


COVID-19 Detection from Cough Recordings Using Bag-of-Words Classifiers

Abstract
1. Introduction
2. Materials and Methods
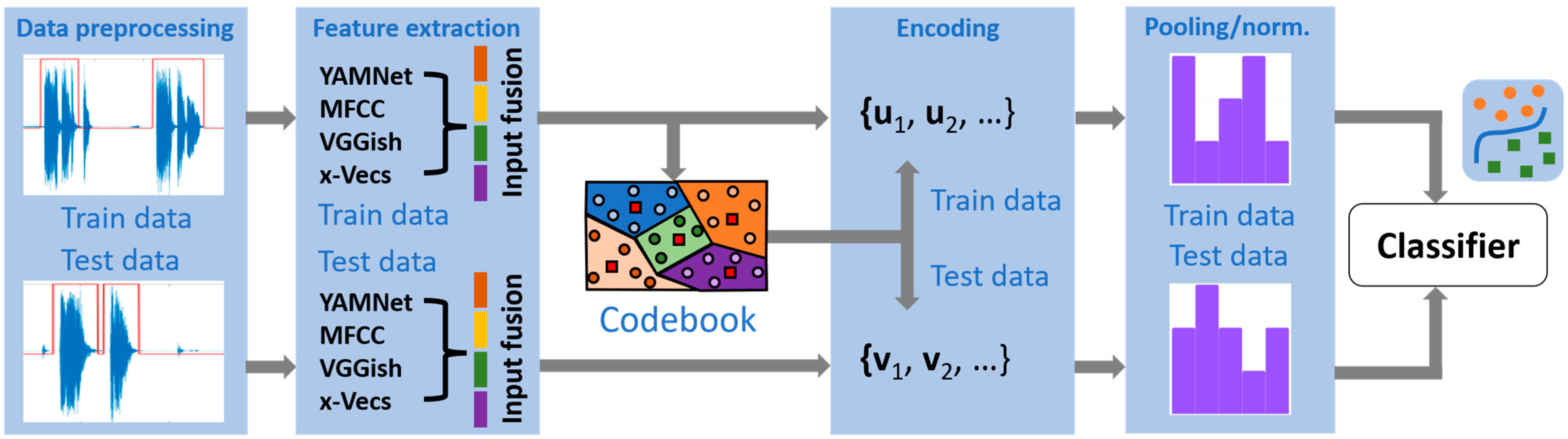
2.1. Overview of Bag-of-Words Models
- (a)
- Preprocessing methods aiming at improving the quality of the data: noise/artifact removal, amplitude/sampling frequency normalization;
- (b)
- Computation of (hand-crafted/automatically generated) feature vectors from successive temporal intervals or localized image patches from each time series/image in the original dataset. The feature vectors are obtained through a similar procedure and using the same setup parameters for the entire dataset under study. In addition, they may typically undergo a subsequent data splitting step into specific (training/test) subsets;
- (c)
- Generating a representative codebook based on the training set feature vectors, usually employing a clustering algorithm. A powerful alternative rooted in redundant representations