4.1. Two-Way Range (TWR) Protocol
The TWR protocol is a widely adopted method in IoT networks, particularly in scenarios where time synchronization is unnecessary. Ultra-wideband (UWB) is a radio technology, standardized as IEEE 802.15.4a, which enables the estimation of distance between an AP and a target node [
34]. This estimate is obtained by measuring the time it takes for radio frequency (RF) signals to travel between them—known as time-of-flight (ToF)—and subsequently multiplying that time by the speed of light (c) [
35]. To estimate the distance between the
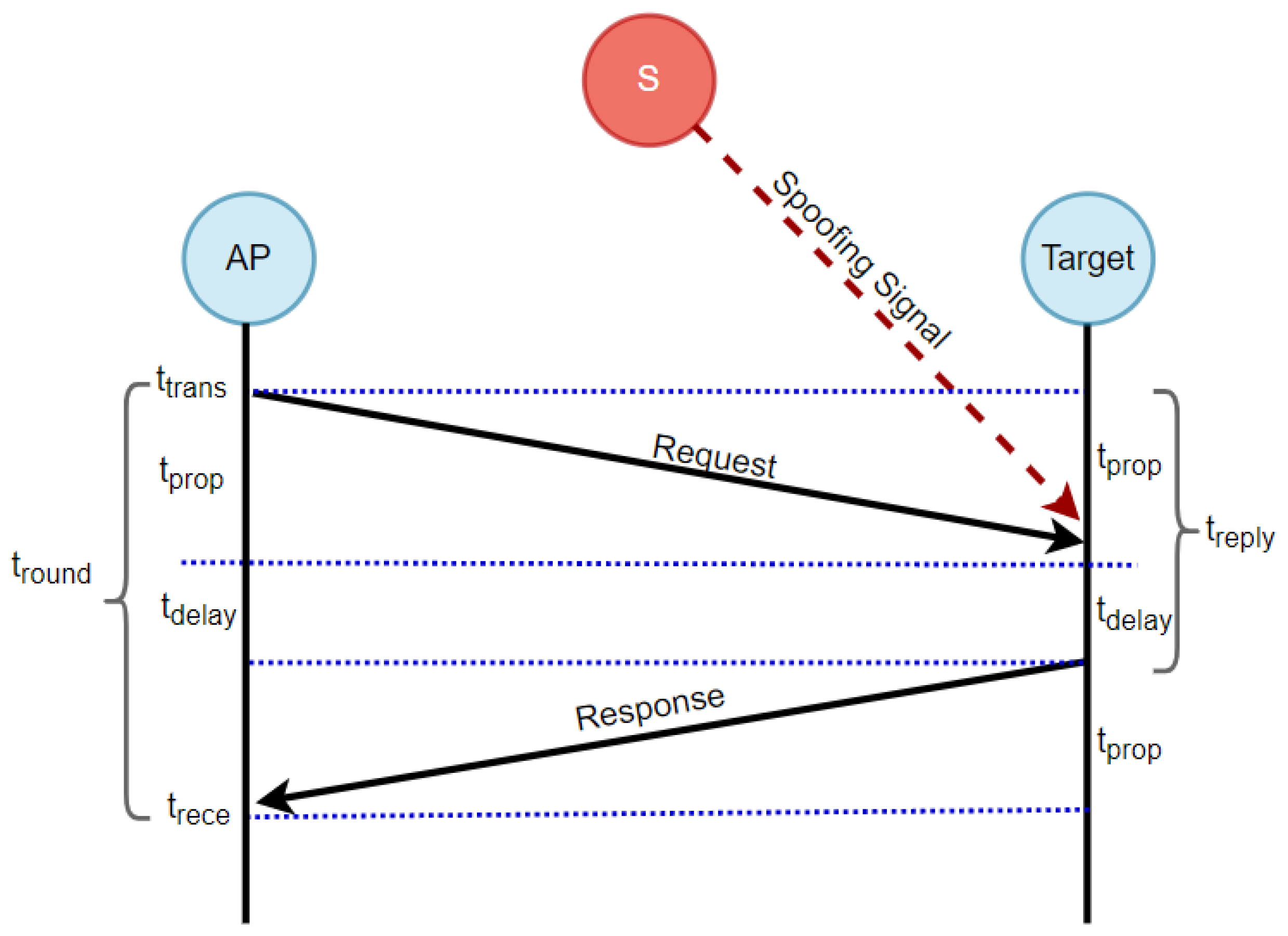
and the target node for localization purposes, the TWR protocol employs the following procedure, as depicted in
Figure 4. The AP initiates the process by sending a request packet to the target node at the starting time
. After a specific delay
, accounting for processing time and other hardware-related delays (which is assumed to be known by both the AP and the target node), the target node responds to the request message. Subsequently, the AP receives the response message and computes the round trip time (
) to the target node using the following formula [
36,
37]:
At the
,
is measured by computing the difference between
and
, which is expressed as
. Based on
, the
can compute the propagation time
and estimate the distance to the target node using the following equations:
In the context of estimating the distance between the AP and the target node, let d represent the distance and c denote the constant speed of light, which is equal to .
