

Joint Fusion and Detection via Deep Learning in UAV-Borne Multispectral Sensing of Scatterable Landmine †
Abstract
1. Introduction
2. Multispectral Dataset
2.1. Landmine Samples
2.2. Equipment
2.3. Experimental Scenes
2.4. Acquisition and Registration
2.5. Labeling
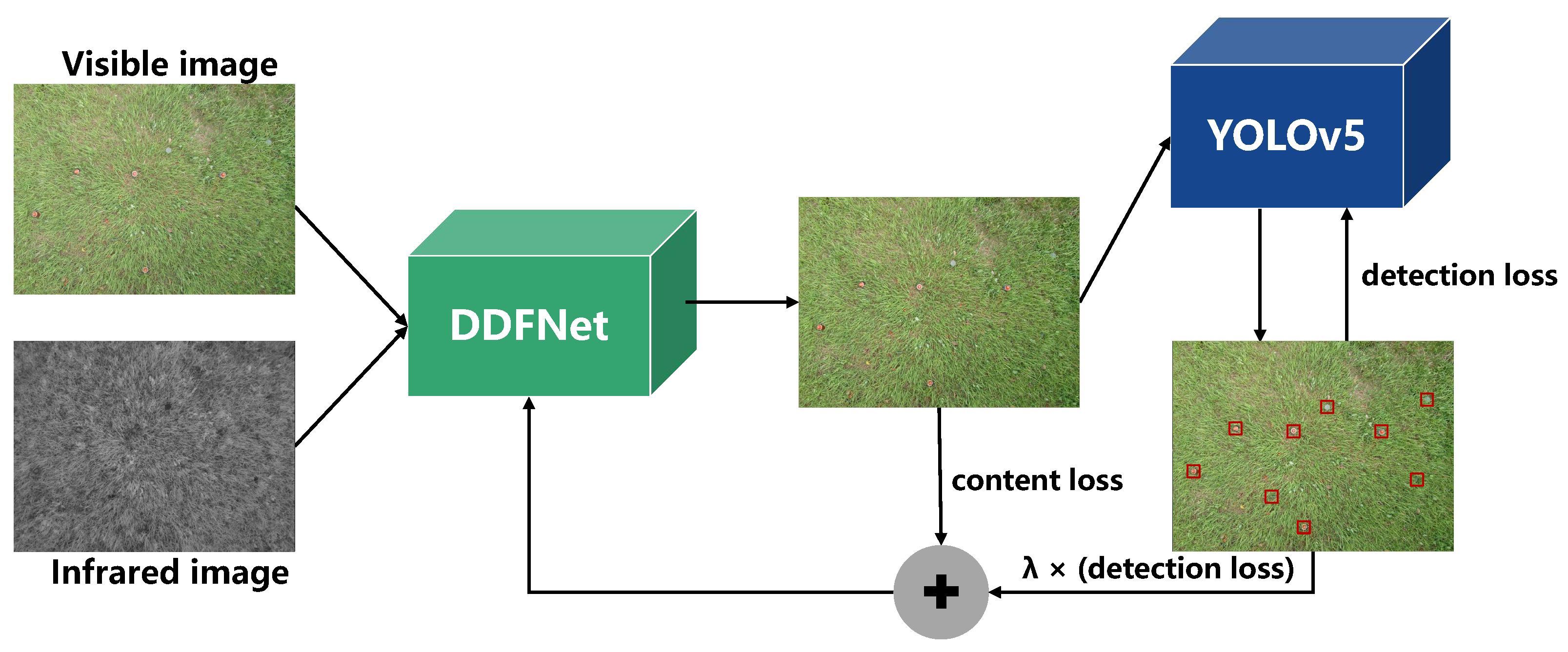
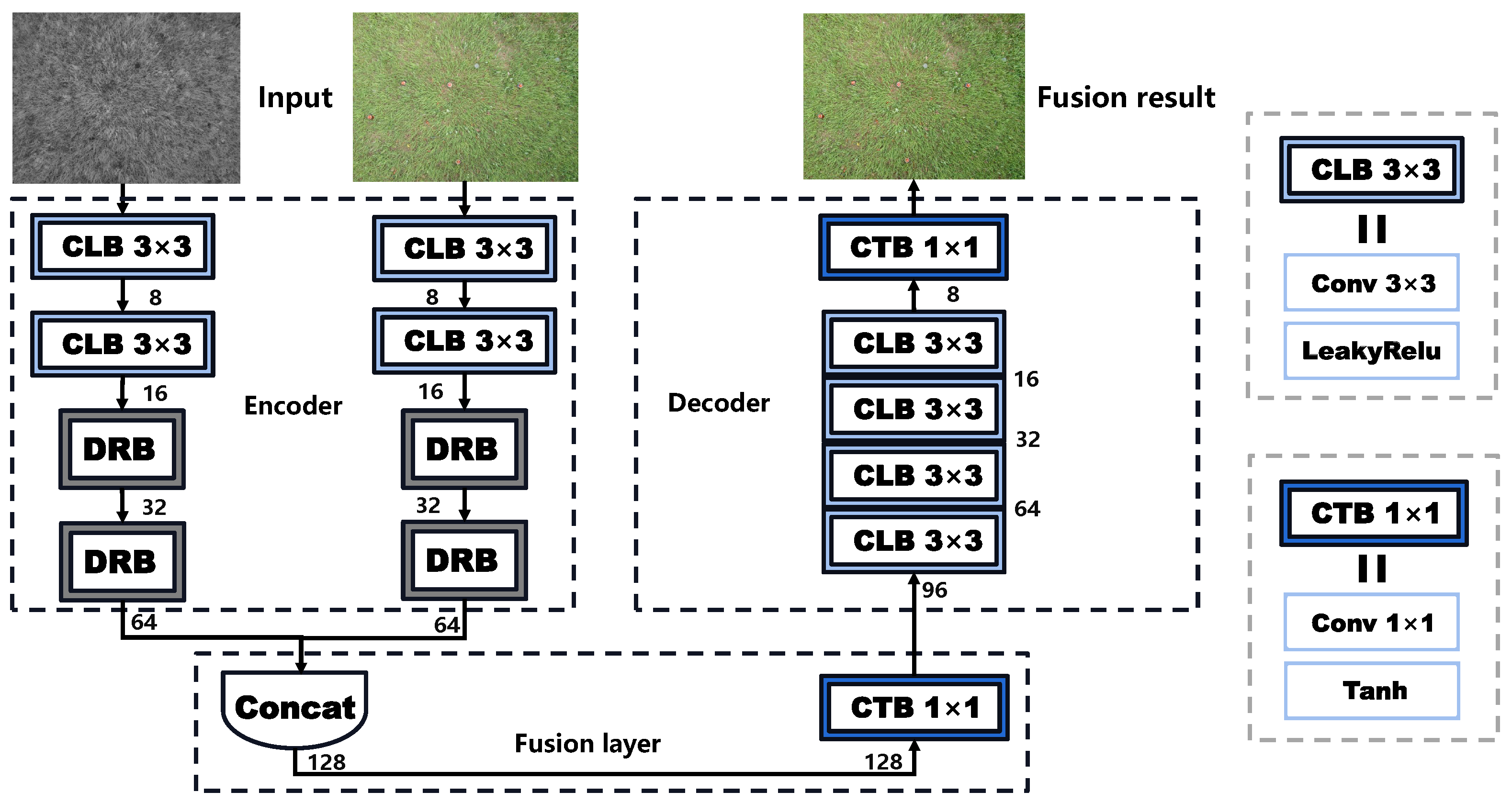
3. Methods
3.1. Detection-Driven Fusion Framework
3.2. Fusion Network
3.3. Loss Function
- All targets in the image should be identified, with a low missed and false alarm rate;
- The bounding boxes should completely and accurately enclose the target;
- The categorization of the detected object should be consistent with its label.
3.4. Joint Training Algorithm
| Algorithm 1: Multi-stage joint training algorithm. |
 |
4. Experiment and Results
4.1. Fusion Result
4.1.1. Comparative Experiment
4.1.2. Generalization Experiment
4.2. Detection Performance
4.2.1. Landmine Detection Evaluation
4.2.2. Efficiency Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- ICBL-CMC. Landmine Monitor 2021. 2021. Available online: http://www.the-monitor.org/media/3318354/Landmine-Monitor-2021-Web.pdf/ (accessed on 13 June 2023).
