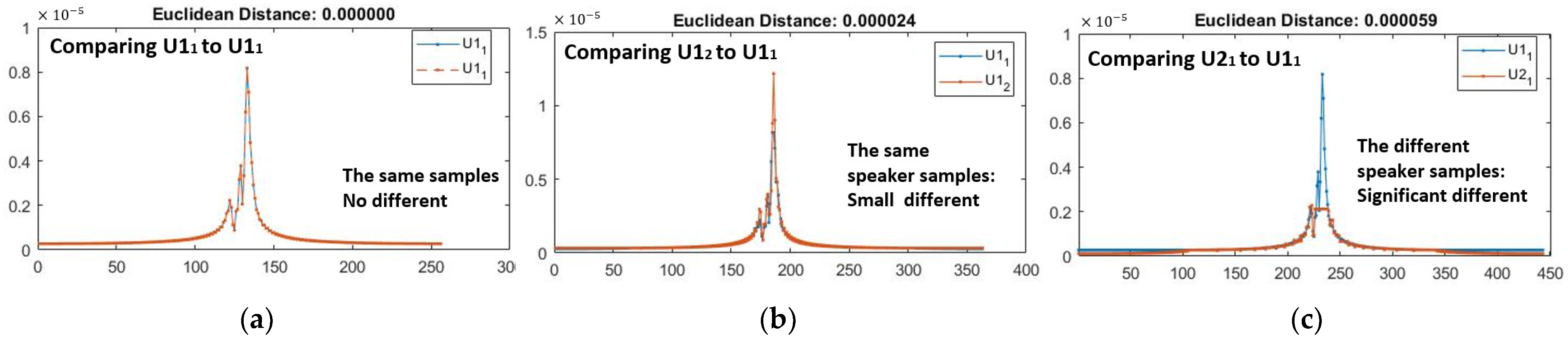
3.6. User Identification Model
3.6.1. Classification Model
3.6.2. Evaluation Metrics
4. Results and Discussion
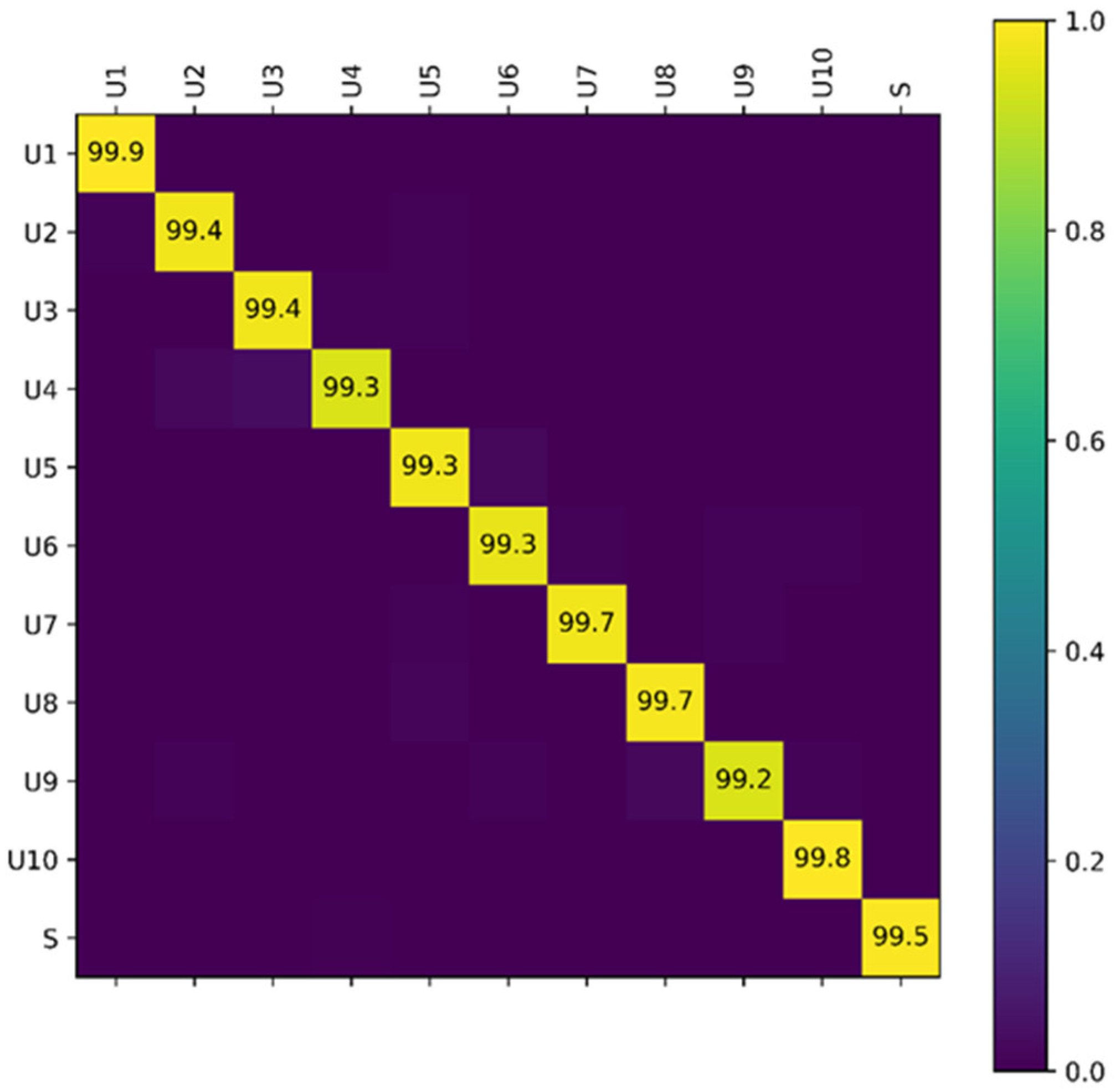
4.1. Performance on User Identification
4.2. Performance of Attack Resistance
4.3. Performance in Different Environments
4.4. Impact of Training Data Size
4.5. Comparison with Other Authentication Systems
4.6. System Advantages Ages
- Strong attack resistance: The proposed system is an authentication technology that integrates physical and behavioral characteristics of how people speak with different speech organs and articulation movements and is robust to mimicry attacks in three environmental interferences with 99% accuracy. Compared with traditional PINs, fingerprints, and other passwords, using articulation as passwords cannot be fully replicated by any hardware device or other means. Even if an attacker learns the content of a password, he or she cannot reproduce the user’s articulation or movement pattern, and thus, malicious attacks can be avoided.
- High usability: Compared with other behavioral habit-based authentication techniques that require a large amount of training data, such as gait-based schemes that require 40 training samples from the user [38], our system requires less than five training samples to achieve the same level of correctness. Therefore, the system considers the shortest possible training process to provide a better user experience while ensuring reliability.
- User friendly: We simultaneously detect audible (speech) and inaudible (ultrasonic) signals to extract articulation features from single utterances based on physiological and behavioral speech characteristics for smartphone user authentication. Registration for the system is easy because it only requires the user to create a small number of samples in a single syllable. In addition, the acoustic system is resistant to light sensitivity in a dim environment compared with image-based authentication, which requires sufficient light, for example, Apple’s Face ID [7].
