
Sparse Reconstruction of Sound Field Using Bayesian Compressive Sensing and Equivalent Source Method


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Theoretical Background
2.1. Equivalent Source Method-Based NAH
2.2. Compressive Sensing Theory
2.3. ESM Based on the CS Theory
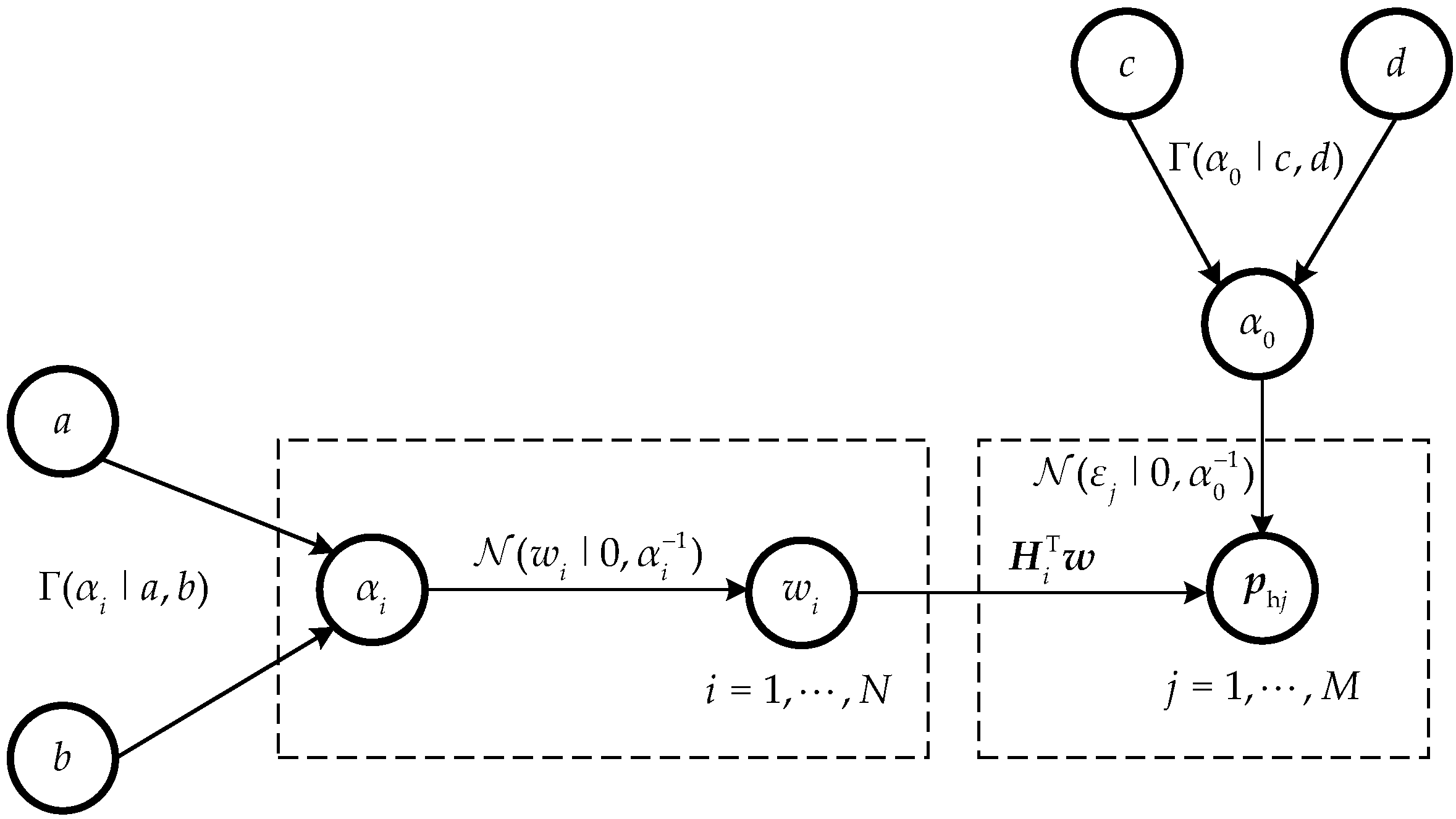
2.4. Bayesian Model via RVM
2.5. Sound Field Reconstruction Based on Bayesian Compressive Sensing
- Take a measurement of complex sound pressure on the hologram measurement surface and then convert the complex model into a real model using Equation (19), which can be processed using Bayesian theory;
- Approximate the measured sound pressure of the real model as a Gaussian likelihood distribution using Equation (20);
- Initialize the values of hyperparameters α and β2 in the Bayesian learning process;
- Calculate Σ and μ using Equations (26) and (27), where Σ and μ are the covariance and mean of the posterior distribution of the sparse coefficient vector Q, respectively;
- Use the MacKay algorithm to iteratively calculate the updated hyperparameters using Equations (30) and (31);
- Determine whether the iteration result satisfies the iteration stopping condition. If it does not, repeat iteration update steps 4 and 5 until the condition is satisfied and the iteration stops;
