1. Introduction
Monitoring water quality is vital for the proper management of valuable freshwater resources for drinking water supply, recreational purposes, and ecosystem support. With the increasing impact of climate change and human activities on water quality, it has become increasingly important to establish monitoring schemes that can provide continuous real-time information on water quality and track its event-scale changes, seasonal patterns, and long-term variations. Among others, nutrients are one of the main focuses of water quality monitoring because of their relevance to unresolved eutrophication problems and further environmental consequences.
The technological advancement in the field of sensors science has allowed for in situ measurements without manual sampling [
1,
2]. Ion-selective electrodes (ISE), wet-chemical analyzers, and optical sensors are the three categories in which current commercially available sensor technologies for nutrient analysis fall [
3]. ISE are cheap and simple to use, however they have been criticized for being imprecise and prone to disruptions and straying. Wet chemical analyzers and optical sensors, on the other hand, exhibit superior resolution and accuracy, but they are costly and have high maintenance needs [
4]. Their utility for long-term in situ and online outdoor monitoring may be constrained by these shortcomings [
5].
The above problems can be addressed using soft sensor technology based on machine learning (ML) models. The soft sensor is a feasible and economical alternative to expensive or impractical physical measurement sensors [
6,
7]. In recent years, the development of soft computing tools based on ML models in the fields of water and environmental engineering has received wide attention [
8,
9,
10,
11,
12]. In this regard, decision-tree-based algorithms such as Random Forest (RF) are widely used due to their high generalization ability. Francke et al. (2008) is one of the earlier studies that employed the RF to predict suspended sediment concentrations [
13]. They compared it with a generalized linear regression model and found the RF to be more robust and it performed well to reproduce sediment dynamics. Ha et al. (2020) using RF found R
2 higher than 0.8 for orthophosphate, nitrite and nitrate in Vietnam (Ha, Nguyen [
14]). Shen et al. (2020) used the RF to predict total nitrogen and total phosphorous covering 62,495 stations across the United States and obtained R
2 between 0.56 and 0.88 (Shen, Amatulli [
15]). Harrison et al. (2021) used the RF models to predict different nitrogen and phosphorus species; their models of total nitrogen and total phosphorous were able to explain variations of 85% and 74%, respectively (Harrison, Lucius [
16]). Among all these studies, the study of Tran et al. (2022) sets the premise of this study, where they used 15-min high-frequency measurements of nutrients and other water quality parameters and developed the soft sensor using the random forest algorithm and found the R
2 higher than 0.95 for NO
3-N, OPO
4-P and NH
4-N [
17]. These studies demonstrate that soft sensors based on ML models can provide reliable alternative real-time monitoring. However, in order to build an effective and efficient soft sensor, the ML models require the appropriate amount of input data of high quality, while balancing cost and feasibility [
18].
To minimize overfitting and hence improve generalization, it is usually recommended to pick a subset of predictors in any ML model [
19]. Furthermore, a simpler model with fewer predictors is preferable since it will take less time and resources to train and test and will be easier for the end-users to understand [
20]. When building soft sensors, using fewer predictors also means lower monitoring costs for practical reasons. The subset specifies the combination of surrogate physical sensors that will be used in the future to operate the soft sensors. The goal is to use the fewest number of predictors possible to save money on the expense of procuring, installing, and maintaining the surrogate physical sensors on which the soft sensors work. However, the selection for the smallest optimal predictor subset in the process of building soft sensors has not yet become a standard procedure. Furthermore, surrogates that are part of the optimal subset for several target variables can be shared across models. The surrogate that is used a greater number of times would naturally become more important. This would help in determining the surrogate sensors that are needed at the stations, as well as provide experience in establishing soft sensors even across stations in large monitoring networks.
Higher sampling frequency is highly useful as it can be used for a variety of applications such as baseline characterization, event-based monitoring, compliance monitoring, and forecasting models for water quality [
21,
22,
23,
24]. However, high data volumes are not always advantageous, as the capacity to manage, store, and process the data must also be taken into account, along with any related expenses [
25]. When data are gathered too infrequently, they will depict an erroneous or incomplete pattern of water quality, but when they are collected too frequently, they will be redundant, expensive, and contain noise [
26]. The frequency of data must be balanced against their manageability, although the exact balance will depend on the overall goal of any monitoring scheme [
27]. Additionally, these measurement frequencies require previous setup and have little leeway when it comes to reacting to unplanned events.
