1. Introduction
Given a video sequence or an RGB image captured from a camera or mobile device, the task of markerless pose estimation is to predict the positions of the body keypoints (including joints and vertices) relative to a certain coordinate system [
1]. As one most frequently used parts that human beings interact with the environment, hand pose estimation (HPE) is of great research interest and has numerous applications in areas such as robotics, virtual reality (VR) and augmented reality (AR), AI-aided diagnosis and smart human-computer interaction (HCI) systems [
2,
3]. Apart from those downstream applications, HPE also plays an important role in many basic upstream tasks, including gesture recognition [
4,
5,
6] and sign language recognition (SLR) [
7,
8]. Accurate hand pose estimation and reconstruction can significantly enhance the understanding of the learning and inference of human behavior, thus enabling a more intelligent interaction between humans and the target system with improved user experience.
In recent years, with the rapid development of hardware (e.g., Microsoft Kinect [
9], Oak-D camera [
10], wearable sensors) and advances in deep learning algorithms, HPE research has achieved considerable progress. The state-of-the-art approaches have achieved promising performance in a controlled environment with different data modalities, such as 2D images, 2D images with depth map [
11,
12,
13], wearable gloves and sensors [
3,
14]. Among these modalities, since single-view 2D RGB images are much more available than sensors and depth images, HPE from a single RGB image can be widely used and easily deployed to various end devices. Meanwhile, HPE from a single RGB image is also a more challenging task in practice due to the following concerns:
