
A Comparison Study between Traditional and Deep-Reinforcement-Learning-Based Algorithms for Indoor Autonomous Navigation in Dynamic Scenarios



Abstract
:1. Introduction
2. Background Studies
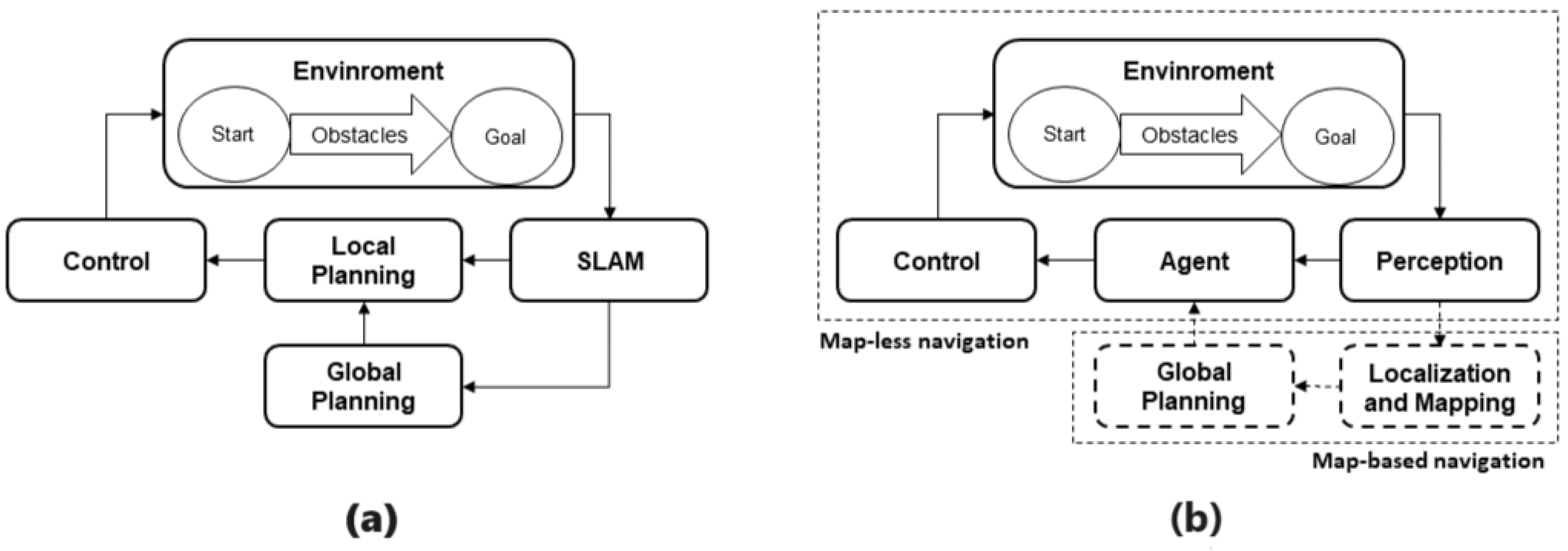
2.1. Simultaneous Localization and Mapping (SLAM)
2.1.1. Gmapping
2.1.2. HectorSLAM
2.1.3. Karto-SLAM
2.2. Global Planning
2.2.1. Artificial Potential Fields
2.2.2. A Star (A*)
| Algorithm 1: Dijkstra’s algorithm. |
 |
2.3. Local Planning
