

Multi-Sensors System and Deep Learning Models for Object Tracking
Abstract
:1. Introduction
- Leverages the need for a large amount of annotated data by dividing the tracking problem into multiple tasks and utilizing single-layer models trained for the association, the prediction, and the update steps.
- Improve the accuracy of objects’ positions by estimating the observation errors rather than direct position estimation, utilizing the updated model.
- Learning an optimized association metric by combining diverse cues such as object position, type, orientation, and trajectory into a unified model that estimates the association score for an observation/track pair.
- Manage tracks by computing a variable existence score that incorporates association scores, participating sensors, lifetime, and track disappearance.
State of the Art
2. Materials and Methods
2.1. The Sensors
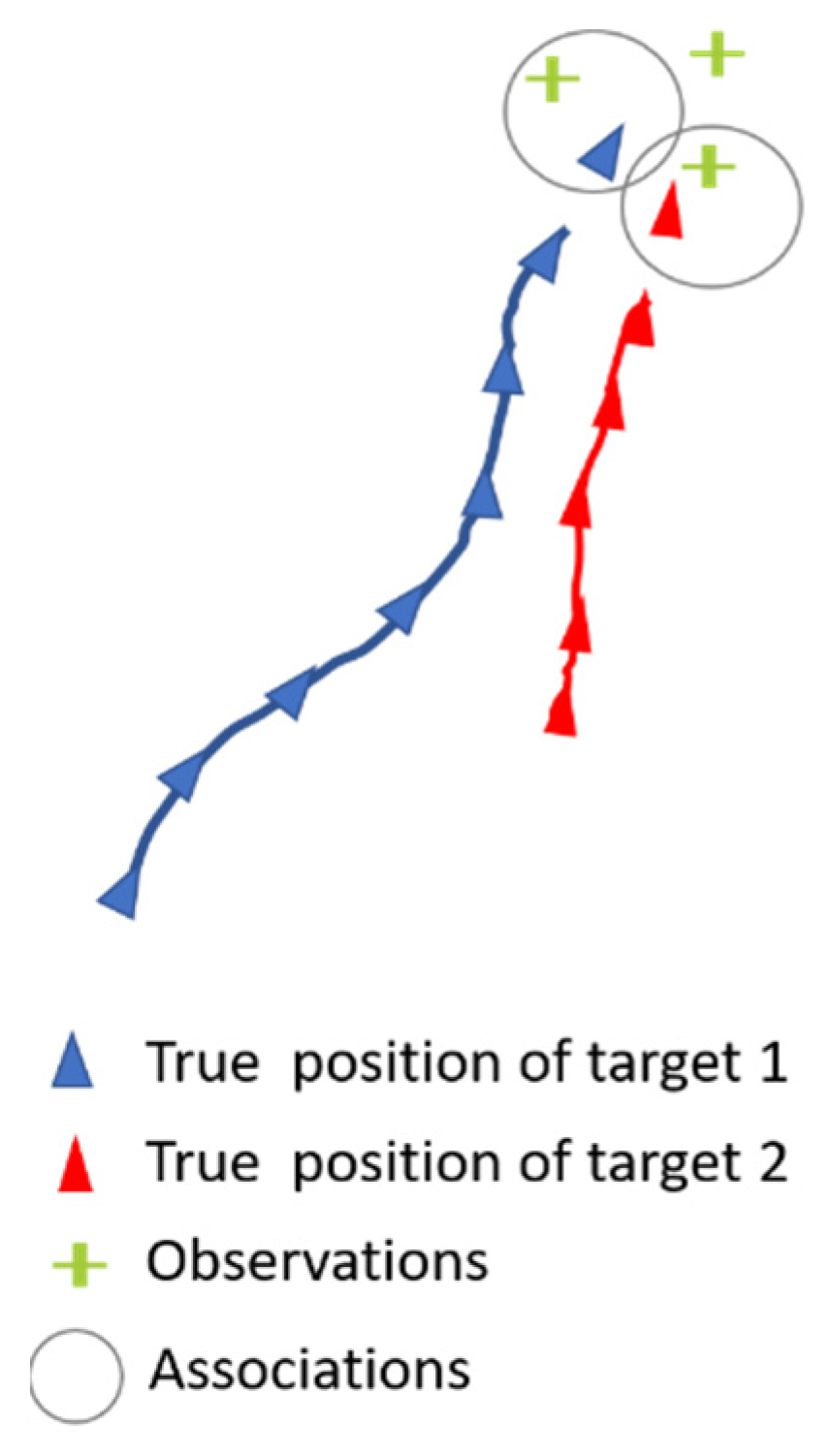
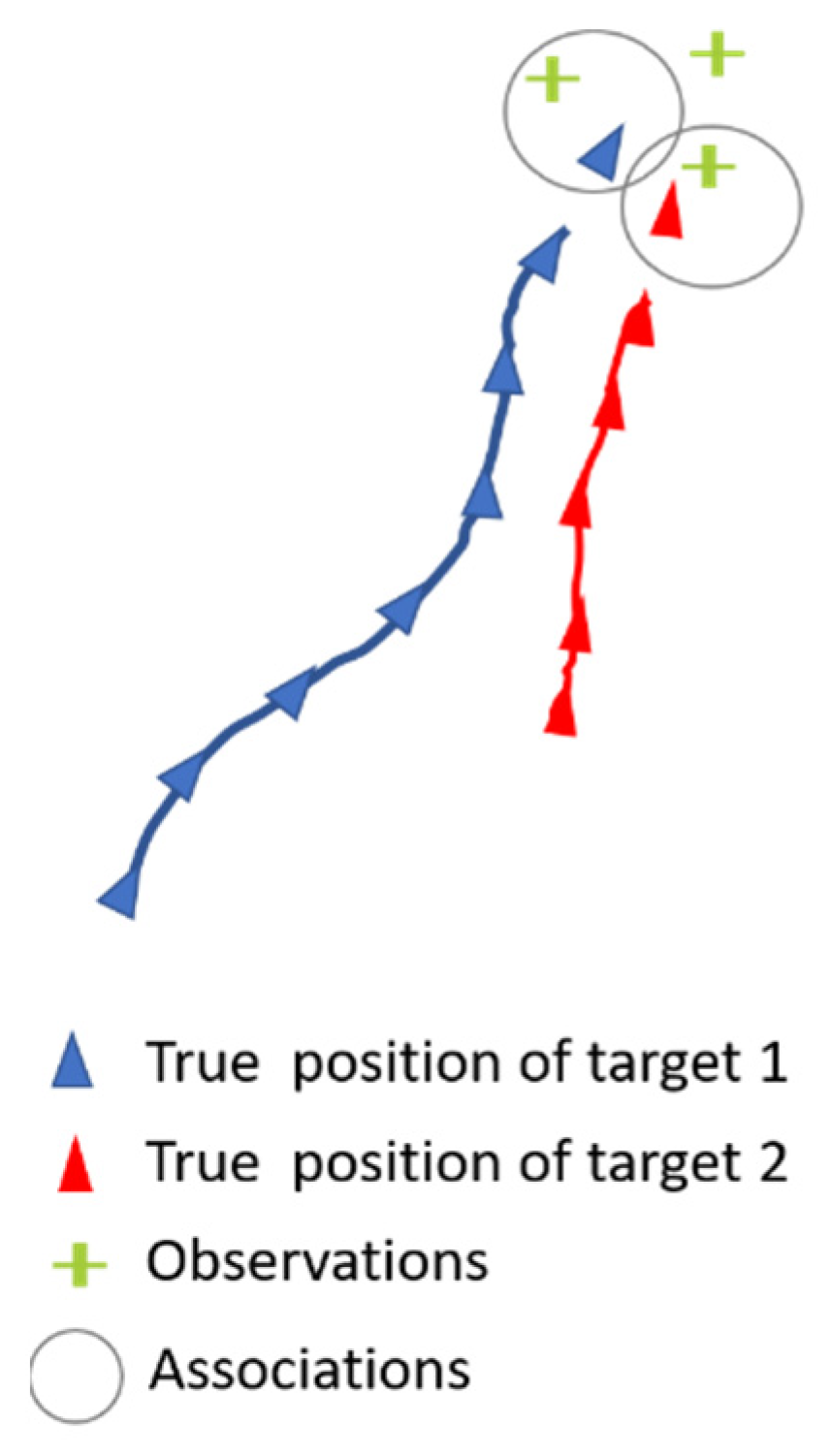
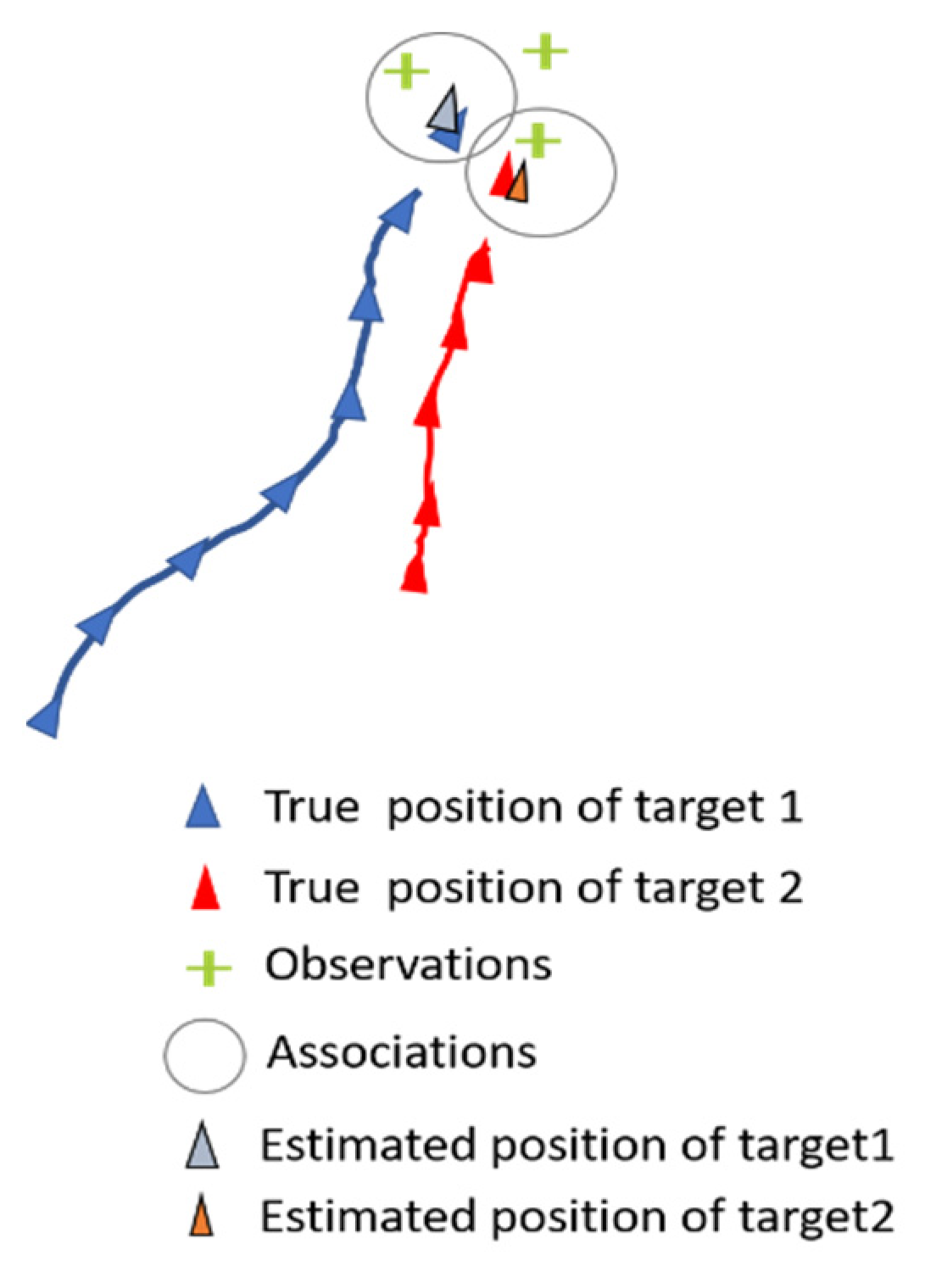
2.2. Problem Formalization
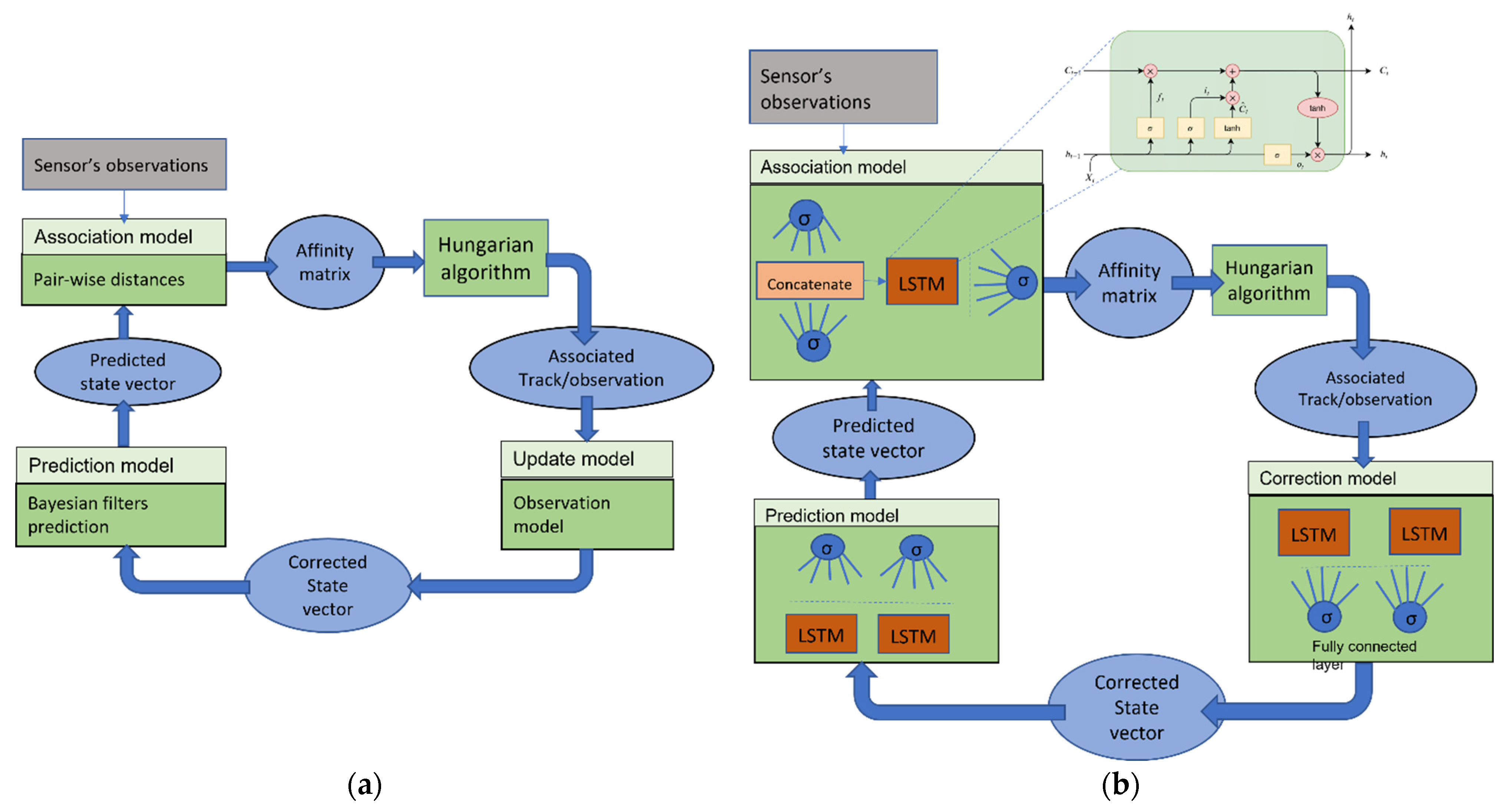
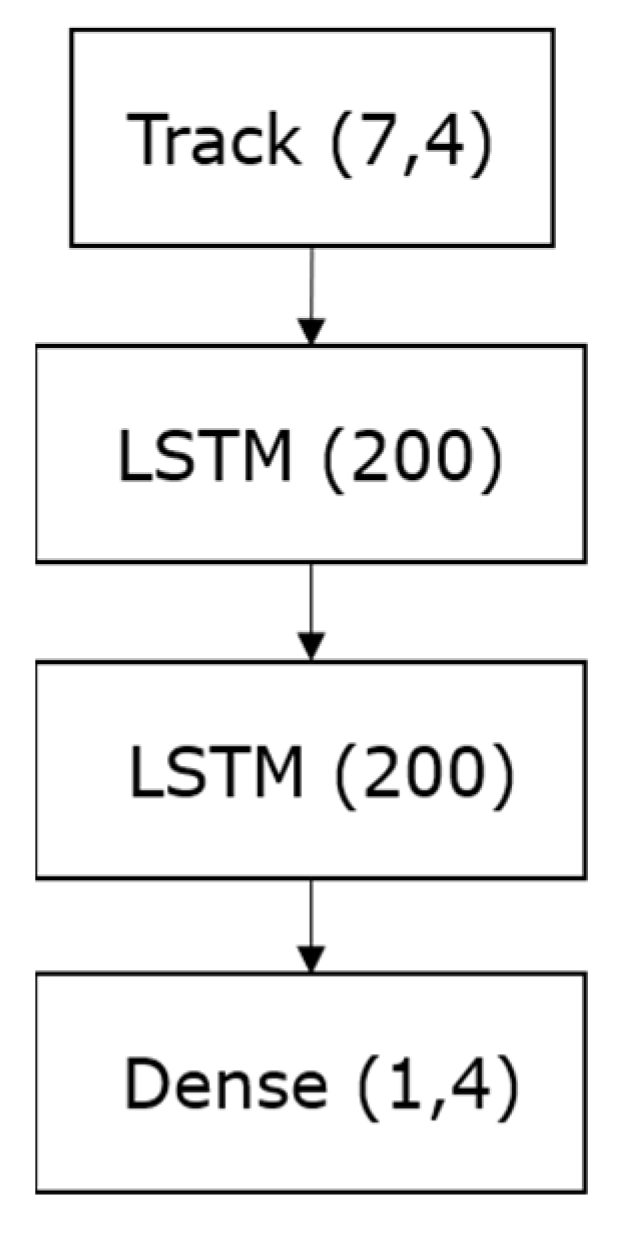
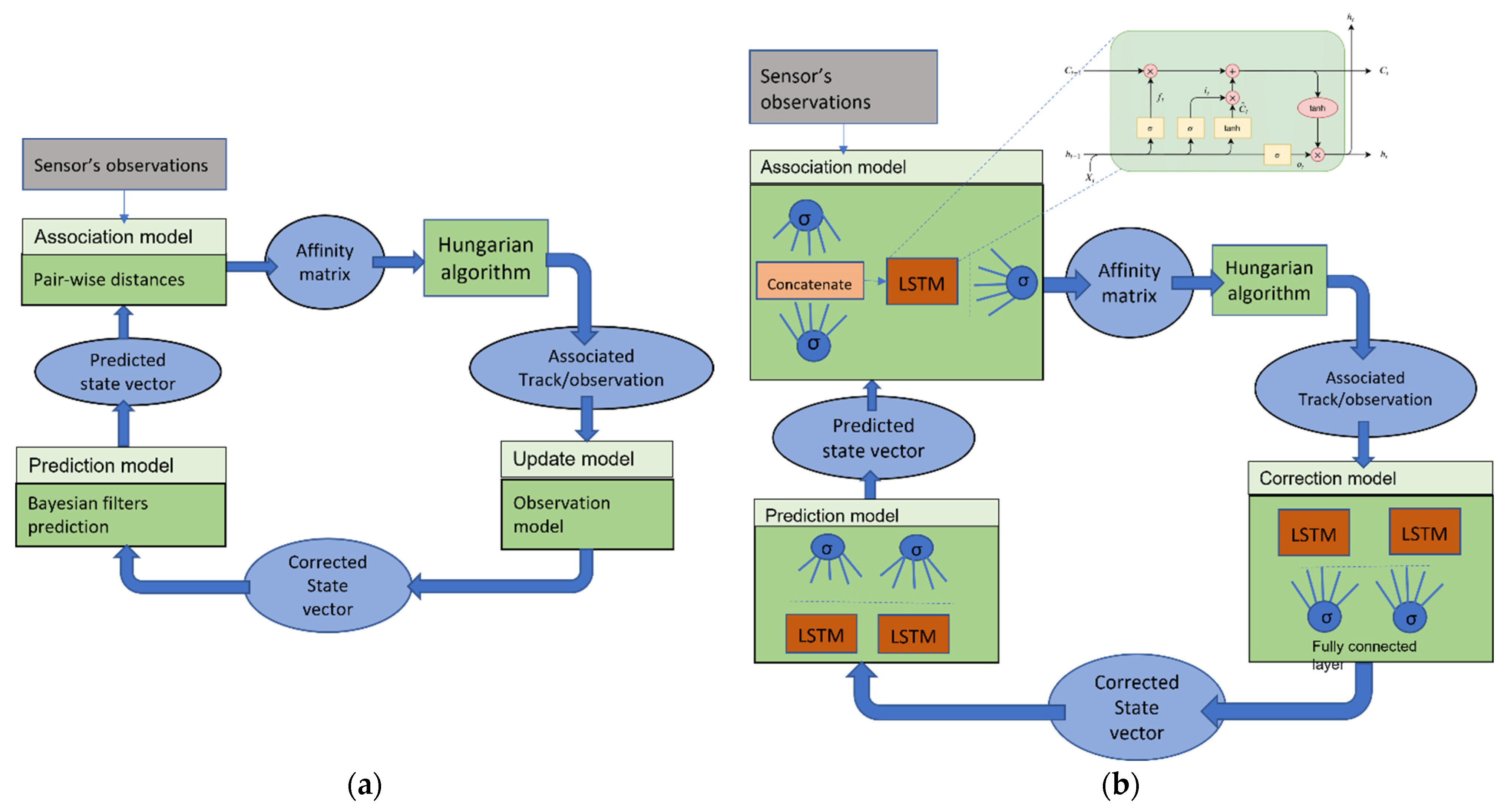
2.3. The Models
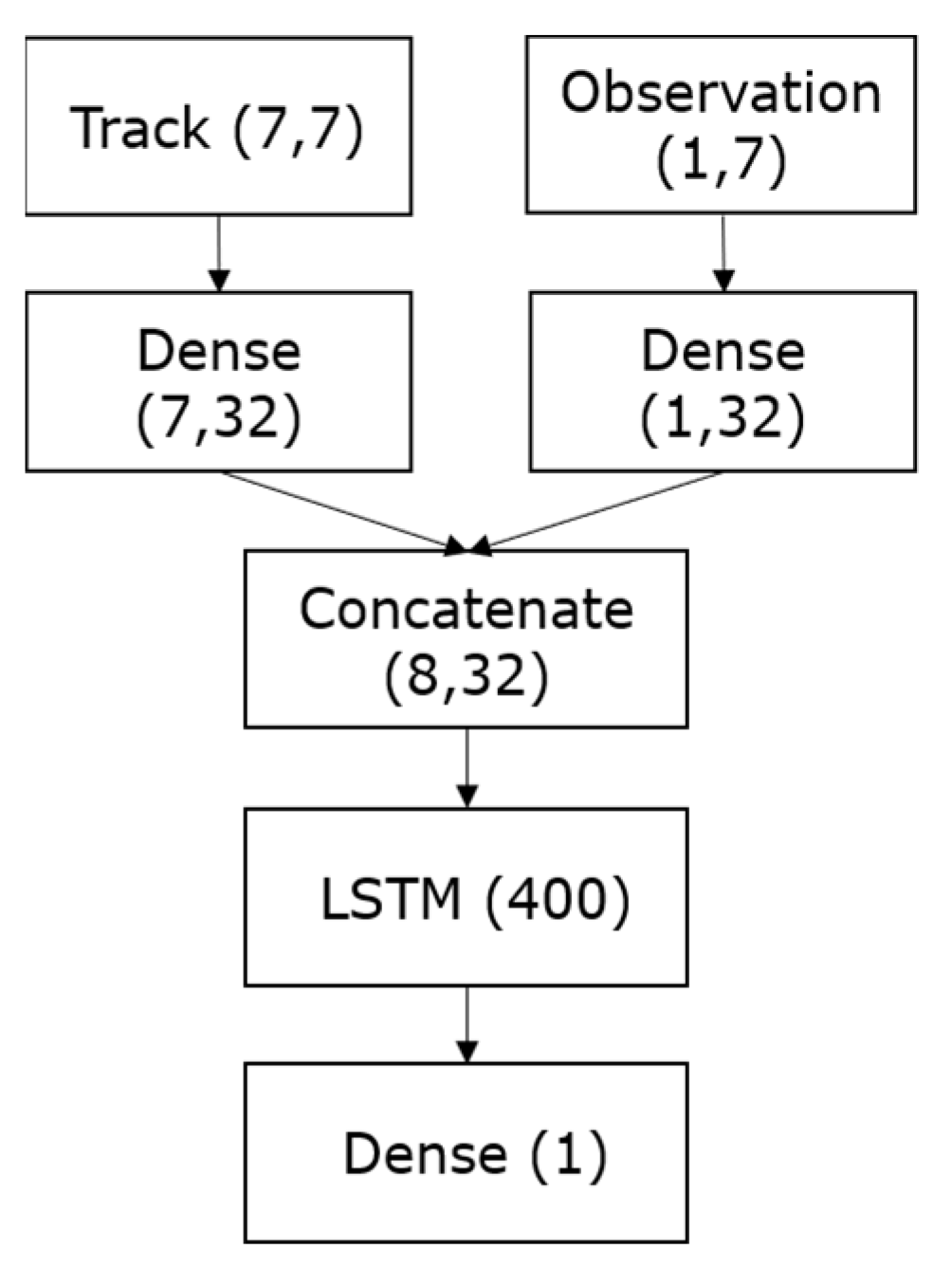
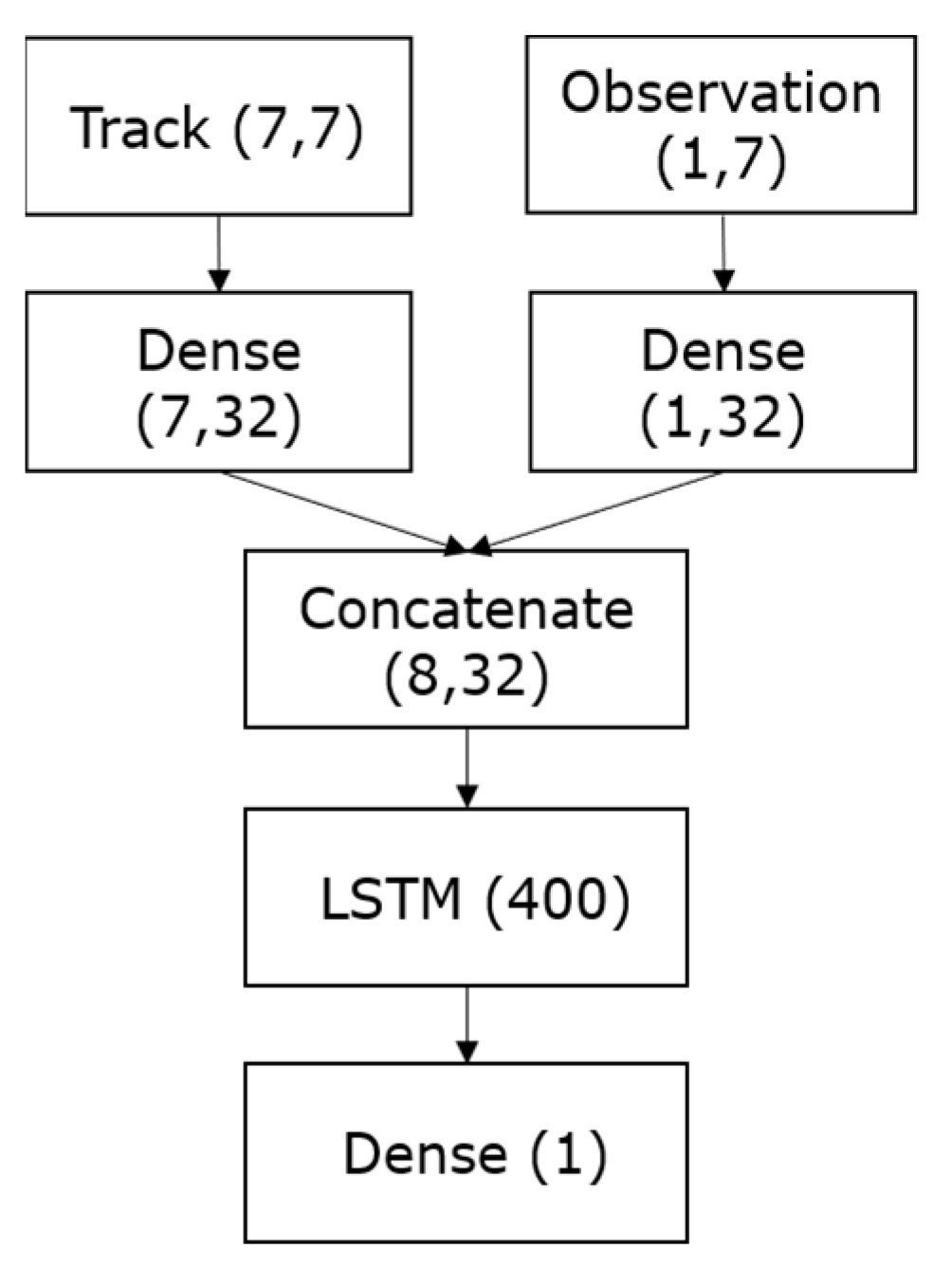
2.3.1. Association Model
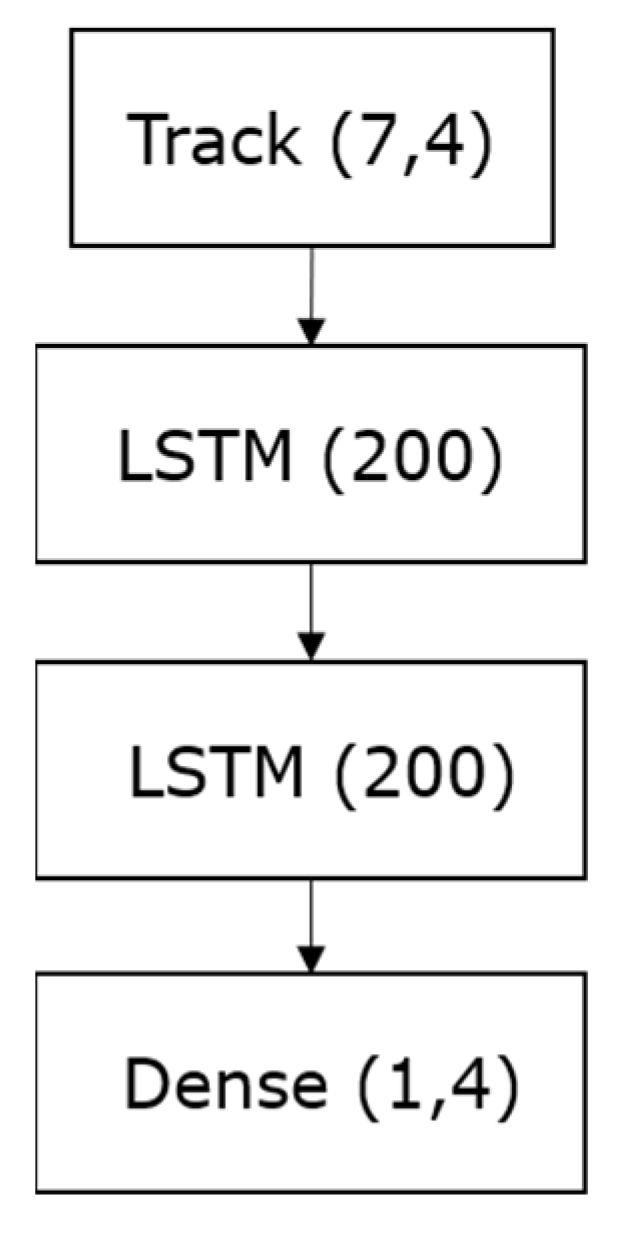
2.3.2. Correction Model
