
AirMLP: A Multilayer Perceptron Neural Network for Temporal Correction of PM2.5 Values in Turin



Abstract
:1. Introduction
- 1.
- Data Understanding and Assembling: Our first step involves the assembly of a comprehensive dataset. We collect data from multiple sources, including five low-cost sensors and one reference station. The resulting dataset is designed to capture the temporal patterns inherent in the data and to consider the influence of various meteorological factors on the detected concentrations;
- 2.
- Neural Network Training: We train various neural network models, using the assembled dataset. These models are designed to minimise the error introduced by the low-cost sensor in estimating PM 2.5 concentrations. Different hyperparameters to identify the optimal model configuration were explored and compared.
- 3.
- Results Comparison: A comparative analysis of the best-performing model has been conducted, and additional insights and considerations derived from our findings are provided.
2. Materials and Methods
2.1. Air Quality Sensors
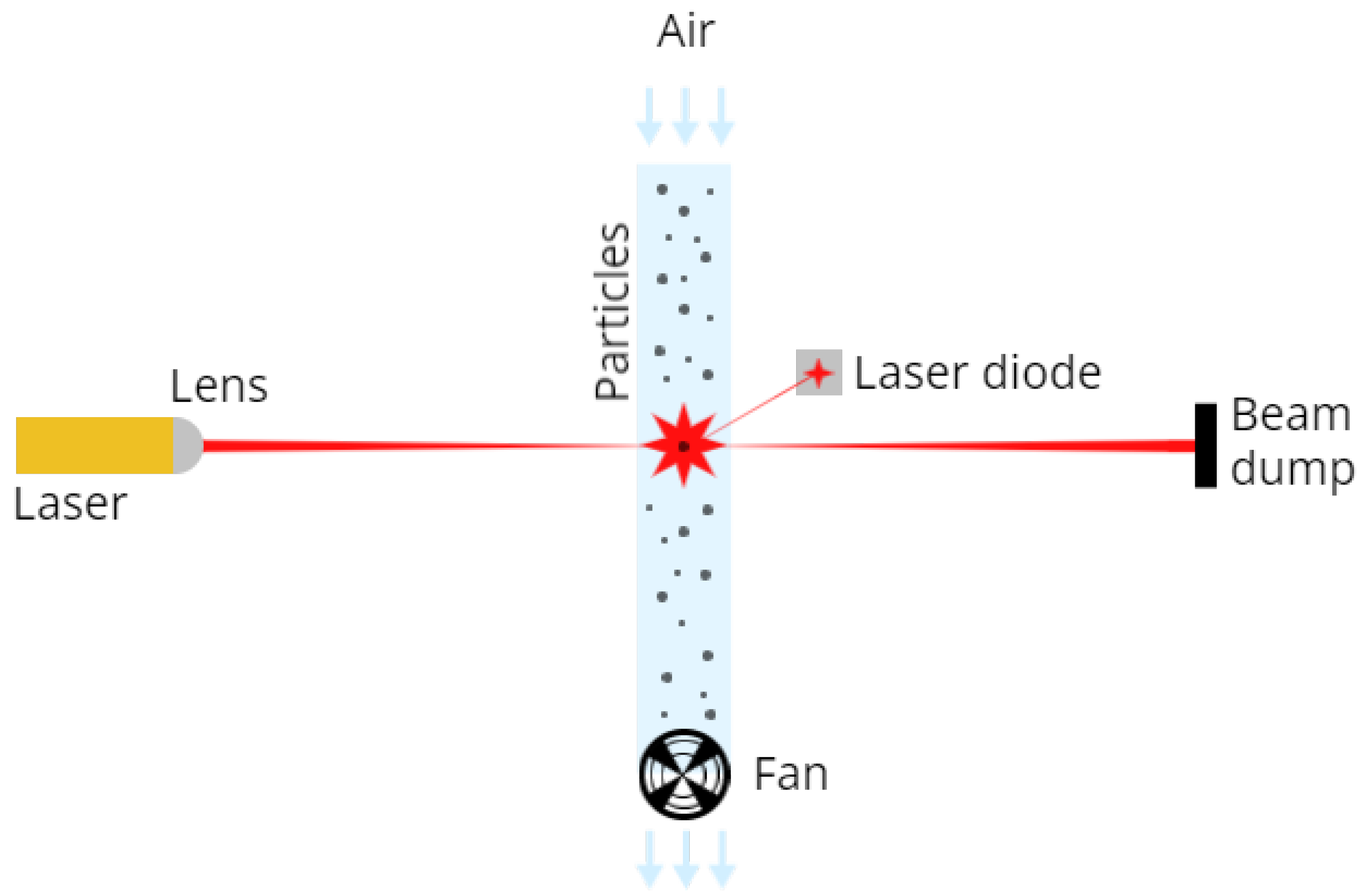
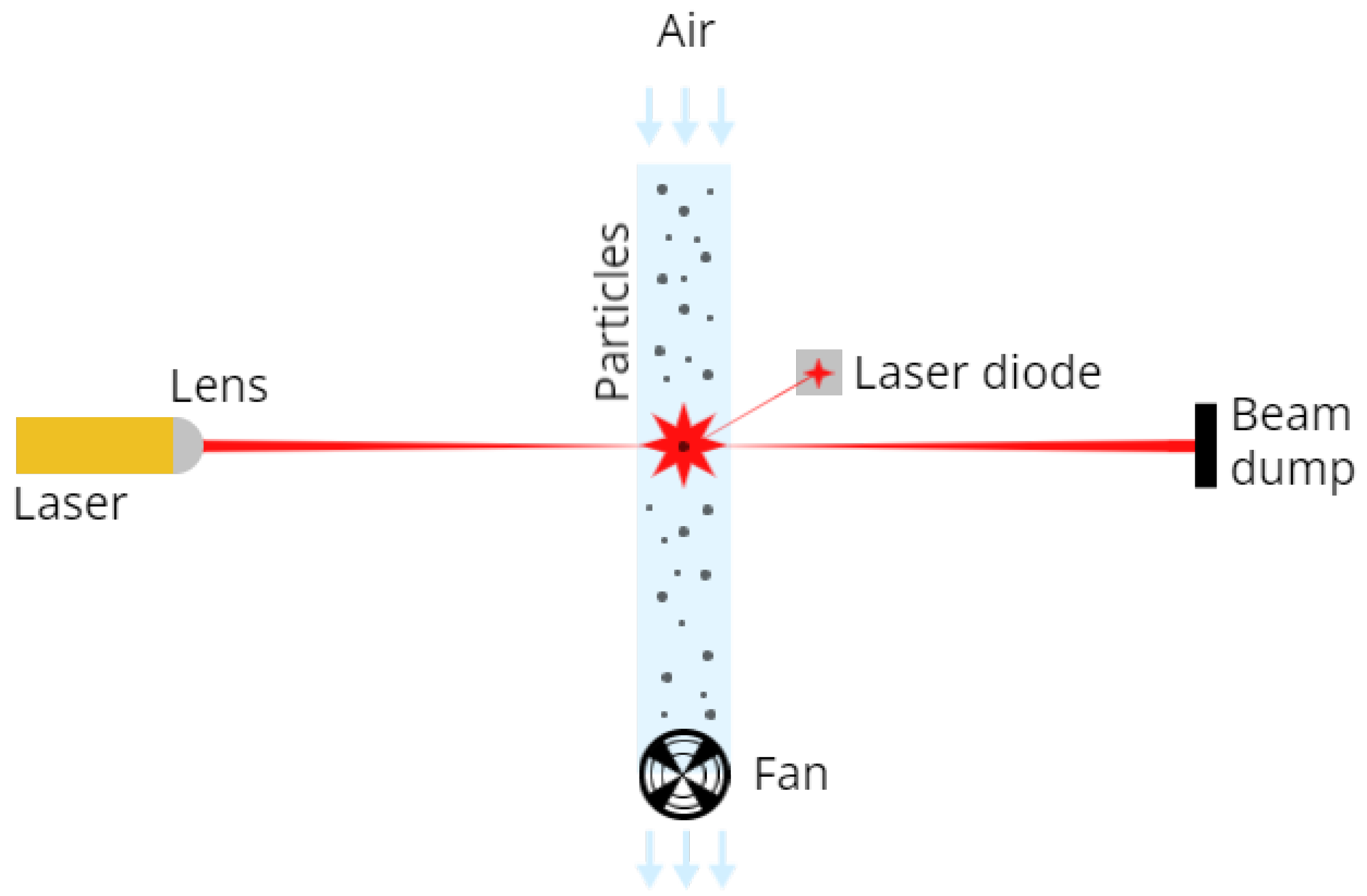
2.1.1. Laser-Scattering Technology
2.1.2. Hygroscopicity Issue
2.1.3. Calibration Challenges
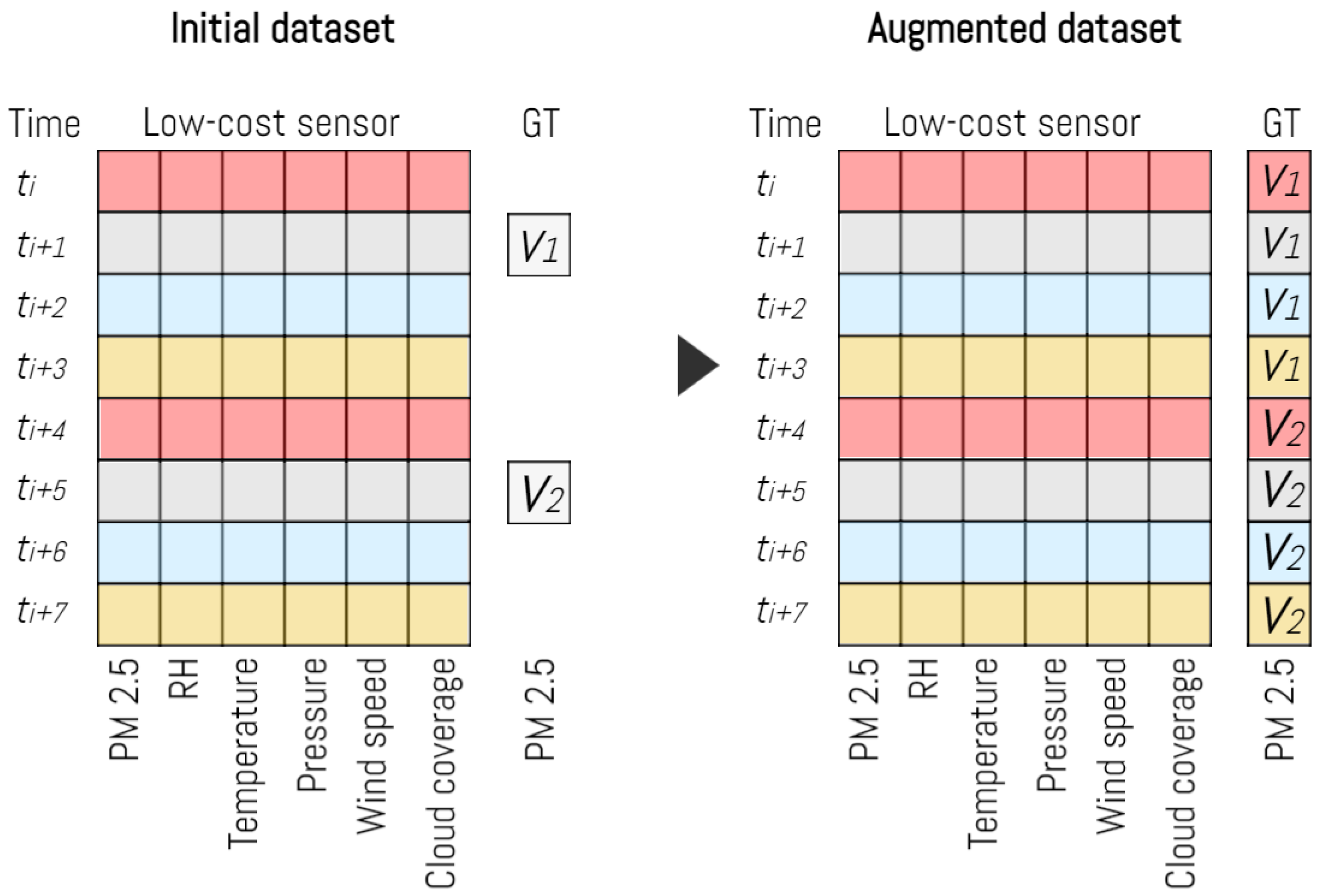
2.2. Dataset Assembly
2.3. MLP Architectures
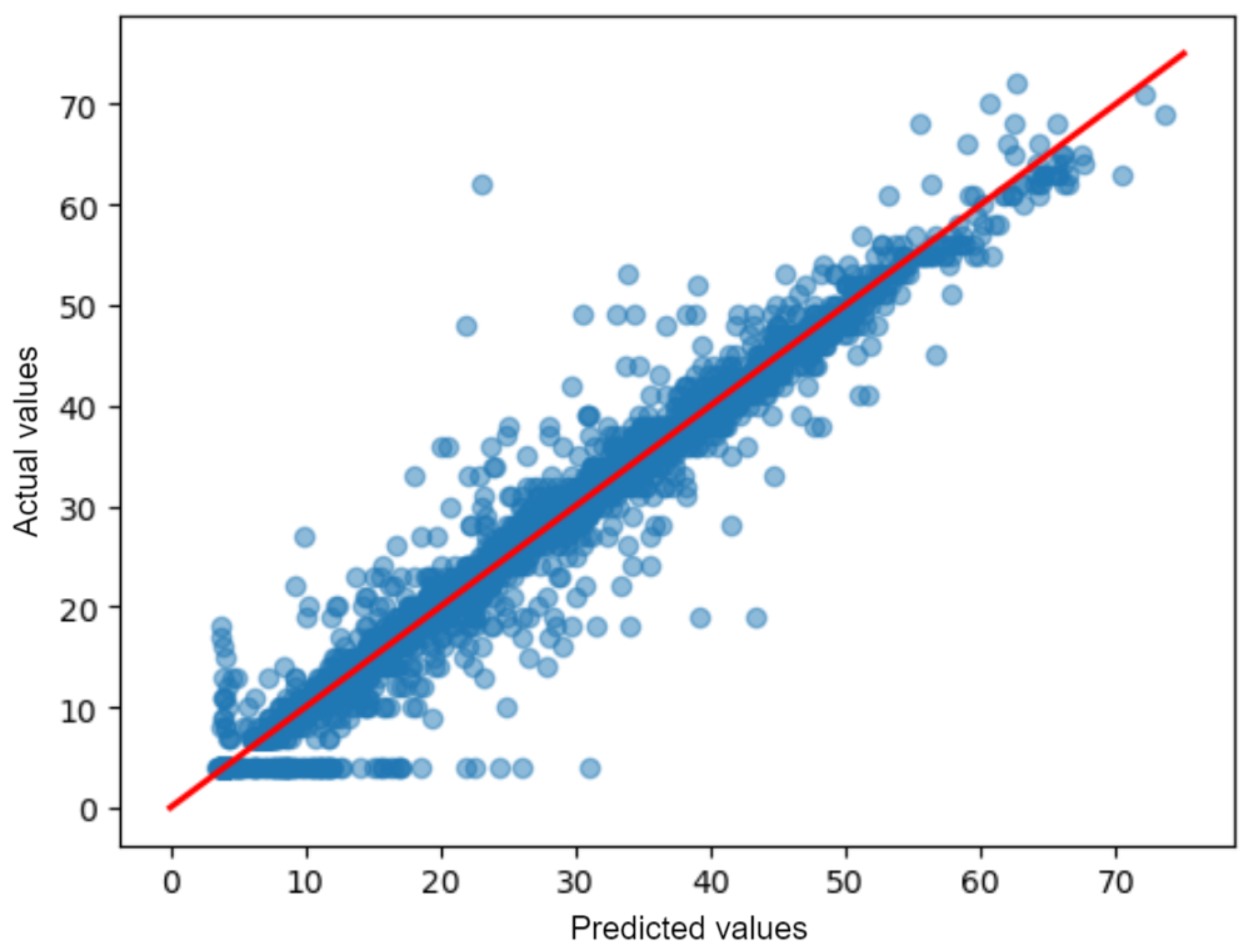
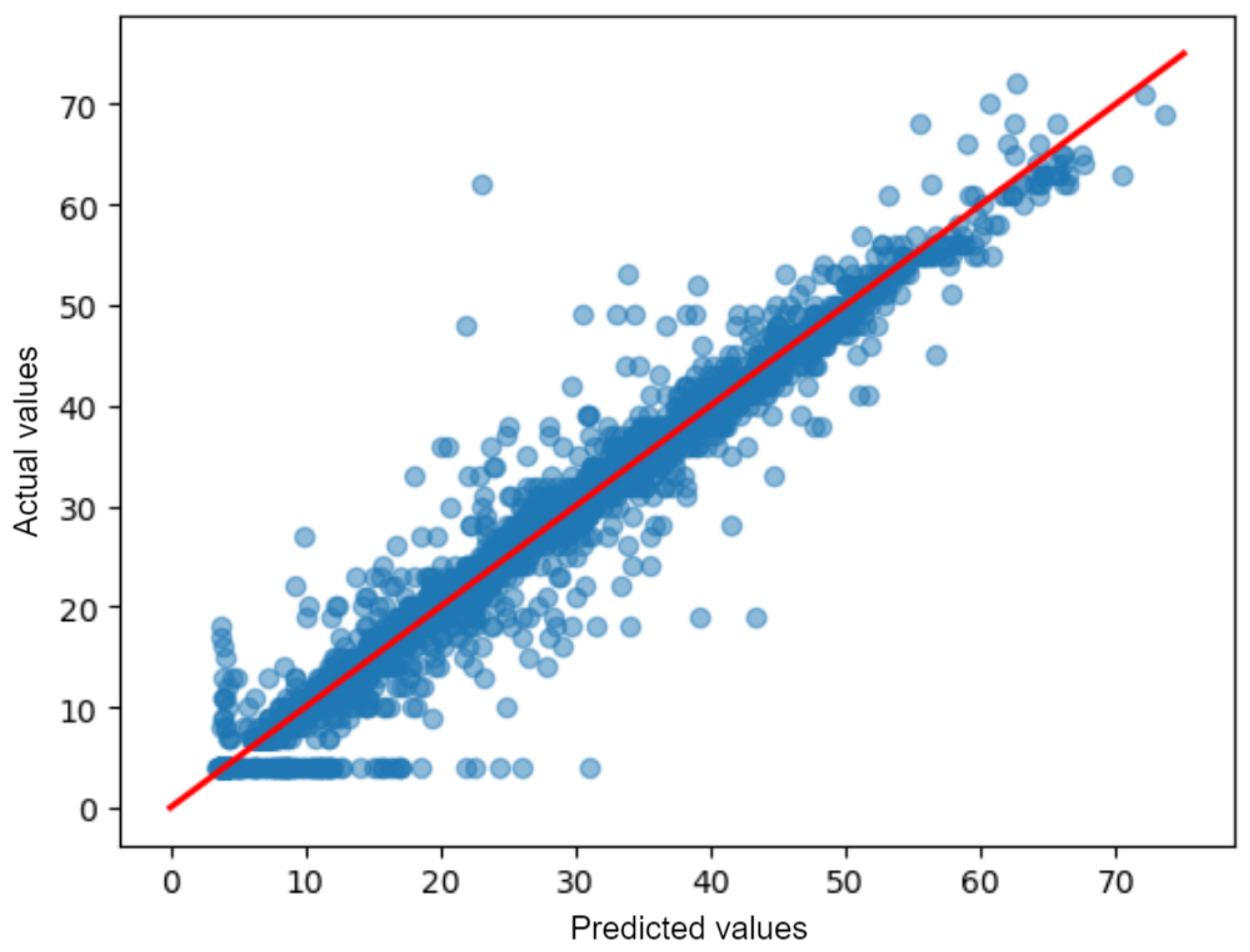
