
SLAV-Sim: A Framework for Self-Learning Autonomous Vehicle Simulation

Abstract
:1. Introduction
2. Related Work
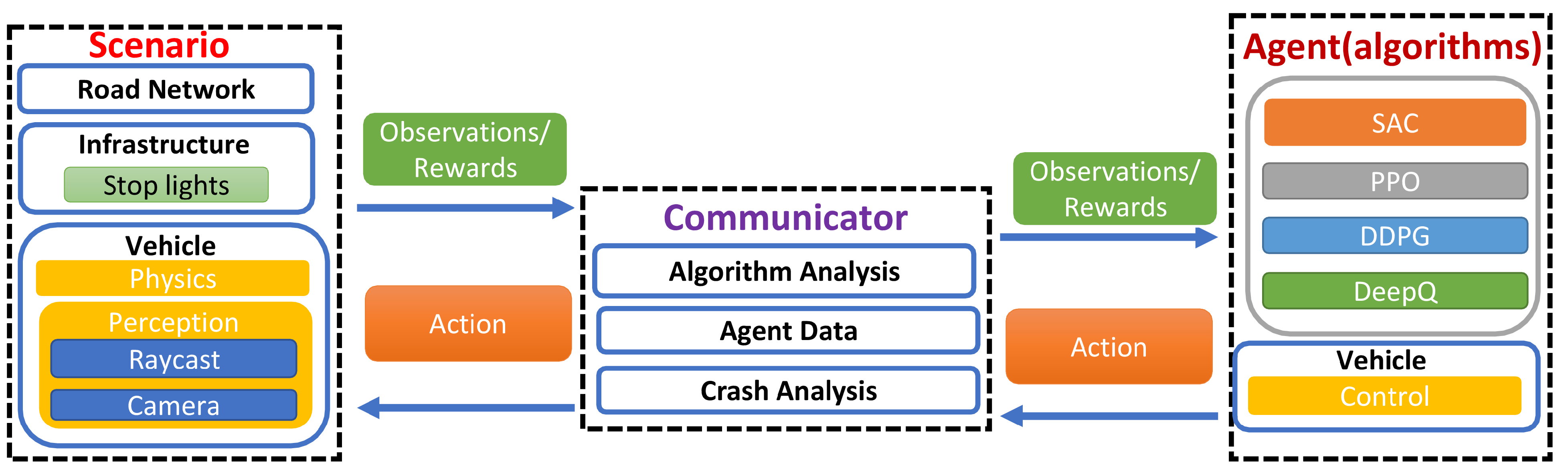
3. Scenario
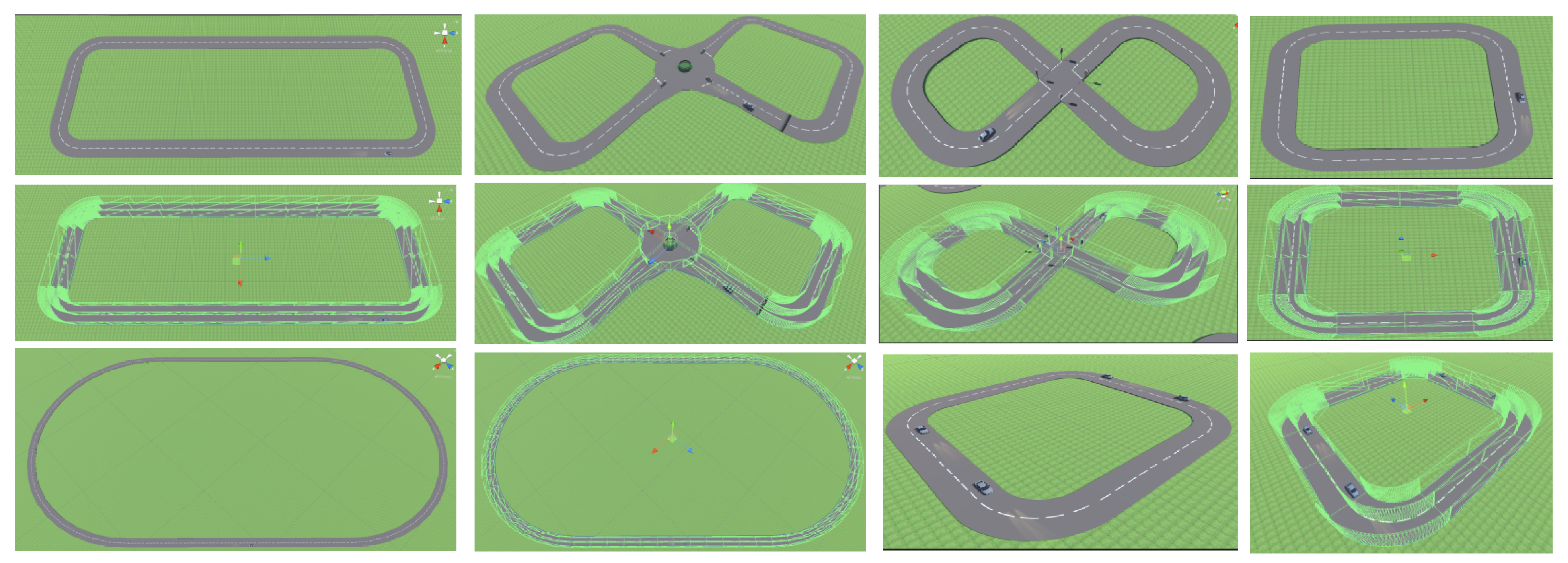
3.1. Road Network
3.1.1. Physics
3.1.2. Perception
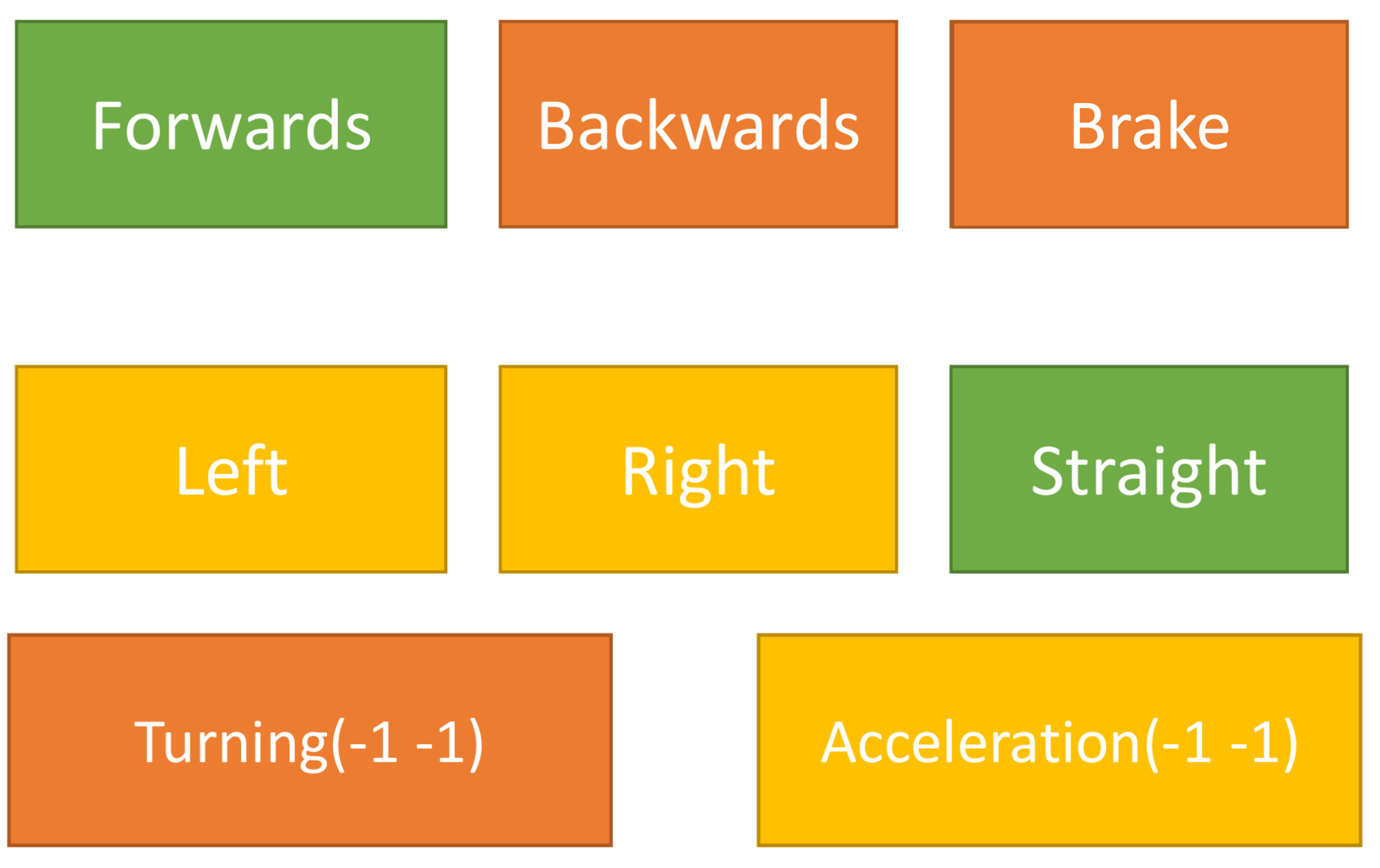
4. Control and Algorithms
