
Sine-Cosine-Adopted African Vultures Optimization with Ensemble Autoencoder-Based Intrusion Detection for Cybersecurity in CPS Environment
 , ,
, ,
Abstract
:1. Introduction
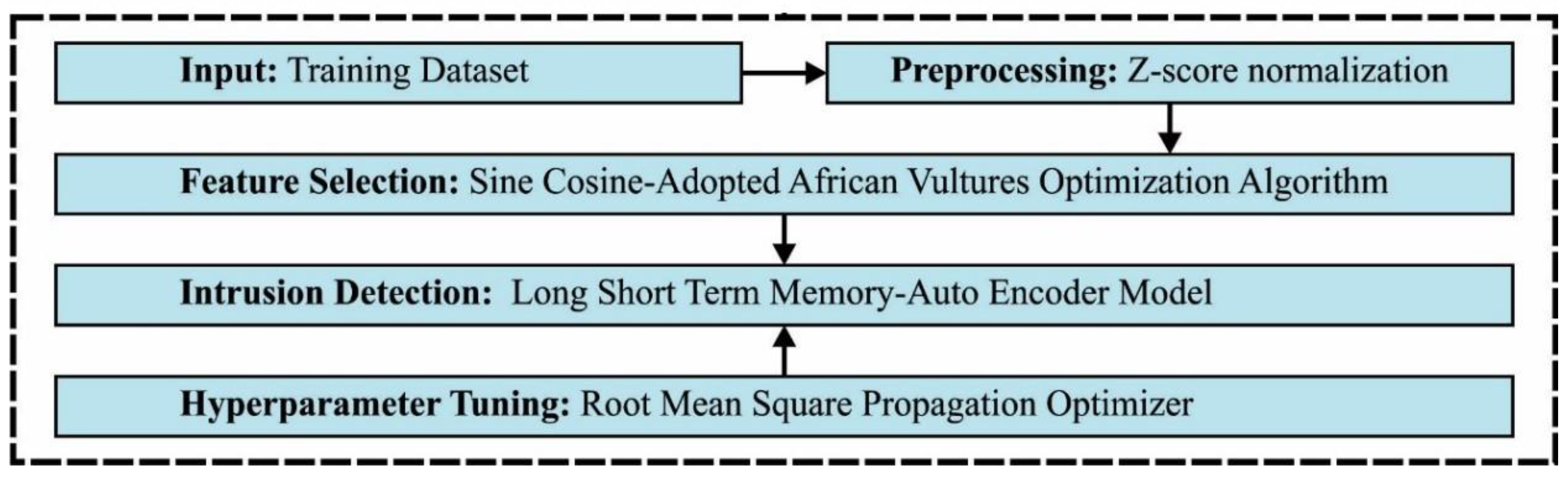
- An automated SCAVO-EAEID technique comprising Z-score normalization, the SCAVO-FS technique, LSTM-AE-based intrusion detection, and the RMSProp optimizer is developed for intrusion detection in the CPS environment. To the best of the researchers’ knowledge, no researchers have proposed the SCAVO-EAEID technique in the literature.
- A new SCAVO-FS technique has been designed by integrating the sine-cosine scaling factor and the AVO algorithm for the repositioning of the vultures at the end of the iterations.
- Both the RMSProp optimizer and the LSTM-AE model are employed in this study for the intrusion detection process.
- The performance of the proposed SCAVO-EAEID technique was validated using two benchmark datasets such as the NSL-KDD 2015 and CICIDS2017 datasets.
2. Related Works
3. Proposed Model
3.1. Data Used
3.2. Data Preprocessing
3.3. Processes Involved in the SCAVO-FS Technique
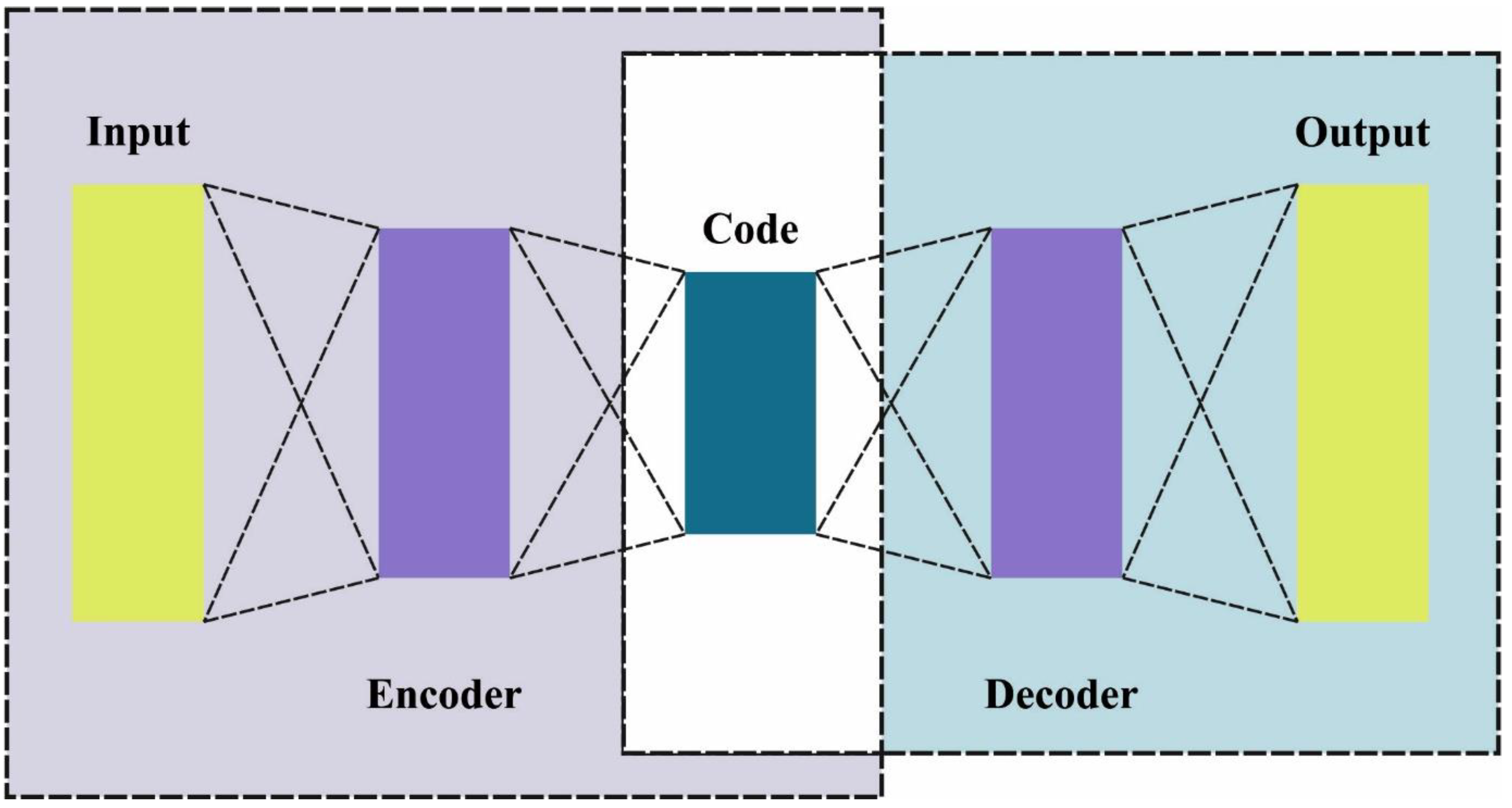
3.4. Classification Model
3.5. Hyperparameter Tuning Model
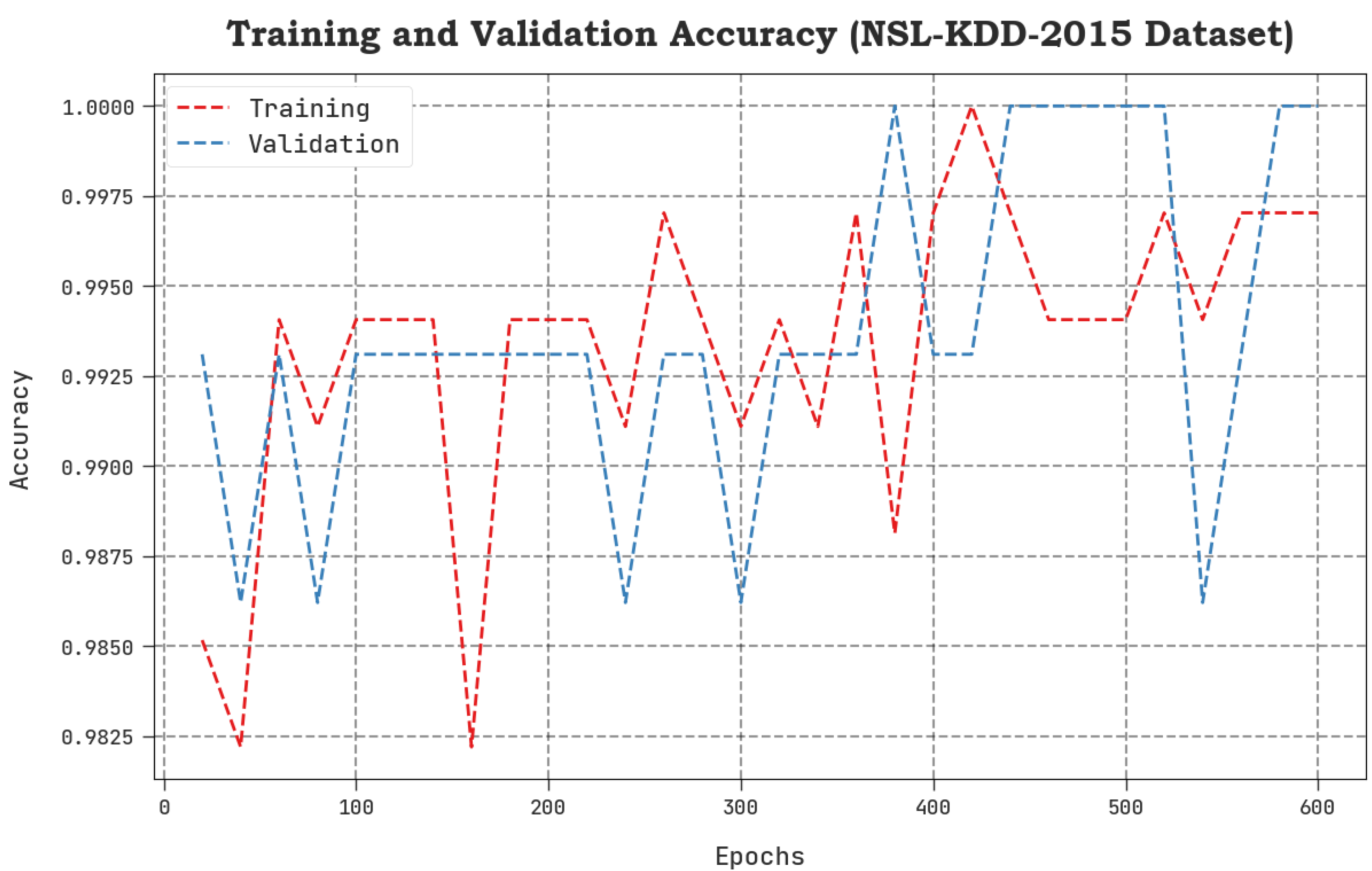
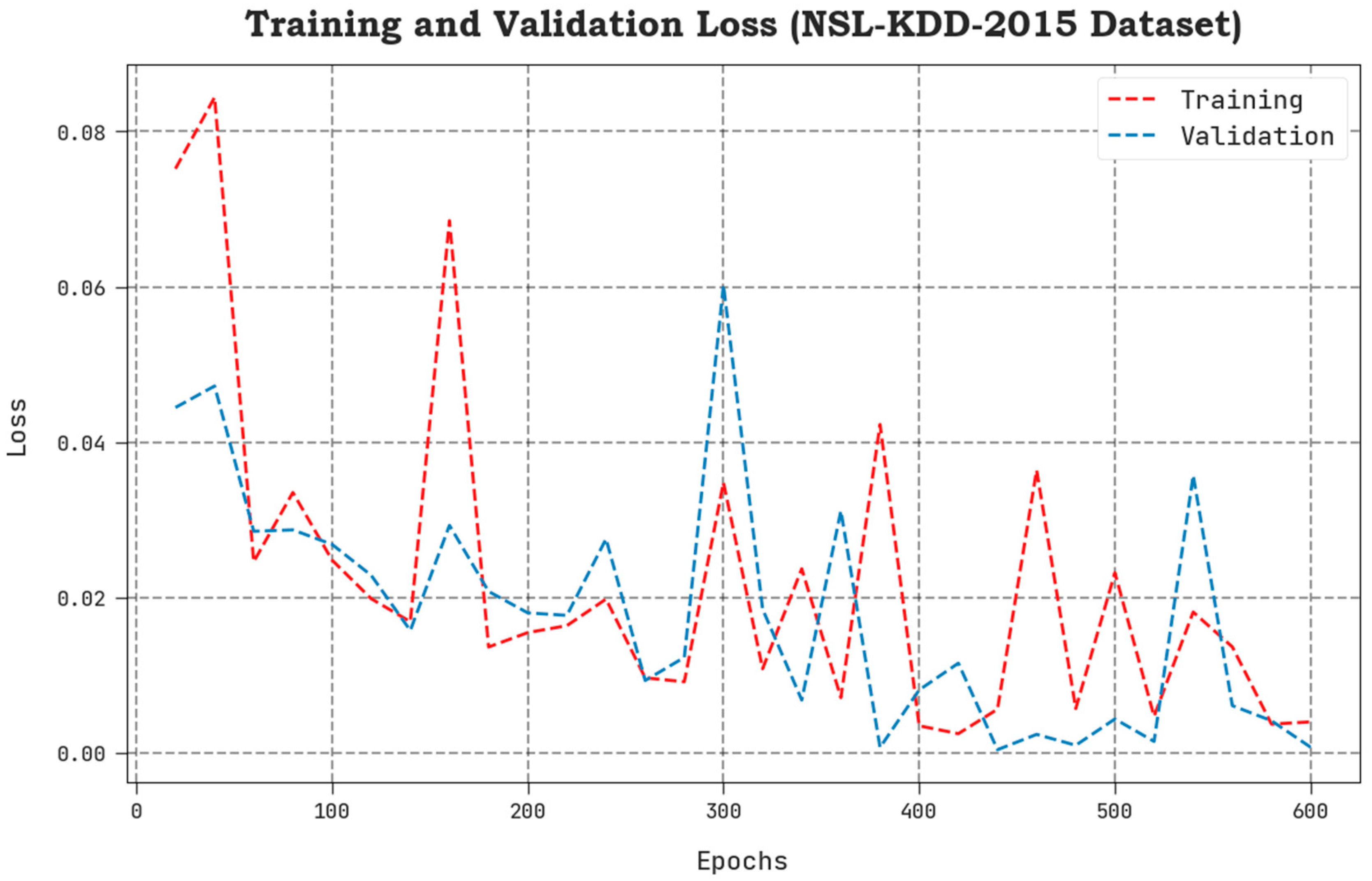
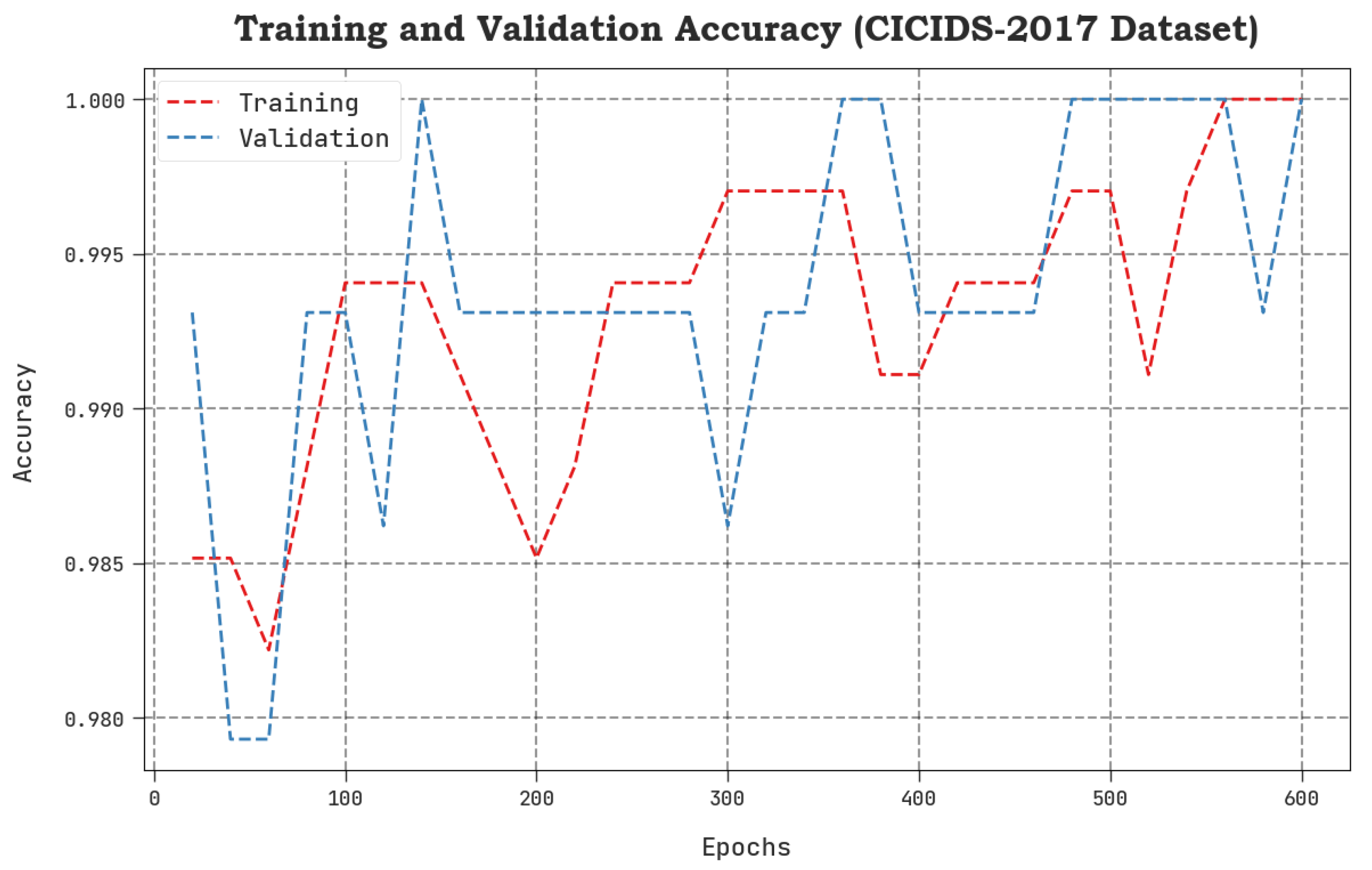
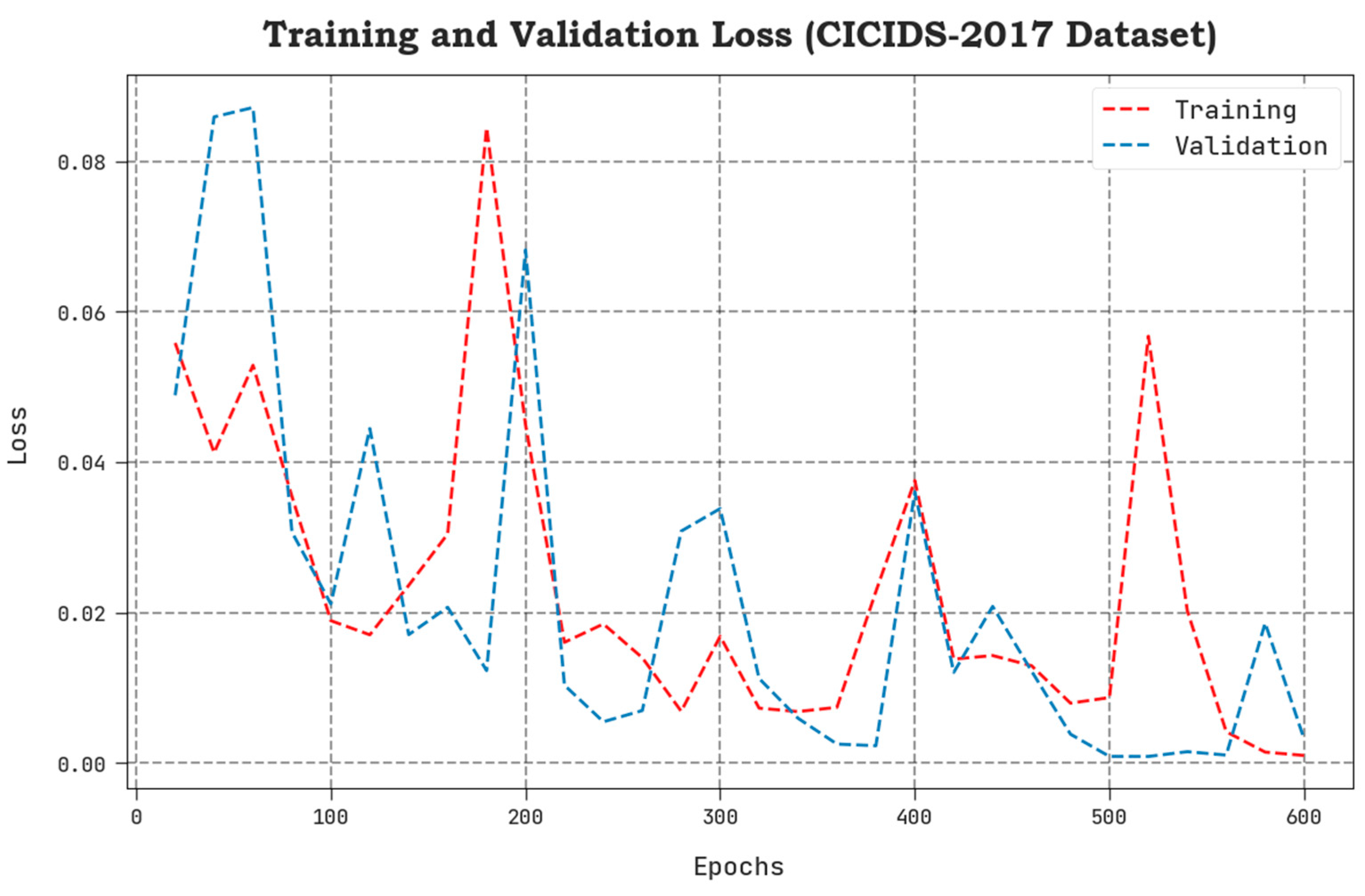
4. Results Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bashendy, M.; Tantawy, A.; Erradi, A. Intrusion response systems for cyber-physical systems: A comprehensive survey. Comput. Secur. 2022, 124, 102984. [Google Scholar] [CrossRef]
