
Development of Language Models for Continuous Uzbek Speech Recognition System

 ,
,  , , and
, , and
Abstract
1. Introduction
- A 105 h speech corpus was created for the development of large-scale continuous speech recognition systems in the Uzbek language.
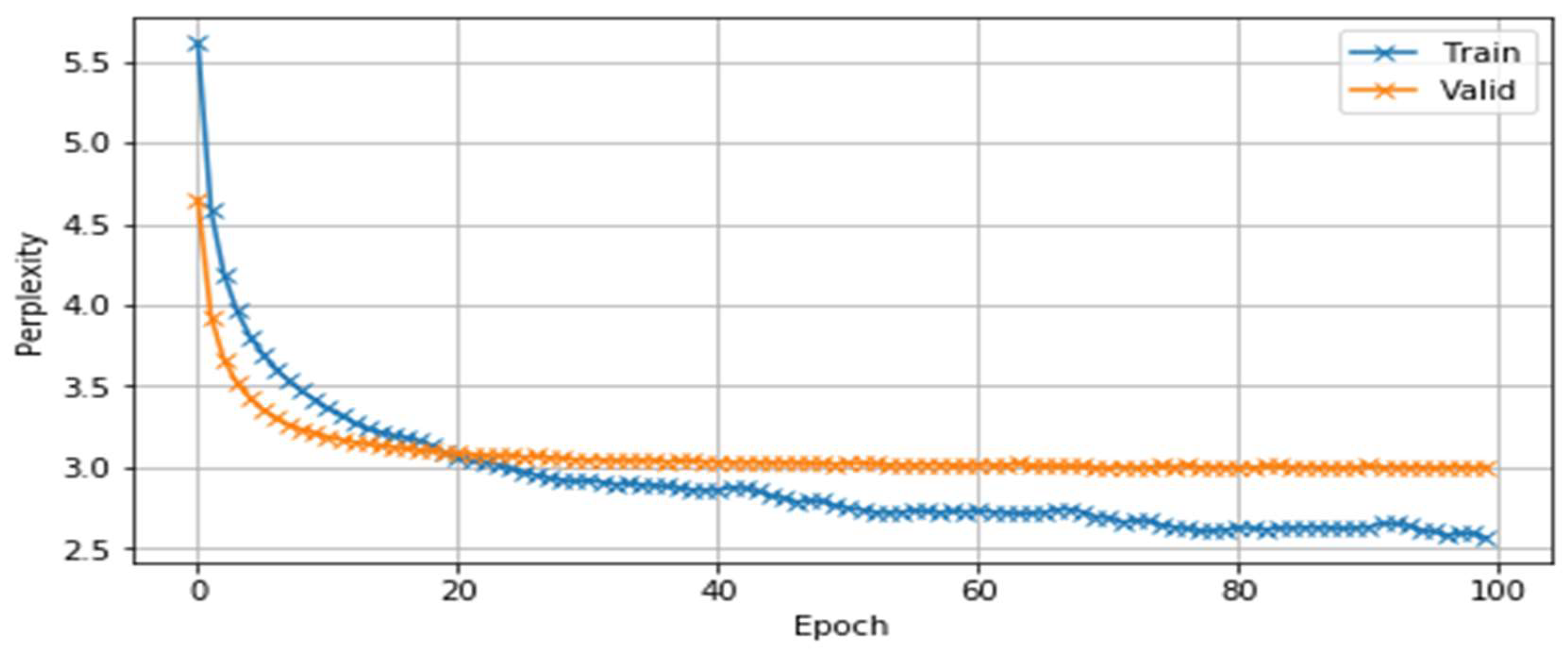
- Language models based on statistics and neural networks have been created for continuous speech recognition in the Uzbek language. The