
Early Fire Detection Using Long Short-Term Memory-Based Instance Segmentation and Internet of Things for Disaster Management


Abstract
:1. Introduction
2. Literature Review
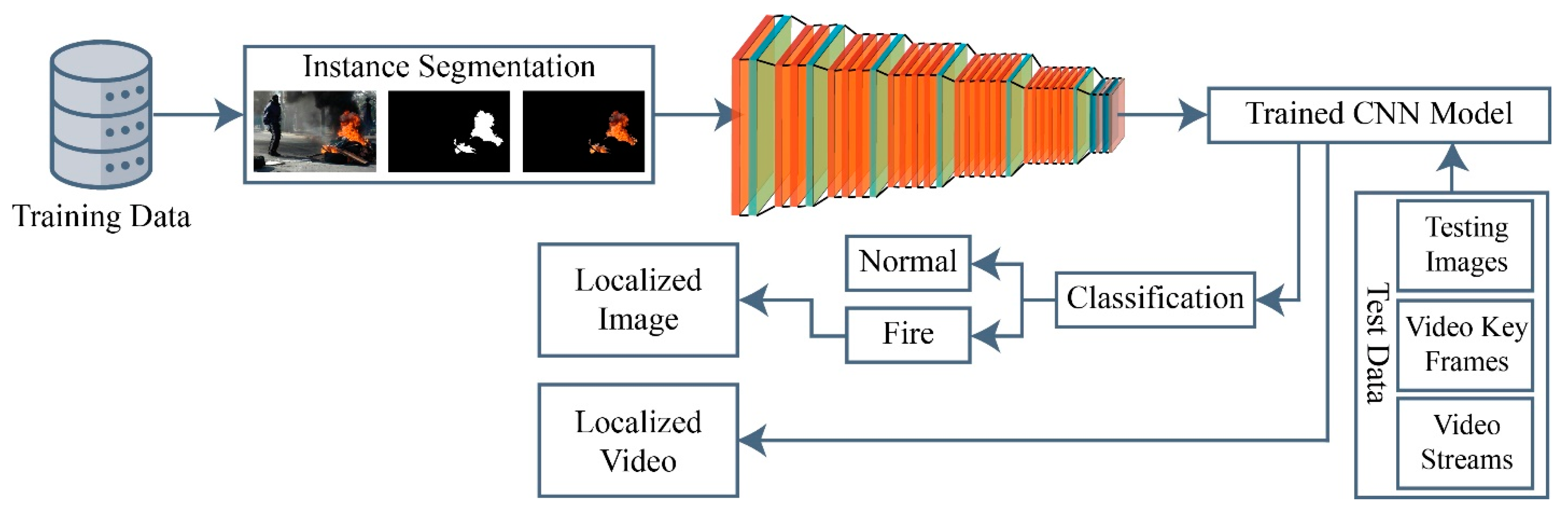
3. Proposed Work
3.1. Instance Segmentation
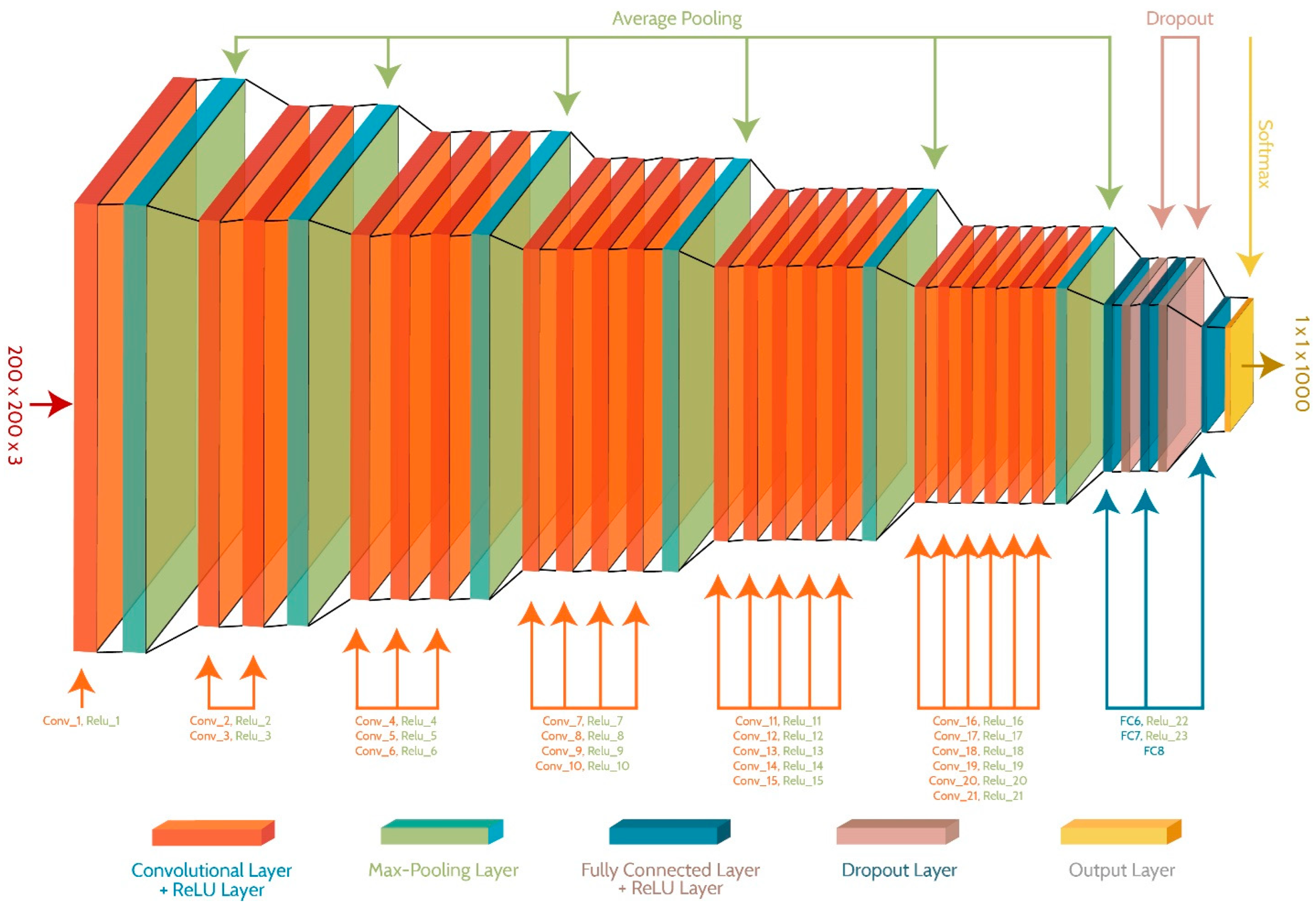
3.2. Deep CNN Architecture
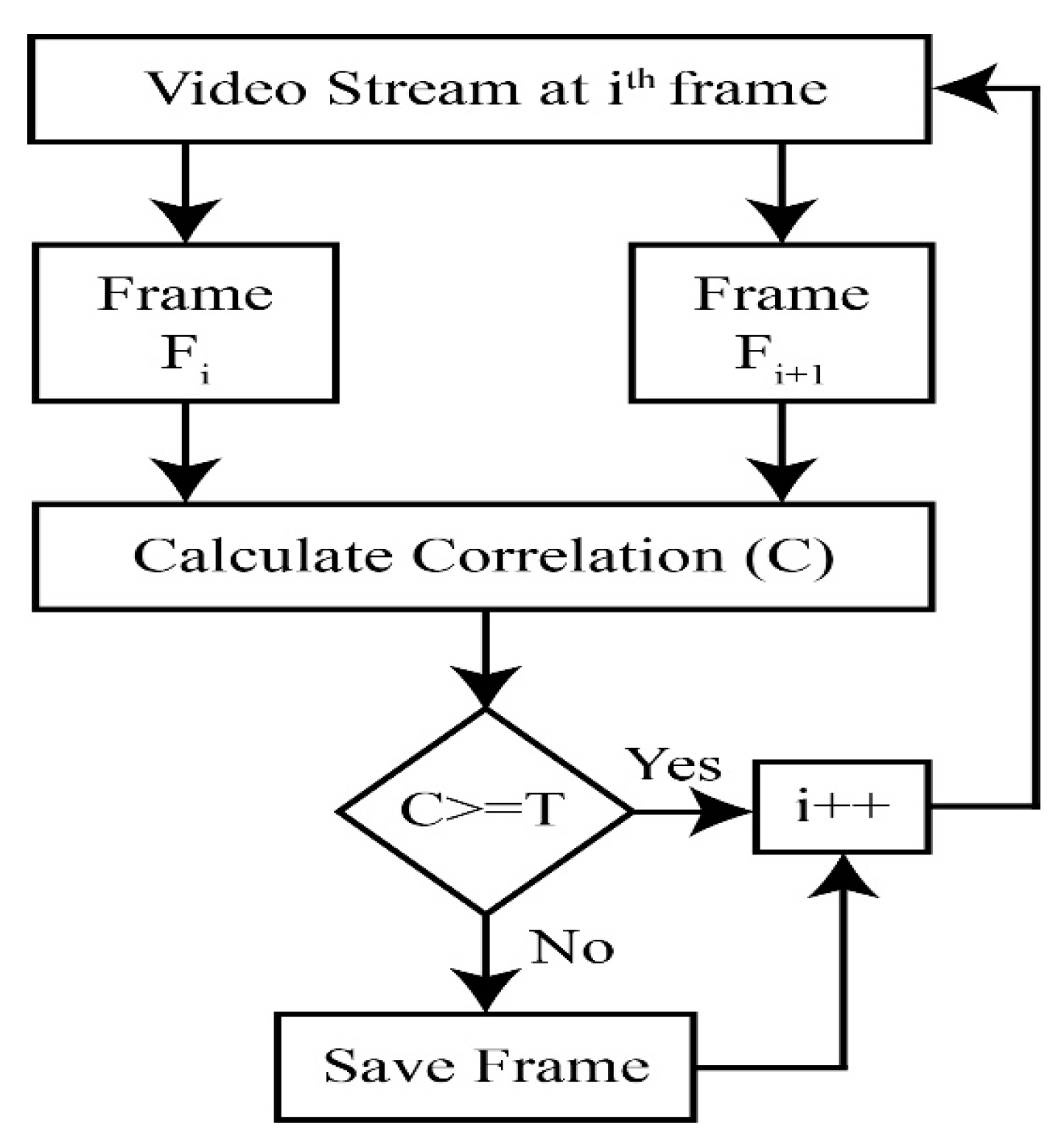
3.3. Key Frames Extraction
| Algorithm 1. Extracting Key Frames from Video |
| Input: A video stream |
| Output: Key frames |
| 1. All video frames |
| 2. |
| 3. |
| 4. then ; |
| ; ; |
| End |
3.4. Fire Classification and Localization
| Algorithm 2. Classification and Localization of Fire |
| Input: Trained classifier (Classifier), test data (TD), output type (OT), and trained CNN model (Net) |
| Output: Localized fire images or video |
| 1. Analyze the input data (ID), either images (I) or video streams (VS) |
| 2. Analyze the OT, either localized image (LI) or localized video (LV) |
| 3. Extract test features of ID and predict label using Net |
| Extract Key Frames Repeat step 3 Resize video as per the Network Size Localize the Video using Net |
| 4. Check the predicted Label No action required |
| Extract the features (FV) using layer FC7 of the CNN model. Apply binarization using Threshold (T) as: |
| 5. Localize the fire in the input image using |
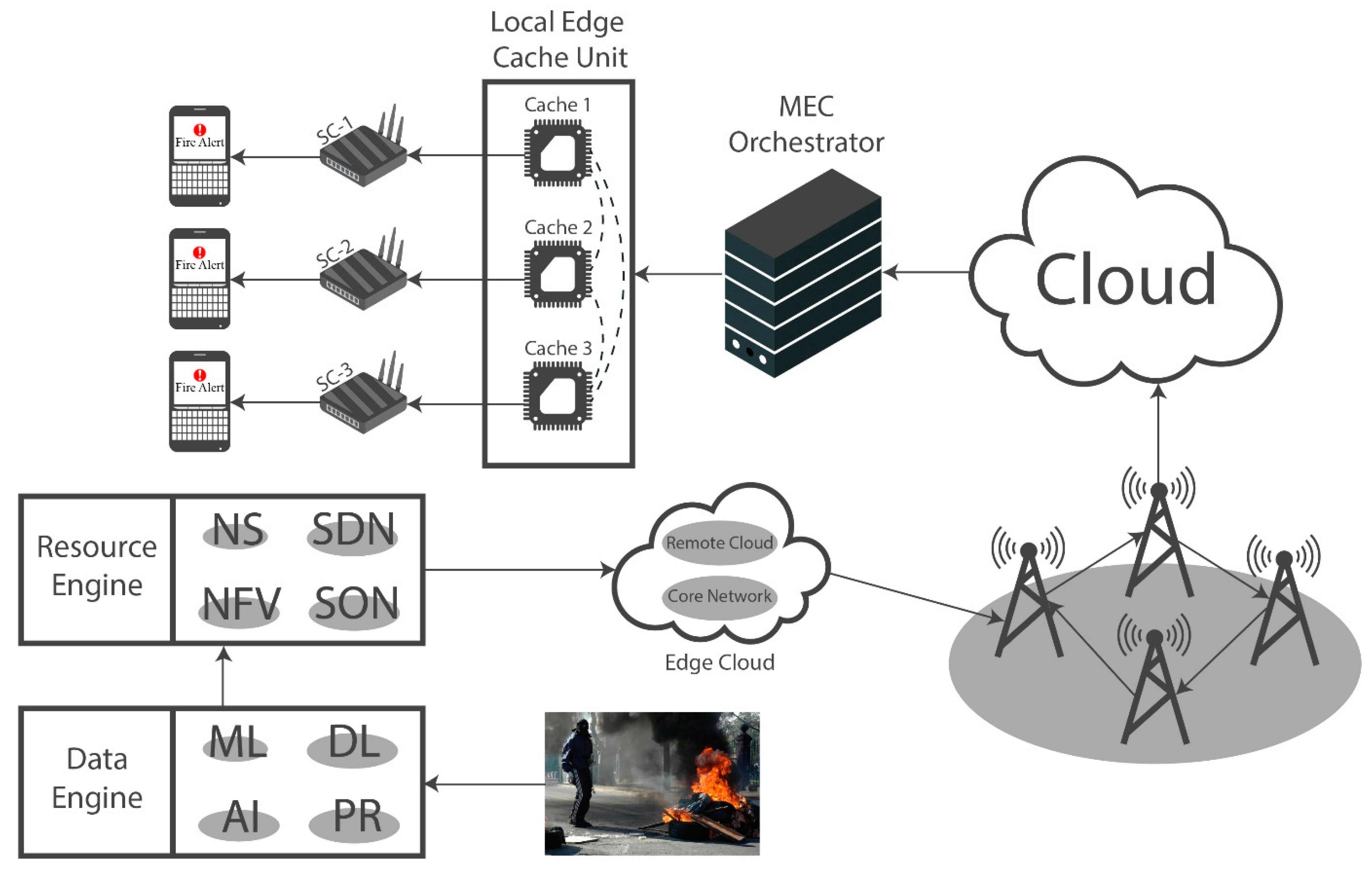
3.5. Fire Analysis
| Algorithm 3. Determining Intensity and Severity of Fire |
| Input: Labelled Image |
| Output: Alert concerning person/department |
| 1. Trained Proposed CNN model on 23 classes |
| 2. Input Image |
| 3. Extracted objects from using Instance Segmentation |
| 4. |
| 5. |
| 6. |
| 7. |
| 8. |
| 9. |
| 10. then Object is times bigger and each pixels will be equal to 1 pixel |
| then Object is either equal or times smaller and each pixel will be equal to pixels in case of smaller object |
| 11. |
| 12. |
| 13. , |
| 14. |
| 15. then label fire as High Severity. then label fire as Medium Severity then label fire as Low Severity. |
4. Experimental Results and Discussion
4.1. Experimental Setup
4.2. Experimental Results
4.3. Robustness of Proposed Model
4.4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gaur, A.; Singh, A.; Kumar, A.; Kulkarni, K.S.; Lala, S.; Kapoor, K.; Srivastava, V.; Kumar, A.; Mukhopadhyay, S.C. Fire sensing technologies: A review. IEEE Sens. J. 2019, 19, 3191–3202. [Google Scholar]