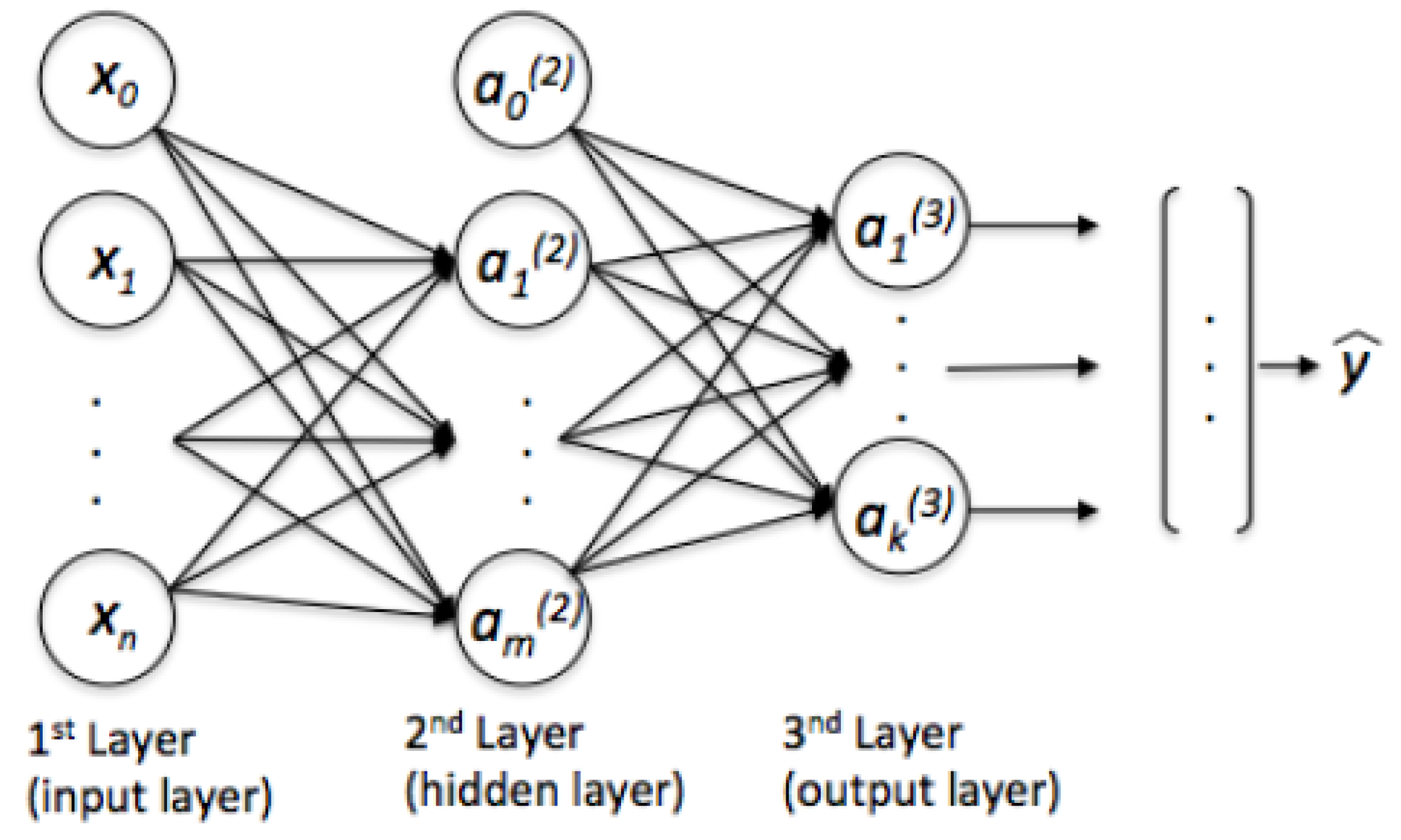
4.2. Feature Extraction Process
In the scenario where a UAV spoofer is present, the TWR protocol is susceptible to deception, particularly in relation to the received request message and the replay time. The adversary emits undesired signals
S toward the target, leading to an elevation in the level of noise experienced at the receiver. Consequently, the processing time required to decode the noisy signal is increased. Furthermore, the transmission time for the response message may also be extended due to the utilization of a channel by the adversary or the spoofer. Consequently, this can result in an extension of the sensing time required to identify an available channel. Therefore, the power received at the AP is considered have a significant amount of noise due to the spoofing signal, as presented in the following equation:
In the presence of a spoofing signal
S, which is considered noise at the receiving side, the
at the
from the target node decreases depending on the position of the UAV spoofer. To estimate the ToA or
, we utilized the power received at the
