
Lightweight Multi-Class Support Vector Machine-Based Medical Diagnosis System with Privacy Preservation

 ,
,  ,
,  ,
,  , , and
, , and 
Abstract
:1. Introduction
- A privacy-preserving and lightweight SVM medical diagnosis scheme has been proposed by modifying an inner product encryption cryptosystem.
- The results of our analysis demonstrate that our proposed scheme successfully fulfills our security and privacy objectives, including preserving the privacy of the patient’s health status and protecting the model’s parameters.
- Our evaluations indicate that our proposal outperforms the most relevant approaches in the overhead while maintaining high classification accuracy.
2. Network and Threat Models
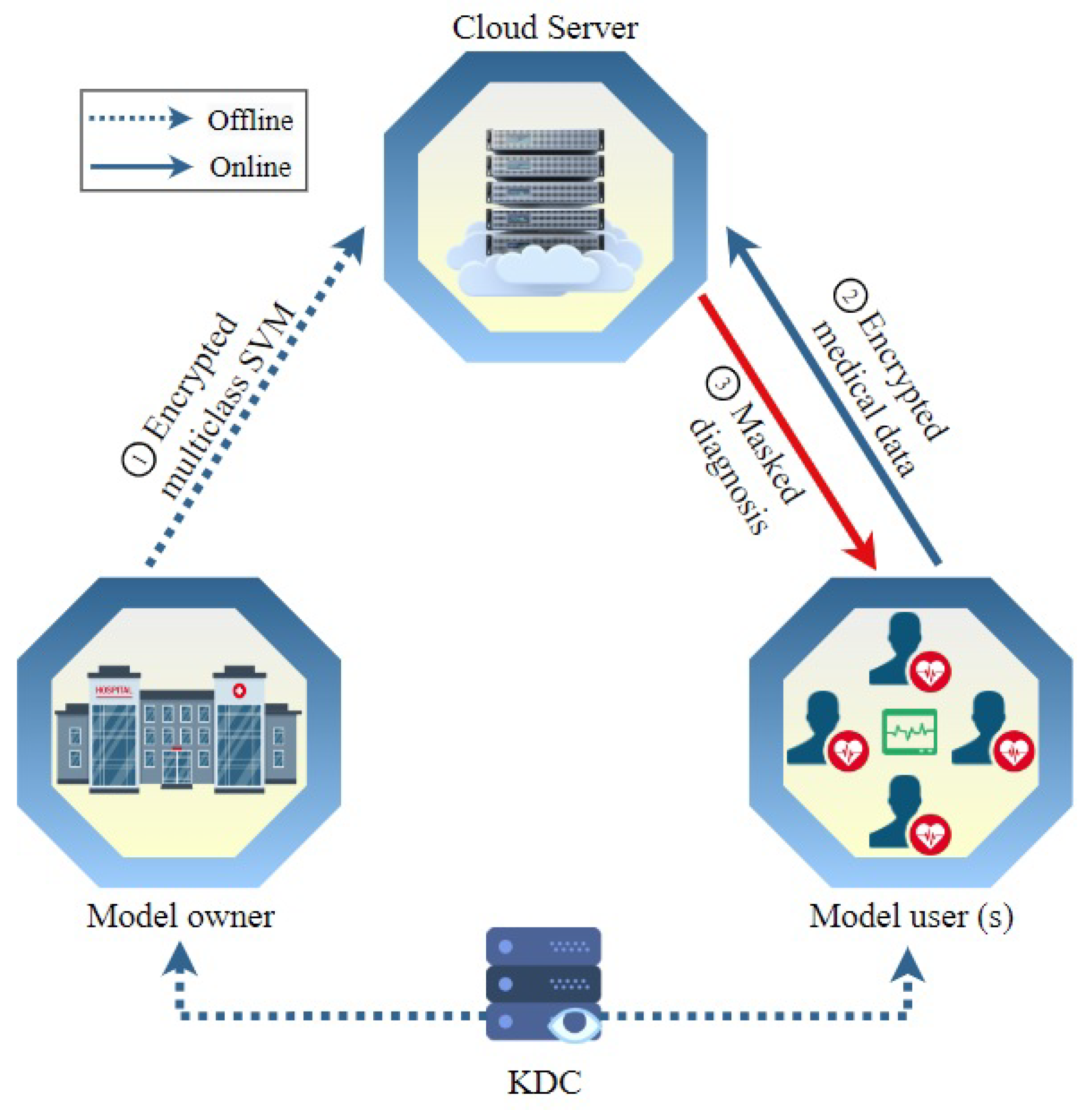
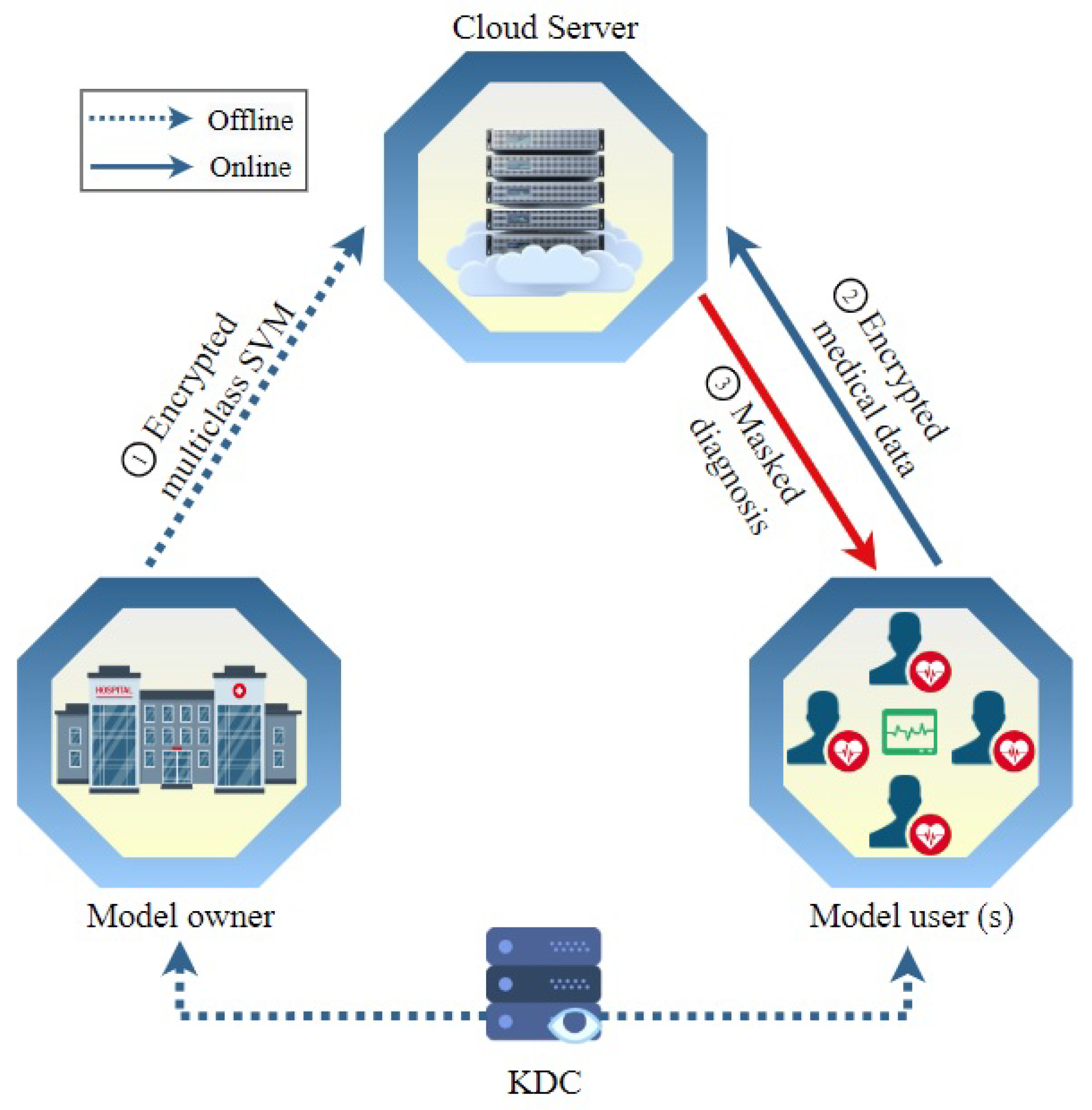
2.1. Network Model
- KDC. The key distribution center is a trusted entity that is responsible for computing secret keys needed to execute our scheme and distribute them to the other entities in the system. To fulfill the trustworthiness of this entity, it can be implemented by a trusted party, e.g., the Department of Health. Although the detailed implementation of the key distribution center is out of this paper’s scope, in the literature, there are many proposed approaches that can implement the KDC without the need for a trusted entity.
- MO. The model owner is a healthcare center that owns medical datasets for patients and uses them to compute a diagnosis model. It is reasonable to assume that the dataset is small. This is an acceptable assumption in medical diagnosis. The model owner does not have enough computation resources to provide the diagnosis service, so it outsources the diagnosis model after encrypting it to a third-party cloud service. Then, users send their data to the cloud to classify them using the model. Using a third-party cloud service can provide several benefits such as no computation burden being needed from the model owner and also the medical diagnosis service is always available.
