
Efficient Underground Tunnel Place Recognition Algorithm Based on Farthest Point Subsampling and Dual-Attention Transformer


Abstract
:1. Introduction
- The use of the farthest point subsampling module significantly reduces the point cloud size, decreasing the computational complexity of the model while preserving point cloud features.
- A point cloud analysis module based on the dual-attention layer Transformer has been developed, enhancing the accuracy and robustness of place recognition.
- Experiments in place recognition and robustness testing on an underground track dataset demonstrate that our approach performs exceptionally well, achieving an average dispersion of 0.841.
2. Model Design
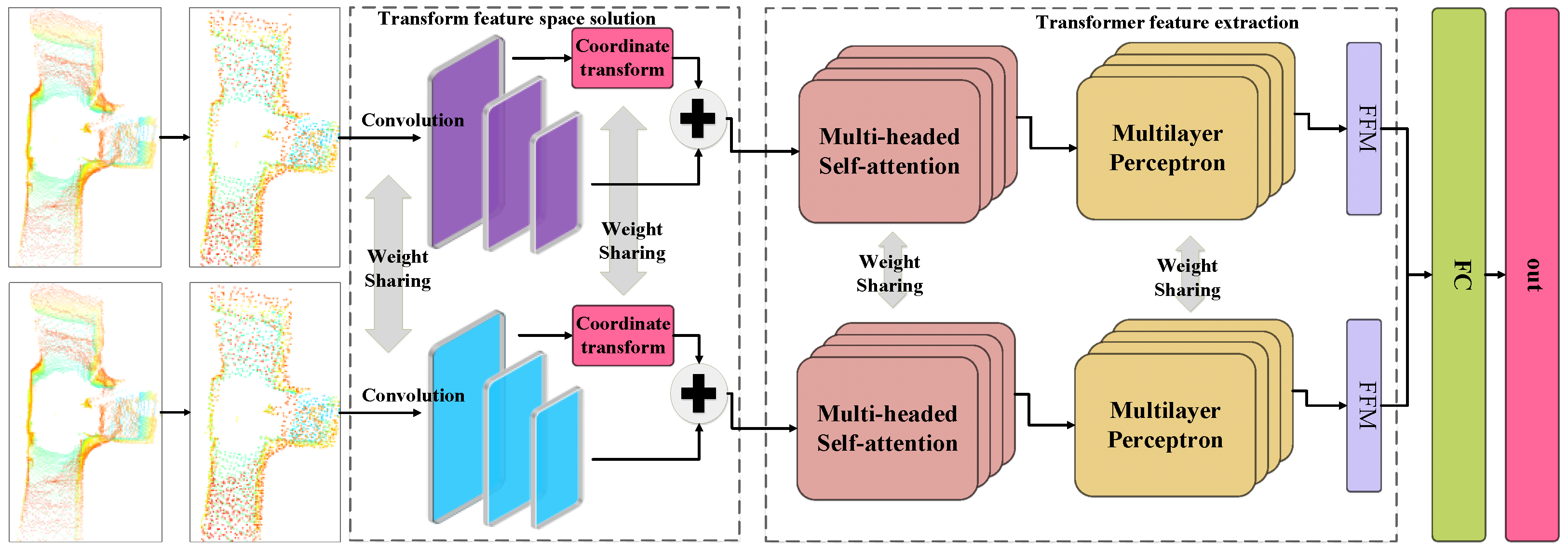
2.1. Overall Network Design
2.2. Farthest Point Downsampling
- Input: initial point cloud data {}.
- Select start point: randomly select a point as from the data or according to the density.
- Initialize the subsampled point set: Begin by creating an empty subsampled point set S, and then add to the subsampled point set, resulting in S = {}.
- Loop until the termination condition is met:
- For each point in the initial point cloud, compute the Euclidean distance from point .
- Sort the calculated Euclidean distance values and select the point furthest from point in the downsampled point set S.
- Update the selected point to .
- Termination condition: the preset number of downsampled points N is reached.
- Output: downsampled point cloud data X.
