
An Efficient and Intelligent Detection Method for Fabric Defects based on Improved YOLOv5
Abstract
:1. Introduction
- Based on the Transformer structure, we optimize the YOLOv5 v6.1 algorithm with the Swin Transformer as the backbone, and the introduction of a multiwindow sliding self-attention mechanism complements the convolutional network to improve classification accuracy.
- In the neck layer, the BiFPN is used to replace the original FPN to enhance the fusion of semantic information between different layers, and a small-target detection layer is added to improve the detection effect of the model on small targets.
- We introduce the generalized focal loss function to enhance the model’s instance learning of positive samples, in order to alleviate the problems caused by the imbalance of fabric samples.
- Finally, we conducted ablation experiments and an in-depth analysis of the impact of the above-mentioned improved methods and several attention mechanisms on detection accuracy and real-time performance. Our proposed method outperforms current popular object detection models on a self-created fabric dataset.
2. Materials and Methods
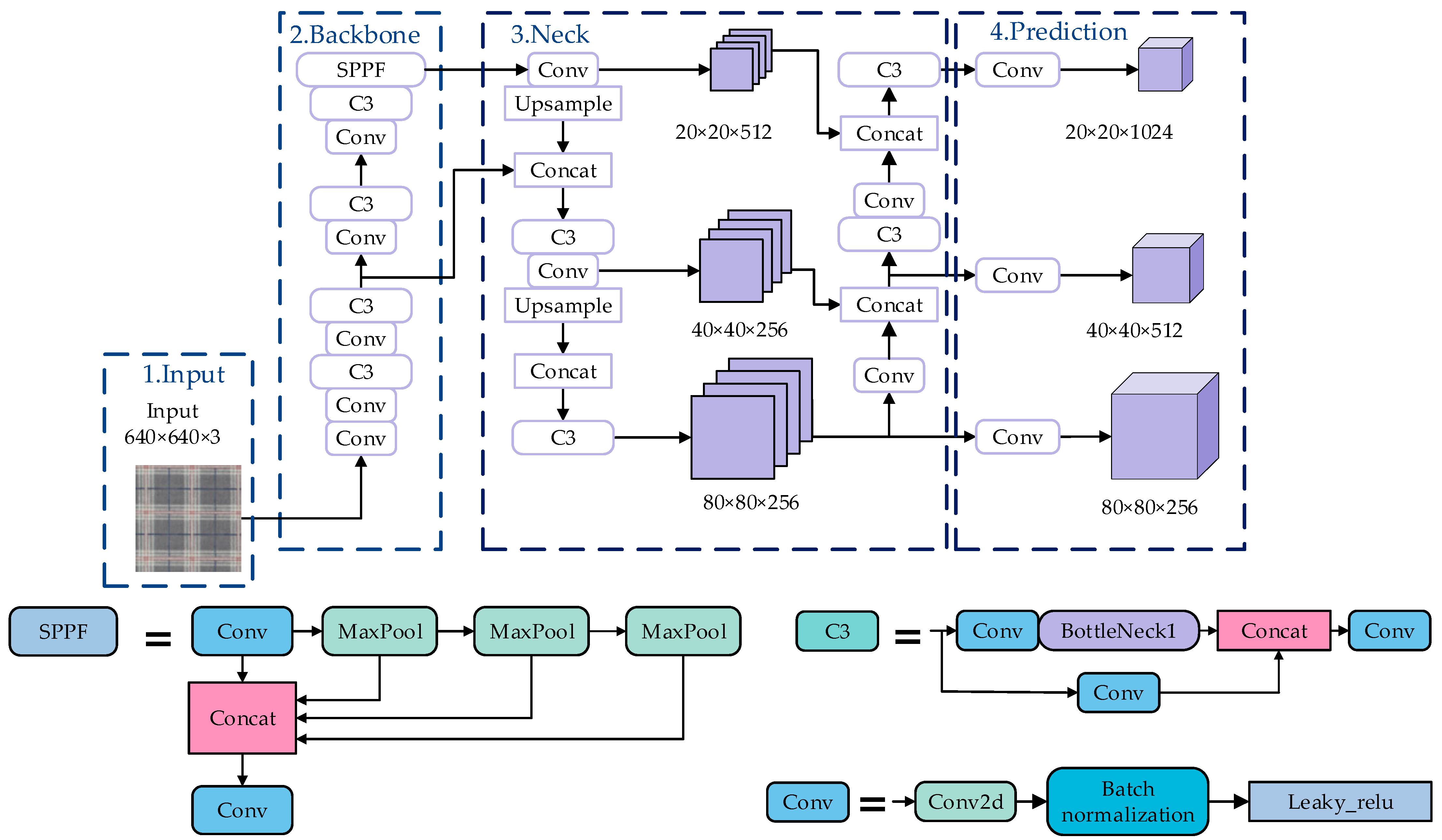
2.1. Structure of the YOLOv5
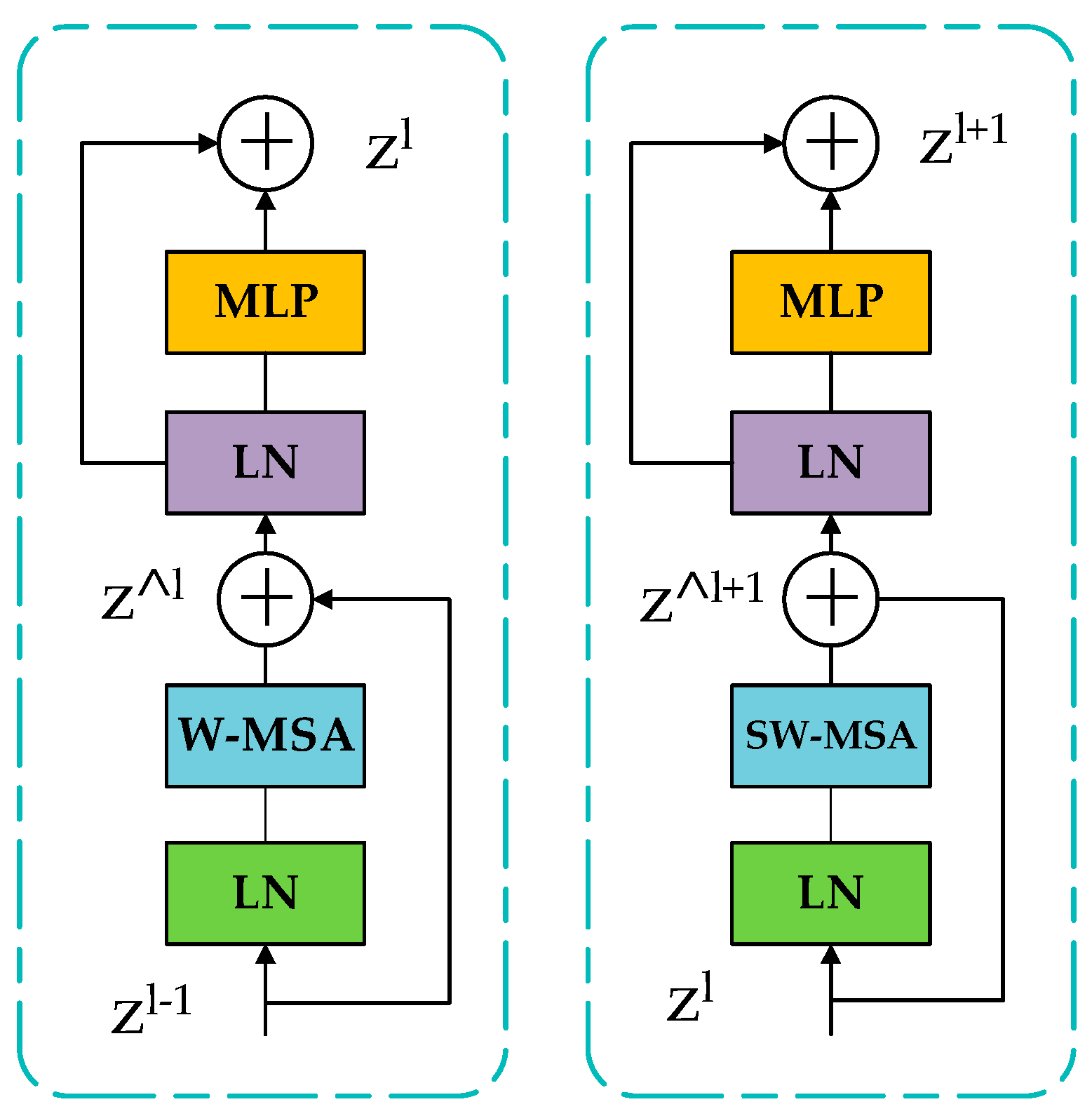