- MUs. The model users include any party that seeks the medical diagnosis service, such as patients, doctors, clinics, healthcare monitoring services, etc. As indicated in Figure 1, users send encrypted medical data that includes vital and symptom data to the cloud server, which uses the ciphertext to compute encrypted classification and send it to the user to decrypt.
- CS: The cloud server offers an online medical diagnosis service. It is possessed and run by a third party, which can be a private company. It uses the ciphertext of the medical data sent by users and the ciphertext of the diagnosis model outsourced by the model owner to conduct operations over encrypted data. The result of these operations is the ciphertext of the classification (or medical diagnosis). Note that the cloud server cannot decrypt any of these ciphertexts to achieve our security and privacy objectives.
2.2. Threat Model
3. Preliminaries
3.1. Bilinear Pairing
- , for all and any , where represents a finite field of order m.
3.2. Support Vector Machine (SVM)
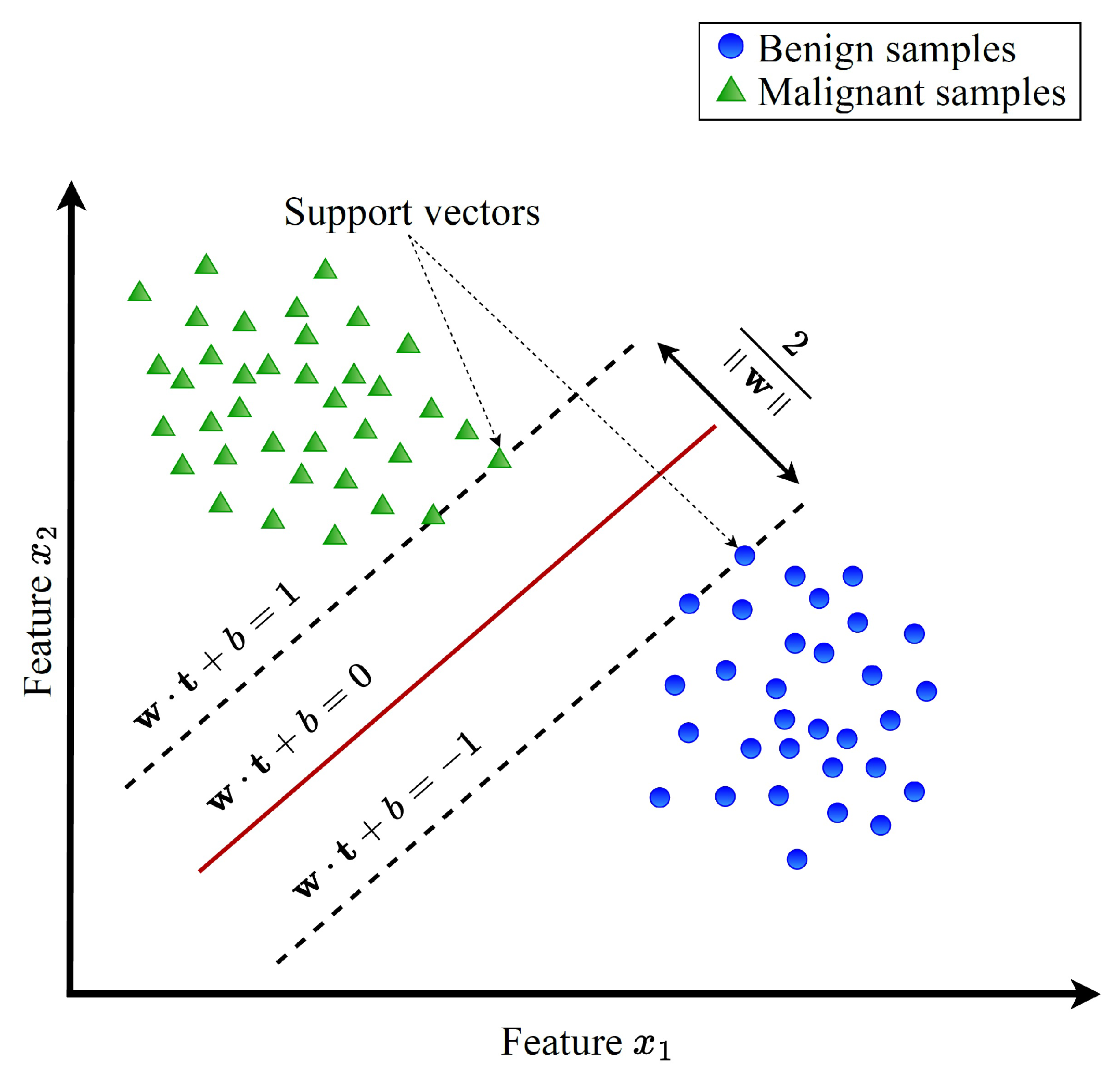
3.2.1. Linear SVM
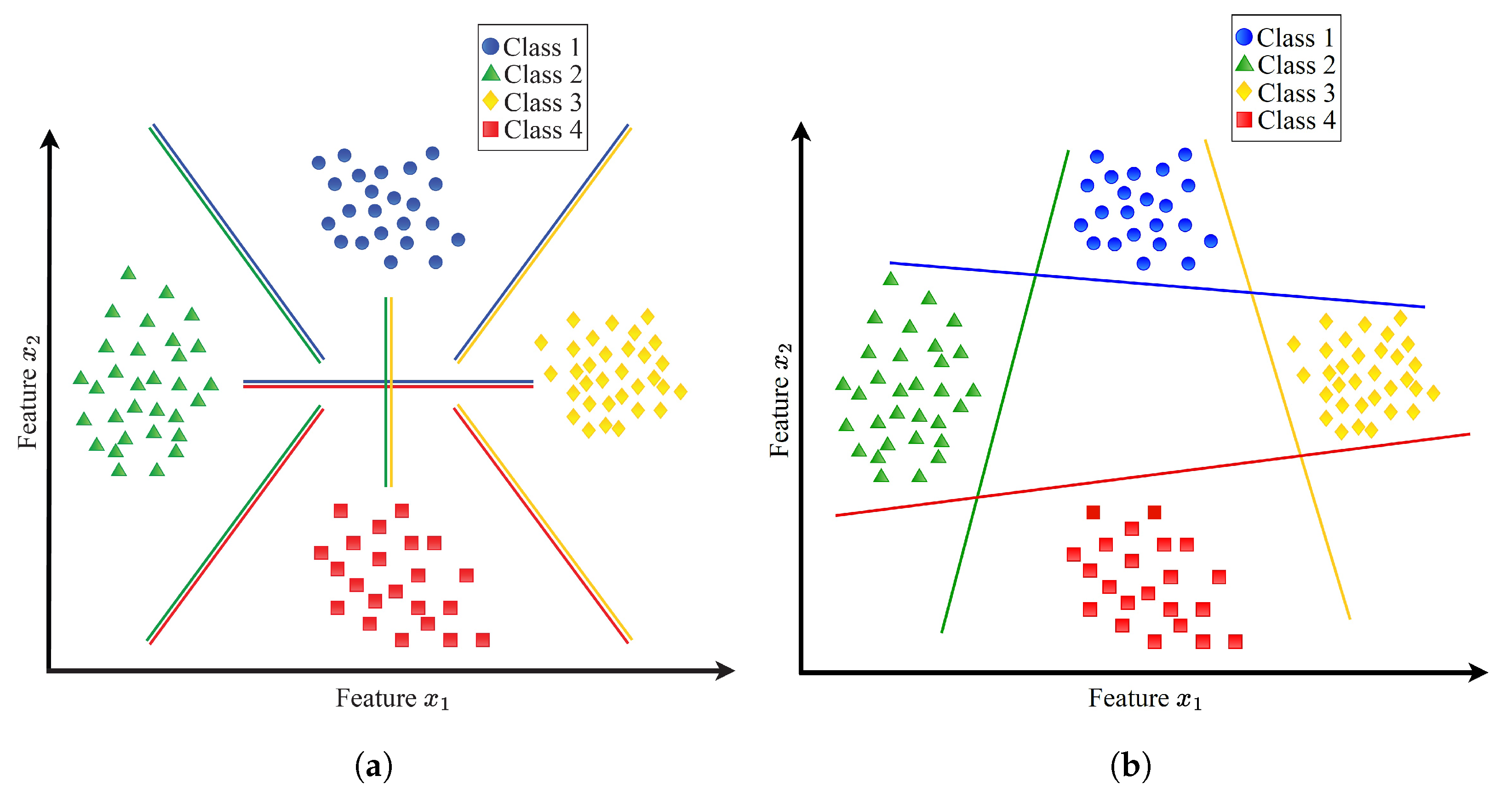
3.2.2. Multi-Classification SVM (MCSVM)
3.3. Function-Hiding Inner-Product Encryption Cryptosystem
- : Given and a vector , the algorithm selects a uniformly random element and produces the secret key pair , where and are the secret key and n elements vector that has values from , respectively.
- : Given and a vector , the algorithm selects a uniformly random element and produces , where and are the ciphertext pair and n element vector that has values from , respectively.