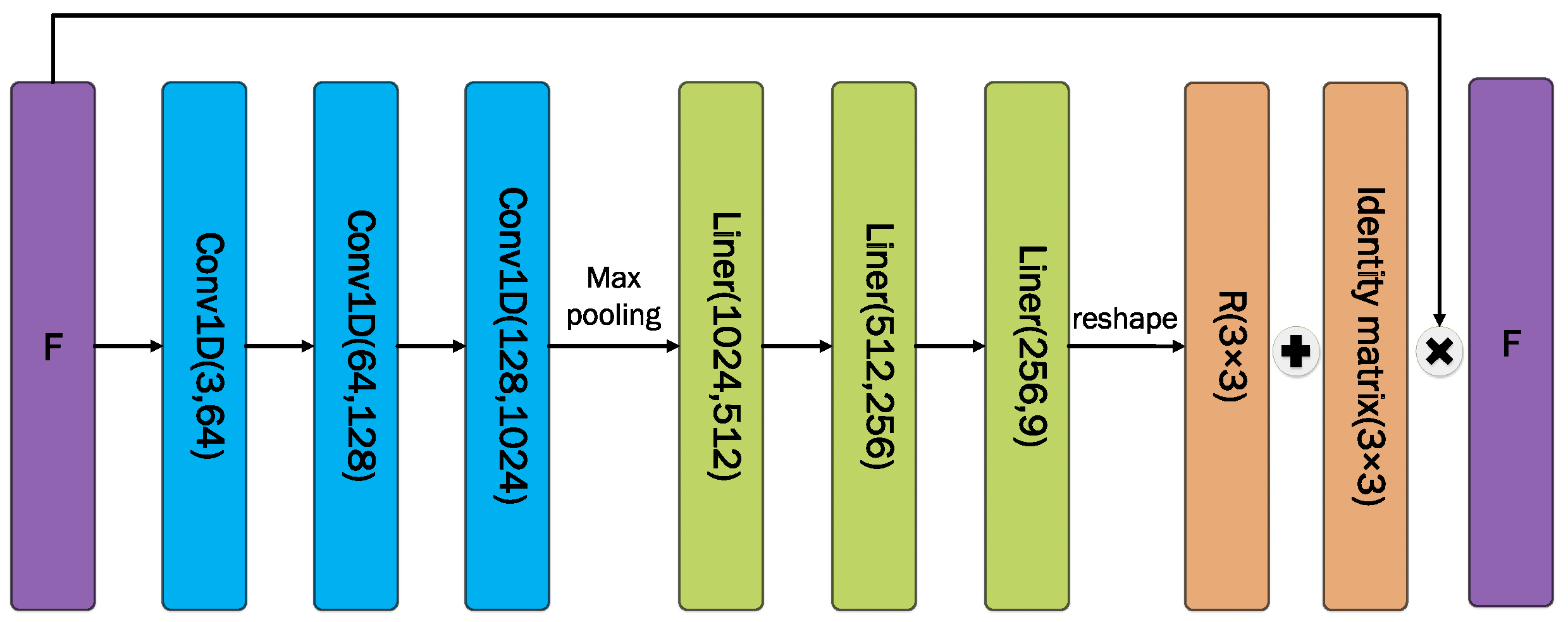
2.3. Solution Module for Transformed Eigenspaces
2.4. Transformer
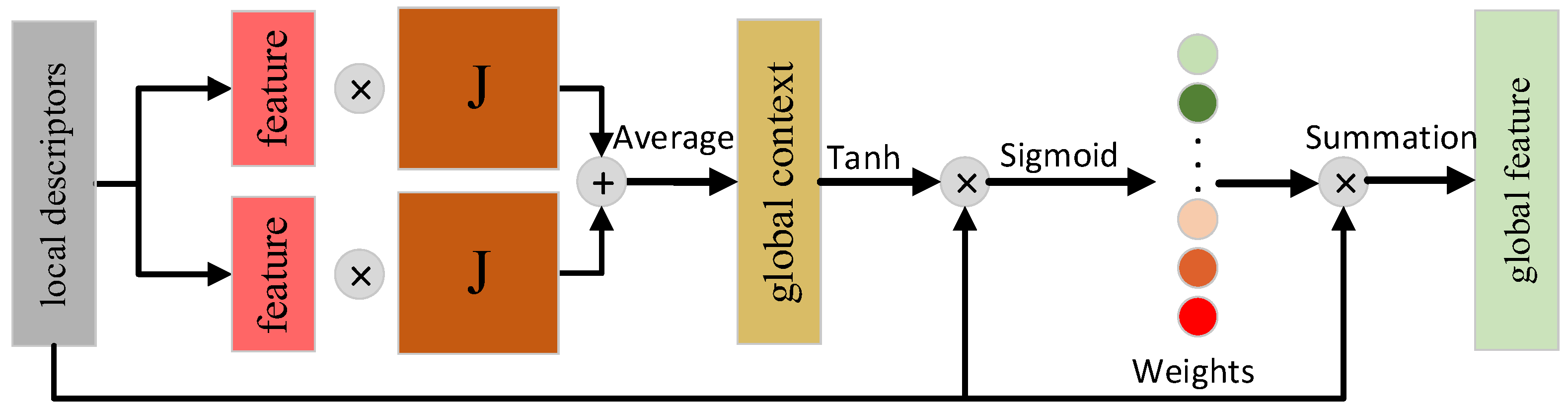
2.5. Feature Fusion Module
2.6. Loss Function
3. Test Results and Performance Analysis
3.1. Experimental Setup
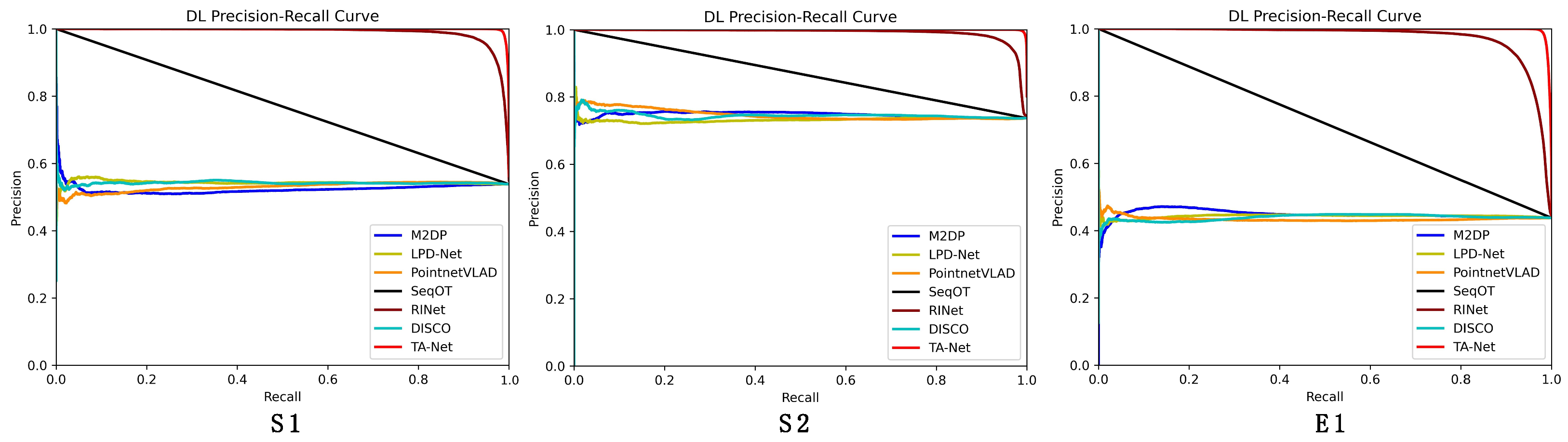
3.2. Analysis of Experimental Results
3.3. Robustness Testing
3.4. Algorithm Efficiency
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Carvalho, G.S.; Silva, F.O.; Pacheco, M.V.O.; Campos, G.A.O. Performance Analysis of Relative GPS Positioning for Low-Cost Receiver-Equipped Agricultural Rovers. Sensors 2023, 23, 8835. [Google Scholar] [CrossRef]
- Cheng, C.; Li, X.; Xie, L.; Li, L. A Unmanned Aerial Vehicle (UAV)/Unmanned Ground Vehicle (UGV) Dynamic Autonomous Docking Scheme in GPS-Denied Environments. Drones 2023, 7, 613. [Google Scholar] [CrossRef]
- Lai, J.; Liu, S.; Xiang, X.; Li, C.; Tang, D.; Zhou, H. Performance Analysis of Visual–Inertial–Range Cooperative Localization for Unmanned Autonomous Vehicle Swarm. Drones 2023, 7, 651. [Google Scholar] [CrossRef]
- Xin, K.; Yang, X.M.; Zhai, G.Y.; Zhao, X.G.; Zeng, X.F. Semantic graph based place recognition for 3D point clouds. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 25–29 October 2020; pp. 8216–8223. [Google Scholar]
- Li, L.; Kong, X.; Zhao, X.R.; Huang, T.X.; Li, W.L. RINet: Efficient 3D lidar-based place recognition using rotation invariant neural network. IEEE Robot. Autom. Lett. 2022, 7, 4321–4328. [Google Scholar] [CrossRef]
- He, L.; Wang, X.; Zhang, H. M2DP: A novel 3D point cloud descriptor and its application in loop closure detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 231–237. [Google Scholar] [CrossRef]
- Dubé, R.; Dugas, D.; Stumm, E.; Nieto, J.; Siegwart, R.; Cadena, C. SegMatch: Segment based place recognition in 3D point clouds. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 5266–5272. [Google Scholar] [CrossRef]
