



Deep Sensing for Compressive Video Acquisition †

 , ,
, ,
Abstract
:1. Introduction
- We propose a new pipeline to optimize the color filter, exposure pattern, and reconstruction decoder in compressive color video sensing using a DNN framework [36]. To the best of our knowledge, ours is the first study that considers the actual hardware sensor constraints and jointly optimizes the color filter, exposure patterns, and decoder in an end-to-end manner.
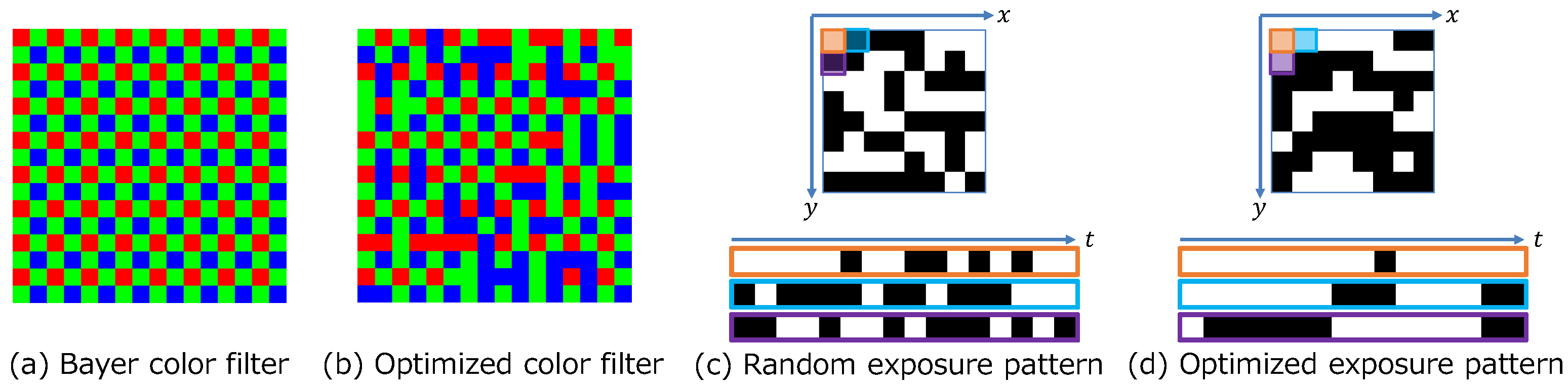
- The proposed method is a general framework for optimizing the exposure patterns with and without hardware constraints. It is difficult to learn the sensing matrix with a DNN because DNNs can only handle differentiable functions. The optimization of the color filter is an arrangement of the RGB filter, but the exposure pattern is binary and needs to take into account the constraints of the sensor.
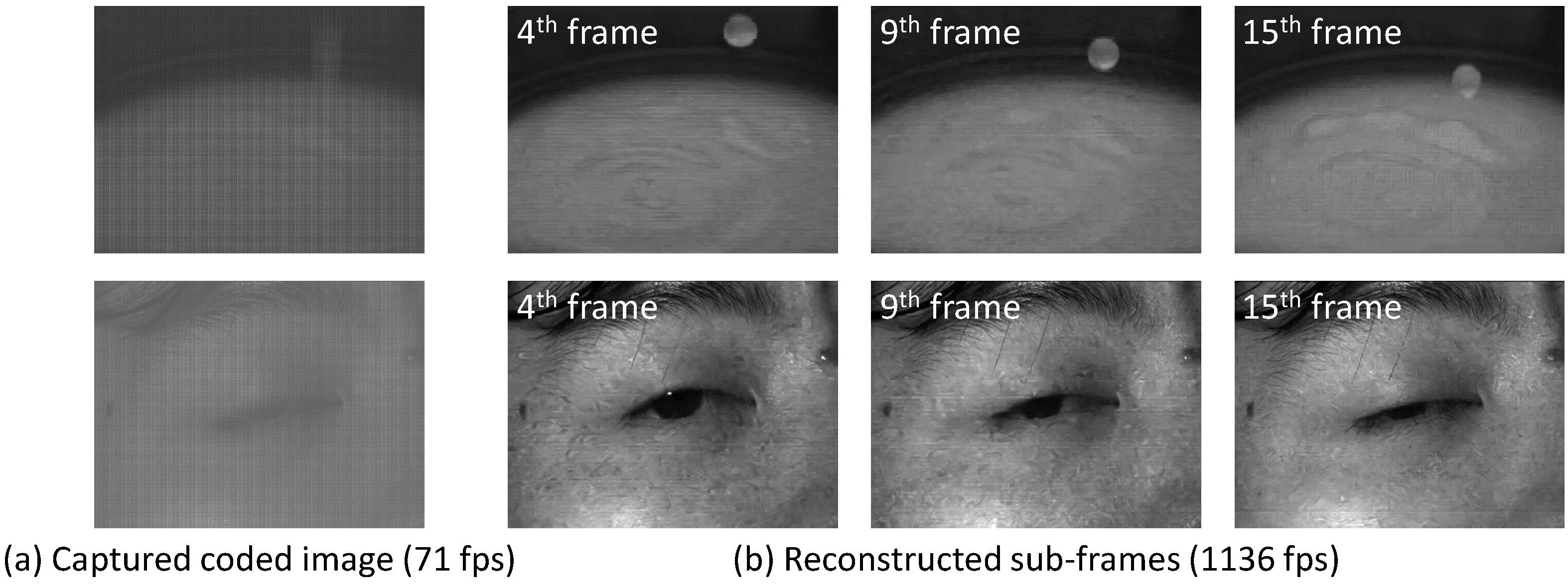
- We demonstrate that the learned exposure pattern can recover high-frame-rate videos with better quality than existing handcrafted and random patterns. Moreover, we demonstrate the effectiveness of our method with images captured by an actual sensor.