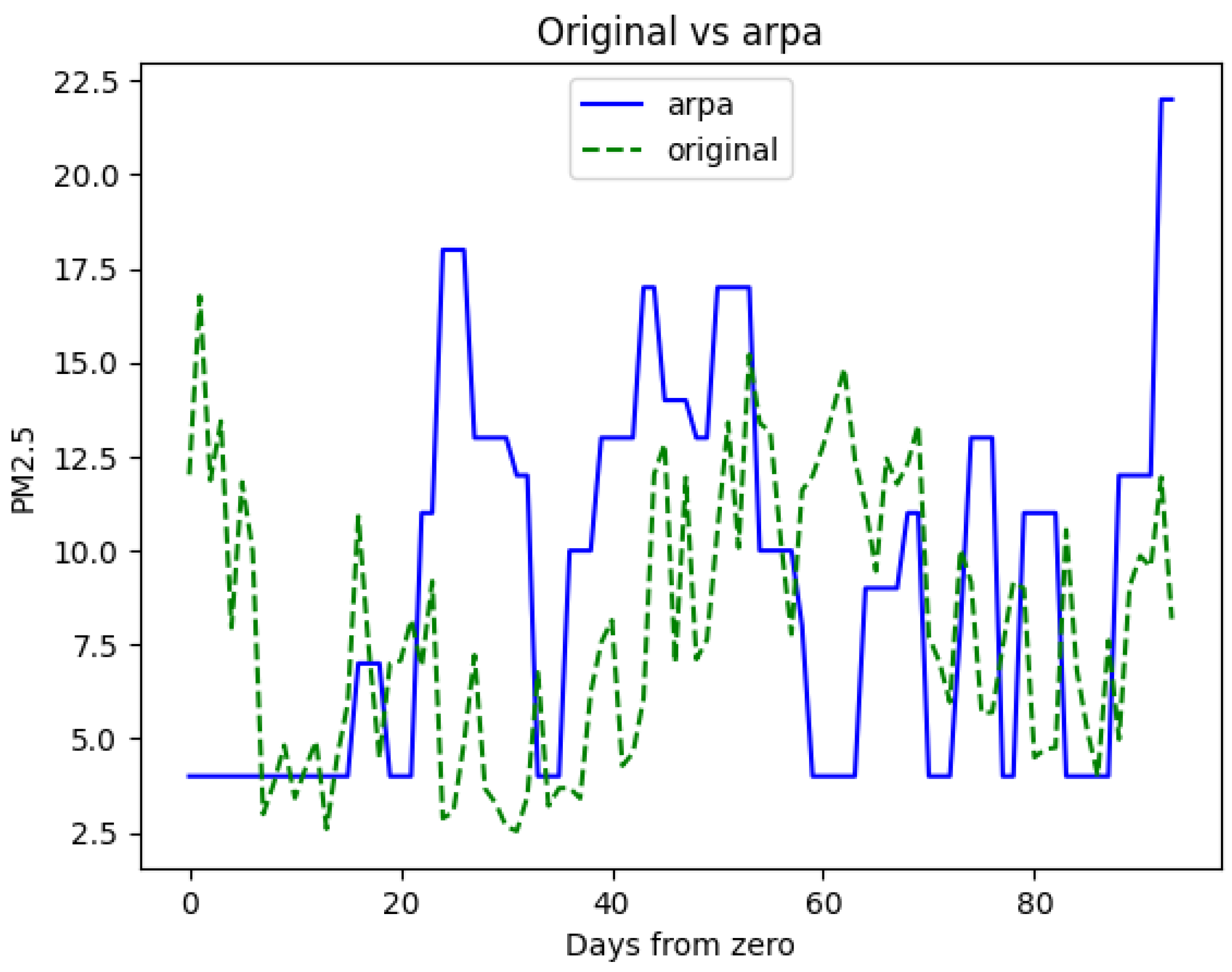
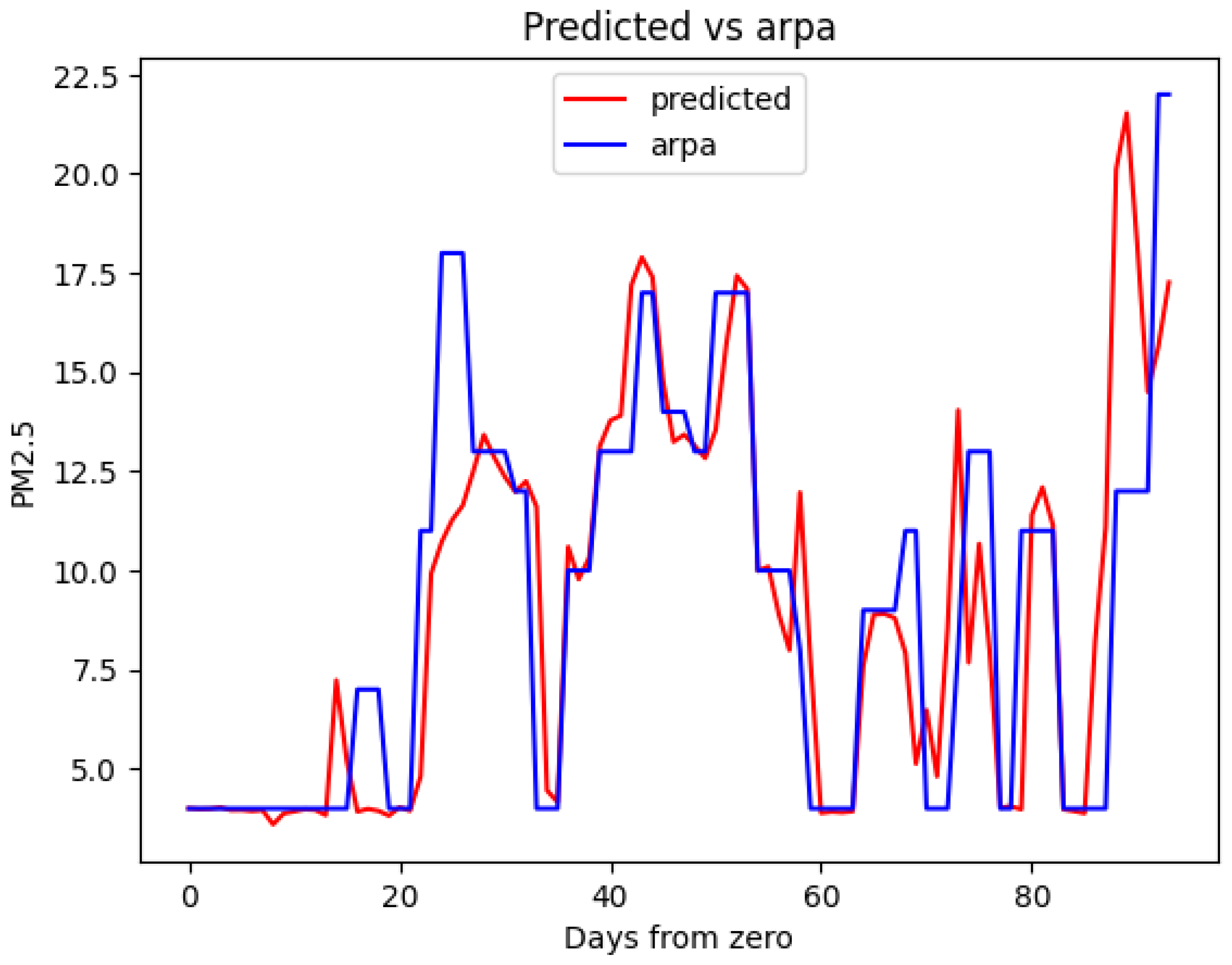
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sharma, S.; Chandra, M.; Kota, S.H. Health effects associated with PM 2.5: A systematic review. Curr. Pollut. Rep. 2020, 6, 345–367. [Google Scholar] [CrossRef]
- Fuller, R.; Landrigan, P.J.; Balakrishnan, K.; Bathan, G.; Bose-O’Reilly, S.; Brauer, M.; Caravanos, J.; Chiles, T.; Cohen, A.; Corra, L.; et al. Pollution and health: A progress update. Lancet Planet. Health 2022, 6, e535–e547. [Google Scholar] [CrossRef]
- Pope, C.A.; Coleman, N.; Pond, Z.A.; Burnett, R.T. Fine particulate air pollution and human mortality: 25+ years of cohort studies. Environ. Res. 2020, 183, 108924. [Google Scholar] [CrossRef] [PubMed]
- Pope, C.A., III; Dockery, D.W. Health effects of fine particulate air pollution: Lines that connect. EM Air Waste Manag. Assoc. Mag. Environ. Manag. 2006, 56, 709–742. [Google Scholar] [CrossRef] [PubMed]
- Thangavel, P.; Park, D.; Lee, Y.C. Recent insights into particulate matter (PM 2.5)-mediated toxicity in humans: An overview. Int. J. Environ. Res. Public Health 2022, 19, 7511. [Google Scholar] [CrossRef] [PubMed]
