
3D Reconstruction with Single-Shot Structured Light RGB Line Pattern


Abstract
:1. Introduction
- (1)
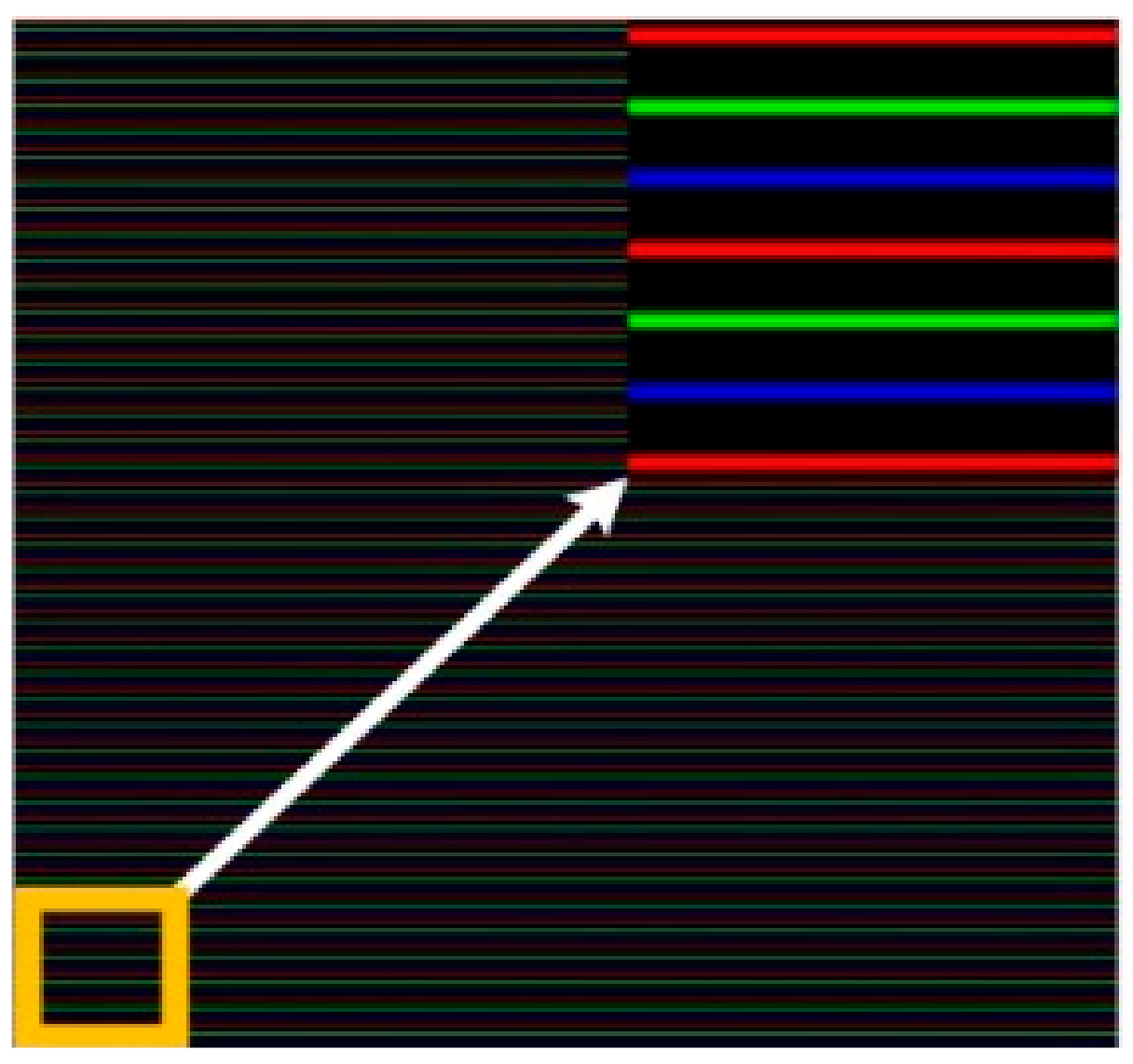
- A fully automatic color stripe segmentation method based on SDD is proposed to extract the RGB line pattern robustly. State-of-the-art methods rely on manually specified thresholds obtained by trial-and-error analysis or the classic classification methods to segment the color stripes. The trial-and-error analysis method is time-consuming and cannot guarantee that the optimal thresholds are always selected for each image. In addition, the demonstration in the paper shows that none of the compared classic classification methods can separate all the adjacent stripes from each other robustly. Due to the bottleneck problem of image segmentation, there are no 3D surface imaging products that are based on the segmented structured light patterns yet, even though the related theory and idea had been proposed for more than three decades. The proposed SDD segmentation method has the potential to solve this bottleneck problem for the single-shot dot-pattern- or line-pattern-based structured light methods.
- (2)
- An exclusion-based line clustering method is proposed to index the segmented stripes robustly. State-of-the-art methods have included different ways to index the segmented lines or dots uniquely. However, they may fail when complex and deforming objects are reconstructed. In [7], a line clustering method was proposed to index the lines from top to bottom, but it is only robust for simple and rigid objects. In [8,9], the line-slope-based clustering method was proposed to index the lines distorted by complex and deforming objects. However, its accuracy is easily affected by occlusion and large discontinuity. The line clustering method proposed in this paper is more robust than the previous methods [7,8,9] in indexing the lines distorted by complex and deforming objects, which is validated by the 3D reconstruction results of a deforming face and a deforming hand in the attached videos.
