

Comprehensive High-Quality Three-Dimensional Display System Based on a Simplified Light-Field Image Acquisition Method and a Full-Connected Deep Neural Network


 ,
,  and
and 
Abstract
:1. Introduction
2. Proposed Method
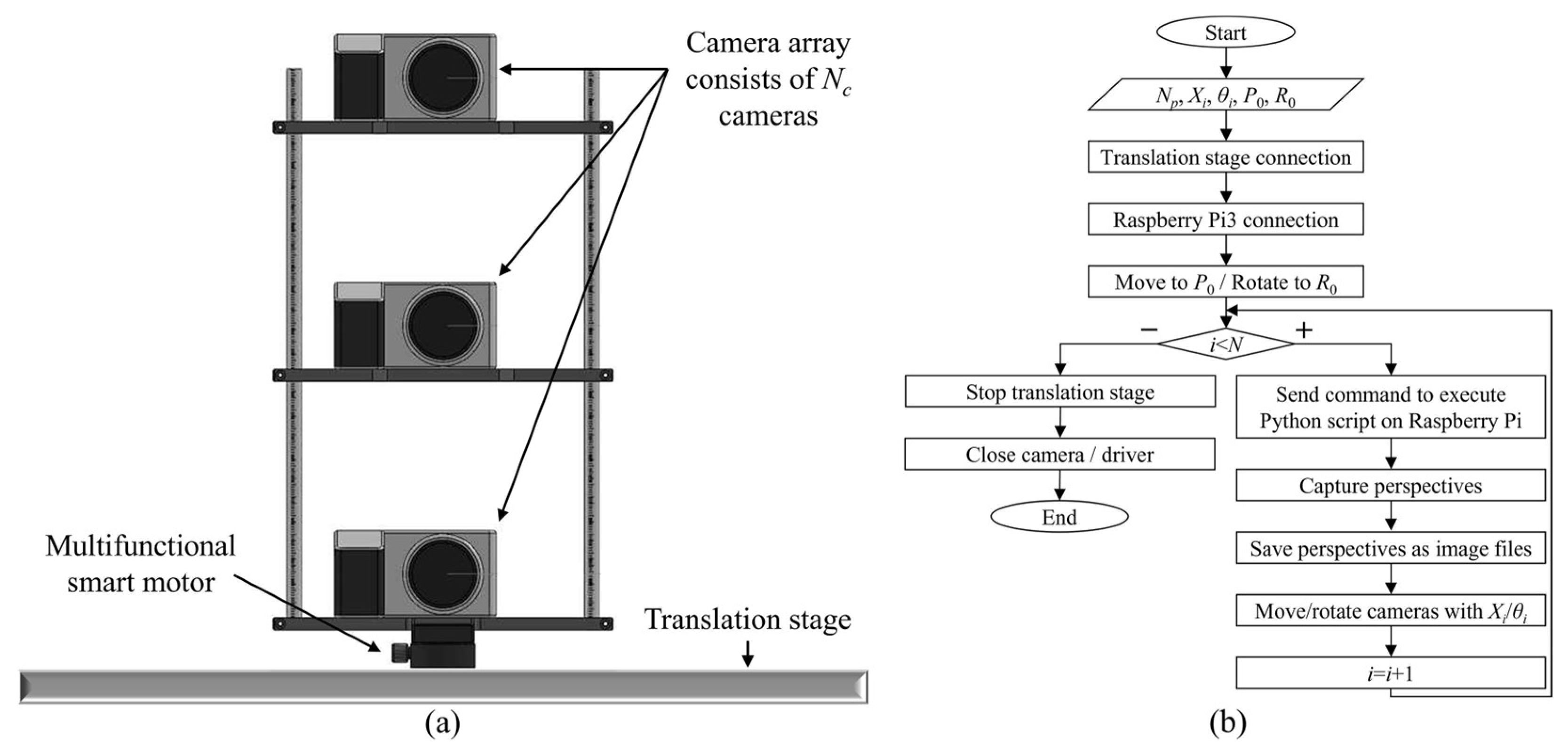
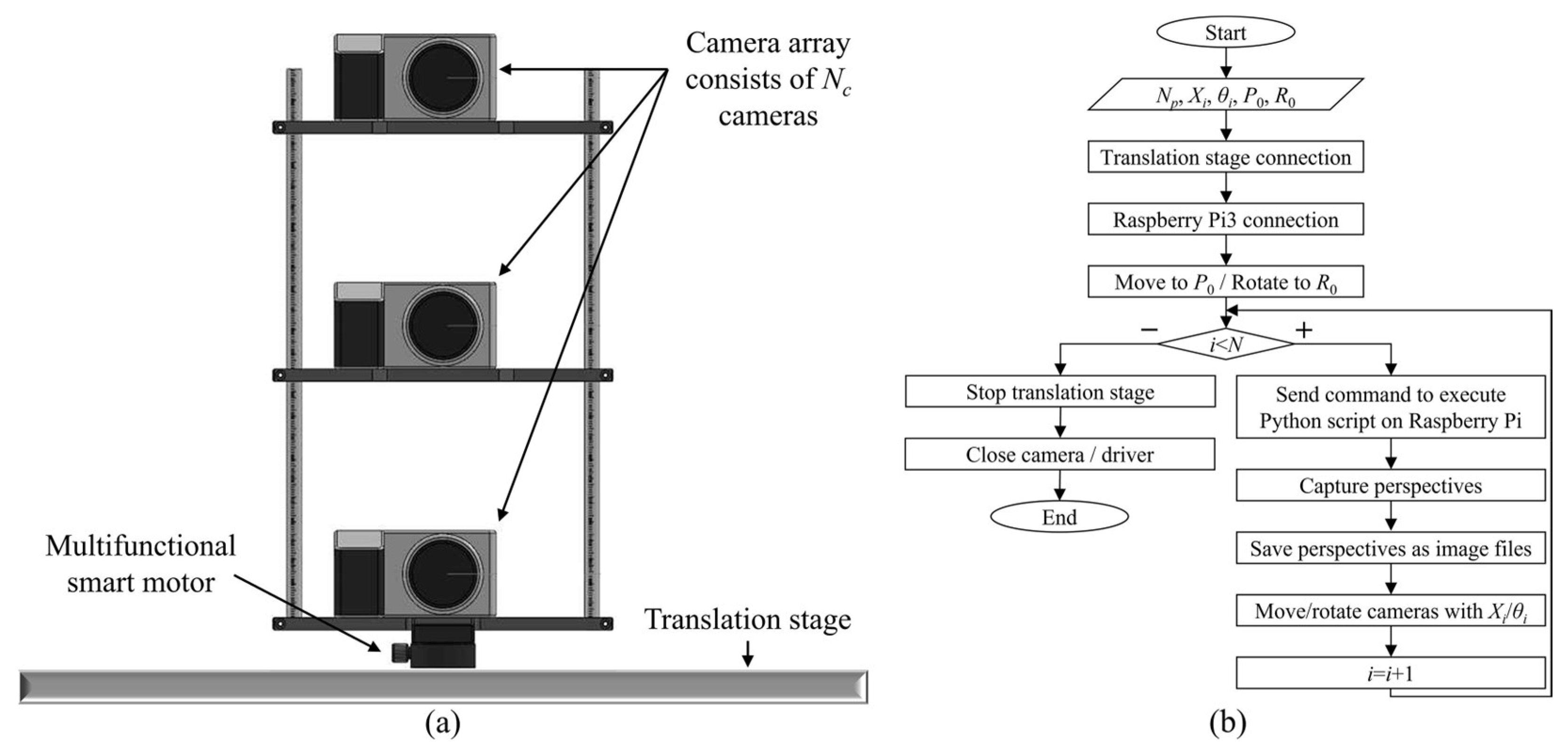
2.1. Simplified Light Field Image Acquisition Method
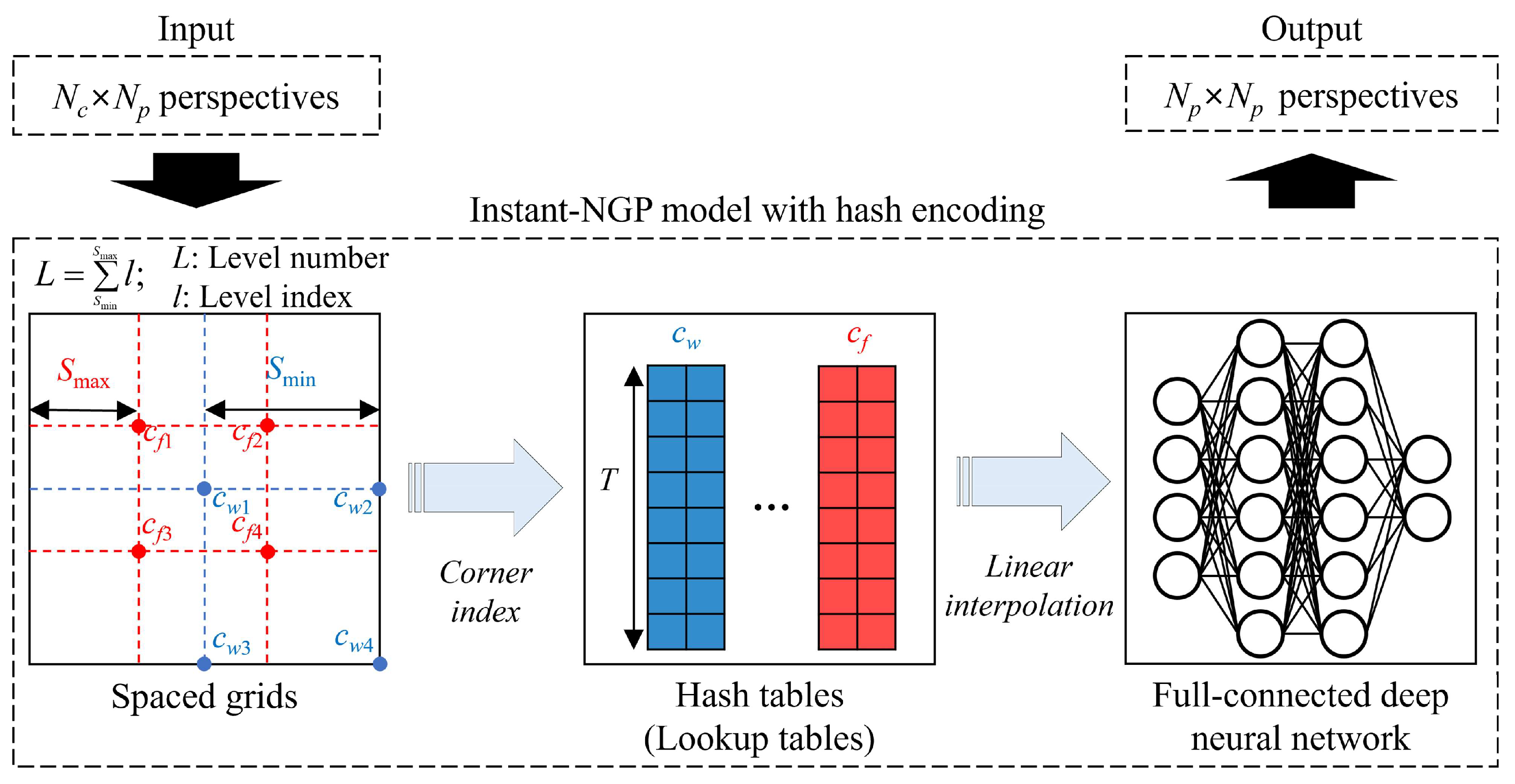
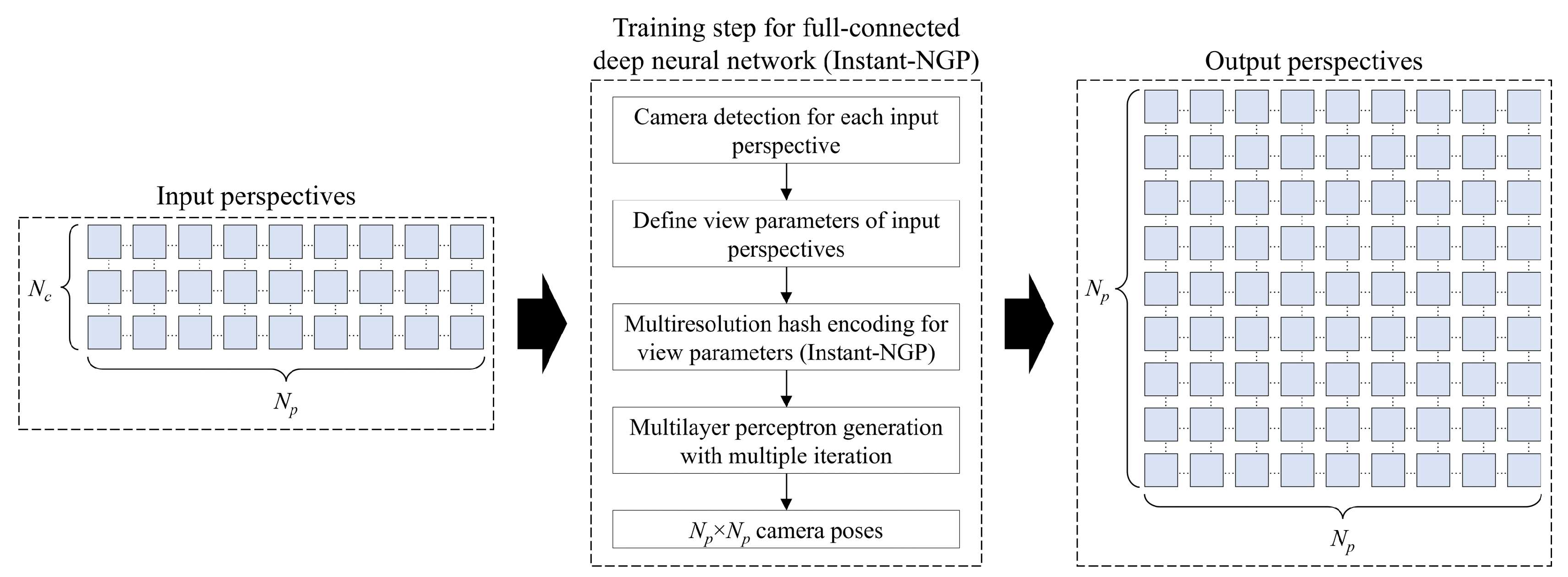
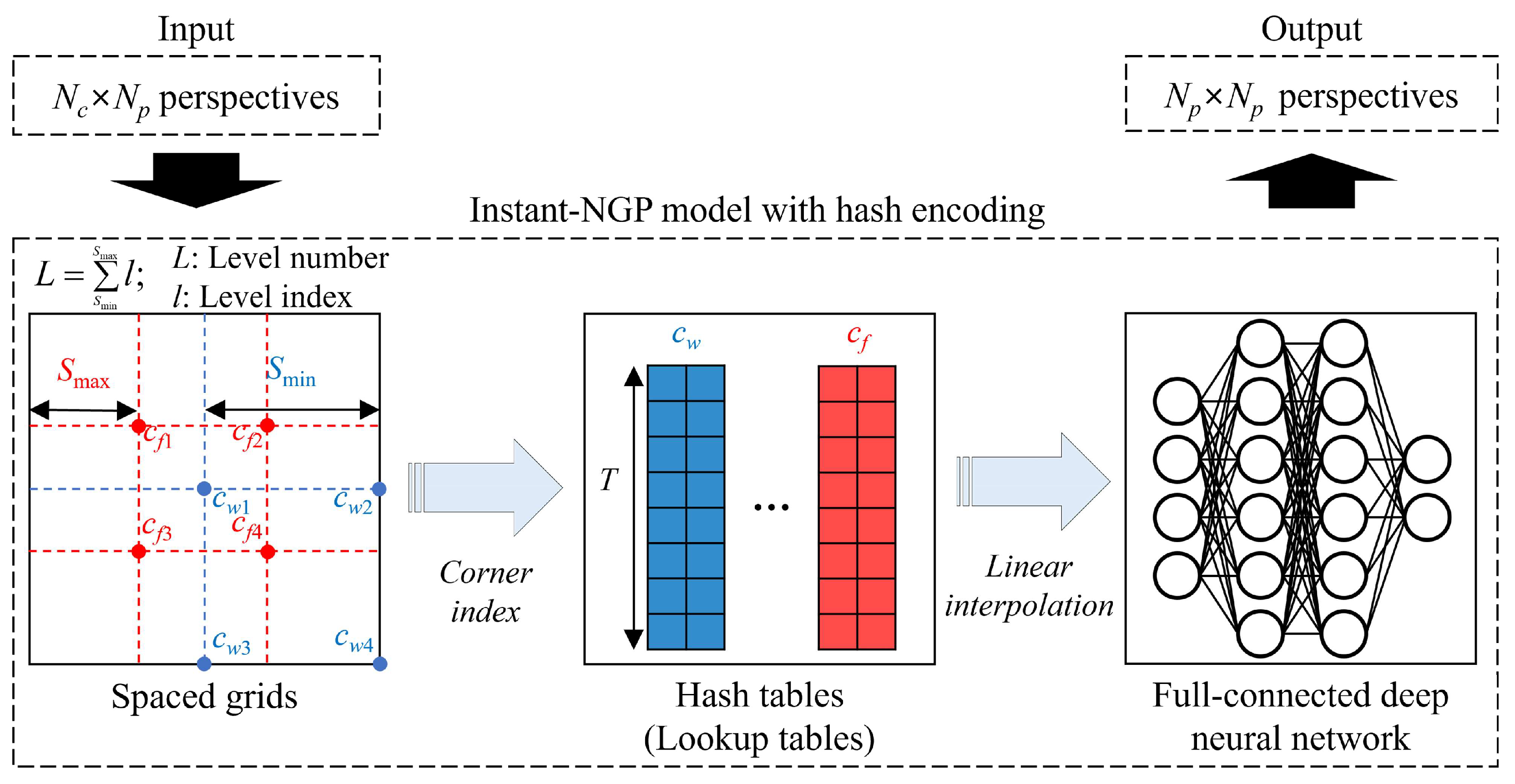
2.2. Train for an Instant-NGP Model with Hash Encoding
2.3. Pixel Re-Arrangement Method-Based EIA Generation
3. Experiment and Results
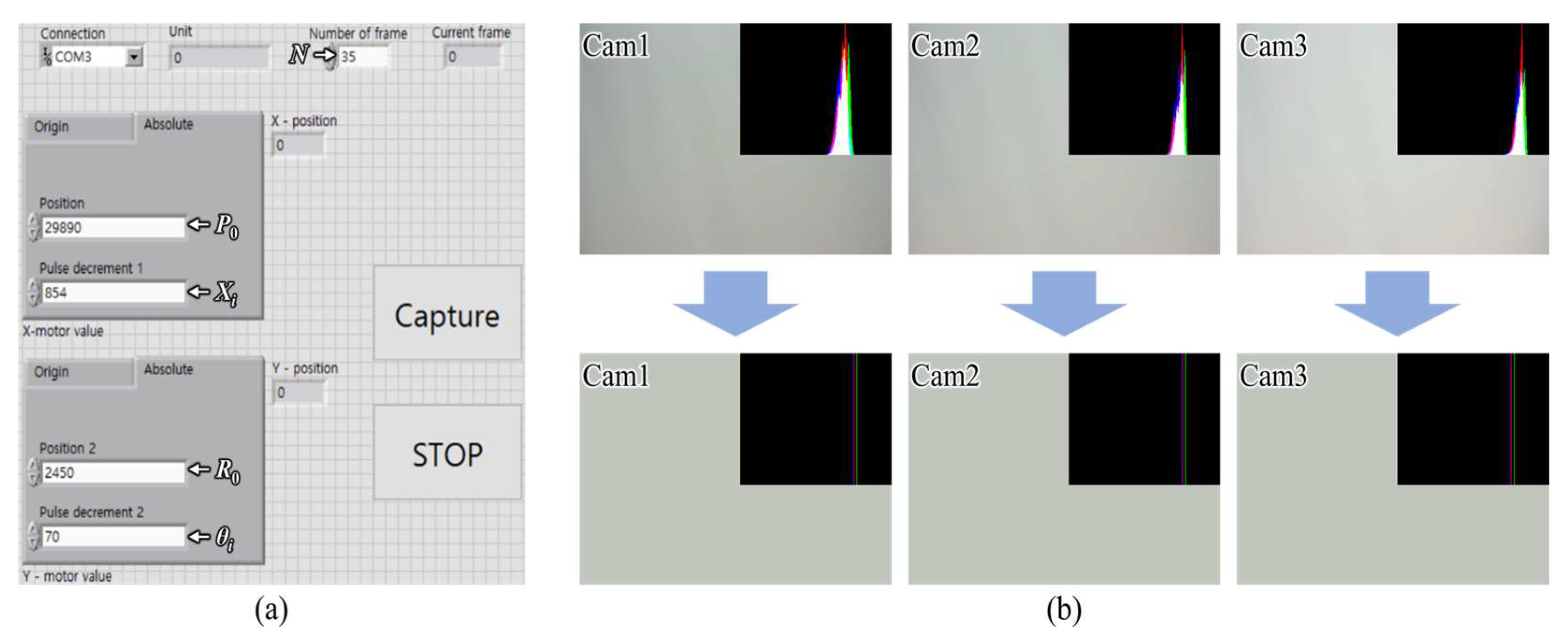
3.1. Simplified Light Field Image Acquisition Performance
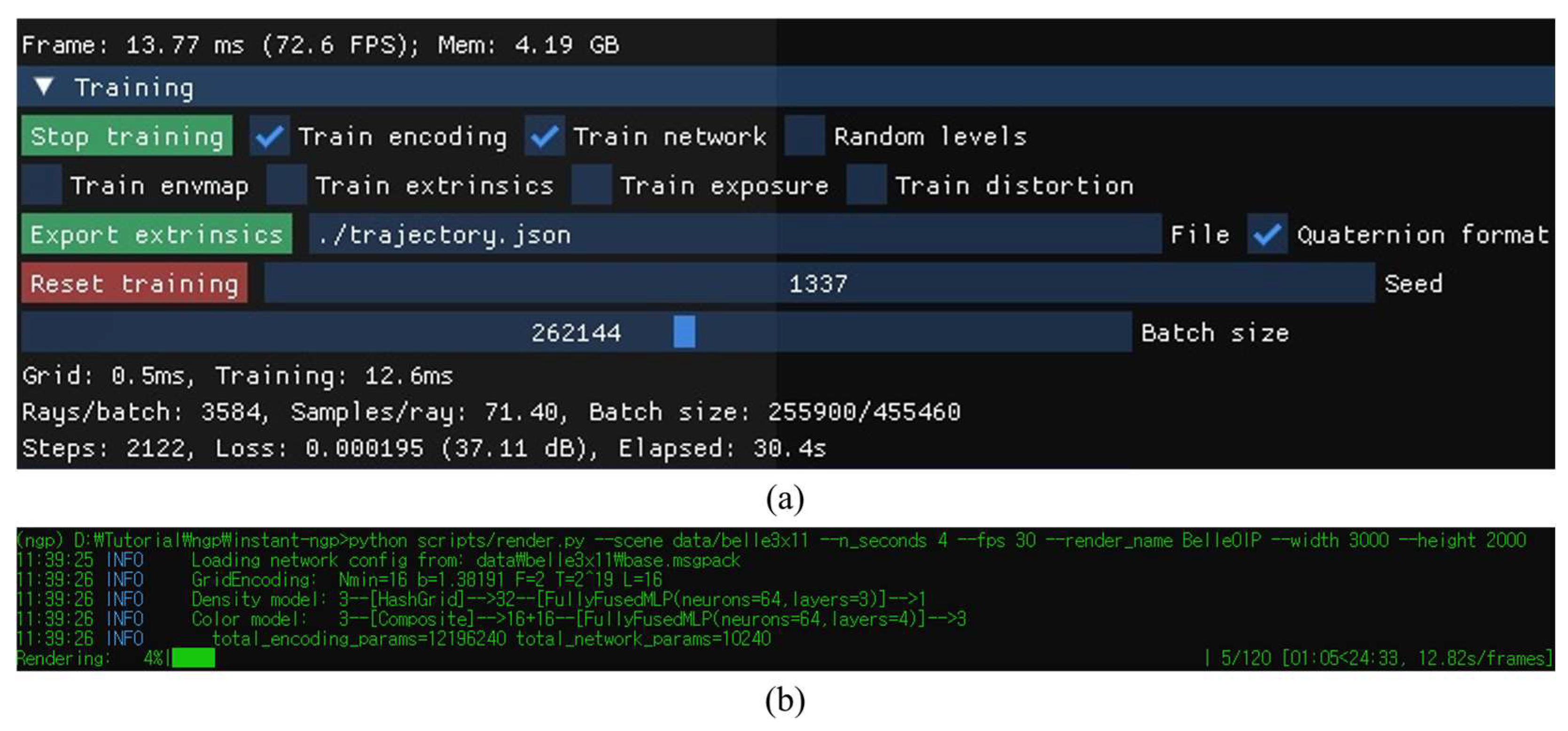
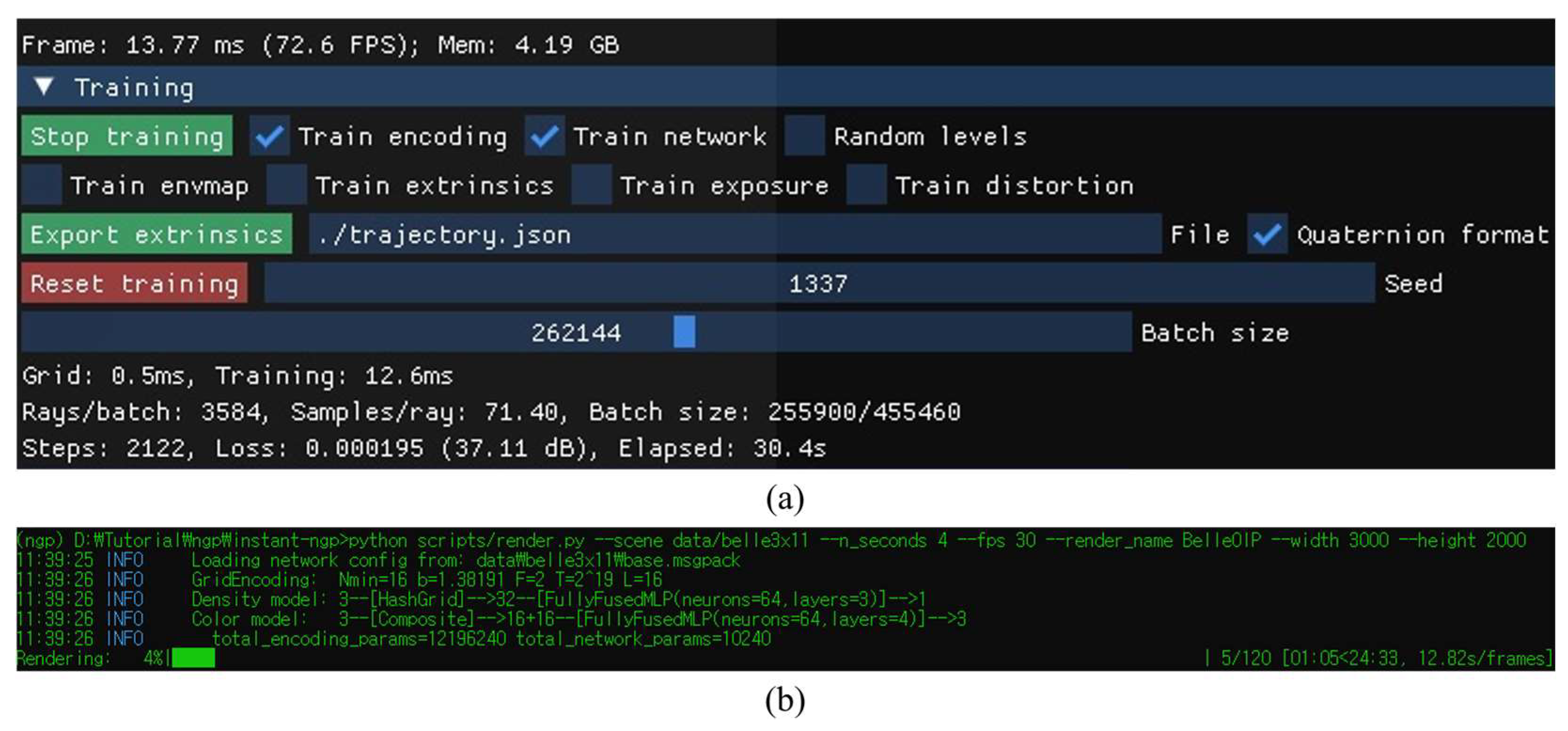
3.2. Instant-NGP Model Training and Generation for View Synthesis
3.3. EIA Generation and 3D Display
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Martínez-Corral, M.; Javidi, B. Fundamentals of 3D imaging and displays: A tutorial on integral imaging, light-field, and plenoptic systems. Adv. Opt. Photon. 2020, 10, 512–566. [Google Scholar]