5. Experiment Design
5.1. Description
5.1.1. Learning Schedule Experiment
5.1.2. Additional Algorithms Experiment
5.1.3. Observation Experiment
5.1.4. Increased Network Size Experiment
5.2. Training Metrics
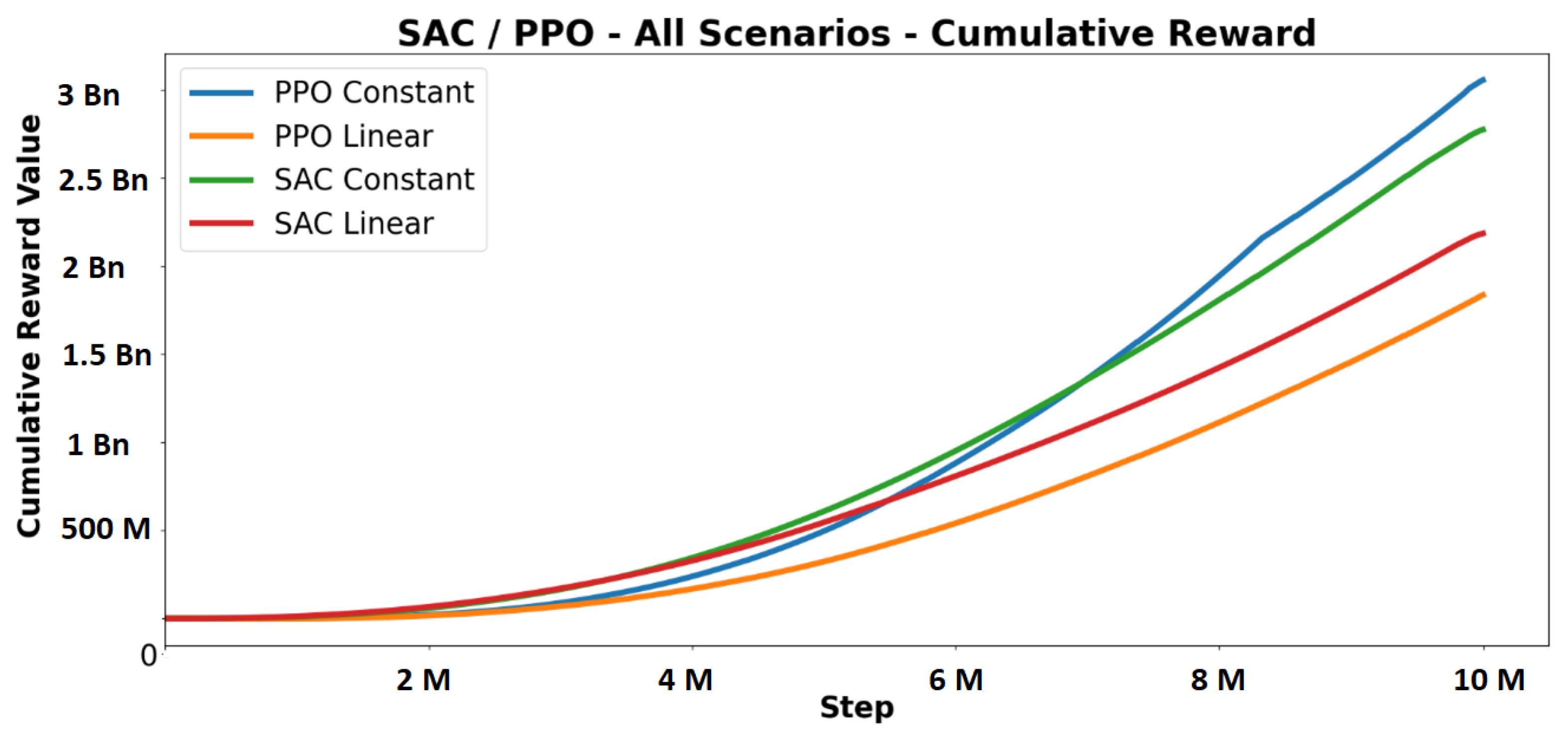
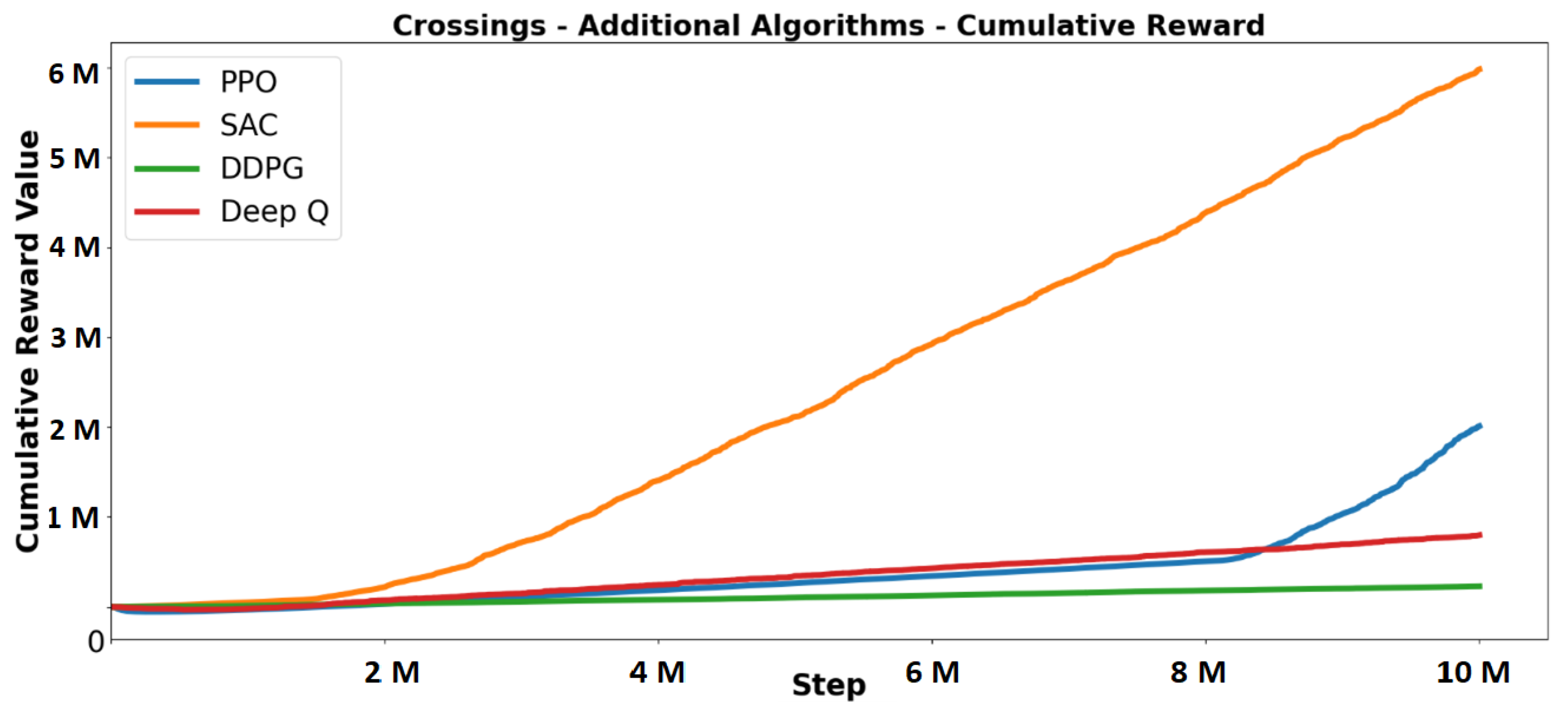
5.2.1. Cumulative Reward