- Pham, L.N.H. Exploring Cyber-Physical Energy and Power System: Concepts, Applications, Challenges, and Simulation Approaches. Energies 2023, 16, 42. [Google Scholar] [CrossRef]
- Alzahrani, A.O.; Alenazi, M.J. Designing a Network Intrusion Detection System Based on Machine Learning for Software Defined Networks. Future Internet 2021, 13, 111. [Google Scholar] [CrossRef]
- Disha, R.A.; Waheed, S. Performance analysis of machine learning models for intrusion detection system using Gini Impurity-based Weighted Random Forest (GIWRF) feature selection technique. Cybersecurity 2022, 5, 1–22. [Google Scholar] [CrossRef]
- Megantara, A.A.; Ahmad, T. A hybrid machine learning method for increasing the performance of network intrusion detection systems. J. Big Data 2021, 8, 142. [Google Scholar] [CrossRef]
- Almomani, O. A Feature Selection Model for Network Intrusion Detection System Based on PSO, GWO, FFA and GA Algorithms. Symmetry 2020, 12, 1046. [Google Scholar] [CrossRef]
- Almomani, O. A Hybrid Model Using Bio-Inspired Metaheuristic Algorithms for Network Intrusion Detection System. Comput. Mater. Contin. 2021, 68, 409–429. [Google Scholar] [CrossRef]
- Mohammad, A.H.; Alwada’n, T.; Almomani, O.; Smadi, S.; ElOmari, N. Bio-inspired Hybrid Feature Selection Model for Intrusion Detection. Comput. Mater. Contin. 2022, 73, 133–150. [Google Scholar] [CrossRef]