- Ahrens, M. Trends and Patterns of US Fire Loss; National Fire Protection Association (NFPA) Report; National Fire Protection Association (NFPA): Batterymarch Park Quincy, MA, USA, 2017. [Google Scholar]
- Fonollosa, J.; Solórzano, A.; Marco, S. Chemical sensor systems and associated algorithms for fire detection: A review. Sensors 2018, 18, 553. [Google Scholar] [CrossRef]
- Li, J.; Yan, B.; Zhang, M.; Zhang, J.; Jin, B.; Wang, Y.; Wang, D. Long-range raman distributed fiber temperature sensor with early warning model for fire detection and prevention. IEEE Sens. J. 2019, 19, 3711–3717. [Google Scholar]
- Li, P.; Zhao, W. Image fire detection algorithms based on convolutional neural networks. Case Stud. Therm. Eng. 2020, 19, 100625. [Google Scholar]
- Wang, H.; Fang, X.; Li, Y.; Zheng, Z.; Shen, J. Research and application of the underground fire detection technology based on multi-dimensional data fusion. Tunn. Undergr. Space Technol. 2021, 109, 103753. [Google Scholar] [CrossRef]
- Pathak, N.; Misra, S.; Mukherjee, A.; Kumar, N. HeDI: Healthcare Device Interoperability for IoT-Based e-Health Platforms. IEEE Internet Things J. 2021, 8, 16845–16852. [Google Scholar] [CrossRef]
- Kumar, M.; Raju, K.S.; Kumar, D.; Goyal, N.; Verma, S.; Singh, A. An efficient framework using visual recognition for IoT based smart city surveillance. Multimed. Tools Appl. 2021, 80, 31277–31295. [Google Scholar] [PubMed]
- Dugdale, J.; Moghaddam, M.T.; Muccini, H. IoT4Emergency: Internet of Things for Emergency Management. Acm Sigsoft Softw. Eng. Notes 2021, 46, 33–36. [Google Scholar] [CrossRef]
- Guha-Sapir, D.; Hoyois, P. Estimating Populations Affected by Disasters: A Review of Methodological Issues and Research Gaps; Brussels: Centre for Research on the Epidemiology of Disasters (CRED), Institute of Health and Society (IRSS), University Catholique de Louvain: Louvain-la-Neuve, Belgium, 2015. [Google Scholar]
- Khalil, A.; Rahman, S.U.; Alam, F.; Ahmad, I.; Khalil, I. Fire Detection Using Multi Color Space and Background Modeling. Fire Technol. 2020, 57, 1221–1239. [Google Scholar] [CrossRef]
- Xie, Y.; Zhu, J.; Cao, Y.; Zhang, Y.; Feng, D.; Zhang, Y.; Chen, M. Efficient Video Fire Detection Exploiting Motion-Flicker-Based Dynamic Features and Deep Static Features. IEEE Access 2020, 8, 81904–81917. [Google Scholar] [CrossRef]
- Luo, Y.; Zhao, L.; Liu, P.; Huang, D. Fire smoke detection algorithm based on motion characteristic and convolutional neural networks. Multimed. Tools Appl. 2018, 77, 15075–15092. [Google Scholar] [CrossRef]