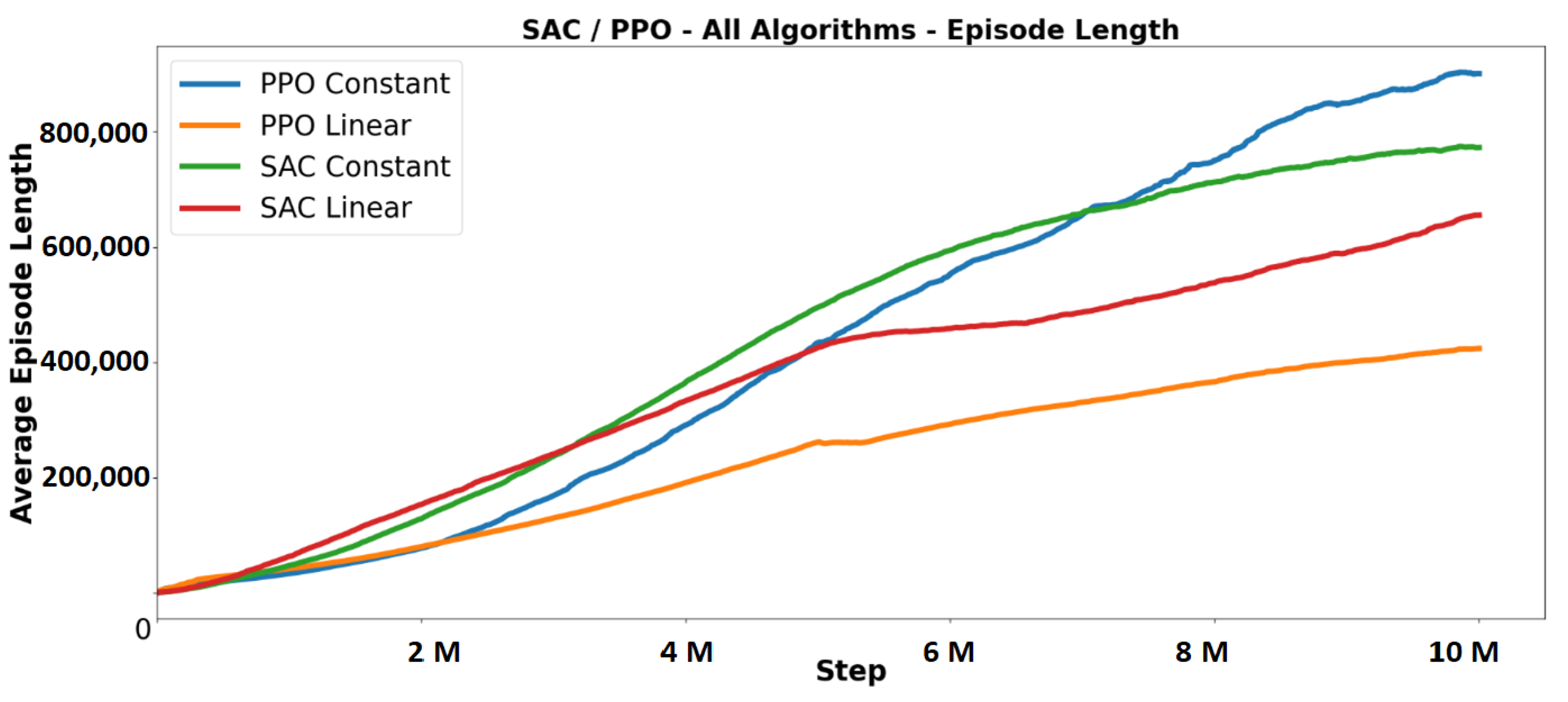
5.2.2. Episode Length Line Graph
5.3. Testing Metrics
5.4. Hyperparameters
5.5. Crash Frequency
6. Rewards and Punishments
7. Results and Discussion
7.1. Learning Schedule Results and Comparison
7.2. Additional Algorithm Results
7.3. Observation Methods
8. Traffic Flow Integration
9. Computational Resources
10. V2X Integration
11. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Aurrigo. Aurrigo Gets into Gear for Rural UK Self-Driving First. 2022. Available online: https://www.computerweekly.com/news/252521747/Aurrigo-gets-into-gear-for-rural-UK-self-driving-first (accessed on 1 March 2023).