perplexity index in the developed language models was 7.2 in the 3-gram language model and 2.56 in the LSTM language model.
- Without an LM, the E2E-Transformer model achieved a WER of 34.1% and a CER of 12.1% on the training set, and a WER of 30.9% and a CER of 8.9% on the test set. By combining the developed language model with a speech recognition system, a WER of 23.9% and a CER of 11.0% occur in the training sample, and a WER of 22.5% and a CER of 8.5% are found in the test sample.
2. Related Work
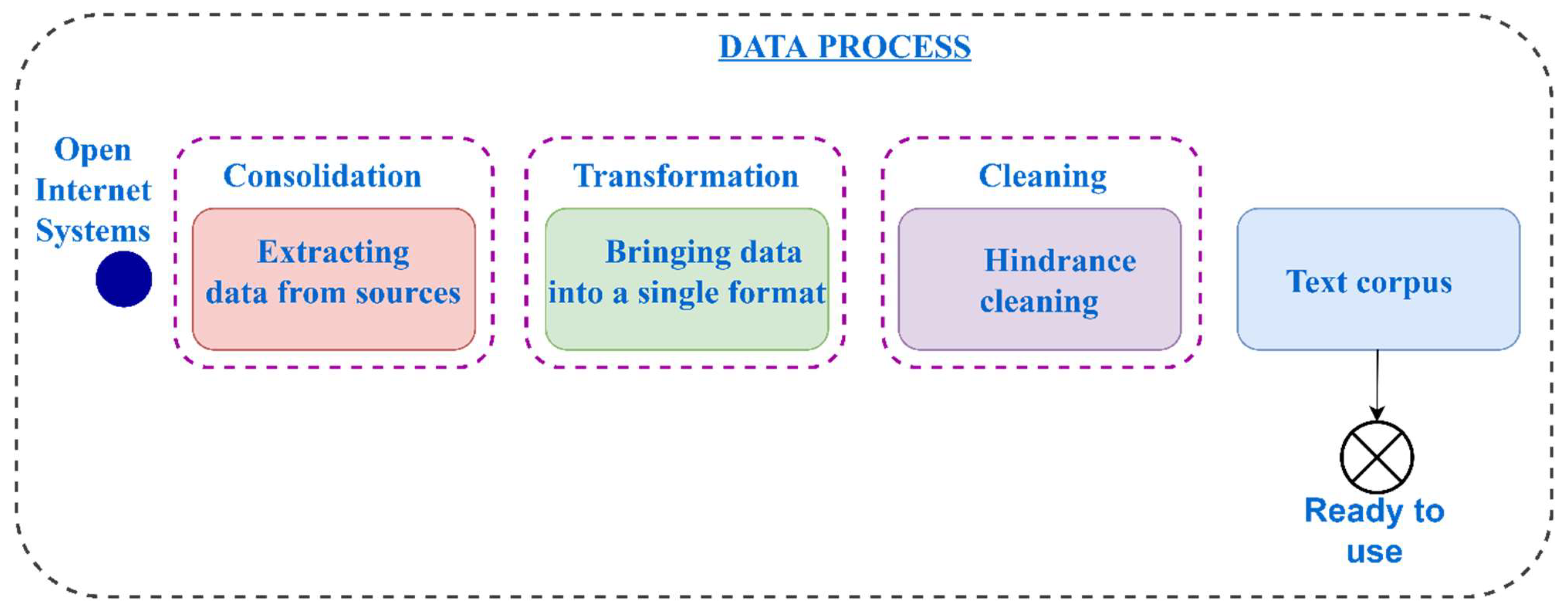
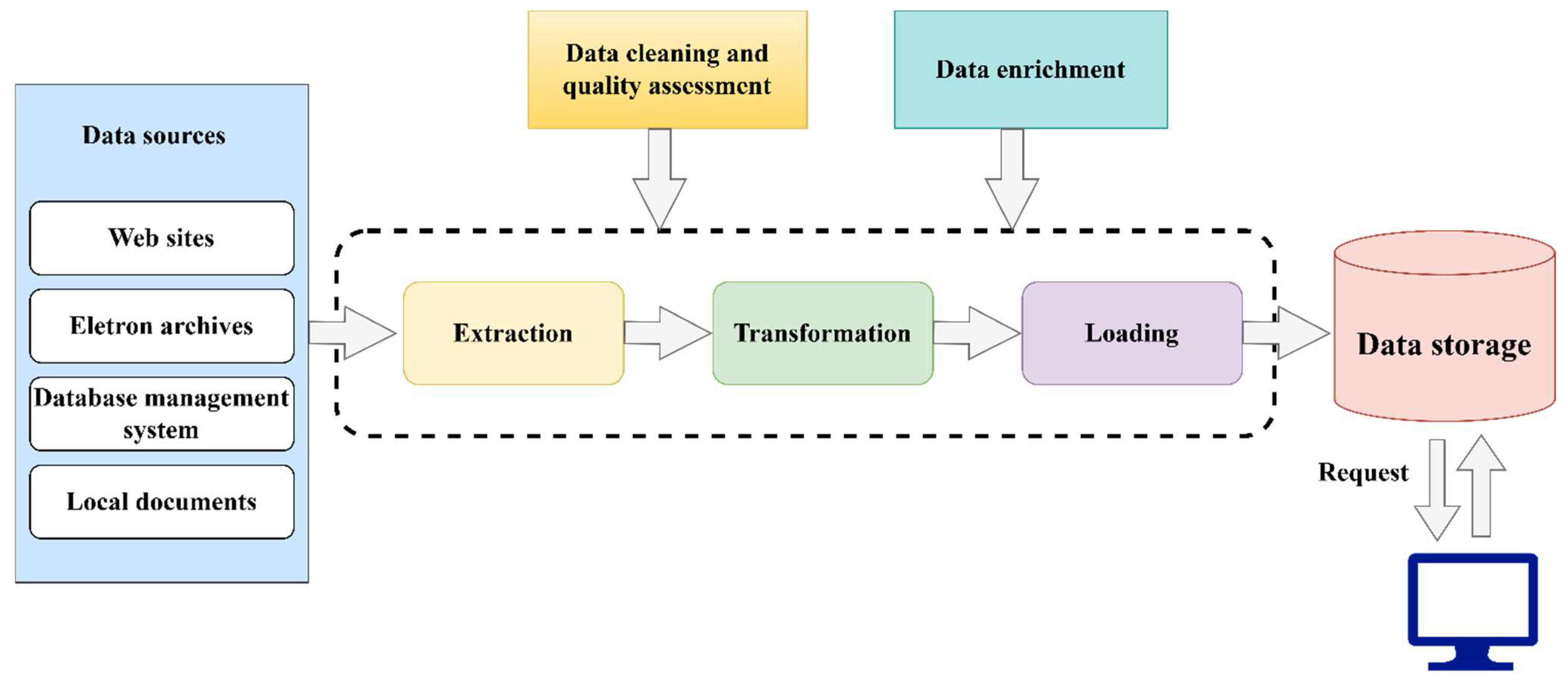
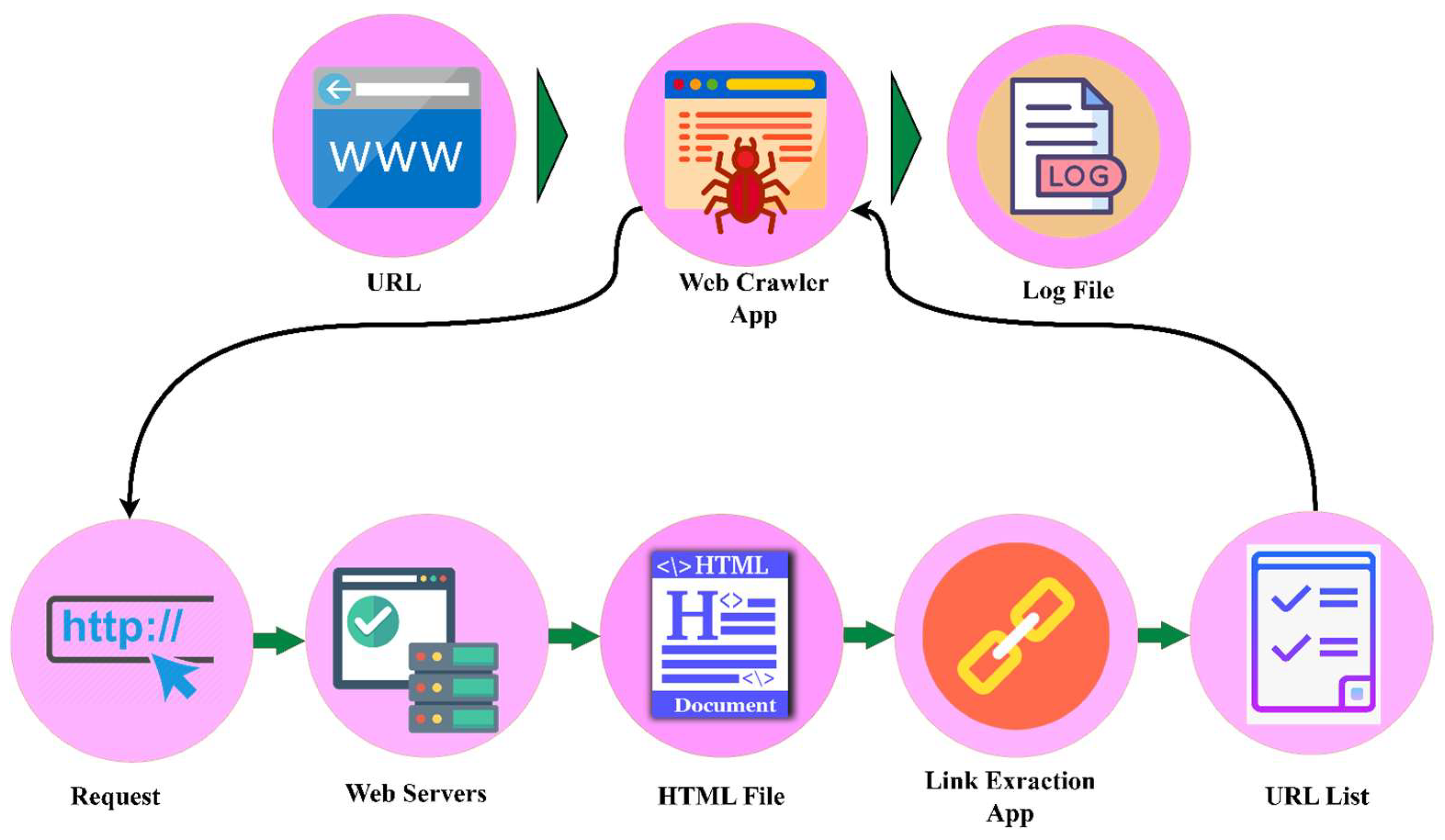
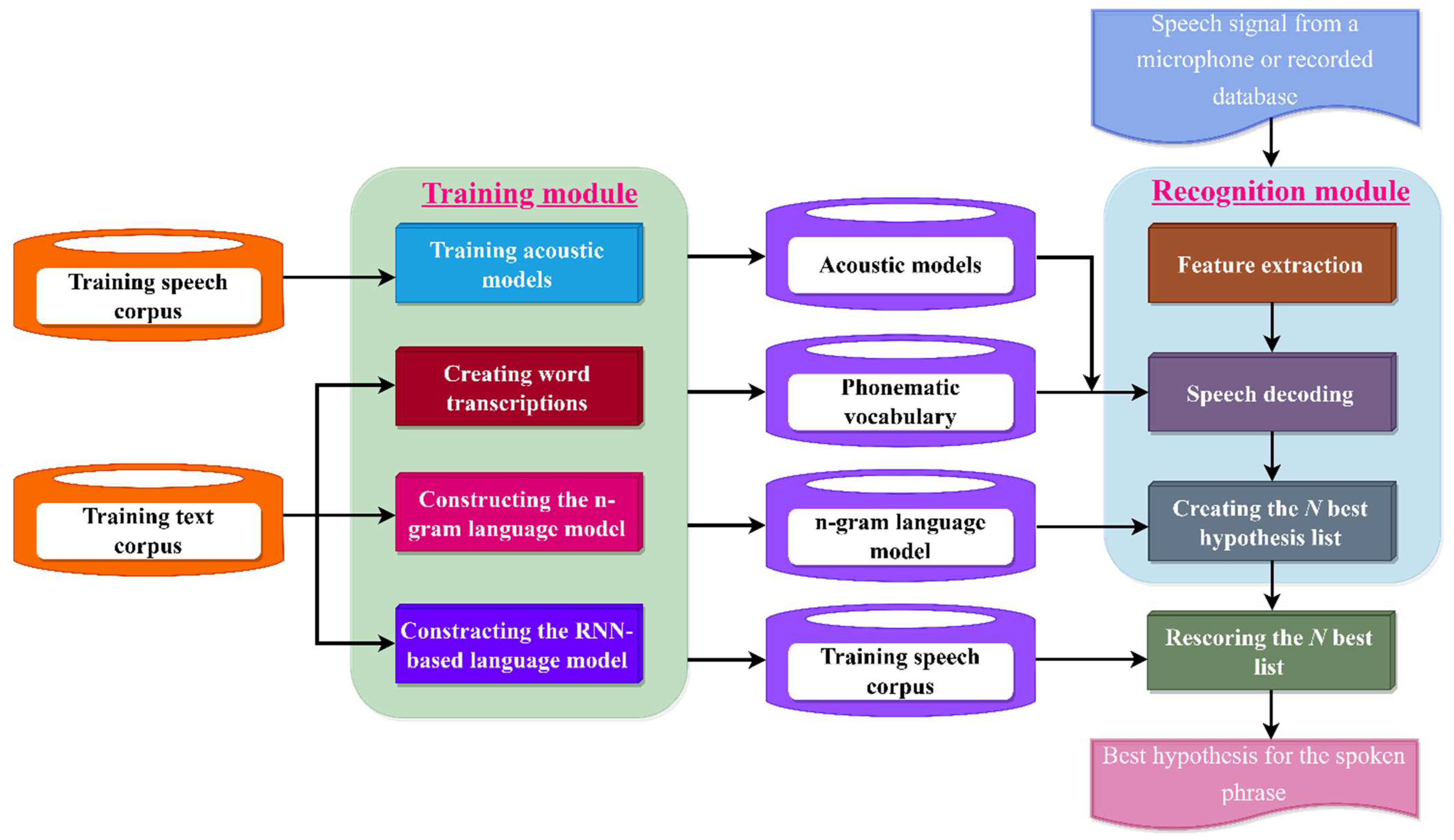
3. Materials and Methods of Language Model
- ➢
- Providing high-speed access to information;
- ➢
- Storage compactness;
- ➢
- Automatic support of data structure integrity;
- ➢
- Data consistency control.
