
STMP-Net: A Spatiotemporal Prediction Network Integrating Motion Perception


Abstract
:1. Introduction
- 1.
- This paper proposes a recurrent neural network-based video prediction method (STMP-Net) combining spatiotemporal memory features and motion perception;
- 2.
- A spatiotemporal attention fusion unit (STAFU) is proposed based on a gated recurrent unit, which adaptively learns important contextual information through a contextual attention mechanism, and also greatly improves the network’s ability to capture video spatiotemporal features by using a spatiotemporal memory unit;
- 3.
- Motion perception is introduced based on a gradient highway unit, and a motion gradient highway unit (MGHU) is proposed to learn transient changes and motion trends between video frames. Additionally, a shortcut gradient is provided between adjacent layers to mitigate the gradient disappearance problem caused by backpropagation.
2. Related Work
3. Model Design
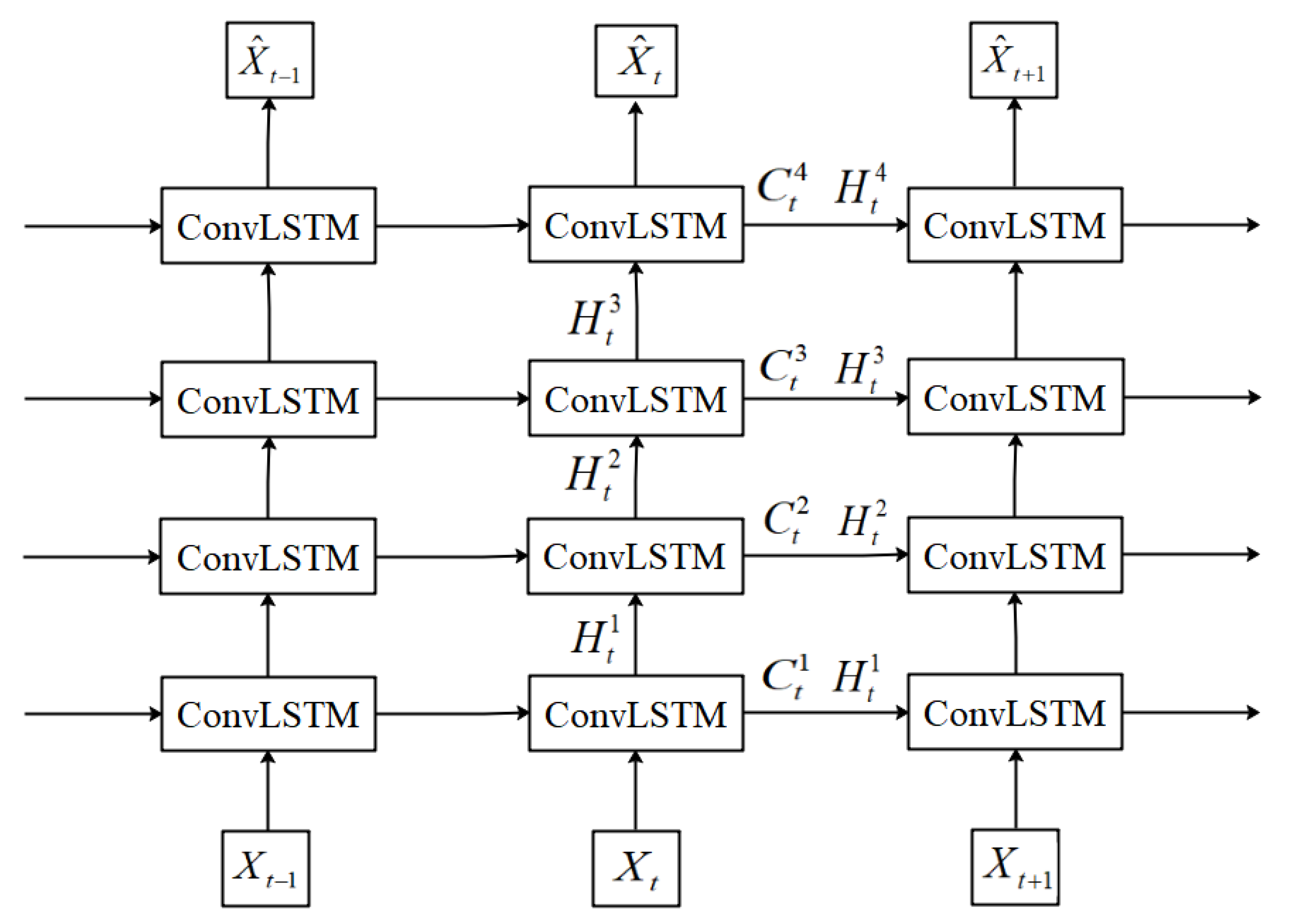
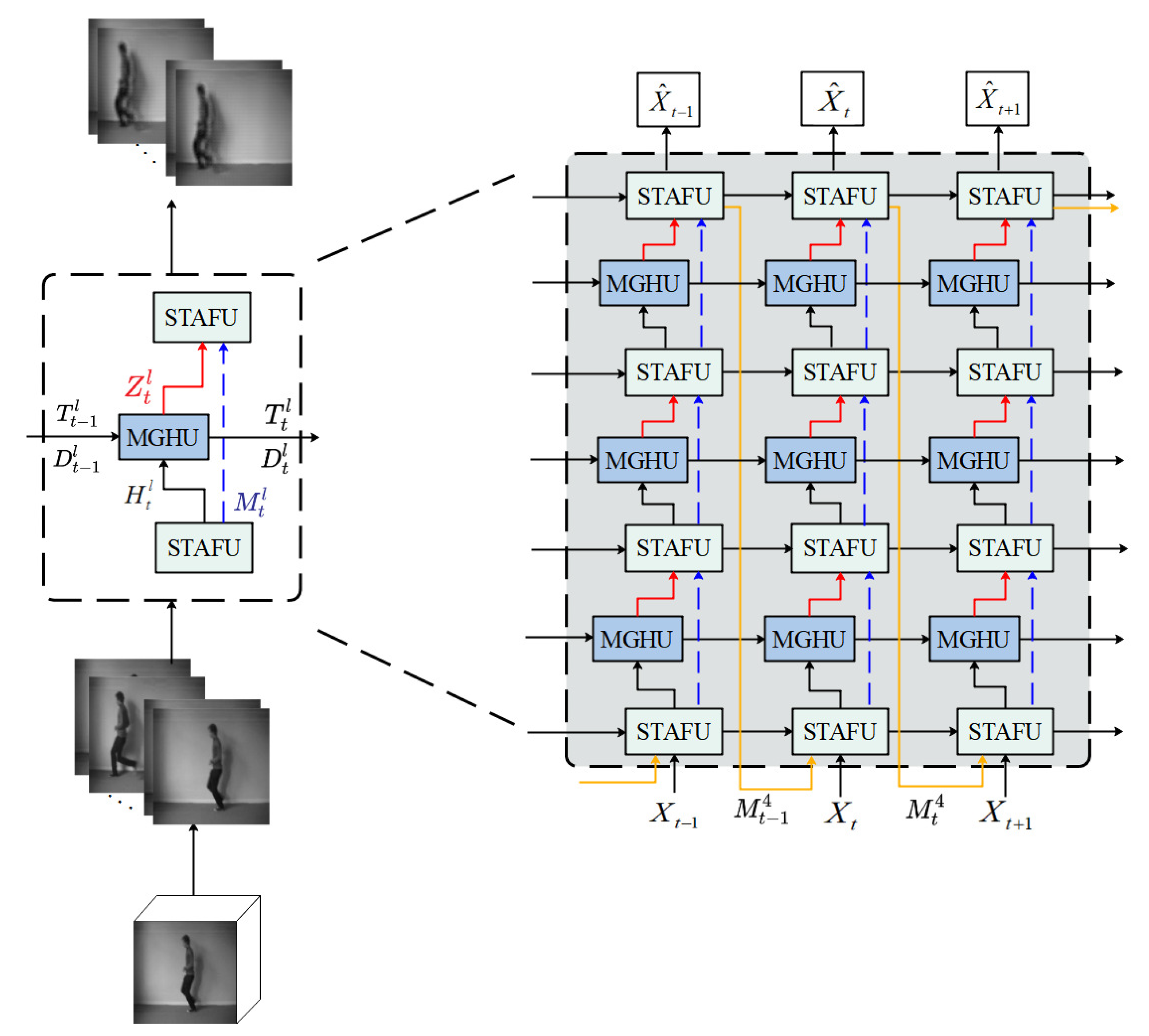
3.1. Prediction Method
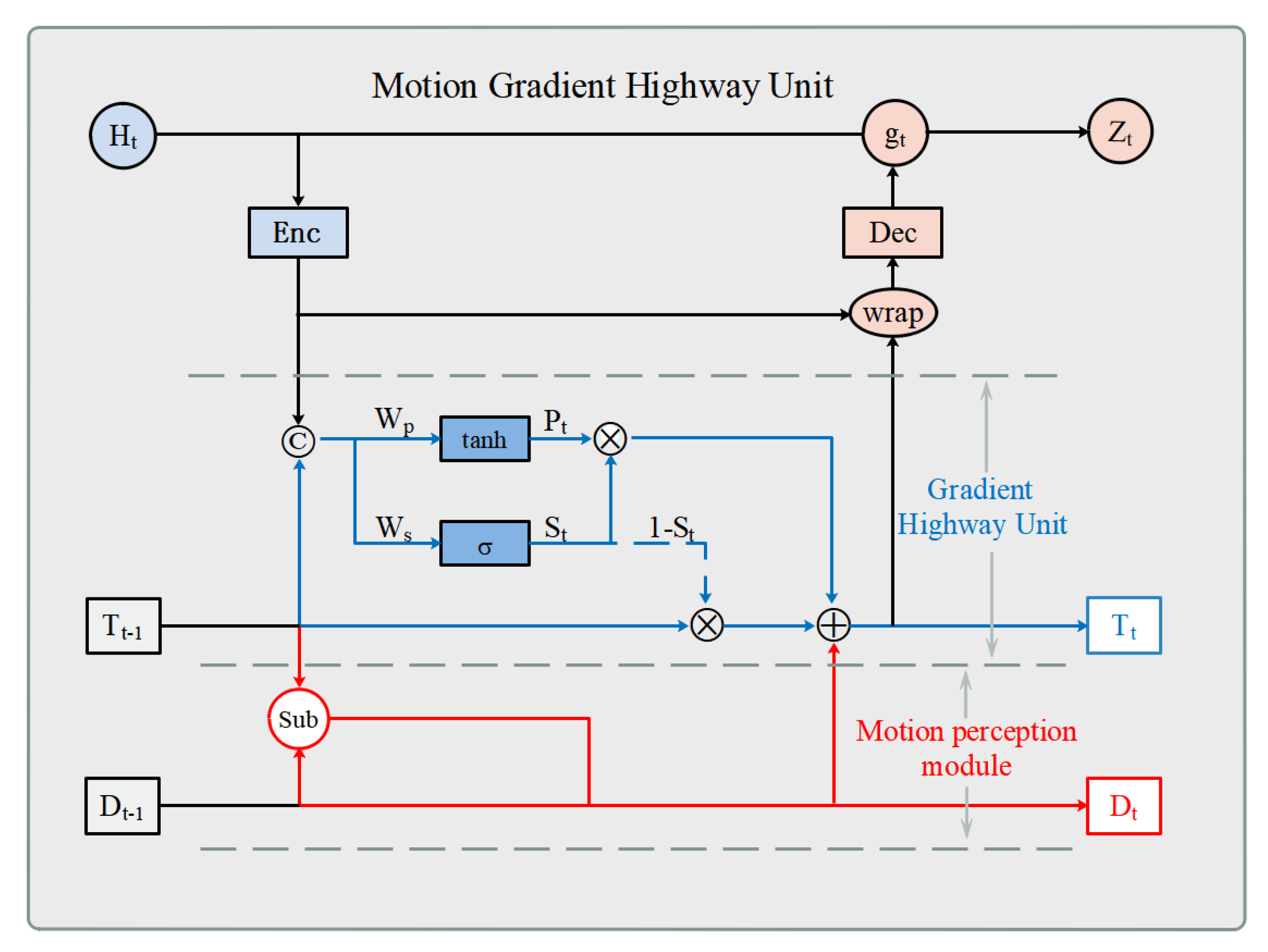
3.2. Motion Gradient Highway Unit (MGHU)
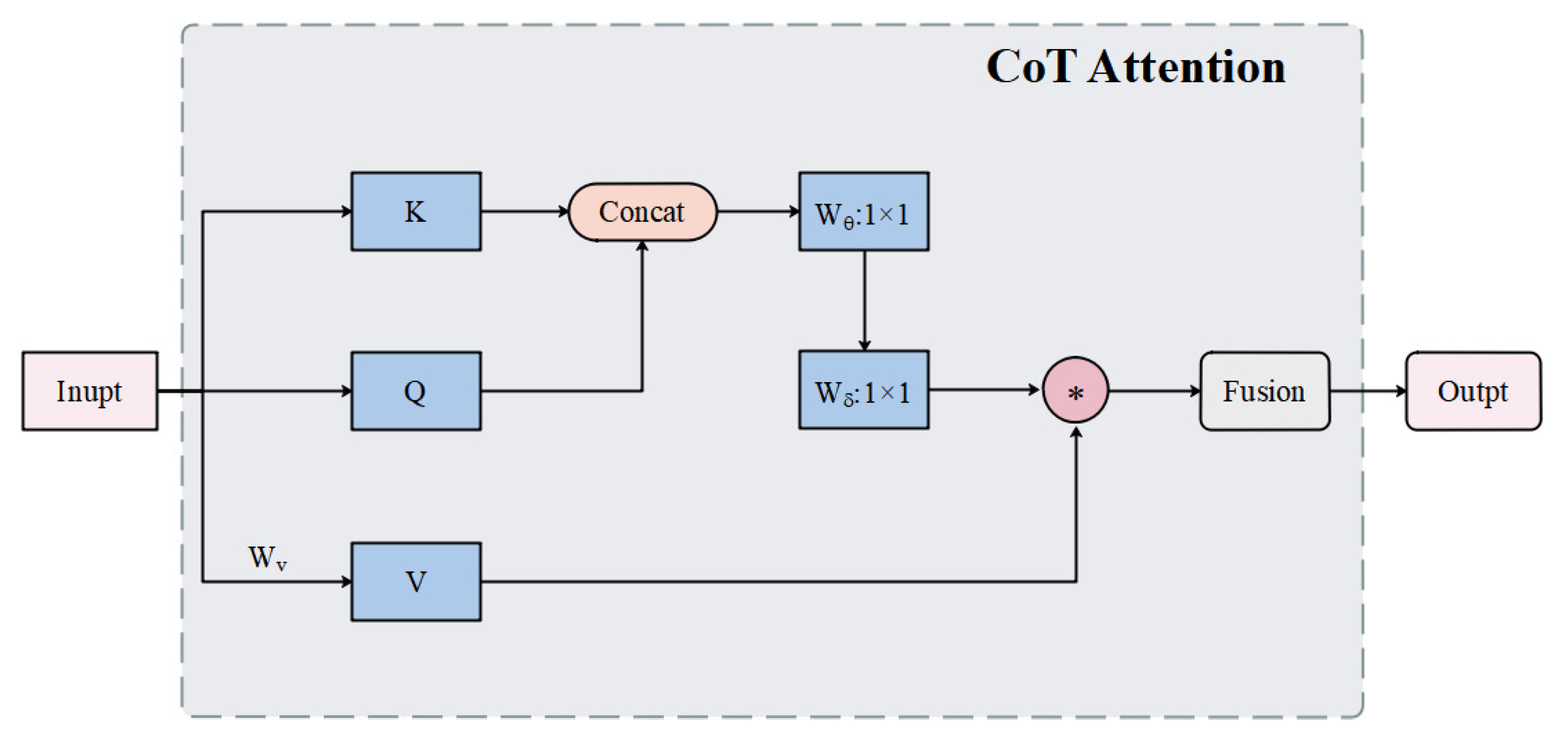