2. Related Studies
2.1. Deep Sensing and Deep Optics
2.2. Optimization of Exposure Patterns and Reconstruction of Video
2.3. Optimization of Chromatic Filter Patterns and Demosaicing
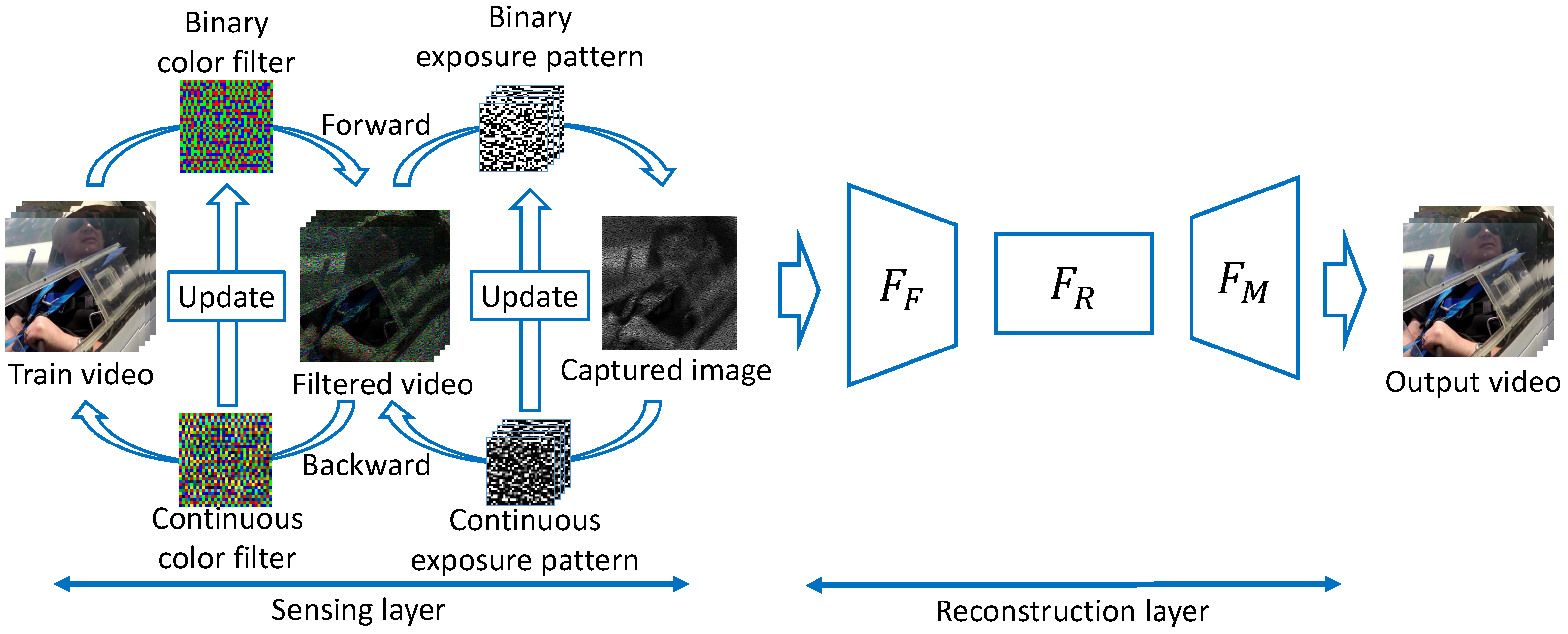
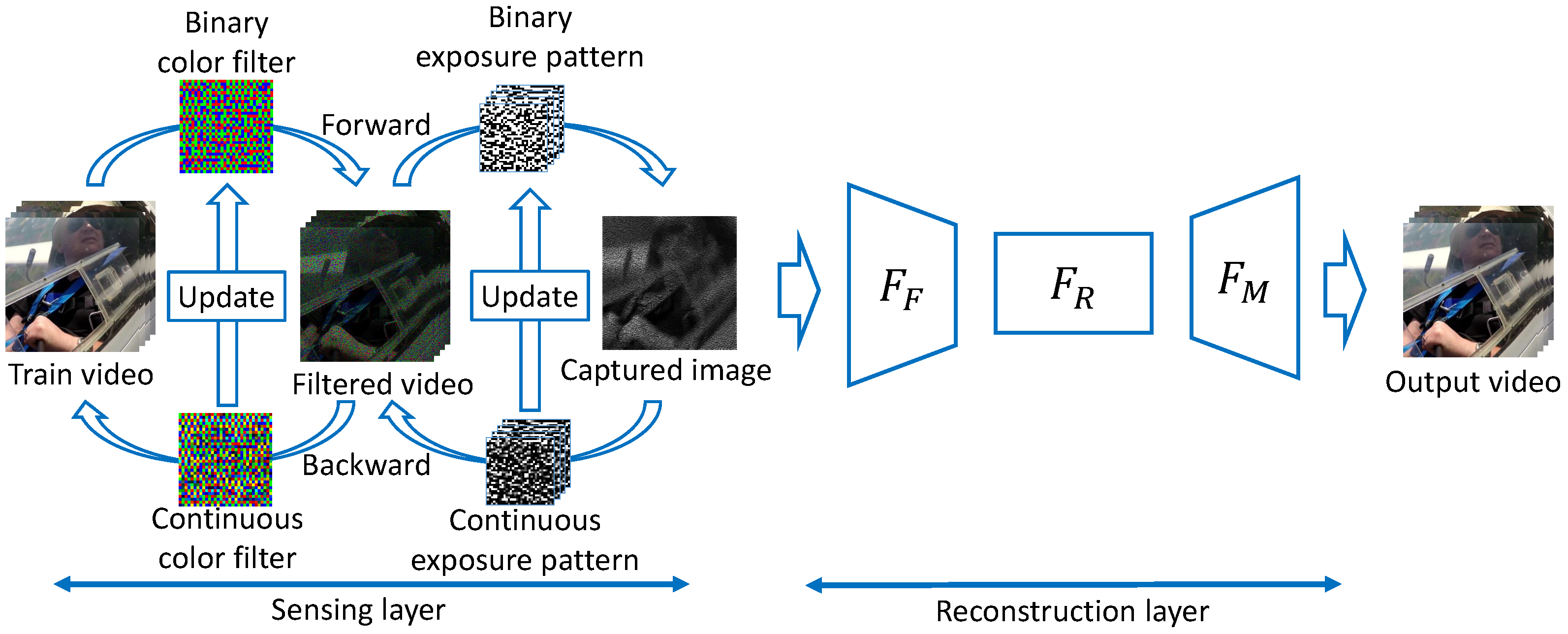
3. Deep Sensing for Compressive Video Acquisition under Hardware Constraints
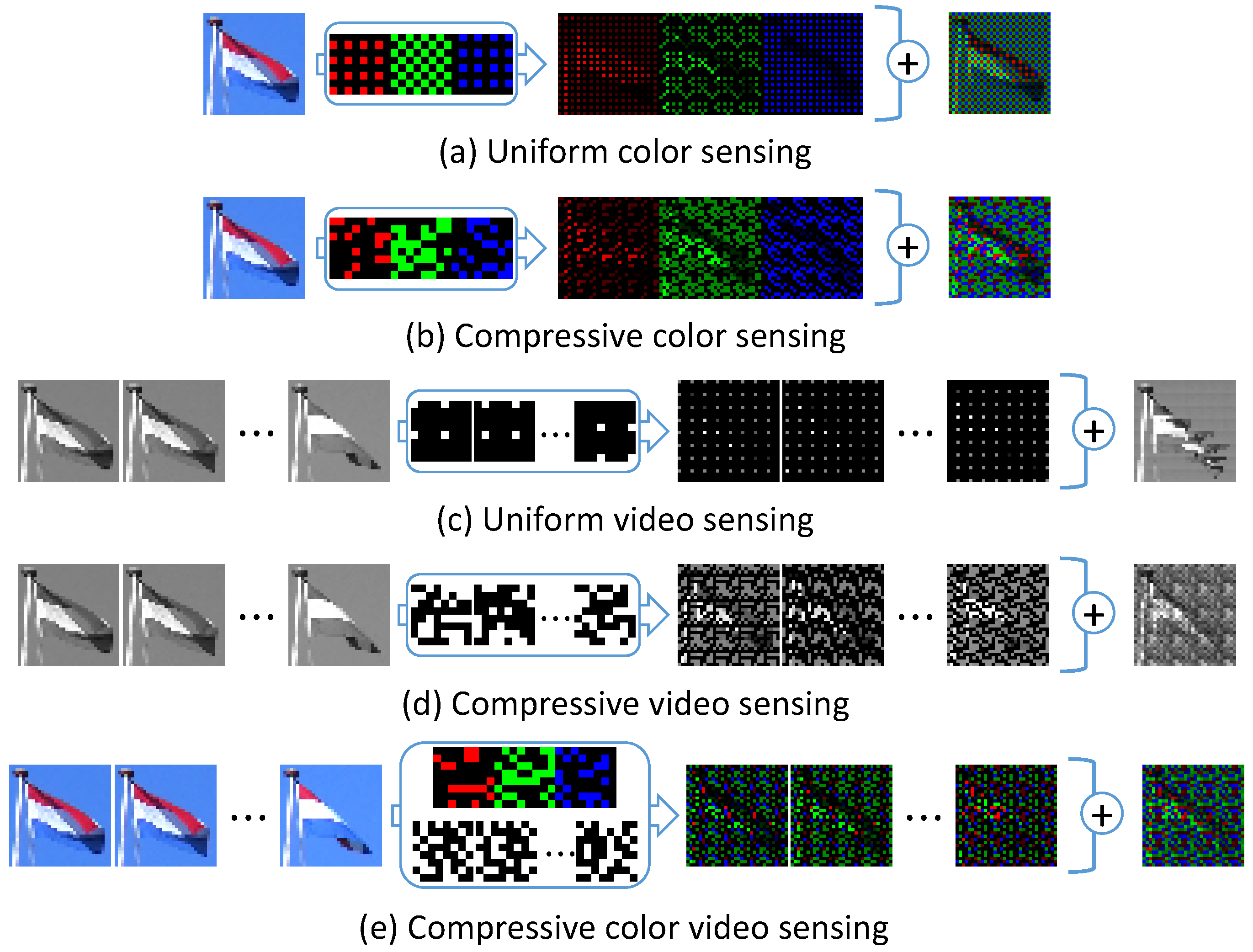
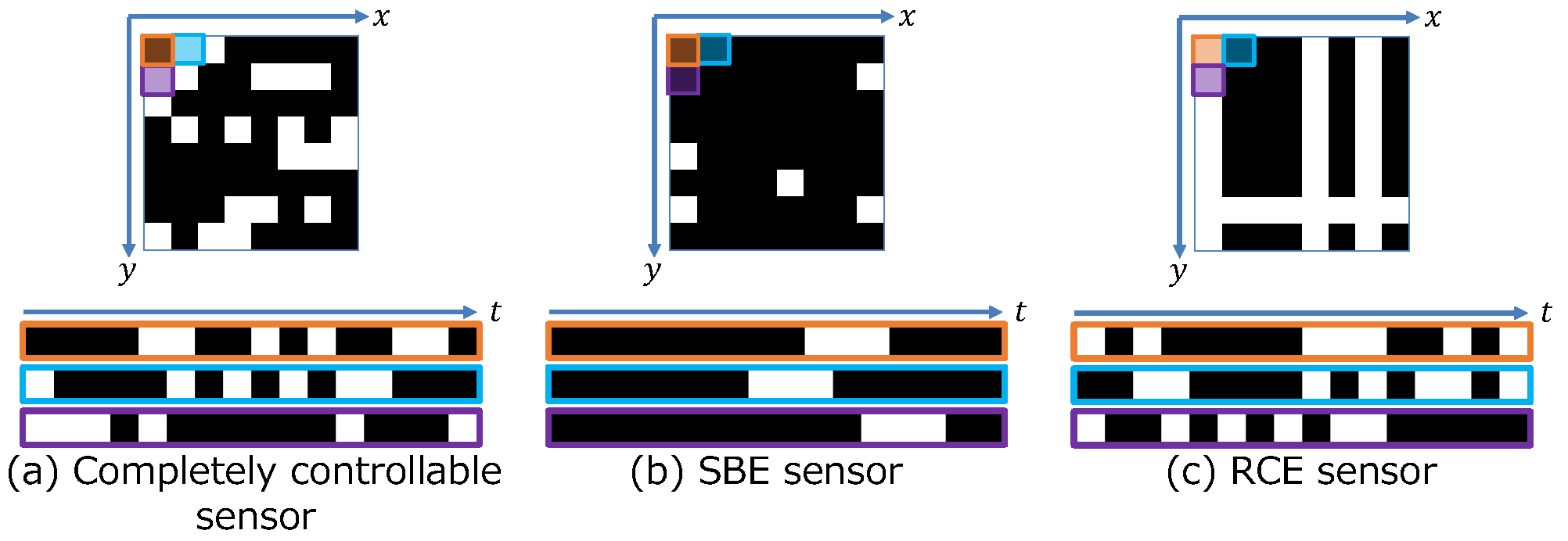
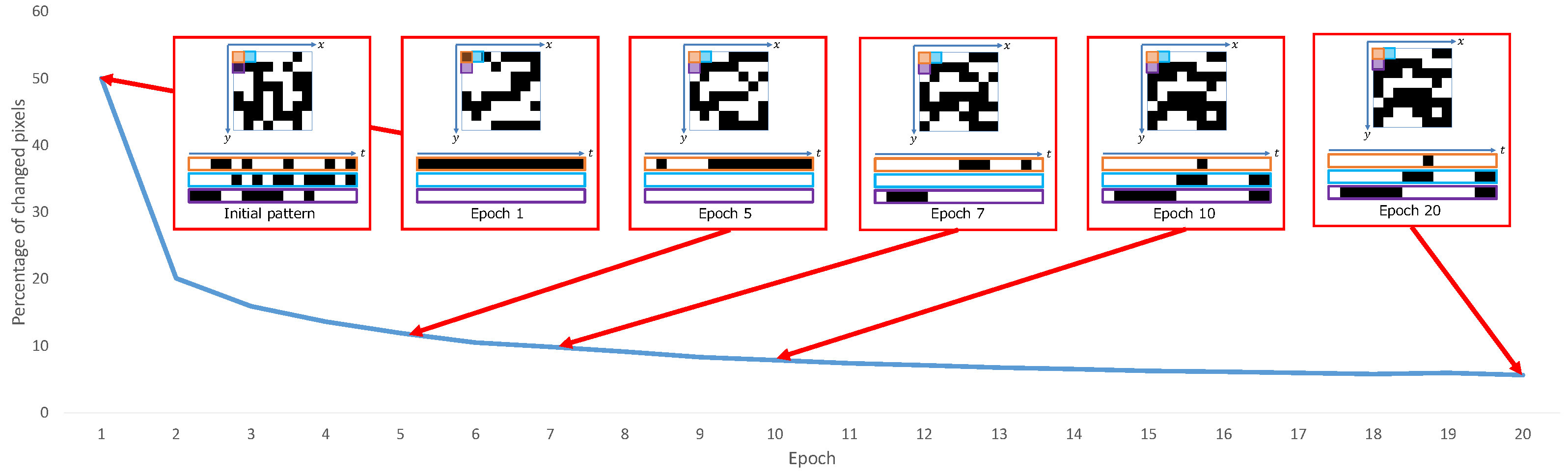
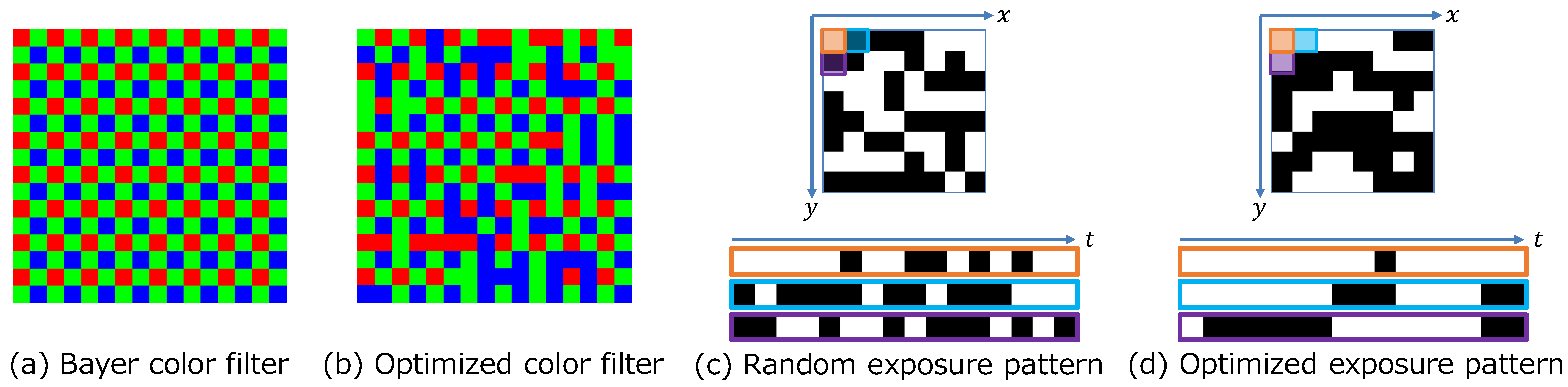
3.1. Sensing Layer
- 1.
- An ideal sensor with a binary exposure pattern but without temporal or spatial constraints (unconstrained sensor);
- 2.
- A sensor with a binary exposure pattern and with temporal constraints (SBE sensor);
- 3.
- A sensor with a binary exposure pattern and spatial constraints (RCE sensor).
- 1.
- Initialize the forward weights (binary weights) and the backward weights (continuous weights) with a random pattern that satisfies sensor constraints.
- 2.
- In the forward propagation, the exposure pattern optimization layer uses the binary weights to simulate a real camera.
- 3.
- Before backward propagation, the weights of the exposure pattern optimization layer are switched to continuous weights.
- 4.
- The continuous weights are updated by backward propagation.
- 5.
- Update the binary weights by using a function that considers the constraints of each sensor on the updated continuous weights.
- 6.
- Repeat Steps 2 to 5 until the network converges.
3.2. Reconstruction Layer
4. Experiments
4.1. Experimental and Training Setup
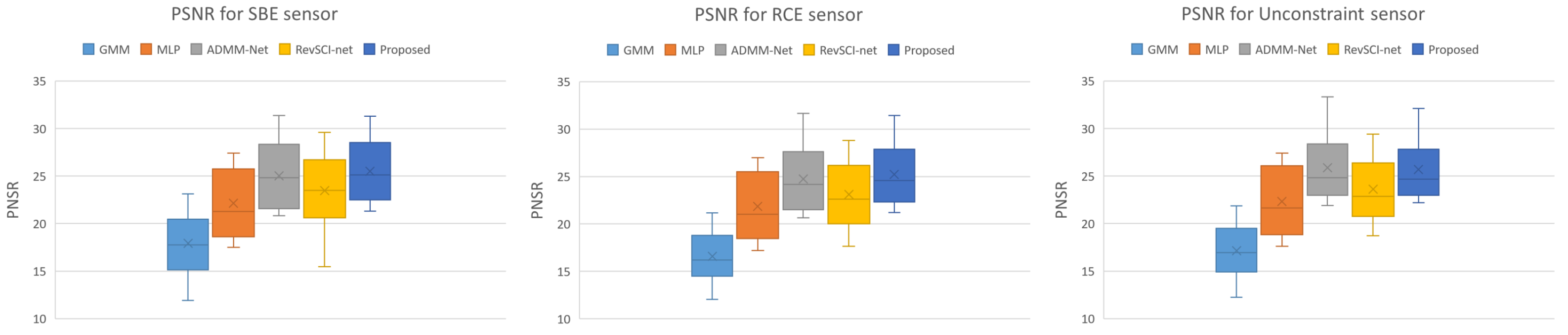
4.2. Simulation Experiments
4.3. Experiments with the Prototype Sensor
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bayer, B.E. Color Imaging Array. U.S. Patent 3,971,065, 20 July 1976. [Google Scholar]
- Condat, L. A new random color filter array with good spectral properties. In Proceedings of the International Conference on Image Processing (ICIP), IEEE, Cairo, Egypt, 7–10 November 2009; pp. 1613–1616. [Google Scholar]
- Hitomi, Y.; Gu, J.; Gupta, M.; Mitsunaga, T.; Nayar, S.K. Video from a single coded exposure photograph using a learned over-complete dictionary. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 287–294. [Google Scholar]
