1. Introduction
The collection and analysis of body signals for human intent detection (HID) are critical for collaborative robotic applications [
1,
2], and the speedy and accurate prediction of human intent is essential to the success of the application [
3]. Many research efforts have addressed the issue of accurate identification. This research, on the other hand, tries to address the issue of how fast one can detect a change in movement.
This paper addresses the detection of motion changes in the lower limbs. The ability to detect lower-limb motion change can help direct the exoskeleton controller to determine the proper gaits that would not conflict with the pilot’s intention. A conflicting maneuver, especially in the case of exoskeleton control, can injure the pilot. Typically, there are three levels of exoskeleton control. The lowest level is a motor driver, to control the speed or torque of the motor. The second level is a robot impedance or admittance control to allow an easy maneuver of the exoskeleton. The impedance control is a robotic pilot model-based control, which would be too difficult if one considers modeling the pilot. Most the available literature has resolved to a reduced model with a single joint with two links [
4,
5,
6]. This inaccurate model is inadequate to handle the situation. Even a slight change in the upper body posture can significantly change the loading condition on the exoskeleton and render the model useless. The wrong interpretation of body inertia can cause the exoskeleton to exert too much torque and cause injury to the pilot. Too little effort, on the other hand, can force the pilot to push the exoskeleton too hard, resulting in excessive torque that causes injury. To accommodate this problem, people have added a third level of control to strategically plan the motion trajectory for various tasks, such as walking, sitting, and standing. Of course, prior knowledge of the driver’s intent is necessary for the controller to issue the appropriate command. Without this knowledge, exoskeletons at present have resolved to have the pilot switch operating modes for changing operating trajectories. This operation is highly inconvenient and is not suitable for regular assistive robot applications. The pilot’s intent detection becomes necessary for the convenient use of the exoskeleton.
The data for analysis in this study collect the body joint-related signals, such as the angles, velocities, torques, and upper body attitude. Body image-based algorithms, such as optical flow and many similar methods [
7,
8,
9], require fixed data collection setups and are unsuitable for mobile applications. The electromyography (EMG)-based method [
10] produces very noisy signals and is not ready at this stage. As a result, the inertial measurement units (IMUs) [
11]—based system, which is wearable and allows the subject to move around with data gathering, is more suitable for exoskeleton use.
With the collected data, an intuitive approach is translating the captured signal into body postures and motion data and then establishing corresponding thresholds for different movements. These thresholds can be magnitude levels in time, frequency, or the combined time–frequency domain, such as the wavelet analysis. One may notice that these methods are either static, unsuitable for motion identification, or time-sequence analysis-based, requiring seconds to collect enough data for a meaningful analysis. On the other hand, machine learning (ML) methods can match short irregular signal patterns into various tags and are catching much attention for motion recognition research. ML methods can be bases on static data or dynamic time series. K-nearest neighbours, decision tree, and support vector machine (SVM) are based upon static data [
12,
13,
14]. More recently, researchers have proposed the use of deep neural networks, such as convolutional neural networks (CNNs) [
15] and recurrent neural networks (RNNs) [
14] for recognition. The CNN is still a static-data-based network and the RNN result is still geared toward large motion trajectories. The result by Ragni et al. [
16] addressed intent recognition, but was limited to predicting the subject’s choice in three possible ways. Additionally, much of their work was dedicated to deciding if the subject was healthy or a post-stroke patient. The study by Li et al. [
17] was about intent prediction, but was about predicting the pitcher’s choice of pitching target. Soliman et al. designed a lower extremity robot for emulating gait maneuvers. They also indicated the possible use of intent control. Additionally, their search was limited to one of the nine targets. Hao et al. [
18] used an IMU-based sensory control method for gait synchronization. They used a force sensor to detect robot-limb contact, an IMU sensor to detect toe-off, and an accelerometer to detect heel strike. All the detections were based on signal thresholds. The system by Ji et al. [
19] was also event-triggered by a unique intention recognition controller. Their system was a wheeled walker with strings and force sensors attached to the subject. The detection was based on a kinematic force model to determine the direction of the intended motion. Moreover, the system was limited to one-degree-of-freedom yaw motion direction. To the best of the authors’ knowledge, there is, to date, no discussion on how rapidly an algorithm can detect a change in human gait with measured signals.