- Uy, M.A.; Lee, G.H. PointNetVLAD: Deep point cloud based retrieval for large-scale place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4470–4479. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Zhang, W.X.; Xiao, C.X. PCAN: 3D attention map learning using contextual information for point cloud based retrieval. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 12436–12445. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Arandjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. NetVLAD: CNN architecture for weakly supervised place recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 27–30 June 2016; pp. 5297–5307. [Google Scholar]
- Sun, Q.; Liu, H.Y.; He, J.; Fan, Z.X.; Du, X.Y. DAGC: Employing dual attention and graph convolution for point cloud based place recognition. In Proceedings of the International Conference on Multimedia Retrieval, Dublin, Ireland, 8–11 June 2020; pp. 224–232. [Google Scholar]
- Liu, Z.; Suo, C.Z.; Zhou, S.B.; Xu, F.; Wei, H.S. SeqLPD: Sequence mtching enhanced loop-closure detection based on large-scale point cloud description for self-driving vehicles. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Macau, China, 4–8 November 2019; pp. 1218–1223. [Google Scholar]
- Liu, Z.; Zhou, S.B.; Suo, C.Z.; Liu, Y.T.; Yin, P. LPD-Net: 3D point cloud learning for large-scale place recognition and environment analysis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2831–2840. [Google Scholar]
- Xia, Y.; Xu, Y.S.; Li, S.; Wang, R.; Du, J. SOE-Net: A self-attention and orientation encoding network for point cloud based place recognition. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 11348–11357. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.H. An image is worth 16x16 words:Transformers for image recognition at scale. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R. PCT: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Zhao, H.S.; Jiang, L.; Jia, J.Y.; Torr, P.H.S.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 16259–16268. [Google Scholar]