- Sonoda, T.; Nagahara, H.; Endo, K.; Sugiyama, Y.; Taniguchi, R. High-speed imaging using CMOS image sensor with quasi pixel-wise exposure. In Proceedings of the International Conference on Computational Photography (ICCP), IEEE, Evanston, IL, USA, 13–15 May 2016; pp. 1–11. [Google Scholar]
- Liu, Y.; Li, M.; Pados, D.A. Motion-Aware Decoding of Compressed-Sensed Video. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 438–444. [Google Scholar] [CrossRef]
- Azghani, M.; Karimi, M.; Marvasti, F. Multihypothesis Compressed Video Sensing Technique. IEEE Trans. Circuits Syst. Video Technol. 2016, 26, 627–635. [Google Scholar] [CrossRef]
- Zhao, C.; Ma, S.; Zhang, J.; Xiong, R.; Gao, W. Video Compressive Sensing Reconstruction via Reweighted Residual Sparsity. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1182–1195. [Google Scholar] [CrossRef]
- Yang, J.; Yuan, X.; Liao, X.; Llull, P.; Brady, D.J.; Sapiro, G.; Carin, L. Video compressive sensing using Gaussian mixture models. IEEE Trans. Image Process. 2014, 23, 4863–4878. [Google Scholar] [CrossRef]
- Chakrabarti, A. Learning sensor multiplexing design through back-propagation. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Barcelona, Spain, 5–10 December 2016; pp. 3081–3089. [Google Scholar]
- Nie, S.; Gu, L.; Zheng, Y.; Lam, A.; Ono, N.; Sato, I. Deeply learned filter response functions for hyperspectral reconstruction. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18 June 2018; pp. 4767–4776. [Google Scholar]
- Iliadis, M.; Spinoulas, L.; Katsaggelos, A.K. Deep fully-connected networks for video compressive sensing. Digit. Signal Process. 2018, 72, 9–18. [Google Scholar] [CrossRef]
- Ma, J.; Liu, X.; Shou, Z.; Yuan, X. Deep tensor admm-net for snapshot compressive imaging. In Proceedings of the International Conference on Computer Vision (ICCV), Long Beach, CA, USA, 15–20 June 2019; pp. 10223–10232. [Google Scholar]
- Yuan, X.; Liu, Y.; Suo, J.; Dai, Q. Plug-and-play algorithms for large-scale snapshot compressive imaging. In Proceedings of the Proceedings of Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1447–1457. [Google Scholar]
