
Toward Energy-Efficient Routing of Multiple AGVs with Multi-Agent Reinforcement Learning




Abstract
1. Introduction
2. Literature Review
3. Background
3.1. Single-Agent Reinforcement Learning Model
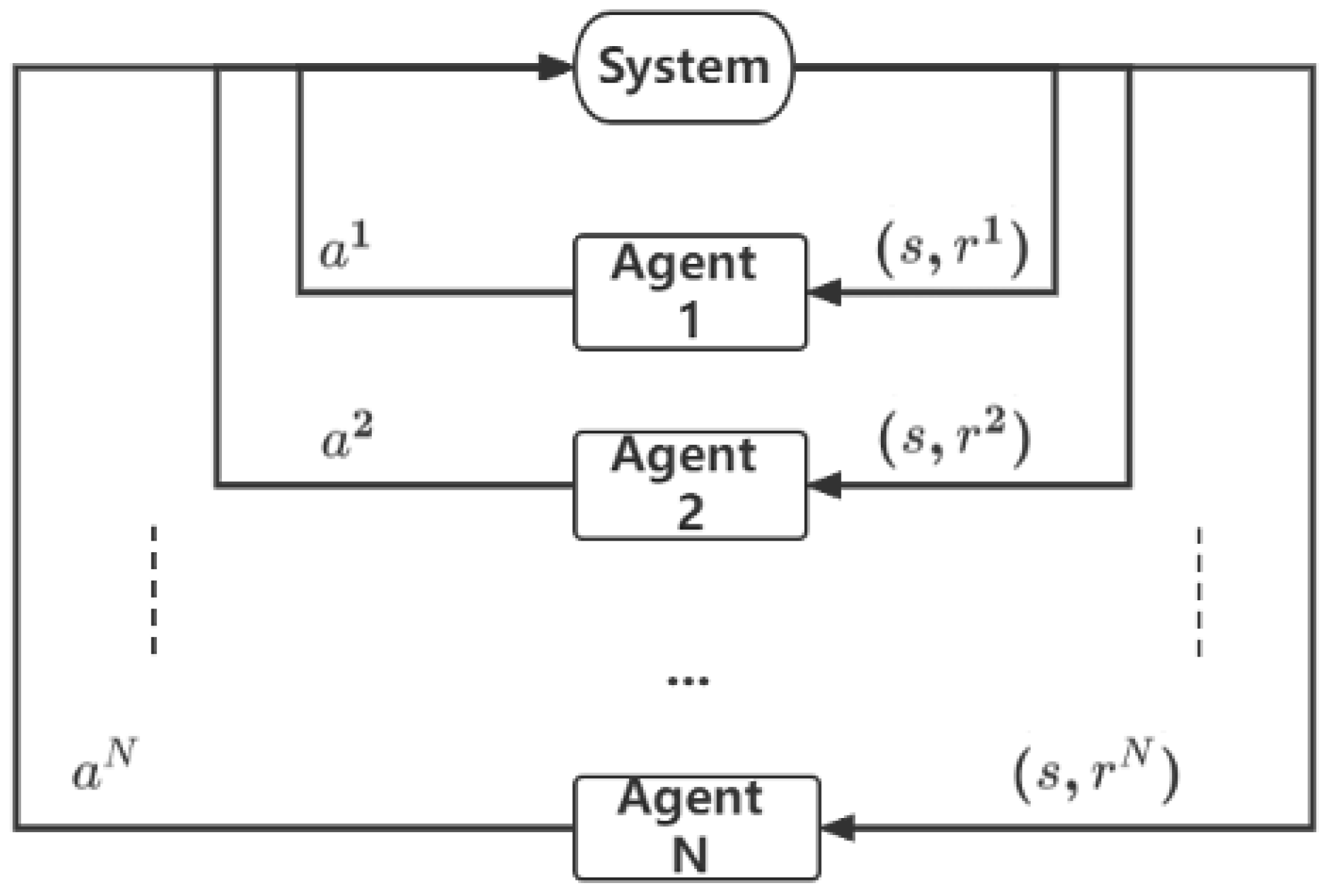
3.2. Multi-Agent Reinforcement Learning Model
4. Methodology
4.1. The Multi-Agent Deep Deterministic Policy Gradient (MADDPG) Algorithm
4.2. Multi-Agent Model for AGV Operations
4.3. MADDPG with -Greedy
| Algorithm 1: An algorithm of MADDPG with the -greedy policy for AGVs. |
| for to max-episode do |
| Initialization of the parameters |
| for to M do |
| for to N do |
| n = random number |
| if then |
| execute any action(a) |
| else |
| execute the action which maximizes with |
| end if |
| end for |
| for agent to N do |
| end for |
| for to N do |
| end for |
| end for |
| end for |
4.4. Three Algorithms in This Experiment
5. Experiments and Results
5.1. Test Scenarios
5.2. Numerical Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- De Ryck, M.; Versteyhe, M.; Debrouwere, F. Automated guided vehicle systems, state-of-the-art control algorithms and techniques. J. Manuf. Syst. 2020, 54, 152–173. [Google Scholar] [CrossRef]
- Shi, Y.; Han, Q.; Shen, W.; Zhang, H. Potential applications of 5G communication technologies in collaborative intelligent manufacturing. IET Collab. Intell. Manuf. 2019, 1, 109–116. [Google Scholar] [CrossRef]
- Yoshitake, H.; Kamoshida, R.; Nagashima, Y. New automated guided vehicle system using real-time holonic scheduling for warehouse picking. IEEE Robot. Autom. Lett. 2019, 4, 1045–1052. [Google Scholar] [CrossRef]
- Shen, W.; Yang, C.; Gao, L. Address business crisis caused by COVID-19 with collaborative intelligent manufacturing technologies. IET Collab. Intell. Manuf. 2020, 2, 96–99. [Google Scholar] [CrossRef]
- Ahmed, S.U.; Affan, M.; Raza, M.I.; Hashmi, M.H. Inspecting Mega Solar Plants through Computer Vision and Drone Technologies. In Proceedings of the 2022 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 12–13 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 18–23. [Google Scholar]
- Alzahrani, A.; Sajjad, K.; Hafeez, G.; Murawwat, S.; Khan, S.; Khan, F.A. Real-time energy optimization and scheduling of buildings integrated with renewable microgrid. Appl. Energy 2023, 335, 120640. [Google Scholar] [CrossRef]
- Xin, J.; Wei, L.; D’Ariano, A.; Zhang, F.; Negenborn, R. Flexible time–space network formulation and hybrid metaheuristic for conflict-free and energy-efficient path planning of automated guided vehicles. J. Clean. Prod. 2023, 398, 136472. [Google Scholar] [CrossRef]
- Hu, H.; Yang, X.; Xiao, S.; Wang, F. Anti-conflict AGV path planning in automated container terminals based on multi-agent reinforcement learning. Int. J. Prod. Res. 2023, 61, 65–80. [Google Scholar] [CrossRef]
