





Use of Domain Labels during Pre-Training for Domain-Independent WiFi-CSI Gesture Recognition


Abstract
:1. Introduction
- Integration of adversarial domain classification in the pre-training phase of a self-supervised contrastive deep learning-based approach.
- Introduction of a multi-class multi-label domain classification loss capable of improving adversarial domain classification performance in situations, in which standard multi-class and single label domain classification loss functions fail.
- Demonstrate that adversarial domain classification integration is negatively impacted by a large proportion of negative view combinations with views that originate from different domains within a substantial amount of positive view combination mini-batches considered during pre-training.
- Present clear future research directions for domain generalization in the area of unsupervised representation learning with WiFi-CSI data.
2. Related Work
2.1. Unsupervised Representation Learning at Different Label Distributions
2.2. Related Work on Domain-Independent Learning with Adversarial Domain Classification
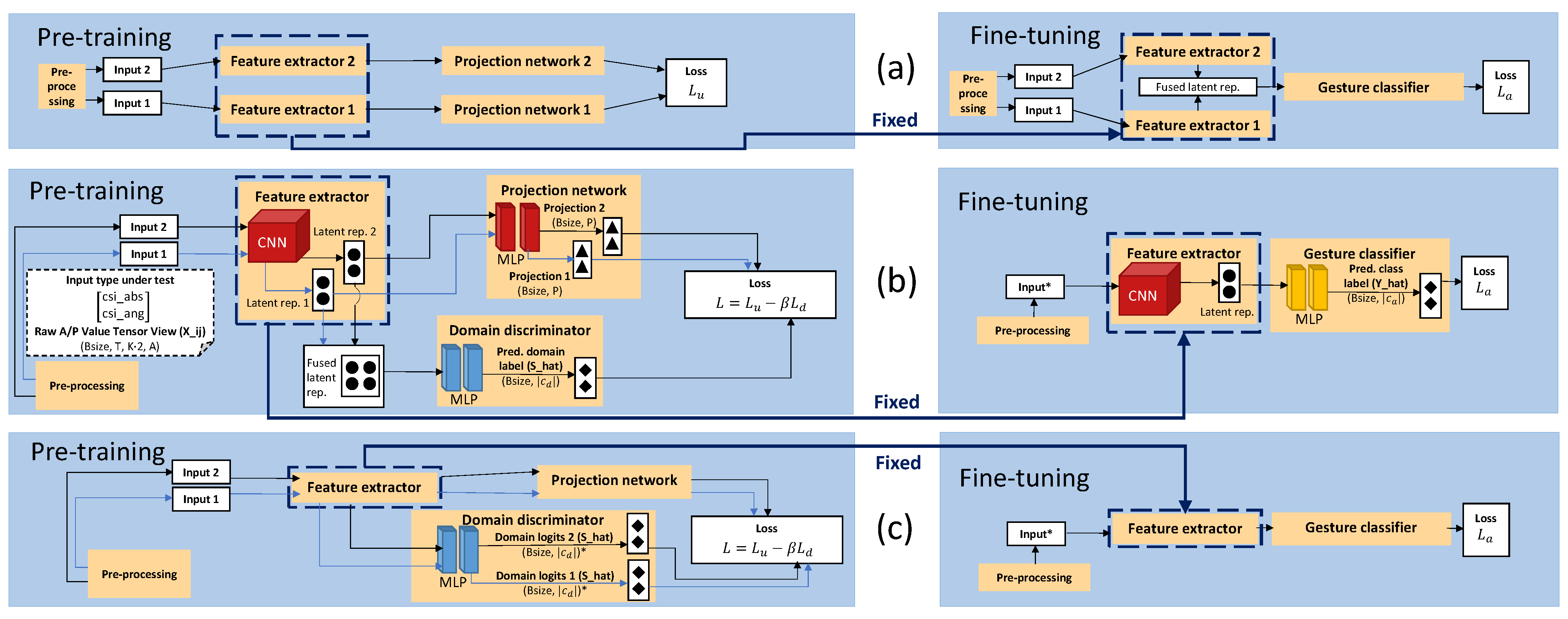
3. Methodology
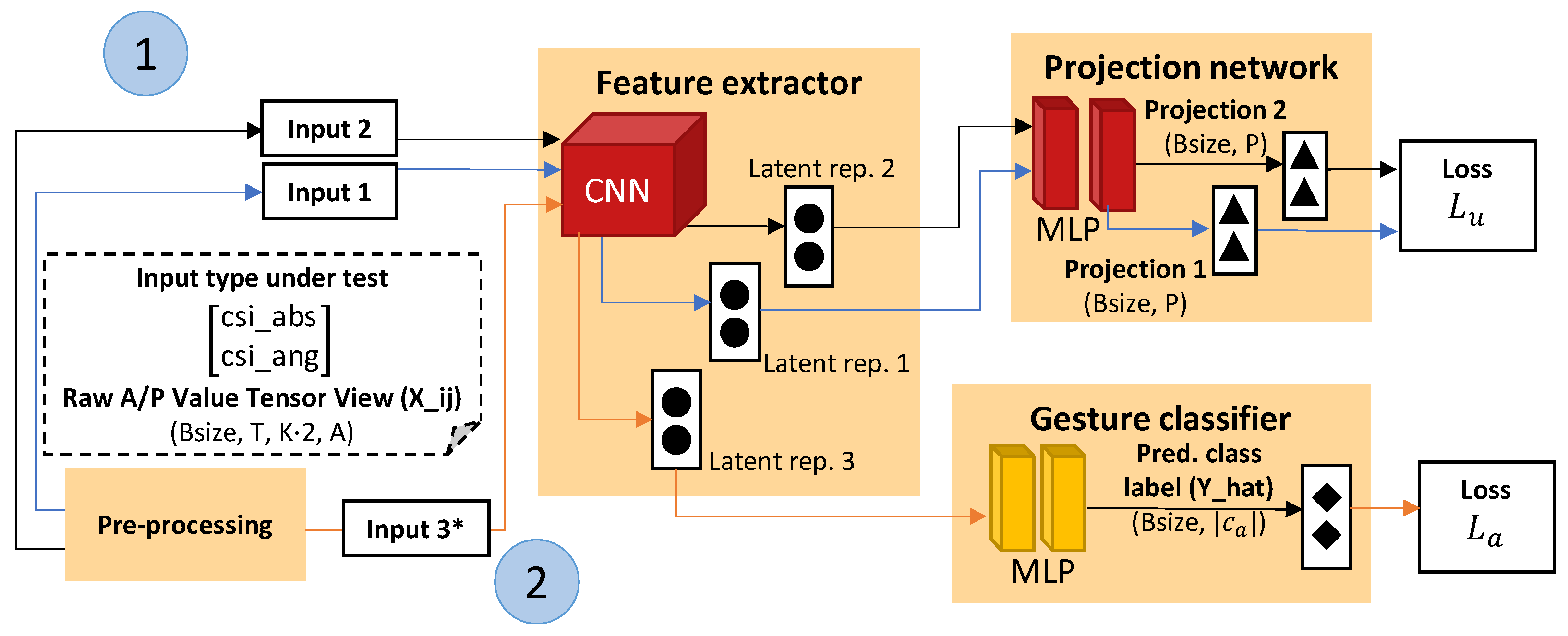
3.1. Data Pre-Processing
Mini-Batch Creation
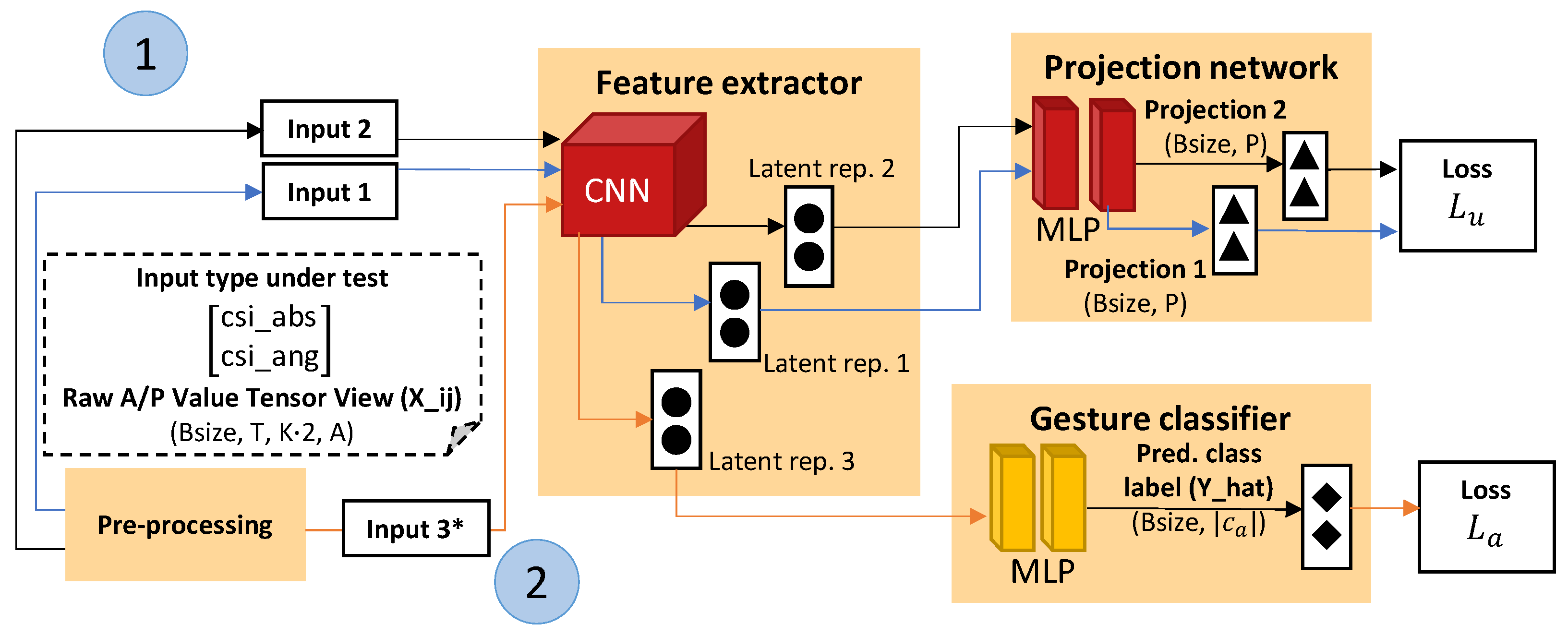
3.2. Feature Extraction
3.3. Projection and Domain Discrimination
3.4. Gesture Classification
4. Experimental Setup
4.1. Datasets
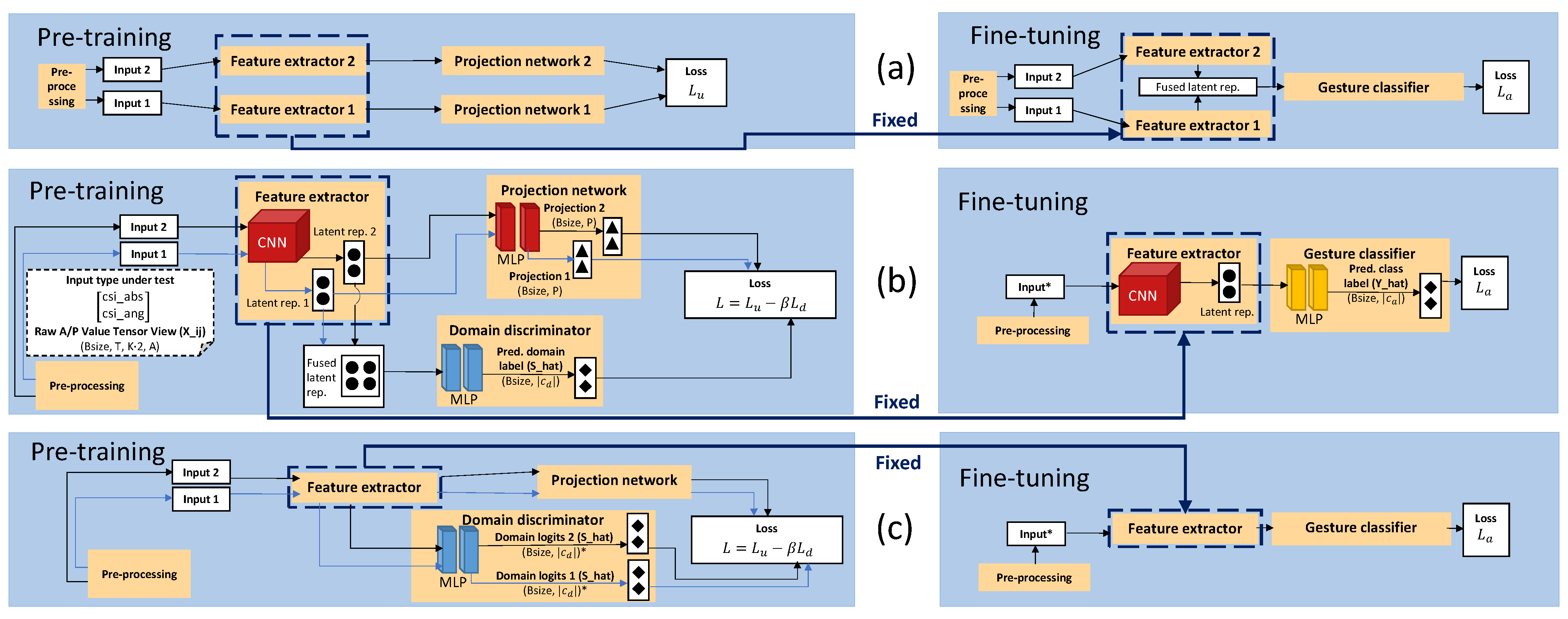
4.2. Domain-Label-Based Domain Shift Mitigation Techniques
4.2.1. End-to-End No Domain Shift Mitigation (STD)
4.2.2. Pre-Training No Domain Shift Mitigation (STD-P)
4.2.3. Pre-Training Domain-Aware Filter NTXENT (DAN-F)
4.2.4. Pre-Training Domain-Aware Batch NTXENT (DAN-B)
4.2.5. Semi-Supervised Alternating Flow Pipelines
4.3. Evaluation Strategy
4.3.1. End-to-End No Domain Shift Mitigation (STD)
4.3.2. Pre-Training Single- and Multi-Label Domain Classification (ADV-S, ADV-M1, and ADV-M2)
4.3.3. Semi-Supervised Alternating Flow Pipelines (ALT-F and ALT-B)
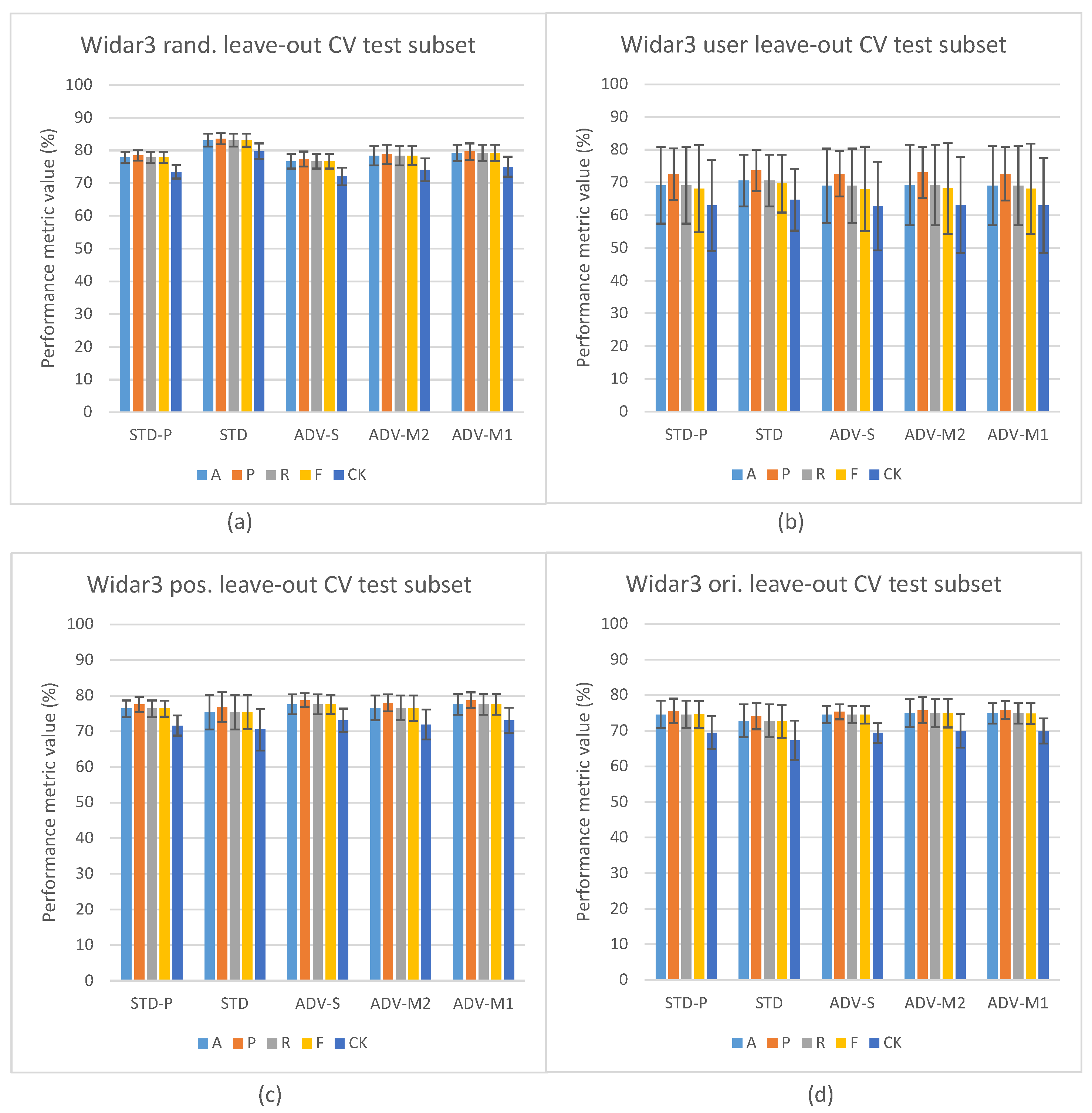
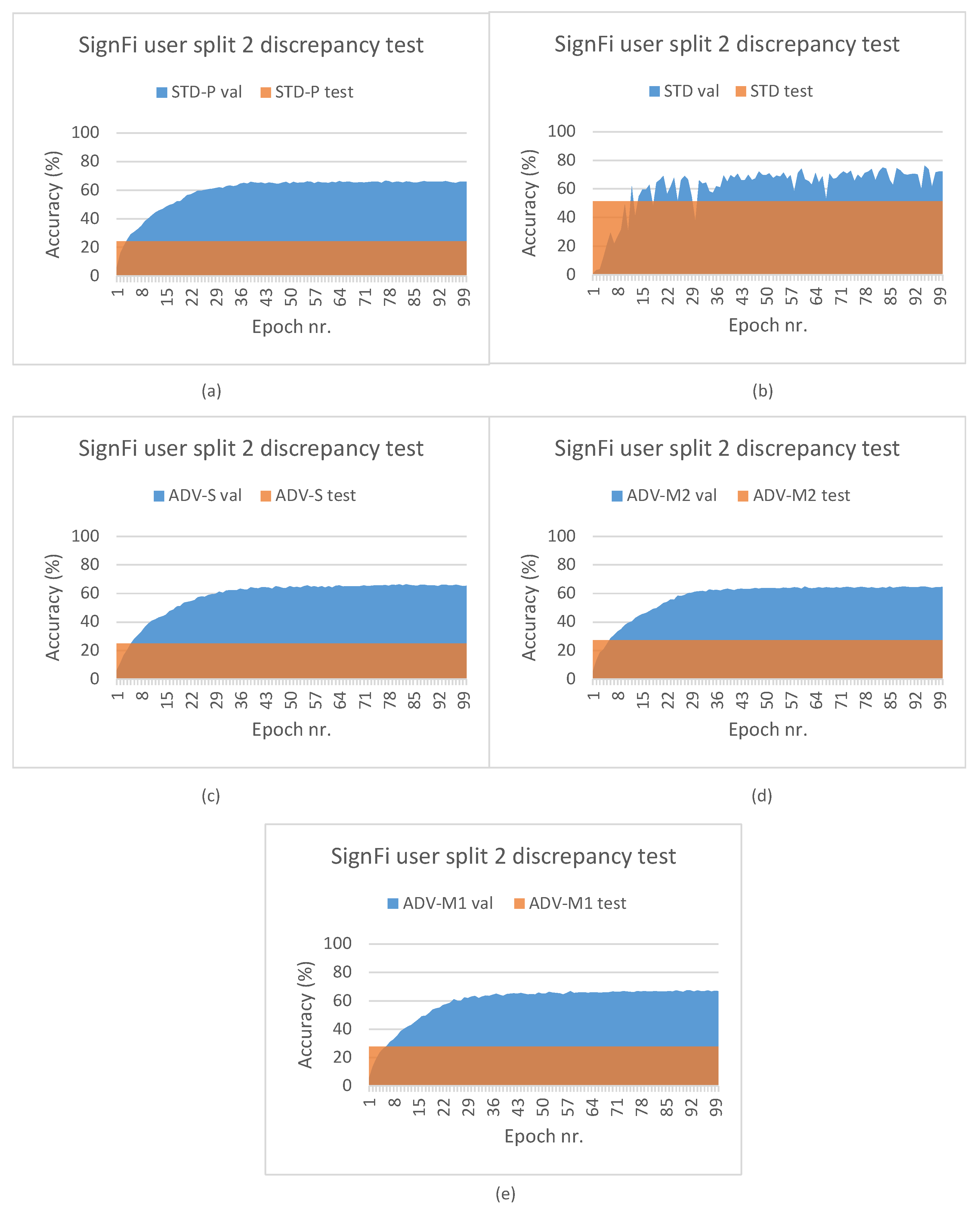
5. Experimental Results
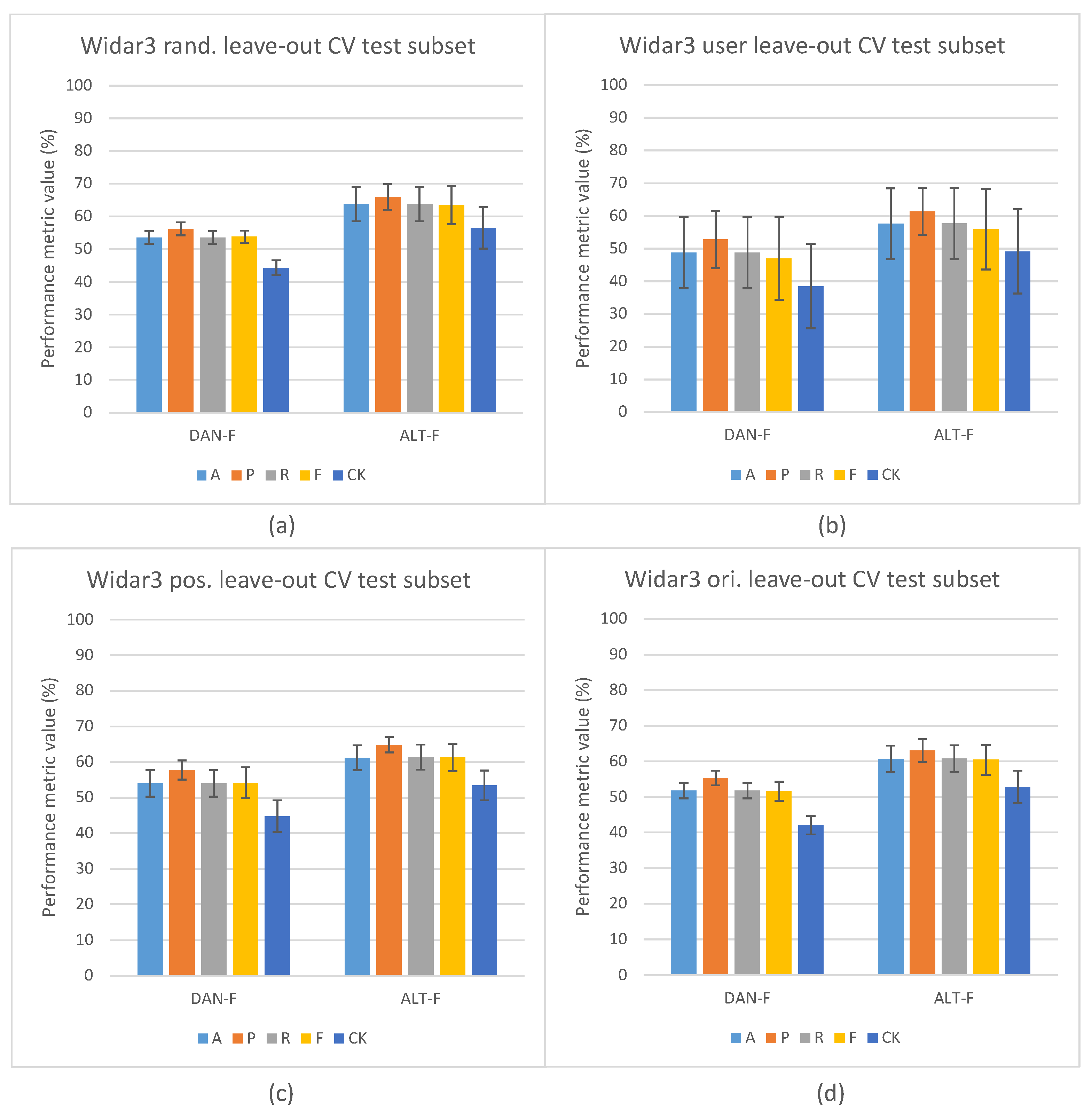
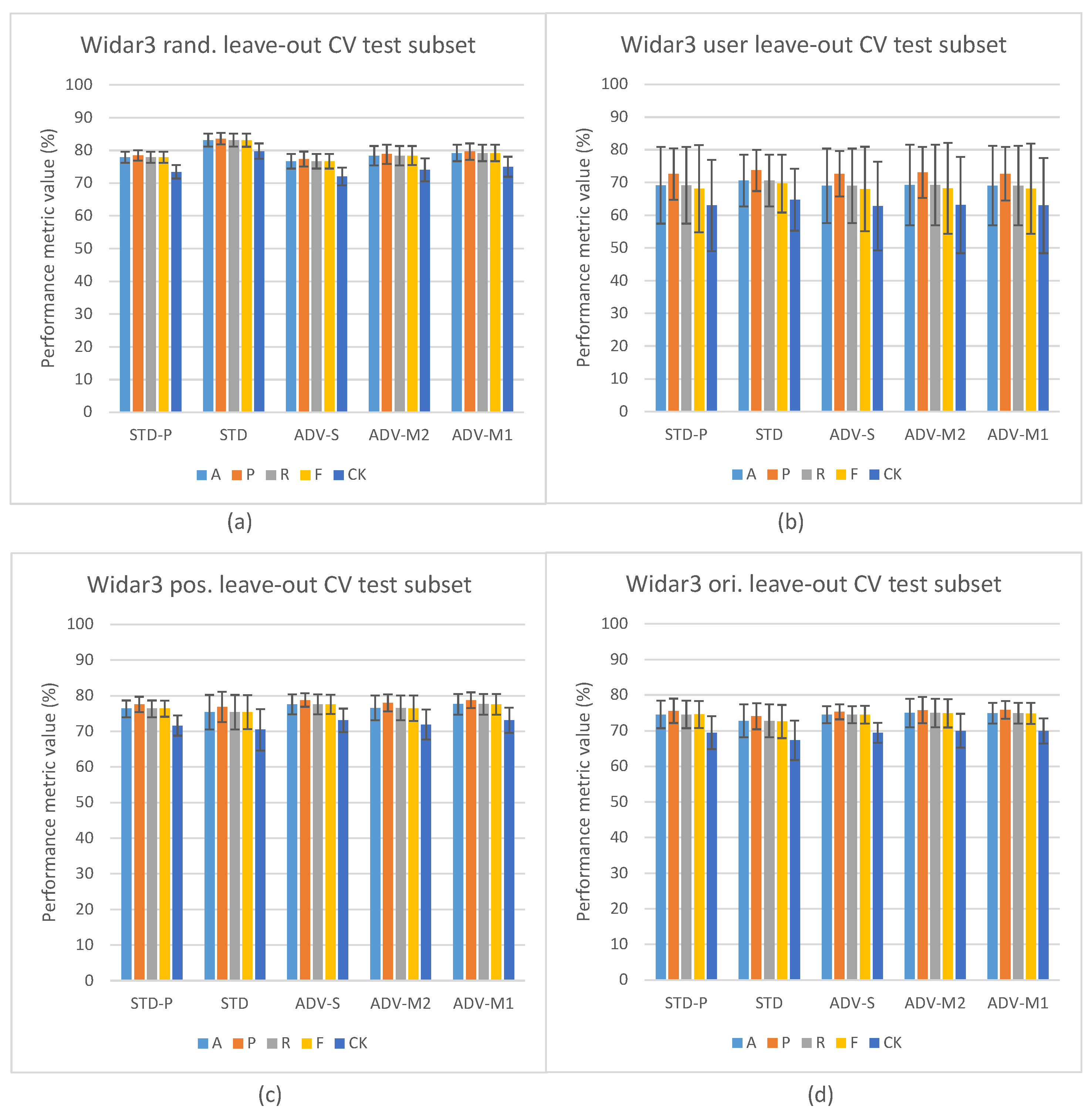
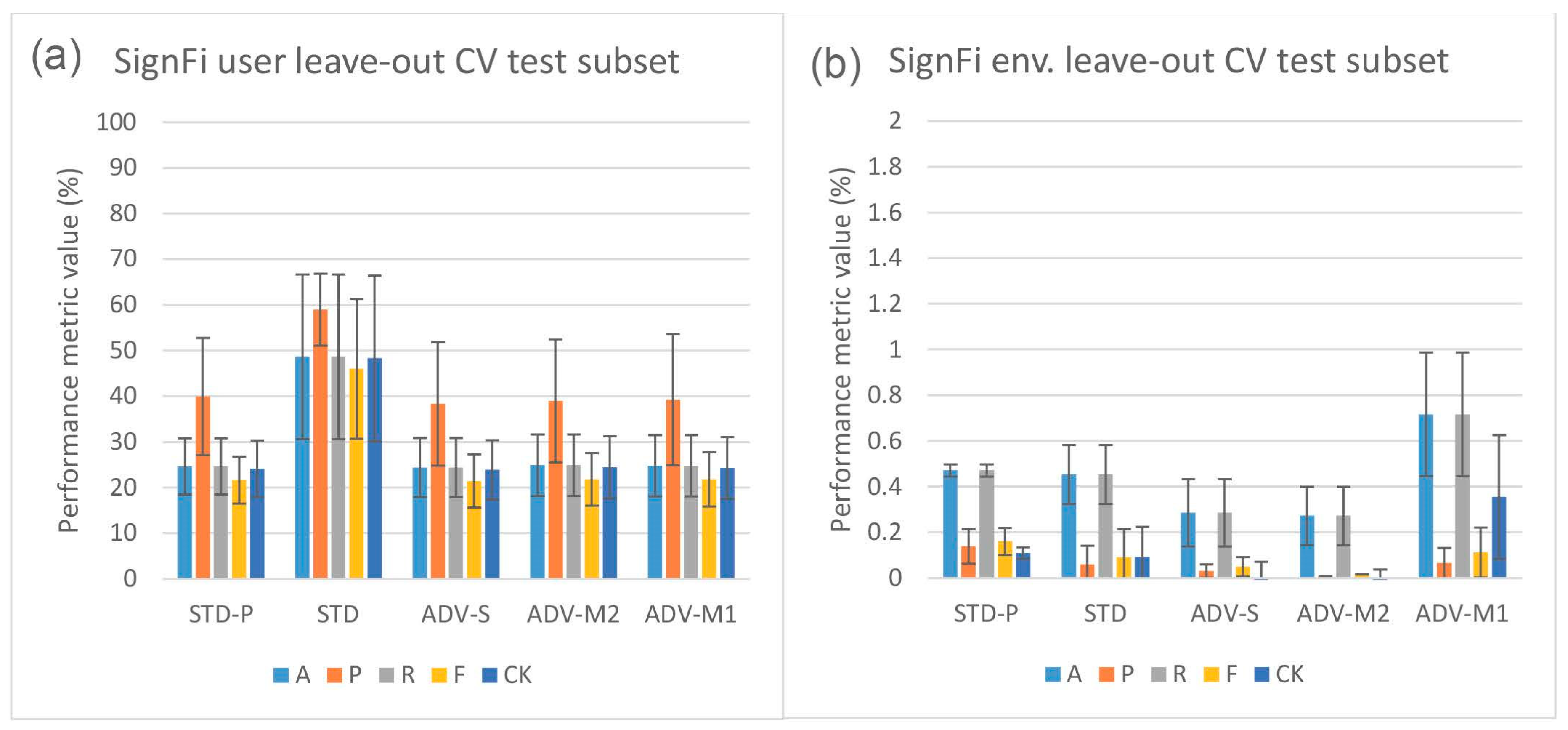
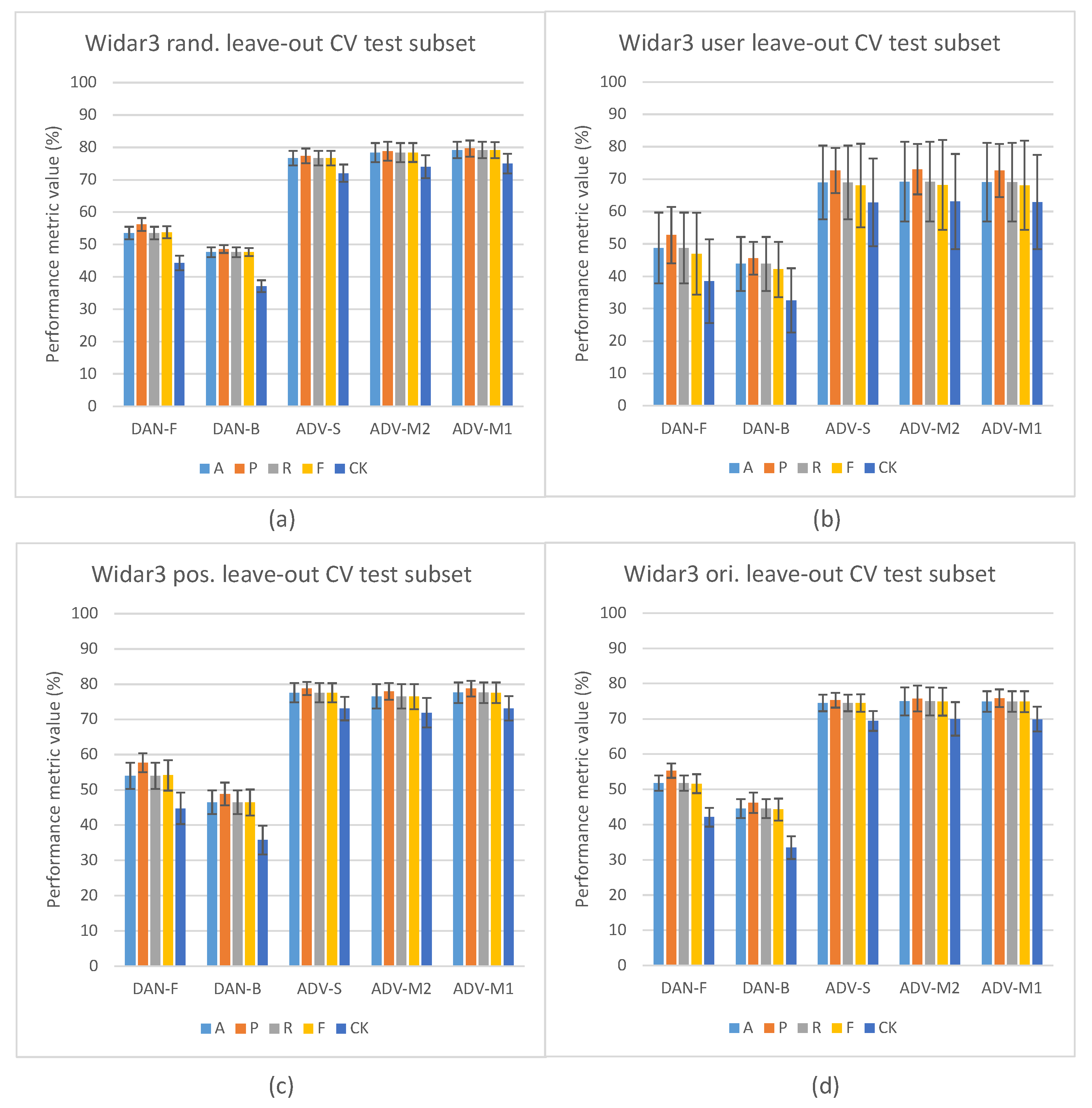
5.1. Domain Classification Integration Results