2.3.3. Prediction Model
2.3.4. Models Training
2.4. Track Management
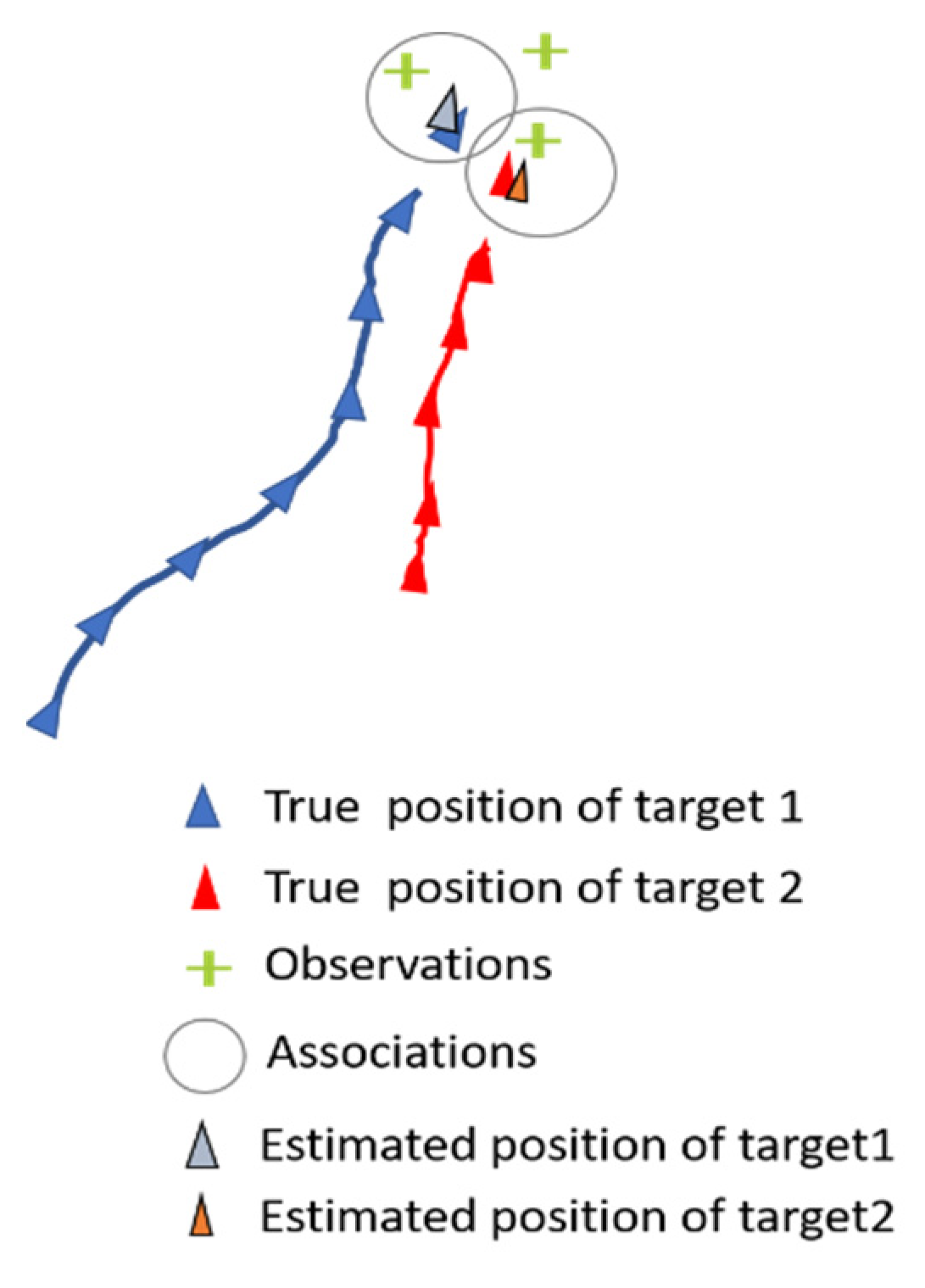
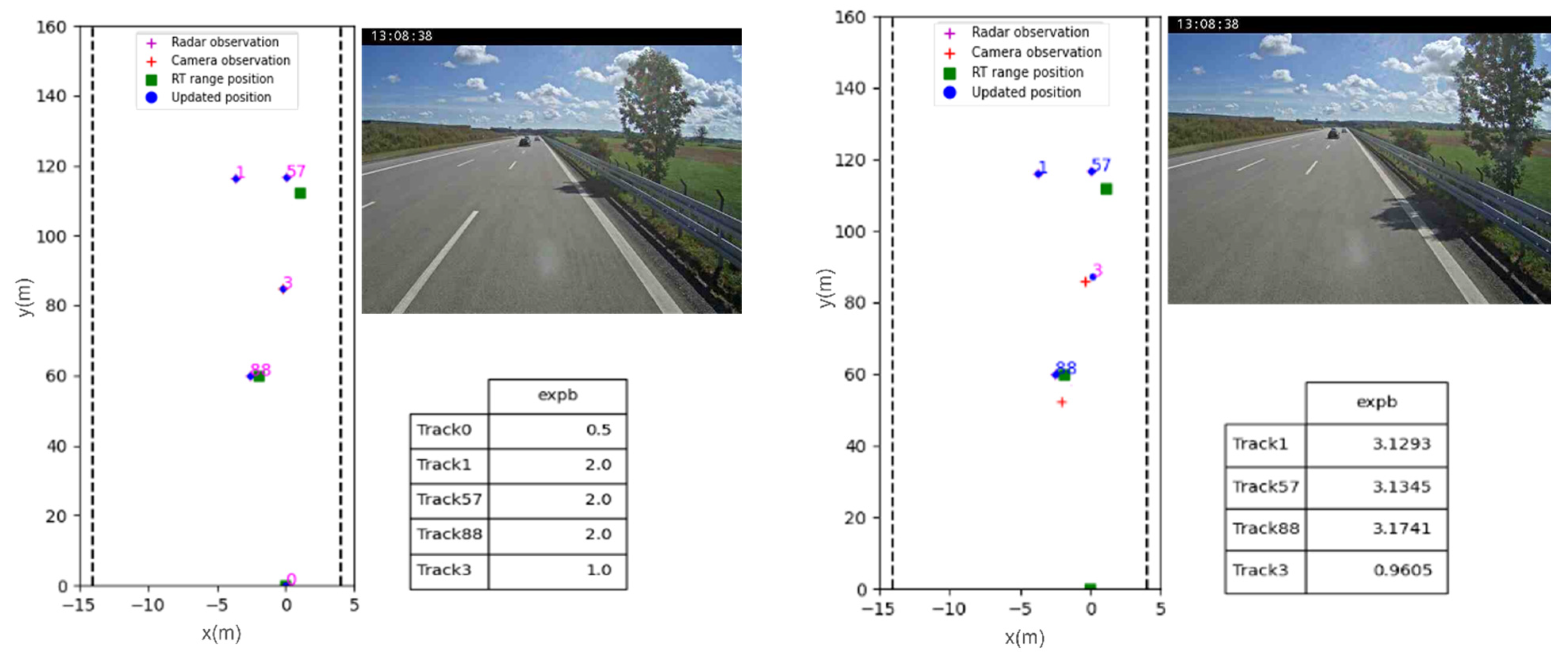
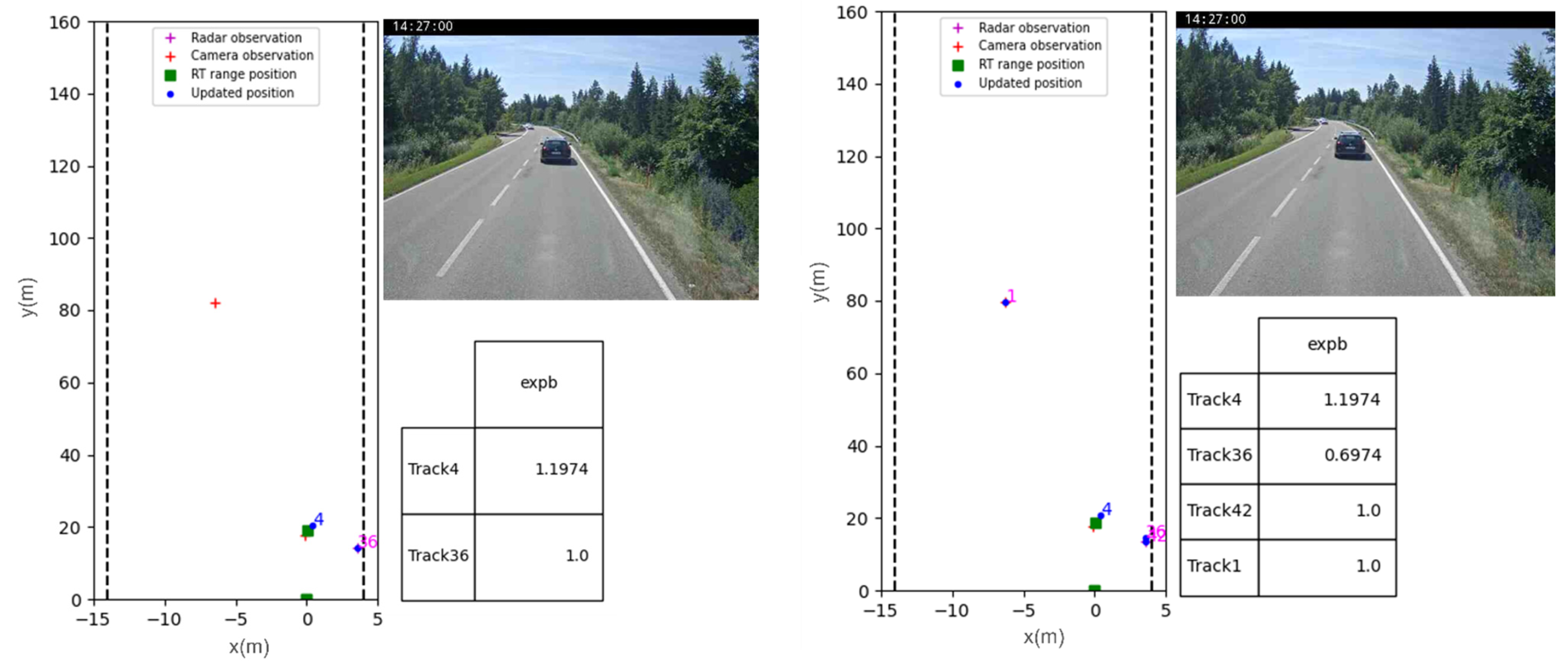
3. Evaluation and Results
- The RMSE (Root-Mean-Square Error) to evaluate object position estimation, calculated as the mean Euclidean distance over all predicted positions and real positions: RMSE= , where are the respective correct (RT ground truth) and predicted outputs.
- The MOTA (multi-object tracking accuracy) [34] to assess the association model and track management process: MOTA= , where t is the frame index, and m, fp, and mme denote the number of misses, false positives, and mismatches, respectively, over g, the total number of objects in the scene across all iterations b. MOTA is a widely used metric as it effectively combines the three sources of errors mentioned above.
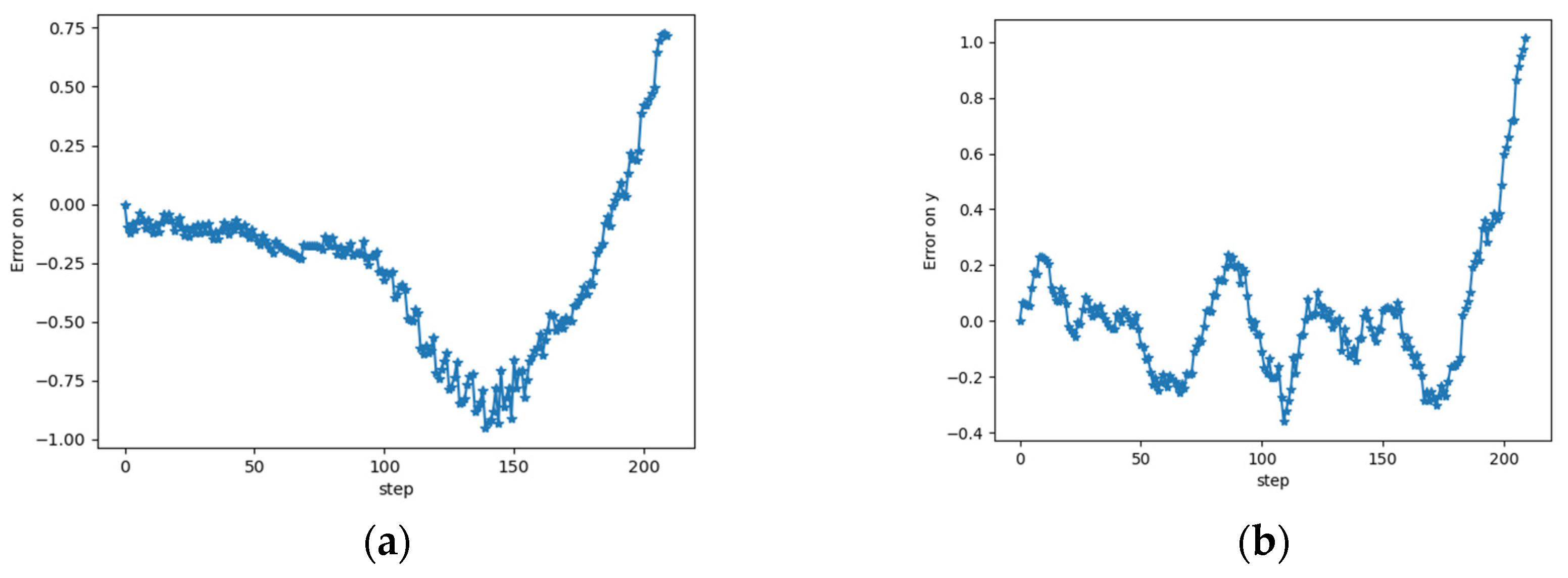
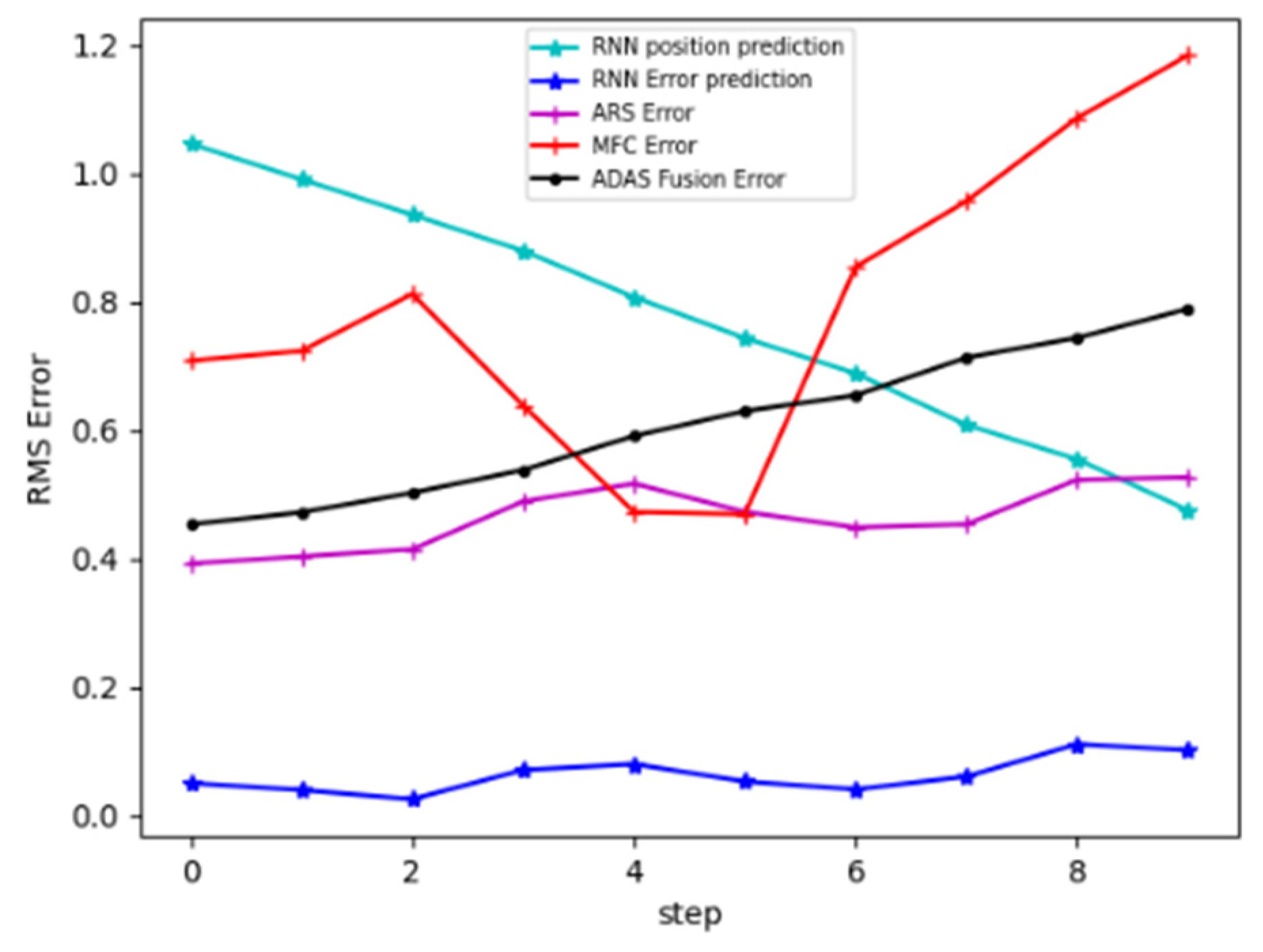
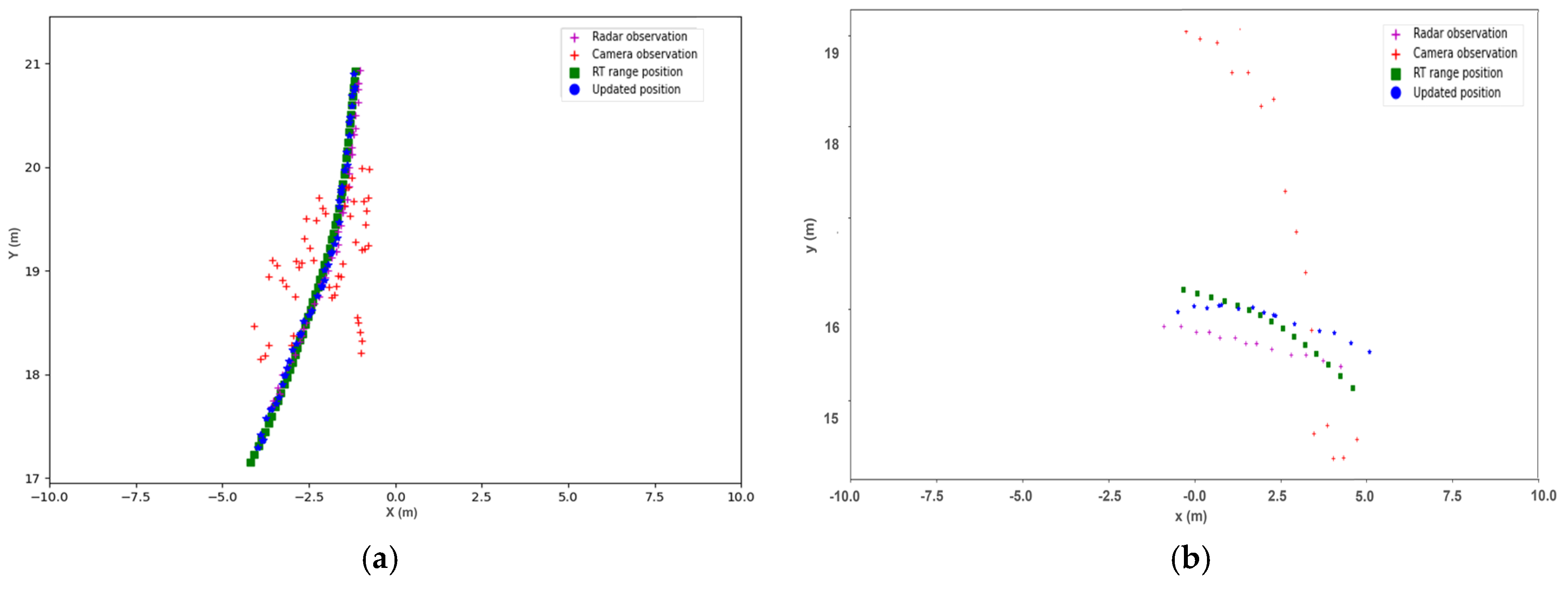
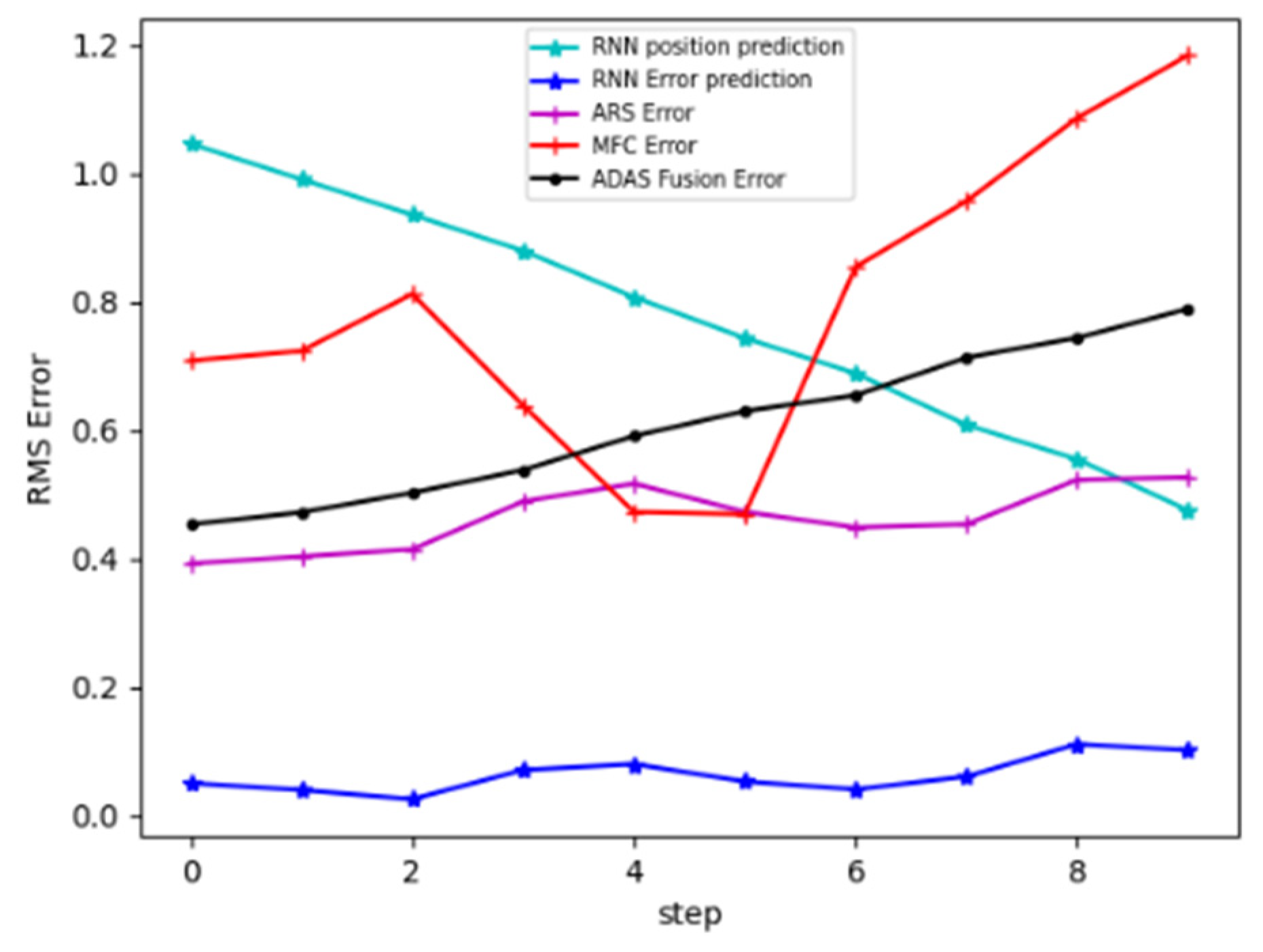
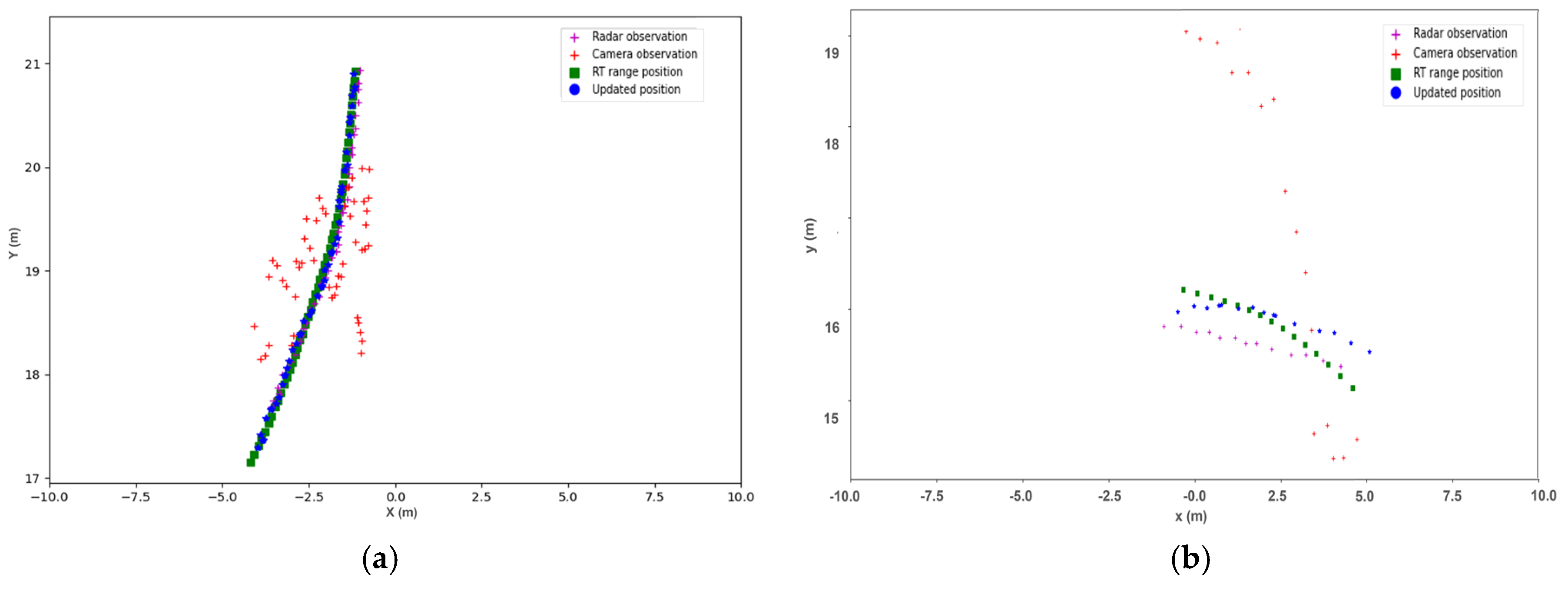
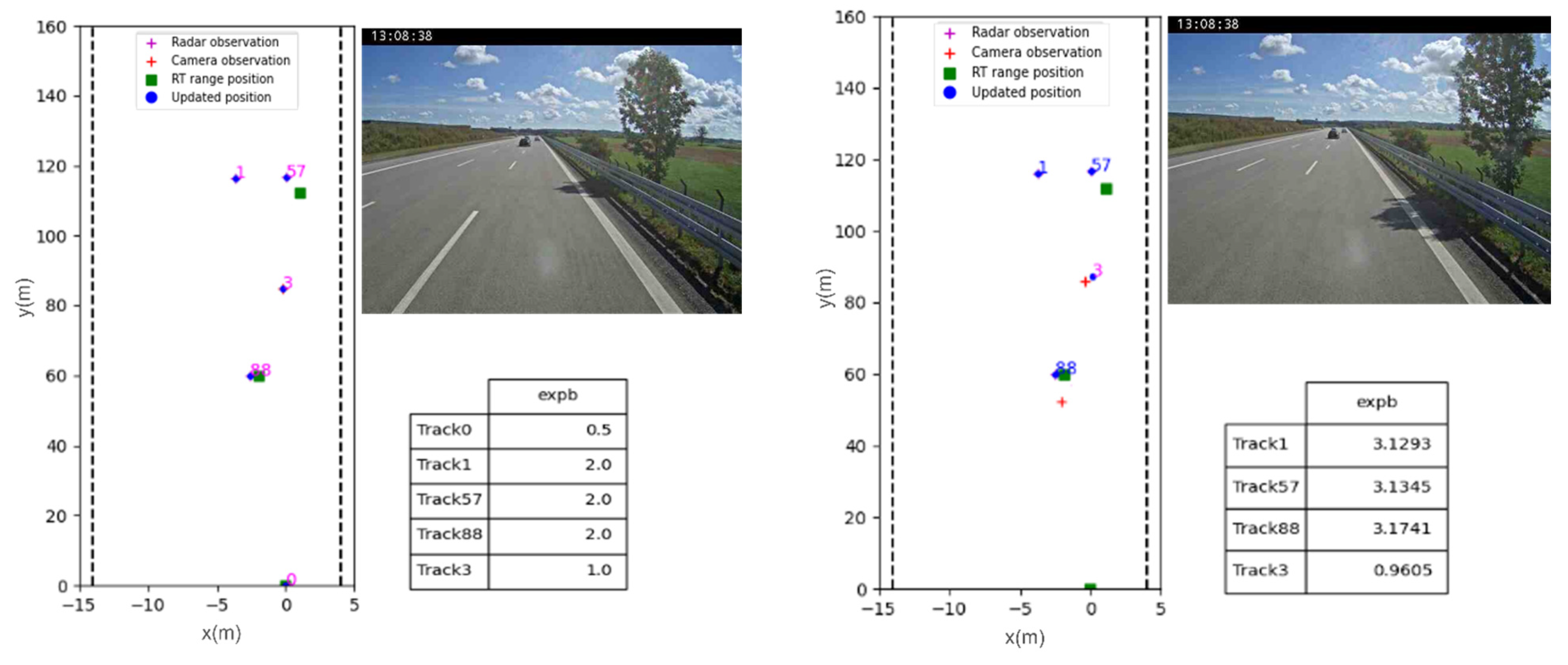
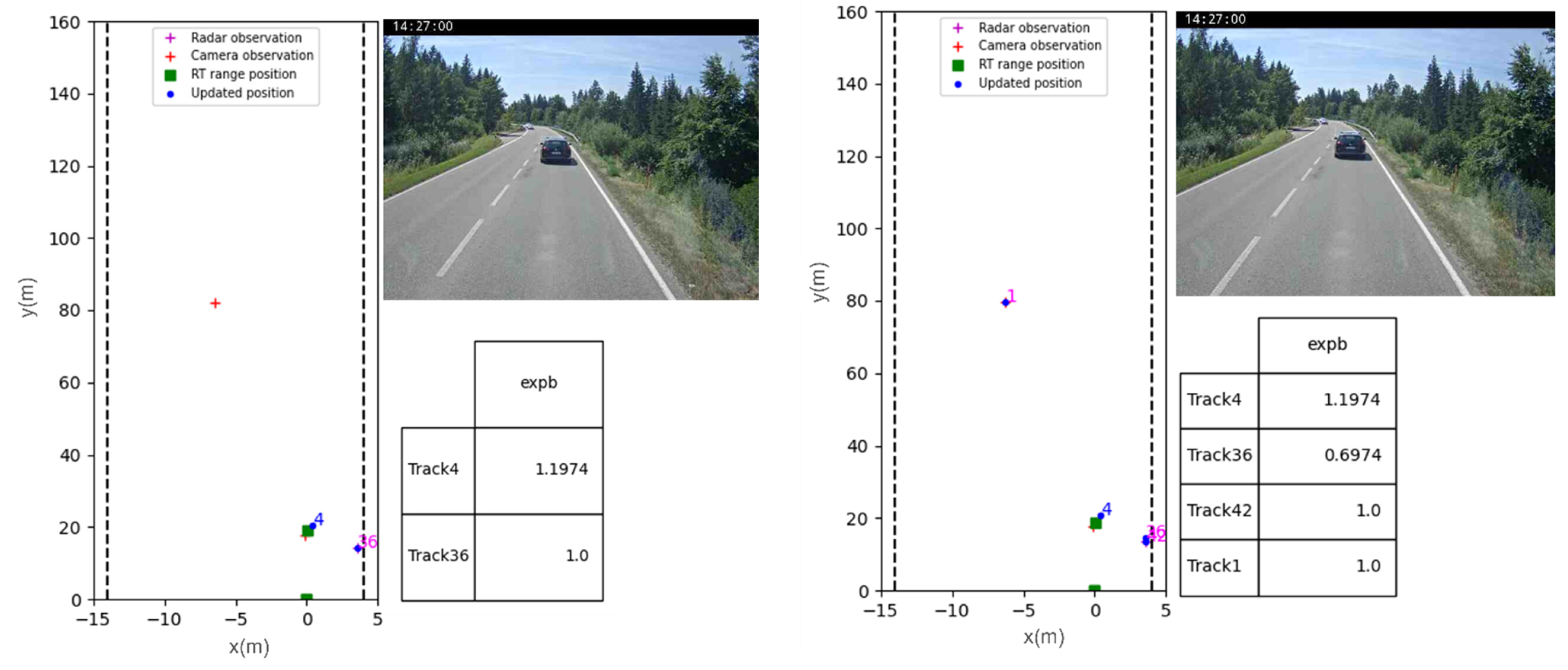
3.1. Results
