
Manipulation Direction: Evaluating Text-Guided Image Manipulation Based on Similarity between Changes in Image and Text Modalities


Abstract
:1. Introduction
- The similarity between a text prompt and the manipulated image completely ignores how an input image has been changed.
- The similarity between the input and manipulated images completely ignores regions manipulated according to the text prompt and evaluates the image reconstruction.
- There are limitations in deriving the performance of image manipulation models from both scores listed above because they commonly have a trade-off relationship.
- We newly propose MD, which is an evaluation metric for text-guided image manipulation.
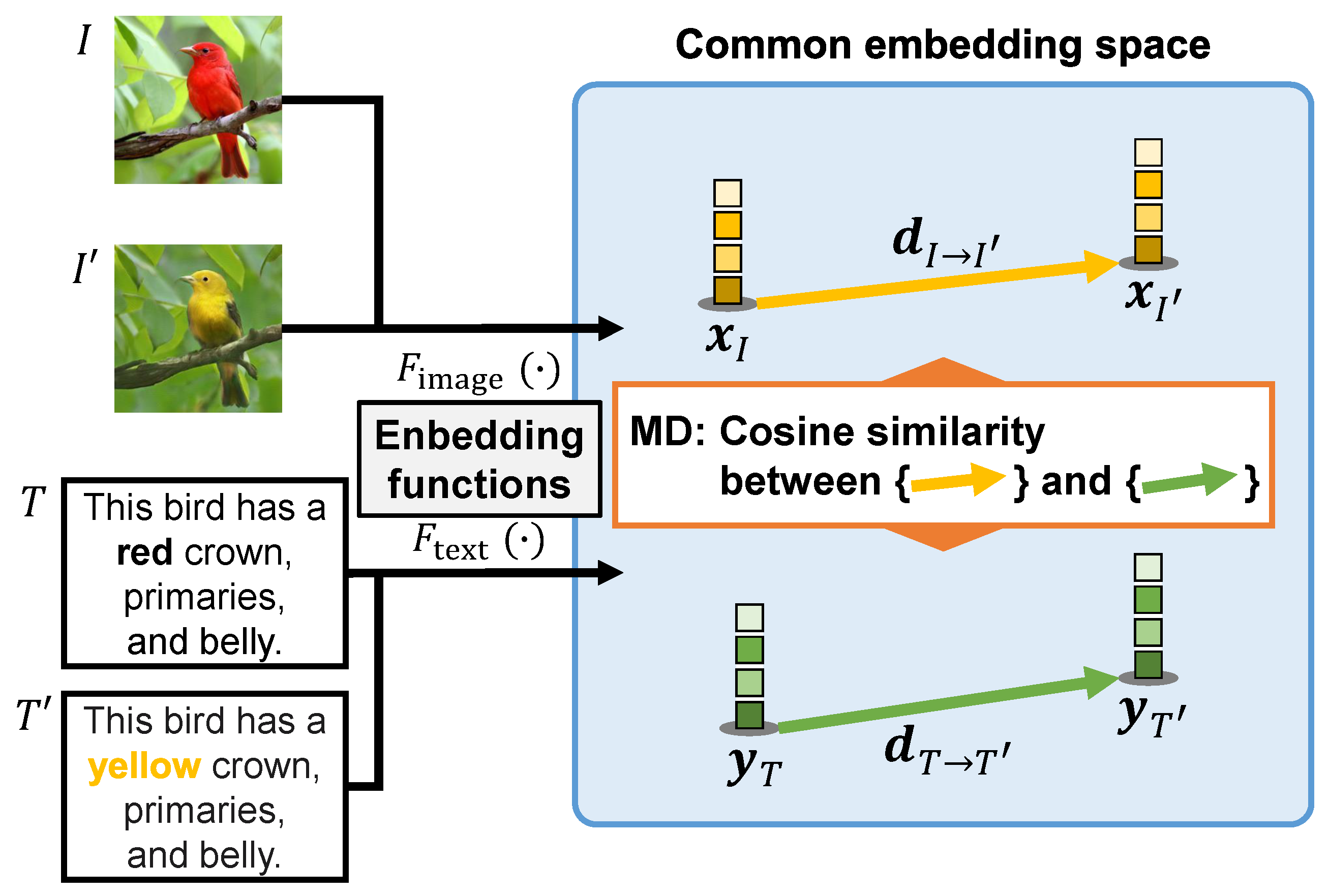
- MD is defined as the consistency of changes between images and texts occurring before and after manipulation in the common embedding space.