5.2. Domain Classification and Domain-Aware NTXENT Results
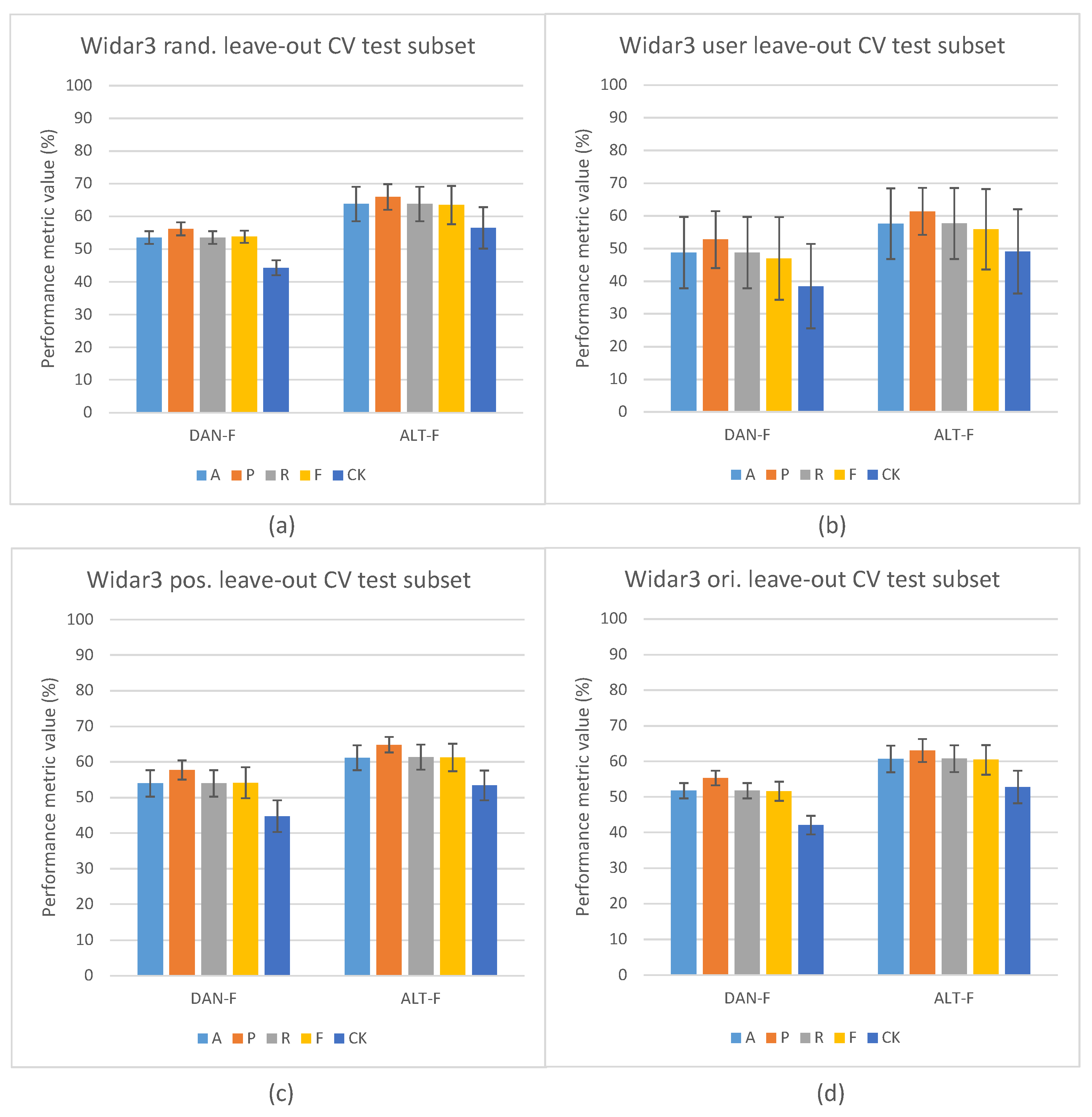
5.3. Domain-Aware NTXENT and Alternating Flow Results
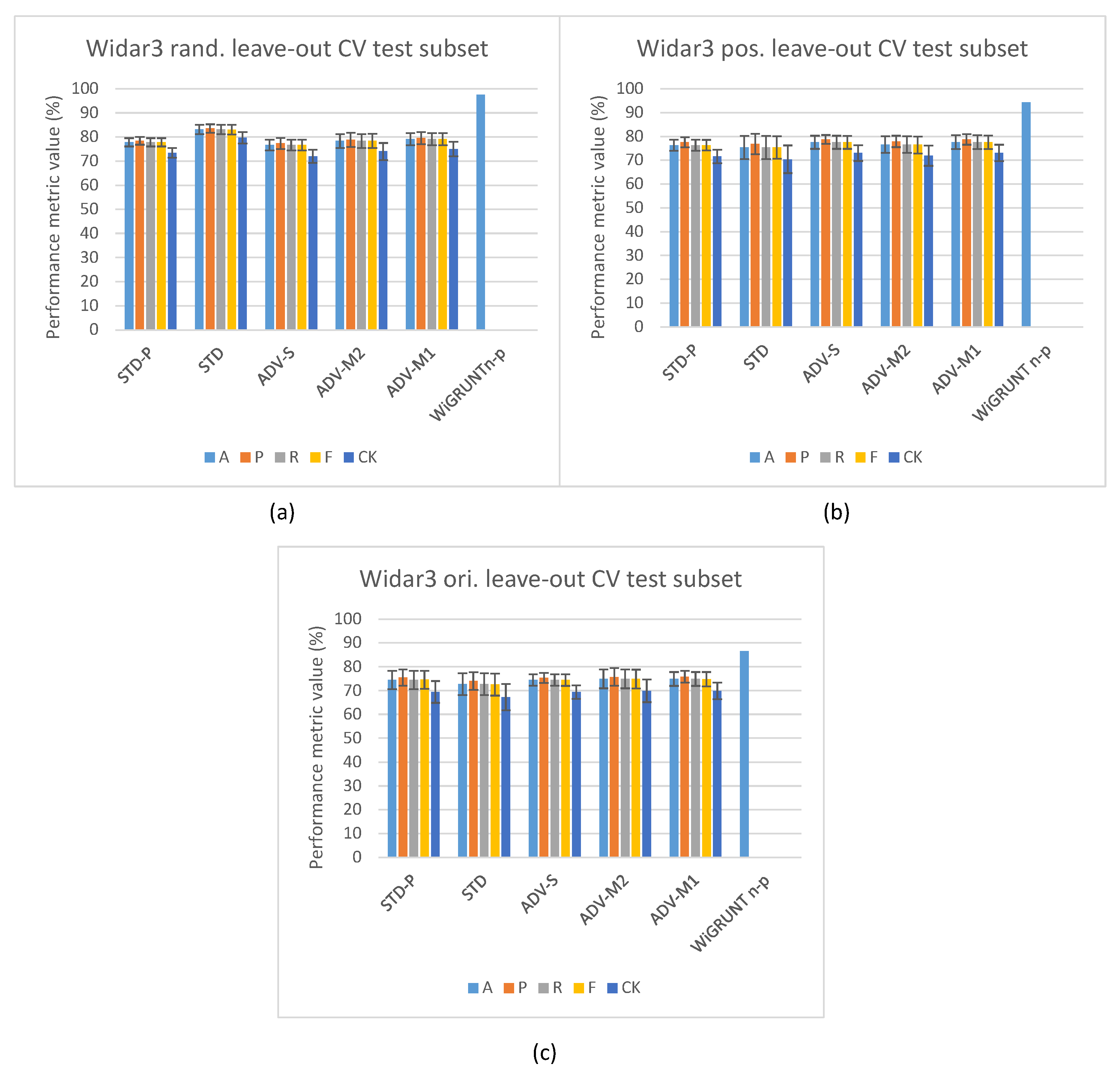
5.4. Domain Classification Integration Comparison against State-of-the-Art Pipelines
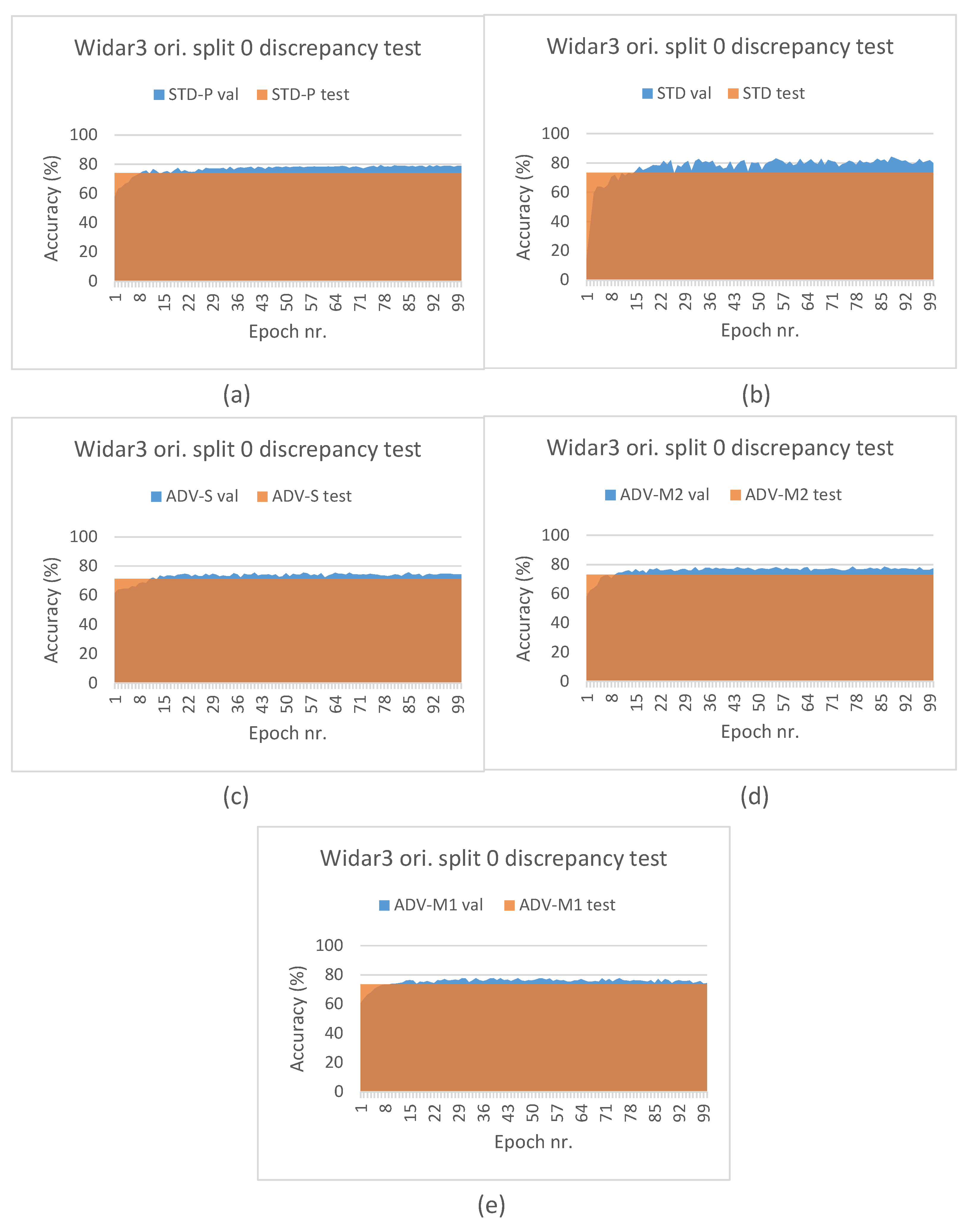
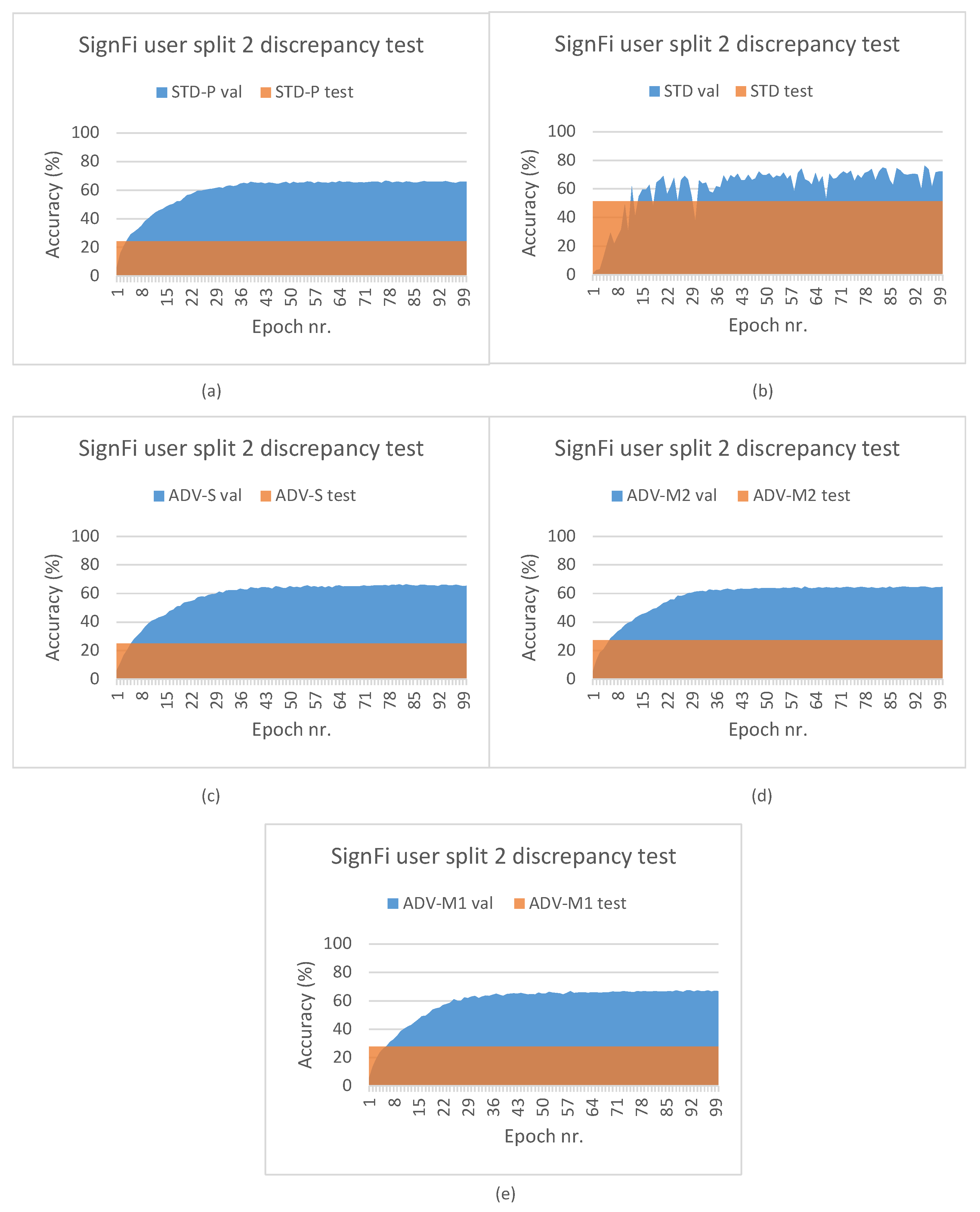
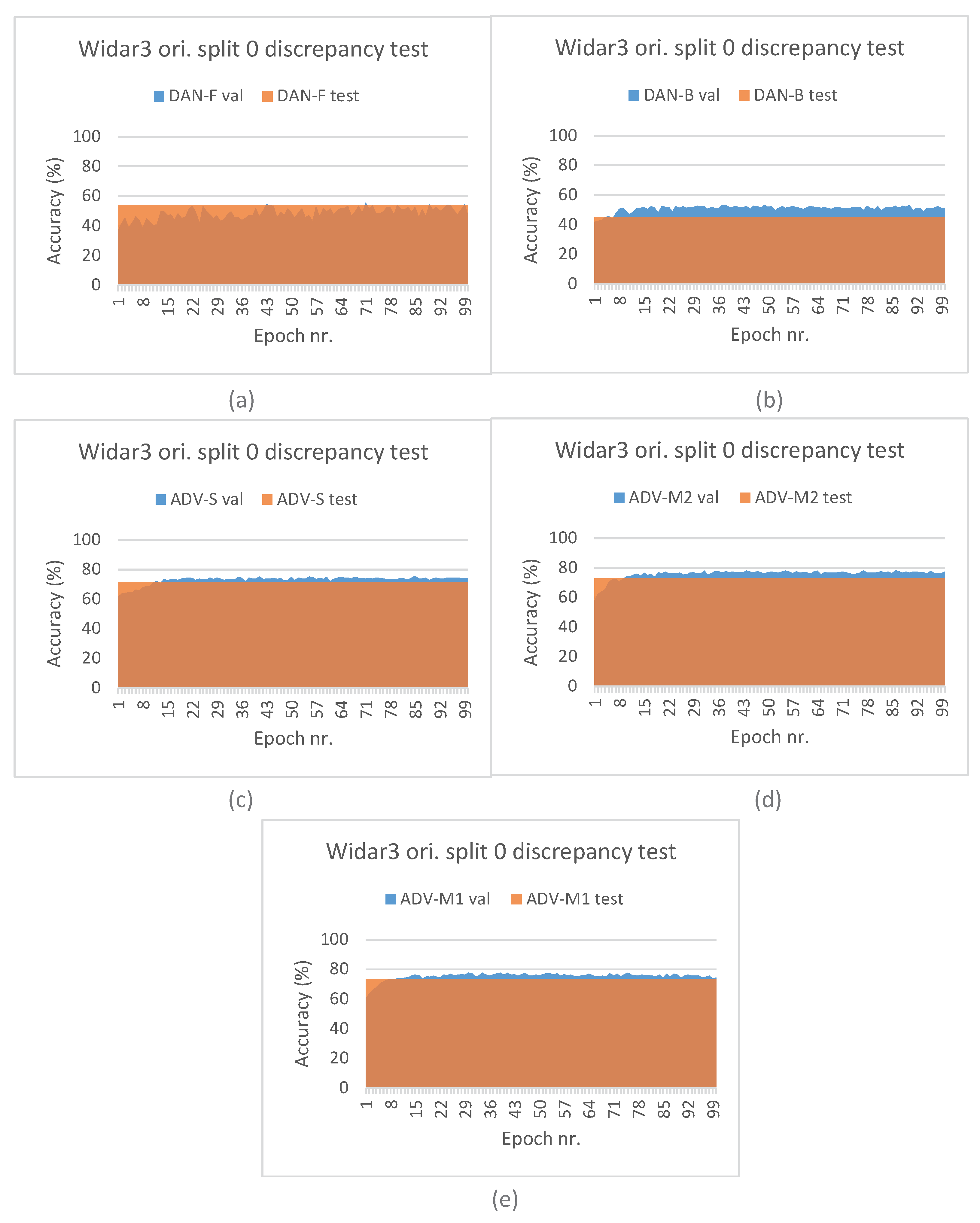
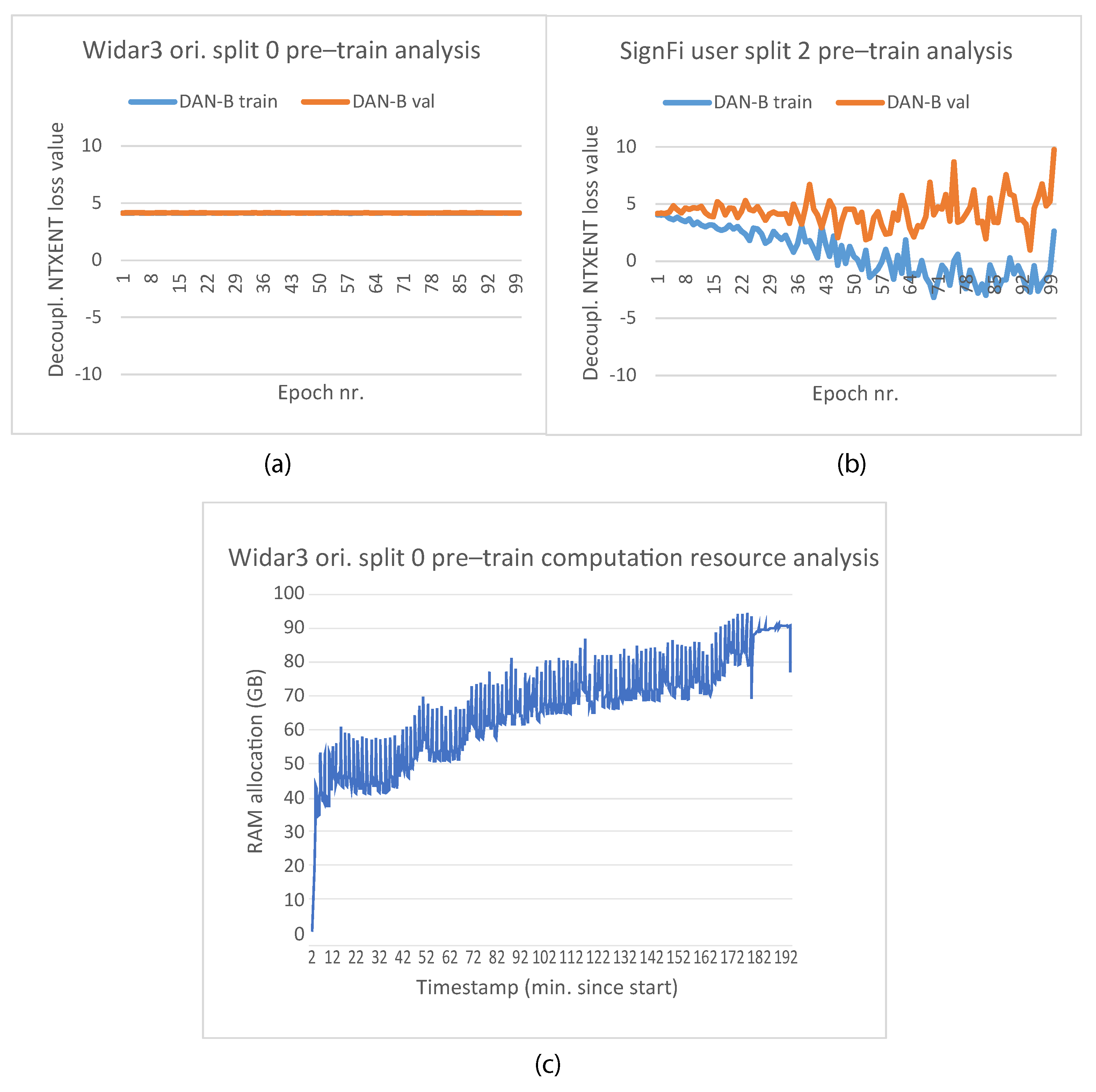
5.5. Hypothesis Validation
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Pseudo Code of Our Proposed Unsupervised Contrastive Learning Approach with Integrated Adversarial Domain Classification in the Pre-Training Phase
| Algorithm A1 Unsupervised contrastive learning split up in two subsequent learning processes: pre-training and fine-tuning. Pseudo code considers the approach in Figure 1b and provides comments for Figure 1c. |
| Input: Memory-mapped pre-train dataset and indices set , Memory-mapped fine-tune dataset and indices set , number of epochs and |
| Output: Feature extractor , and gesture classifier with predictable classes. |
| initialize with learnable parameters |
| initialize projection network with learnable parameters |
| initialize domain discriminator with learnable parameters |
| for epoch from do |
| for iteration from do |
| Fetch elements in list using function |
| ▹: meshgrid func. two |
| Update , , by descending along the respective gradients
|
| ▹ |
| end for |
| end for |
| for epoch from do |
| for iteration from do |
| Fetch elements in list using function |
| Update by descending along the respective gradient
|
| end for |
| end for |
| Algorithm A2 Positive view combination creation input pipeline pseudo coded as a generator. Used during pre-training. The pseudo code example uses the SignFi dataset. | |
| Input: Memory-mapped dataset D, Dataset indices set I, set of augmentations A | |
| Output: Raw A/P value tensor positive view combination (see yield statement) | |
| < Integer, List< Integer > > | |
| while True do | |
| for _ in I do | ▹ _ denotes insignificant index |
| for j in [1, 2, 3] do | |
| ▹ multiple shuffles: sample mixing augmentation support | |
| ▹ Validation version: does not use shuffle | |
| ▹, also retrieve domain/task labels | |
| end for | |
| ▹ Validation version: does not use augmentation | |
| ▹ No sample mixing: only is used | |