- Obtain the final estimation of the sparse coefficient vector with equivalent source strength Q = μ;
- Convert the sparse coefficient vector Q from the real model into the sparse coefficient vector with equivalent source strength w in the complex model using Equation (32);
- Calculate the equivalent source strength q using Equation (13);
- Determine the sound pressure and particle velocity of the reconstruction surface using Equations (6) and (7), thereby allowing sound field reconstruction to be achieved.
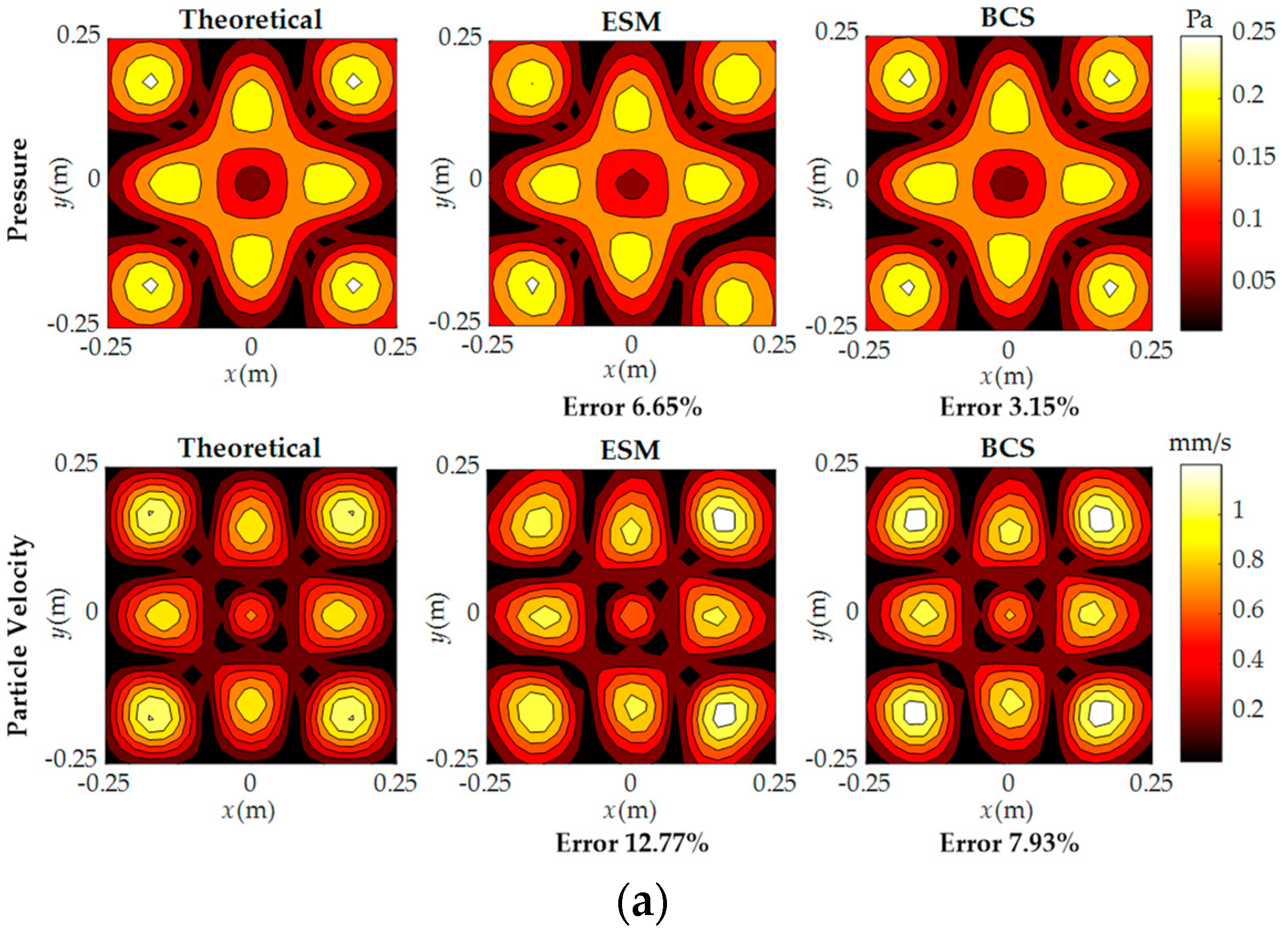
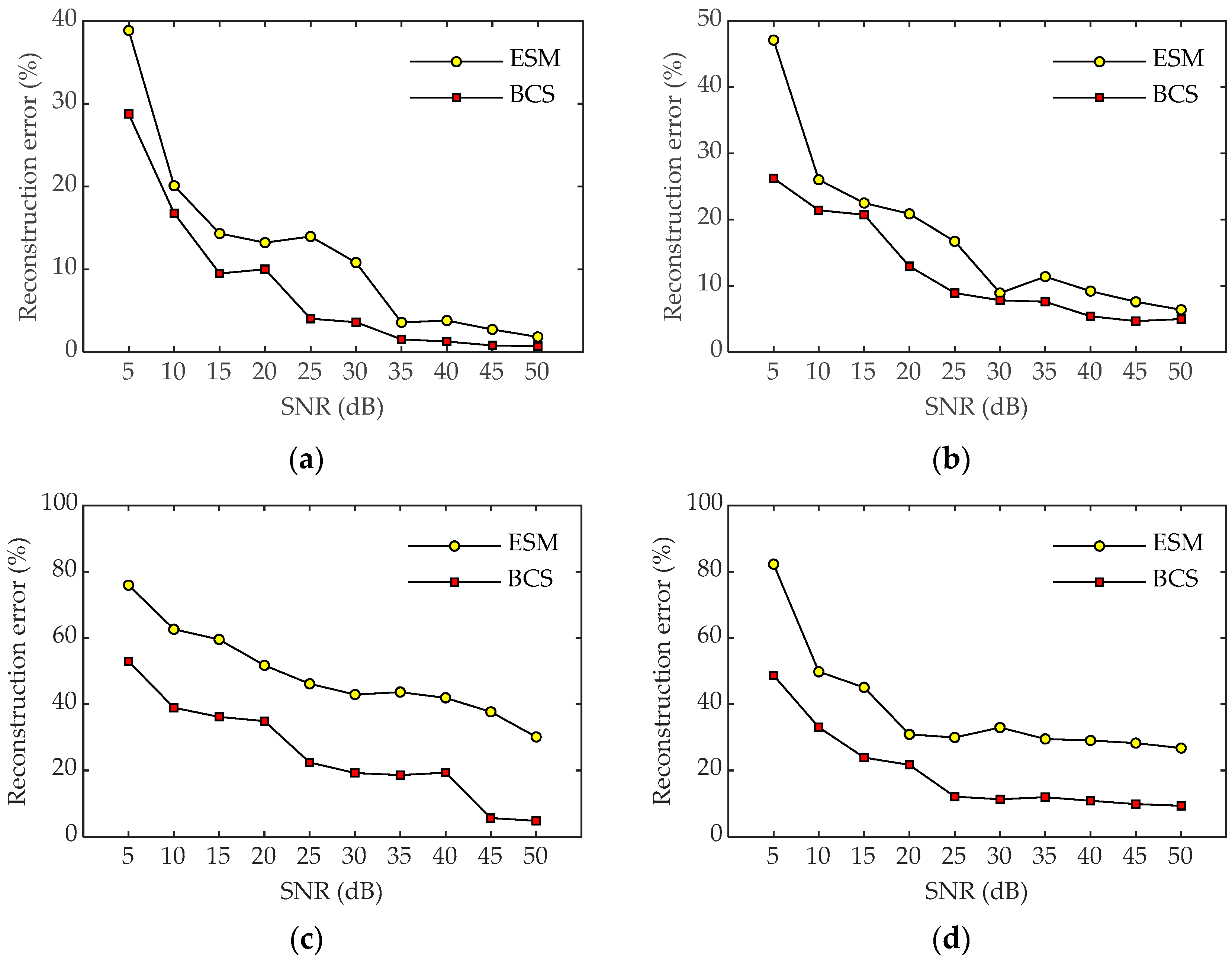
3. Numerical Simulations
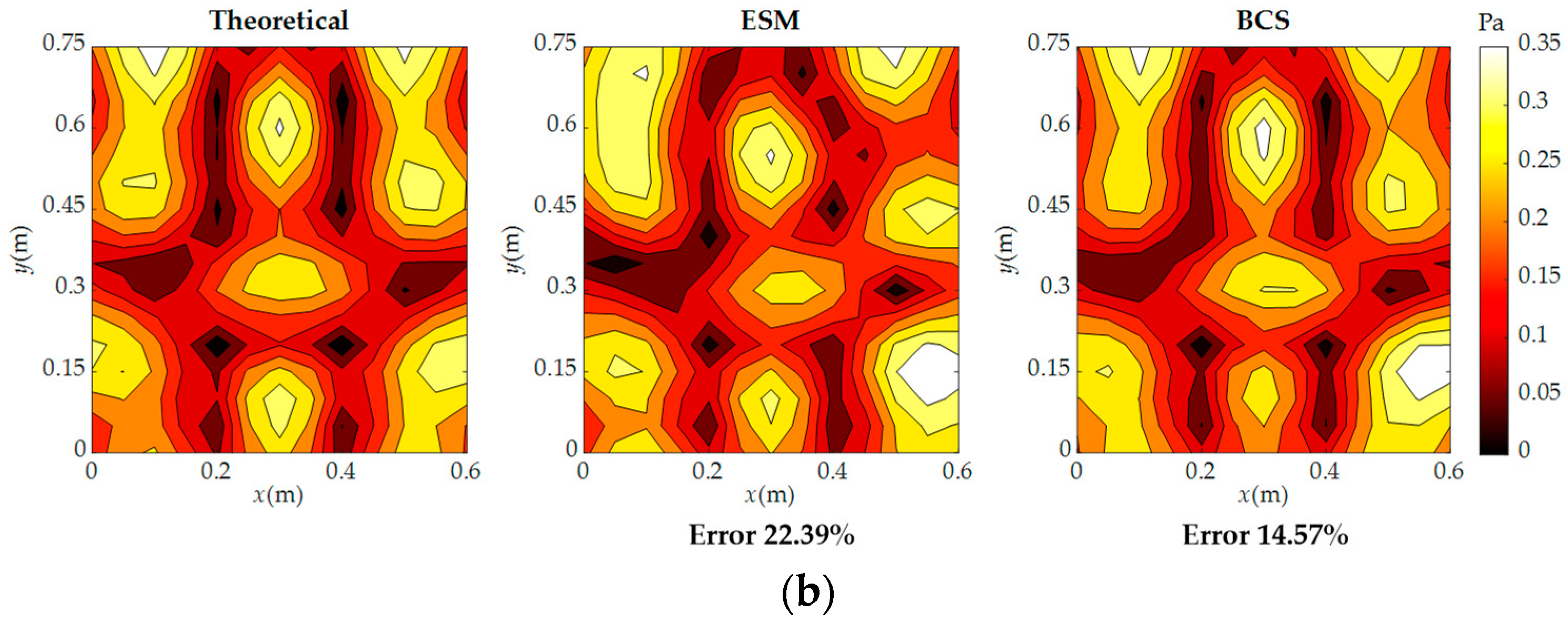
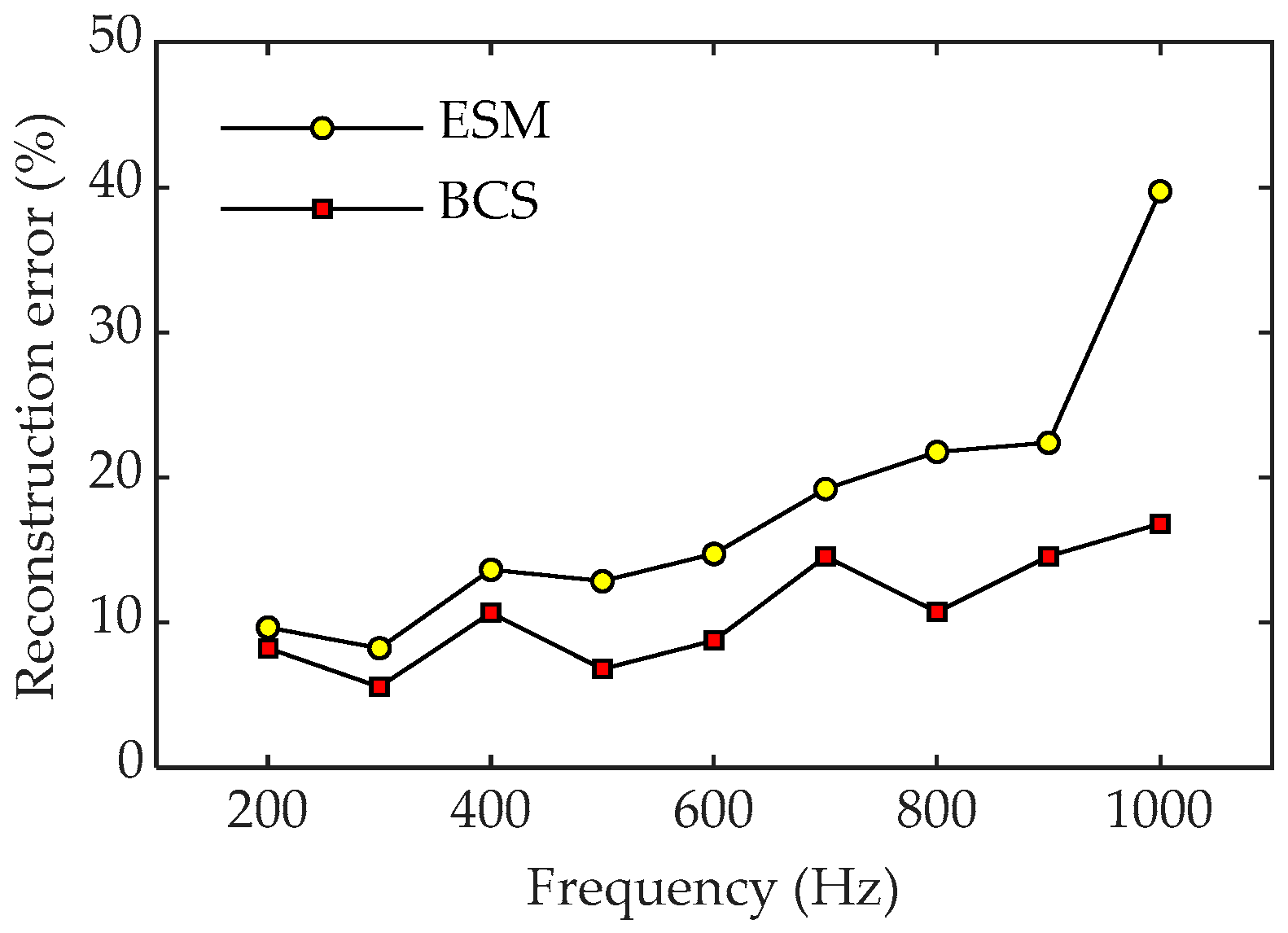
4. Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Veronesi, W.A.; Maynard, J.D. Nearfield acoustic holography (NAH) II. Holographic reconstruction algorithms and computer implementation. J. Acoust. Soc. Am. 1987, 81, 1307–1322. [Google Scholar] [CrossRef]
- Too, G.P.J.; Wu, B.H. Application of similar source method for noise source identification. Mech. Syst. Signal Process. 2007, 21, 3167–3181. [Google Scholar] [CrossRef]
- Yang, C.; Wang, Y.S.; Guo, H. Hybrid patch near-field acoustic holography based on Kalman filter. Appl. Acoust. 2019, 148, 23–33. [Google Scholar] [CrossRef]