by employing the following approach. The spoofing signal received by the
, including the received power from the target node, can be presented as follows:
where the
is the total power received by the AP and S is the spoofing signal. To estimate the
between two nodes in presence of a spoofer, we extended the concept of the distance ratio
, which was described in [
38], to estimate the ToA at different points. The distance ratio concept is based on the received power and SNR level at the receiving node. When the noise increases, the
decreases to reach the threshold value of the system. This means that the
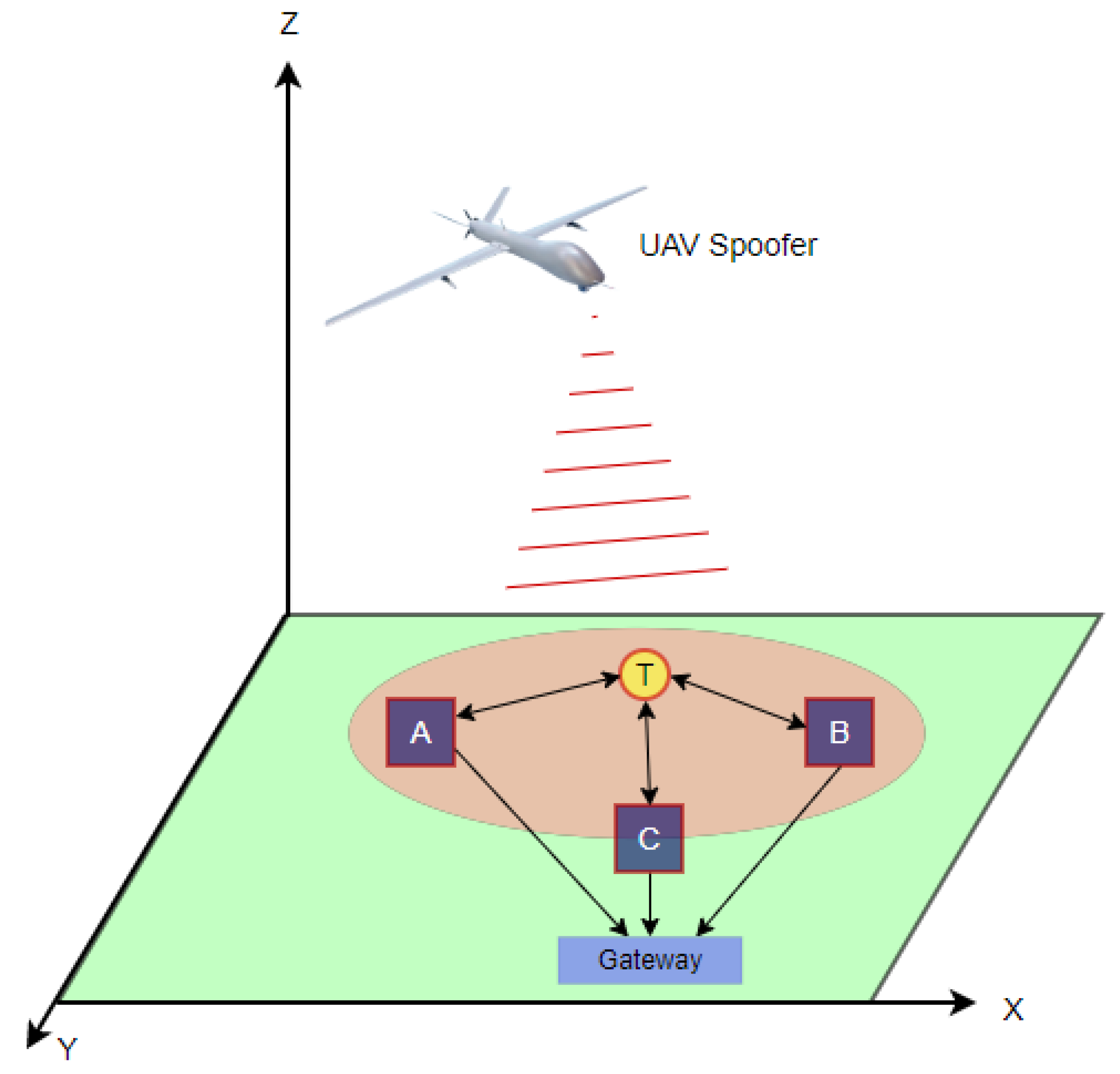
is located at the edge of the spoofing region, as shown in
Figure 5, in which
E is the edge node,
N is the node, and
is the AP. The distance between the spoofer and the
is denoted by
, and the distance from the spoofer to the edge node is
. In this scenario, the edge node is assumed to be a virtual node in order to estimate the ratio of the distance between the spoofer to the edge and from the edge to the AP.
In accordance with Equation (
