
Person Re-Identification with RGB–D and RGB–IR Sensors: A Comprehensive Survey

 ,
, 
Abstract
1. Introduction

- First, we categorize the RGB–D and IR sensor-based person re-identification methods according to different modalities. This proposed categorization aims to help new researchers gain a comprehensive and more profound understanding of depth and infrared sensor-based person Re-ID.
- We summarize the main contributions based on our categorization of person re-identification approaches.
- We also summarize the performance of state-of-the-art methods on several representative RGB–D and IR datasets with detailed data descriptions.
- Finally, we give several considerable points for future insights toward improving the different sensor-based person Re-ID systems.
2. Multi-Modal Person Re-Identification
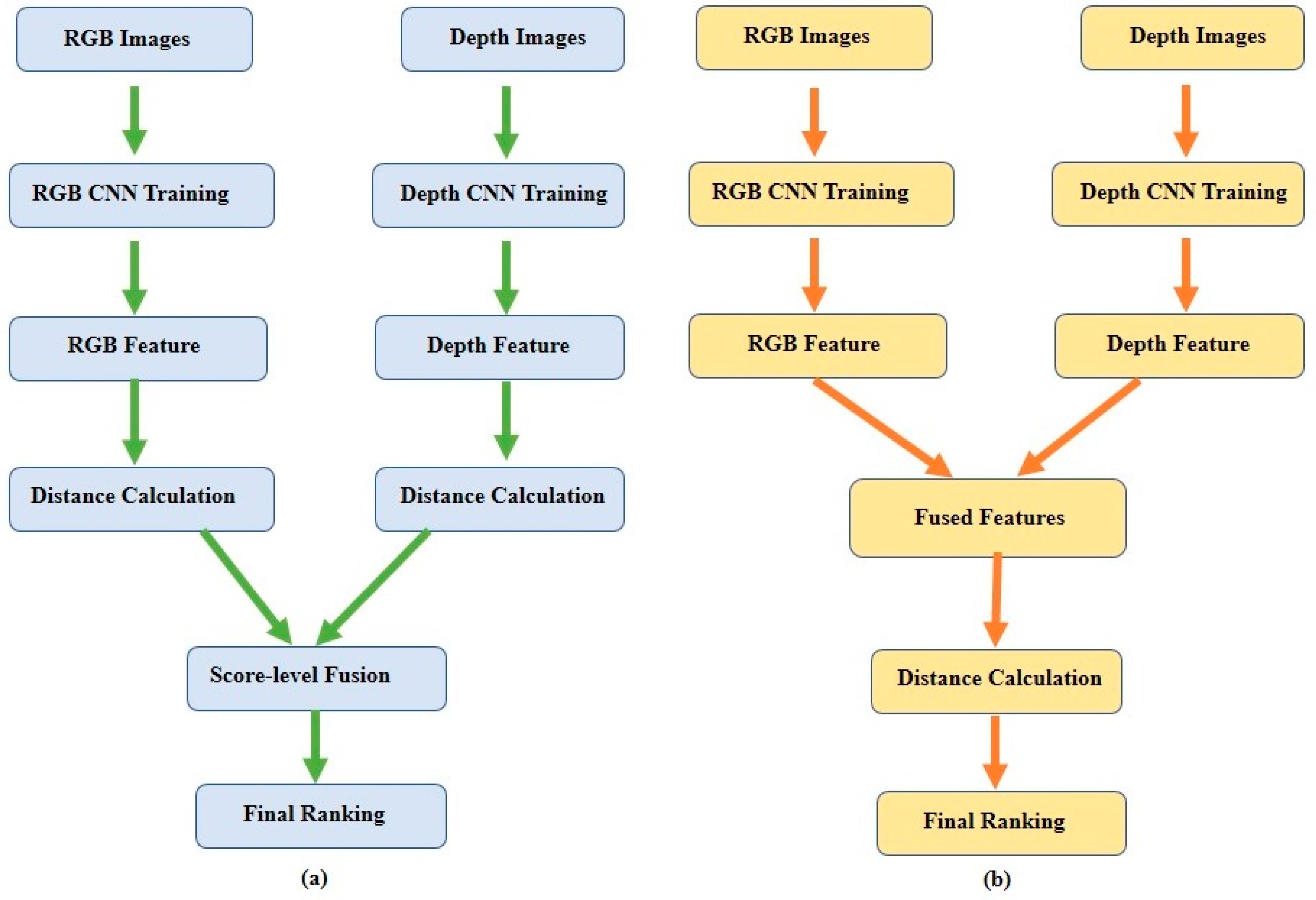
2.1. RGB–Depth Image-Based Person Re-ID
2.2. RGB–Skeleton Image-Based Person Re-ID
2.3. Depth–Skeleton Information-Based Person Re-ID
2.4. RGB-, Depth-, and Skeleton-Based Person Re-ID
2.5. RGB, Depth, and Thermal Image-Based Person Re-ID
3. Cross-Modal Person Re-Identification
3.1. RGB–Sketch Cross-Modal Person Re-ID
3.2. RGB–Depth Cross-Modal Person Re-ID
3.3. RGB–IR Cross-Modal Person Re-ID
4. Single-Modal Person Re-ID
4.1. IR–IR Single-Modal Person Re-ID
4.2. Depth–Depth Single-Modal Person Re-ID
5. Datasets
5.1. Multi-Modal RGB–D Datasets
5.2. Top-View RGB–D Datasets
5.3. RGB–D and Thermal Dataset
5.4. RGB–Sketch Re-ID Dataset
5.5. RGB–IR Cross-Modal Datasets
6. Conclusions and Future Directions
- Available datasets are insufficient for training good models for deep-learning approaches. Though some datasets have a decent number of individuals [58], the number of frames per person is insufficient and is not enough to give the overall variations necessary to build good models.
