
Action Recognition Based on Multi-Level Topological Channel Attention of Human Skeleton

 ,
,  , , , , and
, , , , and 
Abstract
:1. Introduction
2. Related Work
2.1. Skeleton-Based Action Recognition
2.2. Spatiotemporal Representation Learning
2.3. Training/Attention Measure
3. Methodology
3.1. Preliminaries
3.1.1. Skeleton Sequence Representation
3.1.2. Dataset
3.1.3. Experimental Settings
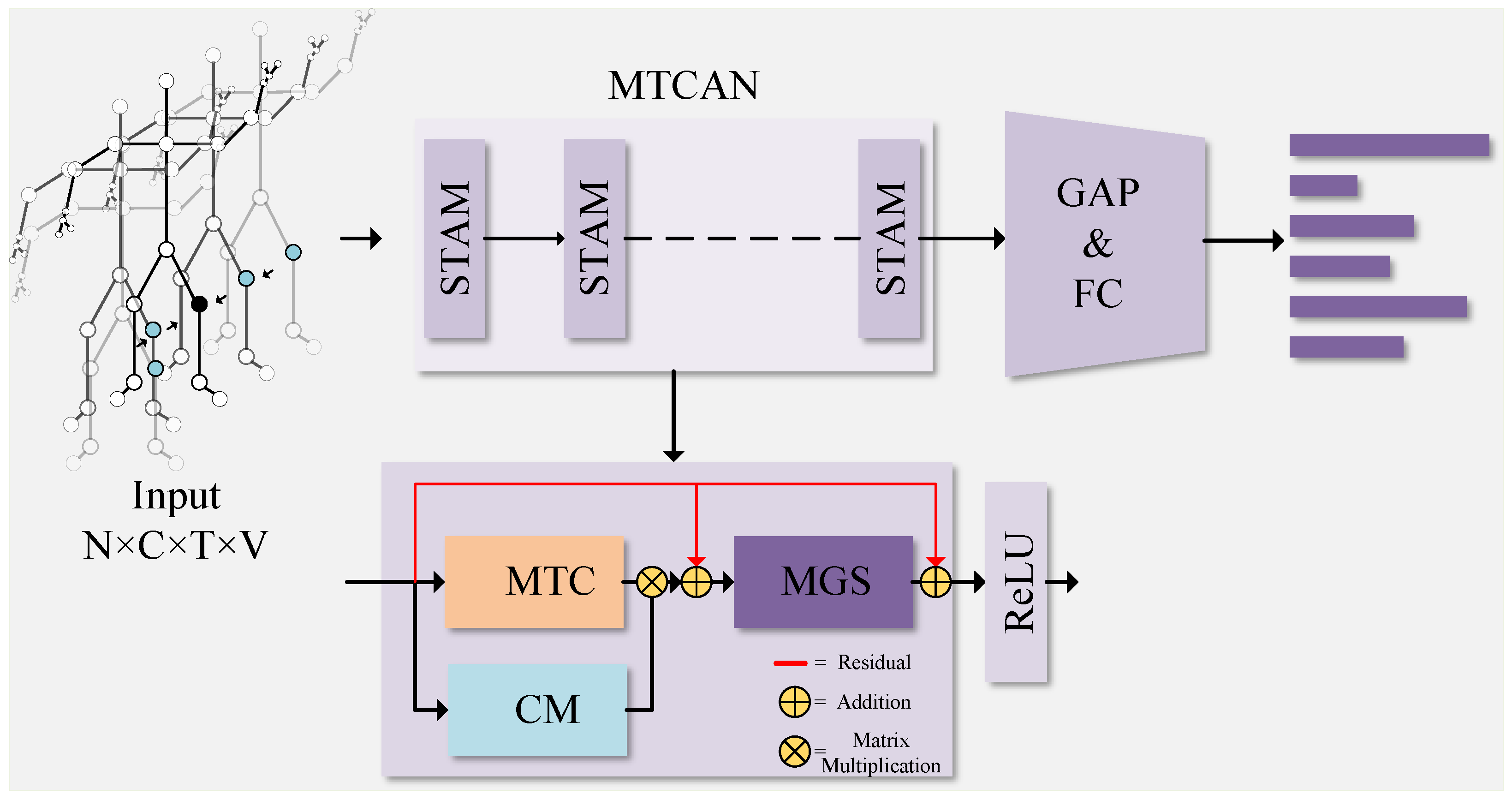
3.2. Multi-Level Topological Channel Attention Network (MTC)
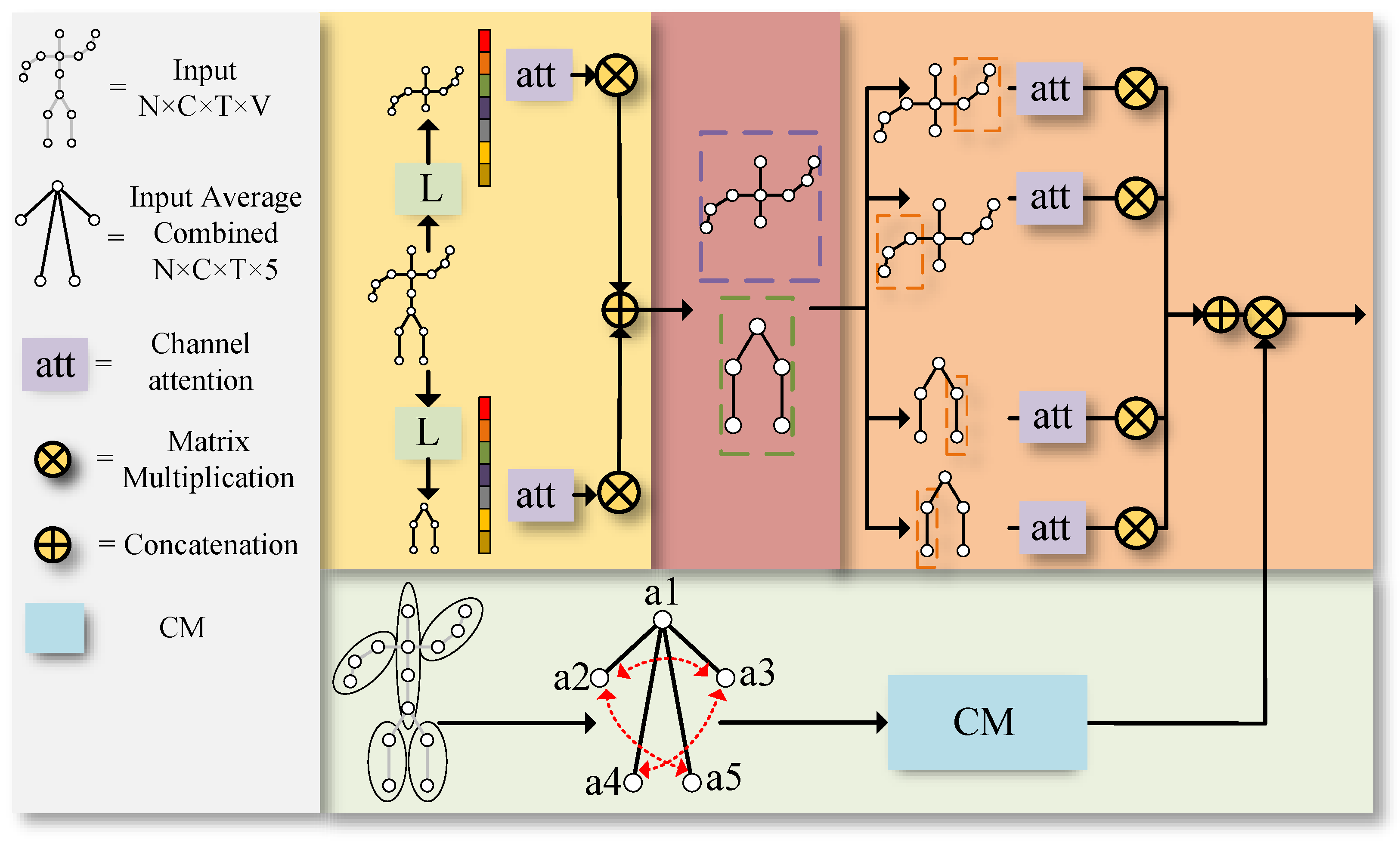
3.2.1. The Multi-Level Topological Channel Attention Module (MTC)
3.2.2. Coordination Module (CM)
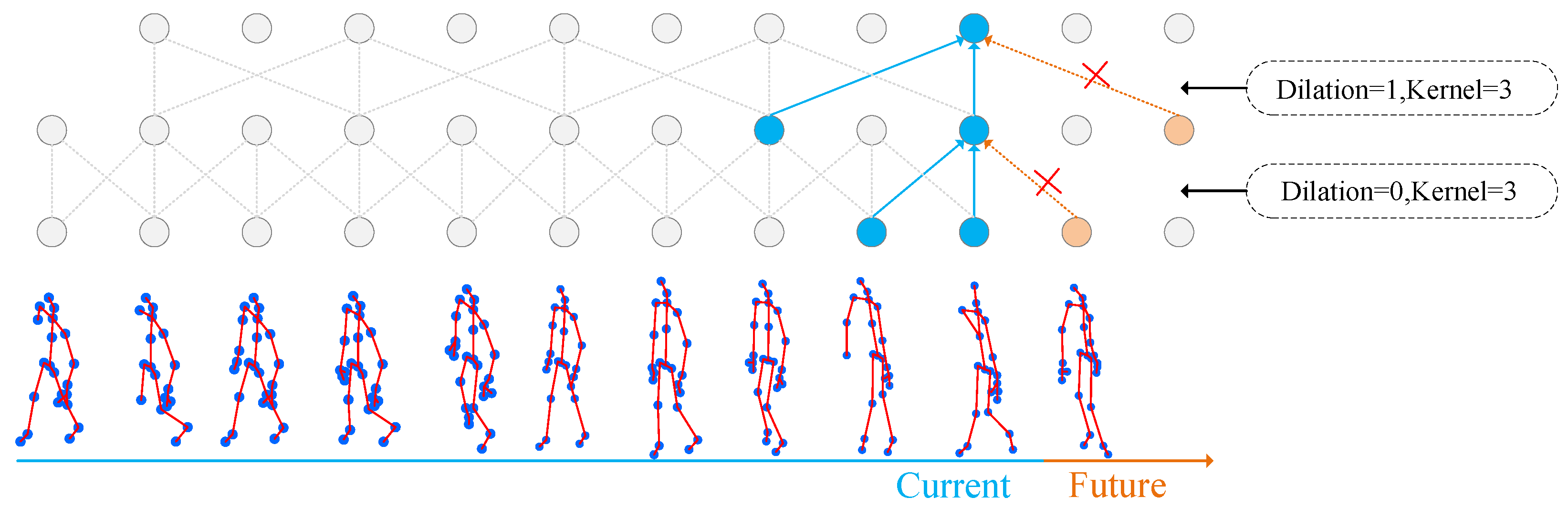
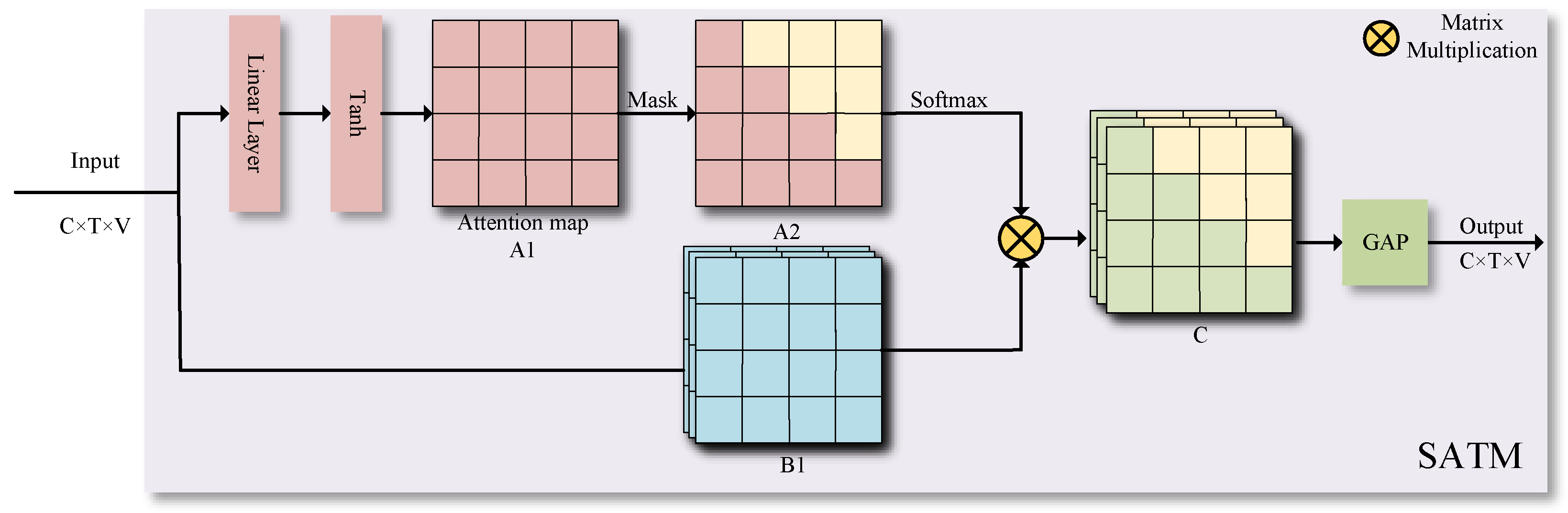
3.3. Multi-Scale Global Spatiotemporal Attention Module (MGS)
4. Experimental Results
4.1. Module Ablation Study
4.2. Ablation Experiments within a Single Model
4.3. Multi-Stream Framework Verification
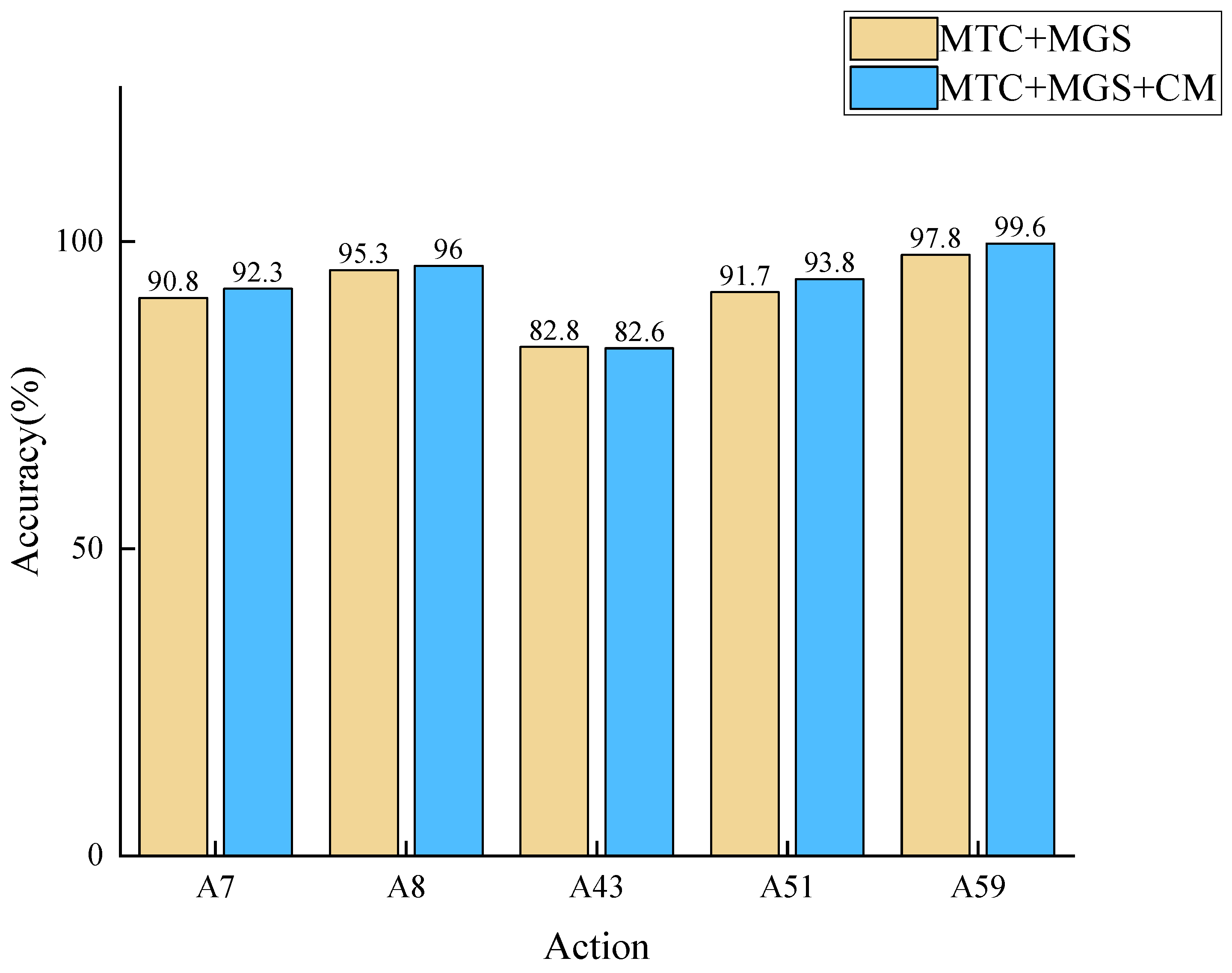
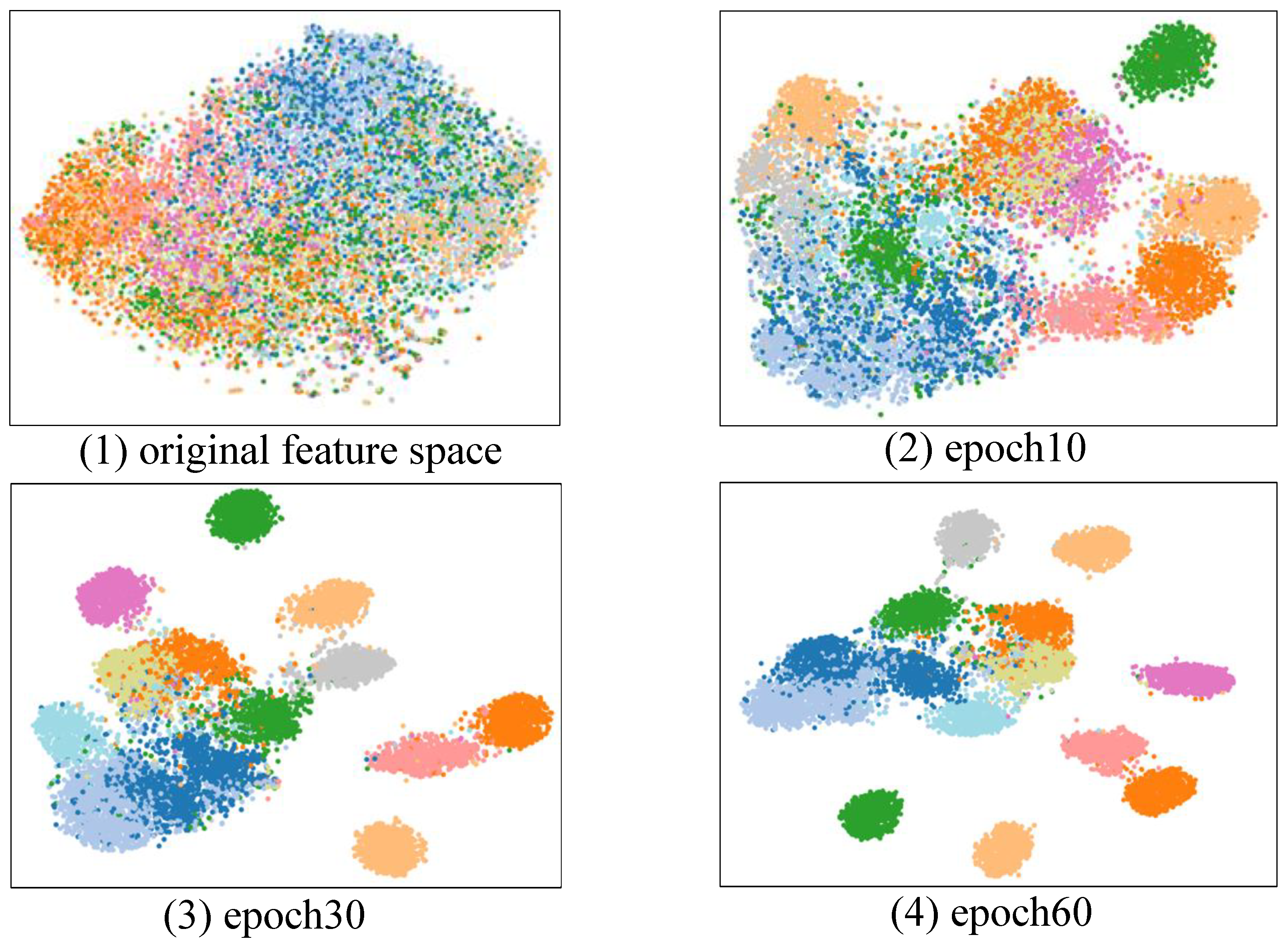
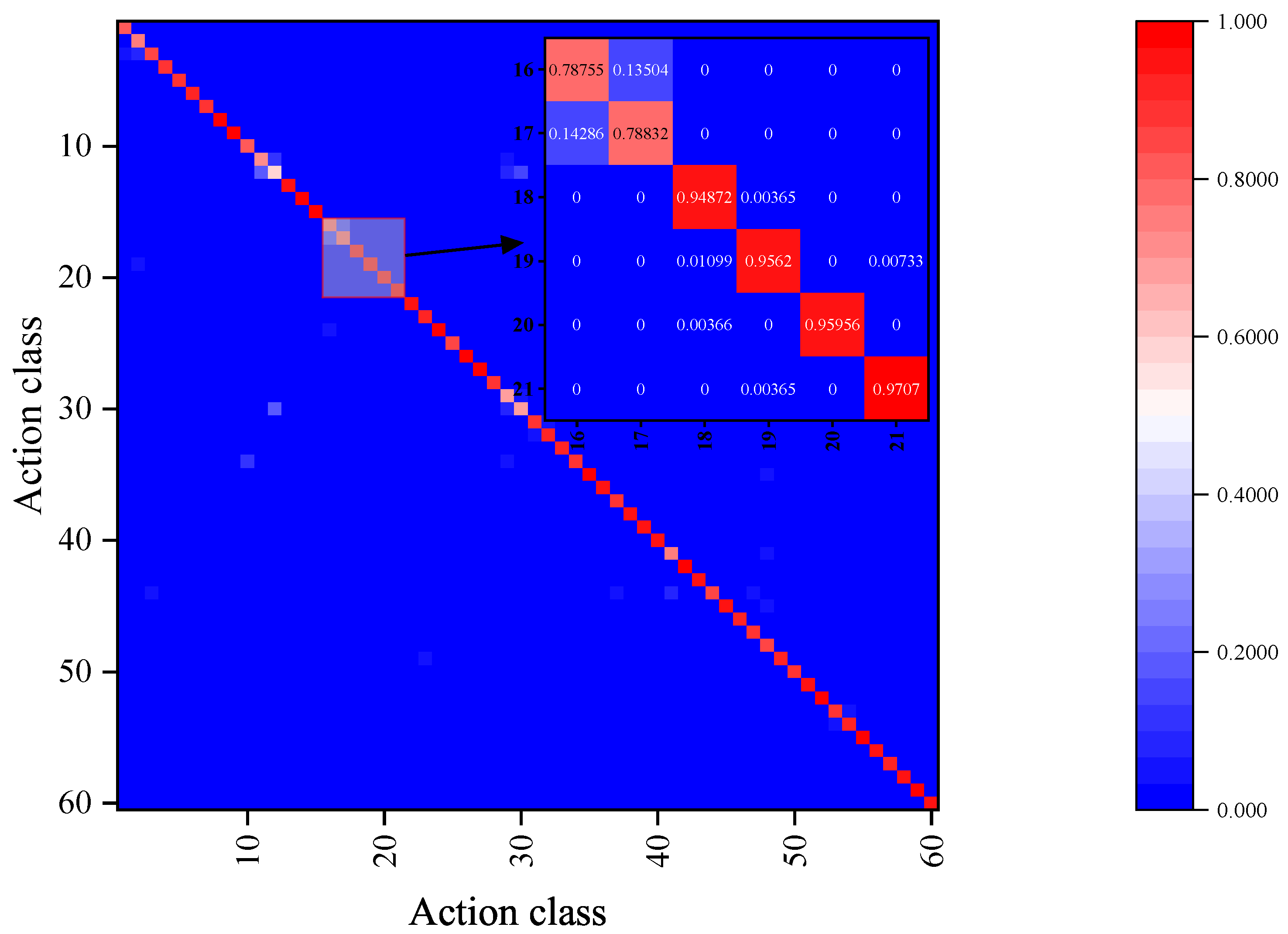
4.4. Visualization
4.5. Comparison with the State of the Art
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, D.A.; Ramanathan, V.; Mahajan, D.; Torresani, L.; Paluri, M.; Fei-Fei, L.; Niebles, J.C. What makes a video a video: Analyzing temporal information in video understanding models and datasets. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7366–7375. [Google Scholar]
- MacKenzie, I.S. Human-Computer Interaction: An Empirical Research Perspective; Newnes: Oxford, UK, 2012. [Google Scholar]
- Burdea, G.C.; Coiffet, P. Virtual Reality Technology; John Wiley & Sons: Hoboken, NJ, USA, 2003. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Wildes, R.P. Spatiotemporal multiplier networks for video action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4768–4777. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Hu, K.; Jin, J.; Shen, C.; Xia, M.; Weng, L. Attentional weighting strategy-based dynamic GCN for skeleton-based action recognition. Multimed. Syst. 2023, 1–14. [Google Scholar] [CrossRef]