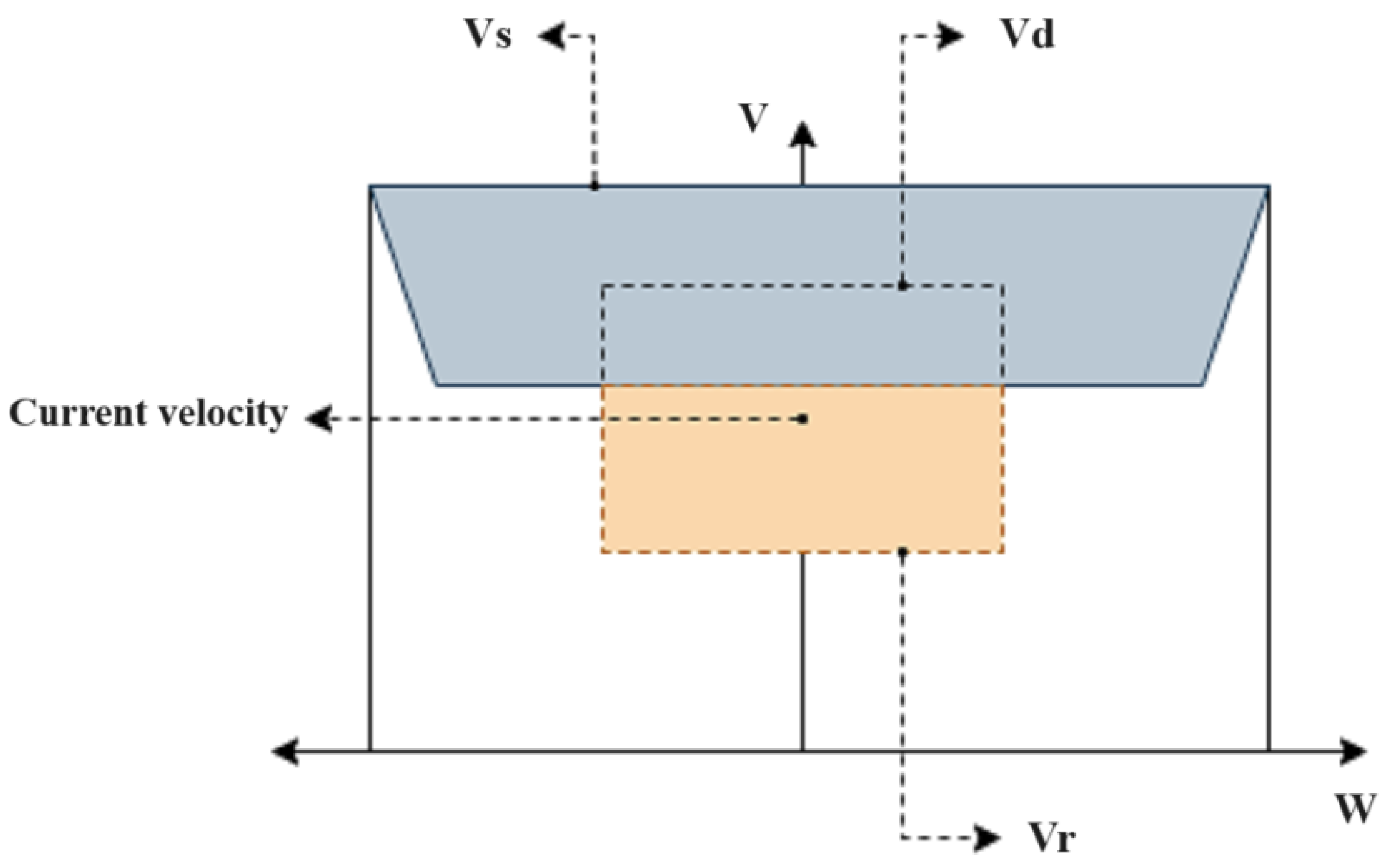
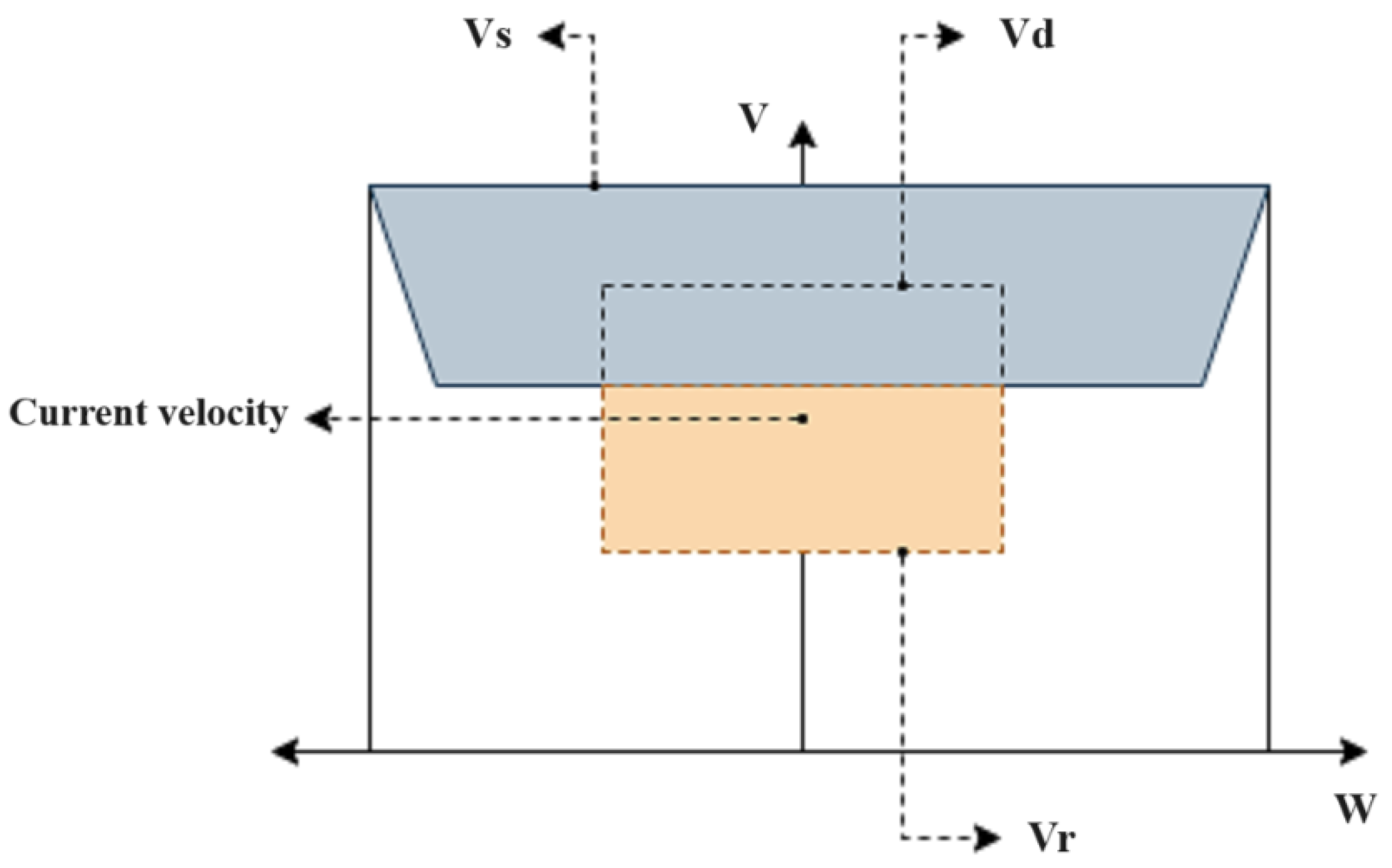
2.3.1. Dynamic-Window Approach (DWA)
2.3.2. Time Elastic Band (TEB)
2.3.3. Model Predictive Control (MPC)
2.3.4. Review of Local Planners
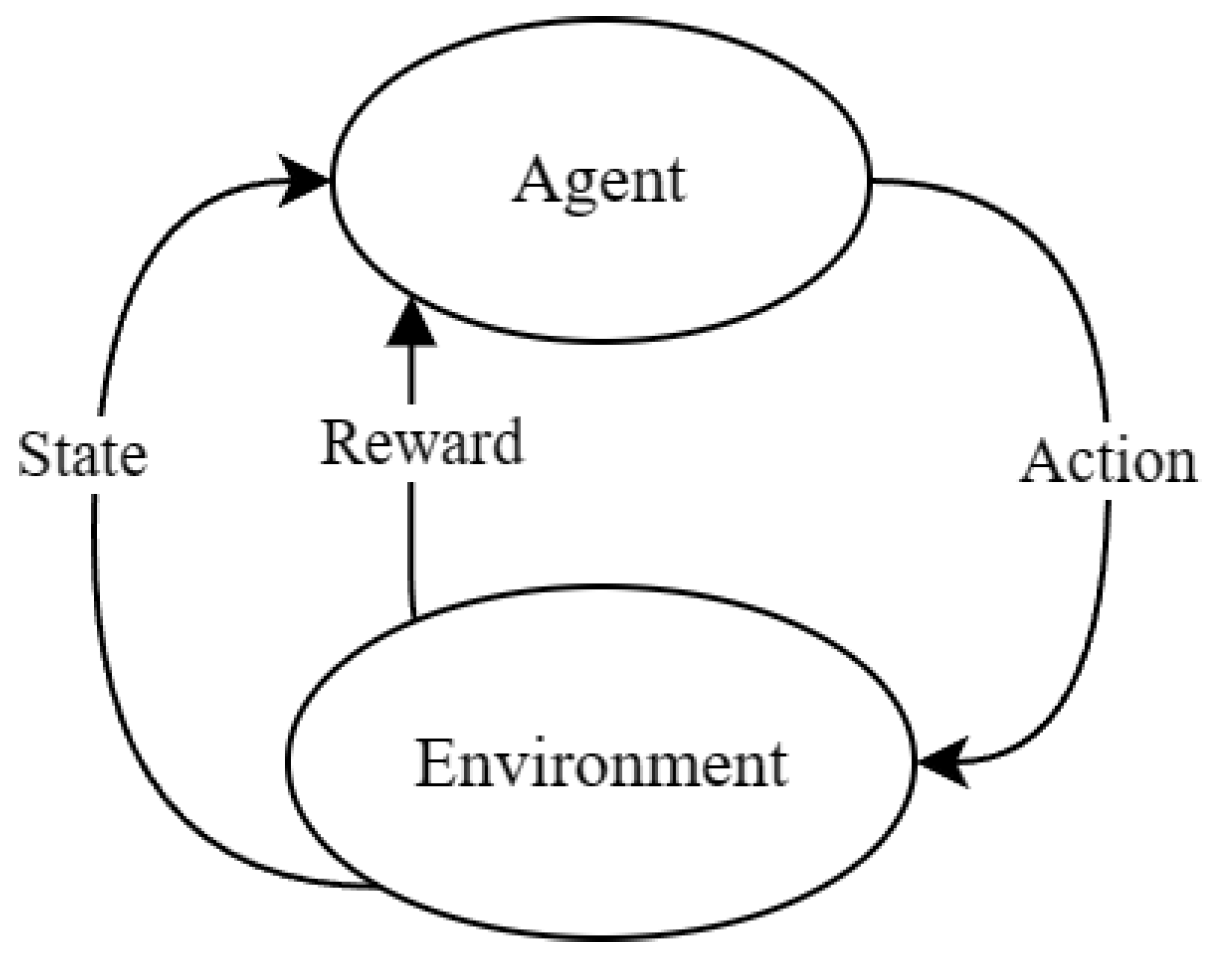
2.4. Reinforcement-Learning Review
2.4.1. Deep Reinforcement Learning
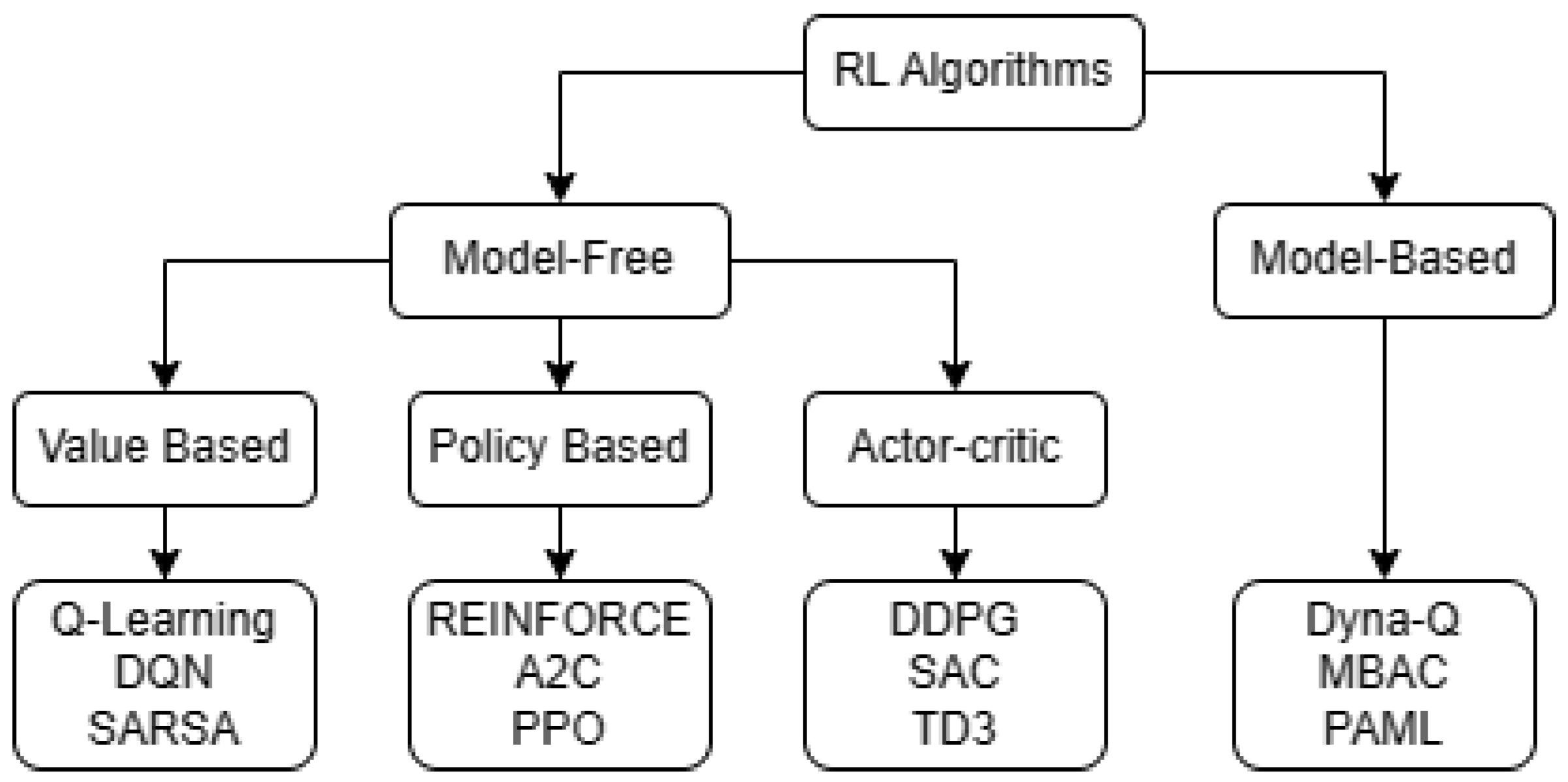
2.4.2. Review of Deep-Reinforcement-Learning Algorithm Classification
2.5. Review of DRL-Based Navigation Algorithms