- Hussein, E.; Waller, E. Landmine detection: The problem and the challenge. Appl. Radiat. Isot. 2000, 53, 557–563. [Google Scholar] [CrossRef] [PubMed]
- Miccinesi, L.; Beni, A.; Pieraccini, M. UAS-Borne Radar for Remote Sensing: A Review. Electronics 2022, 11, 3324. [Google Scholar] [CrossRef]
- Colorado, J.; Devia, C.; Perez, M.; Mondragon, I.; Mendez, D.; Parra, C. Low-altitude autonomous drone navigation for landmine detection purposes. In Proceedings of the 2017 International Conference on Unmanned Aircraft Systems (ICUAS), Miami, FL, USA, 13–16 June 2017; pp. 540–546. [Google Scholar]
- Šipoš, D.; Gleich, D. A lightweight and low-power UAV-borne ground penetrating radar design for landmine detection. Sensors 2020, 20, 2234. [Google Scholar] [CrossRef]
- Colorado, J.; Perez, M.; Mondragon, I.; Mendez, D.; Parra, C.; Devia, C.; Martinez-Moritz, J.; Neira, L. An integrated aerial system for landmine detection: SDR-based Ground Penetrating Radar onboard an autonomous drone. Adv. Robot. 2017, 31, 791–808. [Google Scholar] [CrossRef]
- Sipos, D.; Planinsic, P.; Gleich, D. On drone ground penetrating radar for landmine detection. In Proceedings of the 2017 First International Conference on Landmine: Detection, Clearance and Legislations (LDCL), Beirut, Lebanon, 26–28 April 2017; pp. 1–4. [Google Scholar]
- García-Fernández, M.; López, Y.Á.; Andrés, F.L.H. Airborne multi-channel ground penetrating radar for improvised explosive devices and landmine detection. IEEE Access 2020, 8, 165927–165943. [Google Scholar] [CrossRef]
- Schreiber, E.; Heinzel, A.; Peichl, M.; Engel, M.; Wiesbeck, W. Advanced buried object detection by multichannel, UAV/drone carried synthetic aperture radar. In Proceedings of the 2019 13th European Conference on Antennas and Propagation (EuCAP), Krakow, Poland, 31 March–5 April 2019; pp. 1–5. [Google Scholar]
- Bossi, L.; Falorni, P.; Capineri, L. Versatile Electronics for Microwave Holographic RADAR Based on Software Defined Radio Technology. Electronics 2022, 11, 2883. [Google Scholar] [CrossRef]
- Garcia-Fernandez, M.; Alvarez-Lopez, Y.; Las Heras, F. Autonomous airborne 3D SAR imaging system for subsurface sensing: UWB-GPR on board a UAV for landmine and IED detection. Remote Sens. 2019, 11, 2357. [Google Scholar] [CrossRef]
- Makki, I.; Younes, R.; Francis, C.; Bianchi, T.; Zucchetti, M. A survey of landmine detection using hyperspectral imaging. ISPRS J. Photogramm. Remote Sens. 2017, 124, 40–53. [Google Scholar] [CrossRef]
- Khodor, M.; Makki, I.; Younes, R.; Bianchi, T.; Khoder, J.; Francis, C.; Zucchetti, M. Landmine detection in hyperspectral images based on pixel intensity. Remote Sens. Appl. Soc. Environ. 2021, 21, 100468. [Google Scholar] [CrossRef]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Silva, J.S.; Guerra, I.F.L.; Bioucas-Dias, J.; Gasche, T. Landmine detection using multispectral images. IEEE Sens. J. 2019, 19, 9341–9351. [Google Scholar] [CrossRef]
- DeSmet, T.; Nikulin, A.; Frazer, W.; Baur, J.; Abramowitz, J.; Finan, D.; Denara, S.; Aglietti, N.; Campos, G. Drones and “Butterflies”: A Low-Cost UAV System for Rapid Detection and Identification of Unconventional Minefields. J. Conv. Weapons Destr. 2018, 22, 10. [Google Scholar]