15), we posited the scenario where the
resides at the boundary of the spoofing region and may receive a spoofing signal while its
equals the prescribed system threshold. As a result, the ToA at the
coincides with the ToA observed at the edge node
E. In this context, the distances between the spoofer, AP, and edge node remain uniform. For this scenario, the distance ratio is computed as follows:
We also noted a relationship between the distance ratio, the received power, the system threshold value
, and the noise received (including the spoofing signal), as follows:
In our dataset,
serves as the foundational metric for training the deep learning model, thus enabling the detection of the adversary’s presence and its subsequent localization. Here,
signifies the distance between the target and the spoofer:
Moreover, the following relationship connects the distance from the edge node to the adversary with
:
Expanding upon Equations (
13) and (
15), we proceeded to formulate the ToA-based received power as follows:
Hence, the estimate of the ToA at the AP from the spoofer was determined by the overall power received at the AP, as expressed by the following equation:
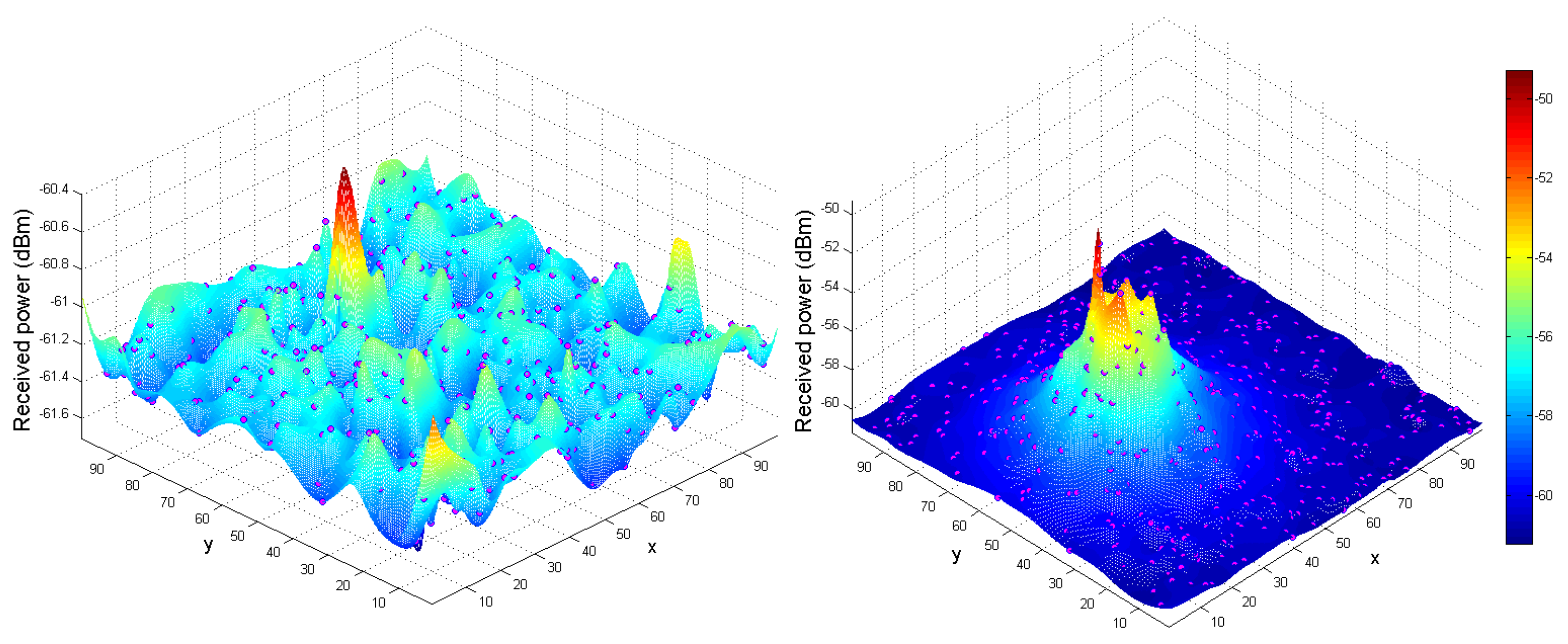
Incorporating the spoofer’s signal introduces variations into the ToA values, thus leading to the emergence of a perturbed or noisy ToA measurement. The total power received by the AP, referred to as
, is illustrated in
Figure 6. This measurement encompasses the power received across diverse spatial positions between the
and the spoofer. Furthermore, it incorporates both the accurate ToA and the ToA for the delayed estimation using
, as demonstrated in
Figure 7. Estimation of the ToA at both the edge nodes and from the edge to the
was accomplished through the utilization of
, as demonstrated by the following equations:
The equations above outline the process for estimating ToA values. This process incorporates relative distances and a constant speed of light.
In order to estimate the ToA of the spoofer UAV, as well as to facilitate the localization and detection of the spoofer using a deep learning model, we introduced the detection dataset, as shown in the following section.
