1. Introduction
Welding is a crucial process in modern manufacturing. Traditional manufacturing methods rely on manual welding, which is not only inefficient but also unable to guarantee welding quality. This method fails to meet the requirements of modern manufacturing for high-efficiency and high-precision welding. In comparison to traditional welding, robot welding possesses inherent advantages such as consistency in welding quality, continuous and repetitive work, and accurate tracking of welds. Against this backdrop, with the development of automation, welding robots with high stability, efficiency, and the ability to work in harsh environments are gradually replacing manual welding. However, due to the inherent nonlinearity, multivariable coupling, and uncertainty in the power system [
1], simple welding robots have become increasingly unsuitable for modern production [
2].
Currently, the “Teach-Playback” mode [
3] is widely used in robot welding, resulting in a more favorable working environment; it increases welding efficiency to some extent and ensures the consistency of welding quality. However, the “Teach-Playback” mode still relies on the worker’s judgment for determining the welding start point and welding mode. In the welding process, thermal deformation of the welded parts can easily lead to the failure of trajectory planning using linear or arc interpolation, resulting in deviation of the welding trajectory. Therefore, many scholars have applied advanced sensor technology to welding robots to achieve real-time correction of welding trajectories [
4,
5,
6]. Among various sensors, active optical-vision sensors are more commonly used in welding tracking due to their ability to overcome complex environmental interference using light sources compared to passive vision sensors that use natural light or arc light generated during welding. The line-structured light sensor based on active optical-vision has become increasingly popular in the automatic welding robot industry because of its noncontact nature, high robustness, high accuracy, low cost, and other advantages [
7,
8,
9]. It is worth noting that some scholars have also explored other methods to build real-time welding automation quality assessment systems for timely detection of potential defects and problems, such as weld defect detection [
10] and melt pool depth prediction [
11]. These methods use detection systems in different forms and employ various technical means, but they are equally effective in helping welding robots instantly adjust welding parameters to ensure the stability and consistency of the welding process, while also improving productivity and reducing energy consumption. These methods can also be used in conjunction with the vision-based weld tracking methods mentioned above to further improve weld accuracy.
The key to achieving weld seam tracking is determining how to quickly and accurately locate the feature points of the weld seam from laser images in a noisy environment [
12]. In previous studies, most scholars used traditional morphological-based image processing methods to extract and locate the feature points of the weld seam [
13,
14,
15], which can ensure a certain accuracy in the absence of welding noise or weak welding noise, but cannot deal with complex noise conditions [
16]. For a long time, researchers have had to design different morphological algorithms for different application scenarios, resulting in low robustness and low production efficiency.
The development of machine learning has changed the landscape. Neural network algorithms have demonstrated powerful capabilities in automatically extracting image features, especially in the automatic welding domain where feature extraction is required under complex noise conditions. Consequently, numerous researchers have conducted extensive studies in this area. Du et al. [
17] addressed atypical weld seams in high-noise environments, initially employing binarization and region scanning for image segmentation, and then using a trained CNN model to extract candidate regions, finally extracting weld seam features through searching. Xiao et al. [
18] utilized a Faster R-CNN model to obtain weld seam types and ROI regions, and then applied targeted morphological methods to detect different types of weld seams. Dong et al. [
19] used a lightweight deep learning network, MobileNet-SSD, to extract ROI regions on an edge GPU device to maintain high processing speed, and used morphological methods such as region growth and centerline repair to gradually obtain strip centerlines and key point locations. However, this method suffers from the problem of low detection accuracy. Zou et al. [
20] designed a two-stage detector that utilized a convolutional filter tracker and a VGG neural network for coarse and fine localization of weld seam feature points, effectively resolving the issue of drift during weld seam tracking and achieving high precision. Zhao et al. [
21] constructed a semantic segmentation model based on an improved VGG Net to extract laser stripe edge features, and then acquired feature point positions using morphological methods such as the gray level centroid method, least squares method, and B-spline method, enabling the model to function well in environments with strong arc interference. Zou et al. [
22], to cope with high-noise environments, proposed a welding image inpainting method based on conditional generative adversarial networks (CGAN), mapping noisy images to noiseless images and integrating them into a tracker for weld seam detection and tracking. Yang et al. [
23] then used the deep encoder–decoder network framework and designed a welding image denoising method to achieve automatic laser stripe extraction from welding images. The method has a strong denoising performance under strong noise such as arc light, smoke, and spatter. Lu et al. [
24] also employed a semantic segmentation strategy combined with morphology, selecting BiseNet V2 as the network architecture and using OHEM to improve segmentation performance. Compared to other segmentation methods, the arc line segmentation effect was slightly inferior, but the segmentation performance in difficult-to-segment areas was significantly improved.
Most of the aforementioned methods are based on a two-stage detection approach, where the first stage utilizes neural networks for preliminary image processing and information extraction, while the second stage typically employs morphological methods or constructs new neural networks to complete feature point detection. The former approach requires the design of different recognition and localization algorithms for various types of weld seams, increasing the design complexity. The latter approach often involves extracting similar and generic low-level features from different stages of the network models, leading to a waste of time due to redundancy. Moreover, most existing research is based on traditional CNNs, which do not achieve very good results when dealing with highly imbalanced positive and negative samples in welding process images.
In recent years, the CNN’s characterization ability has been further improved with the introduction of new neural network techniques such as attention mechanism. The YOLO series of neural networks is one of the representatives in target detection and has been widely applied in various target detection fields, including pavement crack detection [
25], fruit detection [
26], welding quality detection [
27], and more, due to its powerful feature extraction ability, lightweight network structure, and efficient detection speed. This network series has undergone several iterations and has received continuous attention and improvement. Among these versions, YOLOv5 is one of the most mature and stable, with a stable structure, easy deployment, and ease of expansion, making it highly sought-after by researchers. Additionally, the model is continuously updated and its performance is constantly improving. Based on YOLOv5, researchers have made numerous improvements and engineering practices that have yielded significant results [
28,
29].