- Khudayberdiev, O.; Butt, M.H.F. Fire detection in Surveillance Videos using a combination with PCA and CNN. Acad. J. Comput. Inf. Sci. 2020, 3, 27–33. [Google Scholar]
- Khan, M.A.; Nasir, I.M.; Sharif, M.; Alhaisoni, M.; Kadry, S.; Bukhari, S.A.C.; Nam, Y. A blockchain based framework for stomach abnormalities recognition. Comput. Mater. Contin 2021, 67, 141–158. [Google Scholar]
- Nasir, I.M.; Khan, M.A.; Alhaisoni, M.; Saba, T.; Rehman, A.; Iqbal, T. A hybrid deep learning architecture for the classification of superhero fashion products: An application for medical-tech classification. Comput. Model. Eng. Sci. 2020, 124, 1017–1033. [Google Scholar]
- Nasir, I.M.; Khan, M.A.; Armghan, A.; Javed, M.Y. SCNN: A Secure Convolutional Neural Network using Blockchain. In Proceedings of the 2020 2nd International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 13–15 October 2020; pp. 1–5. [Google Scholar]
- Nasir, I.M.; Khan, M.A.; Yasmin, M.; Shah, J.H.; Gabryel, M.; Scherer, R.; Damaševičius, R. Pearson correlation-based feature selection for document classification using balanced training. Sensors 2020, 20, 6793. [Google Scholar]
- Nasir, I.M.; Bibi, A.; Shah, J.H.; Khan, M.A.; Sharif, M.; Iqbal, K.; Nam, Y.; Kadry, S. Deep Learning-Based Classification of Fruit Diseases: An Application for Precision Agriculture. CMC-Comput. Mater. Contin. 2021, 66, 1949–1962. [Google Scholar]
- Nasir, I.M.; Raza, M.; Shah, J.H.; Khan, M.A.; Rehman, A. Human action recognition using machine learning in uncontrolled environment. In Proceedings of the 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA), Riyadh, Saudi Arabia, 6–7 April 2021; pp. 182–187. [Google Scholar]
- Nasir, I.M.; Raza, M.; Shah, J.H.; Wang, S.-H.; Tariq, U.; Khan, M.A. HAREDNet: A deep learning based architecture for autonomous video surveillance by recognizing human actions. Comput. Electr. Eng. 2022, 99, 107805. [Google Scholar] [CrossRef]
- Tariq, J.; Alfalou, A.; Ijaz, A.; Ali, H.; Ashraf, I.; Rahman, H.; Armghan, A.; Mashood, I.; Rehman, S. Fast intra mode selection in HEVC using statistical model. Comput. Mater. Contin. 2022, 70, 3903–3918. [Google Scholar] [CrossRef]
- Mushtaq, I.; Umer, M.; Imran, M.; Nasir, I.M.; Muhammad, G.; Shorfuzzaman, M. Customer prioritization for medical supply chain during COVID-19 pandemic. Comput. Mater. Contin. 2021, 70, 59–72. [Google Scholar] [CrossRef]
- Nasir, I.M.; Raza, M.; Ulyah, S.M.; Shah, J.H.; Fitriyani, N.L.M. Syafrudin ENGA: Elastic Net-Based Genetic Algorithm for human action recognition. Expert Syst. Appl. 2023, 227, 120311. [Google Scholar]
