
A Perspective on Lifelong Open-Ended Learning Autonomy for Robotics through Cognitive Architectures


Abstract
1. Introduction
2. Cognitive Architectures and LOLA
- Symbolic: Most of the traditional cognitive architectures, especially in their initial form, belong to this group, although some of them have been later hybridized. They are characterized by representing concepts through symbols and having predefined instruction sets to manipulate them. This makes them excellent systems in terms of planning and reasoning. However, for the same reason, they present grounding problems and lack the robustness and flexibility needed to adapt to the changing conditions of real environments. In addition, the designer assumes a high degree of knowledge about the domains and tasks to be performed and, therefore, provides a lot of knowledge in the form of specific representations or even complete sets of rules in some cases. They are, therefore, limited to use in an abstract framework and are not generally ready to tackle the LOLA problem. We can take as representative examples of this group ACT-R [6], CLARION [7], 4CAPS [8], or SOAR [9]. SOAR, developed by Allen Newell, Paul Rosenbloom, and John Laird, is one of the most-studied architectures. It was created in 1982 but it has undergone different improvements and additions, including hybridizations, throughout the years. CLARION, 4CAPS, and ACT-R were also built as symbolic architectures but, over the years, have also been hybridized. Their main goal initially was to study and emulate human cognitive processes, and, thus, they led to very few real robot applications. Along the same line, we can also find EPIC [10], created in 1980, whose main objective was to replicate the human motor system. On the other hand, an example of architecture of this group created to be used in robotics is ICARUS [11]; however, it has been tested mainly in experiments related to solving puzzles and driving games.
- Emergent: Based on sub-symbolic or connectionist approaches, they often follow developmental principles [12,13] that seek to progressively build system knowledge from scratch through direct interaction with the world. In them, knowledge is often represented and distributed through neural networks. This approach provides a direct path to the autonomous construction of high-level knowledge, avoiding grounding problems. Thus, they aim to solve the problems of adaptation to the environment and learning through the concatenation of multiple models in parallel, where information flows through activation signals. However, this introduces a high level of complexity in development and the need for very long learning and interaction processes, which is, of course, very costly when considering robotics applications. It also causes the system to lose transparency, as knowledge is no longer represented by well-understood symbols and rules, instead being distributed throughout the network. Some examples of these architectures are MDB [14], GRAIL [15], or SASE [13]. In the case of SASE, its main purpose is the autonomous learning of models. GRAIL (and its modified versions M-GRAIL [16], C-GRAIL [17], and H-GRAIL [18]) comes from the field of intrinsically motivated open-ended learning (IMOL), and its focus is on the handling of motivations to seek and relate goals and skills. MDB is a long-standing project started at the end of the 1990s that seeks to implement an evolutionary cognitive architecture suitable for developmental processes in a direct bottom-up approach so that knowledge is always grounded. Finally, we can also include MicroPSI [19] in this group, which was developed in 2003 and combines associative learning, reinforcement learning, and planning in order to allow autonomous systems to acquire knowledge about their environment.
- Hybrid: Finally, the group of hybrid architectures consists of those that use symbolic representations at higher processing levels but include emerging connectionist paradigm-like sub-symbolic representations at the low level. These approaches have become quite popular for addressing low-level grounding and domain adaptation problems, but they still require many adjustments to construct symbolic information. In fact, even though there are researchers trying to provide autonomous approaches to bridge the gap between sub-symbolic and symbolic representations [20], they are still not very common in cognitive architectures. This makes these architectures difficult to adapt to general use cases in robotics, and their implementations tend to focus on specific functionalities. Recent examples of such architectures (apart from the previously mentioned symbolic architectures that have been hybridized) are, on the one hand OpenCogPrime [21], which is a product of the ideas from the artificial general intelligence (AGI) community, which seeks to address intelligence through a holistic approach and not by creating specific AI-based modules that are then integrated. On the other, we have MLECOG [22], which was created by Janusz A. Starzyk and James Graham in 2017 with the aim of moving towards greater autonomy by including motivations and goal creation. In this group, we also find architectures such as ADAPT [23], designed to solve computer vision problems, or LIDA [24] and DUAL [25], which were both designed to study human cognitive processes. A set of additional architectures emerged from European research projects. Representative examples of these are IMPACT [26], developed by the same authors as GRAIL, which combines planning and reinforcement learning algorithms with intrinsic motivations to represent autonomously learned skills, or iCub [27], created to control the robot to which it gives its name and aimed at the study of how newborns learn.
