

Balancing Accuracy and Speed in Gaze-Touch Grid Menu Selection in AR via Mapping Sub-Menus to a Hand-Held Device


Abstract
:1. Introduction
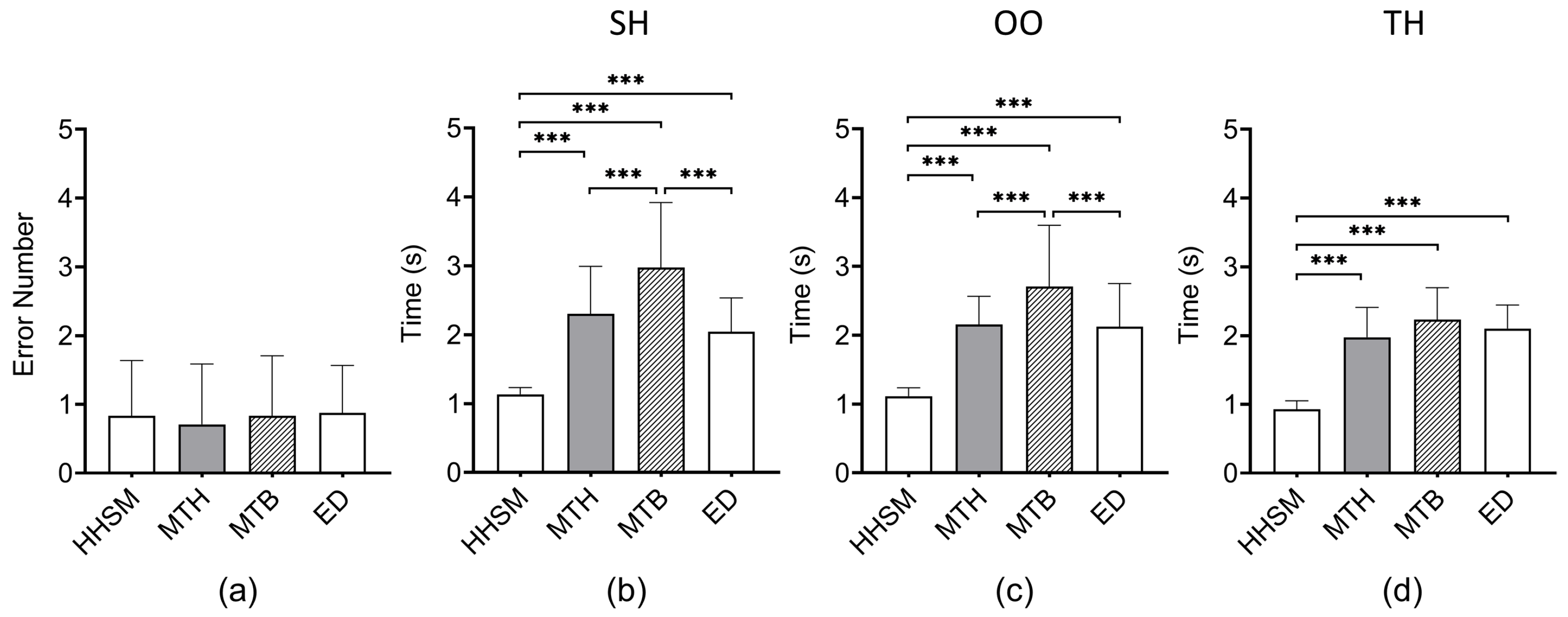
- There was no significant difference in selection accuracy between HHSM, MAGIC touch, MAGIC tab, and Eye + Device. Their error rates were approximately 2% (∼1 error in 36 selection trials).
- Under all three holding gestures, the completion times per selection under HHSM were significantly shorter than those under MAGIC touch, MAGIC tab, and Eye + Device.