- 1.
Full Accurate Annotation: Creating a fully-annotated HPE dataset is time-consuming and requires sufficient human and financial resources. Meanwhile, the hardware for capturing the data, like multi-view and high-resolution cameras, is also costly.
- 2.
Hand Occlusion: During the motion of performing a hand gesture, or holding some objects, the fingers of the same hand may cross over each other or be covered by other objects, making several keypoints unobservable. In such cases, certain hidden keypoint positions cannot be predicted only based on vision.
- 3.
Low Resolution: In a practical scenario, the hand may only occupy a small area in the image, resolving a quite low hand resolution. For instance, even with a 4K capturing system, if the principal focus is not the hand and the object size is small due to the viewing distance, the hand may only occupy tens of pixels.
- 4.
Motion blur: Due to the relatively low sampling rate of cameras in many practical scenarios (e.g., normally 15 fps or 30 fps), fast movements of the fingers will cause motion blur in the captured images and video sequences. Motion blur in the images could significantly affect both the hand pose annotation and estimation tasks.
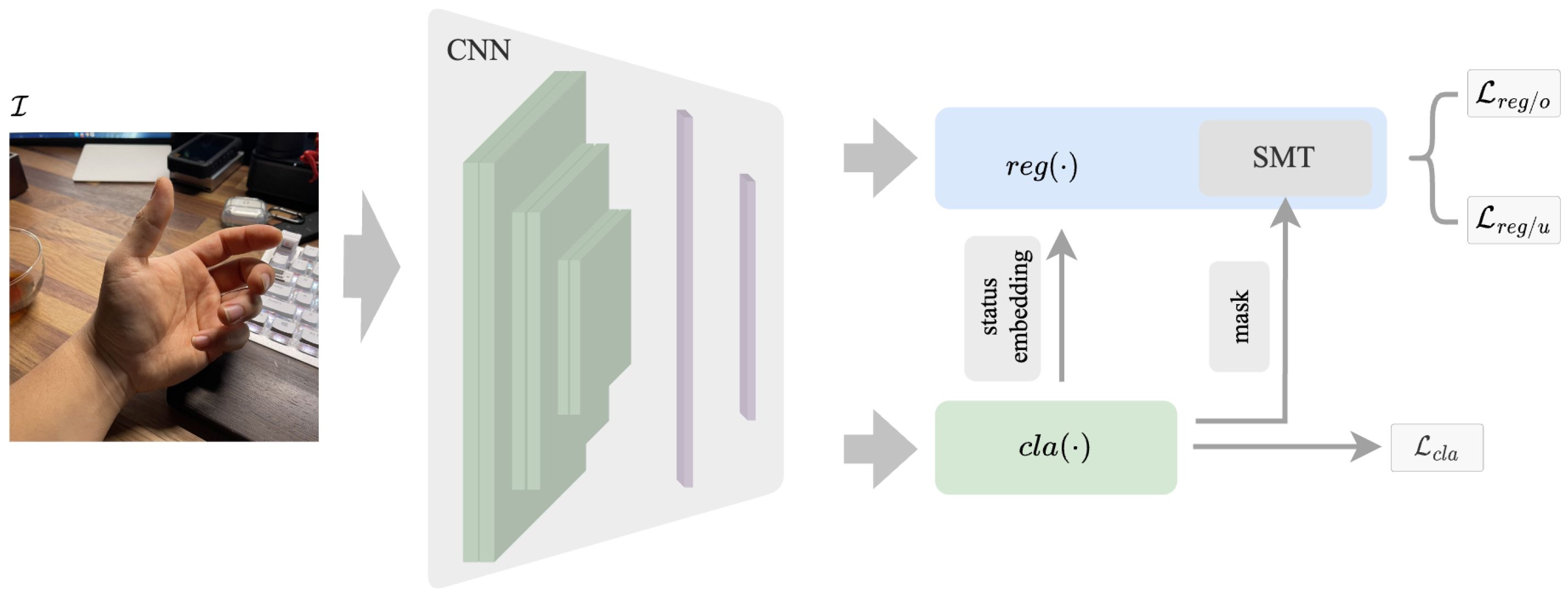
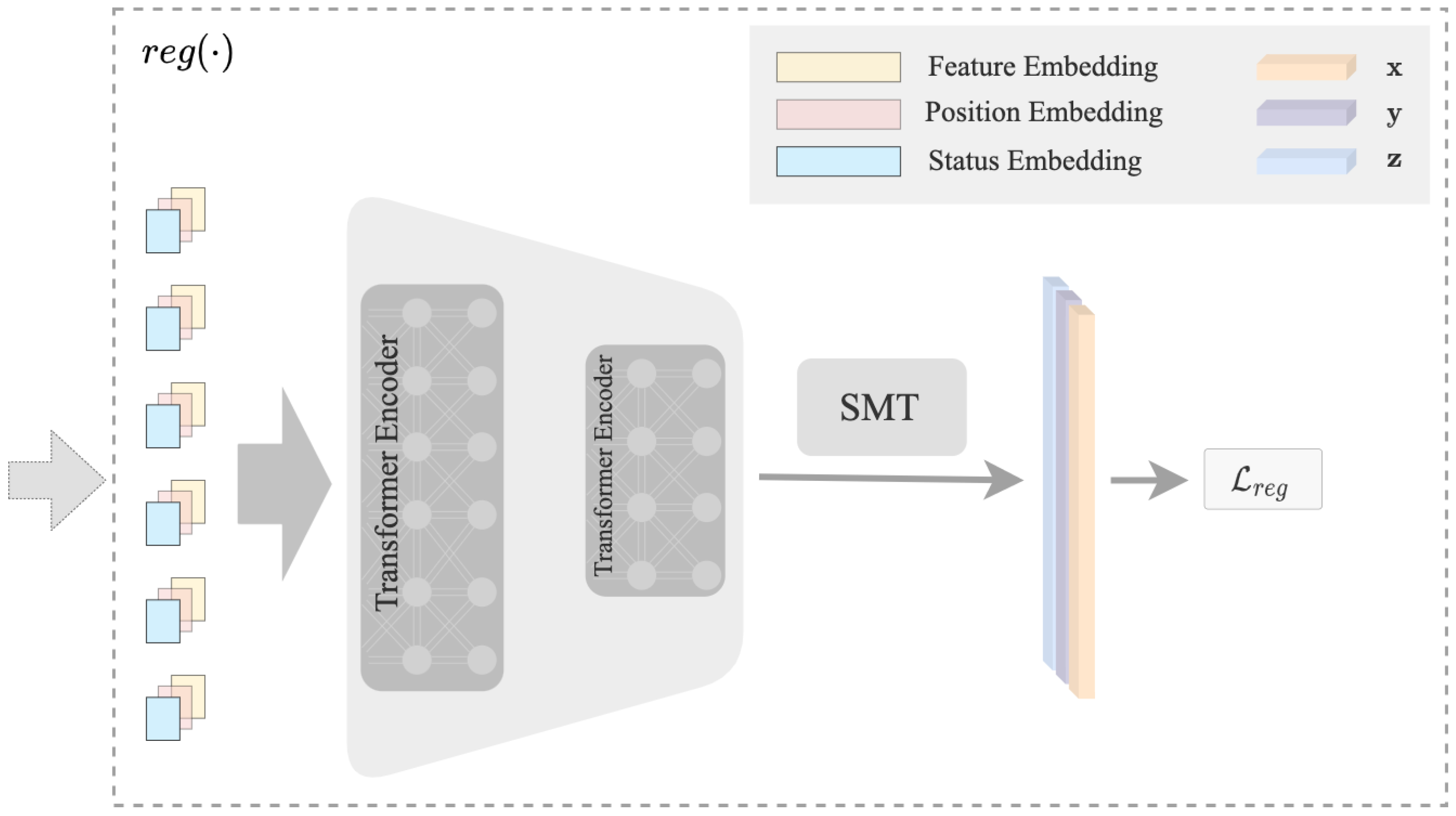
To our best knowledge, no work in the literature has jointly addressed the above concerns, especially the partial annotation challenge. In this work, to fill this research gap, we propose a 3D hand pose estimation approach from a single RGB image with partial annotation. In summary, our contributions are as follows:
- 1.