4.3. Dataset
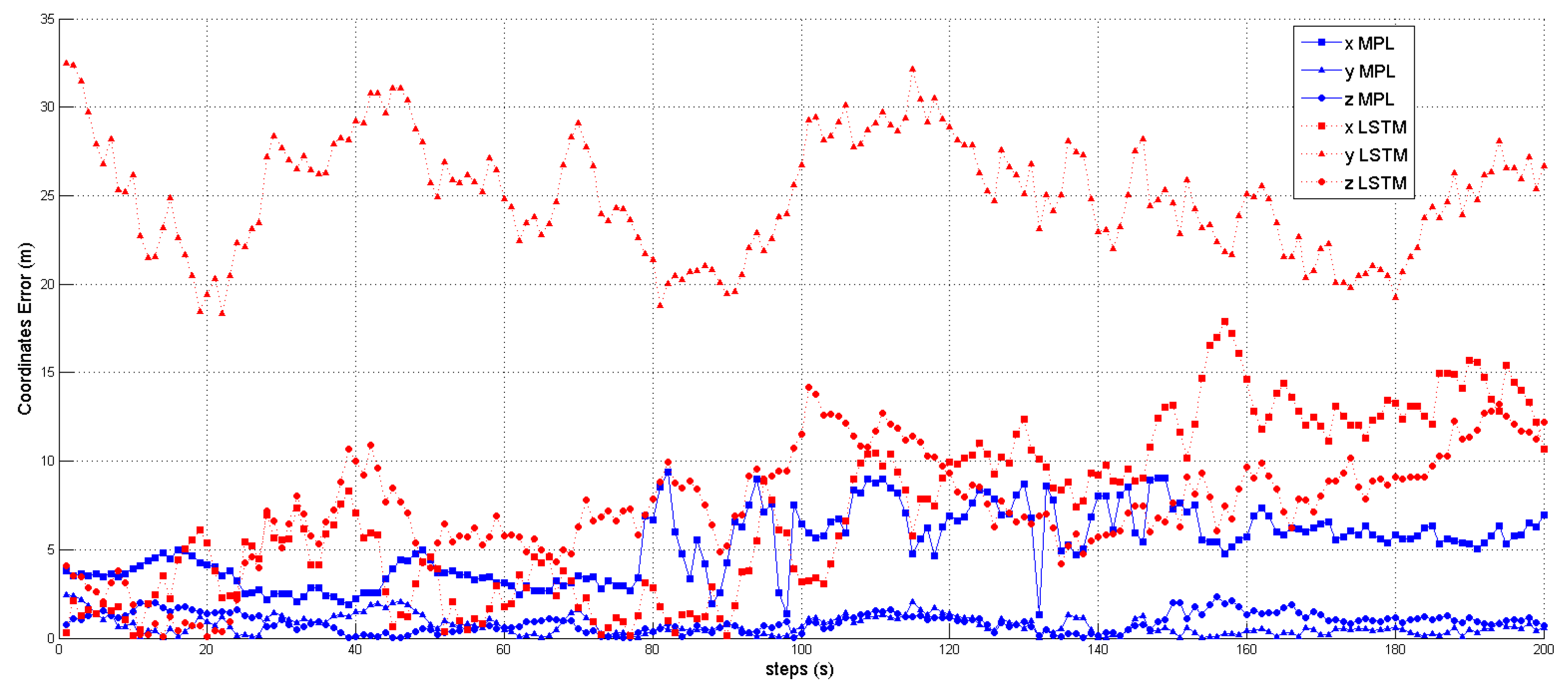
For this study, we meticulously curated a dataset by harnessing the received power data, alongside the development of a comprehensive system model and scenario simulations using MATLAB. Subsequently, we implemented a deep learning model through Python. Our investigative journey involved a series of experiments and simulations, which were meticulously designed to capture both the authentic and spoofed signals originating from various spoofer locations. The data collection process unfolded as the UAV spoofer executed randomized maneuvers around the designated target node, covering a radius of approximately 100 m. Furthermore, we introduced variations in the spoofer’s transmission power, thus effectively diversifying our dataset. Additional adjustments were made to the transmission power of the nodes, as well as variations in the inter-node distances.