4.7. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Voice Biometrics Market by Component, Type (Active and Passive), Application (Authentication and Customer Verification, Transaction Processing), Authentication Process, Organization Size, Deployment Mode, Vertical, and Region—Global Forecast to 2026. Available online: https://www.marketsandmarkets.com/Market-Reports/voice-biometrics-market-104503105.html (accessed on 17 February 2022).
- Phillips, N.; Baechle, T.; Earle, R. Essentials of Strength Training and Conditioning, 4th ed.; Haff, G.G., Triplett, N.T., Eds.; Human Kinetics: Champaign, IL, USA, 2015; Volume 83, ISBN 9781492501626. [Google Scholar]
- WeChat Voiceprint: The New WeChat Password. Available online: https://blog.wechat.com/2015/05/21/voiceprint-the-new-wechat-password/ (accessed on 17 February 2022).
- Voice ID Phone Banking—HSBC, HK. Available online: https://www.hsbc.com.hk/ways-to-bank/phone/voice-id/ (accessed on 17 February 2022).
- Citi Tops 1 Million Mark for Voice Biometrics Authentication for Asia Pacific Consumer Banking Clients. Available online: https://www.citigroup.com/citi/news/2016/160518b.htm (accessed on 14 November 2022).
- Yager, N.; Amin, A. Fingerprint Classification: A Review. Pattern Anal. Appl. 2004, 7, 77–93. [Google Scholar] [CrossRef]
- Apple About Face ID Advanced Technology—Apple Support. Available online: https://support.apple.com/en-us/HT208108 (accessed on 22 March 2022).
- Collins, B.; Mees, I.M. Practical Phonetics and Phonology: A Resource Book for Students; Routledge: Oxfordshire, UK, 2013; ISBN 9781136163722. [Google Scholar]
- Shahzad, M.; Liu, A.X.; Samuel, A. Secure Unlocking of Mobile Touch Screen Devices by Simple Gestures. In Proceedings of the 19th Annual International Conference on Mobile Computing & Networking—MobiCom ’13, Miami, FL, USA, 30 September–4 October 2013; ACM Press: New York, NY, USA, 2013; p. 39. [Google Scholar]
- New Data Uncovers the Surprising Predictability of Android Lock Patterns|Ars Technica. Available online: https://arstechnica.com/information-technology/2015/08/new-data-uncovers-the-surprising-predictability-of-android-lock-patterns/ (accessed on 22 March 2022).