| ▹ is a set because labels were retrieved | |
| if k in H then | ▹ Key grouping: considered for pipelines Figure 1b,c. |
| H.get_by_key(k)[0] | ▹ Key grouping: not required for c. |
| L.insert_after(, (dsa, y, s)) | |
| H.get_by_key(k).append() | |
| else | |
| L.append((dsa, y, s)) | |
| H.insert(k, []) | |
| end if | |
| if size(L) >= 2 then | ▹ 2: number of views in positive combination |
| L.get().next | |
| yield (L.get().dsa, L.get().dsa), L.get().s | |
| if size(L) == prefetch_size then | ▹ prefetch_size: elements in RAM |
| H.get_by_key(k).delete_by_value() | ▹ Also remove k when empty list |
| L.delete() | |
| end if | |
| else | |
| continue | |
| end if | |
| end for | |
| end while | |
| ▹ are pre-processed offline with sequence of methods, see Section 3.1. | |
| Algorithm A3 Input pipeline pseudo coded as a generator. Used during fine-tuning. The pseudo code considers the SignFi dataset. | |
| Input: Memory-mapped dataset D, Dataset indices set I, set of augmentations | |
| Output: Raw A/P value tensor (see yield statement) | |
| while True do | |
| for _ in I do | ▹ _ denotes insignificant index |
| for j in [1, 2, 3] do | |
| ▹ multiple shuffles: sample mixing augmentation support | |
| ▹ Validation version: does not use shuffle | |
| ▹, also retrieve domain/task labels | |
| end for | |
| ▹ Validation version: does not use augmentation | |
| ▹ No sample mixing: only is used | |
| ▹ is a set because labels were retrieved | |
| yield dsa, y | |
| end for | |
| end while | |
| ▹ are pre-processed offline with sequence of methods; see Section 3.1. | |
References
- Tateno, S.; Zhu, Y.; Meng, F. Hand Gesture Recognition System for In-car Device Control Based on Infrared Array Sensor. In Proceedings of the 2019 58th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Hiroshima, Japan, 10–13 September 2019; pp. 701–706. [Google Scholar] [CrossRef]
- Chen, L.; Wang, F.; Deng, H.; Ji, K. A Survey on Hand Gesture Recognition. In Proceedings of the 2013 International Conference on Computer Sciences and Applications, Wuhan, China, 14–15 December 2013; pp. 313–316. [Google Scholar] [CrossRef]
- Ma, Y.; Zhou, G.; Wang, S. WiFi Sensing with Channel State Information: A Survey. ACM Comput. Surv. 2019, 52, 46. [Google Scholar] [CrossRef]
- Ma, Y.; Zhou, G.; Wang, S.; Zhao, H.; Jung, W. SignFi: Sign Language Recognition Using WiFi. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 23. [Google Scholar] [CrossRef]