- Scholte, R.; Lopez, I.; Bert, R.N.; Nijmeijer, H. Truncated aperture extrapolation for Fourier-based near-field acoustic holography by means of border-padding. J. Acoust. Soc. Am. 2009, 125, 3844–3854. [Google Scholar] [CrossRef]
- Valdivia, N.P.; Williams, E.G. Study of the comparison of the methods of equivalent sources and boundary element methods for near-field acoustic holography. J. Acoust. Soc. Am. 2006, 120, 3694–3705. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.B.; Jacobsen, F.; Bi, C.X.; Chen, X.Z. Near field acoustic holography based on the equivalent source method and pressure-velocity transducers. J. Acoust. Soc. Am. 2009, 126, 1257–1263. [Google Scholar] [CrossRef] [PubMed]
- Geng, L.; Bi, C.X.; Xie, F.; Zhang, X.Z. Reconstruction of instantaneous surface normal velocity of a vibrating structure using interpolated time-domain equivalent source method. Mech. Syst. Signal Process. 2018, 107, 1–11. [Google Scholar] [CrossRef]
- Geng, L.; Xie, F.; Lu, S. Reconstructing non-stationary surface normal velocity of a planar structure using pressure-velocity probes. Appl. Acoust. 2018, 134, 46–53. [Google Scholar] [CrossRef]
- Jiang, L.; Xiao, Y.; Zou, G. Data extension near-field acoustic holography based on improved regularization method for resolution enhancement. Appl. Acoust. 2019, 156, 128–141. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candès, E.J.; Wakin, M.B. An introduction to compressive sampling. IEEE Signal Proc. Mag. 2008, 25, 21–30. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C. Signal recovery from random measurements via orthogonal matching pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
- Dai, W.; Milenkovic, O. Subspace pursuit for compressive sensing signal reconstruction. IEEE Trans. Inf. Theory 2009, 55, 2230–2249. [Google Scholar] [CrossRef]
- Yin, S.; Yang, Y.; Chu, Z. Resolution enhanced Newtonized orthogonal matching pursuit solver for compressive beamforming. Appl. Acoust. 2022, 196, 108884. [Google Scholar] [CrossRef]
- Xenaki, A.; Gerstoft, P.; Mosegaard, K. Compressive beamforming. J. Acoust. Soc. Am. 2014, 136, 260–271. [Google Scholar] [CrossRef]
- Bi, C.X.; Liu, Y.; Zhang, Y.B.; Xu, L. Extension of sound field separation technique based on the equivalent source method in a sparsity framework. J. Sound Vib. 2018, 442, 125–137. [Google Scholar] [CrossRef]
- Hu, D.Y.; Li, H.B.; Hu, Y.; Fang, Y. Sound field reconstruction with sparse sampling and the equivalent source method. Mech. Syst. Signal Process. 2018, 108, 317–325. [Google Scholar] [CrossRef]
- Blumensath, T.; Davies, M.E. Iterative hard thresholding for compressed sensing. Appl. Comput. Harmon. Anal. 2009, 27, 265–274. [Google Scholar] [CrossRef]
