
Salient Arithmetic Data Extraction from Brain Activity via an Improved Deep Network
 and
and 
Abstract
:1. Introduction
- (i)
- Presentation of an effective deep network to acquire salient arithmetic content of visual stimulation from EEG recordings.
- (ii)
- Extraction of the arithmetic data is possible using the proposed architecture.
- (iii)
- Presentation of a convolutional deep network for extracting EEG features to recognize 10 patterns of EEG recordings corresponding to 10-digit categories.
- (iv)
- A 14-channel time sample of the EEG dataset is imposed directly as an input signal to the proposed CNN-GAN. The removal of feature vector extraction step results in decreasing the computational load.
- (v)
- It paves the way to connect three modalities: image data, visual salient data, and EEG signals.
2. Related Work
3. Materials and Methods
3.1. Database Settings
3.2. The Layers of Convolutional Neural Networks
3.3. Generative Adversarial Networks
3.4. Evaluation Metrics for Classification and Salient Image Extraction
- : the average of m; : the variance for m;
- : the average of n; : the variance for n;
- : the covariance between m and n;
- ; ;
- K: the variation range of the pixel-intensities ;
- and .
4. Proposed Convolutional Neural Network-Based Generative Adversarial Network
4.1. The Proposed Network Architecture
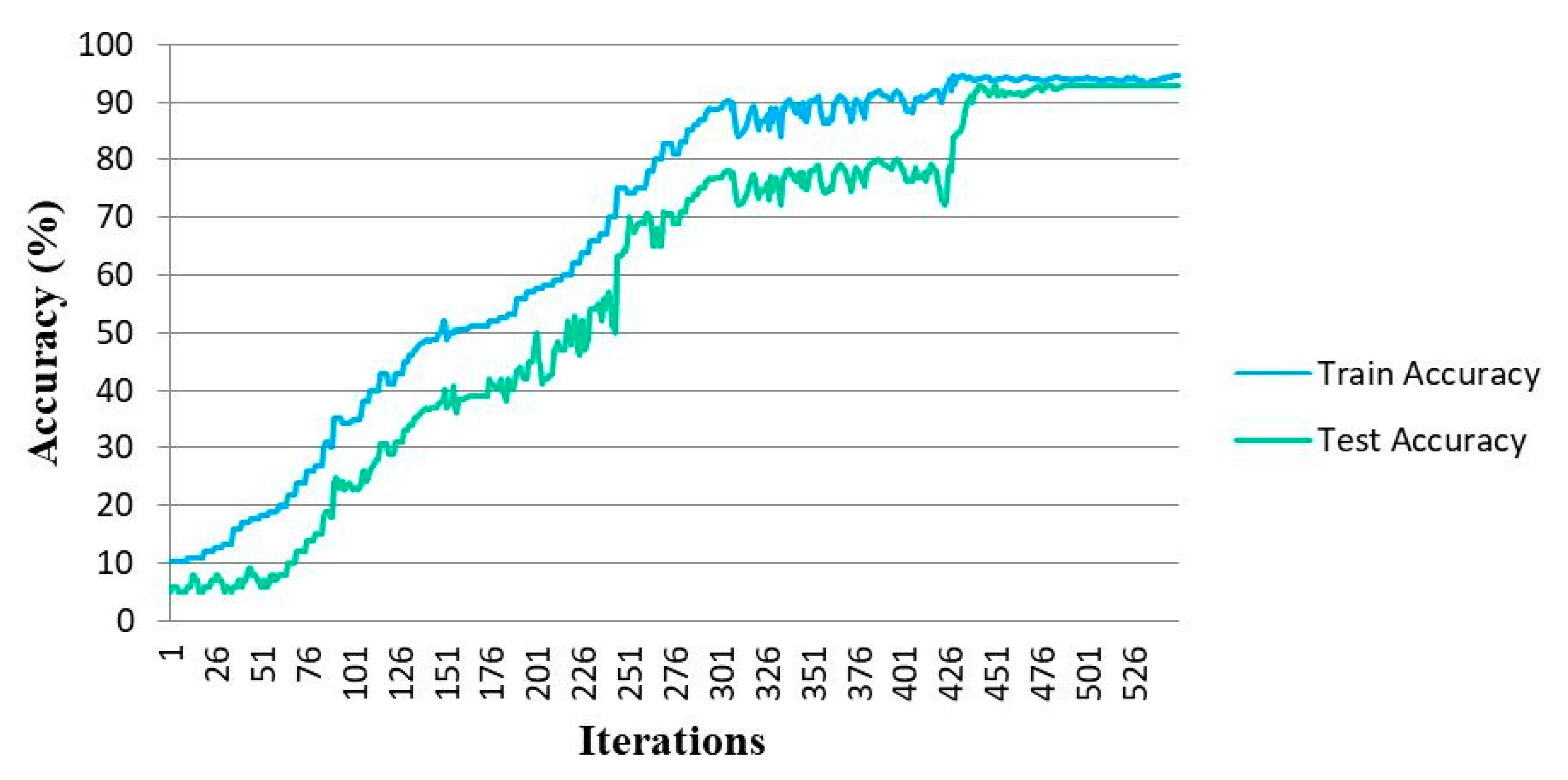
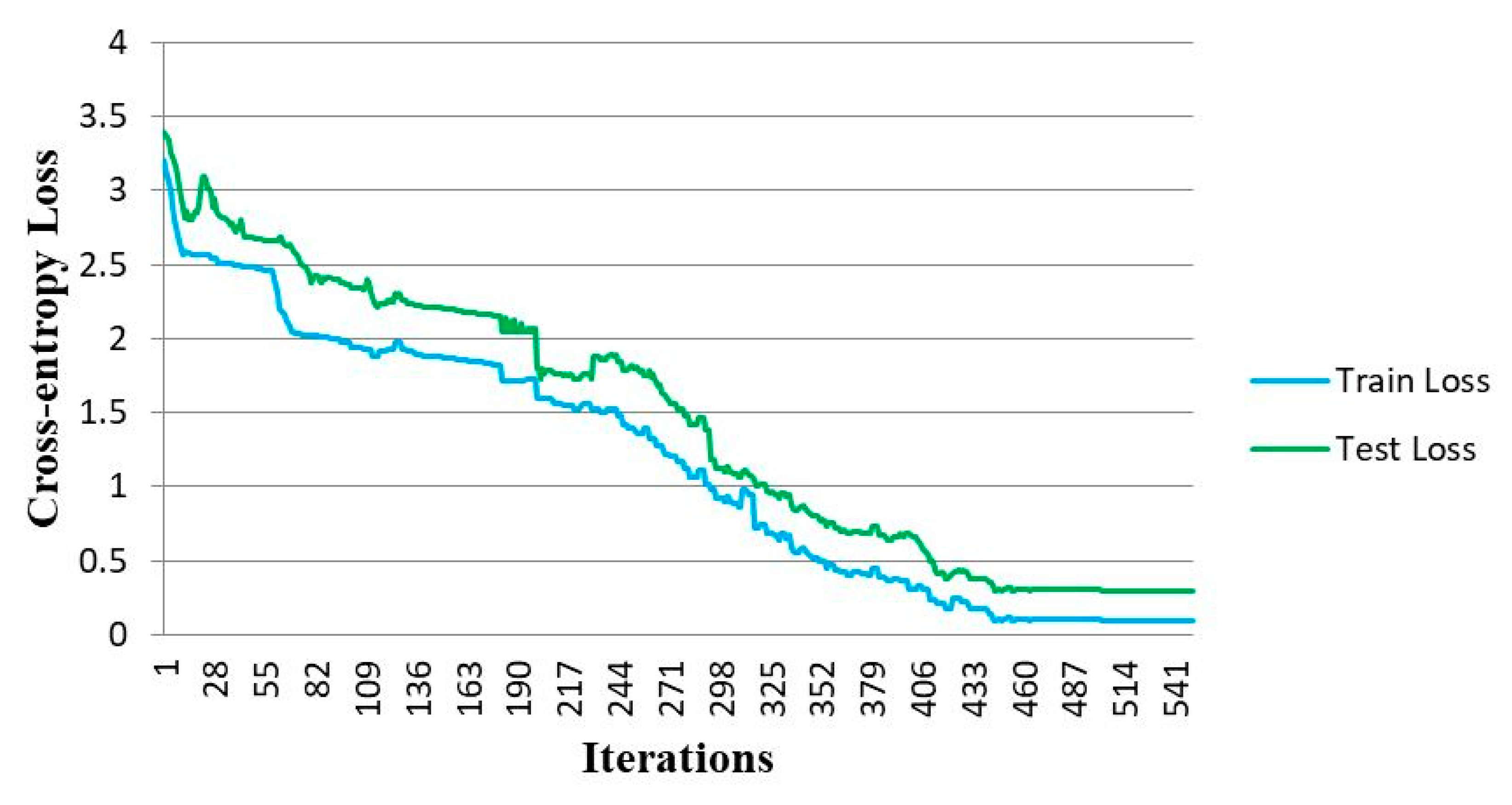
4.2. Training and Evaluation
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| BCI | Brain–Computer Interface |
| CNN | Convolutional Neural Network |
| EEG | Electroencephalogram |
| FN | False Negative |
| FP | False Positive |
| GAN | Generative Adversarial Network |
| GNN | Graph Neural Network |
| LSTM | Long Short-Term Memory |
| MNIST | Modified National Institute of Standards and Technology |
| SALIENCY | Saliency in Context |
| SGD | Standard Gradient Descent |
| SIM | Similarity |
| SSIM | Structural Similarity |
| SSVEP | Steady-State Visually Evoked Potential |
| SVM | Support Vector Machine |
| TN | True Negative |
| TP | True Positive |
| VGG | Visual Geometry Group |
References
- Wang, C.; Xiong, S.; Hu, X.; Yao, L.; Zhang, J. Combining features from ERP components in single-trial EEG for discriminating four-category visual objects. J. Neural Eng. 2012, 9, 056013. [Google Scholar] [CrossRef] [PubMed]