- Hu, K.; Ding, Y.; Jin, J.; Weng, L.; Xia, M. Skeleton motion recognition based on multi-scale deep spatio-temporal features. Appl. Sci. 2022, 12, 1028. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3d skeletons as points in a lie group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Vemulapalli, R.; Chellapa, R. Rolling rotations for recognizing human actions from 3d skeletal data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4471–4479. [Google Scholar]
- Hu, K.; Zhang, E.; Xia, M.; Weng, L.; Lin, H. Mcanet: A multi-branch network for cloud/snow segmentation in high-resolution remote sensing images. Remote Sens. 2023, 15, 1055. [Google Scholar] [CrossRef]
- Hu, K.; Weng, C.; Shen, C.; Wang, T.; Weng, L.; Xia, M. A multi-stage underwater image aesthetic enhancement algorithm based on a generative adversarial network. Eng. Appl. Artif. Intell. 2023, 123, 106196. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef]
- Xie, L.; Yuille, A. Genetic cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1379–1388. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An end-to-end spatio-temporal attention model for human action recognition from skeleton data. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Cao, C.; Lan, C.; Zhang, Y.; Zeng, W.; Lu, H.; Zhang, Y. Skeleton-based action recognition with gated convolutional neural networks. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 3247–3257. [Google Scholar] [CrossRef]
- Hu, K.; Zheng, F.; Weng, L.; Ding, Y.; Jin, J. Action Recognition Algorithm of Spatio–Temporal Differential LSTM Based on Feature Enhancement. Appl. Sci. 2021, 11, 7876. [Google Scholar] [CrossRef]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Skeleton-based action recognition with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 597–600. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Peng, W.; Shi, J.; Varanka, T.; Zhao, G. Rethinking the ST-GCNs for 3D skeleton-based human action recognition. Neurocomputing 2021, 454, 45–53. [Google Scholar] [CrossRef]