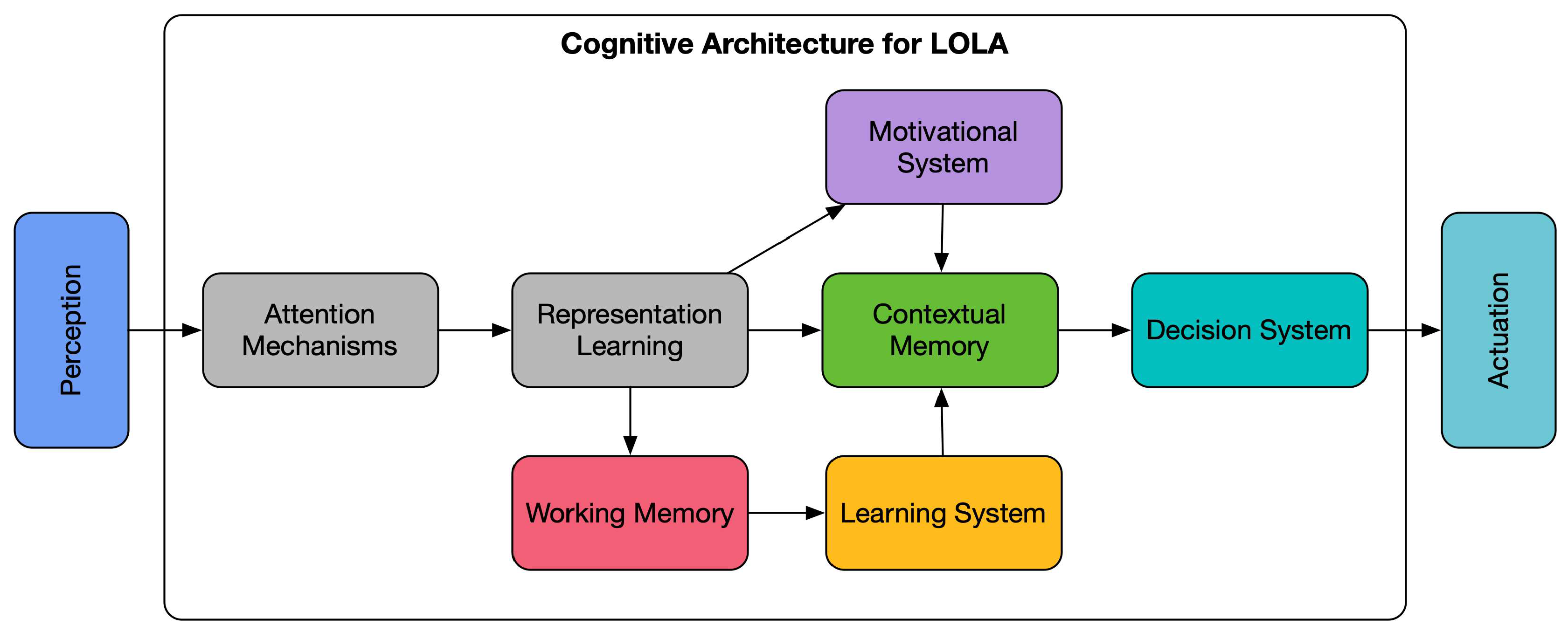
- A motivational system that enables open-ended learning, i.e., that allows the robot to discover new goals and select which ones are active at each moment in time.
- A memory system that permits storing the acquired knowledge and relating it contextually, that is, without having to externally label the knowledge, to facilitate its reuse in the right conditions so that lifelong learning is made possible.
- An online learning system that facilitates acquiring knowledge about the different goals discovered in the different domains, as well as about how to achieve them during robot operation (skills).
- Some type of attention system that helps to reduce the sensory and processing load of the system when operating in real-world conditions would also be very convenient.
2.1. Learning
2.2. Motivational System
- Level 0: The robot has a specific goal set by the designer and the motivational system is able to guide the robot towards the achievement of that goal.
