Abstract
In this paper, based on the information entropy and spatio-temporal correlation of sensing nodes in the Internet of Things (IoT), a Spatio-temporal Scope Information Model (SSIM) is proposed to quantify the scope of the valuable information of sensor data. Specifically, the valuable information of sensor data decays with space and time, which can be used to guide the system to make efficient sensor activation scheduling decisions for regional sensing accuracy. A simple sensing and monitoring system with three sensor nodes is investigated in this paper, and a single-step scheduling decision mechanism is proposed for the optimization problem of maximizing valuable information acquisition and efficient sensor activation scheduling in the sensed region. Regarding the above mechanism, the scheduling results and approximate numerical bounds on the node layout between different scheduling results are obtained through theoretical analyses, which are consistent with simulation. In addition, a long-term decision mechanism is also proposed for the aforementioned optimization issues, where the scheduling results with different node layouts are derived by modeling as a Markov decision process and utilizing the Q-learning algorithm. Concerning the above two mechanisms, the performance of both is verified by conducting experiments using the relative humidity dataset; furthermore, the differences in performance and limitations of the model are discussed and summarized.
1. Introduction
The Internet of Things connects the physical world and transforms physical objects from being traditional to smart [1]. There are a large number of sensing nodes in the IoT, whose role is to collect data and provide information to the upper layers to make relevant adjustments and decisions. Typical application scenarios include temperature and air quality monitoring in urban cities [2], smart traffic [3] and smart agriculture [4], etc. However, due to the cost constraints, most of the sensor nodes are usually low-cost sensors powered by batteries, which are very sensitive to power consumption, including micropower nodes and passive nodes. It has been one of the leading research problems to improve nodes’ sensing efficiency and prolong nodes’ working lives in these applications.
For certain applications that require a high degree of data accuracy, it is crucial to ensure the reliability of data, because significant data errors may lead to serious consequences, including large economic losses, etc. Therefore, some scholars have conducted research on improving the reliability of sensing data. Specifically, a novel unified Bayesian framework is proposed in [5] to enable the simultaneous estimation of a common parameter of interest and identification of multiple and possibly different types of anomalies. In addition, for some time-sensitive applications, the outdated data are not of much value to the system. Based on this idea, the concept of the Age of Information (AoI) [6] is proposed, which is defined as the time difference between the moment of the sensing data generation and acceptance by the receiver. On the one hand, the system expects nodes to send frequent updates so as to ensure the immediacy, but on the other hand, frequent updates can cause congestion in the system and consume too much energy of nodes. Therefore, numerous scholars have studied the trade-off strategy by combining AoI with various queuing and communication models. Specifically, the optimal service rates to minimize the average AoI in different queuing models are derived in [6]. The problem of minimizing the expected weighted sum AoI while simultaneously satisfying timely-throughput constraints is addressed in [7]. Reference [8] investigates the problem of minimizing the average and peak age of information (PAoI) under general interference constraints. A discrete-time queueing model to derive the exact distributions of the AoI and PAoI is proposed in [9].
The freshness of information is linearly decreasing in the definition of AoI, but there is a temporal correlation in some physical sources, which may cause the performance degradation due to information aging not being a linear function of time. Therefore, some scholars have proposed nonlinear functions about AoI and conducted related research. Reference [10] introduces a general age penalty function to characterize the level of dissatisfaction on data staleness. In [11], a general expression of the generating function of AoI and the PAoI metric is provided, which provides a methodology for analyzing general non-linear age functions. Exploiting the temporal correlation between consecutive samples of a Markov source, reference [12] considers a generalized incremental update scheme by sending differential updates.
In addition, the dense deployment of sensing nodes on the space inevitably causes the observations to be highly correlated in the spatial domain. Therefore, some scholars have studied the layout setting of nodes on the spatial domain and the spatial critical sampling rate, etc. The correlation between nodes is used to reconstruct the observed physical phenomena based on a fraction of all available sensor nodes in [13], where a framework for the analysis of sensor density is proposed. In [14], a theoretical analysis of spatio-temporal correlation characteristics of point and field sources is performed. Based on the confident information coverage (CIC) model, refs. [15,16] study the critical sensor density and find the optimal placement pattern to achieve complete coverage in randomly deployed networks. In addition, a node deployment scheme to maximize the network lifetime and ensure CIC with obstacles is proposed in [17].
Meanwhile, some scholars have simultaneously investigated the cooperative scheduling and spatio-temporal sampling rate among nodes in conjunction with the correlation of nodes in the time and space domain. More work related to this paper in this regard is described in detail in Section 1.2.
The main idea of this paper is to measure the value of the real-time useful information of sensor data in the temporal and spatial domains by using the spatio-temporal correlation of the sources. For example, the first data of sensors collected continuously in the time domain can bring the most amount of valuable information due to the lack of a priori knowledge, while the later data in the time domain can bring less valuable information than the first data due to the short time correlation of the physical properties of the sources, i.e., the first data can provide a certain amount of priori information for the later ones. Similarly, there is an overlap in the valuable information provided by the data acquired simultaneously by nodes close to each other in the spatial domain. In this paper, a model to measure the real-time valuable information of sensor data is established to represent the effective spatio-temporal scope of data information, and the optimal node scheduling strategy under different node layouts is investigated to improve the efficiency of sensing information.
1.1. Contributions and Paper Outline
Utilizing the spatio-temporal correlation of the sources, we establish an SSIM, which measures the valuable information of sensor data in the spatio-temporal domain. The main contributions are as follows.
- Utilizing the spatio-temporal correlation of sensor nodes, a SSIM is proposed to quantify the valuable information of sensor data, which decays with space and time.
- A single-step optimal decision-making mechanism is proposed. The possible scheduling results under different node layouts are analyzed, and a method to solve the boundary node distribution among various scheduling situations is provided.
- A long-term optimal decision-making mechanism is proposed, which is modeled as a Markov decision process, and the Q-learning algorithm is utilized to solve the optimal scheduling results.
- With a single-step mechanism, the approximate bounds for the node layout between partial scheduling results are obtained from the theoretical analysis and numerical calculation, which match with the simulation results. The optimal scheduling results with a long-term mechanism corresponding to different node layouts are obtained. Finally, the different performances of the two mechanisms are experimentally verified, and the advantages and limitations of each are summarized.
The rest of the paper is organized as follows: In Section 2, the system model and optimization problem are described. In Section 3, a single-step optimal mechanism is proposed for the established model, and the related theoretical analysis is made. In Section 4, a long-term optimal mechanism is proposed and the modeling and solution methods are described. In Section 5, numerical results and simulation results are presented. In Section 6, an experimental evaluation is performed. Finally, conclusions are drawn and discussions are made in Section 7.