- Zhang, P.; Lan, C.; Zeng, W.; Xing, J.; Xue, J.; Zheng, N. Semantics-guided neural networks for efficient skeleton-based human action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1112–1121. [Google Scholar]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 13359–13368. [Google Scholar]
- Qi, Y.; Hu, J.; Han, X.; Hu, L.; Zhao, Z. MFGCN: An efficient graph convolutional network based on multi-order feature information for human skeleton action recognition. Neural Comput. Appl. 2023, 35, 19979–19995. [Google Scholar] [CrossRef]
- Sheikh, Y.; Sheikh, M.; Shah, M. Exploring the space of a human action. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 144–149. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Mining actionlet ensemble for action recognition with depth cameras. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 1290–1297. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar]
- Wang, P.; Li, W.; Li, C.; Hou, Y. Action recognition based on joint trajectory maps with convolutional neural networks. Knowl.-Based Syst. 2018, 158, 43–53. [Google Scholar] [CrossRef]
- Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-based action recognition with shift graph convolutional network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 183–192. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Constructing stronger and faster baselines for skeleton-based action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1474–1488. [Google Scholar] [CrossRef]
- Chi, H.g.; Ha, M.H.; Chi, S.; Lee, S.W.; Huang, Q.; Ramani, K. Infogcn: Representation learning for human skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 20186–20196. [Google Scholar]
