1. Introduction
The smart manufacturing paradigm is instrumental in fostering a holistic approach to data analytics, wherein the interconnectedness and interdependencies within the manufacturing ecosystem are thoroughly considered. By integrating a plethora of manufacturing agents, it constructs a comprehensive data framework that encapsulates both product specifics and machinery dynamics, thereby enabling analytical interoperability. These integrated data are then processed through a harmonised suite of preprocessing techniques, predictive algorithms, and decision support systems, facilitating the synthesis of this interconnected data into actionable insights.
Furthermore, an interconnected factory facilitates the consistent and systematic analysis of information from individual sections or across the entire plant-wide system. This enables analytics to transcend the cause-and-effect relationships of isolated processes and to encompass plant-wide phenomena. In essence, it allows for an exploration of how product characteristics and sensor data from initial production units impact subsequent processes and final product quality.
Extracting actionable insights from a plant-wide interconnected dataset poses significant challenges. Industrial process data inherently comprise multivariable, non-linear, and frequently, non-Gaussian characteristics, complicating standard analytical approaches [
1]. The complexity is further accentuated in batch processing scenarios, which differ markedly from continuous operations. Batch processes are inherently dynamic and non-stationary, introducing variability, which traditional methods are ill-equipped to handle [
2]. This complexity underscores the necessity of developing sophisticated decision support systems that are capable of deciphering and acting upon the intricate characteristics present within such datasets.
Additionally, the batch process industries, particularly those engaged in producing specialised products and adapting to mass customisation trends, face exacerbated complexities. These complexities pose significant obstacles in the effective implementation of decision support systems. The crux of the challenge lies in developing a normalised production procedure that is versatile enough to manage a diverse range of products, each with its unique composition, while simultaneously upholding stringent quality tolerances. This task is not only demanding, but also critical in ensuring the adaptability and efficiency of the production process in such dynamic environments.
Furthermore, a legacy industrial batch process often lacks labelled or contextualised data. Data contextualisation in the batch process setting involves connecting a batch to a relevant manufacturing process, that is ensuring the sensor data streams have associated time stamps labelling each batch to its corresponding duration [
3]. Correct context is essential. Otherwise, the process parameters are disconnected from the correct batch.
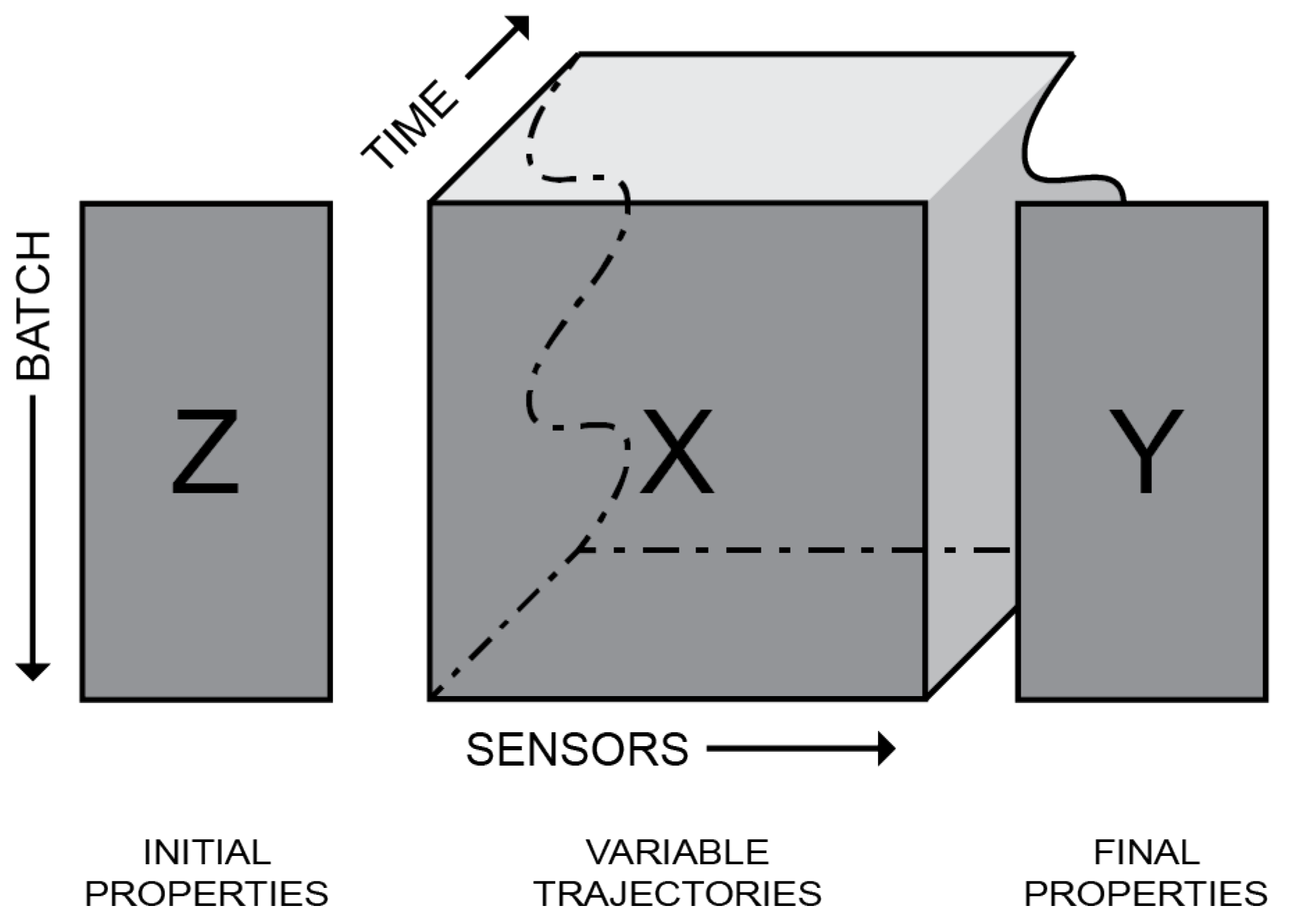
Research in the batch process industry domain frequently utilises Batch Data Analytics (BDA) methodologies. BDA categorises batch process data into three distinct groups: initial properties, variable trajectories, and final properties. The initial and final properties encompass data pertaining to the batch before and after processing, respectively. Meanwhile, data acquired during processing, such as sensor profiles, are classified under variable trajectories.