- Almaiah, M.A.; Hajjej, F.; Ali, A.; Pasha, M.F.; Almomani, O. A Novel Hybrid Trustworthy Decentralized Authentication and Data Preservation Model for Digital Healthcare IoT Based CPS. Sensors 2022, 22, 1448. [Google Scholar] [CrossRef]
- Alohali, M.A.; Al-Wesabi, F.N.; Hilal, A.M.; Goel, S.; Gupta, D.; Khanna, A. Artificial intelligence enabled intrusion detection systems for cognitive cyber-physical systems in industry 4.0 environment. Cogn. Neurodyn. 2022, 16, 1045–1057. [Google Scholar] [CrossRef]
- Huang, X.; Liu, J.; Lai, Y.; Mao, B.; Lyu, H. EEFED: Personalized Federated Learning of Execution & Evaluation Dual Network for CPS Intrusion Detection. IEEE Trans. Inf. Forensics Secur. 2022, 18, 41–56. [Google Scholar]
- Mansour, R.F. Artificial intelligence based optimization with deep learning model for blockchain enabled intrusion detection in CPS environment. Sci. Rep. 2022, 12, 12937. [Google Scholar] [CrossRef] [PubMed]
- Henry, A.; Gautam, S.; Khanna, S.; Rabie, K.; Shongwe, T.; Bhattacharya, P.; Sharma, B.; Chowdhury, S. Composition of Hybrid Deep Learning Model and Feature Optimization for Intrusion Detection System. Sensors 2023, 23, 890. [Google Scholar] [CrossRef] [PubMed]
- Ortega-Fernandez, I.; Sestelo, M.; Burguillo, J.C.; Piñón-Blanco, C. Network intrusion detection system for DDoS attacks in ICS using deep autoencoders. Wirel. Netw. 2023, 1–17. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Z.; He, D.; Chan, S. A lightweight approach for network intrusion detection in industrial cyber-physical systems based on knowledge distillation and deep metric learning. Expert Syst. Appl. 2022, 206, 117671. [Google Scholar] [CrossRef]