- Lian, Y.; Yang, Q.; Xie, W.; Zhang, L. Cyber-physical system-based heuristic planning and scheduling method for multiple automatic guided vehicles in logistics systems. IEEE Trans. Ind. Inform. 2020, 17, 7882–7893. [Google Scholar] [CrossRef]
- Goli, A.; Tirkolaee, E.B.; Aydın, N.S. Fuzzy integrated cell formation and production scheduling considering automated guided vehicles and human factors. IEEE Trans. Fuzzy Syst. 2021, 29, 3686–3695. [Google Scholar] [CrossRef]
- Hu, H.; Chen, X.; Wang, T.; Zhang, Y. A three-stage decomposition method for the joint vehicle dispatching and storage allocation problem in automated container terminals. Comput. Ind. Eng. 2019, 129, 90–101. [Google Scholar] [CrossRef]
- Yue, L.; Fan, H.; Ma, M. Optimizing configuration and scheduling of double 40 ft dual-trolley quay cranes and AGVs for improving container terminal services. J. Clean. Prod. 2021, 292, 126019. [Google Scholar] [CrossRef]
- Fransen, K.; van Eekelen, J. Efficient path planning for automated guided vehicles using A*(Astar) algorithm incorporating turning costs in search heuristic. Int. J. Prod. Res. 2023, 61, 707–725. [Google Scholar] [CrossRef]
- Nishi, T.; Akiyama, S.; Higashi, T.; Kumagai, K. Cell-based local search heuristics for guide path design of automated guided vehicle systems with dynamic multicommodity flow. IEEE Trans. Autom. Sci. Eng. 2019, 17, 966–980. [Google Scholar] [CrossRef]
- Kabir, Q.S.; Suzuki, Y. Comparative analysis of different routing heuristics for the battery management of automated guided vehicles. Int. J. Prod. Res. 2019, 57, 624–641. [Google Scholar] [CrossRef]
- Zhong, M.; Yang, Y.; Dessouky, Y.; Postolache, O. Multi-AGV scheduling for conflict-free path planning in automated container terminals. Comput. Ind. Eng. 2020, 142, 106371. [Google Scholar] [CrossRef]
- Zou, W.Q.; Pan, Q.K.; Meng, T.; Gao, L.; Wang, Y.L. An effective discrete artificial bee colony algorithm for multi-AGVs dispatching problem in a matrix manufacturing workshop. Expert Syst. Appl. 2020, 161, 113675. [Google Scholar] [CrossRef]
- Xiao, X.; Pan, Y.; Lv, L.; Shi, Y. Scheduling multi–mode resource–constrained tasks of automated guided vehicles with an improved particle swarm optimization algorithm. IET Collab. Intell. Manuf. 2021, 3, 93–104. [Google Scholar] [CrossRef]
- Xie, J.; Gao, L.; Peng, K.; Li, X.; Li, H. Review on flexible job shop scheduling. IET Collab. Intell. Manuf. 2019, 1, 67–77. [Google Scholar] [CrossRef]
- Hu, H.; Jia, X.; He, Q.; Fu, S.; Liu, K. Deep reinforcement learning based AGVs real-time scheduling with mixed rule for flexible shop floor in industry 4.0. Comput. Ind. Eng. 2020, 149, 106749. [Google Scholar] [CrossRef]
- Melesse, T.Y.; Di Pasquale, V.; Riemma, S. Digital Twin models in industrial operations: State-of-the-art and future research directions. IET Collab. Intell. Manuf. 2021, 3, 37–47. [Google Scholar] [CrossRef]