- Cheng, K.; Zhang, Y.; Cao, C.; Shi, L.; Cheng, J.; Lu, H. Decoupling gcn with dropgraph module for skeleton-based action recognition. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 536–553. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 143–152. [Google Scholar]
- Hewage, P.; Behera, A.; Trovati, M.; Pereira, E.; Ghahremani, M.; Palmieri, F.; Liu, Y. Temporal convolutional neural (TCN) network for an effective weather forecasting using time-series data from the local weather station. Soft Comput. 2020, 24, 16453–16482. [Google Scholar] [CrossRef]
- Geng, P.; Li, H.; Wang, F.; Lyu, L. Adaptive multi-level graph convolution with contrastive learning for skeleton-based action recognition. Signal Process. 2022, 201, 108714. [Google Scholar] [CrossRef]
- Peng, W.; Hong, X.; Chen, H.; Zhao, G. Learning graph convolutional network for skeleton-based human action recognition by neural searching. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 2669–2676. [Google Scholar]
- Liu, T.; Zhao, R.; Lam, K.M.; Kong, J. Visual-semantic graph neural network with pose-position attentive learning for group activity recognition. Neurocomputing 2022, 491, 217–231. [Google Scholar] [CrossRef]
- Liu, J.; Wang, G.; Hu, P.; Duan, L.Y.; Kot, A.C. Global context-aware attention lstm networks for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1647–1656. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Taud, H.; Mas, J. Multilayer perceptron (MLP). Geomatic Approaches for Modeling Land Change Scenarios, Lecture Notes in Geoinformation and Cartography, Mexico City, Mexico; Springer: Berlin/Heidelberg, Germany, 2018; pp. 451–455. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, K.; Li, Y.; Zhang, S.; Wu, J.; Gong, S.; Jiang, S.; Weng, L. FedMMD: A Federated weighting algorithm considering Non-IID and Local Model Deviation. Expert Syst. Appl. 2024, 237, 121463. [Google Scholar] [CrossRef]
- Hu, K.; Li, Y.; Xia, M.; Wu, J.; Lu, M.; Zhang, S.; Weng, L. Federated learning: A distributed shared machine learning method. Complexity 2021, 2021, 1–20. [Google Scholar]
