
Expand and Shrink: Federated Learning with Unlabeled Data Using Clustering




Abstract
:1. Introduction
- We proposed a data labeling method at the client device for supervised federated learning. The proposed labeling adopts pre-initialized centroid clustering methods to infer the class label of the unlabeled sample at the client device.
- We proposed an aggregation-independent labeling method that complements the existing supervised federated learning architecture, so no further changes are required in the existing communication and aggregation methods.
- We proposed a low cost in terms of the time and extensible labeling approach, i.e., a new sample can be labeled with reduced cost due to newly labeled samples.
- We performed extensive experiments to validate the proposed labeling method. In the federated learning setup, the proposed method provides equivalent performance to the human-labeled dataset in terms of accuracy. It achieves a similar level of global accuracy compared to the existing works while requiring much fewer truth labels.
2. Related Work
3. Expand and Shrink: Federated Learning with Unlabeled Data Using Clustering
3.1. Problem Definition
3.2. System Model
- Model (M): Supervised learning model selected by the parameter server to train using federated learning, for example, CNN, LSTM, etc.
- Validation dataset (V): A small proportion of the labeled datasets are provided to each client for the shrink phase of labeling.
- Clustering method (C): The client can choose a set of clustering methods. We are currently using only K-mean clustering.
3.3. Data Labeling with Expand and Shrink
- Step 1—Join:
- A device joins the federation and obtains policy vector from the parameter server.
- Step 2—Expand:
- Each client applies clustering to its unlabeled data and uses the inertia versus the number of clusters to find the value of K, where K is the total number of clusters that give the best inertia value. The inertia represents the sum of squared distances between each data point and its assigned centroid. Any clustering algorithms can be used, as in the proposed work was evaluated using K-means. Thus, the objective function of the K-means clustering is defined as a minimization problem, and it is presented in Equation (1):where represents the sample of client i, is the set of clients belonging to cluster k, and is the centroid of cluster k.
- Step 3—Shrink:
- The client with K number of clusters starts to shrink by using the distance between the clusters and the sample in validation dataset V shared by the parameter server. The distance calculation will create using Equation (3), which is the score value matrix, where K is the total number of clusters in the expansion step and G is the total number of classes for the supervised learning task. In , each row will have the distance score s of a cluster against all the classes, i.e., . The distance matrix is constructed asEach distance score can be calculated using the Euclidean distance, computed aswhere c and v are vectors for the centroid and sample in the validation set for the respective clusters and class labels. So, and represent the corresponding elements in the vectors c and v at the same index i.For merging clusters, we need to assign one or zero based on distance. The cell with the minimum value in each row will be marked as 1, indicating the cluster close enough to a particular class. In summary, each row of will be converted to aswhere represents an element of the distance matrix on the row cluster index and the column class index.Now, for merging cluster(s), each column vector will be scanned for 1, and the respective cluster k will merge asThen, each member of the respective cluster will be merged as one larger cluster, and it will be labeled as per the respective column class asMerging clusters and labeling with respective class labels will create labeled data of each client i.
- Step 4—Ready State:
- The client can set its status to ready after completing the data labeling so the server can use this information while selecting the client for training.
| Algorithm 1 Data labeling at each client using Expand and Shrink. |
| Require: U: Set of unlabeled data, V: validation dataset |
| Ensure: D () for |
| {Expand: Create K clusters using a clustering algorithm} |
| 1: Expand(U) using Equation (1) |
| 2: using Equations (2) and (3) |
| {Find the minimum score in each row, mark it with 1 and the others with 0} |
| 3: ← |
| {Shrink: Merge clusters} |
| 4: |
| 5: |
| 6: return |
- Step 0—Data Labeling:
- A new client joins the federation and obtains from the parameter server and labels its unlabeled data independently and free from the training round. After labeling, the client changes its status to ready.