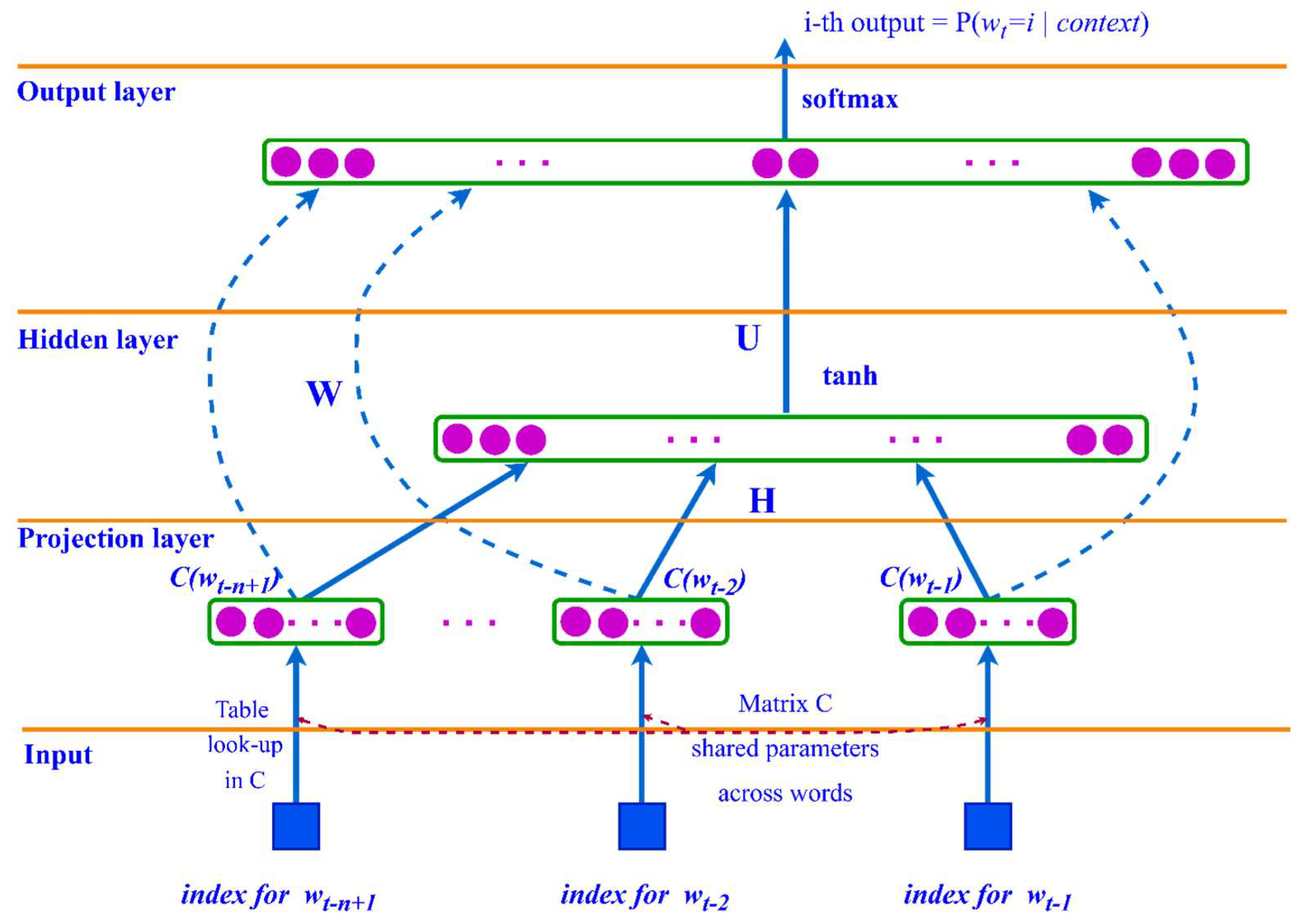
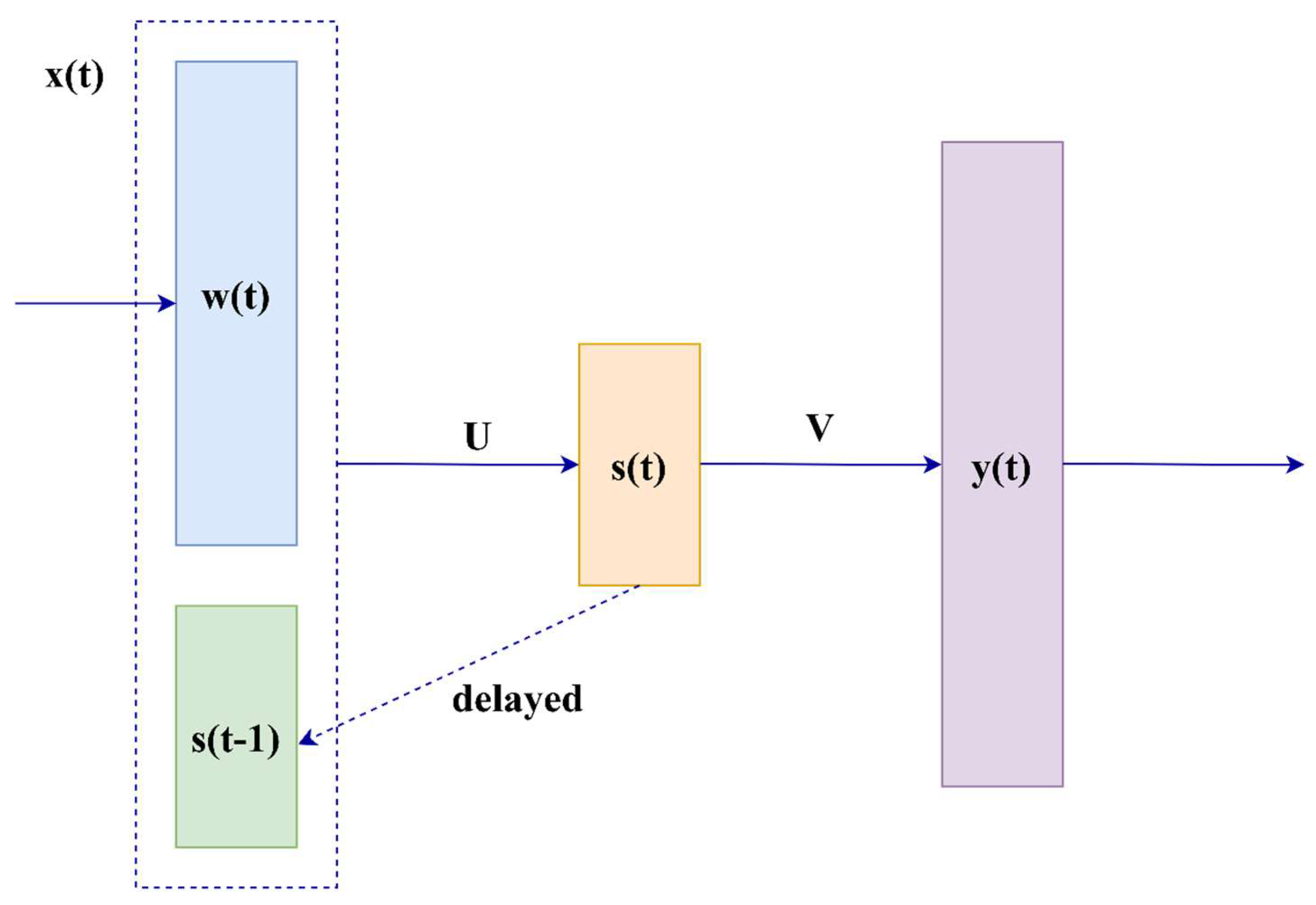
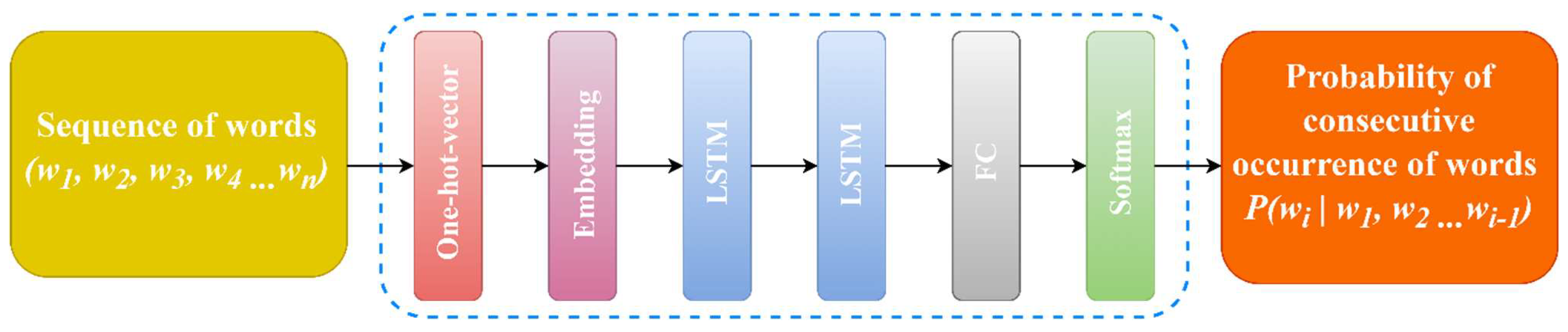
4. ANN Architecture for Language Modeling
5. Experiments on Uzbek Continuous Speech Recognition Based on the Proposed Neural Networks Using LM
5.1. RNN-Based LM Architecture for Continuous Uzbek Speech Recognition
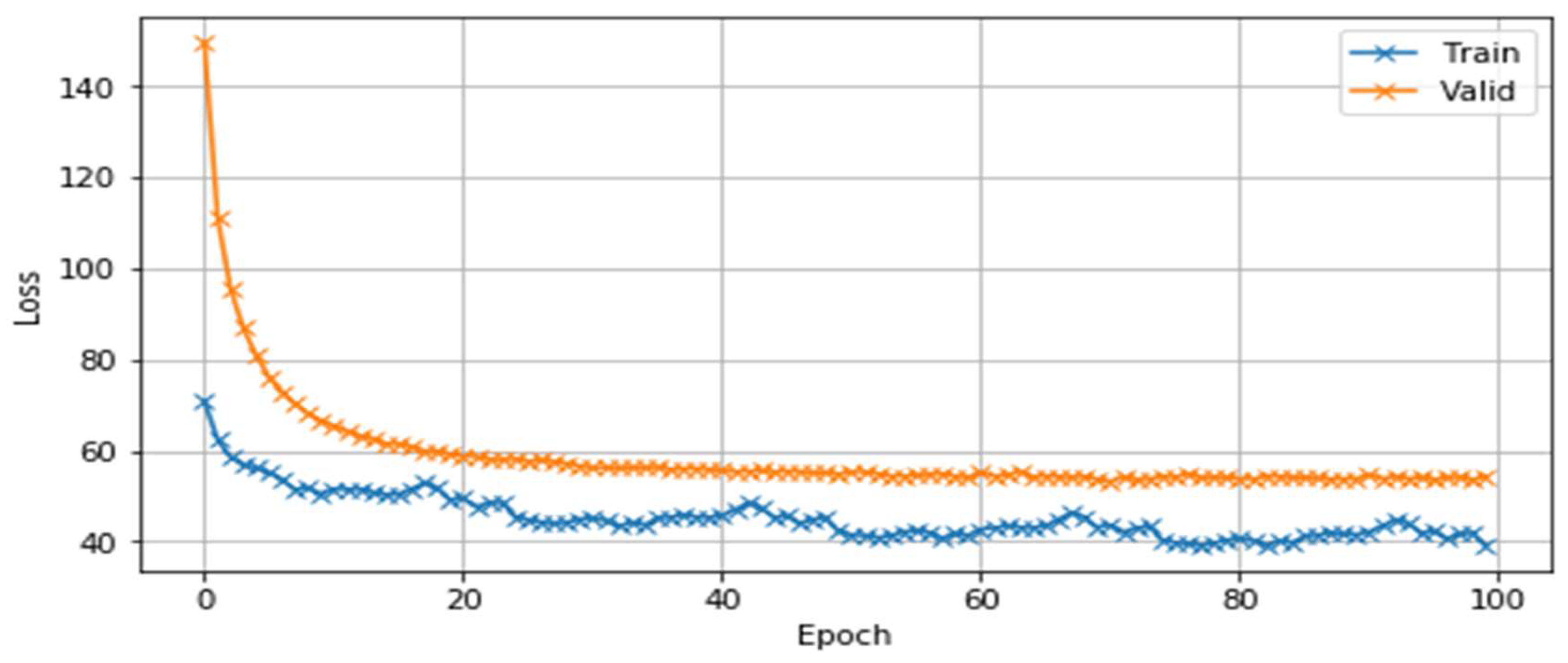
5.2. Training and Test Speech Corpus
5.3. Experimental Results of Using RNN-Based LM in a Continuous Uzbek Speech Recognition System
6. Conclusions and Future Work
Author Contributions
Funding
Informed Consent Statement
Conflicts of Interest
References
- AL-Saffar, A.; Awang, S.; AL-Saiagh, W.; AL-Khaleefa, A.S.; Abed, S.A. A Sequential Handwriting Recognition Model Based on a Dynamically Configurable CRNN. Sensors 2021, 21, 7306. [Google Scholar] [CrossRef] [PubMed]
- de Sousa Neto, A.F.; Bezerra, B.L.D.; Toselli, A.H.; Lima, E.B. A robust handwritten recognition system for learning on different data restriction scenarios. Pattern Recognit. Lett. 2022, 159, 232–238. [Google Scholar] [CrossRef]
- Kang, L.; Riba, P.; Rusinol, M.; Fornes, A.; Villegas, M. Content and Style Aware Generation of Text-Line Images for Handwriting Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8846–8860. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Akmuradov, B.; Djuraev, O. Robust Text Recognition for Uzbek Language in Natural Scene Images. In Proceedings of the 2019 International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 4–6 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Rivera-Trigueros, I. Machine translation systems and quality assessment: A systematic review. Lang. Resour. Evaluation 2021, 56, 593–619. [Google Scholar] [CrossRef]
- Abdusalomov, A.B.; Safarov, F.; Rakhimov, M.; Turaev, B.; Whangbo, T.K. Improved Feature Parameter Extraction from Speech Signals Using Machine Learning Algorithm. Sensors 2022, 22, 8122. [Google Scholar] [CrossRef] [PubMed]
- Musaev, M.; Khujayorov, I.; Ochilov, M. Automatic Recognition of Uzbek Speech Based on Integrated Neural Networks. In World Conference Intelligent System for Industrial Automation; Springer: Cham, Switzerland, 2021; pp. 215–223. [Google Scholar]
- Musaev, M.; Khujayorov, I.; Ochilov, M. Development of integral model of speech recognition system for Uzbek language. In Proceedings of the 2020 IEEE 14th International Conference on Application of Information and Communication Technologies (AICT), Tashkent, Uzbekistan, 7–9 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Musaev, M.; Khujayorov, I.; Ochilov, M. The Use of Neural Networks to Improve the Recognition Accuracy of Explosive and Unvoiced Phonemes in Uzbek Language. In Proceedings of the 2020 Information Communication Technologies Conference (ICTC), Nanjing, China, 29–31 May 2020; pp. 231–234. [Google Scholar] [CrossRef]