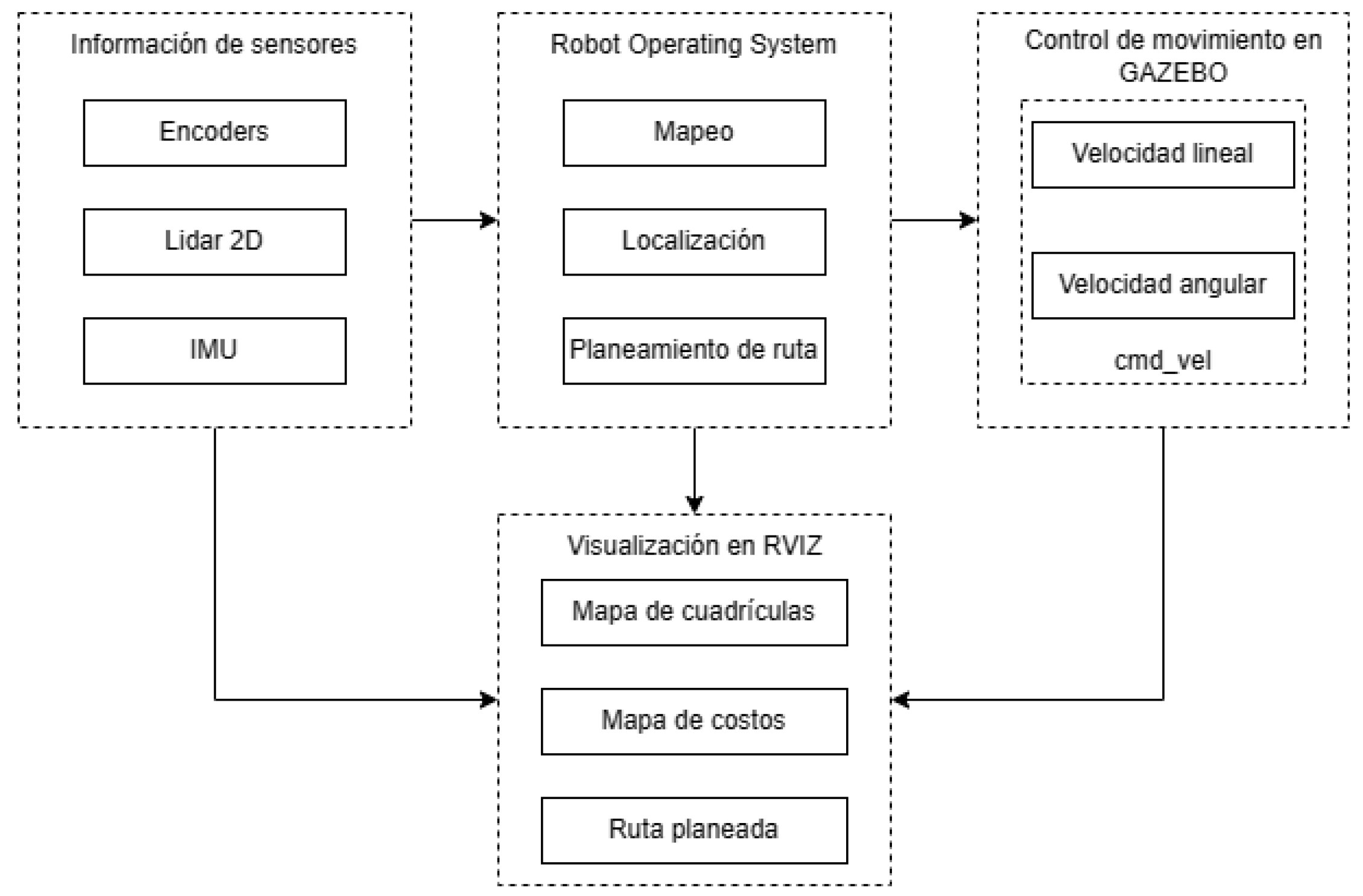
3. Methodology
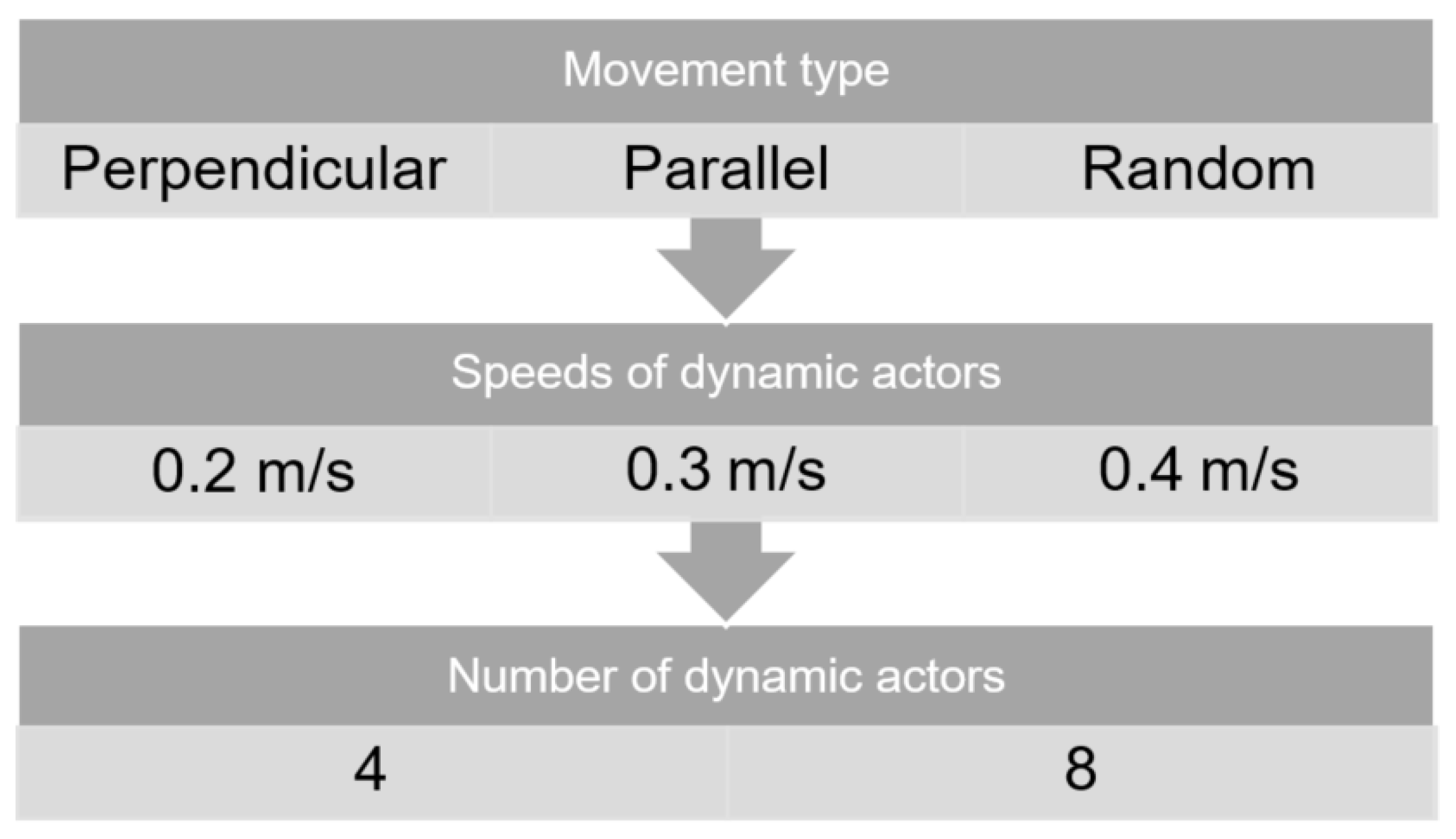
3.1. Simulation Configuration
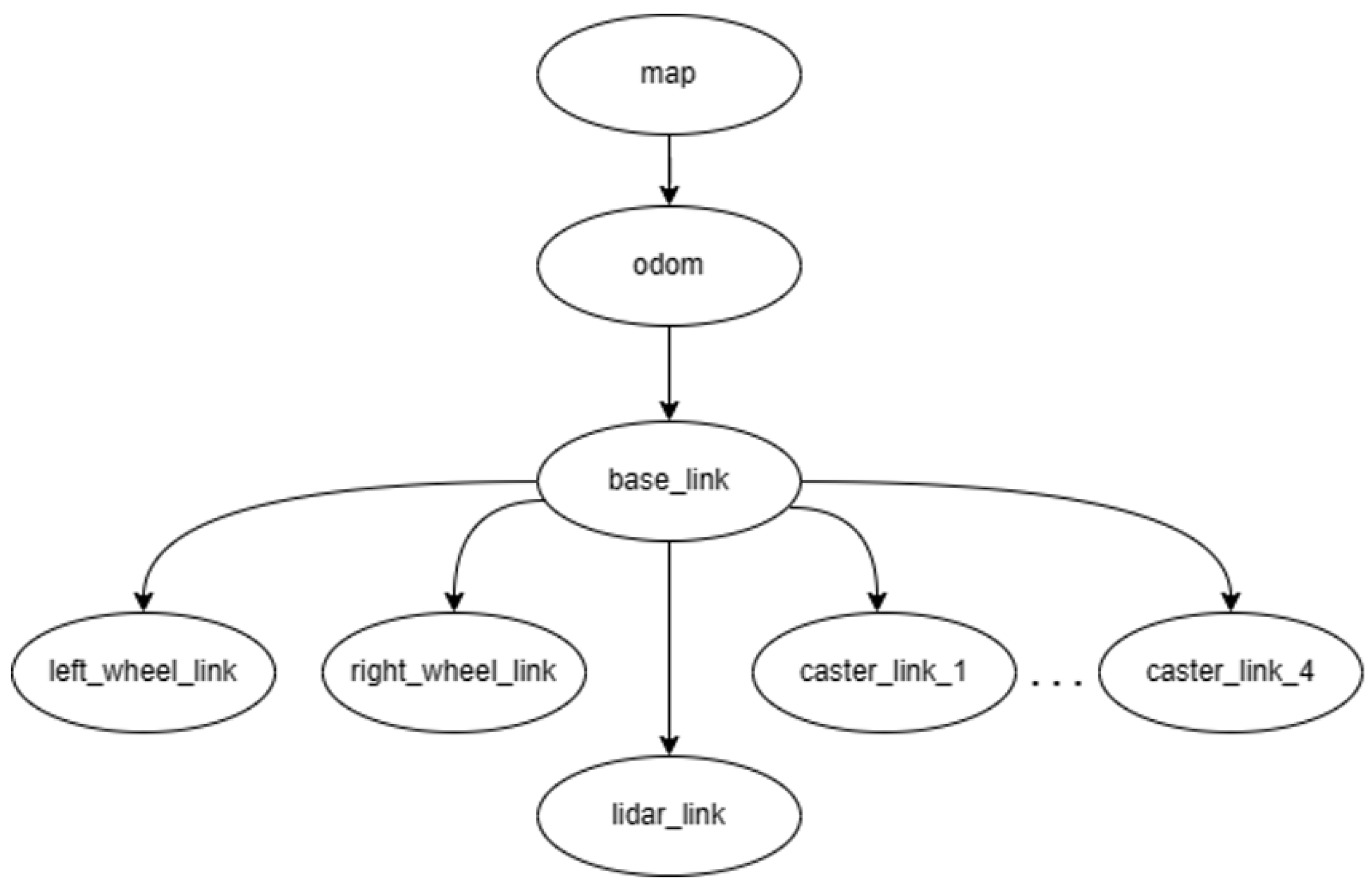
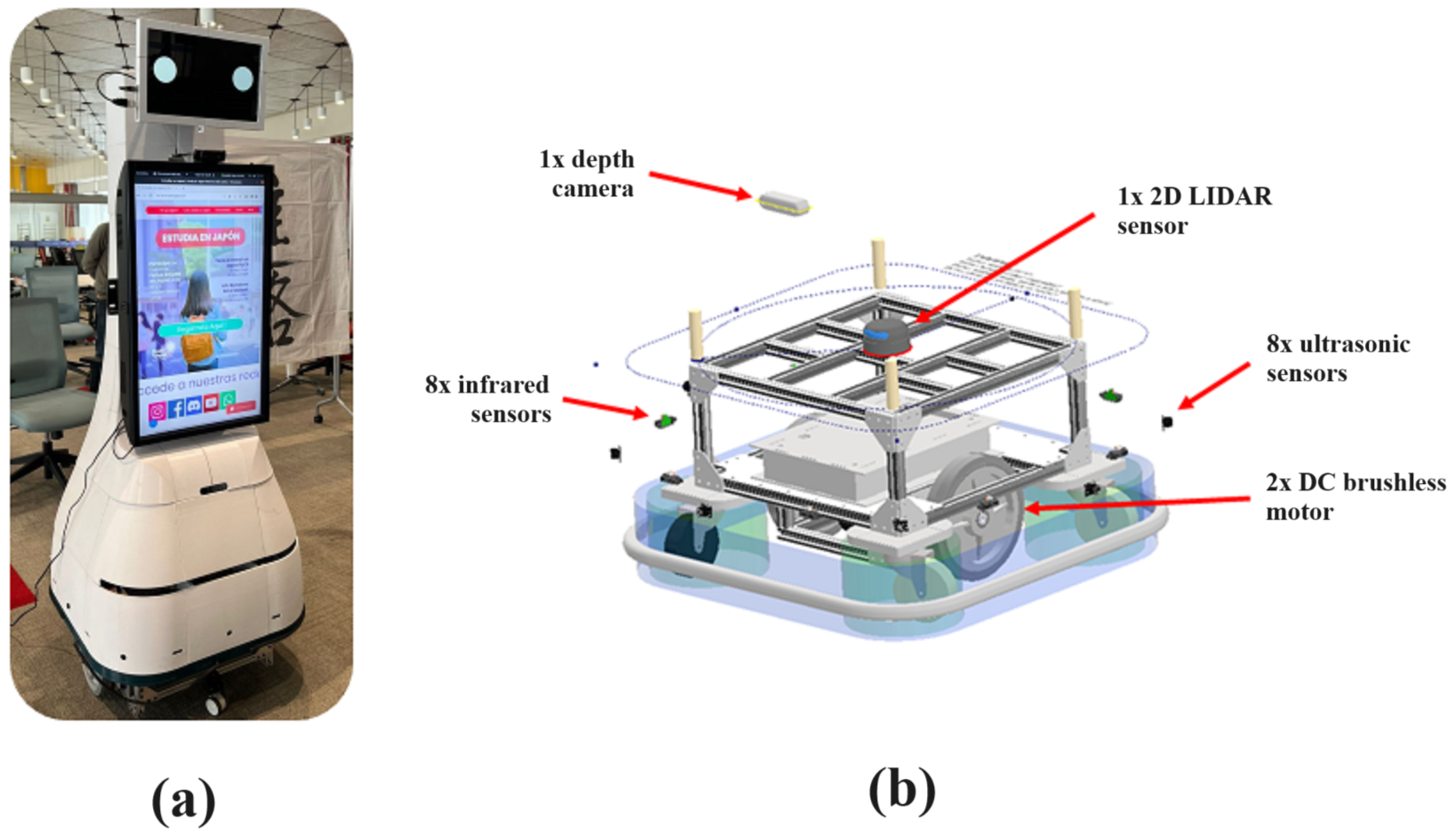
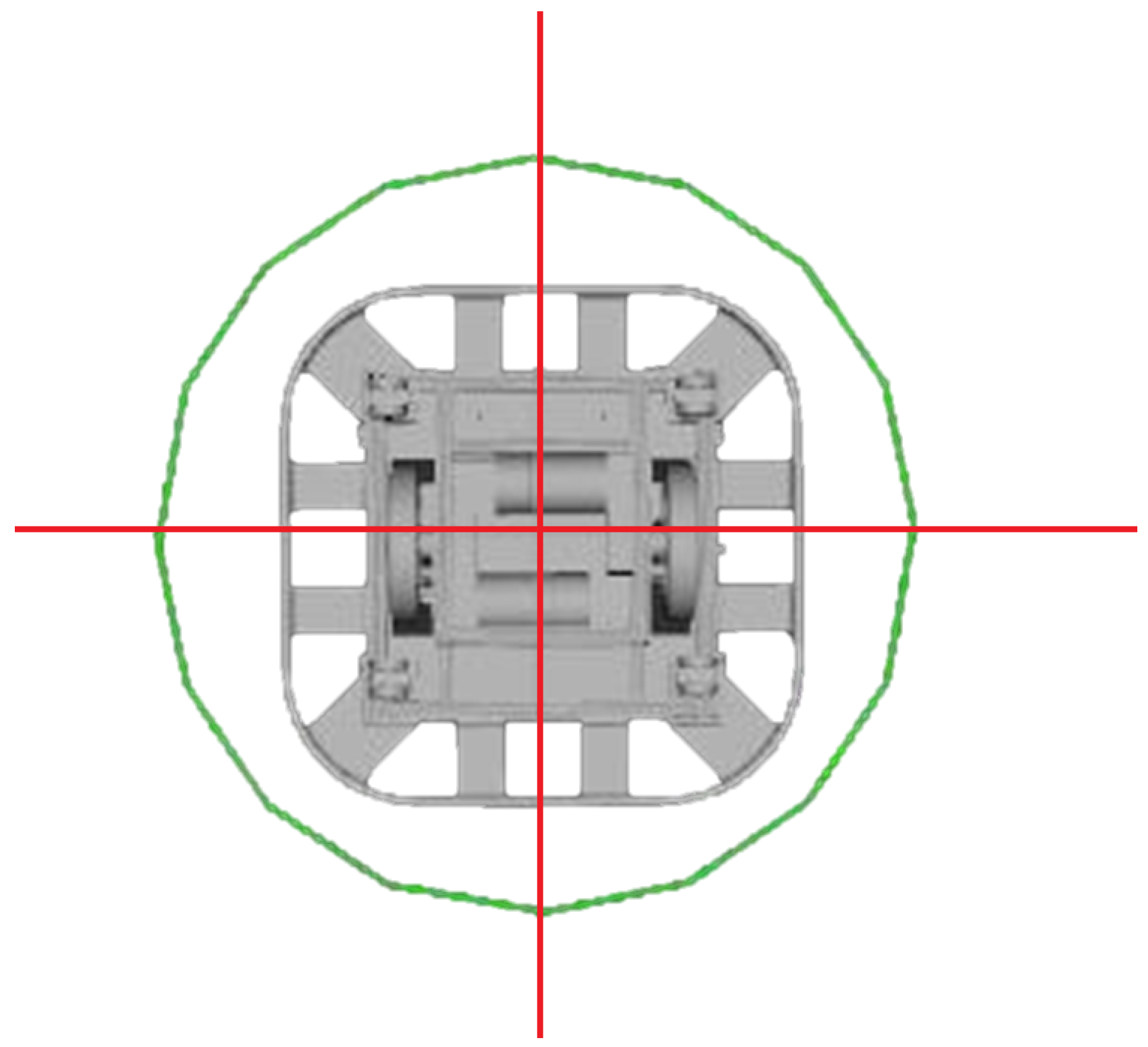
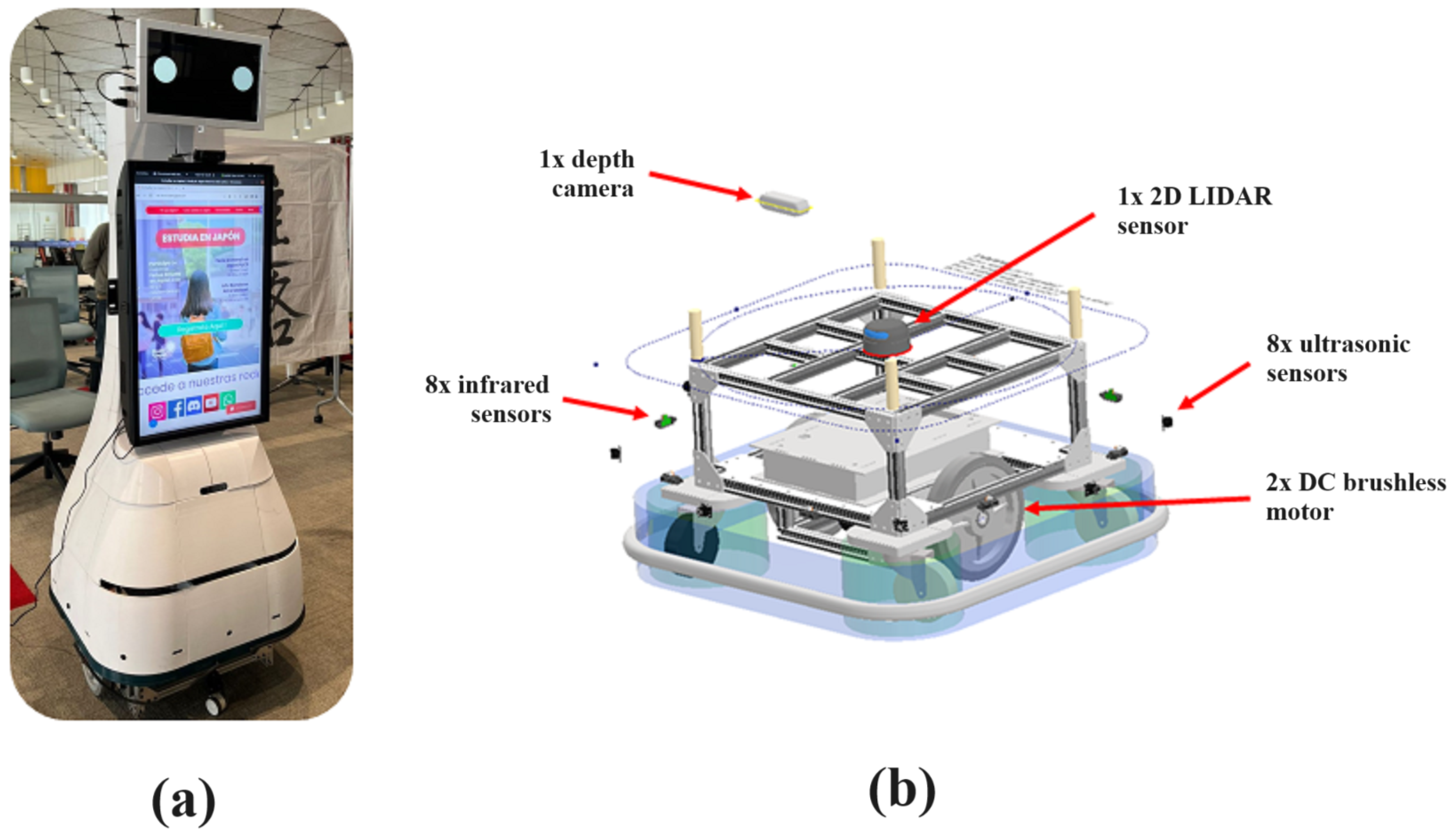
3.1.1. Robot Description
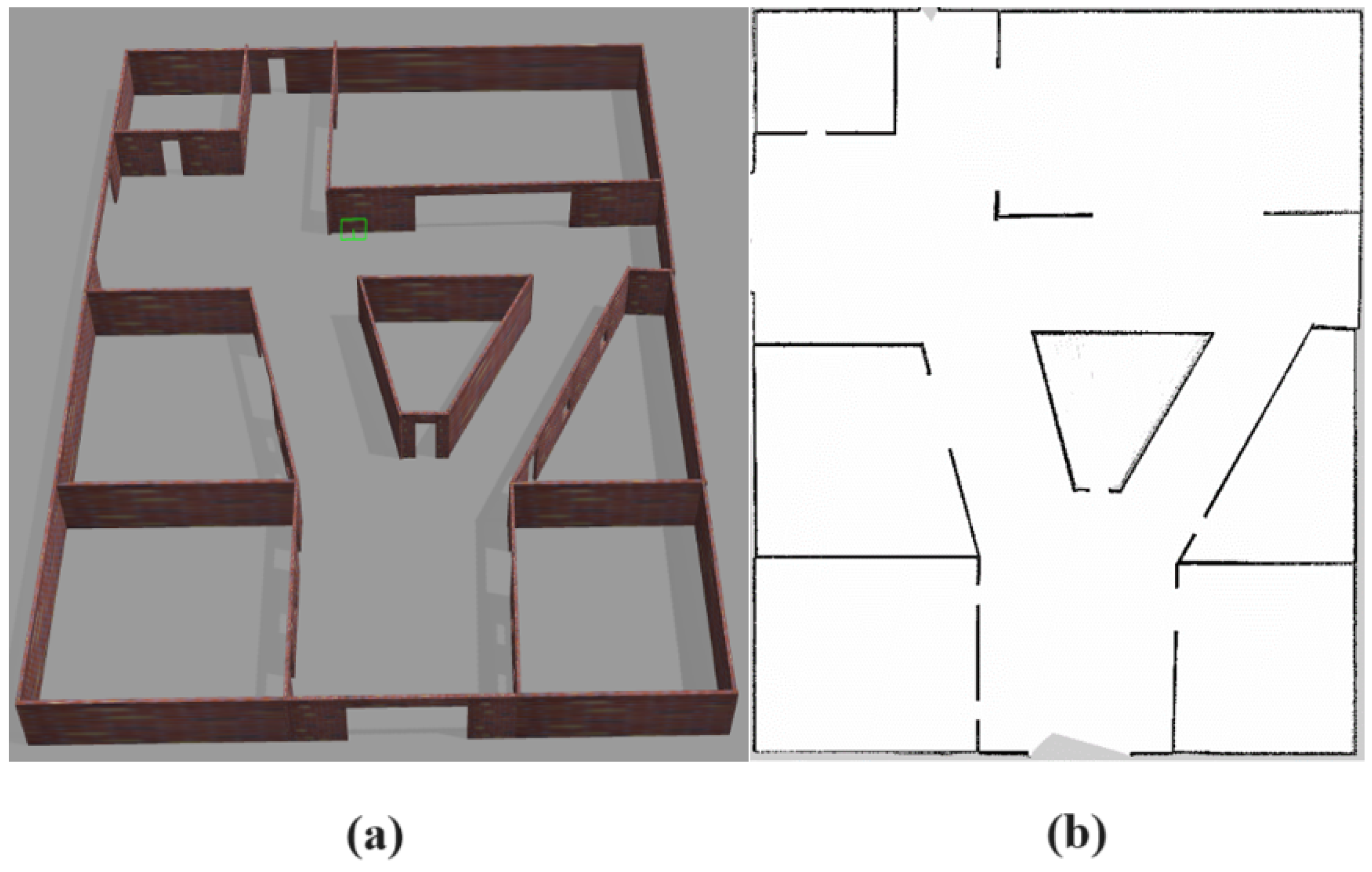
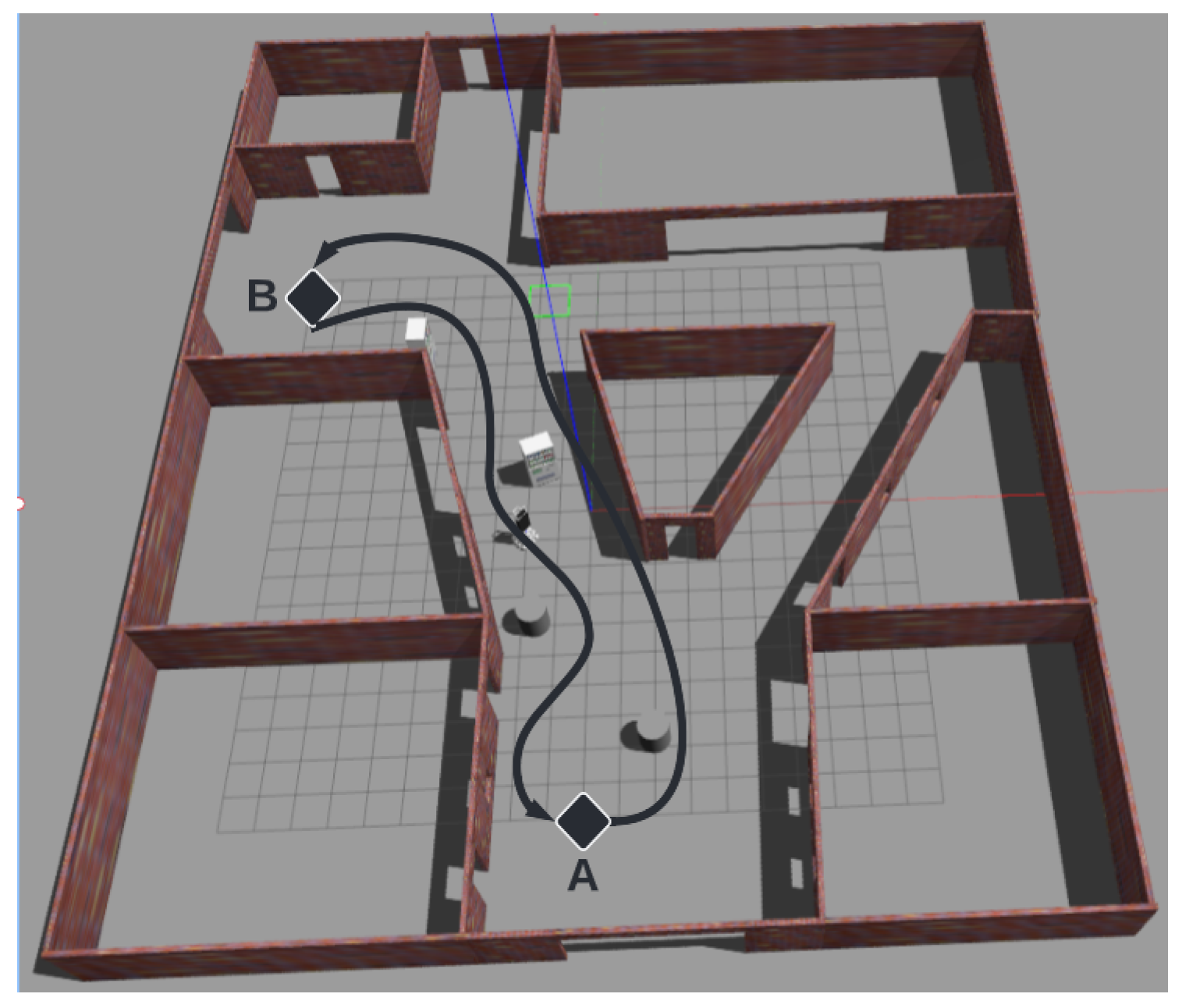
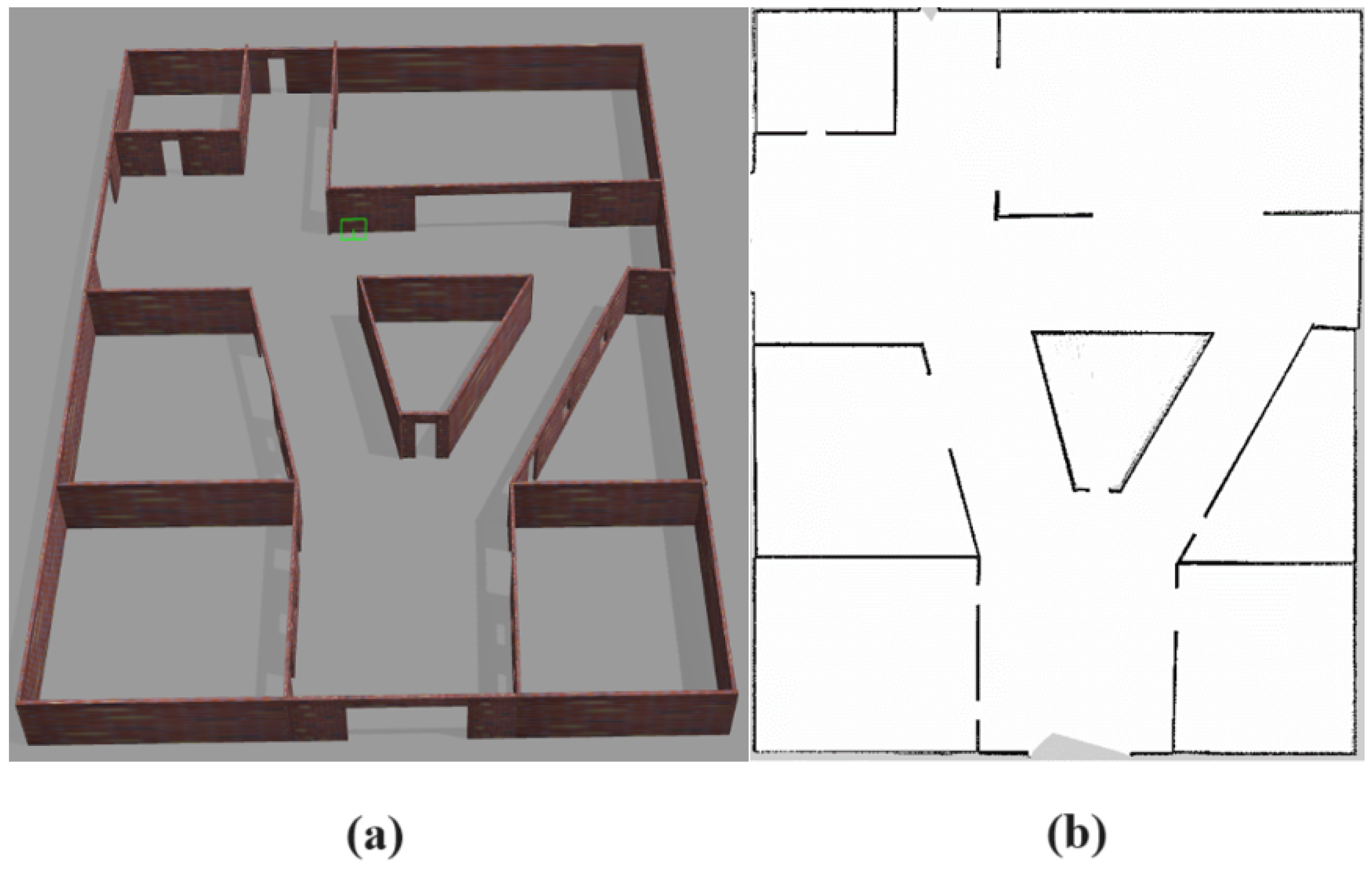
3.1.2. Simulation Environment
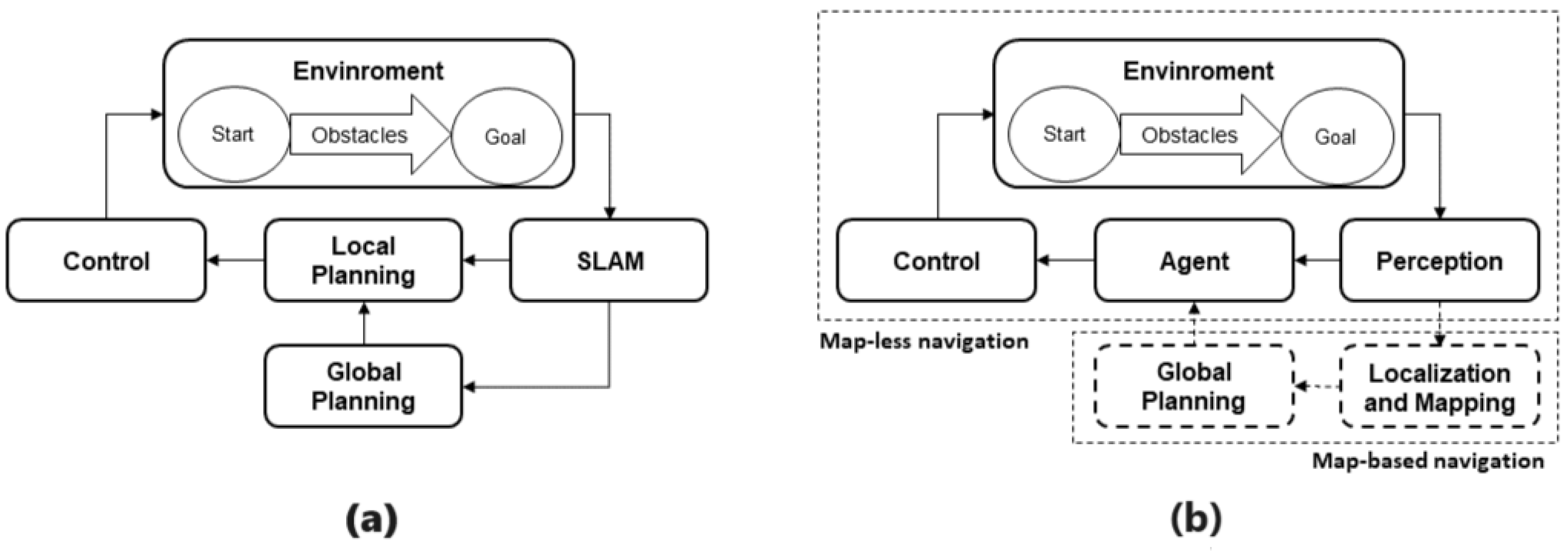
3.2. ROS Navigation Stack
3.2.1. Mapping
3.2.2. Localization
3.2.3. Path Planning
3.3. Local-Planners Algorithms Implementation
3.3.1. Dynamic-Window Approach (DWA)
3.3.2. Time Elastic Band (TEB)
3.4. Map-Based-Deep-Reinforcement-Learning Algorithm Description
Algorithm Architecture
3.5. Mapless-Deep-Reinforcement-Learning Algorithms Implementation
3.5.1. State Space
- Distance and angle to the goal;
- 2D point cloud from the laser sensor;
- Distance and angle to the nearest obstacle.