Precisely quantifying the sampling frequency requirements of physical sensors required for developing soft sensors would yield significant benefits in terms of reducing operational costs and conserving energy while simultaneously improving the quality of data fed into the models. Researchers have used a variety of methods for the determination of optimal sampling frequency (OSF), and they all yielded different results depending on the use of monitoring systems. Zhou (1996) determined that 1 month was the OSF for a ground-water monitoring system for a pumping station using Nyquist frequency [
28]. According to the macro-index level and Mann–Kendall test used by Naddeo et al. (2007) to compare the ecological state of the rivers, OSF was determined to be 1 month [
29]. Anvari et al. (2009) used a qualitative approach to find that the OSF of measuring stations set up to provide data for river water quality modeling systems was 15 min [
30]. For river water quality monitoring systems, Liu et al. (2014) suggested a grab sampling every 2 to 3 months [
27]. Khalil et al. (2014) evaluated the level of ambient water quality based on a historical time series of 36 years measured from 23 different locations [
31]. They suggested varying sampling frequencies for several variables, ranging from 4 to 12 samples each year. Chen and Han (2018) used a novel qualitative technique on a surface water quality monitoring system and reported 5 min as the OSF [
32]. Silva et al. (2019) used spectral analysis and suggested varying sampling frequencies based on the size of the watershed [
33]. However, to our knowledge there is no study that has determined the OSF required for the soft sensors to train on.
The aim of this study is to develop a robust and efficient soft sensor for the surrogating high-frequency nutrient concentrations using other physical sensor measurements. This study attempts to establish the effective and efficient soft sensors through two aspects: (1) identifying the optimal subset of predictors to eliminate redundant predictors and (2) determining the OSF of the sensors required for model training to obtain the best performance to operational cost ratio. Reducing the number of sensors and running them at lower frequency would reduce operational costs. This study facilitates the development of leaner soft sensors with less redundancies and lower costs and promotes real-life applications of the soft sensors.
2. Materials and Methods
In this study, random forest models were developed to predict the nutrients. The models were optimized for the number of predictors and then trained on different sampling frequencies of the physical sensors to determine the OSF of data the models need for their optimal performances. To construct the models, data from two automated measuring stations on the Main River, namely Erlabrunn (upstream) and Kahl am Main (downstream), were used. Four water quality parameters—dissolved oxygen (DO), temperature (Temp), electronic conductivity (EC) and pH—along with two time features—month and week—and discharge rate (Q) at each station were used as predictors. The model targets were the concentrations of nitrate (NO
3-N), orthophosphate (OPO
4-P), and ammonium (NH
4-N). The workflow of this study is presented in
Figure S1 of Supporting Information.
2.1. Data and Study Site Description
The data used in this study were obtained from the Waterscience service of Bavaria (Gewässerkundlicher Dienst Bayern,
https://www.gkd.bayern.de/ (accessed on 7 May 2023)) of the Bavarian State Office for the Environment (Bayerisches Landesamt für Umwelt, LfU, Augsburg, Germany). Two water quality monitoring stations in the Bavarian section of the Main River representing upstream (Station Erlabrunn, Erlabrunn, Germany) and downstream (Station Kahl am Main, Karlstein am Main, Germany) were chosen (
Figure S2). The Main is the Rhine’s third largest tributary. At its mouth, it discharges water at a mean rate of 225 m
3 s
−1. Using automated measuring instruments, Station Erlabrunn and Station Kahl am Main monitor DO, Temp, EC, pH, NO
3-N and OPO
4-P with a 15-min temporal resolution, with station Kahl am Main additionally also monitoring NH
4-N. The discharge rates are not monitored at the same automated water quality stations. Instead, the discharge data from stations that are nearby and are on the mainstream are used, specifically Station Würzburg for Erlabrunn (upstream) and Station Obernau Aschaffenburg for Kahl am Main (downstream).
The surrogate models for the Erlabrunn station were built with a dataset of ~4 years, starting from 15 November 2016 and ending on 30 December 2023. Kahl am Main station does not measure NH4-N, so the models were only developed for NO3-N and OPO4-P. For Kahl am Main, the NO3-N model used a dataset of ~4 years between 16 September 2017 and 31 August 2021. The OPO4-P and NH4-N models used a ~2-year dataset between 2 September 2019 and 31 August 2021.
2.2. Tools Used for Data Analysis
The data were in Comma-Separated Values (CSV) format. All data analysis and model development were carried out with Python3.8-based open-source tools and frameworks. Pandas (1.1.3), NumPy (1.19.2), SciPy (1.5.2), and Scikit-learn (0.23.2) are the major libraries utilized in this study. The chosen libraries are used extensively in the community and have well-prepared documentation openly available. The individual functions are explained in the following text.
2.3. Data Pre-Processing and Spliting
Data pre-processing is important because the dataset has outliers and gaps in measurement. These arise from the maintenance of sensors or when the calibration goes off. For cleaning the outliers, Isolation Forest was used, an outlier detecting function from Scikit-learn library [
34]. An expected percentage of contamination is input into the function and based on that the function cleans out the outliers. For NO
3-N, the database is assumed to be 10% and for NH
4-N and OPO
4-P, 20% are assumed as contaminated.