2.2. Swin Transformer Model
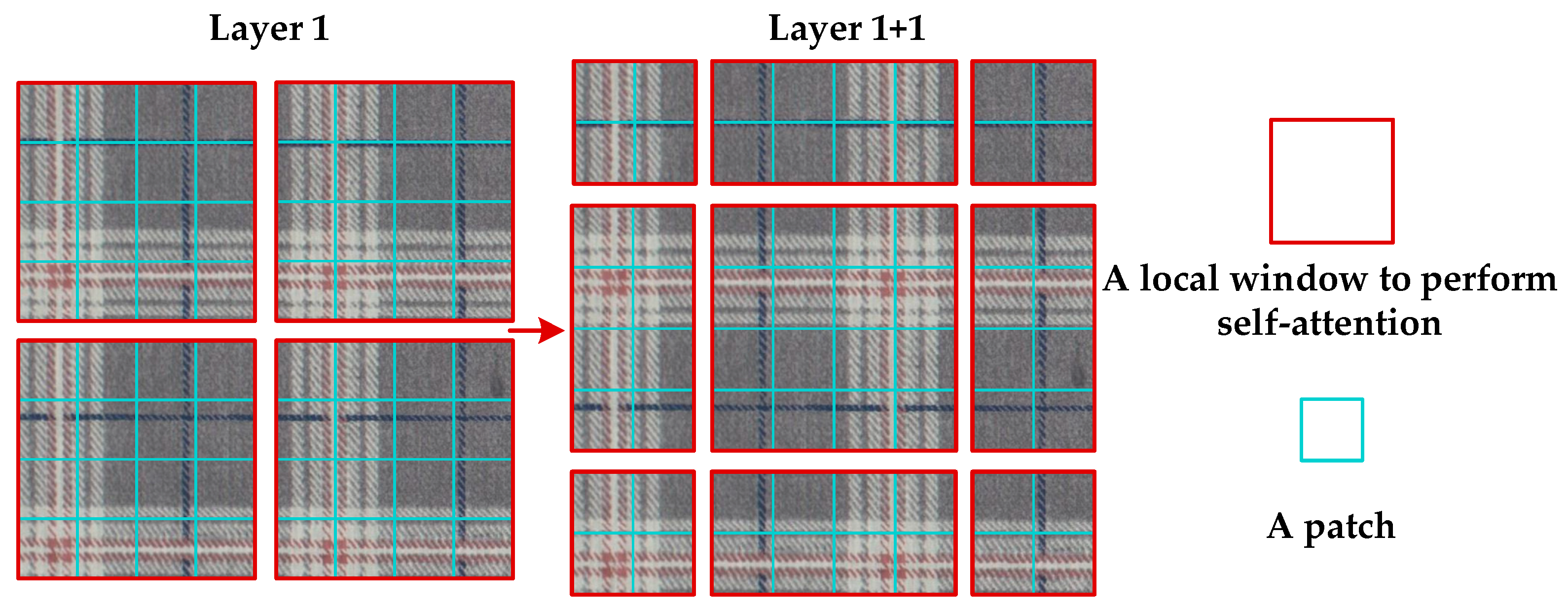
2.3. Multiwindow Sliding Self-Attention Mechanism
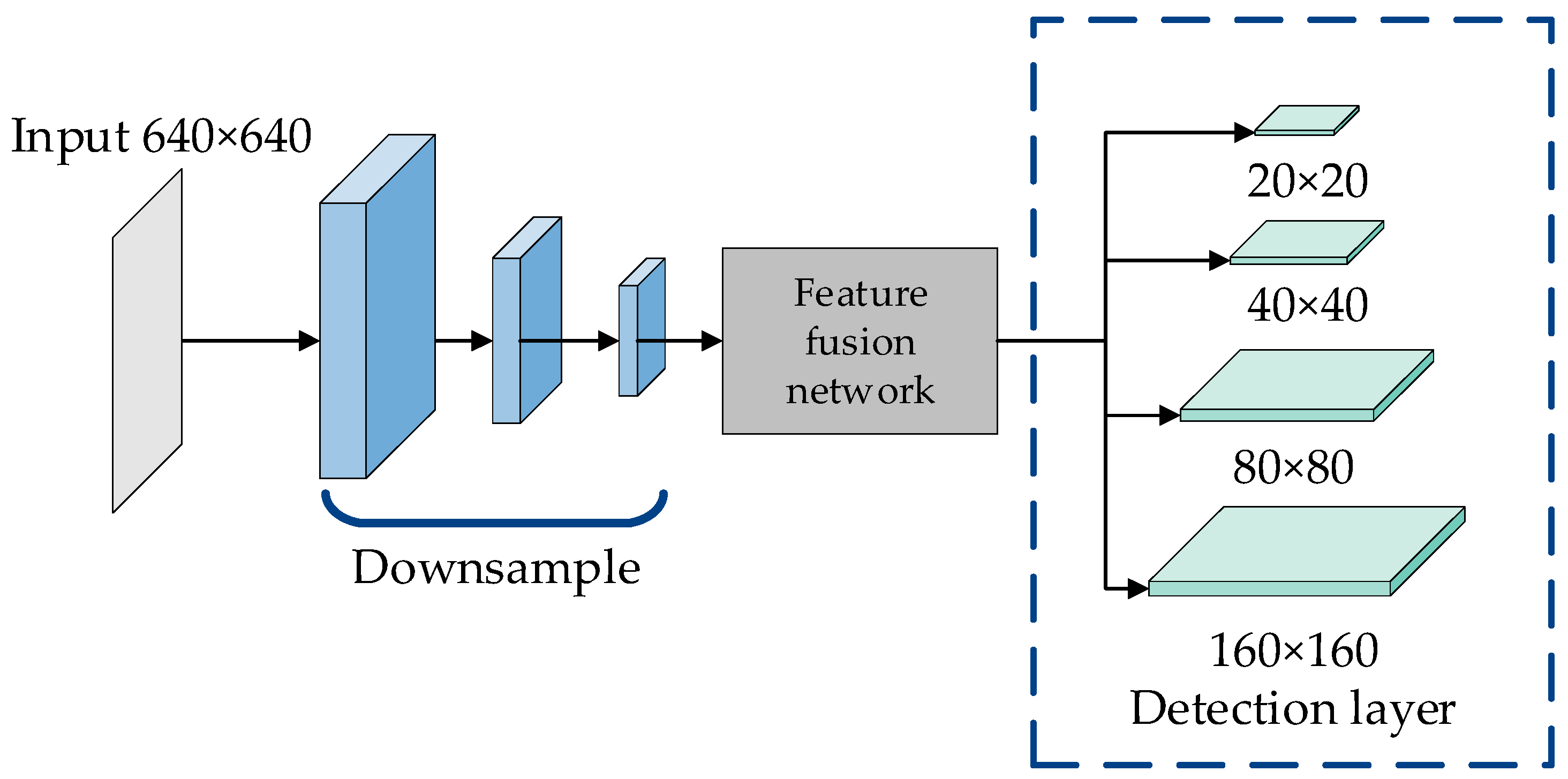
2.4. Multiscale Feature Fusion Feature Pyramid Network
2.5. Improvement of Loss Function
3. Experiments
3.1. Experimental Platform
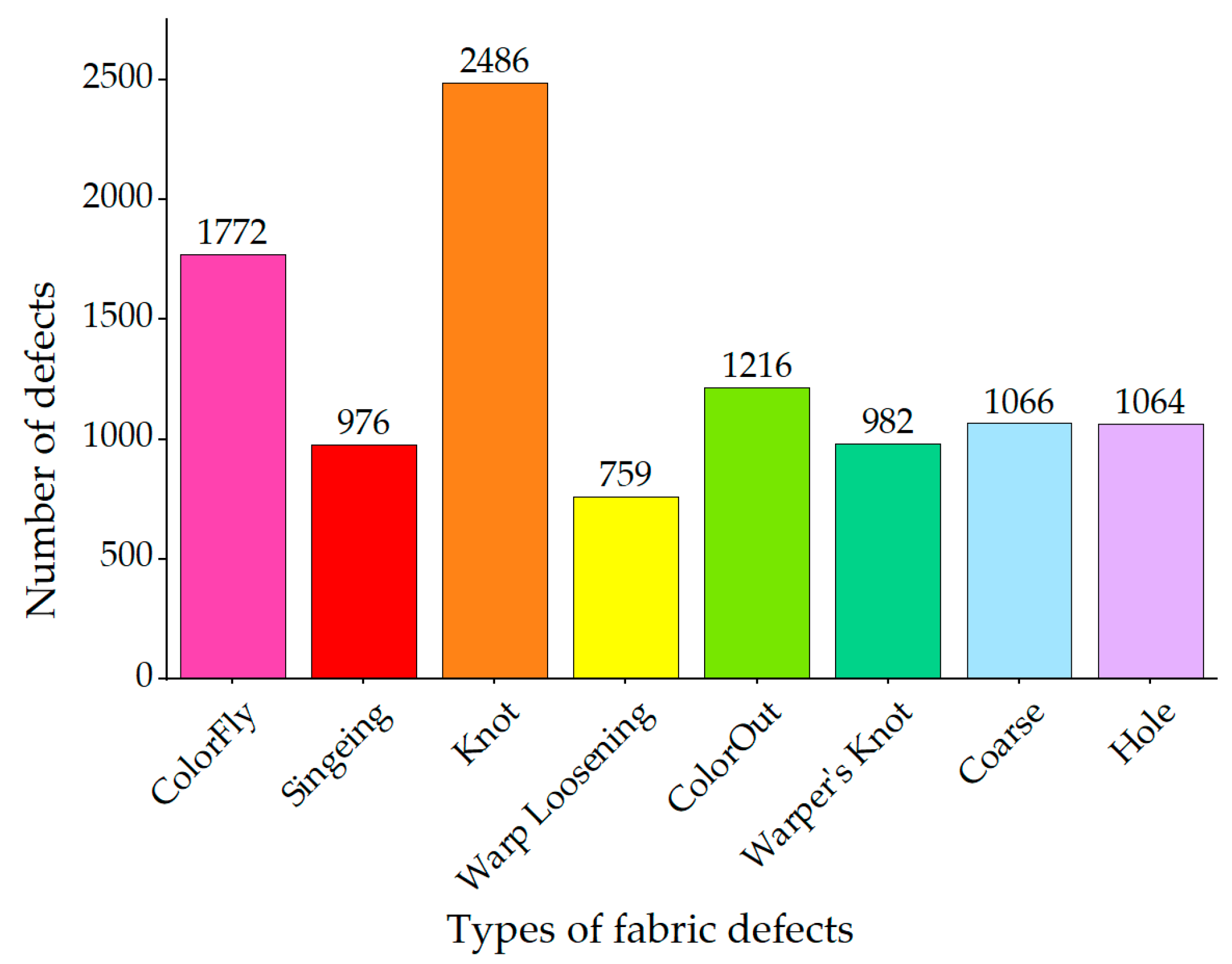
3.2. Dataset Description
3.3. Evaluation Indicators and Experiment
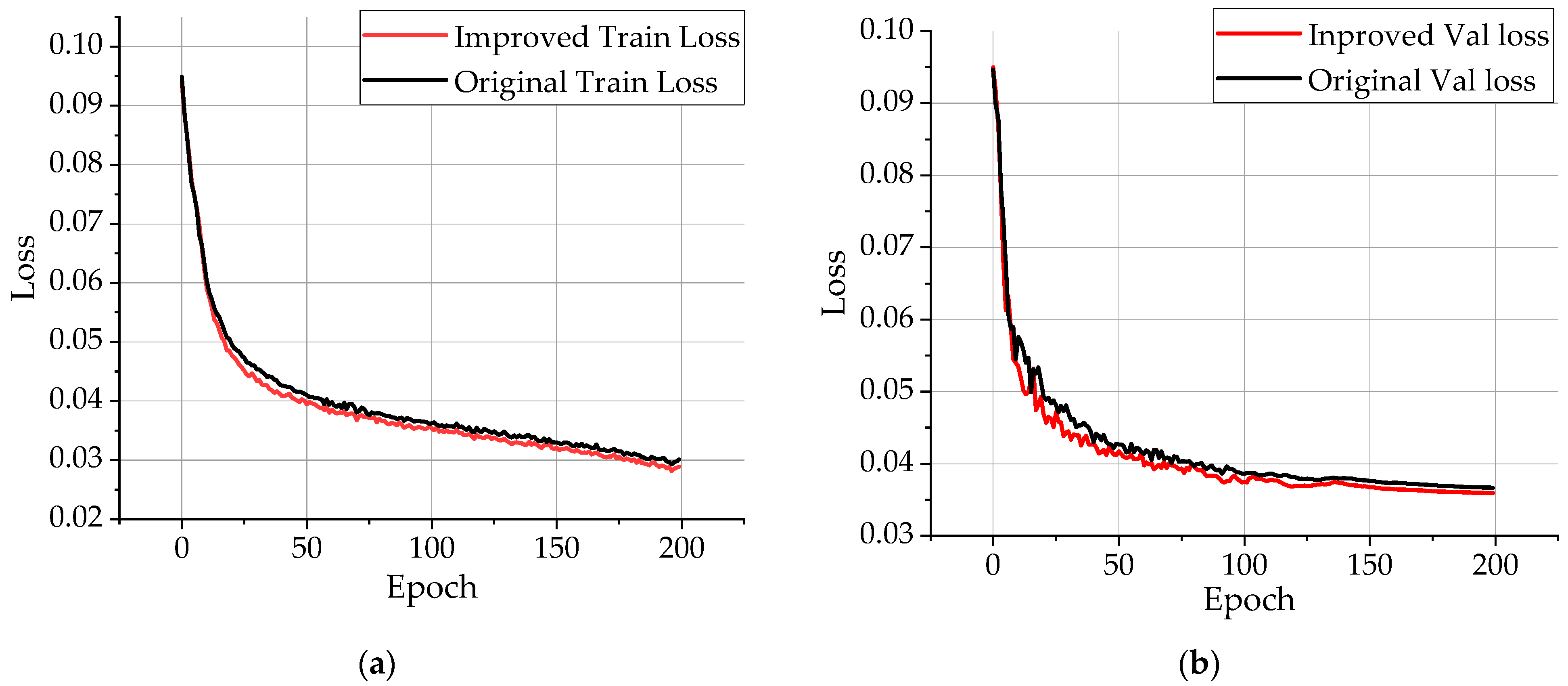