- Gilbert, C.D.; Sigman, M.; Crist, R.E. The neural basis of perceptual learning. Neuron 2001, 31, 681–697. [Google Scholar] [CrossRef] [PubMed]
- Shenoy, P.; Tan, D.S. Human-aided computing: Utilizing implicit human processing to classify images. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Toronto, ON, Canada, 26 April–1 May 2014; pp. 845–854. [Google Scholar]
- Lotte, F.; Bougrain, L.; Cichocki, A.; Clerc, M.; Congedo, M.; Rakotomamonjy, A.; Yger, F. A review of classification algorithms for EEG-based brain–computer interfaces: A 10 year update. J. Neural Eng. 2018, 15, 031005. [Google Scholar] [CrossRef]
- Namazifard, S.; Daru, R.R.; Tighe, K.; Subbarao, K.; Adnan, A. Method for Identification of Multiple Low-Voltage Signal Sources Transmitted Through a Conductive Medium. IEEE Access 2022, 10, 124154–124166. [Google Scholar] [CrossRef]
- Namazifard, S.; Subbarao, K. Multiple dipole source position and orientation estimation using non-invasive EEG-like signals. Sensors 2023, 23, 2855. [Google Scholar] [CrossRef]
- Sabahi, K.; Sheykhivand, S.; Mousavi, Z.; Rajabioun, M. Recognition COVID-19 cases using deep type-2 fuzzy neural networks based on chest X-ray image. Comput. Intell. Electr. Eng. 2023, 14, 75–92. [Google Scholar]
- Seyed Alizadeh, S.M.; Bagherzadeh, A.; Bahmani, S.; Nikzad, A.; Aminzadehsarikhanbeglou, E.; Tatyana Yu, S. Retrograde gas condensate reservoirs: Reliable estimation of dew point pressure by the hybrid neuro-fuzzy connectionist paradigm. J. Energy Resour. Technol. 2022, 144, 063007. [Google Scholar] [CrossRef]
- Baradaran, F.; Farzan, A.; Danishvar, S.; Sheykhivand, S. Customized 2D CNN Model for the Automatic Emotion Recognition Based on EEG Signals. Electronics 2023, 12, 2232. [Google Scholar] [CrossRef]
- Milani, O.H.; Nguyen, T.; Parekh, A.; Cetin, A.E.; Prasad, B. 0537 Incident Hypertension Prediction in Obstructive Sleep Apnea using Machine Learning. Sleep 2023, 46 (Suppl. S1), A236–A237. [Google Scholar] [CrossRef]
- Woodbright, M.; Verma, B.; Haidar, A. Autonomous deep feature extraction based method for epileptic EEG brain seizure classification. Neurocomputing 2021, 444, 30–37. [Google Scholar] [CrossRef]
- Ak, A.; Topuz, V.; Midi, I. Motor imagery EEG signal classification using image processing technique over GoogLeNet deep learning algorithm for controlling the robot manipulator. Biomed. Signal Process. Control 2022, 72, 103295. [Google Scholar] [CrossRef]
