
LAD: Layer-Wise Adaptive Distillation for BERT Model Compression


Abstract
:1. Introduction
- We designed a novel task-specific distillation framework called Layer-wise Adaptive Distillation (LAD), which can train the student model without skipping any teacher layers for better model compression.
- The proposed method achieved competitive performances on several GLUE tasks and reduced the performance gap between the teacher and the student model.
- The proposed method can benefit task-specific distillation by retaining the sentence-processing nature of BERT [16].
- Our method can further be applied to IoT or edge devices to leverage the pre-trained language models for natural language applications.
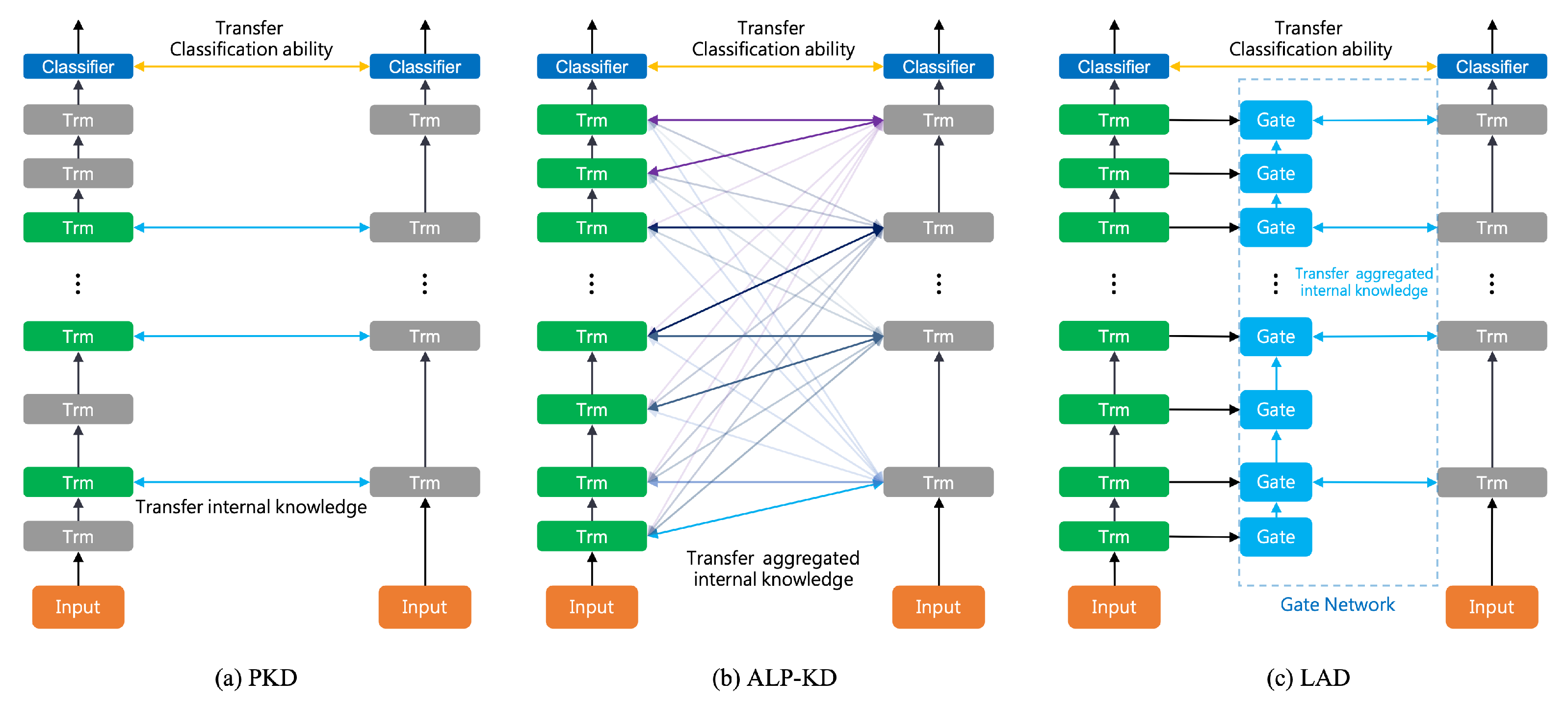
2. Related Work
3. Materials and Methods
3.1. Internal Knowledge in Teacher Layers
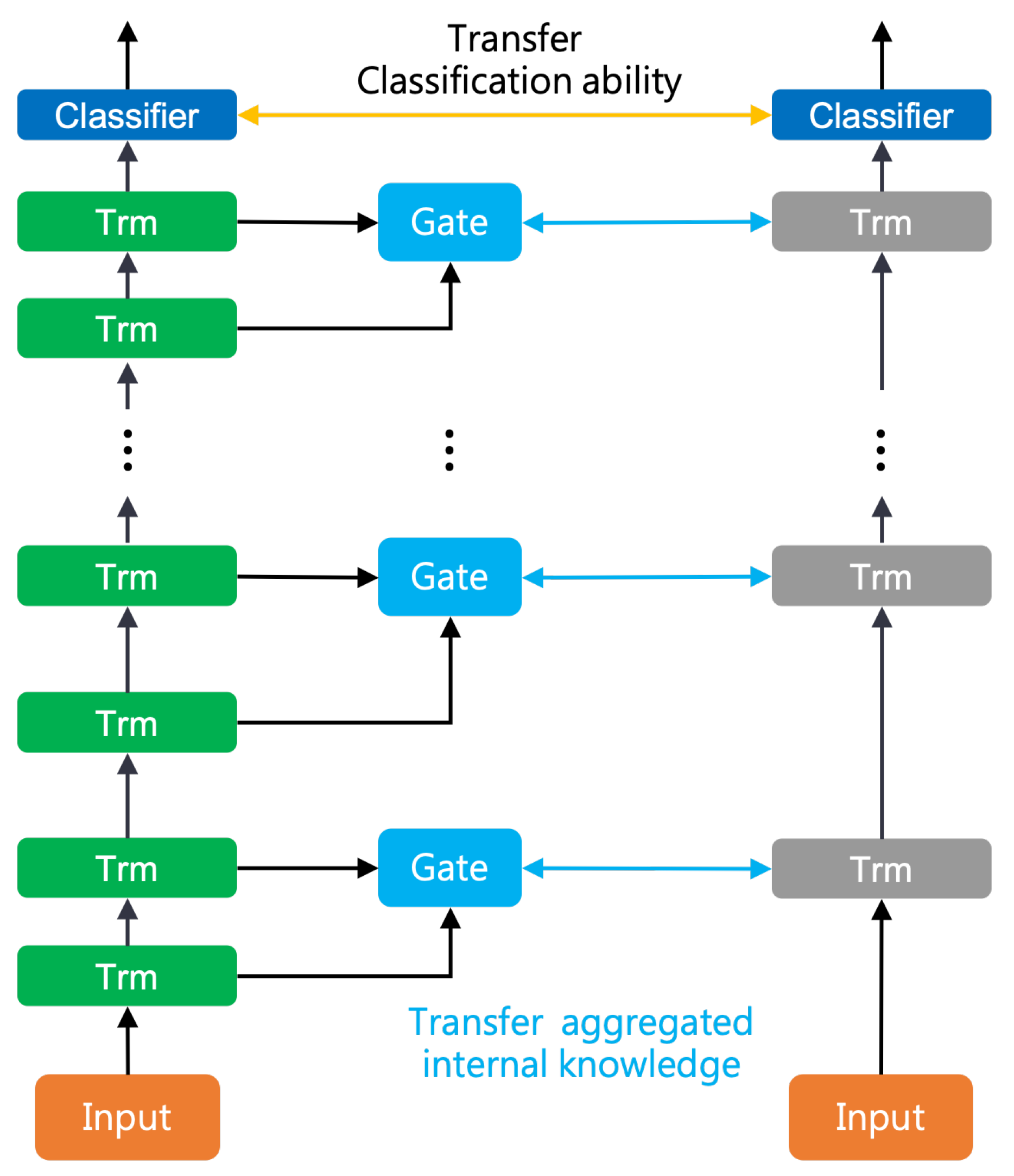
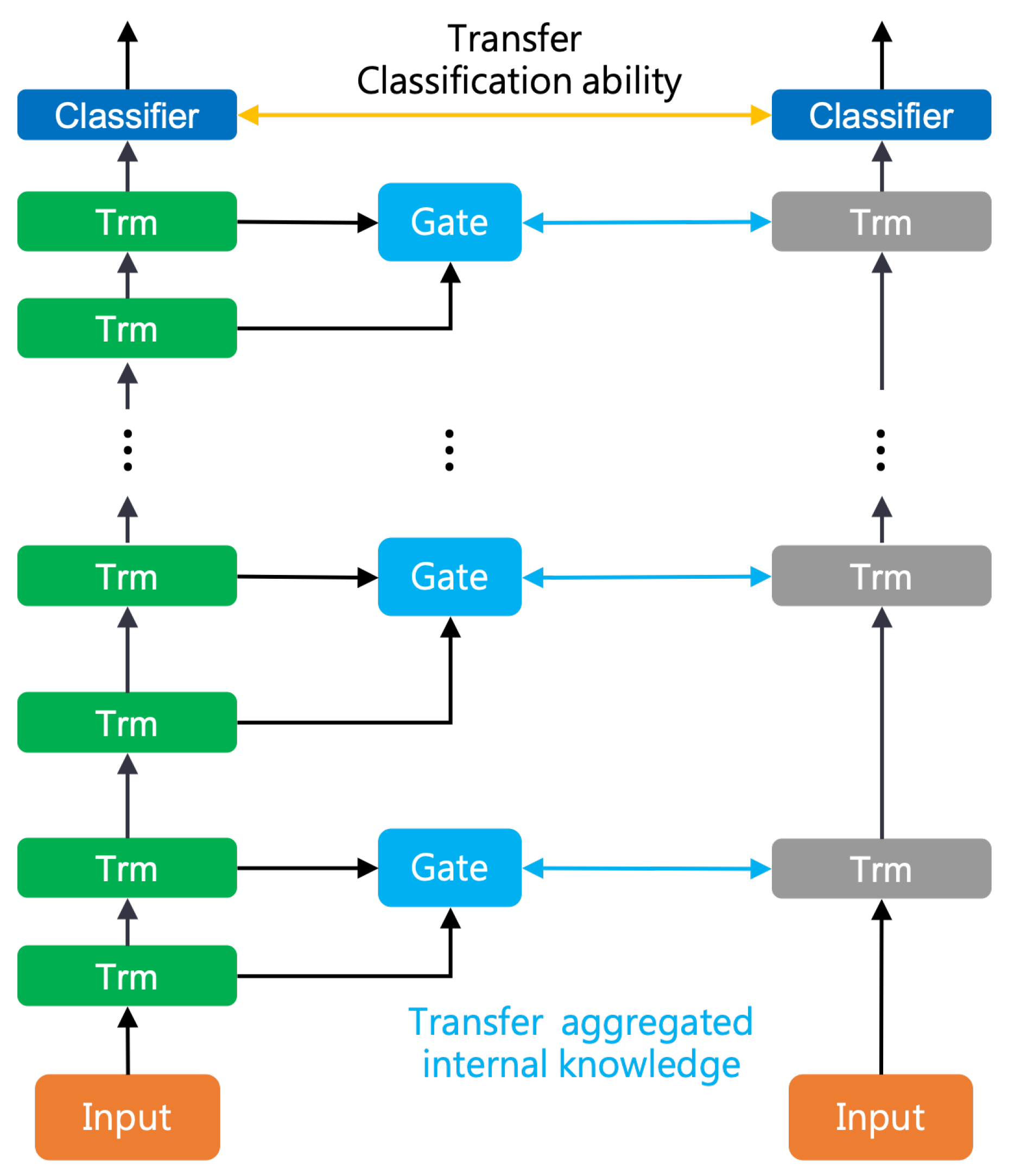
3.2. Gate Block
3.3. Iterative Aggregation Mechanism
3.4. Learn Predictions from the Teacher
3.5. Learn Predictions from a Downstream Task
3.6. Distillation Objective
4. Experiments
4.1. Datasets
4.1.1. SST-2
4.1.2. MRPC
4.1.3. QQP
4.1.4. MNLI
4.1.5. QNLI
4.1.6. RTE
4.2. Teacher Model
4.3. Baselines and Implementation Details
