



Joint Calibration of a Multimodal Sensor System for Autonomous Vehicles


Abstract
1. Introduction
2. Related Work
3. System
- Velodyne VLP-16 LiDAR
- Stereolabs ZED 2
- Dual NIR camera
- Teledyne FLIR BFS-U3-51S5P-C polarization camera
- Thermographic (long wave infrared) camera Device-ALab SmartIR384L.
4. Methods
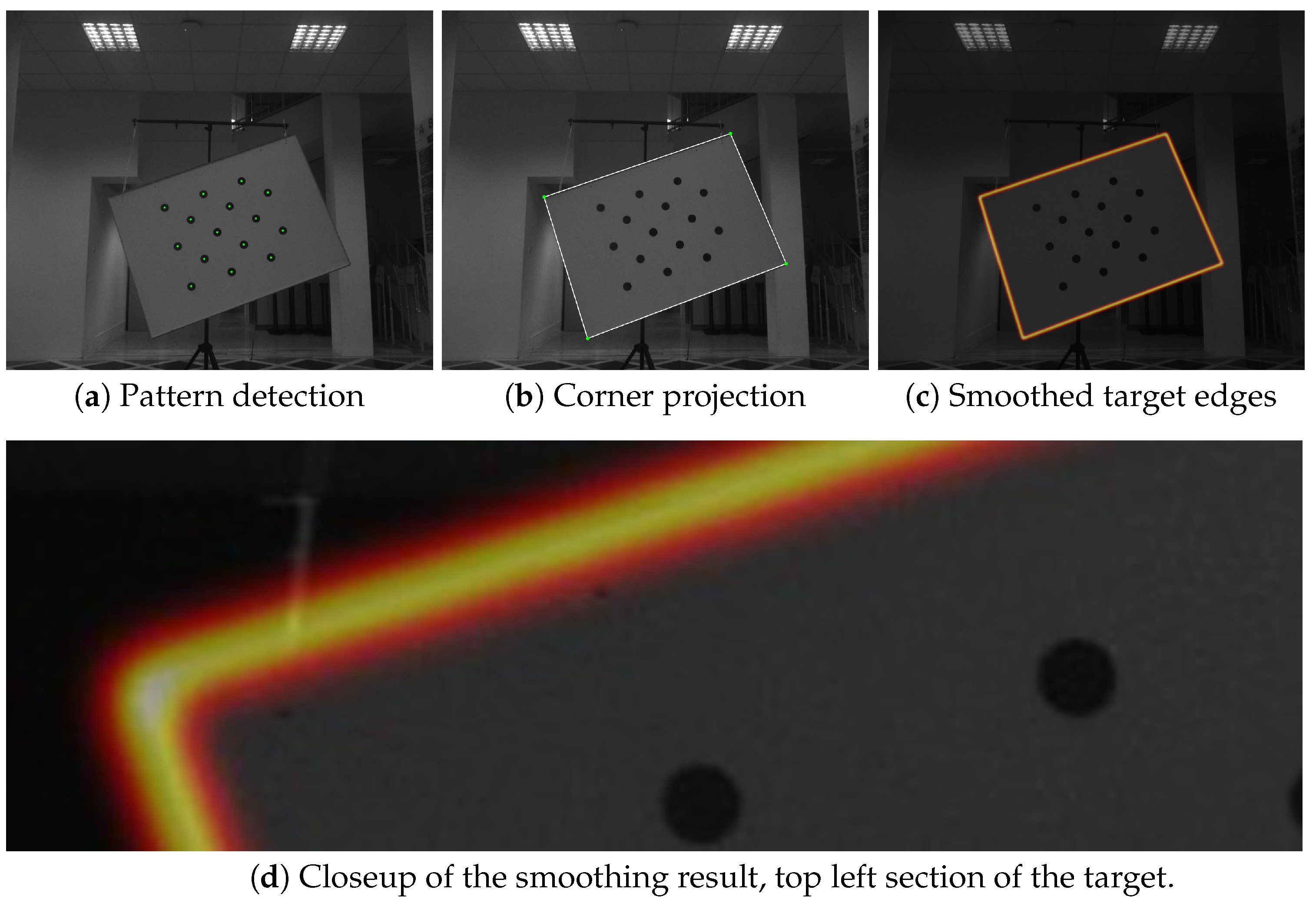
4.1. Calibration Target
4.2. Camera–LiDAR Calibration
4.2.1. Image Features
4.2.2. LiDAR Features
| Algorithm 1: LiDAR planar segments detection algorithm |
| Require: L = list of LiDAR beams Ensure: S = list of line segments [ ] for in L do [ ] for in do if empty () then .insert () else if is Collinear (, , ) and then .insert () else S.insert () [ ] end if end if end for end for |
4.2.3. Optimization of the Camera– LiDAR Transformation and Rotation Parameters
4.2.4. Parameter Ambiguity
4.2.5. Focal Length
4.3. Camera–Camera Alignment
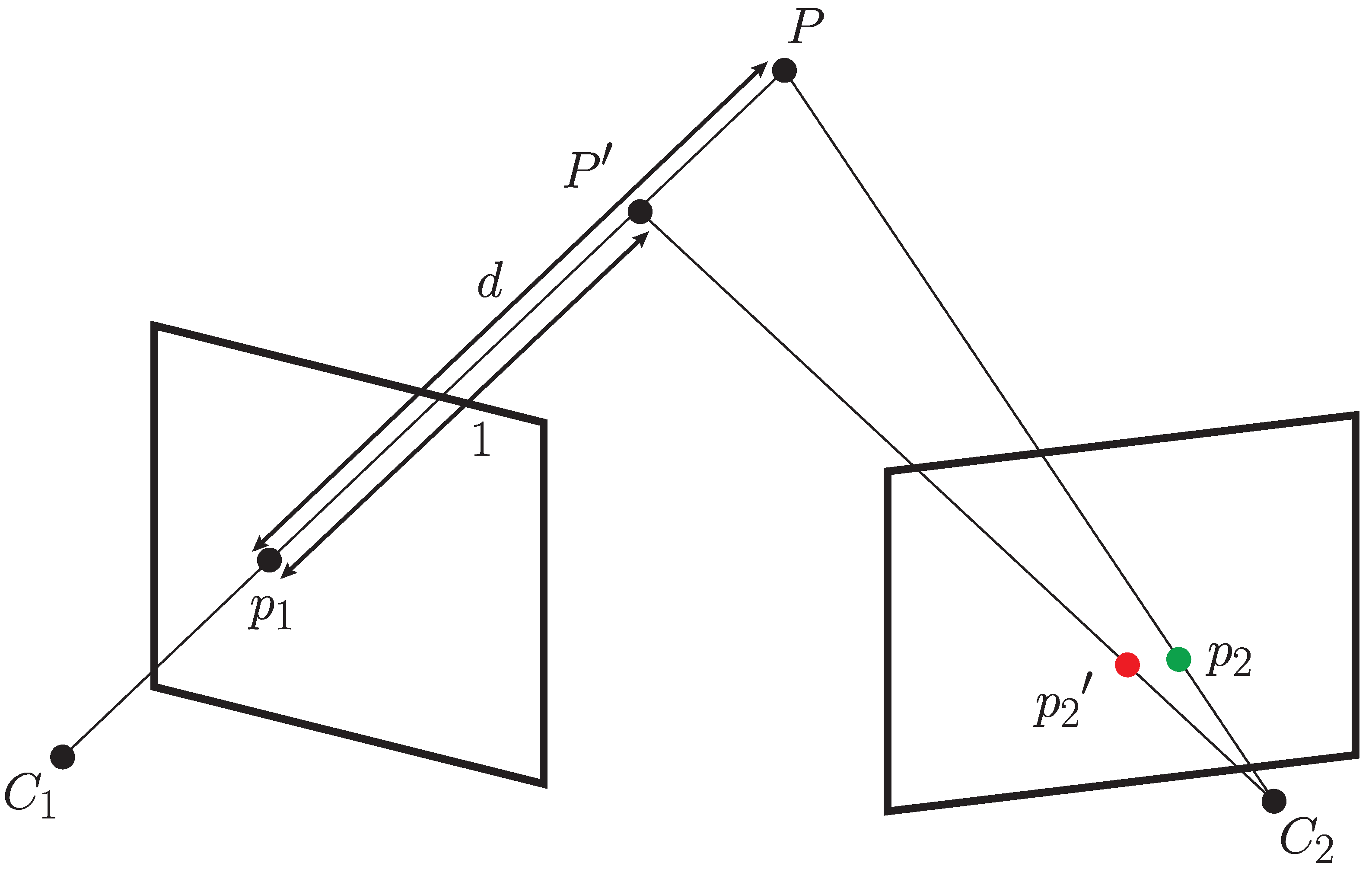
5. Intermodal Annotation Transfer
Obtaining the Pixel Depth
6. Experiments
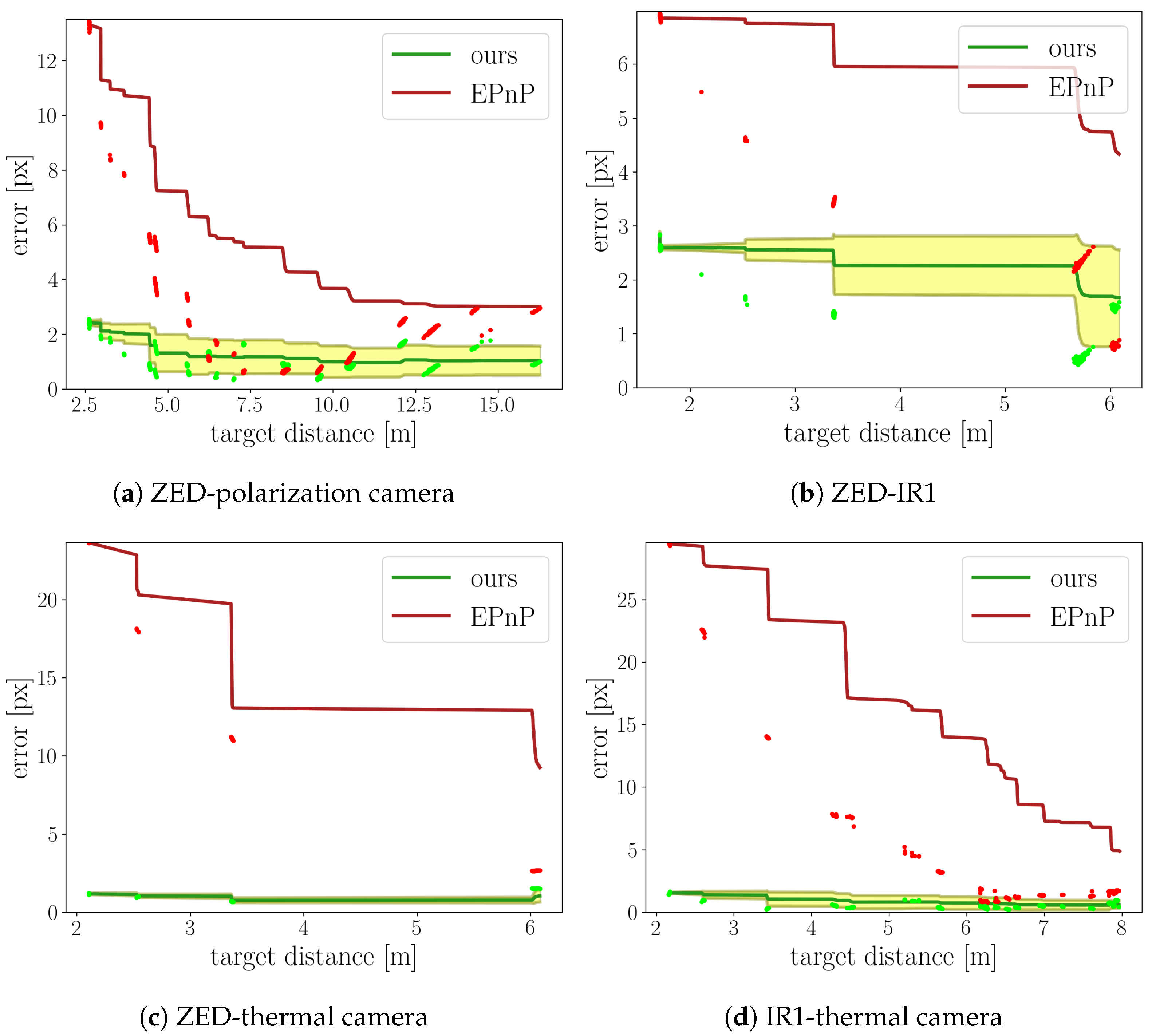
6.1. Camera–LiDAR Calibration Error
6.2. Evaluation of the Reprojection Error
6.3. Evaluation of the Intermodal Label Transfer
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| FLIR | Forward-looking infrared |
| ICP | Iterative closest point |
| IoU | Intersection over union |
| LiDAR | Light detection and ranging |
| NIR | Near infrared |
| PnP | Perspective-n-point |
| RANSAC | Random sampling consensus |
| RGB | Red green blue |
| RGB-D | Red green blue depth |
| SFM | Structure from motion |
| SLAM | Simultaneous localization and mapping |
References
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 year, 1000 km: The Oxford RobotCar dataset. Int. J. Robot. Res. 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.H.; Koltun, V. Point transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 16259–16268. [Google Scholar]