BDA is adept at handling the unique characteristics of the domain. One such idiosyncrasy is the variability in the time required to produce each batch, leading to differing batch durations. Consequently, the time series data from the batch process inherently produce uneven datasets. Therefore, special attention is necessary to effectively manage these variable trajectories in conventional analytics.
To that end, BDA presents feature generation to align the variable trajectories. Feature generation creates statistics from time series data, resulting in an aligned dataset. A variable trajectory transformed using feature generation is called a variable feature. The feature landmark approach, introduced by Wold et al. [
4], is an example of feature generation. A derivation of the feature landmark approach, called Statistical Pattern Analysis (SPA) feature generation, was used and elaborated by Wang and He [
1], He and Wang [
5], He et al. [
6]. Two other feature-generation approaches may also be observed: profile-driven features Rendall et al. [
7] and translation-invariant multiscale energy-based features Rato and Reis [
8].
Another method of BDA feature accommodation approaches the problem by aligning the batch data and is called called trajectory alignment. As the name implies, trajectory alignment warps the trajectory of the batches to a standard duration and, depending on the complexity of the method, synchronises distinct characteristics such as maxima and minima. Notable works on batch data transformation using trajectory alignments are Nomikos and MacGregor [
9,
10,
11].
A machine learning predictive model will serve as the cornerstone of the decision support system, offering probabilistic insights. Utilising supervised machine learning, it is possible to forecast the final properties of a batch process dataset, drawing on initial features and/or variable features as inputs. Supervised learning tasks can manifest as either regression or classification challenges. The key distinction lies in regression predicting quantitative outcomes, while classification focuses on qualitative ones. Additionally, there exists a specific scenario in classification with only two possible outcomes, such as ‘true’ or ‘false’, known as binary classification [
12].
Implementing and comparing various machine learning methods is prudent since no method is inherently superior to another on an unseen dataset [
12]. Additionally, implementing models in increasing order of complexity lends to a parsimonious approach. Striving towards suitable modelling and implementation complexity is beneficial. It reduces the time it takes to analyse the problem and makes it perceptible [
2]. Various models can capture different aspects and characteristics of the process.
In this work, machine learning will be used in the context of batch data to determine if the batch will comply with final property tolerances. The problem was designed as a binary classification problem, determining if the batch is predicted to be compliant or non-compliant. An assortment of classification models will be used to achieve the best-possible accuracy in this scope.