- Zhou, Q.; Xing, J.; Chen, W.; Zhang, X.; Yang, Q. From Signal to Image: Enabling Fine-Grained Gesture Recognition with Commercial Wi-Fi Devices. Sensors 2018, 18, 3142. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Zhang, Y.; Qian, K.; Zhang, G.; Liu, Y.; Wu, C.; Yang, Z. Zero-Effort Cross-Domain Gesture Recognition with Wi-Fi. In Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services, Seoul, Republic of Korea, 17–21 June 2019; pp. 313–325. [Google Scholar] [CrossRef]
- Yang, J.; Zou, H.; Zhou, Y.; Xie, L. Learning Gestures From WiFi: A Siamese Recurrent Convolutional Architecture. IEEE Internet Things J. 2019, 6, 10763–10772. [Google Scholar] [CrossRef]
- Lau, H.-S.; McConville, R.; Bocus, M.J.; Piechocki, R.J.; Santos-Rodriguez, R. Self-Supervised WiFi-Based Activity Recognition. arXiv 2021, arXiv:2104.09072. [Google Scholar]
- Hu, P.; Changpei, T.; Yin, K.; Zhang, X. WiGR: A Practical Wi-Fi-Based Gesture Recognition System with a Lightweight Few-Shot Network. Appl. Sci. 2021, 11, 3329. [Google Scholar] [CrossRef]
- Yang, J.; Chen, X.; Zou, H.; Wang, D.; Xie, L. AutoFi: Towards Automatic WiFi Human Sensing via Geometric Self-Supervised Learning. IEEE Internet Things J. 2022, 10, 7416–7425. [Google Scholar] [CrossRef]
- Sun, B.; Feng, J.; Saenko, K. Return of Frustratingly Easy Domain Adaptation. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; pp. 2058–2065. [Google Scholar]
- Jiang, W.; Miao, C.; Ma, F.; Yao, S.; Wang, Y.; Yuan, Y.; Xue, H.; Song, C.; Ma, X.; Koutsonikolas, D.; et al. Towards Environment Independent Device Free Human Activity Recognition. In Proceedings of the 24th Annual International Conference on Mobile Computing and Networking, New Delhi, India, 29 October–2 November 2018; pp. 289–304. [Google Scholar] [CrossRef]
- Xue, H.; Jiang, W.; Miao, C.; Ma, F.; Wang, S.; Yuan, Y.; Yao, S.; Zhang, A.; Su, L. DeepMV: Multi-View Deep Learning for Device-Free Human Activity Recognition. ACM IMWUT 2020, 4, 34. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, S.; Yang, W.; Xu, Y. Environment-Independent Wi-Fi Human Activity Recognition with Adversarial Network. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3330–3334. [Google Scholar] [CrossRef]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a Few Examples: A Survey on Few-Shot Learning. ACM Comput. Surv. 2020, 53, 63. [Google Scholar] [CrossRef]