- Nikulin, A.; De Smet, T.S.; Baur, J.; Frazer, W.D.; Abramowitz, J.C. Detection and identification of remnant PFM-1 ‘Butterfly Mines’ with a UAV-Based thermal-imaging protocol. Remote Sens. 2018, 10, 1672. [Google Scholar] [CrossRef]
- de Smet, T.S.; Nikulin, A. Catching “butterflies” in the morning: A new methodology for rapid detection of aerially deployed plastic land mines from UAVs. Lead. Edge 2018, 37, 367–371. [Google Scholar] [CrossRef]
- Baur, J.; Steinberg, G.; Nikulin, A.; Chiu, K.; de Smet, T.S. Applying deep learning to automate UAV-based detection of scatterable landmines. Remote Sens. 2020, 12, 859. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Ward, C.M.; Harguess, J.; Hilton, C.; Mediavilla, C.; Sullivan, K.; Watkins, R. Deep learning for automatic ordnance recognition. In Geospatial Informatics IX; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; Volume 10992, p. 109920H. [Google Scholar]
- Priya, C.N.; Ashok, S.D.; Maji, B.; Kumaran, K.S. Deep Learning Based Thermal Image Processing Approach for Detection of Buried Objects and Mines. Eng. J. 2021, 25, 61–67. [Google Scholar] [CrossRef]
- Kafedziski, V.; Pecov, S.; Tanevski, D. Detection and classification of land mines from ground penetrating radar data using faster R-CNN. In Proceedings of the 2018 26th Telecommunications Forum (TELFOR), Belgrade, Serbia, 20–21 November 2018; pp. 1–4. [Google Scholar]
- Picetti, F.; Testa, G.; Lombardi, F.; Bestagini, P.; Lualdi, M.; Tubaro, S. Convolutional autoencoder for landmine detection on GPR scans. In Proceedings of the 2018 41st International Conference on Telecommunications and Signal Processing (TSP), Athens, Greece, 4–6 July 2018; pp. 1–4. [Google Scholar]
- Lameri, S.; Lombardi, F.; Bestagini, P.; Lualdi, M.; Tubaro, S. Landmine detection from GPR data using convolutional neural networks. In Proceedings of the 2017 25th European Signal Processing Conference (EUSIPCO), Kos, Greece, 28 August–2 September 2017; pp. 508–512. [Google Scholar]
- Guo, H.; Jiang, H.; Hu, J.; Luo, C. UAV-Borne Landmine Detection via Intelligent Multispectral Fusion. In Proceedings of the 2022 4th International Conference on Applied Machine Learning (ICAML), Changsha, China, 23–25 July 2022; IEEE Computer Society: Washington, DC, USA, 2022; pp. 179–183. [Google Scholar]
- Jocher, G. yolov5. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 13 June 2023).
- Ye, Y.; Bruzzone, L.; Shan, J.; Bovolo, F.; Zhu, Q. Fast and Robust Matching for Multimodal Remote Sensing Image Registration. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9059–9070. [Google Scholar] [CrossRef]
- Liu, D.; Wen, B.; Jiao, J.; Liu, X.; Wang, Z.; Huang, T.S. Connecting image denoising and high-level vision tasks via deep learning. IEEE Trans. Image Process. 2020, 29, 3695–3706. [Google Scholar] [CrossRef] [PubMed]
- Guo, M.; Chen, M.; Ma, C.; Li, Y.; Li, X.; Xie, X. High-level task-driven single image deraining: Segmentation in rainy days. In Proceedings of the International Conference on Neural Information Processing, Bangkok, Thailand, 23–27 November 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 350–362. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Task-driven super resolution: Object detection in low-resolution images. In Proceedings of the International Conference on Neural Information Processing: 28th International Conference, ICONIP 2021, Sanur, Bali, Indonesia, 8–12 December 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 387–395. [Google Scholar]
