
Image-Based Ship Detection Using Deep Variational Information Bottleneck


Abstract
:1. Introduction
- Regularly, VIB and the parameterization trick are used in classification tasks. However, this paper discusses integrating these techniques into object-detection frameworks. The method outperforms SoTA in detecting ship objects, especially in small-scale datasets.
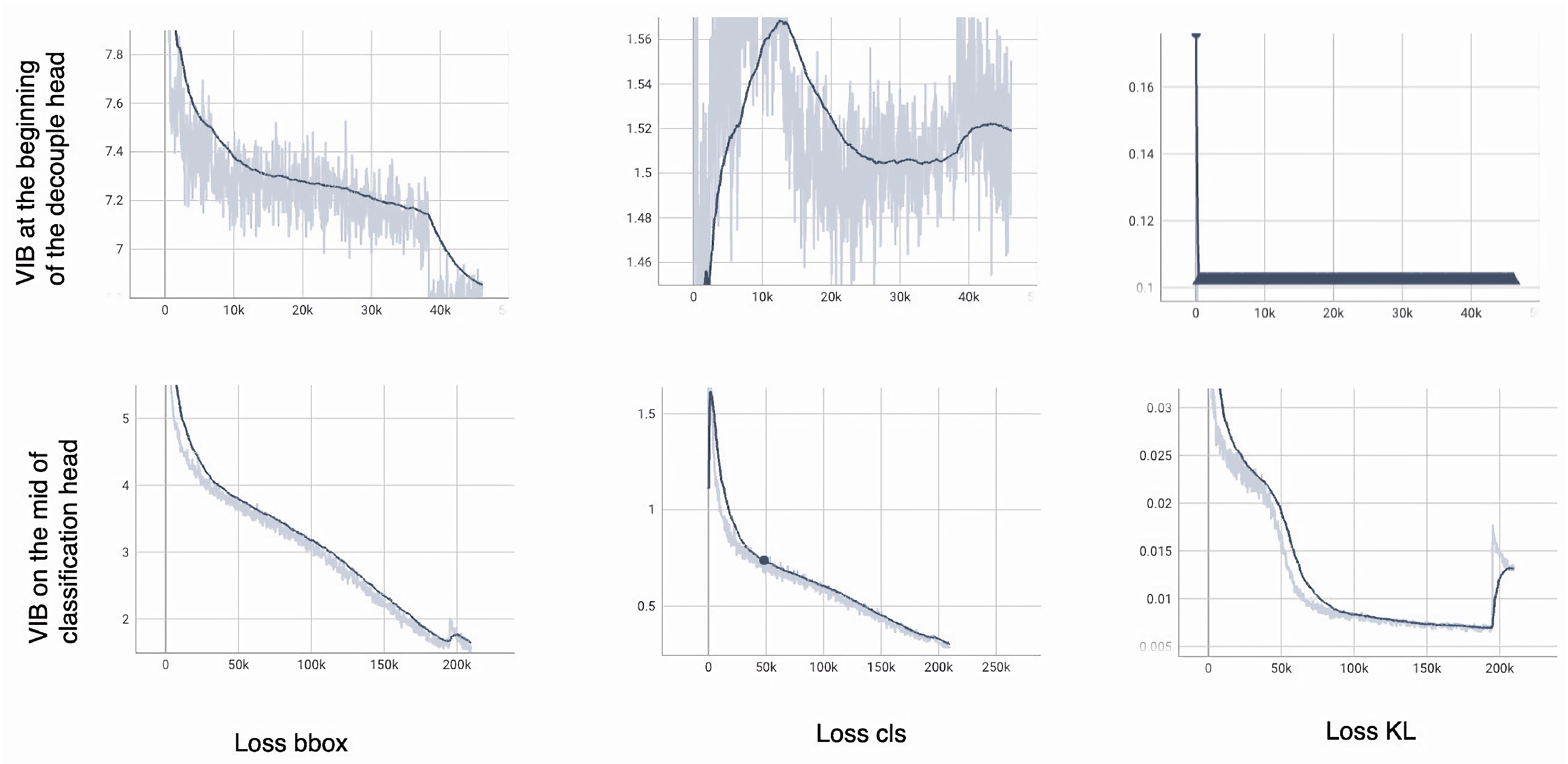
- We carefully test the effect of VIB and parameterization at different positions in decoupled heads. The result shows that VIB can only work on the classification head and should not allow the VIB loss effect on the regression head.
- A feature analysis proves that the proposed method could learn feature focus on objects rather than the background.
2. Related Works
2.1. Object Detection
2.2. Ship Detection
3. Proposed Method
3.1. Overview System
- is the width and height of the output.