- Guardian. Google’s Waymo to Offer Driverless Ride-Hailing Service in San Francisco. 2022. Available online: https://www.theguardian.com/technology/2022/mar/30/waymo-self-driving-ride-hailing-service-san-francisco-alphabet-google (accessed on 1 February 2023).
- Kalra, N. Challenges and Approaches to Realizing Autonomous Vehicle Safety. 2017. Available online: https://www.rand.org/pubs/testimonies/CT463.html (accessed on 1 March 2023).
- Barz, A.; Conrad, J.; Wallach, D. Advantages of using runtime procedural generation of virtual environments based on real world data for conducting empirical automotive research. In Proceedings of the HCI International 2020–Late Breaking Papers: Digital Human Modeling and Ergonomics, Mobility and Intelligent Environments: 22nd HCI International Conference, HCII 2020, Copenhagen, Denmark, 19–24 July 2020; Proceedings 22. Springer: Berlin/Heidelberg, Germany, 2020; pp. 14–23. [Google Scholar]
- Morra, L.; Lamberti, F.; Pratticó, F.G.; La Rosa, S.; Montuschi, P. Building trust in autonomous vehicles: Role of virtual reality driving simulators in HMI design. IEEE Trans. Veh. Technol. 2019, 68, 9438–9450. [Google Scholar] [CrossRef]
- IPG Automotive CarMaker Software. 2022. Available online: https://ipg-automotive.com/en/products-solutions/software/carmaker/ (accessed on 1 January 2023).
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Vijay, R.; Cherian, J.; Riah, R.; De Boer, N.; Choudhury, A. Optimal placement of roadside infrastructure sensors towards safer autonomous vehicle deployments. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 2589–2595. [Google Scholar]
- Haas, J.K. A history of the unity game engine. Diss. Worcest. Polytech. Inst. 2014, 483, 484. [Google Scholar]
- Min, K.; Kim, H.; Huh, K. Deep distributional reinforcement learning based high-level driving policy determination. IEEE Trans. Intell. Veh. 2019, 4, 416–424. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Wang, S.; Jia, D.; Weng, X. Deep reinforcement learning for autonomous driving. arXiv 2018, arXiv:1811.11329. [Google Scholar]
- El Sallab, A.; Abdou, M.; Perot, E.; Yogamani, S. Deep Reinforcement Learning framework for Autonomous Driving. In IS and T International Symposium on Electronic Imaging Science and Technology; Society for Imaging Science and Technology: Springfield, VA, USA, 2017; pp. 70–76. [Google Scholar] [CrossRef]
- Petersen, L.; Robert, L.; Yang, X.J.; Tilbury, D.M. Situational awareness, drivers trust in automated driving systems and secondary task performance. arXiv 2019, arXiv:1903.05251. [Google Scholar]
- Dygalo, V.; Lyashenko, M.; Potapov, P. Ways for improving efficiency of computer vision for autonomous vehicles and driver assistance systems. In Proceedings of the 2019 International Conference on Industrial Engineering, Applications and Manufacturing (ICIEAM), Sochi, Russia, 25–29 March 2019; pp. 1–5. [Google Scholar]
- Kohli, P.; Chadha, A. Enabling pedestrian safety using computer vision techniques: A case study of the 2018 uber inc. self-driving car crash. In Proceedings of the Advances in Information and Communication: Proceedings of the 2019 Future of Information and Communication Conference, San Francisco, CA, USA, 14 March 2020; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1, pp. 261–279. [Google Scholar]
- Schwarting, W.; Alonso-Mora, J.; Rus, D. Planning and decision-making for autonomous vehicles. Annu. Rev. Control. Robot. Auton. Syst. 2018, 1, 187–210. [Google Scholar] [CrossRef]
- Rangesh, A.; Trivedi, M.M. No blind spots: Full-surround multi-object tracking for autonomous vehicles using cameras and lidars. IEEE Trans. Intell. Veh. 2019, 4, 588–599. [Google Scholar] [CrossRef]
- Vargas, J.; Alsweiss, S.; Toker, O.; Razdan, R.; Santos, J. An overview of autonomous vehicles sensors and their vulnerability to weather conditions. Sensors 2021, 21, 5397. [Google Scholar] [CrossRef]
- Cui, Y.; Chen, R.; Chu, W.; Chen, L.; Tian, D.; Li, Y.; Cao, D. Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review. IEEE Trans. Intell. Transp. Syst. 2022, 23, 722–739. [Google Scholar] [CrossRef]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and sensor fusion technology in autonomous vehicles: A review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef]
- Thomas, E.; McCrudden, C.; Wharton, Z.; Behera, A. Perception of autonomous vehicles by the modern society: A survey. IET Intell. Transp. Syst. 2020, 14, 1228–1239. [Google Scholar] [CrossRef]
- Anavatti, S.G.; Francis, S.L.; Garratt, M. Path-planning modules for Autonomous Vehicles: Current status and challenges. In Proceedings of the 2015 International Conference on Advanced Mechatronics, Intelligent Manufacture, and Industrial Automation (ICAMIMIA), Surabaya, Indonesia, 15–17 October 2015; pp. 205–214. [Google Scholar]
- Rosique, F.; Navarro, P.J.; Fernández, C.; Padilla, A. A Systematic Review of Perception System and Simulators for Autonomous Vehicles Research. Sensors 2019, 19, 648. [Google Scholar] [CrossRef]
- Tuncali, C.E.; Fainekos, G.; Prokhorov, D.; Ito, H.; Kapinski, J. Requirements-driven test generation for autonomous vehicles with machine learning components. IEEE Trans. Intell. Veh. 2019, 5, 265–280. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, Z.; Yang, H.; Yang, L. Artificial intelligence applications in the development of autonomous vehicles: A survey. IEEE/CAA J. Autom. Sin. 2020, 7, 315–329. [Google Scholar] [CrossRef]
- Koenig, N.; Howard, A. Design and use paradigms for gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No. 04CH37566), Sendai, Japan, 28 September–2 October 2004; Volume 3, pp. 2149–2154. [Google Scholar]
- Ghodsi, Z.; Hari, S.K.S.; Frosio, I.; Tsai, T.; Troccoli, A.; Keckler, S.W.; Garg, S.; Anandkumar, A. Generating and characterizing scenarios for safety testing of autonomous vehicles. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 157–164. [Google Scholar]
- rFpro. rFpro Simulation Software. Available online: https://rfpro.com/simulation-software/ (accessed on 1 February 2023).