- Javidi, B.; Carnicer, A.; Arai, J.; Fujii, T.; Hua, H.; Liao, H.; Martínez-Corral, M.; Pla, F.; Stern, A.; Waller, L.; et al. Roadmap on 3D integral imaging: Sensing, processing, and display. Opt. Express 2020, 28, 32266–32293. [Google Scholar]
- Hong, S.; Dorado, A.; Saavedra, G.; Barreiro, J.C.; Martinez-Corral, M. Three-dimensional integral-imaging display from calibrated and depth-hole filtered Kinect information. J. Disp. Technol. 2016, 12, 1301–1308. [Google Scholar]
- Xiong, Z.; Zhang, Y.; Wu, F.; Zeng, W. Computational depth sensing: Toward high-performance commodity depth cameras. IEEE Signal Process. Mag. 2017, 34, 55–68. [Google Scholar]
- Erdenebat, M.-U.; Kim, B.-J.; Piao, Y.-L.; Park, S.-Y.; Kwon, K.-C.; Piao, M.-L.; Yoo, K.-H.; Kim, N. Three-dimensional image acquisition and reconstruction system on a mobile device based on computer-generated integral imaging. Appl. Opt. 2017, 56, 7796–7802. [Google Scholar]
- Erdenebat, M.-U.; Piao, Y.-L.; Kwon, K.-C.; Lee, M.H.; Kwon, K.H.; Kim, M.Y.; Kim, N. Advanced visualization using image super-resolution method for three-dimensional mobile system. Opt. Commun. 2021, 480, 126494. [Google Scholar]
- Ng, R.; Levoy, M.; Bredif, M.; Duval, G.; Horowitz, M.; Hanrahan, P. Light field photography with a hand-held plenoptic camera. Stanf. Univ. Comp. Sci. Tech. Rep. 2005, 2005, 02. [Google Scholar]