- Jaiswal, A.; Babu, A.R.; Zadeh, M.Z.; Banerjee, D.; Makedon, F. A Survey on Contrastive Self-Supervised Learning. Technologies 2021, 9, 2. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Saeed, A.; Ozcelebi, T.; Lukkien, J. Multi-Task Self-Supervised Learning for Human Activity Detection. ACM IMWUT 2019, 3, 61. [Google Scholar] [CrossRef]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; Volume 119, PMLR. pp. 1597–1607. [Google Scholar]
- Xu, K.; Wang, J.; Zhang, L.; Zhu, H.; Zheng, D. Dual-Stream Contrastive Learning for Channel State Information Based Human Activity Recognition. IEEE J. Biomed. Health Informatics 2023, 27, 329–338. [Google Scholar] [CrossRef] [PubMed]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Gu, Y.; Zhang, X.; Wang, Y.; Wang, M.; Yan, H.; Ji, Y.; Liu, Z.; Li, J.; Dong, M. WiGRUNT: WiFi-Enabled Gesture Recognition Using Dual-Attention Network. IEEE Trans. Hum.-Mach. Syst. 2022, 52, 736–746. [Google Scholar] [CrossRef]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef]
- Qian, K.; Wu, C.; Zhou, Z.; Zheng, Y.; Yang, Z.; Liu, Y. Inferring Motion Direction using Commodity Wi-Fi for Interactive Exergames. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 1961–1972. [Google Scholar] [CrossRef]
- Li, X.; Zhang, D.; Lv, Q.; Xiong, J.; Li, S.; Zhang, Y.; Mei, H. IndoTrack: Device-Free Indoor Human Tracking with Commodity Wi-Fi. In Proceedings of the 17th Annual International Conference on Mobile Systems, Applications, and Services, Seoul, Republic of Korea, 17–21 June 2019; pp. 1–22. [Google Scholar] [CrossRef]
- Butterworth, S. On the theory of filter amplifiers. Exp. Wirel. Wirel. Eng. 1930, 7, 536–541. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Li, L.; Jamieson, K.; DeSalvo, G.; Rostamizadeh, A.; Talwalkar, A. Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization. JMLR 2017, 18, 6765–6816. [Google Scholar]
- Berkson, J. Application of the Logistic Function to Bio-Assay. J. Am. Stat. Assoc. 1944, 39, 357–365. [Google Scholar] [CrossRef]
- Uspensky, J.V. Introduction to Mathematical Probability; McGraw-Hill: New York, NY, USA, 1937. [Google Scholar]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Multiview Coding. In Computer Vision, Proceedings of the ECCV 2020, Glasgow, UK, 23–28 August 2020; Springer International Publisher: Cham, Switzerland, 2020; pp. 776–794. [Google Scholar]