- Step 1—Initialization:
- The parameter server selects s number of clients from for federated training, initializes the global model M and shares it along with the validation dataset, i.e., V with each selected node in . The V is a set of labeled pairs of .
- Step 2—Local Training:
- Each client applies Algorithm 1 on its local unlabeled samples U (explained in the previous section). Each node trains the model (M) on its self-labeled dataset and calculates the gradient difference using Stochastic Gradient Descent (SGD).
- Step 3—Client Update Sharing:
- Each node shares the calculated gradient difference () with the parameter server. The gradient is calculated by applying local training on using .
- Step 4—Global Aggregation:
- For each global training round, the server collects and aggregates updates from each participating client () and updates the previous model ().
- Step 5—Updated Global Model Sharing:
- The final updated global model is shared with previously participating clients, and if the updated model is shared with new participants, then this step is similar to step 1. So, this step is optional and depends upon the training policy.
| Algorithm 2 Federated learning using Expand and Shrink on unlabeled data. |
Require: : Unlabeled Data, N: Number of clients, E: Number of communication rounds
|
4. Experiments and Result
4.1. Experimental Setup
4.2. Dataset Preparation
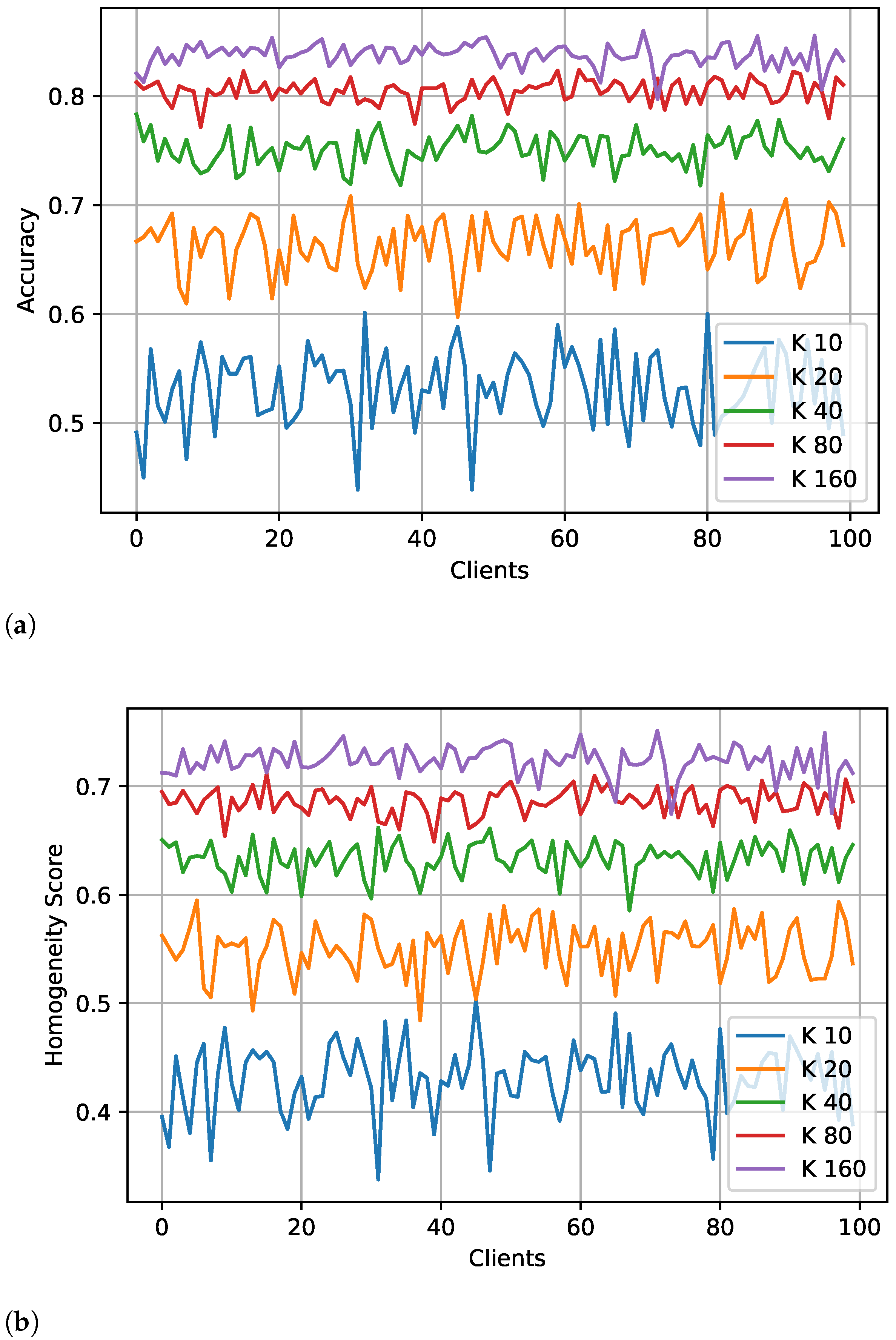
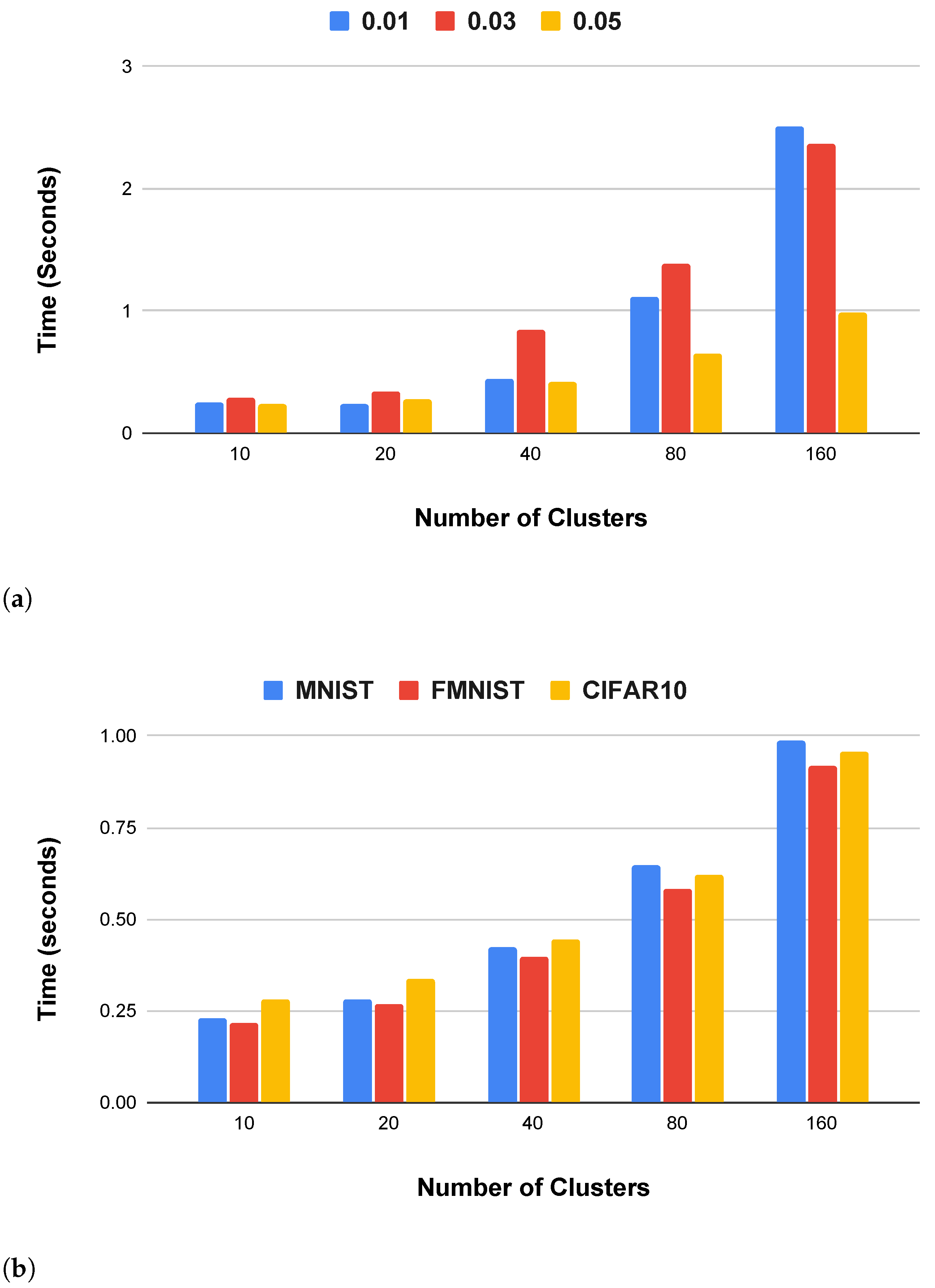
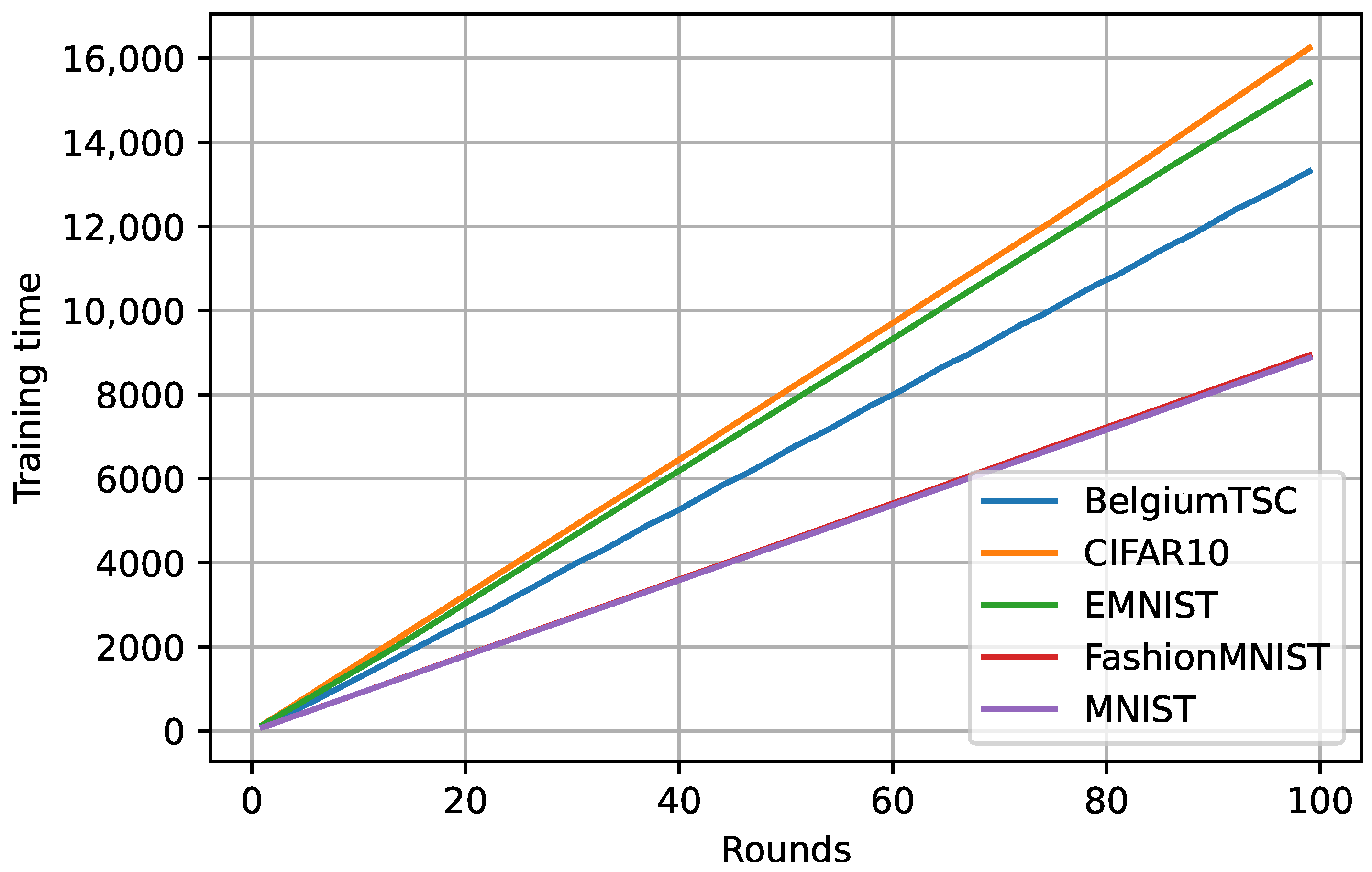
4.3. Labeling and Training Time
4.4. Expand and Shrink: Centralized Learning
4.5. Expand and Shrink: Federated Learning
4.6. Comparison with Existing Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| FL | Federated Learning |
| FSSL | Federated semi-supervised Learning |
| HITL | Human in the Loop |
| IoT | Internet of Things |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| NN | Neural Network |
| non-IID | Not Independent and Identically Distributed |
| SGD | Stochastic Gradient Descent |
| SSFL | Semi-Supervised Federated Learning |
| SSL | Self-Supervised Learning |
| TFF | TensorFlow Federated |
References
