1. Introduction
As sensors become more prevalent in capturing geometric information in 3D scenes, point cloud classification has become increasingly significant for various graphical and visual tasks. Point clouds, as physical 3D world data or an electronic signal, are widely used in mapping, autonomous driving, remote sensing, robotics, and metadata [
1,
2,
3,
4,
5]. Point cloud data are usually generated by optical sensors, acoustic sensors, LiDAR (light detection and ranging), and other direct or indirect contact scanners [
3,
6]. Specifically, researchers can obtain feature information through convolutional neural networks (CNNs) [
7,
8], which can then be used in subsequent processing tasks. Unlike 2D images, 3D point cloud data are nonuniform and unstructured. Point cloud processing can yield rich spatial location features and texture geometry information by designing different algorithms [
9,
10,
11,
12] to complete some 3D tasks. Point cloud classification plays an important role in many fields, such as object recognition in machines. The focus of this paper is on the shape classification of the point cloud, which is a significant task for point cloud processing.
Aimed at the existing works on classification tasks, several properties can be summarized as the following aspects. Applicability. Three-dimensional applications rely on classification tasks. In order to accurately identify the ground objects, researchers design a large number of networks to improve the score of point cloud tasks from the underlying theory. For example, robot fetching technology and face recognition technology require mature classification schemes to be successfully applied. Complexity. For the design of a brand-new method to solve hard-core tasks, simple point networks cannot complete the complex demands. Almost all models with hierarchical structures require complex array operations. Point cloud classification still requires researchers’ efforts to continue to promote theoretical analysis and model building.
Different from convolutional neural networks that process natural language and image data, CNNs cannot be applied to unordered 3D point cloud data directly. Therefore, training neural networks on point sets is a challenging task. The success of CNNs in point cloud analysis has attracted considerable attention. The rapid development of deep learning facilitates the diversification of methods for point cloud processing tasks. After recent years of research, point cloud processing methods have been derived based on a grid format or on converting them to multi-view images. All these point cloud processing methods give good results in point cloud classification tasks. However, numerous experiments have shown that these transformations lead to large computational demands and even loss of much geometric information. The point-based approaches effectively alleviate this aspect of deficiency. PointNet [
10] is a pioneering point-based approach. It obtains the features of the input point cloud by directly processing each point using shared MLPs and a max-pooling symmetry function. This method learns the relative relationships between points by designing models to resolve the irregularities of the point cloud. However, PointNet ignores the correlation features of points in local areas due to the direct processing of points to obtain shape-level features, which leads to an imbalance between local domain and global features. PointNet++ [
11] proposes a hierarchical approach to extracting local features, and the results showed the importance of local features in point cloud analysis. To further investigate the extraction of local features, DGCNN [
12] is a new scheme to explore local features. DGCNN not only refers to the previous work but proposes a unified operator to obtain local features. Although PointNet++ and DGCNN consider mining local region features, almost all of them use a max-pooling strategy to aggregate features. This single operation considers only the most prominent feature, ignoring the other relevant geometric information. Consequently, the local information of the point cloud is not fully exploited. Therefore, to further ameliorate the performance and generalization capability, we introduce a lightweight local geometric affine module. This approach addresses point sparsity and irregular geometric structures in the local threshold.
Recently, with the strong expressiveness of the transformer structure in the field of natural language processing and image recognition, attention mechanisms have also been widely used in point cloud learning tasks. Since transformers are permutation invariant, they are well suited for point cloud learning [
13,
14,
15,
16]. The original structural components of the transformers are mainly composed of input encoding, position encoding, and self-attention (SA) mechanisms [
17]. The attention mechanism is the core structure of the transformer. In detail, the attention mechanism takes the sum of the input encoding and the position encoding as input. Attention weights are obtained by dot-producing queries and keys. Therefore, the attention feature is a weighted sum of all values with attention weights. It is due to the nature of this obtained correlation between features that the extraction of point location features seems to be very effective. Naturally, the output of attention represents the features of the input sequence, which can be learned by the subsequent multi-layer perceptrons to complete the point cloud analysis. In summary, inspired by UFO-ViT [
18], we propose a new framework, UFO-Net, adopting the idea of a unified force operation (UFO) layer that uses the
-norm to normalize the feature map in the attention mechanism. UFO decomposes the transformation layer into a product of multiple heads and feature dimensions. The point cloud features are then obtained by matrix multiplication.
The main contributions of the proposed model are the following three aspects:
- (1)
A novel network UFO-Net conforming to the point cloud input, which leverages the stacked UFO layers to replace the original attention mechanism in PCT [
16]. UFO incorporates the softmax-like scheme CNorm, which is a novel constraint scheme. The essence of CNorm is a common
-norm. CNorm learns point-to-point relational features by generating a unit hypersphere [
18]. Furthermore, the offset matrices [
16] introduced in UFO attention are effective in reducing the impact of noise and providing sufficient characteristic information for downstream tasks.
- (2)
We observe that the input coordinates of the point cloud are less correlated with the features, and while the attention mechanism learns global features effectively, it tends to overlook some local features. Thus, we introduce an augmented sampling and grouping (ASG) module that rethinks the sampling and grouping of the point cloud to improve association between points. ASG selects different points by introducing the farthest point sampling (FPS) algorithm and the k-nearest neighbor (KNN) search. A lightweight geometric affine function is used to solve uneven sampling.