3.5.2. Action Space
3.5.3. Reward Model
- Where the parameter corresponded to the reward assigned to the robot when an obstacle was at a distance .
- The parameter c allowed for controlling the fall of the exponential function. In this case, it was set to 5.
- The parameter was the most relevant for training, as it determined the start of the safe zone in which the robot no longer received a reward for the obstacle’s location.
3.5.4. DRL Algorithm
- Deep Q Network (DQN) [49]: This algorithm is based on a value function—that is, the assignment of a numerical value for each state. A deep neural network is in charge of approximating this value, so that then the policy determines the action to be taken by means of the Equation (14), where the policy chooses the action that maximizes the value function :DQN is an off-policy algorithm, because during training it employs a policy that is different from the optimal policy it is trying to estimate, because, first of all, in order to solve the problem of divergence generated by non-stationary targets, two instances of the neural-network weights are created. In this way, we have a network focused on saving an objective for multiple iterations and we have accumulated-experience data that allow us to treat the optimization problem as supervised learning.
- Soft Actor–Critic (SAC) [50]: This is an algorithm that belongs to the actor–critic category, whereby it is based on the estimation of a policy and a value function. Like DQN, SAC is also an off-policy algorithm, because it employs experiences from a behavior-focused policy that is different from the one used for optimization. SAC is well known for its ability to handle continuous action spaces, which is critical in environments where actions are not limited to discrete choices. In SAC, a deep neural network is used to model the Q function, which assigns a numerical value to each state-action.However, unlike DQN, SAC seeks to learn stochastic policies through the inclusion of an entropy term in the loss function. What this means is that the policy is not a deterministic function that maps states directly to actions, but rather produces probability distributions over actions. This component allows for randomness in actions and, thus, greater exploration in the environment. Consequently, it is important to emphasize that the agent’s objective is not limited to maximizing only the total expected reward, but also entropy. Thus, diversity in the agent’s behavior is promoted, in parallel to the optimization of the objective function.
- Proximal Policy Optimization (PPO) [51]: An algorithm that focuses on improving policies in sequential decision-making environments. Unlike the off-policy approaches discussed above, PPO belongs to the on-policy category, which means that it learns directly from the policy it is executing in the current environment.PPO, instead of approximating a value function, as in DQN, focuses on direct policy optimization. The goal is to find a policy that maximizes the cumulative reward over time, taking into account efficient exploration and exploitation. PPO addresses the policy-optimization problem in a more stable manner by limiting the policy updates at each iteration. This is achieved by imposing a constraint on the magnitude of policy change, which avoids drastic updates that could lead to learning instability.
3.6. Training Evaluation
4. Results and Discussion
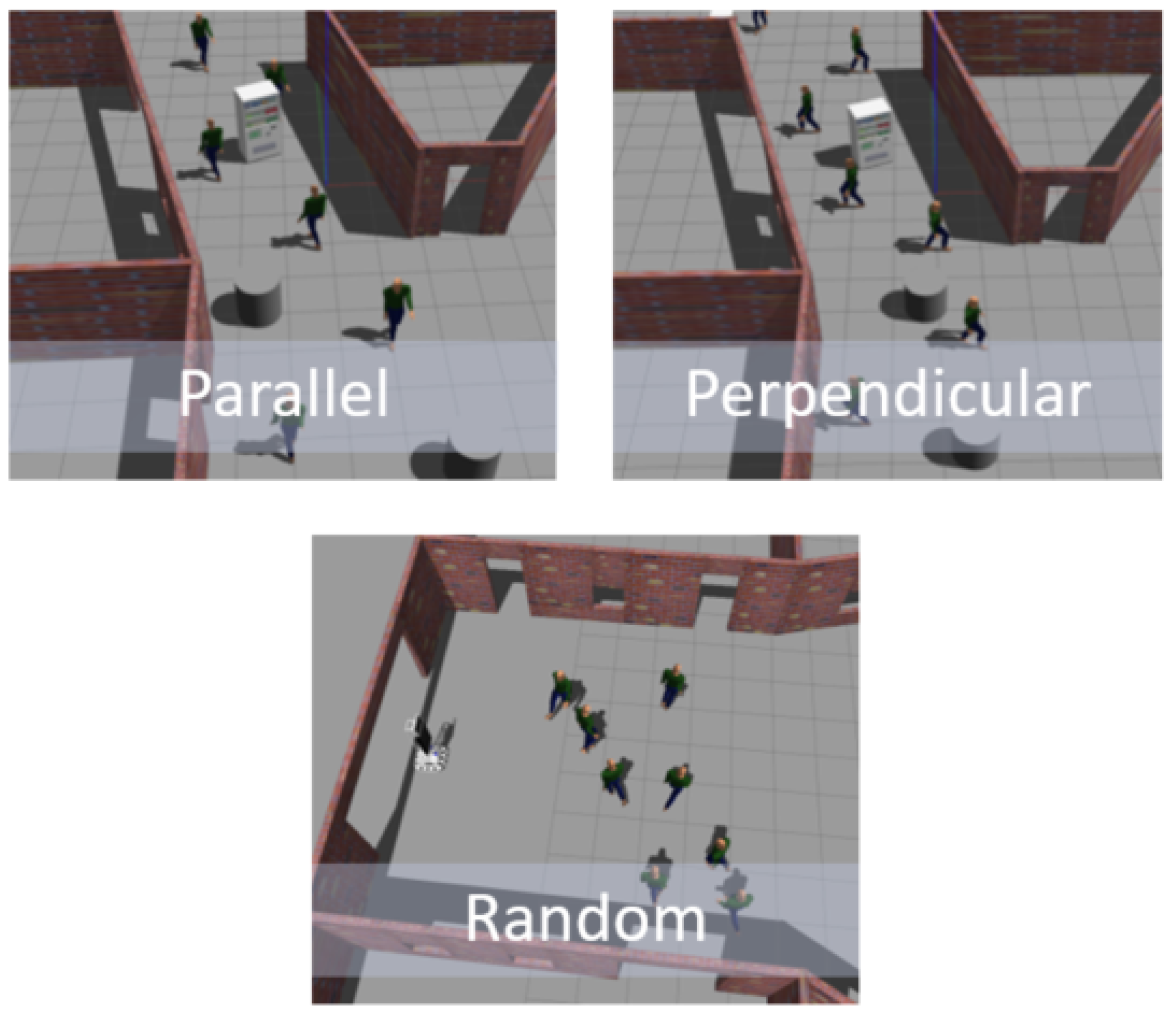
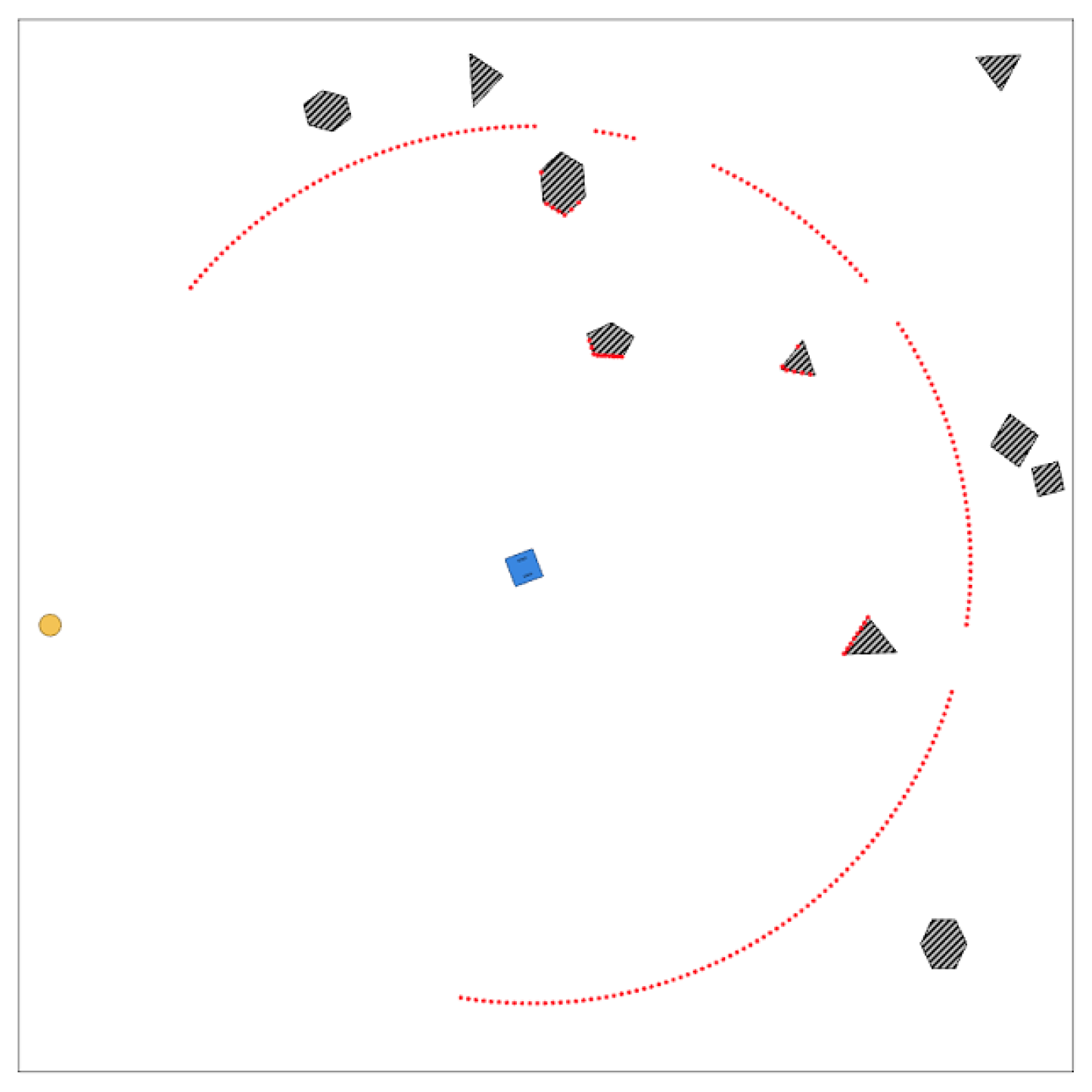
4.1. Review and Definition of the Evaluation Environment
4.2. Definition of Evaluation Metrics
- Number of collisions;
- Safety score (%);
- Navigation time (s);
- Route length (m).