3.2. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Spicer, R.; Vahabaghaie, A.; Bahouth, G.; Drees, L.; von Bülow, R.M.; Baur, P. Field effectiveness evaluation of advanced driver assistance systems. Traffic Inj. Prev. 2018, 19, S91–S95. [Google Scholar] [CrossRef] [PubMed]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Noureldin, A.; El-Shafie, A.; Bayoumi, M. GPS/INS Integration Utilizing Dynamic Neural Networks for Vehicular Navigation. Inf. Fusion 2011, 12, 48–57. [Google Scholar] [CrossRef]
- Wu, G.X.; Ding, Y.; Tahsin, T.; Atilla, I. Adaptive neural network and extended state observer-based non-singular terminal sliding modetracking control for an underactuated USV with unknown uncertainties. Appl. Ocean Res. 2023, 135, 103560. [Google Scholar] [CrossRef]
- El Natour, G.; Ait-Aider, O.; Rouveure, R.; Berry, F.; Faure, P. Toward 3D reconstruction of outdoor scenes using an MMW radar and a monocular vision sensor. Sensors 2015, 15, 25937–25967. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Xu, L.; Sun, H.; Xin, J.; Zheng, N. Bionic vision inspired on-road obstacle detection and tracking using radar and visual information. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 39–44. [Google Scholar]
- Yu, Z.; Bai, J.; Chen, S.; Huang, L.; Bi, X. Camera-Radar Data Fusion for Target Detection via Kalman Filter and Bayesian Estimation. SAE Tech. Pap. 2018. [Google Scholar] [CrossRef]