- (3)
We perform extensive experiments and analyses on two publicly available benchmark datasets—ModelNet40 and ScanObjectNN. Results verify the effectiveness of our framework, which can achieve competitive scores compared to state-of-the-art (SOTA) methods. The proposed framework provides a promising approach for point cloud tasks.
3. Materials and Methods
In this section, we illustrate how UFO-Net can be used for point cloud classification tasks. The designed details of UFO-Net are also systematically presented as follows.
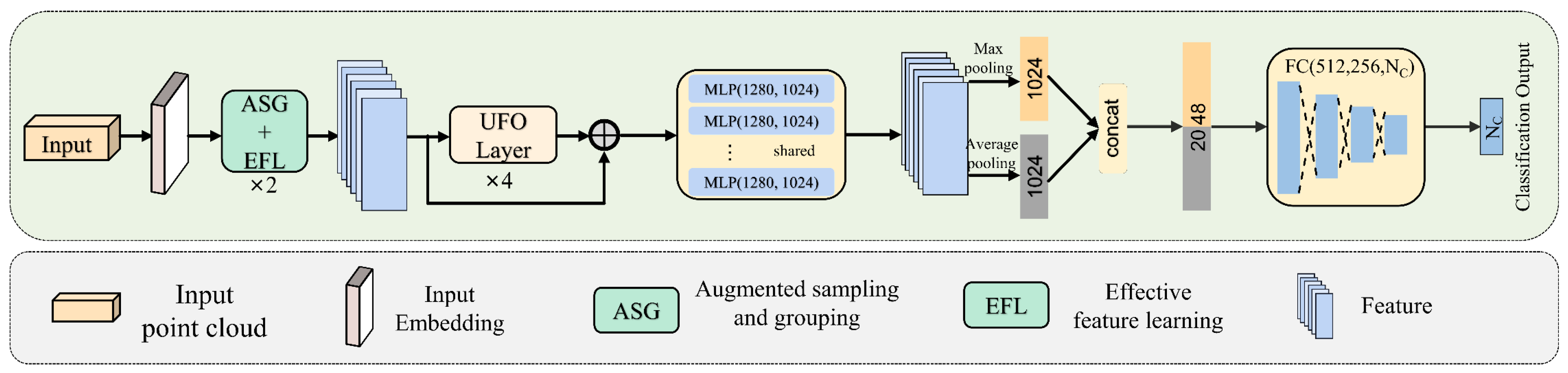
The overall architecture of UFO-Net is depicted in
Figure 1. It consists of four main components: (1) backbone: a backbone for mining features from point clouds; (2) augmented sampling and grouping (ASG) modules: two ASG modules designed to extract features from different dimensions; (3) stacked UFO attention layers: four stacked UFO attention layers to extract more detailed information and form the global feature; (4) prediction heads: global feature classified by the decoder. In detail, UFO-Net aims to transform the input points into a new higher dimensional feature space, which can describe the affinities between points as a basis for various point cloud processing tasks. Mapping points to high-dimensional space enhances the extraction of local and global features of the point cloud. The encoder of UFO-Net starts by embedding the input coordinates into a new feature space. The embedded features are later fed into two cascaded ASG and EFL modules to obtain more local detailed information. The detailed features are then fed into 4 stacked UFO layers to learn a semantically rich and discriminative representation for each point, followed by a linear layer to generate the output feature. Overall, the encoder of UFO-Net shares almost the same philosophy of design as PCT. We refer the reader to [
16] for details of the original point cloud transformer.
3.1. Augmented Sampling and Grouping Module
In 3D point cloud operations, the neighborhood of a single point is defined by the metric distance in the 3D coordinate system. Due to the sparse local regions and irregular geometric structure of the point cloud, the sampling and grouping [
16] operation cannot capture the different 3D geometric structure features among different regions effectively. This indirectly leads to a learning bottleneck in the subsequent nonlinear mapping layer, and a different extractor is required.
This paper uses a KNN search scheme based on comparative experiments. However, the existing local shape model with KNN is vulnerable to the local density of the point cloud. In other words, points near the centroid are feature-rich, while points far from the centroid are easily ignored. Therefore, we seek an optimized feature extractor. We draw upon the ideas of PCT [
16] and PointNorm [
39] to design an augmented local neighbor aggregation strategy ASG.
