
A High Performance and Robust FPGA Implementation of a Driver State Monitoring Application

 ,
,  ,
, 
 and
and
Abstract
1. Introduction
2. Experimental Setup and Datasets
3. ERT Background and Proposed Methods
3.1. Background of the ERT Model
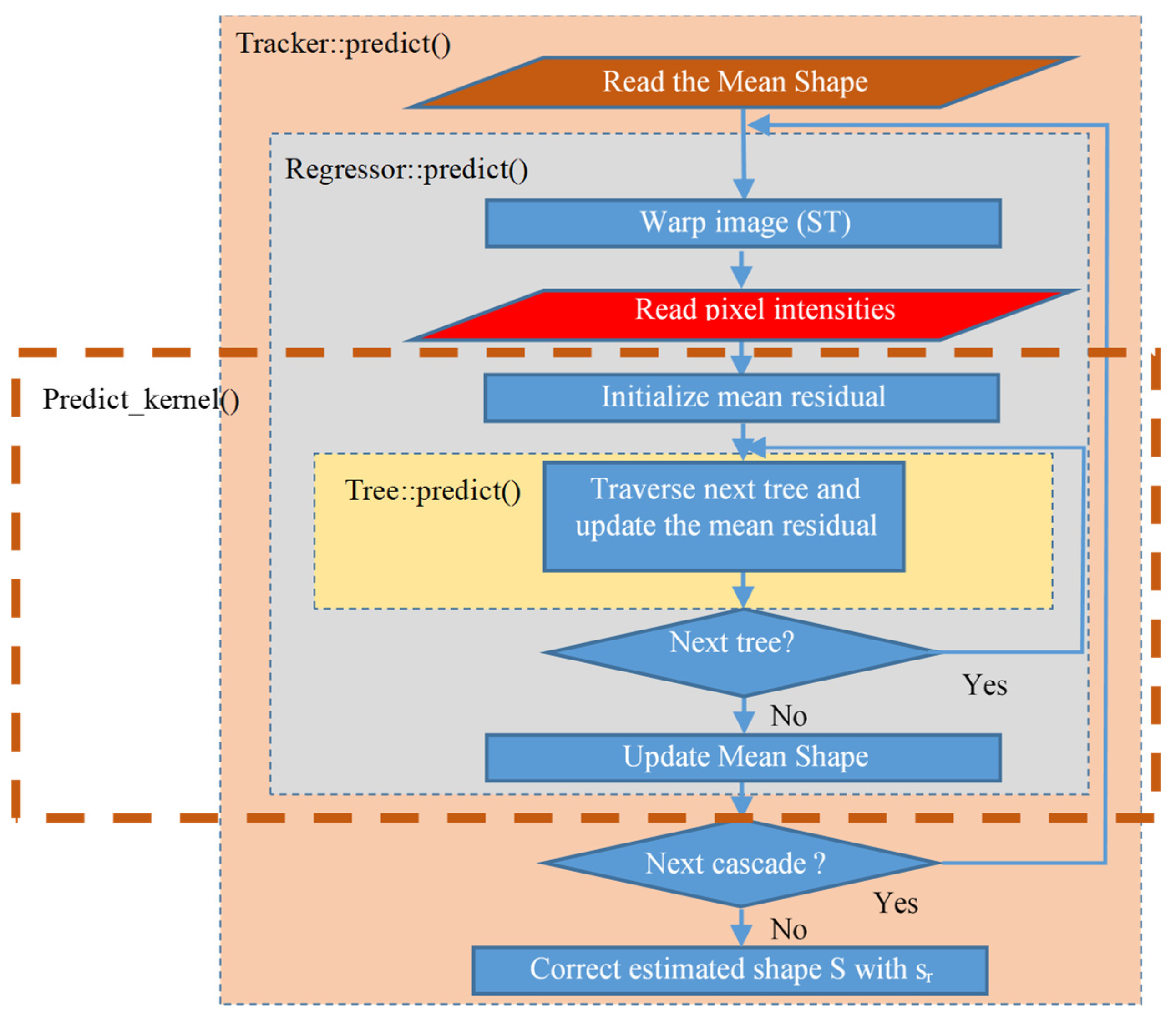
3.2. System Architecture and Operation
| Algorithm 1 Predict_kernel() algorithm implemented as a hardware kernel. |
| Predict_kernel() |
|
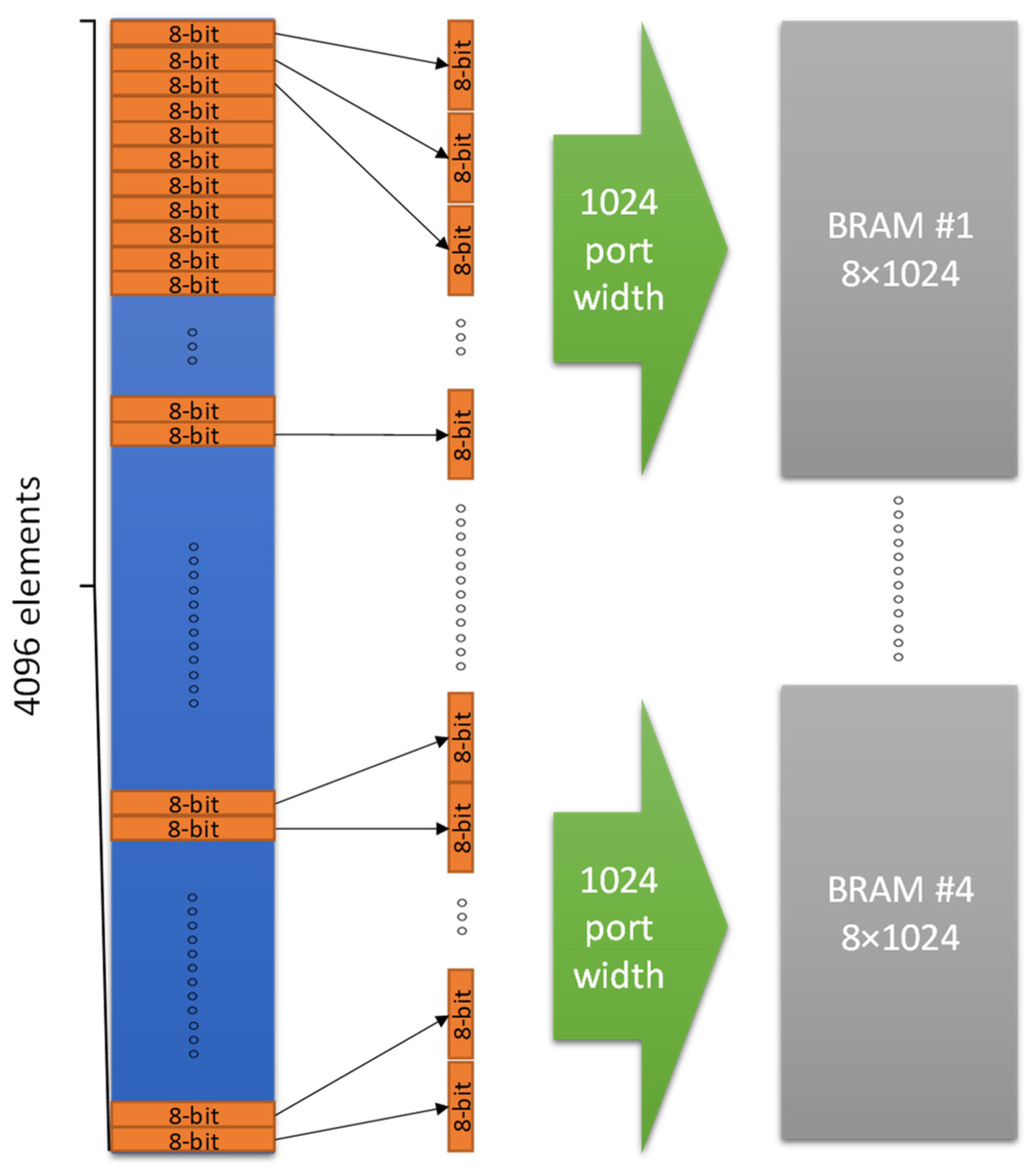
3.3. Hardware Acceleration Methods
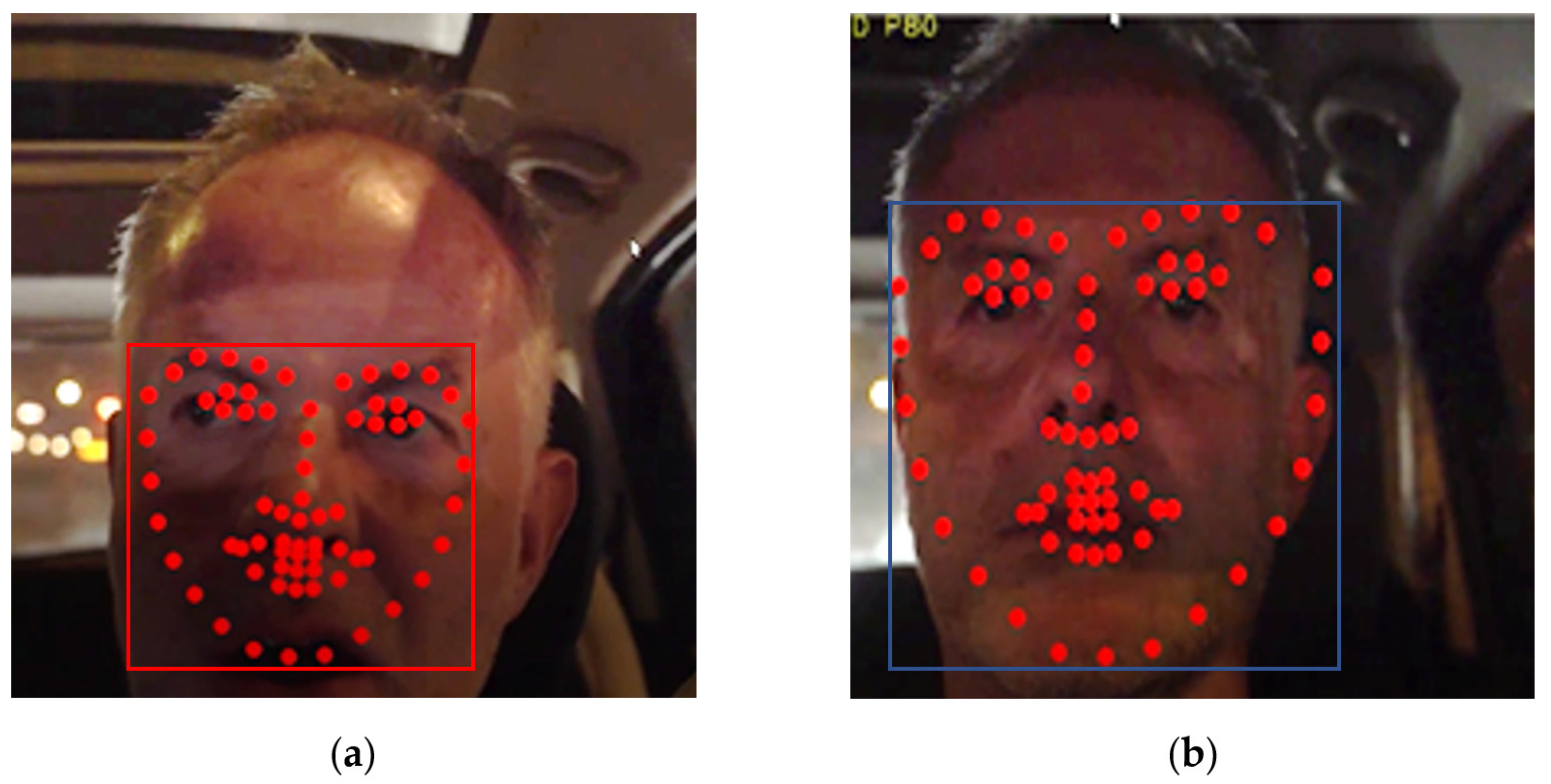
3.4. Employed Rules for Increased Robustness
3.4.1. Head Bounding Box Absolute Dimension Restrictions Related to the Frame Size
3.4.2. Coherency in the Head Bounding Box Dimensions
3.4.3. Coherency in the Head Bounding Box Position
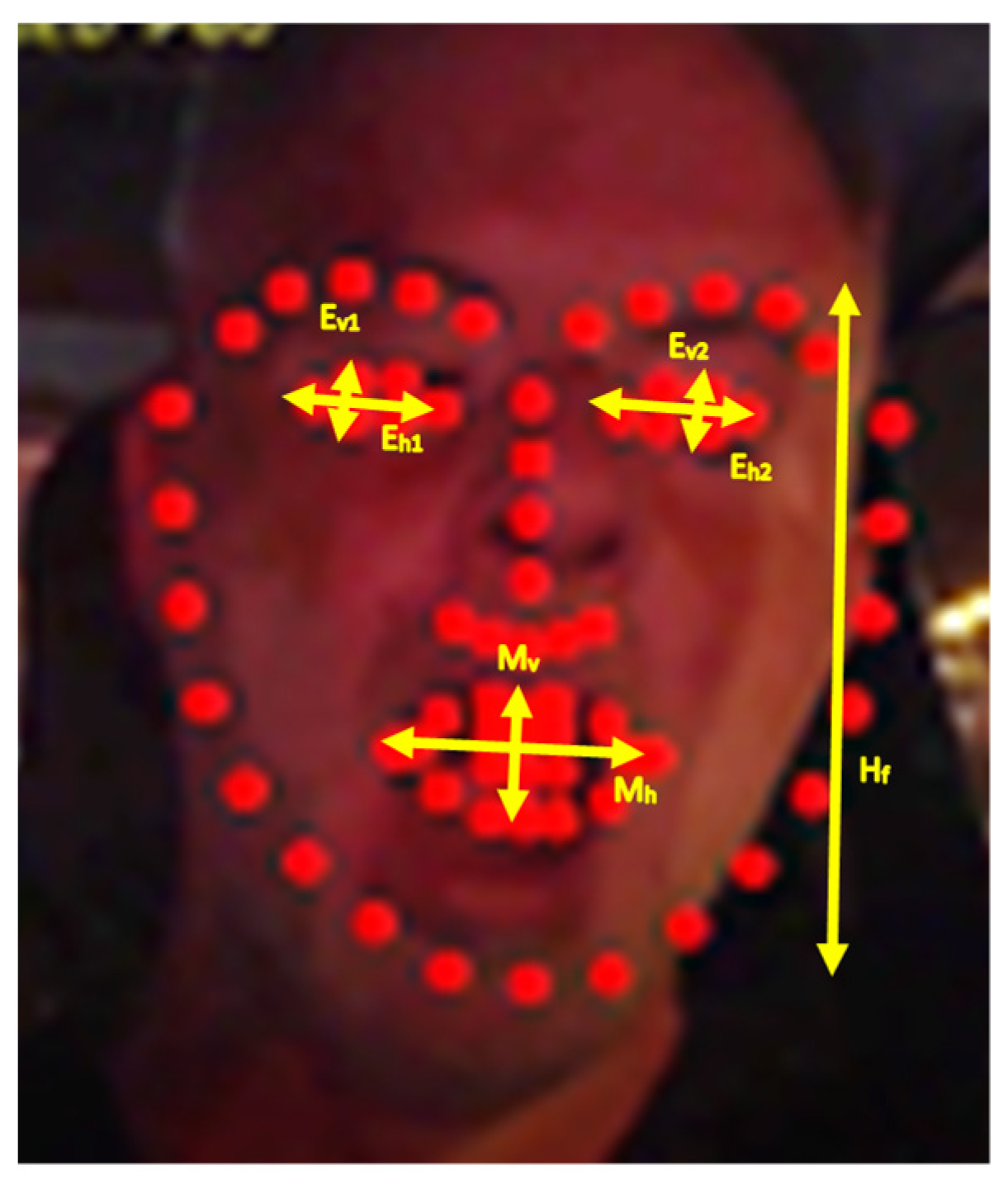
3.4.4. Face Shape Size Restrictions
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Álvarez Casado, C.; Bordallo López, M. Real-time face alignment: Evaluation methods, training strategies and implementation optimization. J. Real-Time Image Process. 2021, 18, 2239–2267. [Google Scholar] [CrossRef]
- Chang, C.Y.; Cheng, M.J.; Ma, M.M.H. Application of Machine Learning for Facial Stroke Detection. In Proceedings of the IEEE 23rd International Conference on Digital Signal Processing (DSP), Shanghai, China, 18–19 November 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Pascual, A.M.; Valverde, E.C.; Kim, J.-I.; Jeong, J.-W.; Jung, Y.; Kim, S.-H.; Lim, W. Light-FER: A Lightweight Facial Emotion Recognition System on Edge Devices. Sensors 2022, 22, 9524. [Google Scholar] [CrossRef] [PubMed]