- Yeh, C.-H.; Hong, C.-Y.; Hsu, Y.-C.; Liu, T.-L.; Chen, Y.; LeCun, Y. Decoupled Contrastive Learning. In Computer Vision, Proceedings of the ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 668–684. [Google Scholar]
- Sohn, K. Improved Deep Metric Learning with Multi-class N-pair Loss Objective. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates, Inc.: New York, NY, USA, 2016; Volume 29. [Google Scholar]
- Smith, D. Leveraging Synthetic Images with Domain-Adversarial Neural Networks for Fine-Grained Car Model Classification. Master’s Thesis, Intelligent Systems, Robotics, Perception and Learning Group, KTH Royal Institute of Technology, Stockholm, Sweden, 2022. [Google Scholar]
- van Berlo, B.; Ozcelebi, T.; Meratnia, N. Insights on Mini-Batch Alignment for WiFi-CSI Data Domain Factor Independent Feature Extraction. In Proceedings of the 2022 IEEE International Conference on Pervasive Computing and Communications Workshops and Other Affiliated Events (PerCom Workshops), Pisa, Italy, 21–25 March 2022; pp. 527–532. [Google Scholar] [CrossRef]
- Jeon, S.; Hong, K.; Lee, P.; Lee, J.; Byun, H. Feature Stylization and Domain-Aware Contrastive Learning for Domain Generalization. In Proceedings of the 29th ACM International Conference on Multimedia (MM’21), Virtual Event, China, 20–24 October 2021; pp. 22–31. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates Inc.: New York, NY, USA, 2012; Volume 2, pp. 2951–2959. [Google Scholar]
- Zhang, J.; Wu, F.; Wei, B.; Zhang, Q.; Huang, H.; Shah, S.W.; Cheng, J. Data Augmentation and Dense-LSTM for Human Activity Recognition Using WiFi Signal. IEEE Internet Things J. 2021, 8, 4628–4641. [Google Scholar] [CrossRef]
- Um, T.T.; Pfister, F.M.J.; Pichler, D.; Endo, S.; Lang, M.; Hirche, S.; Fietzek, U.; Kulić, D. Data Augmentation of Wearable Sensor Data for Parkinson’s Disease Monitoring Using Convolutional Neural Networks. In Proceedings of the 19th ACM International Conference on Multimodal Interaction, Glasgow, UK, 13–17 November 2017; pp. 216–220. [Google Scholar]