theory [19] may consider learning a so-called (fixed or data-dependent) dictionary, which is a matrix whose columns (termed atoms) may be used for parsimonious data representation. Online procedures for computing the codebook have also been introduced, enabling continuous updating of the codewords according to new data;
- (d)
- Once the codebook is available, a unique or, more general, a combination of specific codewords is assigned to each training/test set feature vector, implementing an encoding procedure (both training and test sets should use the same codebook);
- (e)
- Given the encoding of the collection of feature vectors that define each training/test time series or image, a compact representation of those is obtained through a histogram counting the frequency of codeword appearances. Since such a pooling strategy may yield histograms with largely variable dynamic ranges, a scale-normalization procedure is typically applied to enable fair comparison of the results;
- (f)
- Finally, classification is performed based on the available histograms using specific distance measures, some of which are particularly useful when dealing with histogram-type data [20]. Nearest-neighbor, multilayer perceptrons, or Support Vector Machines (SVM) are typical classifier models considered in the literature.
2.2. Components of BoW Models
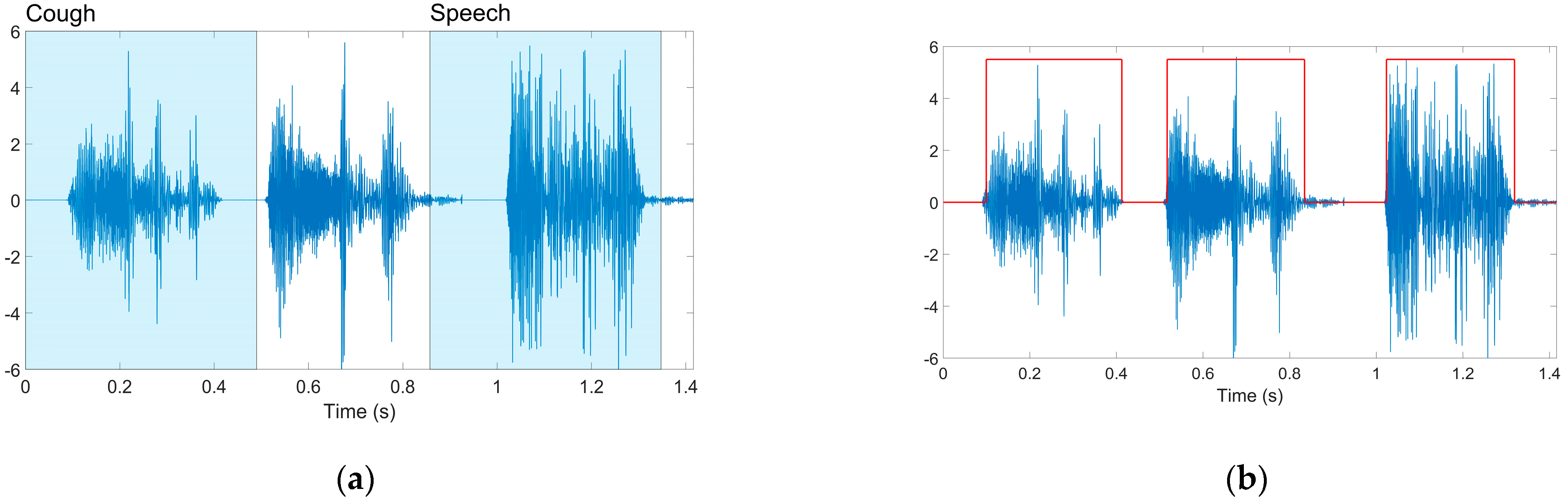
2.2.1. Cough Recordings Preprocessing
2.2.2. Feature Extraction
- Classical mel-frequency cepstrum coefficients (MFCC) spectrograms, computed from 50% overlapping audio segments of 0.96 s. Distinct spectrograms were generated for each segment with a window size of 25 ms, a window hop of 10 ms, and a periodic Hanning window. 64 Mel bins covering the frequency range from 125 Hz to 7500 Hz were used, and after converting the mel-spectrogram into a log scale, we obtained log-mel images with 64 × 96 pixels per segment. Finally, the distinct spectrograms are concatenated along the mel bands dimension to represent the entire audio sample;