However, in the welding field, there is still a lack of research applying the YOLO [
30] series model to weld seam tracking. Therefore, this study proposes a feature point detection network based on YOLOv5 [
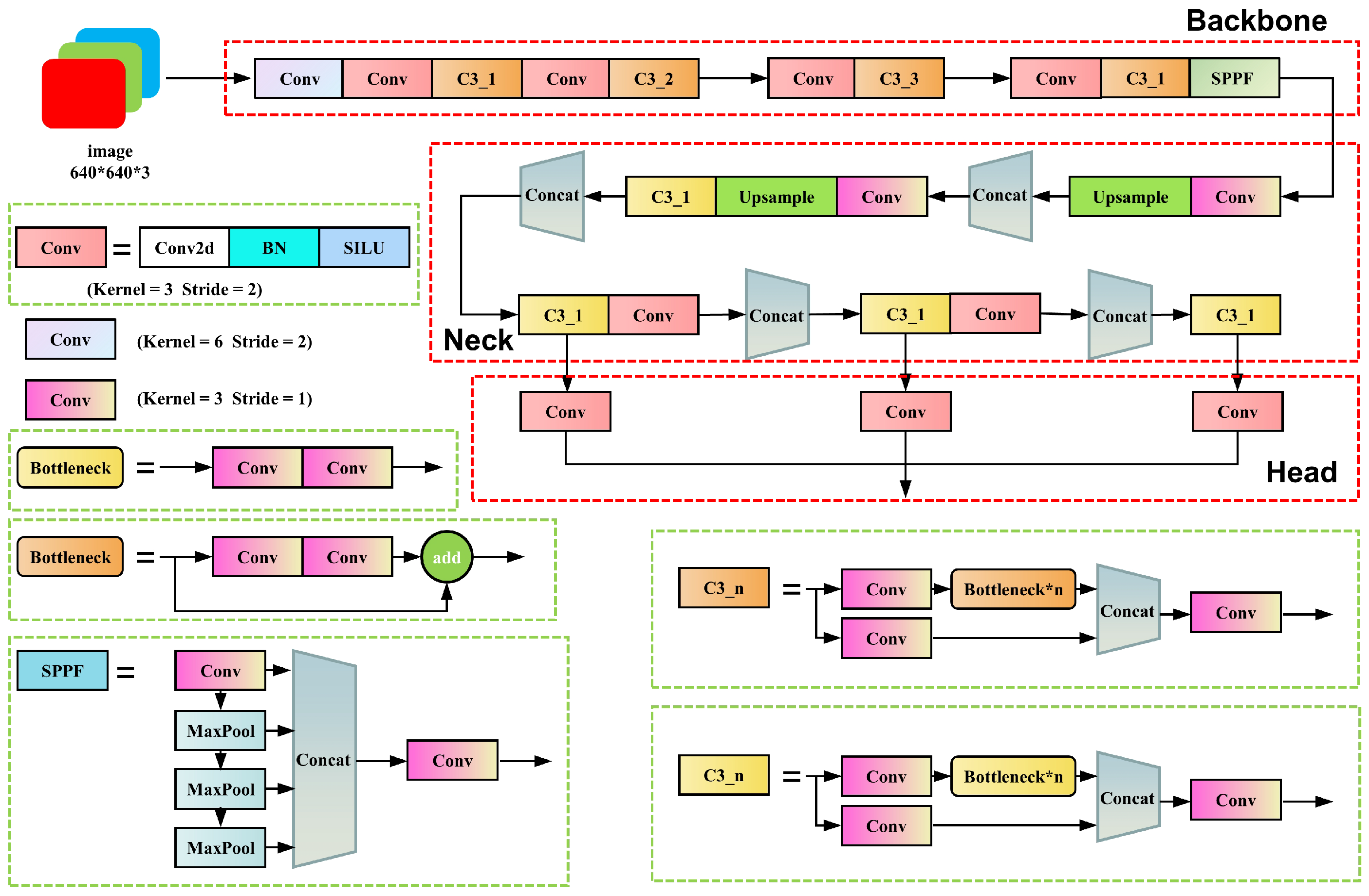
31], called YOLO-weld. It classifies weld seam feature points into 16 categories based on their dissimilarity, with the center coordinates of the target detection boxes in each category representing the weld seam feature point coordinates, transforming the weld seam feature point recognition problem into a target detection and classification problem. A welding noise generation algorithm is also proposed for data augmentation of training samples to enhance the adaptability of the model to extreme weld noise. Experiments demonstrate that YOLO-weld outperforms common CNN models in terms of detection and localization accuracy for weld seam feature points and exhibits excellent generalization capabilities, operating stably under varying intensities of welding noise.
2. Experiment System
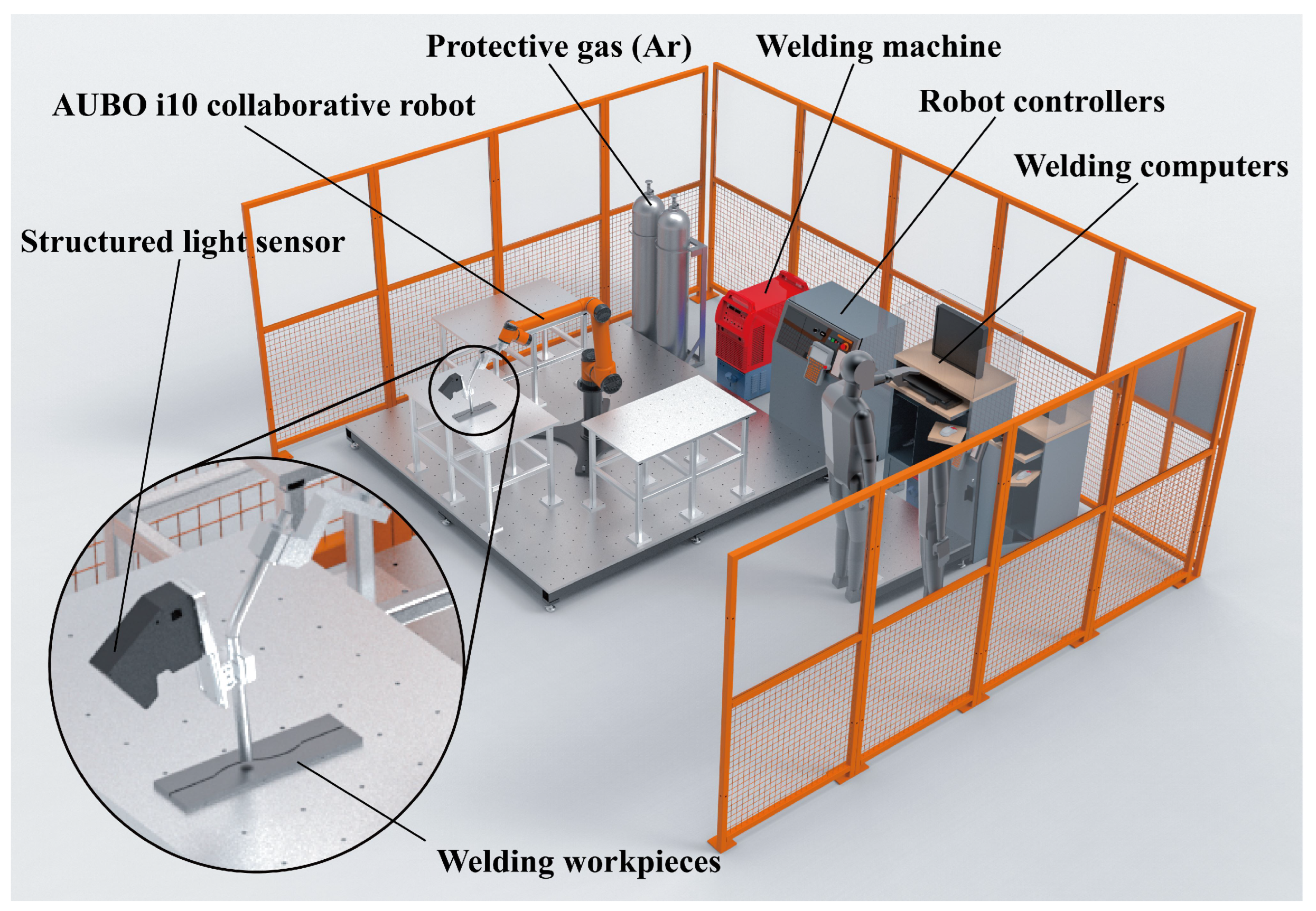
The hardware experimental platform of the optical vision intelligent welding system built in this study is shown in
Figure 1. It is mainly composed of a robot system, a vision system, and a welding machine system. The robot system consists of the robot body, robot controller, and demonstrator. Industrial robots, while offering outstanding advantages in terms of cost and rigidity of the system, do not have anticollision mechanisms. For safety reasons, the robot used in this study is the AUBO i10 collaborative robot, which has comparable system compatibility with industrial robots and is capable of driving a 10 kg load, which meets the needs of this study. The detailed experimental hardware configuration is shown in
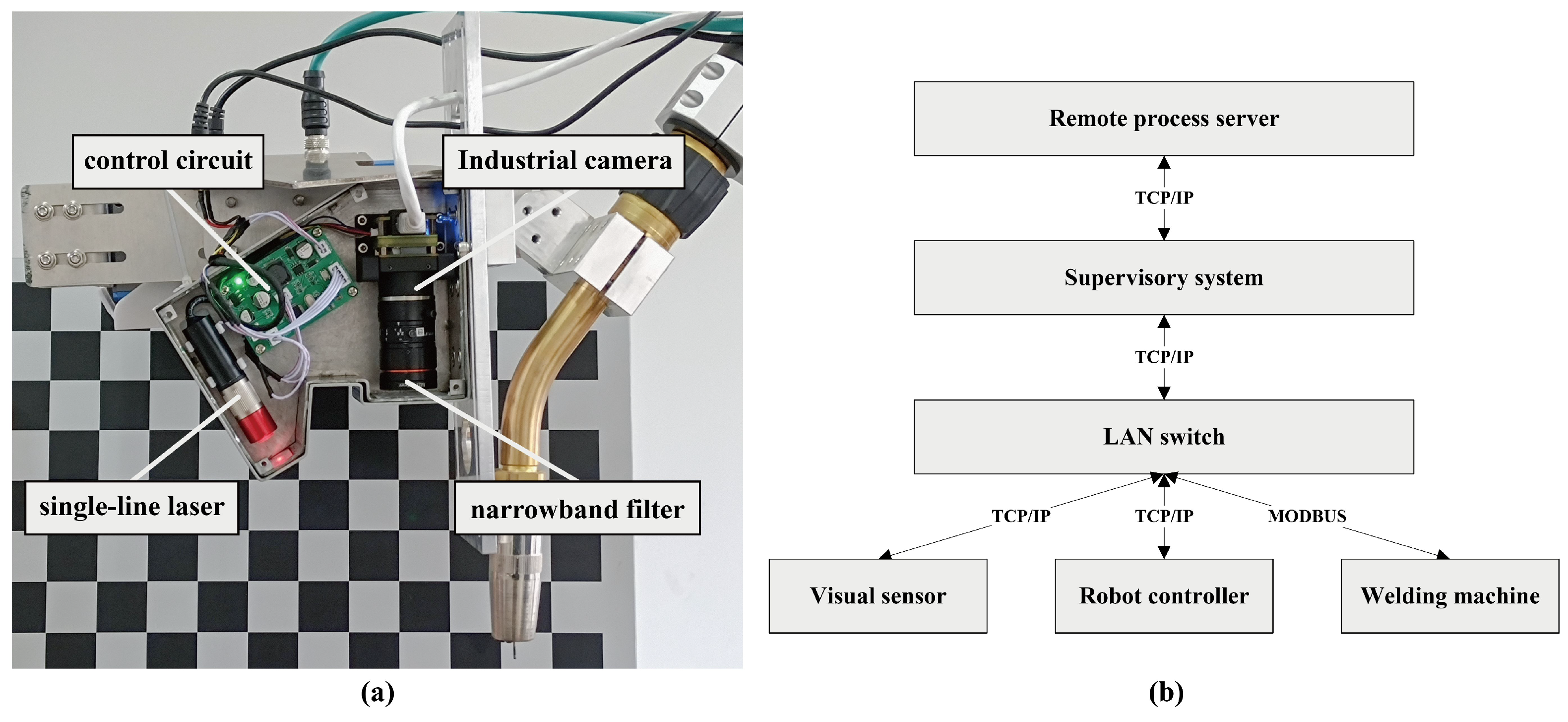
Table 1. The visual sensor component employs a self-developed sensor, as illustrated in
Figure 2a, which includes an HIK board-level industrial camera, a 660 nm narrowband filter, a laser projector emitting a 660 nm single-line laser, and a circuit for controlling the laser brightness.
The visual sensor, welding machine, and robot controller are connected to an enterprise-grade switch via a gigabit Ethernet network. The supervisory system (SS) distributes control commands for the welding process through the switch while also connecting to a remote process server via the internet to obtain process data. The network topology of the hardware system is shown in
Figure 2b. In practical operation, the visual sensor acquires seam type and feature point information, transmitting it to SS. Subsequently, SS retrieves process information from the remote welding process library to direct the welding machine and welding robot in performing their tasks.
4. Experiment and Analysis
4.1. Training of the Model