- Lee, S.-K.; Hong, S.-I.; Kim, Y.-S.; Lim, H.-G.; Jo, N.-Y.; Park, J.-H. Hologram synthesis of three-dimensional real objects using portable integral imaging camera. Opt. Express 2013, 21, 23662–23670. [Google Scholar]
- Jeon, H.-G.; Park, J.; Choe, G.; Park, J.; Bok, Y.; Tai, Y.-W.; Kweon, I.S. Accurate depth map estimation from a lenslet light field camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Kwon, H.; Kizu, Y.; Kizaki, Y.; Ito, M.; Kobayashi, M.; Ueno, R.; Suzuki, K.; Funaki, H. A gradient index liquid crystal microlens array for light-field camera applications. IEEE Photon. Technol. Lett. 2015, 27, 836–839. [Google Scholar]
- Jeong, Y.; Kim, J.; Yeom, J.; Lee, C.-K.; Lee, B. Real-time depth controllable integral imaging pickup and reconstruction method with a light field camera. Appl. Opt. 2015, 54, 10333–10341. [Google Scholar]
- Perra, C.; Murgia, F.; Giusto, D. An analysis of 3D point cloud reconstruction from light field images. In Proceedings of the 2016 Sixth International Conference on Image Processing Theory, Tools and Applications (IPTA), Oulu, Finland, 12–15 December 2016. [Google Scholar]