- Guo, S.; Wang, S.; Yang, Z.; Wang, L.; Zhang, H.; Guo, P.; Gao, Y.; Guo, J. A Review of Deep Learning-Based Visual Multi-Object Tracking Algorithms for Autonomous Driving. Appl. Sci. 2022, 12, 10741. [Google Scholar] [CrossRef]
- Joly, C.; Betaille, D.; Peyret, F. Étude comparative des techniques de filtrage non-linéaire appliquées à la localisation 2D d’un véhicule en temps réel. Trait. Du Signal 2008, 25, 20. [Google Scholar]
- Wang, H.; Bansal, M.; Gimpel, K.; McAllester, D. Machine comprehension with syntax, frames, and semantics. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015; pp. 700–706. [Google Scholar]
- Iter, D.; Kuck, J.; Zhuang, P. Target Tracking with Kalman Filtering, knn and Lstms. 2016, pp. 1–7. Available online: https://cs229.stanford.edu/proj2016/report/IterKuckZhuang-TargetTrackingwithKalmanFilteringKNNandLSTMs-report.pdf (accessed on 2 August 2023).
- Gu, J.; Yang, X.; De Mello, S.; Kautz, J. Dynamic facial analysis: From Bayesian filtering to recurrent neural network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1548–1557. [Google Scholar]
- Altché, F.; de La Fortelle, A. An LSTM network for highway trajectory prediction. 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 353–359. [Google Scholar]
- Ondruska, P.; Posner, I. Deep tracking: Seeing beyond seeing using recurrent neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social lstm: Human trajectory prediction in crowded spaces. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar]