- (3)
- An extensive comparison of the proposed method with state-of-the-art single-shot 3D surface imaging methods (products) was conducted by reconstructing the deforming face and the deforming hand continuously, which is a necessary condition to verify the effectiveness of a single-shot structured light method.
2. Related Work
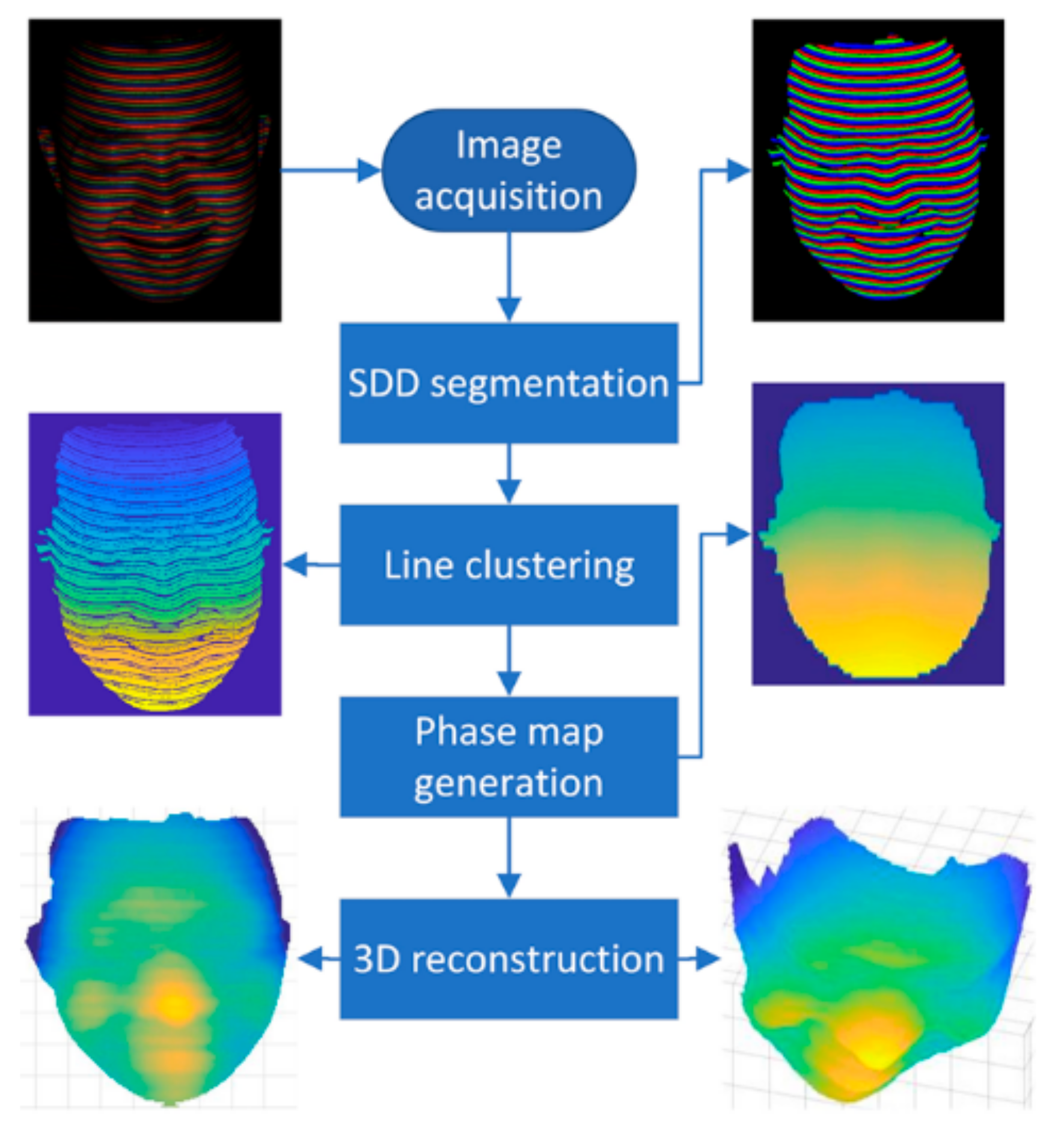
3. The Proposed Approach
3.1. The Proposed Pattern Extraction Method
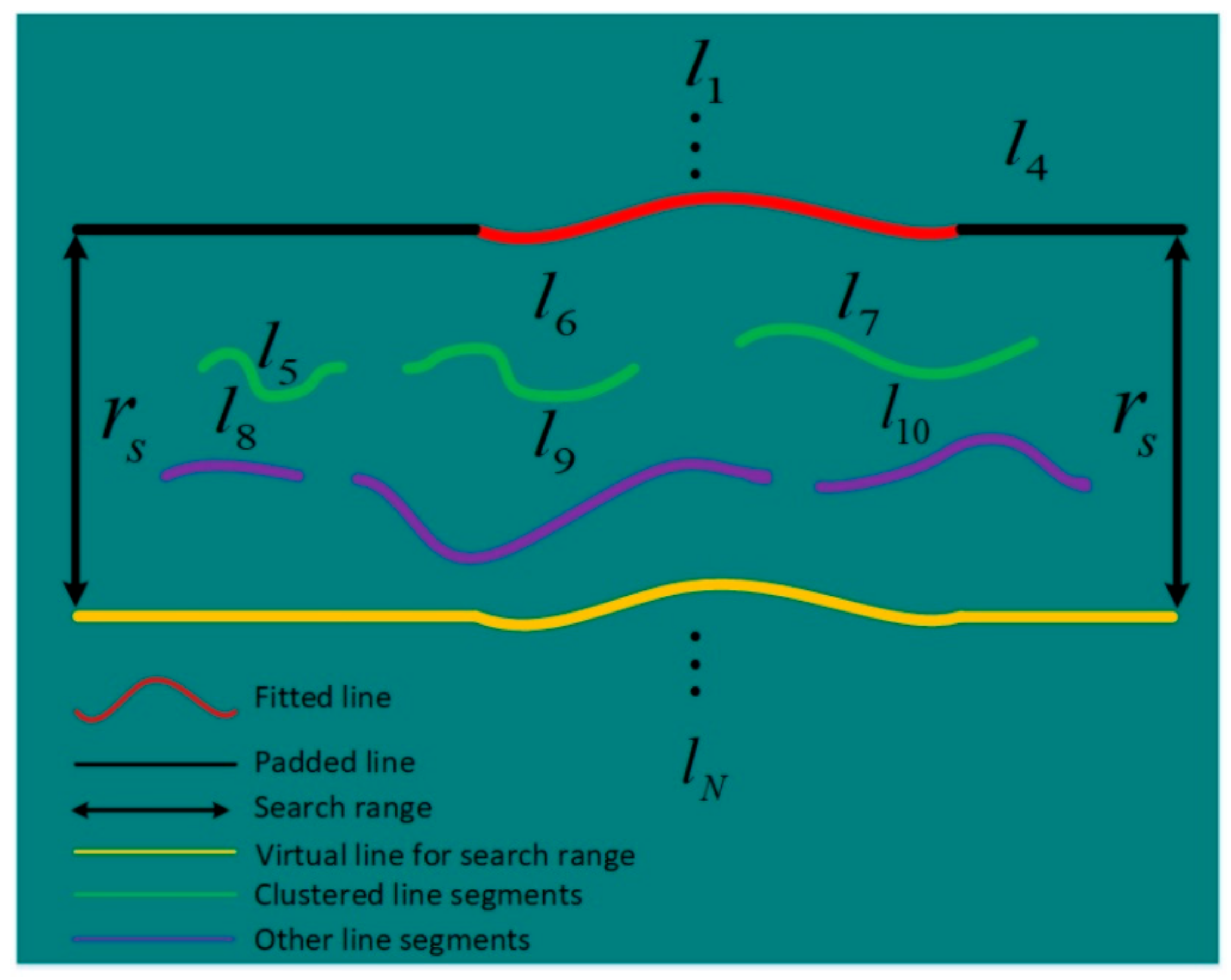
3.2. The Proposed line Clustering Method
- (1)
- If the leftmost point of the line segment falls between the length range of the line segment , i.e., and , the line segment is fitted with the line model by Equation (8) as . If the position of the leftmost point of the line segment is below the position of the fitted line model for the downward clustering, i.e., , the line segment is determined as not belonging to the next clustered line. If the position of the leftmost point of the line segment is above the position of the fitted line model for the upward clustering, i.e., , the line segment is determined as not belonging to the next clustered line.
- (2)
- If the rightmost point of the line segment falls between the length range of the line segment , i.e., and , the line segment is fitted with the line model by Equation (8) as . If the position of the leftmost point of the line segment is below the position of the fitted line for the downward clustering, i.e., , the line segment is determined as not belonging to the next clustered line. If the position of the leftmost point of the line segment is above the position of the fitted line for the upward clustering, i.e., , the line segment is determined as not belonging to the next clustered line.
- (3)
- (3) If the centroid of the line segment falls between the length range of the line segment , i.e., and , the line segment is fitted with the line model by Equation (8) as . If the position of the leftmost point of the line segment is below the position of the fitted line for the downward clustering, i.e., , the line segment is determined as not belonging to the next clustered line. If the position of the leftmost point of the line segment is above the position of the fitted line for upward clustering, i.e., , the line segment is determined as not belonging to the next clustered line.