- Abdullaeva, M.; Khujayorov, I.; Ochilov, M. Formant Set as a Main Parameter for Recognizing Vowels of the Uzbek Language. In Proceedings of the 2021 International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 3–5 November 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Mukhamadiyev, A.; Khujayarov, I.; Djuraev, O.; Cho, J. Automatic Speech Recognition Method Based on Deep Learning Approaches for Uzbek Language. Sensors 2022, 22, 3683. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Stremmel, J.; Singh, A. Pretraining Federated Text Models for Next Word Prediction. In Future of Information and Communication Conference; Springer: Cham, Switzerland, 2021; pp. 477–488. [Google Scholar]
- Pires, T.; Schlinger, E.; Garrette, D. How multilingual is multilingual BERT? arXiv 2019, arXiv:1906.01502. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Kipyatkova, I.S.; Karpov, A.A. A study of neural network Russian language models for automatic continuous speech recognition systems. Autom. Remote. Control. 2017, 78, 858–867. [Google Scholar] [CrossRef]
- Musaev, M.; Mussakhojayeva, S.; Khujayorov, I.; Khassanov, Y.; Ochilov, M.; Atakan Varol, H. USC: An Open-Source Uzbek Speech Corpus and Initial Speech Recognition Experiments. In International Conference on Speech and Computer; Springer: Cham, Switzerland, 2021; pp. 437–447. [Google Scholar]
- Schwenk, H.; Gauvain, J.L. Training neural network language models on very large corpora. In Proceedings of the Human Language Technology Conference and Conference on Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 201–208. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. In Interspeech; Johns Hopkins Universit: Baltimore, MD, USA, 2010; Volume 3, pp. 1045–1048. [Google Scholar]
- Huang, Z.; Zweig, G.; Dumoulin, B. Cache Based Recurrent Neural Network Language Model Inference for First Pass Speech Recognition. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 6354–6358. [Google Scholar]
- Sundermeyer, M.; Oparin, I.; Gauvain, J.L.; Freiberg, B.; Schlüter, R.; Ney, H. Comparison of Feedforward and Recurrent Neural Network Language Models. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 8430–8434. [Google Scholar]
- Morioka, T.; Iwata, T.; Hori, T.; Kobayashi, T. Multiscale Recurrent Neural Network Based Language Model. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; ISCA Speech: Dublin, Ireland, 2015. [Google Scholar]
