
Fuzzy-Based Efficient Healthcare Data Collection and Analysis Mechanism Using Edge Nodes in the IoMT

 , , ,
, , ,
Abstract
:1. Introduction
- We studied the most relevant literature on data aggregation using artificial intelligence techniques.
- We developed the FDAS, a scheme that uses fuzzy logic to select a suitable parent node for each child node in a heterogeneous environment.
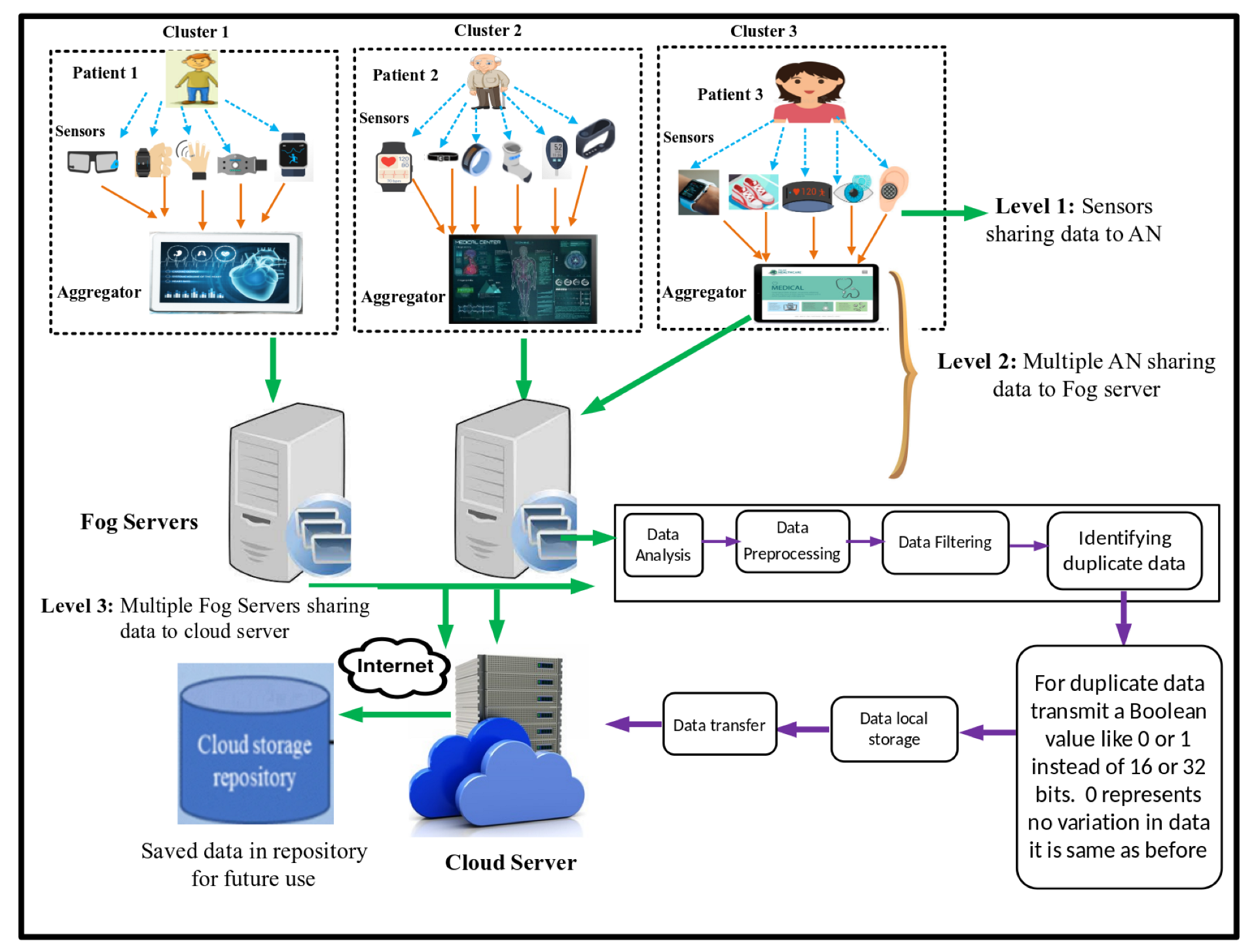
- We developed a detailed mechanism for dealing with in-range normal data by sending Boolean digit zero to reduce the size and transmission of duplicate messages.
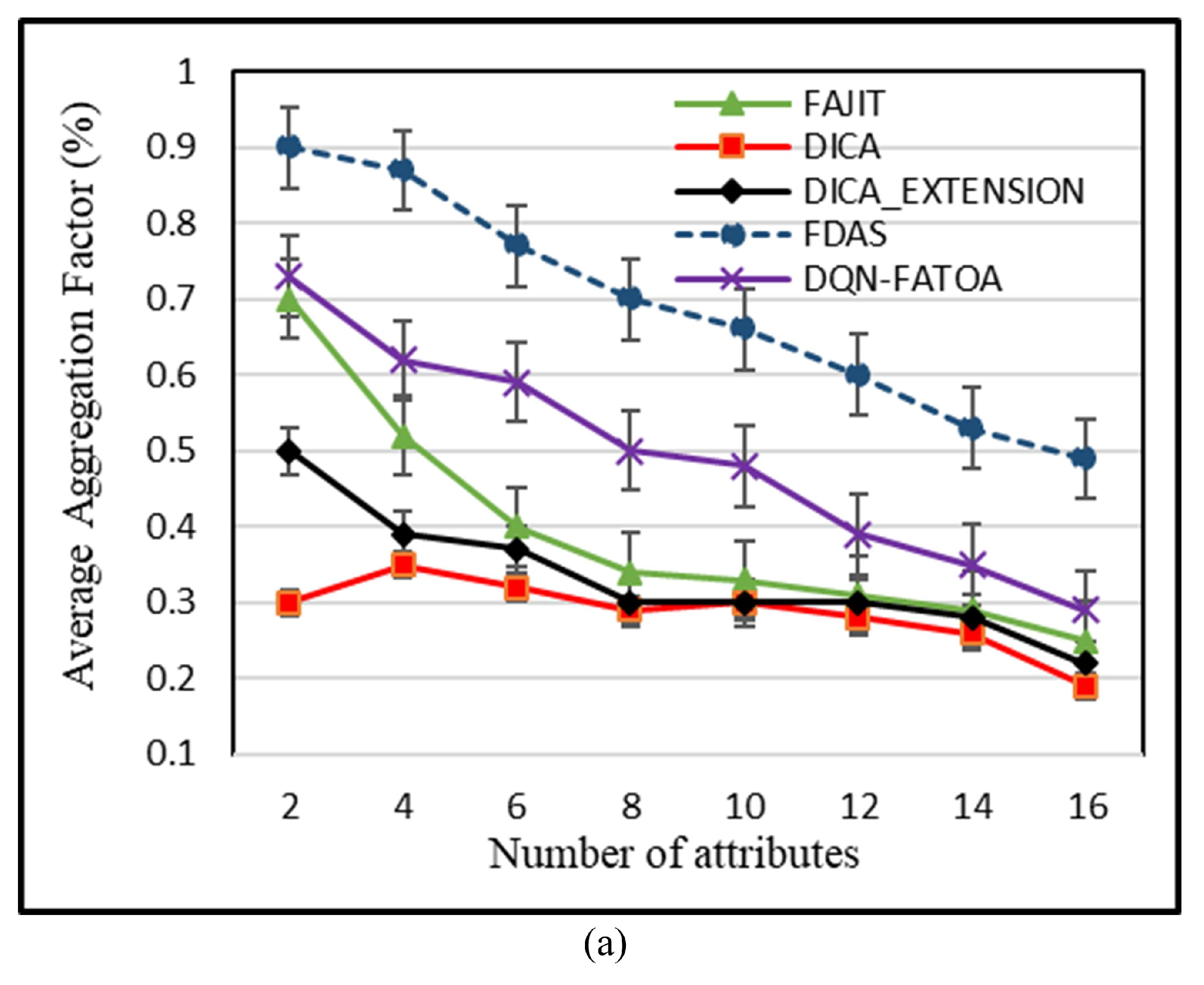
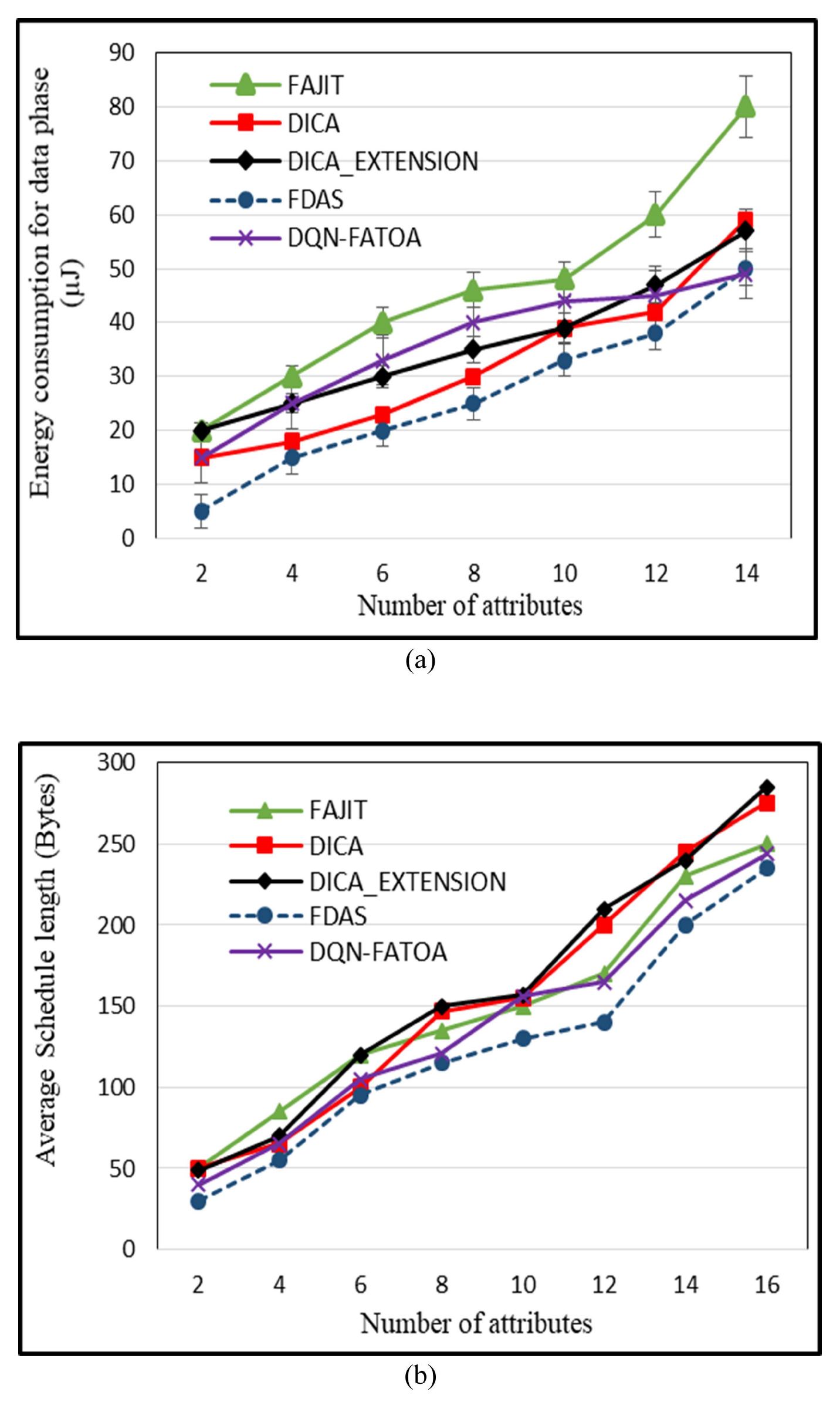
- We conducted simulations and compared the results of the FDAS with those of some prominent schemes, including FAJIT, DQN-FATOA, DICA, and DICA_EXTENSION.