As the first attempt in the literature, we consider the partial annotation challenge in image-based 3D HPE and propose a novel partial annotation learning framework, PA-Tran, for 3D hand pose estimation.
- 2.
Due to the lack of the required dataset in the literature, we created two hand datasets. The first (APDM-Hand) is a synthetic dataset for a specific task (with APDM accessories on the palm). The second is a real-hand dataset with partial annotation collected from PD patients wearing APDM accessories.
- 3.
By explicitly encoding and exploring the label status (observed/unobserved) in the proposed PA-Tran, training with partial annotation is shown to be even more efficient than full annotation. We compare the performances of using different annotation percentages ranging from 50% to full annotation.
The rest of this paper is organized as follows.
Section 2 introduces the related work.
Section 3 presents the major components of the proposed model PA-Tran.
Section 4 provides an experimental evaluation of the proposed model. Finally,
Section 5 concludes the paper and provides potential directions for future research.
2. Related Work
HPE is a long-standing research area due to its wide range of applications. The structure of the human hand is quite complex, with a lot of degrees of freedom (DOF). However, the biological structure enforces the motion of the hand to follow a specific pattern, as shown in
Figure 1. The cylinder and bicylinder represent the flexibility of hand joints. This biological limitation also makes it possible to learn high-dimensional features from a 2D or 2.5D image. In recent years, with the increasing popularity of deep neural networks, researchers have proposed many methods to estimate the hand pose from images [
15]. From the task requirement perspective, single-image-based HPE could be categorized into 2D estimation and 3D estimation, and 2D hand pose estimation is often referred to as hand keypoint detection.
2D Hand Pose Estimation. For the 2D hand keypoint detection task, Ref. [
16] directly regresses the Cartesian coordinates of the keypoints using a normal convolution architecture.
After that, more works turn to regress images into confidence maps. Convolutional Pose Machine (CPM) [
17] inputs the regressed confidence maps into convolutional architectures to learn implicit spatial dependencies. Ref. [
18] designs a novel ’stacked hourglass’ architecture to predict 2D human pose by capturing and consolidating information across all image scales. In [
19], hand pose estimation is separated into five independent finger pose estimations. Meanwhile, multi-view 2D keypoints could be combined to estimate the 3D pose. Ref. [
20] presents a framework called multi-view bootstrapping that uses multi-view images to train keypoints detectors iteratively to denoise the prediction. Ref. [
21] also utilizes the multi-view information and proposes an end-to-end single-stage convolutional neural network to estimate the coordinates of the hand keypoints. The multi-view approach can achieve good performance in an experimental environment. Nevertheless, it is not always feasible to be deployed to a practical environment for two main reasons: first, the multi-view camera system may not always be available; and multi-view feature fusion has high requirements for the consistency and synchronicity of different data acquisition channels.