The model proposed in this study was designed based on the deep learning framework Pytorch. The operating system used in this study is Ubuntu 18.04 with 43 GB RAM, the CPU is Intel(R) Xeon(R) Platinum 8255C CPU @ 2.50 GHz, and the GPU is RTX 2080 Ti. The above platform was used to train and test the models in this study and the comparison models.
In the model training, the input image was resized to 640 × 640 and data enhanced, after which it was used as the network input. We used the stochastic gradient descent (SGD) optimizer in the Pytorch framework, with the initial learning rate set to , and used a weight decay strategy to gradually decay the learning rate during training until it was reduced to times the initial value. The default value of loss gain was chosen, the batch size was set to 8, and the number of training rounds was set to 500.
4.2. Training Results and Evaluation
To better evaluate the performance of the model, we employed the trained model for inference on the test set. As shown in
Figure 12, our model is capable of effectively extracting the class and location information of feature points for different types of weld seams under various noise conditions. Even when the feature point locations in the images are partially obscured by extreme welding noise, the model can still infer the locations of the feature points through analysis of global features, enabling the model to maintain high accuracy and robustness in strong noise environments.
To further quantify the model’s performance, we used the frames per Second (FPS) metric to assess the model’s real-time capabilities, while employing precision, recall, and mAP (mean average precision) metrics to evaluate detection accuracy [
27]. Precision is used to evaluate the accuracy of the object predictions, and recall is used to assess whether all objects have been detected. Their calculation formulas are as follows:
In Equations (
8) and (
9), samples with annotation boxes near the predicted boxes and an IoU value greater than the set IoU threshold are considered correctly predicted samples. TP represents the number of samples that should be classified as positive and are correctly classified as positive, FP represents the number of samples that should be classified as negative but are incorrectly classified as positive, and FN represents the number of samples that should be classified as positive but are incorrectly classified as negative. In Equation (
10), N denotes the number of categories, and average precision (AP) represents the area enclosed by the precision–recall (P–R) curve and represents the AP value of class
c. The mean average precision (mAP) measures the accuracy of the model in detecting N categories, where mAP 0.5 represents the mAP value when the IoU threshold is 0.5, and mAP 0.5:0.95 represents the average mAP value when the IoU threshold increases from 0.5 to 0.95. The mAP comprehensively reflects the precision and recall of object detection. Correspondingly, in the feature point detection task studied in this study, the higher the mAP, the lower the missed and false detection rates of the graphics, which to some extent reflects higher detection accuracy.