2. Related Works
2.1. Data Aggregation Using Artificial Intelligence Techniques
2.2. Schemes Dealing with Data-Aggregation-Based Delay
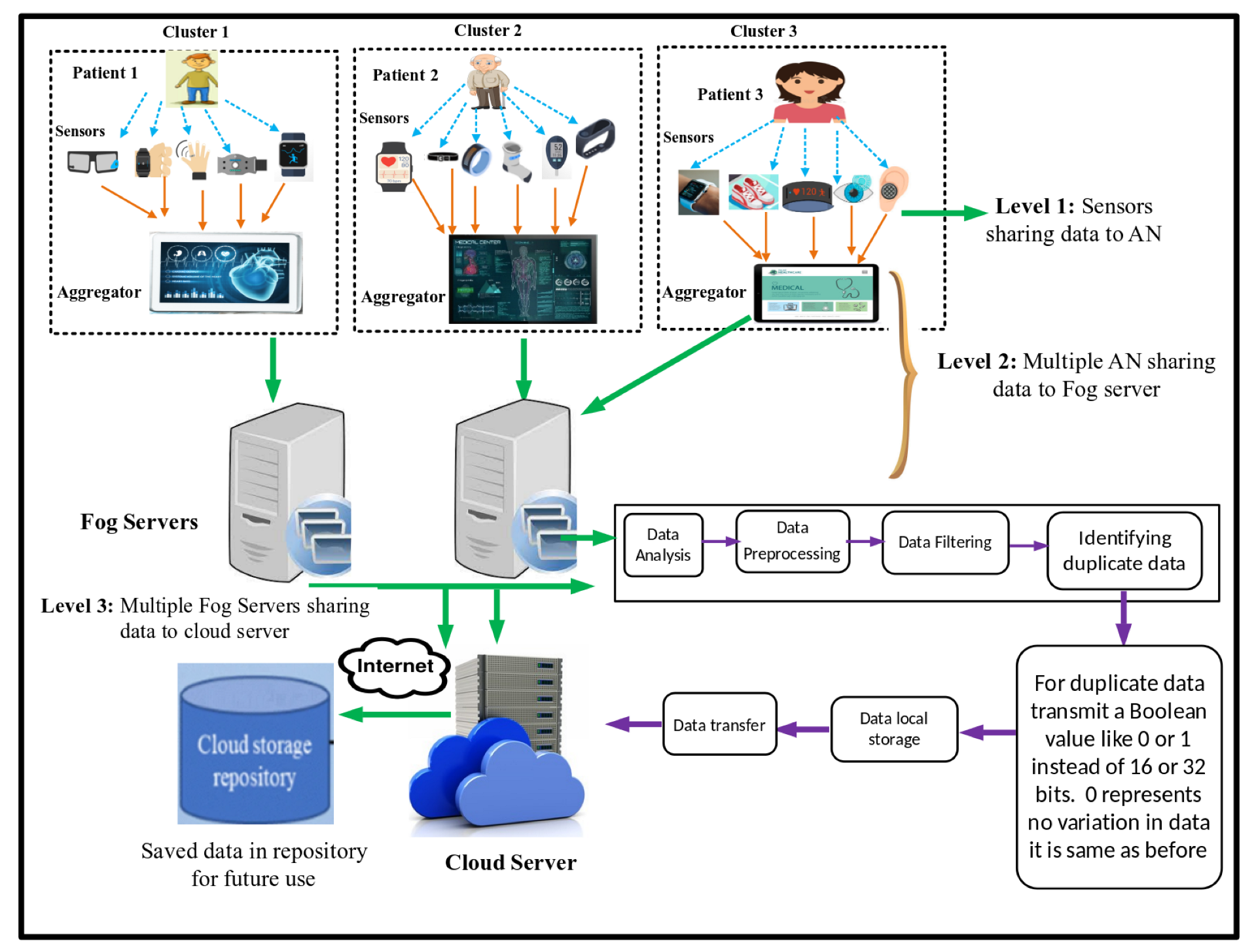
3. System Model and Problem Statement
4. Proposed Solution
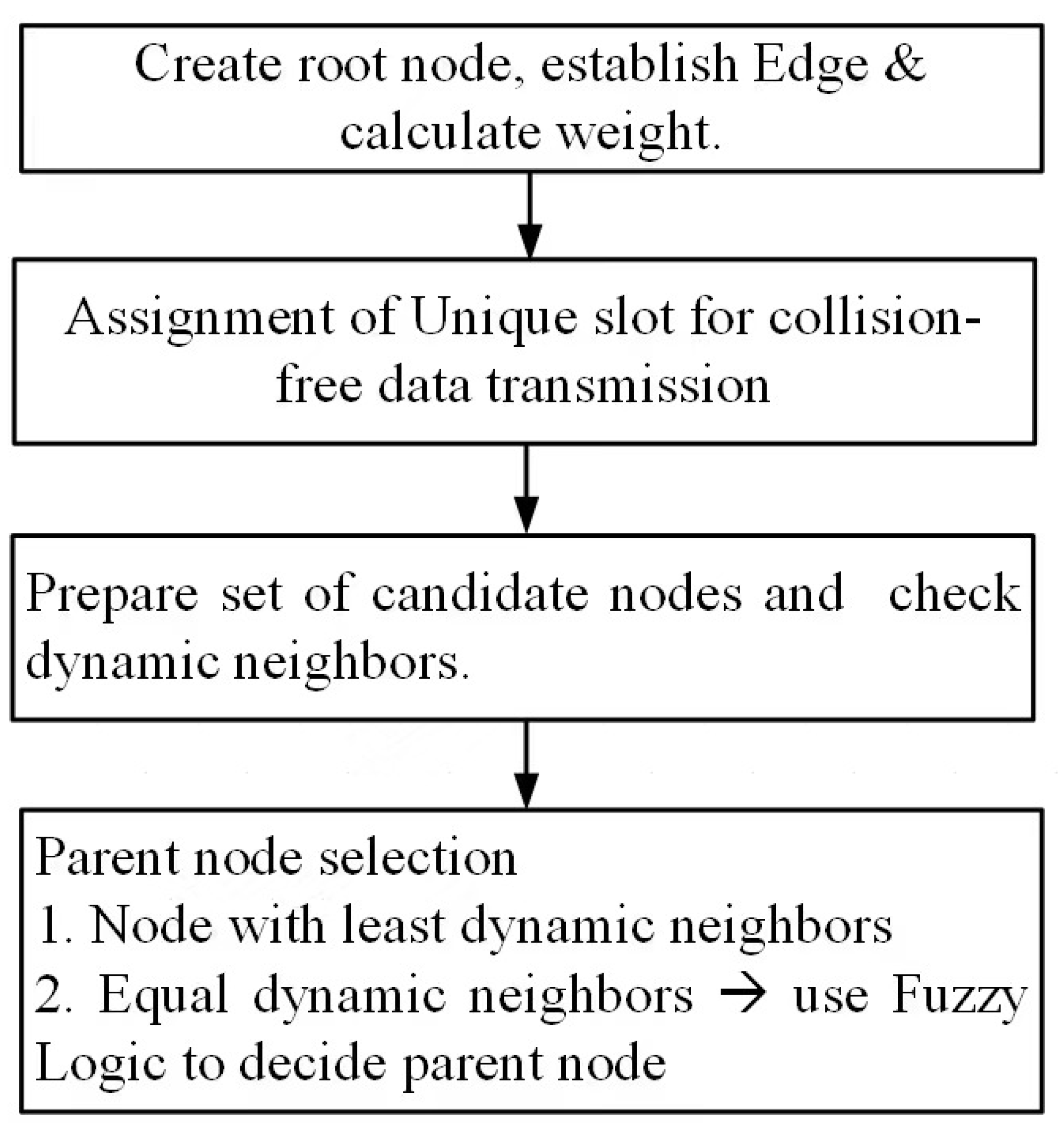
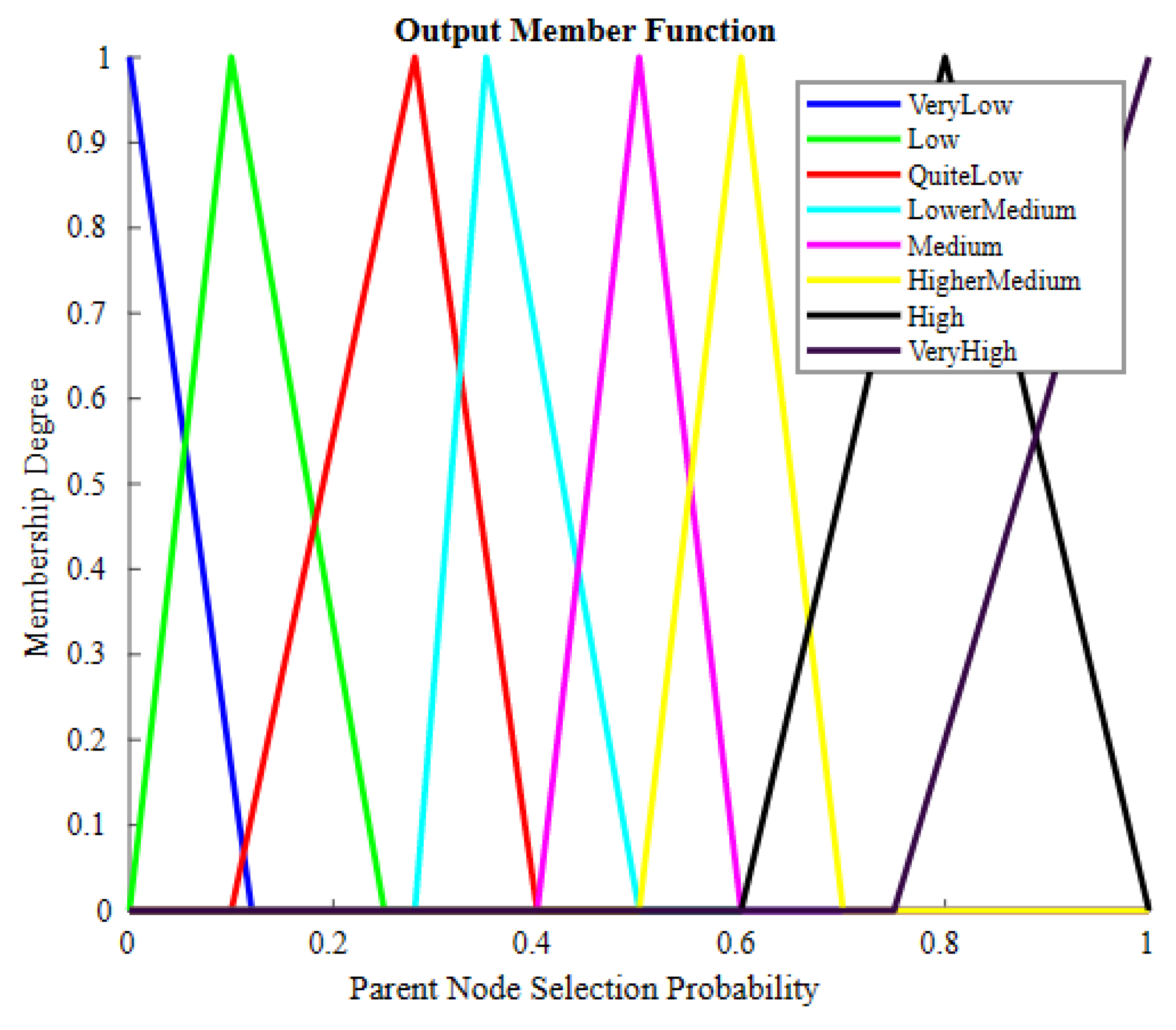
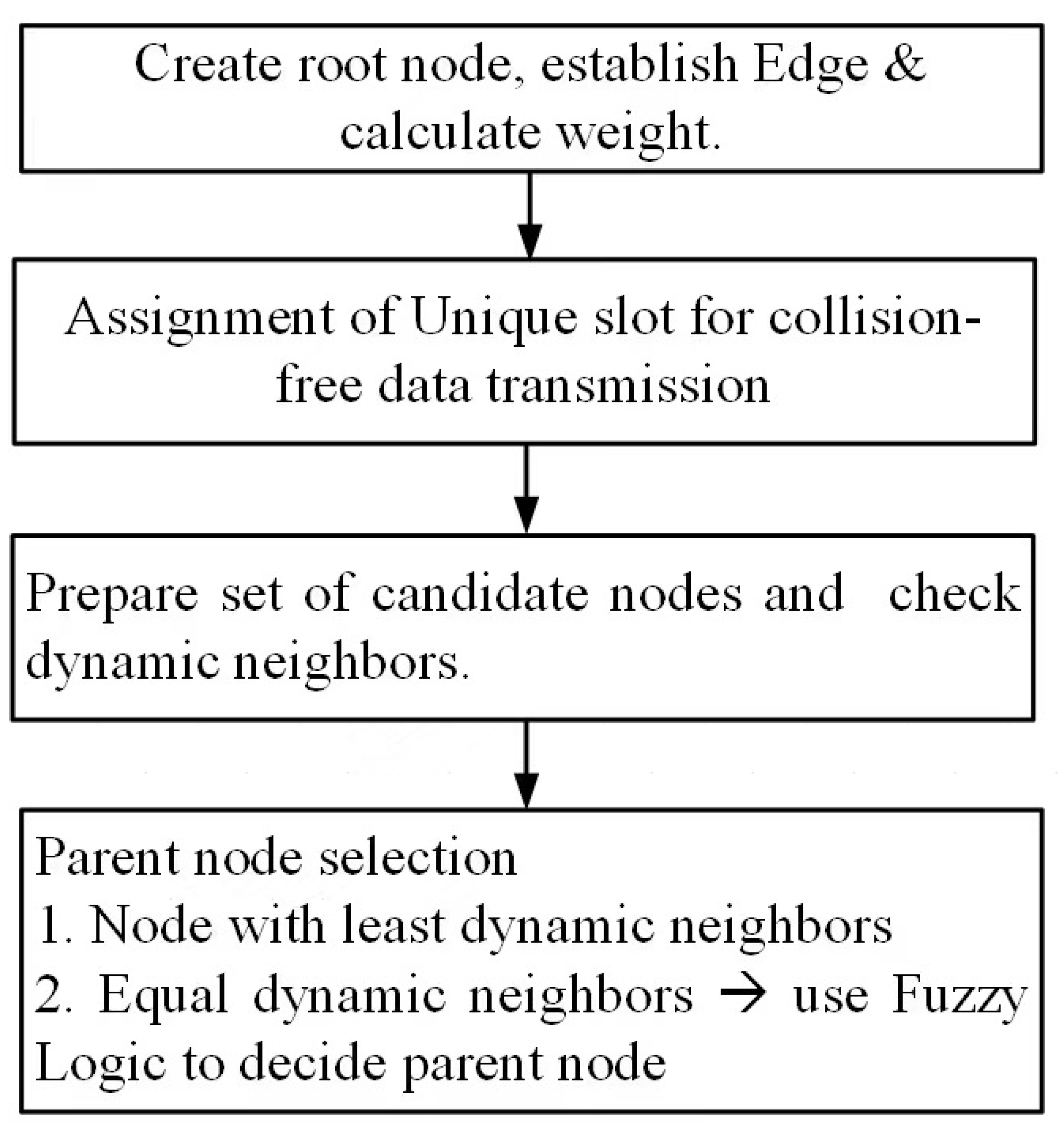
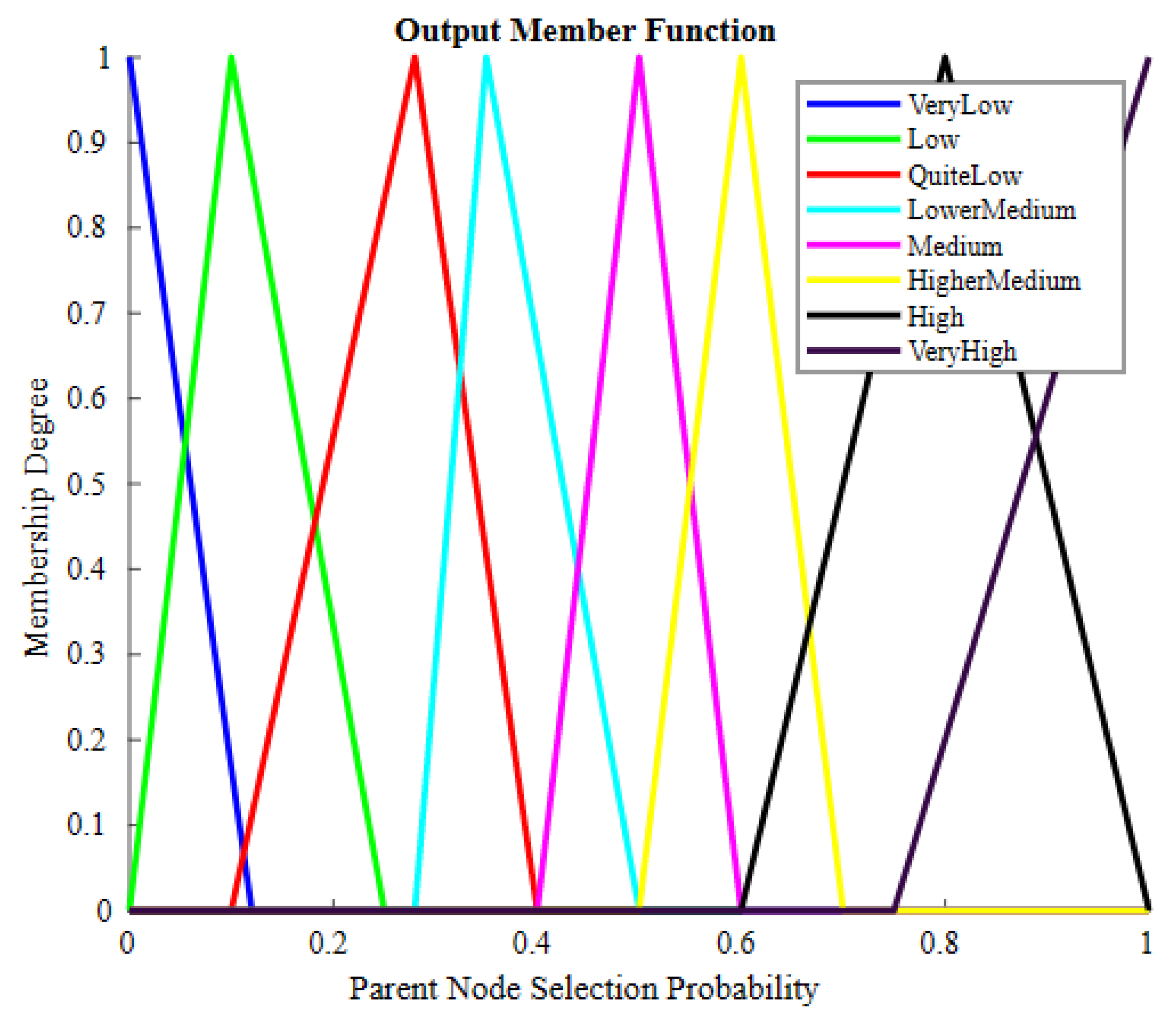
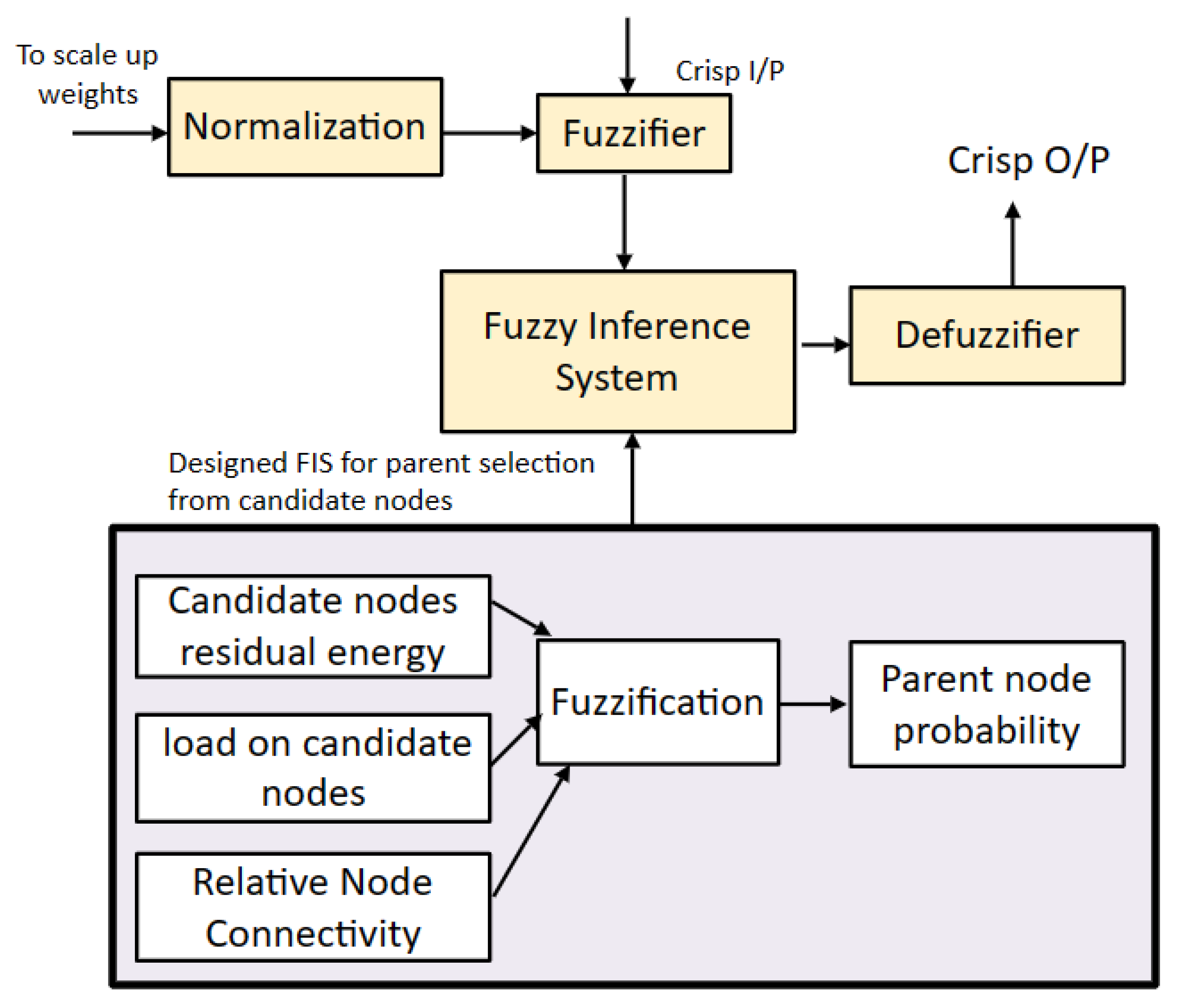
4.1. Appropriate Parent Selection
| Algorithm 1 Parent Selection at Control Phase |
|
| Algorithm 2 Fuzzy algorithm and rules for FIS. |
|
4.2. Data Packet Transmission in Data Phase
| Algorithm 3 Transmission of Packets At Data Phase |
|
5. Results and Analysis
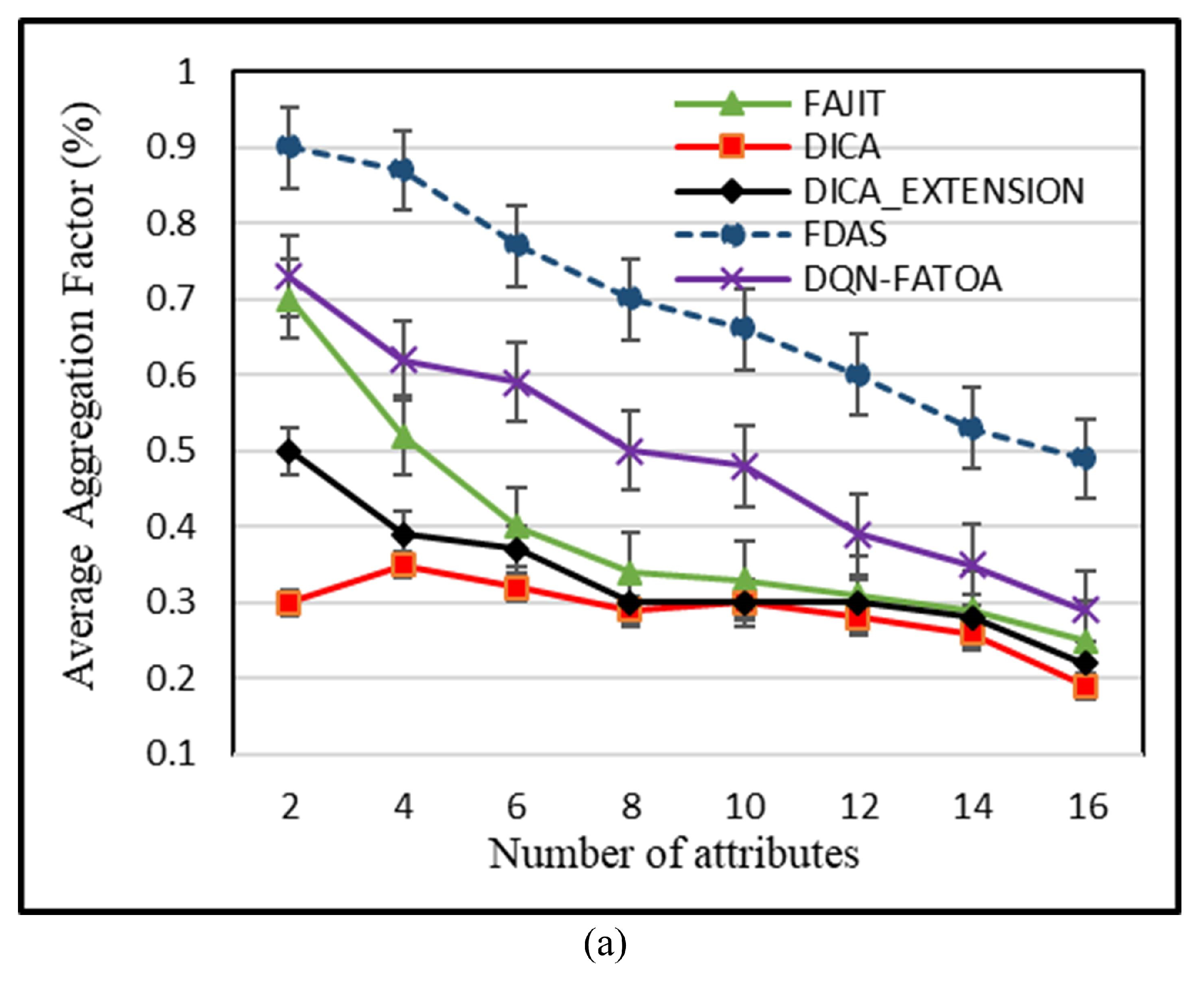
5.1. Effect on Average Aggregation by Number of Attributes
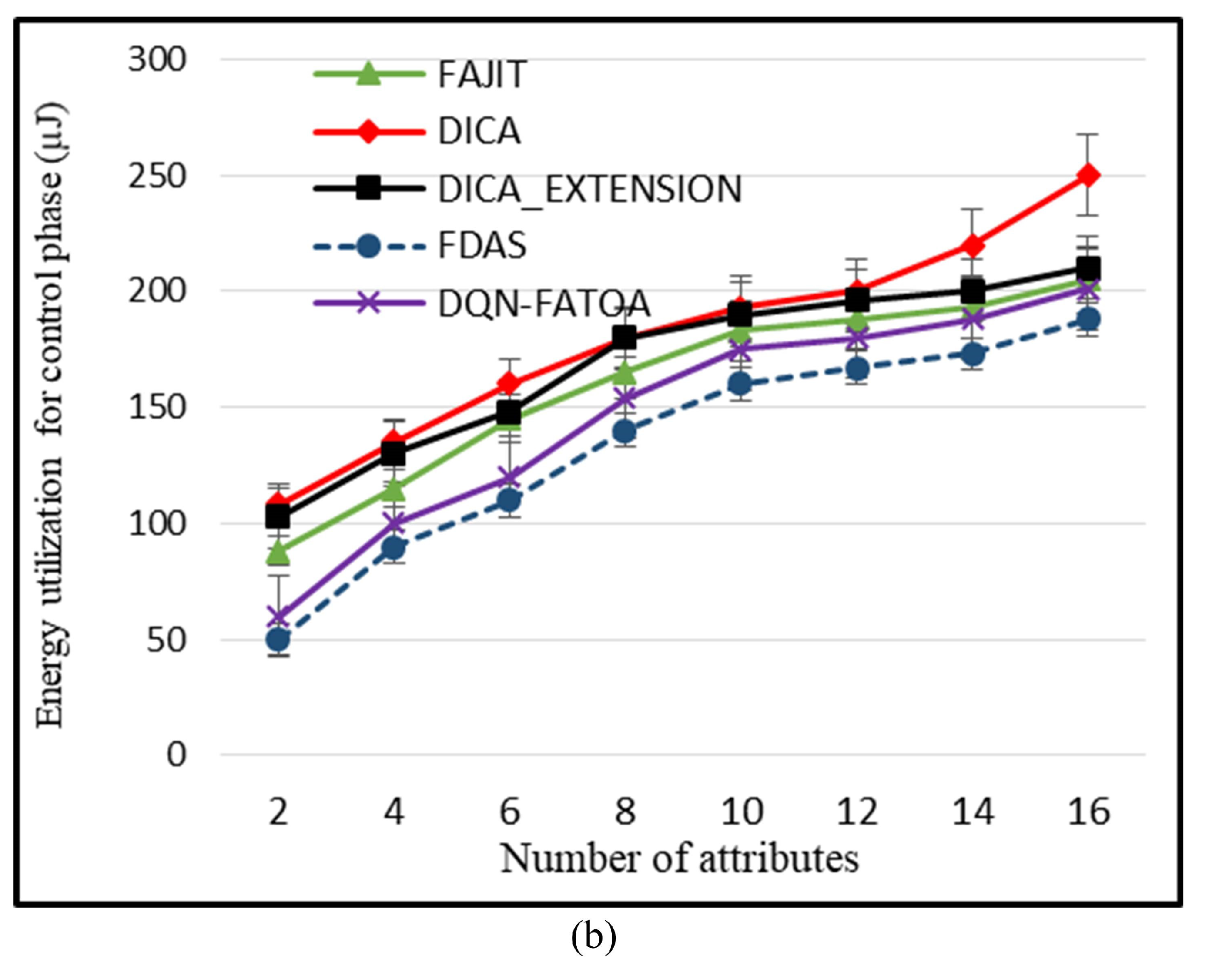
5.2. Energy Utilization during Control Phase
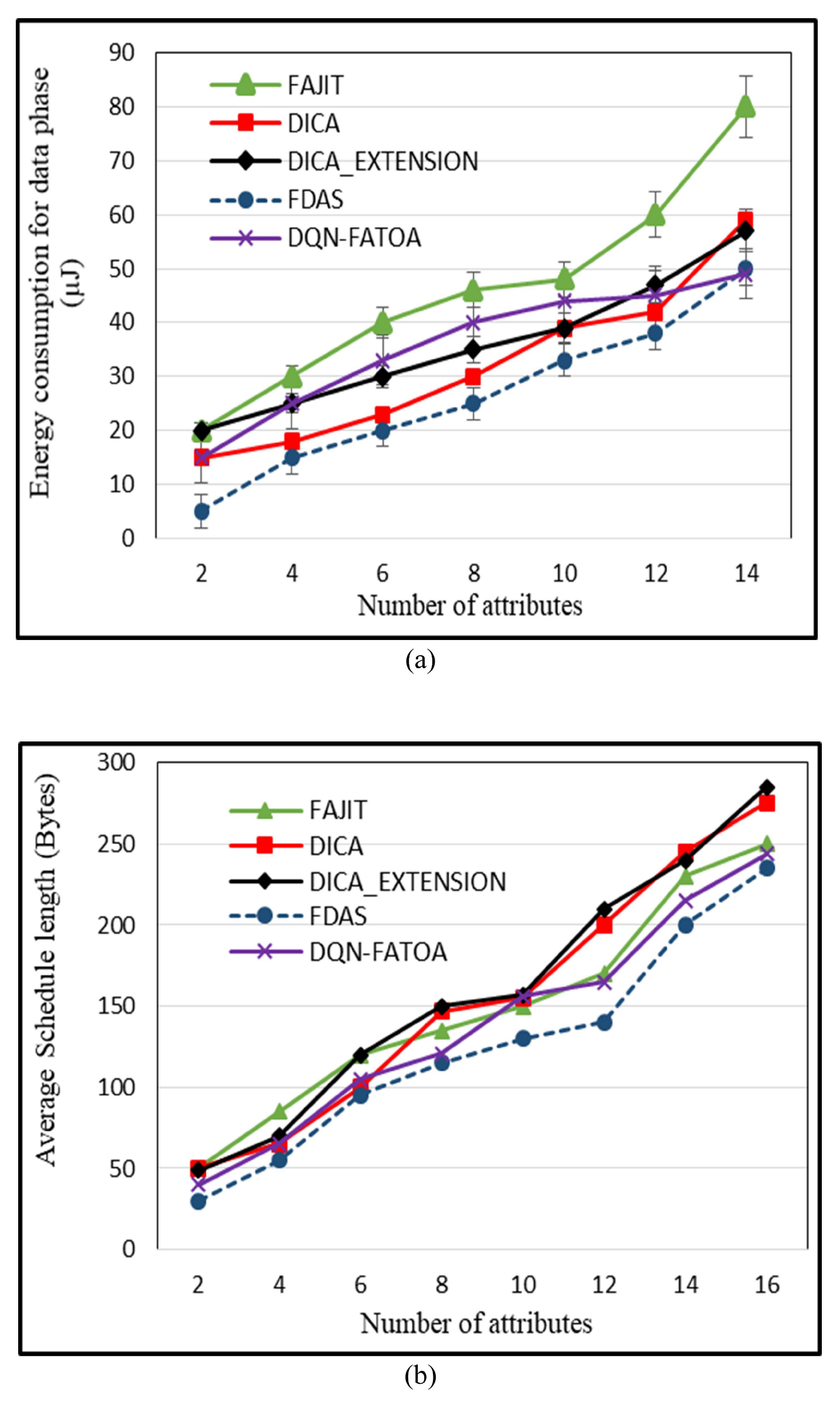
5.3. Energy Utilization during Data Phase
5.4. Effect of Number of Attributes on Schedule Length (SH)
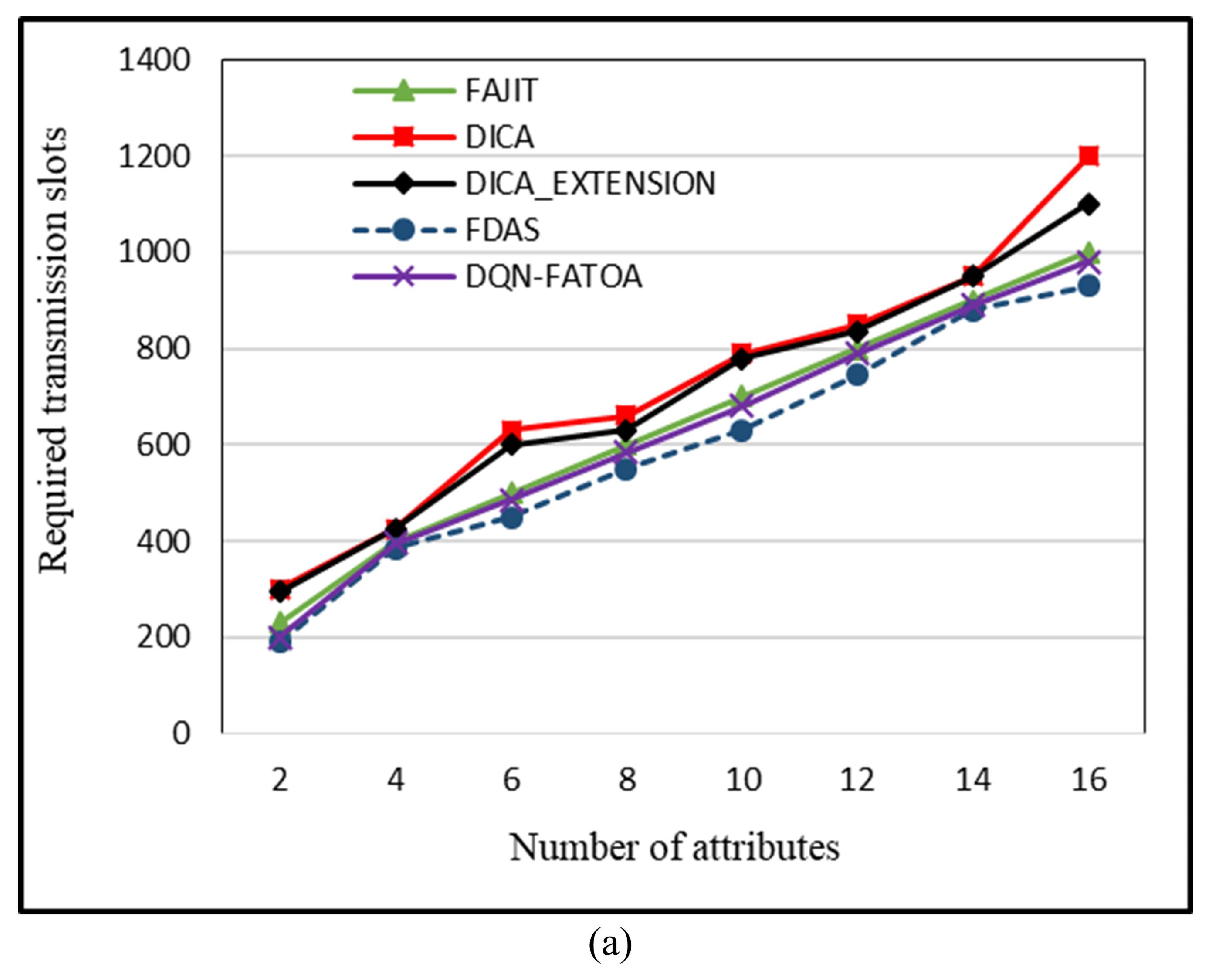
5.5. Required Number of Transmission Slots
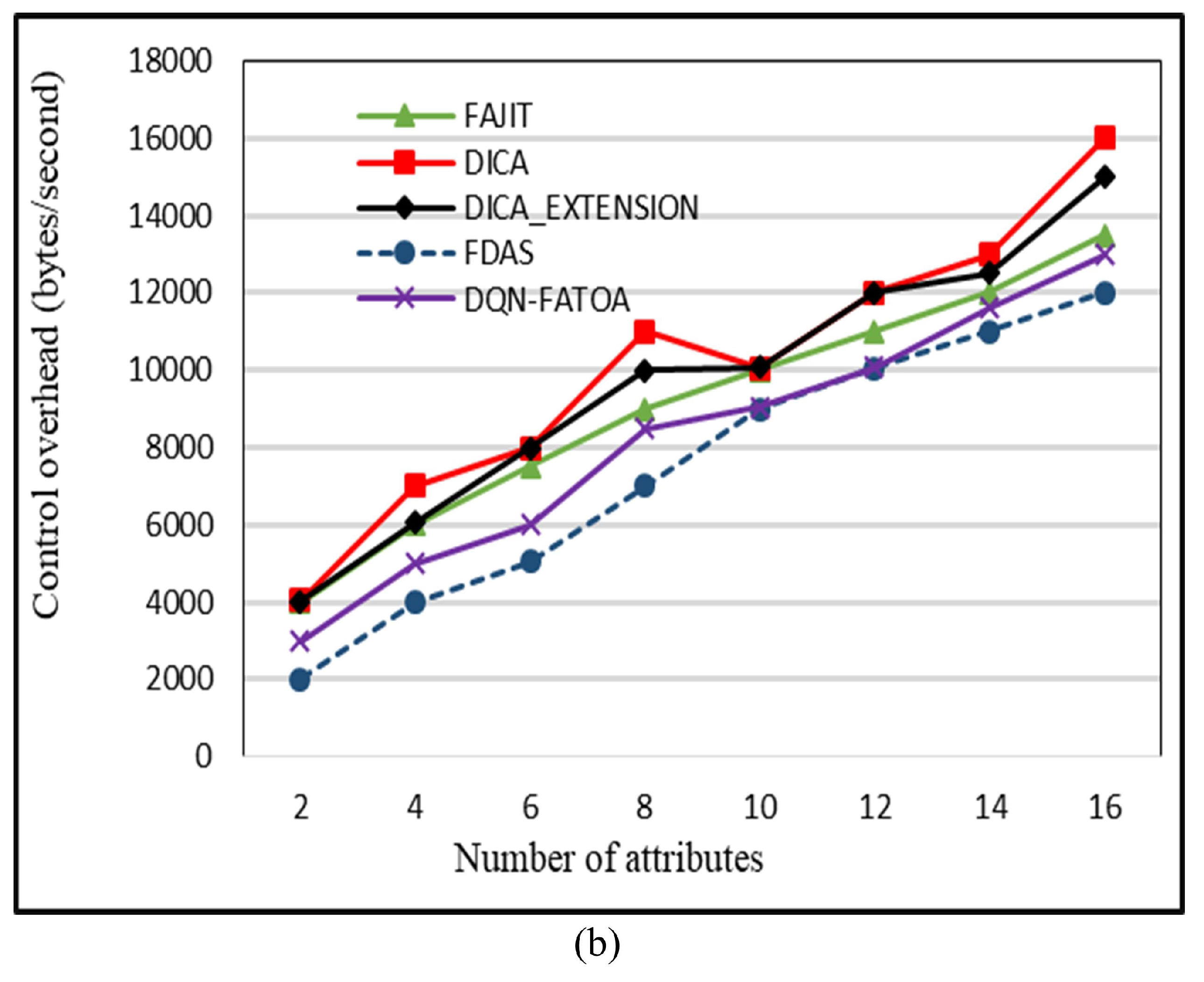
5.6. Effect of Number of Attributes on Control Overhead
5.7. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Das, A.K.; Zeadally, S.; He, D. Taxonomy and analysis of security protocols for Internet of Things. Future Gener. Comput. Syst. 2018, 10, 110–125. [Google Scholar] [CrossRef]
- Pourghebleh, B.; Navimipour, N.J. Data aggregation mechanisms in the Internet of things: A systematic review of the literature and recommendations for future research. J. Netw. Comput. Appl. 2017, 97, 23–34. [Google Scholar] [CrossRef]
- Rahim, A.; Zhong, Y.; Ahmad, T.; Ahmad, S.; Pławiak, P.; Hammad, M. Enhancing Smart Home Security: Anomaly Detection and Face Recognition in Smart Home IoT Devices Using Logit-Boosted CNN Models. Sensors 2023, 23, 6979. [Google Scholar] [CrossRef]
- Ahmad, T.; Wu, J. SDIGRU: Spatial and deep features integration using multilayer gated recurrent unit for human activity recognition. IEEE Trans. Comput. Soc. Syst. 2023, 1–13. [Google Scholar] [CrossRef]
- Ahmad, T.; Wu, J.; Alwageed, H.S.; Khan, F.; Khan, J.; Lee, Y. Human Activity Recognition Based on Deep-Temporal Learning Using Convolution Neural Networks Features and Bidirectional Gated Recurrent Unit With Features Selection. IEEE Access 2023, 11, 33148–33159. [Google Scholar] [CrossRef]
- Aazam, M.; Zeadally, S.; Harras, K.A. Fog computing architecture, evaluation, and future research directions. IEEE Commun. Mag. 2018, 56, 46–52. [Google Scholar] [CrossRef]