- Kwak, N.-S.; Müller, K.-R.; Lee, S.-W. A convolutional neural network for steady state visual evoked potential classification under ambulatory environment. PLoS ONE 2017, 12, e0172578. [Google Scholar] [CrossRef] [PubMed]
- Spampinato, C.; Palazzo, S.; Kavasidis, I.; Giordano, D.; Souly, N.; Shah, M. Deep learning human mind for automated visual classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6809–6817. [Google Scholar]
- Fares, A.; Zhong, S.-h.; Jiang, J. EEG-based image classification via a region-level stacked bi-directional deep learning framework. BMC Med. Inform. Decis. Mak. 2019, 19, 1–11. [Google Scholar] [CrossRef]
- Cudlenco, N.; Popescu, N.; Leordeanu, M. Reading into the mind’s eye: Boosting automatic visual recognition with EEG signals. Neurocomputing 2020, 386, 281–292. [Google Scholar] [CrossRef]
- Mathur, N.; Gupta, A.; Jaswal, S.; Verma, R. Deep learning helps EEG signals predict different stages of visual processing in the human brain. Biomed. Signal Process. Control 2021, 70, 102996. [Google Scholar] [CrossRef]
- Ghosh, L.; Dewan, D.; Chowdhury, A.; Konar, A. Exploration of face-perceptual ability by EEG induced deep learning algorithm. Biomed. Signal Process. Control 2021, 66, 102368. [Google Scholar] [CrossRef]
- Ghebreab, S.; Scholte, S.; Lamme, V.; Smeulders, A. Rapid natural image identification based on EEG data and Global Scene Statistics. J. Vis. 2010, 10, 1394. [Google Scholar] [CrossRef]
- Kay, K.N.; Naselaris, T.; Prenger, R.J.; Gallant, J.L. Identifying natural images from human brain activity. Nature 2008, 452, 352–355. [Google Scholar] [CrossRef]
- Haynes, J.-D.; Rees, G. Predicting the orientation of invisible stimuli from activity in human primary visual cortex. Nat. Neurosci. 2005, 8, 686–691. [Google Scholar] [CrossRef]
- Thirion, B.; Duchesnay, E.; Hubbard, E.; Dubois, J.; Poline, J.-B.; Lebihan, D.; Dehaene, S. Inverse retinotopy: Inferring the visual content of images from brain activation patterns. Neuroimage 2006, 33, 1104–1116. [Google Scholar] [CrossRef]
- Brouwer, G.J.; Heeger, D.J. Decoding and reconstructing color from responses in human visual cortex. J. Neurosci. 2009, 29, 13992–14003. [Google Scholar] [CrossRef]