- Mittal, H.; Tripathi, A.K.; Pandey, A.C.; Alshehri, M.D.; Saraswat, M.; Pal, R. A new intrusion detection method for cyber–physical system in emerging industrial IoT. Comput. Commun. 2022, 190, 24–35. [Google Scholar] [CrossRef]
- Presekal, A.; Stefanov, A.; Rajkumar, V.S.; Palensky, P. Attack Graph Model for Cyber-Physical Power Systems using Hybrid Deep Learning. IEEE Trans. Smart Grid 2023, in press. [CrossRef]
- Choubey, S.; Barde, S.; Badholia, A. Enhancing the prediction efficiency of virus borne diseases using enhanced backpropagation with an artificial neural network. Meas. Sens. 2022, 24, 100505. [Google Scholar] [CrossRef]
- Abdollahzadeh, B.; Gharehchopogh, F.S.; Mirjalili, S. African vultures optimization algorithm: A new nature-inspired metaheuristic algorithm for global optimization problems. Comput. Ind. Eng. 2021, 158, 107408. [Google Scholar] [CrossRef]
- Nayak, S.R.; Khadanga, R.K.; Panda, S.; Sahu, P.R.; Padhy, S.; Ustun, T.S. Participation of Renewable Energy Sources in the Frequency Regulation Issues of a Five-Area Hybrid Power System Utilizing a Sine Cosine-Adopted African Vulture Optimization Algorithm. Energies 2023, 16, 926. [Google Scholar] [CrossRef]
- Yazdinejad, A.; Kazemi, M.; Parizi, R.M.; Dehghantanha, A.; Karimipour, H. An ensemble deep learning model for cyber threat hunting in industrial internet of things. Digit. Commun. Netw. 2022, 9, 101–110. [Google Scholar] [CrossRef]