1.2. Related Work
Among some recent studies, the following ones are more relevant to the work of this paper. Specifically, reference [18] considers a system consisting of two correlated information sources, and establishes a optimal time shift between the two sources’ updates. An energy-aware scheduling mechanism based on Deep Reinforcement Learning (DRL) is proposed in [19,20], which can prolong the lifetime of sensors. A measure for the freshness of information is proposed in [21], which uses the mutual information between the real-time source value and the delivered samples at the receiver. In [22,23], a mutual-information based Value of Information (VoI) framework is formalised to characterise how valuable the status updates are for Hidden Markov Models. An error-tolerable sensing (ETS) coverage, as the area where the estimated information is and with a smaller error than the target value, is defined in [24,25]. The performance of state updates is studied in [26,27], where the status is modeled as a time-varying Gauss–Markov Random Field (GMRF), and the estimation error is analyzed. In [28,29], an optimal scheduling policy over limited communication channels is derived that minimizes the time-average mean squared error (MSE). A novel timeliness metric with spatially and temporally correlative mutual information (STI) is proposed in [30], where an optimal update interval is found by solving an integer optimization problem. Assuming that the information can be commonly observed by multiple sensors, two multi-source information update problems are formulated in [31].
Table 1 shows in detail the comparison between our work and the above references. Although many scholars have studied the cooperative scheduling and sampling strategies among nodes by combining the spatio-temporal correlation of the sources, less attention has been devoted to all possible scheduling results and change rules of the scheduling results for different node layouts with an effective grasp of the whole region. It is the main motivation of this paper to study the possible optimal scheduling results for different node layout cases, and analyze the change law of optimal scheduling results for different node layouts.

Table 1.
Comparison of References.
2. System Model and Problem Formulation
2.1. System Model
In this paper, we mainly consider a simple sensing system composed of three sensing nodes, where the information sensing area is the whole two-dimensional (2D) plane, and the importance attached to each location in the area is the same, as shown in Figure 1a. For simplicity, it is assumed that the system periodically decides to activate a sensing node for information acquisition. The data transmission conditions are assumed to be ideal, ignoring the influence of data sending and transmission.
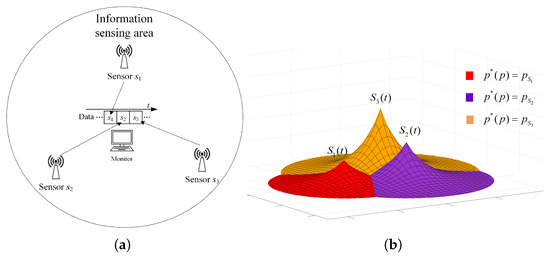
Figure 1.
System model and spatio-temporal scope information map. (a) System model. (b) Scope information map.
2.2. Spatio-Temporal Scope Information Model
In this paper, a Gaussian random field is assumed in the two-dimensional region to be measured, and the variables to be measured between any points in space conform to the joint Gaussian distribution. Without considering the node hardware acquisition error, for a certain node, let the random variable to be monitored corresponding to the spatial location of the node be X. The amount of valuable information that the first activation of the node can bring to X is the entropy . Meanwhile, for any point p, let its corresponding random variable be . Denote the correlation coefficient as , then the amount of information that the node data can provide at position p is
Then, the total amount of information in the two-dimensional plane is
It can be observed from the above equation that although the information calculation result in Equation (1) tends to infinity when the correlation coefficient tends to 1, the total scope information integral in the two-dimensional plane converges and can be calculated. In this paper, for simplicity, we consider the spatiotemporally separable covariance function [18] , where d represents the spatial distance, and t represents the time difference; in addition, and are the scaling parameters with respect to space and time, respectively. When the system has multiple nodes, there will be multiple nodes with spatio-temporal association at each location in the two-dimensional plane. In this paper, for the sake of simplicity, the system keeps only the latest sensor data of each node, and only the sensor data that can eliminate the most uncertainty and provide the most information is selected to provide a reference for a specific location. In other words, the amount of joint information provided by multiple nodes’ previous data together is not considered. That is, the amount of information available at any point p in the two-dimensional plane at moment t is
where is the node location coordinates of the most correlated sensor data for location p, and
where S is the set of all node coordinates. Furthermore, in Equation (3) is the value of AoI for the most correlated data at position p. According to the above equation, the spatio-temporal scope information map of the system at time t can be obtained as illustrated in Figure 1b, where the vertical height represents the amount of valuable information, and the location of the peak is the sensing node’s location.
At this moment, if the node is activated, the incremental information that can be obtained for each point p in the 2D plane is
where is the random variable corresponding to position of node , and is the random variable corresponding to the most spatiotemporally correlated node data at position p. In addition, is the AoI value of the most correlated data. However, each time, a sensor node activated may acquire no new valuable information in certain regions. In other words, the previous data of other nodes provide more information in these regions than the node activated, and the result of the Equation (5) takes a negative value in these regions, which does not meet the definition of information. Because no more information can be provided, temporarily, no loss is caused.
Thus, the scope information increment in the whole two-dimensional plane of the activated node is
2.3. Problem Formulation
In this paper, it is the research objective to find the most efficient way of node activation scheduling given the node location layout and the spatio-temporal correlation coefficient of the region to be measured. That is, it is desired that the total amount of information mastered by the system for the entire two-dimensional plane has the maximum mean value in the time domain, as in the following equation
Let the total amount of information held by the system at each activation node moment be . In addition, let the total two-dimensional information decay function after the activation node of the system be , as follows
Letting , the expression for the information mean can be further written as
and the following relationship holds for the total amount of two-dimensional information and the incremental information of the activated nodes
Recursive induction of the above equation leads to the following result
The above equation is difficult to continue to derive, mainly because is challenging to obtain a clear closed form; thus, it is proposed here to unify the total information decay of all moments approximately expressed as , that is,
The reason for such an approximate assumption here is mainly motivated by the consideration that the system tends to acquire more and smoother information, which leads to similar total information at each activation node moment; thus, causing the decay trend may be approximately the same. Then, Equation (12) can be further written as
Since , for any positive number that is greater than 0 and small enough,
thus, when n tends to infinity, the percentage of terms with coefficients less than is
Therefore, the coefficients can be approximated by 1, the optimization problem becomes the following
where is the node activated at the moment . From the above expression, the original problem is converted to the problem of maximizing the mean value of the incremental information.