2. Related Work
2.1. Incorporating a Mobile Device into VR/AR
2.2. Bimodal Target Selection Involving Eye Gaze
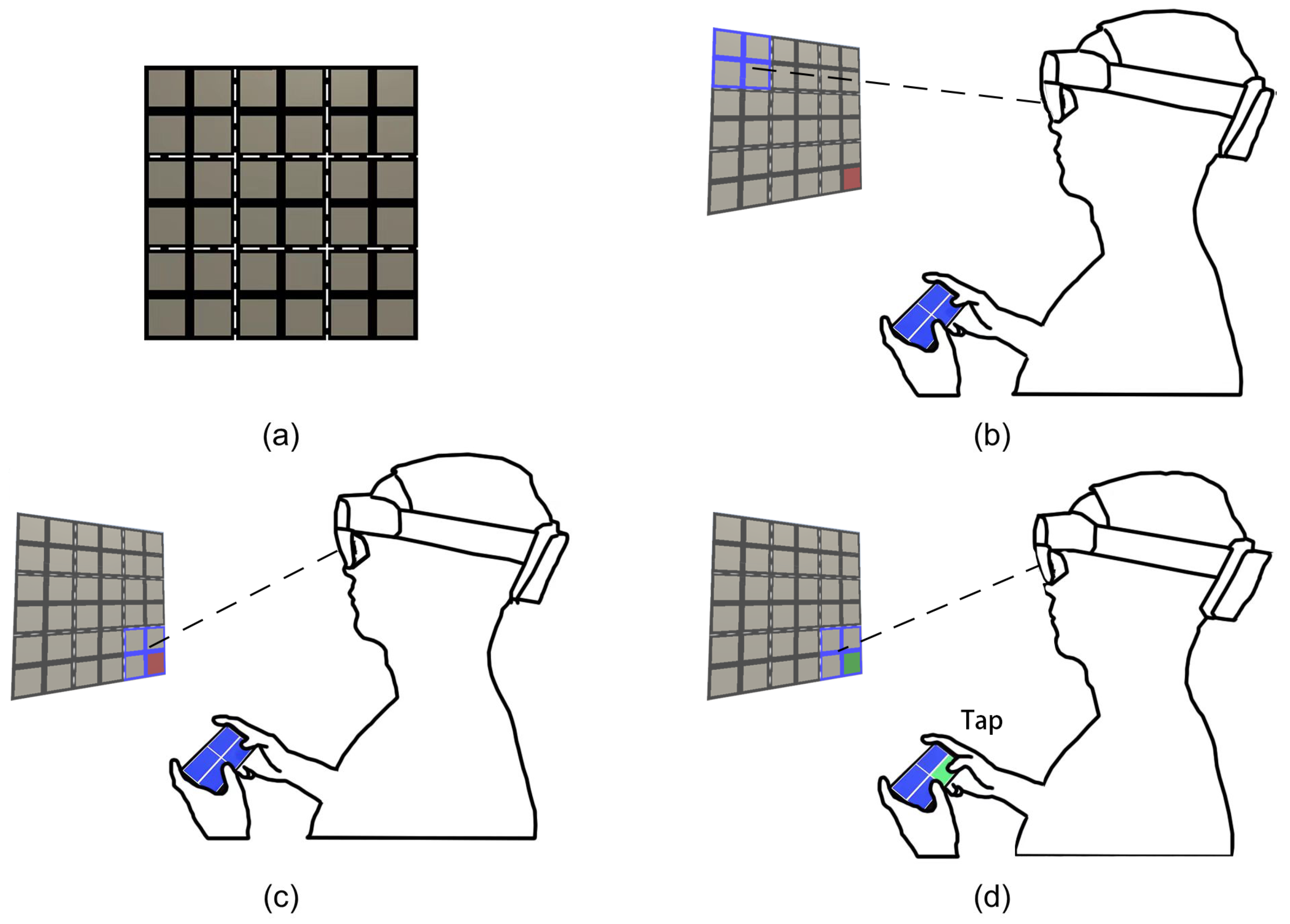
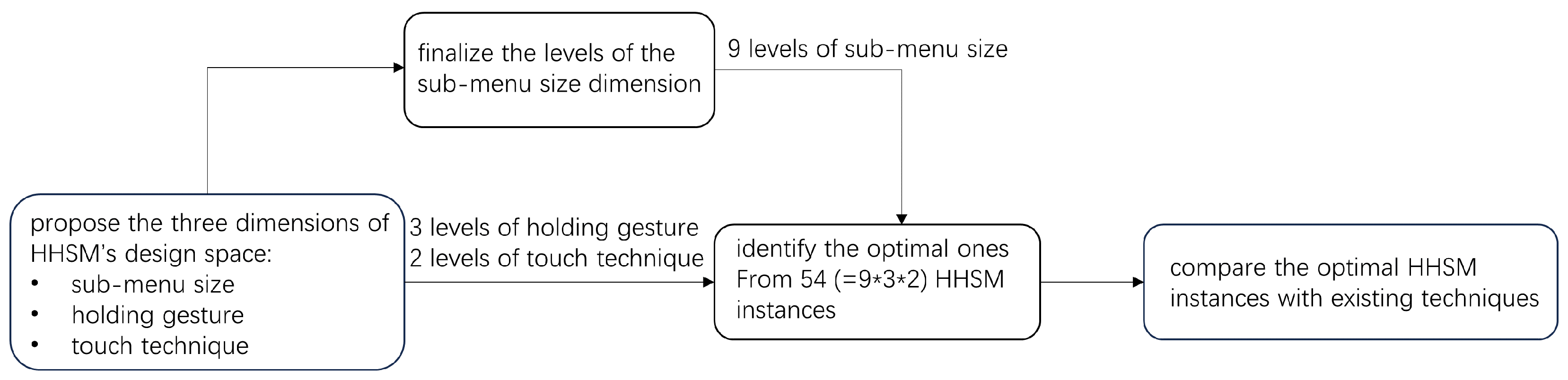
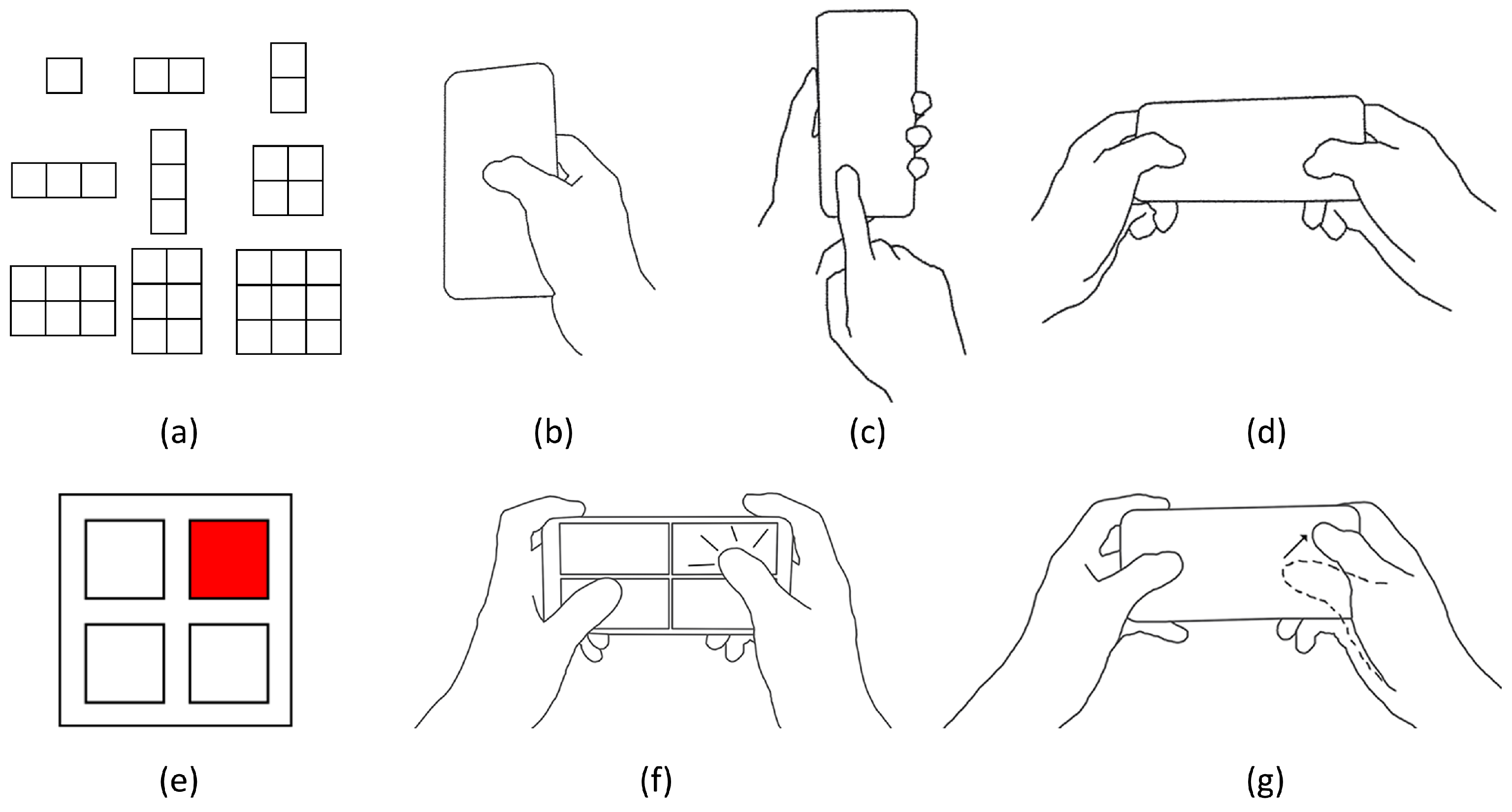
3. Design Space of the Hand-Held Sub-Menu Technique
4. Pilot Study on Sub-Menu Size
5. Pilot Study for Selecting Optimal HHSM Instances
6. User Study
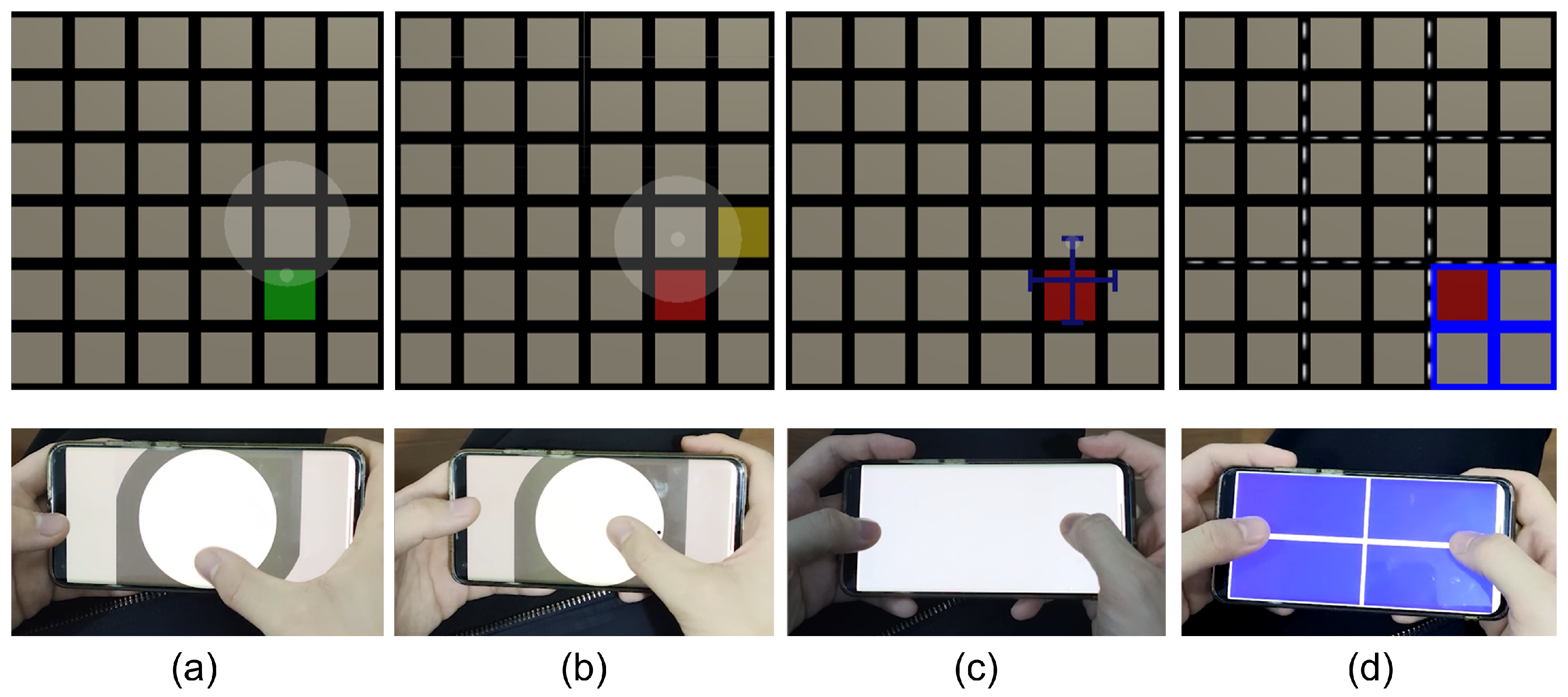
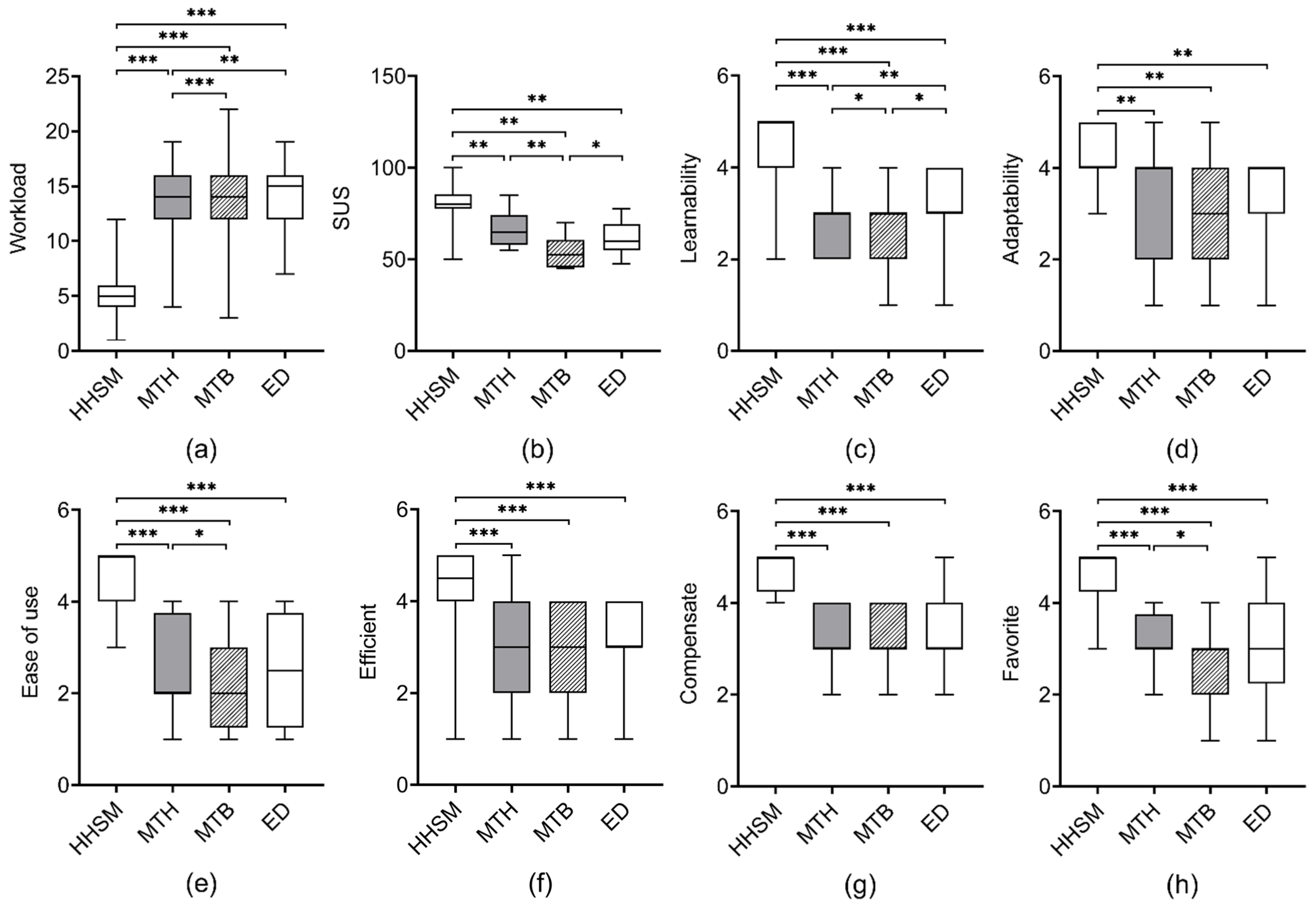
- MAGIC touch (MTH). The user initiates the refinement phase by touching the touchscreen. This touch activates a circular selection mask with a fixed position on the distant display. Subsequently, the selection mask remains stationary and typically overlaps with the target item. Besides, the pointer no longer follows eye gaze. Then the user can use a finger to swipe on the touchscreen to move the pointer according to the finger’s relative movement from the initial touch position (relative positioning). If the user briefly touches a circular area on the device’s touchscreen, the pointer will jump to the corresponding position in the selection mask on the distant display (absolute positioning). Finally, the user confirms the selection by tapping a button at the bottom of the touchscreen.
- MAGIC tab (MTB). The user starts the refinement phase using the same method as MAGIC touch. Note that the selection mask remains stationary and typically overlaps with the target item. Then, the user cycles through the items that intersect the circular selection mask on the distant display using a horizontal swiping gesture on the device’s touchscreen. The user can also change the size of the selection mask with a vertical swiping gesture. The user confirms the selection by tapping the aforementioned button. In cases where the selection mask does not intersect with the target item after activation under both MAGIC Touch and MAGIC tab, the user can press a button located in the top portion of the touchscreen to cancel the selection mask.