- Some RGB–D datasets [14,35,41,58] were collected using a Kinect camera; however, this camera is limited in capturing distant objects because it can only capture objects within 4 m [41]. Therefore, this camera is not suitable for surveillance when individuals exceed a distance of 4.0 m. To overcome this distance limitation, Re-ID researchers can use modern Intel RealSense depth cameras, which can capture images at a range of up to 10 m [100]. Moreover, the dataset [33] did not capture skeleton information properly; even RGB and depth images were not synchronized.
- A thorough review of state-of-the-art RGB–IR-based cross-modal Re-ID approaches suggests that non-generative models deal with the issue of modality gaps at the feature level while the generative model deals with it at the pixel-level. Although the chances of introducing noise with the generative model are high, it can effectively avoid the effects of color information.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gheissari, N.; Sebastian, T.B.; Hartley, R. Person reidentification using spatiotemporal appearance. In Proceedings of the IEEE Computer Society Conference on Computer Vision and pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 1528–1535. [Google Scholar]
- Islam, K. Person search: New paradigm of person re-identification: A survey and outlook of recent works. Image Vis. Comput. 2020, 101, 103970. [Google Scholar] [CrossRef]
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person re-identification: Past, Present and Future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Wu, D.; Zheng, S.J.; Zhang, X.P.; Yuan, C.A.; Cheng, F.; Zhao, Y.; Lin, Y.J.; Zhao, Z.Q.; Jiang, Y.L.; Huang, D.S. Deep learning-based methods for person re-identification: A comprehensive review. Neurocomputing 2019, 337, 354–371. [Google Scholar] [CrossRef]
- Bedagkar-Gala, A.; Shah, S.K. A survey of approaches and trends in person re-identification. Image Vis. Comput. 2014, 32, 270–286. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Lin, G.; Xiang, T.; Shao, L.; Hoi, S.C. Deep learning for person re-identification: A survey and outlook. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2872–2893. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Du, H.; Zhao, Y.; Yan, J. A comprehensive overview of person re-identification approaches. IEEE Access 2020, 8, 45556–45583. [Google Scholar] [CrossRef]
- Leng, Q.; Ye, M.; Tian, Q. A survey of open-world person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1092–1108. [Google Scholar] [CrossRef]
- Almasawa, M.O.; Elrefaei, L.A.; Moria, K. A survey on deep learning-based person re-identification system. IEEE Access 2019, 7, 175228–175247. [Google Scholar] [CrossRef]
- Lavi, B.; Ullah, I.; Fatan, M.; Rocha, A. Survey on Reliable Deep Learning-Based Person Re-Identification Models: Are We There Yet? arXiv 2020, arXiv:2005.00355. [Google Scholar]
- Satta, R. Appearance descriptors for person re-identification: A comprehensive review. arXiv 2013, arXiv:1307.5748. [Google Scholar]
- Yaghoubi, E.; Kumar, A.; Proença, H. SSS-PR: A short survey of surveys in person re-identification. Pattern Recognit. Lett. 2021, 143, 50–57. [Google Scholar] [CrossRef]
- Zheng, H.; Zhong, X.; Huang, W.; Jiang, K.; Liu, W.; Wang, Z. Visible-Infrared Person Re-Identification: A Comprehensive Survey and a New Setting. Electronics 2022, 11, 454. [Google Scholar] [CrossRef]
- Munaro, M.; Basso, A.; Fossati, A.; Van Gool, L.; Menegatti, E. 3D reconstruction of freely moving persons for re-identification with a depth sensor. In Proceedings of the IEEE International Conference on Robotics and Automation, Hong Kong, 31 May–7 June 2014; pp. 4512–4519. [Google Scholar] [CrossRef]
- Ding, S.; Lin, L.; Wang, G.; Chao, H. Deep feature learning with relative distance comparison for person re-identification. Pattern Recognit. 2015, 48, 2993–3003. [Google Scholar] [CrossRef]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable person re-identification: A benchmark. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1116–1124. [Google Scholar]
- Jüngling, K.; Arens, M. Local feature based person reidentification in infrared image sequences. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, Boston, MA, USA, 29 August–1 September 2010; pp. 448–455. [Google Scholar] [CrossRef]
- Cho, Y.J.; Yoon, K.J. Improving person re-identification via pose-aware multi-shot matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1354–1362. [Google Scholar]