3. Single-Step Optimal Mechanism
Regarding the above-mentioned problems, the first optimization mechanism that readily comes to mind is the single-step decision method, which means that the system computationally finds the sensing node that can obtain the most information increments at each discrete decision moment based on the known spatio-temporal information residual map, then makes it active and updates the spatio-temporal information map. The mathematical expression as a rule for each node activation can be written, as follows
According to whether the value of the latter term in the integral equation is greater than 0, the integration region can be divided into two parts, and ; thus, the integral in Equation (18) is equivalent to
where D and D are the sets consisting of points that respectively satisfy the following conditions:
Furthermore, according to Equation (4), the following result can be obtained
where , and are the sets of points that respectively meet the conditions as Equation (22),
in which the , and are the AoI of the latest sensing data of each node. The increment of information that can be obtained by the activated node from the above expression can be written as
where is the set of points that meet the condition as
From the fact that the trajectory of a point with a constant distance difference to two points is a hyperbola, we can preliminarily determine that the boundary of the above set may contain several curves. For example, when the system only has two nodes, and , are taken as , , respectively, let the coordinates of node and node in 2D space be , , as shown in Figure 2a. Abbreviating to , the inequality corresponding to the set can be written as
and is an empty set when , i.e., ; in which case, a certain increment of information can be obtained in the whole 2D plane. However, it should be noted that activating node or node can obtain the same incremental information at this case, and there is no optimal activation scheme from the perspective of information acquisition only. Therefore, in the subsequent analytical modelling, the distance between the nodes must be at least greater than . The area distribution of that can be obtained from Equation (25) is shown in the shaded part of Figure 2a. The remaining blank areas are where new information increments can be obtained, that is, the set .
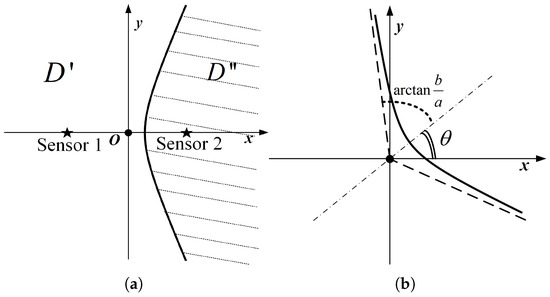
Figure 2.
Schematic diagram of the distribution of set elements and boundary curves. (a) Schematic of the second activation node of the two-point system. (b) Schematic of the curve after rotating counterclockwise around the origin, where the dashed line represents the asymptote of the curve.
However, due to different node positions and different angles of the coordinate system, when the horizontal axis of the curve is not parallel to the x-axis, a 2D rotation matrix can be used to derive the equation of the curve after rotating counterclockwise around the origin as
Moreover, the expression equation of a single curve may be conveniently written as only one of two forms or , with different rotation angles. The primary method of discrimination is based on the maximum number of intersections of the two asymptotic lines of the curve with the horizontal and vertical lines. For example, as shown in Figure 2b, the curve can be expressed as when there is, at most, one intersection point between the two asymptotes of the curve and the line parallel to the x-axis. The applicability of the two expression forms can then be obtained as follows:
where is the absolute value of the slope of the hyperbola asymptote. It is easy to find that when , i.e., , the range of values of in Equation (27) does not completely cover . In other words, there are certain ranges where a single curve cannot be expressed in the above two functional forms, and one solution in this case is to adjust the angle of the coordinate system for the subsequent expression.
When the three nodes present an equilateral triangular layout, it is easy to analyze that the optimal scheduling strategy under the single-step decision mechanism is an alternate activation of the three nodes in turn, according to the decay of information over time and the equal spatial correlation between individual nodes. However, it is essential to note that the above-mentioned alternate activation of nodes presupposes that the distance between nodes is greater than . The reason is that if the node distance is smaller than this value, the valuable information contained in the sensed data of each node can be covered by the data of the other nodes after two moments so that there exists the same increment of information available to two nodes at each decision moment. The following is a preliminary consideration to analyze the possible scheduling scenarios by changing the distance between only two nodes, keeping other conditions unchanged. The location distribution of the three nodes is assumed as shown in Figure 3a.
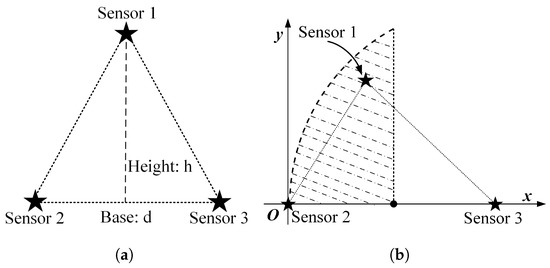
Figure 3.
The location distribution of three nodes: (a) isosceles triangle; (b) general triangular.
3.1. Three-Node Isosceles Triangle Layout
From the previous analysis, it is known that when the three nodes are laid out in an equilateral triangle, the node activation sequence can be set to . Thus from a long-term perspective, when node is activated, the AoI values of the latest sensing data of nodes , , are , , , respectively, which are abbreviated as . The amount of incremental information obtained by activating node is recorded as . Putting the AoI vector into Equation (22), the formulas of the boundary curves for different regions in the information distribution map can be obtained, which satisfy the conditions as
If one of the above conditions is not met, the corresponding boundary curve does not exist. Taking the midpoint of the base of the isosceles triangle as the origin and the base as the x-axis direction to establish a rectangular coordinate system, and setting the base length as d and the height of the triangle as h, the coordinates of the three nodes are , , and , respectively. Then, the information residual distribution map of the system can be drawn according to Equations (22) and (28), as shown in Figure 4a, where the upper triangular, star and circular marker areas represent the sets , , and ; meanwhile, the solid lines are the boundaries of the different set regions. The three boundary curves necessarily intersect at a point, which can be proved by the geometric distance property of the hyperbola. When the rotation angle is 0 and the centre of the curve is at the origin, the general formula of a single curve is
where is a symbolic variable that takes the value , and c is the hyperbolic focal length. Thus, the set and boundary curve expression can be written as
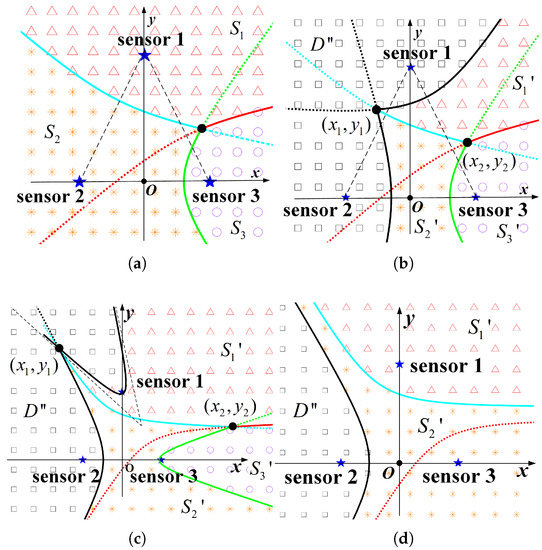
Figure 4.