This study aims to investigate the time required to identify a change in gait or movement and identify the intended gait or posture to enable the system to switch to the corresponding new trajectory rapidly. This rapid automatic recognition of the new gait enables a more comfortable ride without requiring the driver to switch manually among preprogrammed modes. The response time in this research represents the time needed for the system to collect sufficient data for the algorithm to establish recognition. We chose IMU as a wearable sensor due to its non-invasive nature and ease of use with existing exoskeletons. To establish the rapid identification of the change in gait, we introduce the motion transition phase to the detection labels in addition to the commonly used labels of “walking” or “sitting”.
This paper tests two machine learning methods for motion transition detection: the linear feedforward neural network (FNN) and the long short-term memory (LSTM). The subjects wore the IMUs on their waist and right leg and performed three activities: standing, walking, and sitting. The experiments recorded the IMU data and calculated the subjects’ joint angular displacements, angular velocities, and angular accelerations. The experimental results show that 1. The ML networks can rapidly and accurately detect the motion of the subject. 2. With the introduction of the transition phases, the detection time is as fast as 0.17 s when the subject changes from walking to sitting. The detection takes as long as 1.2 s from standing to walking. 3. The results also show that the network trained for one person can apply to different persons without deteriorating the performance. 4. The study also examines the effect of different sampling rates and tests various feature selections for the machine-learning process.
2. The Experimental Setup
2.1. Participants
A convenience sample of five healthy subjects was recruited from July 2021 to February 2022. None of the subjects had current or previous neurological or orthopedic pathologies of the right leg, and all provided informed consent to participate.
Table 1 lists the information on the subjects.
2.2. Equipment