- Mahmud, R.; Koch, F.L.; Buyya, R. Cloud-fog interoperability in IoT-enabled healthcare solutions. In Proceedings of the International Conference on Distributed Computing and Networking, Varanasi, India, 4–7 January 2018; pp. 1–10. [Google Scholar]
- Rubí, J.N.S.; Gondim, P.R.L. IoMT platform for pervasive healthcare data aggregation, processing, and sharing based on OneM2M and OpenEHR. Sensors 2019, 19, 4283. [Google Scholar] [CrossRef]
- Gatouillat, A.; Badr, Y.; Massot, B.; Sejdić, E. Internet of medical things: A review of recent contributions dealing with cyber-physical systems in medicine. IEEE Internet Things J. 2018, 5, 3810–3822. [Google Scholar] [CrossRef]
- Nazir, T.; Banday, M.T. Green Internet of Things: A survey of enabling techniques. In Proceedings of the I2018 International Conference on Automation and Computational Engineering (ICACE), Greater Noida, India, 3–4 October 2018; Volume 5, pp. 197–202. [Google Scholar]
- Zhu, C.; Leung, V.C.; Shu, L.; Ngai, E.C.H. Green internet of things for smart world. IEEE Access 2015, 3, 2151–2162. [Google Scholar] [CrossRef]
- Khezr, S.; Moniruzzaman, M.; Yassine, A.; Benlamri, R. Blockchain technology in healthcare: A comprehensive review and directions for future research. Appl. Sci. 2019, 9, 1736. [Google Scholar] [CrossRef]
- Usak, M.; Kubiatko, M.; Shabbir, M.S.; Viktorovna Dudnik, O.; Jermsittiparsert, K.; Rajabion, L. Health care service delivery based on the Internet of things: A systematic and comprehensive study. Int. J. Commun. Syst. 2020, 33, e4179. [Google Scholar] [CrossRef]
- Wang, W.; Yang, L.; Zhang, Q.; Jiang, T. Securing on-body IoT devices by exploiting creeping wave propagation. IEEE J. Sel. Areas Commun. 2018, 36, 696–703. [Google Scholar] [CrossRef]
- Wouda, H.P.H. Blockchain in Office Building Transactions; Eindhoven University of Technology: Eindhoven, The Netherlands, 2019; Volume 29. [Google Scholar]
- Dubey, H.; Monteiro, A.; Constant, N.; Abtahi, M.; Borthakur, D.; Mahler, L.; Sun, Y.; Yang, Q.; Akbar, U.; Mankodiya, K. Fog computing in medical internet-of-things: Architecture, implementation, and applications. In Handbook of Large-Scale Distributed Computing in Smart Healthcare; Springer: Berlin, Germany, 2017; pp. 281–321. [Google Scholar]
- Kadhim, K.T.; Alsahlany, A.M.; Wadi, S.M.; Kadhum, H.T. An overview of patient’s health status monitoring system based on internet of things (IoT). In Handbook of Large-Scale Distributed Computing in Smart Healthcare; Springer: Berlin, Germany, 2020; Volume 114, pp. 2235–2262. [Google Scholar]