- Kumar, S.; Kumar, D.; Donta, P.K.; Amgoth, T. Land subsidence prediction using recurrent neural networks. Stoch. Environ. Res. Risk Assess. 2022, 36, 373–388. [Google Scholar] [CrossRef]
- Frizzi, S.; Kaabi, R.; Bouchouicha, M.; Ginoux, J.-M.; Moreau, E.; Fnaiech, F. Convolutional neural network for video fire and smoke detection. In Proceedings of the IECON 2016-42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23–26 October 2016; pp. 877–882. [Google Scholar]
- Sharma, J.; Granmo, O.-C.; Goodwin, M.; Fidje, J.T. Deep convolutional neural networks for fire detection in images. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Athens, Greece, 25–27 August 2017; Springer: Cham, Switzerland, 2017; pp. 183–193. [Google Scholar]
- Muhammad, K.; Ahmad, J.; Baik, S.W. Early fire detection using convolutional neural networks during surveillance for effective disaster management. Neurocomputing 2018, 288, 30–42. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional neural networks based fire detection in surveillance videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Lv, Z.; Bellavista, P.; Yang, P.; Baik, S.W. Efficient deep CNN-based fire detection and localization in video surveillance applications. IEEE Trans. Syst. Man Cybern. Syst. 2018, 49, 1419–1434. [Google Scholar] [CrossRef]
- Shen, D.; Chen, X.; Nguyen, M.; Yan, W.Q. Flame detection using deep learning. In Proceedings of the 2018 4th International Conference on Control, Automation and Robotics (ICCAR), Auckland, New Zealand, 20–23 April 2018; pp. 416–420. [Google Scholar]
- Kaabi, R.; Sayadi, M.; Bouchouicha, M.; Fnaiech, F.; Moreau, E.; Ginoux, J.M. Early smoke detection of forest wildfire video using deep belief network. In Proceedings of the 2018 4th International Conference on Advanced Technologies for Signal and Image Processing (ATSIP), Sousse, Tunisia, 21–24 March 2018; pp. 1–6. [Google Scholar]
- Hu, C.; Tang, P.; Jin, W.; He, Z.; Li, W. Real-time fire detection based on deep convolutional long-recurrent networks and optical flow method. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 9061–9066. [Google Scholar]
- Saputra, F.A.; Al Rasyid, M.U.H.; Abiantoro, B.A. Prototype of early fire detection system for home monitoring based on Wireless Sensor Network. In Proceedings of the 2017 International Electronics Symposium on Engineering Technology and Applications (IES-ETA), Surabaya, Indonesia, 26–27 September 2017; pp. 39–44. [Google Scholar]