- (4)
- If the leftmost point of the line segment falls between the length range of the line segment , i.e., and , the line segment is fitted with the line model by Equation (8) as . If the position of the leftmost point of the line segment is below the position of the fitted line for the downward clustering, i.e., , the line segment is determined as not belonging to the next clustered line. If the position of the leftmost point of the line segment is above the position of the fitted line for the upward clustering, i.e., , the line segment is determined as not belonging to the next clustered line.
- (5)
- If the rightmost point of the line segment falls between the length range of the line segment , i.e., and , the line segment is fitted with the line model by Equation (8) as . If the position of the leftmost point of the line segment is below the position of the fitted line for the downward clustering, i.e., , the line segment is determined as not belonging to the next clustered line. If the position of the leftmost point of the line segment is above the position of the fitted line for the upward clustering, i.e., , the line segment is determined as not belonging to the next clustered line.
- (6)
- If the centroid of the line segment falls between the length range of the line segment , i.e., and , the line segment is fitted with the line model by Equation (8) as . If the position of the leftmost point of the line segment is below the position of the fitted line for the downward clustering, i.e., , the line segment is determined as not belonging to the next clustered line. If the position of the leftmost point of the line segment is above the position of the fitted line for the upward clustering, i.e., , the line segment is determined as not belonging to the next clustered line.