- Han, X.; Wu, B.; Shou, Z.; Liu, X.Y.; Zhang, Y.; Kong, L. Tensor FISTA-Net for real-time snapshot compressive imaging. In Proceedings of the AAAI Conference on Artificial Intelligence, Seattle, WA, USA, 13–19 June 2020; Volume 34, pp. 10933–10940. [Google Scholar]
- Li, Y.; Qi, M.; Gulve, R.; Wei, M.; Genov, R.; Kutulakos, K.N.; Heidrich, W. End-to-End Video Compressive Sensing Using Anderson-Accelerated Unrolled Networks. In Proceedings of the International Conference on Computational Photography (ICCP), IEEE, Saint Louis, MO, USA, 24–26 April 2020; pp. 137–148. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Yoshida, M.; Torii, A.; Okutomi, M.; Endo, K.; Sugiyama, Y.; Taniguchi, R.; Nagahara, H. Joint optimization for compressive video sensing and reconstruction under hardware constraints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 634–649. [Google Scholar]
- Inagaki, Y.; Kobayashi, Y.; Takahashi, K.; Fujii, T.; Nagahara, H. Learning to capture light fields through a coded aperture camera. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 418–434. [Google Scholar]
- Wu, Y.; Boominathan, V.; Chen, H.; Sankaranarayanan, A.; Veeraraghavan, A. PhaseCam3D—Learning Phase Masks for Passive Single View Depth Estimation. In Proceedings of the International Conference on Computational Photography (ICCP), IEEE, Tokyo, Japan, 15–17 May 2019; pp. 1–12. [Google Scholar]
- Sun, H.; Dalca, A.V.; Bouman, K.L. Learning a Probabilistic Strategy for Computational Imaging Sensor Selection. In Proceedings of the International Conference on Computational Photography (ICCP), IEEE, Saint Louis, MO, USA, 24–26 April 2020; pp. 81–92. [Google Scholar]
- Iliadis, M.; Spinoulas, L.; Katsaggelos, A.K. Deepbinarymask: Learning a binary mask for video compressive sensing. Digit. Signal Process. 2020, 96, 102591. [Google Scholar] [CrossRef]
- Jee, S.; Song, K.S.; Kang, M.G. Sensitivity and resolution improvement in RGBW color filter array sensor. Sensors 2018, 18, 1647–1664. [Google Scholar] [CrossRef]
- Choi, W.; Park, H.S.; Kyung, C.M. Color reproduction pipeline for an RGBW color filter array sensor. Opt. Express 2020, 28, 15678–15690. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Gunturk, B.; Zhang, L. Image demosaicing: A systematic survey. In Proceedings of the Visual Communications and Image Processing 2008, International Society for Optics and Photonics, San Jose, CA, USA, 27–31 January 2008; Volume 6822, p. 68221J. [Google Scholar]