The dataset contains data gaps in monitoring that are indicated by NaN (Not a Number). NaN values are the consequence of maintenance or calibration operations that are regularly performed at the stations, in addition to being produced by deleting outliers. Because the models can not handle NaN values, they must be eliminated in the dataset before being used in the models. To take advantage of target values as much as possible, the rows with target values as NaN were first eliminated, and the NaN values in the predictors were filled using linear interpolation. A limit of 30 was applied to the number of consecutive NaNs that could be interpolated and if the gap was higher than 30 consecutive NaNs then those readings were removed. To explain further, taking the case of NO
3-N at Erlabrunn station, NO
3-N has 3937 NaN values, so all these 3937 rows were removed. Next, the NaN values of the other predictors were interpolated if the number of consecutive NaNs was below 30, or otherwise deleted. This finally created a data frame with 65,808 rows and the statistics that give an overview of the cleaned dataset are in
Table 1.
In addition to the four physio-chemical parameters measured by sensors, time is introduced as a feature as well to harness the periodicity of the data. Two time features—month and week—were used. To simulate their cyclic behavior they were transformed using sin and cos functions, similar to the methodology developed by Hempel et al. (2020) [
35]. The intrinsic property of sine and cosine adding up to 1 ensures that a circle is formed, and hence the cyclic property of months and weeks is mathematically incorporated into the model. This ensures that the model treats January and December as consecutive months and not as a year apart. This whole exercise gives us four additional predictors, namely week_sin, week_cos, month_sin and month_cos.
The entire dataset was split into working and testing datasets. The latter was made by randomly selecting 20% of the observations from each month. The remaining 80% was the working dataset. The working subset was used to develop the model. Cross-validation was carried out within the working dataset using the Sk-learn. Shuffle split function which used 5 runs, where each run was allocated 20% of the data for validation. The R2 and RMSE for the cross-validation performance were calculated by averaging the results of all 5 cross-validation runs. The testing dataset was used to evaluate the final model’s performance on the unseen data.
2.4. Random Forest Model
In this study, Random Forest was chosen because of its simplicity and easily explainable mechanism [
20]. As the name indicates, a random forest is made up of a huge number of individual decision trees that work together as an ensemble. Each tree in the random forest produces a class prediction, and the most voted class becomes the prediction of our model. The wisdom of crowds is the basic principle of random forest, and itis a simple yet effective one. The reason why the random forest model functions so well is that it consists of a huge number of largely uncorrelated models (trees) that work together to outperform any of the individual constituent models. While some trees may be incorrect, many others will be accurate, allowing the trees to move in the correct direction as a group.
The RandomForestRegressor function of the Scikit-Learn package was utilized in this study, which builds multiple regression trees on different sub-samples of the dataset and employs averaging to increase predicted accuracy and control over-fitting. The models were run on a specified grid of values to determine the optimal value of the hyperparameters. This procedure was carried out using Scikit-Learn’s GridSearchCV function and cross-validation using 5 iterations of ShuffleSplit function on 5 and 50 trees (fewer trees to increase the speed of the searching process).
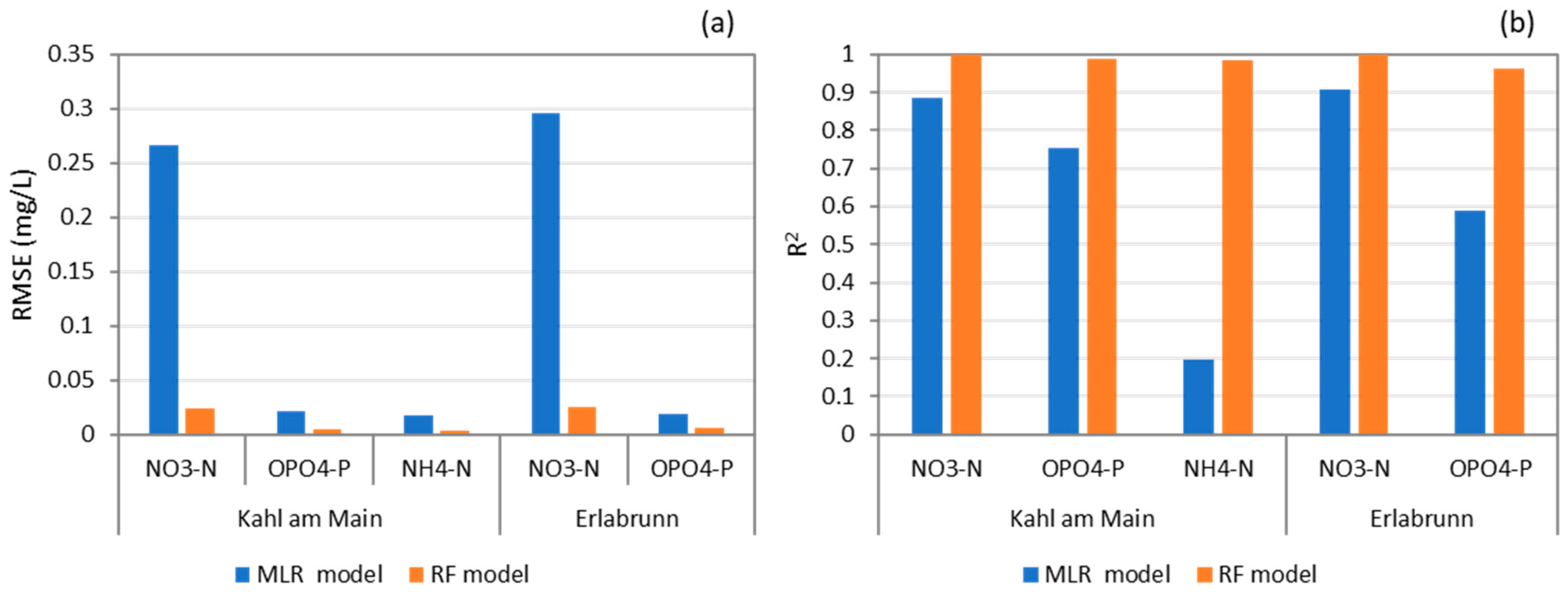
Table 2 lists the hyperparameters and their values found in the grid. These yielded 162 combinations, multiplied by the 5 folds to yield 810 fits. Following the fitting of the hyperparameters, the number of trees was modified by examining the model’s performance with 1, 10, 50, 100, and 200 trees. The greatest number of trees that improved the test error by more than 5% over the results of previous number of trees was picked. Finally, the RF model performances were evaluated using R
2 and RMSE on the unseen testing dataset and compared with the Multi-Linear Regression (MLR) models with the same predictors.