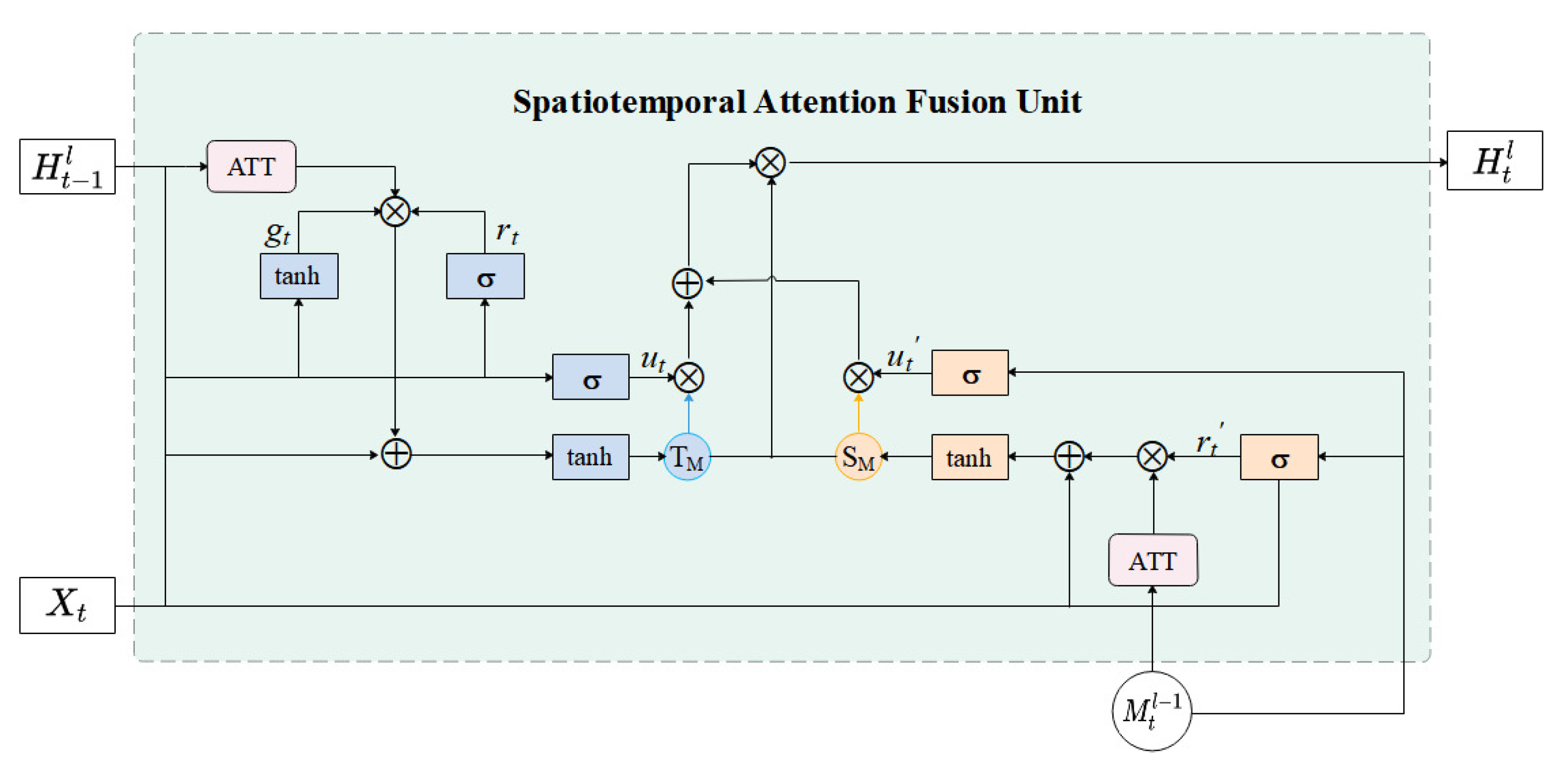
3.3. Spatiotemporal Attention Fusion Unit (STAFU)
3.4. Loss Function
4. Experiments and Analysis
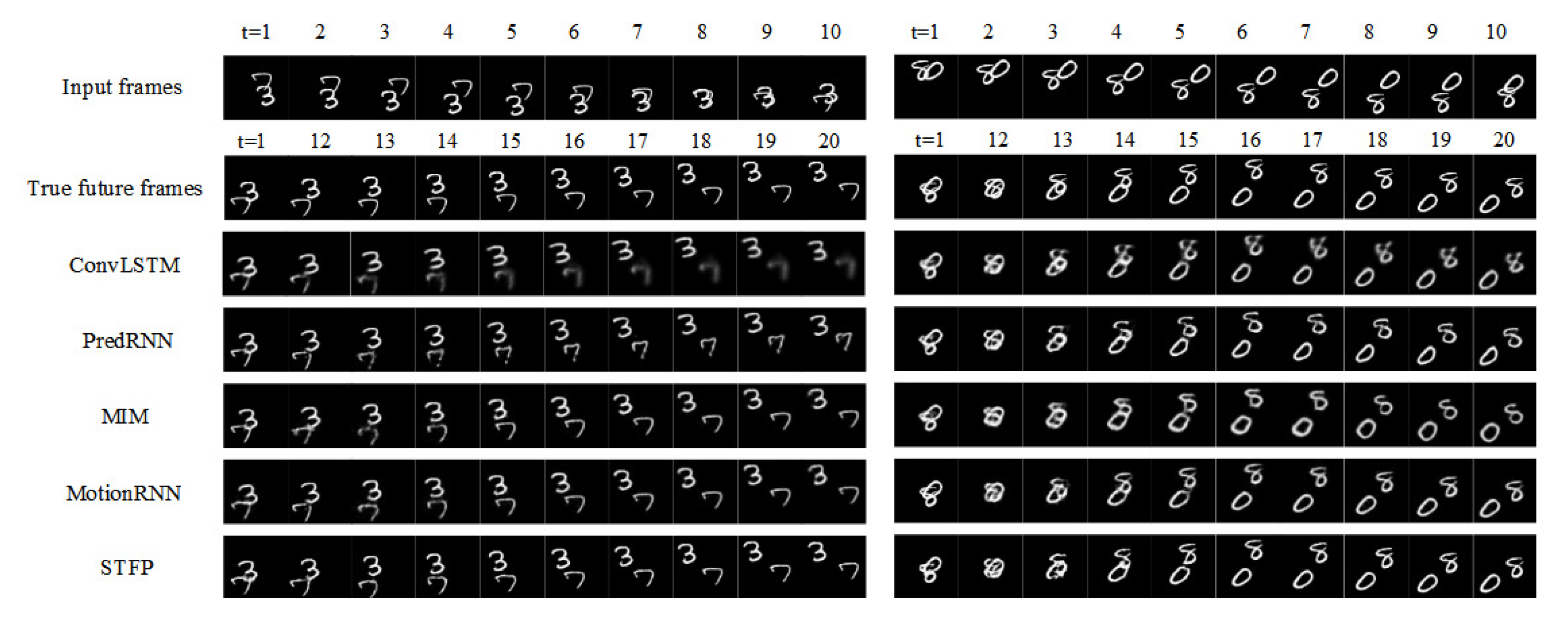
4.1. Moving MNIST
4.1.1. Comparison Experiments
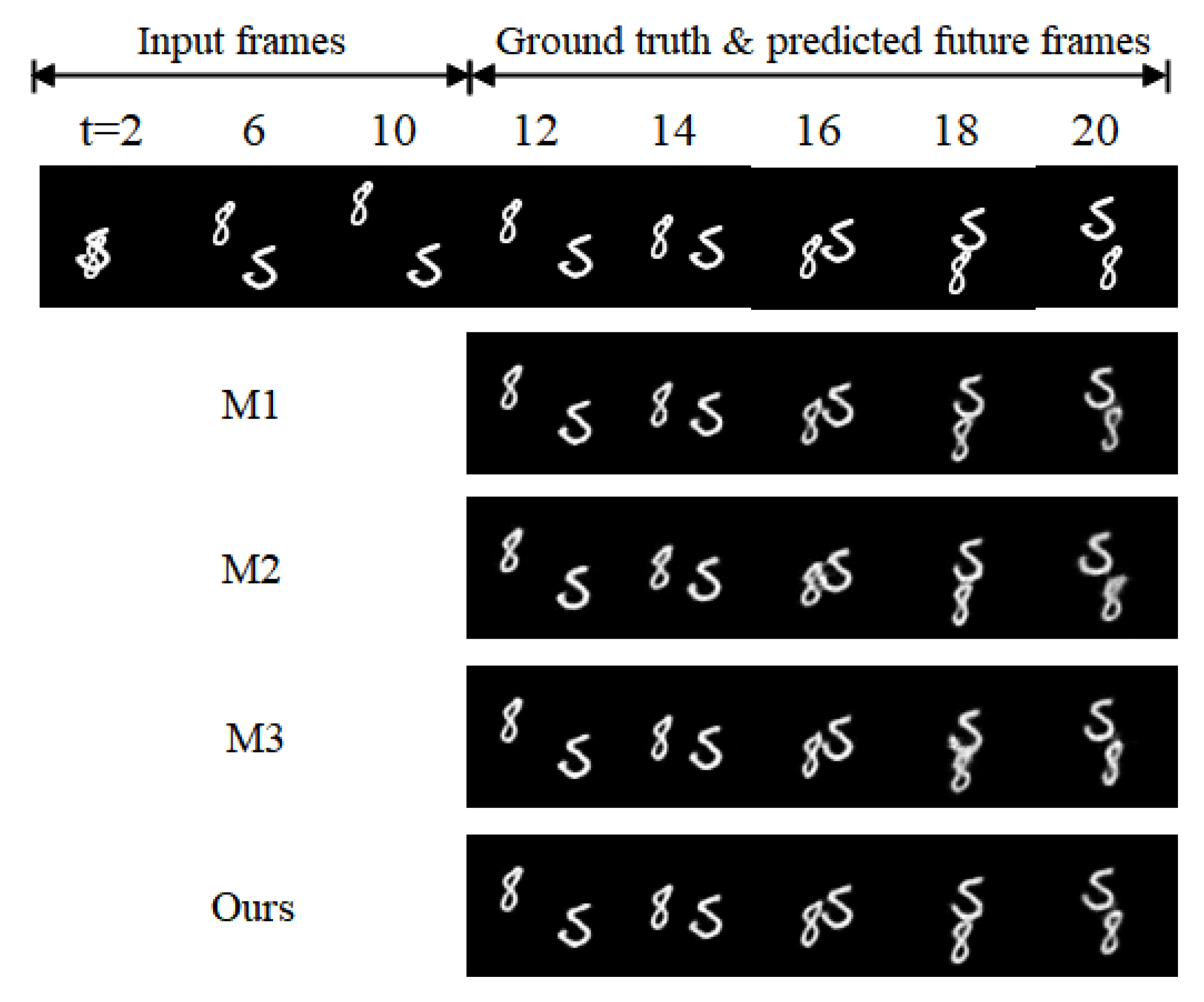
4.1.2. Ablation Study
4.2. KTH Human Action Recognition Dataset
4.2.1. Ablation Experiment
4.2.2. Comparison Experiments
5. Comparative Analysis
6. Conclusions
7. Future Directions
- 1.
- Long-term prediction: Most of the current video prediction methods are based on short-term prediction, and future research directions can explore how to better perform long-term prediction, i.e., predicting tens or even a hundred frames in the future. This will have greater requirements on the complexity of the model and the amount of data.
- 2.
- Multimodal video prediction: The current video prediction mainly considers the data of image sequences, and if other modal data can be integrated, such as audio, semantic segmentation, etc., there will be better prediction results. Future research directions can explore how to integrate data from different modalities for video prediction to improve the accuracy and robustness of prediction.
- 3.