- Zhou, T.; Tang, D.; Zhu, H.; Zhang, Z. Multi-agent reinforcement learning for online scheduling in smart factories. Robot. Comput.-Integr. Manuf. 2021, 72, 102202. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson Education Limited: Berkeley, CA, USA, 2016. [Google Scholar]
- Lu, C.; Long, J.; Xing, Z.; Wu, W.; Gu, Y.; Luo, J.; Huang, Y. Deep Reinforcement Learning for Solving AGVs Routing Problem. In Proceedings of the International Conference on Verification and Evaluation of Computer and Communication Systems, Xi’an, China, 26–27 October 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 222–236. [Google Scholar]
- Yin, Z.; Liu, J.; Wang, D. Multi-AGV Task allocation with Attention Based on Deep Reinforcement Learning. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2252015. [Google Scholar] [CrossRef]
- Chujo, T.; Nishida, K.; Nishi, T. A Conflict-Free Routing Method for Automated Guided Vehicles Using Reinforcement Learning. In Proceedings of the International Symposium on Flexible Automation, Virtual, Online, 8–9 July 2020; American Society of Mechanical Engineers: New York, NY, USA, 2020; Volume 83617, p. V001T04A001. [Google Scholar]
- Yan, J.; Liu, Z.; Zhang, T.; Zhang, Y. Autonomous decision-making method of transportation process for flexible job shop scheduling problem based on reinforcement learning. In Proceedings of the 2021 International Conference on Machine Learning and Intelligent Systems Engineering (MLISE), Chongqing, China, 9–11 July 2021; pp. 234–238. [Google Scholar]
- Zhang, H.; Luo, J.; Lin, X.; Tan, K.; Pan, C. Dispatching and Path Planning of Automated Guided Vehicles based on Petri Nets and Deep Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Networking, Sensing and Control (ICNSC), Xiamen, China, 3–5 December 2021; Volume 1, pp. 1–6. [Google Scholar]
- Liu, H.; Hyodo, A.; Akai, A.; Sakaniwa, H.; Suzuki, S. Action-limited, Multimodal Deep Q Learning for AGV Fleet Route Planning. In Proceedings of the 5th International Conference on Control Engineering and Artificial Intelligence, Sanya, China, 14–16 January 2021; pp. 57–62. [Google Scholar]
- Nagayoshi, M.; Elderton, S.; Sakakibara, K.; Tamaki, H. Adaptive Negotiation-rules Acquisition Methods in Decentralized AGV Transportation Systems by Reinforcement Learning with a State Space Filter. In Proceedings of the International Conference on Artificial Life and Robotics, ICAROB 2017, Miyazaki, Japan, 19–22 January 2017. [Google Scholar]
- Li, M.P. Task Assignment and Path Planning for Autonomous Mobile Robots in Stochastic Warehouse Systems. Ph.D. Thesis, Rochester Institute of Technology, Rochester, NY, USA, 2021. [Google Scholar]