- Sheikh, I.A.; Vincent, E.; Illina, I. Training RNN language models on uncertain ASR hypotheses in limited data scenarios. 2021. Available online: https://hal.inria.fr/hal-03327306 (accessed on 27 August 2021).
- Sheikh, I.A.; Vincent, E.; Illina, I. Transformer Versus LSTM Language Models Trained on Uncertain ASR Hypotheses in Limited Data Scenarios. In Proceedings of the LREC 2022-13th Language Resources and Evaluation Conference, Marseille, France, 20–25 June 2022. [Google Scholar]
- Irie, K. Advancing Neural Language Modeling in Automatic Speech Recognition. Doctoral Dissertation, RWTH Aachen University, Aachen, Germany, 2020. [Google Scholar]
- Irie, K.; Zeyer, A.; Schlüter, R.; Ney, H. Language modeling with deep transformers. arXiv 2019, arXiv:1905.04226. [Google Scholar]
- Huang, C.W.; Chen, Y.N. Adapting Pretrained Transformer to Lattices for Spoken Language Understanding. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Sentosa, Singapore, 14–18 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 845–852. [Google Scholar]
- Liu, C.; Zhu, S.; Zhao, Z.; Cao, R.; Chen, L.; Yu, K. Jointly encoding word confusion network and dialogue context with BERT for spoken language understanding. arXiv 2020, arXiv:2005.11640. [Google Scholar]
- Zhang, P.; Chen, B.; Ge, N.; Fan, K. Lattice transformer for speech translation. arXiv 2019, arXiv:1906.05551. [Google Scholar]
- Xiao, F.; Li, J.; Zhao, H.; Wang, R.; Chen, K. Lattice-based transformer encoder for neural machine translation. arXiv 2019, arXiv:1906.01282. [Google Scholar]
- Mansurov, B.; Mansurov, A. Uzbert: Pretraining a bert model for uzbek. arXiv 2021, arXiv:2108.09814. [Google Scholar]
- Ren, Z.; Yolwas, N.; Slamu, W.; Cao, R.; Wang, H. Improving Hybrid CTC/Attention Architecture for Agglutinative Language Speech Recognition. Sensors 2022, 22, 7319. [Google Scholar] [CrossRef]
- Mamatov, N.S.; Niyozmatova, N.A.; Abdullaev, S.S.; Samijonov, A.N.; Erejepov, K.K. Speech Recognition Based on Transformer Neural Networks. In Proceedings of the 2021 International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 3–5 November 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Laender, A.H.; Ribeiro-Neto, B.A.; Da Silva, A.S.; Teixeira, J.S. A brief survey of web data extraction tools. ACM Sigmod Rec. 2002, 31, 84–93. [Google Scholar] [CrossRef]
- Corporate Management. Data Consolidation—Key Concepts. Corp. Manag. 2016. Available online: http://www.cfin.ru/itm/olap/cons.shtml (accessed on 20 November 2016).