- Zhang, Q.; Pless, R. Extrinsic calibration of a camera and laser range finder (improves camera calibration). In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No. 04CH37566), Sendai, Japan, 28 September–2 October 2004; Volume 3, pp. 2301–2306. [Google Scholar]
- Pandey, G.; McBride, J.; Savarese, S.; Eustice, R. Extrinsic calibration of a 3d laser scanner and an omnidirectional camera. IFAC Proc. Volume 2010, 43, 336–341. [Google Scholar] [CrossRef]
- Guindel, C.; Beltrán, J.; Martín, D.; García, F. Automatic extrinsic calibration for lidar-stereo vehicle sensor setups. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Beltrán, J.; Guindel, C.; de la Escalera, A.; García, F. Automatic extrinsic calibration method for lidar and camera sensor setups. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17677–17689. [Google Scholar] [CrossRef]
- Pusztai, Z.; Eichhardt, I.; Hajder, L. Accurate calibration of multi-lidar-multi-camera systems. Sensors 2018, 18, 2139. [Google Scholar] [CrossRef] [PubMed]
- Grammatikopoulos, L.; Papanagnou, A.; Venianakis, A.; Kalisperakis, I.; Stentoumis, C. An Effective Camera-to-Lidar Spatiotemporal Calibration Based on a Simple Calibration Target. Sensors 2022, 22, 5576. [Google Scholar] [CrossRef] [PubMed]
- Ou, J.; Huang, P.; Zhou, J.; Zhao, Y.; Lin, L. Automatic Extrinsic Calibration of 3D LIDAR and Multi-Cameras Based on Graph Optimization. Sensors 2022, 22, 2221. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.D.; Kim, M.Y. A sensor fusion system with thermal infrared camera and LiDAR for autonomous vehicles and deep learning based object detection. ICT Express 2023, 9, 222–227. [Google Scholar] [CrossRef]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EP n P: An accurate O (n) solution to the P n P problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef]