- Zhao, H.; Tian, M.; Sun, S.; Shao, J.; Yan, J.; Yi, S.; Wang, X.; Tang, X. Spindle net: Person re-identification with human body region guided feature decomposition and fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1077–1085. [Google Scholar]
- Sarfraz, M.S.; Schumann, A.; Eberle, A.; Stiefelhagen, R. A pose-sensitive embedding for person re-identification with expanded cross neighborhood re-ranking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 420–429. [Google Scholar]
- Li, S.; Karanam, S.Y.; Li, R.J. Radke, Person re-identification with discriminatively trained viewpoint invariant dictionaries. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4516–4524. [Google Scholar]
- Bak, S.; Zaidenberg, S.; Boulay, B.; Bremond, F. Improving person re-identification by viewpoint cues. In Proceedings of the IEEE International Conference on Advanced Video and Signal Based Surveillance, Seoul, Republic of Korea, 26–29 August 2014; pp. 175–180. [Google Scholar] [CrossRef]
- Huang, H.; Li, D.; Zhang, Z.; Chen, X.; Huang, K. Adversarially occluded samples for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5098–5107. [Google Scholar]
- Hou, R.; Ma, B.; Chang, H.; Gu, X.; Shan, S.; Chen, X. Vrstc: Occlusion-free video person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7183–7192. [Google Scholar]
- Wang, S.; Liu, R.; Li, H.; Qi, G.; Yu, Z. Occluded Person Re-Identification via Defending Against Attacks From Obstacles. IEEE Trans. Inf. Secur. 2023, 18, 147–161. [Google Scholar] [CrossRef]
- Huang, Y.; Zha, Z.J.; Fu, X.; Zhang, W. Illumination-invariant person re-identification. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 365–373. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Mask-guided contrastive attention model for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1179–1188. [Google Scholar]
- Chen, D.; Zhang, S.; Ouyang, W.; Yang, J.; Tai, Y. Person search via a mask-guided two-stream cnn model. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Cai, H.; Wang, Z.; Cheng, J. Multi-scale body-part mask guided attention for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, X.; Zheng, W.S.; Wang, X.; Xiang, T.; Gong, S. Multi-scale learning for low-resolution person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3765–3773. [Google Scholar]
- Wang, Y.; Wang, L.; You, Y.; Zou, X.; Chen, V.; Li, S.; Huang, G.; Hariharan, B.; Weinberger, K.Q. Resource aware person re-identification across multiple resolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8042–8051. [Google Scholar]
- Khan, S.U.; Haq, I.U.; Khan, N.; Muhammad, K.; Hijji, M.; Baik, S.W. Learning to rank: An intelligent system for person reidentification. Int. J. Intell. Syst. 2022, 39, 5924–5948. [Google Scholar] [CrossRef]
- Liu, H.; Hu, L.; Ma, L. Online RGB–D person re-identification based on metric model update. CAAI Trans. Intell. Technol. 2017, 2, 48–55. [Google Scholar] [CrossRef]
- Wu, A.; Zheng, W.S.; Lai, J.H. Robust depth-based person re-identification. IEEE Trans. Image Process. 2017, 26, 2588–2603. [Google Scholar] [CrossRef]
- Munaro, M.; Fossati, A.; Basso, A.; Menegatti, E.; Van Gool, L. One-shot person re-identification with a consumer depth camera. In Advances in Computer Vision and Pattern Recognition; Gong, S., Cristani, M., Yan, S., Loy, C., Eds.; Person Re-Identification; Springer: London, UK, 2014; pp. 161–181. [Google Scholar] [CrossRef]
- Imani, Z.; Soltanizadeh, H. Person reidentification using local pattern descriptors and anthropometric measures from videos of kinect sensor. IEEE Sens. J. 2016, 16, 6227–6238. [Google Scholar] [CrossRef]
- Ren, L.; Lu, J.; Feng, J.; Zhou, J. Multi-modal uniform deep learning for RGB–D person re-identification. Pattern Recognit. 2017, 72, 446–457. [Google Scholar] [CrossRef]
- Ren, L.; Lu, J.; Feng, J.; Zhou, J. Uniform and variational deep learning for RGB–D object recognition and person re-identification. IEEE Trans. Image Process. 2019, 28, 4970–4983. [Google Scholar] [CrossRef]
- Haque, A.; Alahi, A.; Li, F.-F. Recurrent attention models for depth-based person identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1229–1238. [Google Scholar]
- Lejbolle, A.R.; Nasrollahi, K.; Krogh, B.; Moeslund, T.B. Multimodal neural network for overhead person re-identification. In Proceedings of the International Conference of the Biometrics Special Interest Group, Darmstadt, Germany, 20–22 September 2017; pp. 1–5. [Google Scholar] [CrossRef]
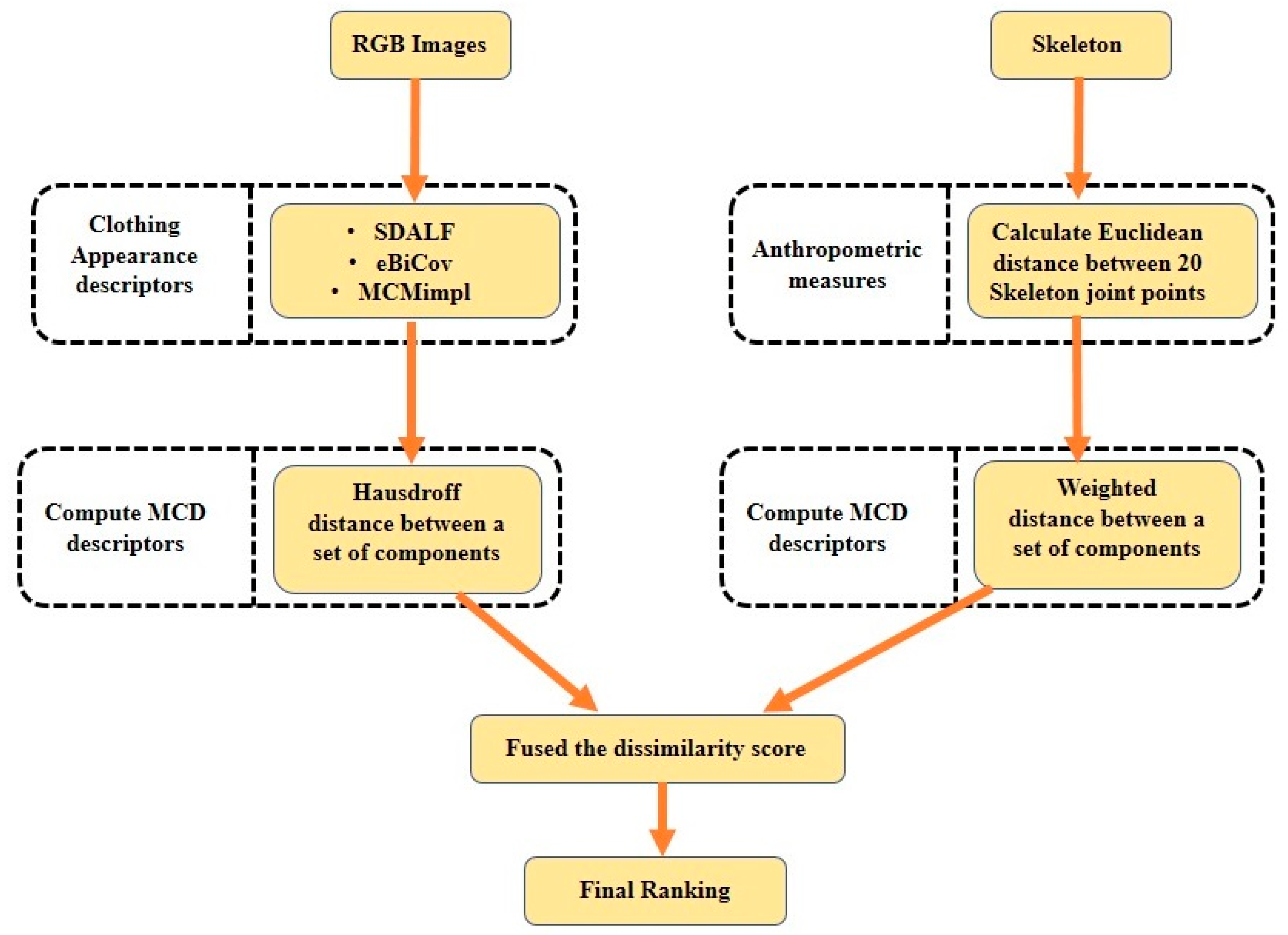