- Saeed, A.; Grangier, D.; Zeghidour, N. Contrastive Learning of General-Purpose Audio Representations. In Proceedings of the 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 3875–3879. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, L.; Xu, R.; Cui, P.; Shen, Z.; Liu, H. Towards Unsupervised Domain Generalization. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18-24 June 2022; pp. 4910–4920. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| I | Op | KP | Ot | E | Ac | St | B | Sk |
|---|---|---|---|---|---|---|---|---|
| 224 × 64 × 3 | Conv. | 12 × 36 | 21 | - | ReLU | 1 × 1 | ✓ | - |
| 224 × 64 × 21 | Avg. Pool | 4 × 16 | - | - | - | DP × 2 | - | - |
| 112 × 32 × 21 | MobileV2 | 4 × 4 | 42 | 2 | ReLU | 1 × 1 | ✓ | - |
| 112 × 32 × 42 | MobileV2 | 4 × 4 | 42 | 2 | ReLU | 1 × 1 | ✓ | - |
| 112 × 32 × 42 | MobileV2 | 4 × 4 | 42 | 2 | ReLU | 1 × 1 | ✓ | - |
| 112 × 32 × 42 | Avg. Pool | 26 × 20 | - | - | - | DPx2 | - | - |
| 56 × 16 × 42 | MobileV2 | 8 × 8 | 84 | 4 | ReLU | 1 × 1 | ✓ | ✓ |
| 56 × 16 × 84 | MobileV2 | 8 × 8 | 84 | 4 | ReLU | 1 × 1 | ✓ | ✓ |
| 56 × 16 × 84 | Avg. Pool | 30 × 22 | - | - | - | DP × 2 | - | - |
| 28 × 8 × 84 | MobileV2 | 5 × 5 | 168 | 7 | ReLU | 1 × 1 | ✓ | ✓ |
| 28 × 8 × 168 | Avg. Pool | 2 × 6 | - | - | - | × 4 | - | - |
| 2 × 2 × 168 | Flatten | - | - | - | - | - | - | - |
| Res. | Data | STD | STD-P | ADV-S | ADV-M1 | ADV-M2 | DAN-F | ALT-F | DAN-B | ALT-B |
|---|---|---|---|---|---|---|---|---|---|---|
| CPU | Widar3 | |||||||||
| nr. | Widar3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | x |
| type | Widar3 | 7R32 | 7R32 | 7R32 | 7R32 | 7R32 | 7R32 | 7R32 | 7R32 | x |
| cores | Widar3 | 8 | 8 | 8 | 8 | 8 | 8 | 48 | 48 | x |
| GPU | Widar3 | |||||||||
| nr. | Widar3 | 1 | 1 | 1 | 1 | 1 | 1 | 4 | 4 | x |
| type | Widar3 | A10G | A10G | A10G | A10G | A10G | A10G | A10G | A10G | x |
| cores | Widar3 | 9216 | 9216 | 9216 | 9216 | 9216 | 9216 | 9216 | 9216 | x |
| mem. | Widar3 | 24 GB | 24 GB | 24 GB | 24 GB | 24 GB | 24 GB | 24 GB | 24 GB | x |
| RAM | Widar3 | |||||||||
| size | Widar3 | 64 GB | 64 GB | 64 GB | 64 GB | 64 GB | 64 GB | 384 GB | 384 GB | x |
| type | Widar3 | DDR5 | DDR5 | DDR5 | DDR5 | DDR5 | DDR5 | DDR5 | DDR5 | x |
| acc. | Widar3 | 69.2 GBs | 69.2 GBs | 69.2 GBs | 69.2 GBs | 69.2 GBs | 69.2 GBs | 69.2 GBs | 69.2 GBs | x |
| SSD | Widar3 | |||||||||
| size | Widar3 | 600 GB | 600 GB | 600 GB | 600 GB | 600 GB | 600 GB | 3.8 TB | 3.8 TB | x |
| int. | Widar3 | NVMe | NVMe | NVMe | NVMe | NVMe | NVMe | NVMe | NVMe | x |