A decision support system was constructed using the classifier. The accuracy metric was used for the model’s confidence and was derived from the confusion matrix. The confidence of the classifiers was used as an intervention threshold for when to utilise the model’s recommendation for decision support. The threshold effectively acts as a filter, discarding samples whose confidence metric is below the threshold. As a result, increasing the lowest allowed confidence reduces the coverage of the model, i.e., the out-of-coverage samples do not receive a recommendation from the decision support system.
For the cost sensitivity analysis to be pertinent, it is imperative to make accommodations for out-of-coverage individuals (called transgressors). Otherwise, the analytics loses relevance with reality. An adjustable probability threshold gives control over the decision support’s accuracy. This control is appealing because it can be configured to conform to the level of uncertainty acceptable by the business. Hence, there is a need to consider the transgressors. Two transgressor strategies’ are presented and compared to discover the most cost-efficient approach. One strategy accepts the transgressors and sends them for further processing; the other strategy rejects them and sends them to be scrapped.
Cost-sensitive learning is incorporated into the decision processes to optimise the net savings of the decision support system. Incorporating the associated mislabelling costs into the modelling and decision support is called cost-sensitive learning, and it is implemented by developing a cost matrix. The cost matrix complements the confusion matrix, but instead of illustrating the false-positive frequency, it depicts the false-positive costs. In other words, the cost matrix displays the corresponding cost of erroneously labelling individuals. The concept of cost-sensitive learning and the cost matrix was introduced by Elkan [
13]. Other notable works on cost-sensitive learning can be found in Gan et al. [
14] and Verbeke et al. [
15].
Cost-sensitive learning stands out as an essential technique in machine learning, especially for addressing the complexities associated with imbalanced datasets and varying misclassification costs. As detailed in the works of Ghatasheh et al. [
16], Lobo et al. [
17], cost-sensitive learning adeptly incorporates cost considerations into the training phase of machine learning models. This is typically achieved through internal re-weighting of dataset instances or by adjusting misclassification errors, which allows for the construction of a prediction model that prioritises lower-cost outcomes over higher probability ones.
This approach is particularly beneficial in scenarios with class imbalance and significant misclassification costs, as emphasised by Zhang et al. [
18] in the context of manufacturing industries. Here, cost-sensitive learning is instrumental in tailoring decision support systems to focus not just on accuracy, but also on cost effectiveness, demonstrating its versatility and efficacy in diverse applications.
The authors found tangential research in several domains. Alves et al. [
19] studied stabilising production planning. However, instead of focusing on the product’s compliance and the associated classification cost, they focused on failure prediction in industrial maintenance in the context of tardiness. Additionally, the general conclusions were that the managerial role is shifting from problem-specific to being able to develop different strategies for various scenarios, such as the solution presented in this work.
Further, Frumosu et al. [
20] worked on predictive maintenance with an imbalanced classification dataset and incorporating cost sensitivity. In the context of the multi-state production of frequency drivers, given historical quality data, they predicted the final product quality before shipping to the client.
Next, the work of Verbeke et al. [
21] analysed the impact of following prognostic recommendations. They designed a decision support model. The concept of an individual treatment effect is similar to the cost-sensitive approach in this work, where the individual treatment effect looks at the difference between the outcome with and without applying the effect.
Additionally, Mählkvist et al. [
22] considered using industrial batch data analysis with machine learning. Here, the industrial batch data were first consolidated using BDA methods to be able to analyse the data with machine learning. Then, the data were explored using the machine learning method kernel-principal component analysis. The results indicated that it is feasible to derive patterns from the batch data trajectories using a combination of SPA (for feature generation) and kernel-principal component analysis.
For a proof of concept, the thermocouple manufacturing process at Kanthal was examined. In this production, thermocouples are created in the form of wire rod coils. Two key production units, the smelting furnace and the wire rod rolling mill, provide input for the decision support system. The wire rod rolling mill, with its complex and unaligned time series data, offers a valuable case for enhancing the decision support system through feature generation. Specifically, this involves integrating and contrasting models that utilise features derived from time series sensor data against those relying solely on product property data. See
Section 2.1 for more details.
