1. Introduction
Time series data are one of the most predominantly generated in modern information systems [
1], with sensors being responsible for a larger portion of such data production. Among several applications requiring exhaustive and extensive sensor data collection, the creation and synchronization of Digital Twins (DT) have been attracting recent and large interest from both academic and industrial sectors [
2]. The data generated from this type of application needs to be collected and processed at a high resolution, which entails high monitoring/telemetry frequencies, i.e., sub-second sampling rates. Several examples of DTs for the modeling and management of smart systems can be found in the literature, e.g., for smart manufacturing [
3], drinking water management and distribution systems [
4], and optical communications [
5].
Typically, DTs require the collection of data from widely distributed sensor network systems and their transport to a centralized place, e.g., the cloud, where it is processed. In fact, the DT is a well-known use case of an emerging service that is pushing the evolution of current transport networks towards the beyond 5G (B5G) era [
6]. This type of service requires reliable and high-bitrate connectivity between plenty of physical locations holding heterogeneous sources (wireless and wired sensors) and the premises where the DT is built and managed, which commonly entails connectivity across domains including access, metro, and core networks. Therefore, developing solutions to compress these dense monitoring data before their transport is essential to reduce operational costs including connectivity, storage, and energy consumption [
7].
Regarding different compression techniques suitable for time series data, two main categories can be identified: lossless and lossy [
8]. On the one hand, lossless compression means that the decompressed data are identical to the compressed data, which tends to produce low compression ratios, e.g., 50% compression. On the other hand, lossy compression techniques are intended to produce a trade-off between the accuracy of the reconstructed data and higher compression ratios, e.g., 90% compression. For the latter category, the use of deep learning (DL) methods has attracted special interest from the research community. Among different DL techniques, autoencoders (AE) represent a promising opportunity in the field of lossy compression. Basically, AEs are a type of deep neural network that has an encoder and a decoder part. The encoder part compresses input data into a number of representations called latent features which have a size much smaller than the input dimension. These representations form the latent space (LS) of the AE. The encoder is usually able to compress the data by discarding non-relevant parts of the data while keeping only the parts that can be effectively used for reconstruction in the decoder part. Another advantage of using AEs is their intrinsic ability for anomaly detection [
9]. Note that this allows performing not only compression but also data analysis at the source before transport. Thus, locally distributed data analysis can be performed and used to add more intelligence to the monitoring system, e.g., increasing a nominal monitoring sampling rate when an anomaly is detected [
10].
In this paper, we propose a novel method for the lossy compression of time series data using deep AEs along with two methods for anomaly detection that operate on both single and multiple time series. For the compression, instead of compressing the input data using a single AE, a pool of AEs with a different number of latent features is used. Thus, the Adaptive AE-based Compression (AAC) method is presented as an autonomous process that is able to choose the best AE in the pool, i.e., the one that reaches a target reconstruction error with the minimum LS size. The variability of the number of latent features means that the size of the compressed data is not fixed, which draws similarities between AE-based compression and conventional compression methods in which the characteristics of the input data play an important role in the compression ratio. It also means that the compression is adaptive to the variations in the data and hence, compression size is indeed a variable that can be analyzed as additional and extended information of collected monitoring data. It is worth mentioning that AEs are trained using data from the specific sensor/s that they operate. However, since this may not be available from the beginning of sensor operation, generic AEs with moderated compression rates trained for heterogeneous sensor data are used until enough data are collected to train the specific AEs.
Regarding the anomaly detection part, the first method, called Single Sensor Anomaly Detection (SS-AD), takes advantage of the specificity of the trained AEs to detect when the collected data contains an anomaly, e.g., if the sensor malfunctions or some kind of additional noise is introduced to the data from an external source. The second method, called the Multiple Sensor Anomalous Group Diagnosis (MS-AGD), detects anomalies that can affect several sensors in a correlated way, even when they cannot be detected by SS-AD in an independent time series. It does this by comparing data points with a certain degree of reconstruction error values across all the time series involved, making it able to detect subtle correlated anomalies.
The remainder of this paper is as follows:
Section 2 describes the latest related work on the subject of time series compression and anomaly detection.
Section 3 describes the network architecture and main components.
Section 4 describes our contribution in terms of the algorithms for compression and anomaly detection.
Section 5 shows the performance evaluation in a simulated environment using an experimental data set, including a comparison to state-of-the-art methods. Eventually,
Section 6 draws the main conclusions of this research work.
3. AE-Based Telemetry Compression and Anomaly Detection
3.1. Concept and Architecture
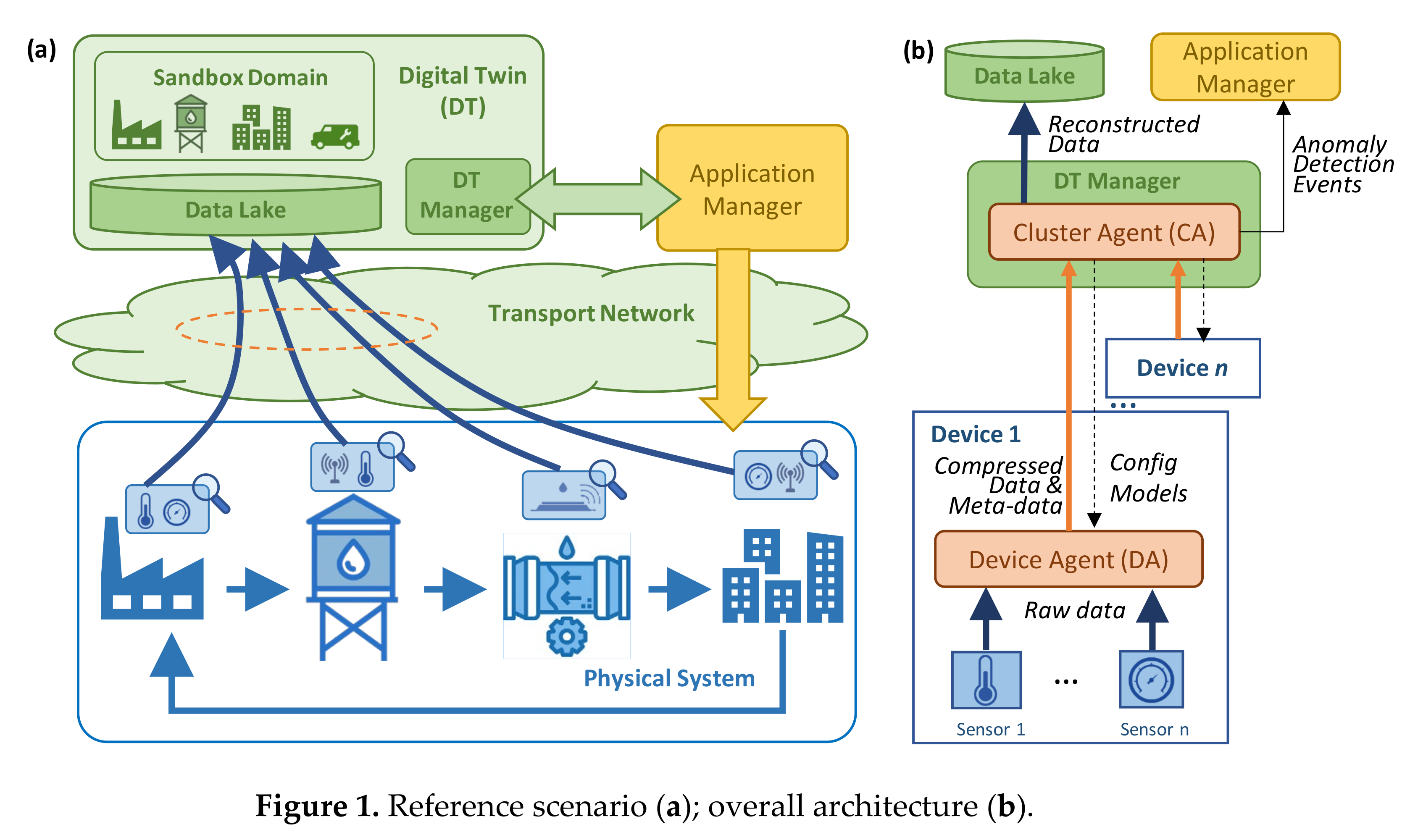
The reference scenario is sketched in
Figure 1a, where a physical system contains a plethora of different sensors that generate heterogeneous telemetry data that need to be gathered and analyzed for several purposes such as smart autonomous operation. Although the example in
Figure 1 sketches a water distribution system, the proposed architecture and algorithms are designed to fit with any smart system collecting time series telemetry data such as smart manufacturing and communication networks, just to mention a few. Without loss of generality, let us assume that the sensors generate data periodically, with a fixed time interval (that can be different among sensors). Therefore, every single sensor is a source of one or more time series telemetry data streams. All these data flows need to be transported from their sources to the centralized location where the DT is running. A typical DT architecture consists of three essential components: (i) a
Data Lake, where the collected, pre-processed, and post-processed data are stored; (ii) the
Sandbox Domain, containing the different models and algorithms that emulate the different components of the physical system; and (iii) the
Digital Twin Manager (DTM) that is in charge of several actions including the management of the models in the sandbox domain. Moreover, the DTM interfaces with the Application Manager in charge of both the physical and DT systems. Note that the Application Manager uses the DT to analyze the current and future state of the physical system, which can be achieved by combining the collected data available in the Data Lake and the models and algorithms in the sandbox domain. The result of such analysis can lead to specific actions to be executed in the physical system. Moreover, the Application Manager can configure rules and policies to the DTM, so that the latter can perform tasks such as intelligent data aggregation and anomaly detection in an autonomous way.