- Luan, T.; Guo, X.; Guo, L.; Zhang, T. Quantifying the relationship between PM2.5 concentration, visibility and planetary boundary layer height for long-lasting haze and fog–haze mixed events in Beijing. Atmos. Chem. Phys. 2018, 18, 203–225. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, Y. Effects of particulate matter (PM2.5) and associated acidity on ecosystem functioning: Response of leaf litter breakdown. Environ. Sci. Pollut. Res. 2018, 25, 30720–30727. [Google Scholar] [CrossRef]
- Zheng, T.; Bergin, M.H.; Johnson, K.K.; Tripathi, S.N.; Shirodkar, S.; Landis, M.S.; Sutaria, R.; Carlson, D.E. Field evaluation of low-cost particulate matter sensors in high-and low-concentration environments. Atmos. Meas. Tech. 2018, 11, 4823–4846. [Google Scholar] [CrossRef]
- US EPA NAAQS Table. 2016. Available online: https://www.epa.gov/criteria-air-pollutants/naaqs-table (accessed on 20 September 2023).
- World Health Organization Regional Office for Europe. Air Quality Guidelines for Europe; World Health Organization, Regional Office for Europe: Copenhagen, Denmark, 2000. [Google Scholar]
- Chen, T.; He, J.; Lu, X.; She, J.; Guan, Z. Spatial and Temporal Variations of PM2.5 and Its Relation to Meteorological Factors in the Urban Area of Nanjing, China. Int. J. Environ. Res. Public Health 2016, 13, 921. [Google Scholar] [CrossRef]
- Chen, M.; Yuan, W.; Cao, C.; Buehler, C.; Gentner, D.R.; Lee, X. Development and Performance Evaluation of a Low-Cost Portable PM2.5 Monitor for Mobile Deployment. Sensors 2022, 22, 2767. [Google Scholar] [CrossRef]