- Kaissis, G.A.; Makowski, M.R.; Rückert, D.; Braren, R.F. Secure, privacy-preserving and federated machine learning in medical imaging. Nat. Mach. Intell. 2020, 2, 305–311. [Google Scholar] [CrossRef]
- Perino, D.; Katevas, K.; Lutu, A.; Marin, E.; Kourtellis, N. Privacy-preserving AI for future networks. Commun. ACM 2022, 65, 52–53. [Google Scholar] [CrossRef]
- Timan, T.; Mann, Z. Data Protection in the Era of Artificial Intelligence: Trends, Existing Solutions and Recommendations for Privacy-Preserving Technologies. In The Elements of Big Data Value; Springer: Cham, Switzerland, 2021; pp. 153–175. [Google Scholar]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1310–1321. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics—PMLR, 2017, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Khan, L.U.; Saad, W.; Han, Z.; Hossain, E.; Hong, C.S. Federated learning for internet of things: Recent advances, taxonomy, and open challenges. IEEE Commun. Surv. Tutorials 2021, 23, 1759–1799. [Google Scholar] [CrossRef]
- Guo, Y.; Zhao, Z.; He, K.; Lai, S.; Xia, J.; Fan, L. Efficient and flexible management for industrial internet of things: A federated learning approach. Comput. Netw. 2021, 192, 108122. [Google Scholar] [CrossRef]