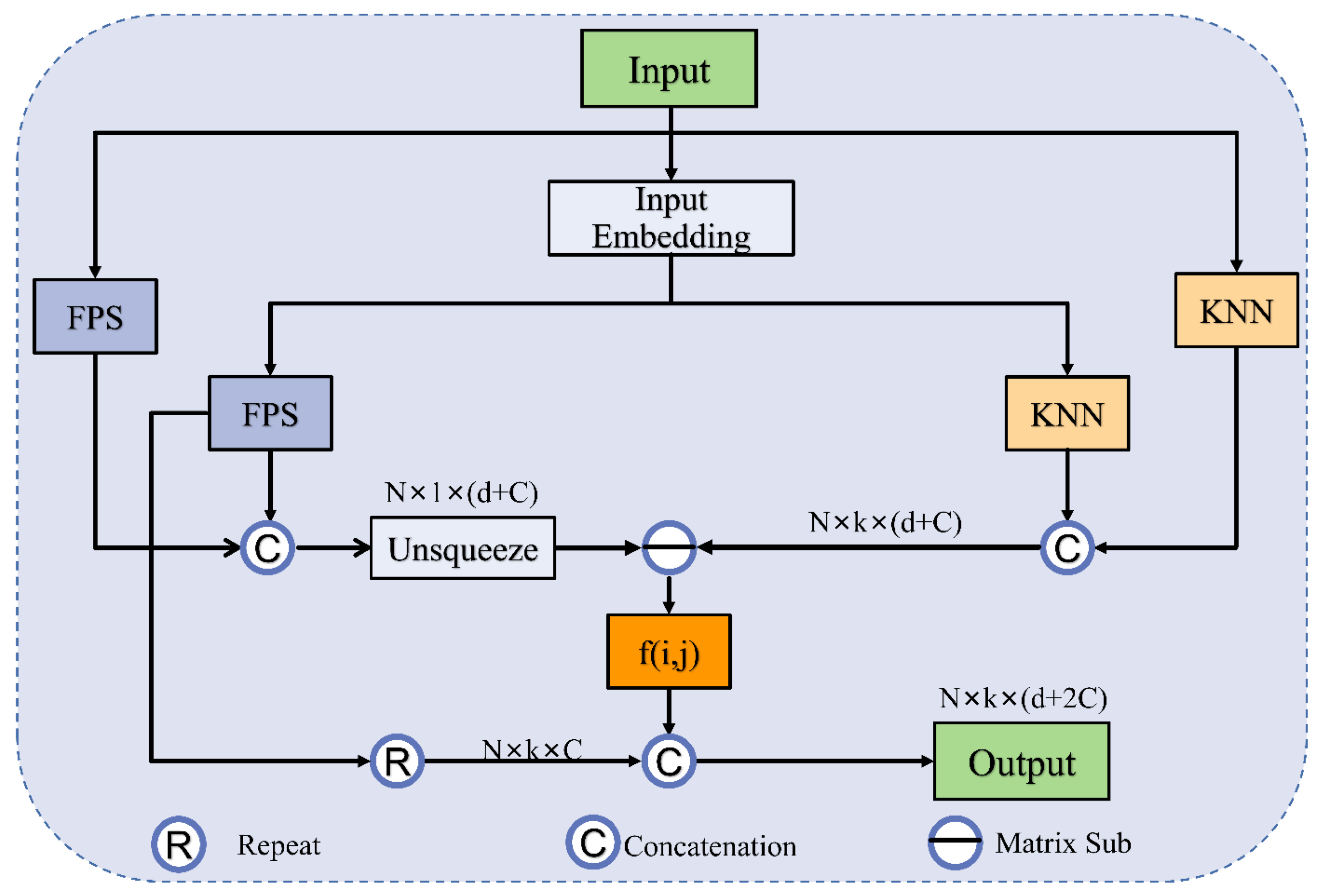
The ASG module introduces a geometric affine operator to local feature extraction. First, the input coordinates are projected using two MLPs to increase the dimension to . In this paper, is taken as 64. Then, the specific implementation of the ASG module is divided into three steps: (i) selecting local centroids by using FPS; (ii) obtaining grouped local neighbors (GLNs) using KNN based on Euclidean distance; (iii) normalizing the GLNs by using the affine function. To obtain features from different local regions, the GLNs are passed through a lightweight geometric affine function. This operation can help overcome the disadvantage of uneven sampling.
The feature process of ASG can be simply described as follows:
The ASG process is shown in
Figure 2, where
is the
k neighbor features found by KNN from the projection coordinates,
is the
k neighbor features found by FPS from the original coordinates,
is the
k neighbor points found by KNN from the original coordinates, and
is the centroid computed by the FPS algorithm from the original coordinates. In addition,
and
are learnable affine transformation parameters,
denotes the Hadamard production of element directions, and
is a number
that keeps the value stable.
I is the unsqueeze operation, and
f (
i, j) is denoted as the lightweight geometric affine function
. Very importantly,
is a scalar describing the deviation of features between all local groups and channels. It is this method that transforms the local features into a normally distributed process that maintains the geometric properties of the original points. Specifically, this method enhances the identification of domain features in the vicinity of each centroid. The sizes of the point cloud are decreased to 512 and 256 points within the two ASG layers.
Herein, differently from the sampling and grouping method, ASG continues to consider the projection features sampled at the farthest point. The input feature is the matrix with subsampling points, d-dim coordinates, and two -dim projection features. The output is the feature matrix , where k is the number of points in the nearest domain of the centroid.