Figure 1b provides a deeper insight into the hierarchical architecture needed to run the proposed telemetry data compression and analysis. The first level is at the sensor layer where data are generated periodically. For the sake of simplicity, let us assume that sensors are those physical elements that are able to monitor one specific metric, e.g., temperature, pressure, etc. Then, a number of these sensors are integrated into a monitoring
device, that provides the support (computing, power) to those sensors, as well as contains the needed transceivers and interfaces (wired or wireless) required to eject the data out of the device. Since the vast majority of multi-purpose monitoring devices are built on top of powerful boards such as Arduino or Raspberry Pi [
30,
31], a software-based
Device Agent (DA) is deployed in the device for several purposes, including telemetry data processing and device control and management. Specifically, in the context of our work, we consider that the DA contains the AEs necessary to compress the collected telemetry data and perform anomaly detection. Then, the DA sends the compressed data to the DTM that is hosted in the remote location. Along with the compressed data, three types of metadata are sent: (i) the device/sensors identification data, including location; (ii) the compression method metadata, including aspects such as the AE id that is required to decompress the data, as well as the expected reconstruction error; and (iii) the anomaly detection diagnosis, in case that some anomaly affecting one or multiple sensors is detected.
The second element in the proposed hierarchical architecture is the Cluster Agent (CA) which runs as one of the processes in DTM and aggregates the inputs received from a number of devices that form a group (cluster). The meaning of a cluster is open: it can represent any subset of monitoring devices in a physical subsystem. Without loss of generality, we assume that the creation of clusters is part of the design of both the physical system and DT, which is out of the scope of this paper. Each CA is in charge of decompressing the data received from its nested DAs and storing such decompressed data in the Data Lake. Moreover, it is also in charge of training AEs as soon as new relevant data are collected and uploading new models to the DAs in an automatized manner. Finally, it processes the anomaly detection diagnosis reports received from DAs, performs multiple anomaly detection if needed, and notifies the application manager in case of some anomaly event has been detected.
The next subsection presents a detailed architecture of the main building blocks running in DA and CA elements, including the three main processes previously introduced: Adaptive AE-based Compression (AAC), Single Sensor Anomaly Detection (SS-AD), and Multiple Sensor Anomalous Group Diagnosis (MS-AGD).
3.2. Main Components
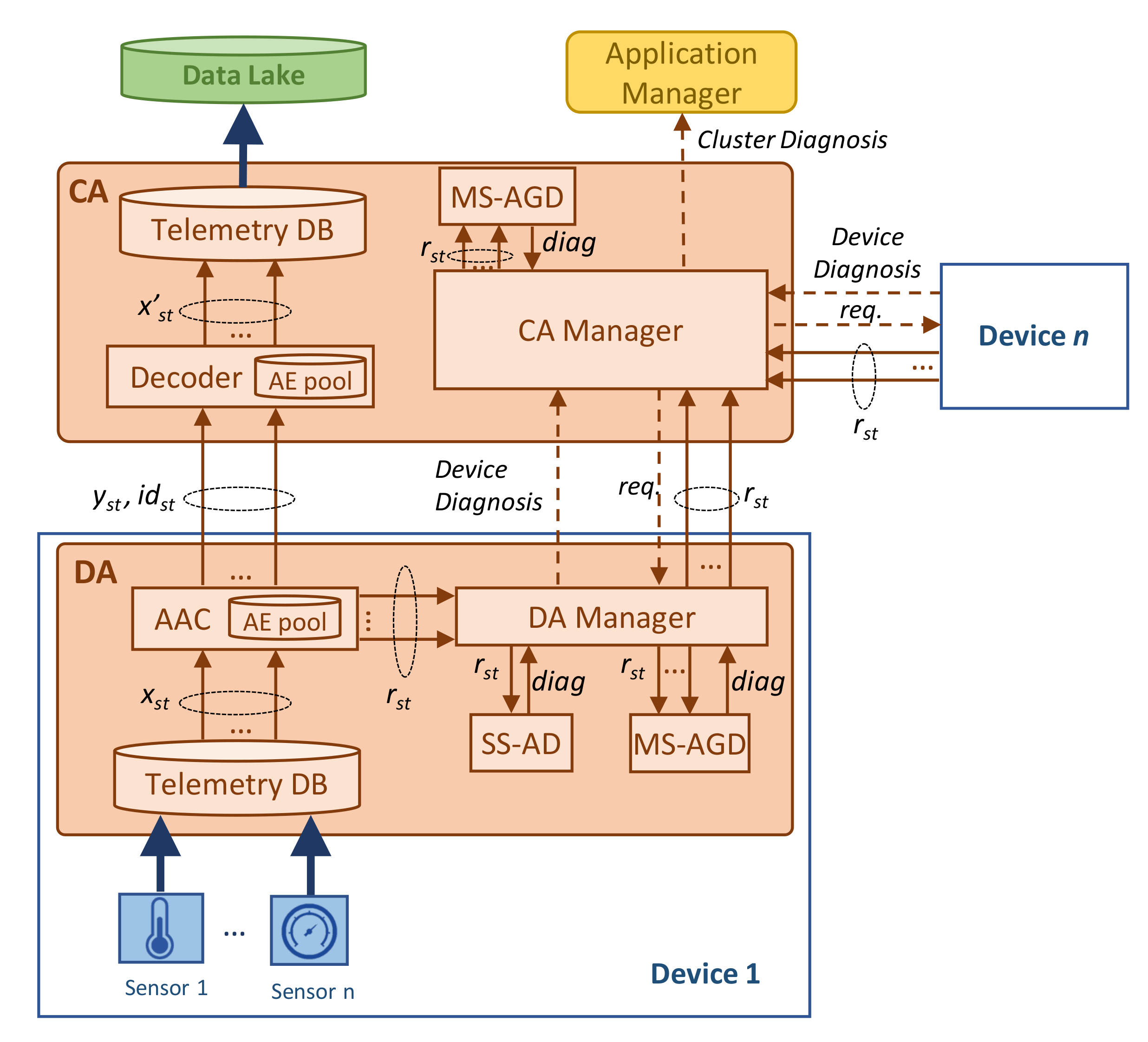
Figure 2 details the architecture previously sketched in
Figure 1b, showing the key building blocks and their relationship. The figure focuses on the processes related to telemetry data compression and anomaly detection. For the sake of simplicity, the processes of training and updating AEs are not depicted in the figure. Let us assume that the DA implements a telemetry database (DB) that temporarily stores the data injected by each of the sensors in the device. We can assume that this data collection is accomplished at a very narrow
telemetry interval, e.g., one measurement per second and device. Then, a larger
monitoring interval, e.g., every minute, is configured to retrieve data from the telemetry DB and compress them. Thus, let us denote
xst as the telemetry measurements collected during monitoring interval
t by sensor
s. These data are then fed to the
compressor module that is responsible for running the AAC process. By means of the AE pool, adaptive and effective compression is achieved. The compressed telemetry data (denoted as
yst) as well as the identifier of the AE selected by AAC for compression (denoted as
idst) are sent to the CA. Without loss of generality, we assume that CA process the received compressed data immediately upon their reception, calling a simple
de-compressor process that uses the decoder of the selected AE to reconstruct the original telemetry stream (denoted as
x’st) and inject it into the data lake.