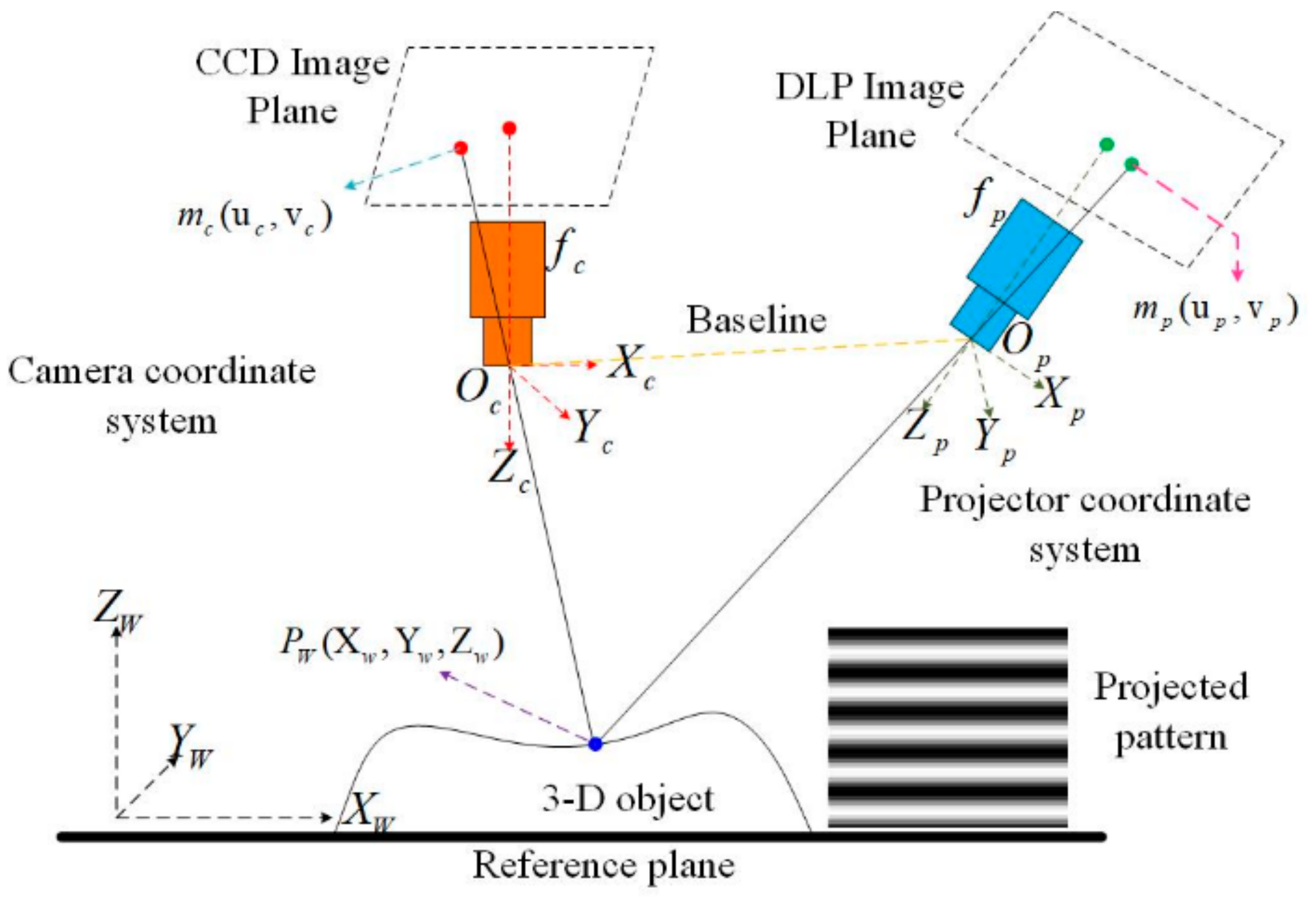
3.3. Three-Dimensional Reconstruction Based on the Phase Map
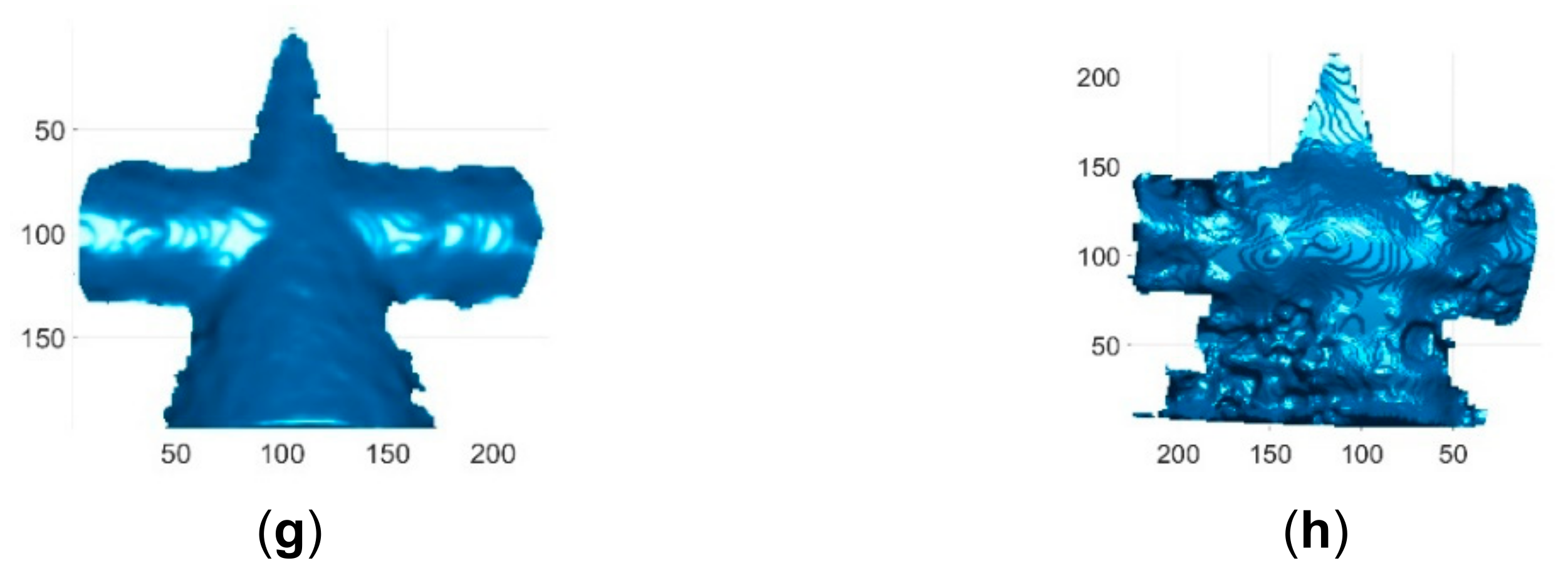
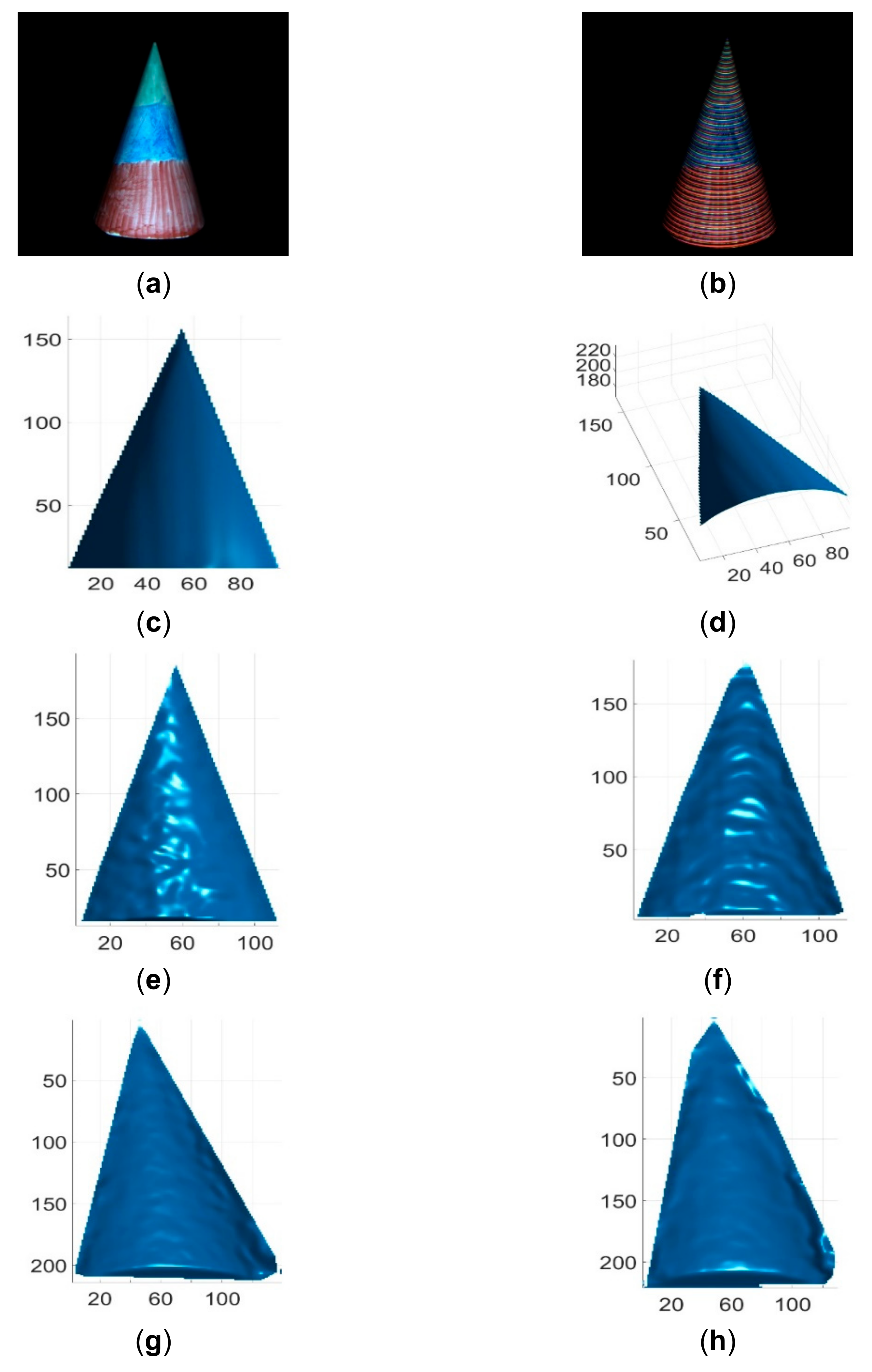
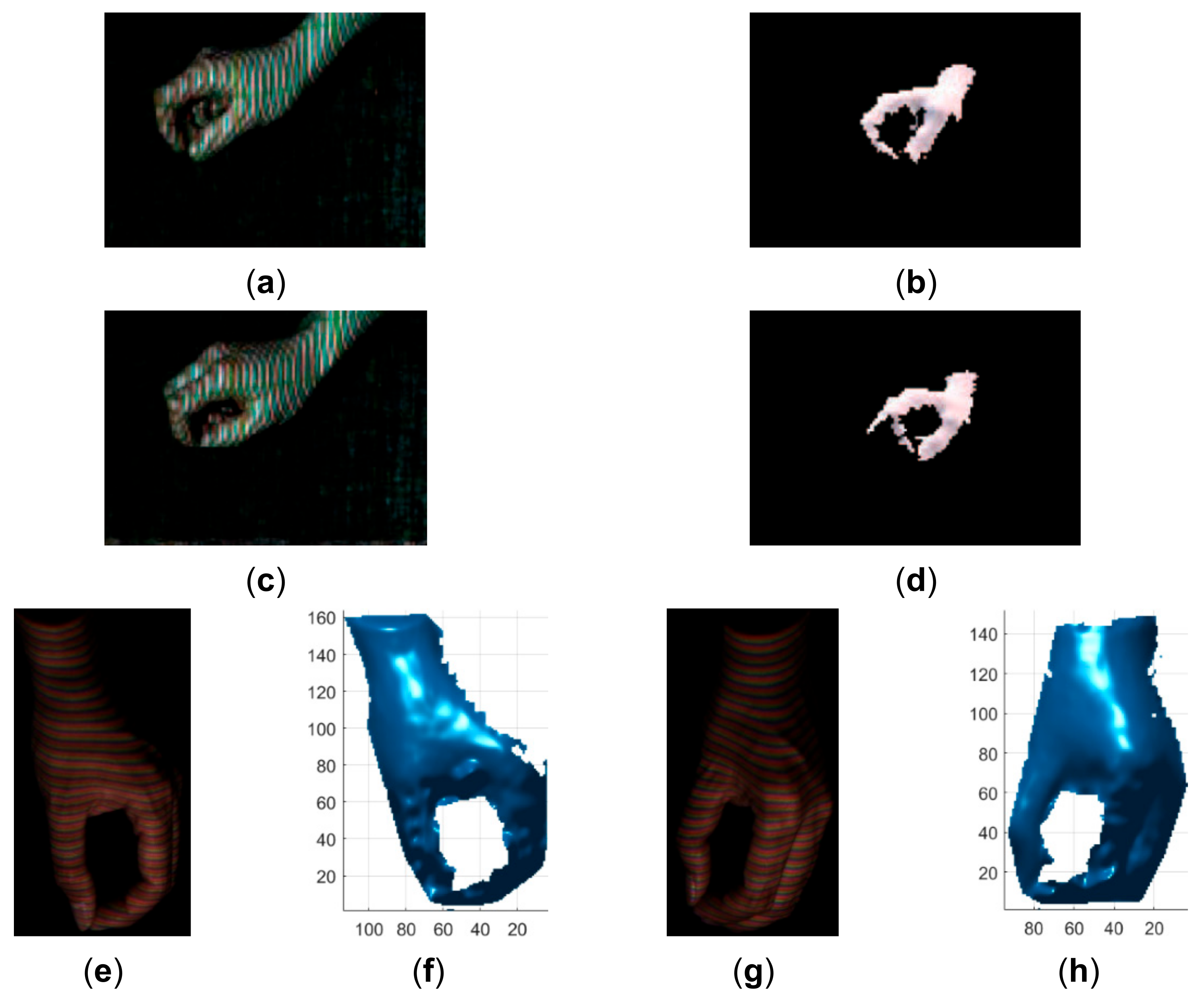
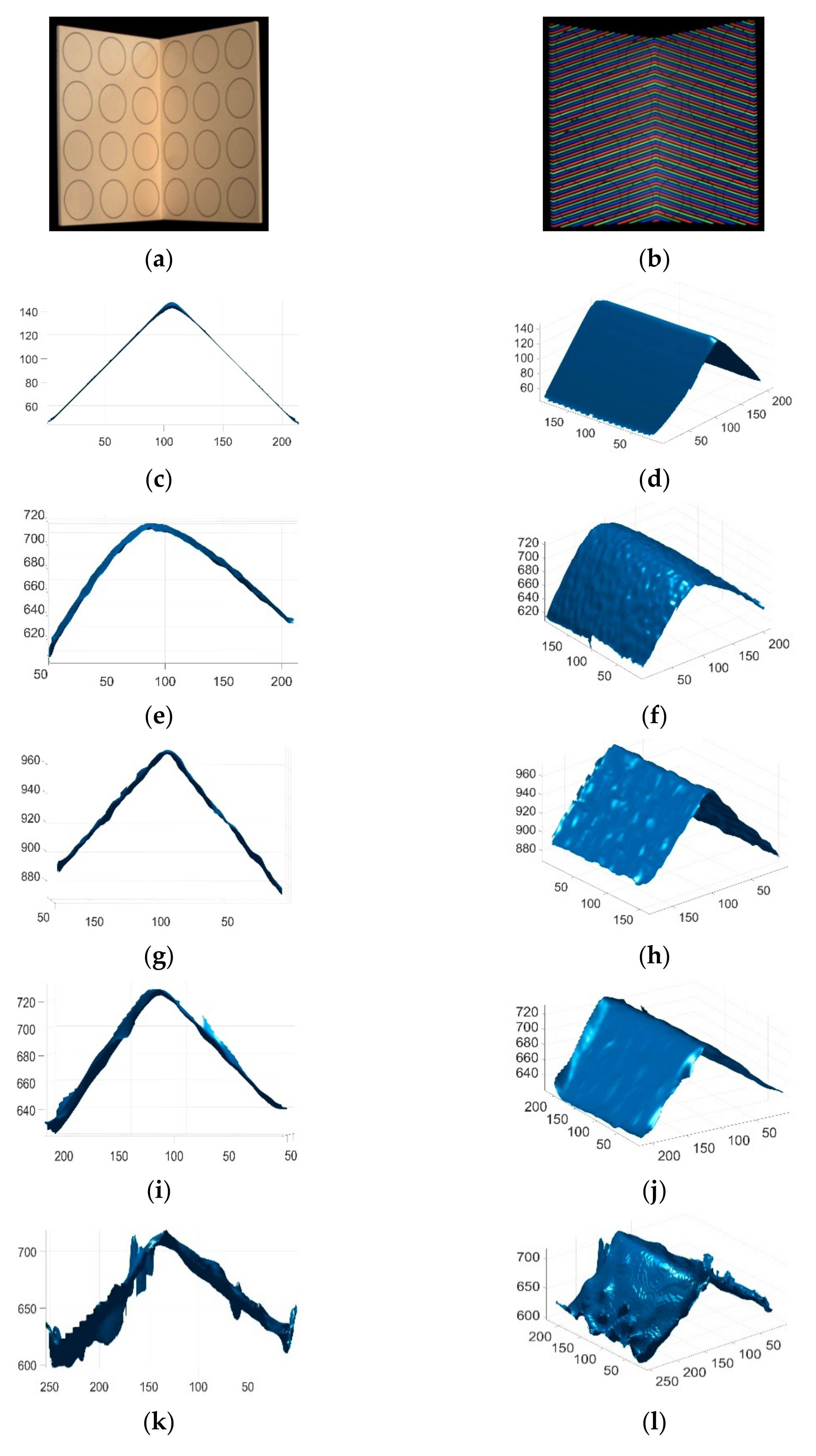
4. Results and Discussion
- (1)
- The measurement distance between the object and the structured light 3D imaging system is constrained in a relatively small range to make sure that both the camera and the projector are in focus, which is a common limitation of structured light technology.
- (2)
- The proposed method is not suitable for applications that require the reconstruction results to be full of accurate 3D details, such as defect detection.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Z.Z. Review of real-time threee-dimensional shape measurement techniques. Measurement 2020, 156, 107624. [Google Scholar] [CrossRef]
- Al Ismaeil, K.; Aouada, D.; Solignac, T.; Mirbach, B.; Ottersten, B. Real-Time Enhancement of Dynamic Depth Videos with Non-Rigid Deformations. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2045–2059. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sabater, N.; Almansa, A.; Morel, J.-M. Meaningful Matches in Stereovision. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 930–942. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jepsen, G. Projectors for Intel® RealSense™ Depth Cameras D4xx. Intel Support; Interl Corporation: Santa Clara, CA, USA, 2018. [Google Scholar]
- Ulrich, L.; Vezzetti, E.; Moos, S.; Marcolin, F. Analysis of RGB-D camera technologies for supporting different facial usage scenarios. Multimed. Tools Appl. 2020, 79, 29375–29398. [Google Scholar] [CrossRef]