2.5. Selection of Variable Predictors
Various variable selection approaches, such as Best Subset Selection, Hierarchical Partitioning and Stepwise Selection with Bootstrapping have previously been used in water sciences modelling [
13]. Stepwise Forward Subset was used in this study, which evaluates the model performance with each individual variable and iteratively more the variable that produces the greatest improvement according to a specific Goodness-of-fit criterion, namely R
2 from the cross-validation results, in this case ma2.6. for determination of the optimal sampling frequency
All 5 RF models for estimating nutrients were trained on 40 different sampling frequencies, ranging from monthly to 30-min intervals. The dataset for different frequencies were prepared by resampling from the original 15-min-interval dataset. For example, for the hourly dataset, we resampled it such that it was 1 datapoint for every 4 datapoints. The performance of each model with different sampling frequencies was evaluated with the testing dataset, which constituted 20% of the entire dataset with the temporal resolution of 15-min intervals. A graph was plotted using the model evaluation results from the 40 runs, visualising the relationship between the sampling frequency and the Root Mean Squared Error (RMSE). The Kneedle algorithm was then applied to identify the knee point for determining the OSF frequency at which an increase in the frequency no longer resulted in a significant improvement in performance [
36]. For the purpose of defining the knee point, Satopaa et al. (2011) in their Kneedle algorithm used the mathematical definition of curvature for a continuous function [
36]. There is a common closed-form formula,
Kf(
x), that expresses the curvature of any continuous function f as a function of its first and second derivative at any point, as follows:
Since curvature is a mathematical measure of how far a function deviates from a straight line, the point of maximum curvature is ideally matched to the ad hoc approaches which operators employ to determine a knee point. As a result, the leveling-off effect that operators employ to detect knees is captured by maximum curvature. The concept of curvature in this application is different than the other work in the area as it is application neutral, does not rely on the link between system characteristics and performance, and does not necessitate the creation of system-specific thresholds.
4. Discussion
4.1. Nutrient Soft Sensor Performance Using RF
The utilization of RF based soft sensors has demonstrated impressive predictive power, as evidenced by R
2 values exceeding 0.95 in the prediction of NO
3-N, OPO
4-P and NH
4-N. Our results are comparable to the similar study using 15-min high-frequency measurements by Yen et al. (2022) and have higher R
2 values than the three studies mentioned in
Section 1 [
13,
14,
15]. Remarkably, this predictive capacity was maintained even with a smaller subset of predictors, comprising of five variables. These findings are consistent with the prior research [
17,
37] in this field, which likewise emphasized the importance of optimizing soft-sensor performance through the identification of optimal predictor sets. In this study it can be seen that the order of the inclusion is random and does not follow the order of the highest correlated variable going first as was previously expected (
Supporting Information, Table S1). The RF model uses predictor variables that, a priori, are irrelevant, neither intuitively nor when looking at correlation coefficients or stepwise subsets with linear models. This is due to the intricate linkages that underlie the model and demonstrates the ability of the RF algorithm to mimic these non-linear relations embedded in the environmental phenomenon. The current work’s findings indicate that in order to successfully complete the variable sub-setting process, it is essential to follow a procedure that is in line with the model that will be implemented. In the literature there exist simpler and less resource-intensive methods such as feature weight coefficient or feature importance [
38,
39]. However, when the goal is to choose the fewest number of predictors without compromising the model’s accuracy, user-defined performance metrics perform better.