- Bhashyam, G.R. ANSYS Mechanical—A Powerful Nonlinear Simulation Tool; Ansys Inc.: Canonsburg, PA, USA, 2002; Volume 1, p. 39. [Google Scholar]
- Tideman, M.; Van Noort, M. A simulation tool suite for developing connected vehicle systems. In Proceedings of the 2013 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2013; pp. 713–718. [Google Scholar] [CrossRef]
- Sanders, A. An Introduction to Unreal Engine 4. In An Introduction to Unreal Engine 4; A K Peters/CRC Press: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Juliani, A.; Berges, V.P.; Teng, E.; Cohen, A.; Harper, J.; Elion, C.; Goy, C.; Gao, Y.; Henry, H.; Mattar, M.; et al. Unity: A General Platform for Intelligent Agents. arXiv 2018, arXiv:1809.02627. [Google Scholar]
- DeepDrive. Deepdrive Simulator. 2022. Available online: https://deepdrive.io/ (accessed on 1 January 2023).
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles. In Springer Proceedings in Advanced Robotics; Springer: Berlin/Heidelberg, Germany, 2018; Volume 5, pp. 621–635. [Google Scholar] [CrossRef]
- Best, A.; Narang, S.; Pasqualin, L.; Barber, D.; Manocha, D. AutonoVi-Sim: Autonomous Vehicle Simulation Platform with Weather, Sensing, and Traffic Control. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1048–1056. [Google Scholar]
- Piazzoni, A.; Cherian, J.; Azhar, M.; Yap, J.Y.; Shung, J.L.W.; Vijay, R. ViSTA: A Framework for Virtual Scenario-based Testing of Autonomous Vehicles. In Proceedings of the 3rd IEEE International Conference on Artificial Intelligence Testing, AITest 2021, Oxford, UK, 23–26 August 2021; pp. 143–150. [Google Scholar] [CrossRef]
- Amini, A.; Wang, T.H.; Gilitschenski, I.; Schwarting, W.; Liu, Z.; Han, S.; Karaman, S.; Rus, D. VISTA 2.0: An Open, Data-driven Simulator for Multimodal Sensing and Policy Learning for Autonomous Vehicles. In Proceedings of the International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2419–2426. [Google Scholar]
- Rong, G.; Hyun Shin, B.; Tabatabaee, H.; Lu, Q.; Lemke, S.; Možeiko, S.; Boise, E.; Uhm, G.; Gerow, M.; Mehta, S.; et al. LGSVL Simulator: A High Fidelity Simulator for Autonomous Driving. In Proceedings of the IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–6. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Ding, W.; Xu, C.; Arief, M.; Lin, H.; Li, B.; Zhao, D. A survey on safety-critical driving scenario generation—A methodological perspective. IEEE Trans. Intell. Transp. Syst. 2023, 24, 2–4. [Google Scholar] [CrossRef]
- Lu, Y.; Fu, J.; Tucker, G.; Pan, X.; Bronstein, E.; Roelofs, B.; Sapp, B.; White, B.; Faust, A.; Whiteson, S.; et al. Imitation Is Not Enough: Robustifying Imitation with Reinforcement Learning for Challenging Driving Scenarios. arXiv 2022, arXiv:2212.11419. [Google Scholar]
- Yu, C.; Velu, A.; Vinitsky, E.; Gao, J.; Wang, Y.; Bayen, A.; Wu, Y. The surprising effectiveness of ppo in cooperative multi-agent games. Adv. Neural Inf. Process. Syst. 2022, 35, 24611–24624. [Google Scholar]
- Shalev-Shwartz, S.; Shammah, S.; Shashua, A. Safe, multi-agent, reinforcement learning for autonomous driving. arXiv 2016, arXiv:1610.03295. [Google Scholar]
- Zhang, Y.; Sun, P.; Yin, Y.; Lin, L.; Wang, X. Human-like autonomous vehicle speed control by deep reinforcement learning with double Q-learning. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1251–1256. [Google Scholar]
- Chen, J.; Yuan, B.; Tomizuka, M. Model-free deep reinforcement learning for urban autonomous driving. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 2765–2771. [Google Scholar]
- Chae, H.; Kang, C.M.; Kim, B.; Kim, J.; Chung, C.C.; Choi, J.W. Autonomous braking system via deep reinforcement learning. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Ure, N.K.; Yavas, M.U.; Alizadeh, A.; Kurtulus, C. Enhancing situational awareness and performance of adaptive cruise control through model predictive control and deep reinforcement learning. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 626–631. [Google Scholar]
- Zhou, C.; Wang, Y.; Wang, L.; He, H. Obstacle avoidance strategy for an autonomous surface vessel based on modified deep deterministic policy gradient. Ocean Eng. 2022, 243, 110166. [Google Scholar] [CrossRef]
- Liu, H.; Huang, Z.; Wu, J.; Lv, C. Improved deep reinforcement learning with expert demonstrations for urban autonomous driving. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022; pp. 921–928. [Google Scholar]