The thermocouples’ production provides the data for the model. After the smelting furnace, the initial properties data are sampled from the batch’s properties. Next, the variable trajectory data are acquired from the wire rod rolling process. After the wire rod rolling mill, the final properties’ data are sampled from the batch’s properties. A binary classifier was designed to predict if a batch will comply with the property tolerances using properties from earlier in the operations. Three classification methods were implemented and reviewed with respect to the model accuracy. The classification models were Logistic Regression (LR), Random Forest Classification (RFC), and Support Vector Machine (SVM).
This paper integrated a constellation of methods and approaches from the different fields of BDA, cost-sensitive learning, and machine learning to optimise operational decision-making for an industrial batch process from a cost-aware perspective. The model acts as a decision support system to prevent redundant processing by salvaging the batch before additional processing, that is preventing superfluous investment. Cost-sensitive learning, machine learning methods, and BDA were combined to create a cost-sensitive decision support system. The model accuracy and the relative cost were compared by subjecting the case study to different scenarios, that is, modelling with and without the trajectory features and varying the two transgressor strategies, accepting or rejecting out-of-coverage batches.
The paper is structured as follows: In
Section 2, the methodology is described. In
Section 3, the results are presented and subsequently discussed. Next, in
Section 4, the details of the paper are synthesised into conclusions.
4. Conclusions
The current study successfully showed that an integrated approach, combining BDA, machine learning, and cost-sensitive learning, plays a pivotal role in reducing overall costs. This synergy effectively aids in determining the most-advantageous discrimination settings, optimising both accuracy and cost efficiency. By leveraging the strengths of each component, this combined methodology presents a comprehensive solution for efficient decision-making in complex scenarios.
Two methods from BDA were implemented, the batch process data structure, which organises the data into initial properties, variable trajectories, and final properties, and the feature accommodation approach SPA, which transforms variable trajectories into variable features. These two methods resulted in an aligned two-dimensional dataset primed for use with machine learning. To determine if the variable features improved the prediction accuracy, the machine learning models were trained both with and without these, and the result was reviewed.
Three machine learning classification methods were implemented and reviewed: logistic regression, Random Forest classification, and support vector machine. These cover an increasing level of complexity where logistic regression is the least complex and Random Forest and support vector machines are about equal. Random Forests and support vector machines differ in that the former are non-parametric and the latter parametric, allowing them to interpret different characteristics.
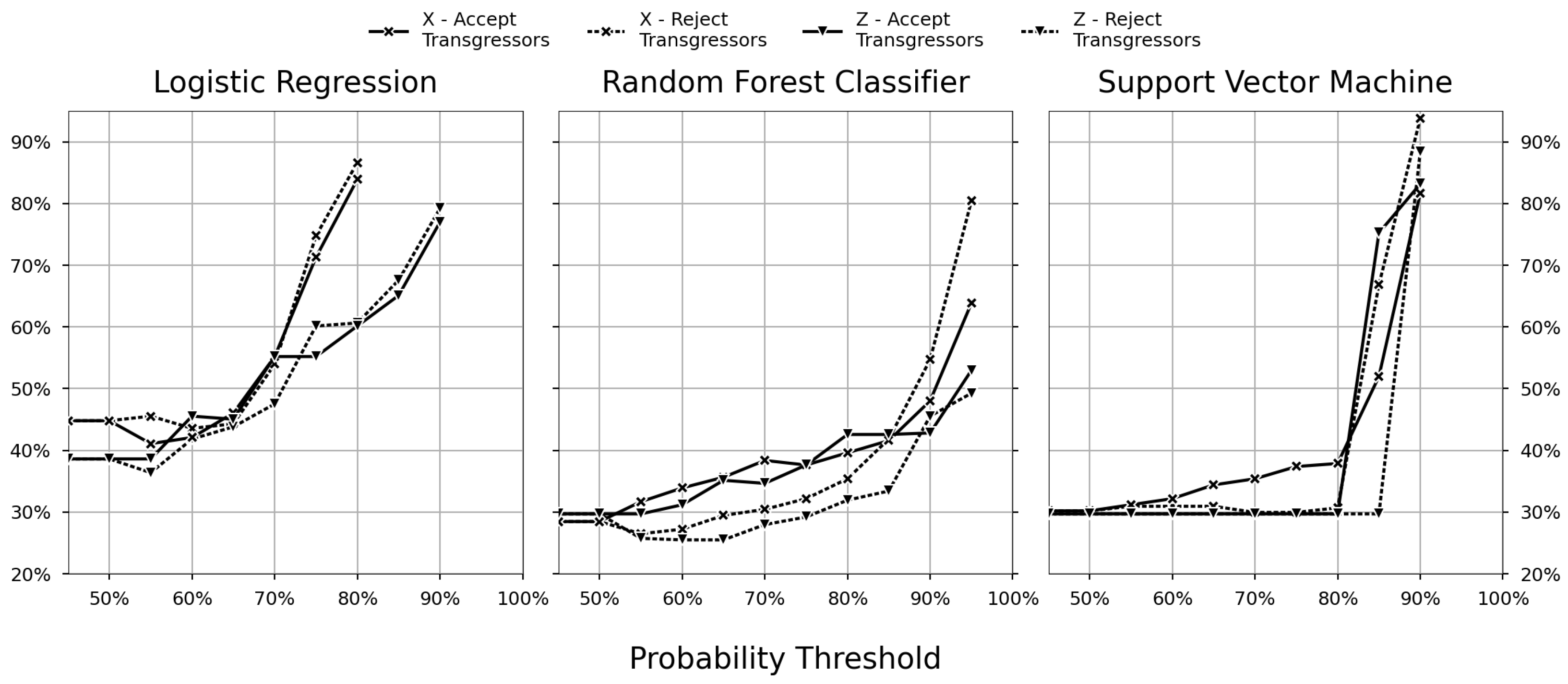
After training the models to achieve optimal accuracy, a probability threshold was introduced. This threshold increased from 50 to 100%, and the filtered out batches met the criteria of the probability limit. Consequently, this evolved into an accuracy–coverage trade-off in which a stringent probability threshold increased the accuracy and reduces coverage. The accuracy–coverage trade-off did not provide an optimal solution, and to this end, the cost matrix can be leveraged.
