
Voxel Transformer with Density-Aware Deformable Attention for 3D Object Detection

Abstract
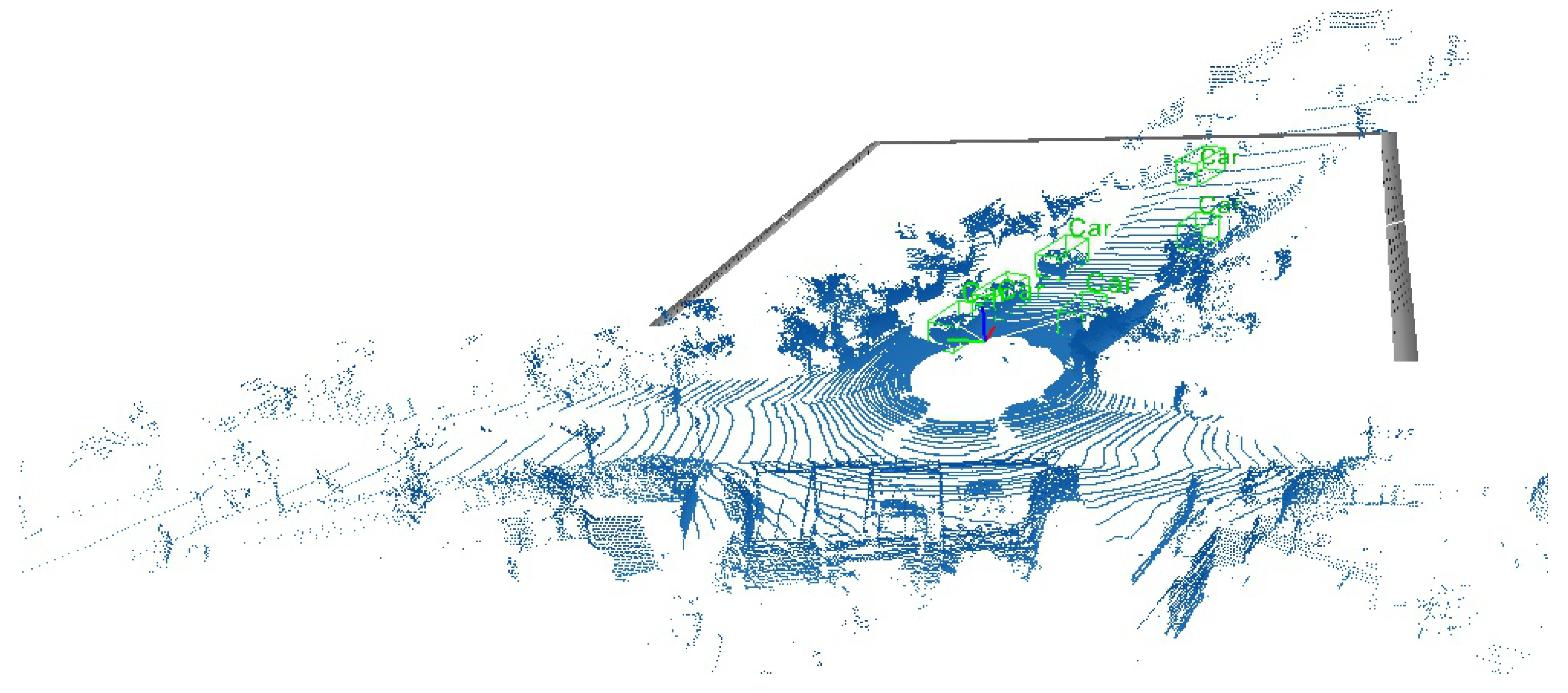
:1. Introduction
- We propose a 3D object detection backbone architecture, VoTr-DADA, which improves VoTr [15] for 3D object detection. The proposed density-aware deformable attention module exploits voxel densities to direct the attending voxels to more informative regions;
- We conducted experiments on the KITTI and Waymo Open datasets and show that the proposed VoTr-DADA outperforms the vanilla VoTr with lower computational costs and comparable performance to other transformer-based 3D object detectors.