- Tang, L.; Yuan, J.; Ma, J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Inf. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Ye, P.; Xiao, G. VIFB: A Visible and Infrared Image Fusion Benchmark. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 468–478. [Google Scholar]
- Zhang, X.; Demiris, Y. Visible and Infrared Image Fusion Using Deep Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 1, 1–20. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J. DenseFuse: A Fusion Approach to Infrared and Visible Images. IEEE Trans. Image Process. 2019, 28, 2614–2623. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Yu, S.; Chen, X. Infrared and Visible Image Fusion Based on a Latent Low-Rank Representation Nested With Multiscale Geometric Transform. IEEE Access 2020, 8, 110214–110226. [Google Scholar] [CrossRef]
- Zhou, Z.; Dong, M.; Xie, X.; Gao, Z. Fusion of infrared and visible images for night-vision context enhancement. Appl. Opt. 2016, 55, 6480–6490. [Google Scholar] [CrossRef] [PubMed]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A Unified Unsupervised Image Fusion Network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, S.; Wang, Z. A general framework for image fusion based on multi-scale transform and sparse representation. Inf. Fusion 2015, 24, 147–164. [Google Scholar] [CrossRef]
- Piella, G.; Heijmans, H. A new quality metric for image fusion. In Proceedings of the Proceedings 2003 International Conference on Image Processing (Cat. No.03CH37429), Barcelona, Spain, 14–17 September 2003; Volume 3, p. III–173. [Google Scholar]
- Chen, Y.; Blum, R.S. A new automated quality assessment algorithm for image fusion. Image Vis. Comput. 2009, 27, 1421–1432. [Google Scholar] [CrossRef]
- Chen, H.; Varshney, P.K. A human perception inspired quality metric for image fusion based on regional information. Inf. Fusion 2007, 8, 193–207. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Dhuli, R. Fusion of Infrared and Visible Sensor Images Based on Anisotropic Diffusion and Karhunen-Loeve Transform. IEEE Sens. J. 2016, 16, 203–209. [Google Scholar] [CrossRef]
- Shreyamsha Kumar, B. Image fusion based on pixel significance using cross bilateral filter. Signal Image Video Process. 2015, 9, 1193–1204. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H.; Wang, Z. Infrared and visible image fusion with convolutional neural networks. Int. J. Wavelets Multiresolution Inf. Process. 2018, 16, 1850018. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. Infrared and visible image fusion using a deep learning framework. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2705–2710. [Google Scholar]
- Bavirisetti, D.P.; Xiao, G.; Liu, G. Multi-sensor image fusion based on fourth order partial differential equations. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–9. [Google Scholar]
- Li, S.; Kang, X.; Hu, J. Image fusion with guided filtering. IEEE Trans. Image Process. 2013, 22, 2864–2875. [Google Scholar]
- Zhang, Y.; Zhang, L.; Bai, X.; Zhang, L. Infrared and visual image fusion through infrared feature extraction and visual information preservation. Infrared Phys. Technol. 2017, 83, 227–237. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Xiao, G.; Zhao, J.; Dhuli, R.; Liu, G. Multi-scale guided image and video fusion: A fast and efficient approach. Circuits Syst. Signal Process. 2019, 38, 5576–5605. [Google Scholar] [CrossRef]