- Koch, C.; Ullman, S. Shifts in selective visual attention: Towards the underlying neural circuitry. In Matters of Intelligence; Springer: Berlin/Heidelberg, Germany, 1987; pp. 115–141. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Achanta, R.; Estrada, F.; Wils, P.; Süsstrunk, S. Salient region detection and segmentation. In Proceedings of the International Conference on Computer Vision Systems, Santorini, Greece, 12–15 May 2008; pp. 66–75. [Google Scholar]
- Ma, Y.-F.; Zhang, H.-J. Contrast-based image attention analysis by using fuzzy growing. In Proceedings of the eleventh ACM International Conference on Multimedia, Berkeley, CA, USA, 4–6 November 2003; pp. 374–381. [Google Scholar]
- Hu, Y.; Rajan, D.; Chia, L.-T. Robust subspace analysis for detecting visual attention regions in images. In Proceedings of the 13th annual ACM International Conference on Multimedia, Singapore, 28 November–30 December 2005; pp. 716–724. [Google Scholar]
- Rosin, P.L. A simple method for detecting salient regions. Pattern Recognit. 2009, 42, 2363–2371. [Google Scholar] [CrossRef]
- Valenti, R.; Sebe, N.; Gevers, T. Image saliency by isocentric curvedness and color. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2185–2192. [Google Scholar]
- Neisser, U. Cognitive psychology. Appleton-Century-Crofts. [aJRH] Newell, A. (1982) The knowledge level. Artif. Intell. 1967, 18, 82127. [Google Scholar]
- Zhang, J.; Sclaroff, S. Saliency detection: A boolean map approach. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 153–160. [Google Scholar]
- Zhao, J. Adaptive Q–S synchronization between coupled chaotic systems with stochastic perturbation and delay. Appl. Math. Model. 2012, 36, 3312–3319. [Google Scholar] [CrossRef]
- Xu, J.; Jiang, M.; Wang, S.; Kankanhalli, M.S.; Zhao, Q. Predicting human gaze beyond pixels. J. Vis. 2014, 14, 28. [Google Scholar] [CrossRef]
- Yang, J.; Yang, M.-H. Top-down visual saliency via joint CRF and dictionary learning. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 576–588. [Google Scholar] [CrossRef] [PubMed]
- He, S.; Lau, R.W.; Liu, W.; Huang, Z.; Yang, Q. Supercnn: A superpixelwise convolutional neural network for salient object detection. Int. J. Comput. Vis. 2015, 115, 330–344. [Google Scholar] [CrossRef]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Huang, X.; Shen, C.; Boix, X.; Zhao, Q. Salicon: Reducing the semantic gap in saliency prediction by adapting deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 262–270. [Google Scholar]