In this paper, we used STT-IWS iSen 3.0 as our inertial measurement unit (IMU) system. Each STT-IWS sensor has nine-degrees-of-freedom gyroscopic and magnetometer data. The sensor’s static roll, pitch, and yaw accuracy are all smaller than , with a maximum sampling rate of 400 Hz. One can obtain instance angles of sagittal, transverse, and coronal planes with the subjects wearing the sensors on the right leg. iSen system gathers the wireless IMU signals and pre-processes them into joint angles. The angles are expressed as quaternions and can be transmitted to the computer through the user datagram protocol (UDP). Obtaining the raw IMU data for even faster data collection is also possible; however, the computed angular data rate is rapid enough for this application, and we decided to use the angular data for the analysis.
2.3. Experiment Procedure
To begin the data collection, we attached four STT-IWS sensor units to the subject’s right leg, placing them on the sacrum, right thigh, right calf, and right foot.
Figure 1 shows how we mounted the sensors on the subject. Then, the STT iSen system was turned on to ensure successful signal capture. At this point, one could set the sampling rate to either 25 or 100 Hz and initiate the data collection. One may notice that the sampling rates are lower than most robotic controllers; however, they are sufficient for human motion.
Because the sensors are hand-tied to the subjects, one must perform a “sensor-to-segment calibration”. The calibration procedure for SST-IWS is very straightforward. Once the locations of the sensors are keyed into the system, the subject only has to stand in a pose that matches the system’s avatar, and the system conducts the calibration on its own.
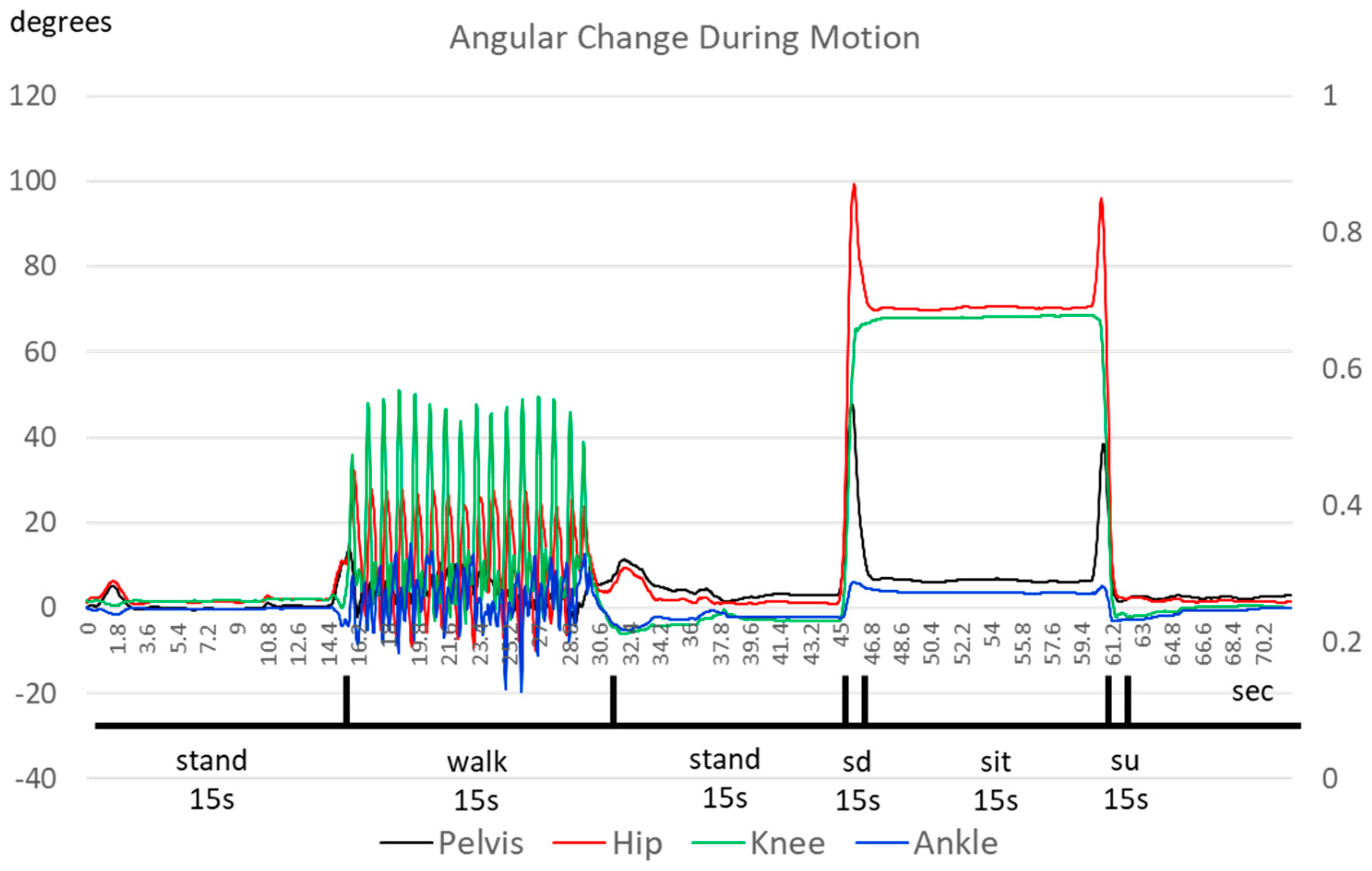
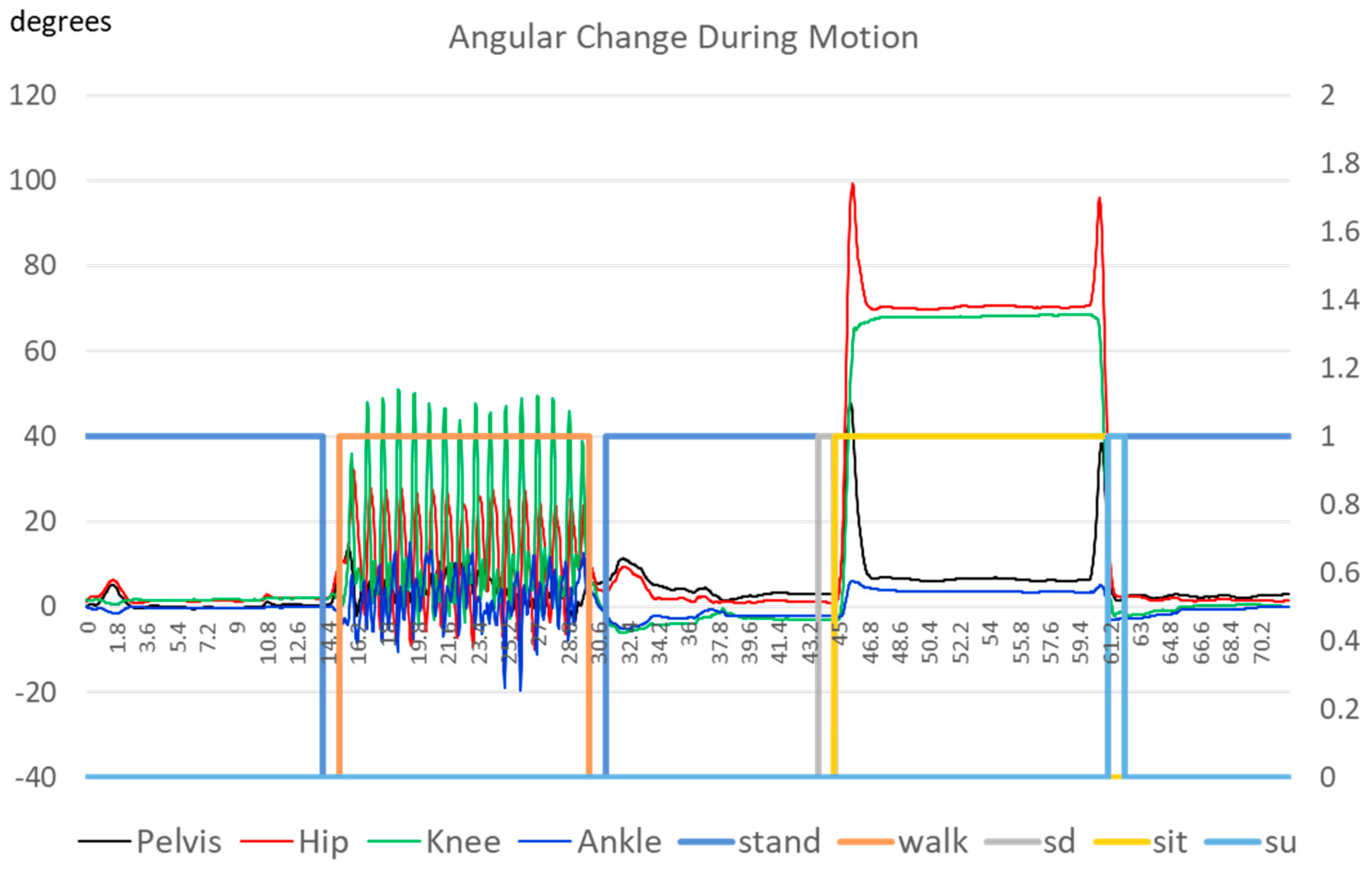
Once calibrated, the system captures the IMU response signals within the sampling period and performs inverse kinematic calculations to obtain the real-time human posture according to the body dimensions of the pilot. To manifest the detection performance, we designed a sequence of changing movements for the subject to perform to cover the changes in the subjects’ gaits. This research instructed the subject to stand straight to allow the system to recognize his initial state. Then, we asked him to perform a “stand–walk–stand–sit” cycle for five to six minutes. During this cycle, “Stand” represented standing straight as the initial state for 15 s, “Walk” indicated walking around a classroom for 15 to 20 s at his usual pace, and “Sit” involved sitting in a chair for 15 s. Finally, we extracted the data and conducted further analyses.