- Jang, J.-Y.; Lee, K.-W.; Kim, Y.-J.; Kim, W.-T. S-FDS: A Smart Fire Detection System based on the Integration of Fuzzy Logic and Deep Learning. J. Inst. Electron. Inf. Eng. 2017, 54, 50–58. [Google Scholar]
- Park, M.; Ko, B.C. Two-step real-time night-time fire detection in an urban environment using Static ELASTIC-YOLOv3 and Temporal Fire-Tube. Sensors 2020, 20, 2202. [Google Scholar] [CrossRef] [PubMed]
- Abdusalomov, A.B.; Islam, B.M.S.; Nasimov, R.; Mukhiddinov, M.; Whangbo, T.K. An improved forest fire detection method based on the detectron2 model and a deep learning approach. Sensors 2023, 23, 1512. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Yao, J.; Raffuse, S.M.; Brauer, M.; Williamson, G.J.; Bowman, D.M.; Johnston, F.H.; Henderson, S.B. Predicting the minimum height of forest fire smoke within the atmosphere using machine learning and data from the CALIPSO satellite. Remote Sens. Environ. 2018, 206, 98–106. [Google Scholar] [CrossRef]
- Xu, S.S.; Mak, M.-W.; Cheung, C.-C. Deep neural networks versus support vector machines for ECG arrhythmia classification. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 127–132. [Google Scholar]
- Abdusalomov, A.; Baratov, N.; Kutlimuratov, A.; Whangbo, T.K. An improvement of the fire detection and classification method using YOLOv3 for surveillance systems. Sensors 2021, 21, 6519. [Google Scholar] [CrossRef]
- Mukhiddinov, M.; Abdusalomov, A.B.; Cho, J. Automatic Fire Detection and Notification System Based on Improved YOLOv4 for the Blind and Visually Impaired. Sensors 2022, 22, 3307. [Google Scholar] [CrossRef]
- Martins, L.; Guede-Fernández, F.; de Almeida, R.V.; Gamboa, H.; Vieira, P. Real-Time Integration of Segmentation Techniques for Reduction of False Positive Rates in Fire Plume Detection Systems during Forest Fires. Remote Sens. 2022, 14, 2701. [Google Scholar] [CrossRef]
- Girdhar, R.; Carreira, J.; Doersch, C.; Zisserman, A. Video action transformer network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 244–253. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5791–5800. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Ye, L.; Rochan, M.; Liu, Z.; Wang, Y. Cross-modal self-attention network for referring image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10502–10511. [Google Scholar]