4.2. Optimal Predictor Subset and Sampling Freuqnecy
The best subgroups of the five predictors for all the soft sensors in both the stations only differ in one predictor: week_sin, EC, and Temp are there in all the five cases; DO is employed in two of the cases and Q in the other three. This indicates that a group of four predictors would be able to predict all the nutrients simultaneously with R2 greater than 0.99 for two cases and greater than 0.95 for the other three. EC, and Temp, DO and Q are commonly measured in rivers and streams by physical sensors within the authority monitoring schemes with high robustness, accuracy, and temporal resolution. Using them as surrogates would increase the applicability of setting up the soft sensors for nutrients in a broader context in the real world.
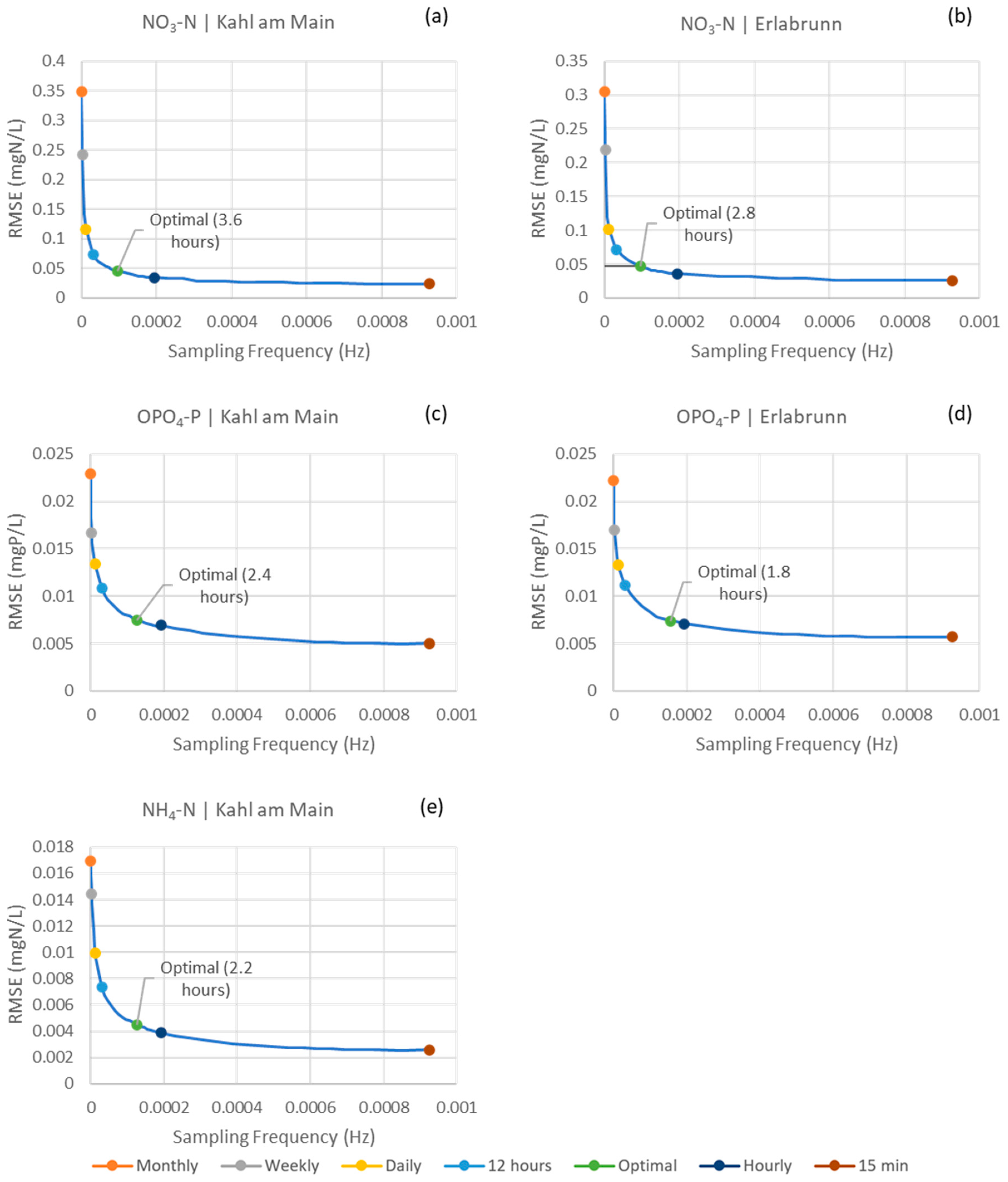
Another main finding of this study is that the performances of the nutrient surrogate models depend on the frequency of the data they are trained with; the higher the frequency, the better the performance in all the soft sensor cases. The graphs presenting the model performances with different sampling frequencies, as
Figure 2 in this study, provide stakeholders with evidence to help them determine the level of accuracy and the corresponding sampling frequency required for a specific case. For example, when being trained on a monthly sampling frequency, commonly performed in routine monitoring schemes, the model for NO
3-N at the Kahl am Main station gave an RMSE of 0.35 mgN L
−1. In comparison, the RMSE was 0.02 mgN L
−1 when the model was trained on the 15-min-interval data. Nevertheless, the model trained with the monthly data and their results can still be useful in certain cases. Overall, this study demonstrates the possible RMSEs when the surrogate models for nutrient soft sensors are trained on different sampling frequencies, offering a first idea of the accuracy level such models might achieve.