- Erik, A.P.; Shen, Y. An adaptive Bayesian algorithm for efficient auditory brainstem response threshold estimation: Numerical validation. J. Acoust. Soc. Am. 2023, 153, A49. [Google Scholar]
- Candès, E.J. The restricted isometry property and its implications for compressed sensing. Comptes Rendus Math. 2008, 346, 589–592. [Google Scholar] [CrossRef]
- Padois, T.; Berry, A. Orthogonal matching pursuit applied to the deconvolution approach for the mapping of acoustic sources inverse problem. J. Acoust. Soc. Am. 2015, 138, 3678–3685. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, J. Multi-fault diagnosis for rolling element bearings based on ensemble empirical mode decomposition and optimized support vector machines. Mech. Syst. Signal Process. 2013, 41, 127–140. [Google Scholar] [CrossRef]
- Tipping, M.E. Sparse Bayesian learning and the relevance vector machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Ji, S.H.; Xue, Y.; Carin, L. Bayesian compressive sensing. IEEE Trans. Signal Process. 2008, 56, 2346–2356. [Google Scholar] [CrossRef]
- Babacan, S.D.; Molina, R.; Katsaggelos, A.K. Bayesian compressive sensing using Laplace priors. IEEE Trans. Image Process. 2010, 19, 53–63. [Google Scholar] [CrossRef] [PubMed]
- Chu, N.; Mohammad-Djafari, A.; Picheral, J. Robust Bayesian super-resolution approach via sparsity enforcing a priori for near-field aeroacoustic source imaging. J. Sound Vib. 2013, 332, 4369–4389. [Google Scholar] [CrossRef]