- Ma, Y.; Zhu, X.; Zhang, S.; Yang, R.; Wang, W.; Manocha, D. TrafficPredict: Trajectory Prediction for Heterogeneous Traffic-Agents. Proc. Conf. AAAI Artif. Intell. 2019, 33, 6120–6127. [Google Scholar] [CrossRef]
- Park, S.H.; Kim, B.; Kang, C.M.; Chung, C.C.; Choi, J.W. Sequence-to-sequence prediction of vehicle trajectory via LSTM encoder-decoder architecture. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1672–1678. [Google Scholar]
- Sengupta, A.; Jin, F.; Cao, S. A DNN-LSTM based target tracking approach using mmWave radar and camera sensor fusion. In Proceedings of the 2019 IEEE National Aerospace and Electronics Conference (NAECON), Dayton, OH, USA, 15–19 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 688–693. [Google Scholar]
- Zhang, D.; Maei, H.; Wang, X.; Wang, Y.-F. Deep reinforcement learning for visual object tracking in videos. arXiv 2017, arXiv:1701.08936. [Google Scholar]
- Kuhn, H.W. The Hungarian method for the assignment problem. Nav. Res. Logist. Q. 1955, 2, 83–97. [Google Scholar] [CrossRef]
- Munkres, J. Algorithms for the assignment and transportation problems. J. Soc. Ind. Appl. Math. 1957, 5, 32–38. [Google Scholar] [CrossRef]
- Reid, D. An algorithm for tracking multiple targets. IEEE Trans. Autom. Control 1979, 24, 843–854. [Google Scholar] [CrossRef]