- Rahman, S.A.; Tout, H.; Talhi, C.; Mourad, A. Internet of things intrusion detection: Centralized, on-device, or federated learning? IEEE Netw. 2020, 34, 310–317. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, J.; Yang, M.; Wang, T.; Wang, N.; Lyu, L.; Niyato, D.; Lam, K.Y. Local differential privacy-based federated learning for internet of things. IEEE Internet Things J. 2020, 8, 8836–8853. [Google Scholar] [CrossRef]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Beutel, D.J.; Topal, T.; Mathur, A.; Qiu, X.; Parcollet, T.; Lane, N.D. Flower: A Friendly Federated Learning Research Framework. arXiv 2020, Preprint . arXiv:2007.14390. [Google Scholar]
- He, C.; Li, S.; So, J.; Zhang, M.; Wang, H.; Wang, X.; Vepakomma, P.; Singh, A.; Qiu, H.; Shen, L.; et al. FedML: A Research Library and Benchmark for Federated Machine Learning. arXiv 2020, Preprint . arXiv:2007.13518. [Google Scholar]
- Bonawitz, K.; Eichner, H.; Grieskamp, W. TensorFlow Federated: Machine Learning on Decentralized Data. 2020. Available online: https://www.tensorflow.org/federated (accessed on 1 June 2023).