- Kosuge, A.; Yamamoto, K.; Akamine, Y.; Yamawaki, T.; Oshima, T. A 4.8x Faster FPGA-Based Iterative Closest Point Accelerator for Object Pose Estimation of Picking Robot Applications. In Proceedings of the IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), San Diego, CA, USA, 28 April–1 May 2019; p. 331. [Google Scholar] [CrossRef]
- Mousouliotis, P.; Petrou, L. CNN-Grinder: From Algorithmic to High-Level Synthesis descriptions of CNNs for Low-end-low-cost FPGA SoCs. Microprocess. Microsyst. 2020, 73, 102990. [Google Scholar] [CrossRef]
- Ezilarasan, M.R.; Britto Pari, J.; Leung, M.F. High Performance FPGA Implementation of Single MAC Adaptive Filter for Independent Component Analysis. World Sci. J. Circuits Syst. Comput. 2023, 2350294. [Google Scholar] [CrossRef]
- Schäffer, L.; Kincses, Z.; Pletl, S. A Real-Time Pose Estimation Algorithm Based on FPGA and Sensor Fusion. In Proceedings of the IEEE 16th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 13–15 September 2018; pp. 000149–000154. [Google Scholar] [CrossRef]
- Matai, J.; Irturk, A.; Kastner, R. Design and Implementation of an FPGA-Based Real-Time Face Recognition System. In Proceedings of the IEEE 19th Annual International Symposium on Field-Programmable Custom Computing Machines, Salt Lake City, UT, USA, 1–3 May 2011; pp. 97–100. [Google Scholar] [CrossRef]
- Joseph, J.M.; Mey, M.; Ehlers, K.; Blochwitz, C.; Winker, T.; Pionteck, T. Design Space Exploration for a Hardware-Accelerated Embedded Real-Time Pose Estimation Using Vivado HLS. In Proceedings of the International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 4–6 December 2017; pp. 1–8. [Google Scholar] [CrossRef]
- Goenetxea, J.; Unzueta, L.; Dornaika, F.; Otaegui, O. Efficient Deformable 3D Face Model Tracking with Limited Hardware Resources. Multimed. Tools Appl. 2020, 79, 12373–12400. [Google Scholar] [CrossRef]
