

Enhancing Mask Transformer with Auxiliary Convolution Layers for Semantic Segmentation


Abstract
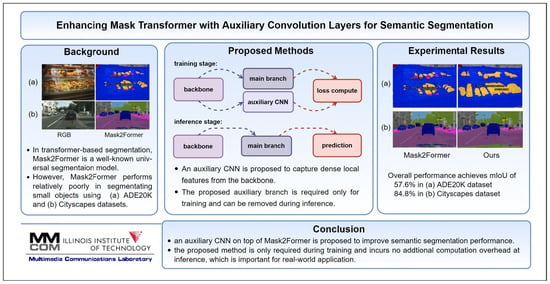
1. Introduction
- (1)
- We design an auxiliary CNN on top of Mask2Former [11] to help improve semantic segmentation performance. The proposed network consists of simple convolutional layers without bells and whistles. We demonstrate that the proposed method improves the semantic segmentation performance quantitatively and qualitatively. Specifically, we show that the proposed method is effective in learning local features and segmenting small objects more accurately.
- (2)
- Since the proposed auxiliary convolution layers are required during the training stage only, the proposed method incurs no additional computation overhead at inference. This is one of the important properties of the proposed method because enhancing the performance while maintaining the complexity at inference is crucial for real-world applications.
- (3)
- The proposed auxiliary convolution layers are effective for both semantic and panoptic segmentation. Since Mask2Former is a universal architecture for different segmentation tasks and our proposed method is designed to enhance Mask2Former, we show that the proposed method achieves state-of-the-art performance for semantic and panoptic segmentation on the ADE20K [16] and Cityscapes [17] datasets.
2. Related Work
2.1. Semantic Segmentation
2.2. Panoptic Segmentation
2.3. Hybrid Models Using Convolutions and Transformers
3. Proposed Method
3.1. Overall Architecture
3.2. Auxiliary CNN
3.3. Auxiliary Loss
4. Experimental Results
4.1. Dataset
4.2. Implementation Details
4.3. Ablation Study
4.4. Experimental Results for Semantic Segmentation
4.5. Experimental Results for Panoptic Segmentation
4.6. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Conference Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training Data-efficient Image Transformers & Distillation through Attention. In Proceedings of the International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021. [Google Scholar]
- Bao, H.; Dong, L.; Piao, S.; Wei, F. BEiT: BERT Pre-Training of Image Transformers. arXiv 2021, arXiv:2106.08254. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Conference Neural Information Processing Systems (NeurIPS), Lake Tahoe, Nevada, USA, 3–6 December 2012. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, X.Z.; Wang, Y.; Fu, Y.; Feng, J.; Xing, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anadkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Proceedings of the Conference Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021. [Google Scholar]
- Cheng, B.; Schwing, A.G.; Kirillov, A. Per-Pixel Classification is Not All You Need for Semantic Segmentation. In Proceedings of the Conference Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention Mask Transformer for Universal Image Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Xiao, T.; Singh, M.; Mintun, E.; Darrell, T.; Dollár, P.; Girshick, R. Early Convolutions Help Transformers See Better. In Proceedings of the Conference Neural Information Processing Systems (NeurIPS), Virtual, 6–14 December 2021. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for Visual Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chen, Z.; Xie, L.; Niu, J.; Liu, X.; Wei, L.; Tian, Q. Visformer: The Vision-friendly Transformer. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. ParseNet: Looking Wider to See Better. In Proceedings of the International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. TPAMI 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T.S. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, October 27–2 November 2019. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. OCNet: Object Context for Semantic Segmentation. IJCV 2021, 129, 2375–2398. [Google Scholar] [CrossRef]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Cheng, B.; Collins, M.D.; Zhu, Y.; Liu, T.; Huang, T.S.; Adam, H.; Chen, L.C. Panoptic-DeepLab: A Simple, Strong, and Fast Baseline for Bottom-Up Panoptic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Li, J.; Raventos, A.; Bhargava, A.; Tagawa, T.; Gaidon, A. Learning to Fuse Things and Stuff. arXiv 2018, arXiv:1812.01192. [Google Scholar]
- Xiong, Y.; Liao, R.; Zhao, H.; Hu, R.; Bai, M.; Yumer, E.; Urtasun, R. UPSNet: A Unified Panoptic Segmentation Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wu, Y.; Zhang, G.; Gao, Y.; Deng, X.; Gong, K.; Liang, X.; Lin, L. Bidirectional Graph Reasoning Network for Panoptic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wu, Y.; Zhang, G.; Xu, H.; Liang, X.; Lin, L. Auto-Panoptic: Cooperative Multi-Component Architecture Search for Panoptic Segmentation. In Proceedings of the Conference Neural Information Processing Systems (NeurIPS), Vancouver, Canada, 6–12 December 2020. [Google Scholar]
- Li, Y.; Zhao, H.; Qi, X.; Chen, Y.; Qi, L.; Wang, L.; Li, Z.; Sun, J.; Jia, J. Fully Convolutional Networks for Panoptic Segmentation with Point-based Supervision. arXiv 2021, arXiv:2012.00720. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Batra, D.; Parikh, D.; Lee, S. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks. In Proceedings of the Conference Neural Information Processing Systems (NeurIPS), Vancouver, Canada, 8–14 December 2019. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster. R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Conference Neural Information Processing Systems (NeurIPS), Montréal, Canada, 11–12 December 2015. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. PVT v2: Improved Baselines with Pyramid Vision Transformer. CVMJ 2022, 8, 1–10. [Google Scholar] [CrossRef]
- Wu, Y.H.; Liu, Y.; Zhan, X.; Cheng, M.M. P2T: Pyramid Pooling Transformer for Scene Understanding. TPAMI 2022, 99, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Conference Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 6 February 2020).