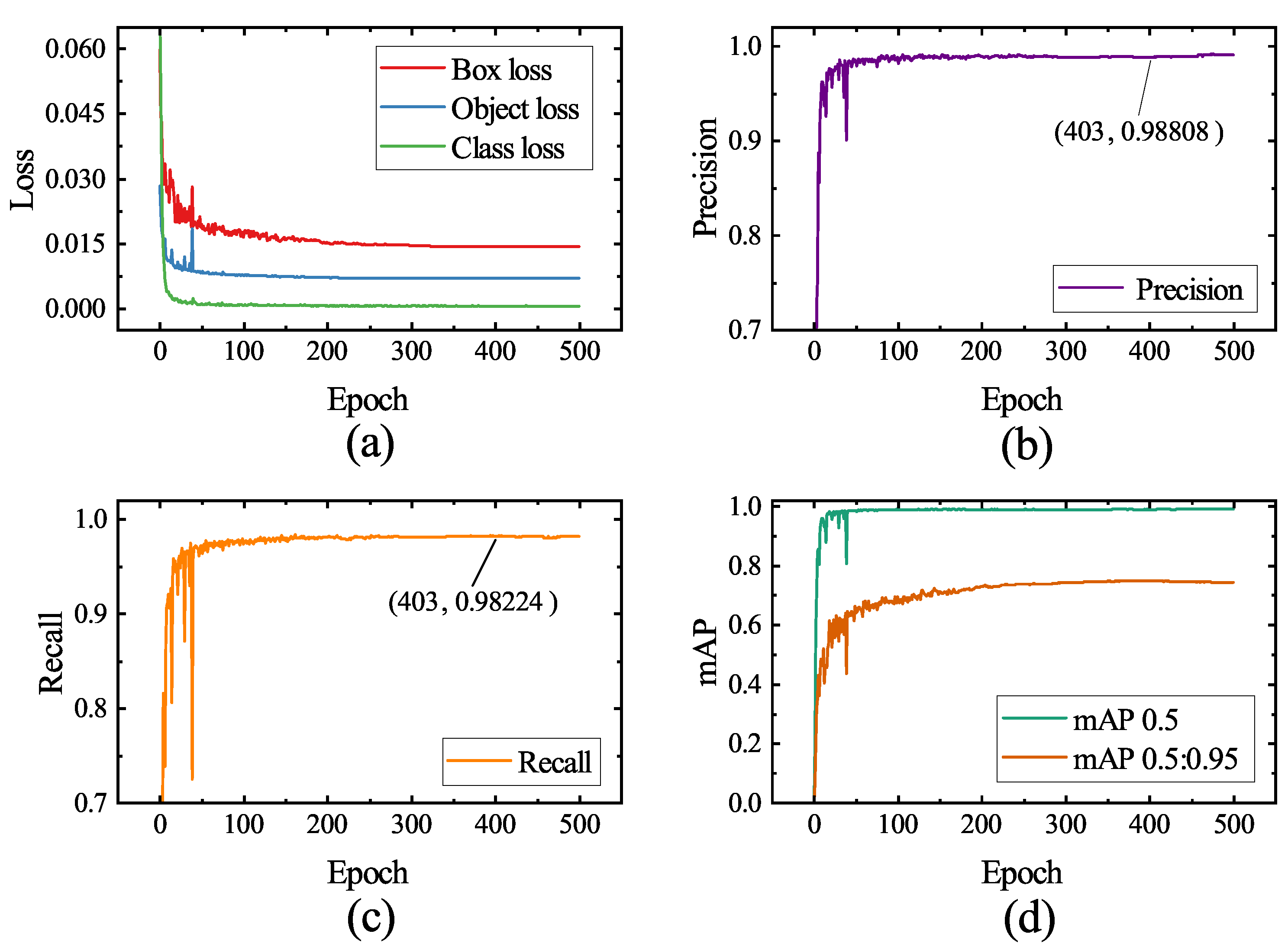
The curves in
Figure 13 depict the variations in loss, precision, recall, and mAP parameters on the validation set as the number of training iterations progresses. The model converges swiftly during the initial training stages, as evidenced by the rapid decrease in box loss, object loss, and class loss, as well as the rapid increase in mAP and other metrics. This occurs as the model fine-tunes the weights obtained from pretraining on a large-scale dataset, adapting to the data distribution present in welding process images. Beyond 190 epochs, the model loss approaches convergence, and the learning rate diminishes to a lower level, initiating fine-grained learning for weld seam noise images. Ultimately, at epoch 402, the model attains its peak mAP, and the weights from this epoch are chosen as the final weights for the model.
Utilizing these weights to evaluate the test set, the assessment results of the aforementioned metrics are presented in
Table 3. The model’s precision and recall achieve 0.990 and 0.983, respectively, signifying the proposed model’s ability to effectively extract image features and accurately detect and classify feature points. With an mAP 0.5:0.95 of 0.751, the model exhibits superior prediction outcomes under various detection standards, further emphasizing the model’s detection performance in highly noisy conditions. The difficulty to further enhance the model’s precision, recall, and mAP during training and testing arises from some images in the actual test set being affected by extreme noise, as illustrated in
Figure 14. The figure reveals that intense arc light and spatter noise occupy a significant portion of the image, entirely concealing the feature points and surrounding areas, resulting in a considerably low signal-to-noise ratio (SNR) in the image. Despite the model’s robust local and global perception capabilities, it cannot make confident inferences. This observation underscores the difficulty of improving accuracy and robustness against weld feature points in the inspection process. Nevertheless, such images constitute a minimal fraction of all images; hence, the model can effectively detect weld seam feature points in highly noisy conditions. Moreover, the model’s inference speed is a mere 9.57 ms, with an FPS as high as 104.46 Hz, satisfying the real-time demands of actual industrial production processes.
To provide a more intuitive reflection of the model’s accuracy in predicting feature points, we project the output coordinate information onto the original size image and calculate the deviation between the predicted and labeled coordinates on the original size image. For different types of weld seams, the Euclidean distance between the predicted and labeled positions is shown in
Figure 15. Our model’s prediction deviation for most images is within 3 pixels, corresponding to an actual deviation of less than 0.15 mm. For a very small number of strong noise images (such as the bottom row in
Figure 12), the feature points may be obscured, resulting in a relatively larger inference deviation for the model. Overall, the model achieves excellent performance in detecting feature points for different types of weld seams.
Moreover, to comprehensively evaluate the model’s prediction accuracy, we introduce mean absolute error (
) and root mean square error (
) as evaluation metrics. MAE is the average absolute distance between predicted and labeled points, reflecting the deviation of predicted values from the actual values.
is the square root of mean square error (
), which is more sensitive to outliers and better reflects the stability of the prediction system. The formulas for the two indicators are as follows:
Where
N represents the number of samples, and
represents the distance difference between the predicted and standard values in different directions. When the prefixes of MAE and RMSE are X, Y, and E, they represent the deviation in the X direction, the deviation in the Y direction, and the Euclidean distance deviation, respectively. The evaluation results are shown in
Table 4. It can be seen that the proposed model’s E-MAE for all predicted feature points is 2.100 pixels, and the MAE in both X and Y directions is controlled at around 1.4 pixels, indicating high prediction accuracy. The E-RMSE is 3.099 pixels.