- Konomura, R.; Hori, K. FPGA-based 6-DoF Pose Estimation with a Monocular Camera Using non Co-Planer Marker and Application on Micro Quadcopter. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 4250–4257. [Google Scholar] [CrossRef]
- Ling, Z.; Qing, X.; Wei, H.; Yingcheng, L. Single View Head Pose Estimation System based on SoC FPGA. In Proceedings of the 13th IEEE International Conference on Electronic Measurement & Instruments (ICEMI), Yangzhou, China, 9–11 August 2017; pp. 369–374. [Google Scholar] [CrossRef]
- Tasson, D.; Montagnini, A.; Marzotto, R.; Farenzena, M.; Cristani, M. FPGA-based Pedestrian Detection under Strong Distortions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 65–70. [Google Scholar] [CrossRef]
- Kazemi, V.; Sullivan, J. One Millisecond Face Alignment with an Ensemble of Regression Trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1867–1874. [Google Scholar] [CrossRef]
- Deformable Shape Tracking (DEST). Available online: https://github.com/cheind/dest (accessed on 17 April 2021).
- Chrysos, G.G.; Antonakos, E.; Snape, P.; Asthana, A.; Zafeiriou, S. A Comprehensive Performance Evaluation of Deformable Face Tracking “In-the-Wild”. Int. J. Comput. Vis. 2018, 126, 198–232. [Google Scholar] [CrossRef] [PubMed]
- Xin, J.; Zhonglan, L.; Ning, N.; Huimin, L.; Xiaodong, L.; Xiaokun, Z.; Xingfa, Z.; Xi, F. Face Illumination Transfer and Swapping via Dense Landmark and Semantic Parsing. IEEE Sens. J. 2022, 22, 17391–17398. [Google Scholar] [CrossRef]
- Zheng, F. Facial Expression Recognition Based on LDA Feature Space Optimization. Comput. Intell. Neurosci. 2022, 9521329. [Google Scholar] [CrossRef] [PubMed]
- Tuna, K.; Akdemir, B. Face Detection by Measuring Thermal Value to Avoid Covid-19. Avrupa Bilim Ve Teknoloji Dergisi 2022, 36, 191–196. [Google Scholar] [CrossRef]
