2.4.1. Classification Vector Response Field
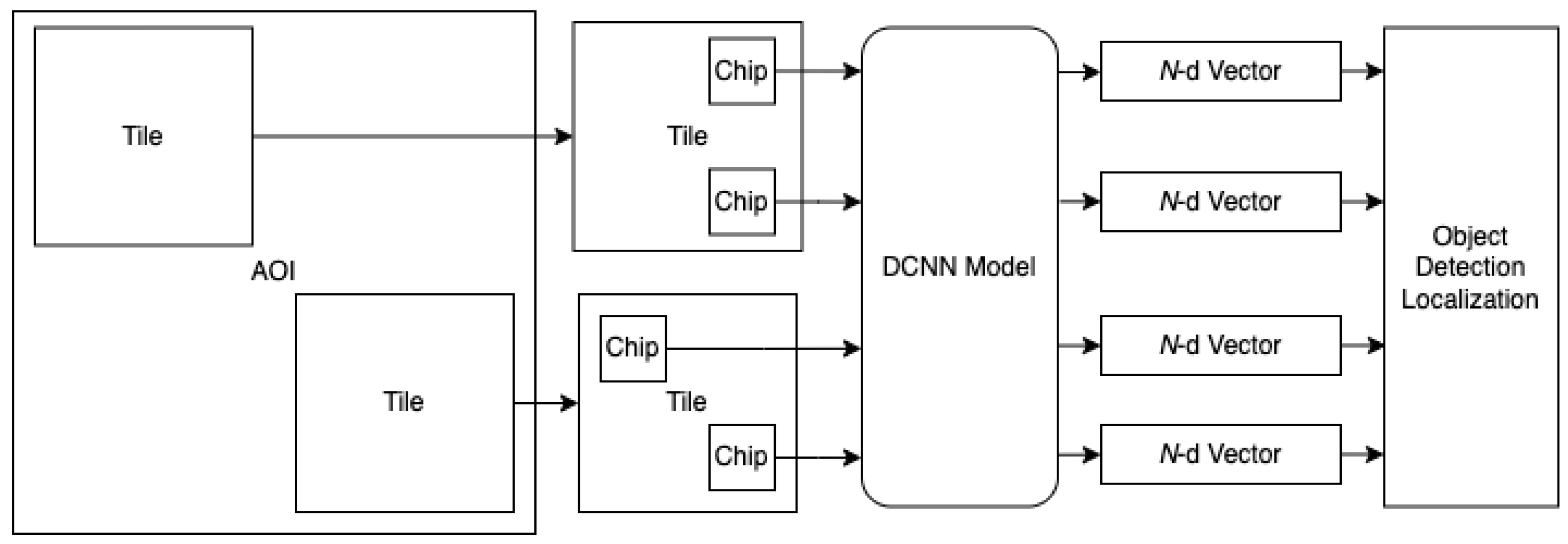
The critical first step for BAS is the generation of the CVRF. It should be noted that the scale of satellite imagery and the area of analysis precludes the use of techniques such as region proposal networks or candidate object nomination non-maximal suppression, which are common in single image bounding box detectors. In this work, we leveraged an HR-EO-RSI provider to acquire two AOIs, the first of which was a quarter geocell and the second being a full geocell, with each covering 1 degree latitude by 1 degree longitude. All imagery were 0.5 m GSD multi-spectral imagery that were reduced to just the traditional color bands: red, green, and blue. The AOIs were scanned via a data collector that moved through each AOI to pull down large image tiles from the imagery provider’s web API. These image tiles were overlapped by 10% of their width, thereby ensuring sufficient AOI coverage by preventing objects from only being partially seen when captured on tile edges. Each tile was then processed with a stride of 90% of its width, which pulled image chips from the broad area that were 227 × 227 pixels in size (113.5 × 113.5 m).
Figure 3 illustrates the chip scanning, which effectively forms a set of overlapping grids over the AOI. In the Beijing AOI, the larger of the two chosen for this study, our source imagery is composed of 33,201 PNGs at 1280 × 1280 pixels, meaning that each of our detectors must evaluate 54,396,518,400 unique pixels, which requires hours of processing even on high-performance NVIDIA V100S GPUs, due to memory limitations of GPU cards.
Each image chip was pushed through the DCNN to generate a geolocated classification response vector.
Figure 4 illustrates the relationship and data path from AOI tiles to chips to DCNN inference to classification vectors. The response vectors were automatically geolocated based on the chip center latitude and longitude (see also
Figure 3). The CVRF generated from the AOIs in this research consisted of 601,344 geolocated classification vectors in the Springfield AOI and 11,983,927 vectors in the Beijing AOI.
The scanning forms an irregular field, i.e., mesh, of classification vectors over the AOI. A very important consideration is the nature of the classification output of the DCNN architectures. DCNNs typically utilize a softmax output layer that generates the final classification response. This layer type aids in the training of the DCNN. However, the effect is that the output vector,
C, during inference is normalized such that
Unfortunately, when the network has low activation because of a lack of presence of relevant visual content, as expected by the classifier, the vector response is lifted up to the normalized condition of Equation (
1). Hence, the CVRF is expected to have densities of detections around true detections, as well as a massive number of artificially high responses that are false alarms (noise). Efficient processing of the CRVF to accommodate this real consequence of applying the DCNN in a real-world application setting is therefore a critical processing step.