4.3. Selecting the Base Model for the Experiment
YOLOv5 offers a range of models designed to accommodate tasks with varying inspection speed and accuracy requirements. In this study, we balance the real-time demands of welding and the accuracy requirements of feature point localization to select the appropriate YOLOv5 model as our base model.
We utilize various YOLOv5 models for testing on our welding dataset, maintaining consistent data enhancement and training parameters throughout the experiments.
Table 5 presents the results, where “Parameter” represents the number of network model parameters, and ”Volume” indicates the memory size occupied by the model.
The comparison results indicate that despite YOLOv5n offering the highest detection speed, it is constrained by the network’s parameter count, limiting its capacity to learn features. Consequently, it exhibits comparatively low accuracy and stability in feature point localization. When the number of parameters of the network model is increased to the number of YOLOv5s, the model can learn relatively complete features and the detection accuracy is substantially improved, while the detection speed is only slightly reduced. Following this, as demonstrated by YOLOv5m and YOLOv5l, the increase in the number of parameters results in a diminished impact on the enhancement of detection accuracy and leads to a decrease in detection speed. This compromise hinders the model’s ability to satisfactorily meet the real-time demands of welding. Therefore, YOLOv5s obtains the best balance between inference speed and accuracy compared to other models with the same number of parameters. Consequently, we select YOLOv5s as our base model, upon which we improve to develop YOLO-weld.
4.4. Ablation Experiments