- Islam, M.M.; Baek, J.-H. A Hierarchical Approach toward Prediction of Human Biological Age from Masked Facial Image Leveraging Deep Learning Techniques. Appl. Sci. 2022, 12, 5306. [Google Scholar] [CrossRef]
- Ramis, S.; Buades, J.M.; Perales, F.J.; Manresa-Yee, C. A Novel Approach to Cross Dataset Studies in Facial Expression Recognition. MultimediaTools Appl. 2022, 81, 39507–39544. [Google Scholar] [CrossRef]
- Pandey, N.N.; Muppalaneni, N.B. A Novel Drowsiness Detection Model Using Composite Features of Head, Eye, and Facial Expression. Neural Comput. Appl. 2022, 34, 13883–13893. [Google Scholar] [CrossRef]
- Zheng, K.; Shen, J.; Sun, G.; Li, H.; Li, Y. Shielding Facial Physiological Information in video. Math. Biosci. Eng. 2022, 19, 5153–5168. [Google Scholar] [CrossRef] [PubMed]
- Pulido-Castro, S.; Palacios-Quecan, N.; Ballen-Cardenas, M.P.; Cancino-Suárez, S.; Rizo-Arévalo, A.; López, J.M.L. Ensemble of Machine Learning Models for an Improved Facial Emotion Recognition. In Proceedings of the IEEE URUCON, Montevideo, Uruguay, 24–26 November 2021; pp. 512–516. [Google Scholar] [CrossRef]
- Gupta, N.K.; Bari, A.K.; Kumar, S.; Garg, D.; Gupta, K. Review Paper on Yawning Detection Prediction System for Driver Drowsiness. In Proceedings of the 5th International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 3–5 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Akrout, B.; Mahdi, W. Yawning Detection by the Analysis of Variational Descriptor for Monitoring Driver Drowsiness. In Proceedings of the International Image Processing, Applications and Systems (IPAS), Hammamet, Tunisia, 5–7 November 2016; pp. 1–5. [Google Scholar] [CrossRef]