Spatio-temporal information distribution maps. The subscript indicates the AoI value of the current node data, and the brackets represent the currently active node. (a) . (b) . (c) . (d) .
The general expression of the , boundary curve and the , boundary curve can be written as Equation (31) by combining Equation (26) with Equation (27),
where are the coordinates of the center point of the corresponding curve, and is the rotation angle of curve. In addition, c is the hyperbolic focal length, and
For the ease of subsequent expression, the Equation (31) is abbreviated to the following form:
where takes the value , representing the selection of positive or negative signs in the two expressions in Equation (31). Then, the , and , dividing lines can be obtained as Equations (34) and (35).
The intersection of the three curves can be solved by combining the equations of the three curves, namely , , and . A quartic equation can be obtained by combining two of the curve formulas. Since the incremental information formula cannot calculate the exact analytical result, the numerical calculation can also be used to find the approximate numerical solution when solving intersections. The multiple solutions are then verified using another curve formula, and the solution that satisfies the condition is selected.
When node is activated, the conditions regarding the set can be determined by the previous analysis method, as follows:
Then, when the conditions and are met, two boundary curves of can be obtained, as shown in Figure 4b, where the rectangular, upper triangular, star, and circular marker regions represent the sets , , , and , respectively, and the set is defined, as shown in Equation (24). The coordinates of the intersection points of curves are set as , , respectively, as shown in the Figure 4b. Let the valuable incremental information that can be obtained at the position be
where is the currently active node, and is the node with information residuals at that location. Then, the valuable information increments that can be acquired in regions , and are shown in Equations (38)–(40), respectively,
where
However, it should be noted that the curve formulas in the above expressions, , , and all take the first expression form , which is applicable to most of the node layout cases, but not to all. In addition, there are a few special layouts where a curve cannot be uniquely expressed as either of the two forms and . For example, when , the regional boundary curve cannot be written as a unique functional expression, as schematically shown in Figure 4c. It is one solution to adjust the angle of the coordinate system to facilitate the integration expression. For example, for Figure 4c, set the direction of the line, where nodes and are located as the horizontal or vertical axis of the coordinate system, and then choose the appropriate order of integration. Moreover, if the distance between nodes does not meet the conditions for the existence of boundary curves, the information map is relatively simplified, as exemplified in Figure 4d when and .
Theoretically, when nodes and are very close to each other, activating node after activating node can obtain very little incremental information due to the strong spatial correlation. In other words, it may not be a good choice to activate nodes alternately at this time. That is, it is better to activate node after activating node at this time, and the scheduling order of the nodes is . The boundary situation of the above two scheduling situations meets the condition as . However, it is challenging to seek the exact analytical solution, and only the approximate numerical solution can be obtained by a numerical calculation. The specific solution algorithm can use the dichotomy method, and the specific calculation results will be given in Section 5.
The remaining possible scheduling cases, and the boundary conditions between different scheduling cases, are mainly shown in Table 2. Due to the limitation of space, other cases are not explained in detail here, and the general analysis idea is similar to the previous one; interested readers can refer to the arxiv version of this paper [32].
Table 2.
Single-step mechanism scheduling situations when three nodes present an isosceles triangle.
3.2. Three-Node General Triangular Layout
When three nodes present a general triangular layout, at least three variables are required to describe a general triangle. Due to the unintuitiveness of the three-dimensional diagram and the difficulty of theoretical analysis, the specific operation in this subsection is to keep the positions of the two nodes with the largest distance unchanged, traversing the different positions of the other node and analyzing the possible scheduling results. For detail, it is assumed that the distance d between nodes and is the largest, and they are located at and , respectively, in the coordinate system. The traversed area can be reduced by half according to the horizontal symmetry. Then node needs to traverse the area as illustrated in the Figure 3b, where the shaded area is the optional position of node .
When the position of node is selected on the boundary of the traversal region, the three nodes present an isosceles triangle. According to the previous analysis, the possible scheduling situation can be roughly obtained. For example, as the vertical height of node increases on the perpendicular bisector of nodes and , the final activation proportion of node may gradually increases from 0 to . In addition, if traversing from the top to the lower left on the arc boundary, the scheduling situation may change from an alternating activation to a situation where the node activation accounts for a half, i.e., scheduling sequence . Based on the above analysis, the possible scheduling results under the general triangular layout can be obtained, as shown in Table 3.
Table 3.
Single-step mechanism scheduling situations when three nodes present an general triangle.
Therefore, the node positions can be traversed in the positive direction from the horizontal axis, and the vertical values can be traversed sequentially in the case of fixed values of each horizontal axis; then, the numerical solutions of the critical case equations in Table 3 can be found, respectively, to determine the critical layout between the different scheduling results.
4. Long-Term Optimal Mechanism
The single-step mechanism only concerns the current gain for each decision, and it does not consider the possible impact of the current decision on the future. The main scheme adopted in this section is to model the process as a Markov decision process, taking the current information residual map of the system as the state, and the number of system states is finite. Then, the Q-learning algorithm can be used to converge to the optimal scheduling result after a finite number of training times.
The main scheme adopted in this section is to model the process as a Markov decision process, taking the current information residual map of the system as the state. The information gain obtained by the node activated at the current moment is only related to the current information residual map, independent of the residual information map at all previous moments. Since the currently analyzed system contains three nodes and activates a node periodically, the number of system states is finite. Then, the Q-learning algorithm can be used to eventually converge to the optimal scheduling result after a finite number of training steps.
4.1. States, Actions, and Rewards
The state-space mainly records the current information residual map of the system and can directly take the AoI of the latest sensed data of each node, as follows:
Since the decision time interval is fixed as , the AoI can be abbreviated only as its coefficient about . From the node spatio-temporal correlation and the previous analysis, it is known that the system takes the same action continuously with poor information gain. Thus, it can be stipulated by default that the system will not take the same action twice and more consecutively, which can reduce the total number of states and improve the training efficiency.
The survival time of data information of each node is limited for the reason that it will always be covered by new data of adjacent nodes after a certain time. Thus, the AoI of each node data has a maximum, greater than which the data contain no valuable information, and the AoI can be abbreviated as . The maximum AoI of each node can be calculated as Equation (44), where
and , . In addition, and represent the two nodes whose data AoI takes the values of 1 and 2, respectively.