- Pala, F.; Satta, R.; Fumera, G.; Roli, F. Multimodal person reidentification using RGB–D cameras. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 788–799. [Google Scholar] [CrossRef]
- Uddin, M.K.; Lam, A.; Fukuda, H.; Kobayashi, Y.; Kuno, Y. Fusion in Dissimilarity Space for RGB–D Person Re-identification. Array 2021, 12, 100089. [Google Scholar] [CrossRef]
- Liciotti, D.; Paolanti, M.; Frontoni, E.; Mancini, A.; Zingaretti, P. Person re-identification dataset with rgb-d camera in a top-view configuration. In Video Analytics. Face and Facial Expression Recognition and Audience Measurement; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 10165, pp. 1–11. [Google Scholar] [CrossRef]
- Mogelmose, A.; Bahnsen, C.; Moeslund, T.; Clapés, A.; Escalera, S. Tri-modal person re-identification with rgb, depth and thermal features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 301–307. [Google Scholar]
- Wu, A.; Zheng, W.S.; Yu, H.X.; Gong, S.; Lai, J. RGB-infrared cross-modality person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5380–5389. [Google Scholar]
- Nguyen, D.T.; Hong, H.G.; Kim, K.W.; Park, K.R. Person recognition system based on a combination of body images from visible light and thermal cameras. Sensors 2017, 17, 605. [Google Scholar] [CrossRef] [PubMed]
- Lejbolle, A.R.; Krogh, B.; Nasrollahi, K.; Moeslund, T.B. Attention in multimodal neural networks for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 179–187. [Google Scholar]
- Uddin, M.K.; Lam, A.; Fukuda, H.; Kobayashi, Y.; Kuno, Y. Depth Guided Attention for Person Re-identification. In Intelligent Computing Methodologies; Lecture Notes in Computer Science; Huang, D.S., Premaratne, P., Eds.; Springer: Cham, Switzerland, 2020; Volume 12465, pp. 110–120. [Google Scholar] [CrossRef]
- Zhuo, J.; Zhu, J.; Lai, J.; Xie, X. Person re-identification on heterogeneous camera network. In CCF Chinese Conference on Computer Vision; Communications in Computer and Information Science; Springer: Singapore, 2017; Volume 773, pp. 280–291. [Google Scholar] [CrossRef]
- Uddin, M.K.; Lam, A.; Fukuda, H.; Kobayashi, Y.; Kuno, Y. Exploiting Local Shape Information for Cross-Modal Person Re-identification. In Intelligent Computing Methodologies; Lecture Notes in Computer Science; Huang, D.S., Huang, Z.K., Hussain, A., Eds.; Springer: Cham, Switzerland, 2019; Volume 11645, pp. 74–85. [Google Scholar] [CrossRef]
- Hafner, F.M.; Bhuiyan, A.; Kooij, J.F.; Granger, E. RGB-depth cross-modal person re-identification. In Proceedings of the 16th IEEE International Conference on Advanced Video and Signal Based Surveillance, Taipei, Taiwan, 18–21 September 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Hafner, F.M.; Bhuiyan, A.; Kooij, J.F.; Granger, E. Cross-modal distillation for RGB-depth person re-identification. Comput. Vis. Image Underst. 2022, 216, 103352. [Google Scholar] [CrossRef]
- Wu, J.; Jiang, J.; Qi, M.; Chen, C.; Zhang, J. An End-to-end Heterogeneous Restraint Network for RGB–D Cross-modal Person Re-identification. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–22. [Google Scholar] [CrossRef]
- Coşar, S.; Bellotto, N. Human Re-identification with a robot thermal camera using entropy-based sampling. J. Intell. Robot. Syst. 2020, 98, 85–102. [Google Scholar] [CrossRef]
- Imani, Z.; Soltanizadeh, H.; Orouji, A.A. Short-term person re-identification using rgb, depth and skeleton information of rgb-d sensors. Iran. J. Sci. Technol. Trans. Electr. Eng. 2020, 44, 669–681. [Google Scholar] [CrossRef]
- Uddin, M.K.; Bhuiyan, A.; Hasan, M. Fusion in Dissimilarity Space between RGB–D and Skeleton for Person Re-identification. Int. J. Innov. Technol. Explor. Eng. 2021, 10, 69–75. [Google Scholar] [CrossRef]
- Martini, M.; Paolanti, M.; Frontoni, E. Open-World Person Re-Identification with RGBD Camera in Top-View Configuration for Retail Applications. IEEE Access 2020, 8, 67756–67765. [Google Scholar] [CrossRef]
- Barbosa, I.B.; Cristani, M.; Del Bue, A.; Bazzani, L.; Murino, V. Re-identification with RGB–D Sensors. In Computer Vision—ECCV 2012; Lecture Notes in Computer Science; Fusiello, A., Murino, V., Cucchiara, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7583, pp. 433–442. [Google Scholar] [CrossRef]
- Patruno, C.; Marani, R.; Cicirelli, G.; Stella, E.; D’Orazio, T. People re-identification using skeleton standard posture and color descriptors from RGB–D data. Pattern Recognit. 2019, 89, 77–90. [Google Scholar] [CrossRef]