- Khujayarov, I.S.; Ochilov, M.M. The Importance of the Language Model in the Development of Automatic Speech Recognition Systems. In Proceedings of the The Importance of Information and Communication Technologies in the Innovative Development of Economic Sectors Republican Scientific and Technical Conference, Tashkent, Uzbekistan, 4–5 March 2021; pp. 427–430. [Google Scholar]
- Al-Rfou, R.; Choe, D.; Constant, N.; Guo, M.; Jones, L. Character-level language modeling with deeper self-attention. arXiv 2018, arXiv:1808.04444. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Jing, K.; Xu, J. A survey on neural network language models. Comput. Res. Repos. 2019, arXiv:abs/1906.03591. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing. In An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition, Chapter-3, N-gram Language Models, 3rd ed.; Pearson: London, UK, 2014; pp. 29–55. [Google Scholar]
- Graves, A. Sequence Transduction with Recurrent Neural Networks. Comput. Sci. 2012, 58, 235–242. [Google Scholar]
- Chen, S.F.; Goodman, J. An empirical study of smoothing techniques for language modeling. Comput. Speech Lang. 1999, 13, 359–394. [Google Scholar] [CrossRef]
- Ayda-Zade, K.; Rustamov, S. On Azerbaijan Speech Recognition System (Azerbaijani). In Proceedings of the Application of Information-Communication Technologies in Science and Education, International Conference, Baku, Azerbaijan, 1–3 November 2007; Volume II, pp. 670–677. [Google Scholar]
- Makhambetov, O.; Makazhanov, A.; Yessenbayev, Z.; Matkarimov, B.; Sabyrgaliyev, I.; Sharafudinov, A. Assembling the Kazakh Language Corpus. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Abu Dhabi, United Arab Emirates, 18–21 October 2013; pp. 1022–1031. [Google Scholar]
- Shi, Y.; Hamdullah, A.; Tang, Z.; Wang, D.; Zheng, T.F. A free Kazakh Speech Database and a Speech Recognition Baseline. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 745–748. [Google Scholar]
- Mamyrbayev, O.; Alimhan, K.; Zhumazhanov, B.; Turdalykyzy, T.; Gusmanova, F. End-to-End Speech Recognition in Agglutinative Languages. In Proceedings of the 12th Asian Conference on Intelligent Information and Database Systems (ACIIDS), Phuket, Thailand, 23–26 March 2020; Volume 12034, pp. 391–401. [Google Scholar]
- Kipyatkova, I.; Karpov, A. Development, and study of a statistical model of the Russian language. SPIIRAS Proc. Issue 2010, 10, 35–49. [Google Scholar] [CrossRef]
- Xu, W.; Rudnicky, A. Can Artificial Neural Networks Learn Language Models? In Proceedings of the 6th International Conference on Spoken Language Processing, Beijing, China, 16–20 October 2000; pp. 202–205. [Google Scholar]
- Sundermeyer, M.; Schlüter, R.; Ney, H. LSTM Neural Networks for Language Modeling; Interspeech: Portland, Oregon, 2012; pp. 194–197. [Google Scholar]
- Arisoy, E.; Sethy, A.; Ramabhadran, B.; Chen, S. Bidirectional Recurrent Neural Network Language Models for Automatic Speech Recognition. In Proceedings of the 40th IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, QLD, Australia, 19–24 April 2015; pp. 5421–5425. [Google Scholar]
- Alexandrescu, A.; Kirchhoff, K. Factored Neural Language Models. In Proceedings of the Human Language Technology Conference of the NAACL, Companion Volume: Short Papers (NAACL-Short’06); Association for Computational Linguistics: New York, NY, USA, 2006; pp. 1–4. [Google Scholar]
- Wu, Y.; Lu, X.; Yamamoto, H.; Matsuda, S.; Hori, C.; Kashioka, H. Factored Language Model Based on Recurrent Neural Network. In Proceedings of the COLING Conference, Kyoto, Japan, 8–15 December 2012; pp. 2835–2850. [Google Scholar]
- Graves, A.; Jaitly, N.; Mohamed, A.-R. Hybrid Speech Recognition with Deep Bidirectional LSTM. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2013; pp. 273–278. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Chan, W.; Lane, I. On Online Attention-Based Speech Recognition and Joint Mandarin Character-Pinyin Training. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 September 2016; pp. 3404–3408. [Google Scholar]
- Vig, J.; Belinkov, Y. Analyzing the structure of attention in a Transformer language model. In Proceedings of the 2nd BlackboxNLP Workshop on Analyzing and Interpreting Neural Networks for NLP (BlackboxNLP), Florence, Italy, 1 August 2019; pp. 63–76. [Google Scholar]
- Federico, M.; Bertoldi, N.; Cettolo, M. IRSTLM: An Open Source Toolkit for Handling Large Scale Language Models; Interspeech: Brisbane, Australia, 2008; pp. 1618–1621. [Google Scholar]