2.4. Data Processing
Data processing was executed using an Intel
® CoreTM i7-4790K processor (4.00 GHz) on a machine running a Windows 10 Enterprise operating system. Following the data extraction, we inputted the data into our machine learning system, which was programmed in Python. Once the machine learning calculations were complete and the prediction results were obtained, we transmitted the data to the MATLAB environment for data post-processing and the final analysis, as depicted in
Figure 2.
As illustrated in the previous section, we outfitted our subject with four STT-IWS sensor units positioned on the sacrum, right thigh, right calf, and right foot. At this point, one must decide if the detection system uses the sensor signals directly or if we first extract useful features from the signals. Considering the signals from the IMU were in the form of the quaternion, it was hard for machine learning algorithms to interpret the meaning of the quaternion directly. In this research, we decided to pre-process the signals into the motion information of the human body. The STT iSen system computed the subject’s flexion and extension angles in the sagittal plane from the captured signals [
20]. One could also obtain the angles of the pelvis, right hip, right knee, and right ankle in the sagittal plane. In addition, the system also provided the first and second derivatives of these angles to obtain the angular velocity and angular acceleration of the subjects’ joints in their sagittal planes. This research adopted these parameters as the features to train the machine learning system.
The following sections describe the Python-based ML algorithm developed in this research.
2.5. Intent Detection
This research developed two programs for two different algorithms, a linear feedforward neural network (FNN) and a long short-term memory (LSTM), to predict the switching among three common human actions: standing, walking, and sitting. The ML training programs were developed in the Python environment.