- Hart, R.; Liang, L.; Dong, P. Monitoring, mapping, and modeling spatial–temporal patterns of PM2.5 for improved understanding of air pollution dynamics using portable sensing technologies. Int. J. Environ. Res. Public Health 2020, 17, 4914. [Google Scholar] [CrossRef]
- Schilt, U.; Barahona, B.; Buck, R.; Meyer, P.; Kappani, P.; Möckli, Y.; Meyer, M.; Schuetz, P. Low-Cost Sensor Node for Air Quality Monitoring: Field Tests and Validation of Particulate Matter Measurements. Sensors 2023, 23, 794. [Google Scholar] [CrossRef]
- Munir, S.; Mayfield, M.; Coca, D.; Jubb, S.A.; Osammor, O. Analysing the performance of low-cost air quality sensors, their drivers, relative benefits and calibration in cities—A case study in Sheffield. Environ. Monit. Assess. 2019, 191, 94. [Google Scholar] [CrossRef] [PubMed]
- Danek, T.; Zaręba, M. The use of public data from low-cost sensors for the geospatial analysis of air pollution from solid fuel heating during the COVID-19 pandemic spring period in Krakow, Poland. Sensors 2021, 21, 5208. [Google Scholar] [CrossRef] [PubMed]
- Zareba, M.; Dlugosz, H.; Danek, T.; Weglinska, E. Big-Data-Driven Machine Learning for Enhancing Spatiotemporal Air Pollution Pattern Analysis. Atmosphere 2023, 14, 760. [Google Scholar] [CrossRef]
- Peltier, R.E.; Castell, N.; Clements, A.L.; Dye, T.; Hüglin, C.; Kroll, J.H.; Lung, S.C.C.; Ning, Z.; Parsons, M.; Penza, M.; et al. An Update on Low-Cost Sensors for the Measurement of Atmospheric Composition, December 2020; WMO: Geneva, Switzerland, 2021. [Google Scholar]