- Farenzena, M.; Bazzani, L.; Perina, A.; Murino, V.; Cristani, M. Person re-identification by symmetry-driven accumulation of local features. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2360–2367. [Google Scholar] [CrossRef]
- Ma, B.; Su, Y.; Jurie, F. Covariance descriptor based on bio-inspired features for person re-identification and face verification. Image Vis. Comput. 2014, 32, 379–390. [Google Scholar] [CrossRef]
- Satta, R.; Fumera, G.; Roli, F.; Cristani, M.; Murino, V. A Multiple Component Matching Framework for Person Re-identification. In Image Analysis and Processing; Lecture Notes in Computer Science; Maino, G., Foresti, G.L., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6979, pp. 140–149. [Google Scholar] [CrossRef]
- Imani, Z.; Soltanizadeh, H. Histogram of the node strength and histogram of the edge weight: Two new features for RGB–D person re-identification. Sci. China Inf. Sci. 2018, 61, 092108. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Ristani, E.; Tomasi, C. Features for multi-target multi-camera tracking and re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6036–6046. [Google Scholar]
- Pang, L.; Wang, Y.; Song, Y.Z.; Huang, T.; Tian, Y. Cross-domain adversarial feature learning for sketch re-identification. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 609–617. [Google Scholar] [CrossRef]
- Feng, Z.; Lai, J.; Xie, X. Learning Modality-Specific Representations for Visible-Infrared Person Re-Identification. IEEE Trans. Image Process. 2020, 29, 579–590. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Wu, Y.; Liu, B.; Zhang, T.; Li, B.; Chu, Q.; Yu, N. Cross-Modality Person Re-Identification With Shared-Specific Feature Transfer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13376–13386. [Google Scholar]
- Ye, M.; Lan, X.; Leng, Q.; Shen, J. Cross-Modality Person Re-Identification via Modality-Aware Collaborative Ensemble Learning. IEEE Trans. Image Process. 2020, 29, 9387–9399. [Google Scholar] [CrossRef]
- Wei, X.; Li, D.; Hong, X.; Ke, W.; Gong, Y. Co-Attentive Lifting for Infrared-Visible Person Re-Identification. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1028–1037. [Google Scholar]
- Wang, H.; Zhao, J.; Zhou, Y.; Yao, R.; Chen, Y.; Chen, S. AMC-Net: Attentive modality-consistent network for visible-infrared person re-identification. Neurocomputing 2021, 463, 226–236. [Google Scholar] [CrossRef]
- Pu, N.; Chen, W.; Liu, Y.; Bakker, E.M.; Lew, M.S. Dual Gaussian-based Variational Subspace Disentanglement for Visible-Infrared Person Re-Identification. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2149–2158. [Google Scholar]
- Kansal, K.; Subramanyam, A.V.; Wang, Z.; Satoh, S. SDL: Spectrum-Disentangled Representation Learning for Visible-Infrared Person Re-Identification. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3422–3432. [Google Scholar] [CrossRef]
- Hao, Y.; Wang, N.; Gao, X.; Li, J.; Wang, X. Dual-alignment Feature Embedding for Cross-modality Person Re-identification. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 57–65. [Google Scholar]
- Wei, Z.; Yang, X.; Wang, N.; Song, B.; Gao, X. ABP: Adaptive Body Partition Model For Visible Infrared Person Re-Identification. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME 2020), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Liu, S.; Zhang, J. Local Alignment Deep Network for Infrared-Visible Cross-Modal Person Re-identification in 6G-Enabled Internet of Things. IEEE Internet Things J. 2020, 8, 15170–15179. [Google Scholar] [CrossRef]
- Ye, M.; Shen, J.; Crandall, D.J.; Shao, L.; Luo, J. Dynamic Dual-Attentive Aggregation Learning for Visible-Infrared Person Re-identification. In Proceedings of the 2020 16th European Conference Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 229–247. [Google Scholar]
- Wang, P.; Zhao, Z.; Su, F.; Zhao, Y.; Wang, H.; Yang, L.; Li, Y. Deep Multi-Patch Matching Network for Visible Thermal Person Re-Identification. IEEE Trans. Multimed. 2021, 23, 1474–1488. [Google Scholar] [CrossRef]
- Wei, Z.; Yang, X.; Wang, N.; Gao, X. Flexible Body Partition-Based Adversarial Learning for Visible Infrared Person ReIdentification. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4676–4687. [Google Scholar] [CrossRef]
- Zhang, L.; Du, G.; Liu, F.; Tu, H.; Shu, X. Global-Local Multiple Granularity Learning for Cross-Modality Visible-Infrared Person Reidentification. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–11. [Google Scholar] [CrossRef]