3.4. Loss Function Effect Verification
3.5. Ablation Experiment
3.6. Ablation Experiments with Different Attention Mechanisms
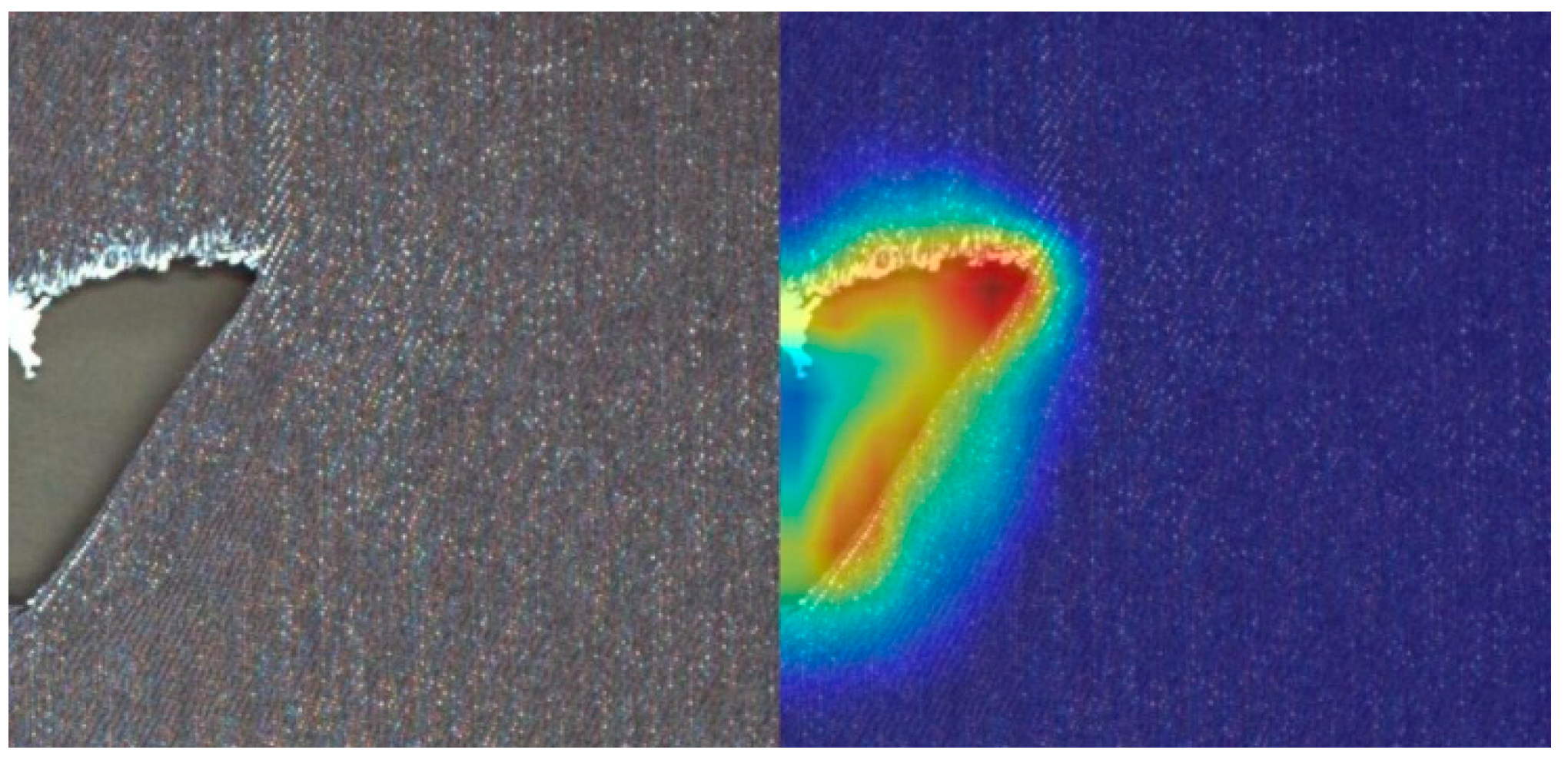
3.7. Results Visualization
3.8. Comparison with State-of-the-Art Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lu, W.; Lin, Q.; Zhong, J.; Wang, C.; Xu, W. Research progress of image processing technology for fabric defect detection. Fangzhi Xuebao/J. Text. Res. 2021, 42, 197–206. [Google Scholar] [CrossRef]
- Gustian, D.A.; Rohmah, N.L.; Shidik, G.F.; Fanani, A.Z.; Pramunendar, R.A.; Pujiono. Classification of Troso Fabric Using SVM-RBF Multi-class Method with GLCM and PCA Feature Extraction. In Proceedings of the 2019 International Seminar on Application for Technology of Information and Communication, iSemantic 2019, Semarang, Indonesia, 21–22 September 2019; pp. 7–11.