- Fortmann, T.; Bar-Shalom, Y.; Scheffe, M. Sonar tracking of multiple targets using joint probabilistic data association. IEEE J. Ocean. Eng. 1983, 8, 173–184. [Google Scholar] [CrossRef]
- Milan, A.; Rezatofighi, S.H.; Dick, A.; Reid, I.; Schindler, K. Online multi-target tracking using recurrent neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Liu, H.; Zhang, H.; Mertz, C. DeepDA: LSTM-based deep data association network for multi-targets tracking in clutter. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Sadeghian, A.; Alahi, A.; Savarese, S. Tracking The Untrackable: Learning To Track Multiple Cues with Long-Term Dependencies. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 300–311. [Google Scholar]
- Wan, X.; Wang, J.; Zhou, S. An online and flexible multi-object tracking framework using long short-term memory. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1230–1238. [Google Scholar]
- Luo, W.; Sun, P.; Zhong, F.; Liu, W.; Zhang, T.; Wang, Y. End-to-end active object tracking via reinforcement learning. In Proceedings of the 35th International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 3286–3295. [Google Scholar]
- Huang, K.; Lertniphonphan, K.; Chen, F.; Li, J.; Wang, Z. Multi-Object Tracking by Self-Supervised Learning Appearance Model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 3162–3168. [Google Scholar]