- : Given , , and , the algorithm computes the inner product . The decryption algorithm produces and , where . The algorithm then checks whether there exists z such that by computing a discrete logarithm in using methods such as the baby-step giant-step algorithm [35]. If a valid z is found, it is output; otherwise, ⊥ is output to indicate that no valid z exists.
4. Proposed Scheme
4.1. Design Objectives
- Preserving Privacy. In our proposed scheme, it is imperative to protect the confidentiality of the model user’s medical data. The outsourced medical data of the MU must remain confidential, ensuring that neither the cloud server (CS) nor the model owner (MO) can access any information about it. Additionally, the classification results should remain concealed from the CS, with only the MU having access to this information.
- Protecting Intellectual Property. Our scheme is designed to preserve the confidentiality of the diagnosis model’s parameters from potential threats posed by the CS, MU, and external eavesdroppers.
- High Diagnosis Accuracy and Low Communication/Computation Cost. The proposed scheme aims to deliver precise medical diagnoses for MUs while minimizing computational and communication burdens. Considering the limited computational and communication resources typically available to MUs, it is crucial to optimize their involvement in the online diagnosis process. The encryption methods utilized for user requests should be lightweight, allowing data users to remain offline during the online diagnosis process until they receive the classification results. Moreover, heavy computation and communication tasks should be offloaded to the CS, which possesses ample communication and computation resources. Notably, the cloud server should be able to compute the medical diagnosis without the need for the participation of the model owner because requiring the model owner to be online and interactive all the time to help the server in the diagnosis computations diminishes the benefits of outsourcing the medical diagnosis to a third party.