- Pan, J.; Sayrol, E.; Giro-i-Nieto, X.; McGuinness, K.; O’Connor, N.E. Shallow and deep convolutional networks for saliency prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 598–606. [Google Scholar]
- Van Humbeeck, N.; Meghanathan, R.N.; Wagemans, J.; van Leeuwen, C.; Nikolaev, A.R. Presaccadic EEG activity predicts visual saliency in free-viewing contour integration. Psychophysiology 2018, 55, e13267. [Google Scholar] [CrossRef]
- Liang, Z.; Hamada, Y.; Oba, S.; Ishii, S. Characterization of electroencephalography signals for estimating saliency features in videos. Neural Netw. 2018, 105, 52–64. [Google Scholar] [CrossRef]
- Tavakoli, H.R.; Laaksonen, J. Bottom-up fixation prediction using unsupervised hierarchical models. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 287–302. [Google Scholar]
- Mao, X.; Li, W.; He, H.; Xian, B.; Zeng, M.; Zhou, H.; Niu, L.; Chen, G. Object extraction in cluttered environments via a P300-based IFCE. Comput. Intell. Neurosci. 2017, 2017. [Google Scholar] [CrossRef]
- Palazzo, S.; Spampinato, C.; Kavasidis, I.; Giordano, D.; Schmidt, J.; Shah, M. Decoding brain representations by multimodal learning of neural activity and visual features. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3833–3849. [Google Scholar] [CrossRef]
- Khaleghi, N.; Rezaii, T.Y.; Beheshti, S.; Meshgini, S.; Sheykhivand, S.; Danishvar, S. Visual Saliency and Image Reconstruction from EEG Signals via an Effective Geometric Deep Network-Based Generative Adversarial Network. Electronics 2022, 11, 3637. [Google Scholar] [CrossRef]
- Khaleghi, N.; Rezaii, T.Y.; Beheshti, S.; Meshgini, S. Developing an efficient functional connectivity-based geometric deep network for automatic EEG-based visual decoding. Biomed. Signal Process. Control 2023, 80, 104221. [Google Scholar] [CrossRef]
- Vivancos, D.; Cuesta, F. MindBigData 2022 A Large Dataset of Brain Signals. arXiv 2022, arXiv:2212.14746. [Google Scholar]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of single neurones in the cat’s striate cortex. J. Physiol. 1959, 148, 574. [Google Scholar] [CrossRef]