- Sato, S.; Wakai, N.; Nobori, K.; Azuma, T.; Miyata, T.; Nakashizuka, M. Compressive color sensing using random complementary color filter array. In Proceedings of the International Conference on Machine Vision Applications (MVA), IEEE, Nagoya, Japan, 8–12 May 2017; pp. 43–46. [Google Scholar]
- Hirakawa, K.; Wolfe, P.J. Spatio-Spectral Color Filter Array Design for Optimal Image Recovery. IEEE Trans. Image Process. 2008, 17, 1876–1890. [Google Scholar] [CrossRef] [PubMed]
- Saideni, W.; Helbert, D.; Courreges, F.; Cances, J.P. An overview on deep learning techniques for video compressive sensing. Appl. Sci. 2022, 12, 2734. [Google Scholar] [CrossRef]
- Xia, K.; Pan, Z.; Mao, P. Video Compressive sensing reconstruction using unfolded LSTM. Sensors 2022, 22, 7172. [Google Scholar] [CrossRef] [PubMed]
- Duarte, M.F.; Davenport, M.A.; Takhar, D.; Laska, J.N.; Sun, T.; Kelly, K.F.; Baraniuk, R.G. Single-pixel imaging via compressive sampling. IEEE Signal Process. Mag. 2008, 25, 83–91. [Google Scholar] [CrossRef]
- Bub, G.; Tecza, M.; Helmes, M.; Lee, P.; Kohl, P. Temporal pixel multiplexing for simultaneous high-speed, high-resolution imaging. Nat. Methods 2010, 7, 209–211. [Google Scholar] [CrossRef] [PubMed]
- Gupta, M.; Agrawal, A.; Veeraraghavan, A.; Narasimhan, S.G. Flexible voxels for motion-aware videography. In Proceedings of the European Conference on Computer Vision (ECCV), Crete, Greece, 5–11 September 2010; pp. 100–114. [Google Scholar]
- Ding, X.; Chen, W.; Wassell, I.J. Compressive Sensing Reconstruction for Video: An Adaptive Approach Based on Motion Estimation. IEEE Trans. Circuits Syst. Video Technol. 2017, 27, 1406–1420. [Google Scholar] [CrossRef]
- Wen, J.; Huang, J.; Chen, X.; Huang, K.; Sun, Y. Transformer-Based Cascading Reconstruction Network for Video Snapshot Compressive Imaging. Appl. Sci. 2023, 13, 5922. [Google Scholar] [CrossRef]
- Dadkhah, M.; Deen, M.J.; Shirani, S. Compressive sensing image sensors-hardware implementation. Sensors 2013, 13, 4961–4978. [Google Scholar] [CrossRef]