In addition to the compressed telemetry data, the AAC process also computes the reconstruction error vector obtained by the selected AE (denoted as rst). This error is defined as the difference between the original and reconstructed telemetry measurements. This relevant output is locally processed at the DA for anomaly detection purposes. Specifically, the DA manager receives a reconstruction error vector per each sensor and monitoring interval and triggers two different anomaly detection processes. On the one hand, the SS-AD analyzes the individual reconstruction error of each sensor in order to find an anomalous error pattern such as continuous large error. On the other hand, the MS-AGD analyzes the reconstruction errors of the sensors in the device and performs a correlated analysis in order to identify subtle anomalies affecting several sensors at the same time. The diagnosis generated by each of the methods is then processed by the DA manager that generates a device diagnosis report when a remarkable event is detected by one or both methods.
Such device diagnosis report (if generated) is sent to the CA manager which can trigger a wider and deeper anomaly analysis. In particular, it can request to the DA of the devices under its control those reconstruction error vectors that have not been sent before. As an illustrative example, let us imagine that an anomaly in a temperature sensor has been detected in device i. The CA can then request the reconstruction error of the rest of the temperature sensors of all the devices in the cluster in order to perform a group analysis and detect, e.g., an incipient temperature anomaly in other elements of the system. Note that, to allow this analysis, we consider that DA managers temporarily store reconstruction errors even when they are not detecting any anomaly. Finally, the results of received device diagnosis reports generated by DA managers and the sensor group analysis (if proceeding) generated by the CA manager compose the cluster diagnosis report that is sent to the application manager.
The next section presents detailed algorithms for AAC, SS-AD, and MS-AGD processes.
4. Algorithms
4.1. Notation
Table 2 provides the main notations that are consistently used in the following algorithms.
4.2. AAC
Algorithm 1 details the pseudo-code of the AAC process which runs for each sensor s in a device and is executed at every interval t a new telemetry stream is available. As introduced in the previous section, it receives the raw telemetry data stream xst containing a number w of measurements, the pool of AEs of the sensor Ψs, and the reconstruction error threshold εcomp to determine whether a given compressed stream yst produces enough of an accurately reconstructed telemetry stream when decoded. In addition to yst, the algorithm also returns the identifier of the selected AE in the pool idst, as well as the reconstruction error vector rst.
After initializing output variables (line 1 of Algorithm 1), the set of AEs in the pool
Ψs are sorted in ascendant order of size of LS (line 2). Thus, they are going to be sequentially evaluated in a loop from the highest to lowest compression ratio (line 3). Given an AE
ψ, the input data are normalized with the min-max values stored as model coefficients (line 4). Then, the normalized input
x is propagated through the encoder part and the compressed stream
y is obtained (line 5). At this point, the decoder is used to compute the reconstructed data stream
x’, which is used to compute the reconstruction error
r that
ψ produces (lines 6–7). Note that if the average reconstruction error is below threshold
εcomp, then an accurate compression is found, and the AE pool search is interrupted (lines 8–10). Finally, the resultant output is returned (line 11). Note that this output can be either a compressed telemetry stream if an AE producing an average reconstruction error below
εcomp is found or the original input if no accurate compression can be effectively accomplished.
| Algorithm 1. AAC method. |
INPUT: xst, Ψs, εcomp
OUTPUT: yst, idst, rst |
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11. | yst ← xst; idst ← ∅; rst ← zeros(w)
sort(Ψs, |ψ.latent|, “ascendent”)
for each ψ ∈ Ψs:
x ← normalize(xst, ψ.minmax)
y ← ψ.encoder.propagate(x)
x’ ← ψ.decoder.propagate(y)
r← computeReconstructionError(x, x’)
if avg(r) ≤ εcomp:
yst ← y; idst ← ψ.id; rst ← r
break
return yst, idst, rst |
Recall that we consider that generic AEs with moderated compression rates trained from heterogeneous generic sensor data are used until enough sensor-specific data are collected to train ad-hoc AEs that better compress the data of a given sensor. Without loss of generality, we can assume that this procedure can run periodically as soon as telemetry data from sensors are available. Algorithm 2 details the proposed procedure to train and update the AEs in a pool. Thus, given an AE pool Ψ (that could be initially empty) and a database DB containing telemetry measurements (that can be either generic or sensor-specific), the algorithm trains a set of AEs with LS sizes defined in set Z in order to find new models that improve existing ones.
| Algorithm 2. AE pool update. |
INPUT: Ψs, Z, DB
OUTPUT: Ψs |
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16. | DBtrain, DBtest ← split(DB)
for each z ∈ Z:
ψnew ← trainAE(DBtrain, z)
ψcur ← select(Ψs, |ψ.latent|= z)
if ψcur = ∅ then
Ψs.add(ψnew)
else
Y ← ψnew.encoder.propagate(DBtest)
X’ ← ψnew.decoder.propagate(Y)
rnew ← computeReconstructionError (DBtest, X’)
Y ← ψcur.encoder.propagate(DBtest)
X’ ← ψcur.decoder.propagate(Y)
rcur ← computeReconstructionError (DBtest, X’)
if avg(rnew) < avg(rcur) and max(rnew) < max(rcur) then
Ψs.replace(ψcur, ψnew)
return Ψs |
The procedure starts by splitting the data in DB in both training and testing datasets, e.g., following a typical 80–20% split [
32] (line 1 in Algorithm 2). Then, each LS size
z in
Z is selected and a new AE
ψnew is trained for such LS size (lines 2–3). This new AE needs to be compared against the current one in the pool with the same LS size (denoted as
ψcur) and therefore, it is retrieved from the pool (line 4). Note that
ψnew is directly added to the pool if there is no currently available AE with such size
z (lines 5–6). Otherwise, the testing dataset is used to evaluate the reconstruction error in both
ψnew and
ψcur (lines 8–13). Thus, the current AE is replaced by the new one if both average and maximum reconstruction errors are reduced by the new AE (lines 14–15). Eventually, the updated AE pool is returned.
4.3. SS-AD
Algorithm 3 details the pseudo-code of the SS-AD procedure that runs locally in the DA every time a new compressed telemetry stream is obtained and hence, a new reconstruction error vector rst is available. Since the principle of anomaly detection using AEs relies on the fact that an anomalous input will be poorly reconstructed, an anomaly error detection threshold εanom is needed to perform such detection. Indeed, anomaly detection is triggered if either one of the following conditions is met: (i) a number α of consecutive measurements produced a reconstruction error larger than threshold εanom or (ii) a number β of total measurements (non-consecutive) produced a reconstruction error larger than threshold εanom.
The algorithm starts by initializing the counters of the consecutive and total number of measurements above the error threshold (line 1 in Algorithm 3). Then, each single error value in the
rst vector is evaluated and compared with the threshold (lines 2–3). When the error exceeds the thresholds, then both counters are increased in one unit (lines 4–5). At this point, it is worth checking if one of the anomaly detection conditions is met and if so, the procedure stops and returns an anomaly detection event (lines 6–7). Therefore, it is necessary to reset the counter of consecutive values above the threshold before analyzing the next error value (lines 8–9). Finally, no anomaly event is returned in the case that none of the conditions is met (line 10).
| Algorithm 3. SS-AD |
INPUT: rst, εanom, α, β
OUTPUT: anomaly |
1.