- Fukushima, K. Self-organization of a neural network which gives position-invariant response. In Proceedings of the 6th International Joint Conference on Artificial Intelligence, Tokyo, Japan, 20–23 August 1979; Volume 1, pp. 291–293. [Google Scholar]
- LeCun, Y. The MNIST Database of Handwritten Digits. 1998. Available online: http://yann.lecun.com/exdb/mnist/ (accessed on 13 November 2023).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Bylinskii, Z.; Judd, T.; Oliva, A.; Torralba, A.; Durand, F. What do different evaluation metrics tell us about saliency models? IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 740–757. [Google Scholar] [CrossRef]
- Gu, K.; Zhai, G.; Yang, X.; Zhang, W.; Liu, M. Structural similarity weighting for image quality assessment. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
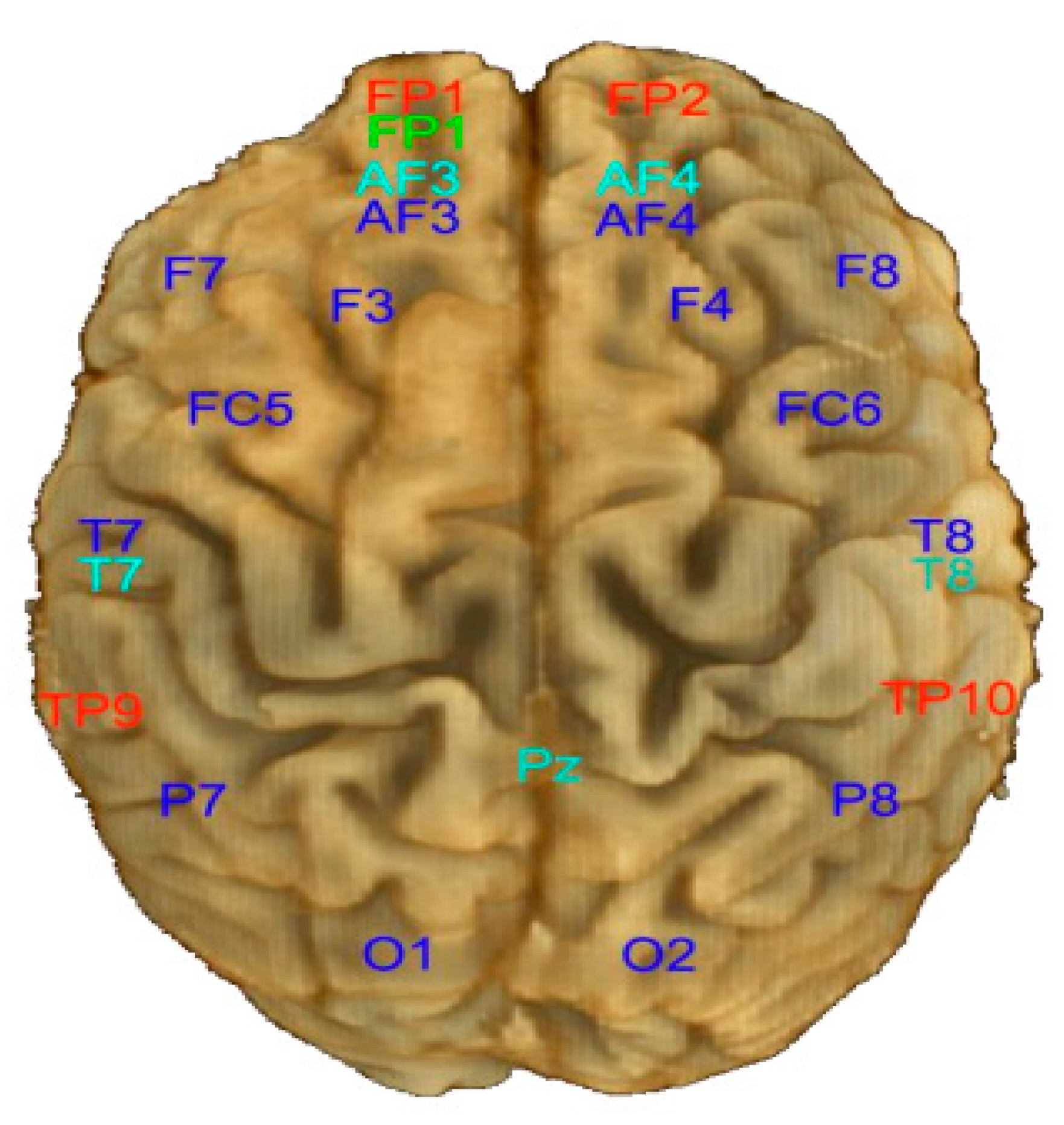
| Channel Name in Left Hemisphere | Channel Name in Right Hemisphere | Channel Full Name |
|---|---|---|
| O1 | O2 | Occipital |
| P7 | P8 | Parietal |
| T7 | T8 | Temporal |
| FC5 | FC6 | FrontoCentral |
| F7 | F8 | Frontal |
| F3 | F4 | Frontal |
| AF3 | AF4 | Between Prefrontal and Frontal |
| FP1 | FP2 | PreFrontal |
| Layer Number | Layer Name | Activation Function | Size of Kernel | Strides | Total Number of Weights | Output Size |
|---|---|---|---|---|---|---|
| 1 | Conv-layer | Leaky ReLU (alpha = 0.1) | 5 × 1 | 1 × 1 | 14 | (1, 14, 14, 250) |
| 2 | Normalization | (1, 14, 14, 250) | ||||
| 3 | Conv-layer | Leaky ReLU (alpha = 0.1) | 5 × 1 | 1 × 1 | 10 | (1, 10, 14, 250) |
| 4 | Normalization | (1, 10, 14, 250) | ||||
| 5 | Conv-layer | Leaky ReLU (alpha = 0.1) | 5 × 1 | 1 × 1 | 10 | (1, 10, 14, 250) |
| 6 | Normalization | (1, 10, 14, 250) | ||||
| 7 | Full-connected | (1, 3500) | ||||
| 8 | Full-connected | (1, 2500) |
| Layer Number | Layer Name | Activation Function | Size of Kernel | Number of Kernels | Strides | Total Number of Weights | Output of the Layer |
|---|---|---|---|---|---|---|---|
| 1 | Full-connected | 250,000 | (1, 100) | ||||
| 2 | Full-connected | Rectified LU (0.1) | 2,000,000 | (1, 20,000) | |||
| 3 | Reshape | 0 | (1, 50, 50, 8) | ||||
| 4 | Conv 2-D Transposed | Rectified LU (0.1) | 4 × 4 | 6 | 2 × 2 | 768 | (1, 100, 100, 6) |
| 5 | Conv 2-D Transposed | Rectified LU (0.1) | 4 × 4 | 6 | 3 × 3 | 768 | (1, 300, 300, 6) |
| 6 | Conv 2-D Transposed | Rectified LU (0.1) | 4 × 4 | 6 | 1 × 1 | 768 | (1, 300, 300, 6) |