- Kieritz, H.; Hübner, W.; Arens, M. Joint detection and online multi-object tracking. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1459–1467. [Google Scholar]
- Kwangjin, Y.; Yong, K.D.; Young-Chul, Y.; Jeon, M. Data association for multi-object tracking via deep neural networks. Sensors 2019, 19, 559. [Google Scholar]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to track: Online multi-object tracking by decision making. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4705–4713. [Google Scholar]
- Mozaffari, S.; Al-Jarrah, O.Y.; Dianati, M.; Jennings, P.; Mouzakitis, A. Deep learning-based vehicle behavior prediction for autonomous driving applications: A review. IEEE Trans. Intell. Transp. Syst. 2020, 23, 33–47. [Google Scholar] [CrossRef]
- Rainer, S.; Keni, B.; Rachel, B. The CLEAR 2006 evaluation. In Multimodal Technologies for Perception of Humans: First International Evaluation Workshop on Classification of Events, Activities and Relationships, CLEAR 2006, Southampton, UK, April 6–7, 2006, Revised Selected Papers 1; Springer: Berlin/Heidelberg, Germany, 2007; pp. 1–44. [Google Scholar]
- Gioele, C.; Luque, S.F.; Siham, T.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep learning in video multi-object tracking: A survey. Neurocomputing 2020, 381, 61–88. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Kalman | Our Proposed Algorithm | |