5. Results
5.1. Results on GLUE Test Sets
5.2. Results on GLUE Development Sets
5.3. Comparison with the Attention Mechanism
5.4. Analysis of the Directions of Gates
5.5. Analysis of Aggregated Knowledge
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LAD | Layer-wise Adaptive Distillation |
| BERT | Bidirectional Encoder Representations from Transformers |
| KD | Knowledge Distillation |
| NLI | Natural Language Inference |
| GLUE | The General Language Understanding Evaluation benchmark |
| SST | The Stanford Sentiment Treebank |
| MRPC | Microsoft Research Paraphrase Corpus |
| QQP | Quora Question Pairs |
| MNLI | Multi-Genre Natural Language Inference |
| QNLI | Question-answering NLI |
| RTE | Recognizing Textual Entailment |
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. In Proceedings of the Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Vancouver, BC, Canada, 2019; Volume 32, pp. 5753–5763. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. International Conference on Learning Representations. 2020. Available online: https://openreview.net/forum?id=r1xMH1BtvB (accessed on 1 November 2022).
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. OpenAI Blog. 2018. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 1 November 2022).
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Online, 2020; Volume 33, pp. 1877–1901. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Buciluǎ, C.; Caruana, R.; Niculescu-Mizil, A. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 535–541. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. TinyBERT: Distilling BERT for Natural Language Understanding. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Online, 2020; pp. 4163–4174. [Google Scholar]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. MobileBERT: A Compact Task-Agnostic BERT for Resource-Limited Devices. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Online, 2020; pp. 2158–2170. [Google Scholar]
- Wang, W.; Wei, F.; Dong, L.; Bao, H.; Yang, N.; Zhou, M. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers. In Proceedings of the Advances in Neural Information Processing Systems; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M.F., Lin, H., Eds.; Curran Associates, Inc.: Online, 2020; Volume 33, pp. 5776–5788. [Google Scholar]