The total number of states of the system is shown in Equation (45),
where is a step function, as follows:
The set of actions is , where , and represent the activation of the corresponding nodes, respectively. The state transfer process is as follows. Firstly, the system performs an action each time and activates the corresponding node, and the AoI value of the corresponding node is set to 0. Secondly, the AoI value of all node data plus 1 elapsed time is .
Then, determine whether the AoI value of the node data exceeds the maximum value, and if it exceeds the maximum value, it is recorded as .
The immediate reward for each action is the incremental amount of information acquired, that is
where the denominator is the information increment that the system can obtain by activating the node for the first time, whose role is to normalize the reward.
4.2. Q Learning Algorithm
The training process mainly adopts a greedy strategy, which means that the agent mainly takes random actions to explore the environment in the initial stage, and gradually increases the greedy coefficient as the number of training steps increases, i.e., the agent tends to choose the action with a larger Q value. The optimal long-term scheduling is obtained by waiting for the almost complete convergence of the Q-table. The process of updating the Q value for each training is as follows [33]
where s denotes the current state, a denotes the action, and is the previous Q value. Meanwhile, is the learning rate, and is the discount factor. The R is the immediate reward observed in the new state , and the represents the estimate of optimal future reward from the next state .
5. Numerical and Simulation Results
5.1. Scheduling Results with Single-Step Optimal Mechanism
Without a loss of generality, the value of is taken as 1 in this section.
5.1.1. Three-Node Isosceles Triangle Layout
When the traversal step is 5 with parameters and , the main scheduling results are illustrated in Figure 5a, where the horizontal axis represents the values of the base of the isosceles triangle, and the vertical axis represents the height of the isosceles triangle. The scatter points of different shapes in Figure 5a represent a different type of scheduling situation, and their corresponding periodic scheduling sequences are shown in the legend of the figure, respectively. The three curves are the approximate numerical bounds on the critical scheduling case obtained from the previous theoretical analysis and numerical calculation. Specifically, the curve marked by circles represents the boundary node distribution for the cycle scheduling sequence of 1213 and 123. The curve marked by triangles represents the boundary node distribution for the cycle scheduling sequence of 123 and the scheduling result of . In addition, the curve marked with pentagrams represents the critical distribution of the scheduling sequence 23 and , and the interval between two node activations is not greater than , where and correspond to the values taken on the boundary curve. In addition, when the traversal step is 4 with and , the result is shown in the Figure 5b.
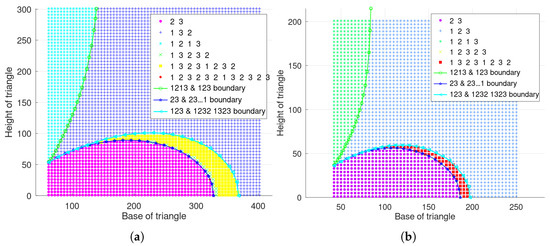
Figure 5.
Scheduling results of single step mechanism with three nodes presenting an isosceles triangle. (a) , . (b) , .
5.1.2. Three-Node General Triangular Layout
When and , the scheduling results with the maximum distance between nodes and are, respectively, illustrated in Figure 6a,b, where the three curves correspond to the boundary conditions in Table 3.
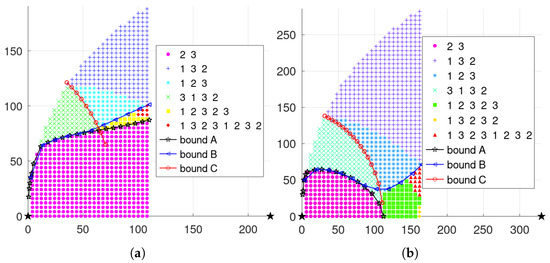
Figure 6.
Single-step mechanism results with general triangle layout when and . (a) . (b) .
5.2. Scheduling Results with Long-Term Optimal Mechanism
To facilitate comparison with the single-step mechanism results, some parameter values are the same. In addition, the learning rate is 0.1, and the discount factor is 0.9. When three nodes present an isosceles triangular layout with parameters and , the final obtained scheduling results are shown in Figure 7a, where the optimal cycle scheduling sequence for each layout is shown in the legend. Moreover, the scheduling results are shown in Figure 7b with parameters , .
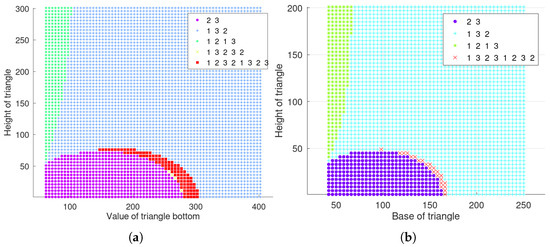
Figure 7.
Scheduling results of long-term mechanism with three nodes presenting an isosceles triangle. (a) , . (b) , .
Meanwhile, the scheduling results are shown in Figure 8a when three nodes present a general triangular layout with , , and . In addition, the the scheduling results are shown in Figure 8b with .
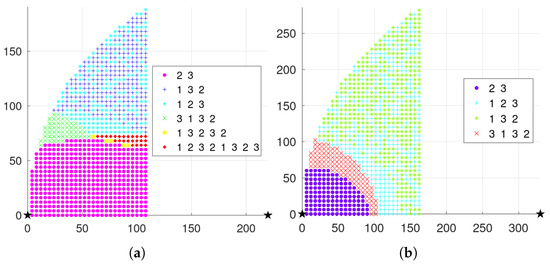
Figure 8.
Long-term mechanism results with general triangle layout when and . (a) . (b) .
5.3. Performance Comparison of Two Mechanisms
The scheduling results with the single-step mechanism and the long-term mechanism are the same in quite a few regions, which can be observed specifically in combination with Figure 5 and Figure 7, or Figure 6 and Figure 8. However, there are some regions where the results of the two mechanisms are not the same; that is, the results of the single-step mechanism in these regions are not the results meeting the long-term mean optimum. Therefore, in the long-term, it is necessary to select a specific moment to select the second-best decision, which may be able to bring more future benefits. Meanwhile, the fluctuation of the incremental information obtained under the long-term mechanism should be slightly larger.