4.2. System Initialization
4.3. Model Encryption
4.4. Encryption of Medical Data
4.5. Classification
5. Security Evaluations
6. Experiments and Results
6.1. Environment of the Experiments
- Accuracy is the number of data samples that are diagnosed correctly to the total number of samples. The diagnosis model performs better as this metric increases. This metric is computed using this equation:where measures the number of data samples of sick people that are diagnosed correctly by the model, measures the number of data samples of healthy people that are diagnosed correctly by the model, measures the number of data samples of healthy people that are diagnosed incorrectly by the model, measures the number of data samples of sick people that are diagnosed incorrectly by the model.
- False Alarm is the number of data samples of sick people that are diagnosed incorrectly to the total number of samples of sick people. The diagnosis model performs better as this metric decreases. This metric is measured as follows:
- Recall is the number of samples of sick people that are correctly diagnosed to the total number of samples of sick people. The diagnosis model performs better as this metric increases. This metric is measured as follows:
- Precision is the number of samples of sick people that are diagnosed correctly to the total number of samples of sick people. The diagnosis model performs well as this metric increases. This metric is measured as follows:
- F1-score gives the average of Precision and Recall. This metric is especially a good indicator of the model’s performance when the dataset is not balanced. This metric is measured as follows:
6.2. Experimental Results
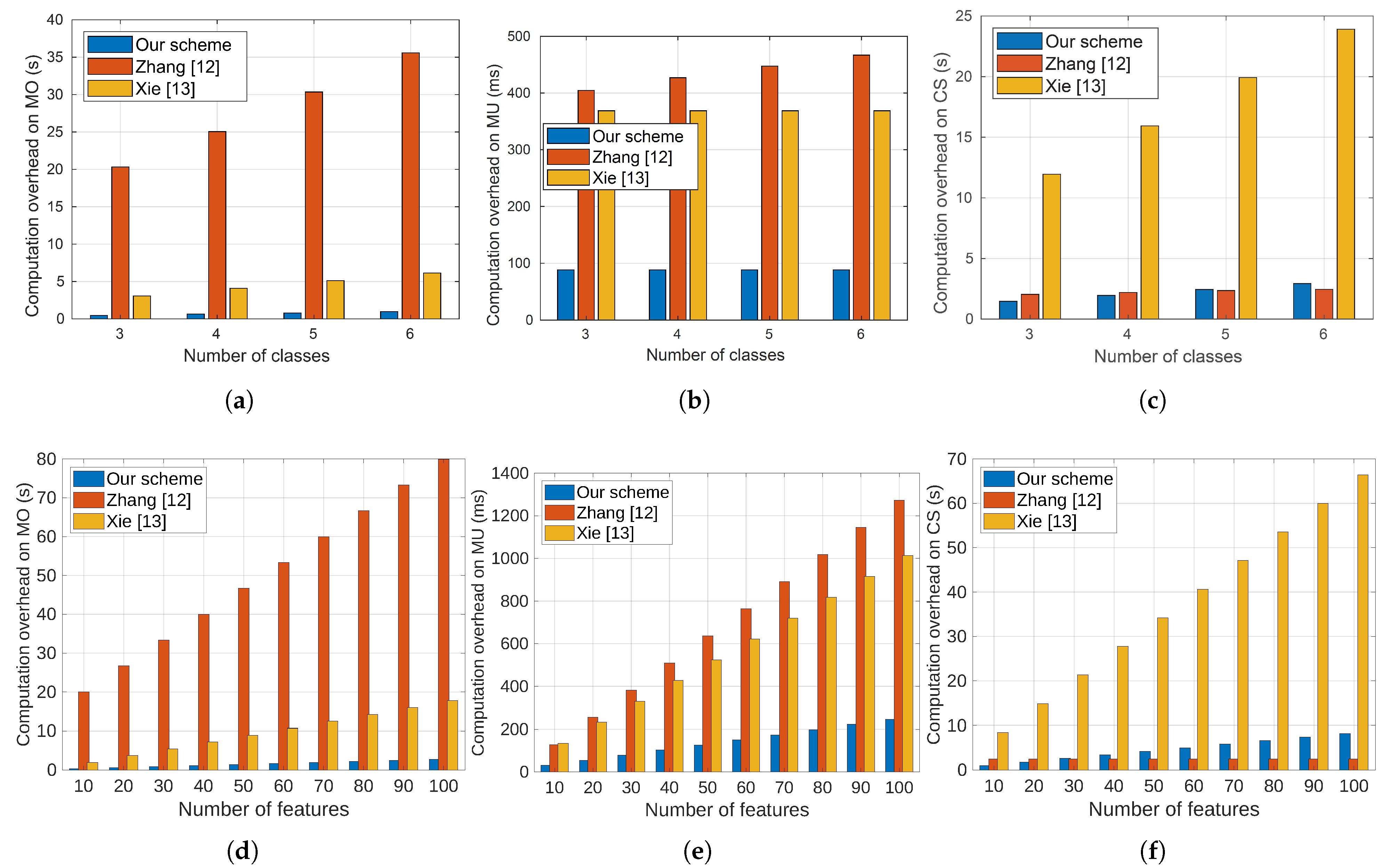
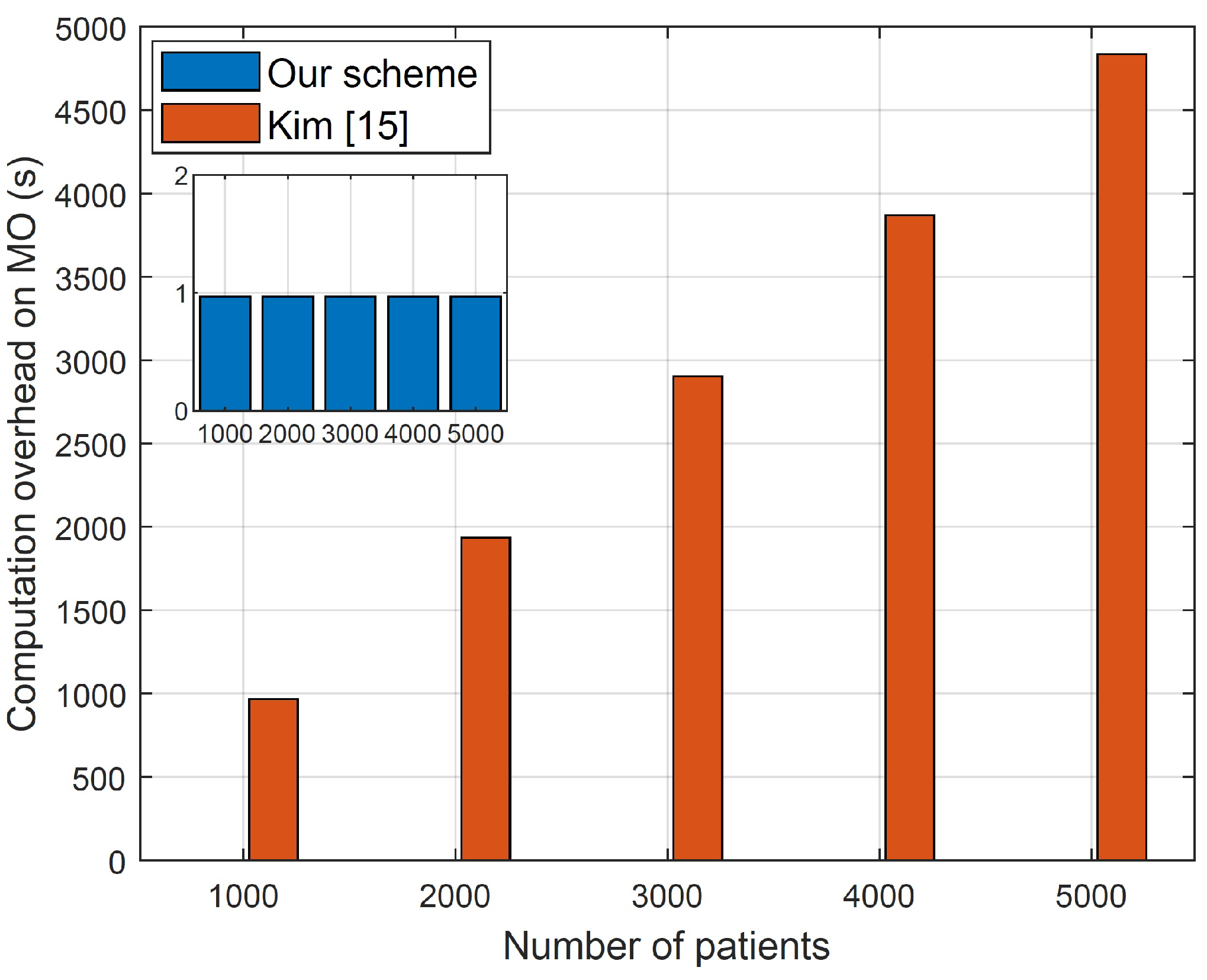
6.2.1. Computation Cost
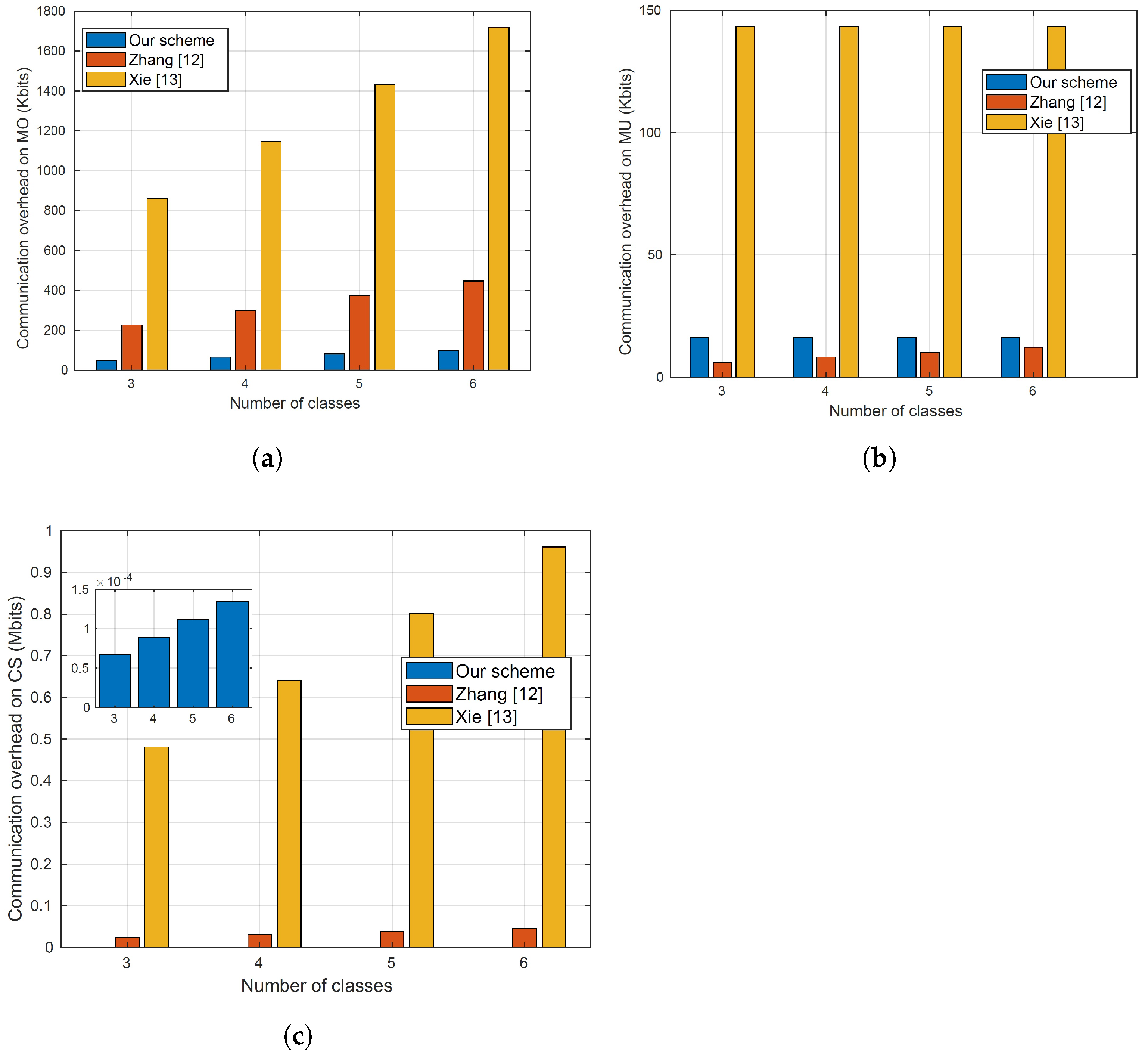
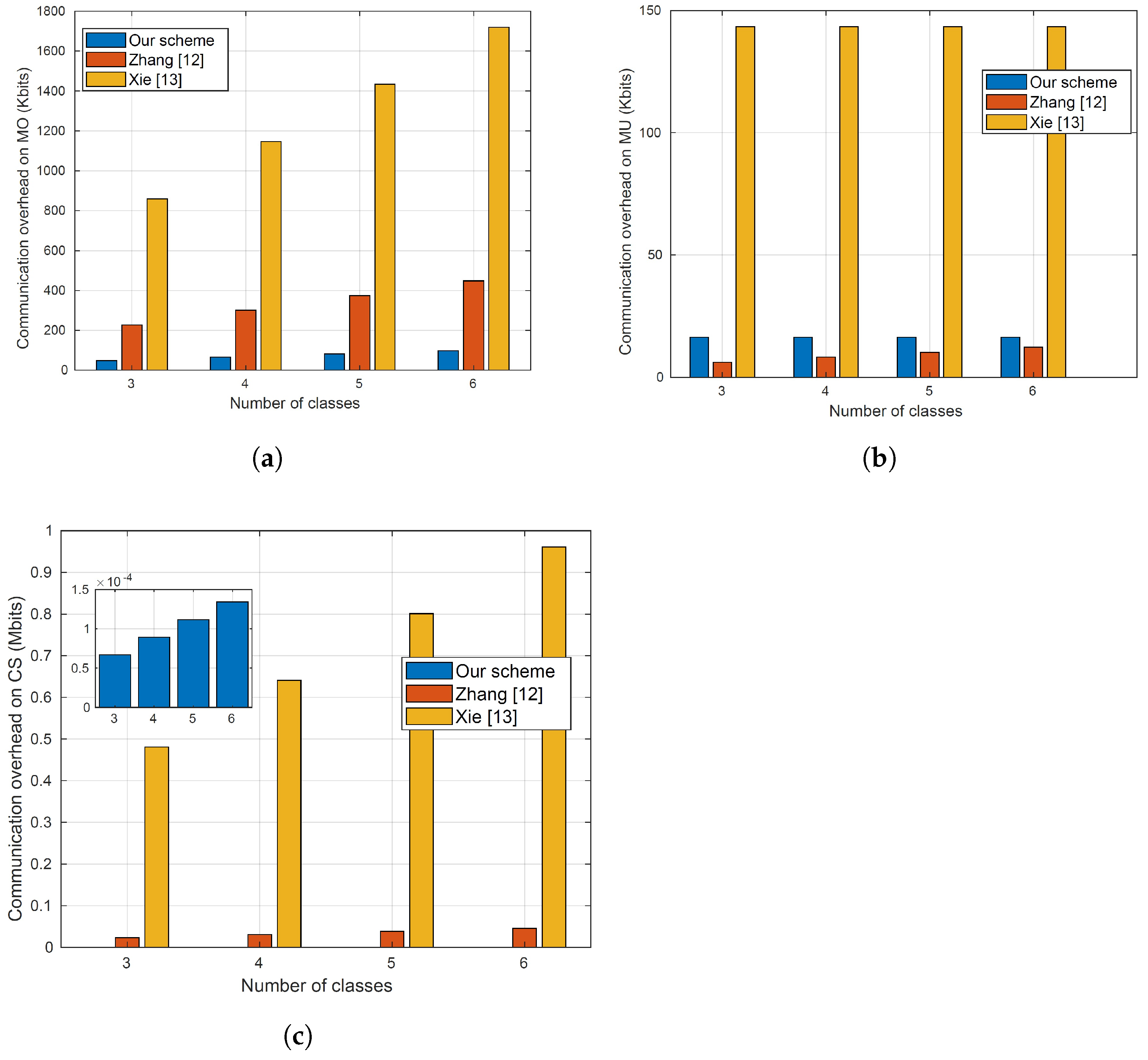
6.2.2. Communication Cost
6.2.3. Diagnosis Accuracy
7. Literature Review
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 1V1 | One-Versus-One |
| 1VA | One Versus-All |
| CS | Cloud Server |
| FN | False Negative |
| FP | False Positive |
| IoT | Internet of Things |
| KDC | Key Distribution Center |
| LSVM | Linear Support Vector Machine |
| ML | Machine Learning |
| MO | Model Owner |
| MUs | Model Users |
| NB | Naive Bayes |
| OU | Okamoto–Uchiyama |
| SVM | Support Vector Machine |
| TN | True Negative |
| TP | True positive |
References
- Guo, R.; Shi, H.; Zheng, D.; Jing, C.; Zhuang, C.; Wang, Z. Flexible and efficient blockchain-based ABE scheme with multi-authority for medical on demand in telemedicine system. IEEE Access 2019, 7, 88012–88025. [Google Scholar] [CrossRef]
- Teladochealth. Teladoc Health. Available online: https://www.teladochealth.com/ (accessed on 15 September 2023).
- Google. Google Machine Learning Project. Available online: https://www.mercurynews.com/2017/03/03/google-computers-trained-to-detect-cancer/ (accessed on 15 September 2023).