- The following two feature types are obtained by applying the MFCC images described above as inputs to a couple of pre-trained convolutional neural network models extensively used in audio-oriented applications and reading the appropriate output of specific inner layers.The YAMNet model (referenced in the previous section as a means of detecting cough segments from audio recordings) may offer valuable discriminative information by intercepting the output of the last layer placed before the classification module (the layer is termed global_average_pooling2d in MATLAB 2022a). This yields a series of 1024-long feature vectors whose number of elements depends on the length of the analyzed time series.The second choice considers a VGGish model [18], where the EmbeddingBatch layer returns a set of 128-long feature vectors, each corresponding to 0.975 s of audio data;
- The fourth option is represented by the so-called x-vectors originating from (text-independent) speaker verification applications using deep neural network embeddings [24]. Features are computed from successive 1 s audio segments and a window hop of 0.1 s, extracted from the output of the first fully-connected layer of the pre-trained model described in [24]. The resulting 512-long vectors are further reduced to a 150-long common length by linear projection using a pre-trained linear discriminant analysis matrix also available from [24].
2.2.3. Codebook Generation
2.2.4. Encoding Procedure
- A.
- Vector Quantization (VQ) [30]:
- B.
- Soft Assignment using the k nearest codewords (SA-k) [31]:
- C.
- Locality-constrained Linear Coding (LLC) [32]:
- D.
- Sparse Coding (SC) [27]:
2.2.5. Similarity Measures
3. Results
3.1. Cough Recording Datasets
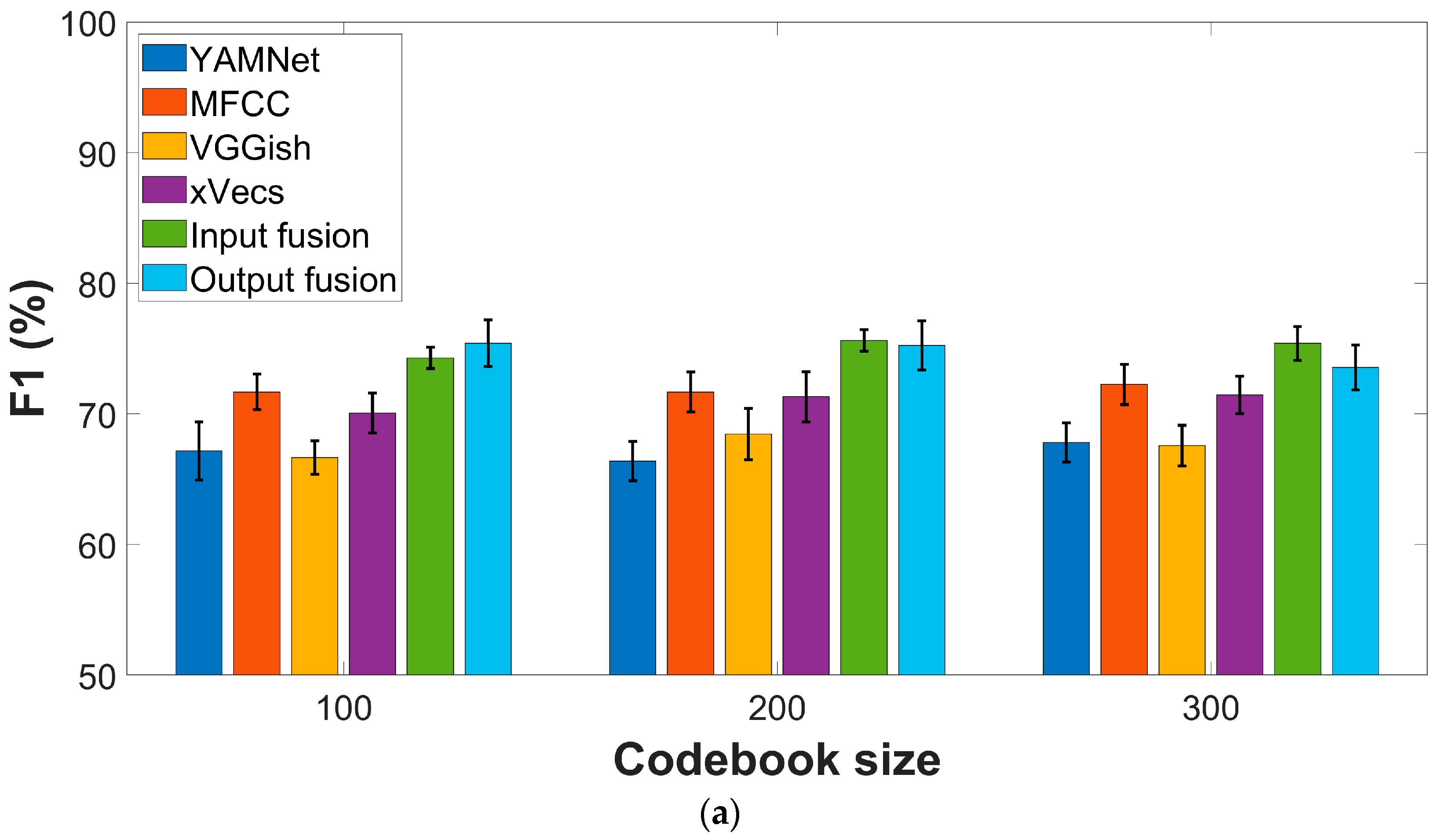
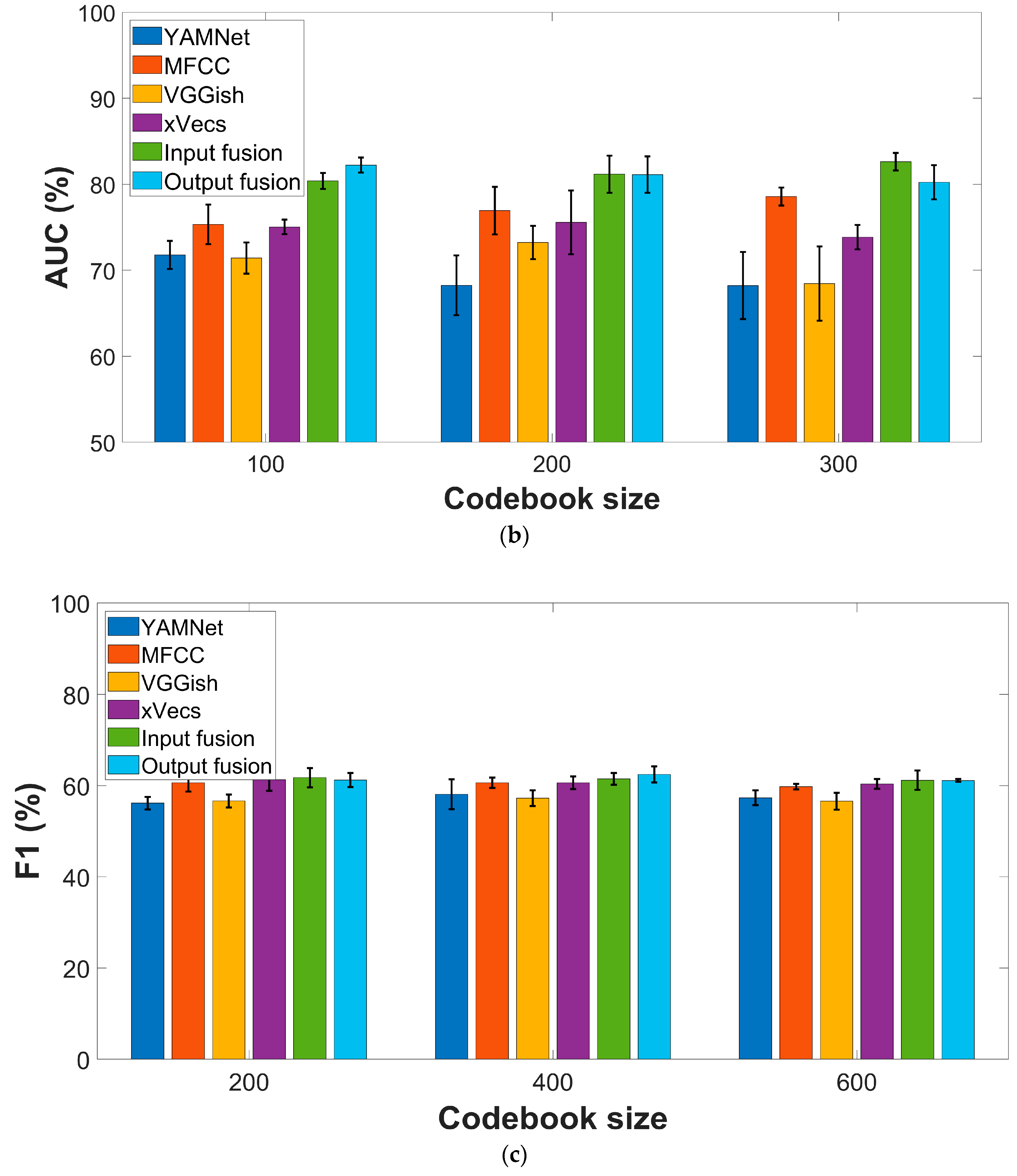