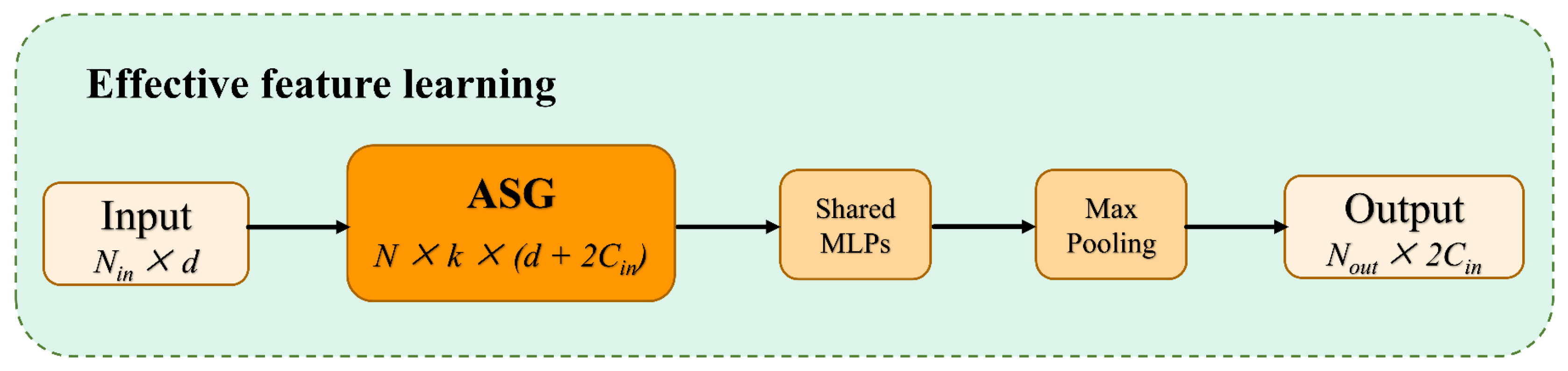
3.2. Effective Local Feature Learning Module
The existing works [
10,
40,
41] usually use symmetric functions, such as max/mean/sum pooling, to downscale and preserve the main features to solve the disorder of point clouds. The features obtained from the original point clouds processed by the ASG module lack global properties. In order to utilize the feature information collected from ASG, it is necessary to find a reasonable bridging technique between the two feature processing methods, the ASG module, and the following UFO layers. To solve this problem, an effective local feature learning (EFL) module is designed as
Figure 3. Usually, the max-pooling function is applied to
k neighbors of each elaborated local graph to obtain feature representations that aggregate local contexts as the center. Here, we denote the EFL module as:
For local sampling and grouping regions, —a shared neural network comprising two cascaded LBRs A and a max-pooling operator M as symmetric functions—is used to aggregate features. The alignment invariance of the point cloud can be fully guaranteed by EFL. By this learning, the output size of EFL changes from the input matrix to the feature size .
3.3. Stacked UFO Attention Layers
To develop the exposition of the single UFO attention layer, we first revisit the principle of the self-attention (SA) mechanism. The key to the SA mechanism is made up of query, key, and value matrices, which are denoted by
Q,
K, and