When the three nodes show an isosceles triangular layout and the traversal step is 5 with , , the highest mean information increment with a long-term mechanism is about higher than that with a single-step mechanism. Regarding the node layouts with different results obtained by two mechanisms, the mean information increment with a long-term mechanism is about 0.8% higher on average than the other one. As for all layout cases, the mean information increment with the long-term mechanism is slightly higher by about 0.1% on average. The standard deviation of the incremental information acquisition with the long-term mechanism is also larger, and it is on average about 60% higher in the situation of node layouts for which the two mechanisms obtain different results. Similarly, when the three nodes are distributed in a general triangle and traversal step length is 4 with , and , the mean information increment obtained by the long-term mechanism is up to 2.1% higher than that of the single-step mechanism, which is about 0.6% higher on average for the situation of node layouts with different results obtained by the two mechanisms. As for all layout cases, the mean information increment with the long-term mechanism is slightly higher by about 0.1% on average. On the other hand, the standard deviation with the long-term mechanism is about 80% higher on average in the node layout cases with different scheduling results for the two mechanisms. In summary, the mean information increment with long-term mechanism is slightly larger, but the standard deviation is also slightly larger.
5.4. Complexity Analysis
The computation of both mechanisms can be conducted offline when the correlation coefficient parameters are determined. The time complexity of the offline computation of the single-step mechanism is at most, where N is the number of all valid states of AoI. If the system requires obtaining decision actions for all AoI states with the single-step mechanism, the offline computation complexity would be , and the computation speed largely depends on the computation speed of the numerical integration. The program can utilize a memory storage pool to record encountered states and selected actions for subsequent queries, keeping the space complexity within . If the system only focuses on the periodic scheduling results with the single-step mechanism, the time complexity would be , where m represents the corresponding period of the scheduling result.
On the other hand, the long-term mechanism requires a Q-table to record the values of corresponding actions for all states, resulting in a space complexity of . The time complexity is not directly measurable, as the algorithm requires training for multiple rounds until the Q-table converges. However, overall, the computation speed is slower compared to the single-step mechanism. When the correlation coefficients remain unchanged, the system can directly obtain scheduling results offline. Therefore, if the system is used in actual online applications, there is no need for additional computational costs. However, if adjustments to the correlation coefficient parameters are necessary, recalculations are required, and the majority of computational consumption could be attributed to the calculation of numerical integration. This also reflects the limitation of the model algorithm when the correlation properties of the source are time-varying. Therefore, considering the performance and resource consumption, in practical deployment applications, the single-step decision mechanism may have a slight advantage.
6. Experimental Evaluation
In this section, the relative humidity grid dataset [34,35,36,37,38] is used to evaluate our proposed scheduling mechanism. In the first part, the data are analyzed to extract the scaling parameters of the covariance model described earlier. In the second part, four scheduling methods are compared in terms of their two-dimensional sense performance. In the third part, a summary and discussion are presented, illustrating the model’s performance and limitations.
6.1. Data Analysis
In order to fully reflect the stochastic variation among the data, a down-sampling operation with a step size of two is performed on the grid data; then, a circular grid area data with a radius of 15 is selected to compare the global sensing performance of different scheduling methods.
The Pearson correlation coefficient formula is used to calculate the spatio-temporal correlation of the grid data. Firstly, the correlation coefficients about the spatial distance between the same moments of grid data are calculated, and then the can be fitted. Secondly, the time correlation between different moments of the same grid data is calculated, and the can be fitted. The joint spatio-temporal correlation between the data is then verified by calculating the correlation coefficient when both the distance and time difference between different grid data are not zero. If the fitting results deviate from the actual results, it may affect the performance of the subsequent scheduling.
6.2. Performance Comparison
The specific implementation steps of the experiment are as follows: within the circular region mesh data, an equilateral triangle of suitable size is selected, and two of the vertices are set as the location of the node, while the traversal region of the other node remains as shown in Figure 3b.
The metric of the experiment is the mean square error over the entire area. The effective coverage area of each node data can be determined by the previous analysis. Within the effective coverage area of each node, the corresponding conditional distribution mean based on the correlation coefficient between each location and the node position is used as the estimated data for that location. The scheduling methods include the single-step and long-term mechanisms previously proposed in this paper, and the other two are the ideal scheduling and STI-based scheduling, respectively. The ideal scheduling method is that the system has all the grid data and makes the scheduling decision that provides the minimum total scope error.
Currently, there is relatively limited research on effective information for modeling the joints of nodes in the spatio-temporal domain. Most of the existing literature focuses on the effective information at individual node locations. Therefore, as an comparison approach abbreviated as STI-based scheduling, we referred to reference [30], which uses point spatially and temporally correlative mutual information at the sensor location as a metric for system scheduling. In other words, in the modeling scenario of this paper, the STI-based scheduling activates the node with the least point of spatially and temporally information based on the point of spatially temporally information of each node location at each moment.
This method is similar to the approach in this paper. However, the main difference between the two methods proposed in this paper and the referenced method is that the former integrates the node information over the entire spatio-temporal domain and uses it as a measure for information quantification.
The time span of each evaluation is nine years, which are 1982–1990, 1991–1999, 2000–2008, 2009–2017, respectively. Moreover, the model parameters were extracted mainly using the data from the first three years used in each experiment. The experimental results are shown in Figure 9. The ideal scheduling method has the best performance with the minimum scope mean square error.
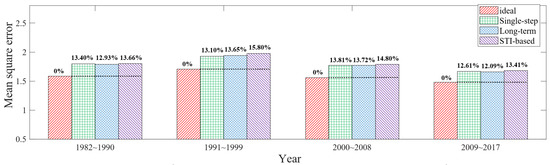
Figure 9.
Experimental results of global circular grid data.
The STI-based method has the maximum mean square error, averaging 14.42% higher than the ideal scheduling method. The performance of single-step and long-term mechanisms lies between the two aforementioned methods, with the mean square error that is on average 13.16% higher than that of the ideal scheduling method. Since two mechanisms obtain the same scheduling results in many node layouts, and the global average difference in the information mean obtained by two mechanisms is less than 1% in simulation, the global performance difference caused by two methods in the experiment is also minimal, as shown in Figure 9.
In addition, due to the higher variance in information acquisition of the long-term mechanism compared to the single-step mechanism, and considering the impact of error and randomness in data parameter fitting, it is possible that the long-term mechanism may exhibit slightly inferior results compared to the single-step mechanism in experiments, as shown in Figure 9. Furthermore, since the scheduling results of the two mechanisms are the same in many node layout scenarios, the average performance difference between them is very small, with minor fluctuations present.
If the reasonableness of node layout within the information sense region is considered when traversing node locations, it is not very reasonable to uniformly examine the total scope error in the circular region. For example, when two nodes are very close to each other, the effective coverage of three nodes may converge to an ellipse. For this consideration, circles of appropriate size are selected with each node position in the experiments; then, the joint coverage of the three circles is set as the data evaluation scope for examining the model performance. Under the above experimental operation, the performance comparison of the four scheduling methods is obtained, as shown in Figure 10. The single-step and long-term mechanisms have the mean square error that is on average 19.54% higher than that of the ideal scheduling method. The mean square error of the STI-based scheduling method is on average 21.20% higher than that of the ideal scheduling method.