2.4.2. Multi-Object Localization
As just discussed, the CVRF cannot be taken as raw confidence in detections due to the softmax output layers on DCNN architectures. As such, we present an algorithm to perform multi-object localization across a broad area’s CVRF. The CVRF generated from the DCNN broad area scan can be accessed one classification layer at a time, thus effectively processing one response surface at a time. We refer to a single response classification layer, R, as a classification surface.
Based on DCNNs trained on the datasets used in this study, we yielded 21-layer, 38-layer, 45-layer, and 33-layer CVRFs for the UCM, PatternNet, RESISC-45, and MDSv2, respectively. The number of layers in a given model’s CVRF is equal to the number of classes in the dataset upon which the model was trained. Knowing this, we can, for each model, slice out a response field, R, for a single class, such as Baseball Field. This response field is then a surface over the AOI, therein having a topology shaped by a single DCNN output neuron. We can expect regions within the AOI that have probable baseball fields, in this example, to have a peak in R. R will, therefore, have some unknown number of peaks that we can discover and rank to achieve a broad-area search assisted by the DCNN. Recall, however, that the response surface may have many artificial spikes where the softmax layer has lifted up the confidence.
To discover the true detection peaks, we first apply an alpha cut using a confidence threshold. Recall that the output of the DCNN is a softmax layer; therefore, each output neuron produces a value in the range . We used a threshold to drastically reduce our data space to only the points where the DCNN was most certain of the target class. In essence, we can produce a spatial field of densities where the dense regions will be the highest likelihood objects of interest. Afterward, we can seek the modes under the densities (localized peaks), and then we can label and rank the detection clusters.
Due to the nature of the softmax classification vectors from the DCNN, the density surface can have irregularities and holes when examined in the isolated context of a single-class surface,
R, thus creating multiple small disparate densities (peaks) where, in fact, we expect a single larger density. Therefore, we seek to simultaneously smooth false alarms (outliers) and amplify the true detection densities for enhanced mode seeking. This is accomplished using a function-to-function morphology, with a distance decaying structuring function positioned over a detection response, i.e., the chip centers on the
R that survive the alpha cut. We define our structuring function,
, as follows:
where
p is the chip position (center point),
D is the maximum aperture of the structuring function (kernel), and
d is the computed haversine distance of neighbor,
n, as a function of
p:
In this work, we constrained the aperture to m; however, this should be adjusted, in practice, based on various factors such as image resolution, target object size, and spatial distribution of image chip centers.
To generate the amplified spatial density surface,
, we apply
to
R, (Algorithm 1, step 3). Let
be the spatial neighborhood of a point
p having points
n. Then, we define
p’s value in the amplified spatial density field as the intersected volume defined by the spatial neighbors of of
p and
, i.e.,
| Algorithm 1: Spatial Clustering of Classification Vector Response Field (R) |
![Sensors 23 07766 i001]() |
Mode-seeking clustering algorithms are designed to discover the number of clusters (or peaks) without relying on the specification of expected clusters ahead of time. This is an ideal approach for refining broad-area scans of HR-EO-RSI, as we do not know
a priori the number of objects we expect to find. In the case of
, the clusters are the modes within the field that are the local maxima. These maxima are peaks found as the center of mass of spatially connected densities in
. A straightforward approach to discovering these modes is the mean shift algorithm, which defines a spatial aperture of the nearest neighbors to be evaluated at each iteration for each point. Each point is then moved to the center of mass of its spatially local neighbor set. Algorithm 1, steps 4–8, provides the algorithm to mode cluster
. The algorithm defines the processing of a classification response
R from the CVRF into the amplified spatial density surface,
, which then leads to the evolution of the
into clusters representing object detections. A sample AOI response surface and amplified spatial density surface can be seen in
Figure 5.
In this work, we utilized a variant of the mean shift algorithm that operated in both the spatial proximity and amplified spatial field domain, which was labeled as the
weighted meanshift in Algorithm 1, step 5. The spatial decay function, Equation (
2), was used to weight the computation of the local field mean density. We defined the
weighted meanshift as the standard mean shift algorithm, thereby computing the weighted distance between
and
as
. Points were continually evaluated and shifted until the total Earth surface movement of all the points was less than one meter. As above, we used 150 m as the aperture radius (i.e., neighborhood) around each point during weighted mean shift evaluation.
Once the points have converged under the modes, they are then mapped onto their respective clusters, which are labeled and ranked. Each cluster’s score is computed as the volume under its amplified spatial density. The cluster score can then be used to rank (highest to lowest score) all clusters in an AOI to determine the order for subsequent human analysis. Algorithm 2 provides the algorithm with the means to extract the rank-ordered clusters from the mean-shifted data. In this study, single-detection clusters (i.e., spatial outliers) were filtered out from the results.
Figure 6 shows the result of the clustering along the application of a top 100 cluster limit.
| Algorithm 2: Object Detection Ranking () |
![Sensors 23 07766 i002]() |













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}