- Babu, D.V.; Karthikeyan, C.; Kumar, A. Performance Analysis of Cost and Accuracy for Whale Swarm and RMSprop Optimizer. IOP Conf. Ser. Mater. Sci. Eng. 2020, 993, 012080. [Google Scholar] [CrossRef]
- Althobaiti, M.M.; Kumar, K.P.M.; Gupta, D.; Kumar, S.; Mansour, R.F. An intelligent cognitive computing based intrusion detection for industrial cyber-physical systems. Measurement 2021, 186, 110145. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Best Cost | ||
|---|---|---|
| Methods | NSL-KDD-2015 | CICIDS-2017 |
| SCAVO-FS | 0.05101 | 0.41204 |
| AHSA-FS | 0.05433 | 0.04311 |
| BBFO-FS | 0.07382 | 0.06445 |
| BFO-FS | 0.09371 | 0.08753 |
| SSO-FS | 0.10384 | 0.09422 |
| WOA-FS | 0.11940 | 0.11790 |
| Number of Selected Features | ||
|---|---|---|
| Methods | NSL-KDD-2015 | CICIDS-2017 |
| Total Features | 41 | 80 |
| SCAVO-FS | 14 | 17 |
| AHSA-FS | 15 | 19 |
| BBFO-FS | 18 | 24 |
| BFO-FS | 19 | 30 |
| SSO-FS | 20 | 28 |
| WOA-FS | 20 | 33 |
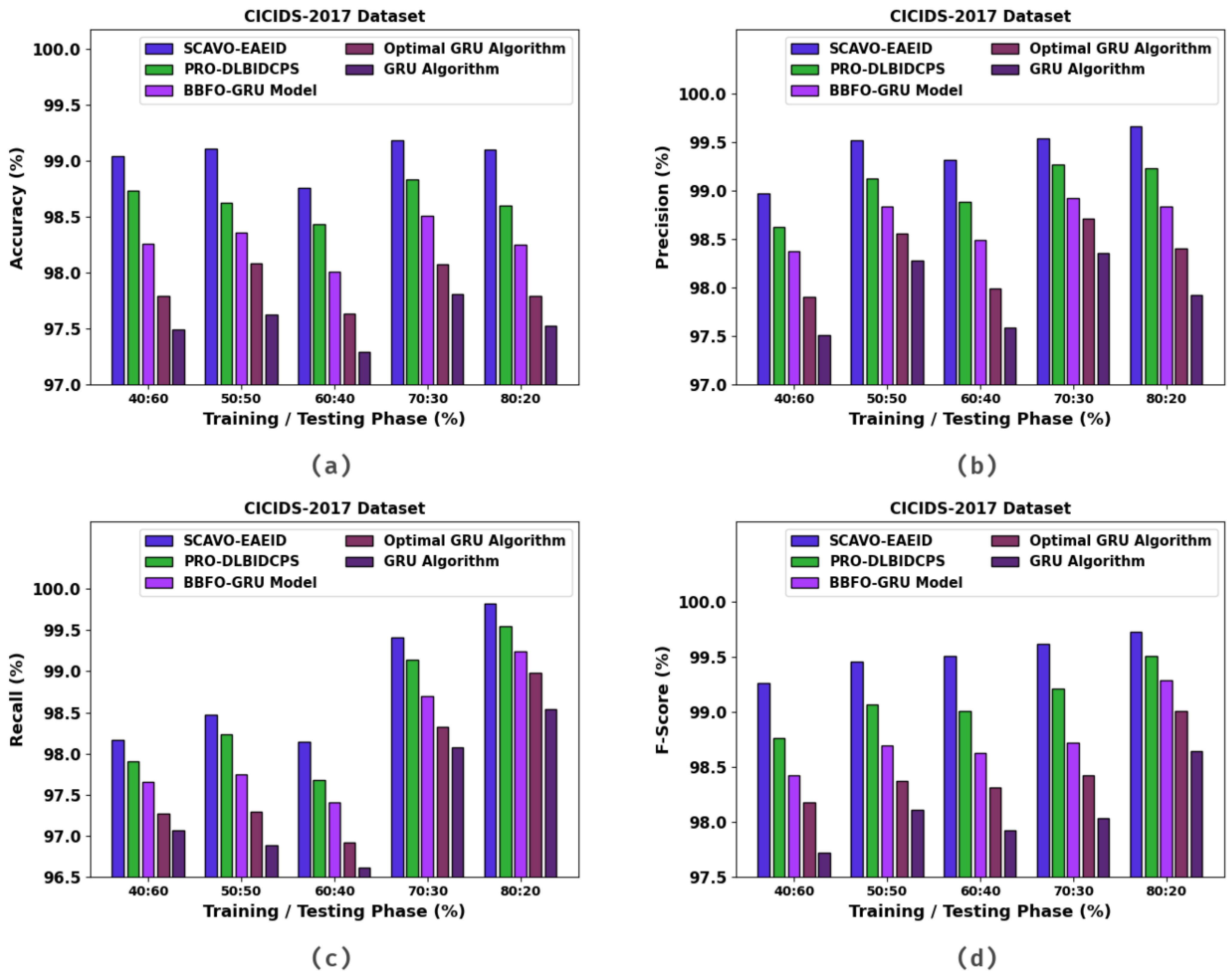
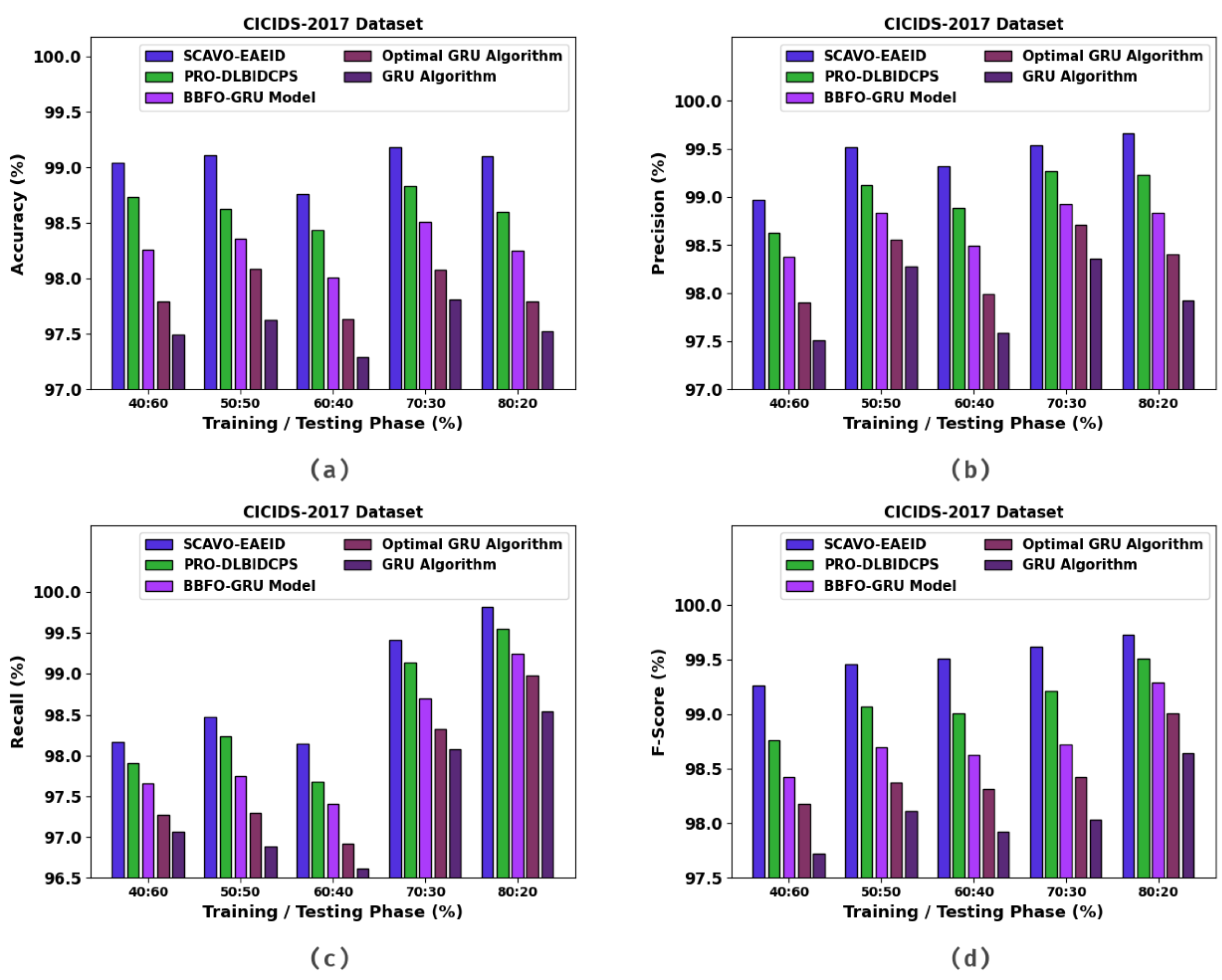
| Training/Testing Phase (%) | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| 40:60 | ||||
| SCAVO-EAEID | 98.70 | 99.16 | 98.13 | 99.23 |
| PRO-DLBIDCPS | 98.29 | 98.80 | 97.74 | 98.91 |
| BBFO-GRU Model | 97.92 | 98.44 | 97.42 | 98.41 |
| Optimal GRU Algorithm | 97.44 | 98.21 | 97.02 | 98.05 |
| GRU Algorithm | 97.16 | 97.85 | 96.79 | 97.69 |
| 50:50 | ||||
| SCAVO-EAEID | 98.74 | 99.24 | 98.14 | 99.53 |
| PRO-DLBIDCPS | 98.48 | 99.03 | 97.92 | 99.30 |
| BBFO-GRU Model | 98.12 | 98.73 | 97.65 | 98.96 |