- Level 1: The robot has a series of goals set in advance by the designer and the motivational system is able to select which goals should be active at any given moment in time and guide the robot towards their achievement.
- Level 2: The robot has a series of goals set in advance by the designer and the motivational system is able to select which goals are active at any given moment in time and is capable of autonomously generating sub-goals to reach those goals.
- Level 3: The goals/domains are not known at the time of design and the motivational system is able to discover goals, select which ones are active, and guide the robot towards their achievement.
2.3. Decision Systems and Contextual Memory
2.4. Attention
3. Discussion
4. Conclusions and Perspective
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Laird, J.E.; Lebiere, C.; Rosenbloom, P.S. A Standard Model of the Mind: Toward a Common Computational Framework across Artificial Intelligence, Cognitive Science, Neuroscience, and Robotics. AI Mag. 2017, 38, 13–26. [Google Scholar] [CrossRef]
- Doncieux, S.; Filliat, D.; Diaz-Rodriguez, N.; Hospedales, T.; Duro, R.; Coninx, A.; Roijers, D.M.; Girard, B.; Perrin, N.; Sigaud, O. Open-Ended Learning: A Conceptual Framework Based on Representational Redescription. Front. Neurorobot. 2018, 12, 59. [Google Scholar] [CrossRef]
- Thrun, S.; Mitchell, T.M. Lifelong Robot Learning. Robot. Auton. Syst. 1995, 15, 25–46. [Google Scholar] [CrossRef]
- Kotseruba, I.; Tsotsos, J.K. A Review of 40 Years of Cognitive Architecture Research: Core Cognitive Abilities and Practical Applications. arXiv 2016, arXiv:1610.08602. [Google Scholar]
- Vernon, D. Artificial Cognitive Systems: A Primer; MIT Press: Cambrige, UK, 2014. [Google Scholar]
- Lebiere, C.; Anderson, J.R. A Connectionist Implementation of the ACT-R Production System. In Proceedings of the Fifteenth Annual Conference of the Cognitive Science Society, Boulder, CO, USA, 18–21 June 1993; pp. 635–640. [Google Scholar]
- Sun, R. The Importance of Cognitive Architectures: An Analysis Based on CLARION. J. Exp. Theor. Artif. Intell. 2007, 19, 159–193. [Google Scholar] [CrossRef]
- Varma, S.; Just, M.A. 4CAPS: An Adaptive Architecture for Human Information Processing. In Proceedings of the AAAI Spring Symposium: Between a Rock and a Hard Place: Cognitive Science Principles Meet AI-Hard Problems, Stanford, CA, USA, 27–29 March 2006; pp. 91–96. [Google Scholar]
- Laird, J.E.; Newell, A.; Rosenbloom, P.S. SOAR: An Architecture for General Intelligence. Artif. Intell. 1987, 33, 1–64. [Google Scholar] [CrossRef]
- Kieras, D.E.; Wakefield, G.H.; Thompson, E.R.; Iyer, N.; Simpson, B.D. Modeling Two-Channel Speech Processing With the EPIC Cognitive Architecture. Top. Cogn. Sci. 2016, 8, 291–304. [Google Scholar] [CrossRef]
- Langley, P.; Choi, D. A Unified Cognitive Architecture for Physical Agents. In Proceedings of the National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; Volume 21, p. 1469. [Google Scholar]
- Asada, M.; Hosoda, K.; Kuniyoshi, Y.; Ishiguro, H.; Inui, T.; Yoshikawa, Y.; Ogino, M.; Yoshida, C. Cognitive Developmental Robotics: A Survey. IEEE Trans. Auton. Ment. Dev. 2009, 1, 12–34. [Google Scholar] [CrossRef]
- Weng, J. Developmental Robotics: Theory and Experiments. Int. J. Hum. Robot 2004, 1, 199–236. [Google Scholar] [CrossRef]