Cost-sensitive learning introduces the cost matrix. The cost matrix determines which probability threshold provides the optimal relative cost. The accuracy–coverage trade-off can be interconnected with the associated relative costs. Further, the flexibility to configure the probability to suit a risk is deemed acceptable by the industry. This work also improved the relative cost of a case study using the aforementioned decision support system.
The optimal cost-efficient solution was RFCZ in the reject transgressor scenario. The Random Forest classifiers only use the initial features as the input data. The best probability threshold was at 65% and resulted in a relative cost of 26%.
When comparing the models using a dataset with or without variable features (aggregated sensor data), the impact that the variable features had on the accuracy was negligible or even detrimental (as one can observe in the accuracy–coverage trade-off in
Figure 7). In particular, models trained with variable features performed inferior to those without. The possible causes can be as follows:
Despite the variance in the variable features (seen in
Figure 5), the models discerned no correlation between the process and the response;
The statistics used (mean, skewness, and kurtosis) were not sufficient to interpret the features’ intrinsic behaviour;
The classifiers were not flexible enough to interpret the relationship between the features and response.
There are other metrics to consider besides the relative cost. It may be that the operation needs to optimise against quantity rather than quality. Hence, depending on the need of the system, it may be beneficial to tighten or lessen the probability constraint. But, having a sparse strategy provides other benefits, such as: lowering the strain on down-stream production, reducing the time for quality products to be produced by cutting the process short for sub-par products, and higher quality stock.
Another aspect that could improve the decision support system is to expand the definition of non-compliant batches. A non-compliant individual may match another non-compliant individual that balances out the out-of-bounds EMF; hence, a supplemental model that determines the likelihood of matching other sub-par individuals can be used to capture this. Also, it may be possible to redeem some of the cost for the metallurgical process by re-melting the batch since a scrap value is associated with the batch. Hence, leaving the rejected non-compliant batch cost at zero may not represent the reality for the cost matrix.
In conclusion, this approach provides a cost-sensitive decision support system with accommodation scenarios for out-of-coverage batches. It allows for configurable sensitivity constraints, either based on the needs of the industry or by optimal cost. The accuracy–coverage trade-off illustrates clearly how a stricter threshold results in reduced decision support coverage. While it is infeasible to analyse the optimal cut-off point from the accuracy–coverage trade-off, the relative cost plot is discernible. Thus, the cost-sensitive approach allows the accuracy coverage to be extended to the relative cost in which an optimal value can be identified. This allows for a clear decision about the cut-off point, converting the abstract problem into actionable insights, consequently, creating value from the data.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}