- Ng, D.; Lan, X.; Yao, M.M.S.; Chan, W.P.; Feng, M. Federated learning: A collaborative effort to achieve better medical imaging models for individual sites that have small labelled datasets. Quant. Imaging Med. Surg. 2021, 11, 852. [Google Scholar] [CrossRef]
- Deng, L. The mnist database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- de Sa, V.R. Learning classification with unlabeled data. Adv. Neural Inf. Process. Syst. 1994, 112–119. [Google Scholar]
- Caron, M.; Bojanowski, P.; Joulin, A.; Douze, M. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 132–149. [Google Scholar]
- Jin, Y.; Wei, X.; Liu, Y.; Yang, Q. A Survey towards Federated Semi-Supervised Learning; The Hong Kong University of Science and Technology: Kowloon, China, 2020. [Google Scholar]
- Albaseer, A.; Ciftler, B.S.; Abdallah, M.; Al-Fuqaha, A. Exploiting unlabeled data in smart cities using federated edge learning. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1666–1671. [Google Scholar]
- Jeong, W.; Yoon, J.; Yang, E.; Hwang, S.J. Federated semi-supervised learning with inter-client consistency & disjoint learning. arXiv 2020, arXiv:2006.12097. [Google Scholar]
- Long, Z.; Wang, J.; Wang, Y.; Xiao, H.; Ma, F. FedCon: A Contrastive Framework for Federated Semi-Supervised Learning. arXiv 2021, arXiv:2109.04533. [Google Scholar]
- Gálvez, R.; Moonsamy, V.; Diaz, C. Less is More: A privacy-respecting Android malware classifier using federated learning. arXiv 2020, arXiv:2007.08319. [Google Scholar] [CrossRef]
- Pei, X.; Deng, X.; Tian, S.; Zhang, L.; Xue, K. A Knowledge Transfer-based Semi-Supervised Federated Learning for IoT Malware Detection. IEEE Trans. Dependable Secur. Comput. 2022, 20, 2127–2143. [Google Scholar] [CrossRef]
- Itahara, S.; Nishio, T.; Koda, Y.; Morikura, M.; Yamamoto, K. Distillation-based semi-supervised federated learning for communication-efficient collaborative training with non-iid private data. IEEE Trans. Mob. Comput. 2021, 22, 191–205. [Google Scholar] [CrossRef]
- Lu, N.; Wang, Z.; Li, X.; Niu, G.; Dou, Q.; Sugiyama, M. Federated Learning from Only Unlabeled Data with Class-Conditional-Sharing Clients. arXiv 2022, arXiv:2204.03304. [Google Scholar]
- Zhang, Z.; Yang, Y.; Yao, Z.; Yan, Y.; Gonzalez, J.E.; Ramchandran, K.; Mahoney, M.W. Improving semi-supervised federated learning by reducing the gradient diversity of models. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 1214–1225. [Google Scholar]
- Zhu, T.; Wang, X.; Ren, W.; Zhang, D.; Xiong, P. Migrating Federated Learning to Centralized Learning with the Leverage of Unlabeled Data. Knowl. Inf. Syst. 2023, 65, 3725–3752. [Google Scholar]