- Ahn, K.H.; Lee, H.; Lee, H.D.; Kim, S.C. Extensive evaluation and classification of low-cost dust sensors in laboratory using a newly developed test method. Indoor Air 2020, 30, 137–146. [Google Scholar] [CrossRef] [PubMed]
- Raysoni, A.U.; Pinakana, S.D.; Mendez, E.; Wladyka, D.; Sepielak, K.; Temby, O. A Review of Literature on the Usage of Low-Cost Sensors to Measure Particulate Matter. Earth 2023, 4, 168–186. [Google Scholar] [CrossRef]
- Dhall, S.; Mehta, B.; Tyagi, A.; Sood, K. A review on environmental gas sensors: Materials and technologies. Sensors Int. 2021, 2, 100116. [Google Scholar] [CrossRef]
- Li, J.; Biswas, P. Calibration and applications of low-cost particle sensors: A review of recent advances. In Aerosols; De Gruyter: Berlin, Germany, 2022; pp. 91–114. [Google Scholar] [CrossRef]
- Liang, L. Calibrating low-cost sensors for ambient air monitoring: Techniques, trends, and challenges. Environ. Res. 2021, 197, 111163. [Google Scholar] [CrossRef]
- Liang, L.; Daniels, J. What Influences Low-cost Sensor Data Calibration?—A Systematic Assessment of Algorithms, Duration, and Predictor Selection. Aerosol Air Qual. Res. 2022, 22, 220076. [Google Scholar] [CrossRef]
- Wiseair Site. Available online: https://wiseair.vision/ (accessed on 20 September 2023).