- Takeda, M.; Motoh, K. Fourier transform profilometry for the automatic measurement of 3-D object shapes. Appl. Opt. 1983, 22, 3977–3982. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, Y. Single-shot three-dimensional reconstruction based on structured light line pattern. Opt. Lasers Eng. 2018, 106, 10–16. [Google Scholar] [CrossRef]
- Wang, Z.Z. Unsupervised Recognition and Characterization of the Reflected Laser Lines for Robotic Gas Metal Arc Welding. IEEE Trans. Ind. Inform. 2017, 13, 1866–1876. [Google Scholar] [CrossRef]
- Wang, Z.Z. Robust three-dimensional face reconstruction by one-shot structured light line pattern. Opt. Lasers Eng. 2020, 124, 105798. [Google Scholar] [CrossRef]
- Beumier, C.; Acheroy, M. Automatic Face Authentication from 3D surface. Br. Mach. Vis. Conf. 1998, 45, 45. [Google Scholar] [CrossRef]
- Kemelmacher-Shlizerman, I.; Basri, R. 3D Face Reconstruction from a Single Image Using a Single Reference Face Shape. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 394–405. [Google Scholar] [CrossRef]
- Garrido, P.; Valgaerts, L.; Wu, C.; Theobalt, C. Reconstructing detailed dynamic face geometry from monocular video. ACM Trans. Graph. 2013, 32, 1. [Google Scholar]
- Moss, J.; Linney, A.; Grindrod, S.; Mosse, C. A laser scanning system for the measurement of facial surface morphology. Opt. Lasers Eng. 1989, 10, 179–190. [Google Scholar] [CrossRef]
- You, Y.; Shen, Y.; Zhang, G.; Xing, X. Real-Time and High-Resolution 3D Face Measurement via a Smart Active Optical Sensor. Sensors 2017, 17, 734. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vilchez-Rojas, H.L.; Rayas, J.A.; Martínez-García, A. Use of white light profiles for the contouring of objects. Opt. Lasers Eng. 2020, 134, 106295. [Google Scholar] [CrossRef]