- Li, C.; Gao, G.; Liu, Z.; Huang, D.; Xi, J. Defect Detection for Patterned Fabric Images Based on GHOG and Low-Rank Decomposition. IEEE Access 2019, 7, 83962–83973. [Google Scholar] [CrossRef]
- Pan, Z.; He, N.; Jiao, Z. FFT used for fabric defect detection based on CUDA. In Proceedings of the 2nd IEEE Advanced Information Technology, Electronic and Automation Control Conference, IAEAC 2017, Chongqing, China, 25–26 March 2017; pp. 2104–2107. [Google Scholar]
- Wen, Z.; Cao, J.; Liu, X.; Ying, S. Fabric Defects Detection using Adaptive Wavelets. Int. J. Cloth. Sci. Technol. 2014, 26, 202–211. [Google Scholar] [CrossRef]
- Chen, M.; Yu, L.; Zhi, C.; Sun, R.; Zhu, S.; Gao, Z.; Ke, Z.; Zhu, M.; Zhang, Y. Improved faster R-CNN for fabric defect detection based on Gabor filter with Genetic Algorithm optimization. Comput. Ind. 2022, 134, 103551. [Google Scholar] [CrossRef]
- Yapi, D.; Mejri, M.; Allili, M.S.; Baaziz, N. A learning-based approach for automatic defect detection in textile images. IFAC-PapersOnLine 2015, 48, 2423–2428. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, W.; Pan, J. Deformable patterned fabric defect detection with fisher criterion-based deep learning. IEEE Trans. Autom. Sci. Eng. 2016, 14, 1256–1264. [Google Scholar] [CrossRef]
- Zhang, H.-W.; Zhang, L.-J.; Li, P.-F.; Gu, D. Yarn-dyed fabric defect detection with YOLOV2 based on deep convolution neural networks. In Proceedings of the 2018 IEEE 7th Data Driven Control and Learning Systems Conference (DDCLS), Enshi, China, 25–27 May 2018; pp. 170–174. [Google Scholar]
- Wang, Z.; Jing, J. Pixel-wise fabric defect detection by CNNs without labeled training data. IEEE Access 2020, 8, 161317–161325. [Google Scholar] [CrossRef]
- Mei, S.; Wang, Y.; Wen, G. Automatic fabric defect detection with a multi-scale convolutional denoising autoencoder network model. Sensors 2018, 18, 1064. [Google Scholar] [CrossRef] [Green Version]
- Huang, Y.; Jing, J.; Wang, Z. Fabric defect segmentation method based on deep learning. IEEE Trans. Instrum. Meas. 2021, 70, 1–15. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Santos, C.; Aguiar, M.; Welfer, D.; Belloni, B. A New Approach for Detecting Fundus Lesions Using Image Processing and Deep Neural Network Architecture Based on YOLO Model. Sensors 2022, 22, 6441. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Liu, H.; Sun, F.; Gu, J.; Deng, L. SF-YOLOv5: A Lightweight Small Object Detection Algorithm Based on Improved Feature Fusion Mode. Sensors 2022, 22, 5817. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 658–666. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 10012–10022. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Chen, J.; Mai, H.; Luo, L.; Chen, X.; Wu, K. Effective feature fusion network in BIFPN for small object detection. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 699–703. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; Yang, J. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inf. Process. Syst. 2020, 33, 21002–21012. [Google Scholar]
- Yu, X.; Lyu, W.; Zhou, D.; Wang, C.; Xu, W. ES-Net: Efficient Scale-Aware Network for Tiny Defect Detection. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 8–12 June 2018; pp. 7132–7141. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Liu, X.; Gao, J. Surface Defect Detection Method of Hot Rolling Strip Based on Improved SSD Model. In Proceedings of the International Conference on Database Systems for Advanced Applications, Taipei, Taiwan, 11–14 April 2021; pp. 209–222. [Google Scholar]