In the previous session, the signals of the subject measured by the IMU had three kinds of features, the angles, angular velocity, and angular acceleration of the subject in his sagittal plane, and each signal set included the data of the pelvis, right hip, right knee, and right ankle of the subject. These 12 features were treated as the inputs of our ML training system, and the outputs were the five labels of human actions: standing, walking, sitting down, sitting, and standing up. Notice that instead of the three actions, we introduced two additional labels for “sitting down” and “standing up” for reasons that are explained later.
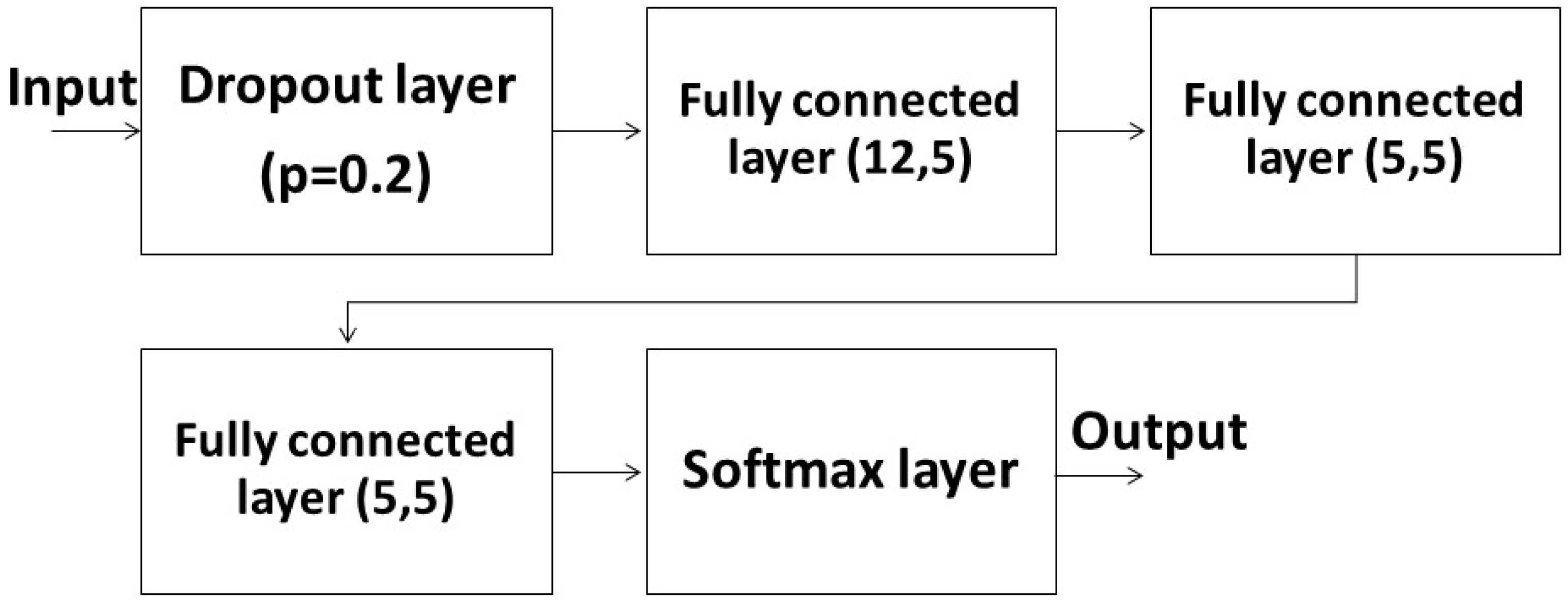
Then, we chose either FNN or LSTM as our learning algorithms. The FNN used three fully connected layers to run the ML system (
Figure 3). There were 12 input nodes in the first layer because it contained the data of three kinds of features in the four joints of the subject. The remaining inputs and outputs of other layers were set as five because we needed the output to match the five labels of human actions. Before feeding the input to the fully connected layers, we inserted a dropout layer with
, where
was the probability of the layer forcing the input to be zeroed. The purpose of the dropout layer was to reduce the chance of overfitting. After being operated by the fully connected layers, the output would run through a softmax layer to ensure that all outputs lay within [0, 1] and its summation equaled 1 to match the probability distribution. The output could be easier to discriminate after passing through the softmax layer.