- Feng, M.; Gilani, S.Z.; Wang, Y.; Mian, A. 3D face reconstruction from light field images: A model-free approach. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhu, S.; Lai, A.; Eaton, K.; Jin, P.; Gao, L. On the fundamental comparison between unfocused and focused light field cameras. Appl. Opt. 2018, 57, A1–A11. [Google Scholar]
- Kwon, K.-C.; Kwon, K.H.; Erdenebat, M.-U.; Piao, Y.-L.; Lim, Y.-T.; Kim, M.Y.; Kim, N. Resolution-enhancement for an integral imaging microscopy using deep learning. IEEE Photon. J. 2019, 11, 6900512. [Google Scholar]
- Kwon, K.H.; Erdenebat, M.-U.; Kim, N.; Khuderchuluun, A.; Imtiaz, S.M.; Kim, M.Y.; Kwon, K.-C. High-quality 3D visualization system for light-field microscopy with fine-scale shape measurement through accurate 3D surface data. Sensors 2023, 23, 2173. [Google Scholar]
- Taguchi, Y.; Koike, T.; Takahashi, K.; Naemure, T. TransCAIP: A live 3D TV system using a camera array and an integral photography display with interactive control of viewing parameters. IEEE Trans. Vis. Comput. Graph. 2009, 15, 841–852. [Google Scholar]
- Lin, X.; Wu, J.; Zheng, G.; Dai, Q. Camera array based light field microscopy. Biomed. Opt. Express 2015, 15, 3179–3189. [Google Scholar]