- Bellas, F.; Duro, R.J.; Faiña, A.; Souto, D. Multilevel Darwinist Brain (MDB): Artificial Evolution in a Cognitive Architecture for Real Robots. IEEE Trans. Auton. Ment. Dev. 2010, 2, 340–354. [Google Scholar] [CrossRef]
- Santucci, V.G.; Baldassarre, G.; Mirolli, M. Grail: A Goal-Discovering Robotic Architecture for Intrinsically-Motivated Learning. IEEE Trans. Cogn. Dev. Syst. 2016, 8, 214–231. [Google Scholar] [CrossRef]
- Santucci, V.G.; Baldassarre, G.; Cartoni, E. Autonomous Reinforcement Learning of Multiple Interrelated Tasks. In Proceedings of the 2019 Joint IEEE 9th International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), Olso, Norway, 19–22 August 2019; pp. 221–227. [Google Scholar]
- Santucci, V.G.; Montella, D.; Baldassarre, G. C-GRAIL: Autonomous Reinforcement Learning of Multiple, Context-Dependent Goals. IEEE Trans. Cogn. Dev. Syst. 2022. [Google Scholar] [CrossRef]
- Romero, A.; Baldassarre, G.; Duro, R.J.; Santucci, V.G. Autonomous Learning of Multiple Curricula with Non-Stationary Interdependencies. In Proceedings of the IEEE International Conference on Development and Learning, ICDL, London, UK, 12–15 September 2022; pp. 272–279. [Google Scholar] [CrossRef]
- Bach, J. MicroPsi 2: The next Generation of the MicroPsi Framework. In Proceedings of the International Conference on Artificial General Intelligence, Oxford, UK, 8–11 December 2012; pp. 11–20. [Google Scholar]
- Laird, J.E. Toward Cognitive Robotics. Proc. SPIE 2009, 7332, 242–252. [Google Scholar] [CrossRef]
- Goertzel, B. OpenCogPrime: A Cognitive Synergy Based Architecture for Artificial General Intelligence. In Proceedings of the 8th IEEE International Conference on Cognitive Informatics, Hong Kong, China, 15–17 June 2009; pp. 60–68. [Google Scholar]
- Starzyk, J.A.; Graham, J. MLECOG: Motivated Learning Embodied Cognitive Architecture. IEEE Syst. J. 2015, 11, 1272–1283. [Google Scholar] [CrossRef]
- Benjamin, D.P.; Lyons, D.M.; Lonsdale, D.W. ADAPT: A Cognitive Architecture for Robotics. In Proceedings of the ICCM, Pittsburgh, PA, USA, 30 July–1 August 2004; pp. 337–338. [Google Scholar]
- Friedlander, D.; Franklin, S. LIDA and a Theory of Mind. Front. Artif. Intell. Appl. 2008, 171, 137. [Google Scholar]
- Nestor, A.; Kokinov, B. Towards Active Vision in the Dual Cognitive Architecture. Int. J. ITA 2004, 11, 1. [Google Scholar]
- Oddi, A.; Rasconi, R.; Santucci, V.G.; Sartor, G.; Cartoni, E.; Mannella, F.; Baldassarre, G. Integrating Open-Ended Learning in the Sense-Plan-Act Robot Control Paradigm. In ECAI 2020; IOS Press: Amsterdam, The Netherlands, 2020; pp. 2417–2424. [Google Scholar]
- Tsagarakis, N.G.; Metta, G.; Sandini, G.; Vernon, D.; Beira, R.; Becchi, F.; Righetti, L.; Ijspeert, A.J.; Carrozza, M.C.; Caldwell, D.G. ICub: The Design and Realization of an Open Humanoid Platform for Cognitive and Neuroscience Research. Adv. Robot. 2007, 21, 1151–1175. [Google Scholar] [CrossRef]
- Anderson, J.R.; Bothell, D.; Byrne, M.D.; Douglass, S.; Lebiere, C.; Qin, Y. An Integrated Theory of the Mind. Psychol. Rev. 2004, 111, 1036. [Google Scholar] [CrossRef] [PubMed]
- Prieto, A.; Romero, A.; Bellas, F.; Salgado, R.; Duro, R.J. Introducing Separable Utility Regions in a Motivational Engine for Cognitive Developmental Robotics. Integr. Comput. Aided. Eng. 2019, 26, 3–20. [Google Scholar] [CrossRef]