3.2. Effect of the Feature Extraction Procedure
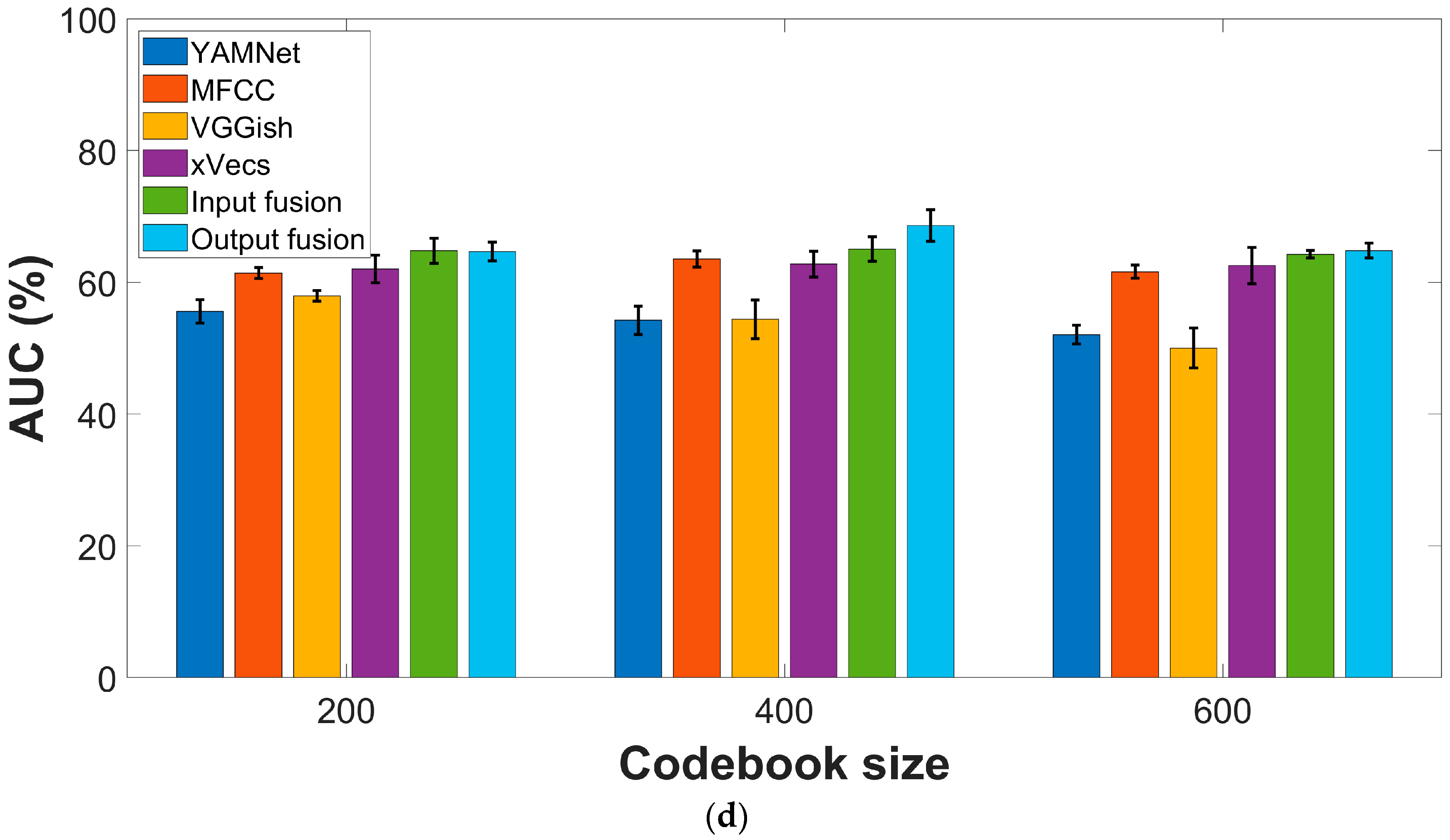
3.3. Effect of the Fusion Strategies
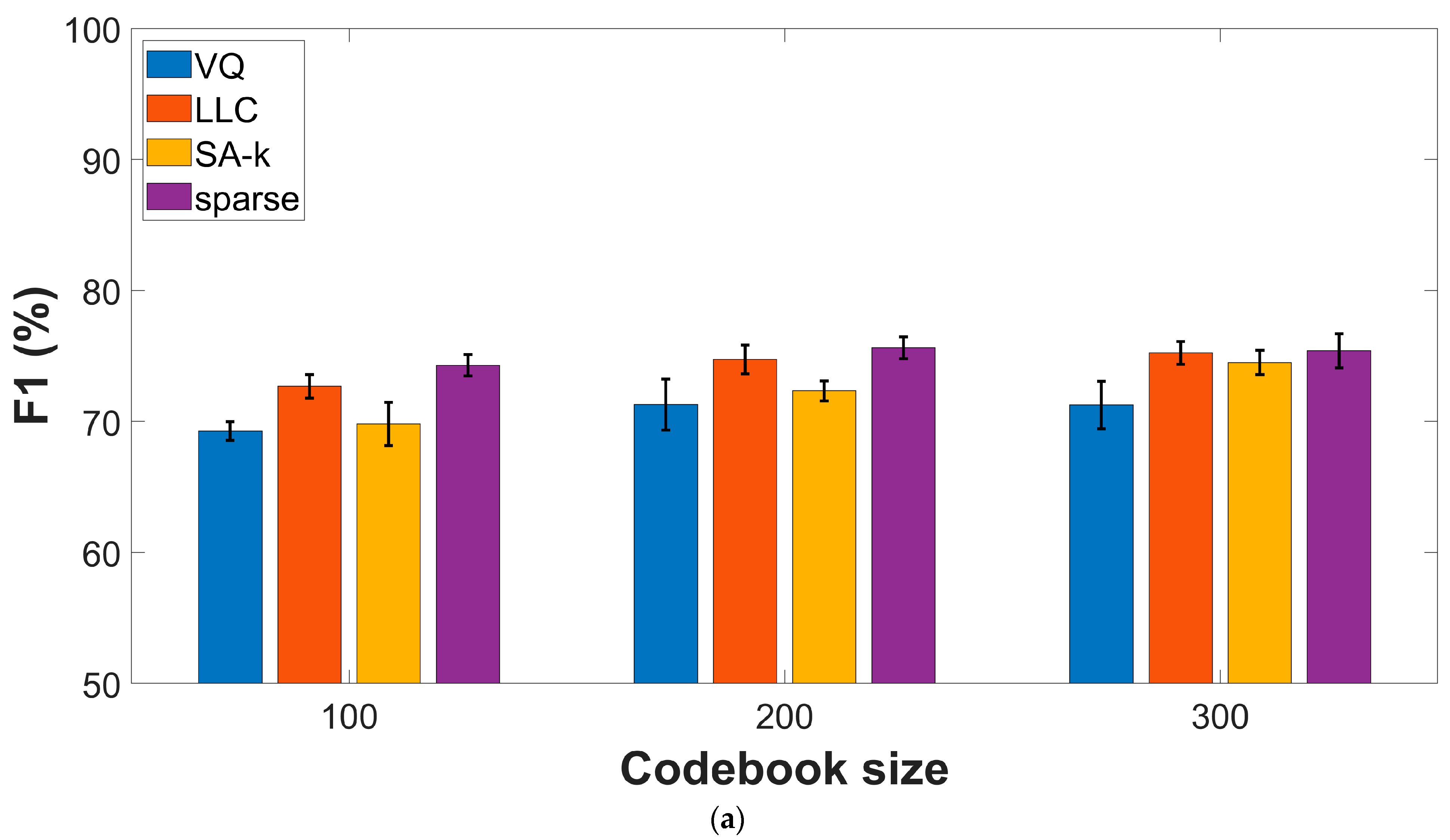
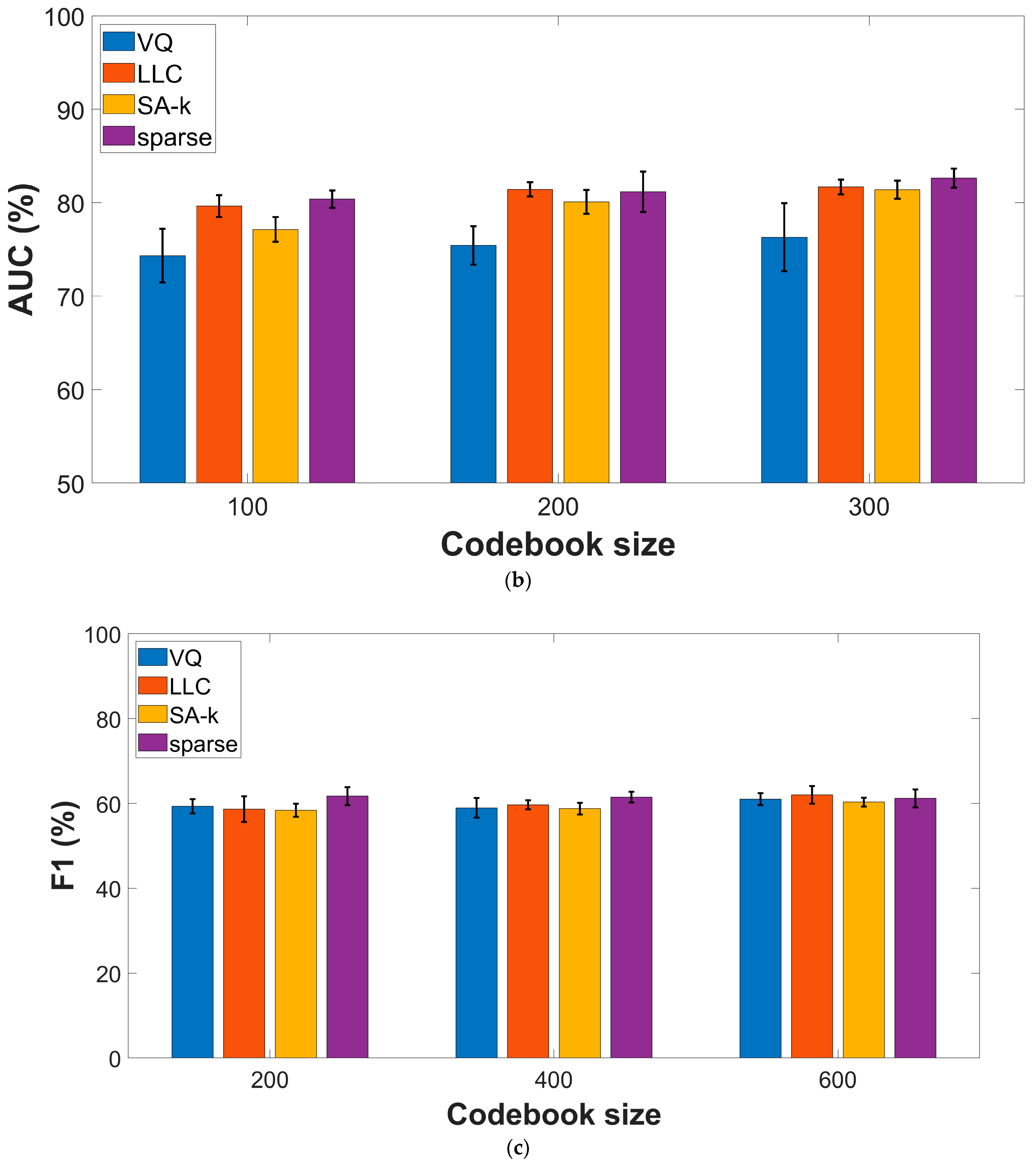
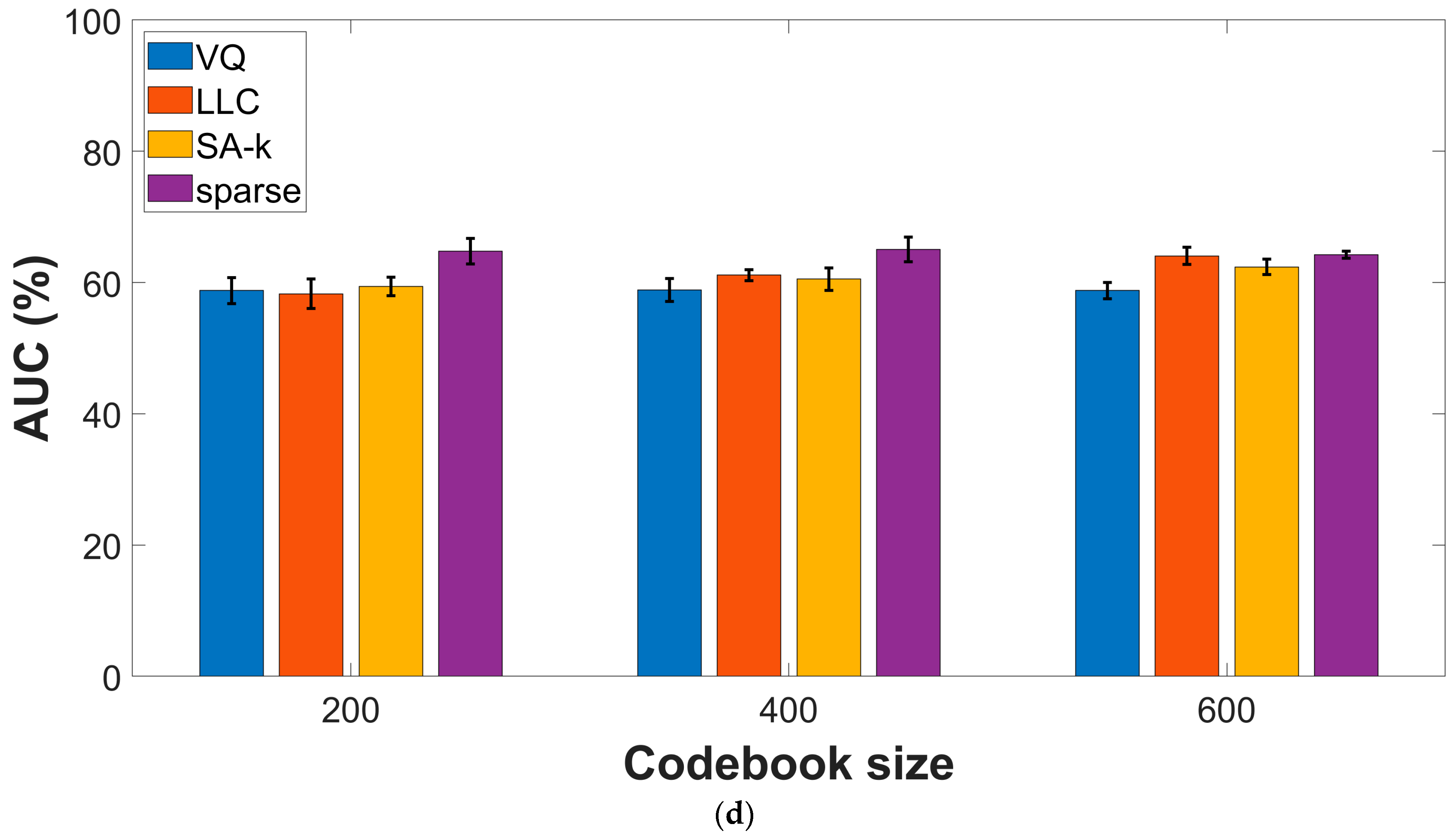
3.4. Effect of the Encoding Procedures
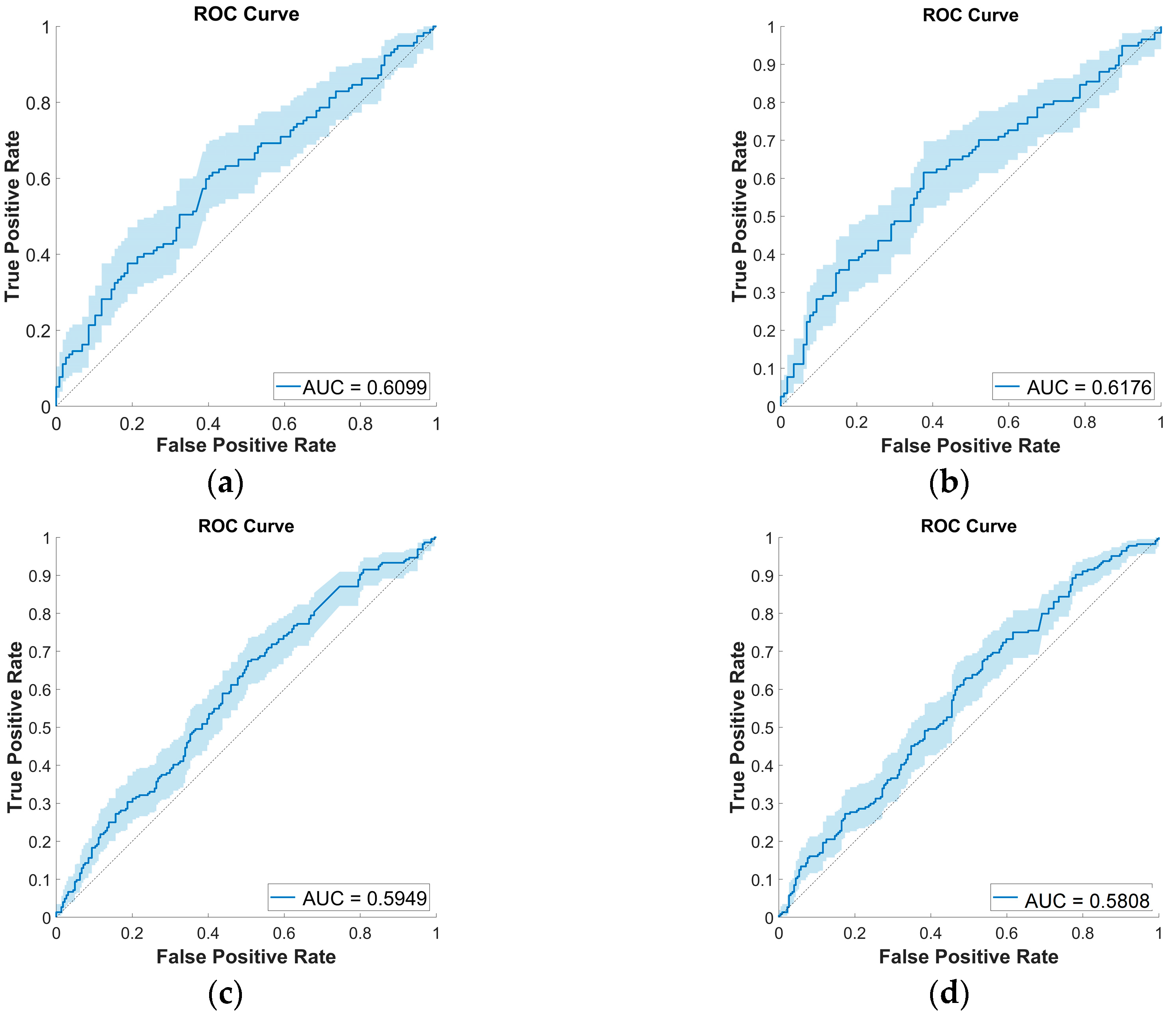
3.5. External Test Set Performance Evaluation
3.6. Comparison with CNN Classifiers
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Our World in Data. Available online: https://ourworldindata.org/grapher/cumulative-covid-cases-region (accessed on 6 April 2023).
- Wang, H.; COVID-19 Excess Mortality Collaborators. Estimating excess mortality due to the COVID-19 pandemic: A systematic analysis of COVID-19-related mortality, 2020–2021. Lancet 2022, 399, 1513–1536. [Google Scholar] [CrossRef] [PubMed]
- WHO COVID-19 Research Database. Available online: https://search.bvsalud.org/global-literature-on-novel-coronavirus-2019-ncov (accessed on 7 April 2023).