- He, X.; Chen, Y.; Lin, Z. Spatial-spectral transformer for hyperspectral image classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhang, K.; Wang, B.; Tong, X.; Liu, K. Fire detection using vision transformer on power plant. Energy Rep. 2022, 8, 657–664. [Google Scholar] [CrossRef]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kinnunen, T.; Kamarainen, J.-K.; Lensu, L.; Lankinen, J.; Käviäinen, H. Making visual object categorization more challenging: Randomized caltech-101 data set. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 476–479. [Google Scholar]
- Jais, I.K.M.; Ismail, A.R.; Nisa, S.Q. Adam optimization algorithm for wide and deep neural network. Knowl. Eng. Data Sci 2019, 2, 41–46. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Bellavista, P.; Ota, K.; Lv, Z.; Mehmood, I.; Rho, S. Towards Smarter Cities: Learning from Internet of Multimedia Things-Generated Big Data; Elsevier: Amsterdam, The Netherlands, 2020. [Google Scholar]
- Rafiee, A.; Dianat, R.; Jamshidi, M.; Tavakoli, R.; Abbaspour, S. Fire and smoke detection using wavelet analysis and disorder characteristics. In Proceedings of the 2011 3rd International Conference on Computer Research and Development, Shanghai, China, 11–13 March 2011; Volume 3, pp. 262–265. [Google Scholar]
- Habiboğlu, Y.H.; Günay, O.; Çetin, A.E. Covariance matrix-based fire and flame detection method in video. Mach. Vis. Appl. 2012, 23, 1103–1113. [Google Scholar] [CrossRef]
- Chen, T.-H.; Wu, P.-H.; Chiou, Y.-C. An early fire-detection method based on image processing. In Proceedings of the 2004 International Conference on Image Processing (ICIP’04), Singapore, 24–27 October 2004; Volume 3, pp. 1707–1710. [Google Scholar]
- Foggia, P.; Saggese, A.; Vento, M. Real-time fire detection for video-surveillance applications using a combination of experts based on color, shape, and motion. IEEE Trans. Circuits Syst. Video Technol. 2015, 25, 1545–1556. [Google Scholar] [CrossRef]
- Talaat, F.M.; ZainEldin, H. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Guede-Fernández, F.; Martins, L.; de Almeida, R.V.; Gamboa, H.; Vieira, P. A deep learning based object identification system for forest fire detection. Fire 2021, 4, 75. [Google Scholar] [CrossRef]
- Wahyono; Harjoko, A.; Dharmawan, A.; Adhinata, F.D.; Kosala, G.; Jo, K.-H. Real-time forest fire detection framework based on artificial intelligence using color probability model and motion feature analysis. Fire 2022, 5, 23. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Combinations | Filters | Total Filters | Stride Size | Weight Size | Bias Vector | Activations |