2. Related Work
2.1. 3D Object Detection
2.2. Deformable Attention
2.3. Density in 3D Object Detection
3. Proposed Method
3.1. Preliminaries
3.2. Overall Architecture
3.3. Density-Aware Deformable Attention Module
4. Experimental Results
4.1. Dataset and Evaluation Metric
4.2. Experimental Setup
4.3. Experimental Results for 3D Object Detection
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Deng, J.; Shi, S.; Li, P.; Zhou, W.; Zhang, Y.; Li, H. Voxel r-cnn: Towards high performance voxel-based 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 1201–1209. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 918–927. [Google Scholar]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- He, C.; Zeng, H.; Huang, J.; Hua, X.S.; Zhang, L. Structure aware single-stage 3d object detection from point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11873–11882. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11040–11048. [Google Scholar]
- Yoo, J.H.; Kim, Y.; Kim, J.; Choi, J.W. 3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXVII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 720–736. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10386–10393. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part I 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- He, C.; Li, R.; Li, S.; Zhang, L. Voxel set transformer: A set-to-set approach to 3d object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8417–8427. [Google Scholar]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel transformer for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3164–3173. [Google Scholar]
- Dong, S.; Ding, L.; Wang, H.; Xu, T.; Xu, X.; Wang, J.; Bian, Z.; Wang, Y.; Li, J. MsSVT: Mixed-scale Sparse Voxel Transformer for 3D Object Detection on Point Clouds. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Fan, L.; Pang, Z.; Zhang, T.; Wang, Y.X.; Zhao, H.; Wang, F.; Wang, N.; Zhang, Z. Embracing single stride 3d object detector with sparse transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8458–8468. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision transformer with deformable attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4803. [Google Scholar]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable convolutional networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 1, p. 4. [Google Scholar]
- Misra, I.; Girdhar, R.; Joulin, A. An end-to-end transformer model for 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2906–2917. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Li, J.; Hu, Y. A density-aware pointrcnn for 3d object detection in point clouds. arXiv 2020, arXiv:2009.05307. [Google Scholar]
- Qian, H.; Wu, P.; Sun, X.; Guo, X.; Su, S. Density Awareness and Neighborhood Attention for LiDAR-Based 3D Object Detection. Photonics 2022, 9, 820. [Google Scholar] [CrossRef]
- Ning, J.; Da, F.; Gai, S. Density aware 3D object single stage detector. IEEE Sens. J. 2021, 21, 23108–23117. [Google Scholar] [CrossRef]
- Hu, J.S.; Kuai, T.; Waslander, S.L. Point density-aware voxels for lidar 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8469–8478. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Wilhelms, J.; Van Gelder, A. Octrees for faster isosurface generation. ACM SIGGRAPH Comput. Graph. 1990, 24, 57–62. [Google Scholar] [CrossRef]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar]
- Sheng, H.; Cai, S.; Liu, Y.; Deng, B.; Huang, J.; Hua, X.S.; Zhao, M.J. Improving 3d object detection with channel-wise transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 2743–2752. [Google Scholar]
- Zhou, Y.; Sun, P.; Zhang, Y.; Anguelov, D.; Gao, J.; Ouyang, T.; Guo, J.; Ngiam, J.; Vasudevan, V. End-to-end multi-view fusion for 3d object detection in lidar point clouds. In Proceedings of the Conference on Robot Learning, PMLR, Virtual, 6–18 November 2020; pp. 923–932. [Google Scholar]