- Naidu, V. Image fusion technique using multi-resolution singular value decomposition. Def. Sci. J. 2011, 61, 479. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.j.; Durrani, T.S. Infrared and visible image fusion with ResNet and zero-phase component analysis. Infrared Phys. Technol. 2019, 102, 103039. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Dhuli, R. Two-scale image fusion of visible and infrared images using saliency detection. Infrared Phys. Technol. 2016, 76, 52–64. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Zhou, Z.; Wang, B.; Li, S.; Dong, M. Perceptual fusion of infrared and visible images through a hybrid multi-scale decomposition with Gaussian and bilateral filters. Inf. Fusion 2016, 30, 15–26. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band Name | Wavelength | Bandwidth | Definition |
|---|---|---|---|
| Green | 550 nm | 40 nm | 1.2 Mpx |
| Red | 660 nm | 40 nm | 1.2 Mpx |
| Red-edge | 735 nm | 10 nm | 1.2 Mpx |
| Near-infrared | 790 nm | 40 nm | 1.2 Mpx |
| RGB | 16 Mpx |
| AG | CE↓ | EI | EN | MI | PSNR | [47] | [48] | ↓ [49] | RMSE↓ | SF | SSIM | SD | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NIR | 7.77 | 0.38 | 76.85 | 6.73 | 4.72 | 63.36 | 0.36 | 0.76 | 258.12 | 0.03 | 16.84 | 1.16 | 26.32 |
| RGB | 19.19 | 0.25 | 172.83 | 7.35 | 5.15 | 63.36 | 0.72 | 0.67 | 50.26 | 0.03 | 46.56 | 1.16 | 39.91 |
| ADF [50] | 15.33 | 0.23 | 135.17 | 6.96 | 0.94 | 62.98 | 0.55 | 0.53 | 67.19 | 0.03 | 37.07 | 1.14 | 30.18 |
| CBF [51] | 17.43 | 0.22 | 157.78 | 7.23 | 1.41 | 62.87 | 0.60 | 0.58 | 44.02 | 0.03 | 42.17 | 1.15 | 36.40 |
| CNN [52] | 19.19 | 0.26 | 173.17 | 7.35 | 1.19 | 62.52 | 0.62 | 0.60 | 49.31 | 0.04 | 46.29 | 1.13 | 39.88 |
| DLF [53] | 11.57 | 0.32 | 107.21 | 6.79 | 0.92 | 63.20 | 0.39 | 0.56 | 67.18 | 0.03 | 27.25 | 1.24 | 26.83 |
| FPDE [54] | 10.93 | 0.36 | 102.27 | 6.74 | 0.90 | 63.21 | 0.36 | 0.56 | 69.68 | 0.03 | 25.23 | 1.24 | 25.98 |
| GFCE [44] | 19.74 | 0.52 | 178.80 | 7.37 | 1.05 | 61.36 | 0.51 | 0.57 | 54.73 | 0.05 | 47.53 | 1.19 | 40.43 |
| GFF [55] | 19.13 | 0.26 | 173.62 | 7.35 | 1.56 | 62.64 | 0.63 | 0.62 | 50.90 | 0.04 | 45.82 | 1.11 | 39.88 |
| IFEVIP [56] | 14.95 | 0.96 | 139.82 | 7.23 | 1.06 | 60.55 | 0.39 | 0.57 | 188.01 | 0.06 | 34.99 | 1.21 | 37.23 |
| LatLRR [43] | 32.01 | 1.07 | 92.68 | 7.50 | 1.03 | 59.11 | 0.38 | 0.59 | 142.03 | 0.08 | 77.57 | 0.94 | 62.47 |
| MGFF [57] | 18.80 | 0.19 | 173.10 | 7.41 | 0.95 | 62.48 | 0.47 | 0.61 | 100.80 | 0.04 | 44.61 | 1.23 | 41.67 |
| MST_SR [46] | 19.16 | 0.21 | 173.35 | 7.35 | 1.26 | 62.58 | 0.62 | 0.61 | 48.88 | 0.04 | 46.05 | 1.13 | 39.68 |
| MSVD [58] | 15.00 | 0.20 | 132.86 | 7.00 | 0.82 | 62.88 | 0.42 | 0.50 | 72.12 | 0.03 | 39.02 | 1.17 | 30.98 |
| NSCT_SR [46] | 19.13 | 0.26 | 173.36 | 7.35 | 1.55 | 62.64 | 0.63 | 0.61 | 49.99 | 0.04 | 45.91 | 1.12 | 39.84 |
| ResNet [59] | 10.72 | 0.36 | 100.72 | 6.73 | 0.90 | 63.20 | 0.34 | 0.56 | 71.61 | 0.03 | 24.72 | 1.25 | 25.83 |
| RP_SR [46] | 18.84 | 0.24 | 167.85 | 7.32 | 1.12 | 62.43 | 0.58 | 0.56 | 60.42 | 0.04 | 46.31 | 1.14 | 38.92 |
| TIF [60] | 15.57 | 0.17 | 144.09 | 7.18 | 0.93 | 62.74 | 0.46 | 0.60 | 60.56 | 0.03 | 37.35 | 1.18 | 35.25 |