| 7 | Conv 2-D Transposed | Rectified LU (0.1) | 4 × 4 | 6 | 1 × 1 | 768 | (1, 300, 300, 6) |
| 8 | Conv 2-D | Rectified LU (0.1) | 2 × 2 | 1 | 2 × 2 | 33 | (1, 299, 299, 1) |
| Layer | Layer Name | Activation Function | Size of Kernel | Kernels | Stride | Total Number of Weights | Output Weight |
|---|---|---|---|---|---|---|---|
| 1 | Conv 2-D | Rectified LU (0.1) | 4 | 2 | 2 | 32 | (None, 150, 150, 2) |
| 2 | Dropout (rate = 0.2) | 0 | (None, 150, 150, 2) | ||||
| 3 | Conv 2-D | Rectified LU (0.1) | 4 | 2 | 2 | 130 | (None, 75, 75, 2) |
| 4 | Dropout (rate = 0.2) | 0 | (None, 75, 75, 2) | ||||
| 5 | Conv 2-D | Rectified LU (0.1) | 4 | 2 | 2 | 130 | (None, 38, 38, 2) |
| 6 | Dropout (rate = 0.2) | 0 | (None, 38, 38, 2) | ||||
| 7 | Flattening | 0 | (1, 2888) | ||||
| 8 | Full-connected | 2889 | (1, 1) |
| Parameters | Search Scope | Optimal Value |
|---|---|---|
| Optimizer for CNN | SGD, Adam | SGD |
| Loss-function | Cross-Entropy, MSE | Cross-Entropy |
| Number of convolutional layers | 1, 2, 3, 4 | 3 |
| Learning-rate for CNN | 0.001, 0.01, 0.1 | 0.001 |
| Weight loss of SGD for CNN part | 5 × 10−5, 5 × 10−3 | 5 × 10−5 |
| Dropout rate of CNN | 0.2, 0.3 | 0.2 |
| Optimizer for GAN | SGD, Adam | Adam |
| Learning-rate for GAN | 0.01, 0.001, 0.0001, 0.00001 | 0.0001 |
| Number of 2D-conv transposed layers of generator | 4, 3, 2 | 4 |
| Number of 2D-conv layers of discriminator | 4, 3, 2 | 3 |
| Filters for the first conv-layer in CNN | 10, 14, 28 | 14 |
| Filters for the second conv-layer in CNN | 10, 14, 30 | 10 |
| Evaluation Metrics | CNN | CNN + LSTM | GNN [46] | LSTM [14] |
|---|---|---|---|---|
| Accuracy | 95.4% | 86.7% | 73% | 84.3% |
| Precision | 96.7% | 87.8% | 73.6% | 84.52% |
| F1-score | 96.7% | 87.8% | 73.6% | 84.52% |
| Cohen’s Kappa Coefficient | 96.7% | 87.8% | 73.6% | 84.52% |
| Layer Number | Layer Name | Activation Function | Ouput Size | Size of Kernel | Strides | Number of Kernels | Padding |
|---|---|---|---|---|---|---|---|
| 1 | Full-Connected | - | (7 × 125 × 8) | ||||
| 2 | Conv-2D Transposed | ReLU (alpha = 0.3) | (7, 125, 8) | 1 × 4 | 1 × 1 | 8 | Yes |
| 3 | Conv-2D Transposed | ReLU (alpha = 0.3) | (7, 125, 8) | 1 × 4 | 1 × 1 | 8 | Yes |
| 4 | Conv-2D Transposed | ReLU (alpha = 0.3) | (14, 250, 30) | 1 × 4 | 2 × 2 | 30 | Yes |