| Optimal GRU Algorithm | 97.92 | 98.32 | 97.27 | 98.53 |
| GRU Algorithm | 97.63 | 97.87 | 96.80 | 98.27 |
| 60:40 | ||||
| SCAVO-EAEID | 98.91 | 99.50 | 98.17 | 99.71 |
| PRO-DLBIDCPS | 98.41 | 99.15 | 97.90 | 99.30 |
| BBFO-GRU Model | 97.96 | 98.71 | 97.54 | 98.87 |
| Optimal GRU Algorithm | 97.62 | 98.34 | 97.21 | 98.60 |
| GRU Algorithm | 97.25 | 97.99 | 96.86 | 98.40 |
| 70:30 | ||||
| SCAVO-EAEID | 98.95 | 99.50 | 99.12 | 99.81 |
| PRO-DLBIDCPS | 98.6 | 99.15 | 98.81 | 99.58 |
| BBFO-GRU Model | 98.33 | 98.93 | 98.45 | 99.19 |
| Optimal GRU Algorithm | 98.02 | 98.44 | 97.99 | 98.69 |
| GRU Algorithm | 97.69 | 98.16 | 97.62 | 98.29 |
| 80:20 | ||||
| SCAVO-EAEID | 99.20 | 99.58 | 99.42 | 99.84 |
| PRO-DLBIDCPS | 99.00 | 99.12 | 99.03 | 99.41 |
| BBFO-GRU Model | 98.79 | 98.89 | 98.55 | 98.95 |
| Optimal GRU Algorithm | 98.49 | 98.47 | 98.24 | 98.52 |
| GRU Algorithm | 98.24 | 98.16 | 97.91 | 98.26 |
| Training/Testing Phase (%) | Accuracy | Precision | Recall | F-Score |
|---|---|---|---|---|
| 40:60 | ||||
| SCAVO-EAEID | 99.04 | 98.97 | 98.17 | 99.26 |
| PRO-DLBIDCPS | 98.73 | 98.63 | 97.91 | 98.76 |
| BBFO-GRU Model | 98.26 | 98.38 | 97.65 | 98.42 |
| Optimal GRU Algorithm | 97.79 | 97.90 | 97.27 | 98.18 |
| GRU Algorithm | 97.49 | 97.51 | 97.07 | 97.72 |
| 50:50 | ||||
| SCAVO-EAEID | 99.11 | 99.52 | 98.47 | 99.46 |
| PRO-DLBIDCPS | 98.62 | 99.13 | 98.23 | 99.07 |
| BBFO-GRU Model | 98.36 | 98.84 | 97.74 | 98.69 |
| Optimal GRU Algorithm | 98.08 | 98.56 | 97.29 | 98.37 |