- Eye + Device (ED). The user starts the refinement phase by pressing the device’s touchscreen with a finger. The user can then use the yaw and pitch of the device to finely control the pointer’s movements along the X and Y axes. The user confirms the selection by releasing the finger from the touchscreen.
7. Limitations and Future Work
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kytö, M.; Ens, B.; Piumsomboon, T.; Lee, G.A.; Billinghurst, M. Pinpointing: Precise Head- and Eye-Based Target Selection for Augmented Reality. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–14. [Google Scholar]
- Jacob, R.J.K. What You Look at is What You Get: Eye Movement-Based Interaction Techniques. In Proceedings of the Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, New York, NY, USA, 1–5 April 1990; pp. 11–18. [Google Scholar] [CrossRef]
- Stellmach, S.; Dachselt, R. Look & Touch: Gaze-Supported Target Acquisition. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 2981–2990. [Google Scholar] [CrossRef]
- Ahn, S.; Lee, G. Gaze-Assisted Typing for Smart Glasses. In Proceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology, New Orleans, LA, USA, 20–23 October 2019; pp. 857–869. [Google Scholar] [CrossRef]
- Kumar, C.; Hedeshy, R.; MacKenzie, I.S.; Staab, S. TAGSwipe: Touch Assisted Gaze Swipe for Text Entry. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–12. [Google Scholar]
- Budhiraja, R.; Lee, G.A.; Billinghurst, M. Using a HHD with a HMD for mobile AR interaction. In Proceedings of the ISMAR, Adelaide, Australia, 1–4 October 2013. [Google Scholar]
- Hincapié-Ramos, J.D.; Özacar, K.; Irani, P.; Kitamura, Y. GyroWand: IMU-based Raycasting for Augmented Reality Head-Mounted Displays. In Proceedings of the SUI ’15: Proceedings of the 3rd ACM Symposium on Spatial User Interaction, Los Angeles, CA, USA, 8–9 August 2015. [Google Scholar] [CrossRef]
- Pietroszek, K.; Wallace, J.R.; Lank, E. Tiltcasting: 3D Interaction on Large Displays Using a Mobile Device. In Proceedings of the 28th Annual ACM Symposium on User Interface Software & Technology, Charlotte, NC, USA, 11–15 November 2015; pp. 57–62. [Google Scholar] [CrossRef]
- Ha, T.; Woo, W. ARWand: Phone-Based 3D Object Manipulation in Augmented Reality Environment. In Proceedings of the 2011 International Symposium on Ubiquitous Virtual Reality, Jeju, Republic of Korea, 1–3 July 2011; pp. 44–47. [Google Scholar] [CrossRef]
- Liang, H.N.; Shi, Y.; Lu, F.; Yang, J.; Papangelis, K. VRMController: An Input Device for Navigation Activities in Virtual Reality Environments. In Proceedings of the 15th ACM SIGGRAPH Conference on Virtual-Reality Continuum and Its Applications in Industry-Volume 1, Zhuhai, China, 3–4 December 2016; pp. 455–460. [Google Scholar] [CrossRef]
- Ro, H.; Chae, S.; Kim, I.; Byun, J.; Yang, Y.; Park, Y.; Han, T.D. A dynamic depth-variable ray-casting interface for object manipulation in ar environments. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 2873–2878. [Google Scholar]
- Henderson, S.J.; Feiner, S. Evaluating the benefits of augmented reality for task localization in maintenance of an armored personnel carrier turret. In Proceedings of the 2009 8th IEEE International Symposium on Mixed and Augmented Reality, Orlando, FL, USA, 19–22 October 2009; pp. 135–144. [Google Scholar] [CrossRef]
- Lipari, N.G.; Borst, C.W. Handymenu: Integrating menu selection into a multifunction smartphone-based VR controller. In Proceedings of the 2015 IEEE Symposium on 3D User Interfaces (3DUI), Arles, France, 23–24 March 2015; pp. 129–132. [Google Scholar] [CrossRef]