2.
3.
4.
5.
6.
7.
8.
9.
10. | kcons, ktotal ← 0
for each r ∈ rst do:
if r > εanom then
kcons ← kcons +1
ktotal ← ktotal +1
if kcons == α or ktotal = β then
return True
else
kcons ← 0
return False |
4.4. MS-AGD
The pseudo-code of the MS-AGD procedure is detailed in Algorithm 4, which aims at computing a score that increases when a number of sensors within a group generate a high reconstruction error at the same time. Indeed, this score has the form of a vector of w positions, indicating the score at a given time unit within the analyzed monitoring interval (which allows fine multiple anomaly detection analysis). Moreover, recall that the MS-AGD can be executed at the device level, e.g., analyzing all (or a subset) of the sensors of a given device, or at the cluster level, e.g., analyzing all (or a subset) of the sensors in a given cluster. Regardless of the case, let us consider that the reconstruction error vectors obtained at a given monitoring time interval of a given group of sensors are denoted as R. This is the main input of MS-AGD, which also requires the specific parameter γ that defines the time interval size needed to compute the score.
The first step is to initialize the score vector, as well as the auxiliary matrix Q that is going to facilitate score computation (lines 1–2 of Algorithm 4). In particular, Q is a sparse 0–1 matrix, where cell <
i,
j> is 1 if and only if the sensor
i at time unit
j took a measurement above the average value of that sensor within monitoring interval
t. After computing Q (lines 3–9), the score is computed for every time unit within the monitoring interval (lines 10–13). The score of each time unit
i is the product of components a and b. On the one hand, a is the normalized sum of 1 s in Q that time, i.e., which proportion of sensors generates a measurement that produced a reconstruction error above the average. On the other hand, b computes the normalized dot product of Q in the last γ time units. Note that a large value indicates that there are consecutive time units where several sensors are above the average. In particular, b = 1 when all sensors in S
g stay above average reconstruction error during a consecutive number γ of time units.
| Algorithm 4. MS-AGD |
INPUT: R = {rst, ∀s ∈ Sg}, γ
OUTPUT: score |
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14. | score ← zeros(w)
Q ← zeros(|Sg|, w)
i ← 0
for s ∈Sg do
i ← i + 1
ravg ← avg(R.rst)
for j == 1..w do
if R.rst[j] > ravg then
Q[i,j] ← 1
for j == γ..w do
a ← sum(Q[:, j])/|Sg|
b ← dotproduct(Q[:,j-γ+1:j])/γ
score[j] ← a·b
return score |
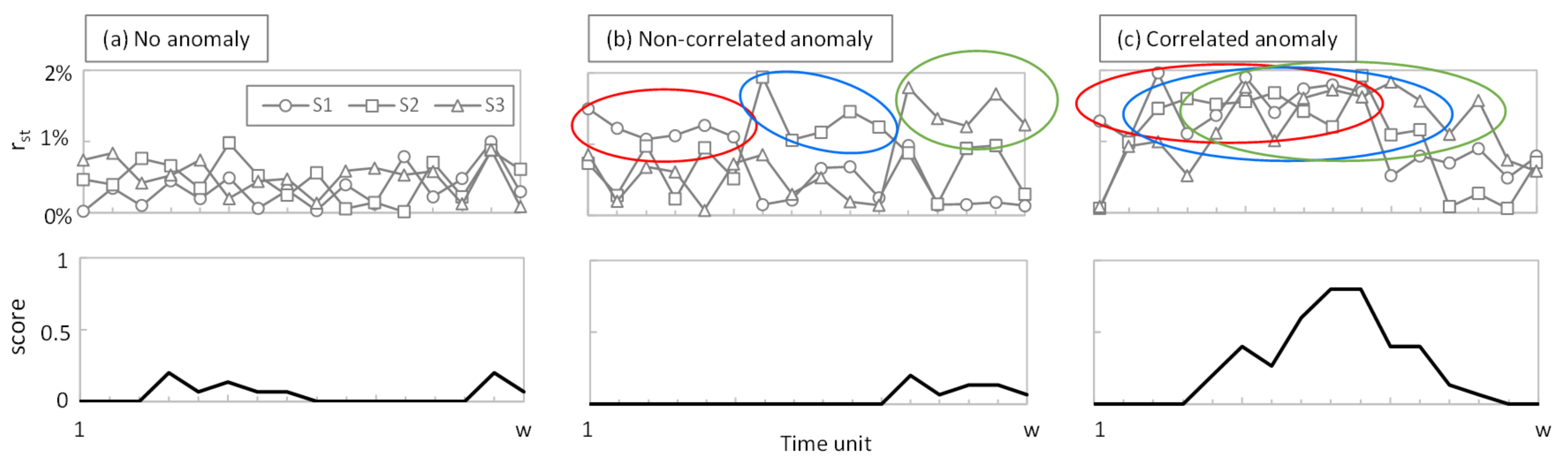
To better understand the rationale behind the MS-AGD score,
Figure 3 shows the reconstruction error r
st and the score in a monitoring time interval of w = 20 of an example with three sensors. Three different cases are depicted, assuming γ = 5: (i) the error stays constant and low for all the time and sensors (no anomaly,
Figure 3a); (ii) the error increases in all the sensors but not at the same time (non-correlated subtle anomaly,
Figure 3b); and (iii) the error increases in all the sensors and partially coincides in time (correlated subtle anomaly,
Figure 3c). For the sake of simplicity, the average reconstruction error is around 0.5% in all the sensors in
Figure 3a and around 1.5% in all the sensors in
Figure 3b,c. Colored circles indicate when the reconstruction error is above the threshold. As can be observed, the score reaches significant values (above 0.5) only when several sensors exceed the average reconstruction error at the same time.
5. Performance Evaluation
In this section, we first introduce the simulation environment developed to evaluate the methods and algorithms presented in previous sections. Then, we analyze the performance of AAC, SS-AD, and MS-AGD using telemetry data from a real physical system. Finally, we analyze the impact of the proposed methods on a network case study where transport network capacity savings are shown.
5.1. Simulation Environment
For numerical evaluation purposes, we implemented a Python-based simulator reproducing the main blocks of the architecture presented in
Figure 2, as well as the algorithms in
Section 4. In particular, a CA with three Das was configured, where every DA processes data from one single sensor. Sensors were implemented as time series data generators injecting real measurements (one per second) from the Water Distribution (WADI) dataset [
33]. The WADI dataset contains experimental sensor data measured in a water distribution testbed under different conditions, including normal operation and operation in the presence of system perturbations. The testbed comprises several water tanks as well as chemical dosing systems, booster pumps, valves, instrumentation, and analyzers, thus forming a complete and appropriate physical system for the performance evaluation of the proposed methods. Among all available data in WADI, we selected three time series from three different sensor types (hereafter, referred to as
S1,
S2, and
S3) with different behaviors and patterns. Specifically, the selected sensors are located in a water pressure valve and collect measurements of pressure, volume, and voltage.