| GRU Algorithm | 97.62 | 98.28 | 96.88 | 98.11 |
| 60:40 | ||||
| SCAVO-EAEID | 98.76 | 99.32 | 98.14 | 99.51 |
| PRO-DLBIDCPS | 98.43 | 98.89 | 97.68 | 99.01 |
| BBFO-GRU Model | 98.01 | 98.49 | 97.40 | 98.63 |
| Optimal GRU Algorithm | 97.63 | 97.99 | 96.92 | 98.31 |
| GRU Algorithm | 97.29 | 97.59 | 96.61 | 97.92 |
| 70:30 | ||||
| SCAVO-EAEID | 99.18 | 99.54 | 99.42 | 99.62 |
| PRO-DLBIDCPS | 98.83 | 99.27 | 99.14 | 99.21 |
| BBFO-GRU Model | 98.51 | 98.93 | 98.70 | 98.72 |
| Optimal GRU Algorithm | 98.07 | 98.71 | 98.33 | 98.42 |
| GRU Algorithm | 97.81 | 98.36 | 98.07 | 98.03 |
| 80:20 | ||||
| SCAVO-EAEID | 99.10 | 99.67 | 99.82 | 99.73 |
| PRO-DLBIDCPS | 98.60 | 99.23 | 99.55 | 99.51 |
| BBFO-GRU Model | 98.25 | 98.84 | 99.24 | 99.29 |
| Optimal GRU Algorithm | 97.79 | 98.40 | 98.98 | 99.01 |
| GRU Algorithm | 97.52 | 97.92 | 98.54 | 98.64 |
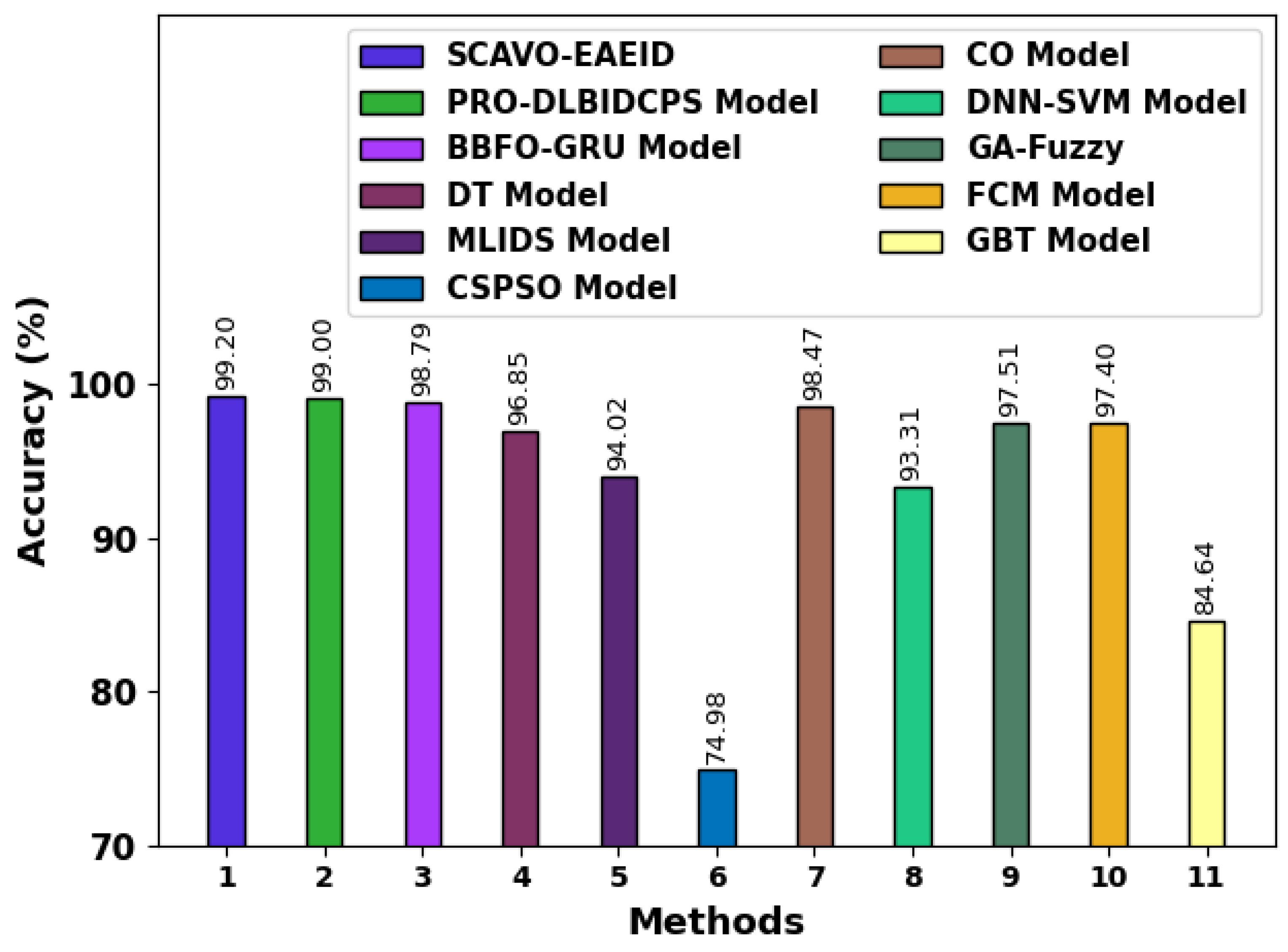
| Methods | Accuracy (%) |
|---|---|
| SCAVO-EAEID | 99.20 |
| PRO-DLBIDCPS Model [12] | 99.00 |
| BBFO-GRU Model [23] | 98.79 |
| DT Model [12] | 96.85 |
| MLIDS Model [12] | 94.02 |
| CSPSO Model [12] | 74.98 |
| CO Model [12] | 98.47 |
| DNN-SVM Model [12] | 93.31 |
| GA-Fuzzy [12] | 97.51 |
| FCM Model [12] | 97.4 |
| GBT Model [12] | 84.64 |
| Methods | Training Time (min) | Testing Time (min) |
|---|---|---|
| SCAVO-EAEID | 0.542 | 0.246 |
| PRO-DLBIDCPS Model [12] | 0.752 | 0.381 |
| BBFO-GRU Model [23] | 1.106 | 0.363 |
| DT Model [12] | 0.888 | 0.677 |
| MLIDS Model [12] | 1.212 | 0.331 |
| CSPSO Model [12] | 1.242 | 0.425 |