- Dey, N.; Ashour, A.S.; Shi, F.; Fong, S.J.; Tavares, J.M.R. Medical cyber-physical systems: A survey. In Handbook of Large-Scale Distributed Computing in Smart Healthcare; Springer: Berlin, Germany, 2018; Volume 42, pp. 1–13. [Google Scholar]
- Tahir, S.; Bakhsh, S.T.; Abulkhair, M.; Alassafi, M.O. An energy-efficient fog-to-cloud Internet of Medical Things architecture. Int. J. Distrib. Sens. Netw. 2019, 15, 1550147719851977. [Google Scholar] [CrossRef]
- Okay, F.Y.; Ozdemir, S. A secure data aggregation protocol for fog computing based smart grids. In Proceedings of the 2018 IEEE 12th International Conference on Compatibility, Power Electronics and Power Engineering (CPE-POWERENG 2018), Doha, Qatar, 10–12 April 2018; pp. 1–6. [Google Scholar]
- Lo’ai, A.T.; Mehmood, R.; Benkhlifa, E.; Song, H. Mobile cloud computing model and big data analysis for healthcare applications. IEEE Access 2016, 4, 6171–6180. [Google Scholar]
- Mouradian, C.; Naboulsi, D.; Yangui, S.; Glitho, R.H.; Morrow, M.J.; Polakos, P.A. A comprehensive survey on fog computing: State-of-the-art and research challenges. IEEE Commun. Surv. Tutor. 2017, 20, 416–464. [Google Scholar] [CrossRef]
- Jan, S.U.; Lee, Y.D.; Shin, J.; Koo, I. Sensor fault classification based on support vector machine and statistical time-domain features. IEEE Access 2017, 5, 8682–8690. [Google Scholar] [CrossRef]
- Yuehong, Y.I.N.; Zeng, Y.; Chen, X.; Fan, Y. The internet of things in healthcare: An overview. J. Ind. Inf. Integr. 2016, 1, 3–13. [Google Scholar]
- Dantu, R.; Dissanayake, I.; Nerur, S. Exploratory analysis of internet of things (IoT) in healthcare: A topic modelling & co-citation approaches. Inf. Syst. Manag. 2021, 38, 62–78. [Google Scholar]
- Hu, P.; Dhelim, S.; Ning, H.; Qiu, T. Survey on fog computing: Architecture, key technologies, applications and open issues. J. Netw. Comput. Appl. 2017, 98, 27–42. [Google Scholar] [CrossRef]
- Puliafito, C.; Mingozzi, E.; Longo, F.; Puliafito, A.; Rana, O. Fog computing for the internet of things: A survey. J. Netw. Comput. Appl. 2019, 19, 1–41. [Google Scholar]
- Kshetri, N. Privacy and security issues in cloud computing: The role of institutions and institutional evolution. Telecommun. Policy 2013, 37, 372–386. [Google Scholar] [CrossRef]
- Engineer, M.; Tusha, R.; Shah, A.; Adhvaryu, K. Insight into the importance of fog computing in Internet of Medical Things (IoMT). In Proceedings of the 2019 International Conference on Recent Advances in Energy-efficient Computing and Communication (ICRAECC), Nagercoil, India, 7–8 March 2019; pp. 1–7. [Google Scholar]
- Tang, W.; Ren, J.; Zhang, K.; Zhang, D.; Zhang, Y.; Shen, X. Efficient and privacy-preserving fog-assisted health data sharing scheme. ACM Trans. Intell. Syst. Technol. TIST 2019, 10, 1–23. [Google Scholar] [CrossRef]