Our dataset encompasses a set of seven distinct input features and two critical output variables, as meticulously delineated in
Table 2. These input features are leveraged by our deep learning models to serve a dual purpose: first, to effectively discern the authenticity of the received signals, and, second, to accurately estimate the
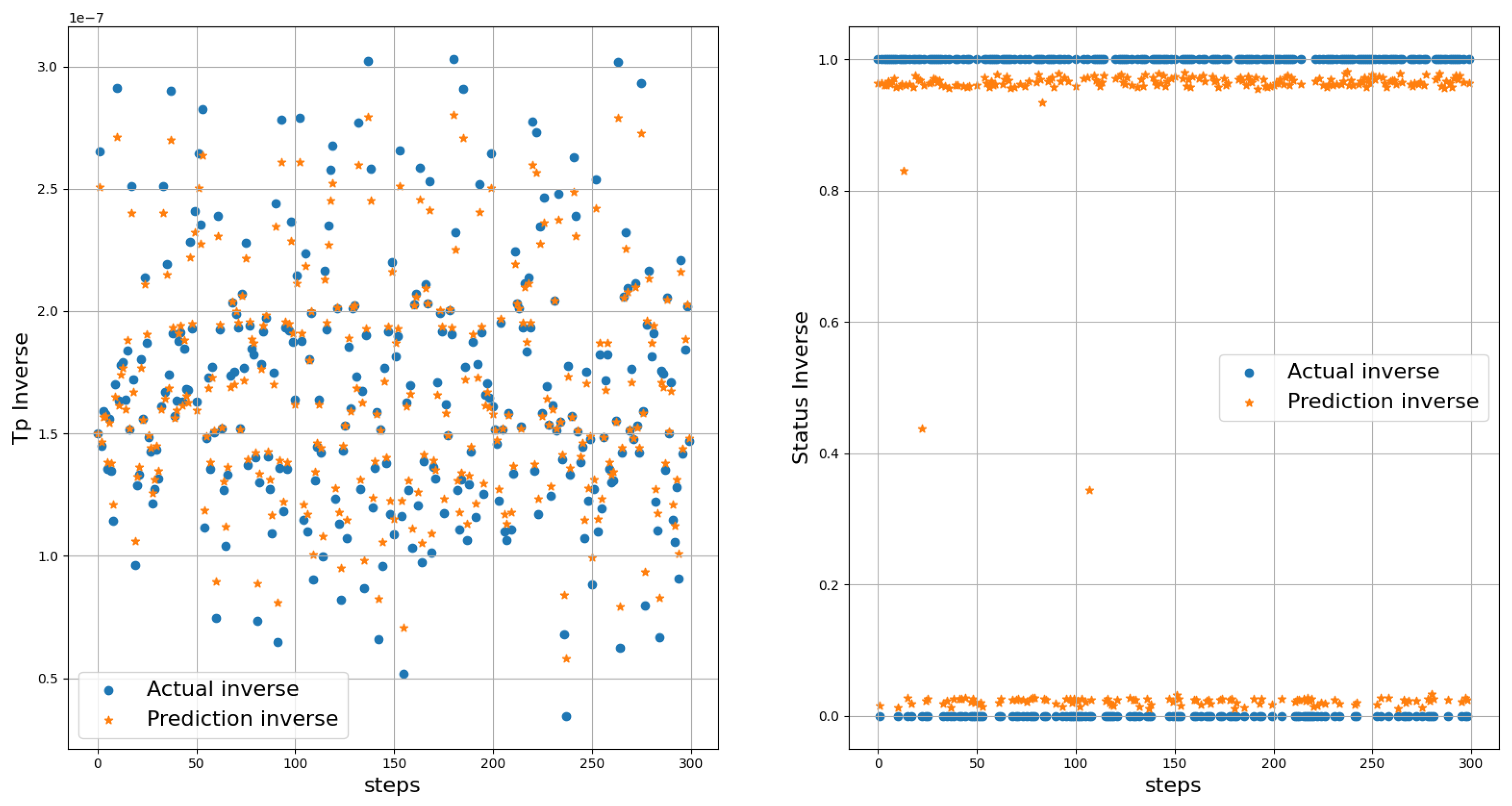
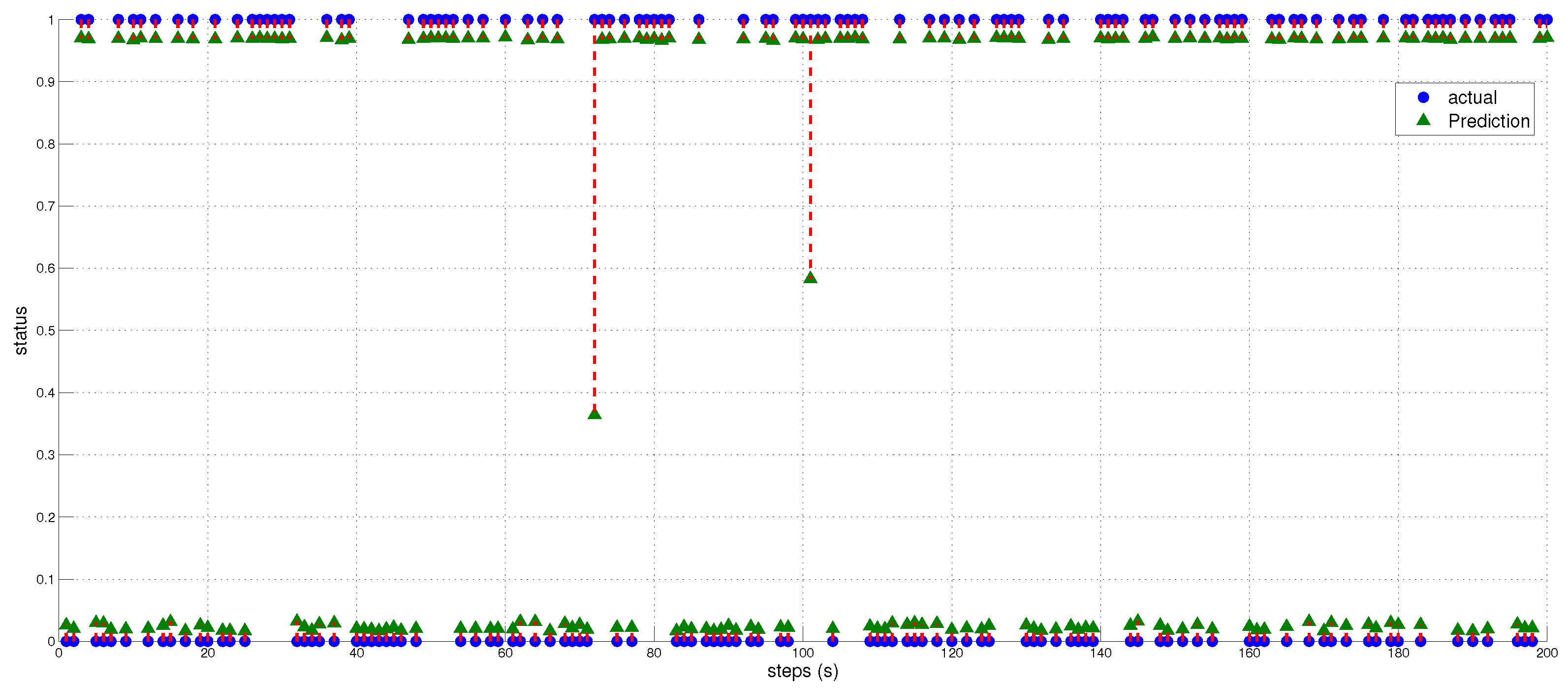
of the spoofer. Upon the reception of any signal, the AP meticulously extracts the relevant feature values, which are seamlessly integrated into the model’s analytical framework. The dataset used for testing and training the model comprises precisely 2000 samples for testing and 8000 samples for training. This dataset has been thoughtfully curated to ensure balance, whereby it contains an equal number of authentic and spoofed flight times in the scenario.
4.4. Pre-Processing and Re-Scaling
Prior to feeding the dataset into the deep learning model, a series of pre-processing steps were meticulously applied to the samples. These pre-processing procedures included the elimination of null and duplicate rows, thus ensuring the integrity of the dataset. Furthermore, encoding techniques were adeptly employed to transform categorical data into numerical representations. In our dataset, a binary classification was established with only two categorical data classes, namely
and
. To facilitate this categorization, we encoded authentic signals as 0 and spoofed signals as 1, thus effectively converting them into numerical values. Additionally, the ToA values underwent a scaling transformation, whereby they were multiplied by a factor of
. This scaling operation was undertaken to alleviate the presence of extensive fractional values within the dataset, thereby enhancing its suitability for deep learning analysis [
39]. Furthermore, the datasets underwent a standardization process using the min-max scaling method. This technique effectively centers the features to have a mean of 0 and a STD of 1, and this achieved using the following equation:
where
x represents the original data feature,
corresponds to the feature’s minimum value, and
denotes the feature’s maximum value. This transformation effectively re-scaled the features within the dataset to span a normalized range of
. Consequently, the minimum and maximum values of each feature or variable were precisely adjusted to 0 and 1, respectively, as illustrated in
Table 3. The dataset features are described in
Table 4.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}