| CO Model [12] | 0.802 | 0.572 |
| DNN-SVM Model [12] | 1.384 | 0.996 |
| GA-Fuzzy [12] | 1.351 | 0.444 |
| FCM Model [12] | 1.749 | 0.873 |
| GBT Model [12] | 1.463 | 0.875 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almuqren, L.; Al-Mutiri, F.; Maashi, M.; Mohsen, H.; Hilal, A.M.; Alsaid, M.I.; Drar, S.; Abdelbagi, S. Sine-Cosine-Adopted African Vultures Optimization with Ensemble Autoencoder-Based Intrusion Detection for Cybersecurity in CPS Environment. Sensors 2023, 23, 4804. https://doi.org/10.3390/s23104804
Almuqren L, Al-Mutiri F, Maashi M, Mohsen H, Hilal AM, Alsaid MI, Drar S, Abdelbagi S. Sine-Cosine-Adopted African Vultures Optimization with Ensemble Autoencoder-Based Intrusion Detection for Cybersecurity in CPS Environment. Sensors. 2023; 23(10):4804. https://doi.org/10.3390/s23104804
Chicago/Turabian StyleAlmuqren, Latifah, Fuad Al-Mutiri, Mashael Maashi, Heba Mohsen, Anwer Mustafa Hilal, Mohamed Ibrahim Alsaid, Suhanda Drar, and Sitelbanat Abdelbagi. 2023. "Sine-Cosine-Adopted African Vultures Optimization with Ensemble Autoencoder-Based Intrusion Detection for Cybersecurity in CPS Environment" Sensors 23, no. 10: 4804. https://doi.org/10.3390/s23104804
APA StyleAlmuqren, L., Al-Mutiri, F., Maashi, M., Mohsen, H., Hilal, A. M., Alsaid, M. I., Drar, S., & Abdelbagi, S. (2023). Sine-Cosine-Adopted African Vultures Optimization with Ensemble Autoencoder-Based Intrusion Detection for Cybersecurity in CPS Environment. Sensors, 23(10), 4804. https://doi.org/10.3390/s23104804