3D Hand Pose Estimation. Compared with the multi-view-based approach for 3D HPE, the single-RGB-image condition has lower requirements for hardware devices and less restriction on implementation scenarios [
22]. One commonly used approach is extracting the image features using convolutional neural networks (CNNs). Different from previous work, in [
23], the researchers, for the first time, propose a learning-based architecture to estimate 3D hand pose from a single RGB image. They use synthetic data with various augmentation options and sequently design the three networks, i.e., HandSegNet, PoseNet, and PoserPrior, showing the possibility of predicting reasonable 3D hand poses from 2D keypoints. As a new type of convolutional neural network, the graph convolutional neural network (GCN) has been used to estimate the relationship in knowledge graphs and, more recently, in many areas of computer vision. Integrating GCN for RGB image-based hand pose estimation has become a new direction. Similarly to [
23], a framework based on graph convolutional neural networks, HOPE-Net, is proposed in [
24]. HOPE-Net uses a cascade of two adaptive graph convolutional neural networks. One network estimates the 2D coordinates of the hand joints and the object’s corners. The 2D coordinates predictions are passed to the second adaptive Graph U-Net to estimate the 3D coordinates of both the hand and the object. Compared with the works above, some methods have changed to estimate the 3D coordinates directly. Ref. [
25] proposes a weakly-supervised method that could be trained without using any paired 2D-to-3D supervision. Ref. [
26] presents the first end-to-end deep learning method for 3D hand pose estimation from RGB images in the wild and utilizes a 3D to 2D reprojection loss. Ref. [
27] propose the first large-scale multi-view hand dataset FreiHAND with 3D hand pose and shape annotations. And a framework aggregating information from all the multi-view cameras is proposed to predict a single 3D hand pose. I2L-MeshNet [
28] is a novel network for 3D pose and mesh estimation from a single RGB image. It consists of two modules: PoseNet and MeshNet. PoseNet estimates the three lixel(line+pixel)-based 1D heatmaps of all joints. MeshNet takes the pre-computed image features from the PoseNet and estimates the hand shape. Ref. [
29] proposes a novel framework based on the vision transformer and achieves state-of-the-art results. In the meantime, hand pose estimation also started to be explored in more directions and scenarios. Ref. [
30] proposes a multi-modal approach that uses 2D labels on RGB images as weak supervision to perform 3D HPE. And the multi-modal architecture also incorporates the camera and LiDAR with an auxiliary segmentation branch. Ref. [
31] proposes a new scenario when the input images come from a single fisheye camera.
Partial Annotation Learning. As a non-fully-supervised direction (e.g., semi- supervised and weakly-supervised), learning with partial annotation has been actively studied very recently in many topics, including multi-label image classification [
32], object detection [
33], and segmentation [
34]. Hand pose estimation is inherently a partial annotation learning problem as, most of the time, only a part of the hand is visible in an image because of the high DOFs of the hand. However, only a few works with semi-/weakly-supervision have been studied for hand pose estimation. Ref. [
35] proposes a weakly-supervised network for training with RGB images and corresponding depth maps, and does inference with RGB images only. In [
36], the researchers propose a semi-supervised framework to form a shared latent space between the synthetic depth image, real depth image, and pose. These works leverage the depth information to train the model in a weakly-supervised manner and don’t focus on partial annotation learning for hand pose estimation. While in our settings, the input is RGB images captured from general webcams and has no depth information. To fill this research gap, we propose a framework for single-image-based 3D hand pose estimation with partial annotation by jointly estimating the status and the position of hand keypoints.
Table 1 provides a summary to illustrate different assumptions and problem settings of related hand pose estimation approaches in the literature.
Synthetic Hand Dataset. Acquiring full annotations for real images is complicated and may not be feasible in practice as it requires complex setups and labor-intensive manual annotations in different perspectives, Refs. [
37,
38] create synthetic datasets to help relieve the problem of lacking fully-annotated hand data. Within these synthetic datasets, Dart [
38] explores the hand synthetic dataset to a new frontier that generates synthetic hand data with several accessories like watches and rings. However, as required by our specific motivating application in Parkinson’s disease research, we have a practical demand to estimate the hand pose with a wearable sensor on the palm, which will significantly affect hand pose estimation performance when applying pre-trained methods. Motivated by Dart [
38], we generate a synthetic dataset called APDM-Hand, to help improve the performance of HPE in our specific scenario in the PD study. APDM-Hand contains hand images wearing an accessory of the APDM sensor on the palm and could be treated as an additional subset of Dart. The description of APDM-Hand is detailed in
Section 4.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}