- Frank, M.; Biedert, R.; Ma, E.; Martinovic, I.; Song, D. Touchalytics: On the Applicability of Touchscreen Input as a Behavioral Biometric for Continuous Authentication. IEEE Trans. Inf. Forensics Secur. 2013, 8, 136–148. [Google Scholar] [CrossRef]
- A Survey on Gait Recognition. ACM Comput. Surv. 2019, 51, 1–35. [CrossRef]
- Ajibola Alim, S.; Khair Alang Rashid, N. Some Commonly Used Speech Feature Extraction Algorithms. In From Natural to Artificial Intelligence—Algorithms and Applications; IntechOpen: London, UK, 2018. [Google Scholar]
- Sithara, A.; Thomas, A.; Mathew, D. Study of MFCC and IHC Feature Extraction Methods with Probabilistic Acoustic Models for Speaker Biometric Applications. Procedia Comput. Sci. 2018, 143, 267–276. [Google Scholar] [CrossRef]
- Paulose, S.; Mathew, D.; Thomas, A. Performance Evaluation of Different Modeling Methods and Classifiers with MFCC and IHC Features for Speaker Recognition. Procedia Comput. Sci. 2017, 115, 55–62. [Google Scholar] [CrossRef]
- Hassan, A.K.; Ahmed, A.M. Robust Speaker Identification System Based on Variational Bayesian Inference Gaussian Mixture Model and Feature Normalization. In Intelligent Systems and Networks; Tran, D.T., Jeon, G., Nguyen, T.D.L., Lu, J., Xuan, T.D., Eds.; Springer: Singapore, 2021; pp. 516–525. [Google Scholar]
- Khalid, S.S.; Tanweer, S.; Mobin, D.A.; Alam, D.A. A Comparative Performance Analysis of LPC and MFCC for Noise Estimation in Speech Recognition Task. Int. J. Electron. Eng. Res. 2017, 9, 377–390. [Google Scholar]
- Martinez, J.; Perez, H.; Escamilla, E.; Suzuki, M.M. Speaker Recognition Using Mel Frequency Cepstral Coefficients (MFCC) and Vector Quantization (VQ) Techniques. In Proceedings of the CONIELECOMP 2012, 22nd International Conference on Electrical Communications and Computers, Cholula, Puebla, Mexico, 27–29 February 2012; pp. 248–251. [Google Scholar]
- Wali, S.S.; Hatture, S.M.; Nandyal, S. MFCC Based Text-Dependent Speaker Identification Using BPNN. Int. J. Signal Process. Syst. 2014, 3, 30–34. [Google Scholar] [CrossRef]
- Lu, L.; Yu, J.; Chen, Y.; Wang, Y. VocalLock: Sensing Vocal Tract for Passphrase-Independent User Authentication Leveraging Acoustic Signals on Smartphones. Proc. ACM Interact. Mobile Wearable Ubiquitous Technol. 2020, 4, 1–24. [Google Scholar] [CrossRef]
- Zhang, L.; Tan, S.; Yang, J.; Chen, Y. VoiceLive. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; ACM: New York, NY, USA, 2016; pp. 1080–1091. [Google Scholar]
- Xu, C.; Li, Z.; Zhang, H.; Rathore, A.S.; Li, H.; Song, C.; Wang, K.; Xu, W. WaveEar. In Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services, Seoul, Republic of Korea, 17–21 June 2019; ACM: New York, NY, USA, 2019; pp. 14–26. [Google Scholar]
- Lu, L.; Yu, J.; Chen, Y.; Liu, H.; Zhu, Y.; Liu, Y.; Li, M. LipPass: Lip Reading-Based User Authentication on Smartphones Leveraging Acoustic Signals. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1466–1474. [Google Scholar] [CrossRef]
- Tan, J.; Wang, X.; Nguyen, C.-T.; Shi, Y. SilentKey. Proc. ACM Interact. Mobile Wearable Ubiquitous Technol. 2018, 2, 1–18. [Google Scholar] [CrossRef]
- Johnson, K. Acoustic and Auditory Phonetics, 2nd ed.; John and Wiley and Sons: Hoboken, NJ, USA, 2005; ISBN 9781405194662. [Google Scholar]
- The Oxford Handbook of Chinese Linguistics; Wang, W.S.-Y., Sun, C., Eds.; Oxford University Press: Oxford, UK, 2015; ISBN 9780199856336. [Google Scholar]
- Pu, Q.; Gupta, S.; Gollakota, S.; Patel, S. Whole-Home Gesture Recognition Using Wireless Signals. In Proceedings of the 19th Annual International Conference on Mobile Computing & Networking—MobiCom ’13, Miami, FL, USA, 30 September–4 October 2013; ACM Press: New York, NY, USA, 2013; p. 27. [Google Scholar]