- MD comprehensively evaluates the image manipulation according to a text prompt and the preservation of text-irrelevant regions on a single scale.
2. Related Works
2.1. Text-Guided Image Manipulation
2.2. Image Quality Assessment
2.3. Assessment of Text-Guided Image Manipulation
3. MD-Based Evaluation of Text-Guided Image Manipulation
3.1. Embedding of Image and Text Prompt
3.2. Calculation of Evaluation Score via Proposed MD
4. Experiments
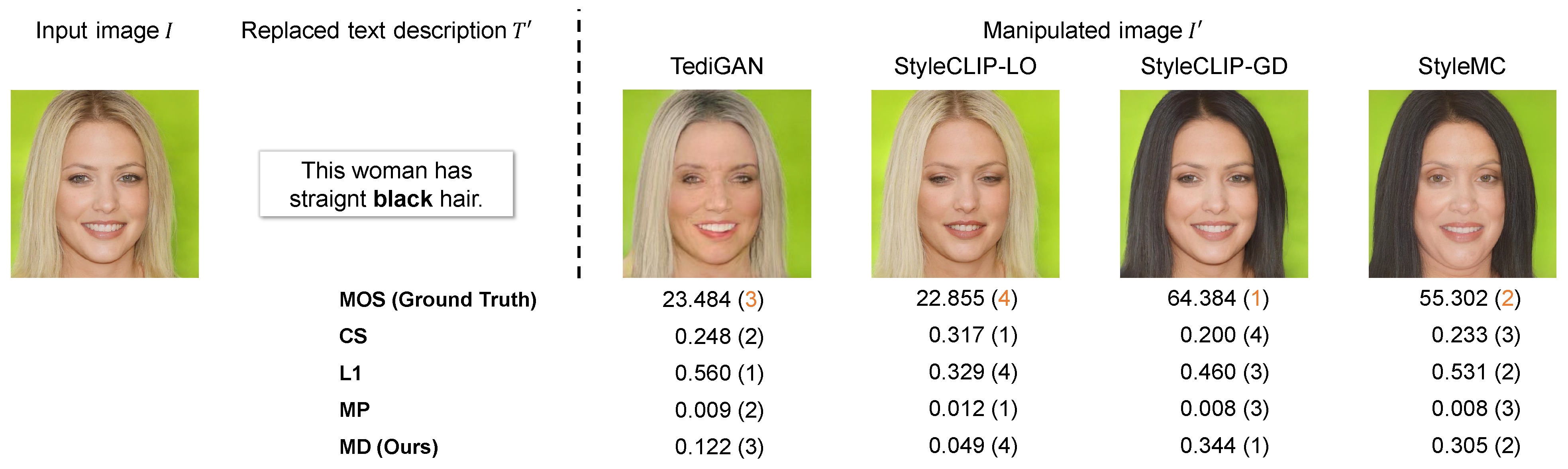
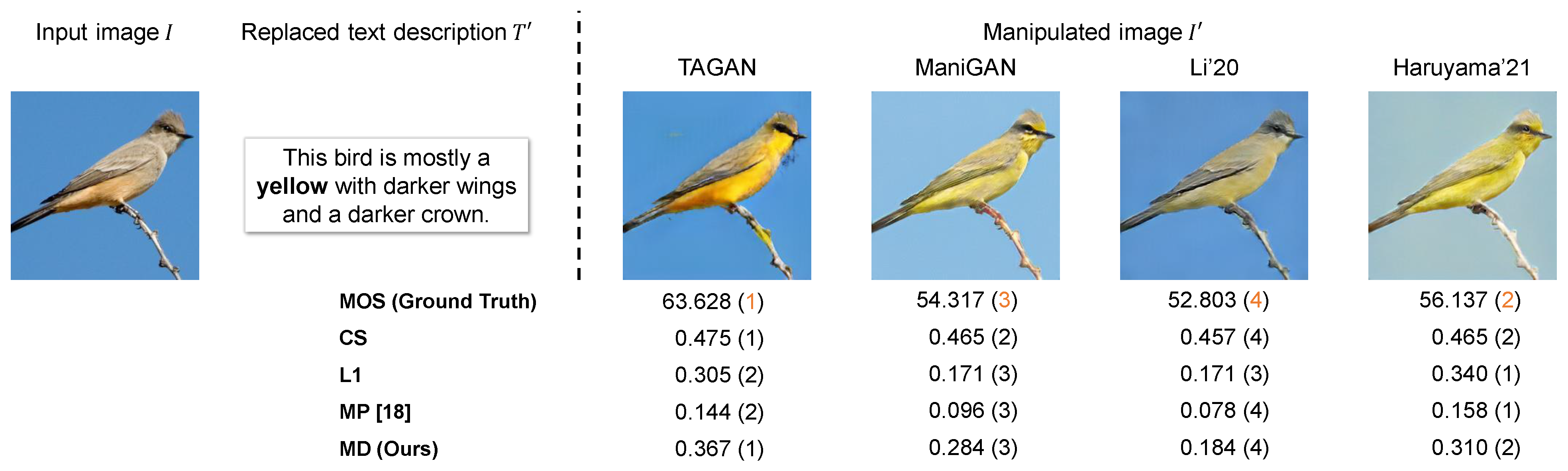
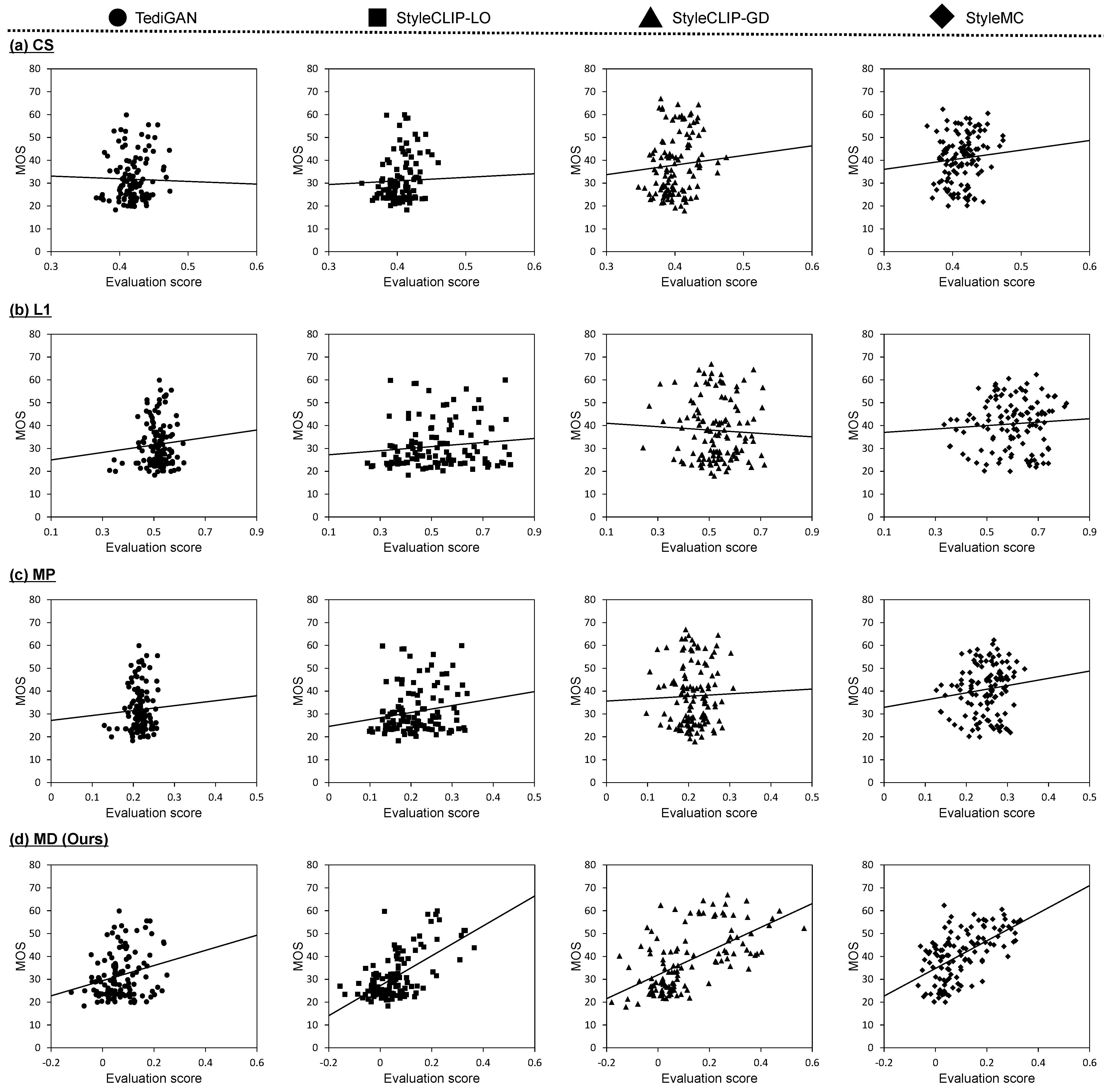
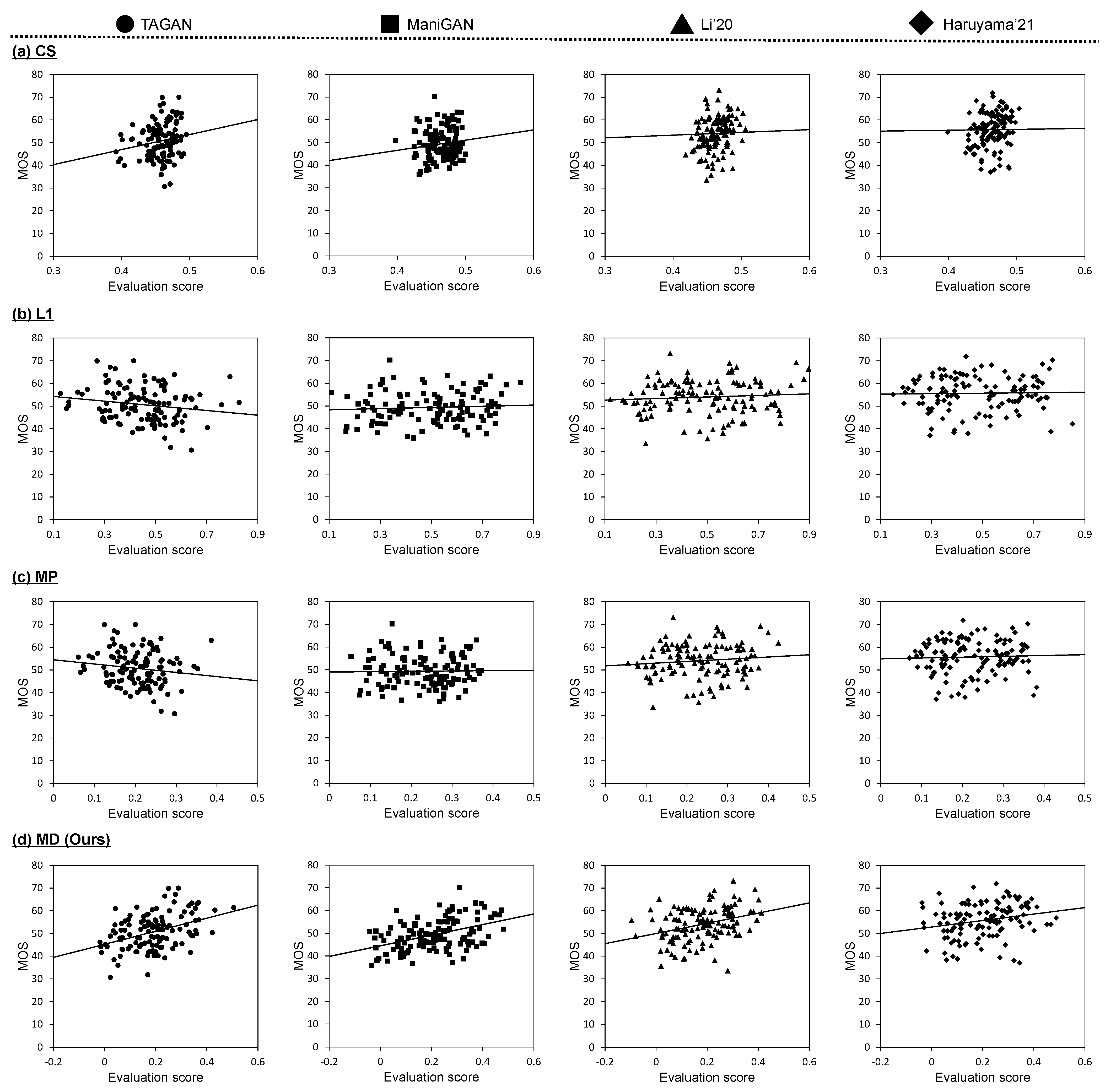
4.1. Verification of Correlation between Metrics and Subjective Evaluations
4.1.1. Experimental Conditions
- CS calculates the cosine similarity between the manipulated image and the replaced text prompt in the common embedding space based on CLIP [43]. This metric takes a value between −1 and 1.
- L1 calculates the L1 distance between the input image I and the manipulated image . This distance evaluates the image reconstruction performance, so a smaller score indicates better performance. To make it consistent with other metrics, the L1 distance is adjusted as follows:where C, H, and W denote the number of color channels, height, and width of the images, respectively. This metric takes a value between 0 and 1.
- MP evaluates the performance of text-guided image manipulation by multiplying the normalized CS and L1 values. This metric takes a value between 0 and 1.