V, respectively. The
Q,
K, and
V matrices are generated from encoded local features using linear transformations [
33]. Here,
is the dimension of the key vectors, and the
softmax function is applied to the dot product of the query and key matrices. Formally, the traditional SA mechanism is expressed as:
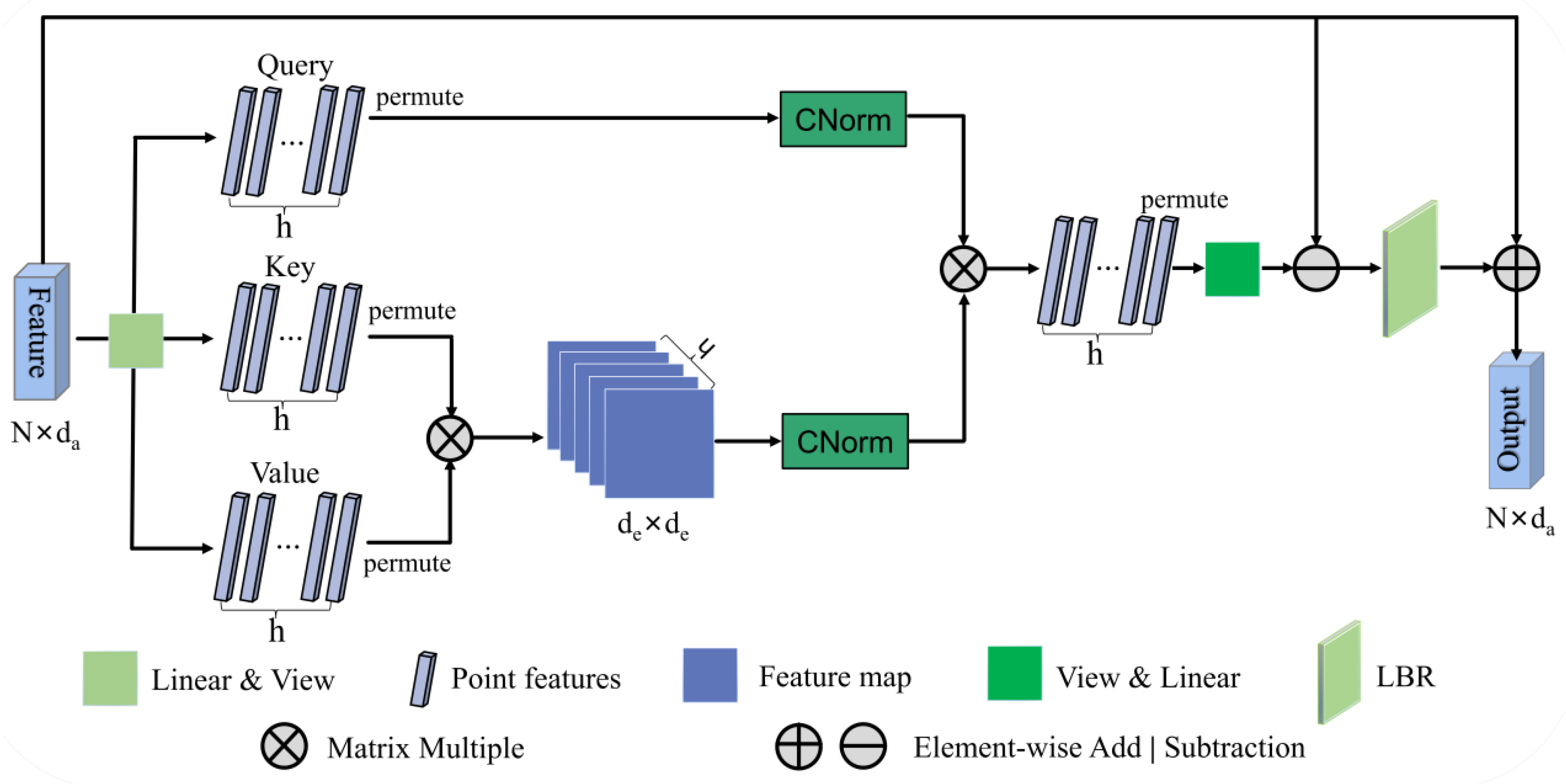
The UFO attention mechanism is explained in the forthcoming note. The architecture of the single UFO attention layer is depicted in
Figure 4. We use linear transformation and view operation to convert the input features
into three new representations: query, key, and value matrices. Given the input feature mapping
,
N is the number of point clouds and
is the feature dimension. Formally, the feature dimension
, where
h is the number of head and
de is the dimension of each head.
Then the single UFO attention layer is expressed as:
where
ψ,
Φ, and
γ are linear transformation and view operation. After permutation,
, , . Note that
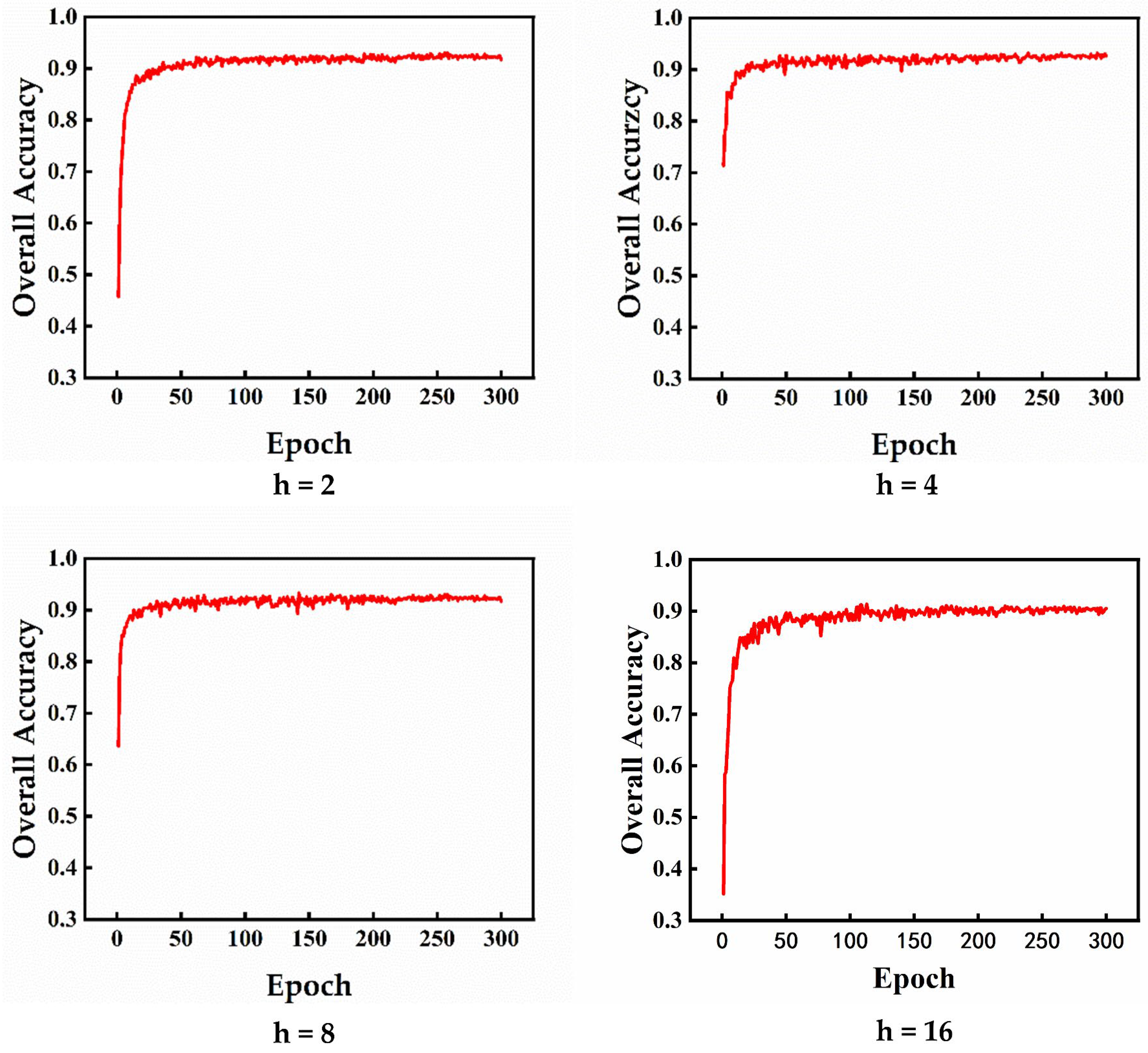
h = 4 was selected by the ablation experiment. We compute the product of
and
to obtain the spatial correlation matrix
KV_Attention for all points. Next, we use CN to normalize
KV_Attention to obtain
KV_Norm. At the same time, we use CN to normalize
QU to obtain
Q_Norm. It is a common
L2-norm, but it is applied along two dimensions: the spatial dimension of
and the channel dimension of
QU. Thus, it is called CrossNorm. Then, permutation and view operation are also adopted.