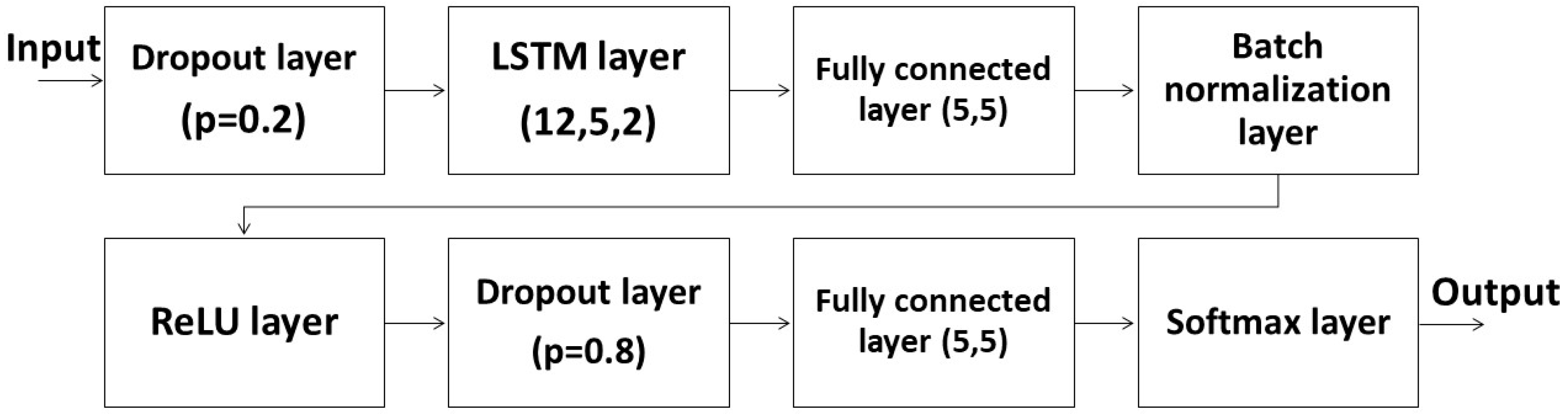
The LSTM used a 2-layer LSTM as the main structure (
Figure 4). The reason for a 2-layer LSTM was the computing limitation. A 2-layer LSTM here could cause the entire network to be too complicated to calculate. The input of the LSTM layer was 12, and the remaining inputs and outputs of other layers were 5 for a reason similar to the FNN. In addition to dropout layers and a softmax layer, we added a batch normalization layer and a ReLU layer to the LSTM system. The batch normalization layer helped avoid overfitting similar to dropout layers, while the ReLU layer helped eliminate negative terms. Some important parameters of the FNN and LSTM ML systems are shown in
Table 2. The study aimed to detect the change in the pilot’s motion rapidly. The data size, which affected the time required to gather enough data, was limited. We used the same batch size and number of epochs for a fair comparison. We also used the same optimizer to check the learning performance. Because of the limited number of volunteers, we carefully separated the data for training and validation. The learning rate and weight decay are the results of a long process of iterations.
4. Conclusions
This paper described the successful development of a machine learning system for human intent detection (HID) using two algorithms: linear feedforward neural network (FNN) and long short-term memory (LSTM). The system detected transitions between three common human movements (standing, walking, and sitting) using data from four inertial measurement units (IMUs) attached to the subject’s right leg. This research also proposed to distinctively separate the transition before and after sitting into “sitting down” and “standing up” to highlight the ability to detect a change in the pilots’ intent. The results show that both algorithms achieve good accuracy, with LSTM outperforming the FNN in terms of the average time difference and accuracy; although, it takes longer to train. The identification accuracy of the two structures was above 80%, while LSTM could improve the accuracy from 82.5% to 88%. The accuracy is better than the previous results of 83.3% using a single inertial sensor [
21]. The average time difference and accuracy of LSTM were better than the FNN; however, it also took longer to train. Because training time is irrelevant to the application run time, LSTM is more suitable than FNN.
This paper showed that ML networks could: 1. Rapidly and accurately identify the motion of the subject. 2. The introduction of the transition phase helped rapidly detect the change in motion with a detection time as fast as 0.17 s when the subject changed from walking to sitting. The detection could be as long as 1.2 s for the transition between standing and walking. 3. The network trained for one person could apply to different persons without considerable changes in performance. 4. The study also compared different sampling rates and found that higher rates led to improved accuracy and a lower detection time but with a longer training time.