- Ali, M.; Abdullah, S.; Raizal, C.S.; Rohith, K.F.; Menon, V.G. A Novel and Efficient Real Time Driver Fatigue and Yawn Detection-Alert System. In Proceedings of the 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 687–691. [Google Scholar] [CrossRef]
- Tipprasert, W.; Charoenpong, T.; Chianrabutra, C.; Sukjamsri, C. A Method of Driver’s Eyes Closure and Yawning Detection for Drowsiness Analysis by Infrared Camera. In Proceedings of the First International Symposium on Instrumentation, Control, Artificial Intelligence, and Robotics (ICA-SYMP), Bangkok, Thailand, 16–18 January 2019; pp. 61–64. [Google Scholar] [CrossRef]
- Hasan, F.; Kashevnik, A. State-of-the-Art Analysis of Modern Drowsiness Detection Algorithms Based on Computer Vision. In Proceedings of the 29th Conference of Open Innovations Association (FRUCT), Tampere, Finland, 12–14 May 2021; pp. 141–149. [Google Scholar] [CrossRef]
- Omidyeganeh, M.; Shirmohammadi, S.; Abtahi, S.; Khurshid, A.; Farhan, M.; Scharcanski, J.; Hariri, B.; Laroche, D.; Martel, L. Yawning Detection Using Embedded Smart Cameras. IEEE Trans. Instrum. Meas. 2016, 65, 570–582. [Google Scholar] [CrossRef]
- Safie, S.; Ramli, R.; Azri, M.A.; Aliff, M.; Mohammad, Z. Raspberry Pi Based Driver Drowsiness Detection System Using Convolutional Neural Network (CNN). In Proceedings of the IEEE 18th International Colloquium on Signal Processing & Applications (CSPA), Selangor, Malaysia, 12 May 2022; pp. 30–34. [Google Scholar] [CrossRef]
- Mousavikia, S.K.; Gholizadehazari, E.; Mousazadeh, M.; Yalcin, S.B.O. Instruction Set Extension of a RISCV Based SoC for Driver Drowsiness Detection. IEEE Access 2022, 10, 58151–58162. [Google Scholar] [CrossRef]