CrossNorm (CN) is computed as follows:
where
λ is a learnable parameter initialized as a random matrix and
x is the transformed feature. This generates
h clusters through the linear kernel method. The operation process can be described as:
Let
. Then, U(
x) can be represented as:
x is replaced by
.
The computational nature of CN shows that this is an
l2-normalization, acting successively on the feature channels of
KUTVU and
QU. Similarly, based on the analysis of the graph convolutional network [
42] for the Laplace matrix
L = D − E in place of the adjacency matrix
E, the offset matrix can diminish the effect of noise [
16]. This method provides sufficient discriminative feature information. Therefore, the offset method is also designed to efficiently learn the representation of the distinction of the embedded features. Additionally, the output feature is further obtained through an LBR network and an element-wise addition operation with the input feature.
As the output dimension of each layer is kept the same as the input features, the output of the single UFO attention layer is concatenated four times through the feature dimension, followed by a linear transformation, and more features are obtained. This process can be denoted as:
where
represents the
ith single UFO attention layer;
is the weights of the linear layer.
Then, the input features and the output of stacked UFO attention layers are concatenated to fully obtain contextual features.
4. Experiments and Results
In this section, we first introduced the experimental settings as well as some general parameters and experimental data. Then, we showed how to train UFO-Net to perform the shape classification tasks. Immediately, we compared our model to other existing methods quantitatively and qualitatively. We evaluated the performance of the network on two public classification datasets. We implemented the project with Pytorch [
43] and Python. This paper involved experiments using a single Tesla T4 GPU card under CUDA 10.0.
The overall framework of UFO-Net network is shown in
Figure 1. The input point cloud contained only three-dimensional space coordinate information (x, y, z). The model derived 64-dimensional features from the embedding module and subsequently fed them to the transformer block. To examine the performance of our network, we replaced the two SG modules in PCT with two ASG and EFL modules and replaced the original attention mechanism with stacked UFO attention layers as the backbone. In particular, the number of nearest neighbors
k for ASG was set as 32, derived from subsequent ablation experiments. To classify the input point cloud data into
categories, the output processed by a max-pooling (MP) operator and an average-pooling (AP) operator were concatenated on the learned point-wise feature to obtain the global feature sufficiently. The decoder consisted of two cascaded feed-forward neural network LBRDs layers (including Linear, BatchNorm (BN), and LeakyRelu layers, each with a probability of 0.2 and a dropout rate of 0.5). The final classification score was predicted by a linear layer.
During training, to prevent overfitting, we performed random input dropout, random panning, and random anisotropic scaling operations to augment the input point clouds. The same soft cross-entropy loss function as [
16] was adopted. The stochastic gradient descent (SGD) optimizer with a momentum of 0.9 and a weight decay of 0.0001 was used for training. During the testing period, a post-processing voting strategy was used. For 300 training phases, the batch size was set to 32, and the initial learning rate was 0.01, with a cosine annealing schedule to adjust the learning rate at each epoch. We chose the mean classification accuracy (mAcc) and the overall accuracy (OA) as evaluation metrics for the experiment.
4.1. Experiments on ModelNet40 Dataset
The ModelNet40 dataset is a widely used benchmark for point cloud shape classification proposed by Princeton University [
43]. It contains 12,311 CAD models of 40 classes of man-made objects in the 3D world. For a fair comparison, we divided the dataset into a training/testing ratio of 8:2 following the convention, with 9843 universally divided objects for training and 2468 objects for testing. Using a common sampling strategy, each object was sampled uniformly to 1024 points and normalized to the unit length.