- Levinson, J.; Thrun, S. Automatic Online Calibration of Cameras and Lasers. In Proceedings of the Robotics: Science and Systems, Berlin, Germany, 24–28 June 2013; Volume 2. [Google Scholar]
- Pandey, G.; McBride, J.R.; Savarese, S.; Eustice, R.M. Automatic targetless extrinsic calibration of a 3d lidar and camera by maximizing mutual information. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Iyer, G.; Ram, R.K.; Murthy, J.K.; Krishna, K.M. CalibNet: Geometrically supervised extrinsic calibration using 3D spatial transformer networks. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1110–1117. [Google Scholar]
- Lv, X.; Wang, B.; Dou, Z.; Ye, D.; Wang, S. LCCNet: LiDAR and camera self-calibration using cost volume network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2894–2901. [Google Scholar]
- Lv, X.; Wang, S.; Ye, D. CFNet: LiDAR-camera registration using calibration flow network. Sensors 2021, 21, 8112. [Google Scholar] [CrossRef] [PubMed]
- Yuan, C.; Liu, X.; Hong, X.; Zhang, F. Pixel-level extrinsic self calibration of high resolution lidar and camera in targetless environments. IEEE Robot. Autom. Lett. 2021, 6, 7517–7524. [Google Scholar] [CrossRef]
- Zhu, Y.; Li, C.; Zhang, Y. Online camera-lidar calibration with sensor semantic information. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 4970–4976. [Google Scholar]
- Wang, W.; Nobuhara, S.; Nakamura, R.; Sakurada, K. Soic: Semantic online initialization and calibration for lidar and camera. arXiv 2020, arXiv:2003.04260. [Google Scholar]