- Khan, S.M.; Liu, X.; Nath, S.; Korot, E.; Faes, L.; Wagner, S.K.; Keane, P.A.; Sebire, N.J.; Burton, M.J.; Denniston, A.K. A global review of publicly available datasets for ophthalmological imaging: Barriers to access, usability, and generalisability. Lancet Digit. Health 2021, 3, 51–66. [Google Scholar] [CrossRef] [PubMed]
- Li, D.C.; Liu, C.W. Extending attribute information for small data set classification. IEEE Trans. Knowl. Data Eng. 2010, 24, 452–464. [Google Scholar] [CrossRef]
- Pasupa, K.; Sunhem, W. A comparison between shallow and deep architecture classifiers on small dataset. In Proceedings of the 2016 8th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 5–6 October 2016; IEEE: New York, NY, USA, 2016; pp. 1–6. [Google Scholar]
- Conforti, D.; Guido, R. Kernel based support vector machine via semidefinite programming: Application to medical diagnosis. Comput. Oper. Res. 2010, 37, 1389–1394. [Google Scholar] [CrossRef]
- Rahulamathavan, Y.; Veluru, S.; Phan, R.C.W.; Chambers, J.A.; Rajarajan, M. Privacy-preserving clinical decision support system using Gaussian kernel-based classification. IEEE J. Biomed. Health Inform. 2014, 18, 56–66. [Google Scholar] [CrossRef]
- Rahulamathavan, Y.; Phan, R.C.W.; Veluru, S.; Cumanan, K.; Rajarajan, M. Privacy-preserving multi-class support vector machine for outsourcing the data classification in cloud. IEEE Trans. Dependable Secur. Comput. 2014, 11, 467–479. [Google Scholar] [CrossRef]
- Li, X.; Zhu, Y.; Wang, J.; Liu, Z.; Liu, Y.; Zhang, M. On the soundness and security of privacy-preserving SVM for outsourcing data classification. IEEE Trans. Dependable Secur. Comput. 2018, 15, 906–912. [Google Scholar] [CrossRef]
- Yu, H.; Vaidya, J.; Jiang, X. Privacy-Preserving SVM Classification on Vertically Partitioned Data. In Proceedings of the Advances in Knowledge Discovery and Data Mining, Singapore, 9–12 April 2006; pp. 647–656. [Google Scholar]
- Zhang, M.; Song, W.; Zhang, J. A Secure Clinical Diagnosis With Privacy-Preserving Multiclass Support Vector Machine in Clouds. IEEE Syst. J. 2022, 16, 67–78. [Google Scholar] [CrossRef]
- Xie, B.; Xiang, T.; Liao, X.; Wu, J. Achieving Privacy-Preserving Online Diagnosis with Outsourced SVM in Internet of Medical Things Environment. IEEE Trans. Dependable Secur. Comput. 2021, 19, 4113–4126. [Google Scholar] [CrossRef]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 223–238. [Google Scholar]
- Kim, S.; Lewi, K.; Mandal, A.; Montgomery, H.; Roy, A.; Wu, D.J. Function-hiding inner product encryption is practical. In Proceedings of the International Conference on Security and Cryptography for Networks, Leuven, Belgium, 2–4 July 2018; pp. 544–562. [Google Scholar]
- Laur, S.; Lipmaa, H.; Mielikäinen, T. Cryptographically private support vector machines. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 618–624. [Google Scholar]
- Yu, H.; Jiang, X.; Vaidya, J. Privacy-preserving SVM using nonlinear kernels on horizontally partitioned data. In Proceedings of the 2006 ACM symposium on Applied Computing, Dijon, France, 23–27 April 2006; pp. 603–610. [Google Scholar]
- Chen, K.; Liu, L. Privacy preserving data classification with rotation perturbation. In Proceedings of the Fifth IEEE International Conference on Data Mining (ICDM’05), Houston, TX, USA, 27–30 November 2005; pp. 4–7. [Google Scholar]
- Ilter, N.; Guvenir, H.A. Dermatology Dataset. 1998. Available online: https://www.openml.org/search?type=data&sort=runs&id=35&status=active (accessed on 15 September 2023).
- Caliskan, A.; Badem, H.; Basturk, A.; Yuksel, M.E. The effect of autoencoders over reducing the dimensionality of a dermatology data set. In Proceedings of the 2016 Medical Technologies National Congress (TIPTEKNO), Antalya, Turkey, 27–29 October 2016; IEEE: New York, NY, USA, 2016; pp. 1–4. [Google Scholar]
- Abdelfatah, S. Privacy-Preserving Cloud Assisted Search and Diagnosis for Smart Healthcare. Ph.D. Thesis, Tennessee Tech University, Cookeville, TN, USA, 2022. [Google Scholar]
- Xia, Z.; Wang, X.; Sun, X.; Wang, Q. A secure and dynamic multi-keyword ranked search scheme over encrypted cloud data. IEEE Trans. Parallel Distrib. Syst. 2015, 27, 340–352. [Google Scholar] [CrossRef]
- Abdelfattah, S.; Baza, M.; Badr, M.M.; Mahmoud, M.; Srivastava, G.; Alsolami, F.; Ali, A.M. Efficient Search Over Encrypted Medical Data With Known-Plaintext/Background Models and Unlinkability. IEEE Access 2021, 9, 151129–151141. [Google Scholar] [CrossRef]
- Fu, Z.; Ren, K.; Shu, J.; Sun, X.; Huang, F. Enabling personalized search over encrypted outsourced data with efficiency improvement. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 2546–2559. [Google Scholar] [CrossRef]
- Tong, Q.; Miao, Y.; Liu, X.; Choo, K.K.R.; Deng, R.; Li, H. VPSL: Verifiable privacy-preserving data search for cloud-assisted Internet of Things. IEEE Trans. Cloud Comput. 2020, 10, 2964–2976. [Google Scholar] [CrossRef]
- Abdelfattah, S.; Baza, M.; Mahmoud, M.; Fouda, M.M.; Abualsaud, K.A.; Guizani, M. Multidata-Owner Searchable Encryption Scheme Over Medical Cloud Data With Efficient Access Control. IEEE Syst. J. 2022, 16, 5067–5078. [Google Scholar] [CrossRef]
- Qureshi, K.N.; Din, S.; Jeon, G.; Piccialli, F. An accurate and dynamic predictive model for a smart M-Health system using machine learning. Inf. Sci. 2020, 538, 486–502. [Google Scholar] [CrossRef]
- Baza, M.; Salazar, A.; Mahmoud, M.; Abdallah, M.; Akkaya, K. On sharing models instead of data using mimic learning for smart health applications. In Proceedings of the IEEE International Conference on Informatics, IoT, and Enabling Technologies (ICIoT), Doha, Qatar, 2–5 February 2020; pp. 231–236. [Google Scholar]
- Wu, J.; Guo, P.; Cheng, Y.; Zhu, H.; Wang, X.B.; Shao, X. Ensemble generalized multiclass support-vector-machine-based health evaluation of complex degradation systems. IEEE/ASME Trans. Mechatron. 2020, 25, 2230–2240. [Google Scholar] [CrossRef]
- Karpagachelvi, S.; Arthanari, M.; Sivakumar, M. Classification of electrocardiogram signals with support vector machines and extreme learning machine. Neural Comput. Appl. 2012, 21, 1331–1339. [Google Scholar] [CrossRef]
- Sahu, B.; Mohanty, S.N. CMBA-SVM: A clinical approach for Parkinson disease diagnosis. Int. J. Inf. Technol. 2021, 13, 647–655. [Google Scholar] [CrossRef]