- Chen, G.; Wang, H.; Liu, M.; Liao, H. Hybrid camera array based calibration for computer-generated integral photography display. J. Opt. Soc. Am. 2015, 35, 1567–1574. [Google Scholar]
- Xu, Y.; Maeno, K.; Nagahara, H.; Taniguchi, R.-i. Camera array calibration for light field acquisition. Front. Comput. Sci. 2015, 9, 691–702. [Google Scholar]
- Xing, Y.; Xiong, Z.-L.; Zhao, M.; Wang, Q.-H. Real-time integral imaging pickup system using camera array. In Proceedings of the SPIE Photonics West 2018, San Francisco, CA, USA, 19 February 2018. [Google Scholar]
- Huang, Y.; Yan, Z.; Jiang, X.; Jing, T.; Chen, S.; Lin, M.; Zhang, J.; Yan, X. Performance enhanced elemental array generation for integral image display using pixel fusion. Front. Phys. 2021, 9, 639117. [Google Scholar]
- Shin, C.; Jeon, H.-G.; Yoon, Y.; Kweon, I.S.; Kim, S.J. EPINET: A fully-convolutional neural network using epipolar geometry for depth from light field images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kwon, K.-C.; Kwon, K.H.; Erdenebat, M.-U.; Piao, Y.-L.; Lim, Y.-T.; Zhao, Y.; Kim, M.Y.; Kim, N. Advanced three-dimensional visualization system for an integral imaging microscope using a fully convolutional depth estimation network. IEEE Photon. J. 2020, 12, 3900714. [Google Scholar]