- Sun, S.; Cheng, Y.; Gan, Z.; Liu, J. Patient Knowledge Distillation for BERT Model Compression. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP); Association for Computational Linguistics: Hong Kong, China, 2019; pp. 4323–4332. [Google Scholar]
- Passban, P.; Wu, Y.; Rezagholizadeh, M.; Liu, Q. ALP-KD: Attention-Based Layer Projection for Knowledge Distillation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 13657–13665. [Google Scholar]
- Tenney, I.; Das, D.; Pavlick, E. BERT Rediscovers the Classical NLP Pipeline. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Florence, Italy, 2019; pp. 4593–4601. [Google Scholar]
- Srivastava, R.K.; Greff, K.; Schmidhuber, J. Training Very Deep Networks. In Proceedings of the Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Montreal, QC, Canada, 2015; Volume 28, pp. 2377–2385. [Google Scholar]
- Li, J.; Liu, X.; Zhao, H.; Xu, R.; Yang, M.; Jin, Y. BERT-EMD: Many-to-Many Layer Mapping for BERT Compression with Earth Mover’s Distance. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP); Association for Computational Linguistics: Online, 2020; pp. 3009–3018. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. International Conference on Learning Representations. 2019. Available online: https://openreview.net/forum?id=rJ4km2R5t7 (accessed on 1 November 2022).