- Xue, T.; Zeng, P.; Yu, H. A reinforcement learning method for multi-AGV scheduling in manufacturing. In Proceedings of the 2018 IEEE International Conference on Industrial Technology (ICIT), Lyon, France, 19–22 February 2018; pp. 1557–1561. [Google Scholar]
- Nagayoshi, M.; Elderton, S.J.; Sakakibara, K.; Tamaki, H. Reinforcement Learning Approach for Adaptive Negotiation-Rules Acquisition in AGV Transportation Systems. J. Adv. Comput. Intell. Intell. Inform. 2017, 21, 948–957. [Google Scholar] [CrossRef]
- Sierra-Garcia, J.E.; Santos, M. Combining reinforcement learning and conventional control to improve automatic guided vehicles tracking of complex trajectories. Expert Syst. 2022, e13076. [Google Scholar] [CrossRef]
- Zhang, Y.; Qian, Y.; Yao, Y.; Hu, H.; Xu, Y. Learning to cooperate: Application of deep reinforcement learning for online AGV path finding. In Proceedings of the 19th International Conference on Autonomous Agents and Multiagent Systems, Auckland, New Zealand, 9–13 May 2020; pp. 2077–2079. [Google Scholar]
- Takahashi, K.; Tomah, S. Online optimization of AGV transport systems using deep reinforcement learning. Bull. Netw. Comput. Syst. Softw. 2020, 9, 53–57. [Google Scholar]
- Popper, J.; Yfantis, V.; Ruskowski, M. Simultaneous production and agv scheduling using multi-agent deep reinforcement learning. Procedia CIRP 2021, 104, 1523–1528. [Google Scholar] [CrossRef]
- Li, M.; Guo, B.; Zhang, J.; Liu, J.; Liu, S.; Yu, Z.; Li, Z.; Xiang, L. Decentralized Multi-AGV Task Allocation based on Multi-Agent Reinforcement Learning with Information Potential Field Rewards. In Proceedings of the 2021 IEEE 18th International Conference on Mobile Ad Hoc and Smart Systems (MASS), Denver, CO, USA, 4–7 October 2021; pp. 482–489. [Google Scholar]
- Zhang, K.; Yang, Z.; Başar, T. Multi-agent reinforcement learning: A selective overview of theories and algorithms. In Handbook of Reinforcement Learning and Control; Springer: Cham, Switzerland, 2021; pp. 321–384. [Google Scholar]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. In Machine Learning Proceedings 1994; Elsevier: Amsterdam, The Netherlands, 1994; pp. 157–163. [Google Scholar]
- Koenig, S.; Likhachev, M. Fast replanning for navigation in unknown terrain. IEEE Trans. Robot. 2005, 21, 354–363. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. In Proceedings of the Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 6–9 December 2017. [Google Scholar]
- Mordatch, I.; Abbeel, P. Emergence of Grounded Compositional Language in Multi-Agent Populations. arXiv 2017, arXiv:1703.04908. [Google Scholar] [CrossRef]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic policy gradient algorithms. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 387–395. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Wunder, M.; Littman, M.L.; Babes, M. Classes of multiagent q-learning dynamics with epsilon-greedy exploration. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 1167–1174. [Google Scholar]