- Schonberger, J.L.; Frahm, J.-M. Structure-from-motion revisited. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. NeRF: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2022, 65, 99–106. [Google Scholar]
- Hu, T.; Liu, S.; Chen, Y.; Shen, T.; Jia, J. EfficientNeRF efficient neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Müller, T.; Evans, A.; Schied, C.; Keller, A. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph. 2022, 41, 102. [Google Scholar]
- Park, J.; Stoykova, E.; Kang, H.; Hong, S.; Lee, S.; Jung, K. Numerical reconstruction of full parallax holographic stereograms. 3D Res. 2012, 3, 6. [Google Scholar]
- Khuderchuluun, A.; Erdenebat, M.-U.; Dashdavaa, E.; Lee, M.H.; Jeon, S.-H.; Kim, N. Simplified digital content generation based on an inverse-directed propagation algorithm for holographic stereogram printing. Appl. Opt. 2021, 60, 4235–4244. [Google Scholar]
- Vieira, A.; Duarte, H.; Perra, C.; Tavora, L.; Assuncao, P. Data formats for high efficiency coding of Lytro-Illum light fields. In Proceedings of the 2015 International Conference on Image Processing Theory, Tools and Applications (IPTA), Orleans, France, 10–13 November 2015. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a completely blind image quality analyzer. IEEE Sig. Process. Lett. 2013, 60, 209–212. [Google Scholar]
- Venkatanath, N.; Praneeth, D.; Chandrasekhar, B.M.; Channappayya, S.S.; Medasani, S.S. Blind image quality evaluation using perception based features. In Proceedings of the IEEE 21st National Conference on Communications, Montréal, QC, Canada, 14–23 June 2021. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Commercial Light Field Camera [31] | Camera Array (3 × 11 Cameras) | Proposed System (3 Cameras) |
|---|---|---|---|
| Resolution (single perspective) | 625 × 434 px | 6000 × 4000 px | 6000 × 4000 px |
| Data quality (for proposed system) | Low | High | High |
| Data quantity | Common | Common | Common |
| Data storage | NA | Can be required | NA |
| Viewing angle | Narrow (fixed) | Wide (can be controllable) | Wide (can be controllable) |
| Depth-of-field | Common (fixed) | Wide (can be controllable) | Wide (can be controllable) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Erdenebat, M.-U.; Amgalan, T.; Khuderchuluun, A.; Nam, O.-S.; Jeon, S.-H.; Kwon, K.