- Zhao, W.; Huang, H.; Li, D.; Chen, F.; Cheng, W. Pointer defect detection based on transfer learning and improved cascade-RCNN. Sensors 2020, 20, 4939. [Google Scholar] [CrossRef]
- Sujee, R.; Shanthosh, D.; Sudharsun, L. Fabric Defect Detection Using YOLOv2 and YOLO v3 Tiny. In Proceedings of the International Conference on Computational Intelligence in Data Science, Chennai, India, 20–22 February 2020; pp. 196–204. [Google Scholar]
- Dlamini, S.; Kao, C.-Y.; Su, S.-L.; Jeffrey Kuo, C.-F. Development of a real-time machine vision system for functional textile fabric defect detection using a deep YOLOv4 model. Text. Res. J. 2022, 92, 675–690. [Google Scholar] [CrossRef]
- Jin, R.; Niu, Q. Automatic Fabric Defect Detection Based on an Improved YOLOv5. Math. Probl. Eng. 2021, 2021, 7321394. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | Hardware Specifications (Software Version) |
|---|---|
| operating system | Ubuntu18.04 |
| CPU | AMD Ryzen5 5600X |
| GPU | NVIDIA GeForce RTX 3060TI |
| Software environment | Pytorch 1.7.0, Python3.9, OpenCV 4.6, CUDA 11.6, CuDNN 8.4.0 |
| Algorithm | mAP (%) |
|---|---|
| YOLO | 72.3 |
| YOLO + Focal Loss | 72.4 (+0.1) |
| YOLO+ Generalized Focal Loss | 72.8 (+0.5) |
| Algorithm | With Swin T | With Loss | With BiFPN | mAP@0.5 | Recall | Weight (MB) |
|---|---|---|---|---|---|---|
| YOLO-LB | √ | √ | 73.8 | 71.4 | 14.9 | |
| YOLO-SL | √ | √ | 74.6 | 70.6 | 18.3 | |
| YOLO-SB | √ | √ | 74.8 | 71.8 | 20.0 | |
| YOLO-TLB | √ | √ | √ | 75.9 | 73.1 | 20.1 |
| Defect Type | mAP@0.5 | ||||
|---|---|---|---|---|---|
| YOLOv5 | YOLO-LB | YOLO-SL | YOLO-SB | YOLO-TBL | |
| ColorFly | 77.6 | 79.8 | 76.9 | 79.1 | 81.9 |
| Singeing | 60.3 | 68.8 | 67.5 | 64.9 | 66.7 |
| Knot | 72.7 | 68.2 | 65.8 | 73.1 | 73.7 |
| Warp Loosening | 58.5 | 61.7 | 66.8 | 66.8 | 62.6 |
| ColorOut | 88.0 | 89.1 | 91.2 | 89.6 | 91.3 |
| Warper’s Knot | 53.6 | 53.2 | 59.0 | 55.4 | 55.2 |
| Hole | 73.7 | 79.5 | 78.2 | 76.9 | 82.1 |
| Coarse | 92.7 | 90.2 | 91.3 | 92.8 | 93.7 |
| All classes | 72.2 | 73.8 | 74.6 | 74.8 | 75.9 |
| Attention Mechanism Model | mAP (%) |
|---|---|
| YOLO-TLB | 75.9 |
| +CBAM [32] | 76.1 (+0.2) |
| +SE [33] | 75.1 (−0.8) |
| +GAM [34] | 76.5 (+0.6) |
| Algorithm | Backbone Network | Precision (%) | mAP (%) | FPS |
|---|---|---|---|---|
| SDD [35] | VGG16 | 50.6 | 40.2 | 83.3 |
| Faster R-CNN [36] | ResNet50 | 76.2 | 65.9 | 12.5 |
| YOLOv3-Tiny [37] | Darknet53 | 46.1 | 46.7 | 113.6 |
| YOLOv4-Mish [38] | CSPDarknet | 67.8 | 58.8 | 111.1 |
| YOLOv5 [39] | CSPDarknet | 77.0 | 72.1 | 90.9 |
| OUR | Swin Transformer | 85.6 | 76.5 | 58.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, G.; Liu, K.; Xia, X.; Yan, R. An Efficient and Intelligent Detection Method for Fabric Defects based on Improved YOLOv5. Sensors 2023, 23, 97. https://doi.org/10.3390/s23010097
Lin G, Liu K, Xia X, Yan R. An Efficient and Intelligent Detection Method for Fabric Defects based on Improved YOLOv5. Sensors. 2023; 23(1):97. https://doi.org/10.3390/s23010097
Chicago/Turabian StyleLin, Guijuan, Keyu Liu, Xuke Xia, and Ruopeng Yan. 2023. "An Efficient and Intelligent Detection Method for Fabric Defects based on Improved YOLOv5" Sensors 23, no. 1: 97. https://doi.org/10.3390/s23010097
APA StyleLin, G., Liu, K., Xia, X., & Yan, R. (2023). An Efficient and Intelligent Detection Method for Fabric Defects based on Improved YOLOv5. Sensors, 23(1), 97. https://doi.org/10.3390/s23010097