- Heafield, K. KenLM: Faster and Smaller Language Model Queries. In Proceedings of the Sixth Workshop on Statistical Machine Translation, Edinburgh, Scotland, 30–31 July 2011; pp. 187–197. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| № | Name of Layer | Parameters of Layer | Number of Layers |
|---|---|---|---|
| 1 | Input layer | One-hot vector based word sequence | 1 |
| 2 | Embedding layer | Size of layer = [|V|,300] Activation function = RELU, Dropout = 20% | 1 |
| 3 | Recurrent layer | Type of RNN = MultiCell LSTM, Number of memory cells = 650, Activation function = RELU, Dropout = 20% | 2 |
| 4 | Fully bonded layer | Size of layer = |V|, Activation function = softmax | 1 |
| 5 | Learning Options | Optimization algorithm: Adam, Learning stride length = 0.001, size of Batch = 30 |
| CORPUS | Total Number of Words | Total Number of Unique Words | Total Number of Sentences |
|---|---|---|---|
| Test Data | 16 M | 13.6 K | 3 M |
| Train Data | 64 M | 54.4 K | 12 M |
| Total | 80 M | 68 K | 15 M |
| N-Gram Model Baseline, Soothing Type | N-Gram Order | Perplexity | |
|---|---|---|---|
| Training Set | Test Set | ||
| Kneser–Ney + back-off | 3 | 142.1 | 121.2 |
| 5 | 134.3 | 114.5 | |
| 7 | 128.8 | 112.3 | |
| 9 | 122.2 | 108.1 | |
| Katz + back-off | 3 | 165.5 | 132.3 |
| 5 | 151.2 | 123.8 | |
| 7 | 145.9 | 119.3 | |
| 9 | 139.4 | 112.1 | |
| Type of RNN | Perplexity | |
|---|---|---|
| Training Set | Test Set | |
| Vanilla RNN | 76.4 | 63.6 |
| LSTM | 62.3 | 51.4 |
| Type of LM | Perplexity | |
|---|---|---|
| Training Set | Testing Set | |
| Word-Based | 62.1 | 51.2 |
| Character-Based | 7.2 | 4.7 |
| Model | Character Based LM | SP | SA | Valid | Test | ||
|---|---|---|---|---|---|---|---|
| CER | WER | CER | WER | ||||
| E2E-LSTM | ✗ | ✗ | ✗ | 13.8 | 43.1 | 14.0 | 44.0 |
| ✗ | ✗ | ✗ | 14.9 | 30.0 | 14.3 | 31.4 | |
| ✗ | ✓ | ✗ | 13.7 | 27.6 | 14.4 | 30.6 | |
| ✗ | ✓ | ✓ | 12.6 | 24.9 | 12.0 | 27.0 | |
| ✓ | ✓ | ✓ | 10.5 | 21.7 | 11.1 | 23.2 | |
| DNN-HMM | ✗ | ✗ | ✗ | 12.8 | 34.7 | 10.2 | 32.1 |
| ✗ | ✗ | ✗ | 10.3 | 20.5 | 8.6 | 24.9 | |
| ✗ | ✓ | ✗ | 6.9 | 18.8 | 7.5 | 23.5 | |
| ✗ | ✓ | ✓ | 6.9 | 19.9 | 8.1 | 24.9 | |
| ✓ | ✓ | ✓ | 5.2 | 16.4 | 6.0 | 21.3 | |
| RNN-CTC | ✗ | ✗ | ✗ | 13.3 | 35.8 | 9.7 | 32.3 |
| ✗ | ✗ | ✗ | 12.2 | 27.2 | 9.1 | 24.3 | |
| ✗ | ✓ | ✗ | 10.9 | 25.1 | 8.7 | 23.9 | |
| ✗ | ✓ | ✓ | 8.3 | 24.7 | 7.9 | 22.3 | |
| ✓ | ✓ | ✓ | 5.9 | 22.7 | 6.9 | 20.8 | |
| E2E-Transformer | ✗ | ✗ | ✗ | 12.3 | 35.2 | 9.4 | 31.6 |
| ✗ | ✗ | ✗ | 11.7 | 25.7 | 8.7 | 23.9 | |
| ✗ | ✓ | ✗ | 10.7 | 23.9 | 8.4 | 23.0 | |
| ✗ | ✓ | ✓ | 9.9 | 21.4 | 7.6 | 21.0 | |
| ✓ | ✓ | ✓ | 5.9 | 19.3 | 6.0 | 18.9 | |
| E2E-Conformer | ✗ | ✗ | ✗ | 12.7 | 37.6 | 10.7 | 35.1 |
| ✗ | ✗ | ✗ | 11.5 | 27.5 | 9.7 | 26.3 | |
| ✗ | ✓ | ✗ | 9.2 | 21.7 | 7.5 | 21.2 | |
| ✗ | ✓ | ✓ | 7.8 | 18.1 | 5.8 | 17.4 | |
| ✓ | ✓ | ✓ | 5.5 | 15.1 | 5.26 | 13.9 | |
| N | Original Text | Recognized Text | WER | CER |
|---|---|---|---|---|
| 1 | Davlat qonunchiligiga ko’ra barcha bepul ta’lim olish xuquqiga ega | Davlat qonunchiligiga ko’ra bacha bepul ta’lim olish xuquq ega | 11% | 1.5% |
| 2 | ilova hozircha faqat ios dasturlarida ishlaydi android versiyasi ishlab chiqish jarayonida | ilm va hozircha faqat ios dasturlarida ishlaydi andro versiyasi ishlab chiqish jarayonida | 27.2% | 4.5% |
| 3 | qonun oldida barcha teng | qon oldinda barcha teng | 50% | 13% |
| 4 | yakka tartibdagi tadbirkor davlat ro’yxatidan o’tkazilganligi to’g’risida guvohnoma beriladi | yakka tartibdagi tadbirkor davlat ro’yxatidan o’tkazilganligi to’g’risida guvohnoma beriladi | 0 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mukhamadiyev, A.; Mukhiddinov, M.; Khujayarov, I.; Ochilov, M.; Cho, J. Development of Language Models for Continuous Uzbek Speech Recognition System. Sensors 2023, 23, 1145. https://doi.org/10.3390/s23031145
Mukhamadiyev A, Mukhiddinov M, Khujayarov I, Ochilov M, Cho J. Development of Language Models for Continuous Uzbek Speech Recognition System. Sensors. 2023; 23(3):1145. https://doi.org/10.3390/s23031145
Chicago/Turabian StyleMukhamadiyev, Abdinabi, Mukhriddin Mukhiddinov, Ilyos Khujayarov, Mannon Ochilov, and Jinsoo Cho. 2023. "Development of Language Models for Continuous Uzbek Speech Recognition System" Sensors 23, no. 3: 1145. https://doi.org/10.3390/s23031145
APA StyleMukhamadiyev, A., Mukhiddinov, M., Khujayarov, I., Ochilov, M., & Cho, J. (2023). Development of Language Models for Continuous Uzbek Speech Recognition System. Sensors, 23(3), 1145. https://doi.org/10.3390/s23031145