4.1.2. Correlation between Metrics and Subjective Evaluations
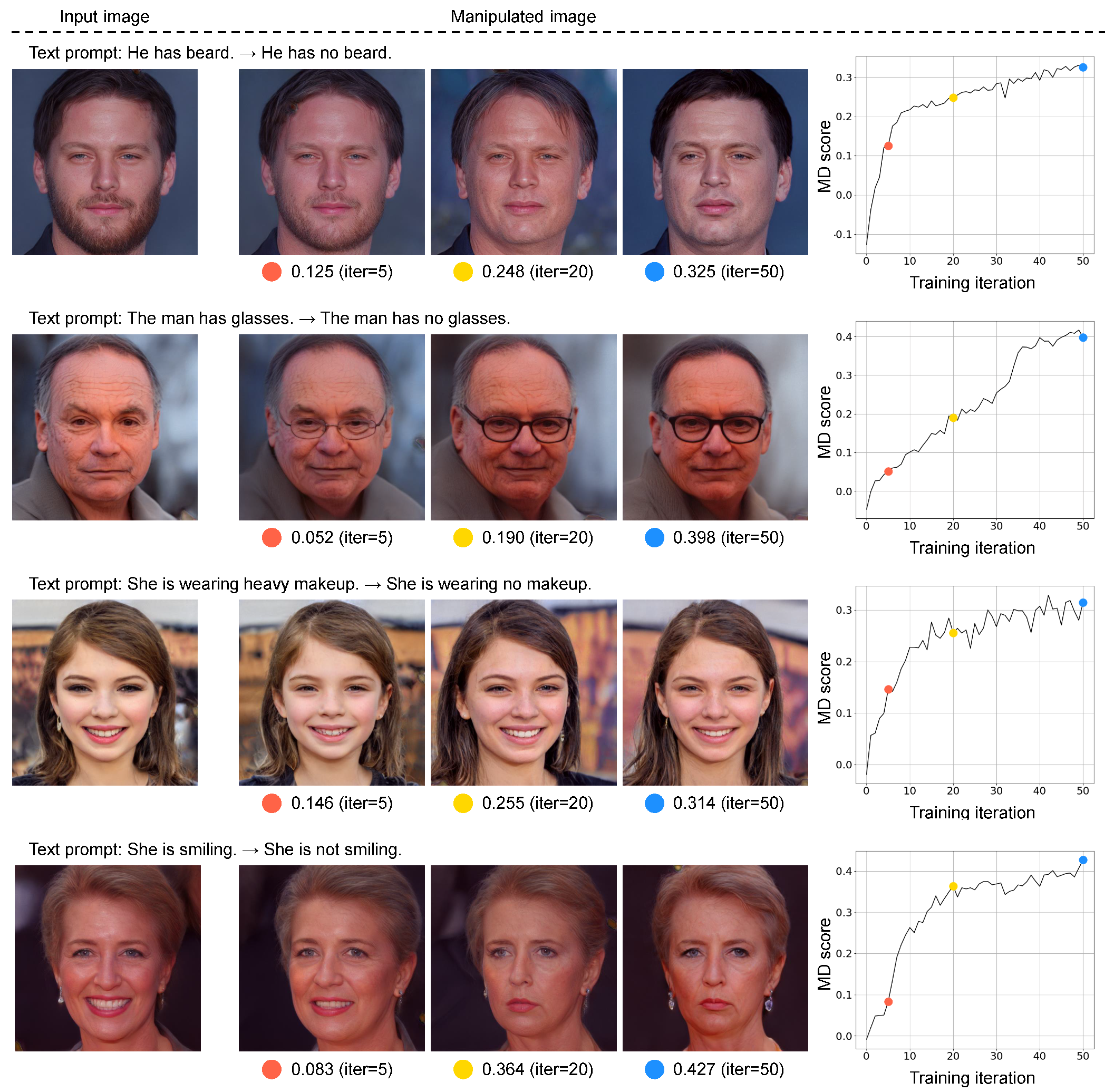
4.2. Verification of Correspondence between Results of Image Manipulation and MD Scores
4.2.1. Experimental Conditions
4.2.2. Results of Image Manipulation Introducing MD as the Loss Function
4.3. Verification of Performance Dependence on Common Embedding Space
4.3.1. Experimental Conditions
4.3.2. Influence of Common Embedding Space on Performance of MD

5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008.