| VSMWLS [61] | 18.93 | 0.16 | 164.55 | 7.23 | 0.93 | 62.70 | 0.51 | 0.55 | 66.87 | 0.03 | 47.41 | 1.19 | 36.70 |
| Densefuse [41] | 10.97 | 0.35 | 101.20 | 6.74 | 1.00 | 63.32 | 0.39 | 0.57 | 68.92 | 0.03 | 26.05 | 1.30 | 26.01 |
| IFCNN [42] | 18.14 | 0.17 | 161.98 | 7.18 | 1.06 | 62.97 | 0.55 | 0.53 | 68.25 | 0.03 | 44.46 | 1.27 | 35.22 |
| FusionGAN [39] | 15.26 | 0.23 | 136.93 | 7.26 | 0.25 | 60.88 | 0.44 | 0.43 | 485.24 | 0.05 | 37.39 | 0.99 | 37.40 |
| RFN-Nest [40] | 12.11 | 0.25 | 119.23 | 7.11 | 0.89 | 62.71 | 0.48 | 0.59 | 97.02 | 0.04 | 25.75 | 1.22 | 33.52 |
| U2Fusion [45] | 12.12 | 0.25 | 114.42 | 7.00 | 0.33 | 61.30 | 0.29 | 0.46 | 337.34 | 0.05 | 26.74 | 0.89 | 31.53 |
| DDF | 18.92 | 0.44 | 173.87 | 7.33 | 1.45 | 61.96 | 0.62 | 0.58 | 45.14 | 0.04 | 44.53 | 1.20 | 39.31 |
| AG | CE↓ | EI | EN | MI | PSNR | [47] | [48] | ↓ [49] | RMSE↓ | SF | SSIM | SD | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ADF [50] | 4.58 | 1.46 | 46.53 | 6.79 | 1.92 | 58.41 | 0.52 | 0.47 | 777.82 | 0.10 | 14.13 | 1.40 | 35.19 |
| CBF [51] | 7.15 | 0.99 | 74.59 | 7.32 | 2.16 | 57.59 | 0.58 | 0.53 | 1575.15 | 0.13 | 20.38 | 1.17 | 48.54 |
| CNN [52] | 5.81 | 1.03 | 60.24 | 7.32 | 2.65 | 57.93 | 0.66 | 0.62 | 512.57 | 0.12 | 18.81 | 1.39 | 60.08 |
| DLF [53] | 3.82 | 1.41 | 38.57 | 6.72 | 2.03 | 58.44 | 0.43 | 0.45 | 759.81 | 0.10 | 12.49 | 1.46 | 34.72 |
| FPDE [54] | 4.54 | 1.37 | 46.02 | 6.77 | 1.92 | 58.40 | 0.48 | 0.46 | 780.11 | 0.10 | 13.47 | 1.39 | 34.93 |
| GFCE [44] | 7.50 | 1.93 | 77.47 | 7.27 | 1.84 | 55.94 | 0.47 | 0.53 | 898.95 | 0.17 | 22.46 | 1.13 | 51.56 |
| GFF [55] | 5.33 | 1.19 | 55.20 | 7.21 | 2.64 | 58.10 | 0.62 | 0.62 | 881.62 | 0.11 | 17.27 | 1.40 | 50.06 |
| GTF [62] | 4.30 | 1.29 | 43.66 | 6.51 | 1.99 | 57.86 | 0.44 | 0.41 | 2138.37 | 0.12 | 14.74 | 1.37 | 35.13 |
| HMSD_GF [63] | 6.25 | 1.16 | 65.03 | 7.27 | 2.47 | 57.94 | 0.62 | 0.60 | 532.96 | 0.12 | 19.90 | 1.39 | 57.62 |
| Hybrid_MSD [63] | 6.13 | 1.26 | 63.49 | 7.30 | 2.62 | 58.17 | 0.64 | 0.62 | 510.87 | 0.11 | 19.66 | 1.41 | 54.92 |
| IFEVIP [56] | 4.98 | 1.34 | 51.78 | 6.94 | 2.25 | 57.17 | 0.49 | 0.46 | 573.77 | 0.14 | 15.85 | 1.39 | 48.49 |
| LatLRR [43] | 8.96 | 1.68 | 92.81 | 6.91 | 1.65 | 56.18 | 0.44 | 0.50 | 697.29 | 0.17 | 29.54 | 1.18 | 57.13 |
| MGFF [57] | 5.84 | 1.29 | 60.61 | 7.11 | 1.77 | 58.21 | 0.57 | 0.54 | 676.89 | 0.11 | 17.92 | 1.41 | 44.29 |
| MST_SR [46] | 5.85 | 0.96 | 60.78 | 7.34 | 2.81 | 57.95 | 0.66 | 0.64 | 522.69 | 0.12 | 18.81 | 1.39 | 57.31 |
| MSVD [58] | 3.54 | 1.46 | 36.20 | 6.71 | 1.95 | 58.41 | 0.33 | 0.43 | 808.99 | 0.10 | 12.53 | 1.43 | 34.37 |
| NSCT_SR [46] | 6.49 | 0.90 | 67.96 | 7.40 | 2.99 | 57.43 | 0.65 | 0.62 | 1447.34 | 0.13 | 19.39 | 1.28 | 52.47 |
| ResNet [59] | 3.67 | 1.36 | 37.26 | 6.73 | 1.99 | 58.44 | 0.41 | 0.44 | 724.83 | 0.10 | 11.74 | 1.46 | 34.94 |
| RP_SR [46] | 6.36 | 0.99 | 65.22 | 7.35 | 2.34 | 57.78 | 0.57 | 0.61 | 888.85 | 0.12 | 21.17 | 1.33 | 55.81 |
| TIF [60] | 5.56 | 1.37 | 57.84 | 7.08 | 1.77 | 58.23 | 0.58 | 0.54 | 613.00 | 0.11 | 17.74 | 1.40 | 42.64 |
| VSMWLS [61] | 5.61 | 1.41 | 57.25 | 7.03 | 2.03 | 58.19 | 0.55 | 0.50 | 754.70 | 0.11 | 17.66 | 1.42 | 46.25 |
| Densefuse-L1 [41] | 3.54 | 1.34 | 36.17 | 6.70 | 2.03 | 58.44 | 0.37 | 0.44 | 762.80 | 0.10 | 11.02 | 1.46 | 34.24 |