- Chen, Q.; Sun, L.; Cheung, E.; Yuille, A.L. Every view counts: Cross-view consistency in 3d object detection with hybrid-cylindrical-spherical voxelization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 21224–21235. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Methods | (%) | ||
|---|---|---|---|
| Easy | Mod | Hard | |
| PointRCNN [3] | 88.88 | 78.63 | 77.38 |
| VoxelNet [5] | 81.97 | 65.46 | 62.85 |
| Voxel R-CNN [1] | 89.41 | 84.52 | 78.93 |
| PointPillars [31] | 86.62 | 76.06 | 68.91 |
| SA-SSD [6] | 90.15 | 79.91 | 78.78 |
| VoxSeT [14] | 89.21 | 86.71 | 78.56 |
| SECOND [7] | 87.43 | 76.48 | 69.10 |
| PV-RCNN [4] | 89.35 | 83.69 | 78.70 |
| VoTr-SSD * [15] | 87.86 | 78.27 | 76.93 |
| VoTr-DADA (SSD) | 88.57 | 79.31 | 77.74 |
| VoTr-TSD * [15] | 89.04 | 84.04 | 78.68 |
| VoTr-DADA (TSD) | 89.46 | 84.63 | 78.90 |
| Methods | (%) | ||
|---|---|---|---|
| Easy | Mod | Hard | |
| MV3D [32] | 74.97 | 63.63 | 54 |
| AVOD-FPN [33] | 83.07 | 71.76 | 65.73 |
| F-PointNet [2] | 82.19 | 69.79 | 60.59 |
| 3D-CVF [9] | 89.2 | 80.05 | 73.11 |
| CLOCs [10] | 88.94 | 80.67 | 77.15 |
| VoxelNet [5] | 77.47 | 65.11 | 57.73 |
| SECOND [7] | 83.34 | 72.55 | 65.82 |
| PointPillars [31] | 82.58 | 74.31 | 68.99 |
| PointRCNN [3] | 86.96 | 75.64 | 70.7 |
| SA-SSD [6] | 88.75 | 79.79 | 74.16 |
| 3DSSD [8] | 88.36 | 79.57 | 74.55 |
| PV-RCNN [4] | 90.25 | 81.43 | 76.82 |
| Voxel-RCNN [1] | 87.95 | 79.71 | 75.09 |
| CT3D [34] | 87.83 | 81.77 | 77.16 |
| VoxSeT [14] | 88.53 | 82.06 | 77.46 |
| VoTr-TSD * [15] | 89.90 | 82.09 | 79.14 |
| VoTr-DADA (TSD) | 90.04 | 82.36 | 79.33 |
| Methods | L1 | L2 | L1 mAP/mAPH by Distance | ||
|---|---|---|---|---|---|
| mAP/mAPH | mAP/mAPH | 0–30 m | 30–50 m | 50 m–Inf | |
| PointPillars [31] | 63.3 | 55.2 | 84.9 | 59.2 | 35.8 |
| MVF [35] | 62.93 | – | 86.30 | 60.02 | 36.02 |
| CVCNet [36] | 65.2 | – | 86.80 | 62.19 | 29.27 |
| Voxel-RCNN [1] | 75.59 | 66.59 | 92.49 | 74.09 | 53.15 |
| SECOND [7] | 67.94 | 59.46 | 88.10 | 65.31 | 40.36 |
| PV-RCNN [4] | 70.3 | 65.4 | 91.9 | 69.2 | 42.2 |
| VoxSeT [14] | 76.02 | 68.16 | 91.13 | 75.75 | 54.23 |
| VoTr-SSD * [15] | 68.99 | 60.22 | 88.18 | 66.73 | 42.08 |
| VoTr-DADA(SSD) | 70.02 | 61.19 | 88.9 | 67.79 | 43.21 |
| VoTr-TSD * [15] | 74.95 | 65.91 | 92.28 | 73.36 | 51.09 |
| VoTr-DADA (TSD) | 75.69 | 66.74 | 92.46 | 73.83 | 51.61 |
| Methods | Inference Speed (Hz) |
|---|---|
| Vanilla VoTr | 14.65 |
| VoTr with Conv-based Deformable Attention | 12.08 |
| VoTr with Density-Aware Deformable Attention | 13.32 |
| Methods | Model Parameters |
|---|---|
| Vanilla VoTr | 4.8 M |
| VoTr with Conv-based Deformable Attention | 5.1 M |
| VoTr with Density-Aware Deformable Attention | 4.8 M |
| Methods | Number of Attending Voxels | (%) |
|---|---|---|
| (a) | 32 Voxels | 78.19 |
| (b) | 40 Voxels | 79.29 |
| (c) | 48 Voxels | 79.54 |
| Method | Replaced DADA Blocks | (%) |
|---|---|---|
| (a) | Only First DADA Block | 77.53 |
| (b) | First and Second DADA Blocks | 78.88 |
| (c) | Second and Third DADA Blocks | 79.54 |
| (d) | All DADA Blocks | 79.36 |
| Method | Search Range Parameter r | (%) |
|---|---|---|
| (a) | 2 | 78.87 |
| (b) | 4 | 79.54 |
| (c) | 8 | 77.61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, T.; Kim, J. Voxel Transformer with Density-Aware Deformable Attention for 3D Object Detection. Sensors 2023, 23, 7217. https://doi.org/10.3390/s23167217
Kim T, Kim J. Voxel Transformer with Density-Aware Deformable Attention for 3D Object Detection. Sensors. 2023; 23(16):7217. https://doi.org/10.3390/s23167217
Chicago/Turabian StyleKim, Taeho, and Joohee Kim. 2023. "Voxel Transformer with Density-Aware Deformable Attention for 3D Object Detection" Sensors 23, no. 16: 7217. https://doi.org/10.3390/s23167217
APA StyleKim, T., & Kim, J. (2023). Voxel Transformer with Density-Aware Deformable Attention for 3D Object Detection. Sensors, 23(16), 7217. https://doi.org/10.3390/s23167217