- Chen, S.Y.; Li, Y.F.; Zhang, J. Vision Processing for Realtime 3-D Data Acquisition Based on Coded Structured Light. IEEE Trans. Image Process. 2008, 17, 167–176. [Google Scholar] [CrossRef] [Green Version]
- Payeur, P.; Desjardins, D. Structured Light Stereoscopic Imaging with Dynamic Pseudo-random Patterns. In Image Analysis and Recognition, ICIAR 2009; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5627, pp. 687–696. [Google Scholar]
- Griffin, P.M.; Narasimhan, L.S.; Yee, S.R. Generation of uniquely encoded light patterns for range data acquisition. Pattern Recognit. 1992, 25, 609–616. [Google Scholar] [CrossRef]
- Morano, R.; Ozturk, C.; Conn, R.; Dubin, S.; Zietz, S.; Nissano, J. Structured light using pseudorandom codes. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 322–327. [Google Scholar] [CrossRef]
- Ito, M.; Ishii, A. A three-level checkerboard pattern (TCP) projection method for curved surface measurement. Pattern Recognit. 1995, 28, 27–40. [Google Scholar] [CrossRef]
- Vuylsteke, P.; Oosterlinck, A. Range image acquisition with a single binary-encoded light pattern. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 148–164. [Google Scholar] [CrossRef]
- Wang, J.; Xiong, Z.; Wang, Z.; Zhang, Y.; Wu, F. FPGA Design and Implementation of Kinect-Like Depth Sensing. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 1175–1186. [Google Scholar] [CrossRef]
- Khoshelham, K.; Elberink, S.O. Accuracy and Resolution of Kinect Depth Data for Indoor Mapping Applications. Sensors 2012, 12, 1437–1454. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Xiong, Z.; Yang, Z.; Wu, F. Real-Time Scalable Depth Sensing with Hybrid Structured Light Illumination. IEEE Trans. Image Process. 