| Densefuse-Add [41] | 3.54 | 1.34 | 36.17 | 6.70 | 2.03 | 58.44 | 0.37 | 0.44 | 762.80 | 0.10 | 11.02 | 1.46 | 34.24 |
| IFCNN-Max [42] | 5.85 | 1.56 | 60.39 | 6.91 | 2.00 | 58.04 | 0.58 | 0.47 | 470.48 | 0.11 | 18.67 | 1.41 | 44.15 |
| IFCNN-Sum [42] | 5.32 | 1.62 | 54.43 | 6.84 | 1.92 | 58.39 | 0.57 | 0.47 | 757.32 | 0.10 | 17.61 | 1.45 | 36.99 |
| IFCNN-Mean [42] | 5.03 | 1.64 | 50.96 | 6.77 | 1.91 | 58.39 | 0.53 | 0.45 | 742.89 | 0.10 | 16.64 | 1.45 | 36.37 |
| FusionGAN [39] | 4.25 | 1.56 | 43.51 | 6.77 | 1.92 | 57.97 | 0.48 | 0.47 | 825.04 | 0.11 | 14.56 | 1.38 | 39.50 |
| RFN-Nest [40] | 3.66 | 1.50 | 39.42 | 7.15 | 2.08 | 58.10 | 0.41 | 0.48 | 829.63 | 0.11 | 10.03 | 1.40 | 45.36 |
| U2Fusion [45] | 3.57 | 1.12 | 38.00 | 6.92 | 2.14 | 58.28 | 0.41 | 0.50 | 739.27 | 0.11 | 10.16 | 1.46 | 40.26 |
| DDF | 5.63 | 1.52 | 58.61 | 6.96 | 2.12 | 57.28 | 0.59 | 0.46 | 417.23 | 0.13 | 17.64 | 1.45 | 49.40 |
| All | |||||
|---|---|---|---|---|---|
| TP | FP | Precision | Recall | mAP@0.5 | |
| Labels | 991 | \ | \ | \ | \ |
| NIR [29] | 674 | 229 | 0.746 | 0.680 | 0.632 |
| RGB [29] | 840 | 123 | 0.872 | 0.848 | 0.848 |
| Decision Fuse [29] | 859 | 196 | 0.814 | 0.867 | 0.841 |
| DDF | 898 | 64 | 0.933 | 0.906 | 0.922 |
| IFCNN [42] | 835 | 93 | 0.9 | 0.843 | 0.884 |
| Densefuse [41] | 856 | 84 | 0.911 | 0.864 | 0.884 |
| U2Fusion [45] | 833 | 84 | 0.908 | 0.841 | 0.87 |
| RFN-Nest [40] | 713 | 134 | 0.842 | 0.719 | 0.728 |
| FusionGAN [39] | 585 | 59 | 0.908 | 0.590 | 0.611 |
| Conventional Fusion Models | Deep-Learning-Based Fusion Models | ||||
|---|---|---|---|---|---|
| VIFB | Landmine | VIFB | Landmine | ||
| ADF [50] | 1.00 | 2.89 | CNN [52] | 31.76 | 117.82 |
| CBF [51] | 22.97 | 80.29 | DLF [53] | 18.62 | 36.68 |
| FPDE [54] | 2.72 | 10.12 | ResNet [59] | 4.8 | 10.76 |
| GFCE [44] | 2.13 | 6.62 | Densefuse [41] | 0.03 | 0.51 |
| GFF [55] | 0.41 | 1.02 | IFCNN-Max [42] | 0.03 | 0.21 |
| IFEVIP [56] | 0.17 | 0.35 | IFCNN-Sum [42] | 0.02 | 0.20 |
| LatLRR [43] | 271.04 | 910.48 | IFCNN-Mean [42] | 0.03 | 0.24 |
| MGFF [57] | 1.08 | 3.33 | FusionGAN [39] | 0.38 | 0.65 |
| MST_SR [46] | 0.76 | 2.20 | RFN-Nest [40] | 0.08 | 0.44 |
| MSVD [58] | 1.06 | 2.27 | U2Fusion [45] | 0.04 | 0.28 |
| NSCT_SR [46] | 94.65 | 500.29 | DDF | 0.08 | 0.24 |
| RP_SR [46] | 0.86 | 2.91 | |||
| TIF [60] | 0.13 | 0.37 | |||
| VSMWLS [61] | 3.51 | 12.87 | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, Z.; Guo, H.; Hu, J.; Jiang, H.; Luo, C. Joint Fusion and Detection via Deep Learning in UAV-Borne Multispectral Sensing of Scatterable Landmine. Sensors 2023, 23, 5693. https://doi.org/10.3390/s23125693
Qiu Z, Guo H, Hu J, Jiang H, Luo C. Joint Fusion and Detection via Deep Learning in UAV-Borne Multispectral Sensing of Scatterable Landmine. Sensors. 2023; 23(12):5693. https://doi.org/10.3390/s23125693
Chicago/Turabian StyleQiu, Zhongze, Hangfu Guo, Jun Hu, Hejun Jiang, and Chaopeng Luo. 2023. "Joint Fusion and Detection via Deep Learning in UAV-Borne Multispectral Sensing of Scatterable Landmine" Sensors 23, no. 12: 5693. https://doi.org/10.3390/s23125693
APA StyleQiu, Z., Guo, H., Hu, J., Jiang, H., & Luo, C. (2023). Joint Fusion and Detection via Deep Learning in UAV-Borne Multispectral Sensing of Scatterable Landmine. Sensors, 23(12), 5693. https://doi.org/10.3390/s23125693