- is intersection over union between the predicted box and the ground-truth box at the position .
- is a mask that decides which locations will be used to compute the loss.
- is the predicted objectness probability.
- is the ground-truth objectness label.
- is a mask that decides which locations will be used to compute the loss.
- C is the number of object classes.
- is the predicted class probability (usually obtained through softmax activation).
- is the ground-truth class label for the j-th location and the c-th class.
- is a mask that decides which locations will be used to compute the loss.
- d is the dimension of latent features.
3.2. Feature Section Loss
- The latent z must help to well predict the output y (vessel categories);
- Given the latent z, we cannot infer input x very well.
3.3. Backbone and Neck Module
4. Experimental Results
4.1. Datasets and Experiment Setting
4.2. Select the Hyper-Parameter
4.3. Compare with SoTA
4.4. Contribution of the VIB Loss on Small Datasets
4.5. Effect of Backbone
4.6. Effect of Pre-Processing Methods
4.7. The Position of VIB Network
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Szeto, A.; Pelot, R. The use of long range identification and tracking (LRIT) for modelling the risk of ship-based oil spills. In Proceedings of the AMOP Technical Seminar on Environmental Contamination and Response 2011, Banff, AB, Canada, 4–6 October 2011. [Google Scholar]
- Mao, S.; Tu, E.; Zhang, G.; Rachmawati, L.; Rajabally, E.; Huang, G. An Automatic Identification System (AIS) Database for Maritime Trajectory Prediction and Data Mining. arXiv 2016, arXiv:1607.03306. [Google Scholar]
- Paterniani, G.; Sgreccia, D.; Davoli, A.; Guerzoni, G.; Di Viesti, P.; Valenti, A.C.; Vitolo, M.; Vitetta, G.M.; Boriani, G. Radar-Based Monitoring of Vital Signs: A Tutorial Overview. Proc. IEEE 2023, 111, 277–317. [Google Scholar] [CrossRef]
- Zhou, X.; Gong, W.; Fu, W.; Du, F. Application of deep learning in object detection. In Proceedings of the 2017 IEEE/ACIS 16th International Conference on Computer and Information Science (ICIS), Wuhan, China, 24–26 May 2017; pp. 631–634. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2013, arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Girshick, R.; Iandola, F.; Darrell, T.; Malik, J. Deformable Part Models are Convolutional Neural Networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 July 2015. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; Available online: https://www.computer.org/csdl/proceedings-article/iccv/2021/281200j992/1BmGKZoEzug (accessed on 10 July 2023).
- Lee, S.H.; Park, H.G.; Kwon, K.H.; Kim, B.H.; Kim, M.Y.; Jeong, S.H. Accurate Ship Detection Using Electro-Optical Image-Based Satellite on Enhanced Feature and Land Awareness. Sensors 2022, 22, 9491. [Google Scholar] [CrossRef]
- Patel, K.; Bhatt, C.; Mazzeo, P.L. Deep Learning-Based Automatic Detection of Ships: An Experimental Study Using Satellite Images. J. Imaging 2022, 8, 182. [Google Scholar] [CrossRef]
- Stofa, M.M.; Zulkifley, M.A.; Zaki, S.Z.M. A deep learning approach to ship detection using satellite imagery. IOP Conf. Ser. Earth Environ. Sci. 2020, 540, 012049. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge 2012 (VOC2012) Results. 2012. Available online: http://www.pascal-network.org/challenges/VOC/voc2012/workshop/index.html (accessed on 10 July 2023).