- Huang, Y.; Beck, J.L.; Wu, S.; Li, H. Robust Bayesian compressive sensing for signals in structural health monitoring. Comput.-Aided Civ. Infrastruct. Eng. 2014, 29, 160–179. [Google Scholar] [CrossRef]
- Pereira, A.; Antoni, J.; Leclere, Q. Empirical Bayesian regularization of the inverse acoustic problem. Appl. Acoust. 2015, 97, 11–29. [Google Scholar] [CrossRef]
- Bush, D.; Xiang, N. A model-based Bayesian framework for sound source enumeration and direction of arrival estimation using a coprime microphone array. J. Acoust. Soc. Am. 2018, 143, 3934–3945. [Google Scholar] [CrossRef]
- Niu, H.Q.; Gerstoft, P.; Ozanich, E.; Li, Z.L.; Zhang, R.H.; Gong, Z.X.; Wang, H.B. Block sparse Bayesian learning for broadband mode extraction in shallow water from a vertical array. J. Acoust. Soc. Am. 2020, 147, 3729–3739. [Google Scholar] [CrossRef]
- Reichel, L.; Yu, X.B. Matrix decompositions for Tikhonov regularization. Electron. Trans. Numer. Anal. 2015, 43, 223–243. [Google Scholar]
- Shin, M.; Fazi, F.M.; Nelson, P.A.; Hirono, F.C. Controlled sound field with a dual layer loudspeaker array. J. Sound Vib. 2014, 333, 3794–3817. [Google Scholar] [CrossRef]