- Dai, H.; Xie, Q.; Li, J.; Ma, Y.; Li, L.; Liu, Y. Visible-infrared Person Re-identification with Human Body Parts Assistance. In Proceedings of the 2021 International Conference on Multimedia Retrieval, Taipei, Taiwan, 21–24 August 2021; pp. 631–637. [Google Scholar]
- Ye, M.; Lan, X.; Li, J.; Yuen, P.C. Hierarchical Discriminative Learning for Visible Thermal Person Re-Identification. In Proceedings of the 2018 32th AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7501–7508. [Google Scholar]
- Liu, H.; Tan, X.; Zhou, X. Parameters Sharing Exploration and Hetero-Center based Triplet Loss for Visible-Thermal Person Re-Identification. IEEE Trans. Multimed. 2020, 23, 4414–4425. [Google Scholar] [CrossRef]
- Ye, H.; Liu, H.; Meng, F.; Li, X. Bi-Directional Exponential Angular Triplet Loss for visible-Infrared Person Re-Identification. IEEE Trans. Image Process. 2021, 30, 1583–1595. [Google Scholar] [CrossRef] [PubMed]
- Cai, X.; Liu, L.; Zhu, L.; Zhang, H. Dual-modality hard mining triplet-center loss for visible infrared person re-identification. Knowl. Based Syst. 2021, 215, 106772. [Google Scholar] [CrossRef]
- Zhang, Q.; Lai, J.; Xie, X. Learning Modal-Invariant Angular Metric by Cyclic Projection Network for VIS-NIR Person ReIdentification. IEEE Trans. Image Process. 2021, 30, 8019–8803. [Google Scholar] [CrossRef] [PubMed]
- Hao, Y.; Wang, N.; Li, J.; Gao, X. HSME: Hypersphere Manifold Embedding for Visible Thermal Person Re-Identification. In Proceedings of the 2019 33th AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; pp. 8385–8392. [Google Scholar]
- Zhong, X.; Lu, T.; Huang, W.; Yuan, J.; Liu, W.; Lin, C. Visible-infrared Person Re-identification via Colorization-based Siamese Generative Adversarial Network. In Proceedings of the 2020 ACM International Conference Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; pp. 421–427. [Google Scholar]
- Kniaz, V.V.; Knyaz, V.A.; Hladuvka, J.; Kropatsch, W.G.; Mizginov, V. ThermalGAN: Multimodal Color-to-Thermal Image Translation for Person Re-identification in Multispectral Dataset. In Proceedings of the 2018 European Conference Computer Vision Workshops, Munich, Germany, 8–14 September 2018; pp. 606–624. [Google Scholar]
- Liu, H.; Ma, S.; Xia, D.; Li, S. SFANet: A Spectrum-Aware Feature Augmentation Network for Visible-Infrared Person ReIdentification. IEEE Trans. Neural Netw. Learn. Sys. 2021, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Wang, Z.; Zheng, Y.; Chuang, Y.; Satoh, S. Learning to Reduce Dual-Level Discrepancy for Infrared-Visible Person Re-Identification. In Proceedings of the 2019 IEEE/CVF Conference Computer Vision Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 618–626. [Google Scholar]
- Choi, S.; Lee, S.; Kim, Y.; Kim, T.; Kim, C. Hi-CMD: Hierarchical Cross-Modality Disentanglement for Visible-Infrared Person Re-Identification. In Proceedings of the2020 IEEE/CVF Conference Computer Vision Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10254–10263. [Google Scholar]
- Wang, G.; Zhang, T.; Yang, Y.; Cheng, J.; Chang, J.; Liang, X.; Hou, Z. Cross-Modality Paired-Images Generation for RGB-Infrared Person Re-Identification. In Proceedings of the 2020 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12144–12151. [Google Scholar]
- Hu, B.; Liu, J.; Zha, Z.J. Adversarial Disentanglement and Correlation Network for RGB-Infrared Person Re-Identification. In Proceedings of the 2021 IEEE International Conference on Multimedia Expo, Shenzhen, China, 5–9 July 2021. [Google Scholar]
- Li, D.; Wei, X.; Hong, X.; Gong, Y. Infrared-Visible Cross-Modal Person Re-Identification with an X Modality. In Proceedings of the 2020 34th AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 4610–4617. [Google Scholar]
- Huang, Y.; Wu, Q.; Xu, J.; Zhong, Y.; Zhang, P.; Zhang, Z. Alleviating Modality Bias Training for Infrared-Visible Person Re-Identification. IEEE Trans. Multimed. 2021, 24, 1570–1582. [Google Scholar] [CrossRef]
- Wei, Z.; Yang, X.; Wang, N.; Gao, X. Syncretic Modality Collaborative Learning for Visible Infrared Person Re-Identification. In Proceedings of the 2021 IEEE/CVF International Conference Computer Vision, Virtual, 11–17 October 2021. [Google Scholar]
- Zhang, Y.; Yan, Y.; Lu, Y.; Wang, H. Towards a Unified Middle Modality Learning for Visible-Infrared Person Re-Identification. In Proceedings of the 2021 ACM International Conference Multimedia, Chengdu, China, 20–24 October 2021; pp. 788–796. [Google Scholar]
- CASIA Gait Database. Available online: http://www.cbsr.ia.ac.cn/english/Gait%20Databases.asp (accessed on 12 November 2022).