Furthermore, the results of this study show that the RF models can perform without losing much of their accuracy when trained at a lower frequency than 15-min intervals. In the cases of OPO4-P and NH4-N, the OSFs were found to be approximately every 2 h. By using these OSF, the R2 values when compared to those of the models trained on 15-min interval had a worsening of 2.75% and 1.69% in the case of OPO4-P at the upstream and downstream stations, respectively, and had a worsening of 3.72% for NH4-N at the downstream station. However, at those OSFs, the amount of data collected and stored is only 1/8 of what was previously being monitored at 15-min intervals. In the case of the NO3-N soft sensor at the Kahl am Main station, the OSF was found to be approximately every 4 h. By using this frequency, the model had a worsening of 0.25% in the R2 values compared to the 15-min ones. Similarly, for the Erlabrunn station, the OSF for NO3-N was determined to be approximately every 3 h and resulted in a compromise of 0.15% in the R2. These results would allow the physical sensors installed on the rivers to operate at lower frequencies and would save significant storage space and costs associated with measuring, handling and processing data for building soft sensors.
Coraggio et al. (2022) used the power spectral density (PSD) function to determine the frequencies with the highest density in the water quality measurements with high-frequency sensors [
40]. This helped them determine how representative a particular frequency is of the overall situation. Their PSD cumulation curve showed that after a certain point, increasing the frequency does not provide any additional information, enabling them to identify a knee point for OSF, similar to the current study. They analyzed electrical conductivity, dissolved organic matter, dissolved oxygen, turbidity, and temperature measurements, and found their OSFs of 6, 5, 5, 3, and 9 h, respectively. These results are comparable with the present study, indicating that the OSF of the water quality data for training soft sensors is also nearly optimal for monitoring them. In other words, if a physical sensor is set up to accurately measure and provide a comprehensive understanding of what it is measuring, it will also provide an optimal amount of data for building soft sensors.