- Ioannidis, J.P.A.; Salholz-Hillel, M.; Boyack, K.W.; Baas, J. The rapid, massive growth of COVID-19 authors in the scientific literature. Royal Soc. Open Sci. 2021, 8, 210389. [Google Scholar] [CrossRef] [PubMed]
- Roberts, M.; Driggs, D.; Thorpe, M.; Gilbey, J.; Yeung, M.; Ursprung, S.; Aviles-Rivero, A.I.; Etmann, C.; McCague, C.; Beer, L.; et al. Common pitfalls and recommendations for using machine learning to detect and prognosticate for COVID-19 using chest radiographs and CT scans. Nat. Mach. Intell. 2021, 3, 199–217. [Google Scholar] [CrossRef]
- Coppock, H.; Nicholson, G.; Kiskin, I.; Koutra, V.; Baker, K.; Budd, J.; Payne, R.; Karoune, E.; Hurley, D.; Titcomb, A.; et al. Audio-based AI classifiers show no evidence of improved COVID-19 screening over simple symptoms checkers. arXiv 2023, arXiv:2212.08570. Available online: https://arxiv.org/abs/2212.08570 (accessed on 7 April 2023).
- Wynants, L.; Van Calster, B.; Collins, G.S.; Riley, R.D.; Heinze, G.; Schuit, E.; Bonten, M.M.J.; Dahly, D.L.; Damen, J.A.A.; Debray, T.P.A.; et al. Prediction models for diagnosis and prognosis of COVID-19: Systematic review and critical appraisal. BMJ 2020, 369, m1328. [Google Scholar] [CrossRef]
- Wang, J.; Yang, X.; Zhou, B.; Sohn, J.J.; Zhou, J.; Jacob, J.T.; Higgins, K.A.; Bradley, J.D.; Liu, T. Review of Machine Learning in Lung Ultrasound in COVID-19 Pandemic. J. Imaging 2022, 8, 65. [Google Scholar] [CrossRef]
- Han, J.; Xia, T.; Spathis, D.; Bondareva, E.; Brown, C.; Chauhan, J.; Dang, T.; Grammenos, A.; Hasthanasombat, A.; Floto, A.; et al. Sounds of COVID-19: Exploring realistic performance of audio-based digital testing. NPJ Digit. Med. 2022, 16, 16. [Google Scholar] [CrossRef]
- Nguyen, T.; Pham, H.H.; Le, K.H.; Nguyen, A.T.; Thanh, T.; Do, C. Detecting COVID-19 from digitized ECG printouts using 1D convolutional neural networks. PLoS ONE 2022, 17, e0277081. [Google Scholar] [CrossRef]
- Prashant, K.; Choudhary, P.; Agrawal, T.; Kaushik, E. OWAE-Net: COVID-19 detection from ECG images using deep learning and optimized weighted average ensemble technique. Intell. Syst. Appl. 2022, 16, 200154. [Google Scholar] [CrossRef]
- Eyben, F.; Wöllmer, M.; Schuller, B. openSMILE—The Munich Versatile and Fast Open-Source Audio Feature Extractor. In Proceedings of the ACM Multimedia (MM), Florence, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Ciocoiu, I.B. Comparative analysis of bag-of-words models for ECG-based biometrics. IET Biom. 2017, 6, 495–502. [Google Scholar] [CrossRef]
- Pavel, I.; Ciocoiu, I.B. Evaluation of Bag-of-Words Classifiers for COVID-19 Detection from Cough Recordings. In Proceedings of the E-Health and Bioengineering Conference (EHB), Iasi, Romania, 16–18 November 2022; pp. 1–4. [Google Scholar]
- Goldberg, Y. Neural Network Methods in Natural Language Processing; Morgan & Claypool Publishers: Williston, ND, USA, 2017; p. 69. [Google Scholar]
- Lin, J.; Keogh, E.; Li, W.; Lonardi, S. Experiencing SAX: A novel symbolic representation of time series. Data Min. Knowl. Discov. 2007, 15, 107–144. [Google Scholar] [CrossRef]
- Baydogan, M.G.; Runger, G.; Tuv, E. A bag-of-features framework to classify time series. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2796–2802. [Google Scholar] [CrossRef] [PubMed]
- Sivic, J.; Zisserman, A. Video Google: A Text Retrieval Approach to Object Matching in Videos. In Proceedings of the International Conference on Computer Vision (ICCV), Nice, France, 13–16 October 2003; pp. 1–8. [Google Scholar]
- Olshausen, B.A.; Field, D.J. Natural image statistics and efficient coding. Netw. Comput. Neural Syst. 1996, 7, 333–339. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Liu, P.; She, M.F.H.; Nahavandi, S.; Kouzani, A. Bag-of-words representation for biomedical time series classification. Biomed. Signal Proc. Control 2013, 8, 634–644. [Google Scholar] [CrossRef]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M. Audio Set: An Ontology and Human-Labeled Dataset for Audio Events. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN Architectures for Large-Scale Audio Classification. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar]
- Orlandic, L.; Teijeiro, T.; Atienza, D. The COUGHVID crowdsourcing dataset, a corpus for the study of large-scale cough analysis algorithms. Scientific Data 2021, 8, 156. [Google Scholar] [CrossRef]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; Povey, D.; Khudanpur, S. x-vectors: Robust DNN Embeddings for Speaker Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5329–5333. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Lewicki, M.S.; Sejnowski, T.J. Learning over complete representations. Neural Comput. 2000, 12, 337–365. [Google Scholar] [CrossRef]
- Candès, E.; Wakin, M. An introduction to compressive sampling. IEEE Signal Process. Mag. 2008, 21, 21–30. [Google Scholar] [CrossRef]
- Rubinstein, R.; Bruckstein, A.M.; Elad, M. Dictionaries for sparse representation modeling. Proc. IEEE 2010, 98, 1045–1057. [Google Scholar] [CrossRef]
- Mairal, J.; Bach, F.; Ponce, J.; Sapiro, G. Online learning for matrix factorization and sparse coding. J. Mach. Learn. Res. 2010, 11, 19–60. [Google Scholar]
- Wang, X.; Wang, L.; Qiao, Y. A Comparative Study of Encoding, Pooling and Normalization Methods for Action Recognition. In Proceedings of the Asian Conference on Computer Vision (ACCV), Daejeon, Korea, 5–9 November 2012; pp. 572–585. [Google Scholar]
- Liu, L.; Wang, L.; Liu, X. In Defense of Soft-Assignment Coding. In Proceedings of the International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2486–2493. [Google Scholar]
- Wang, J.; Yang, J.; Yu, K.; Lv, F.; Huang, T.; Gong, Y. Locality-Constrained Linear Coding for Image Classification. In Proceedings of the IEEE Computer Vision and Pattern Recognition (CVPR), San Francisco, CA, USA, 13–18 June 2010; pp. 3360–3367. [Google Scholar]
- Chen, S.S.; Donoho, D.L.; Saunders, M.A. Atomic decomposition by basis pursuit. SIAM Rev. 2001, 43, 129–159. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM Toolbox. Available online: https://www.csie.ntu.edu.tw/~cjlin/libsvm/ (accessed on 1 October 2022).