As shown in
Table 1, we compare the proposed UFO-Net with a series of previous representative methods. The results of the classification experiments indicate that UFO-Net can effectively aggregate the global features of the point cloud. In
Table 1, the mAcc and OA of the ModelNet40 dataset are 90.8% and 93.7%, respectively. As shown in
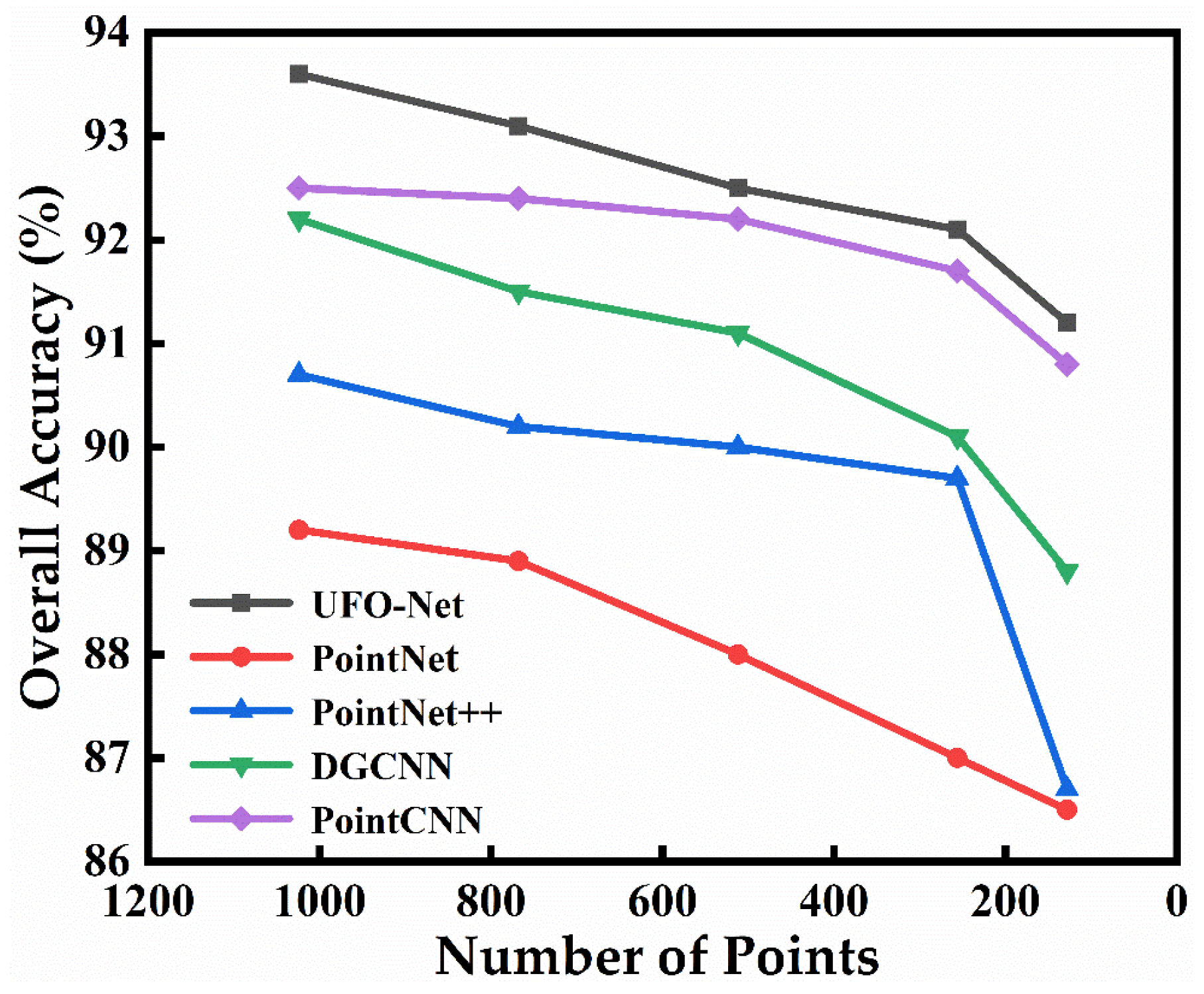
Table 1, we can observe that (1) compared to the classical point-based PointNet, the mAcc of UFO-Net increased by 4.6%, and the OA improved by 4.5%. (2) Compared to the convolution-based DGCNN, the mAcc of UFO-Net increased by 0.6%, and the OA increased by 0.8%. (3) Compared to the transformer-based LFT-Net, the mAcc of UFO-Net increased by 1.1%, and the OA increased by 0.5%. We can also observe from
Table 1 that almost all of the voxel-based methods perform worse than the point-based methods. Therefore, our method can effectively learn the spatial invariance of point clouds, and the network has obvious advantages over other methods in 3D object classification.