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Antol, S.; Agrawal, A.; Lu, J.; Mitchell, M.; Batra, D.; Zitnick, C.L.; Parikh, D. VQA: Visual question answering. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 2425–2433. [Google Scholar]
- Shao, Z.; Yu, Z.; Wang, M.; Yu, J. Prompting large language models with answer heuristics for knowledge-based visual question answering. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 14974–14983. [Google Scholar]
- Frome, A.; Corrado, G.S.; Shlens, J.; Bengio, S.; Dean, J.; Ranzato, M.; Mikolov, T. Devise: A deep visual-semantic embedding model. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Stateline, NV, USA, 5–8 December 2013; pp. 2121–2129. [Google Scholar]
- Diao, H.; Zhang, Y.; Ma, L.; Lu, H. Similarity reasoning and filtration for image-text matching. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 1218–1226. [Google Scholar]
- Donahue, J.; Anne Hendricks, L.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar]
- Luo, J.; Li, Y.; Pan, Y.; Yao, T.; Feng, J.; Chao, H.; Mei, T. Semantic-conditional diffusion networks for image captioning. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 23359–23368. [Google Scholar]
- Hu, R.; Rohrbach, M.; Darrell, T. Segmentation from natural language expressions. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 108–124. [Google Scholar]
- Wang, Z.; Lu, Y.; Li, Q.; Tao, X.; Guo, Y.; Gong, M.; Liu, T. CRIS: Clip-driven referring image segmentation. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 11686–11695. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the International Conference on Machine Learning (ICML), New York City, NY, USA, 19–24 June 2016; pp. 1060–1069. [Google Scholar]
- Kang, M.; Zhu, J.Y.; Zhang, R.; Park, J.; Shechtman, E.; Paris, S.; Park, T. Scaling up GANs for text-to-image synthesis. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 10124–10134. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; pp. 6840–6851. [Google Scholar]
- Nam, S.; Kim, Y.; Kim, S.J. Text-adaptive generative adversarial networks: Manipulating images with natural language. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 3–8 December 2018; pp. 42–51. [Google Scholar]
- Li, B.; Qi, X.; Lukasiewicz, T.; Torr, P.H. ManiGAN: Text-guided image manipulation. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Virtual, 14–19 June 2020; pp. 7880–7889. [Google Scholar]
- Li, B.; Qi, X.; Torr, P.H.; Lukasiewicz, T. Lightweight generative adversarial networks for text-guided image manipulation. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–12 December 2020; pp. 22020–22031. [Google Scholar]
- Haruyama, T.; Togo, R.; Maeda, K.; Ogawa, T.; Haseyama, M. Segmentation-aware text-guided image manipulation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2433–2437. [Google Scholar]
- Xia, W.; Yang, Y.; Xue, J.H.; Wu, B. TediGAN: Text-guided diverse face image generation and manipulation. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Virtual, 19–25 June 2021; pp. 2256–2265. [Google Scholar]
- Patashnik, O.; Wu, Z.; Shechtman, E.; Cohen-Or, D.; Lischinski, D. StyleCLIP: Text-driven manipulation of stylegan imagery. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 2085–2094. [Google Scholar]
- Kocasari, U.; Dirik, A.; Tiftikci, M.; Yanardag, P. StyleMC: Multi-channel based fast text-guided image generation and manipulation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2022; pp. 895–904. [Google Scholar]
- Hertz, A.; Mokady, R.; Tenenbaum, J.; Aberman, K.; Pritch, Y.; Cohen-Or, D. Prompt-to-prompt image editing with cross attention control. arXiv 2022, arXiv:2208.01626. [Google Scholar]
- Brooks, T.; Holynski, A.; Efros, A.A. InstructPix2Pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 18392–18402. [Google Scholar]
- Cheng, Z.; Yang, Q.; Sheng, B. Deep colorization. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 415–423. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful image colorization. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 649–666. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Donahue, J.; Darrell, T.; Efros, A.A. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2536–2544. [Google Scholar]