- Carpenter, J.; Bithell, J. Bootstrap confidence intervals: When, which, what? A practical guide for medical statisticians. Stat. Med. 2000, 19, 1141–1164. [Google Scholar] [CrossRef]
- Xia, T.; Spathis, D.; Brown, C.; Chauhan, J.; Grammenos, A.; Han, J.; Hasthanasombat, A.; Bondareva, E.; Dang, T.; Floto, A.; et al. COVID-19 Sounds: A Large-Scale Audio Dataset for Digital Respiratory Screening. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Online, 6–14 December 2021; pp. 1–13. [Google Scholar]
- Orlandic, L.; Teijeiro, T.; Atienza, D. A Semi-Supervised Algorithm for Improving the Consistency of Crowdsourced Datasets: The COVID-19 Case Study on Respiratory Disorder Classification. arXiv 2022, arXiv:2209.04360. Available online: https://arxiv.org/abs/2209.04360 (accessed on 10 December 2022).
- Campana, M.G.; Delmastro, F.; Pagani, E. Transfer learning for the efficient detection of COVID-19 from smartphone audio data. Pervasive Mob. Comp. 2023, 89, 101754. [Google Scholar] [CrossRef] [PubMed]
- Coppock, H.; Gaskell, A.; Tzirakis, P.; Baird, A.; Jones, L.; Schuller, B. End-to-end convolutional neural network enables COVID-19 detection from breath and cough audio: A pilot study. BMJ Innov. 2021, 7, 356–362. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Model | Codewords | Accuracy (%) | Sensitivity (%) | F1 (%) | AUC (%) |
|---|---|---|---|---|---|---|
| COUGHVID | input fusion, sparse encoding | 300 | 72.7 ± 1.3 | 61.8 ± 1.1 | 75.4 ± 1.3 | 82.6 ± 1 |
| output fusion, sparse encoding | 100 | 74.3 ± 2 | 70.2 ± 4.3 | 75.4 ± 1.8 | 82.2 ± 0.9 | |
| output fusion, LLC encoding | 300 | 74.1 ± 1.9 | 71.4 ± 2 | 74.8 ± 1.8 | 81.4 ± 1.6 | |
| COVID-19 Sounds | output fusion, sparse encoding | 400 | 63.2 ± 1.5 | 65.3 ± 1.1 | 62.4 ± 1.7 | 68.6 ± 2.4 |
| input fusion, sparse encoding | 400 | 60.3 ± 1.8 | 56.8 ± 3.7 | 61.4 ± 1.3 | 65 ± 1.9 | |
| input fusion, LLC encoding | 600 | 58.7 ± 1.7 | 49.4 ± 2.2 | 62 ± 2 | 64 ± 1.3 |
| Dataset | Model | Accuracy (%) | Sensitivity (%) | F1 (%) | AUC (%) |
|---|---|---|---|---|---|
| COUGHVID | All frames | ||||
| Resnet-50 | 68.81 | 66.27 | 69.29 | 74.72 | |
| MobileNet.v2 | 67.12 | 63.05 | 68.36 | 71.88 | |
| EfficientNet-B0 | 69.06 | 68.13 | 68.35 | 76.08 | |
| Random frame | |||||
| Resnet-50 | 68.91 | 58.09 | 64.92 | 76.89 | |
| MobileNet.v2 | 66.09 | 63.09 | 64.10 | 73.06 | |
| EfficientNet-B0 | 67.36 | 61.91 | 65.04 | 73.65 | |
| Average frame | |||||
| Resnet-50 | 66.95 | 65.45 | 66.23 | 72.96 | |
| MobileNet.v2 | 65.41 | 60.55 | 66.88 | 71.82 | |
| EfficientNet-B0 | 68.27 | 67.09 | 67.76 | 75.25 | |
| COVID-19 Sounds | All frames | ||||
| Resnet-50 | 53.53 | 53.43 | 53.38 | 55.53 | |
| MobileNet.v2 | 53.50 | 48.13 | 50.83 | 55.65 | |
| EfficientNet-B0 | 52.47 | 50.06 | 51.31 | 54.01 | |
| Random frame | |||||
| Resnet-50 | 55.71 | 52.89 | 53.86 | 58.64 | |
| MobileNet.v2 | 54.33 | 55.11 | 54.43 | 56.93 | |
| EfficientNet-B0 | 55.56 | 51.19 | 53.28 | 58.17 | |
| Average frame | |||||
| Resnet-50 | 57.93 | 51.55 | 54.87 | 62.39 | |
| MobileNet.v2 | 54.14 | 48.95 | 50.81 | 56.04 | |
| EfficientNet-B0 | 56.07 | 44.41 | 50.07 | 58.43 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pavel, I.; Ciocoiu, I.B. COVID-19 Detection from Cough Recordings Using Bag-of-Words Classifiers. Sensors 2023, 23, 4996. https://doi.org/10.3390/s23114996
Pavel I, Ciocoiu IB. COVID-19 Detection from Cough Recordings Using Bag-of-Words Classifiers. Sensors. 2023; 23(11):4996. https://doi.org/10.3390/s23114996
Chicago/Turabian StylePavel, Irina, and Iulian B. Ciocoiu. 2023. "COVID-19 Detection from Cough Recordings Using Bag-of-Words Classifiers" Sensors 23, no. 11: 4996. https://doi.org/10.3390/s23114996
APA StylePavel, I., & Ciocoiu, I. B. (2023). COVID-19 Detection from Cough Recordings Using Bag-of-Words Classifiers. Sensors, 23(11), 4996. https://doi.org/10.3390/s23114996