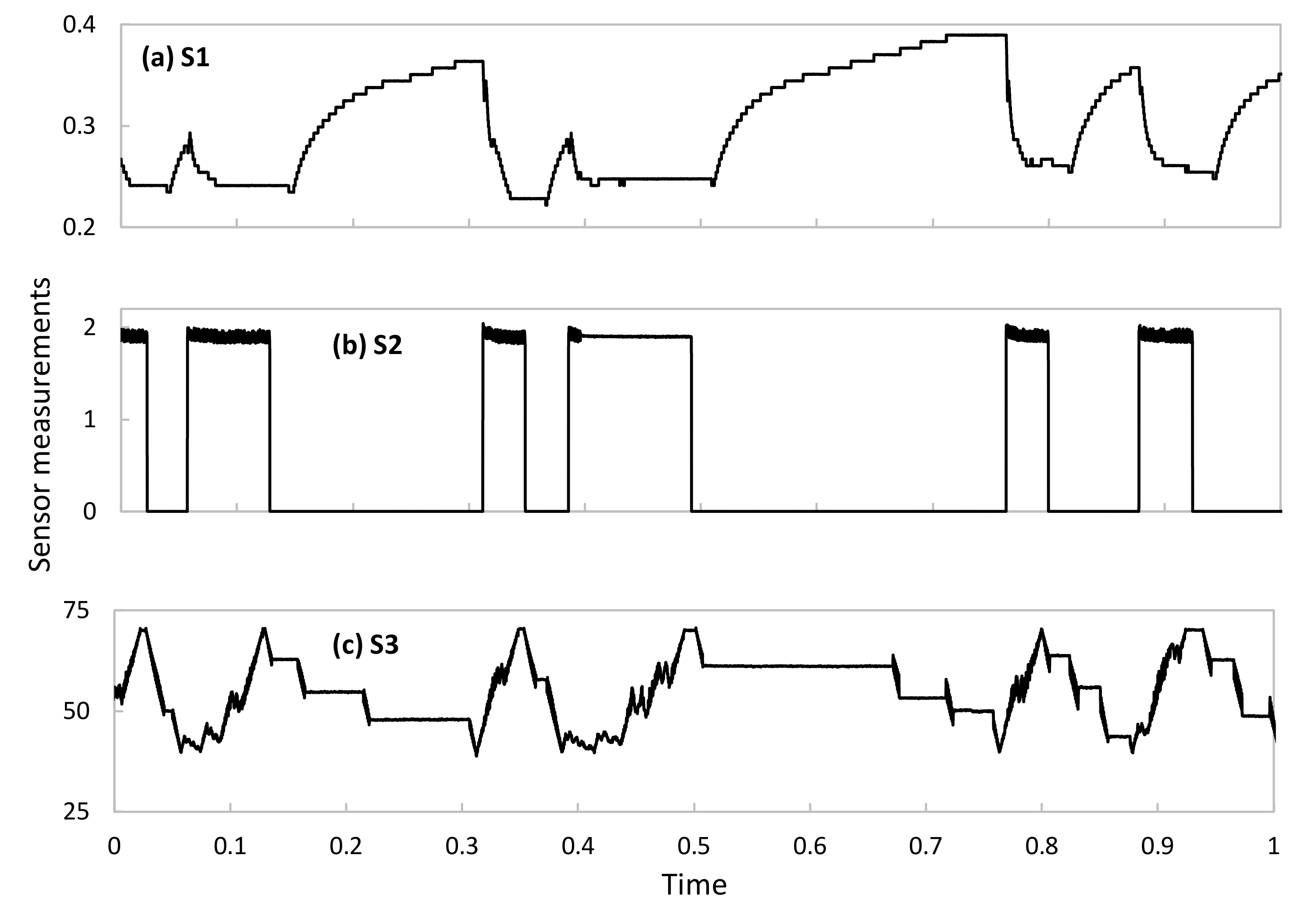
Figure 4 shows an example of each sensor time series data under normal operation. As can be observed, they are different in terms of time patterns, as well as in the magnitude and range of the telemetry data. Note that these data cover typical and widespread patterns observed in telemetry data, which will allow extending this performance evaluation analysis to other DT-based systems such as smart manufacturing and communication networks.
For the sake of simplicity, we assume that AEs in the pool of CA and Das are trained using Algorithm 2 after a period of raw data collection to populate the initial database DB. Without loss of generality, we assume that the measurements collected during this period belong to the normal operation of the physical system. Then, fixing interval w to 256 s, we obtained 7.68e5 samples for training, as well as 9.6e4 samples for testing. Regarding AE pool configuration, we considered four different AEs with Z = {4, 8, 16, 32} LS sizes. In all the cases, we considered two hidden layers, with 128 and 64 hidden neurons each. We used the keras library for AE training and testing, as well as pandas and numpy to load and manipulate the datasets. AEs were trained during 100 epochs using the adam optimizer and mean absolute errors as loss function, which results in reconstruction accuracy values around 99%.
5.2. AAC Performance
The first numerical study is focused on evaluating the performance of the AAC procedure in Algorithm 1 once the AE pool of every DA has been trained with the telemetry data of its specific sensor.
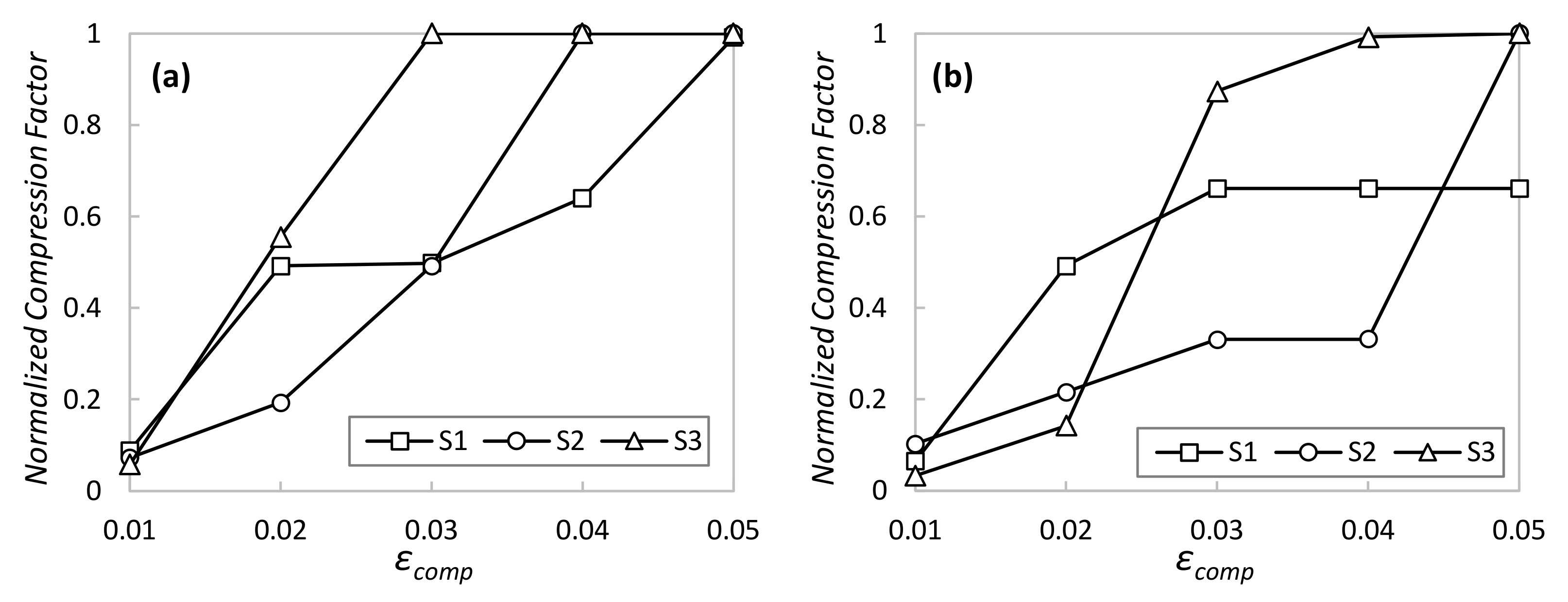
Figure 5 shows the compression factor as a function of target reconstruction error
εcomp for both normal operation (
Figure 5a) and operation with perturbations (
Figure 5b) after 9 h of simulated time (~32,000 monitoring samples per sensor). The compression factor was normalized between 0 and 1, where 0 means that the AAC cannot compress any measurement below the target
εcomp and 1 means that all measurements are compressed with the AE with the lowest LS size (in our case, 4). As can be observed, the AAC shows the desired adaptability, sharply increasing the compression factor when
εcomp is relaxed. Interestingly, we can observe that different time series produce different compression performances, even when AEs were specifically trained for that data. However, maximum compression is always achieved with low reconstruction error (0.05) under normal system operation and remains very high when perturbations appear in the system, which validates the applicability of the proposed method in systems subject to changes in the telemetry data generated.