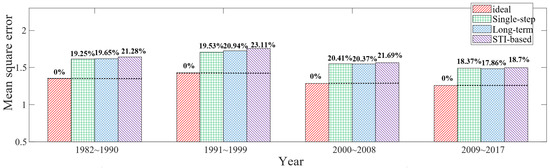
Figure 10.
Experimental results of adaptive regional grid data.
6.3. Summary and Discussion
The above experimental results demonstrate that considering the spatio-temporal scope effective information of sensor nodes, as opposed to solely considering the point information at their individual positions, can guide system decisions and improve perception accuracy in area monitoring applications of the IoT. Therefore, in resource-constrained IoT deployment scenarios in practical real-world settings, the use of a spatio-temporal information model provides an optimized method for efficient node activation decisions, thereby improving the overall system sensing with accuracy and energy efficiency. This will potentially provide further support for the development of efficient perception in the future of the IoT.
It is known that the correctness of the correlation parameter fit is the primary factor in determining the model performance. In addition, whether the adopted covariance function model fits the distribution of the data set is also an important factor. In the case of stochastic processes, the correlation model may not be stationary, i.e., the correlation coefficients may be time-varying. The limitations of the current model mainly come from the above aspects, which may be addressed in future studies.
Furthermore, sensing nodes in IoT applications may experience changes in their positions due to intrinsic or extrinsic factors, making their locations non-static. This implies that the mobility of nodes is also worth considering and studying. In other words, node mobility can be broadly classified into active and passive mobility. In the case of passive mobility, sensor nodes may be influenced by external environmental factors, leading to random movements in their positions. In such cases, it may be necessary to predict the passive motion trajectories of multiple nodes, estimate their distributions, and adjust system decisions accordingly. On the other hand, an example of a typical application scenario involving the active mobility of nodes is the current stage of Unmanned Aerial Vehicle (UAV) surveillance. When nodes possess the ability to actively move, a preliminary consideration is to establish a metric that measures the trade-off between the energy consumption for node movement and the amount of effective information acquired. This metric aims to quantify the information gain from mobile data collection. By integrating the planning of multiple node trajectories, it is possible to investigate optimization decision algorithms for maximizing system energy efficiency. These aspects require further modeling and analysis and are important research directions for the future work on this paper.
7. Conclusions
In this paper, a SSIM is developed to quantify the valuable information of sensor data, which decays with space and time. Two optimal scheduling mechanisms are proposed. One is the single-step mechanism, and the approximate numerical bounds for node layout between partial scheduling results are obtained by theoretical analysis and numerical calculation, which coincide with the simulation results. The other one is the long-term mechanism, which is modeled as a Markov decision process, and the optimal scheduling results with different node layouts are obtained using the Q-learning algorithm. Through simulation and experiments, the scheduling results of both mechanisms are the same in many node layout cases. In few node layouts, the mean incremental information obtained by the long-term mechanism is up to about 2% higher than that of the single-step mechanism, but the standard deviation with the long-term mechanism is also higher than that of the single-step mechanism. The average performance of the two mechanisms is similar under all node layouts, and the long-term mechanism is slightly higher. In future work, we may focus on the SSIM with time-varying covariance functions and node mobility, and study the cooperative scheduling of multiple nodes to improve energy efficiency and extend lifetime.
Author Contributions
Conceptualization, C.D. and X.Q.; methodology, Y.L.; software, C.D. and Y.L.; validation, Y.L.; formal analysis, C.D. and Y.L.; investigation, Y.L.; resources, X.X.; data curation, Y.L.; writing—original draft preparation, Y.L.; writing—review and editing, C.D., Y.L., X.X. and X.Q.; visualization, Y.L.; supervision, C.D.; project administration, C.D.; funding acquisition, C.D. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported in part by project U2001208 funded by the National Natural Science Foundation of China (NSFC). (Corresponding author: Chen Dong).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of Things: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Villa, T.; Salimi, F.; Morton, K.; Morawska, L.; Gonzalez, F. Development and validation of a UAV based system for air pollution measurements. Sensors 2016, 16, 2202. [Google Scholar] [CrossRef] [PubMed]
- de Oliveira, L.F.P.; Manera, L.T.; Luz, P.D.G.D. Development of a Smart Traffic Light Control System with Real-Time Monitoring. IEEE Internet Things J. 2021, 8, 3384–3393. [Google Scholar] [CrossRef]
- Friha, O.; Ferrag, M.A.; Shu, L.; Maglaras, L.; Wang, X. Internet of Things for the Future of Smart Agriculture: A Comprehensive Survey of Emerging Technologies. IEEE/CAA J. Autom. Sin. 2021, 8, 718–752. [Google Scholar] [CrossRef]
- Fascista, A.; Coluccia, A.; Ravazzi, C. A Unified Bayesian Framework for Joint Estimation and Anomaly Detection in Environmental Sensor Networks. IEEE Access 2023, 11, 227–248. [Google Scholar] [CrossRef]
- Kaul, S.; Yates, R.; Gruteser, M. Real-time status: How often should one update? In Proceedings of the 2012 Proceedings IEEE INFOCOM, Orlando, FL, USA, 25–30 March 2012; pp. 2731–2735. [Google Scholar]
- Kadota, I.; Sinha, A.; Modiano, E. Scheduling Algorithms for Optimizing Age of Information in Wireless Networks with Throughput Constraints. IEEE/ACM Trans. Netw. 2019, 27, 1359–1372. [Google Scholar] [CrossRef]
- Talak, R.; Karaman, S.; Modiano, E. Optimizing Information Freshness in Wireless Networks under General Interference Constraints. IEEE/ACM Trans. Netw. 2020, 28, 15–28. [Google Scholar] [CrossRef]