2013, 23, 97–109. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Li, H.; Zhang, H. Light plane calibration and accuracy analysis for multi-line structured light vision measurement system. Optik 2020, 207, 163882. [Google Scholar] [CrossRef]
- Je, C.; Lee, S.W.; Park, R.-H. Colour-stripe permutation pattern for rapid structured-light range imaging. Opt. Commun. 2012, 285, 2320–2331. [Google Scholar] [CrossRef]
- Robinson, A.; Alboul, L.; Rodrigues, M. Methods for indexing stripes in uncoded structured light scanning systems. J. WSCG 2004, 12, 371–378. [Google Scholar]
- Brink, W.; Robinson, A.; Rodrigues, M.A. Indexing Uncoded Stripe Patterns in Structured Light Systems by Maximum Spanning Trees. BMVC 2008, 2018, 1–10. [Google Scholar]
- Boyer, K.L.; Kak, A.C. Color-Encoded Structured Light for Rapid Active Ranging. IEEE Trans. Pattern Anal. Mach. Intell. 1987, 9, 14–28. [Google Scholar] [CrossRef]
- Koninckx, T.; Van Gool, L. Real-time range acquisition by adaptive structured light. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 432–445. [Google Scholar] [CrossRef]
- Yalla, V.G.; Hassebrook, L.G. Very high resolution 3D surface scanning using multi-frequency phase measuring profilometry. Def. Secur. 2005, 5798, 44–53. [Google Scholar] [CrossRef]
- Wang, Z. Robust measurement of the diffuse surface by phase shift profilometry. J. Opt. 2014, 16, 105407. [Google Scholar] [CrossRef]
- Wang, Z. Robust segmentation of the colour image by fusing the SDD clustering results from different colour spaces. IET Image Process. 2020, 14, 3273–3281. [Google Scholar] [CrossRef]
- Wang, Z. Automatic Localization and Segmentation of the Ventricles in Magnetic Resonance Images. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 621–631. [Google Scholar] [CrossRef]