- Guo, C.; Tian, P.; Choo, K.K.R. Enabling privacy-assured fog-based data aggregation in E-healthcare systems. IEEE Trans. Ind. Inform. 2020, 17, 1948–1957. [Google Scholar] [CrossRef]
- Sicari, S.; Rizzardi, A.; Grieco, L.A.; Coen-Porisini, A. Security, privacy and trust in Internet of Things: The road ahead. Comput. Netw. 2015, 76, 146–164. [Google Scholar] [CrossRef]
- Yang, P.; Zhang, N.; Zhang, S.; Yang, K.; Yu, L.; Shen, X. Identifying the most valuable workers in fog-assisted spatial crowdsourcing. IEEE Internet Things J. 2017, 4, 1193–1203. [Google Scholar] [CrossRef]
- Shen, J.; Chang, S.; Shen, J.; Liu, Q.; Sun, X. A lightweight multi-layer authentication protocol for wireless body area networks. Future Gener. Comput. Syst. 2018, 78, 956–963. [Google Scholar] [CrossRef]
- Hou, J.; Qu, L.; Shi, W. A survey on internet of things security from data perspectives. Comput. Netw. 2019, 148, 295–306. [Google Scholar] [CrossRef]
- Ahmadi, H.; Arji, G.; Shahmoradi, L.; Safdari, R.; Nilashi, M.; Alizadeh, M. The application of internet of things in healthcare: A systematic literature review and classification. Univers. Access Inf. Soc. 2019, 18, 837–869. [Google Scholar] [CrossRef]
- Kraemer, F.A.; Braten, A.E.; Tamkittikhun, N.; Palma, D. Fog computing in healthcare—A review and discussion. IEEE Access 2017, 5, 9206–9222. [Google Scholar] [CrossRef]
- Suhardi, R.A. A survey of security aspects for Internet of Things in healthcare. In Information Science and Applications (ICISA); Springer: Singapore, 2016; pp. 1237–1247. [Google Scholar]
- Lin, H.; Yan, Z.; Chen, Y.; Zhang, L. A survey on network security-related data collection technologies, special section on internet of things big datatrust management. IEEE Access 2018, 6, 18345–18365. [Google Scholar] [CrossRef]
- Zhang, H.; Shi, Y.; Qiu, B. Applying catastrophe progression method to evaluate the service quality of cold chain logistics. In Complex Intelligent Systems; Springer: Berlin, Germany, 2020; pp. 1–15. [Google Scholar]
- Kulkarni, R.V.; Förster, A.; Venayagamoorthy, G.K. Computational Intelligence in Wireless Sensor Networks: A Survey. IEEE Commun. Surv. Tutor. 2011, 1, 68–96. [Google Scholar] [CrossRef]
- Sarobin, M.V.R.; Ganesan, R. Swarm intelligence in wireless sensor networks: A survey. Int. J. Pure Appl. Math. 2015, 101, 773–807. [Google Scholar]
- Lin, C.; Wu, G.; Xia, F.; Li, M.; Yao, L.; Pei, Z. Energy efficient ant colony algorithms for data aggregation in wireless sensor networks. J. Comput. Syst. Sci. 2012, 78, 1686–1702. [Google Scholar] [CrossRef]