- Kowalski, M.; Naruniec, J.; Trzcinski, T. Deep alignment network: A convolutional neural network for robust face alignment. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Petrellis, N.; Zogas, S.; Christakos, P.; Mousouliotis, P.; Keramidas, G.; Voros, N.; Antonopoulos, C. Software Acceleration of the Deformable Shape Tracking Application. In Proceedings of the ACM, 2nd Symposium on Pattern Recognition and Applications as workshop of ESSE 2021, Larissa, Greece, 6–8 November 2021. [Google Scholar] [CrossRef]
- Petrellis, N.; Christakos, P.; Zogas, S.; Mousouliotis, P.; Keramidas, G.; Voros, N.; Antonopoulos, C. Challenges Towards Hardware Acceleration of the Deformable Shape Tracking Application. In Proceedings of the IFIP/IEEE 29th International Conference on Very Large-Scale Integration (VLSI-SoC), Singapore, 4–8 October 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Abtahi, S.; Omidyeganeh, M.; Shirmohammadi, S.; Hariri, B. YawDD: Yawning Detection Dataset. IEEE Dataport 2020. [Google Scholar] [CrossRef]
- Petrellis, N.; Voros, N.; Antonopoulos, C.; Keramidas, G.; Christakos, P.; Mousouliotis, P. NITYMED. IEEE Dataport 2022. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
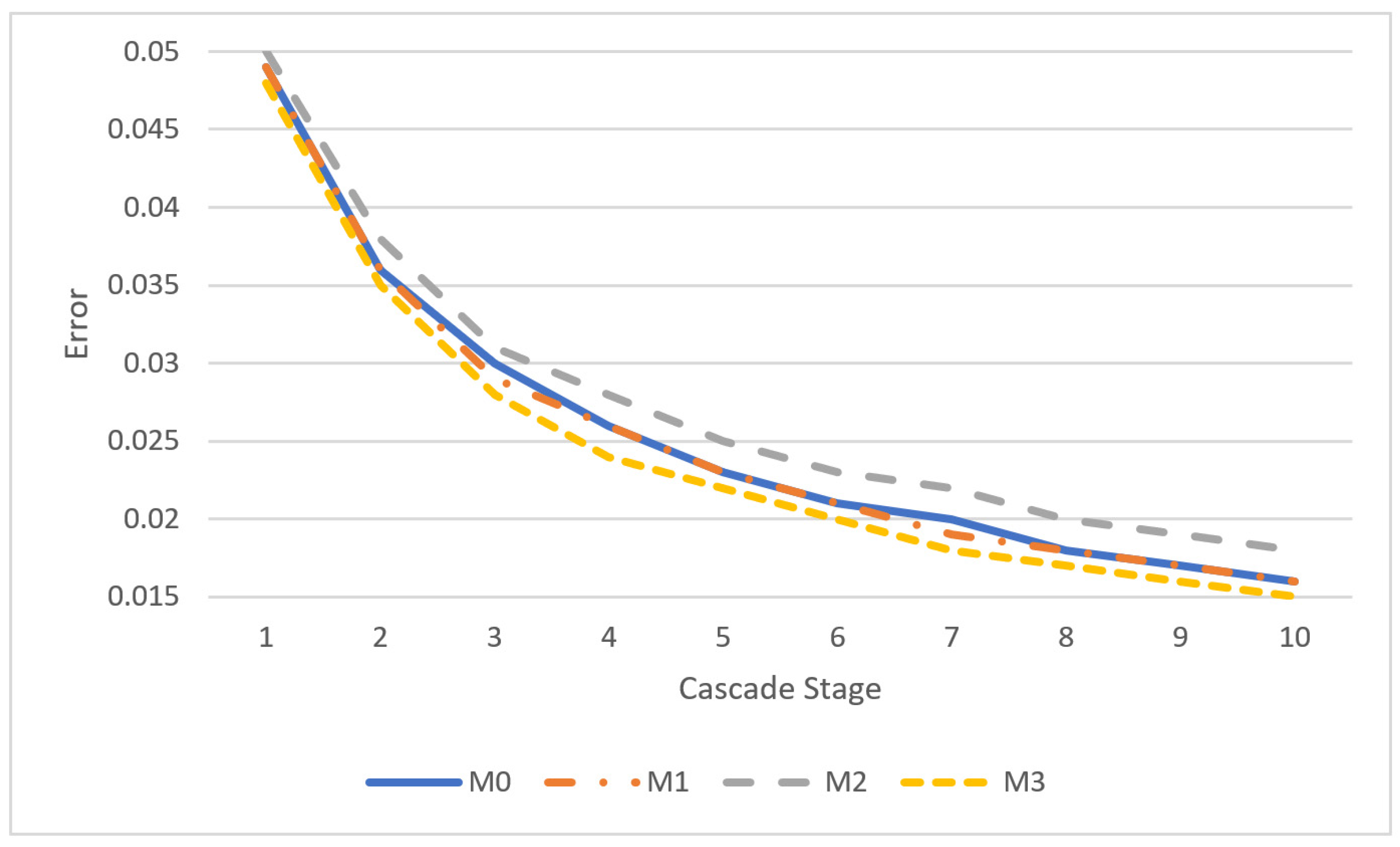{kind=link}
| Acceleration Technique | Justification |
|---|---|
| Wide Ports | High-speed transfer of large arguments to the HW kernel. |
| Double, Wide Ports Per Argument | To transfer concurrently parts of big arguments to the HW kernel. |
| Local BRAM | To store locally the arguments transferred through wide ports and access them with high speed from the HW kernel. |
| Dataflow | To exploit parallelism in successive C commands if they do not have data dependencies. |
| Loop Unrolling | To reduce loop iterations. |