- Turin Air Quality Monitoring Station. Available online: http://www.cittametropolitana.torino.it/cms/ambiente/qualita-aria/rete-monitoraggio/stazioni-monitoraggio (accessed on 13 September 2023).
- Turin Air Quality Monitoring Station Characteristics. Available online: http://www.sistemapiemonte.it/ambiente/srqa/stazioni/pdf/226.pdf (accessed on 13 September 2023).
- Sensirion PM2.5 Sensor for HVAC and Air Quality Applications SPS30. Available online: https://sensirion.com/products/catalog/SPS30/ (accessed on 13 September 2023).
- Kuula, J.; Mäkelä, T.; Aurela, M.; Teinilä, K.; Varjonen, S.; González, Ó.; Timonen, H. Laboratory evaluation of particle-size selectivity of optical low-cost particulate matter sensors. Atmos. Meas. Tech. 2020, 13, 2413–2423. [Google Scholar] [CrossRef]
- Giorgio, N. Relation between Cloud Cover and Relative Humidity. B.S. Thesis, Universiteit Utrecht, Utrecht, The Netherlands, 2017. [Google Scholar]
- Hagan, D.H.; Kroll, J.H. Assessing the accuracy of low-cost optical particle sensors using a physics-based approach. Atmos. Meas. Tech. 2020, 13, 6343–6355. [Google Scholar] [CrossRef]
- Alfano, B.; Barretta, L.; Giudice, A.D.; De Vito, S.; Francia, G.D.; Esposito, E.; Formisano, F.; Massera, E.; Miglietta, M.L.; Polichetti, T. A review of low-cost particulate matter sensors from the developers’ perspectives. Sensors 2020, 20, 6819. [Google Scholar] [CrossRef] [PubMed]
- Giordano, M.R.; Malings, C.; Pandis, S.N.; Presto, A.A.; McNeill, V.; Westervelt, D.M.; Beekmann, M.; Subramanian, R. From low-cost sensors to high-quality data: A summary of challenges and best practices for effectively calibrating low-cost particulate matter mass sensors. J. Aerosol Sci. 2021, 158, 105833. [Google Scholar] [CrossRef]
- Malings, C.; Tanzer, R.; Hauryliuk, A.; Saha, P.K.; Robinson, A.L.; Presto, A.A.; Subramanian, R. Fine particle mass monitoring with low-cost sensors: Corrections and long-term performance evaluation. Aerosol Sci. Technol. 2020, 54, 160–174. [Google Scholar] [CrossRef]
- Jayaratne, R.; Liu, X.; Ahn, K.H.; Asumadu-Sakyi, A.; Fisher, G.; Gao, J.; Mabon, A.; Mazaheri, M.; Mullins, B.; Nyaku, M.; et al. Low-cost PM2.5 sensors: An assessment of their suitability for various applications. Aerosol Air Qual. Res. 2020, 20, 520–532. [Google Scholar] [CrossRef]
- Ueda, S.; Osada, K.; Yamagami, M.; Ikemori, F.; Hisatsune, K. Estimating mass concentration using a low-cost portable particle counter based on full-year observations: Issues to obtain reliable atmospheric PM2.5 data. Asian J. Atmos. Environ. 2020, 14, 155–169. [Google Scholar] [CrossRef]
- Gao, R.; Telg, H.; McLaughlin, R.; Ciciora, S.; Watts, L.; Richardson, M.; Schwarz, J.; Perring, A.; Thornberry, T.; Rollins, A.; et al. A light-weight, high-sensitivity particle spectrometer for PM2.5 aerosol measurements. Aerosol Sci. Technol. 2016, 50, 88–99. [Google Scholar] [CrossRef]
- SDS011 Datasheet. Available online: https://cdn-reichelt.de/documents/datenblatt/X200/SDS011-DATASHEET.pdf (accessed on 20 September 2023).
- SPS30 Datasheet. Available online: https://sensirion.com/media/documents/8600FF88/616542B5/Sensirion_PM_Sensors_Datasheet_SPS30.pdf (accessed on 20 September 2023).
- HPMA115C0 Datasheet. Available online: https://media.distrelec.com/Web/Downloads/_t/ds/HPMA115C0-003_eng_tds.pdf (accessed on 20 September 2023).
- OPC-N2 Datasheet. Available online: https://parmex.com.mx/show_catalogue_pdf/142183/1 (accessed on 20 September 2023).
- 10000 Ambient Air Monitor Datasheet. Available online: https://particlesplus.com/wp-content/datasheets/10000/Particles%20Plus%2010000%20Datasheet.pdf (accessed on 20 September 2023).
- 12000 Ambient Air Monitor Datasheet. Available online: https://particlesplus.com/wp-content/datasheets/12000/Particles%20Plus%2012000%20Datasheet.pdf (accessed on 20 September 2023).
- AM520 Datasheet. Available online: https://tsi.com/getmedia/3b6a2fdc-b348-466f-b6f6-b2014be9a0d5/SidePak_AM520-AM520i_A4_5001738_RevC_Web?ext=.pdf (accessed on 20 September 2023).
- AQMESH Technical Documentation. Available online: https://d3pcsg2wjq9izr.cloudfront.net/files/84570/download/667711/10reasonswhyyoushouldchooseAQMesh.pdf (accessed on 20 September 2023).