- He, C.; Yang, Z.; Mushtaq, E.; Lee, S.; Soltanolkotabi, M.; Avestimehr, S. Ssfl: Tackling label deficiency in federated learning via personalized self-supervision. arXiv 2021, arXiv:2110.02470. [Google Scholar]
- Yan, R.; Qu, L.; Wei, Q.; Huang, S.C.; Shen, L.; Rubin, D.; Xing, L.; Zhou, Y. Label-Efficient Self-Supervised Federated Learning for Tackling Data Heterogeneity in Medical Imaging. arXiv 2022, arXiv:2205.08576. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, K.; Li, Y.; Tian, Y.; Tedrake, R. Does Decentralized Learning with Non-IID Unlabeled Data Benefit from Self Supervision? arXiv 2022, arXiv:2210.10947. [Google Scholar]
- Bommel, J. Active Learning during Federated Learning for Object Detection. B.S. Thesis, University of Twente, Enschede, The Netherlands, 2021. [Google Scholar]
- Li, D.; Wang, J. Fedmd: Heterogenous federated learning via model distillation. arXiv 2019, arXiv:1910.03581. [Google Scholar]
- Guha, N.; Talwalkar, A.; Smith, V. One-shot federated learning. arXiv 2019, arXiv:1902.11175. [Google Scholar]
- Northcutt, C.G.; Athalye, A.; Mueller, J. Pervasive label errors in test sets destabilize machine learning benchmarks. arXiv 2021, arXiv:2103.14749. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. 2009. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 1 June 2023).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| C | Clustering method |
| Vector representation of centroid of cluster k | |
| Set of the local dataset of client i | |
| E | Total number of communication rounds |
| g | Index of the class label |
| G | Total number of classes |
| i | Client index |
| j | Round index |
| k | Cluster index |
| K | Total number of clusters () |
| Set of the local labeled dataset of client i | |
| M | Learning model |
| Centroid of cluster k | |
| N | Total number of clients () |
| number data samples of client i | |
| Policy set | |
| Distance matrix | |
| Normalized (1/0) distance matrix | |
| S | Total number of selected clients () |
| Set of clients belonging to cluster k | |
| Element of distance matrix on row r and column c | |
| Set of unlabeled dataset of client i | |
| V | Truth set |
| coordinate of validation sample | |
| Data sample of client i | |
| Set of class label |
| Ratio of Truth Label /Number of Clusters | 0.01 | 0.03 | 0.05 | 0.07 | 0.09 |
|---|---|---|---|---|---|
| 10 | 57 | 58 | 59 | 58 | 59 |
| 20 | 68 | 70 | 73 | 68 | 72 |
| 40 | 78 | 79 | 80 | 79 | 79 |
| 80 | 85 | 85 | 84 | 85 | 84 |
| 160 | 88 | 90 | 90 | 90 | 90 |
| Ratio of Truth Label | 0.01 | 0.03 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Number of Clusters /Number of Clients | 10 | 20 | 40 | 80 | 160 | 10 | 20 | 40 | 80 | 160 |
| 0.1 | 62 | 73 | 82 | 87 | 89 | 63 | 75 | 83 | 88 | 90 |
| 0.2 | 62 | 74 | 81 | 86 | 88 | 60 | 74 | 82 | 88 | 91 |