| Layer Number | Layer Name | Activation Function | Output Size | Size of Kernel | Strides | Number of Kernels | Padding |
|---|---|---|---|---|---|---|---|
| 1 | Conv-2D | ReLU (alpha = 0.3) | (1, 14, 250, 6) | 1 × 4 | 1 × 1 | 6 | Yes |
| 2 | Dropout (0.2) | - | (1, 14, 250, 6) | ||||
| 3 | Conv-2D | ReLU (alpha = 0.3) | (1, 7, 125, 6) | 1 × 4 | 2 × 2 | 6 | Yes |
| 4 | Dropout (0.2) | - | (1, 7, 125, 6) | ||||
| 5 | Conv-2D | ReLU (alpha = 0.3) | (1, 7, 125, 6) | 1 × 4 | 1 × 1 | 6 | Yes |
| 6 | Dropout (0.2) | - | (1, 7, 125, 6) | ||||
| 7 | Flatten | - | (1, 5250) | ||||
| 8 | Fully Connected | - | (1, 1) |
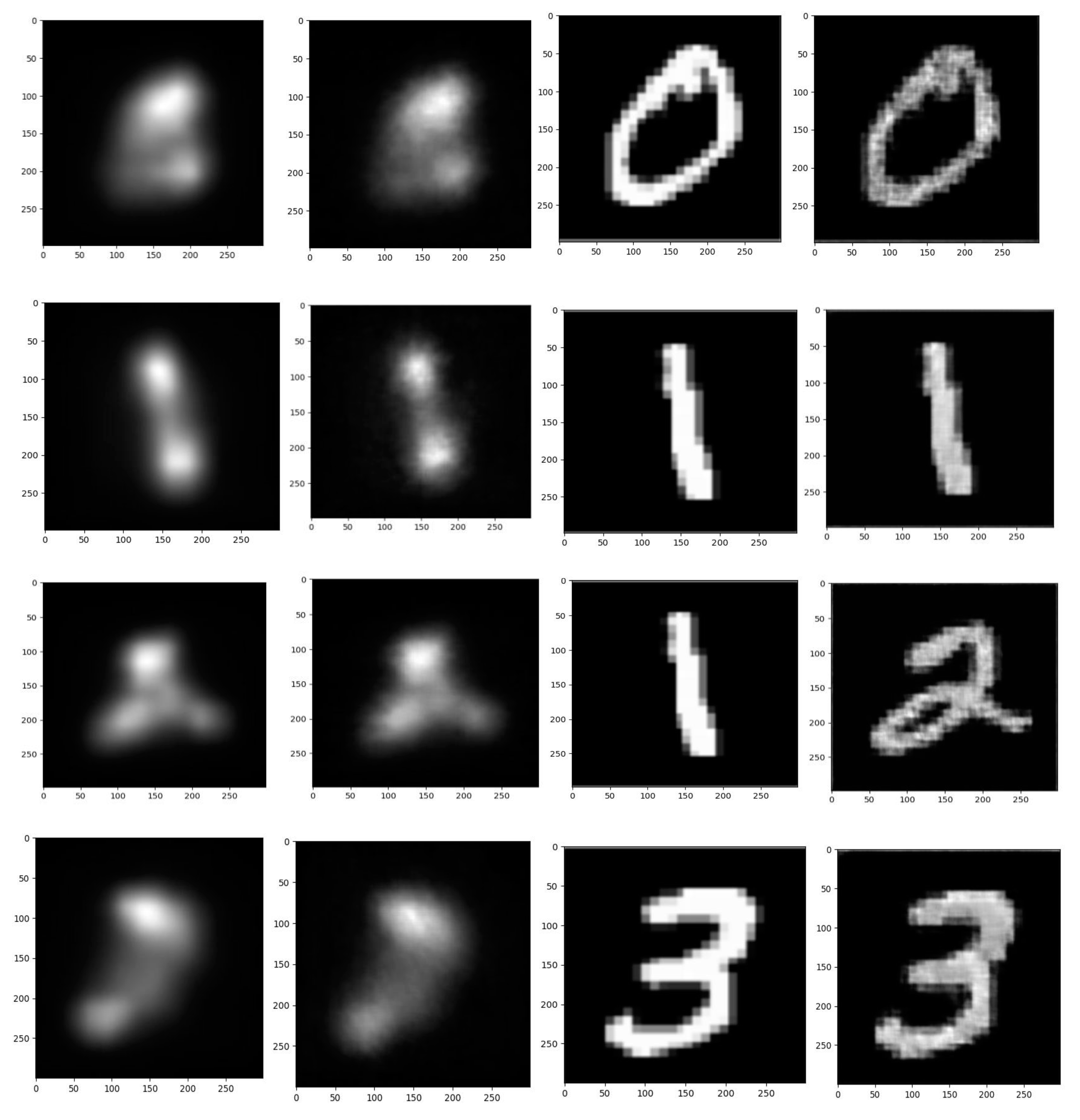
| Category Number | Arithmetic Category | SSIM | CC |
|---|---|---|---|
| 1 | Zero | 91.7 | 95.6 |
| 2 | One | 93.2 | 98.2 |
| 3 | Two | 95.3 | 97.1 |
| 4 | Three | 92.4 | 96.8 |
| 5 | Four | 91.5 | 96.1 |
| 6 | Five | 91.1 | 96.8 |
| 7 | Six | 94.8 | 99.4 |
| 8 | Seven | 93.6 | 97.7 |
| 9 | Eight | 94.5 | 99.2 |
| 10 | Nine | 91.8 | 95.9 |
| - | Average | 92.9 | 97.28 |
| Method | Dataset | SSIM | CC |
|---|---|---|---|
| Visual classifier-driven detector [44] | EEG-ImageNet | - | 17.30% |
| Neural-driven detector [44] | EEG-ImageNet | - | 35.7% |
| SalNet [39] | ImageNet | - | 27.10% |
| SALICON [38] | ImageNet | - | 34.8% |
| GNN-based deep network [45] | EEG-ImageNet | 89.46% | 99.39% |
| CNN-GAN | MindBigData | 92.9% | 97.28% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khaleghi, N.; Hashemi, S.; Ardabili, S.Z.; Sheykhivand, S.; Danishvar, S. Salient Arithmetic Data Extraction from Brain Activity via an Improved Deep Network. Sensors 2023, 23, 9351. https://doi.org/10.3390/s23239351
Khaleghi N, Hashemi S, Ardabili SZ, Sheykhivand S, Danishvar S. Salient Arithmetic Data Extraction from Brain Activity via an Improved Deep Network. Sensors. 2023; 23(23):9351. https://doi.org/10.3390/s23239351
Chicago/Turabian StyleKhaleghi, Nastaran, Shaghayegh Hashemi, Sevda Zafarmandi Ardabili, Sobhan Sheykhivand, and Sebelan Danishvar. 2023. "Salient Arithmetic Data Extraction from Brain Activity via an Improved Deep Network" Sensors 23, no. 23: 9351. https://doi.org/10.3390/s23239351
APA StyleKhaleghi, N., Hashemi, S., Ardabili, S. Z., Sheykhivand, S., & Danishvar, S. (2023). Salient Arithmetic Data Extraction from Brain Activity via an Improved Deep Network. Sensors, 23(23), 9351. https://doi.org/10.3390/s23239351