- Akar, N.; Dogan, O. Discrete-Time Queueing Model of Age of Information with Multiple Information Sources. IEEE Internet Things J. 2021, 8, 14531–14542. [Google Scholar] [CrossRef]
- Sun, Y.; Uysal-Biyikoglu, E.; Yates, R.D.; Koksal, C.E.; Shroff, N.B. Update or Wait: How to Keep Your Data Fresh. IEEE Trans. Inf. Theory 2017, 63, 7492–7508. [Google Scholar] [CrossRef]
- Kosta, A.; Pappas, N.; Ephremides, A.; Angelakis, V. The Age of Information in a Discrete Time Queue: Stationary Distribution and Non-Linear Age Mean Analysis. IEEE J. Sel. Areas Commun. 2021, 39, 1352–1364. [Google Scholar] [CrossRef]
- Poojary, S.; Bhambay, S.; Parag, P. Real-Time Status Updates for Markov Source. IEEE Trans. Inf. Theory 2019, 65, 5737–5749. [Google Scholar] [CrossRef]
- Chamberland, J.-F.; Veeravalli, V.V. How Dense Should a Sensor Network Be for Detection with Correlated Observations? IEEE Trans. Inf. Theory 2006, 52, 5099–5106. [Google Scholar] [CrossRef]
- Vuran, M.C.; Akan, O.B. Spatio-temporal Characteristics of Point and Field Sources in Wireless Sensor Networks. In Proceedings of the 2006 IEEE International Conference on Communications, Istanbul, Turkey, 11–15 June 2006; pp. 234–239. [Google Scholar]
- Wang, B.; Zhu, J.; Yang, L.T.; Mo, Y. Sensor Density for Confident Information Coverage in Randomly Deployed Sensor Networks. IEEE Trans. Wirel. Commun. 2016, 15, 3238–3250. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, B. The Optimal Placement Pattern for Confident Information Coverage in Wireless Sensor Networks. IEEE Trans. Mob. Comput. 2016, 15, 1022–1032. [Google Scholar] [CrossRef]
- Dai, L.; Wang, B.; Yang, L.T.; Deng, X.; Yi, L. A Nature-Inspired Node Deployment Strategy for Connected Confident Information Coverage in Industrial Internet of Things. IEEE Internet Things J. 2019, 6, 9217–9225. [Google Scholar] [CrossRef]
- Hribar, J.; Costa, M.; Kaminski, N.; DaSilva, L.A. Using Correlated Information to Extend Device Lifetime. IEEE Internet Things J. 2019, 6, 2439–2448. [Google Scholar] [CrossRef]
- Hribar, J.; Marinescu, A.; Ropokis, G.A.; DaSilva, L.A. Using Deep Q-Learning to Prolong the Lifetime of Correlated Internet of Things Devices. In Proceedings of the 2019 IEEE International Conference on Communications Workshops (ICC Workshops), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Hribar, J.; Marinescu, A.; Chiumento, A.; Dasilva, L.A. Energy-Aware Deep Reinforcement Learning Scheduling for Sensors Correlated in Time and Space. IEEE Internet Things J. 2022, 9, 6732–6744. [Google Scholar] [CrossRef]
- Sun, Y.; Cyr, B. Information Aging Through Queues: A Mutual Information Perspective. In Proceedings of the 2018 IEEE 19th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Kalamata, Greece, 25–28 June 2018; pp. 1–5. [Google Scholar]
- Wang, Z.; Badiu, M.-A.; Coon, J.P. A Value of Information Framework for Latent Variable Models. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Wang, Z.; Badiu, M.-A.; Coon, J.P. A Framework for Characterizing the Value of Information in Hidden Markov Models. IEEE Trans. Inf. Theory 2022, 68, 5203–5216. [Google Scholar] [CrossRef]
- Kim, J.; Kim, M.; Lee, J. Sensing and Transmission Design for AoI-Sensitive Wireless Sensor Networks. In Proceedings of the 2020 IEEE Globecom Workshops (GC Wkshps), Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Kim, J.; Kim, M.; Lee, J. Securing fresh data in wireless monitoring networks: Age-of-information sensitive coverage perspective. arXiv 2021, arXiv:2103.07149. [Google Scholar]
- Jiang, Z.; Zhou, S. Status from a Random Field: How Densely Should One Update? In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1037–1041. [Google Scholar]
- Zhang, H.; Jiang, Z.; Xu, S.; Zhou, S. Error Analysis for Status Update From Sensors with Temporally and Spatially Correlated Observations. IEEE Trans. Wirel. Commun. 2021, 20, 2136–2149. [Google Scholar] [CrossRef]
- Håkansson, V.W.; Venkategowda, N.K.D.; Werner, S.; Varshney, P.K. Optimal Scheduling of Multiple Spatio-temporally Dependent Observations for Remote Estimation using Age-of-Information. IEEE Internet Things J. 2022, 9, 20308–20321. [Google Scholar] [CrossRef]
- Håkansson, V.W.; Venkategowda, N.K.D.; Werner, S.; Varshney, P.K. Optimal Transmission-Constrained Scheduling of Spatio-Temporally Dependent Observations Using Age-of-Information. IEEE Sens. J. 2022, 22, 15596–15606. [Google Scholar] [CrossRef]
- Li, Y.; Xu, Y.; Zhang, Q.; Yang, Z. Age-Driven Spatially Temporally Correlative Updating in the Satellite-Integrated Internet of Things via Markov Decision Process. IEEE Internet Things J. 2022, 9, 13612–13625. [Google Scholar] [CrossRef]
- Pan, W.; Deng, Z.; Wang, X.; Zhou, P.; Wu, W. Optimizing the Age of Information for Multi-Source Information Update in Internet of Things. IEEE Trans. Netw. Sci. Eng. 2022, 9, 904–917. [Google Scholar] [CrossRef]
- Liu, Y.; Dong, C.; Qin, X.; Xu, X. Efficient Sensor Scheduling Strategy Based on Spatio-temporal Scope Information Model. arXiv 2022, arXiv:2212.07008. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Feng, F.; Wang, K.C. Merging satellite retrievals and reanalyses to produce global long-term and consistent surface incident solar radiation datasets. Remote Sens. 2018, 10, 115. [Google Scholar] [CrossRef]
- Feng, F.; Wang, K.C. Merging ground-based sunshine duration observations with satellite cloud and aerosol retrievals to produce high-resolution long-term surface solar radiation over China. Earth Syst. Sci. Data 2021, 13, 907–922. [Google Scholar] [CrossRef]
- Mao, Y.N.; Wang, K.C.; Liu, X.M.; Liu, C.M. Water storage in reservoirs built from 1997 to 2014 significantly altered the calculated evapotranspiration trends over China. J. Geophys. Res.-Atmos. 2016, 121, 10097–10112. [Google Scholar] [CrossRef]
- Mao, Y.N.; Wang, K.C. Comparison of Evapotranspiration Estimates based on the Surface Water Balance, Modified Penman-Monteith Model, and Reanalysis Datasets for Continental China. J. Geophys. Res. Atmos. 2017, 122, 3228–3244. [Google Scholar] [CrossRef]
- Wang, K. Homogeneous Grid Dataset of Chinaese Land Surface Observation (Surface Solar Radiation, Surface Wind Speed, Relative Humidity and Land Surface Evapotranspiration); National Tibetan Plateau Data Center: Beijing, China, 2022. [Google Scholar]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).