- Hoang, D.C.; Kumar, R.; Panda, S.K. Optimal data aggregation tree in wireless sensor networks based on intelligent water drops algorithm. IET Wirel. Sens. Syst. 2012, 2, 282–292. [Google Scholar] [CrossRef]
- Qiu, L.; Zhang, D.; Tian, Y.; Al-Nabhan, N. Deep learning-based algorithm for vehicle detection in intelligent transportation systems. J. Supercomput. 2021, 77, 11083–11098. [Google Scholar] [CrossRef]
- Chang, W.L.; Zeng, D.; Chen, R.C.; Guo, S. An artificial bee colony algorithm for data collection path planning in sparse wireless sensor networks. Int. J. Mach. Learn. Cybern. 2015, 6, 375–383. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. Int. J. Mach. Learn. Cybern. 2013, 30, 3. [Google Scholar]
- Abirami, T.; Anandamurugan, S. Data aggregation in wireless sensor network using shuffled frog algorithm. Wirel. Pers. Commun. 2016, 90, 537–549. [Google Scholar] [CrossRef]
- Tang, C.; Yang, N. CoDA: Collaborative Data Aggregation in Emerging Sensor Networks Using Bio-Level Voronoi Diagrams. Sensors 2022, 16, 1235. [Google Scholar] [CrossRef]
- Sajedi, S.N.; Maadani, M.; Nesari Moghadam, M. F-LEACH: A fuzzy-based data aggregation scheme for healthcare IoT systems. J. Supercomput. 2022, 78, 1030–1047. [Google Scholar] [CrossRef]
- Abid, B.; Nguyen, T.T.; Seba, H. New data aggregation approach for time-constrained wireless sensor networks. J. Supercomput. 2015, 71, 1678–1693. [Google Scholar] [CrossRef]
- Singh, S. An energy aware clustering and data gathering technique based on nature inspired optimization in WSNs. Peer-to-Peer Netw. Appl. 2020, 12, 1357–1374. [Google Scholar] [CrossRef]
- Babu, V.; Kumar, C.V.; Parthiban, S.; Padmavathi, U.; Rahman, M.Z.U. AE-LEACH: An Incremental Clustering Approach for Reducing the Energy Consumption in WSN. Microprocess. Microsyst. 2022, 93, 104602. [Google Scholar] [CrossRef]
- Amutha, J.; Sharma, S.; Sharma, S.K. An energy efficient cluster based hybrid optimization algorithm with static sink and mobile sink node for Wireless Sensor Networks. Expert Syst. Appl. 2022, 203, 1117334. [Google Scholar] [CrossRef]
- Yan, X.; Huang, C.; Gan, J.; Wu, X. Game theory-based energy-efficient clustering algorithm for wireless sensor networks. Expert Syst. Appl. 2022, 22, 478. [Google Scholar] [CrossRef] [PubMed]
- Shukla, P.; Sharma, V.; Pughat, A. Data aggregation in wireless sensor networks. In Energy-Efficient Wireless Sensor Networks; CRC Press: Boca Raton, FL, USA, 2017; pp. 165–178. [Google Scholar]
- Sert, S.A.; Alchihabi, A.; Yazici, A. A two-tier distributed fuzzy logic based protocol for efficient data aggregation in multihop wireless sensor networks. IEEE Trans. Fuzzy Syst. 2018, 26, 3615–3629. [Google Scholar] [CrossRef]