- Tran, V.T.; Yang, B.S.; Gu, F.S.; Ball, A. Thermal image enhancement using bi-dimensional empirical mode decomposition in combination with relevance vector machine for rotating machinery fault diagnosis. Mech. Syst. Signal Process. 2013, 38, 601–614. [Google Scholar] [CrossRef]
- Zhang, L. Fault prognostic algorithm based on multivariate relevance vector machine and time series iterative prediction. Procedia Eng. 2012, 29, 678–686. [Google Scholar]
















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, Y.; Yuan, L.; Wang, J.; Hu, W.; Sun, R. Sparse Reconstruction of Sound Field Using Bayesian Compressive Sensing and Equivalent Source Method. Sensors 2023, 23, 5666. https://doi.org/10.3390/s23125666
Xiao Y, Yuan L, Wang J, Hu W, Sun R. Sparse Reconstruction of Sound Field Using Bayesian Compressive Sensing and Equivalent Source Method. Sensors. 2023; 23(12):5666. https://doi.org/10.3390/s23125666
Chicago/Turabian StyleXiao, Yue, Lei Yuan, Junyu Wang, Wenxin Hu, and Ruimin Sun. 2023. "Sparse Reconstruction of Sound Field Using Bayesian Compressive Sensing and Equivalent Source Method" Sensors 23, no. 12: 5666. https://doi.org/10.3390/s23125666
APA StyleXiao, Y., Yuan, L., Wang, J., Hu, W., & Sun, R. (2023). Sparse Reconstruction of Sound Field Using Bayesian Compressive Sensing and Equivalent Source Method. Sensors, 23(12), 5666. https://doi.org/10.3390/s23125666