- Normand, E.; McGuffin, M.J. Enlarging a Smartphone with AR to Create a Handheld VESAD (Virtually Extended Screen-Aligned Display). In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 16–20 October 2018; pp. 123–133. [Google Scholar]
- Grubert, J.; Heinisch, M.; Quigley, A.; Schmalstieg, D. MultiFi: Multi Fidelity Interaction with Displays On and Around the Body. In Proceedings of the Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea, 18–23 April 2015; pp. 3933–3942. [Google Scholar] [CrossRef]
- Mohr, P.; Tatzgern, M.; Langlotz, T.; Lang, A.; Schmalstieg, D.; Kalkofen, D. TrackCap: Enabling Smartphones for 3D Interaction on Mobile Head-Mounted Displays. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–11. [Google Scholar]
- Matulic, F.; Ganeshan, A.; Fujiwara, H.; Vogel, D. Phonetroller: Visual Representations of Fingers for Precise Touch Input with Mobile Phones in VR. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021; Association for Computing Machinery: New York, NY, USA, 2021. [Google Scholar]
- Sidenmark, L.; Gellersen, H. Eye & Head: Synergetic Eye and Head Movement for Gaze Pointing and Selection. In Proceedings of the 32nd Annual ACM Symposium on User Interface Software and Technology, New Orleans, LA, USA, 20–23 October 2019; pp. 1161–1174. [Google Scholar] [CrossRef]
- Lystbæk, M.N.; Rosenberg, P.; Pfeuffer, K.; Grønbæk, J.E.; Gellersen, H. Gaze-Hand Alignment: Combining Eye Gaze and Mid-Air Pointing for Interacting with Menus in Augmented Reality. In Proceedings of the ACM on Human-Computer Interaction; ETRA; Association for Computing Machinery: New York, NY, USA, 2022; Volume 6. [Google Scholar] [CrossRef]
- Hedeshy, R.; Kumar, C.; Menges, R.; Staab, S. Hummer: Text Entry by Gaze and Hum. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. [Google Scholar] [CrossRef]
- Kumar, C.; Akbari, D.; Menges, R.; MacKenzie, S.; Staab, S. TouchGazePath: Multimodal Interaction with Touch and Gaze Path for Secure Yet Efficient PIN Entry. In Proceedings of the 2019 International Conference on Multimodal Interaction, Suzhou, China, 14–18 October 2019; pp. 329–338. [Google Scholar] [CrossRef]
- Yu, D.; Zhou, Q.; Newn, J.; Dingler, T.; Velloso, E.; Goncalves, J. Fully-Occluded Target Selection in Virtual Reality. IEEE Trans. Vis. Comput. Graph. 2020, 26, 3402–3413. [Google Scholar] [CrossRef] [PubMed]
- Kopper, R.; Bacim, F.; Bowman, D.A. Rapid and accurate 3D selection by progressive refinement. In Proceedings of the 2011 IEEE Symposium on 3D User Interfaces (3DUI), Singapore, 19–20 March 2011; pp. 67–74. [Google Scholar] [CrossRef]
- Mendes, D.; Medeiros, D.; Sousa, M.; Cordeiro, E.; Ferreira, A.; Jorge, J.A. Design and evaluation of a novel out-of-reach selection technique for VR using iterative refinement. Comput. Graph. 2017, 67, 95–102. [Google Scholar] [CrossRef]
- Stellmach, S.; Dachselt, R. Still Looking: Investigating Seamless Gaze-Supported Selection, Positioning, and Manipulation of Distant Targets. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 285–294. [Google Scholar] [CrossRef]
- Feick, M.; Bateman, S.; Tang, A.; Miede, A.; Marquardt, N. Tangi: Tangible proxies for embodied object exploration and manipulation in virtual reality. In Proceedings of the 2020 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Porto de Galinhas, Brazil, 9–13 November 2020; pp. 195–206. [Google Scholar]
- Hettiarachchi, A.; Wigdor, D. Annexing reality: Enabling opportunistic use of everyday objects as tangible proxies in augmented reality. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 1957–1967. [Google Scholar]
- NASA TLX. Available online: https://humansystems.arc.nasa.gov/groups/tlx/ (accessed on 28 August 2021).