To verify the impact of the WNGM and the improved network structure on the feature point recognition and localization task, we have specifically designed two ablation experiments in this study.
First, we applied different data augmentation methods to the same dataset. One group did not use WNGM augmentation, while the other group used WNGM augmentation for 50% of the data. The comparison of prediction performance after using WNGM augmentation is shown in
Figure 16, and the corresponding evaluation metrics are shown in
Table 6. It can be observed that the model with WNGM augmentation has better robustness, and its ability to detect feature points in strong noise images is effectively improved, as well as the regression accuracy of feature points.
We subsequently conducted four experimental sets to illustrate the efficacy of the enhanced network structure. Each utilized WNGM data augmentation and maintained identical training parameters. The test results are displayed in
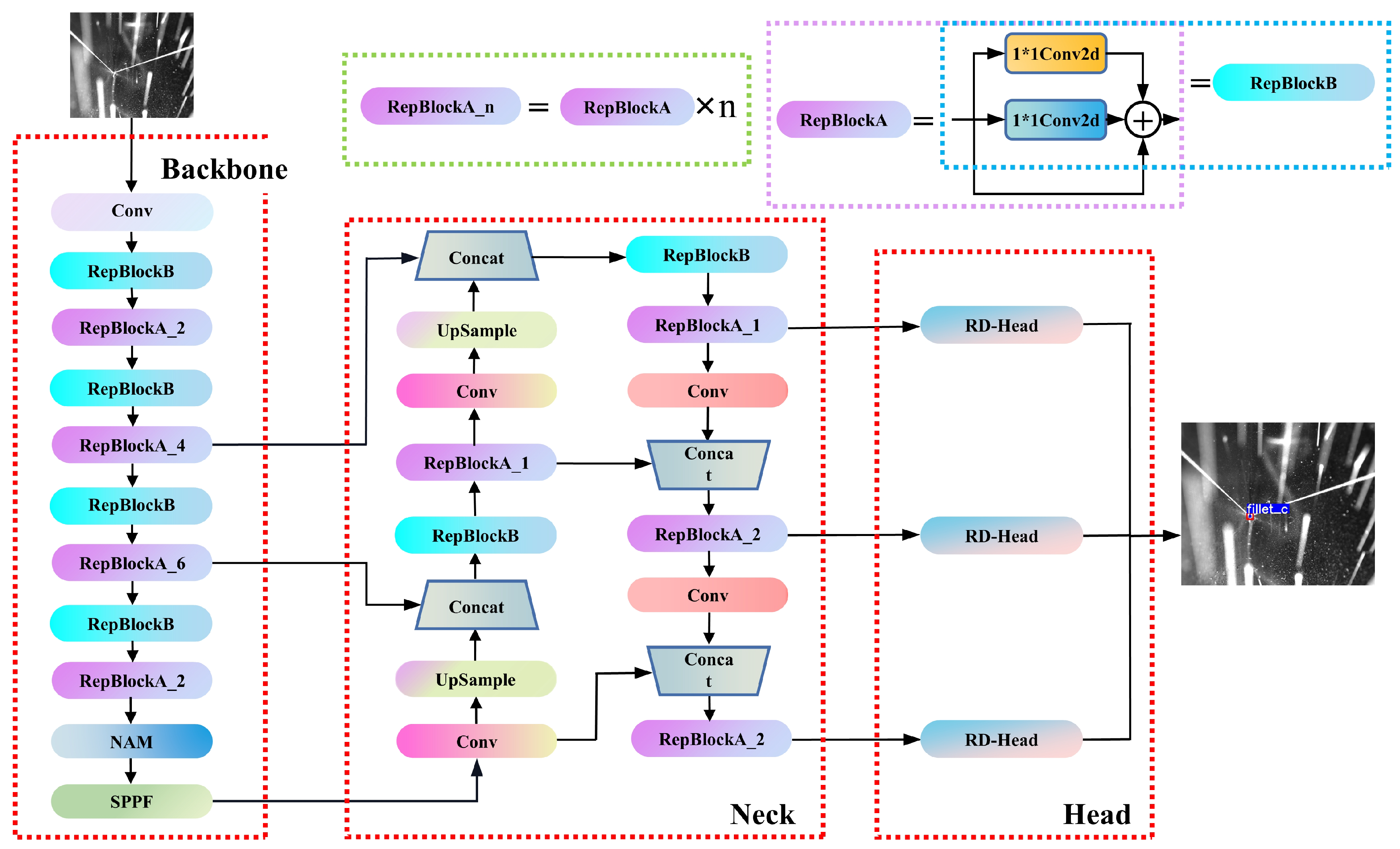
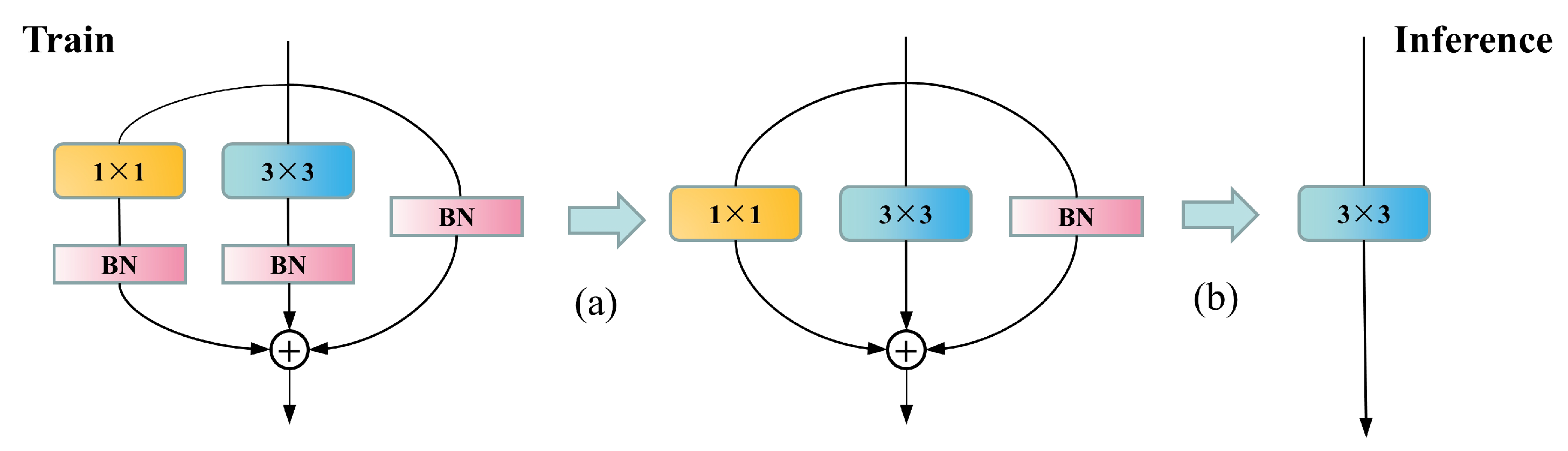
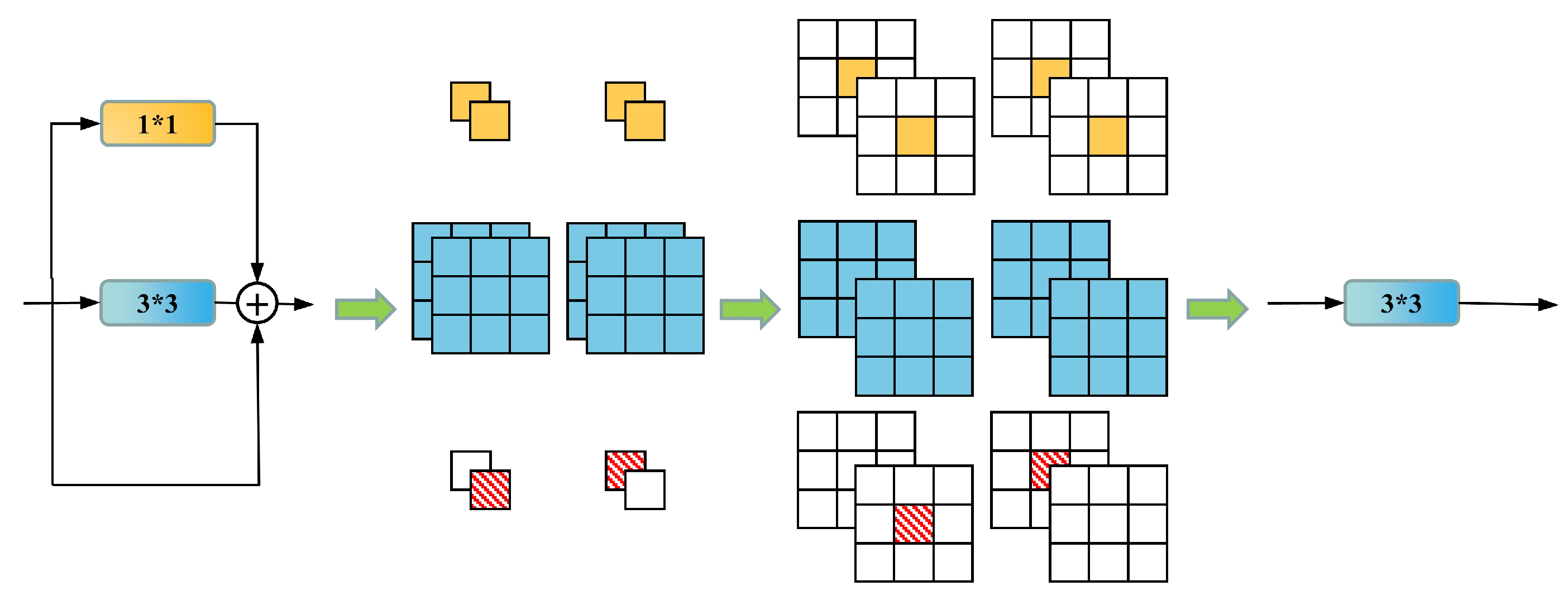
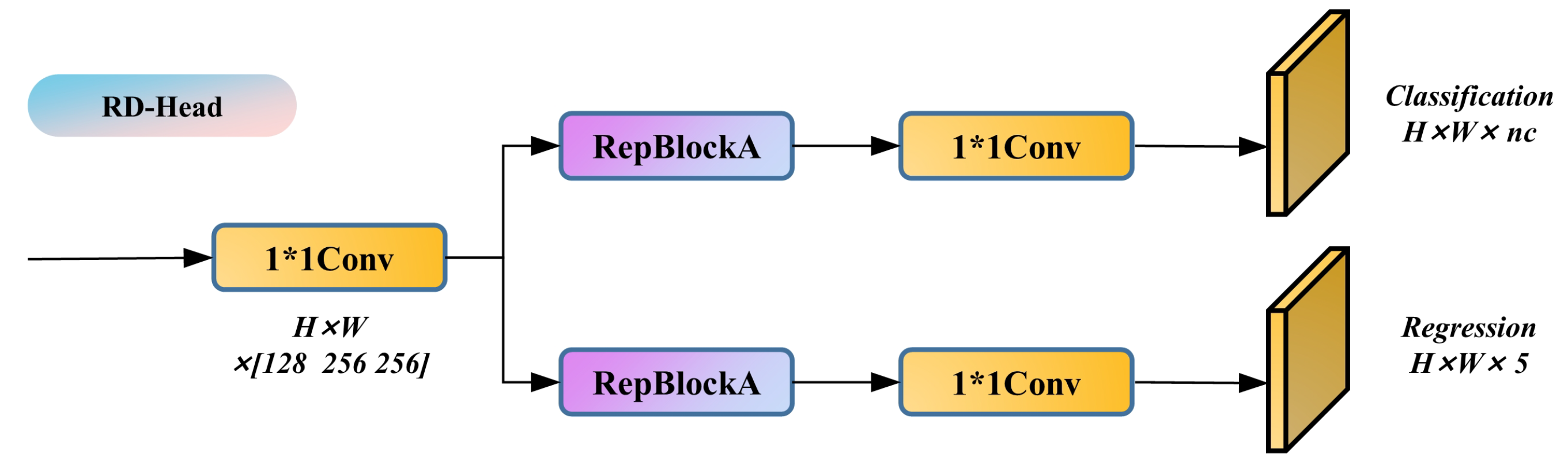
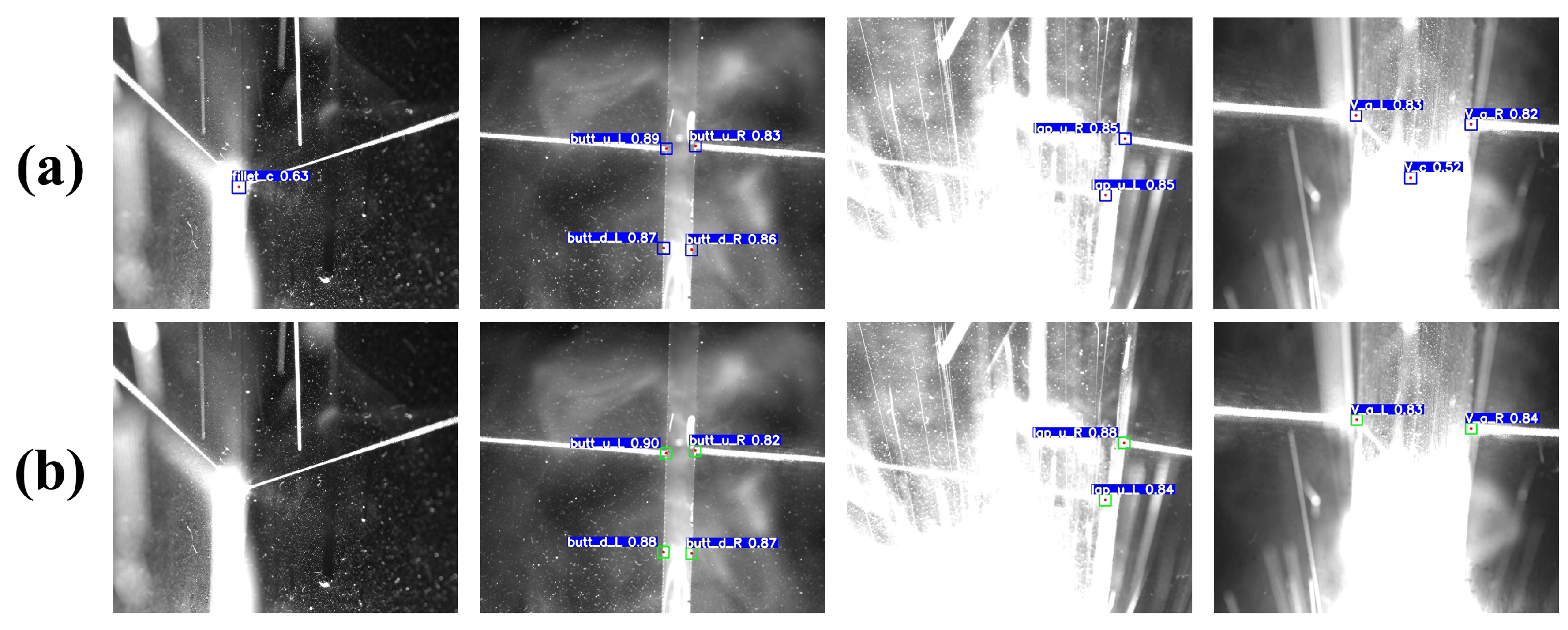
Table 7. The improvements primarily encompass three aspects: the incorporation of the RepVGG structure, which elevates the test GPU inference speed by 56.2%, achieving 124.8 Hz, albeit with a slight reduction in feature point prediction accuracy. Subsequently, the integration of the NAM bolsters the model’s local perception capabilities and global feature extraction capacity for feature points, enabling the model to better concentrate on regions surrounding feature points. This enhances the mAP 0.5:0.95 by 0.4% while minimally impacting the inference