| IOPS | Widar3 | 20,000 | 20,000 | 20,000 | 20,000 | 20,000 | 20,000 | 80,000 | 80,000 | x |
| TIME | Widar3 | 53.1 s | 53.4 s | 53.8 s | 56.5 s | 56.6 s | 53.3 s | 99.8 s | 104.4 s | x |
| CPU | SignFi | |||||||||
| nr. | SignFi | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| type | SignFi | 7R32 | 7R32 | 7R32 | 7R32 | 7R32 | 7R32 | 7R32 | 7R32 | 7R32 |
| cores | SignFi | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 |
| GPU | SignFi | |||||||||
| nr. | SignFi | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| type | SignFi | A10G | A10G | A10G | A10G | A10G | A10G | A10G | A10G | A10G |
| cores | SignFi | 9216 | 9216 | 9216 | 9216 | 9216 | 9216 | 9216 | 9216 | 9216 |
| mem. | SignFi | 24 GB | 24 GB | 24 GB | 24 GB | 24 GB | 24 GB | 24 GB | 24 GB | 24 GB |
| RAM | SignFi | |||||||||
| size | SignFi | 64 GB | 64 GB | 64 GB | 64 GB | 64 GB | 64 GB | 64 GB | 64 GB | 64 GB |
| type | SignFi | DDR5 | DDR5 | DDR5 | DDR5 | DDR5 | DDR5 | DDR5 | DDR5 | DDR5 |
| acc. | SignFi | 69.2 GBs | 69.2 GBs | 69.2 GBs | 69.2 GBs | 69.2 GBs | 69.2 GBs | 69.2 GBs | 69.2 GBs | 69.2 GBs |
| SSD | SignFi | |||||||||
| size | SignFi | 600 GB | 600 GB | 600 GB | 600 GB | 600 GB | 600 GB | 600 GB | 600 GB | 600 GB |
| int. | SignFi | NVMe | NVMe | NVMe | NVMe | NVMe | NVMe | NVMe | NVMe | NVMe |
| IOPS | SignFi | 20,000 | 20,000 | 20,000 | 20,000 | 20,000 | 20,000 | 20,000 | 20,000 | 20,000 |
| TIME | SignFi | 7.4 s | 12.9 s | 13.7 s | 15.6 s | 15.6 s | 12.9 s | 19.4 s | 18 s | 24 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Berlo, B.v.; Verhoeven, R.; Meratnia, N. Use of Domain Labels during Pre-Training for Domain-Independent WiFi-CSI Gesture Recognition. Sensors 2023, 23, 9233. https://doi.org/10.3390/s23229233
Berlo Bv, Verhoeven R, Meratnia N. Use of Domain Labels during Pre-Training for Domain-Independent WiFi-CSI Gesture Recognition. Sensors. 2023; 23(22):9233. https://doi.org/10.3390/s23229233
Chicago/Turabian StyleBerlo, Bram van, Richard Verhoeven, and Nirvana Meratnia. 2023. "Use of Domain Labels during Pre-Training for Domain-Independent WiFi-CSI Gesture Recognition" Sensors 23, no. 22: 9233. https://doi.org/10.3390/s23229233
APA StyleBerlo, B. v., Verhoeven, R., & Meratnia, N. (2023). Use of Domain Labels during Pre-Training for Domain-Independent WiFi-CSI Gesture Recognition. Sensors, 23(22), 9233. https://doi.org/10.3390/s23229233