4.3. Measures against Overfitting
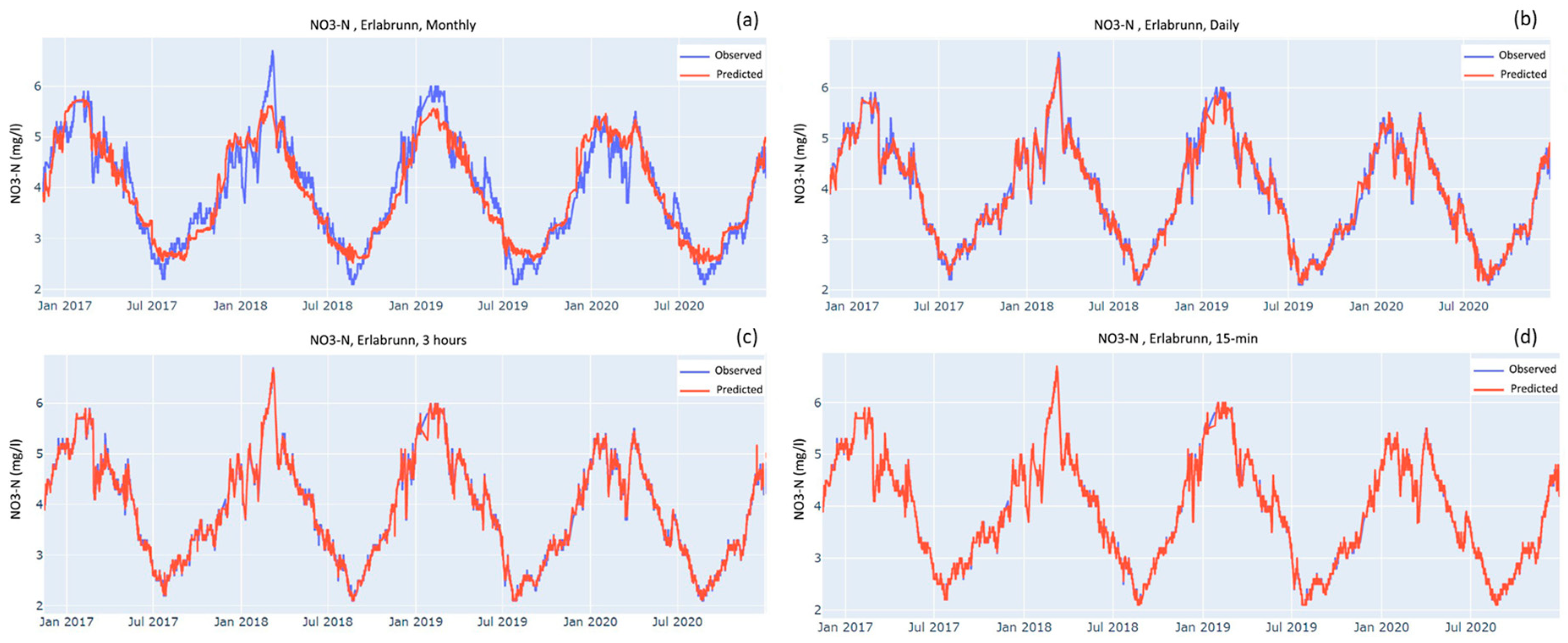
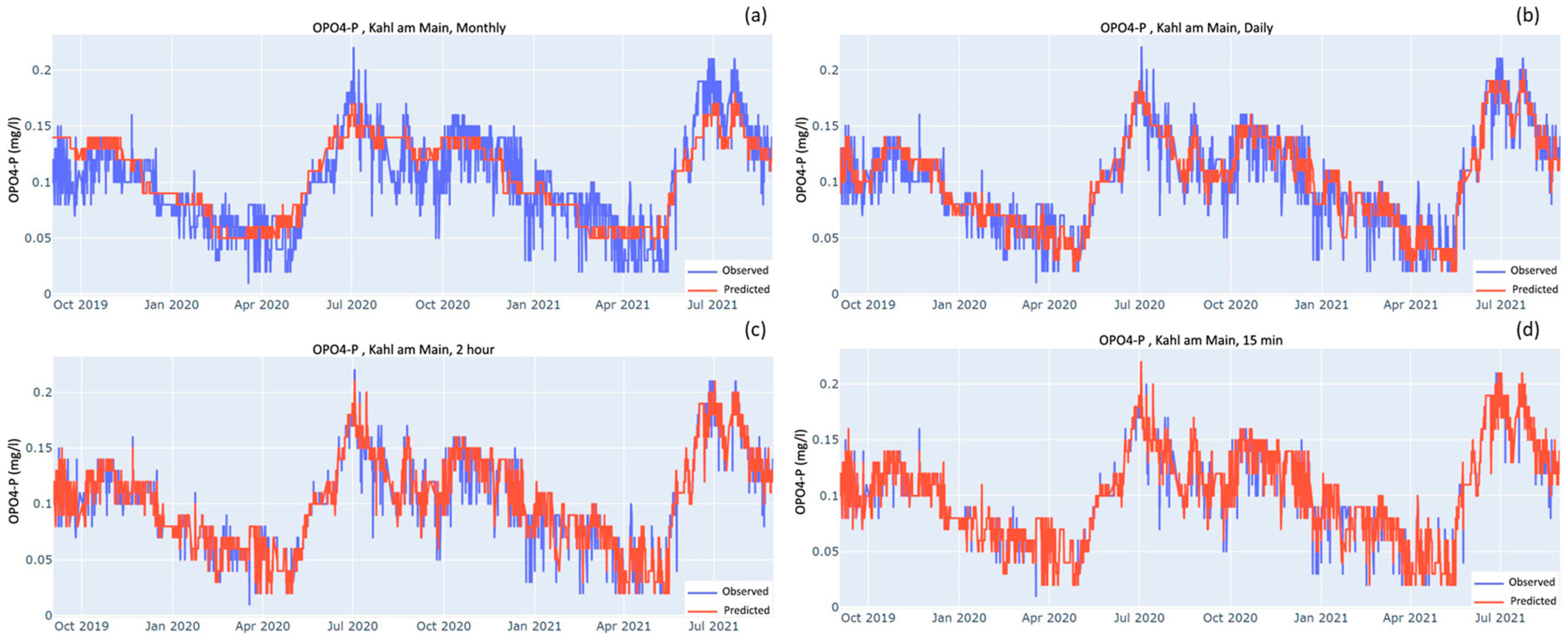
A big concern with random forest models is that they are highly susceptible to overfitting. The results of this study, with the R
2 values higher than 0.95 in all cases, suggest the possibility of this issue. To make sure the models were not overfitted, in the first place, all models regardless of at which frequencies and which subsets of predictors were tested with 20% of the of the datapoints from the whole dataset. Furthermore, in some cases, the models using lower frequencies were tested on a much larger dataset than they were trained on. For example, the models, as shown in
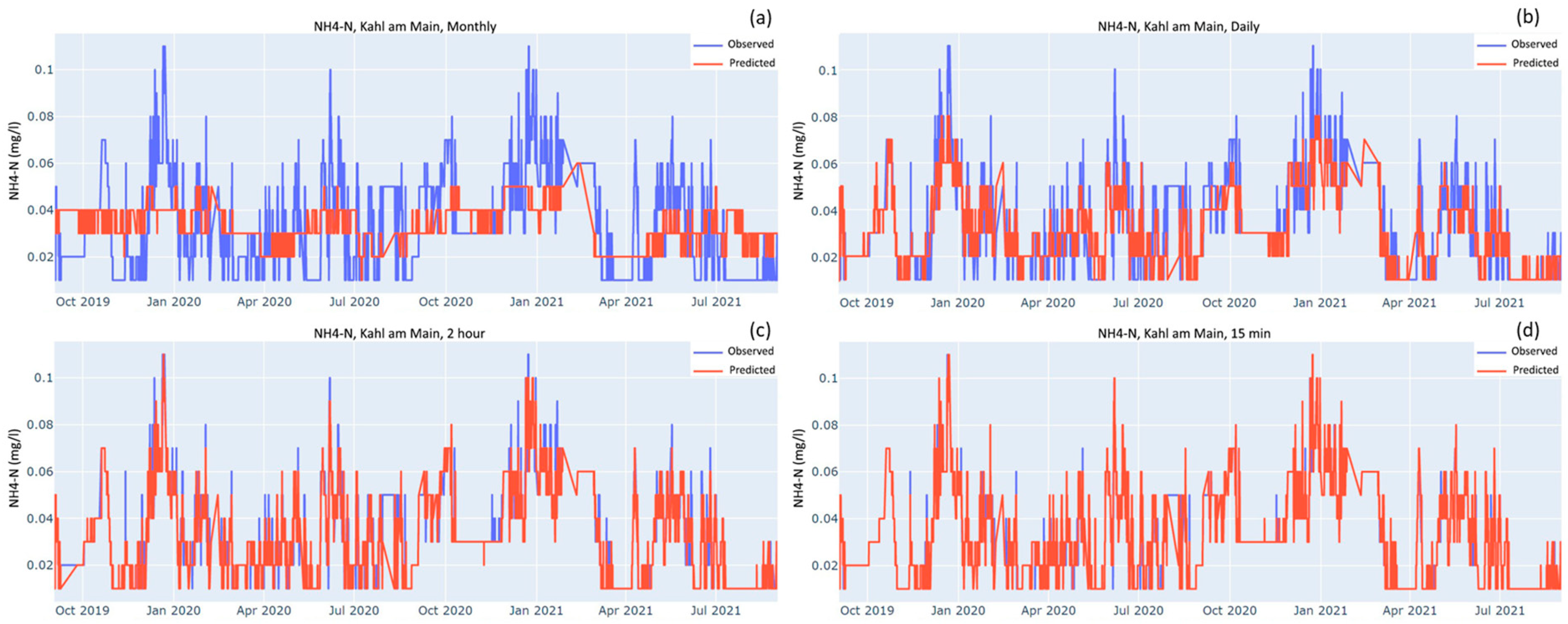
Figure 3b,
Figure 4b and
Figure 5b, were tested on a dataset that was 19 times larger than the training dataset, and they achieved the R
2 values of 0.98, 0.72, and 0.73, respectively, and these R
2 values point towards a low likelihood of overfitting. Additionally, visual inspection of the aforementioned figures also suggests against overfitting as the models perform well especially when considering the substantial difference between the size of the training and testing dataset. The models in the figures simulate the periodicity of the time series rather well, although they miss out on predicting the highs and lows.
4.4. Limination and Future Research Perspective
Although the models for NH
4-N and OPO
4-P produced R
2 values of 0.95 and above, there should be a word of caution. Both sensors have a least count of 0.01 mg L
−1, which means there is an uncertainty of 0.01 mg L
−1 with each measurement. The mean concentrations of NH
4-N and OPO
4-P at the Kahl am Main station were 0.03 mgN L
−1 and 0.10 mgP L