speed. Lastly, the introduction of the RD-Head resolves the shared weights issue for classification and bounding box regression tasks in the head, effectively augmenting the prediction accuracy of bounding boxes. Following its implementation, the model’s mAP 0.5:0.95 increases by 2%, significantly improving the detection accuracy and stability of feature points. Ultimately, our proposed YOLO-weld model, in comparison to the baseline YOLOv5s model, attains a 30.8% increase in inference speed, a 1.1% enhancement in mAP 0.5:0.95, and superior feature point detection accuracy and stability.
To further validate the performance of our proposed YOLO-weld model and the generalizability of the improved method, we conducted additional experiments on VOC2007, an open-source dataset widely used for target detection.The experiments involve a comparison between YOLOv5s and YOLO-weld, using identical training parameters. The training is halted if there is no growth in the mAP values on the validation set within 100 epochs.
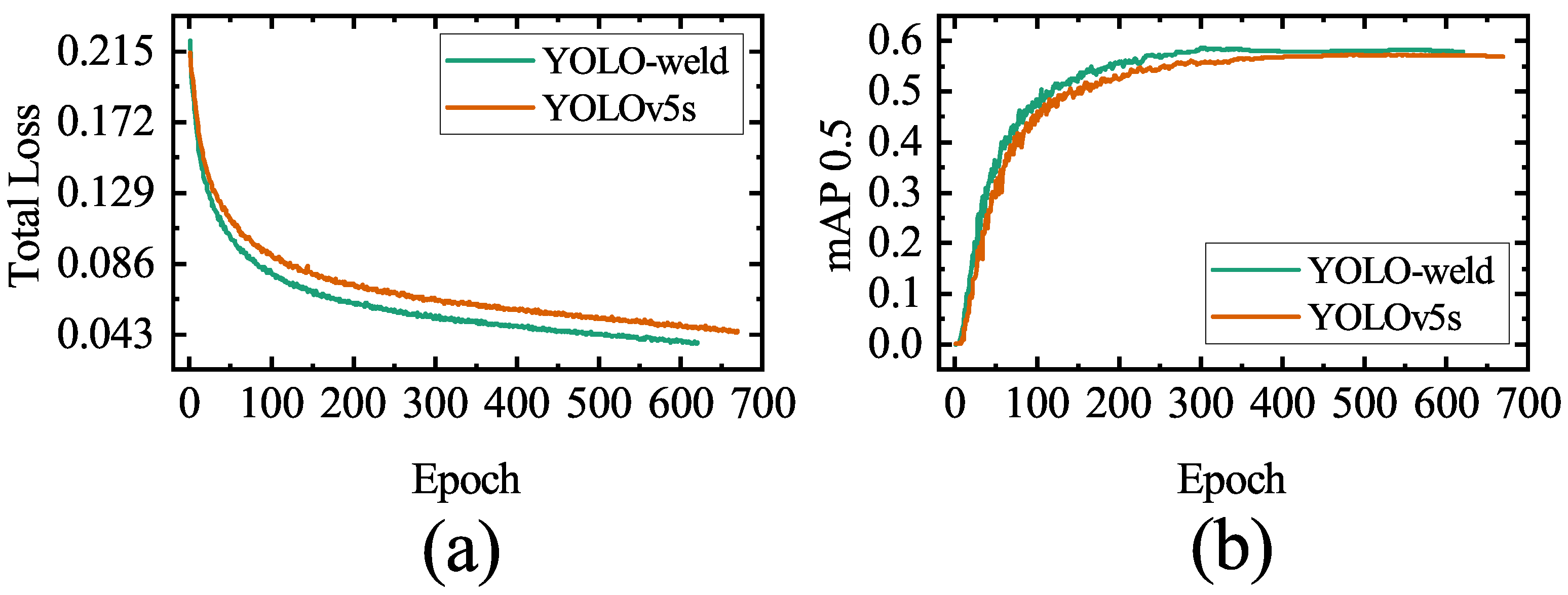
The variation of mAP 0.5 and total loss with the number of training rounds for both models is shown in
Figure 17. Notably, YOLO-weld, an improvement over YOLOv5s, exhibits faster convergence, higher optimal accuracy, and superior regression performance. The test results of the model on the test set are shown in
Table 8. The YOLO-weld proposed in this study has a slightly lower recall compared to YOLOv5s, but both precision and mAP are significantly improved, and the detection speed is significantly enhanced. Consequently, YOLO-weld also demonstrates enhanced stability and performance in nonwelding target detection tasks, further substantiating its advanced, stable, and scalable characteristics.