| Model | Wide Ports per Argument | Trees (Ntr) | Reference Pixels (Nc) |
|---|---|---|---|
| Model M0 (single wide port) | 1 | 500 | 600 |
| Model M0 (double wide port) | 2 | 500 | 600 |
| Model M1 (double wide port) | 2 | 500 | 800 |
| Model M2 (double wide port) | 2 | 400 | 600 |
| Model M3 (double wide port) | 2 | 600 | 600 |
| Resources | M0 (Single Wide Port per Argument) | Model M0 (Single Wide Port) | Model M1 (Double Wide Port) | Model M2 (Double Wide Port) | Model M3 (Double Wide Port) |
|---|---|---|---|---|---|
| LUT | 54,149 (19.76%) | 98,776 (36.06%) | 98,776 (36.04%) | 98,145 (35.81%) | 98,145 (35.81%) |
| LUTRAM | 2862 (1.99%) | 6205 (4.31%) | 6205 (4.31%) | 5765 (4%) | 5765 (4%) |
| FF | 84,221 (15.36%) | 168,067 (30.66%) | 168,067 (30.66%) | 166,400 (30.36%) | 166,433 (30.36%) |
| BRAM | 139 (15.19%) | 652 (71.55%) | 653 (71.55%) | 653 (71.55%) | 653 (71.55%) |
| DSP | 40 (1.59%) | 56 (2.22%) | 56 (2.22%) | 56 (2.22%) | 56 (2.22%) |
| Processing Latency | 46.632 ms | 19.881 ms | 21.367 ms | 15.881 ms | 22.956 ms |
| Reference Application | Frame Processing | Number of Landmarks | Image Resolution |
|---|---|---|---|
| [1] (Face Recognition based on LBF) | 1.1 ms to 7.2 ms | 68 | 1920 × 1080 |
| [8] (Face Recognition) | 45 fps | - | 20 × 20 |
| [9] (Pose Estimation) | 30 fps | 23 | 320 × 240 |
| [10] (Head Pose Estimation) | 30 fps | 68 | - |
| [12] (3D Face Alignment) | 16 fps | 68 | 640 × 480 |
| [30] (Yawning classification) | 3 fps | CNN (no landmarks) | 640 × 480 |
| [32] (Driving Drowsiness) | 4.33 fps | CNN (no landmarks) | 100 × 100 |
| [33] (Face Recognition on a GeForce GTX 1070 GPU) | 45 fps | 68 | 1920 × 1080 |
| M0 Model on Intel i7 (no robustness rules) | 0.45 ms | 68 | 640 × 480 to 1920 × 1080 |