The IMU system is still limited by causality; therefore, one can only try to detect the changes as soon as possible after the pilot starts the movement. It would be desirable to be able to foretell the pilot’s intention. Future research will measure the signals from the core muscles to investigate the possibility of detecting core muscle signals and using them for advanced detection purposes.



 and
and 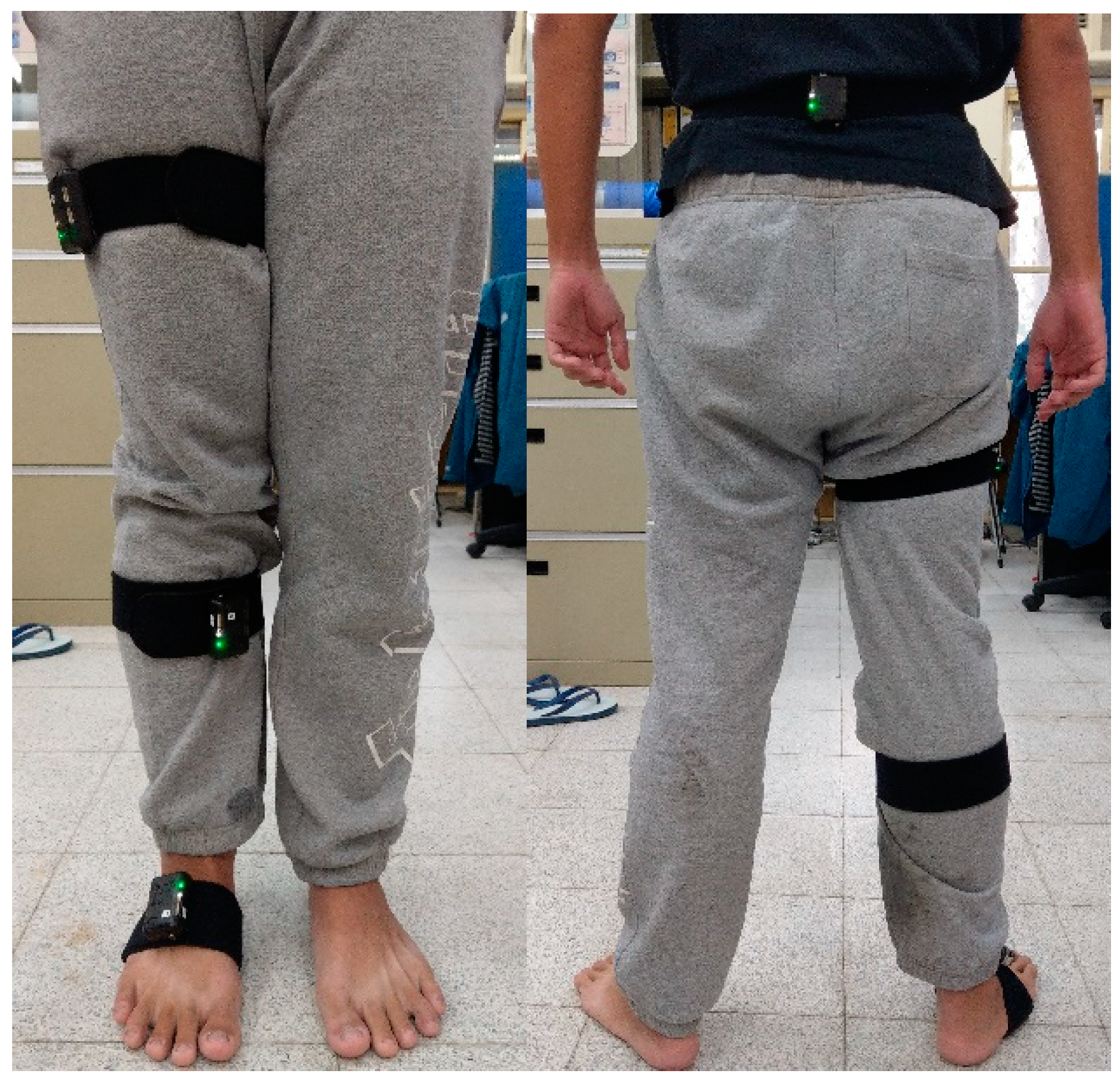


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}