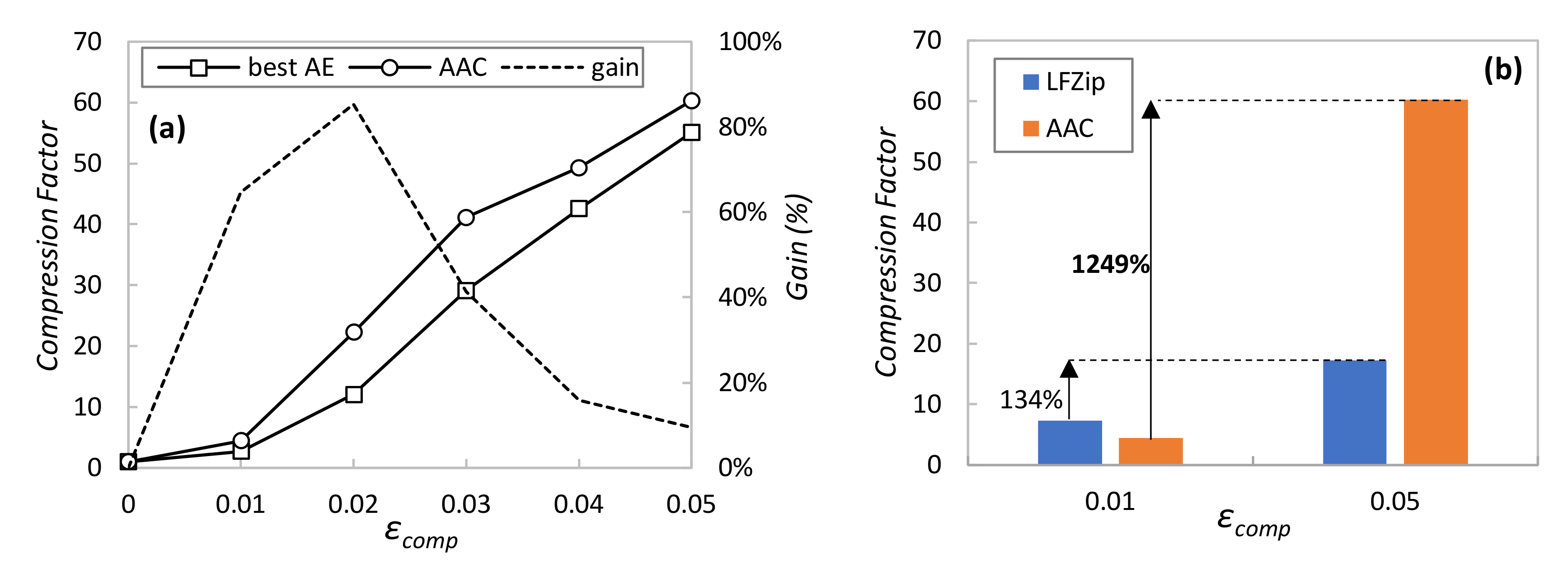
Once the AAC has been presented as an adaptive and polyvalent method, let us now focus on evaluating its performance compared to the two benchmarking methods. Firstly,
Figure 6a compares AAC against the simplest method consisting of the single AE that works better for a given
εcomp, i.e., the one with the smallest LS size that always achieves a reconstruction error less than
εcomp. Note that this benchmarking method is easy to deploy in our system, provided that the required
εcomp does not (often) change in time, because every requirement variation could entail a new AE re-training to adjust LS size. The figure shows the absolute compression factor (not normalized), as well as the relative gain of AAC with respect to using the best AE in each case. In light of the results, we can conclude that AAC produces a larger compression ratio than using a single AE, reaching a remarkable relative gain above 60% for stringent reconstruction errors around 0.01. Recall that AAC can adapt to changes in
εcomp without the need of retraining AEs; that, combined with its high performance, makes AAC the best option for AE-based compression.
In order to have a second benchmarking evaluation,
Figure 6b compares the achieved compression ratio for two selected
εcomp values against the compression method presented in [
14], called LFZip. Similar to AAC, LFZip is a lossy compression method using fully connected neural network decoders that achieves good compression ratios. In [
14], the authors provide the achieved compression ratio for the selected target reconstruction errors using different time series data. The figure compares the performance of AAC (averaging all sensors under normal operation) and LFZip (results from [
14]), where the large benefits of AAC can be observed. However, since we were not able to reproduce either the LFZip method with our sensor data or AAC with the data in [
14] (due to the lack of algorithm details and data availability), the conclusions of such comparison are mild. For this reason, we included the relative gain of each method when
εcomp is relaxed from 0.01 to 0.05. In view of the values, we can state that AAC clearly outperforms LFZip in terms of adaptability to variable requirements and relative compression gain.
It is worth noting that the outstanding AAC performance illustrated so far requires the availability of a pool of aEs specifically trained for each of the sensors. Once a new sensor is installed in the physical system and telemetry is starting to be collected and processed by a new or existing DA, such specific aEs are not available until enough data have been collected. This is the reason why, as introduced in previous sections, our approach proposes initializing the AAC with a pool of generic aEs trained with heterogeneous data, i.e., a mix of data from other sensors available in the data lake.
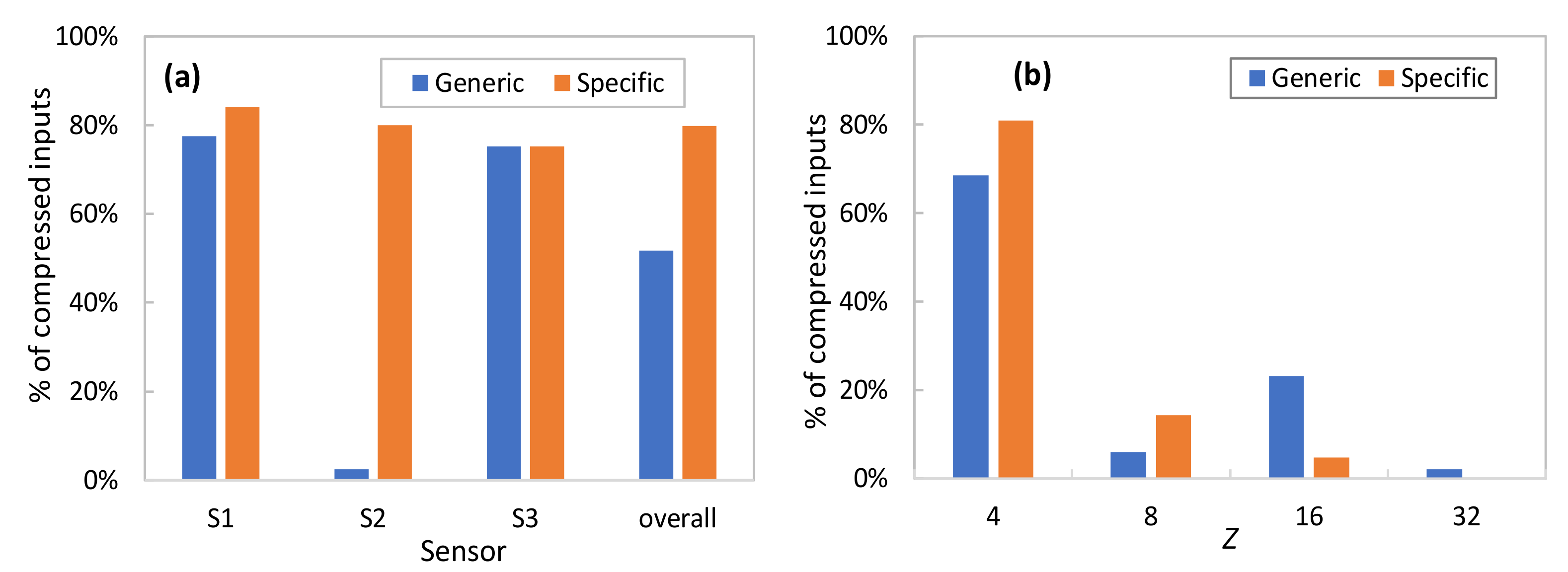
Figure 7a compares the percentage of compressed samples using generic aEs trained with a mix of telemetry measurements of all sensors and specific aEs for each of the sensors individually. In both cases, the AAC has been configured with a stringent
εcomp = 0.01. As can be seen, generic aEs produce an overall good performance (around 50% of samples can be effectively compressed), although this provides a negligible benefit for sensors that behave very differently from the considered generic data. This occurs in S2 data, showing a clear on-off period (recall the example in
Figure 4) that vastly differs from the generic data used for training. As soon as specific AEs can be trained, then both individual and overall compression increases (around 80% of samples can be compressed).