|---|---|---|---|---|---|---|
| Input Layer | - | - | - | - | - | |
| Convolutional + ReLU | ||||||
| Max Pooling | - | - | - | |||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Max Pooling | - | - | - | |||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Max Pooling | - | - | - | |||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Max Pooling | - | - | - | |||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Max Pooling | - | - | - | |||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Convolutional + ReLU | ||||||
| Max Pooling | - | - | - | |||
| FC6 + ReLU + Dropout | - | - | - | |||
| FC7 + ReLU + Dropout | - | - | - | |||
| FC8 | - | - | - | |||
| Softmax | - | - | - | - | - |
| Video Name | Original File Name | Resolution | Frames | Modality | Total Frames |
|---|---|---|---|---|---|
| Video 1 | Flame1 | 402 | Fire | 64,049 | |
| Video 2 | Flame2 | 411 | Fire | ||
| Video 3 | Flame3 | 613 | Fire | ||
| Video 4 | Flame4 | 373 | Fire | ||
| Video 5 | Flame5 | 748 | Fire | ||
| Video 6 | indoor_night_20m_heptane_CCD_001 | 1658 | Fire | ||
| Video 7 | indoor_night_20m_heptane_CCD_002 | 3846 | Fire | ||
| Video 8 | outdoor_daytime_10m_gasoline_CCD_001 | 3491 | Fire | ||
| Video 9 | outdoor_daytime_10m_heptane_CCD_001 | 4548 | Fire | ||
| Video 10 | outdoor_daytime_20m_gasoline_CCD_001 | 3924 | Fire | ||
| Video 11 | outdoor_daytime_20m_heptane_CCD_001 | 4430 | Fire | ||
| Video 12 | outdoor_daytime_30m_gasoline_CCD_001 | 6981 | Fire | ||
| Video 13 | outdoor_daytime_30m_heptane_CCD_001 | 3754 | Fire | ||
| Video 14 | outdoor_night_10m_gasoline_CCD_001 | 1208 | Fire | ||
| Video 15 | outdoor_night_10m_gasoline_CCD_002 | 1298 | Fire | ||
| Video 16 | outdoor_night_10m_heptane_CCD_001 | 3275 | Fire | ||
| Video 17 | outdoor_night_10m_heptane_CCD_002 | 776 | Fire | ||
| Video 18 | outdoor_night_20m_gasoline_CCD_001 | 5055 | Fire | ||
| Video 19 | outdoor_night_20m_heptane_CCD_001 | 4141 | Fire | ||
| Video 20 | outdoor_night_20m_heptane_CCD_002 | 1645 | Fire | ||
| Video 21 | outdoor_night_30m_gasoline_CCD_001 | 6977 | Fire | ||
| Video 22 | outdoor_night_30m_heptane_CCD_001 | 4495 | Fire | ||
| Video 23 | smoke_or_flame_like_object_1 | 171 | Normal | 25,511 | |
| Video 24 | smoke_or_flame_like_object_2 | 530 | Normal | ||
| Video 25 | smoke_or_flame_like_object_3 | 862 | Normal | ||
| Video 26 | smoke_or_flame_like_object_4 | 904 | Normal | ||
| Video 27 | smoke_or_flame_like_object_5 | 8229 | Normal | ||