- Hu, K.; Wu, J.; Weng, L.; Zhang, Y.; Zheng, F.; Pang, Z.; Xia, M. A novel federated learning approach based on the confidence of federated Kalman filters. Int. J. Mach. Learn. Cybern. 2021, 12, 3607–3627. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar] [CrossRef]
- Wang, L.; Ge, L.; Li, R.; Fang, Y. Three-stream CNNs for action recognition. Pattern Recognit. Lett. 2017, 92, 33–40. [Google Scholar] [CrossRef]
- Le, C.; Liu, X. Spatio-temporal Attention Graph Convolutions for Skeleton-based Action Recognition. In Proceedings of the Scandinavian Conference on Image Analysis, Levi Ski Resort, Finland, 18–21 April 2023; pp. 140–153. [Google Scholar]
- Liu, J.; Shahroudy, A.; Perez, M.; Wang, G.; Duan, L.Y.; Kot, A.C. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2684–2701. [Google Scholar] [CrossRef]
- Wang, J.; Nie, X.; Xia, Y.; Wu, Y.; Zhu, S.C. Cross-view action modeling, learning and recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2649–2656. [Google Scholar]
- Qin, Z.; Liu, Y.; Ji, P.; Kim, D.; Wang, L.; McKay, R.; Anwar, S.; Gedeon, T. Fusing higher-order features in graph neural networks for skeleton-based action recognition. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Gedamu, K.; Ji, Y.; Gao, L.; Yang, Y.; Shen, H.T. Relation-mining self-attention network for skeleton-based human action recognition. Pattern Recognit. 2023, 139, 109455. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, C.; Tao, D. Context aware graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14333–14342. [Google Scholar]
- Qin, X.; Cai, R.; Yu, J.; He, C.; Zhang, X. An efficient self-attention network for skeleton-based action recognition. Sci. Rep. 2022, 12, 4111. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Ye, G.; Tu, Z.; Qin, Y.; Qin, Q.; Zhang, J.; Liu, J. A spatial attentive and temporal dilated (SATD) GCN for skeleton-based action recognition. CAAI Trans. Intell. Technol. 2022, 7, 46–55. [Google Scholar] [CrossRef]