- Adapt to different scenes: Current video prediction models are usually trained and predicted in specific scenes, and often do not perform as well in the face of different scenes or different motion patterns. In the future, we can explore how to design pervasive video prediction models that can adapt to different scenes and motion patterns.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Z.; Yeh, R.A.; Tang, X.; Liu, Y.; Agarwala, A. Video frame synthesis using deep voxel flow. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4463–4471. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 802–810. [Google Scholar]
- Shi, X.; Gao, Z.; Lausen, L.; Wang, H.; Yeung, D.Y.; Wong, W.k.; Woo, W.C. Deep learning for precipitation nowcasting: A benchmark and a new model. Adv. Neural Inf. Process. Syst. 2017, 30, 5622–5632. [Google Scholar]
- Castrejon, L.; Ballas, N.; Courville, A. Improved conditional vrnns for video prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7608–7617. [Google Scholar]
- Bhattacharyya, A.; Fritz, M.; Schiele, B. Long-term on-board prediction of people in traffic scenes under uncertainty. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4194–4202. [Google Scholar]
- Li, J.; Liu, X.; Zhang, W.; Zhang, M.; Song, J.; Sebe, N. Spatio-temporal attention networks for action recognition and detection. IEEE Trans. Multimed. 2020, 22, 2990–3001. [Google Scholar] [CrossRef]
- Liu, H.; Nie, H.; Zhang, Z.; Li, Y.F. Anisotropic angle distribution learning for head pose estimation and attention understanding in human-computer interaction. Neurocomputing 2021, 433, 310–322. [Google Scholar] [CrossRef]
- Liu, T.; Liu, H.; Yang, B.; Zhang, Z. LDCNet: Limb Direction Cues-aware Network for Flexible Human Pose Estimation in Industrial Behavioral Biometrics Systems. IEEE Trans. Ind. Inform. 2023, 1–11. [Google Scholar] [CrossRef]
- Guo, X.; Yang, F.; Ji, L. A Mimic Fusion Method Based on Difference Feature Association Falling Shadow for Infrared and Visible Video. Infrared Phys. Technol. 2023, 132, 104721. [Google Scholar] [CrossRef]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Philip, S.Y. Predrnn++: Towards a resolution of the deep-in-time dilemma in spatiotemporal predictive learning. In Proceedings of the International Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2018; pp. 5123–5132. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef]
- Wu, H.; Yao, Z.; Wang, J.; Long, M. MotionRNN: A flexible model for video prediction with spacetime-varying motions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 20–25 June 2021; pp. 15435–15444. [Google Scholar]
- Srivastava, N.; Mansimov, E.; Salakhudinov, R. Unsupervised learning of video representations using lstms. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 7–9 July 2015; pp. 843–852. [Google Scholar]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the 17th International Conference on Pattern Recognition, 2004 (ICPR), Cambridge, UK, 23–26 August 2004; Volume 3, pp. 32–36. [Google Scholar]
- Liu, H.; Zhang, C.; Deng, Y.; Xie, B.; Liu, T.; Zhang, Z.; Li, Y.F. TransIFC: Invariant Cues-aware Feature Concentration Learning for Efficient Fine-grained Bird Image Classification. IEEE Trans. Multimed. 2023, 1–14. [Google Scholar] [CrossRef]
- Wang, D.; Lan, J. PPDet: A novel infrared pedestrian detection network in a per-pixel prediction fashion. Infrared Phys. Technol. 2021, 119, 103965. [Google Scholar] [CrossRef]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M.H. Flow-grounded spatial-temporal video prediction from still images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 4–8 September 2018; pp. 600–615. [Google Scholar]
- Villegas, R.; Yang, J.; Hong, S.; Lin, X.; Lee, H. Decomposing motion and content for natural video sequence prediction. arXiv 2017, arXiv:1706.08033. [Google Scholar]
- Bei, X.; Yang, Y.; Soatto, S. Learning semantic-aware dynamics for video prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 902–912. [Google Scholar]
- Patraucean, V.; Handa, A.; Cipolla, R. Spatio-temporal video autoencoder with differentiable memory. arXiv 2015, arXiv:1511.06309. [Google Scholar]
- Liu, H.; Liu, T.; Zhang, Z.; Sangaiah, A.K.; Yang, B.; Li, Y. ARHPE: Asymmetric relation-aware representation learning for head pose estimation in industrial human–computer interaction. IEEE Trans. Ind. Inform. 2022, 18, 7107–7117. [Google Scholar] [CrossRef]
- Wu, H.; Liu, G. A dynamic infrared object tracking algorithm by frame differencing. Infrared Phys. Technol. 2022, 127, 104384. [Google Scholar] [CrossRef]
- Liu, H.; Fang, S.; Zhang, Z.; Li, D.; Lin, K.; Wang, J. MFDNet: Collaborative poses perception and matrix Fisher distribution for head pose estimation. IEEE Trans. Multimed. 2021, 24, 2449–2460. [Google Scholar] [CrossRef]