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the EMNLP, Seattle, MA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Dolan, W.B.; Brockett, C. Automatically Constructing a Corpus of Sentential Paraphrases. In Proceedings of the International Workshop on Paraphrasing; 2005. Available online: https://aclanthology.org/I05-5002 (accessed on 1 November 2022).
- Dagan, I.; Glickman, O.; Magnini, B. The PASCAL Recognising Textual Entailment Challenge. In Machine Learning Challenges. Evaluating Predictive Uncertainty, Visual Object Classification, and Recognising Tectual Entailment; Springer: Berlin/Heidelberg, Germany, 2005; pp. 177–190. [Google Scholar]
- Bar Haim, R.; Dagan, I.; Dolan, B.; Ferro, L.; Giampiccolo, D.; Magnini, B.; Szpektor, I. The Second PASCAL Recognising Textual Entailment Challenge. In Proceedings of the Second PASCAL Challenges Workshop on Recognising Textual Entailment; 2006; Volume 7. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=33f25fae10da978fad3f48eb6bded2f733b28e92 (accessed on 1 November 2022).
- Giampiccolo, D.; Magnini, B.; Dagan, I.; Dolan, B. The third PASCAL recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing; Association for Computational Linguistics: Minneapolis, MN, USA, 2007; pp. 1–9. [Google Scholar]
- Bentivogli, L.; Dagan, I.; Dang, H.T.; Giampiccolo, D.; Magnini, B. The Fifth PASCAL Recognizing Textual Entailment Challenge, Text Analysis Conference (TAC). 2009. Available online: https://tac.nist.gov//publications/2009/additional.papers/RTE5_overview.proceedings.pdf (accessed on 1 November 2022).
- Xu, C.; Zhou, W.; Ge, T.; Wei, F.; Zhou, M. BERT-of-Theseus: Compressing BERT by Progressive Module Replacing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 7859–7869. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Long Beach, CA, USA, 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. International Conference on Learning Representations. 2019. Available online: https://openreview.net/forum?id=Bkg6RiCqY7 (accessed on 1 November 2022).

{kind=link}
{kind=link}
| Method | Teacher Model | Use of External Data? | Knowledge Distillation Type |
|---|---|---|---|
| BERTBASE [1] | - | - | - |
| BERT-PKD [14] | BERTBASE | No | Task-specific |
| BERT-of-Theseus [27] | |||
| ALP-KD [15] | |||
| DistilBERT [10] | BERTBASE | Yes | Task-agnostic |
| MobileBERT [12] | IB-BERTLARGE | Yes | |
| TinyBERT [11] | BERTBASE | Yes | |
| MINILM [13] | BERTBASE | No | |
| BERT-EMD [18] | BERTBASE | Yes | |
| LAD (ours) | BERTBASE | No | Task-specific |
| Model | #Params | SST-2 | MRPC | QQP | MNLI m/mm | QNLI | RTE |
|---|---|---|---|---|---|---|---|