- Lempitsky, V.; Vedaldi, A.; Ulyanov, D. Deep image prior. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 9446–9454. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Madaan, A.; Setlur, A.; Parekh, T.; Poczos, B.; Neubig, G.; Yang, Y.; Salakhutdinov, R.; Black, A.W.; Prabhumoye, S. Politeness transfer: A tag and generate approach. arXiv 2020, arXiv:2004.14257. [Google Scholar]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training GANs. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017; pp. 6626–6637. [Google Scholar]
- Watanabe, Y.; Togo, R.; Maeda, K.; Ogawa, T.; Haseyama, M. Assessment of image manipulation using natural language description: Quantification of manipulation direction. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 1046–1050. [Google Scholar]
- Dong, H.; Yu, S.; Wu, C.; Guo, Y. Semantic image synthesis via adversarial learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5706–5714. [Google Scholar]
- Nilsback, M.E.; Zisserman, A. Automated flower classification over a large number of classes. In Proceedings of the 6th Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP), Bhubaneswar, India, 16–19 December 2008; pp. 722–729. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4401–4410. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. AttnGAN: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 1316–1324. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of GANs for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Talebi, H.; Milanfar, P. NIMA: Neural image assessment. IEEE Trans. Image Process. 2018, 27, 3998–4011. [Google Scholar] [CrossRef] [PubMed]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The earth mover’s distance as a metric for image retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Kiros, R.; Salakhutdinov, R.; Zemel, R.S. Unifying visual-semantic embeddings with multimodal neural language models. arXiv 2014, arXiv:1411.2539. [Google Scholar]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. TACL 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021; pp. 12116–12128. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset: Multi-Modal-CelebA-HQ [21] | Dataset: CUB [32] | |||||
|---|---|---|---|---|---|---|
| PCC (↑) | SRCC (↑) | EMD (↓) | PCC (↑) | SRCC (↑) | EMD (↓) | |
| CS | 0.178 | 0.159 | 0.136 | 0.120 | 0.197 | 0.096 |
| L1 | 0.136 | 0.136 | 0.169 | 0.013 | 0.002 | 0.043 |
| MP [18] | 0.180 | 0.174 | 0.151 | 0.022 | 0.008 | 0.056 |
| MD (Ours) | 0.547 | 0.490 | 0.095 | 0.316 | 0.323 | 0.029 |
| Multi-Modal-CelebA-HQ [21] | CUB [32] | ||||
|---|---|---|---|---|---|
| PCC (↑) | SRCC (↑) | PCC (↑) | SRCC (↑) | ||
| MD with VSE [48] | 300 | 0.205 | 0.205 | 0.232 | 0.241 |
| MD with CLIP (ResNet50) | 1024 | 0.545 | 0.494 | 0.287 | 0.300 |
| MD with CLIP (ResNet101) | 512 | 0.547 | 0.490 | 0.316 | 0.323 |
| MD with CLIP (ViT-B/32) | 512 | 0.444 | 0.424 | 0.312 | 0.310 |
| MD with CLIP (ViT-L/14) | 768 | 0.514 | 0.465 | 0.248 | 0.243 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Watanabe, Y.; Togo, R.; Maeda, K.; Ogawa, T.; Haseyama, M. Manipulation Direction: Evaluating Text-Guided Image Manipulation Based on Similarity between Changes in Image and Text Modalities. Sensors 2023, 23, 9287. https://doi.org/10.3390/s23229287
Watanabe Y, Togo R, Maeda K, Ogawa T, Haseyama M. Manipulation Direction: Evaluating Text-Guided Image Manipulation Based on Similarity between Changes in Image and Text Modalities. Sensors. 2023; 23(22):9287. https://doi.org/10.3390/s23229287
Chicago/Turabian StyleWatanabe, Yuto, Ren Togo, Keisuke Maeda, Takahiro Ogawa, and Miki Haseyama. 2023. "Manipulation Direction: Evaluating Text-Guided Image Manipulation Based on Similarity between Changes in Image and Text Modalities" Sensors 23, no. 22: 9287. https://doi.org/10.3390/s23229287
APA StyleWatanabe, Y., Togo, R., Maeda, K., Ogawa, T., & Haseyama, M. (2023). Manipulation Direction: Evaluating Text-Guided Image Manipulation Based on Similarity between Changes in Image and Text Modalities. Sensors, 23(22), 9287. https://doi.org/10.3390/s23229287