- Romero, A.; Bellas, F.; Duro, R.J. Open-Ended Learning of Reactive Knowledge in Cognitive Robotics Based on Neuroevolution BT—Hybrid Artificial Intelligent Systems; Sanjurjo González, H., Pastor López, I., García Bringas, P., Quintián, H., Corchado, E., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 65–76. [Google Scholar]
- Fuster, J.M.; Bressler, S.L. Past Makes Future: Role of PFC in Prediction. J. Cogn. Neurosci. 2015, 27, 639–654. [Google Scholar] [CrossRef]
- Vernon, D.; Beetz, M.; Sandini, G. Prospection in Cognition: The Case for Joint Episodic-Procedural Memory in Cognitive Robotics. Front. Robot. AI 2015, 2, 19. [Google Scholar] [CrossRef]
- Shiffrin, R.M.; Schneider, W. Controlled and Automatic Human Information Processing: II. Perceptual Learning, Automatic Attending and a General Theory. Psychol. Rev. 1977, 84, 127. [Google Scholar] [CrossRef]
- Wood, R.; Baxter, P.; Belpaeme, T. A Review of Long-Term Memory in Natural and Synthetic Systems. Adapt. Behav. 2012, 20, 81–103. [Google Scholar] [CrossRef]
- Fuster, J.M. Cortex and Memory: Emergence of a New Paradigm. J. Cogn. Neurosci. 2009, 21, 2047–2072. [Google Scholar] [CrossRef] [PubMed]
- Salvucci, D.D. Integration and Reuse in Cognitive Skill Acquisition. Cogn. Sci. 2013, 37, 829–860. [Google Scholar] [CrossRef]
- Bellemare, M.; Srinivasan, S.; Ostrovski, G.; Schaul, T.; Saxton, D.; Munos, R. Unifying Count-Based Exploration and Intrinsic Motivation. Adv. Neural Inf. Process. Syst. 2016, 29. Available online: https://proceedings.neurips.cc/paper/2016/hash/afda332245e2af431fb7b672a68b659d-Abstract.html (accessed on 3 January 2023).
- Schillaci, G.; Pico Villalpando, A.; Hafner, V.V.; Hanappe, P.; Colliaux, D.; Wintz, T. Intrinsic Motivation and Episodic Memories for Robot Exploration of High-Dimensional Sensory Spaces. Adapt. Behav. 2021, 29, 549–566. [Google Scholar] [CrossRef]
- Nehmzow, U.; Gatsoulis, Y.; Kerr, E.; Condell, J.; Siddique, N.; McGuinnity, T.M. Novelty Detection as an Intrinsic Motivation for Cumulative Learning Robots. Intrinsically Motiv. Learn. Nat. Artif. Syst. 2013, 185–207. [Google Scholar] [CrossRef]
- Schmidhuber, J. Formal Theory of Creativity, Fun, and Intrinsic Motivation (1990–2010). IEEE Trans. Auton. Ment. Dev. 2010, 2, 230–247. [Google Scholar] [CrossRef]
- Hester, T.; Stone, P. Intrinsically Motivated Model Learning for Developing Curious Robots. Artif. Intell. 2017, 247, 170–186. [Google Scholar] [CrossRef]
- Oudeyer, P.-Y.; Baranes, A.; Kaplan, F. Intrinsically Motivated Learning of Real-World Sensorimotor Skills with Developmental Constraints. In Intrinsically Motivated Learning in Natural and Artificial Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 303–365. [Google Scholar]
- Colas, C.; Fournier, P.; Chetouani, M.; Sigaud, O.; Oudeyer, P.-Y. Curious: Intrinsically Motivated Modular Multi-Goal Reinforcement Learning. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 1331–1340. [Google Scholar]
- Romero, A.; Baldassarre, G.; Duro, R.J.; Santucci, V.G. Analysing Autonomous Open-Ended Learning of Skills with Different Interdependent Subgoals in Robots. In Proceedings of the 2021 20th International Conference on Advanced Robotics (ICAR), Ljubljana, Slovenia, 6–10 December 2021; pp. 646–651. [Google Scholar]