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-paste is A Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Huang, S.; Lu, Z.; Cheng, R.; He, C. Fapn: Feature-aligned Pyramid Network for Dense Image Prediction. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, L.; Wang, H.; Qiao, S. Scaling Wide Residual Networks for Panoptic Segmentation. arXiv 2020, arXiv:2011.11675. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Setups | Baseline | mIoU (ss) | mIoU (ms) | #params | |||
|---|---|---|---|---|---|---|---|
| Setup 1 | √ | 53.9 | 55.1 | 107.0M | |||
| Setup 2 | √ | √ | 54.2 (↑0.3) | 55.3 (↑0.2) | 107.1M | ||
| Setup 3 | √ | √ | 54.3 (↑0.4) | 55.3 (↑0.2) | 107.3M | ||
| Setup 4 | √ | √ | 54.0 (↑0.1) | 55.1 (-) | 109.2M | ||
| Setup 5 | √ | √ | √ | 54.3 (↑0.4) | 55.3 (↑0.2) | 107.4M | |
| Setup 6 | √ | √ | √ | 54.2 (↑0.3) | 55.2 (↑0.1) | 109.3M | |
| Setup 7 | √ | √ | √ | 54.3 (↑0.4) | 55.3 (↑0.2) | 109.5M | |
| Setup 8 | √ | √ | √ | √ | 54.5 (↑0.6) | 55.5 (↑0.4) | 109.6M |
| Auxiliary Structure | mIoU (ss) | mIoU (ms) | #params |
|---|---|---|---|
| - | 53.9 | 55.1 | - |
| conv. | 53.6 (↓0.3) | 54.7 (↓0.4) | 1.4M |
| conv. | 54.0 (↑0.1) | 55.0 (↓0.1) | 12.4M |
| one residual block | 54.2 (↑0.3) | 55.2 (↑0.1) | 1.3M |
| two residual blocks | 54.5 (↑0.6) | 55.5 (↑0.4) | 2.6M |
| Weighting Parameter | mIoU (ss) | mIoU (ms) |
|---|---|---|
| - | 53.9 | 55.1 |
| 0.1 | 54.5 (↑0.6) | 55.5 (↑0.4) |
| 0.2 | 54.4 (↑0.5) | 55.3 (↑0.2) |
| 0.3 | 54.1 (↑0.2) | 55.2 (↑0.1) |
| 0.05 | 54.2 (↑0.3) | 55.3 (↑0.2) |
| Method | Backbone | Crop Size | mIoU (ss) | mIoU (ms) |
|---|---|---|---|---|
| PVTv1 [39] | PVTv1-L | 512 × 512 | 44.8 | - |
| PVTv2 [40] | PVTv2-B5 | 512 × 512 | 48.7 | - |
| P2T [41] | P2T-L | 512 × 512 | 49.4 | - |
| Swin-UperNet [42,47] | Swin-L † | 640 × 640 | - | 53.5 |
| FaPN-MaskFormer [10,48] | Swin-L † | 640 × 640 | 55.2 | 56.7 |
| BEiT-UperNet [4,47] | BEiT-L † | 640 × 640 | - | 57.0 |
| MaskFormer [10] | Swin-T | 512 × 512 | 46.7 | 48.8 |
| Swin-S | 512 × 512 | 49.8 | 51.0 | |
| Swin-B † | 640 × 640 | 52.7 | 53.9 | |
| Swin-L † | 640 × 640 | 54.1 | 55.6 | |
| Mask2Former [11] | Swin-T | 512 × 512 | 47.7 | 49.6 |
| Swin-S | 512 × 512 | 51.3 | 52.4 | |
| Swin-B † | 640 × 640 | 53.9 | 55.1 | |
| Swin-L † | 640 × 640 | 56.1 | 57.3 | |
| Mask2Former (Ours) | Swin-T | 512 × 512 | 47.9 | 49.7 |
| Swin-S | 512 × 512 | 51.3 | 52.5 | |
| Swin-B † | 640 × 640 | 54.1 | 54.9 | |
| Swin-L † | 640 × 640 | 56.0 | 57.1 | |
| Ours | Swin-T | 512 × 512 | 48.8 | 50.3 |
| Swin-S | 512 × 512 | 52.2 | 53.1 | |