- Jayaratne, R.; Liu, X.; Thai, P.; Dunbabin, M.; Morawska, L. The influence of humidity on the performance of a low-cost air particle mass sensor and the effect of atmospheric fog. Atmos. Meas. Tech. 2018, 11, 4883–4890. [Google Scholar] [CrossRef]
- Wang, P.; Xu, F.; Gui, H.; Wang, H.; Chen, D.R. Effect of relative humidity on the performance of five cost-effective PM sensors. Aerosol Sci. Technol. 2021, 55, 957–974. [Google Scholar] [CrossRef]
- Won, W.S.; Oh, R.; Lee, W.; Ku, S.; Su, P.C.; Yoon, Y.J. Hygroscopic properties of particulate matter and effects of their interactions with weather on visibility. Sci. Rep. 2021, 11, 16401. [Google Scholar] [CrossRef]
- Carslaw, K.S. Chapter 5—Aerosol processes. In Aerosols and Climate; Carslaw, K.S., Ed.; Elsevier: Amsterdam, The Netherlands, 2022; pp. 135–185. [Google Scholar] [CrossRef]
- Chacón-Mateos, M.; Laquai, B.; Vogt, U.; Stubenrauch, C. Evaluation of a low-cost dryer for a low-cost optical particle counter. Atmos. Meas. Tech. 2022, 15, 7395–7410. [Google Scholar] [CrossRef]
- Samad, A.; Melchor Mimiaga, F.E.; Laquai, B.; Vogt, U. Investigating a low-cost dryer designed for low-cost PM sensors measuring ambient air quality. Sensors 2021, 21, 804. [Google Scholar] [CrossRef]
- Kim, H.; Kim, J.; Roh, S. Effects of Gas and Steam Humidity on Particulate Matter Measurements Obtained Using Light-Scattering Sensors. Sensors 2023, 23, 6199. [Google Scholar] [CrossRef] [PubMed]
- Samad, A.; Obando Nuñez, D.R.; Solis Castillo, G.C.; Laquai, B.; Vogt, U. Effect of relative humidity and air temperature on the results obtained from low-cost gas sensors for ambient air quality measurements. Sensors 2020, 20, 5175. [Google Scholar] [CrossRef]
- DeSouza, P.; Kahn, R.; Stockman, T.; Obermann, W.; Crawford, B.; Wang, A.; Crooks, J.; Li, J.; Kinney, P. Calibrating networks of low-cost air quality sensors. Atmos. Meas. Tech. 2022, 15, 6309–6328. [Google Scholar] [CrossRef]
- Crilley, L.R.; Shaw, M.; Pound, R.; Kramer, L.J.; Price, R.; Young, S.; Lewis, A.C.; Pope, F.D. Evaluation of a low-cost optical particle counter (Alphasense OPC-N2) for ambient air monitoring. Atmos. Meas. Tech. 2018, 11, 709–720. [Google Scholar] [CrossRef]
- Casari, M.; Po, L. Mitigating the Impact of Humidity on Low-Cost PM Sensors. In Proceedings of the 3rd National Conference on Artificial Intelligence, Organized by CINI, Pisa, Italy, 29–31 May 2023; Volume 3486, pp. 599–604. [Google Scholar]
- Bulot, F.M.; Ossont, S.J.; Morris, A.K.; Basford, P.J.; Easton, N.H.; Mitchell, H.L.; Foster, G.L.; Cox, S.J.; Loxham, M. Characterisation and calibration of low-cost PM sensors at high temporal resolution to reference-grade performance. Heliyon 2023, 9, e15943. [Google Scholar] [CrossRef] [PubMed]
- Brattich, E.; Bracci, A.; Zappi, A.; Morozzi, P.; Di Sabatino, S.; Porcù, F.; Di Nicola, F.; Tositti, L. How to Get the Best from Low-Cost Particulate Matter Sensors: Guidelines and Practical Recommendations. Sensors 2020, 20, 3073. [Google Scholar] [CrossRef] [PubMed]
- Kosmopoulos, G.; Salamalikis, V.; Wilbert, S.; Zarzalejo, L.F.; Hanrieder, N.; Karatzas, S.; Kazantzidis, A. Investigating the Sensitivity of Low-Cost Sensors in Measuring Particle Number Concentrations across Diverse Atmospheric Conditions in Greece and Spain. Sensors 2023, 23, 6541. [Google Scholar] [CrossRef]
- Rollo, F.; Sudharsan, B.; Po, L.; Breslin, J.G. Air Quality Sensor Network Data Acquisition, Cleaning, Visualization, and Analytics: A Real-world IoT Use Case. In Proceedings of the UbiComp/ISWC ’21: 2021 ACM International Joint Conference on Pervasive and Ubiquitous Computing and 2021 ACM International Symposium on Wearable Computers, Virtual Event, 21–25 September 2021; Doryab, A., Lv, Q., Beigl, M., Eds.; ACM: New York, NY, USA, 2021; pp. 67–68. [Google Scholar] [CrossRef]
- Rollo, F.; Bachechi, C.; Po, L. Anomaly Detection and Repairing for Improving Air Quality Monitoring. Sensors 2023, 23, 640. [Google Scholar] [CrossRef]
- Bodor, Z.; Bodor, K.; Keresztesi, Á.; Szép, R. Major air pollutants seasonal variation analysis and long-range transport of PM 10 in an urban environment with specific climate condition in Transylvania (Romania). Environ. Sci. Pollut. Res. 2020, 27, 38181–38199. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Zhang, L.; Wang, Y.; Song, J.; Sun, H. Temporal and Spatial Trends in Particulate Matter and the Responses to Meteorological Conditions and Environmental Management in Xi’an, China. Atmosphere 2021, 12, 1112. [Google Scholar] [CrossRef]
- Dejchanchaiwong, R.; Tekasakul, P.; Saejio, A.; Limna, T.; Le, T.C.; Tsai, C.J.; Lin, G.Y.; Morris, J. Seasonal Field Calibration of Low-Cost PM2.5 Sensors in Different Locations with Different Sources in Thailand. Atmosphere 2023, 14, 496. [Google Scholar] [CrossRef]
- Nowack, P.; Konstantinovskiy, L.; Gardiner, H.; Cant, J. Machine learning calibration of low-cost NO2 and PM 10 sensors: Non-linear algorithms and their impact on site transferability. Atmos. Meas. Tech. 2021, 14, 5637–5655. [Google Scholar] [CrossRef]
- Martina Casari, L.P.; Zini, L. AirMLP—Source Code. 2023. Available online: https://zenodo.org/records/10044375 (accessed on 1 November 2023).