| M0 Model on ZCU102 | 50 fps | 68 | 640 × 480 to 1920 × 1080 |
| M1 Model on ZCU102 | 47 fps | 68 | 640 × 480 to 1920 × 1080 |
| M2 Model on ZCU102 | 63 fps | 68 | 640 × 480 to 1920 × 1080 |
| M3 Model on ZCU102 | 43 fps | 68 | 640 × 480 to 1920 × 1080 |
| Reference | Success Rate | Metric |
|---|---|---|
| [1] (LBF) | 8.2–25.5% | Landmark position error |
| [30] | 65–75% | Accuracy |
| [31] | 80–98% | Accuracy |
| [32] | 64% | Accuracy |
| [33] | 3.89–5.03% | Landmark position error |
| M0 Model | 75.75% | Sensitivity |
| 80.6% | Precision | |
| M1 Model | 92.3% | Sensitivity |
| 85.7% | Precision | |
| M2 Model | 82.85% | Sensitivity |
| 96.66% | Precision | |
| M3 Model | 85% | Sensitivity |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Christakos, P.; Petrellis, N.; Mousouliotis, P.; Keramidas, G.; Antonopoulos, C.P.; Voros, N. A High Performance and Robust FPGA Implementation of a Driver State Monitoring Application. Sensors 2023, 23, 6344. https://doi.org/10.3390/s23146344
Christakos P, Petrellis N, Mousouliotis P, Keramidas G, Antonopoulos CP, Voros N. A High Performance and Robust FPGA Implementation of a Driver State Monitoring Application. Sensors. 2023; 23(14):6344. https://doi.org/10.3390/s23146344
Chicago/Turabian StyleChristakos, P., N. Petrellis, P. Mousouliotis, G. Keramidas, C. P. Antonopoulos, and N. Voros. 2023. "A High Performance and Robust FPGA Implementation of a Driver State Monitoring Application" Sensors 23, no. 14: 6344. https://doi.org/10.3390/s23146344
APA StyleChristakos, P., Petrellis, N., Mousouliotis, P., Keramidas, G., Antonopoulos, C. P., & Voros, N. (2023). A High Performance and Robust FPGA Implementation of a Driver State Monitoring Application. Sensors, 23(14), 6344. https://doi.org/10.3390/s23146344