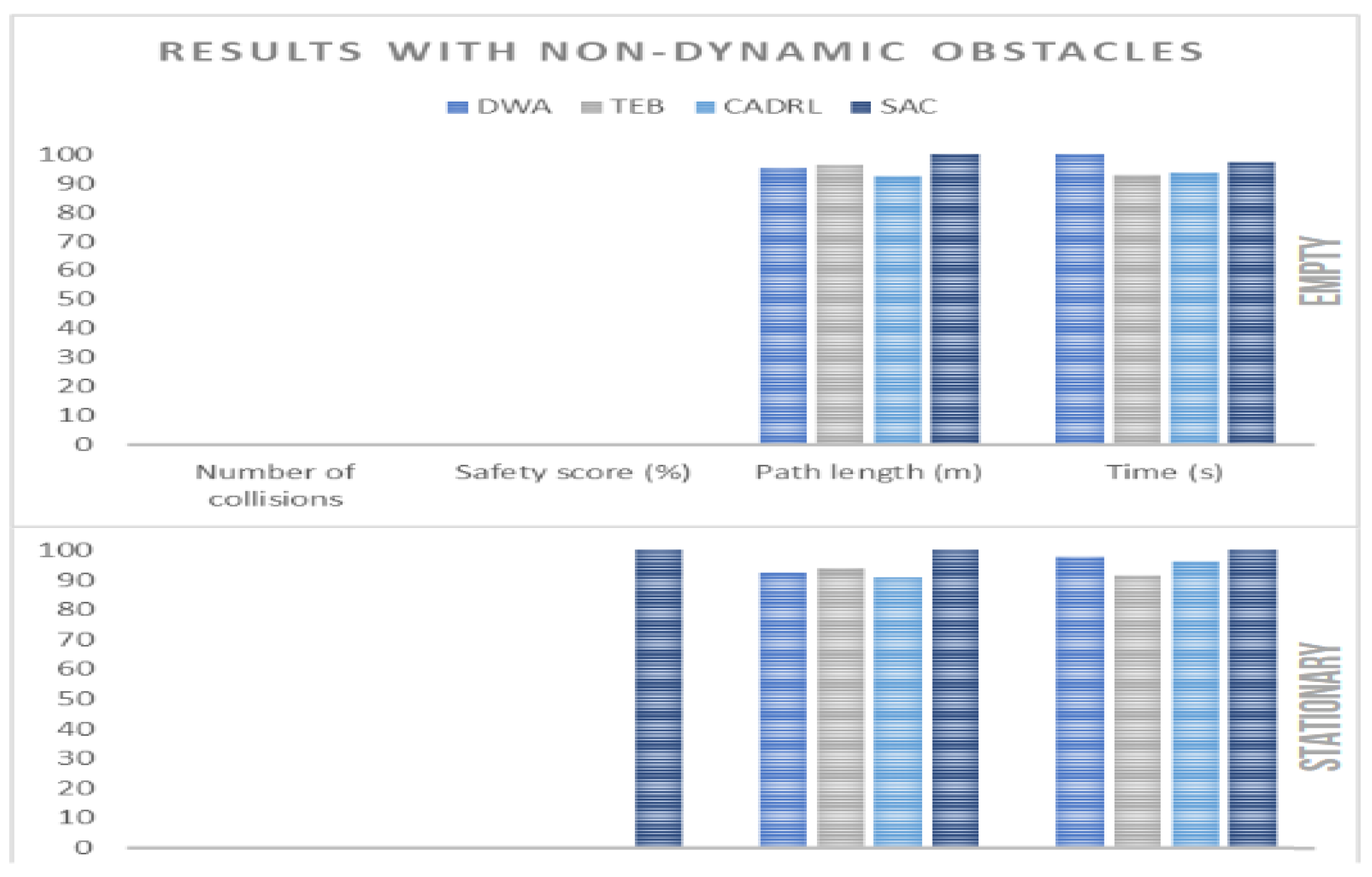
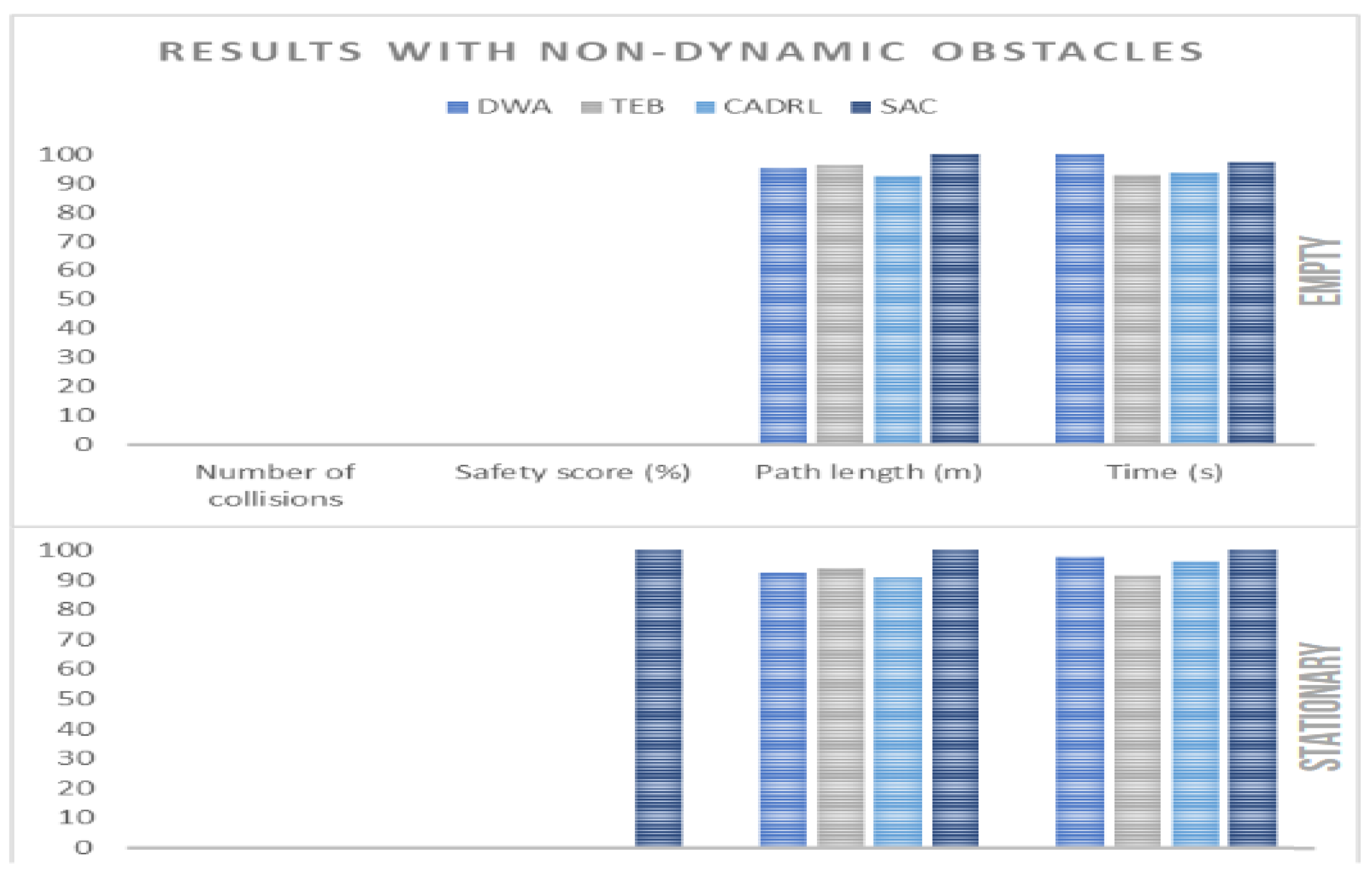
4.3. Performance with Non-Dynamic Obstacles
- TEB provided a more optimal route on average, in terms of the navigation time.
- SAC had a less safe route on average, as it was the only algorithm that had a non-zero safety score for stationary environments.
- CADRL provided a more optimal route, in terms of distance traveled.
- All the algorithms provided collision-free routes.
4.4. Performance with Dynamic Obstacles
4.4.1. Performance with Dynamic Obstacles: Crossing
- Low obstacle concentration:
- -
- DWA provided the second-shortest route with the highest temporal efficiency. However, its collision rate was higher for obstacles with a velocity of 0.3 m/s.
- -
- TEB provided the route with the least number of collisions, away from obstacles (high safety score). It also had high temporal efficiency.
- -
- CADRL, on average, provided the longest route with low temporal efficiency. Additionally, it exhibited a high collision rate.
- -
- SAC, on average, had the lowest safety score and the highest number of collisions but with high temporal efficiency.
- High obstacle concentration:
- -
- DWA provided high temporal efficiency and, on average, the shortest route but at the cost of a significant increase in the collision rate.
- -
- TEB provided the route with the least number of collisions, away from obstacles (high safety score). However, it significantly reduced its temporal efficiency compared to low obstacle concentration.
- -
- CADRL improved its collision rate and provided the second route with the lowest percentage. However, it offered the longest path and a low safety score.
- -
- SAC provided a route with high navigation time efficiency and a short route length. However, it had the highest collision rate and a fairly low safety score.
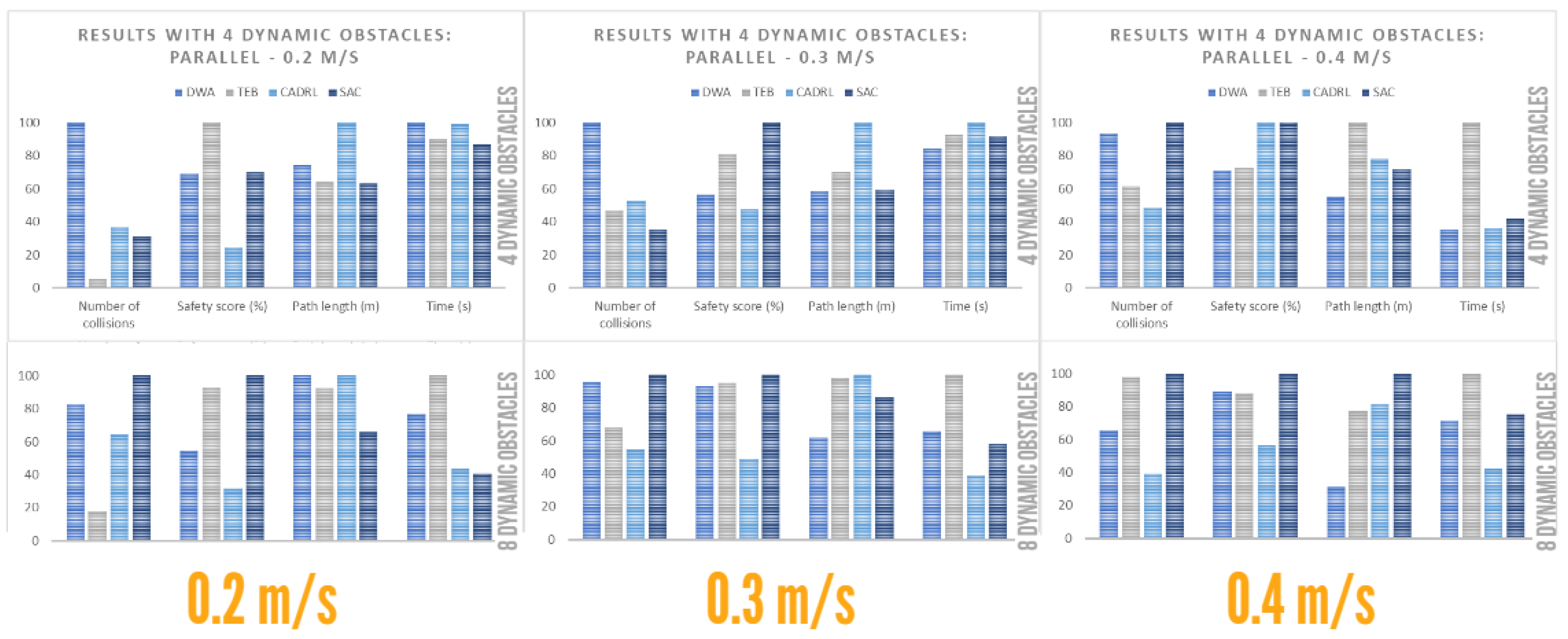
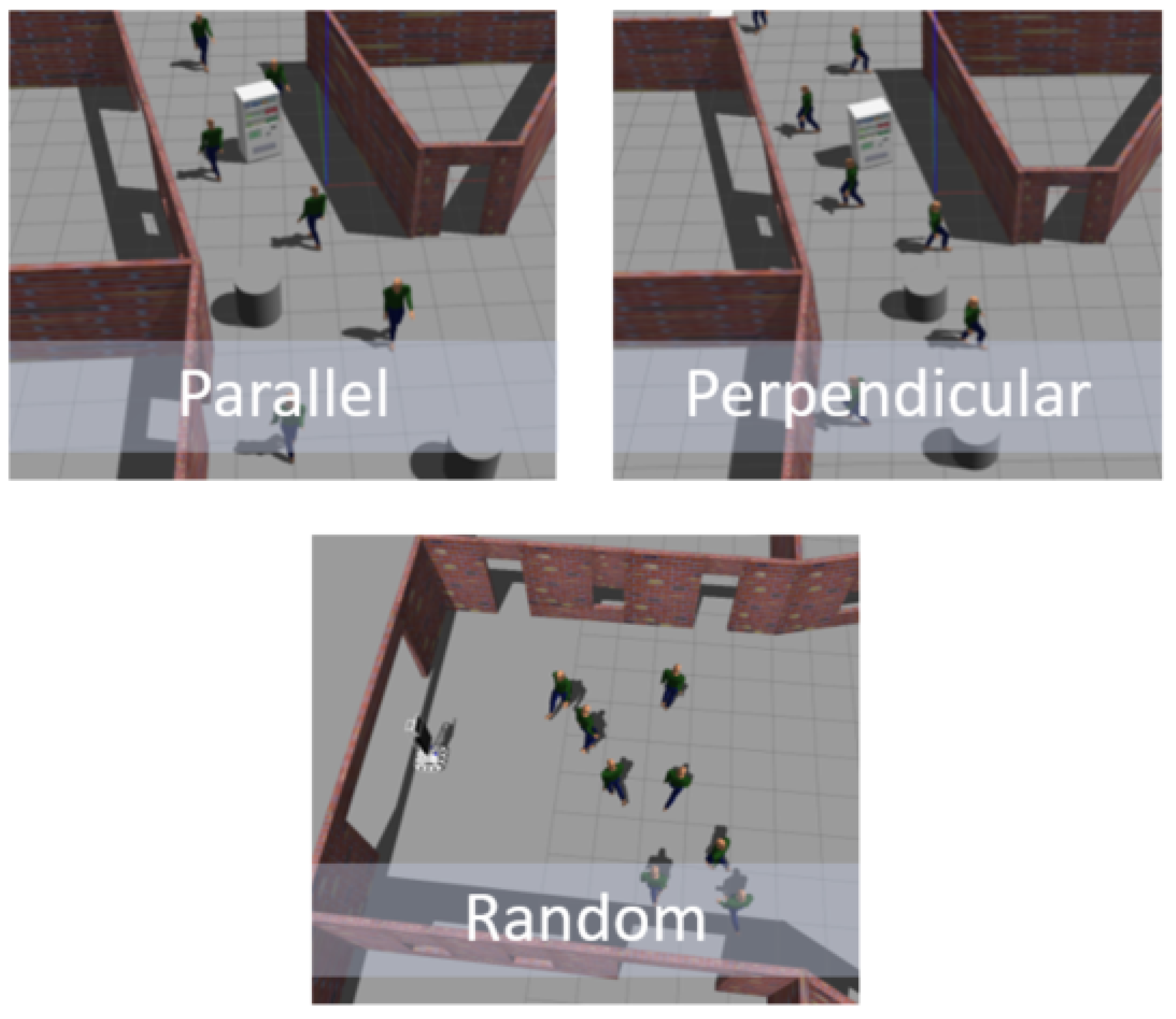
4.4.2. Performance with Dynamic Obstacles: Parallel
- Low obstacle concentration:
- -
- DWA provided, on average, the route with the highest number of collisions. However, it had high temporal efficiency, similar to the shortest navigation route.
- -
- TEB provided a route with the least number of collisions at low speeds. However, the number of collisions and navigation time increased, while the safety score decreased considerably at high speeds.
- -
- SAC had the highest number of collisions only at very high speeds; otherwise, it performed well. It also had the route with the best average safety score.
- -
- CADRL had the least number of collisions at high speeds but a low average for low speeds. However, its safety score was the lowest and it provided a long route.