- Wei, M.; Sarhangnejad, N.; Xia, Z.; Gusev, N.; Katic, N.; Genov, R.; Kutulakos, K.N. Coded Two-Bucket Cameras for Computer Vision. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Lenz, W. Beitrag zum Verständnis der magnetischen Erscheinungen in festen Körpern. Phys. Z. 1920, 21, 613–615. [Google Scholar]
- Brush, S.G. History of the Lenz-Ising model. Rev. Mod. Phys. 1967, 39, 883. [Google Scholar] [CrossRef]
- Yuan, X. Generalized alternating projection based total variation minimization for compressive sensing. In Proceedings of the International Conference on Image Processing (ICIP), IEEE, Phoenix, AZ, USA, 25–28 September 2016; pp. 2539–2543. [Google Scholar]
- Cheng, Z.; Chen, B.; Liu, G.; Zhang, H.; Lu, R.; Wang, Z.; Yuan, X. Memory-efficient network for large-scale video compressive sensing. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16246–16255. [Google Scholar]
- Sun, Y.; Chen, X.; Kankanhalli, M.S.; Liu, Q.; Li, J. Video Snapshot Compressive Imaging Using Residual Ensemble Network. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5931–5943. [Google Scholar] [CrossRef]
- Martel, J.N.; Mueller, L.K.; Carey, S.J.; Dudek, P.; Wetzstein, G. Neural sensors: Learning pixel exposures for hdr imaging and video compressive sensing with programmable sensors. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1642–1653. [Google Scholar] [CrossRef] [PubMed]
- Saragadam, V.; Sankaranarayanan, A.C. Programmable Spectrometry: Per-pixel Material Classification using Learned Spectral Filters. In Proceedings of the International Conference on Computational Photography (ICCP), IEEE, Saint Louis, MS, USA, 24–26 April 2020; pp. 1–10. [Google Scholar]
- Tan, R.; Zhang, K.; Zuo, W.; Zhang, L. Color image demosaicking via deep residual learning. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; Volume 2, p. 6. [Google Scholar]
- Tan, D.S.; Chen, W.Y.; Hua, K.L. DeepDemosaicking: Adaptive image demosaicking via multiple deep fully convolutional networks. IEEE Trans. Image Process. 2018, 27, 2408–2419. [Google Scholar] [CrossRef] [PubMed]