- Lu, H.; Wang, T. Joint Spatiotemporal Collaborative Relationship Network for Skeleton-Based Action Recognition. In Proceedings of the International Conference on Intelligent Computing, Hyderabad, India, 25–26 August 2023; pp. 775–786. [Google Scholar]
- Wu, L.; Zhang, C.; Zou, Y. SpatioTemporal focus for skeleton-based action recognition. Pattern Recognit. 2023, 136, 109231. [Google Scholar] [CrossRef]
- Lee, I.; Kim, D.; Kang, S.; Lee, S. Ensemble deep learning for skeleton-based action recognition using temporal sliding lstm networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1012–1020. [Google Scholar]
- Gammulle, H.; Denman, S.; Sridharan, S.; Fookes, C. Two stream lstm: A deep fusion framework for human action recognition. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 177–186. [Google Scholar]
- Soo Kim, T.; Reiter, A. Interpretable 3d human action analysis with temporal convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 20–28. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3595–3603. [Google Scholar]
- Peng, W.; Shi, J.; Zhao, G. Spatial temporal graph deconvolutional network for skeleton-based human action recognition. IEEE Signal Process. Lett. 2021, 28, 244–248. [Google Scholar] [CrossRef]
- Peng, W.; Hong, X.; Zhao, G. Tripool: Graph triplet pooling for 3D skeleton-based action recognition. Pattern Recognit. 2021, 115, 107921. [Google Scholar] [CrossRef]
- Cheng, Q.; Cheng, J.; Ren, Z.; Zhang, Q.; Liu, J. Multi-scale spatial–temporal convolutional neural network for skeleton-based action recognition. Pattern Anal. Appl. 2023, 26, 1303–1315. [Google Scholar] [CrossRef]