- Feng, S.; Sun, H.; Yan, X.; Zhu, H.; Zou, Z.; Shen, S.; Liu, H.X. Dense reinforcement learning for safety validation of autonomous vehicles. Nature 2023, 615, 620–627. [Google Scholar] [CrossRef] [PubMed]
- Samak, T.; Samak, C.; Kandhasamy, S.; Krovi, V.; Xie, M. AutoDRIVE: A Comprehensive, Flexible and Integrated Digital Twin Ecosystem for Autonomous Driving Research & Education. Robotics 2023, 12, 77. [Google Scholar] [CrossRef]
- Winters, T.; Johnson, M.; Paruchuri, V. LITS: Lightweight Intelligent Traffic Simulator. In Proceedings of the 2009 International Conference on Network-Based Information Systems, Indianapolis, IN, USA, 19–21 August 2009; pp. 386–390. [Google Scholar] [CrossRef]
- Zhao, H.; Cui, A.; Cullen, S.A.; Paden, B.; Laskey, M.; Goldberg, K. FLUIDS: A First-Order Lightweight Urban Intersection Driving Simulator. In Proceedings of the 2018 IEEE 14th International Conference on Automation Science and Engineering (CASE), Munich, Germany, 20–24 August 2018; pp. 697–704. [Google Scholar] [CrossRef]
- Malik, S.; Khan, M.A.; Aadam; El-Sayed, H.; Iqbal, F.; Khan, J.; Ullah, O. CARLA+: An Evolution of the CARLA Simulator for Complex Environment Using a Probabilistic Graphical Model. Drones 2023, 7, 111. [Google Scholar] [CrossRef]
- Chance, G.; Ghobrial, A.; McAreavey, K.; Lemaignan, S.; Pipe, T.; Eder, K. On determinism of game engines used for simulation-based autonomous vehicle verification. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20538–20552. [Google Scholar] [CrossRef]
- Prokop, G.; Tüschen, T.; Eisenköck, N.; Bönninger, J. Highly immersive driving simulator for scenario based testing of automated driving functions. In Proceedings of the 22. Internationales Stuttgarter Symposium, Stuttgart, Germany, 14 March 2022; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2022; pp. 145–154. [Google Scholar]
- Nandy, A.; Biswas, M. Unity ML-Agents. In Neural Networks in Unity: C# Programming for Windows 10; Springer: Berlin/Heidelberg, Germany, 2018; pp. 27–67. [Google Scholar] [CrossRef]
- GOV.UK. The Highway Code Department for Transport and Driver and Vehicle Standards Agency, United Kingdom. Available online: https://www.gov.uk/government/news/the-highway-code-8-changes-you-need-to-know-from-29-january-2022 (accessed on 1 January 2022).
- Zeb, A.; Khattak, K.S.; Rehmat Ullah, M.; Khan, Z.H.; Gulliver, T.A. HetroTraffSim: A Macroscopic Heterogeneous Traffic Flow Simulator for Road Bottlenecks. Future Transp. 2023, 3, 368–383. [Google Scholar] [CrossRef]
- Chen, J.; Belleman, R.G. Measvre: Measurement tools for unity vr applications. In Proceedings of the 2022 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Christchurch, New Zealand, 12–16 March 2022; pp. 760–761. [Google Scholar]
- Espeholt, L.; Soyer, H.; Munos, R.; Simonyan, K.; Mnih, V.; Ward, T.; Doron, Y.; Firoiu, V.; Harley, T.; Dunning, I.; et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ye, Y.; Zhang, X.; Sun, J. Automated vehicle’s behavior decision making using deep reinforcement learning and high-fidelity simulation environment. Transp. Res. Part Emerg. Technol. 2019, 107, 155–170. [Google Scholar] [CrossRef]
- Zhao, X.; Liao, X.; Wang, Z.; Wu, G.; Barth, M.; Han, K.; Tiwari, P. Co-simulation platform for modeling and evaluating connected and automated vehicles and human behavior in mixed traffic. SAE Int. J. Connect. Autom. Veh. 2022, 5, 313–326. [Google Scholar] [CrossRef]
- Kuzmic, J.; Rudolph, G. Unity 3D Simulator of Autonomous Motorway Traffic Applied to Emergency Corridor Building. In Proceedings of the IoTBDS, Online, 7–9 May 2020; pp. 197–204. [Google Scholar]
- Cusin, O.; Lou, H. Traffic Simulation Using the Intelligent Driver Model: A Study of the Impact of Safe Distance on Traffic Flow; School of Electrical Engineering and Computer Science (EECS), KTH Royal Institute of Technology: Stockholm, Sweden, 2023. [Google Scholar]
- Jacob Näsman, J.S. Unity 3D Traffic Simulation Investigating the Impacts of Safe Distance on Traffic Flow: Investigating How Safe Distance Impacts Traffic Flow on a One Lane Highway during Three Road Scenarios; Department of Computer Science and Engineering, KTH Royal Institute of Technology: Stockholm, Sweden, 2022. [Google Scholar]