|---|---|---|
| Sensor model | Yes | No |
| Dynamic model | Yes | No |
| Needs learning | No | Yes |
| Estimation update accuracy | 0.7 m | 0.09 |
| Computational complexity | Low | Moderate |
| Versatility | Restricted | Wide range of scenarios |
| Error Type | % Association Model | % Euclidean Distance |
|---|---|---|
| False Positives | 2.12% | 3.45% |
| Misses | 0.17% | 0.15% |
| Mismatches | 2.60% | 4.11% |
| MOTA | 95.10% | 92.30% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
El Natour, G.; Bresson, G.; Trichet, R. Multi-Sensors System and Deep Learning Models for Object Tracking. Sensors 2023, 23, 7804. https://doi.org/10.3390/s23187804
El Natour G, Bresson G, Trichet R. Multi-Sensors System and Deep Learning Models for Object Tracking. Sensors. 2023; 23(18):7804. https://doi.org/10.3390/s23187804
Chicago/Turabian StyleEl Natour, Ghina, Guillaume Bresson, and Remi Trichet. 2023. "Multi-Sensors System and Deep Learning Models for Object Tracking" Sensors 23, no. 18: 7804. https://doi.org/10.3390/s23187804
APA StyleEl Natour, G., Bresson, G., & Trichet, R. (2023). Multi-Sensors System and Deep Learning Models for Object Tracking. Sensors, 23(18), 7804. https://doi.org/10.3390/s23187804