Finally,
Figure 7b details how many times every AE in the pool is used, for both generic and specific AE pools. Results show the average performance for all DAs and
εcomp = 0.01. Note that the smallest LS size is frequently selected; however, sometimes a smaller compression (larger LS) is needed to guarantee the target reconstruction error, which adds value to the proposed AAC method. Moreover, the use of larger AEs is reduced when specific AEs are trained. For this very reason, we can conclude that the use of generic AEs is useful to provide compression from the beginning of sensor operation but needs to be substituted by specific AEs to reach maximum performance.
5.3. SS-AD and MS-AGD Performance
Once the AAC has been numerically evaluated and validated, in this section, we focus on evaluating the performance of anomaly detection procedures assuming that specific AE are already trained and working. In particular, we configured our simulator to reproduce two different use cases: (i) large individual anomalies for SS-AD evaluation and (ii) subtle time-correlated anomalies for MS-AGD evaluation.
For the first use case, we assume that SS-AD is continuously running for each sensor during 9 h of normal operation followed by a drastic change in the pattern of the generated data (happening at time tanom). In order to introduce a variety of anomalies, we consider that sensor Si starts generating at tanom data similar to that of sensor Sj, being i≠j and i, j ∈ {1, 2, 3}, thus reproducing six different anomalies.
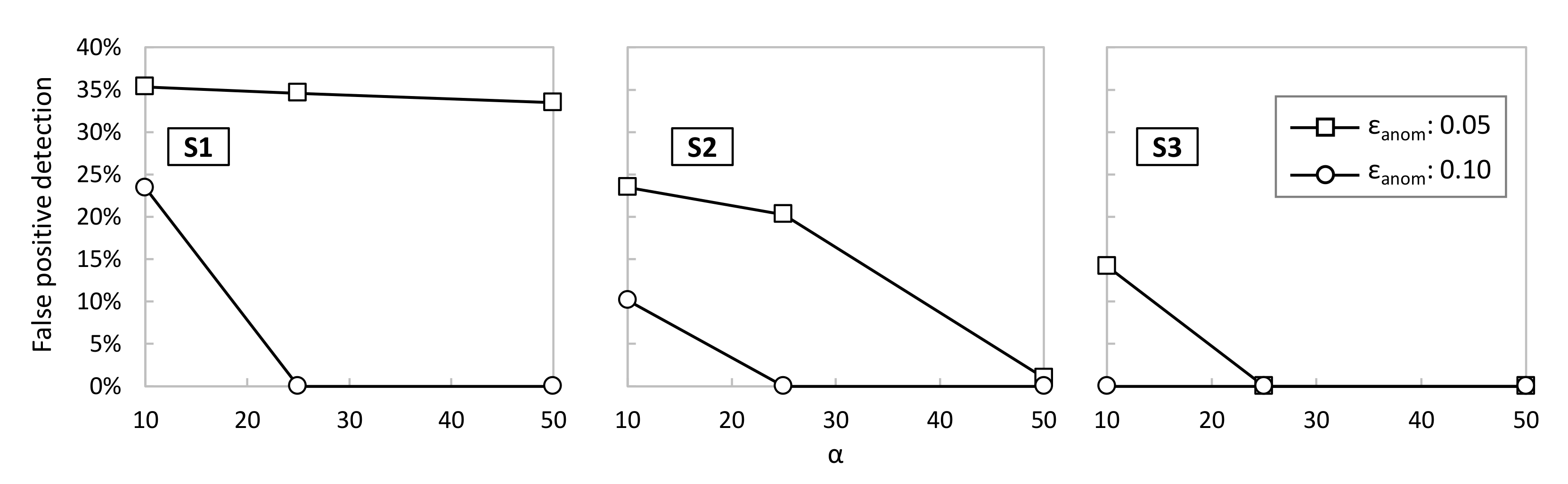
Figure 8 evaluates the percentage of false positives detected by each of the sensors as a function of different values of SS-AD parameters
εanom and α (β was fixed to 100). A false positive is detected if SS-AD returns True during the period of normal operation, i.e., when no anomalies are introduced. In light of the results, we can conclude that increasing
εanom to 0.10 is sufficient to reduce α to short values (25 for
S1 and
S2 and 10 for S3) that lead to zero false positive detections. Note that, the shorter α is, the faster the detection of true anomalies. Then, assuming the best configuration of parameters for every sensor,
Table 3 shows the detection accuracy of all the aforementioned anomalies. It is worth noting that SS-AD achieves very high accuracy (>95%) for most of the considered anomalies. Indeed, only the
S1 SS-AD process is not able to detect
S3-like data, which is reasonable due to the similarity of both the
S1 and
S3 time series. Therefore, we can conclude that SS-AD performs accurate and robust detection of individual anomalies.
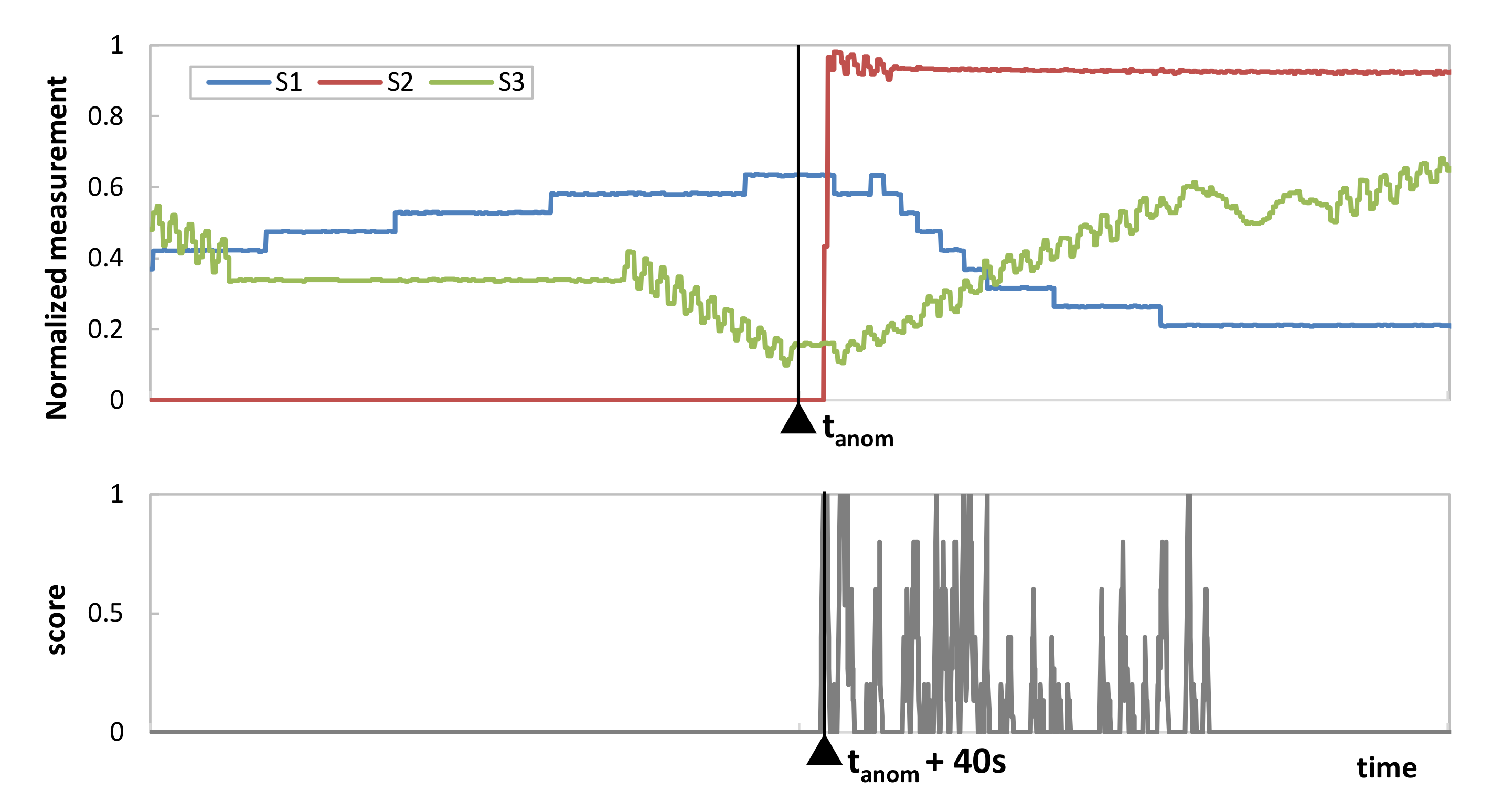
Regarding the second use case, we took advantage of WADI dataset measurements collected under perturbations that were intentionally introduced in the system. The available metadata clearly indicates the time when a perturbation starts, which we identified as
tanom.