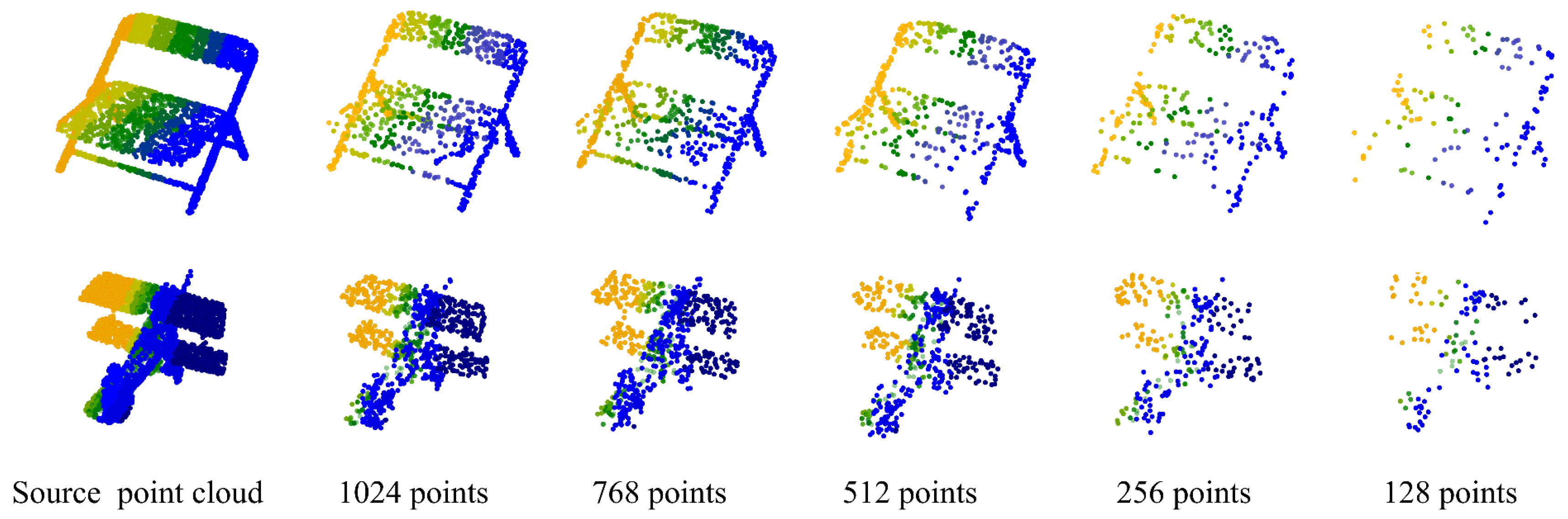
To further explore the neighbor feature extraction capability of our UFO-Net, we evaluate the accuracy of each class. The classification accuracy calculation results are shown in
Table 2. When the model is tested, the data are classified according to the label. Models with the same label are grouped into the same category to create 40 model categories. The number in parentheses after each category indicates the number of models. Under a given number of test models, the classification accuracy of 10 objects—such as airplane, bed, bowl, guitar, laptop, person, sofa, stairs, stool, toilet—reaches 100%. Although there are also some categories that have a low classification accuracy, it can be seen that the classification accuracy rate of most categories is high. Therefore, it can be concluded that our model has good feature extraction ability for some objects that are important for edge articulation features.
4.2. Experiments on ScanObjectNN Dataset
Due to the rapid development of point cloud research, it can no longer fully meet some practical needs. For this reason, we also conducted experiments on the Scanned Object Neural Network dataset (ScanObjectNN) [
53], a real-world point cloud dataset based on LiDAR scanning. ScanObjectNN is a more cumbersome set of point cloud category benchmarks, dividing about 15k objects in 700 specific scenarios into 15 classes and 2902 different object instances in the real world. The ScanObjectNN dataset has some variables, of which we are considering the most troublesome variable in the evaluation (PB_T50_RS). Each perturbation variable (prefix PB) in this dataset randomly shifts from the box centroid of the bounding box to 50% of the original size along a specific axis. Suffixes R and S represent rotation and scaling, respectively [
53]. PB_T50_RS contains 13,698 real-world point cloud objects from 15 categories. In particular, 11,416 objects are used for training and 2282 objects are used for testing. This dataset is an especially large challenge for existing point cloud classification techniques. In this experiment, each point cloud object sampled 1024 points, and the model was trained using only the local (x, y, z) coordinates.
For real-world point cloud classification, we use the same network, training strategy, and 1000 3D coordinates as input. We quantitatively compared our UFO-Net with other state-of-the-art methods on the hardest ScanObjectNN benchmark dataset. In
Table 3, we show the results of competing methods for scanning objective network datasets. Our network has an overall accuracy of 83.8% and an average class accuracy of 82.3%, which is a significant improvement on this benchmark. The results show that mAcc is improved by 5% and that OA is increased by 3.8% compared to the classical PCT. Furthermore, even when measured using the dynamic local geometry capture network RPNet++, we still have a fairly good lifting in mAcc and OA, with increments of 2.4% and 1.8%, respectively, which seems to be tailor-made for this dataset. Additionally, we observe that our UFO-Net creates the smallest gap between mAcc and OA. This phenomenon shows that our method has good robustness.
Since the ScanObjectNN dataset has some difficult cases to classify, the presence of feature-independent background points in ScanObjectNN can pose a challenge to the network. To obtain a global representation of the point cloud, we use the ASG module to learn a local fine-grained feature representation. This is because the design of ASG enhances the relationships between points and enriches the information of geometric features distributed on long edges. Furthermore, our approach provides an efficient solution with stacked UFO attention layers aiming to minimize the impact of these points by equally weighting them according to their channel affinity.
4.3. Model Complexity
We now compute the complexity of UFO-Net with previous state-of-the-art methods on ModelNet40 dataset [
43], as shown in
Table 4. We compared the number of model parameters to different creative algorithms. PointNet and PointNet++ have fewer parameters as they only use MLPs to extract features. Additionally, DGCNN and PCT also have few parameters, while KPConv and Point Transformer have more parameters due to their complex network designs. Despite this, our UFO-Net achieves a higher accuracy of 93.7%. Notably, our method achieves a similar parameter count to PointNet yet realizes state-of-the-art (SOTA) performance on ModelNet40. This result reveals that UFO-Net effectively improves attention-based methods.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}