- Dann, C.; Mansour, Y.; Mohri, M.; Sekhari, A.; Sridharan, K. Guarantees for epsilon-greedy reinforcement learning with function approximation. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 4666–4689. [Google Scholar]
- Wadhwania, S.; Kim, D.K.; Omidshafiei, S.; How, J.P. Policy distillation and value matching in multiagent reinforcement learning. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 8193–8200. [Google Scholar]
- Afsar, M.M.; Crump, T.; Far, B. Reinforcement learning based recommender systems: A survey. Acm Comput. Surv. 2022, 55, 1–38. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transfer Type | Task List | Load Cargo Position | Unload Cargo Position |
|---|---|---|---|
| Goods Delivered | Task 01 | Door | A24 |
| Task 02 | Door | A17 | |
| Task 03 | Door | A16 | |
| Task 04 | Door | A09 | |
| Task 05 | Door | A08 | |
| Task 06 | Door | A01 | |
| Task 07 | Door | E24 | |
| Task 08 | Door | E17 | |
| Task 09 | Door | E16 | |
| Task 10 | Door | E09 | |
| Task 11 | Door | E08 | |
| Task 12 | Door | E01 | |
| Goods Transported | Task 13 | I24 | Door |
| Task 14 | I17 | Door | |
| Task 15 | I16 | Door | |
| Task 16 | I09 | Door | |
| Task 17 | I08 | Door | |
| Task 18 | I01 | Door | |
| Task 19 | M24 | Door | |
| Task 20 | M17 | Door | |
| Task 21 | M16 | Door | |
| Task 22 | M09 | Door | |
| Task 23 | M08 | Door | |
| Task 24 | M01 | Door | |
| Goods Relocated | Task 25 | Q24 | Z01 |
| Task 26 | Q17 | Z08 | |
| Task 27 | Q16 | Z09 | |
| Task 28 | S24 | W01 | |
| Task 29 | S17 | W08 | |
| Task 30 | S16 | W09 |
| Description | Notation and Value |
|---|---|
| Weight Parameters | |
| Reward Value | |
| Velocity Coefficient | |
| Energy Consumption | |
| Target Coefficient | |
| Energy Coefficient | |
| Collision Parameter between AGVs | |
| Collision Parameter between AGV and Obstacle | |
| Learning Rate | 0.15 |
| Discount Factor | 0.99 |
| 0.01 | |
| 0.01 | |
| 0.95 | |
| 0.01 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, X.; Deng, Z.; Shi, Y.; Shen, W. Toward Energy-Efficient Routing of Multiple AGVs with Multi-Agent Reinforcement Learning. Sensors 2023, 23, 5615. https://doi.org/10.3390/s23125615
Ye X, Deng Z, Shi Y, Shen W. Toward Energy-Efficient Routing of Multiple AGVs with Multi-Agent Reinforcement Learning. Sensors. 2023; 23(12):5615. https://doi.org/10.3390/s23125615
Chicago/Turabian StyleYe, Xianfeng, Zhiyun Deng, Yanjun Shi, and Weiming Shen. 2023. "Toward Energy-Efficient Routing of Multiple AGVs with Multi-Agent Reinforcement Learning" Sensors 23, no. 12: 5615. https://doi.org/10.3390/s23125615
APA StyleYe, X., Deng, Z., Shi, Y., & Shen, W. (2023). Toward Energy-Efficient Routing of Multiple AGVs with Multi-Agent Reinforcement Learning. Sensors, 23(12), 5615. https://doi.org/10.3390/s23125615