- Bai, Y.; Ding, H.; Bian, S.; Chen, T.; Sun, Y.; Wang, W. Simgnn:A neural network approach to fast graph similarity computation. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, Melbourne, VIC, Australia, 11–15 February 2019; pp. 384–392. [Google Scholar]
- Rogers, J.G.; Gregory, J.M.; Fink, J.; Stump, E. Test your SLAM! The SubT-Tunnel dataset and metric for mapping. In Proceedings of the IEEE International Conference on Robotics and Automation, Paris, France, 31 May–31 August 2020; pp. 955–961. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A. Reasoning with neural tensor networks for knowledge base completion. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 926–934. [Google Scholar]
- Xu, X.; Yin, H.; Chen, Z.; Li, Y.; Wang, Y. Disco: Differentiable scan context with orientation. IEEE Robot. Autom. Lett. 2021, 6, 2791–2798. [Google Scholar] [CrossRef]
- Ma, J.; Chen, X.; Xu, J.; Xiong, G. SeqOT: A Spatial–Temporal Transformer Network for Place Recognition Using Sequential LiDAR Data. IEEE Trans. Ind. Electron. 2023, 70, 8225–8234. [Google Scholar] [CrossRef]
- Chinchor, N. MUC-4 Evaluation Metrics. In Proceedings of the Fourth Message Understanding Conference, McLean, Virginia, 16–18 June 1992; pp. 22–29. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | S1 | S2 | E1 | Mean |
|---|---|---|---|---|
| M2DP | 0.456 | 0.550 | 0.428 | 0.478 |
| LPD-Net | 0.472 | 0.540 | 0.426 | 0.479 |
| SeqOT | 0.350 | 0.424 | 0.305 | 0.360 |
| DISCO | 0.472 | 0.547 | 0.424 | 0.481 |
| PointNetVLAD | 0.466 | 0.545 | 0.415 | 0.475 |
| RINet | 0.716 | 0.706 | 0.700 | 0.707 |
| DAT-Net (Our) | 0.837 | 0.888 | 0.797 | 0.841 |
| Methods | S1 | S2 | E1 | Mean |
|---|---|---|---|---|
| M2DP | 0.489 | 0.553 | 0.410 | 0.484 |