| Swin-B † | 640 × 640 | 54.5 | 55.5 | |
| Swin-L † | 640 × 640 | 56.4 | 57.6 |
| Method | Backbone | Crop Size | mIoU (ss) | mIoU (ms) |
|---|---|---|---|---|
| Segmenter [9] | ViT-L † | 768 × 768 | - | 81.3 |
| SETR [7] | ViT-L † | 768 × 768 | - | 82.2 |
| SegFormer [8] | MiT-B5 | 768 × 768 | - | 84.0 |
| Mask2Former [11] | Swin-S | 512 × 1024 | 82.6 | 83.6 |
| Swin-B † | 512 × 1024 | 83.3 | 84.5 | |
| Swin-L † | 512 × 1024 | 83.3 | 84.3 | |
| Mask2Former (Ours) | Swin-S | 512 × 1024 | 82.4 | 83.5 |
| Swin-B † | 512 × 1024 | 83.2 | 84.3 | |
| Swin-L † | 512 × 1024 | 83.3 | 84.3 | |
| Ours | Swin-S | 512 × 1024 | 82.9 | 83.8 |
| Swin-B † | 512 × 1024 | 83.8 | 84.8 | |
| Swin-L † | 512 × 1024 | 83.6 | 84.5 |
| Method | Backbone | Panoptic Model | ||
|---|---|---|---|---|
| PQ (ss) | APpan | mIoUpan | ||
| BGRNet [34] | R50 | 31.8 | - | - |
| Auto-Panoptic [35] | ShuffleNetV2 [49] | 32.4 | - | - |
| MaskFormer [10] | R50 | 34.7 | - | - |
| Kirillov et al. [30] | R50 | 35.6 * | - | - |
| Panoptic-DeepLab [31] | SWideRNet [50] | 37.9 * | - | 50.0 * |
| Mask2Former [11] | Swin-L † | 48.1 | 34.2 | 54.5 |
| Mask2Former (Ours) | Swin-L † | 48.3 | 34.0 | 54.4 |
| Ours | Swin-L † | 48.8 | 35.1 | 54.7 |
| Method | Backbone | Panoptic Model | ||
|---|---|---|---|---|
| PQ (ss) | APpan | mIoUpan | ||
| TASCNet [32] | R50 ‡ | 59.2 | - | - |
| Kirillov et al. [30] | R50 | 61.2 * | 36.4 * | 80.9 * |
| UPSNet [33] | R101 ‡ | 61.8 * | 39.0 * | 79.2 * |
| Panoptic-DeepLab [31] | SWideRNet [50] | 66.4 | 40.1 | 82.2 |
| Panoptic-FCN [36] | Swin-L † | 65.9 | - | - |
| Mask2Former [11] | Swin-B † | 66.1 | 42.8 | 82.7 |
| Swin-L † | 66.6 | 43.6 | 82.9 | |
| Mask2Former (Ours) | Swin-B † | 65.7 | 42.8 | 82.1 |
| Swin-L † | 66.4 | 43.0 | 82.9 | |
| Ours | Swin-B † | 66.6 | 43.8 | 82.9 |
| Swin-L † | 66.7 | 44.6 | 83.2 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xia, Z.; Kim, J. Enhancing Mask Transformer with Auxiliary Convolution Layers for Semantic Segmentation. Sensors 2023, 23, 581. https://doi.org/10.3390/s23020581
Xia Z, Kim J. Enhancing Mask Transformer with Auxiliary Convolution Layers for Semantic Segmentation. Sensors. 2023; 23(2):581. https://doi.org/10.3390/s23020581
Chicago/Turabian StyleXia, Zhengyu, and Joohee Kim. 2023. "Enhancing Mask Transformer with Auxiliary Convolution Layers for Semantic Segmentation" Sensors 23, no. 2: 581. https://doi.org/10.3390/s23020581
APA StyleXia, Z., & Kim, J. (2023). Enhancing Mask Transformer with Auxiliary Convolution Layers for Semantic Segmentation. Sensors, 23(2), 581. https://doi.org/10.3390/s23020581