-C.; Kim, N. Comprehensive High-Quality Three-Dimensional Display System Based on a Simplified Light-Field Image Acquisition Method and a Full-Connected Deep Neural Network. Sensors 2023, 23, 6245. https://doi.org/10.3390/s23146245
Erdenebat M-U, Amgalan T, Khuderchuluun A, Nam O-S, Jeon S-H, Kwon K-C, Kim N. Comprehensive High-Quality Three-Dimensional Display System Based on a Simplified Light-Field Image Acquisition Method and a Full-Connected Deep Neural Network. Sensors. 2023; 23(14):6245. https://doi.org/10.3390/s23146245
Chicago/Turabian StyleErdenebat, Munkh-Uchral, Tuvshinjargal Amgalan, Anar Khuderchuluun, Oh-Seung Nam, Seok-Hee Jeon, Ki-Chul Kwon, and Nam Kim. 2023. "Comprehensive High-Quality Three-Dimensional Display System Based on a Simplified Light-Field Image Acquisition Method and a Full-Connected Deep Neural Network" Sensors 23, no. 14: 6245. https://doi.org/10.3390/s23146245
APA StyleErdenebat, M.-U., Amgalan, T., Khuderchuluun, A., Nam, O.-S., Jeon, S.-H., Kwon, K.-C., & Kim, N. (2023). Comprehensive High-Quality Three-Dimensional Display System Based on a Simplified Light-Field Image Acquisition Method and a Full-Connected Deep Neural Network. Sensors, 23(14), 6245. https://doi.org/10.3390/s23146245