- Liu, Y.; Xiao, M.; Tie, Y. A Noise Reduction Method Based on LMS Adaptive Filter of Audio Signals. In Proceedings of the 3rd International Conference on Multimedia Technology (ICMT-13), Guangzhou, China, 29 November–1 December 2013; Volume 84. [Google Scholar]
- Tan, J.; Nguyen, C.-T.; Wang, X. SilentTalk: Lip Reading through Ultrasonic Sensing on Mobile Phones. In Proceedings of the IEEE INFOCOM 2017—IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; IEEE: Nanjing, China, 2017; pp. 1–9. [Google Scholar]
- Ciciora, W.; Farmer, J.; Large, D.; Adams, M. Digital Modulation. In Modern Cable Television Technology; Elsevier: Amsterdam, The Netherlands, 2004; pp. 137–181. [Google Scholar]
- Garg, V.K. An Overview of Digital Communication and Transmission. In Wireless Communications & Networking; Elsevier: Amsterdam, The Netherlands, 2007; pp. 85–122. [Google Scholar]
- Boersma, P.; Weenink, D. Praat: Doing Phonetics by Computer. 2021. Available online: https://github.com/praat/praat (accessed on 16 May 2022).
- Shadle, C.H.; Nam, H.; Whalen, D.H. Comparing Measurement Errors for Formants in Synthetic and Natural Vowels. J. Acoust. Soc. Am. 2016, 139, 713–727. [Google Scholar] [CrossRef] [PubMed]
- Awatade, M.H. Theoretical Survey of the Formant Tracking Algorithm. Proc. Publ. Int. J. Comput. Appl. 2012, ncipet, 14–17. [Google Scholar]
- Escudero, P.; Boersma, P.; Rauber, A.S.; Bion, R.A.H. A Cross-Dialect Acoustic Description of Vowels: Brazilian and European Portuguese. J. Acoust. Soc. Am. 2009, 126, 1379–1393. [Google Scholar] [CrossRef] [PubMed]
- Boersma, P. Accurate Short-Term Analysis of the Fundamental Frequency and the Harmonics-to-Noise Ratio of a Sampled Sound. Proc. Inst. Phon. Sci. 1993, 17, 97–110. [Google Scholar]
- Set up Voice Recognition for Personal Requests—Apple Support. Available online: https://support.apple.com/guide/homepod/set-up-voice-recognition-apd1841a8f81/homepod (accessed on 29 January 2023).
- Wang, W.; Liu, A.X.; Shahzad, M. Gait Recognition Using WiFi Signals. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tongue-Height | Tongue-Backness | |||
|---|---|---|---|---|
| Front | Back | |||
| Lip shape | unrounded | rounded | unrounded | rounded |
| Hight | /i/ | /y/ | /u/ | |
| Mid | /ɤ/ | /o/ | ||
| Low | /a/ | |||
| System | ArtiLock | LipPass | SilentKey | VocalLock |
|---|---|---|---|---|
| Performance | 99.5% ACC | 90.2% ACC | 82.5% ACC | 91% ACC |
| No. of required samples | 1–5 | 3–10 | 5–9 | 1–5 |
| Different Passphrase | 6 | 10 | 6 | 20 |
| Passphrase required length | 1 | More than 4 | 4–6 | 3–12 |
| Frequency band | Speech and Ultrasonic | Ultrasonic | Speech | Speech |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wong, A.B.; Huang, Z.; Chen, X.; Wu, K. ArtiLock: Smartphone User Identification Based on Physiological and Behavioral Features of Monosyllable Articulation. Sensors 2023, 23, 1667. https://doi.org/10.3390/s23031667
Wong AB, Huang Z, Chen X, Wu K. ArtiLock: Smartphone User Identification Based on Physiological and Behavioral Features of Monosyllable Articulation. Sensors. 2023; 23(3):1667. https://doi.org/10.3390/s23031667
Chicago/Turabian StyleWong, Aslan B., Ziqi Huang, Xia Chen, and Kaishun Wu. 2023. "ArtiLock: Smartphone User Identification Based on Physiological and Behavioral Features of Monosyllable Articulation" Sensors 23, no. 3: 1667. https://doi.org/10.3390/s23031667
APA StyleWong, A. B., Huang, Z., Chen, X., & Wu, K. (2023). ArtiLock: Smartphone User Identification Based on Physiological and Behavioral Features of Monosyllable Articulation. Sensors, 23(3), 1667. https://doi.org/10.3390/s23031667