- Takahashi, H.; Tomita, F. Self-calibration of stereo cameras. In Proceedings of the 1988 Second International Conference on Computer Vision, Tampa, FL, USA, 5–8 December 1988; pp. 123–128. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Rangel, J.; Soldan, S.; Kroll, A. 3D thermal imaging: Fusion of thermography and depth cameras. In Proceedings of the International Conference on Quantitative InfraRed Thermography, Bordeaux, France, 7–11 July 2014; Volume 3. [Google Scholar]
- Shivakumar, S.S.; Rodrigues, N.; Zhou, A.; Miller, I.D.; Kumar, V.; Taylor, C.J. Pst900: Rgb-thermal calibration, dataset and segmentation network. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 9441–9447. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2446–2454. [Google Scholar]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A Visible-infrared Paired Dataset for Low-light Vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 3496–3504. [Google Scholar]
- González, A.; Fang, Z.; Socarras, Y.; Serrat, J.; Vázquez, D.; Xu, J.; López, A.M. Pedestrian detection at day/night time with visible and FIR cameras: A comparison. Sensors 2016, 16, 820. [Google Scholar] [CrossRef] [PubMed]
- Lee, A.J.; Cho, Y.; Yoon, S.; Shin, Y.; Kim, A. ViViD: Vision for visibility dataset. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA) Workshop: Dataset Generation and Benchmarking of SLAM Algorithms for Robotics and VR/AR, Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Lee, A.J.; Cho, Y.; Shin, Y.s.; Kim, A.; Myung, H. ViViD++: Vision for Visibility Dataset. IEEE Robot. Autom. Lett. 2022, 7, 6282–6289. [Google Scholar] [CrossRef]
- Kniaz, V.V.; Knyaz, V.A.; Hladuvka, J.; Kropatsch, W.G.; Mizginov, V. Thermalgan: Multimodal color-to-thermal image translation for person re-identification in multispectral dataset. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September; pp. 606–624.