- Sanjay Gandhi, G.; Vikas, K.; Ratnam, V.; Suresh Babu, K. Grid clustering and fuzzy reinforcement-learning based energy-efficient data aggregation scheme for distributed WSN. IET Commun. 2020, 14, 2840–2848. [Google Scholar] [CrossRef]
- Yousefpoor, E.; Barati, H.; Barati, A. A hierarchical secure data aggregation method using the dragonfly algorithm in wireless sensor networks. Peer-to-Peer Netw. Appl. 2021, 14, 1917–1942. [Google Scholar] [CrossRef]
- Mehmood, G.; Khan, M.Z.; Bashir, A.K.; Al-Otaibi, Y.D.; Khan, S. An Efficient QoS-Based Multi-Path Routing Scheme for Smart Healthcare Monitoring in Wireless Body Area Networks. Comput. Electr. Eng. 2023, 109, 108517. [Google Scholar] [CrossRef]
- Javaheri, D.; Lalbakhsh, P.; Gorgin, S.; Lee, J.A.; Masdari, M. A new energy-efficient and temperature-aware routing protocol based on fuzzy logic for multi-WBANs. Ad Hoc Netw. 2023, 139, 103042. [Google Scholar] [CrossRef]
- Misra, S.; Pal, S.; Deb, P.K.; Gupta, E. KEdge: Fuzzy-Based Multi-AI Model Coalescence Solution for Mobile Healthcare System. IEEE Syst. J. 2023, 17, 1721–1728. [Google Scholar] [CrossRef]
- Yuan, X.; Zhang, Z.; Feng, C.; Cui, Y.; Garg, S.; Kaddoum, G.; Yu, K. A DQN-Based Frame Aggregation and Task Offloading Approach for Edge-Enabled IoMT. IEEE Trans. Netw. Sci. Eng. 2023, 10, 1339–1351. [Google Scholar] [CrossRef]
- Raja Basha, A.; Yaashuwanth, C. Optimal partial aggregation based energy delay compromise technique for wireless sensor network. IETE J. Res. 2019, 65, 855–871. [Google Scholar] [CrossRef]
- Raj, P.P.; Khedr, A.M.; Aghbari, Z.A. Data gathering via mobile sink in WSNs using game theory and enhanced ant colony optimization. Wirel. Netw. 2020, 26, 2983–2998. [Google Scholar] [CrossRef]
- Vasavada, T.M. Distributed TDMA Scheduling in Tree Based Wireless Sensor Networks with Multiple Data Attributes and Multiple Sinks. Ph.D. Thesis, Dhirubhai Ambani Institute of Information and Communication Technology, Gandhinagar, India, 2018. [Google Scholar]
- Fanian, F.; Rafsanjani, M.K. A new fuzzy multi-hop clustering protocol with automatic rule tuning for wireless sensor networks. Appl. Soft Comput. 2020, 89, 106115. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sr. | Notation | Description |
|---|---|---|
| 1. | t_slot_n[i] | Time slot assigned to node i |
| 2. | C_node[] | Set of child nodes |
| 3. | ANs | Aggregating nodes |
| 4. | FIS | Fuzzy inference system |
| 5. | a_slot | Assigned time slot |
| 6. | neigh[i] | Neighbor node i |
| 7. | FL | Fuzzy logic |