- Liu, Y.; Dong, L.; Zhang, B.; Xin, Y.; Geng, L. Real Time ECG Classification System Based on DWT and SVM. In Proceedings of the IEEE International Conference on Integrated Circuits, Technologies and Applications (ICTA), Nanjing, China, 23–25 November 2020; pp. 155–156. [Google Scholar]
- Kang, J.; Han, X.; Song, J.; Niu, Z.; Li, X. The identification of children with autism spectrum disorder by SVM approach on EEG and eye-tracking data. Comput. Biol. Med. 2020, 120, 103722. [Google Scholar] [CrossRef]
- Jia, A.D.; Li, B.Z.; Zhang, C.C. Detection of cervical cancer cells based on strong feature CNN-SVM network. Neurocomputing 2020, 411, 112–127. [Google Scholar]
- Shoup, V. Lower Bounds for Discrete Logarithms and Related Problems. In Proceedings of the Advances in Cryptology—EUROCRYPT ’97, Konstanz, Germany, 11–15 May 1997; Fumy, W., Ed.; Springer: Berlin/Heidelberg, Germany, 1997; pp. 256–266. [Google Scholar]
- Akinyele, J.A.; Garman, C.; Miers, I.; Pagano, M.W.; Rushanan, M.; Green, M.; Rubin, A.D. Charm: A framework for rapidly prototyping cryptosystems. J. Cryptogr. Eng. 2013, 3, 111–128. [Google Scholar] [CrossRef]
- Su, Y.; Shen, J.; Qian, H.; Ma, H.; Ji, J.; Ma, H.; Ma, L.; Zhang, W.; Meng, L.; Li, Z.; et al. Diagnosis of gastric cancer using decision tree classification of mass spectral data. Cancer Sci. 2007, 98, 37–43. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.M.; Harman, M.; Ma, L.; Liu, Y. Machine Learning Testing: Survey, Landscapes and Horizons. IEEE Trans. Softw. Eng. 2022, 48, 1–36. [Google Scholar] [CrossRef]
- Tanveer, M.; Richhariya, B.; Khan, R.; Rashid, A.; Khanna, P.; Prasad, M.; Lin, C. Machine learning techniques for the diagnosis of Alzheimer’s disease: A review. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2020, 16, 1–35. [Google Scholar] [CrossRef]
- Senturk, Z.K. Early diagnosis of Parkinson’s disease using machine learning algorithms. Med. Hypotheses 2020, 138, 1S. [Google Scholar]
- Klöppel, S.; Stonnington, C.M.; Chu, C.; Draganski, B.; Scahill, R.I.; Rohrer, J.D.; Fox, N.C.; Jack, C.R., Jr.; Ashburner, J.; Frackowiak, R.S. Automatic classification of MR scans in Alzheimer’s disease. Brain 2008, 131, 681–689. [Google Scholar] [CrossRef]
- Abdulkareem, K.H.; Mohammed, M.A.; Salim, A.; Arif, M.; Geman, O.; Gupta, D.; Khanna, A. Realizing an effective COVID-19 diagnosis system based on machine learning and IoT in smart hospital environment. IEEE Internet Things J. 2021, 8, 15919–15928. [Google Scholar] [CrossRef]
- González-Serrano, F.J.; Navia-Vázquez, Á.; Amor-Martín, A. Training support vector machines with privacy-protected data. Pattern Recognit. 2017, 72, 93–107. [Google Scholar] [CrossRef]
- Liu, X.; Deng, R.H.; Choo, K.K.R.; Yang, Y. Privacy-preserving outsourced support vector machine design for secure drug discovery. IEEE Trans. Cloud Comput. 2018, 8, 610–622. [Google Scholar] [CrossRef]
- Shen, M.; Tang, X.; Zhu, L.; Du, X.; Guizani, M. Privacy-preserving support vector machine training over blockchain-based encrypted IoT data in smart cities. IEEE Internet Things J. 2019, 6, 7702–7712. [Google Scholar] [CrossRef]
- Shen, M.; Zhang, J.; Zhu, L.; Xu, K.; Tang, X. Secure SVM training over vertically-partitioned datasets using consortium blockchain for vehicular social networks. IEEE Trans. Veh. Technol. 2019, 69, 5773–5783. [Google Scholar] [CrossRef]
- Carpov, S.; Nguyen, T.H.; Sirdey, R.; Constantino, G.; Martinelli, F. Practical privacy-preserving medical diagnosis using homomorphic encryption. In Proceedings of the IEEE 9th International Conference on Cloud Computing (CLOUD), San Francisco, CA, USA, 27 June–2 July 2016; pp. 593–599. [Google Scholar]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the Forty-First Annual ACM Symposium On Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; pp. 169–178. [Google Scholar]
- Alabdulkarim, A.; Al-Rodhaan, M.; Ma, T.; Tian, Y. PPSDT: A novel privacy-preserving single decision tree algorithm for clinical decision-support systems using IoT devices. Sensors 2019, 19, 142. [Google Scholar] [CrossRef] [PubMed]
- Okamoto, T.; Uchiyama, S. A new public-key cryptosystem as secure as factoring. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Espoo, Finland, 31 May–4 June 1998; pp. 308–318. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric/Scheme | [13] | [12] | Our Proposal |
|---|---|---|---|
| Accuracy | 97% | 97% | 97% |
| Precision | 97% | 97% | 97% |
| Recall | 98% | 98% | 98% |
| F1-score | 97% | 97% | 97% |
| False Alarm | 0.4% | 0.5% | 0.5% |
| [8] | [9,10] | [12] | [13] | Our Scheme | |
|---|---|---|---|---|---|
| Uses cloud server | √ | √ | √ | √ | √ |
| Preserving the privacy of patients | √ | √ | √ | √ | √ |
| Model’s intellectual property protection | × | × | √ | √ | √ |
| Concealing classifications | √ | √ | × | √ | √ |
| Multiple classes | × | √ | √ | √ | √ |
| Uses a single cloud | × | √ | √ | × | √ |
| Computation of diagnosis without the MO | × | × | × | √ | √ |
| Requires low resources | × | × | × | × | √ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdelfattah, S.; Baza, M.; Mahmoud, M.; Fouda, M.M.; Abualsaud, K.; Yaacoub, E.; Alsabaan, M.; Guizani, M. Lightweight Multi-Class Support Vector Machine-Based Medical Diagnosis System with Privacy Preservation. Sensors 2023, 23, 9033. https://doi.org/10.3390/s23229033
Abdelfattah S, Baza M, Mahmoud M, Fouda MM, Abualsaud K, Yaacoub E, Alsabaan M, Guizani M. Lightweight Multi-Class Support Vector Machine-Based Medical Diagnosis System with Privacy Preservation. Sensors. 2023; 23(22):9033. https://doi.org/10.3390/s23229033
Chicago/Turabian StyleAbdelfattah, Sherif, Mohamed Baza, Mohamed Mahmoud, Mostafa M. Fouda, Khalid Abualsaud, Elias Yaacoub, Maazen Alsabaan, and Mohsen Guizani. 2023. "Lightweight Multi-Class Support Vector Machine-Based Medical Diagnosis System with Privacy Preservation" Sensors 23, no. 22: 9033. https://doi.org/10.3390/s23229033
APA StyleAbdelfattah, S., Baza, M., Mahmoud, M., Fouda, M. M., Abualsaud, K., Yaacoub, E., Alsabaan, M., & Guizani, M. (2023). Lightweight Multi-Class Support Vector Machine-Based Medical Diagnosis System with Privacy Preservation. Sensors, 23(22), 9033. https://doi.org/10.3390/s23229033