- Zhang, Z.; Zhang, L.; Wang, Y.; Feng, P.; He, R. ShipRSImageNet: A Large-Scale Fine-Grained Dataset for Ship Detection in High-Resolution Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 8458–8472. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, M.; Rong, X.; Yu, X. Light-SDNet: A Lightweight CNN Architecture for Ship Detection. IEEE Access 2022, 10, 86647–86662. [Google Scholar] [CrossRef]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep Variational Information Bottleneck. arXiv 2016, arXiv:1612.00410. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. arXiv 2019, arXiv:1904.08189. [Google Scholar]
- Chen, W.; Shah, T. Exploring Low-light Object Detection Techniques. arXiv 2021, arXiv:cs.CV/2107.14382. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. arXiv 2020, arXiv:cs.CV/1911.09070. [Google Scholar]
- Grekov, A.N.; Shishkin, Y.E.; Peliushenko, S.S.; Mavrin, A.S. Application of the YOLOv5 Model for the Detection of Microobjects in the Marine Environment. arXiv 2022, arXiv:cs.CV/2211.15218. [Google Scholar]
- Katz, D.M.; Hartung, D.; Gerlach, L.; Jana, A.; Bommarito, M.J., II. Natural Language Processing in the Legal Domain. arXiv 2023, arXiv:cs.CL/2302.12039. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Doll’a r, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In ECCV; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693. [Google Scholar] [CrossRef]
- Zheng, J.; Liu, Y. A Study on Small-Scale Ship Detection Based on Attention Mechanism. IEEE Access 2022, 10, 77940–77949. [Google Scholar] [CrossRef]
- Ye, B.; Qin, T.; Zhou, H.; Lai, J.; Xie, X. Cross-level Attention and Ratio Consistency Network for Ship Detection. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 4644–4650. [Google Scholar] [CrossRef]
- Cui, H.; Yang, Y.; Liu, M.; Shi, T.; Qi, Q. Ship Detection: An Improved YOLOv3 Method. In Proceedings of the OCEANS 2019, Marseille, France, 17–20 June 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Liu, T.; Pang, B.; Ai, S.; Sun, X. Study on Visual Detection Algorithm of Sea Surface Targets Based on Improved YOLOv3. Sensors 2020, 20, 7263. [Google Scholar] [CrossRef]
- Li, H.; Deng, L.; Yang, C.; Liu, J.; Gu, Z. Enhanced YOLO v3 Tiny Network for Real-Time Ship Detection From Visual Image. IEEE Access 2021, 9, 16692–16706. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I. CBAM: Convolutional Block Attention Module. In Proceedings of the 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar] [CrossRef]
- Liu, T.; Pang, B.; Zhang, L.; Yang, W.; Sun, X. Sea Surface Object Detection Algorithm Based on YOLO v4 Fused with Reverse Depthwise Separable Convolution (RDSC) for USV. J. Mar. Sci. Eng. 2021, 9, 753. [Google Scholar] [CrossRef]
- Guo, J.; Li, Y.; Lin, W.; Chen, Y.; Li, J. Network Decoupling: From Regular to Depthwise Separable Convolutions. arXiv 2018, arXiv:cs.CV/1808.05517. [Google Scholar]
- Han, X.; Zhao, L.; Ning, Y.; Hu, J. ShipYOLO: An Enhanced Model for Ship Detection. J. Adv. Transp. 2021, 2021, 1060182. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. arXiv 2020, arXiv:cs.CV/1911.11907. [Google Scholar]
- Ye, R.; Liu, F.; Zhang, L. 3D Depthwise Convolution: Reducing Model Parameters in 3D Vision Tasks. arXiv 2018, arXiv:cs.CV/1808.01556. [Google Scholar]
- Zhang, Q.; Huang, Y.; Song, R. A Ship Detection Model Based on YOLOX with Lightweight Adaptive Channel Feature Fusion and Sparse Data Augmentation. In Proceedings of the 2022 18th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Madrid, Spain, 29 November–2 December 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar] [CrossRef]