- Brooke, J. Sus: A quick and dirty’usability. Usability Eval. Ind. 1996, 189, 189–194. [Google Scholar]
- Khan, I.; Khusro, S. Towards the design of context-aware adaptive user interfaces to minimize drivers’ distractions. Mob. Inf. Syst. 2020, 2020, 8858886. [Google Scholar] [CrossRef]
- Wobbrock, J.O.; Findlater, L.; Gergle, D.; Higgins, J.J. The Aligned Rank Transform for Nonparametric Factorial Analyses Using Only Anova Procedures. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 143–146. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SH | OO | TH | ||||||
|---|---|---|---|---|---|---|---|---|
| Tap | Swipe (+ Tap) | Tap | Swipe (+ Tap) | Tap | Swipe (+ Tap) | |||
| 1R1C | 4.0 | 3.2 | 1R1C | 4.2 | 3.3 | 1R1C | 3.7 | 4.5 |
| 1.4 s | 1.2 s | 1.3 s | 1.2 s | 1.3 s | 1.3 s | |||
| 1R2C | 2.3 | 1R2C | 3.1 | 2.7 | 1R2C | 3.1 | 2.7 | |
| 1.3 s | 1.3 s | 1.3 s | 1.4 s | 1.2 s | 1.3 s | |||
| 2R1C | 2.6 | 2.3 | 2R1C | 2.8 | 2.1 | 2R1C | ||
| 1.3 s | 1.2 s | 1.2 s | 1.2 s | 1.2 s | 1.2 s | |||
| 1R3C | 3.2 | 3.2 | 1R3C | 2.3 | 3.3 | 1R3C | 4.2 | 2.7 |
| 1.2 s | 1.2 s | 1.1 s | 1.2 s | 1.2 s | 1.1 s | |||
| 3R1C | 3.0 | 2.5 | 3R1C | 3.2 | 3.7 | 3R1C | 2.2 | 2.7 |
| 1.3 s | 1.1 s | 1.1 s | 1.1 s | 1.1 s | 1.1 s | |||
| 2R2C | 2.2 | 2R2C | 2.1 | 2R2C | 2.0 | |||
| 1.3 s | 1.2 s | 1.2 s | 1.3 s | 1.2 s | 1.2 s | |||
| 2R3C | 2.4 | 5.7 | 2R3C | 2.2 | 6.1 | 2R3C | 2.3 | 3.0 |
| 1.3 s | 1.3 s | 1.2 s | 1.1 s | 1.1 s | 1.2 s | |||
| 3R2C | 4.2 | 3.4 | 3R2C | 3.4 | 2.2 | 3R2C | 3.2 | |
| 1.3 s | 1.2 s | 1.2 s | 1.1 s | 1.1 s | 1.2 s | |||
| 3R3C | 4.7 | 4.3 | 3R3C | 3.6 | 2.9 | 3R3C | 2.8 | 3.9 |
| 1.2 s | 1.2 s | 1.1 s | 1.1 s | 1.0 s | 1.1 s | |||
| Variable | Group | Number of Participants | |
|---|---|---|---|
| Count | Percentage | ||
| Gender | Female | 6 | 25.00% |
| Male | 18 | 75.00% | |
| Age | 19 to 22 years | 17 | 70.83% |
| 22 to 25 years | 1 | 4.17% | |
| 25 to 28 years | 6 | 25.00% | |
| Background | Undergraduate | 17 | 70.83% |
| Graduate student | 7 | 29.17% | |
| Preferred hand | Right hand | 24 | 100.00% |
| Left hand | 0 | 0.00% | |
| Both hands | 0 | 0.00% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, Y.; Zheng, Y.; Zhao, S.; Ma, X.; Wang, Y. Balancing Accuracy and Speed in Gaze-Touch Grid Menu Selection in AR via Mapping Sub-Menus to a Hand-Held Device. Sensors 2023, 23, 9587. https://doi.org/10.3390/s23239587
Tian Y, Zheng Y, Zhao S, Ma X, Wang Y. Balancing Accuracy and Speed in Gaze-Touch Grid Menu Selection in AR via Mapping Sub-Menus to a Hand-Held Device. Sensors. 2023; 23(23):9587. https://doi.org/10.3390/s23239587
Chicago/Turabian StyleTian, Yang, Yulin Zheng, Shengdong Zhao, Xiaojuan Ma, and Yunhai Wang. 2023. "Balancing Accuracy and Speed in Gaze-Touch Grid Menu Selection in AR via Mapping Sub-Menus to a Hand-Held Device" Sensors 23, no. 23: 9587. https://doi.org/10.3390/s23239587
APA StyleTian, Y., Zheng, Y., Zhao, S., Ma, X., & Wang, Y. (2023). Balancing Accuracy and Speed in Gaze-Touch Grid Menu Selection in AR via Mapping Sub-Menus to a Hand-Held Device. Sensors, 23(23), 9587. https://doi.org/10.3390/s23239587