- Gharbi, M.; Chaurasia, G.; Paris, S.; Durand, F. Deep joint demosaicking and denoising. ACM Trans. Graph. 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Kokkinos, F.; Lefkimmiatis, S. Deep image demosaicking using a cascade of convolutional residual denoising networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 303–319. [Google Scholar]
- Park, B.; Jeong, J. Color Filter Array Demosaicking Using Densely Connected Residual Network. IEEE Access 2019, 7, 128076–128085. [Google Scholar] [CrossRef]
- Gomez, A.N.; Ren, M.; Urtasun, R.; Grosse, R.B. The reversible residual network: Backpropagation without storing activations. arXiv 2017, arXiv:1707.04585. [Google Scholar]
- Pont-Tuset, J.; Perazzi, F.; Caelles, S.; Arbeláez, P.; Sorkine-Hornung, A.; Van Gool, L. The 2017 DAVIS Challenge on Video Object Segmentation. arXiv 2017, arXiv:1704.00675. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Hamamatsu Photonics, K.K. Imaging Device. Japan Patent JP2015-216594A, 3 December 2015. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application | Sensing Matrix | Method | |
|---|---|---|---|
| Inagaki et al. [18] | Compressive light-field sensing | Joint optimization | Neural network |
| Wu et al. [19] | Passive 3D imaging | ||
| Sun et al. [20] | VLBI | ||
| Hitomi et al. [3] | Compressive video sensing | Random | Model-based |
| Sonoda et al. [4] | |||
| Liu et al. [5] | |||
| Azghsni et al. [6] | |||
| Zhao et al. [7] | |||
| Yang et al. [8] | |||
| Yuan et al. [39] | |||
| Ma et al. [12] | Compressive video sensing | Random | Neural network |
| Wen et al. [33] | |||
| Cheng et al. [40] | |||
| Sun et al. [41] | |||
| Iliadis et al. [21] | Compressive video sensing | Joint optimization | Neural network |
| Li et al. [15] | |||
| Martel et al. [42] | |||
| Condat [2] | RGB imaging | Random | Model-based |
| Sato et al. [25] | |||
| Hirakawa et al. [26] | RGB imaging | Optimization | Model-based |
| Tan et al. [44] | RGB imaging | Random | Neural network |
| Tan et al. [45] | |||
| Gharbi et al. [46] | |||
| Kokkinos et al. [47] | |||
| Park et al. [48] | |||
| Chakrabarti [9] | RGB imaging | Joint optimization | Neural network |
| Nie et al. [10] | Compressive hyperspectral sensing | Joint optimization | Neural network |
| Saragadam et al. [43] |
| Module | Operation | Kernel | Stride | Output Size |
|---|---|---|---|---|
| Conv. | (1, 1, 1) | |||