- Zhang, Y.; Er, M.J.; Gao, W.; Wu, J. High Performance Ship Detection via Transformer and Feature Distillation. In Proceedings of the 2022 5th International Conference on Intelligent Autonomous Systems (ICoIAS), Dalian, China, 23–25 September 2022; pp. 31–36. [Google Scholar] [CrossRef]
- Tishby, N.; Pereira, F.C.; Bialek, W. The information bottleneck method. In Proceedings of the 37-th Annual Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 22–24 September 1999; pp. 368–377. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Ashwani Kumar Aggarwal, P.J. Segmentation of Crop Images for Crop Yield Prediction. Int. J. Biol. Biomed. 2022, 7, 40–44. [Google Scholar]
- Thukral, R.; Arora, A.; Kumar, A.; Kumar, G. Denoising of Thermal Images Using Deep Neural Network; Springer: Singapore, 2022; pp. 827–833. [Google Scholar] [CrossRef]
- Thukral, R.; Kumar, A.; Arora, A.; Gulshan. Effect of Different Thresholding Techniques for Denoising of EMG Signals by using Different Wavelets. In Proceedings of the 2019 2nd International Conference on Intelligent Communication and Computational Techniques (ICCT), Jaipur, India, 28–29 September 2019; pp. 161–165. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| The input, the output, and the latent feature of the network. | |
| i | The index of scale level. |
| j | The index of position on a feature map. |
| d | The dimension of latent vectors in VIB module |
| The latent feature and its corresponding variance at the ith scale. | |
| The feature and its corresponding variance at the position jth in a map | |
| , | The classification ground truth and output. |
| , | The box ground truth and output. |
| , | The object ground truth and output. |
| Block | Layer | Parameters |
|---|---|---|
| nn.conv | Size=(1,1), In = , Out = | |
| nn.conv | Size=(1,1), In = , Out = | |
| Re-parametrize |
| Scenario | |||
|---|---|---|---|
| first | 10 | 1 | 1 |
| first | 1 | 10 | 1 |
| first | 1 | 1 | 10 |
| Scenario | Fishing Boat | Container Ship | Ore Carrier | Bulk Cargo Carrier | Passenger Ship | General Cargo Ship | mAP |
|---|---|---|---|---|---|---|---|
| first | 0.977 | 0.999 | 0.994 | 0.994 | 0.982 | 0.987 | 0.989 |
| first | 0.967 | 0.987 | 0.992 | 0.992 | 0.942 | 0.987 | 0.978 |
| first | 0.966 | 0.988 | 0.984 | 0.990 | 0.959 | 0.990 | 0.979 |
| Method | Train + Val/Test (in %) | Fishing Boat | Container Ship | Ore Carrier | Bulk Cargo Carrier | Passenger Ship | General Cargo Ship | mAP |
|---|---|---|---|---|---|---|---|---|
| Zhang_2022 [47] | 90/10 | 0.824 | 0.940 | 0.859 | 0.915 | 0.787 | 0.914 | 0.873 |
| Zhang_2021 [42] | 90/10 | - | - | - | - | - | - | 0.946 |
| Liu_2020 [39] | 80/20 | - | - | - | - | - | - | 0.908 |
| Liu_2022 [36] | 80/20 | - | - | - | - | - | - | 0.964 |
| Han_2021 [44] | 80/20 | - | - | - | - | - | - | 0.906 |
| Light_SDNet [21] | 80/20 | 0.986 | 0.995 | 0.989 | 0.990 | 0.982 | 0.989 | 0.988 |
| Proposed method | 80/20 | 0.979 | 1 | 0.987 | 0.994 | 0.994 | 0.993 | 0.991 |
| Yani_2022 (ESDT) [49] | 50/50 | - | - | - | - | - | - | 0.593 |
| Yani_2022 (DETR) [49] | 50/50 | - | - | - | - | - | - | 0.965 |
| Biaohua_2022 [37] | 50/50 | 0.940 | 0.987 | 0.966 | 0.978 | 0.937 | 0.972 | 0.963 |
| Proposed method | 50/50 | 0.970 | 0.986 | 0.984 | 0.991 | 0.964 | 0.989 | 0.98 |
| Method | Metrics | Fishing Boat | Container Ship | Ore Carrier | Bulk Cargo Carrier | Passenger Ship | General Cargo Ship | mAP |
|---|---|---|---|---|---|---|---|---|
| with VIB | dets | 2849 | 1272 | 5374 | 3581 | 774 | 3598 | |
| recall | 0.878 | 0.941 | 0.924 | 0.913 | 0.657 | 0.946 | ||
| AP | 0.796 | 0.884 | 0.831 | 0.765 | 0.524 | 0.794 | 0.766 | |
| without VIB | dets | 3201 | 884 | 4654 | 2851 | 696 | 2944 | |
| recall | 0.892 | 0.920 | 0.923 | 0.876 | 0.637 | 0.940 | ||
| AP | 0.805 | 0.890 | 0.822 | 0.710 | 0.466 | 0.743 | 0.739 | |