- Intel RealSense Depth Camera. Available online: https://www.intelrealsense.com/depth-camera-d435/ (accessed on 20 November 2022).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Approach | Brief Description | Dataset and Accuracy (Rank 1/nAUC) |
|---|---|---|---|---|
| Barbosa et al. [58] | 2012 | Soft-biometric feature-learning approach. | This Re-ID approach has two distinct phases: soft-biometric feature extraction and matching. Soft-biometric features are extracted from depth data, and these features are matched against test samples from the gallery set. | RGBD-ID: 88.1% (nAUC). |
| Mogelmose et al. [44] | 2013 | RGB, depth, and thermal feature-based score-level fusion technique. | In this approach, color information from different parts of the body, soft biometrics, and local structural information are extracted from RGB, depth, and thermal data, respectively. This information is combined in a joined classifier to perform the Re-ID task. | RGB–D–T: 82% (rank 1). |
| Munaro et al. [35] | 2014 | One-shot person Re-ID with soft-biometric cues. | This approach compares the performance of Re-IDs between skeleton information and point-cloud-estimation techniques. The authors considered four different classifiers, Nearest Neighbor, SVM, Generic SVM, and Naïve Bayes, to compare the performance between them. | BIWI RGBD-ID: For skeleton, 26.6% (rank 1) and 89.7% (nAUC). For point cloud, 22.4% (rank 1) and 81.6% (nAUC). |
| Munaro et al. [14] | 2014 | 3D-model reconstruction of freely moving people from point clouds which are used to re-identify individuals. | This approach shows how the 3D model of a person is effectively used for person re-identification tasks and also overcomes the issue of pose variation by turning the skeleton information of a person’s point clouds into a standard pose. | BIWI RGBD-ID: 32.5% (rank 1), 89.0% (nAUC). IAS-Lab RGBD-ID: 43.7% (rank 1), 81.7% (nAUC). |
| Pala et al. [41] | 2015 | RGB appearance features and skeleton information-based score-level fusion technique. | In this approach, the re-identification accuracy of RGB appearance features is improved by fusing them with anthropometric information extracted from depth data. A dissimilarity-based framework is employed for fusing multi-modal features. | RGBD-ID: 73.85% (rank 1). KinectREID: 50.37% (rank 1). |
| Imani et al. [36] | 2016 | Re-identification using local pattern descriptors and anthropometric measures. | In this approach, the histograms of Local Binary Patterns (LBP) and Local Tetra Patterns (LTrP) are computed as features for person Re-ID. These histogram features are fused with anthropometric features using score-level fusion. | RGBD-ID: 76.58% (rank 1). KinectREID: 66.08% (rank 1). |
| Wu et al. [34] | 2017 | Depth-shape-based Re-ID approach. | This approach exploits depth–voxel covariance descriptors and local, invariant Eigen-depth features. The authors also extracted skeleton features from joint points of the skeleton. Finally, they combined depth-shape descriptors with skeleton-based features to form complete representations of individuals for re-identification | RGBD-ID: 67.64% (rank 1). BIWI RGBD-ID: 30.52% (rank 1). IAS-Lab RGBD-ID: 58.65% (rank 1). |
| Ren et al. [37] | 2017 | Uniform deep-learning-based person Re-ID approach. | This approach uses the deep network to extract anthropometric features from depth images and design a multi-modal fusion layer combining the extracted features and RGB images through the network with a uniform latent variable. | RGBD-ID: 76.7% (rank 1). KinectREID: 97% (rank 1). |
| Lejbolle et al. [40] | 2017 | CNN-based multi-modal feature fusion approach. | This Re-ID approach considers an overhead view rather than a frontal view of individuals, which reduces privacy issues and occlusion problems. Two CNN models are trained using RGB and depth images to provide fused features, which improve the accuracy of Re-ID. | OPR: 74.69% (rank 1). TVPR: 77.66% (rank 1). DPI-T: 90.36% (rank 1). |
| Liu et al. [33] | 2017 | Person re-identification based on metric model updates. | In this approach, each person is described by RGB appearance cues and geometric features using skeleton information. Then, a metric model is pre-trained offline using label data, and face information is utilized to update the metric model online. Finally, feature similarities are fused using the feature funnel model. | RobotPKU: 77.94% (rank 1). BIWI RGBD-ID: 91.4% (rank 1). |
| Lejbolle et al. [47] | 2018 | A multi-modal attention network based on RGB and depth modalities. | This Re-ID approach considers an overhead view for person Re-ID to decrease occlusion problems and increase privacy preservation. A CNN and an attention module are combined to extract local and discriminative features that are fused with globally extracted features. The authors finally fused RGB and depth features to generate joint multilevel RGB–D features. | DPI-T: 90.36% (rank 1). TVPR: 63.83% (rank 1). OPR: 45.63% (rank 1). |