−1, respectively, which inherently introduces an uncertainty of 33% and 10%. This high level of uncertainty makes the measurements from these sensors imprecise. For comparison, the mean of NO
3-N is 3.66 mgN L
−1 at the Kahl am Main station and is also measured with a sensor with a least count of 0.01 mgN L
−1, which amounts to only 0.26% uncertainty. Since the measurements for NH
4-N and OPO
4-P are not that precise, the models might have also incorporated these patterns of errors. This problem is evident from the time series in
Figure 4 and
Figure 5, which are patchy with sudden peaks when compared to the relatively continuous time series of NO
3-N (
Figure 3). Therefore, for the development of reliable soft sensors for NH
4-N and OPO
4-P, there is a need for the development of physical sensors with higher precision for them.
The findings of this study would give the stakeholders the optimal number of physical sensors and their OSFs for the development of a soft sensor for measuring continuous real-time nutrients. However, it has not been verified whether the results are applicable for the long run or for large-scale monitoring networks. With a better understanding of the marginal return on sampling efforts, physical sensors and their sampling frequency can be changed to balance effort and collect more meaningful information. Following up on these findings, additional studies are suggested, including: (1) investigating the spatial variation of sampling sites and how it affects optimal sampling frequency, (2) investigating the spatial variation of sampling sites and how it affects optimal subset of predictors, and (3) building a generalized model for soft sensors which go beyond site-specific to larger and wider monitoring networks. This could be accomplished by following the idea of the present study i.e., applying the methodology from this study to more stations and comparing the results of optimal predictors and sampling frequencies. This approach is equally applicable to building soft sensors for other water quality parameters, such as turbidity, total dissolved solids, heavy metals and so on.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}