- Martina Casari, L.P.; Zini, L. AirMLP—Data. 2023. Available online: https://zenodo.org/records/10037781 (accessed on 1 November 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Conditions | Value | Units |
|---|---|---|---|
| Mass concentration range | - | 0 to 1000 | g/m |
| Mass concentration size range | PM 2.5 | 0.3 to 2.5 | m |
| Mass concentration precision for PM 2.5 | 0 to 100 g/m | g/m | |
| 100 to 1000 g/m | % m.v. * | ||
| Maximum long-term mass concentration precision limit drift | 0 to 100 g/m | g/m/year | |
| 100 to 1000 g/m | % m.v./year | ||
| Number concentration range | - | 0 to 3000 | #/cm |
| Number concentration size range | PM 2.5 | 0.3 to 2.5 | m |
| Number concentration precision for PM 2.5 | 0 to 1000 #/cm | #/cm | |
| 1000 to 3000 #/cm | % m.v. | ||
| Maximum long-term number concentration precision limit drift | 0 to 1000 #/cm | #/cm/year | |
| 1000 to 3000 #/cm | % m.v./year | ||
| Lifetime | 24 h/day operating | >10 | years |
| Temperature range | - | 10 to 40 | C |
| Relative humidity | - | 20 to 80 | % |
| Model | Make | Technology | PM Detected | Output | Approximate Cost (USD) |
|---|---|---|---|---|---|
| SDS011 [38] | Nova | Laser scattering OPC | PM 2.5, PM 10 | Particle mass concentration | 30 |
| SPS30 [39] | Sensirion | Laser scattering OPC | PM 1, PM 2.5, PM 4, PM 10 | Particle count and mass concentration | 50 |
| HPMA115C0 | Honeywell | Laser-based light scattering | PM 1, PM 2.5, PM 4, PM 10 | Particle mass concentration | 80 |
| HPMA115S0 [40] | PM 2.5, PM 10 | ||||
| OPC-N2/OPC-N3 [41] | Alphasense | Laser scattering OPC | PM 1, PM 2.5, PM 10 | Particle mass concentration | 500 |
| Model | Make | Air Conditioner or Built-in Heater | Technology | PM Detected | Output |
|---|---|---|---|---|---|
| Arianna | Wiseair [25] | No | Laser scattering OPC | PM 1, PM 2.5, PM 4, PM 10 | Fine particle counts and mass concentration |
| 10,000/12,000 [42,43] | Particle Plus | Yes (humidity and condensation control) | Optical light scattering | PM 0.3, PM 0.5, PM 1, PM 2.5, PM 5, PM 10 | Fine particle counts and mass concentration |
| AM520 [44] | SidePak | Yes (Inlet conditioner) | Light-scattering laser photometers | PM 0.8, PM 1, PM 2.5, PM 4, PM 10 | Particle mass concentration |
| AQMesh [45] | Environmental Instruments | Yes | Light-scattering OPC | PM 1, PM 2.5, PM 10 | Particle mass concentration |
| Model | Neurons | 64:6 | 256:6 | 512:6 | 64:12 | 256:12 | 512:12 | 64:20 | 256:20 | 512:20 |
|---|---|---|---|---|---|---|---|---|---|---|
| AirMLP6 | 300 | 0.801 | 0.772 | 0.752 | 0.827 | 0.793 | 0.758 | 0.859 | 0.812 | 0.788 |
| 500 | 0.833 | 0.801 | 0.769 | 0.863 | 0.830 | 0.808 | 0.884 | 0.841 | 0.821 | |
| 700 | 0.862 | 0.821 | 0.780 | 0.878 | 0.853 | 0.819 | 0.901 | 0.858 | 0.849 | |
| AirMLP7 | 300 | 0.811 | 0.780 | 0.760 | 0.847 | 0.805 | 0.778 | 0.865 | 0.823 | 0.801 |
| 500 | 0.844 | 0.814 | 0.770 | 0.883 | 0.838 | 0.815 | 0.888 | 0.859 | 0.826 | |
| 700 | 0.857 | 0.826 | 0.813 | 0.886 | 0.855 | 0.841 | 0.904 | 0.871 | 0.848 | |
| AirMLP8 | 300 | 0.801 | 0.775 | 0.751 | 0.848 | 0.805 | 0.773 | 0.878 | 0.830 | 0.812 |
| 500 | 0.840 | 0.807 | 0.792 | 0.884 | 0.848 | 0.809 | 0.901 | 0.862 | 0.842 | |
| 700 | 0.885 | 0.848 | 0.807 | 0.896 | 0.876 | 0.826 | 0.905 | 0.883 | 0.859 | |
| AirMLP7h | 300 | 0.797 | 0.768 | 0.738 | 0.836 | 0.876 | 0.826 | 0.856 | 0.825 | 0.805 |
| 500 | 0.833 | 0.789 | 0.778 | 0.872 | 0.833 | 0.808 | 0.887 | 0.853 | 0.812 | |
| 700 | 0.848 | 0.823 | 0.796 | 0.883 | 0.855 | 0.829 | 0.910 | 0.860 | 0.844 | |
| AirMLP8h | 300 | 0.808 | 0.760 | 0.769 | 0.853 | 0.819 | 0.785 | 0.876 | 0.836 | 0.807 |
| 500 | 0.851 | 0.822 | 0.803 | 0.873 | 0.836 | 0.808 | 0.887 | 0.859 | 0.841 | |
| 700 | 0.867 | 0.832 | 0.810 | 0.887 | 0.867 | 0.840 | 0.916 | 0.867 | 0.848 |
| Model | Neurons | R2 |
|---|---|---|
| AirMLP6 | 900 | 0.901 |
| 1100 | 0.912 | |
| 1500 | 0.926 | |
| AirMLP7 | 900 | 0.919 |
| 1100 | 0.926 | |
| 1500 | 0.932 | |
| AirMLP8 | 900 | 0.917 |
| 1100 | 0.928 | |
| 1500 | 0.925 | |
| AirMLP7h | 900 | 0.915 |
| 1100 | 0.921 | |
| 1500 | 0.927 | |
| AirMLP8h | 900 | 0.917 |
| 1100 | 0.921 | |
| 1500 | 0.923 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casari, M.; Po, L.; Zini, L. AirMLP: A Multilayer Perceptron Neural Network for Temporal Correction of PM2.5 Values in Turin. Sensors 2023, 23, 9446. https://doi.org/10.3390/s23239446
Casari M, Po L, Zini L. AirMLP: A Multilayer Perceptron Neural Network for Temporal Correction of PM2.5 Values in Turin. Sensors. 2023; 23(23):9446. https://doi.org/10.3390/s23239446
Chicago/Turabian StyleCasari, Martina, Laura Po, and Leonardo Zini. 2023. "AirMLP: A Multilayer Perceptron Neural Network for Temporal Correction of PM2.5 Values in Turin" Sensors 23, no. 23: 9446. https://doi.org/10.3390/s23239446
APA StyleCasari, M., Po, L., & Zini, L. (2023). AirMLP: A Multilayer Perceptron Neural Network for Temporal Correction of PM2.5 Values in Turin. Sensors, 23(23), 9446. https://doi.org/10.3390/s23239446