| BERTBASE * [1] | 110M | 93.2 | 89.1 | 71.7/89.2 | 84.2/84.3 | 91.0 | 67.4 |
| BERT-PKD [14] | 66.5M | 92.0 | 85.0 | 70.7/88.9 | 81.5/81.0 | 89.0 | 65.6 |
| BERT-of-Theseus [27] | 66.5M | 92.2 | 87.6 | 71.6/89.3 | 82.4/82.1 | 89.6 | 66.2 |
| LAD | 66.5M | 92.5 | 87.6 | 72.2/89.4 | 84.0/83.0 | 90.1 | 65.8 |
| Model | #Params | SST-2 | MRPC | QQP | MNLI m/mm | QNLI | RTE |
|---|---|---|---|---|---|---|---|
| BERTBASE * [1] | 110M | 93.46 | 90.81/87.01 | 88.02/91.07 | 84.6/85.04 | 91.94 | 70.04 |
| BERT-of-Theseus [27] | 66.5M | 91.5 | 89.0/– | 89.6/– | 82.3 | 89.5 | 68.2 |
| ALP-KD6 [15] | 66.5M | 91.86 | –/85.05 | –/90.73 | 81.86/– | 89.67 | 68.59 |
| LAD6 | 66.5M | 91.86 | 89.59/84.56 | 88.20/91.16 | 83.78/84.40 | 90.74 | 68.59 |
| BERT-of-Theseus [27] | 52.5M | 89.1 | 87.5/– | 88.7/– | 80.0 | 86.1 | 61.9 |
| ALP-KD4 [15] | 52.5M | 90.37 | –/82.57 | –/90.54 | 79.62/– | 87.02 | 67.15 |
| LAD4 | 52.5M | 91.74 | 88.71/83.09 | 87.56/90.78 | 81.01/81.47 | 89.24 | 67.15 |
| Model | #Params | SST-2 | MRPC | QQP | MNLI m/mm | QNLI | RTE |
|---|---|---|---|---|---|---|---|
| BERTBASE * [1] | 110M | 93.46 | 90.81/87.01 | 88.02/91.07 | 84.6/85.04 | 91.94 | 70.04 |
| ALP-NO6 ‡ | 66.5M | 91.86 | –/85.78 | –/90.64 | 81.99/– | 89.71 | 68.95 |
| LAD-NO6 | 66.5M | 92.32 | 88.52/82.84 | 87.59/90.77 | 83.42/83.66 | 90.72 | 68.95 |
| Prediction Set | Strategy | SST-2 | MRPC | QQP | MNLI (m/mm) | QNLI | RTE |
|---|---|---|---|---|---|---|---|
| GLUE test | LAD | 92.5 | 87.6/82.0 | 72.2/89.4 | 84.0/83.0 | 90.1 | 65.8 |
| LAD-Reverse | 91.4 | 84.3/75.9 | 71.9/89.1 | 83.8/82.9 | 89.9 | 63.1 |
| Gate ID | Student Layer ID | SST-2 | QNLI | RTE |
|---|---|---|---|---|
| 12 | 6 | 87.04 | 85.92 | 55.60 |
| 12,10 | 6,5 | 87.73 | 86.84 | 57.04 |
| 12,10,8 | 6,5,4 | 90.25 | 88.32 | 58.84 |
| 12,10,8,6 | 6,5,4,3 | 90.48 | 89.27 | 59.21 |
| 12,10,8,6,4 | 6,5,4,3,2 | 91.28 | 90.43 | 66.43 |
| 12,10,8,6,4,2 | 6,5,4,3,2,1 | 91.86 | 90.76 | 67.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.-J.; Chen, K.-Y.; Kao, H.-Y. LAD: Layer-Wise Adaptive Distillation for BERT Model Compression. Sensors 2023, 23, 1483. https://doi.org/10.3390/s23031483
Lin Y-J, Chen K-Y, Kao H-Y. LAD: Layer-Wise Adaptive Distillation for BERT Model Compression. Sensors. 2023; 23(3):1483. https://doi.org/10.3390/s23031483
Chicago/Turabian StyleLin, Ying-Jia, Kuan-Yu Chen, and Hung-Yu Kao. 2023. "LAD: Layer-Wise Adaptive Distillation for BERT Model Compression" Sensors 23, no. 3: 1483. https://doi.org/10.3390/s23031483
APA StyleLin, Y.-J., Chen, K.-Y., & Kao, H.-Y. (2023). LAD: Layer-Wise Adaptive Distillation for BERT Model Compression. Sensors, 23(3), 1483. https://doi.org/10.3390/s23031483