- High obstacle concentration:
- -
- DWA provided the route with the shortest path length. However, its average collision rate increased significantly compared to a low-obstacle-concentration environment.
- -
- TEB provided a route with a low number of collisions, away from obstacles, except at high speeds. However, it reduced its temporal efficiency.
- -
- CADRL provided the route with the least number of collisions and better temporal efficiency. However, it had a low safety score.
- -
- SAC provided the route with the highest safety score. However, it had, on average, the route with the highest number of collisions.
4.4.3. Performance with Dynamic Obstacles: Random
- Low obstacle concentration:
- -
- DWA provided the second-shortest route.
- -
- TEB provided the route with the least number of collisions, away from obstacles. However, it had a long trajectory.
- -
- CADRL provided the longest route and, on average, the lowest safety score.
- -
- SAC provided a route with a high safety score. It also provided the shortest route.
- High obstacle concentration:
- -
- DWA provided the shortest route. However, the number of collisions increased significantly compared to an environment with low obstacle concentration.
- -
- TEB provided the route with the least number of collisions, away from obstacles.
- -
- CADRL provided an efficient route, in terms of navigation time. However, it had a low safety score and the longest path length.
- -
- SAC had the highest average collision rate and was the least efficient, in terms of navigation time.
5. Conclusions
- DWA provides a route with a high percentage of collisions, mainly due to its inability to generate reverse motion. However, it has, on average, good temporal efficiency and path length.
- TEB provides, on average, the route with the least amount of collisions and away from obstacles at low speeds and concentrations. However, at high speeds or concentrations, evasion and, consequently, temporal efficiency worsens.
- CADRL provides good obstacle avoidance in concentrated and fast environments, but at the cost of low temporal and routing efficiency.
- SAC provides a route with a high percentage of collisions, mainly due to the fact that it is a map-less algorithm. However, it has, on average, good temporal efficiency and path length.
- For the exposed robot configuration, a dynamic environment where the movement of the actors is parallel to or in the same direction as the movement of the robot is more complicated to navigate. This is due to the limited range of vision, due to the dimensions of the robot, mainly in reverse movements.
- The most relevant dynamic parameter for social environments is the number of dynamic actors, as its variation entails a considerable reduction in the performance of the navigation algorithms.
- On average, metrics such as the number of obstacles, navigation time, path length and safety score increase as the number of dynamic agents and their speed increases.
- When the information of the map is not available for the robot, it must be used with a mapless-DRL-based algorithm, such as SAC.
- If the map information is available and it is required to reduce the number of collisions even if the movement is slower, then a traditional algorithm, such as TEB, can be used.
- If the map information is available and it is required that the movement must be fast, then a traditional algorithm, such as DWA, can be used.
- If the map information is available and it is required that the trajectory must be the shortest, then a DRL-based algorithm, such as CADRL, can be used.
- CASE 1: Robot for delivery of products in indoor environments (such as hospitals or offices): This type of application usually prioritizes the time it takes to deliver the products, for which it is recommended to use a traditional algorithm, such as DWA, or a DRL-based, such as CADRL, that uses shorter trajectories.
- CASE 2: Robot for marketing and interaction with users (in malls, universities, events, etc.): For any type of HRI applications, such as this one, it is recommended to use an algorithm that prioritizes the number of collisions, such as TEB, which is a traditional algorithm.
- CASE 3: Robot for security and inspection (in malls, offices, industrial plants or warehouses): This type of application usually prioritizes the shorter trajectories, in order to increase the robot’s autonomy. Hence, a DRL-based algorithm, such as CADRL, could be the best alternative.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhu, K.; Zhang, T. Deep reinforcement learning based mobile robot navigation: A review. Tsinghua Sci. Technol. 2021, 26, 674–691. [Google Scholar] [CrossRef]
- Rone, W.; Ben-Tzvi, P. Mapping, localization and motion planning in mobile multi-robotic systems. Robotica 2013, 31, 1–23. [Google Scholar] [CrossRef]
- Siciliano, B.; Khatib, O.; Kröger, T. Springer Handbook of Robotics; Springer: Berlin/Heidelberg, Germany, 2008; Volume 200. [Google Scholar]
- Kahn, G.; Villaflor, A.; Ding, B.; Abbeel, P.; Levine, S. Self-supervised deep reinforcement learning with generalized computation graphs for robot navigation. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5129–5136. [Google Scholar]
- Kulhánek, J.; Derner, E.; De Bruin, T.; Babuška, R. Vision-based navigation using deep reinforcement learning. In Proceedings of the 2019 European Conference on Mobile Robots (ECMR), Prague, Czech Republic, 4–6 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Ruan, X.; Ren, D.; Zhu, X.; Huang, J. Mobile robot navigation based on deep reinforcement learning. In Proceedings of the 2019 Chinese Control and Decision Conference (CCDC), Nanchang, China, 3–5 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6174–6178. [Google Scholar]
- Li, H.; Zhang, Q.; Zhao, D. Deep reinforcement learning-based automatic exploration for navigation in unknown environment. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 2064–2076. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Liu, Y.; Kreiss, S.; Alahi, A. Crowd-robot interaction: Crowd-aware robot navigation with attention-based deep reinforcement learning. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 6015–6022. [Google Scholar]
- Marchesini, E.; Farinelli, A. Discrete deep reinforcement learning for mapless navigation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10688–10694. [Google Scholar]
- Bruce, J.; Sünderhauf, N.; Mirowski, P.; Hadsell, R.; Milford, M. One-shot reinforcement learning for robot navigation with interactive replay. arXiv 2017, arXiv:1711.10137. [Google Scholar]
- Kato, Y.; Kamiyama, K.; Morioka, K. Autonomous robot navigation system with learning based on deep Q-network and topological maps. In Proceedings of the 2017 IEEE/SICE International Symposium on System Integration (SII), Taipei, Taiwan, 11–14 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1040–1046. [Google Scholar]
- Lin, J.; Yang, X.; Zheng, P.; Cheng, H. End-to-end decentralized multi-robot navigation in unknown complex environments via deep reinforcement learning. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation (ICMA), Tianjin, China, 4–7 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2493–2500. [Google Scholar]
- Liu, L.; Dugas, D.; Cesari, G.; Siegwart, R.; Dubé, R. Robot navigation in crowded environments using deep reinforcement learning. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; IEEE: Piscataway, NJ, USA, 2020; pp. 5671–5677. [Google Scholar]
- Quan, H.; Li, Y.; Zhang, Y. A novel mobile robot navigation method based on deep reinforcement learning. Int. J. Adv. Robot. Syst. 2020, 17, 1729881420921672. [Google Scholar] [CrossRef]
- Surmann, H.; Jestel, C.; Marchel, R.; Musberg, F.; Elhadj, H.; Ardani, M. Deep reinforcement learning for real autonomous mobile robot navigation in indoor environments. arXiv 2020, arXiv:2005.13857. [Google Scholar]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 31–36. [Google Scholar]
- Yue, P.; Xin, J.; Zhao, H.; Liu, D.; Shan, M.; Zhang, J. Experimental research on deep reinforcement learning in autonomous navigation of mobile robot. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1612–1616. [Google Scholar]
- Zhang, J.; Springenberg, J.T.; Boedecker, J.; Burgard, W. Deep reinforcement learning with successor features for navigation across similar environments. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2371–2378. [Google Scholar]
- Zhu, Y.; Mottaghi, R.; Kolve, E.; Lim, J.J.; Gupta, A.; Li, F.-F.; Farhadi, A. Target-driven visual navigation in indoor scenes using deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3357–3364. [Google Scholar]
- Banino, A.; Barry, C.; Uria, B.; Blundell, C.; Lillicrap, T.; Mirowski, P.; Pritzel, A.; Chadwick, M.J.; Degris, T.; Modayil, J.; et al. Vector-based navigation using grid-like representations in artificial agents. Nature 2018, 557, 429–433. [Google Scholar] [CrossRef] [PubMed]
- Zou, Q.; Sun, Q.; Chen, L.; Nie, B.; Li, Q. A Comparative Analysis of LiDAR SLAM-Based Indoor Navigation for Autonomous Vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 6907–6921. [Google Scholar] [CrossRef]
- Murphy, K.P. Bayesian Map Learning in Dynamic Environments. In Advances in Neural Information Processing Systems; Solla, S., Leen, T., Müller, K., Eds.; MIT Press: Cambridge, MA, USA, 1999; Volume 12. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved techniques for grid mapping with Rao-Blackwellized particle filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef]
- Kohlbrecher, S.; Von Stryk, O.; Meyer, J.; Klingauf, U. A flexible and scalable SLAM system with full 3D motion estimation. In Proceedings of the 9th IEEE International Symposium on Safety, Security, and Rescue Robotics, SSRR 2011. Kyoto, Japan, 1–5 November 2011; pp. 155–160. [Google Scholar] [CrossRef]
- Konolige, K.; Grisetti, G.; Kümmerle, R.; Burgard, W.; Limketkai, B.; Vincent, R. Efficient sparse pose adjustment for 2D mapping. In Proceedings of the IEEE/RSJ 2010 International Conference on Intelligent Robots and Systems, IROS 2010-Conference Proceedings, Taipei, Taiwan, 18–22 October 2010; pp. 22–29. [Google Scholar] [CrossRef]
- Warren, C. Global Path Planning Using Artificial Potential Fields. In Proceedings of the International Conference on Robotics and Automation, Scottsdale, AZ, USA, 14–19 May 1989. [Google Scholar]
- Savage, J.; Morales, M.; Osario, R. Learning mobile robot’s paths using potential field methods. IFAC Manag. Control Prod. Logist. 2000, 33, 1253–1256. [Google Scholar] [CrossRef]
- Zhou, C.; Huang, B.; Fränti, P. A review of motion planning algorithms for intelligent robotics. arXiv 2021, arXiv:2102.02376. [Google Scholar]
- Ferrer, J. Implementation and Comparison in Local Planners for Ackermann Vehicles. Ph.D. Thesis, Politecnico di Milano, Milan, Italy, 2017. [Google Scholar]
- Fox, D.; Burgard, W.; Thrun, S. The dynamic window approach to collision avoidance. IEEE Robot. Autom. Mag. 1997, 4, 23–33. [Google Scholar] [CrossRef]
- Roesmann, C.; Feiten, W.; Woesch, T.; Hoffmann, F.; Bertram, T. Trajectory modification considering dynamic constraints of autonomous robots. In Proceedings of the ROBOTIK-7th German Conference on Robotics, Munich, Germany, 21–22 May 2012. [Google Scholar]
- Lin, Y.C.; Chou, C.C.; Lian, F.L. Indoor Robot Navigation Based on DWA*: Velocity Space Approach with Region Analysis. In Proceedings of the ICROS-SICE International Joint Conference, Fukuoka, Japan, 18–21 August 2009. [Google Scholar]
- Liu, T.; Yan, R.; Wei, G.; Sun, L. Local Path Planning Algorithm for Blind-guiding Robot Based on Improved DWA Algorithm. In Proceedings of the Chinese Control And Decision Conference (CCDC), Nanchang, China, 3–5 June 2019. [Google Scholar]
- Li, M.; Yang, C. Navigation Simulation of Autonomous Mobile Robot Based on TEB Path Planner. In Proceedings of the International Conference on Control and Intelligent Robotics, Guangzhou, China, 18–20 June 2021. [Google Scholar]
- Dai, W.; Ma, X. Improvement of collision detection using Time Elastic Band algorithm. In Proceedings of the International Conference on Information Technology: IoT and Smart City, Guangzhou, China, 22–25 December 2021. [Google Scholar]