Figure 9 plots the three sensors’ data in the period before and after
tanom, as well as the score computed in all such periods. In view of the results, we can conclude that the proposed score clearly identifies when the correlated anomaly starts (no false positive detection is observed before
tanom). Note that the first time interval where the score reaches a value significantly larger than 0 is only 40 s later than
tanom, which validates MS-AGD as a prompt time-correlated anomaly detection method.
5.4. Case Study
Eventually, we conducted a numerical case study in order to evaluate the impact of the proposed methodology assuming a larger network scenario such as the one sketched in
Figure 1a. Thus, we assume that a physical system containing hundreds to thousands of sensors is geographically distributed among a number of locations where the DAs are locally deployed. For the sake of simplicity, let us assume that the overall telemetry data generated by all the sensors in the system, i.e., the total volume that needs to be gathered by the DT, is fixed at 400 Gb/s. Moreover, let us assume an optical transport network that allows transparent connectivity between the remote physical locations and the location where the DT is deployed, e.g., a data center. To support the transport of such telemetry data, optical connections taking advantage of digital subcarrier multiplexing technology can be deployed [
34]. This ensures that optical connections can be established with a fine granularity of 25 Gb/s each.
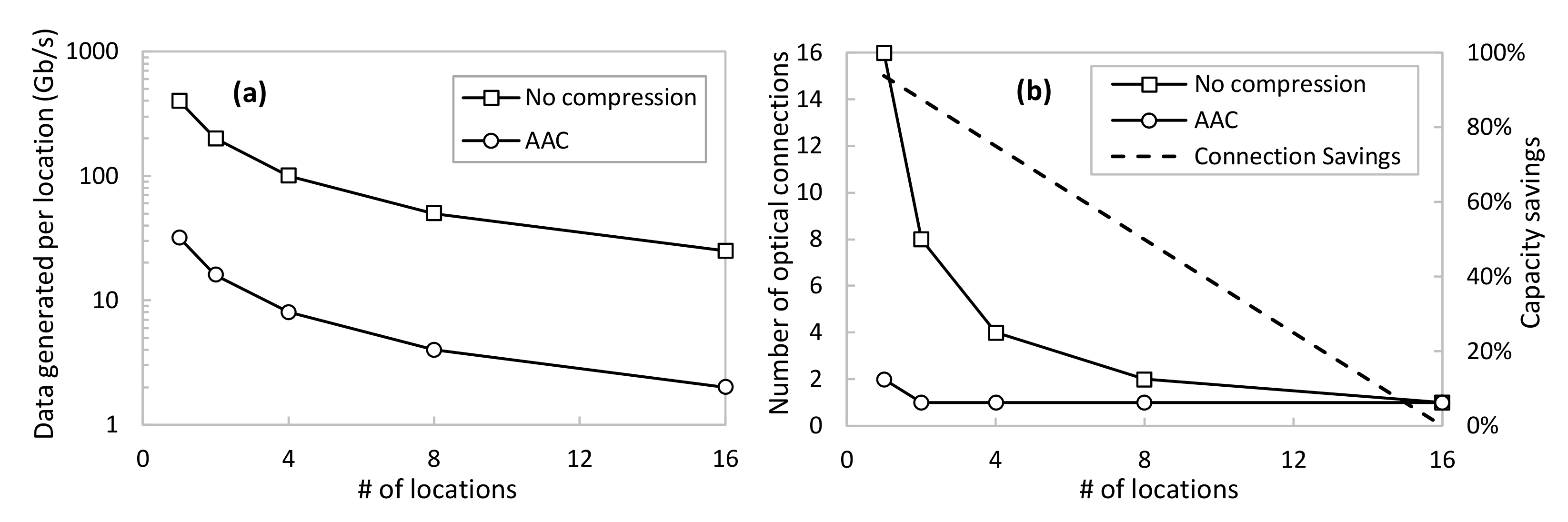
Figure 10a shows the amount of data injected as a function of the number of locations, assuming an even split among locations of the total amount of telemetry data. Two cases are shown: no compression and using AAC. For the latter, we consider
εcomp = 0.01 and, according to
Figure 6 and considering that the sensors behave similarly to the ones used before, the average compression factor is around 12.5. Assuming this compression performance, the figure shows great savings in the total amount of data generated by every location distributed in the network. Nevertheless, the impact on the true amount of data that needs to be conveyed in the transport network will depend on the number of optical connections needed to carry out such data. This is shown in
Figure 10b as a function of a number of locations, as well as the capacity savings of using AAC with respect to the no compression scenario. For instance, 50% of optical capacity savings are achieved when 400 Gb/s of raw data are generated among eight different locations. In this case, every location is generating around 50 Gb/s of raw telemetry data, which requires two optical connections between the location and the centralized DT. On the contrary, the proposed AAC method reduces the conveyed data to 4 Gb/s, which can be served with only one optical connection per location.
Hence, we can definitively conclude that the proposed adaptive telemetry compression mechanism allows a large reduction in the number of optical connections and true data to be conveyed through the transport network.
6. Conclusions
In this paper, we presented a smart management system of DT telemetry data consisting of different processes for adaptive telemetry data compression (AAC), single sensor anomaly detection (SS-AD), and multiple sensor anomalous group diagnosis (MS-AGD). All the methods made use of AEs trained with generic and specific sensor telemetry data, as well as a set of algorithms that used those AEs to maximize the performance of compression and anomaly detection.
The numerical evaluation of such models and algorithms was performed using an experimental data set from a water distribution system. The main conclusions derived from such numerical analysis are (i) AAC produces a larger compression ratio than using a single AE, reaching a remarkable relative gain above 60% for stringent reconstruction errors around 1%; (ii) AAC achieves compression ratios one order of magnitude larger than other benchmarking lossy compression mechanisms in the literature; (iii) SS-AD achieves an anomaly detection accuracy larger than 95% when telemetry data anomalies are injected; and iv) MS-AGD is able to accomplish the prompt detection (<1 min) of subtle correlated anomalies affecting a group of sensors.
In addition, the proposed smart management of telemetry data for the DT use case was evaluated in terms of the reduction in transport network resources. To this aim, we considered distributed scenarios where telemetry data sources were spread among different network locations, thus needing to gather such telemetry data in a centralized location. Results showed that remarkable capacity savings, measured in terms of dedicated optical connections, were achieved for moderately-high distributed scenarios.
As a final remark, it is worth mentioning that this work allows for promoting the deployment of DT-based management solutions for those industrial systems that have not yet adopted it. Since telemetry data sources are currently available (sensors in automated control systems are widely used in industry), one of the major current obstacles for migrating towards DT-based solutions is the high cost of the management and curation of such a large amount of generated telemetry data. In this regard, the proposed contributions showed a significant reduction in such cost by efficient compression and decentralized analysis, thus facilitating the adoption of DT in industry.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