- Liao, X.; Zhao, X.; Wang, Z.; Han, K.; Tiwari, P.; Barth, M.J.; Wu, G. Game theory-based ramp merging for mixed traffic with unity-sumo co-simulation. IEEE Trans. Syst. Man Cybern. Syst. 2021, 52, 5746–5757. [Google Scholar] [CrossRef]
- Vukić, M.; Grgić, B.; Dinčir, D.; Kostelac, L.; Marković, I. Unity based Urban Environment Simulation for Autonomous Vehicle Stereo Vision Evaluation. In Proceedings of the 2019 42nd International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 20–24 May 2019; pp. 949–954. [Google Scholar] [CrossRef]
- Paranjape, I.; Jawad, A.; Xu, Y.; Song, A.; Whitehead, J. A modular architecture for procedural generation of towns, intersections and scenarios for testing autonomous vehicles. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 162–168. [Google Scholar]
- Fremont, D.J.; Kim, E.; Pant, Y.V.; Seshia, S.A.; Acharya, A.; Bruso, X.; Wells, P.; Lemke, S.; Lu, Q.; Mehta, S. Formal scenario-based testing of autonomous vehicles: From simulation to the real world. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC 2020), Rhodes, Greece, 20–23 September 2020; pp. 1–8. [Google Scholar]
- Wang, Z.; Han, K.; Tiwari, P. Digital twin-assisted cooperative driving at non-signalized intersections. IEEE Trans. Intell. Veh. 2021, 7, 198–209. [Google Scholar] [CrossRef]
- Tang, X.; Qin, Z.; Zhang, F.; Wang, Z.; Xu, Z.; Ma, Y.; Zhu, H.; Ye, J. A deep value-network based approach for multi-driver order dispatching. In Proceedings of the 25th ACM Sigkdd International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 25 July 2019; pp. 1780–1790. [Google Scholar]
- Oczko, M.C.H.; Stratmann, L.; Klingler, F.; Dressler, F. On Time Constraints for Internet-Connected Multi-User Real-Time Traffic Simulation. In Proceedings of the 2023 IEEE Vehicular Networking Conference (VNC), Istanbul, Turkiye, 26–28 April 2023; pp. 187–190. [Google Scholar]
- Barbi, M.; Ruiz, A.A.; Handzel, A.M.; Inca, S.; Garcia-Roger, D.; Monserrat, J.F. Simulation-based Digital Twin for 5G Connected Automated and Autonomous Vehicles. In Proceedings of the 2022 Joint European Conference on Networks and Communications & 6G Summit (EuCNC/6G Summit), Grenoble, France, 7–10 June 2022; pp. 273–278. [Google Scholar]
- Oczko, M.C.H.; Stratmann, L.; Franke, M.; Heinovski, J.; Buse, D.S.; Klingler, F.; Dressler, F. Integrating haptic signals with V2X-based safety systems for vulnerable road users. In Proceedings of the 2020 International Conference on Computing, Networking and Communications (ICNC), Big Island, HI, USA, 17–20 February 2020; pp. 692–697. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Observation | Rewards | Punishment | Comment |
|---|---|---|---|
| Correct side of the road | +0.1 | The agent is encouraged to consistently remain on the correct side of the road. | |
| Middle of the road | −0.5 | Encourages the agent to stay between the wall and middle line of the road | |
| Moving forward | Reward Value = (Speed limit − Distance from speed limit)/10 | −0.5 (Above speed limit) | Prevents backward driving during initial learning |
| Correct braking | +0.5 | Encourages the agent to brake before crashing. | |
| Unnecessary braking | −0.5 | Promotes a smoother driving | |
| Distance from the wall | −0.02 (>2 mtr) −0.05 (<1 mtr) | Prevents chances of crashing by encouraging the vehicle to stay in the lane | |
| Traffic light pass when green | +10 | Promotes traffic light behaviour understanding | |
| Stop zone at red light | +0.15 | Promotes traffic light behaviour understanding | |
| Crash | −15 | Prevents vehicle from going off-track |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Crewe, J.; Humnabadkar, A.; Liu, Y.; Ahmed, A.; Behera, A. SLAV-Sim: A Framework for Self-Learning Autonomous Vehicle Simulation. Sensors 2023, 23, 8649. https://doi.org/10.3390/s23208649
Crewe J, Humnabadkar A, Liu Y, Ahmed A, Behera A. SLAV-Sim: A Framework for Self-Learning Autonomous Vehicle Simulation. Sensors. 2023; 23(20):8649. https://doi.org/10.3390/s23208649
Chicago/Turabian StyleCrewe, Jacob, Aditya Humnabadkar, Yonghuai Liu, Amr Ahmed, and Ardhendu Behera. 2023. "SLAV-Sim: A Framework for Self-Learning Autonomous Vehicle Simulation" Sensors 23, no. 20: 8649. https://doi.org/10.3390/s23208649
APA StyleCrewe, J., Humnabadkar, A., Liu, Y., Ahmed, A., & Behera, A. (2023). SLAV-Sim: A Framework for Self-Learning Autonomous Vehicle Simulation. Sensors, 23(20), 8649. https://doi.org/10.3390/s23208649