- Lloyd, S. Least squares quantization in PCM. IEEE Trans. Inf. Theory 1982, 28, 129–137. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar] [CrossRef] [Green Version]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. 1977, 39, 1–38. [Google Scholar]
- Hartley, R.; Zisserman, A.; Faugeras, O. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar] [CrossRef] [Green Version]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Line Segmentation | Line Indexing |
|---|---|---|
| [26] | Color classification | Permutation |
| [27] | Local maxima | Flood fill |
| [28] | Local maxima | Spanning tree |
| [29] | Manual | Unique word |
| [30] | Color classification | Graph cut |
| Proposed | SDD thresholds | Exclusion |
| Methods\Objects | Grid | Ball |
|---|---|---|
| Intel D435 SV | 5.83 mm | 5.3 mm |
| Intel D435 ASV | 0.79 mm | 0.86 mm |
| Kinect V1 | 14.36 mm | 1.18 mm |
| Kinect V2 | 3.05 mm | 0.36 mm |
| Proposed | 0.46 mm | 0.24 mm |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Wang, Z. 3D Reconstruction with Single-Shot Structured Light RGB Line Pattern. Sensors 2021, 21, 4819. https://doi.org/10.3390/s21144819
Li Y, Wang Z. 3D Reconstruction with Single-Shot Structured Light RGB Line Pattern. Sensors. 2021; 21(14):4819. https://doi.org/10.3390/s21144819
Chicago/Turabian StyleLi, Yikang, and Zhenzhou Wang. 2021. "3D Reconstruction with Single-Shot Structured Light RGB Line Pattern" Sensors 21, no. 14: 4819. https://doi.org/10.3390/s21144819
APA StyleLi, Y., & Wang, Z. (2021). 3D Reconstruction with Single-Shot Structured Light RGB Line Pattern. Sensors, 21(14), 4819. https://doi.org/10.3390/s21144819