| Video 28 | smoke_or_flame_like_object_6 | 7317 | Normal | ||
| Video 29 | smoke_or_flame_like_object_7 | 2012 | Normal | ||
| Video 30 | smoke_or_flame_like_object_8 | 849 | Normal | ||
| Video 31 | smoke_or_flame_like_object_9 | 2807 | Normal | ||
| Video 32 | smoke_or_flame_like_object_10 | 1830 | Normal | ||
| Total Frames | 89,560 | ||||
| Model | Fine-Tuning | Accuracy (%) | FPR (%) | FNR (%) | Training Time (s) | Prediction Time (s) | ||
|---|---|---|---|---|---|---|---|---|
| No | Yes | |||||||
| CNN Pre-Trained Models | AlexNet | ✓ | 78.31 | 41.18 | 14.29 | 78.9 | 1.19 | |
| ✓ | 86.04 | 13.58 | 7.14 | 114.3 | 1.63 | |||
| InceptionV3 | ✓ | 83.87 | 29.33 | 10.65 | 69.8 | 0.83 | ||
| ✓ | 87.56 | 7.22 | 2.13 | 93.4 | 0.94 | |||
| SqueezeNet | ✓ | 74.39 | 14.67 | 7.80 | 63.5 | 0.98 | ||
| ✓ | 84.77 | 9.41 | 5.50 | 87.4 | 1.23 | |||
| Fused | ✓ | 89.47 | 11.76 | 9.74 | 397.2 | 0.78 | ||
| ✓ | 90.35 | 5.88 | 1.50 | 247.9 | 0.63 | |||
| Proposed | Without IS | ✓ | 91.62 | 3.38 | 2.94 | 54.7 | 0.32 | |
| ✓ | 93.84 | 1.82 | 1.43 | 73.5 | 0.18 | |||
| With IS | ✓ | 92.40 | 0.65 | 0.84 | 84.3 | 0.12 | ||
| ✓ | 95.25 | 0.09 | 0.65 | 100.8 | 0.08 | |||
| Technique | FPR (%) | FNR (%) | Accuracy (%) |
|---|---|---|---|
| Rafiee [61] | 17.65 | 07.14 | 87.10 |
| Habiboğlu [62] | 5.88 | 14.29 | 90.32 |
| Chen [63] | 11.76 | 14.29 | 87.10 |
| Bellavista [60] | 9.07 | 02.13 | 94.39 |
| Foggia [64] | 11.76 | - | 93.55 |
| Muhammad [30] | 8.87 | 02.12 | 94.50 |
| Fernández [66] | - | - | 92.6 |
| Wahyono [67] | 2.78 | 10.03 | 89.97 |
| Talaat [65] | - | - | 94.21 |
| Proposed | 0.09 | 00.65 | 95.25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malebary, S.J. Early Fire Detection Using Long Short-Term Memory-Based Instance Segmentation and Internet of Things for Disaster Management. Sensors 2023, 23, 9043. https://doi.org/10.3390/s23229043
Malebary SJ. Early Fire Detection Using Long Short-Term Memory-Based Instance Segmentation and Internet of Things for Disaster Management. Sensors. 2023; 23(22):9043. https://doi.org/10.3390/s23229043
Chicago/Turabian StyleMalebary, Sharaf J. 2023. "Early Fire Detection Using Long Short-Term Memory-Based Instance Segmentation and Internet of Things for Disaster Management" Sensors 23, no. 22: 9043. https://doi.org/10.3390/s23229043
APA StyleMalebary, S. J. (2023). Early Fire Detection Using Long Short-Term Memory-Based Instance Segmentation and Internet of Things for Disaster Management. Sensors, 23(22), 9043. https://doi.org/10.3390/s23229043