- Perš, J.; Muhovič, J.; Bobek, U.; Brinšek; Cvenkel, T.; Gregorin, D.; Mitja, K.; Lukek, M.; Sedej, N.; Kristan, M. Modular Multi-Sensor System for Unmanned Surface Vehicles. In Proceedings of the 30th International Electrotechnical and Computer Science Conference ERK2021, Portorož, Slovenia, 20–21 September 2021. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Wright, G.B. Radial Basis Function Interpolation: Numerical and Analytical Developments; University of Colorado at Boulder: Boulder, CO, USA, 2003. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Bovcon, B.; Kristan, M. WaSR—A water segmentation and refinement maritime obstacle detection network. IEEE Trans. Cybern. 2021, 52, 12661–12674. [Google Scholar] [CrossRef] [PubMed]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Images | Distance Range [m] | [px] | [px] | |
|---|---|---|---|---|
| ZED-polarization camera | 654 | 3–16 | 3.02 | 1.03 |
| ZED-IR1 | 385 | 2–6 | 4.33 | 1.67 |
| ZED-thermal camera | 112 | 2–6 | 9.26 | 1.09 |
| IR1-thermal camera | 554 | 2–8 | 4.90 | 0.63 |
| polarization camera | 0.70 |
| IR1 | 0.69 |
| IR2 | 0.63 |
| thermal camera | 0.63 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Muhovič, J.; Perš, J. Joint Calibration of a Multimodal Sensor System for Autonomous Vehicles. Sensors 2023, 23, 5676. https://doi.org/10.3390/s23125676
Muhovič J, Perš J. Joint Calibration of a Multimodal Sensor System for Autonomous Vehicles. Sensors. 2023; 23(12):5676. https://doi.org/10.3390/s23125676
Chicago/Turabian StyleMuhovič, Jon, and Janez Perš. 2023. "Joint Calibration of a Multimodal Sensor System for Autonomous Vehicles" Sensors 23, no. 12: 5676. https://doi.org/10.3390/s23125676
APA StyleMuhovič, J., & Perš, J. (2023). Joint Calibration of a Multimodal Sensor System for Autonomous Vehicles. Sensors, 23(12), 5676. https://doi.org/10.3390/s23125676