- Chang, Z.; Zhang, X.; Wang, S.; Ma, S.; Gao, W. Strpm: A spatiotemporal residual predictive model for high-resolution video prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13946–13955. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Schmidhuber, J. Learning complex, extended sequences using the principle of history compression. Neural Comput. 1992, 4, 234–242. [Google Scholar] [CrossRef]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Ballas, N.; Yao, L.; Pal, C.; Courville, A. Delving deeper into convolutional networks for learning video representations. arXiv 2015, arXiv:1511.06432. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. Adv. Neural Inf. Process. Syst. 2017, 30, 879–888. [Google Scholar]
- Wang, Y.; Wu, H.; Zhang, J.; Gao, Z.; Wang, J.; Philip, S.Y.; Long, M. Predrnn: A recurrent neural network for spatiotemporal predictive learning. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2208–2225. [Google Scholar] [CrossRef]
- Liang, X.; Lee, L.; Dai, W.; Xing, E.P. Dual motion GAN for future-flow embedded video prediction. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1744–1752. [Google Scholar]
- Huang, J.; Chia, Y.K.; Yu, S.; Yee, K.; Küster, D.; Krumhuber, E.G.; Herremans, D.; Roig, G. Single Image Video Prediction with Auto-Regressive GANs. Sensors 2022, 22, 3533. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Gao, L.; Song, J.; Shen, H. Beyond Frame-level CNN: Saliency-Aware 3-D CNN With LSTM for Video Action Recognition. IEEE Signal Process. Lett. 2017, 24, 510–514. [Google Scholar] [CrossRef]
- Liu, W.; Luo, W.; Lian, D.; Gao, S. Future frame prediction for anomaly detection—A new baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6536–6545. [Google Scholar]
- Chang, Z.; Zhang, X.; Wang, S.; Ma, S.; Gao, W. STIP: A SpatioTemporal Information-Preserving and Perception-Augmented Model for High-Resolution Video Prediction. arXiv 2022, arXiv:2206.04381. [Google Scholar]
- Wang, Y.; Jiang, L.; Yang, M.H.; Li, L.J.; Long, M.; Fei-Fei, L. Eidetic 3d lstm: A model for video prediction and beyond. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Wang, Y.; Zhang, J.; Zhu, H.; Long, M.; Wang, J.; Yu, P.S. Memory in memory: A predictive neural network for learning higher-order non-stationarity from spatiotemporal dynamics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9154–9162. [Google Scholar]
- Yu, W.; Lu, Y.; Easterbrook, S.; Fidler, S. Efficient and information-preserving future frame prediction and beyond. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Su, J.; Byeon, W.; Kossaifi, J.; Huang, F.; Kautz, J.; Anandkumar, A. Convolutional tensor-train lstm for spatio-temporal learning. Adv. Neural Inf. Process. Syst. 2020, 33, 13714–13726. [Google Scholar]
- Xu, Z.; Wang, Y.; Long, M.; Wang, J.; KLiss, M. PredCNN: Predictive Learning with Cascade Convolutions. In Proceedings of the IJCAI, Stockholm, Sweden, 13–19 July 2018; pp. 2940–2947. [Google Scholar]
- Gao, H.; Xu, H.; Cai, Q.Z.; Wang, R.; Yu, F.; Darrell, T. Disentangling propagation and generation for video prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9006–9015. [Google Scholar]
- Guen, V.L.; Thome, N. Disentangling physical dynamics from unknown factors for unsupervised video prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11474–11484. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Related Literatures | Limitations |
|---|---|---|
| Traditional methods | [1,17,18,19,20] | The prediction accuracy is affected by factors such as video resolution and frame rate. |
| Deep Learning methods | [2,10,13,24,25,26,27,28,29,30] | Poor performance in long-term prediction and high time cost for both training and inference. |
| Motion estimation methods | [14,31,32,33,34] | High requirements for both the quantity and quality of data and motion estimation. |
| Model | MSE (↓) | SSIM (↑) |
|---|---|---|
| ConvLSTM [2] (2015) | 103.3 | 0.707 |
| PredRNN [29] (2017) | 56.8 | 0.867 |
| MIM [37] (2019) | 44.2 | 0.910 |
| CrevNet [38] (2020) | 38.5 | 0.928 |
| MotionRNN [12] (2021) | 34.2 | 0.926 |
| STMP-Net | 29.3 | 0.935 |
| Model | Backbone | MSE (↓) | SSIM (↑) |
|---|---|---|---|
| M1 | 4×STLSTM [30] | 47.5 | 0.889 |
| M2 | 4×STLSTM, 3×MGHU | 35.2 | 0.923 |
| M3 | 4×STAFU | 42.7 | 0.902 |
| Ours | 4×STAFU, 3×MGHU | 29.3 | 0.935 |
| Model | Backbone | PSNR (↑) | SSIM (↑) |
|---|---|---|---|
| M1 | 4×STLSTM [30] | 29.6 | 0.838 |
| M2 | 4×STLSTM, 3×MGHU | 31.2 | 0.871 |
| M3 | 4×STAFU | 30.3 | 0.852 |
| Ours | 4×STAFU, 3×MGHU | 31.7 | 0.887 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Yang, N. STMP-Net: A Spatiotemporal Prediction Network Integrating Motion Perception. Sensors 2023, 23, 5133. https://doi.org/10.3390/s23115133
Chen S, Yang N. STMP-Net: A Spatiotemporal Prediction Network Integrating Motion Perception. Sensors. 2023; 23(11):5133. https://doi.org/10.3390/s23115133
Chicago/Turabian StyleChen, Suting, and Ning Yang. 2023. "STMP-Net: A Spatiotemporal Prediction Network Integrating Motion Perception" Sensors 23, no. 11: 5133. https://doi.org/10.3390/s23115133
APA StyleChen, S., & Yang, N. (2023). STMP-Net: A Spatiotemporal Prediction Network Integrating Motion Perception. Sensors, 23(11), 5133. https://doi.org/10.3390/s23115133