- Veeriah, V.; Zhuang, N.; Qi, G.J. Differential recurrent neural networks for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4041–4049. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Learning actionlet ensemble for 3D human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 914–927. [Google Scholar] [CrossRef]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1227–1236. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MTC | CM | MGS | Xsub (%) | Xview (%) |
|---|---|---|---|---|
| ✓ | × | ✓ | 91.6 | 96.1 |
| × | ✓ | ✓ | 91.3 | 95.8 |
| ✓ | ✓ | × | 91.5 | 95.7 |
| ✓ | ✓ | ✓ | 91.9 | 96.3 |
| Action | Xsub | |||
|---|---|---|---|---|
| Joint (%) | Joint + CM (%) | Bone (%) | Bone + CM (%) | |
| Action3 | 77.8 | 78.3 (+0.5) | 85.7 | 86.1 (+0.4) |
| Action8 | 95.3 | 96.0 (+0.7) | 95.9 | 96.7 (+0.8) |
| Action13 | 91.1 | 92.3 (+1.2) | 91.7 | 93.4 (+1.7) |
| Action22 | 89.2 | 91.0 (+1.8) | 93.2 | 96.3 (+3.1) |
| Action25 | 81.1 | 81.3 (+0.2) | 82.8 | 84.3 (+1.5) |
| Action32 | 87.4 | 90.9 (+3.5) | 89.9 | 91.3 (+1.4) |
| Action34 | 91.3 | 91.7 (+0.4) | 88.2 | 88.4 (+0.2) |
| Action38 | 93.5 | 94.6 (+1.1) | 93.2 | 93.5 (+0.3) |
| Action42 | 99.5 | 99.6 (+0.1) | 99.4 | 99.6 (+0.2) |
| Action52 | 93.2 | 95.7 (+2.5) | 95.4 | 96.7 (+1.3) |
| Methods | NTU-RGB+D 60 | NW-UCLA (%) |
|---|---|---|
| Xsub (%) | ||
| sampling | 88.4 | 92.5 |
| center of gravity | 91.5 | 96.3 |
| average | 91.9 | 96.4 |
| MST | SATM | NTU-RGB+D 60 Xsub (%) | NW-UCLA (%) |
|---|---|---|---|
| × | ✓ | 90.8 | 96.1 |
| ✓ | × | 91.7 | 95.7 |
| ✓ | ✓ | 91.9 | 96.4 |
| Methods | Year | NTU-RGB+D 60 | NTU-RGB+D 120 | ||
|---|---|---|---|---|---|
| Xsub (%) | Xview (%) | Xsub (%) | Xset (%) | ||
| DeepLSTM [57] | 2017 | 60.7 | 67.3 | - | - |
| Temporal ConvNet [58] | 2017 | 74.3 | 83.1 | - | - |
| Two-stream CNN [18] | 2017 | 83.3 | 89.3 | - | - |
| ST-GCN [5] | 2018 | 81.5 | 88.3 | - | - |
| AS-GCN [59] | 2019 | 86.8 | 94.2 | - | - |
| 2s-AGCN [19] | 2019 | 88.5 | 95.1 | 82.9 | 84.9 |
| MS-G3D [32] | 2020 | 91.5 | 96.2 | 86.9 | 88.4 |
| CA-GCN [51] | 2020 | 83.5 | 91.4 | - | - |
| NAS-GCN [35] | 2020 | 89.4 | 95.0 | - | - |
| Global-GCN [20] | 2021 | 90.1 | 95.9 | 80.9 | 81.7 |