| Imani et al. [63] | 2018 | Two novel histogram feature-based Re-ID. | The authors extracted two features, a histogram of the edge weight and a histogram of the node strength, from depth images. Then, the histograms were combined with skeleton features using score-level fusion and were used for person re-identification. | KinectREID: 58.35% (rank 1). RGBD-ID: 62.43% (rank 1). |
| Patruno et al. [59] | 2019 | Person Re-ID using Skeleton Standard Postures and color descriptors. | This approach introduces Skeleton Standard Postures (SSPs) for computing partition grids to generate independent and robust color-based features. A combination of the color and the depth of information identifies very informative features of a person to increase re-identification performance. | BIWI RGBD-ID: 97.84% (rank 1). KinectREID: 61.97% (rank 1). RGBD-ID: 89.71% (rank 1). |
| Ren et al. [38] | 2019 | Uniform and variational deep learning for person Re-ID. | This approach uses uniform and variational deep learning for person re-identification. The authors extracted RGB appearance features and depth features using one CNN for each feature from RGB–D images. To combine the appearance features and depth features, uniform and variational auto-encoders were designed on the top layer of the deep network to find a uniform latent variable. | KinectREID: 99.4% (rank 1). RGBD-ID: 76.7% (rank 1). |
| Imani et al. [55] | 2020 | Re-identification using RGB, depth, and skeleton information. | In this approach, the depth and RGB images are divided into three regions: the head, the torso, and the legs. For each region, a histogram of local vector patterns is estimated. The skeleton features are extracted by calculating the various Euclidean distances for the joint points of skeleton images. Then, extracted features are combined as double and triple combinations using score-level fusion. | KinectREID: 75.83% (rank 1). RGBD-ID: 85.5% (rank 1). |
| Uddin et al. [48] | 2020 | Depth-guided attention of person Re-ID. | This approach introduces depth-guided, attention-based person re-identification. The key component of this framework is the depth-guided foreground extraction that helps the model improve the performance of Re-ID. | RobotPKU: 92.04% (rank 1). |
| Martini et al. [57] | 2020 | A deep-learning approach for top-view, open-world person Re-ID. | The authors present top-view, open-world person Re-ID. This approach is based on a pretrained deep CNN, finetuned using a dataset acquired by using top-view configuration. A triplet loss function is used to train the network. | TVPR: 95.13% (rank 1). TVPR2 [42]: 93.30% (rank 1). |
| Uddin et al. [42] | 2021 | Fusion in a dissimilarity space for RGB–D person Re-ID. | In this approach, two CNNs are separately trained with three-channel RGB and four-channel RGB–D images to produce two different feature embeddings and compute the dissimilarities between queries and galleries in different feature embeddings. The computed dissimilarities for two individual modes are then fused in a dissimilarity space to obtain their final matching scores. | RobotPKU: 93.33% (rank 1). RGBD-ID: 82.05% (rank 1). SUCVL: 87.65% (rank 1). |
| Dataset | Year | #ID | #Camera and Location | RGB | Depth | Skeleton |
|---|---|---|---|---|---|---|
| RGBD-ID | 2012 | 79 | 1 (same location but different clothes and poses) | √ | √ | √ |
| BIWI-RGBD-ID | 2014 | 50 | 1 (same location but different days with different clothes and poses) | √ | √ | √ |
| IAS-Lab | 2014 | 11 | 2 (different locations and people wearing different clothes) | √ | √ | √ |
| KinectREID | 2015 | 71 | 1 (same room with different poses) | √ | √ | √ |
| RobotPKU RGBD-ID | 2017 | 90 | 2 (two different rooms with pose variations) | √ | √ | √ |
| SUCVL RGBD-ID * | 2021 | 58 | 3 (three different indoor locations) | √ | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uddin, M.K.; Bhuiyan, A.; Bappee, F.K.; Islam, M.M.; Hasan, M. Person Re-Identification with RGB–D and RGB–IR Sensors: A Comprehensive Survey. Sensors 2023, 23, 1504. https://doi.org/10.3390/s23031504
Uddin MK, Bhuiyan A, Bappee FK, Islam MM, Hasan M. Person Re-Identification with RGB–D and RGB–IR Sensors: A Comprehensive Survey. Sensors. 2023; 23(3):1504. https://doi.org/10.3390/s23031504
Chicago/Turabian StyleUddin, Md Kamal, Amran Bhuiyan, Fateha Khanam Bappee, Md Matiqul Islam, and Mahmudul Hasan. 2023. "Person Re-Identification with RGB–D and RGB–IR Sensors: A Comprehensive Survey" Sensors 23, no. 3: 1504. https://doi.org/10.3390/s23031504
APA StyleUddin, M. K., Bhuiyan, A., Bappee, F. K., Islam, M. M., & Hasan, M. (2023). Person Re-Identification with RGB–D and RGB–IR Sensors: A Comprehensive Survey. Sensors, 23(3), 1504. https://doi.org/10.3390/s23031504