- Ishihara, S.; Kanai, M.; Narikawa, R.; Ohtsuka, T. A Proposal of Path Planning for Robots in Warehouses by Model Predictive Control without Using Global Paths. Int. Fed. Autom. Control (IFAC) 2022, 55, 573–578. [Google Scholar] [CrossRef]
- Li, J.; Ran, M.; Wang, H.; Xie, L. MPC-based Unified Trajectory Planning and Tracking Control Approach for Automated Guided Vehicles. In Proceedings of the International Conference on Control and Automation (ICCA), Edinburgh, UK, 16–19 July 2019. [Google Scholar]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction, 2nd ed.; The MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Morales, M. Grokking Deep Reinforcement Learning; Manning Publications Co.: Shelter Island, NY, USA, 2020. [Google Scholar]
- Nguyen, H.; La, H. Review of Deep Reinforcement Learning for Robot Manipulation. In Proceedings of the IEEE International Conference on Robotic Computing, Naples, Italy, 25–27 February 2019. [Google Scholar]
- François-Lavet, V.; Henderson, P.; Bellemare, M.; Pineau, J.; Islam, R. An Introduction to Deep Reinforcement Learning. In Foundations and Trends® in Machine Learning; NOW: Boston, MA, USA; Delft, The Netherlands, 2018; Volume 11. [Google Scholar]
- Lu, Z.; Huang, R. Autonomous mobile robot navigation in uncertain dynamic environments based on deep reinforcement learning. In Proceedings of the International Conference on Real-Time Computing and Robotics, Xining, China, 15–19 July 2021. [Google Scholar]
- Leiva, F.; Ruiz-del Solar, J. Robust RL-Based Map-Less Local Planning: Using 2D Point Clouds as Observations. IEEE Robot. Autom. Lett. 2020, 5, 5787–5794. [Google Scholar] [CrossRef]
- Min-Fan, R.; Sharfiden, H. Mobile Robot Navigation Using Deep Reinforcement Learning. In Proceedings of the Chinese Control and Decision Conference, Nanchang, China, 3–5 June 2019. [Google Scholar]
- Sasaki, Y.; Matsuo, S.; Kanezaki, A.; Takemura, H. A3C Based Motion Learning for an Autonomous Mobile Robot in Crowds. In Proceedings of the International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019. [Google Scholar]
- Zheng, K. ROS Navigation Tuning Guide; Technical Report; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Everett, M.; Chen, Y.F.; How, J.P. Motion Planning Among Dynamic, Decision-Making Agents with Deep Reinforcement Learning. arXiv 2018, arXiv:1805.01956. [Google Scholar]
- Kastner, L.; Buiyan, T.; Jiao, L.; Anh Le, T.; Zhao, X.; Shen, Z.; Lambrecht, J. Arena-Rosnav: Towards Deployment of Deep-Reinforcement-Learning-Based Obstacle Avoidance into Conventional Autonomous Navigation Systems. In Proceedings of the International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M.A. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Abbeel, P.; Levine, S. Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor. arXiv 2018, arXiv:1801.01290. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Naotunna, I.; Wongratanaphisan, T. Comparison of ROS Local Planners with Differential Drive Heavy Robotic System. In Proceedings of the International Conference on Advanced Mechatronic Systems, Hanoi, Vietnam, 10–13 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Cybulski, B.; Wegierska, A.; Granosik, G. Accuracy comparison of navigation local planners on ROS-based mobile robot. In Proceedings of the 2019 12th International Workshop on Robot Motion and Control (RoMoCo), Poznan, Poland, 8–10 July 2019; pp. 104–111. [Google Scholar] [CrossRef]
- Wen, J.; Zhang, X.; Bi, Q.; Pan, Z.; Feng, Y.; Yuan, J.; Fang, Y. MRPB 1.0: A Unified Benchmark for the Evaluation of Mobile Robot Local Planning Approaches. In Proceedings of the ICRA, Xi’an, China, 30 May–5 June 2021. [Google Scholar]
- Chen, Y.F.; Liu, M.; Everett, M.; How, J.P. Decentralized Non-communicating Multiagent Collision Avoidance with Deep Reinforcement Learning. arXiv 2016, arXiv:1609.07845. [Google Scholar]
- Chen, Y.F.; Everett, M.; Liu, M.; How, J.P. Socially Aware Motion Planning with Deep Reinforcement Learning. arXiv 2017, arXiv:1703.08862. [Google Scholar]
- Jin, J.; Nguyen, N.M.; Sakib, N.; Graves, D.; Yao, H.; Jagersand, M. Mapless Navigation among Dynamics with Social-safety-awareness: A reinforcement learning approach from 2D laser scans. In Proceedings of the ICRA, Paris, France, 31 May–31 August 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Publication | Scenario | Upgrade | Strongness | Tests | |
|---|---|---|---|---|---|---|
| Static | Dynamic | |||||
| DWA | Y. Lin et al. [32] | X | X | Fusion of Best-First Search (BFS) and DWA. | Improved performance in dynamic environments. | Simulation |
| L. Tianyu et al. [33] | X | Modification of evaluation function for angle variation. | Improved reaction to obstacles and smoother trajectory. | Simulation, Real | ||
| TEB | M. Li and C. Yang [34] | X | X | Parameter setting and optimization method for the Ackerman model. | Ackerman obstacle avoidance. | Simulation |
| Q. Dai and X. Ma [35] | X | X | Fusion A* and TEB for collision detection. | Reduced navigation time, route efficiency and performance in dynamic environments. | Simulation | |
| MPC | S. Ishihara and M. Kanai [36] | X | Adaptability for multiple robots and unmapped environments. | No prior information on the environment is required. | Simulation | |
| J. Li and M. Ran [37] | X | X | Improved speed and trajectory planning. | Route efficiency and performance in dynamic environments. | Simulation | |
| Publication | Navigation | Algorithm | Scenario | Perception Type | Actions Space | Test | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| S | D | SC | RGB Camera | Depth Camera | 2D Laser | |||||
| G. Chen et al. [8] | Map-Based | DQN | X | X | X | X | X | Discrete (28) | Simulation, Real | |
| L. Liu, et al. [13] | Map-Based | A3C | X | X | X | X | X | Discrete (28) | Simulation, Real | |
| Z. Lu and R. Huang [42] | Mapless | LDDPG | X | X | X | X | Continuous | Simulation | ||
| F. Leiva and Javier R. [43] | Mapless | DDPG | X | X | X | Continuous | Simulation, Real | |||
| R. Min-Fan and H. Sharfiden [44] | Mapless | DDQN | X | X | X | X | X | Discrete (5) | Simulation, Real | |
| Y. Sasaki, et al. [45] | Map-Based | A3C | X | X | X | X | Continuous | Simulation, Real | ||
| Name | Notation | Value |
|---|---|---|
| Speed and acceleration limits | max_vel_x | 0.4 |
| max_vel_theta | 0.6 | |
| acc_lim_x | 2 | |
| acc_lim_theta | 0.1 | |
| Goal tolerance | xy_goal_tolerance | 0.1 |
| yaw_tolerance | 0.2 | |
| DWA parameters | sim_time | 2.5 |
| vx_samples | 20 | |
| vth_samples | 40 | |
| path_distance_bias | 32 | |
| goal_distance_bias | 24 | |
| occdist_scale | 0.02 | |
| TEB parameters | max_vel_x_backwards | 0.4 |
| footprint_model_radius | 0.335 | |
| min_obstacle_dist | 0.4 | |
| include_dynamic_obstacles | True |
| Discrete | Continuous |
|---|---|
|
|
| Mean Reward | Success Value (%) | Mean Collision | |
|---|---|---|---|
| 0.6 | 197.14 | 98.10 | 0.085 |
| 0.8 | 200.58 | 97.50 | 0.063 |
| 1 | 196.47 | 96.40 | 0.062 |
| Algorithm | Action Space | Mean Reward | Success Rate (%) | Mean Collision | Training Time |
|---|---|---|---|---|---|
| SAC | Continuous | 200.58 | 97.50 | 0.063 | 1 h 4 min |
| PPO | Discrete | 170.58 | 97.60 | 0.372 | 1 h 23 min |
| Continuous | 151.43 | 98.00 | 0.483 | 1 h 24 min | |
| DQN | Discrete | 170.29 | 84.00 | 1.360 | 1 d 15 h 58 min |
| Continuous | 161.79 | 80.90 | 0.089 | 1 d 11 h 47 min |
| Scenario | Empty Map | Static Obstacles | |
|---|---|---|---|
| Number of collisions | DWA | 0.0 | 0.0 |
| TEB | |||
| CADRL | |||
| SAC | |||
| Safety score (%) | DWA | 0.0 | 0.0 |
| TEB | |||
| CADRL | |||
| SAC | 1.57 | ||
| Path length (m) | DWA | 22.90 | 24.44 |
| TEB | 23.24 | 24.85 | |
| CADRL | 22.27 | 24.05 | |
| SAC | 24.03 | 26.50 | |
| Navigation time (s) | DWA | 64.70 | 69.51 |
| TEB | 60.07 | 64.95 | |
| CADRL | 60.58 | 68.47 | |
| SAC | 63.05 | 71.08 |
| Collisions Number | Safety Score (%) | Navigation Time (s) | Path Length (m) | Collisions Number | Safety Score (%) | Navigation Time (s) | Path Length (m) | |
|---|---|---|---|---|---|---|---|---|
| 4 Dynamic Obstacles | 8 Dynamic Obstacles | |||||||
| DWA | 0.7 | 7.41 | 80.78 | 27.10 | 2.8 | 18.01 | 85.90 | 27.09 |
| TEB | 0.3 | 5.87 | 77.70 | 29.13 | 0.3 | 5.87 | 91.00 | 32.27 |
| CADRL | 0.9 | 25.30 | 90.16 | 36.85 | 1.2 | 24.03 | 90.40 | 42.90 |
| SAC | 1.4 | 23.44 | 78.41 | 26.89 | 1.5 | 25.44 | 90.14 | 28.82 |
| 4 Dynamic Obstacles | 8 Dynamic Obstacles | |||||||
| DWA | 2.1 | 9.30 | 79.72 | 26.34 | 2.8 | 21.61 | 83.02 | 25.90 |
| TEB | 0.5 | 7.33 | 81.11 | 30.08 | 1.4 | 15.33 | 106.24 | 37.39 |
| CADRL | 1.4 | 22.60 | 87.27 | 42.98 | 1.8 | 29.65 | 90.25 | 43.05 |
| SAC | 2.0 | 22.97 | 73.13 | 26.06 | 3.9 | 35.00 | 79.11 | 27.30 |
| 4 Dynamic Obstacles | 8 Dynamic Obstacles | |||||||
| DWA | 1.3 | 9.45 | 77.06 | 26.34 | 2.5 | 23.97 | 89.43 | 27.98 |
| TEB | 0.9 | 6.94 | 82.93 | 30.48 | 2.2 | 14.59 | 107.20 | 36.93 |
| CADRL | 2.0 | 24.71 | 90.69 | 43.02 | 1.9 | 25.08 | 92.20 | 43.25 |
| SAC | 1.7 | 13.68 | 73.11 | 26.04 | 3.5 | 33.13 | 76.80 | 26.80 |
| Collisions Number | Safety Score (%) | Navigation Time (s) | Path Length (m) | Collisions Number | Safety Score (%) | Navigation Time (s) | Path Length (m) | |
|---|---|---|---|---|---|---|---|---|
| 4 Dynamic Obstacles | 8 Dynamic Obstacles | |||||||
| DWA | 1.9 | 8.9 | 91.5 | 32.16 | 1.4 | 17.14 | 156.04 | 26.50 |
| TEB | 0.1 | 6.15 | 82.64 | 27.79 | 0.3 | 10.13 | 203.09 | 39.80 |
| CADRL | 0.7 | 25.00 | 90.70 | 43.17 | 1.1 | 29.67 | 89.19 | 43.13 |
| SAC | 0.6 | 8.77 | 79.55 | 27.34 | 1.7 | 9.39 | 82.31 | 28.33 |
| 4 Dynamic Obstacles | 8 Dynamic Obstacles | |||||||
| DWA | 1.7 | 18.25 | 74.36 | 25.38 | 2.1 | 15.78 | 142.50 | 26.73 |
| TEB | 0.8 | 12.65 | 82.21 | 30.34 | 1.5 | 15.47 | 215.74 | 42.41 |
| CADRL | 0.9 | 21.71 | 88.26 | 43.06 | 1.2 | 30.11 | 83.25 | 43.10 |
| SAC | 0.6 | 10.31 | 81.43 | 25.70 | 2.2 | 14.70 | 125.33 | 37.30 |
| 4 Dynamic Obstacles | 8 Dynamic Obstacles | |||||||
| DWA | 2.9 | 22.35 | 83.51 | 25.97 | 3.0 | 19.38 | 146.38 | 26.36 |
| TEB | 1.9 | 21.8 | 234.26 | 47.03 | 4.5 | 19.71 | 205.31 | 40.78 |
| CADRL | 1.5 | 15.81 | 85.29 | 36.74 | 1.8 | 30.64 | 86.71 | 43.03 |
| SAC | 3.1 | 10.4 | 98.24 | 33.84 | 4.6 | 17.34 | 154.99 | 52.65 |
| Collisions Number | Safety Score (%) | Navigation Time (s) | Path Length (m) | Collisions Number | Safety Score (%) | Navigation Time (s) | Path Length (m) | |
|---|---|---|---|---|---|---|---|---|
| 4 Dynamic Obstacles | 8 Dynamic Obstacles | |||||||
| DWA | 0.6 | 6.85 | 89.16 | 26.97 | 1.4 | 10.97 | 86.82 | 27.14 |
| TEB | 0.3 | 7.95 | 84.88 | 31.63 | 0.2 | 9.78 | 84.46 | 30.73 |
| CADRL | 0.4 | 15.66 | 80.96 | 42.74 | 1.1 | 29.67 | 89.19 | 43.13 |
| SAC | 0.5 | 8.41 | 107.15 | 26.86 | 1.2 | 13.11 | 112.33 | 34.17 |
| 4 Dynamic Obstacles | 8 Dynamic Obstacles | |||||||
| DWA | 1 | 10.99 | 83.43 | 26.62 | 1.3 | 10.97 | 80.19 | 27.16 |
| TEB | 0.5 | 7.29 | 86.32 | 31.56 | 0.8 | 9.78 | 96.92 | 33.78 |
| CADRL | 0.8 | 19.38 | 85.22 | 40.84 | 1.1 | 30.10 | 83.24 | 43.10 |
| SAC | 1.1 | 9.92 | 79.56 | 27.23 | 1.2 | 13.11 | 96 | 31.06 |
| 4 Dynamic Obstacles | 8 Dynamic Obstacles | |||||||
| DWA | 0.4 | 9.62 | 80.54 | 27.52 | 1.9 | 21.34 | 85.62 | 27.86 |
| TEB | 0.3 | 8.84 | 81.17 | 30.29 | 1.0 | 11.50 | 99.54 | 34.34 |
| CADRL | 1.3 | 21.60 | 84.68 | 42.90 | 1.8 | 30.64 | 86.71 | 43.03 |
| SAC | 0.8 | 8.53 | 81.04 | 27.09 | 2.0 | 13.49 | 143.53 | 27.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arce, D.; Solano, J.; Beltrán, C. A Comparison Study between Traditional and Deep-Reinforcement-Learning-Based Algorithms for Indoor Autonomous Navigation in Dynamic Scenarios. Sensors 2023, 23, 9672. https://doi.org/10.3390/s23249672
Arce D, Solano J, Beltrán C. A Comparison Study between Traditional and Deep-Reinforcement-Learning-Based Algorithms for Indoor Autonomous Navigation in Dynamic Scenarios. Sensors. 2023; 23(24):9672. https://doi.org/10.3390/s23249672
Chicago/Turabian StyleArce, Diego, Jans Solano, and Cesar Beltrán. 2023. "A Comparison Study between Traditional and Deep-Reinforcement-Learning-Based Algorithms for Indoor Autonomous Navigation in Dynamic Scenarios" Sensors 23, no. 24: 9672. https://doi.org/10.3390/s23249672
APA StyleArce, D., Solano, J., & Beltrán, C. (2023). A Comparison Study between Traditional and Deep-Reinforcement-Learning-Based Algorithms for Indoor Autonomous Navigation in Dynamic Scenarios. Sensors, 23(24), 9672. https://doi.org/10.3390/s23249672