4.5. Comparative Experiments
To demonstrate the superiority of our proposed network, we compared the feature point detection model designed in this study with other neural network models. The comparative experiments used the same dataset and data augmentation methods, selected default training parameters, trained for 500 epochs, and finally performed validation and testing on the constructed validation set.
The test results are shown in
Figure 18, and the evaluation results are presented in
Table 9. Among the compared models, Faster RCNN is a common two-stage network. The two-stage design increases the model’s training and inference costs. Simultaneously, due to the constraints of the backbone network structure, the detection accuracy is relatively poor, and there are many misidentifications. SSD adopts the prior box method from Faster RCNN and uses an end-to-end design, which improves the model’s detection speed. However, as shown in
Figure 18b, the model still cannot accurately recognize feature targets in strong noise environments. CenterNet abandons the use of prior boxes and instead predicts the center point of the bounding boxes through heatmaps and regression offsets. From the actual detection data, the heatmap-based method provides the model with excellent stability, but the overly slow inference speed cannot meet the real-time requirements of welding tasks. YOLOv4 and YOLOv5, as classic models of the YOLO series, significantly improve detection speed while further enhancing prediction accuracy. YOLOv7, as the most advanced object detector currently, performs better than YOLOv5 on the COCO dataset but does not achieve a significant performance advantage in welding detection tasks and causes some loss of detection speed. In contrast, our proposed YOLO-weld model is based on the high-performance YOLOv5 and has been improved for seam feature point detection tasks. The modified YOLO-weld achieves the fastest inference speed and obtains a more significant improvement in feature point detection accuracy and stability, effectively meeting the needs of welding tasks.
4.6. Welding Experiment
To better evaluate the performance of YOLO-weld in practical welding tasks, V-shape welds were selected for welding experiments. First, a dense 3D point cloud was obtained as the reference by scanning the welds using the Zeiss COMET L3D 2 system, as shown by the gray portion in
Figure 19. Subsequently, continuous welding images were captured during the actual welding process, and YOLO-weld was employed to perform inference on these images. Finally, the predicted coordinates were transformed into the world coordinate system, as illustrated by the green portion in
Figure 19. It can be observed that YOLO-weld is capable of making accurate predictions for the feature points of the V-shape welds.
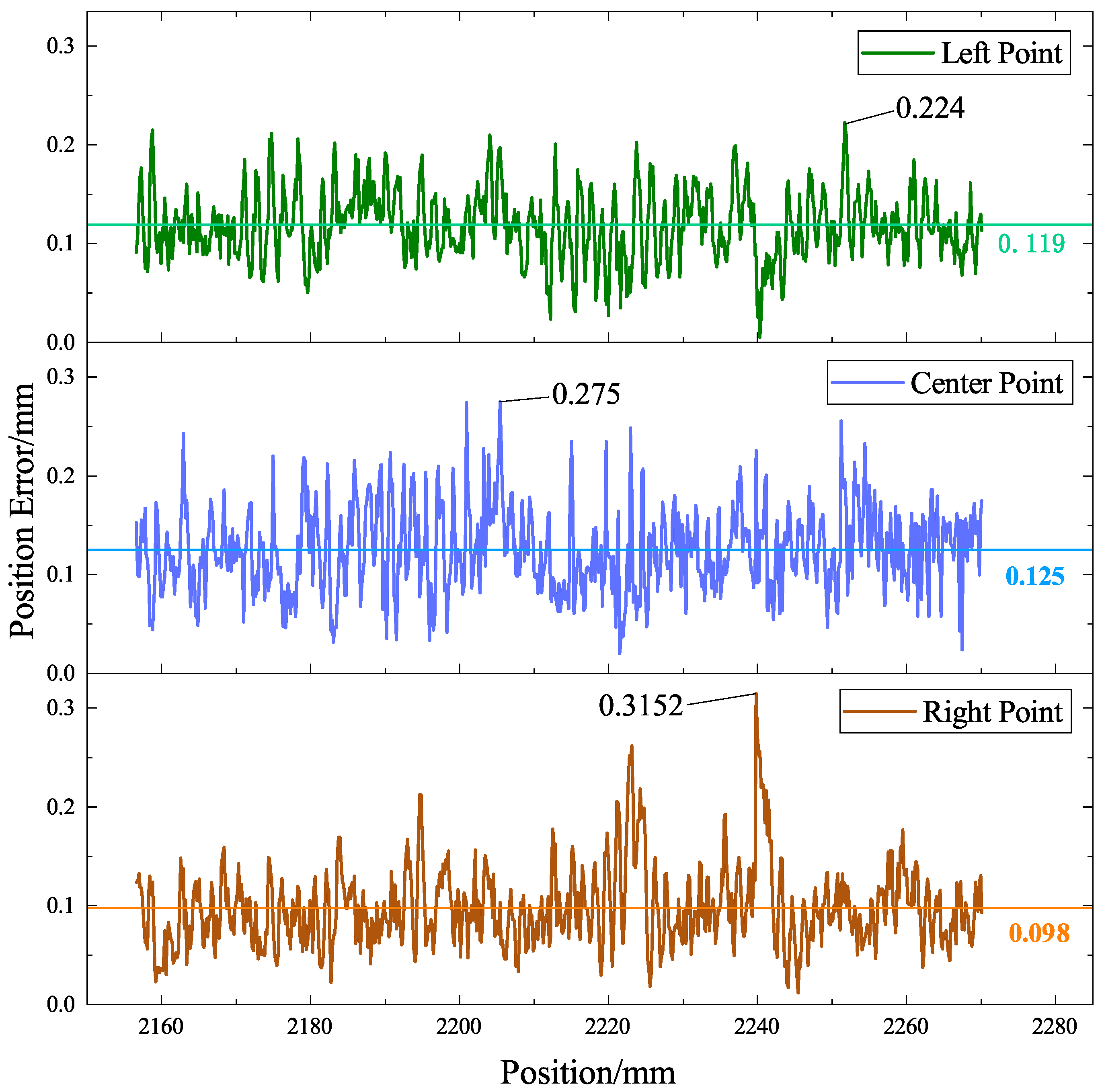
To further quantify the performance of the model, the Euclidean distances between the point cloud of the weld feature points predicted by YOLO-weld and the reference point cloud results were calculated. The comparison results are shown in
Figure 20. As can be seen from the figure, the three feature points of the V-shape welds have high accuracy. The average position error of the left feature point is 0.119 mm, with a maximum error of 0.224 mm; the average error of the center feature point is 0.125 mm, with a maximum error of 0.275 mm; and the average error of the right feature point is 0.098 mm, with a maximum error of 0.3152 mm. The average error of all feature points is 0.114 mm, which adequately meets the practical welding requirements and reflects the ability of the proposed model to overcome noise interference and ensure accurate recognition of the weld feature points.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}