| Conv. | (1, 1, 1) | |||
| Conv. | (1, 1, 1) | |||
| Conv. | (1, 2, 2) | |||
| ResNet block in | Conv. | (1, 1, 1) | ||
| Conv. | (1, 1, 1) | |||
| Conv. Transpose | (1, 2, 2) | |||
| Conv. | (1, 1, 1) | |||
| Conv. | (1, 1, 1) | |||
| Conv. | (1, 1, 1) |
| GMM [8] | MLP [17] | ADMM-Net [12] | RevSCI-Net [40] | Proposed | ||
|---|---|---|---|---|---|---|
| SBE sensor | PSNR | 17.91 | 22.13 | 25.04 | 23.48 | 25.50 |
| SSIM | 0.6531 | 0.7185 | 0.8109 | 0.6996 | 0.8300 | |
| RCE sensor | PSNR | 16.58 | 21.84 | 24.76 | 23.10 | 25.23 |
| SSIM | 0.5637 | 0.7086 | 0.7822 | 0.7030 | 0.8109 | |
| Unconstrained | PSNR | 17.16 | 22.32 | 25.89 | 23.64 | 25.69 |
| sensor | SSIM | 0.5756 | 0.7118 | 0.8102 | 0.7343 | 0.8253 |
| Time | 162.3 s | 0.2050 s | 0.02109 s | 0.01378 s | 0.01411 s |
| Handcrafted | Optimized | Handcrafted | Optimized | Random | Optimized | ||
|---|---|---|---|---|---|---|---|
| SBE | SBE | RCE | RCE | Unconstrained | Unconstrained | ||
| Random | PSNR | 23.48 | 24.20 | 23.10 | 23.50 | 23.63 | 24.52 |
| filter | SSIM | 0.6996 | 0.7443 | 0.7030 | 0.6913 | 0.7343 | 0.7776 |
| Optimized | PSNR | 23.71 | 25.50 | 25.02 | 25.23 | 24.32 | 25.69 |
| filter | SSIM | 0.7820 | 0.8300 | 0.8046 | 0.8109 | 0.7687 | 0.8253 |
| KITTI Optimized | Generally Optimized | RevSCI-net [40] | |
|---|---|---|---|
| PSNR | 27.53 | 27.01 | 25.57 |
| SSIM | 0.8594 | 0.8507 | 0.8220 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoshida, M.; Torii, A.; Okutomi, M.; Taniguchi, R.-i.; Nagahara, H.; Yagi, Y. Deep Sensing for Compressive Video Acquisition. Sensors 2023, 23, 7535. https://doi.org/10.3390/s23177535
Yoshida M, Torii A, Okutomi M, Taniguchi R-i, Nagahara H, Yagi Y. Deep Sensing for Compressive Video Acquisition. Sensors. 2023; 23(17):7535. https://doi.org/10.3390/s23177535
Chicago/Turabian StyleYoshida, Michitaka, Akihiko Torii, Masatoshi Okutomi, Rin-ichiro Taniguchi, Hajime Nagahara, and Yasushi Yagi. 2023. "Deep Sensing for Compressive Video Acquisition" Sensors 23, no. 17: 7535. https://doi.org/10.3390/s23177535
APA StyleYoshida, M., Torii, A., Okutomi, M., Taniguchi, R.-i., Nagahara, H., & Yagi, Y. (2023). Deep Sensing for Compressive Video Acquisition. Sensors, 23(17), 7535. https://doi.org/10.3390/s23177535