- Romero, A.; Bellas, F.; Becerra, J.A.; Duro, R.J. Motivation as a Tool for Designing Lifelong Learning Robots. Integr. Comput. Aided. Eng. 2020, 27, 353–372. [Google Scholar] [CrossRef]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D. A Survey of Transfer Learning. J. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Lesort, T.; Lomonaco, V.; Stoian, A.; Maltoni, D.; Filliat, D.; Diaz-Rodriguez, N. Continual Learning for Robotics: Definition, Framework, Learning Strategies, Opportunities and Challenges. Inf. Fusion 2020, 58, 52–68. [Google Scholar] [CrossRef]
- McCloskey, M.; Cohen, N.J. Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem. In Psychology of Learning and Motivation; Elsevier: Amsterdam, The Netherlands, 1989; Volume 24, pp. 109–165. [Google Scholar]
- French, R.M. Catastrophic Forgetting in Connectionist Networks. Trends Cogn. Sci. 1999, 3, 128–135. [Google Scholar] [CrossRef]


{kind=link}
| Architecture | Type (Following [4]) | Design Objective | Motivational System Level | Learning System | Contextual Memory | Attention Mechanism | Real Robot Applications |
|---|---|---|---|---|---|---|---|
| EPIC [10] | Symbolic | Emulate human cognition | 0 | NO | NO | YES | NO |
| ICARUS [11] | Symbolic | Robotics | 1 | YES (rule-based) | NO | NO | NO |
| ADAPT [23] | Hybrid | Computer vision | 0 | YES (rule-based) | NO | YES | NO |
| CLARION [7] | Hybrid | Emulate human cognition | 1 | YES | YES | NO | NO |
| LIDA [24] | Hybrid | Emulate human cognition | 1 | YES | YES | YES | NO |
| iCub [27] | Hybrid | Robotics | 3 | YES | NO | YES | YES |
| SOAR [9] | Hybrid | Robotics | 2 | YES | YES | NO | YES |
| OpenCogPrime [21] | Hybrid | Artificial General Intelligence | 1 | YES | YES | NO | NO |
| DUAL [25] | Hybrid | Emulate human cognition | 0 | YES (rule-based) | YES | NO | YES |
| 4CAPS [8] | Hybrid | Emulate human cognition | 0 | NO | NO | NO | NO |
| ACT-R [28] | Hybrid | Emulate human cognition | 0 | YES | YES | YES | YES |
| MLECOG [22] | Hybrid | Autonomy | 2 | YES | YES | YES | NO |
| IMPACT [26] | Hybrid | Robotics | 3 | YES | NO | NO | NO |
| MicroPSI [19] | Emergent | Autonomy | 2 | YES | NO | YES | NO |
| GRAIL [15] | Emergent | Robotics | 3 | YES | NO | NO | YES |
| MDB [14] | Emergent | Robotics | 2 | YES | NO | NO | YES |
| SASE [13] | Emergent | Model learning | 0 | YES | NO | NO | YES |
| Architecture | EPIC | ICARUS | ADAPT | CLARION | LIDA | iCub | SOAR | OpenCogPrime | DUAL | 4CAPS | ACT-R | MLECOG | IMPACT | MicroPSI | GRAIL | MDB | SASE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Motivational system for OEL | 0 | 1 | 0 | 1 | 1 | 3 | 2 | 1 | 0 | 0 | 0 | 2 | 3 | 2 | 3 | 2 | 0 |
| Learning system | rule-based | rule-based | rule-based | ||||||||||||||
| Contextual memory | |||||||||||||||||
| Attention mechanism |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romero, A.; Bellas, F.; Duro, R.J. A Perspective on Lifelong Open-Ended Learning Autonomy for Robotics through Cognitive Architectures. Sensors 2023, 23, 1611. https://doi.org/10.3390/s23031611
Romero A, Bellas F, Duro RJ. A Perspective on Lifelong Open-Ended Learning Autonomy for Robotics through Cognitive Architectures. Sensors. 2023; 23(3):1611. https://doi.org/10.3390/s23031611
Chicago/Turabian StyleRomero, Alejandro, Francisco Bellas, and Richard J. Duro. 2023. "A Perspective on Lifelong Open-Ended Learning Autonomy for Robotics through Cognitive Architectures" Sensors 23, no. 3: 1611. https://doi.org/10.3390/s23031611
APA StyleRomero, A., Bellas, F., & Duro, R. J. (2023). A Perspective on Lifelong Open-Ended Learning Autonomy for Robotics through Cognitive Architectures. Sensors, 23(3), 1611. https://doi.org/10.3390/s23031611