| 0.3 | 59 | 71 | 77 | 82 | 87 | 63 | 74 | 82 | 86 | 90 |
| 0.4 | 61 | 70 | 79 | 82 | 86 | 62 | 74 | 81 | 86 | 90 |
| 0.5 | 63 | 71 | 81 | 85 | 87 | 62 | 74 | 82 | 88 | 90 |
| L% | 0.01 | 0.03 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| NoC /C% | Dataset | 10 | 20 | 40 | 80 | 160 | 10 | 20 | 40 | 80 | 160 |
| 0.1 | MNIST | 0.6237 | 0.7384 | 0.8211 | 0.8719 | 0.8926 | 0.6387 | 0.7528 | 0.8335 | 0.883 | 0.9077 |
| FMNIST | 0.6194 | 0.6996 | 0.7222 | 0.7237 | 0.7617 | 0.6142 | 0.7001 | 0.7207 | 0.7461 | 0.779 | |
| CIFAR10 | 0.2319 | 0.242 | 0.2478 | 0.2547 | 0.2663 | 0.2343 | 0.2486 | 0.2601 | 0.2706 | 0.2841 | |
| 0.2 | MNIST | 0.6244 | 0.7499 | 0.8165 | 0.8644 | 0.8879 | 0.6047 | 0.7491 | 0.8253 | 0.884 | 0.911 |
| FMNIST | 0.6002 | 0.7017 | 0.7165 | 0.7443 | 0.756 | 0.612 | 0.6982 | 0.7208 | 0.7477 | 0.7614 | |
| CIFAR10 | 0.2283 | 0.2362 | 0.2535 | 0.2624 | 0.2662 | 0.2341 | 0.2551 | 0.2666 | 0.2674 | 0.2963 | |
| 0.3 | MNIST | 0.5942 | 0.7126 | 0.7767 | 0.8246 | 0.8699 | 0.6321 | 0.7472 | 0.8202 | 0.8691 | 0.9015 |
| FMNIST | 0.6164 | 0.6963 | 0.7198 | 0.7391 | 0.7622 | 0.606 | 0.695 | 0.7163 | 0.7394 | 0.7666 | |
| CIFAR10 | 0.2244 | 0.2403 | 0.2501 | 0.2521 | 0.2617 | 0.2332 | 0.2478 | 0.2609 | 0.2765 | 0.2927 | |
| 0.4 | MNIST | 0.6121 | 0.7066 | 0.7969 | 0.8269 | 0.8601 | 0.6271 | 0.7462 | 0.8116 | 0.8671 | 0.9003 |
| FMNIST | 0.6191 | 0.6958 | 0.715 | 0.7305 | 0.761 | 0.6042 | 0.6974 | 0.7212 | 0.7372 | 0.7775 | |
| CIFAR10 | 0.2304 | 0.2363 | 0.2421 | 0.2495 | 0.2662 | 0.2399 | 0.2549 | 0.2634 | 0.2741 | 0.2905 | |
| 0.5 | MNIST | 0.6397 | 0.7115 | 0.8175 | 0.8522 | 0.8788 | 0.6245 | 0.7423 | 0.8276 | 0.8817 | 0.9012 |
| FMNIST | 0.5977 | 0.6945 | 0.7184 | 0.7262 | 0.7635 | 0.5876 | 0.6981 | 0.7168 | 0.7381 | 0.7684 | |
| CIFAR10 | 0.2331 | 0.2296 | 0.2456 | 0.2525 | 0.2762 | 0.2385 | 0.2533 | 0.267 | 0.2731 | 0.2843 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, A.; Singh, A.K.; Ali, S.S.; Choi, B.J. Expand and Shrink: Federated Learning with Unlabeled Data Using Clustering. Sensors 2023, 23, 9404. https://doi.org/10.3390/s23239404
Kumar A, Singh AK, Ali SS, Choi BJ. Expand and Shrink: Federated Learning with Unlabeled Data Using Clustering. Sensors. 2023; 23(23):9404. https://doi.org/10.3390/s23239404
Chicago/Turabian StyleKumar, Ajit, Ankit Kumar Singh, Syed Saqib Ali, and Bong Jun Choi. 2023. "Expand and Shrink: Federated Learning with Unlabeled Data Using Clustering" Sensors 23, no. 23: 9404. https://doi.org/10.3390/s23239404
APA StyleKumar, A., Singh, A. K., Ali, S. S., & Choi, B. J. (2023). Expand and Shrink: Federated Learning with Unlabeled Data Using Clustering. Sensors, 23(23), 9404. https://doi.org/10.3390/s23239404