| LPD-Net | 0.481 | 0.543 | 0.422 | 0.482 |
| SeqOT | 0.350 | 0.424 | 0.305 | 0.360 |
| DISCO | 0.475 | 0.501 | 0.421 | 0.466 |
| PointNetVLAD | 0.475 | 0.553 | 0.417 | 0.476 |
| RINet | 0.567 | 0.610 | 0.520 | 0.566 |
| DAT-Net (Our) | 0.801 | 0.854 | 0.764 | 0.806 |
| Methods | S1 | S2 | E1 | Mean |
|---|---|---|---|---|
| M2DP | 0.456 | 0.549 | 0.428 | 0.478 |
| LPD-Net | 0.461 | 0.544 | 0.418 | 0.474 |
| SeqOT | 0.350 | 0.424 | 0.305 | 0.360 |
| DISCO | 0.476 | 0.540 | 0.421 | 0.479 |
| PointNetVLAD | 0.464 | 0.541 | 0.417 | 0.474 |
| RINet | 0.501 | 0.585 | 0.476 | 0.521 |
| DAT-Net (Our) | 0.757 | 0.823 | 0.722 | 0.767 |
| Methods | Parameters (M) | FLOPs (G) | Runtime (ms) |
|---|---|---|---|
| LPD-Net | 2.49 | 5.51 | 42.3 |
| SeqOT | 1.99 | 0.67 | 27.0 |
| DISCO | 7.79 | 1.33 | 38.3 |
| PointNetVLAD | 2.81 | 0.90 | 28.4 |
| RINet | 1.82 | 0.058 | 10.7 |
| DAT-Net (Our) | 3.18 | 0.112 | 36.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chai, X.; Yang, J.; Yan, X.; Di, C.; Ye, T. Efficient Underground Tunnel Place Recognition Algorithm Based on Farthest Point Subsampling and Dual-Attention Transformer. Sensors 2023, 23, 9261. https://doi.org/10.3390/s23229261
Chai X, Yang J, Yan X, Di C, Ye T. Efficient Underground Tunnel Place Recognition Algorithm Based on Farthest Point Subsampling and Dual-Attention Transformer. Sensors. 2023; 23(22):9261. https://doi.org/10.3390/s23229261
Chicago/Turabian StyleChai, Xinghua, Jianyong Yang, Xiangming Yan, Chengliang Di, and Tao Ye. 2023. "Efficient Underground Tunnel Place Recognition Algorithm Based on Farthest Point Subsampling and Dual-Attention Transformer" Sensors 23, no. 22: 9261. https://doi.org/10.3390/s23229261
APA StyleChai, X., Yang, J., Yan, X., Di, C., & Ye, T. (2023). Efficient Underground Tunnel Place Recognition Algorithm Based on Farthest Point Subsampling and Dual-Attention Transformer. Sensors, 23(22), 9261. https://doi.org/10.3390/s23229261