| ST-GDNs [60] | 2021 | 89.7 | 95.9 | 80.8 | 82.3 |
| Tripool [61] | 2021 | 89.7 | 95.9 | 80.1 | 82.8 |
| SATD-GCN [53] | 2022 | 89.3 | 95.5 | - | - |
| Qin method [52] | 2022 | 90.5 | 96.1 | 85.7 | 86.8 |
| Qin method [49] | 2022 | 91.6 | 96.3 | 88.2 | 89.2 |
| MSSTNet [62] | 2023 | 89.6 | 95.3 | 85.3 | 86.0 |
| JSCR [54] | 2023 | 88.7 | 96.1 | 84.1 | 86.8 |
| STF-Net [55] | 2023 | 91.1 | 96.5 | 86.5 | 88.2 |
| RSA-Net [50] | 2023 | 91.8 | 96.8 | 88.4 | 89.7 |
| Ours (joint) | - | 89.3 | 93.4 | 84.6 | 86.2 |
| Ours (bone) | - | 90.0 | 93.5 | 86.3 | 87.8 |
| Ours (joint-motion) | - | 87.6 | 92.9 | 81.3 | 83.0 |
| Ours (bone-motion) | - | 87.3 | 91.8 | 81.1 | 82.9 |
| Ours | - | 91.9 | 96.3 | 88.5 | 90.3 |
| Methods | Year | NW-UCLA (Top-1 (%)) |
|---|---|---|
| Lie Group [63] | 2017 | 74.2 |
| Action ensemble [64] | 2017 | 76.0 |
| Ensemble TS-LSTM [56] | 2017 | 89.2 |
| AGC-LSTM [65] | 2020 | 93.3 |
| Shift-GCN [28] | 2021 | 94.6 |
| CTR-GCN [22] | 2022 | 96.5 |
| Ours | - | 96.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, K.; Shen, C.; Wang, T.; Shen, S.; Cai, C.; Huang, H.; Xia, M. Action Recognition Based on Multi-Level Topological Channel Attention of Human Skeleton. Sensors 2023, 23, 9738. https://doi.org/10.3390/s23249738
Hu K, Shen C, Wang T, Shen S, Cai C, Huang H, Xia M. Action Recognition Based on Multi-Level Topological Channel Attention of Human Skeleton. Sensors. 2023; 23(24):9738. https://doi.org/10.3390/s23249738
Chicago/Turabian StyleHu, Kai, Chaowen Shen, Tianyan Wang, Shuai Shen, Chengxue Cai, Huaming Huang, and Min Xia. 2023. "Action Recognition Based on Multi-Level Topological Channel Attention of Human Skeleton" Sensors 23, no. 24: 9738. https://doi.org/10.3390/s23249738
APA StyleHu, K., Shen, C., Wang, T., Shen, S., Cai, C., Huang, H., & Xia, M. (2023). Action Recognition Based on Multi-Level Topological Channel Attention of Human Skeleton. Sensors, 23(24), 9738. https://doi.org/10.3390/s23249738