| with VIB | dets | 1863 | 584 | 2012 | 1653 | 354 | 1129 | |
| recall | 0.940 | 0.984 | 0.962 | 0.971 | 0.891 | 0.964 | ||
| AP | 0.922 | 0.980 | 0.935 | 0.953 | 0.873 | 0.946 | 0.935 | |
| without VIB | dets | 2324 | 674 | 2848 | 1923 | 570 | 1585 | |
| recall | 0.936 | 0.975 | 0.964 | 0.963 | 0.899 | 0.978 | ||
| AP | 0.903 | 0.970 | 0.932 | 0.928 | 0.862 | 0.945 | 0.923 | |
| with VIB | dets | 1544 | 466 | 1562 | 1341 | 297 | 948 | |
| recall | 0.978 | 0.986 | 0.990 | 0.995 | 0.972 | 0.993 | ||
| AP | 0.970 | 0.986 | 0.984 | 0.991 | 0.964 | 0.989 | 0.98 | |
| without VIB | dets | 1574 | 470 | 1561 | 1360 | 294 | 883 | |
| recall | 0.965 | 0.989 | 0.995 | 0.993 | 0.960 | 0.993 | ||
| AP | 0.957 | 0.988 | 0.990 | 0.987 | 0.953 | 0.989 | 0.977 |
| With VIB | Without VIB | |||
|---|---|---|---|---|
| Sparse ↑ | Discriminate ↑ | Sparse ↑ | Discriminate ↑ | |
| mean | 194.44 | 32.45 | 0.183 | 0.587 |
| std | 136 | 59.557 | 0.486 | 0.599 |
| min | 0 | 0.277 | 0 | 0.203 |
| percentiles (25%) | 0 | 0.6698 | 0 | 0.203 |
| percentiles (50%) | 270 | 0.6698 | 0 | 0.3648 |
| percentiles (75%) | 304 | 34.011 | 0 | 0.5318 |
| max | 335 | 281.06 | 3 | 4.2183 |
| With VIB | Without VIB | |
|---|---|---|
| FPS | 12.39 | 12.45 |
| GFlops | 9.92 | 9.91 |
| # parameters (M) | 55.33 | 54.15 |
| Backbone | With VIB | Fishing Boat | Container Ship | Ore Carrier | Bulk Cargo Carrier | Passenger Ship | General Cargo Ship | mAP |
|---|---|---|---|---|---|---|---|---|
| ResNet-18 | Yes | 0.837 | 0.978 | 0.861 | 0.886 | 0.741 | 0.931 | 0.873 |
| No | 0.817 | 0.961 | 0.824 | 0.735 | 0.706 | 0.841 | 0.814 | |
| DarkNet | Yes | 0.922 | 0.980 | 0.935 | 0.953 | 0.873 | 0.946 | 0.935 |
| No | 0.903 | 0.970 | 0.932 | 0.928 | 0.862 | 0.945 | 0.923 | |
| MobileNetv2 | Yes | 0.895 | 0.975 | 0.895 | 0.880 | 0.794 | 0.908 | 0.891 |
| No | 0.872 | 0.965 | 0.918 | 0.902 | 0.772 | 0.914 | 0.890 |
| Method | Fishing Boat | Container Ship | Ore Carrier | Bulk Cargo Carrier | Passenger Ship | General Cargo Ship | mAP |
|---|---|---|---|---|---|---|---|
| Seg-based [52] | 0.873 | 0.952 | 0.896 | 0.859 | 0.805 | 0.894 | 0.880 |
| NoiBased [53,54] | 0.912 | 0.973 | 0.923 | 0.935 | 0.871 | 0.935 | 0.925 |
| No noise | 0.903 | 0.970 | 0.932 | 0.928 | 0.862 | 0.945 | 0.923 |
| Proposed method | 0.922 | 0.980 | 0.935 | 0.953 | 0.873 | 0.946 | 0.935 |
| Method | Metrics | Fishing Boat | Container Ship | Ore Carrier | Bulk Cargo Carrier | Passenger Ship | General Cargo Ship | mAP |
|---|---|---|---|---|---|---|---|---|
| VIB at the middle of classification head | dets | 1863 | 584 | 2012 | 1653 | 354 | 1129 | |
| recall | 0.940 | 0.984 | 0.962 | 0.971 | 0.891 | 0.964 | ||
| AP | 0.922 | 0.980 | 0.935 | 0.953 | 0.873 | 0.946 | 0.935 | |
| VIB at the beginning of decouple head | dets | - | - | - | - | - | - | |
| recall | - | - | - | - | - | - | ||
| AP | - | - | - | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ngo, D.-D.; Vo, V.-L.; Nguyen, T.; Nguyen, M.-H.; Le, M.-H. Image-Based Ship Detection Using Deep Variational Information Bottleneck. Sensors 2023, 23, 8093. https://doi.org/10.3390/s23198093
Ngo D-D, Vo V-L, Nguyen T, Nguyen M-H, Le M-H. Image-Based Ship Detection Using Deep Variational Information Bottleneck. Sensors. 2023; 23(19):8093. https://doi.org/10.3390/s23198093
Chicago/Turabian StyleNgo, Duc-Dat, Van-Linh Vo, Tri Nguyen, Manh-Hung Nguyen, and My-Ha Le. 2023. "Image-Based Ship Detection Using Deep Variational Information Bottleneck" Sensors 23, no. 19: 8093. https://doi.org/10.3390/s23198093
APA StyleNgo, D.-D., Vo, V.-L., Nguyen, T., Nguyen, M.-H., & Le, M.-H. (2023). Image-Based Ship Detection Using Deep Variational Information Bottleneck. Sensors, 23(19), 8093. https://doi.org/10.3390/s23198093