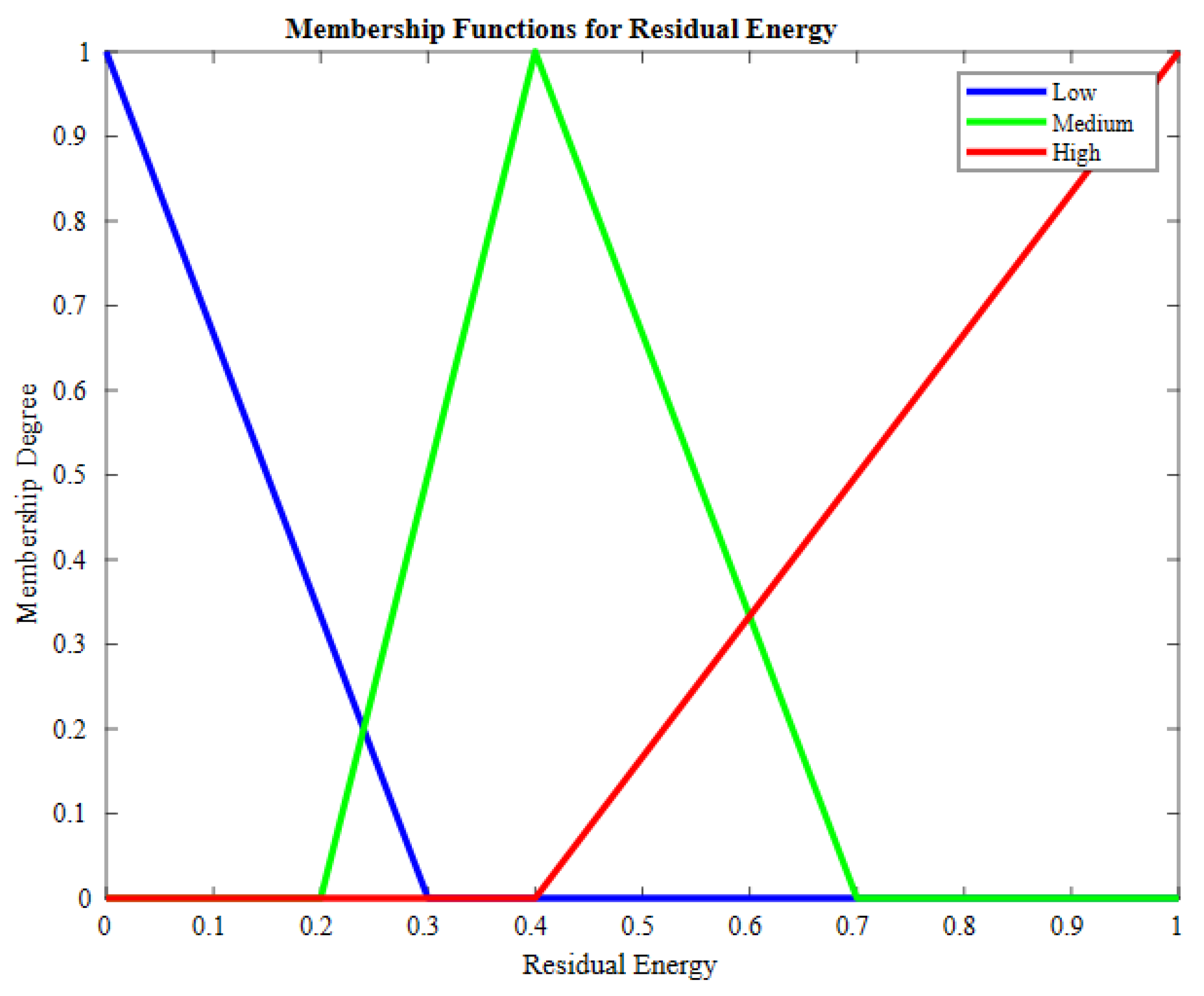
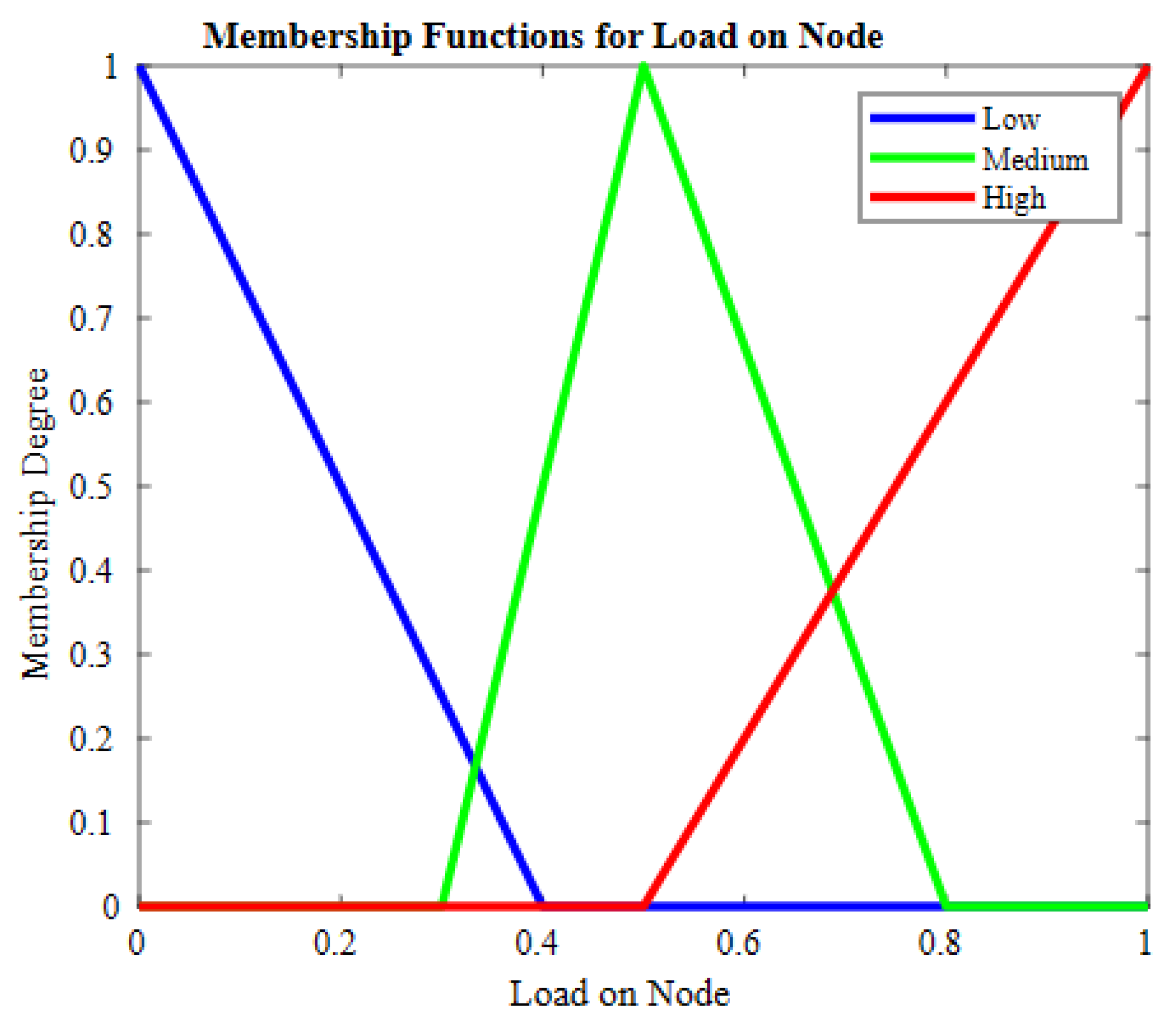
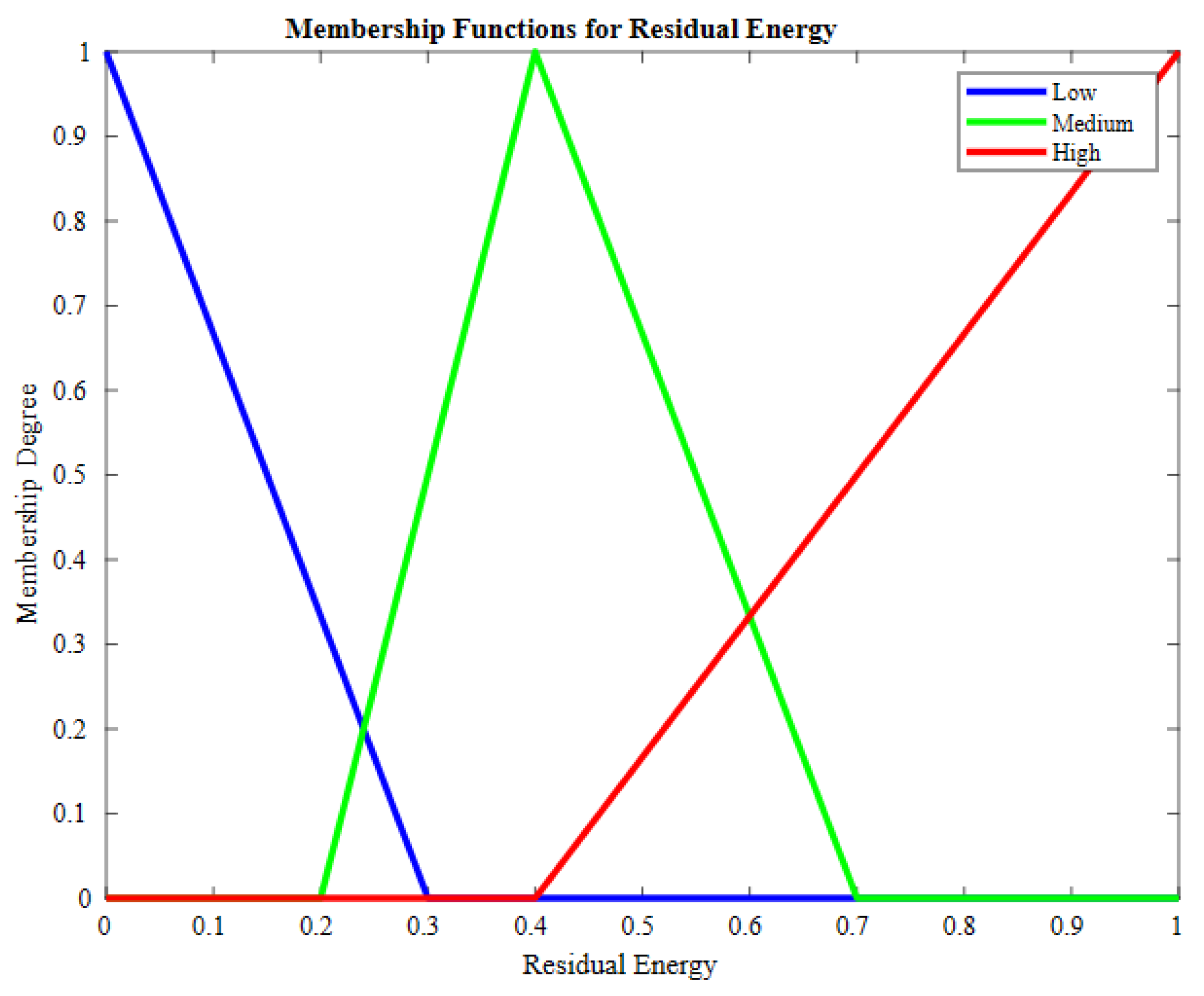
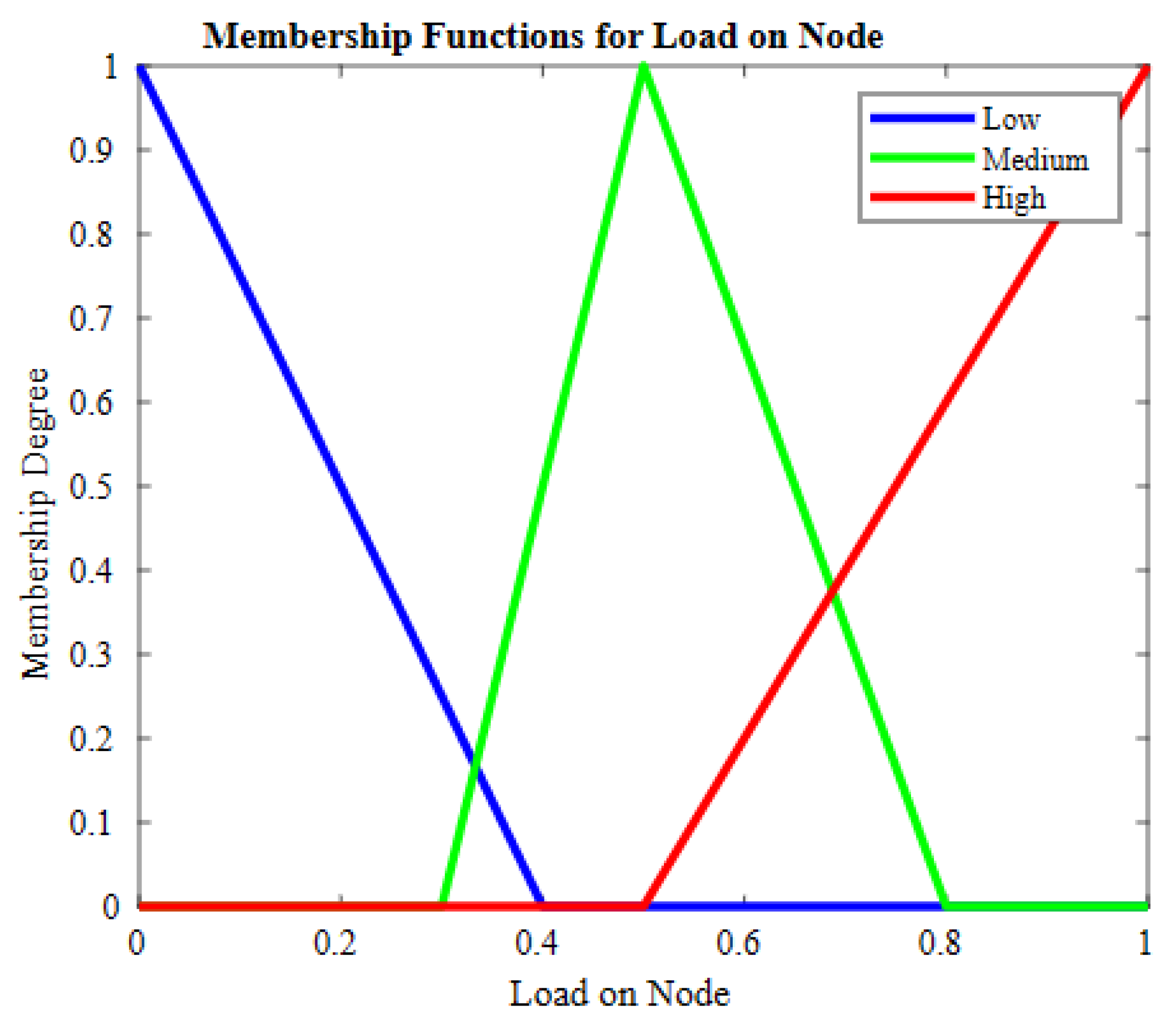
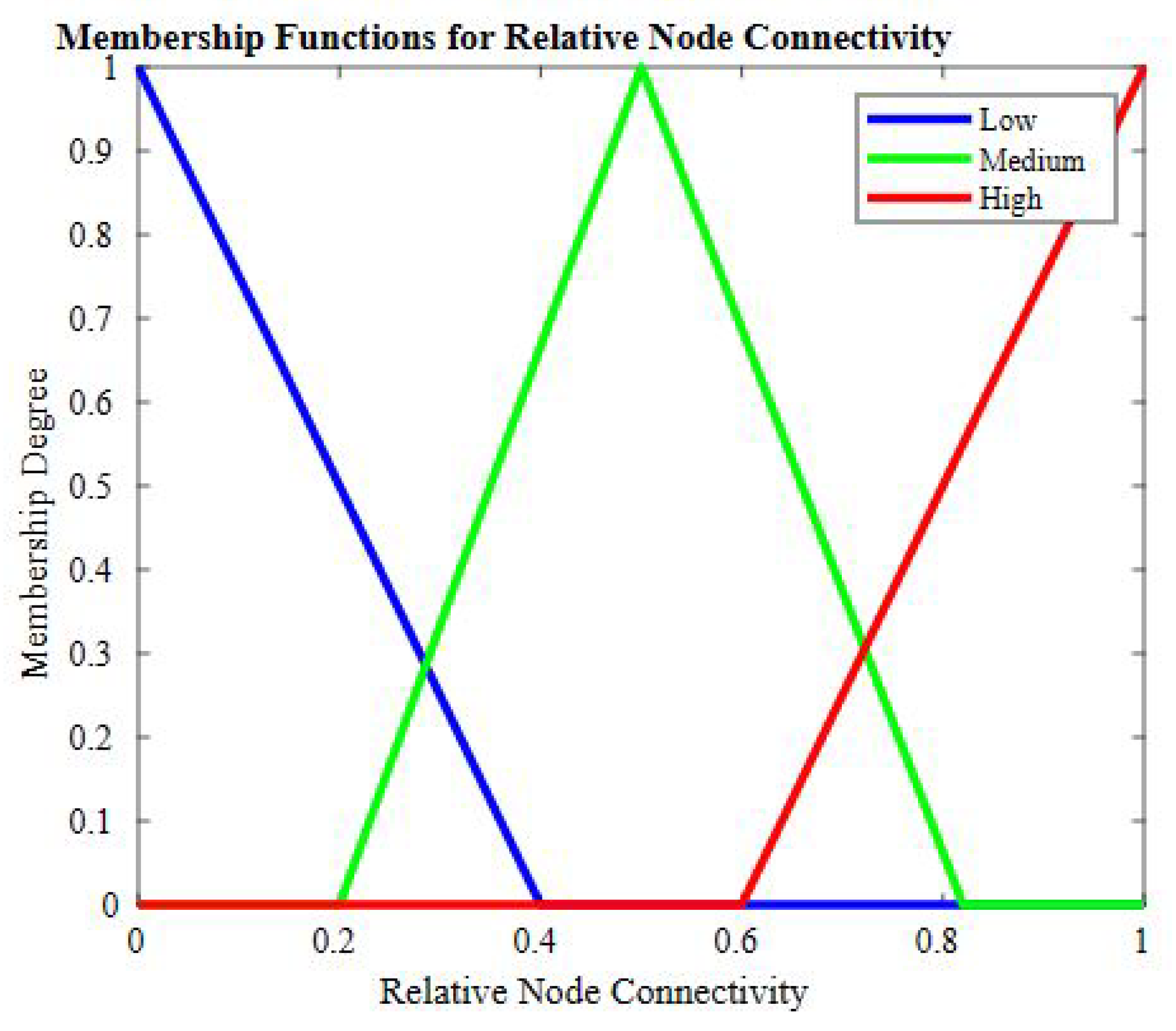
| Sr. | Residual Energy | RNC | Load on Node | Crisp Output |
|---|---|---|---|---|
| 1 | High | High | High | High Medium |
| 2 | High | High | Medium | High |
| 3 | High | High | Low | Very High |
| 4 | High | Medium | High | Medium |
| 5 | High | Medium | Medium | Medium |
| 6 | High | Medium | Low | Higher Medium |
| 7 | High | Low | High | Lower Medium |
| 8 | High | Low | Medium | Medium |
| 9 | High | Low | Low | Medium |
| 10 | Medium | High | High | Low |
| 11 | Medium | High | Medium | Low |
| 12 | Medium | High | Low | Medium |
| 13 | Medium | Medium | High | Lower Medium |
| 14 | Medium | Medium | Medium | Medium |
| 15 | Medium | Medium | Low | Medium |
| 16 | Medium | Low | High | Lower Medium |
| 17 | Medium | Low | Medium | Medium |
| 18 | Medium | Low | Low | Medium |
| 19 | Low | High | High | Low |
| 20 | Low | High | Medium | Quite |
| 21 | Low | High | Low | Quite |
| 22 | Low | Medium | High | Very Low |
| 23 | Low | Medium | Medium | Low |
| 24 | Low | Medium | Low | Quite Low |
| 25 | Low | Low | High | Very Low |
| 26 | Low | Low | Medium | Low |
| 27 | Low | Low | Low | Very Low |
| Parameters | Values |
|---|---|
| Simulation Time | 2500 s |
| No. of deployed nodes | 300 |
| Arrangement of nodes | Random |
| Transmission range of data packets | 30 m |
| Dissemination power utilization | 0.5819 µj |
| Received power utilization | 0.049 µj |
| Size of network | 3000 m × 3000 m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.N.U.; Tang, Z.; Cao, W.; Abid, Y.A.; Pan, W.; Ullah, A. Fuzzy-Based Efficient Healthcare Data Collection and Analysis Mechanism Using Edge Nodes in the IoMT. Sensors 2023, 23, 7799. https://doi.org/10.3390/s23187799
Khan MNU, Tang Z, Cao W, Abid YA, Pan W, Ullah A. Fuzzy-Based Efficient Healthcare Data Collection and Analysis Mechanism Using Edge Nodes in the IoMT. Sensors. 2023; 23(18):7799. https://doi.org/10.3390/s23187799
Chicago/Turabian StyleKhan, Muhammad Nafees Ulfat, Zhiling Tang, Weiping Cao, Yawar Abbas Abid, Wanghua Pan, and Ata Ullah. 2023. "Fuzzy-Based Efficient Healthcare Data Collection and Analysis Mechanism Using Edge Nodes in the IoMT" Sensors 23, no. 18: 7799. https://doi.org/10.3390/s23187799
APA StyleKhan, M. N. U., Tang, Z., Cao, W., Abid, Y. A., Pan, W., & Ullah, A. (2023). Fuzzy-Based Efficient Healthcare Data Collection and Analysis Mechanism Using Edge Nodes in the IoMT. Sensors, 23(18), 7799. https://doi.org/10.3390/s23187799